POLITECNICO DI MILANO
Scuola di Ingegneria Industriale e dell'Informazione
Corso di Laurea Magistrale in
Ingegneria Informatica
A VOICE VISUALIZATION TOOL FOR IMPROVING PROSODY OF PEOPLE
LEARNING A SECOND LANGUAGE
Relatore: Prof. Licia SBATTELLA Correlatore: Ing. Roberto TEDESCO
Tesi di Laurea di:
Andrea TUGNOLI Matr. 823817
Andrea Tugnoli: A VOICE VISUALIZATION TOOL FOR IMPROVING PROSODY OF PEOPLE LEARNING A SECOND LANGUAGE | Tesi di Laurea Magistrale
in Ingegneria Informatica, Politecnico di Milano. c
Copyright Luglio 2016.
Politecnico di Milano:
www.polimi.it
Scuola di Ingegneria Industriale e dell’Informazione:
Acknowledgements
I think that those who really know the topic of this paper can be counted on the fingers of the hand: the argument is neither common nor intuitive. Nevertheless, I have had many close people and, even without knowing exactly what I was working on, they have helped me.
I want to thank my family and my friends for their support and my classmates for the path followed together for many years. In particular, I want to thank Angelo Di Pilla for his technical consultancies and tips.
Special thanks go to Marta Zampollo, for her support and love.
My gratitude goes to Professor Licia Sbattella for ’Natural Language Processing’ course, that introduced me to main arguments of this dissertation.
A special thank to the Ing. Roberto Tedesco for his support and help while developing of this work, without which it would not be possible to realize.
My gratitude goes to the Ing. Sonia Cenceschi for her work on KaSPAR project and for the documentation about it.
Furthermore, I want to dedicate this dissertation to those who are asking ques-tions, to those whose curiosity and fantasy is alive and also whose enthusiasm has died hoping to turn it back with this work.
Enjoy the reading !
Como, Luglio 2016 Andrea Tugnoli
for us, wherever we are, and whatever path we will choose together
Contents
Introduction 1
1 Foundations: KaSPAR Project 5
1.1 The dyslexia disease related to English . . . 5
1.2 KaSPAR solutions . . . 5
1.2.1 Requirements analysis . . . 6
1.2.2 Exercises proposed . . . 7
1.3 Relation between KaSPAR exercises and this project . . . 12
2 Project design 13 2.1 Requirements analysis . . . 14 2.1.1 Hardware requirements . . . 14 2.1.2 Software requirements . . . 15 2.2 Project specifications . . . 16 2.2.1 Hardware specification . . . 16 2.2.2 Software specification . . . 17 3 Technological supports 21 3.1 The Praat application . . . 21
3.2 Java environment . . . 23
4 Java implementation 25 4.1 The Client configuration . . . 25
4.2 The Recording . . . 26
4.3 The Wave file . . . 29
4.3.1 The generic WAV file structure . . . 29
4.4 Sending and receiving data . . . 31
4.5 The final results . . . 32
5 Praat implementation 35 5.1 Praat scripts . . . 35
5.2 The Praat stand-alone version . . . 36
5.3 The Server . . . 37
5.4 The sound analysis . . . 39
5.4.1 The creation of the sound object . . . 39
5.4.2 The extraction of the intensity points . . . 41
5.4.3 The extraction of the pitch points . . . 43
x CONTENTS
5.5 Reading and sending data . . . 44
6 Communications between Client and Server 47
6.1 Data from Java to C++ . . . 47
6.2 Data from C++ to Java . . . 52
7 Testing 55 8 Conclusions 59 8.1 Future improvements . . . 59 8.2 Personal considerations . . . 60 Bibliography 61 . . . 61
List of Figures
1.1 The audio-video chain . . . 6
1.2 A private session . . . 8
1.3 A public session . . . 9
1.4 A possible result of prosodic exercises . . . 10
1.5 Example of vowel map . . . 11
1.6 The vowel trapezoid . . . 11
2.1 The hardware requirements . . . 15
2.2 The main characteristics of the computer used to develop the system 16 2.3 How this system works . . . 18
2.4 Client architecture . . . 19
2.5 Server architecture . . . 19
3.1 The main screen of Praat . . . 22
3.2 Some Praat operations . . . 23
3.3 Some Praat operations . . . 24
3.4 Many possibilities with Java . . . 24
4.1 The Wav file structure . . . 30
4.2 The final result . . . 33
6.1 Exchange of an integer from Java to C++ . . . 50
6.2 Exchange of a double precision number from Java to C++ . . . 51
6.3 Exchange of a double precision number from C++ to Java . . . 53
7.1 Intensity tier test 1 result . . . 55
7.2 Intensity tier test 2 result . . . 56
7.3 Intensity tier test 3 result . . . 56
7.4 Pitch tier test 1 result . . . 56
7.5 Pitch tier test 2 result . . . 57
7.6 Pitch tier test 3 result . . . 57
Abstract
This dissertation is based on KaSPAR project, with the aim of supporting people with learning disabilities, focusing particularly on people with dyslexia. It deal with the realization of a system which allows users to capture a sound track, analyze it and show as result a graph which can be used for a comparison. This is possible due to a real time sound analysis which allows the display of the graph right after the end of sound recording and can be immediately repeated. The sound analysis is made with Praat, a specialized open source program which makes very precise operations.
This system’s aim is the improvement of the process of learning English with a method based on listening and imitation, letting the user to compare his results with a mother tongue person, an English teacher, and so on.
Summary
Questa tesi è basata in gran parte sul progetto KaSPAR, che aveva l’obiettivo di supportare persone con disabilità nell’apprendimento. KaSPAR in particolare si concentrava sulla dislessia e su tutti i problemi legati ad essa. Questo progetto innovativo si propone di realizzare un sistema che permetta agli utenti di registrare una traccia audio e, grazie ad una analisi in tempo reale, permette di visualizzare un grafico subito dopo la registrazione del suono. Inoltre è possibile effettuare questa operazione ripetutamente, in modo da poter confrontare i risultati ottenuti. Le analisi della traccia audio sono svolte da Praat, un programma open source specializzato nel trattamento del suono, che permette di avere dei risultati molto precisi.
L’obiettivo di questo sistema è migliorare l’apprendimento dell’inglese tramite un processo di ascolto ed imitazione, proponendo all’utente la possibilità di confrontare in modo intuitivo la propria pronuncia con quella di un madrelingua inglese oppure di un’insegnante di inglese.
Introduction
This is an initial general overview of reasons why this project was born and the structure of this paper.
Motivations
Specific learning disabilities [11] are a set of learning disorders regarding spe-cific abilities. People with this kinds of learning problems usually are not fully self-sufficient in different learning aspects. These types of learning disorders in-clude reading, mathematics and writing, respectively with dyslexia, dyscalculia and dysgrahia. In this project I focus my effort to support one type of these learn-ing disabilities, the readlearn-ing learnlearn-ing disease and, more specifically, the problems regarding dyslexic people.
Dyslexia is probably the most common learning disability. It has many different effects: troubles with reading, spelling words, reading quickly, writing words, pronouncing words and understanding what it is written. Dyslexia affects more or less 3-7% of the world population, even if an additional 20%of people may have symptoms of various degrees [12]. So it is important for people with some kind of disabilities to have a different learning method in addition to the normal ones.
The KaSPAR project [8] includes a set of complex operations which can extract a set of features. These features can describe in a complete way a sound track, but the system needs lots of time to execute these operations. This project focuses on real time execution, with simpler operations and analysis. So, this project is a starting point to KaSPAR project evolution, avoiding complex operation and focusing on simpler real time execution.
Starting from these bases, this paper introduces a method used to record and analyze an audio as input, giving back an easily understandable graph as output. These results appear in very short time, in comparison with real time programs. This project wants to realize a finished product that might be the starting point for more complex projects, able to support people with dyslexic diseases.
Aims
The main objective of this work is the development and realization of a system capable of recording a sound track registered by the user, making an analysis, returning a meaningful result. The period of time between the recording and the
2 Introduction
final graph should be as short as possible, in order to avoid waiting time before using the program again for a new attempt. The speed is crucial for the success of this work: it must guarantee the possibility of repeating the process constantly without excessive delay between the attempts. In this way the user should have the feeling of being able to test his improvements immediately after having seen the previous results.
To achieve these aims, the analysis operations must be simple and highly focused on simplicity and velocity. The comprehensibility of the final graph is one of the most important target that this dissertation aims to get, even if its completeness and precision is not comparable with the results hypothesized with KaSPAR project.
Introduction 3
Outline
The contents of this paper are divided as follows:
In the first chapter there is, first of all, a presentation of KaSPAR project meant as the starting point of this work: the problems of dyslexia and the issues related to learning English. There is also a description of the system thought for KaSPAR project and the related phases analysis.
In the second chapter there is an introduction of the design of this project, including requirements analysis and project specifications. It also explains the evolution from KaSPAR project to this paper and the choices forced by some technological constraints or issues found during this preliminary phase.
The third chapter describes all technological aspects of this work. Here are the introductions and descriptions of the used programs’ and the explanation of the choice of the programming language. Furthermore, there is an overview of Praat stand-alone version, essential for the success of this project.
The fourth chapter contains all the Java implementation: here there are pri-marily the Client configuration, the recording analysis and the final graph realization. Furthermore, there a general overview of the sending and receiving data and the definition of Wave file.
The fifth chapter describes the Praat implementation: a complete analysis of praat stand-alone version, the definition of the Server and the description of the audio analysis methods. There is also a brief explanation of how the data are sent and received from and to the Client.
In the sixth chapter the problem of communication between Client and Server is faced. There are many issues to work with two different programming language and this is the chapter where the aspects met during this project development are explored.
The seventh chapter shows the obtained results and compares them with the initial expectations.
The last chapter collects conclusions about this project: there are an intro-duction of possible future improvements and development, some personal comments regarding this project and other considerations.
Chapter 1
Foundations: KaSPAR Project
In this chapter, I describe the main aspects of KaSPAR project, which is the base of this dissertation. The starting section summarizes KaSPAR’s paper on dyslexia which explains the problems of dyslexic people and some possible ways to face these problems. In the following sections there are the requirements analysis and the definition of a set of exercises. The idea that I want to highlight in this chapter is the possibility of dealing with each problem with a specific exercise, in order to support people affected by specific learning difficulties, more specifically affected by dyslexia.
1.1
The dyslexia disease related to English
The dyslexia causes many problems in learning languages, especially during the studying of second language. The biggest problems in learning English is that there is not a correspondence between visual signs and pronunciation [7]. This determines the opacity of language, which causes problem in learning implicit rules, discrimination of phonemes (i.e. confusing ’did’ with ’dad’), expressiveness reduction, weak vocabulary, etc. On the other side, there are transparent languages, where there is a correspondence between visual sign and sound, like Italian or Spanish. In these kinds of languages, the problems are less severe.
For people who are learning English as second language, these issues are amplified: these subjects have problems to remember phonemes, as a result they can be less fluid, especially in the school ages. In the worst cases, these people could reverse syllables and/or speak not clearly.
1.2
KaSPAR solutions
Kaspar proposes a set of exercises aimed to support dyslexic people learning english as a second languages:
• An exercise based on prosodic parameters visualization.
• An exercise that shows a correct pronunciation map and the user’s mistake. • An exercise for the expressive skills.
6 Chapter 1. Foundations: KaSPAR Project
Furthermore, KaSPAR planned an innovate use of musical parameters which allows an improvement of the tests. This innovation opens new future possibilities for to new unconventional exercises not treated in this project.
Below I introduce the requirements analysis and a deeper description of these exercises’ features.
1.2.1
Requirements analysis
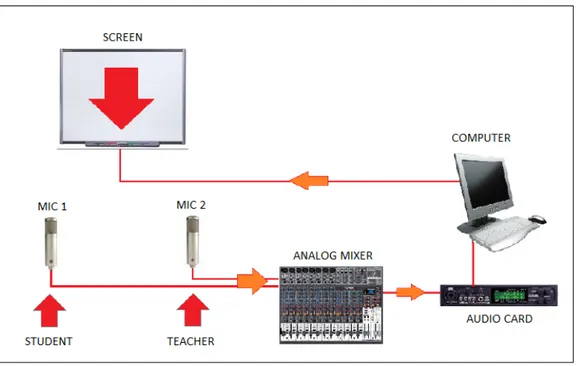
The system is thought as an audio-video chain which can be represented as it is in Figure 1.1. The two microphones are cardioid condensers, with shielding to
Figure 1.1: The audio-video chain
maximize the quality of recording audio tracks. Furthermore, an analog mixer can remove some noises and significantly improve the audio quality. The other necessary tools are a classical hardware equipments present in every personal computer: an audio card, a screen and the computer itself. If you can have a real interaction with the screen, it is possible to replace the screen with an interactive whiteboard [4].
It was thought to use Matlab for the on-line and off-line data elaborations, while an embedded Java code was considered the best choice for the graphical representation of the results. This choice was considered necessary due to the slowness of Matlab with the realization of figure. So the system development is divided in two parts: the core of the system and all the system operations were supposed to use Matlab, while the graphical realization of the final result and some elaborated data were supposed to use Java.
Finally, all the audio material needs to be saved and stored in archives for possible successive use, such as the definition of personal learning paths or other tests. Each audio track must be available for the data extraction to evaluate user progress and as possible references for implications on exercises or other tests.
1.2. KaSPAR solutions 7
1.2.2
Exercises proposed
The exercises provide a real time feedback which allows the user a self-correction on determined characteristics or a slightly delayed global evaluation. Repetitions and multimedia modalities help the user to memorize new terms and improve prosodic and linguistic skills. These improvements are considering the test exam as a training to reach personal targets and not to fill the gap between the user and a mother tongue.
General scenario
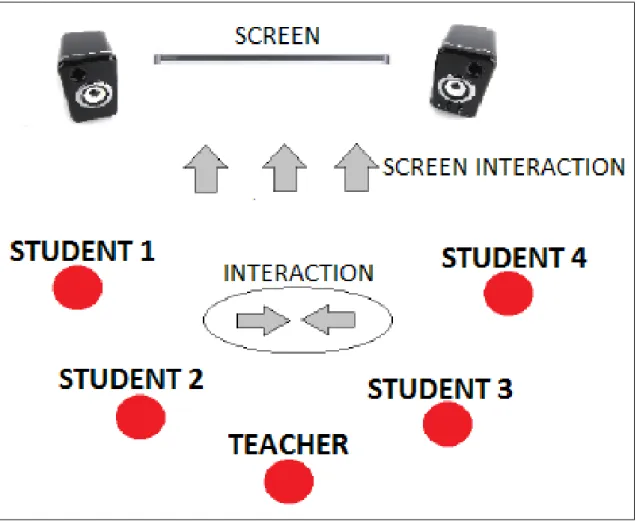
The scenario of the tests was composed by an English mother tongue teacher and one or more dyslexic students, in a soundproof room or in a similar place. The tests are divided in sessions:
• The training session: the first session is useful to become familiar with the system, testing its functionalities, trying its sensibility and looking at the graphical modality. All participants must be present together in the room to understand how the system works and how to adapt their voices to the system. The system could be more or less precise depending on the voice volume while the video response could change. These aspects are very important to determine the right settings in order to find useful parameters for a personal experience and evaluation.
After this session it is possible to have some private sessions, where there is only one student with a teacher, or public sessions, where there may be until five student simultaneously.
• In the private sessions the student is supported by a teacher to gain confidence with the system, as it is shown in Figure 1.2. Here the students only deal with short sentences. This is necessary for the student to be prepared for the following public sessions.
• In the public sessions there are maximum four students with a more complex objective. Here there is the analysis and evaluation of linguistic reactions caused by more complex stimuli, such as the introduction of a discussion topic. The aim is to introduce an higher degree of autonomy and adaptation, to increase the complexity from imitation only to something more creative. The students can interact between themselves under the teacher supervision and they can do something all together, like dubbing cartoons or short film scenes, as it is displayed in Figure 1.3.
The method has not be defined yet, but the fundamental idea is to provide new tools to stimulate the students, for example starting with game or fun activities.
The prosodic exercise
This kind of exercise is used to stimulate the self-correction through an au-dio/video feedback of main prosodic parameters. The core of this exercise is the
8 Chapter 1. Foundations: KaSPAR Project
Figure 1.2: A private session
imitation, which can cause different problems to the students related to phonemes reading, memorization, its emotional part and its recognition/association. These difficulties can be possibles solutions of these issues can be reached through the imitation of an optimal reference model and the following visualization of graphical representations of his/her level of linguistic efficiency. The student can observe in real-time the differences between an exercise and another one to realize his/her progressive improvements. These differences are generally meant as a qualitative intuitive deviation, so they are hard to understand for the students. For this reason there is a teacher, attending the learning process and contributing with his/her experiences and knowledges, even if in this phase the student is supposed to use his/her capacities to self-correct himself/herself. A translation of a sound in a representation is fundamental to do this self-correction process: it must be transparent and easy understand for the students, who should be able to recognize the main prosodic parameters. So, the aim is not to make the students reach the teacher’s level, but to stimulate him/her to modify his/her voice.
The teacher has the responsibility of the choice of the contents, the types, the grammatical and terminological difficulty levels and the personalization of the test, depending on the knowledges and the capacities of the student.
The operational phases of this process can be summarized in six steps: 1. The training phase described above.
2. A calibration phase, useful for the users to become familiar to the system responses.
1.2. KaSPAR solutions 9
Figure 1.3: A public session
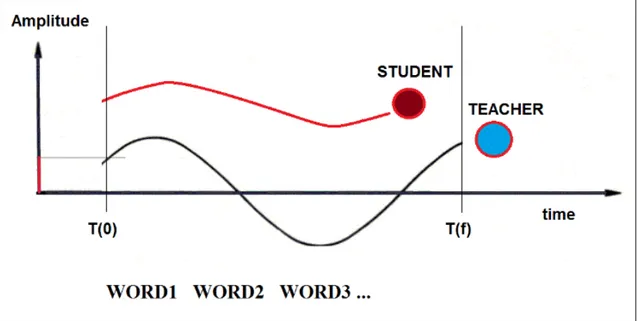
3. The teacher phase, where the teacher says the sentence.
4. On the screen the parameters are displayed in real-time and they are aligned to the corresponding words.
5. After seeing the screen, the student tries to imitate the teacher. 6. Finally, it is possible to see the global result of the performance..
This operating model is available also for public sessions, with the comparison of the results and the analysis of a more complex conversation.
The prosodic parameters visualization is very important. We start with the idea that displaying the voice, through a set of parameters, brings a possibility of improvements of the verbal consciousness, pronunciation and memory. Working in the continuous time, it is important to maintain the correspondence between the perceived and measured time along the x-axis, making clear the association between the vocal act and the manipulation of the characteristic that we want to modify.
So it is fundamental to maintain these assumptions to visualize the text under the pictures and the periods of time. Furthermore, using a more accurate scientific
10 Chapter 1. Foundations: KaSPAR Project
graph can be counterproductive for our aim. The purpose of this prototype is to stimulate the attention and the desire to improve themselves in playful and fun ways. So it is possible to show a loud sound or a weak one, and the conceptual association must be as simple as possible, while the attention of the user must not be attracted to other details, like a suggestive graphic scenography. For example to describe the voice volume, it is enough to use a reference point that moves up and down in time. In the future many different interfaces could be implemented depending on the age of the students. A possible result of this kind of exercise is shown in Figure 1.4.
Figure 1.4: A possible result of prosodic exercises
The pronunciation exercise
The training of specific pronunciation of phonemes focuses on the memory reinforcement and on development of implicit linguistic rules. This kind of exercise consists in repeating a series of words to train the appropriate choice of specific sounds and visualize the phonemes/words just pronounced on an interactive map. With this exercise the student can understand if his/her pronunciation is correct or how big is the gap with the optimal one.
The test is thought in three steps:
1. The visualization of the word considered.
2. The student tries the first time to say the word.
3. Finally, the visualization of the students pronunciation is shown in a map. It is important to specify that the map is a guidance graph considering all the pronunciations (the teacher one and the student one), so it is possible to have a comparison between them. For example if the word considered is ’dad’ and the attempt of the student produces a word similar to ’did’, the position will be closer
1.2. KaSPAR solutions 11
Figure 1.5: Example of vowel map
to the vowel ’i’, like it is displayed in Figure 1.5. If an interacting whiteboard is available, it is possible to realize a more efficient system: it works with a more complex graph, where it is possible to listen to the pronunciation touching the whiteboard. A similar graph for the vowels already exists, called vowel trapezoid Figure1.6, while it is possible to develop more graphs with consonants and to work on a simplification of existing graphs, which are too complex at the moment to be easily understood.
Figure 1.6: The vowel trapezoid
The expressiveness exercise
The shape and expressiveness are applied to the voice from the musical world. The project has exercises specifically dedicated to the expressiveness, which support the student from an emotional point of view with results aiming to improve directly the linguistic expression. The scenario to their realization is different from the
12 Chapter 1. Foundations: KaSPAR Project
previous exercises, even thought they use the same parameters of the audio analysis. The modalities to use these parameters are different too.
This is the most experimental section of this project and can be expanded searching for more ’artistic’ results. The first hypothesis are:
• The realization of a dubbing session of film or documentary: there is still the idea of imitating a teacher, but this exercise focuses on the emotional factor because the student needs to provide his/her voice to an external character. • The detection of biosignals: these signals represent an alternative way and an
added value to monitor possible users progresses.
• The search of specific noise parameters: all aspects of learning which the user has problem with. These aspects are not directly correlated with learning English as second language, but it helps us to understand if the whole project can have a general good results.
• Amplitude and pitch envelope: make an a posteriori off-line data elaboration for other studies, for example the prosodic differences between voices.
1.3
Relation between KaSPAR exercises and this
project
This project is focused on prosodic exercises, so results visualization is similar to what it is shown in Figure1.4. The aim is to visualize the result of a single audio track analysis in a time series graph. This is the starting point for the realization of the whole system.
The result is shown through a graph after recording an audio track. This graph shows a single set of pitch values in function on time, useful for prosodic analysis. Furthermore, the system provides a graph with intensity points values, to increase the information quantity available for the user. However a more complete description of this project’s features is available in Chapter 2.
Chapter 2
Project design
In this chapter I present the requirements analysis and the project specifics. The main core of this chapter is the KaSPAR project inheritance. First of all, the hardware requirements analysis is a simplified version of the original analysis, because some aspects were useless for the aims of this work. Secondly, the software requirements have inherited Java as programming language for the graphical part. Java is more significant in this paper, rather than in the KaSPAR project though. Matlab is replaced with C++, due to Praat, and partially by Java. The Matlab substitution is mandatory due to the choice done: while Java is easily embedded in Matlab, it is not possible with Praat. Praat [14] is an open source program specialized in sound analysis popular for its huge possibilities, but it is not possible to embed the code in Matlab. There is not any embedded code in this work, it only shows two different realities in two different programming languages communicating between them.
This relation with KaSPAR project is show in the table 2.1. It summarizes the strong relation between KaSPAR and this project, especially in the hardware requirements. In the next section I explain more in details the hardware and software requirements analysis of this work, while the KaSPAR project’s requirements analysis is treated in theChapter 1.
KaSPAR Project This Project
Aim Support dyslexic people through Visualize a graph made with an stimulating exercises audio track registered by the user Hardware The Audio-Video chain: A simplified Audio-Video chain: Requirements microphones - analog mixer - microphone audio card
-audio card - computer - screen computer - screen
Software Matlab and Java Java, C++ and Praat
Requirements
Table 2.1: Comparison between KaSPAR and this project
14 Chapter 2. Project design
2.1
Requirements analysis
The requirements of this project are in large part taken from KaSPAR project due to the background of this work. The requirements analysis is simple and without particular precautions about hardware and software, with the only exception of the microphone. It is recommended to use a microphone with a good shielding of the noise, but the system also works with a non specific microphone, even though it will get slightly less precise results Figure 2.1.
2.1.1
Hardware requirements
This system needs a set of hardware tools, which can be generally found in every personal computer:
• A computer able to execute the program: there are not particular requirements for the machine used for the program’s execution; a standard computer is enough to satisfy the power needed by the system.
• A microphone for registering the audio track: it is better to use an high quality microphone, because it directly influence the quality of the results. There are many types of microphones and they can be referred by their transducer principle and by their directional characteristics. However, for this project’s aims are useful only two kind of microphone [16][1]:
1. Condenser microphone, called also capacitor microphone or electrostatic microphone. In this kind of microphone the main component is a con-denser. It is realized with a metal plate and a mobile plate composing the armature. A pressure variation generated by a sound produces a vibration which generates a change in the distance between the plates. This is the most popular microphone for conference, simultaneous trans-lation and it is often used in the soundtrack of many film in direct drive. This is the best choice recommended for KaSPAR project and so for this one. The main flaws is the fragility which can be a problem if they are used by children or negligent people and the needed of a power supply. 2. Dynamic microphone is composed by a diaphragm situated in a magnetic field. A sound generates a variation of the air pressure which produces movements of the diaphragm. Finally, these vibrations generate an electric signal. This kind of microphones is robust, relatively cheap and resistant to moisture, so they are used in public events or in live concerts. However, the quality and the sound sensibility are lower than the condenser one, but they are a valid alternative.
• An audio card for sounds acquisition: a standard computer’s sound card is enough due to the simplicity of recording an audio track.
2.1. Requirements analysis 15
• Speakers for listening to the recorded audio track: this system saves the audio tracks registered, so it is possible to hear the previous recordings with any speakers or headphones.
Figure 2.1: The hardware requirements
2.1.2
Software requirements
This system has to have some essential features to perform analysis operations and show the final results. The system is divided in two essential parts, a Client one and a Server one. This choice was made due to Praat program: there is not the possibility to embed some Praat code in Java, more precisely it is not possible execute a Praat script in Java. So to find a solution, the system was thought with this features:
• A Client: the Client has to record the sound tracks, send data to a Server and eventually show the results. These are elaborated from the data received from the Server after some operations. The Client also performs some initial operations to make the data suitable to the Server.
• A Server: the Server receives the data from the Client and executes the sound analysis operations to find the final data. Finally, it sends the results to the Client, where they are shown to the user.
16 Chapter 2. Project design
The advantages of this kind of structure is the possibility of simultaneous connection: a single Server can accept many connection coming from different Client. Further-more, it is possible imagine different Client developed in different programming languages which, with a dedicated interfaces, connect to the same Server, designed to accept this kinds of connections.
2.2
Project specifications
This system is thought to work in every computer without problems regard minimum hardware or software requirements. So the choices derived from the requirements analysis are thought with the consciousness of this aim. The results of this analysis are describe in this section, dividing the contents in hardware and software specifications.
2.2.1
Hardware specification
A not too old computer is enough for the execution of this program due to its aims: the speed is one of the main purposes and to reach it I decided to use the most simple way. So there are not general minimum requirements regarding processor’s power or size of RAM. The same reasoning is applied to the audio card, the screen and the speakers: the embedded ones are enough for this project. It’s better to use a good microphone though, because the quality of the sound affects the quality of the operations and the result, so the microphone embedded in the normal computer are not the best choice for this project.
This project has been developed on a Lenovo laptop with Windows 10 as oper-ating system. The main features of this computer are available in Figure2.2. These characteristics can be a valid benchmark for the system’s hardware requirements, even if it is not a lower bound for a useful use of the system.
Figure 2.2: The main characteristics of the computer used to develop the system
Furthermore, I can recommend to use a Steinberg UR22 mkII audio card [20] and one between these microphone:
2.2. Project specifications 17
• Line 6 XD-V35L Digital Wireless Lavalier Microphone: a cardioid condenser microphone with a good quality and comfort due to its tie-clip feature [9]. • RØDE NT2-A Microphone: another cardioid condenser microphone with an
higher quality than the Line 6, but also an higher cost. This is a professional microphone with an high noise isolation and lots of settings to customize every tests [13].
2.2.2
Software specification
Java is the most efficient programming language for the operations executed by the Client. Furthermore, Java has many ways to communicate with a Server and its versatility is very useful, especially because the Server is not developed in Java but in C++. This choice is forced by the decision of integrating the Server with Praat: with the possibility to have the source code and many possible customizations, I thought that it would be better to create the server at the launch of the program. This choice was made because it masks the delay of the Server’s build with the starting time of Praat. In Figure2.3 there is a general overview of the system.
All the system is developed in Linux due to Praat stand-alone version: this version is available for all the classic operating systems, Windows, OS X and Linux, but I tested it only for Windows and Linux. I tried to work with Windows, but I found some unexpected behaviours of compilers. So, the choice to change operating system was forced and the system was developed on a virtual machine with Linux Mint[10]. Mint is a simplified Ubuntu version focused on simplicity and efficiency [19]. The aim of this Linux release is to be available for all the computer, independently of their hardware. This is, probably, the best option for this project, which has not required particular bounds about computer hardware.
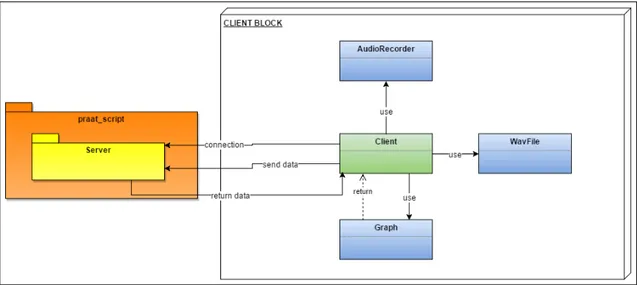
The system can be described by two diagrams, one for the Client and on for the Server: these diagrams shown a general overview of the architecture of Client and Server. While the Client can be easily described due to its standard structure, as it is shown in Figure 2.4, the Server is more complex. It is embedded in the Praat’s source code, so it is almost impossible to follow its data flow. The Server’s diagram focuses on an high level description of its main functionalities and operations, as it is shown in Figure2.5.
18 Chapter 2. Project design
2.2. Project specifications 19
Figure 2.4: Client architecture
Chapter 3
Technological supports
In this chapter I present the technologies used for the realization of this work: the two main tools used are Praat and Java. The choice for both of them is forced due to the requirements analysis, but they were also chosen for their potentiality.
Praat can handle the audio truck very precisely and it allows a set of powerful transformations and operations: it is possible to see the spectral shape of the track; it allow you to transform an audio track in many domains, like amplitude and intensity domain; it is possible to show the pitch and the pulses; for each of these operations you can get the pitch, intensity, frequency, it is possible to select some audio parts, etc.
Java is probably one of the most used object programming language in the world. The huge quantity of libraries in all field, from graphical aspects to the possibility to read every kind of files, makes it extremely versatile.
3.1
The Praat application
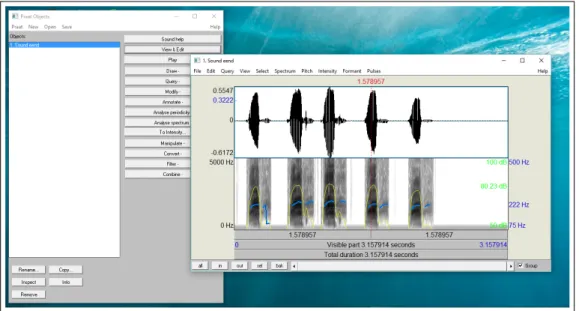
I use Praat, an open source program specialized in the sound analysis with a really rich set of functionalities, better than the ones offered by other programmes. In the Figure 3.1it is possible to see the Objects window and a view of a generic sound.
Praat has a dedicated grammar and works reading code blocks, called ’script’, that are compiled and executed after their writing.
This program has many tools useful for all needs: starting from an audio track, you can extract a huge quantity of information, as it is shown in Figure 3.2. The menu is divided in six parts:
1. First of all, three general operations: an operation to retrieve the number of channels of the audio track considered and two sub-menus regard other time domain and time sampling queries.
2. Then two operations regard values, specifically the value at a determinate time or a sample’s value.
3. Now there are a set of queries regard the points: retrieve the minimum, maximum and relative times.
22 Chapter 3. Technological supports
Figure 3.1: The main screen of Praat
4. Then some mathematical operations, like the mean and, root mean square and standard deviation.
5. Here there are only two operations: recovery the audio energy and power. 6. Finally, three general operations regarding the influence of the sound in the
air: energy, power and intensity.
There are also many operations available to modify the audio track considered, as it is displayed in Figure3.3. In this menu it is possible to find many operation, but the more important are grouped in three different sets:
1. First of all, three complex operation, like reverse the audio track, the genera-tion of a formula or only a part of it.
2. Then a set of basic operations: add, multiply, subtract mean, scale peaks and many other.
3. After all, two set operations: Set value at sample number and Set part to zero.
These are some examples of the possibilities of Praat. There are many other menu, like Draw, where it is possible to find the tools to modify graphically the view result, or Analyze periodicity, where there are the operations to change the domain, like To Pitch or To Harmonicity.
Furthermore, it is open source, so it can be possible add custom operations, which is an important feature and one of the main reasons of the choice to use Praat.
One of most interesting feature of Praat is the possibility to turn a script in a double-click stand-alone program including it into Praat’s main procedure. These stand-alone versions of the program do not load the Praat’s main windows, increasing the speed of the launch of the program significantly[15]. Praat was
3.2. Java environment 23
Figure 3.2: Some Praat operations
chosen for the sound’s analysis and management especially for this property. Praat is developed in C++ so the choice to integrate the Server in its code forced the implementation of the Server in C++.
3.2
Java environment
Despite to the fact that the Server is in C++, for the Client’s development and its operation, such as the recording and the viewing of the results, Java was chosen. This choice was made because of Java versatility and its significant number of libraries available, in addition to the large community of Java programmers on the net.
One important feature is the possibility to read almost every kind of files and to modify them: text file, sound files, video files, all image types and also compressed files. This wide range of files that can be read makes Java perfect to handle all the preparation aspects of the audio file, like registering and reading it, and for the final video output.
Another core feature of Java is the availability of many graphic libraries Figure3.4
which can be used to show the final graph to the user. The use of Matlab was considered in requirements analysis phase but I decided that it was better to avoid it because of its slowness in realizing figures and graphs. The use of Java provides some efficient graphic libraries which can make graphs really quickly, as it was requested in this project.
24 Chapter 3. Technological supports
Figure 3.3: Some Praat operations
Chapter 4
Java implementation
In this chapter there is the description of the complete Java code implementation, about the Client development and all its aspects: how the audio tracks are recorded and the definition of the wav file extension. It also deals with a brief discussion about how the data are sent, while a more complete description is present in the
Chapter 6. Finally, there is a description of the final results display.
4.1
The Client configuration
The Client works with two threads, the main thread and the recording one. In Java the multi threading execution is managed by the function ’synchronized(class)’, the functions to wait and to trigger the execution are respectively ’class.wait()’ and ’class.notifyAll()’. So the Client starts with the creation of a new thread of recording class and then waits for the end of the recording thread. After receiving the notification that the record is finished, the execution restarts. Then the Client defines the audio file with a dedicated class, the WavFile class. Now the audio file previously recorded is defined as a WavFile instance and the amplitude values are extracted in an double precision array. Afterwards, the remained three initializations are the socket, the output and the input streams. The socket instance is used to communicate with the Server and has to be initialized with the Server IP address and port number: the local host 127.0.0.1 and port 8888. The output and input streams are initialized with the socket instance to create a stream with the Server.
Listing 4.1: The Client configuration
1 // New R e c o r d i n g t h r e a d 2 new A u d i o R e c o r d e r () ; 3 4 // S y n c h r o n i z a t i o n with the r e c o r d i n g t h r e a d 5 s y n c h r o n i z e d ( A u d i o R e c o r d e r .c l a s s) { 6 7 try {
8 // Wait the end of the r e c o r d i n g 9 A u d i o R e c o r d e r .c l a s s. wait () ;
10
26 Chapter 4. Java implementation
11 // D e f i n i t i o n of the Wav file s t a r t i n g from the
r e c o r d e d a u d i o t r a c k file ’ junk . wav ’
12 W a v F i l e w a v F i l e = W a v F i l e . o p e n W a v F i l e (new File ("
junk . wav ") ) ;
13
14 // A m p l i t u d e a r r a y d e f i n i t i o n and i n i t i a l i z a t i o n 15 d o u b l e[] ampl = new d o u b l e[(int) w a v F i l e .
g e t N u m F r a m e s () 16 * w a v F i l e . g e t N u m C h a n n e l s () ]; 17 ampl = w a v F i l e . r e a d F r a m e s T o D o u b l e ( ampl , w a v F i l e . g e t N u m F r a m e s () ) ; 18 19 // S o c k e t c r e a t i o n and i n i t i a l i z a t i o n 20 S o c k e t s = new S o c k e t (" 1 2 7 . 0 . 0 . 1 ", 8 8 8 8 ) ; 21 22 // O u t p u t s t r e a m d e f i n i t i o n 23 D a t a O u t p u t S t r e a m dos = new D a t a O u t p u t S t r e a m ( s . g e t O u t p u t S t r e a m () ) ; 24 25 // I n p u t s t r e a m d e f i n i t i o n 26 D a t a I n p u t S t r e a m dis = new D a t a I n p u t S t r e a m ( s . g e t I n p u t S t r e a m () ) ;
Now all the aspects necessary to run correctly the Client are defined and initialized. In the next sections I specify the contents of the Client, the recording class and the class for the definition of the wav file. Finally there are the descriptions of the communication functions used to exchange data between Client and Server, and the realization of the final graph.
4.2
The Recording
The AudioRecorder class collects the code necessary to record and to set the format of the audio track file. First of all, there is a definition of the control panel composed by two buttons, ’Capture’ and ’Stop’, and the file extension identifier, in this case ’WAVE’.
Listing 4.2: The panel definition
1 // B u t t o n s and p a n e l d e f i n i t i o n 2 f i n a l J B u t t o n c a p t u r e B t n = new J B u t t o n (" C a p t u r e ") ; 3 f i n a l J B u t t o n s t o p B t n = new J B u t t o n (" Stop ") ; 4 5 f i n a l J P a n e l b t n P a n e l = new J P a n e l () ; 6 f i n a l J R a d i o B u t t o n a u B t n = new J R a d i o B u t t o n (" WAVE ", true) ;
The ’main’ function is composed only by the constructor of the class: the panel settings, with the starting value of the button and the panel construction, and the
4.2. The Recording 27
listeners definition, one for each event expected. The listeners’ aim is to capture a specific event and to trigger a chain reaction of events. More specifically, the first listener captures a click on the ’capture’ button and, after changing the buttons state, calls the function to create the file and to start the registration. the second one captures a click on the ’Stop’ button which stops the registration and saves the file ’junk.wav’.
Listing 4.3: The constructor
1 p u b l i c A u d i o R e c o r d e r () { 2 3 // B o t t o n s i n i t i a l c o n f i g u r a t i o n 4 c a p t u r e B t n . s e t E n a b l e d (true) ; 5 s t o p B t n . s e t E n a b l e d (f a l s e) ; 6 7 // I n s e r t b o t t o n s into J F r a m e s 8 g e t C o n t e n t P a n e () . add ( c a p t u r e B t n ) ; 9 g e t C o n t e n t P a n e () . add ( s t o p B t n ) ; 10 11 // I n s e r t J P a n e l into J F r a m e 12 g e t C o n t e n t P a n e () . add ( a u B t n ) ; 13 14 // W i n d o w s e t t i n g s 15 g e t C o n t e n t P a n e () . s e t L a y o u t (new F l o w L a y o u t () ) ; 16 s e t T i t l e (" A u d i o R e c o r d e r ") ; 17 s e t D e f a u l t C l o s e O p e r a t i o n ( E X I T _ O N _ C L O S E ) ; 18 s e t S i z e (300 , 70) ; 19 s e t V i s i b l e (true) ; 20 21 // L i s t e n e r s d e f i n i t i o n 22 // F i r s t : c l i c k on ’ c a p t u r e ’ b u t t o n 23 c a p t u r e B t n . a d d A c t i o n L i s t e n e r (new A c t i o n L i s t e n e r () { 24 p u b l i c void a c t i o n P e r f o r m e d ( A c t i o n E v e n t e ) { 25 c a p t u r e B t n . s e t E n a b l e d (f a l s e) ; 26 s t o p B t n . s e t E n a b l e d (true) ; 27 28 c a p t u r e A u d i o () ; 29 } 30 }) ; 31 // S e c o n d : c l i c k on ’ stop ’ b u t t o n 32 s t o p B t n . a d d A c t i o n L i s t e n e r (new A c t i o n L i s t e n e r () { 33 p u b l i c void a c t i o n P e r f o r m e d ( A c t i o n E v e n t e ) { 34 c a p t u r e B t n . s e t E n a b l e d (true) ; 35 s t o p B t n . s e t E n a b l e d (f a l s e) ; 36 37 t a r g e t D a t a L i n e . stop () ; 38 t a r g e t D a t a L i n e . c l o s e () ; 39
28 Chapter 4. Java implementation
40 }
41 }) ;
42 }
The function called ’captureAudio()’ defines the audio format through pre-filled fields and the data line, which is the path of the source of audio data: in this case, the microphone. So a new thread is created and starts, considering the synchronization with the Client class. The thread is a sub-class with a function ’run()’ which starts the thread and makes some operations. In this case all operations are included in a synchronized function to guarantee the correct order of the thread execution. So a new ’WAVE’ file is created and a real time file writing starts. This is possible without a ’while loop’ because of the ’AudioSystem.write()’ function, a library function used to avoid unnecessary loops.
When the ’stop’ button is clicked, the data line is closed and the writing ends. So the file is saved and the end of these operations is notified to the Client function so it can restart its execution.
Listing 4.4: The ’captureAudio’ function and the ’CaptureThread’ class
1 p r i v a t e void c a p t u r e A u d i o () {
2 try {
3 // R e t r i v e the A u d i o f o r m a t and t a r g e t D a t a L i n e
i n i t i a l i z a t i o n
4 a u d i o F o r m a t = g e t A u d i o F o r m a t () ;
5 D a t a L i n e . Info d a t a L i n e I n f o = new D a t a L i n e . Info ( 6 T a r g e t D a t a L i n e .class, a u d i o F o r m a t ) ; 7 t a r g e t D a t a L i n e = ( T a r g e t D a t a L i n e ) A u d i o S y s t e m . g e t L i n e ( d a t a L i n e I n f o ) ; 8 9 // T h r e a d c r e a t i o n 10 new C a p t u r e T h r e a d () . s t a r t () ; 11 } c a t c h ( E x c e p t i o n e ) { 12 e . p r i n t S t a c k T r a c e () ; 13 S y s t e m . exit (0) ; 14 } 15 } 16
17 // Sub - c l a s s to run the t h r e a d and to save the file 18 c l a s s C a p t u r e T h r e a d e x t e n d s T h r e a d { 19 p u b l i c void run () { 20 s y n c h r o n i z e d ( A u d i o R e c o r d e r .c l a s s) { 21 22 // New file d e f i n i t i o n 23 A u d i o F i l e F o r m a t . Type f i l e T y p e = null; 24 File a u d i o F i l e = null; 25 26 // File s e t t i n g s 27 f i l e T y p e = A u d i o F i l e F o r m a t . Type . WAVE ;
4.3. The Wave file 29
28 a u d i o F i l e = new File (" junk . wav ") ; 29 30 try { 31 // Data flow is m a n a g e d by ’ t a r g e t D a t a L i n e ’ 32 t a r g e t D a t a L i n e . open ( a u d i o F o r m a t ) ; 33 t a r g e t D a t a L i n e . s t a r t () ; 34 35 // File w r i t i n g 36 A u d i o S y s t e m . w r i t e (new A u d i o I n p u t S t r e a m ( t a r g e t D a t a L i n e ) , 37 fileType , a u d i o F i l e ) ; 38 39 // C l a s s n o t i f i c a t i o n for s y n c h r o n i z a t i o n 40 A u d i o R e c o r d e r .c l a s s. n o t i f y A l l () ; 41 42 } c a t c h ( E x c e p t i o n e ) { 43 e . p r i n t S t a c k T r a c e () ; 44 } 45 } 46 47 } 48 }
Now it is important to understand how the Wave file is defined and why it is important to define a specific kind of files for this project.
4.3
The Wave file
The ’WavFile’ class includes many functions unnecessary for this work, which could be used for a future improvement or for adding other features to this project. I use this function to create a WavFile starting from the file previously created. There are some other functions to retrieve some information, but it is possible create a new WavFiles without any bases or create one from a non audio file. Now, I describe in details the used functions only, but it is important to specify the high complexity of this class.
4.3.1
The generic WAV file structure
To create a WavFile from ’junk.wav’ it is necessary to know what is its internal structure [6]. The file is divided in three main parts: the ’RIFF’ chunk descriptor, the ’fmt’ sub-chunk and the ’data’ sub-chunk as it is shown in Figure 4.1.
The ’RIFF’ chunk is the header of the file and describes the file type and its data dimension in bytes. It is composed by 12 bytes, so the first 12 bytes of ’junk.wav’ are only useful for the data dimension. The ’WavFile’ class extracts all information: with a buffer and a counter to know how many bytes are already read.
30 Chapter 4. Java implementation
Figure 4.1: The Wav file structure
1 // Read the f i r s t 12 b y t e s of the file
2 int b y t e s R e a d = w a v F i l e . i S t r e a m . read ( w a v F i l e . buffer ,
0 , 12) ;
3 if ( b y t e s R e a d != 12) t h r o w new W a v F i l e E x c e p t i o n (" Not e n o u g h wav file b y t e s for h e a d e r ") ;
4
5 // E x t r a c t p a r t s from the h e a d e r
6 long r i f f C h u n k I D = g e t L E ( w a v F i l e . buffer , 0 , 4) ; 7 long c h u n k S i z e = g e t L E ( w a v F i l e . buffer , 4 , 4) ; 8 long r i f f T y p e I D = g e t L E ( w a v F i l e . buffer , 8 , 4) ;
The same operation is applied for the ’fmt’ sub-chunk, which contains the encoding information. The most useful chuck is the last one: after the first 8 bytes which identify the chunk and its dimension, there are the data bytes of the audio track. So it is possible to extract these bytes into an array: I use the function ’readFramesToDouble’ to extract the data into a double precision array.
4.4. Sending and receiving data 31 1 p u b l i c d o u b l e[] r e a d F r a m e s T o D o u b l e (d o u b l e[] s a m p l e B u f f e r , 2 long n u m F r a m e s T o R e a d ) t h r o w s I O E x c e p t i o n , W a v F i l e E x c e p t i o n { 3 int c o u n t = 0; 4 if ( i o S t a t e != I O S t a t e . R E A D I N G )
5 t h r o w new I O E x c e p t i o n (" C a n n o t read from W a v F i l e
i n s t a n c e ") ; 6 7 for (long f = 0; f < n u m F r a m e s T o R e a d ; f ++) { 8 for (int c = 0; c < n u m C h a n n e l s ; c ++) { 9 s a m p l e B u f f e r [ c o u n t ] = f l o a t O f f s e t + (d o u b l e) r e a d S a m p l e () 10 / f l o a t S c a l e ; 11 c o u n t ++; 12 } 13 } 14 15 r e t u r n s a m p l e B u f f e r ; 16 }
Now I have all information needed and other information which can be used in future.
4.4
Sending and receiving data
This section contains a brief introduction of the functions used to send and receive data in Java. A more complete description is available in theChapter 6.
The output and the input streams are defined with the functions DataOutput-Stream and DataInputDataOutput-Stream and they are used to handle specific data: I send to the Server the dimension of the audio data array, the number of channels used to record the audio track, the audio track duration, the sample rate and, finally, the samples; I receive from the Server the length of the final data array and the final data. These data are exchanged between Client and Server in byte array due to their different programming languages.
Listing 4.7: The buffer and the counter ’bytesRead’
1 // S e n d i n g the a r r a y d i m e n s i o n 2 byte[] a m p l D i m = B y t e B u f f e r . a l l o c a t e (4) . p u t I n t ( b y t e A m p l . l e n g t h ) 3 . a r r a y () ; 4 dos . w r i t e ( a m p l D i m ) ; 5 6 // S e n d i n g the n u m b e r of c h a n n e l s 7 byte[] n u m O f C h a n n e l s = B y t e B u f f e r . a l l o c a t e (4) 8 . p u t I n t ( w a v F i l e . g e t N u m C h a n n e l s () ) . a r r a y () ;
32 Chapter 4. Java implementation
9 dos . w r i t e ( n u m O f C h a n n e l s ) ; 10
11 // S e n d i n g the a u d i o t r a c k d u r a t i o n
12 byte[] dur = new byte[8];
13 B y t e B u f f e r . wrap ( dur ) . p u t D o u b l e ( d u r a t i o n ) ;
14 dos . w r i t e ( dur ) ; 15
16 // S e n d i n g the s a m p l e rate
17 byte[] s R a t e = new byte[8];
18 B y t e B u f f e r . wrap ( s R a t e ) . p u t D o u b l e ( 19 (d o u b l e) w a v F i l e . g e t S a m p l e R a t e () ) ; 20 dos . w r i t e ( s R a t e ) ; 21 22 // S e n d i n g s a m p l e s 23 dos . w r i t e ( b y t e A m p l ) ; 24 25 // R e c e i v i n g i n t e n s i t y tier data a r r a y l e n g t h
26 byte[] l e n g t h I n t = new byte[8]; 27 dis . read ( l e n g t h I n t ) ;
28
29 // R e c e i v i n g i n t e n s i t y f i n a l data 30 byte[] f i n a l D a t a I n t = new byte[
l e n g t h F i n a l D a t a I n t ];
31 dis . read ( f i n a l D a t a I n t ) ; 32
33 // R e c e i v i n g p i t c h tier data a r r a y l e n g t h
34 byte[] l e n g t h P i t c h = new byte[8]; 35 dis . read ( l e n g t h P i t c h P i t c h ) ;
36
37 // R e c e i v i n g p i t c h f i n a l data 38 byte[] f i n a l D a t a P i t c h = new byte[
l e n g t h F i n a l D a t a P i t c h ];
39 dis . read ( f i n a l D a t a P i t c h ) ;
The received data are converted from byte to the original primitive type, both of them in double precision numbers. There is a problem to convert a byte array in an integer number: there is not a dedicated function, so it is very difficult to find the right conversion. Due to this problem, I decided to send the array length of the final data in double precision data, like the final data. However, a full disclosure is treated in the Chapter 6.
4.5
The final results
In this section, the final data, expressed in double precision numbers, are ready to be shown to the user: I use JFree [21] Chart library to render the graph, but it is possible to implement other libraries. In this case, the result is a ’TimeSeries
4.5. The final results 33
Chart’ and an example is shown in Figure4.2.
Chapter 5
Praat implementation
In this chapter I explain the role of Praat in this project. The development of this project’s part is the hardest challenge of the system. I needed to explore in deep how this program works to understand how I can modify its functionalities: I spent lots of time at the beginning of the project analysing its source code. The result of this analysis is the discovery of the Praat stand-alone version, that is the possibility to run Praat executing a script without loading the initial graphical interfaces. This aspect allows to create a double-click program which quickly executes a script in Praat environment.
The main problem is how to translate the Praat functions: when I execute Praat there is a set of available functions, as it is introduced inChapter 3, and, for some of them, I can set some parameters. So, I need to understand how to call a function and set parameters in a script. This is explained in the next section, because it is important understand how scripts work before to deal the stand-alone version.
5.1
Praat scripts
A script is a text that consists of Praat commands [17]. When a script is executed the correspondence commands are executed as if they are clicked in the interface. So, to execute a command, it is necessary to know its name and its parameter: to separate the command name from its parameters there are three dots. In Praat, three dots are the separator between name and parameters. Then if a function has many parameters, they are separated with a space. In this project I use one script to trigger the stand-alone version and one to other operations.
Listing 5.1: Example of Praat script
1 c o n s t c h a r 3 2 m y S c r i p t [ ] = U" "
2 " demo Text : 0.5 , \" c e n t r e \" , 0.5 , \" half \" , \" H e l l o
w o r l d \"\ n "
3 " d e m o W a i t F o r I n p u t ( ) \ n "
4 ;
However, this does not represent the complete syntax of Praat script, but only the useful part for this project, that is commands execution. Praat has a dedicated
36 Chapter 5. Praat implementation
syntax which allows to write complex script using special operations in addition to the typical programming language constructs, like loops or if statements.
Another particularity of this script is the type: it is defined as a char32_t array. Char32_t it is a character representation, required to be large enough to represent any UTF-32 code unit (32 bits) [5].
The execution of this script follows an tortuous path: it start when a script is executed. When a script is executed its contents are examinated: if it is not empty, a dedicated function is called to execute the script. Here, an interpreter is created and executed with the script: the interpreter explores the script’s text to analyze one command at a time.
Listing 5.2: The scripts execution function
1 void p r a a t _ e x e c u t e S c r i p t F r o m T e x t (c o n s t c h a r 3 2 * text ) { 2 try { 3 a u t o I n t e r p r e t e r i n t e r p r e t e r = I n t e r p r e t e r _ c r e a t e ( nullptr , n u l l p t r ) ; 4 a u t o s t r i n g 3 2 s t r i n g = M e l d e r _ d u p ( text ) ; 5 I n t e r p r e t e r _ r u n ( i n t e r p r e t e r . peek () , s t r i n g . peek () ) ; 6 } c a t c h ( M e l d e r E r r o r ) { 7 M e l d e r _ t h r o w ( U" S c r i p t not c o m p l e t e d . ") ; 8 } 9 }
For each command it extracts its name and its argument, addressing the execution in ’praat_Fon.cpp’ file. This file contains many command’s execution definition and it gives back the result of commands execution. Then, the execution of a single command ends and the interpreter checks if there is another command. If the script is finished the interpreter ends and the program stop its execution.
This is the script execution, even if it is not the only possible execution. It is possible nested script or concatenate their execution. Finally, there is the stand-alone version script execution, which is described in the next section.
After understanding this concepts it is possible to introduce the Praat stand-alone version.
5.2
The Praat stand-alone version
This Praat version allows to avoid the load of graphical interfaces, execut-ing directly a script. This aspect allows to increase significantly the speed of execution. The ’main’ function of Praat source code is in the ’main_Praat.cpp’ file: here there are functions to initialize and run Praat and the function that allows to switch the execution of the program from classical to stand-alone mode: ’praat_setStandAloneScriptText(myScript)’. Originally, this function is executed
after the initialize function, without any kind of effects. To make useful this func-tion, it is necessary to execute it before the Praat initialization funcfunc-tion, as it is reported in Praat manual [15]. The other main aspect is the script, which must not to be equal to ’NULL’. If the script is equal to ’NULL’ the execution of this
5.3. The Server 37
function produces no effects. The definition of this function is in ’Praat.cpp’ file, the same of the initialization function. So, when the script is different to ’NULL’, the stand-alone function set a variable with the script value.
Listing 5.3: The Praat stand-alone function
1 s t a t i c c o n s t c h a r 3 2 * t h e P r a a t S t a n d A l o n e S c r i p t T e x t = n u l l p t r ; 2 3 void p r a a t _ s e t S t a n d A l o n e S c r i p t T e x t (c o n s t c h a r 3 2 * text ) { 4 t h e P r a a t S t a n d A l o n e S c r i p t T e x t = text ; 5 }
Then the initialization function is executed. After it, the Praat execution starts until an if statement which checks the contents of the ’thePraatStandAloneScript-Text’ variable: if it is ’true’ a function dedicated to execute script is called and Praat execution ends.
Listing 5.4: Scripts’ control, execution and termination
1 if ( t h e P r a a t S t a n d A l o n e S c r i p t T e x t ) { 2 try { 3 // The s c r i p t e x e c u t i o n d e d i c a t e d f u n c t i o n 4 p r a a t _ e x e c u t e S c r i p t F r o m T e x t ( t h e P r a a t S t a n d A l o n e S c r i p t T e x t ) ; 5 // P r a a t is t e r m i n a t e d 6 p r a a t _ e x i t (0) ; 7 } c a t c h ( M e l d e r E r r o r ) { 8 M e l d e r _ f l u s h E r r o r ( p r a a t P . title , U" : stand - a l o n e s c r i p t s e s s i o n i n t e r r u p t e d . ") ; 9 p r a a t _ e x i t ( -1) ; 10 } 11 }
This is the stand-alone Praat version standard execution, but for this project it is not enough. I had changed this code to hijack the Praat execution: I have replaced the ’praat_executeScriptFromText (thePraatStandAloneScriptText)’ function with another one, which allows the creation of the Server.
The execution of this function and its effects are treated in the next section, to better understand how this system works and how it is possible to realize with this method.
5.3
The Server
In this section I explain in details the Server implementation and all the modifies introduced in the Praat source code to realize it.
First of all, there is an hijacking of the stand-alone execution: as it said in the previously section, I have introduced a change in the original code. I create a new
38 Chapter 5. Praat implementation
’interpreter’, which is the object that recognize the script commands and execute them, and a function to create the Server istance.
Listing 5.5: Interpreter creation and Server function call
1 if ( t h e P r a a t S t a n d A l o n e S c r i p t T e x t ) { 2 try { 3 // I n t e r p r e t e r c r e a t i o n 4 a u t o I n t e r p r e t e r i n t e r p r e t e r = I n t e r p r e t e r _ c r e a t e ( nullptr , n u l l p t r ) ; 5 // S e r v e r f u n c t i o n call 6 s o c k e t S e r v e r ( i n t e r p r e t e r . t r a n s f e r () , t h e P r a a t S t a n d A l o n e S c r i p t T e x t ) ; 7 p r a a t _ e x i t (0) ; 8 } c a t c h ( M e l d e r E r r o r ) { 9 M e l d e r _ f l u s h E r r o r ( p r a a t P . title , U" : stand - a l o n e s c r i p t s e s s i o n i n t e r r u p t e d . ") ; 10 p r a a t _ e x i t ( -1) ; 11 }
The Server definition is in ’Praat_script.cpp’ because of there is also the function to execute the script from a script, that is the ’praat_executeScriptFromText’ function. I have made this choice because this Server is an alternative to the standard execution of the Praat stand-alone version: the aim of this Server is to execute some operations, included scripts execution. So I thought that the right Server location is in the same file of the function which usually executes scripts.
The function ’socketServer’ has two parameters: an interpreter instance, to execute the script, and the the script to execute. Then the Server is defined, initialized and started: there are the classical operation, like the socket address structure definition and the binding of the Server.
Listing 5.6: Socket definition, binding and listening
1 // C r e a t e the s o c k e t 2 s o c k e t _ d e s c = s o c k e t ( AF_INET , S O C K _ S T R E A M , 0) ; 3 if ( s o c k e t _ d e s c == -1) { 4 p r i n t f (" C o u l d not c r e a t e s o c k e t ") ; 5 } 6 puts (" S o c k e t c r e a t e d ") ; 7 8 // P r e p a r e the s o c k a d d r _ i n s t r u c t u r e 9 s e r v e r . s i n _ f a m i l y = A F _ I N E T ; 10 s e r v e r . s i n _ a d d r . s _ a d d r = I N A D D R _ A N Y ; 11 s e r v e r . s i n _ p o r t = h t o n s ( 8 8 8 8 ) ; 12 13 // Bind
14 if ( bind ( s o c k e t _ d e s c , (s t r u c t s o c k a d d r *) & server ,
s i z e o f( s e r v e r ) ) < 0) {
15 // p r i n t the e r r o r m e s s a g e 16 p e r r o r (" bind f a i l e d . E r r o r ") ;
5.4. The sound analysis 39
17 exit (0) ; 18
19 }
20 puts (" bind done ") ; 21
22 // L i s t e n
23 l i s t e n ( s o c k e t _ d e s c , 3) ;
After this preliminary definition, the Server waits an incoming connection from the Client. When the connection is accepted there are a set of incoming informa-tion from the Client, which needed a conversion from byte array in their original primitive types.
After this operations, data are ready to be analyze, as it is described in the next section.
5.4
The sound analysis
In this section I describe and analyze processes, particular aspects and problems treated. The first phase is a meticulous exploration of the Praat source code, to understand how the system works and deals the audio track. In particular how create a sound object and how make it ready with a set of operations thought for it: extraction of points in the intensity domain and in pitch domain. These operations are treated in a dedicated section, to better understand the different between them. Chronologically, I start with the presentation of the sound object creation and then with descriptions of the points extraction in intensity domain and, finally, of the points extraction in pitch domain.
5.4.1
The creation of the sound object
The data coming to the Client are rough: the analysis operations consider the samples of the audio track only. These samples, represented by double precision numbers, are the audio part of the track recorded into the Client. So I need to create a Praat object to represent these data as a single sound. Exploring the source code, I have found the ’SoundRecorder.cpp’ file, where there are the Praat functionalities aimed to record an audio track. I follow these functions to realize a dedicated set of operations to create a new audio object directly from the samples, more specifically, from the function ’publish’. So I create a new sound object, with the ’Sound_create’ function, with the information reached from the Client: the track number of channels, the track duration, the number of samples and the sample rate.
Listing 5.7: The sound creation function
1 a u t o S o u n d S o u n d _ c r e a t e (long n u m b e r O f C h a n n e l s , d o u b l e
xmin , d o u b l e xmax , long nx , d o u b l e dx , d o u b l e x1 ) {
2 try {


![Figure 2.2: The main characteristics of the computer used to develop the system Furthermore, I can recommend to use a Steinberg UR22 mkII audio card [20]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7525201.106418/32.892.139.784.748.1021/figure-characteristics-computer-develop-furthermore-recommend-steinberg-audio.webp)