Dipartimento di Ingegneria dell'Informazione
CORSO DI LAUREA MAGISTRALE IN
INGEGNERIA INFORMATICA PER LA GESTIONE D’AZIENDA
Progetto e implementazione di un sistema per
l'individuazione di eventi critici per la viabilità
mediante analisi dei tweet
Candidato:
Fabio Cempini
Relatori:
Prof. Francesco Marcelloni
Prof.ssa Beatrice Lazzerini
Ing. Pietro Ducange
Indice Generale
Riassunto...5
Introduzione...6
Capitolo 1: Workflow Requisiti...8
1.1 Requisiti funzionali...9
1.2 Blocchi funzionali...11
1.2.1 Modulo Social Sensing...13
1.2.2 Modulo di Pre-Elaborazione dei dati...14
1.2.3 Modulo Text Analysis...14
1.2.4 Modulo Classificazione...15
1.3 Analisi dei dati...15
1.4 Principali Funzionalità...18
1.4.1 Funzionalità Amministratore Utenti...18
1.4.2 Funzionalità Utente...19
1.4.3 Funzionalità Amministratore Modulo Classificazione...19
1.5 Requisiti non funzionali...20
Capitolo 2: Studio di Fattibilità...21
2.1 Analisi contesto...21
2.1.1 Introduzione a Twitter...21
2.1.2 Introduzione alla Pre-Elaborazione dei dati...24
2.1.3 Introduzione all'apprendimento automatico...27
2.1.4 Introduzione al Text Mining...27
2.1.6 Introduzione ai problemi del linguaggio naturale della lingua Italiana....34
2.1.5 Situazione attuale...35
2.2 Possibili soluzioni riguardanti aspetti legati all'Implementazione...36
2.2.1 Architettura software...36
2.2.2 Gestione server...38
2.2.3 Connessione tra host...40
2.2.4 Linguaggi di programmazione...40
2.2.5 Sicurezza informatica...42
2.3 Soluzione proposta...43
Capitolo 3: Workflow Analisi...49
3.1 Casi d'uso...50
3.1.1 Diagramma dei casi d'uso...51
3.1.1 Specifiche dei casi d'uso...54
3.2 Classi di analisi...74
3.2.1 Package Utente...76
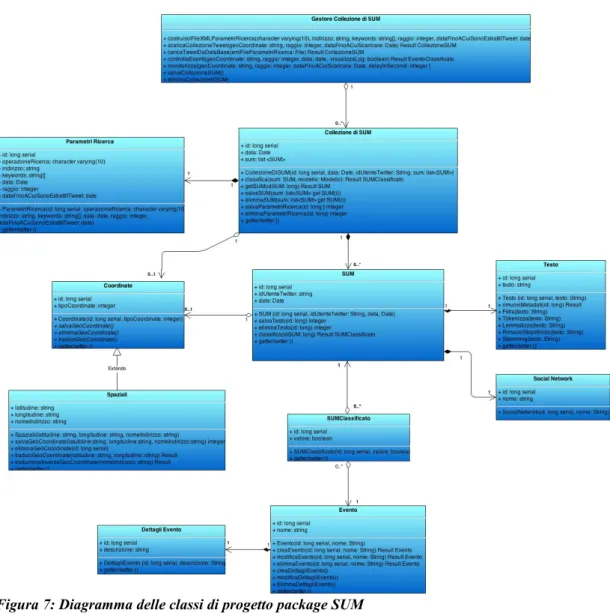
3.2.2 Package SUM...77
3.2.3 Diagramma delle classi di analisi completo...80
Capitolo 4: Workflow Progetto...82
4.1 Classi di progetto...82
4.1.1 Package Utente...83
4.1.2 Package SUM...84
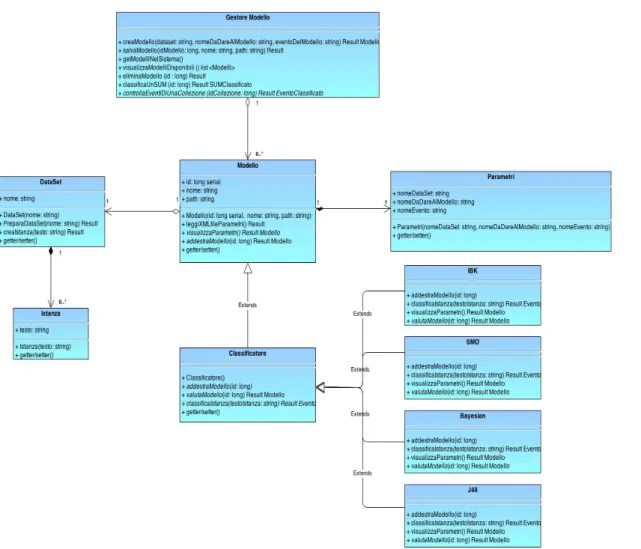
4.1.3 Package Modello...86
4.1.4 Package Completo...87
Capitolo 5: Workflow Implementazione...89
5.1 Architettura software...90
5.2 Il database...93
5.3 Social Sensing da Twitter...103
5.3.1 Twitter4J...104
5.4 Gestione delle GeoLocazioni: GoogleMapsAPI...106
5.5 Integrazione nel sistema delle funzionalità di Weka...109
5.6 Rimozione dei metadati dai tweet...112
5.7 JDBC: Collegamento tra EJB e database...113
5.8 Web Service...114
5.9 Servizi esposti...115
5.9.1 Servizi esposti agli utenti...116
5.9.2 Servizi esposti all'amministratore del modulo di classificazione...125
5.10 Oggetti restituiti dai servizi...136
5.10.1 Codici di Errore...143
Capitolo 6: Sperimentazione e Test...145
6.1 Training set...146
6.2 Considerazioni sui filtri...149
6.3 Filtered Classifier...152
6.3.1 MultiFilter...153
6.3.2 StringToWordVector...153
6.3.3 AttributeSelection...157
6.4 Classificatori...158
6.5 Valutazioni sul modello con 3 classi...165
6.6 Test su caso reale di evento critico...167
Capitolo 7: Conclusioni e sviluppi futuri...178
Indice delle Illustrazioni...179
“I computer sono incredibilmente veloci, accurati e stupidi. Gli uomini sono incredibilmente lenti, inaccurati e intelligenti. L'insieme dei due costituisce una forza incalcolabile.”
Riassunto
Il lavoro svolto riguarda il progetto e l'implementazione di una piattaforma informatica per l'estrazione di informazioni da SUM (Status Update Messages) provenienti dai social network. Le informazioni estratte vengono analizzate tramite tecniche di text mining ed utilizzate per il riconoscimento di eventi critici legati alla viabilità (presenza di traffico, manifestazioni, incidenti, ecc.).
Inizialmente sono stati analizzati i requisiti funzionali del sistema da realizzare ed è stato effettuato uno studio di fattibilità. E' stata condotta una fase di analisi nella quale sono stati individuati e descritti i vari casi d’uso. Sono state poi realizzate le classi di analisi per modellare i concetti chiave del dominio. La successiva fase di progetto è stata realizzata evolvendo gli studi effettuati durante la fase di analisi. Il sistema progettato è stato realizzato implementando dei servizi web tramite il paradigma J2EE (Java 2 Enterprise Ediction). Dopo una fase di test dei servizi implementati, è stata condotta una sperimentazione sul campo in cui la piattaforma è stata utilizzata per individuare degli eventi di criticità della viabilità.
Parole chiav e : Sistema informativo, text mining, analisi di tweet, identificazione di eventi, viabilità, locazione, traduzione di geo-coordinate, classificazione.
Introduzione
Con “social sensing” si intende un'attività di monitoraggio che ha lo scopo di rilevare, attraverso sensori sociali, informazioni inerenti alle attività di un insieme di persone in una città [1]. I sensori sociali non sono altro che i vari dispositivi mobili (smartphone, tablet, netbook, ecc.) usati ogni giorno dalle persone, che permettono la creazione e lo scambio di contenuti attraverso i Social Network; le informazioni raccolte da questi sensori, definite "Status Update Messages" sono i post, i tweet, i commenti, ecc. [2].
Attraverso il social sensing è possibile acquisire informazioni su un certo tema o sul verificarsi di un evento sfruttando le informazioni (inerenti a quel tema o a quell’evento) che gli utenti, singolarmente o in gruppi, condividono sui Social Network.
Oggi la quantità di Status Update Messages prodotti dai social network è estremamente elevata: Twitter ha recentemente dichiarato di gestire oltre mezzo miliardo di tweet al giorno, Facebook ha superato il miliardo di utenti e gestisce altrettanti status update ogni giorno [3]. Oltre a ciò si deve tenere in considerazione il successo e il diffondersi dei “nuovi” social network in continua crescita, come ad esempio Linkedin, Instragram, Google+, MySpace, ecc [4].
Per estrarre conoscenza dalle informazioni ricavate tramite il social sensing, sono necessarie applicazioni software che sfruttino e implementino la teoria dell'estrazione di informazioni da dati testuali “Knowledge discovery from data” [5].
potenzialità delle informazioni ricavate tramite social sensing e che estragga da queste “conoscenza” con tecniche specifiche di Text Mining [6], al fine di individuare eventi critici per la viabilità in maniera "real time". Senza alcun dubbio, la tempestiva individuazione di tali eventi migliorerebbe la qualità della vita e ridurrebbe gli sprechi economici.
Per creare un sistema informativo idoneo è innanzitutto stato necessario effettuare un'analisi dei requisiti funzionali del sistema e uno studio di fattibilità che permetta di capire cosa deve essere realizzato e in che modo. Tali fasi vengono descritte rispettivamente nei Capitoli 1 e 2. La fase successiva è stata quella di "workflow analisi" [7] e viene descritta nel Capitolo 3. Questa fase ha consentito di descrivere il problema con l’utilizzo di vari diagrammi, nonché di creare dei modelli in grado di esprimere con chiarezza il comportamento desiderato del sistema. Nel capitolo 4 viene descritta la fase di "workflow progetto" [8], nella quale partendo dal modello di analisi, si è arrivato a specificare completamente come saranno implementate le funzionalità del sistema. Nel Capitolo 5 si descrive l'implementazione effettiva di quanto specificato nelle fase precedenti. Nella tesi, questa fase ha previsto la realizzazione della base di dati e l’implementazione di servizi web che compongono la logica di business dell'applicazione. Il Capitolo 6 descrive la fase di test dei servizi implementati e messi a disposizione degli utenti finali. In particolare, è stata effettuata una sperimentazione sul campo in cui la piattaforma è stata utilizzata per individuare eventi reali di criticità della viabilità.
Capitolo 1: Workflow Requisiti
La maggior parte delle attività riguardanti il flusso di lavoro dei requisiti vengono svolte durante le fasi di avvio ed elaborazione, proprio all'inizio del ciclo di vita di un progetto. Difatti, il flusso di lavoro dei requisiti deve definire con chiarezza e semplicità quello che il sistema dovrà fare prima ancora di iniziare le attività di analisi e progettazione OO (Object Oriented), è necessario quindi avere un'idea ben chiara su cosa si voglia ottenere, ed è questo il fine ultimo del flusso di lavoro dei requisiti.
Con il termine “Ingegneria dei requisiti” si descrivono le attività necessarie per raccogliere, documentare e tenere aggiornato l'insieme dei requisiti di un sistema software. Secondo “Standish” [9] requisiti incompleti e mancanza di coinvolgimento degli attori sono due delle principali cause di fallimento dei progetti software.
Esistono due tipologie di requisiti: i requisiti funzionali che, catturati dai casi d'uso, indicano cosa il sistema farà; i requisiti non funzionali che riguardano vincoli aggiuntivi sul sistema in merito a proprietà o vincoli specifici del sistema stesso (prestazioni, affidabilità, scalabilità, ecc).
I diagrammi dei casi d’uso, delle classi, di sequenza e attività che sono stati usati in questo e nei capitoli successivi sono stati realizzati tramite i programmi Visual Paradigm 11.0 e draw.io seguendo le specifiche UML standard 2.0 (Unified Modeling Language), un linguaggio di modellazione unificato che fornisce una sintassi di modellazione visuale unica per l’intero ciclo di vita del software (dalle specifiche all’implementazione). Usato anche per modellare differenti domini applicativi (da sistemi embedded a sistemi di supporto alle decisioni) UML è indipendente dal linguaggio di
programmazione e dalla piattaforma su cui viene sviluppato il software. Questi diagrammi hanno il compito di descrivere in modo chiaro tutto ciò che durante un progetto potrebbe risultare difficile o troppo lungo descrivere con una documentazione di tipo testuale.
Grazie a tali diagrammi è stato possibile analizzare e progettare sia la struttura statica del sistema in esame, che descrive quali tipi di oggetti sono importanti per modellare il sistema e come essi siano connessi, sia il comportamento dinamico, che descrive il ciclo di vita di questi oggetti e come essi interagiscono l’un l’altro per compiere le funzionalità richieste.
1.1 Requisiti funzionali
L'obbiettivo principale dell’applicazione che si intende progettare è quello di monitorare la presenza di eventi critici riguardanti la viabilità e scoprire così informazioni interessanti ed importanti relative ad una città, alla viabilità urbana e alle abitudini della gente che la popola.
L’idea è quella di andare a leggere gli Status Update Messages [2] (che chiameremo con l'acronimo di SUM da qui in avanti) provenienti dai social network e riconoscere tramite questi possibili situazioni di traffico intenso e le eventuali cause che l'hanno generato (incidente, manifestazione, ecc). Attualmente la macchina è il mezzo di trasporto più in uso e popolare. Le congestioni di traffico causano perdite di denaro, tempo e pazienza da parte delle persone. Ad esempio le perdite di denaro in America a causa del Traffico superano i 100 miliardi di dollari [10]. Quindi, guidare in maniera efficiente evitando il traffico, strade congestionate, incidenti stradali, manifestazioni è
quantomai attuale e necessario.
Studi attuali indicano che la mole delle informazioni testuali al giorno d'oggi è superiore all'80% delle informazioni totali disponibili [11] e che di queste, una percentuale estremamente elevata è relativa ai dati provenienti dai social network tramite i SUM. Queste informazioni sono in continuo aumento ed evoluzione esponenziale con il diffondersi dell'uso di nuovi social network (Twitter, Linkedin, Instragram, Google+ ecc). Molte delle informazioni attualmente postate sono effettuate in maniera real-time dagli utenti con l'ausilio dei propri smartphone (circa il 46% dei SUM postati). É pensabile quindi utilizzare le persone come dei “Social Sensors” real-time [12]. La piattaforma software che andremo a sviluppare deve quindi andare a scaricare i SUM d'interesse dai social network sulla base di parametri di ricerca spaziali, geografici, temporali, testuali; tali SUM saranno poi passati al processo di estrazione di conoscenza dai dati (Knowledge Discovery in Databases o KDD) che è il processo automatico iterativo di esplorazione ed analisi dei dati con lo scopo di estrarre da questi nuova conoscenza utile e questa sarà utilizzata per trarre delle conclusioni sulla presenza o meno di eventi in maniera real-time.
La piattaforma software dovrà inoltre integrare un database in maniera efficiente ed efficace per la memorizzazione della grande quantità di dati che si prevede e fornire una grande scalabilità per poter gestire la grande eterogeneità dei dati riguardante i differenti formati dei SUM provenienti da differenti social network.
In tutti i servizi che la piattaforma software mette a disposizione si fa riferimento all'oggetto SUM che codifica i messaggi postati dagli utenti dei vari social network. Si parla di tweet per i SUM provenienti da Twitter, di post per quelli di Facebook, ecc. I web service saranno implementati nella maniera
più scalabile possibile al fine di essere utilizzati anche con SUM provenienti da altri social network.
1.2 Blocchi funzionali
In Figura 1 si mostra lo schema a blocchi dell’architettura logica del sistema software progettato. Essa è costituita da quattro blocchi funzionali.
La piattaforma software progettata coinvolge al suo interno diverse tipologie di attori e la Tabella 1 descrive le principali mansioni che essi
svolgono e i legami che questi hanno con il sistema. Le possibilità d'interazione attore per attore con il sistema proposto saranno presentate nei capitoli successivi.
Tabella 1: Principali attori e loro mansioni
Attori Principali mansioni
Amministratore Utenti Si occupa della gestione degli utenti.
Utente L'utente del sistema. Effettua una
richiesta specificando parametri di ricerca spaziali, temporali, testuali, aspettandosi come restituzione la lista dei SUM corrispondenti, le classificazioni per i SUM, il verificarsi o meno di eventi.
Tempo Attiva alcuni servizi offerti dal sistema ad
intervalli temporali.
Amministratore Modulo Classificazione Costruisce i modelli di classificazione per effettuare il text mining. Imposta valori e parametri per quanto concerne il modulo di pre-elaborazione dei dati. Effettua operazioni di testing e sviluppo sulla piattaforma.
Nel progettare la piattaforma software si dà per scontata la presenza di una gestione degli utenti a “monte” dei servizi offerti. Tale gestione non si sa ancora se sarà gestita da noi o sarà delegata appoggiandosi su servizi offerti da un ente esterno. Gli attori del sistema vengono descritti nella Tabella 1 e
mostrati in Figura 1 per avere una maggiore visione d'insieme e per capire come i servizi che il sistema software proposto mette a disposizione e come questi vengono invocati e da chi. Tratteremo brevemente quella che potrebbe essere una gestione degli utenti a monte della nostra piattaforma software in questo contesto: ogni utente per accedere al sistema deve eseguire una semplice operazione di login che si basa sull’inserimento di una username e di una password. Queste saranno rilasciate dall’amministratore degli utenti del sistema al momento dell’iscrizione alla piattaforma software, oppure si potrà integrare un sistema per l'identificazione e il login degli utenti tramite i loro account social network. Il sistema è stato pensato per consentire in futuro l’aggiunta di altri utenti in maniera molto semplice e in maniera di integrare quanto più possibile i diversi utenti aventi uno o più account di social network differenti.
Di seguito vengono descritti brevemente i blocchi funzionali dell’architettura logica della piattaforma software mostrata precedentemente.
1.2.1 Modulo Social Sensing
Le principali funzionalità offerte da questo modulo sono lo scaricamento dei SUM da social network e il caricamento dei SUM salvati in precedenza nel database. Tale modulo consente di specificare i parametri di ricerca tramite i quali vengono scaricati o caricati i SUM corrispondenti. Solamente alcuni di questi parametri saranno dichiarati dall'utente, tutti gli altri saranno impostati di default dall'applicazione caricandoli ad esempio tramite appositi file XML.
1.2.2 Modulo di Pre-processazione dei dati
Le funzionalità offerte dal modulo riguardano la macro fase di pre-processazione dei dati del processo di estrazione di conoscenza dai dati. In particolare, questo modulo dovrebbe offrire funzionalità per la pulizia, l'integrazione, la selezione e poi la trasformazione dei dati [13].
La fase di pulizia avrà il compito di rimuovere dal testo dei tweet i metadati: link esterni, spaziature, ritorni carrello, fine paragrafo, fine capitolo, caratteri speciali. Ovvero di tutto ciò che non porta al proprio interno alcuna informazione significativa.
Le fasi di selezione e trasformazione dei dati avvengono al momento della classificazione dei tweet o alla creazione di un nuovo modello di classificazione. Ad esempio le caratteristiche possono essere estratte tramite tecniche di selezione degli attributi. Le caratteristiche devono poi essere trasformate tramite tecniche di normalizzazione da dati testuali a numerici.
1.2.3 Modulo Text Analysis
All'interno del modulo text analysis i SUM vengono elaborati e preparati per poi consentire la classificazione vera e propria su di essi. Le operazioni principali che devono essere fatte sono lo stemming (riduzione di parole complesse alla loro radice), eliminazione delle stopwords (parole comuni di una lingua), tokenizzazione in singole parole, lemmatizzazione e traduzione delle coordinate spaziali dei SUM in indirizzi testuali e viceversa. Tale modulo si occupa anche della gestione dei risultati restituiti dalla classificazione, della valutazione e della presentazione del risultato finale con l'individuazione di eventi.
1.2.4 Modulo Classificazione
All'interno del modulo classificazione vengono svolte tutte le operazioni riguardanti la gestione, creazione e eliminazione dei modelli di classificazione dei SUM, nonché la classificazione vera e propria per il riconoscimento di eventi. L'amministratore del modulo classificazione e gli ingegneri di data mining lavoreranno a stretto contatto con tale modulo che consente loro di: poter visualizzare i modelli attualmente in uso sulla piattaforma applicativa, poter caricare dataset di training per allenare o testare i modelli di classificazione e poter effettuare tutte le operazioni di gestione del caso (creazione, modifica, eliminazione) su detti modelli.
1.3 Analisi dei dati
Per andare ad effettuare un'attenta progettazione di tutta la piattaforma software e far si che questa risulti quanto più scalabile possibile per future integrazioni e innovazioni sia software sia di servizi esportati, è stato necessario individuare e prendere in considerazione i seguenti flussi di informazioni:
a) SUM provenienti dai vari social network: Gli status update message provenienti da social network distinti sono molto diversi tra loro sia in termini di struttura, sia in termini di privacy dell'utente [14]. I SUM di Facebook si chiamano post, hanno una struttura testuale con una lunghezza massima di 60.000 caratteri, consentono di aggiungere link esterni, foto, e taggare (riferire) determinati utenti. Sono visibili
solamente dagli “amici” dell'utente o persone appartenenti a determinati gruppi (insiemi di utenti che condividono passioni, lavoro, ecc). I SUM di Twitter sono chiamati tweet, sono anch'essi in un formato testuale ma hanno una dimensione massima di 140 caratteri. All'interno dei tweet è possibile inserire foto e links, taggare utenti e argomenti e parole chiave tramite l'uso degli hashtag. L'hashtag serve per dare visibilità al proprio tweet e per facilitarne la ricerca dato che lega il tweet ad un determinato argomento. I profili di Twitter hanno una visibilità pubblica con minori restrizioni di accesso e privacy. Un tweet postato da un utente è totalmente visibile da tutti gli altri utenti. Per quanto riguarda Instagram invece i SUM hanno si un formato testuale, ma questo è principalmente legato al commento inserito sotto ogni foto o immagine postata. La privacy in questo caso è molto simile a quella di Twitter. Una foto inserita all'interno del social network ottiene una visibilità globale. Le foto con maggior numero di “mi piace” e commenti hanno maggiore visibilità. E così via per tutti gli altri social network (Google+, Linkedin, ecc). Per tali motivi il database è stato strutturato nella maniera più scalabile possibile al fine di poter in futuro memorizzare i SUM provenienti da tutti i social network. Nella versione attuale della piattaforma software i servizi offerti prendono in considerazione solamente i SUM provenienti da Twitter, scelti come caso “base” per la poca ristrettezza sulla privacy che offre tale social network. Per tale motivo da qui in avanti useremo in maniera intercambiabile il concetto di tweet con quello di SUM. In contesti reali come questo, in cui si vogliono applicare tecniche di data mining per estrarre conoscenza dai dati, ci si trova spesso davanti ad una notevole quantità di informazioni a disposizione (basti pensare
che l'applicazione può scaricare fino a 35.000 tweet l'ora e salvarli sul database). Tali informazioni provengono da numerose sorgenti eterogenee, per cui frequentemente i dati con cui ci si trova a lavorare sono caratterizzati da inconsistenze, rumore e inesattezze. Di conseguenza, tali dati risultano essere di bassa qualità e la loro successiva analisi potrebbe essere poco soddisfacente. Per evitare ciò, è necessario porre estrema attenzione e dedicare del tempo ad una accurata pre-elaborazione degli stessi; grazie alla quale si possono ottenere dati di qualità, su cui poi basare una specifica analisi. Per tale motivo ai tweet estratti viene applicata una serie di operazioni del processo di pre-elaborazione e data cleaning (operazioni mostrate in dettaglio nei capitoli successivi), al fine di rendere i tweet di qualità. I principali fattori che caratterizzano la qualità dei dati sono: Accuratezza, determina la correttezza di un dato. Completezza, valuta se i dati analizzati sono completi o meno. Consistenza, verifica la consistenza dei dati. Tempo invarianza, valuta il livello di aggiornamento dei dati. Credibilità, riflette quanto i dati sono ritenuti veritieri dagli utenti. Interpretabilità, rispecchia la facilità di comprensione dei dati da parte degli utenti.
b) Dati riguardanti i modelli di classificazione utilizzati: Gli sviluppatori avranno la possibilità di poter accedere alla piattaforma software per prelevare i modelli utilizzati e per poterli testare, modificare, eliminare o semplicemente visualizzare. Per la creazione di un nuovo modello di classificazione, sarà possibile caricare uno o più dataset con cui allenarlo e testarlo per poi renderlo disponibile all'applicazione. Tutti i dati riguardanti i modelli di classificazione sono integrati all'interno dell'applicazione.
c) Dati relativi ai clienti: Si tratta di dati di tipo anagrafico e informazioni relative agli account social network associati ad ogni utente.
d) Dati geografici: Dato che molti servizi messi a disposizione dall'applicazione software usano delle coordinate spaziali o degli indirizzi per poter comunicare con la GoogleMapsApi, è stato necessario integrare opportunamente tali informazioni all'interno del sistema e del database. Sarà possibile, data una coppia di coordinate spaziali latitudine-longitudine, ottenere il corrispettivo indirizzo e viceversa.
1.4 Principali Funzionalità
1.4.1 Funzionalità Amministratore Utenti
La principale funzionalità dell’amministratore è la gestione degli account utente del sistema. Come detto anche in precedenza diamo per scontato a monte dell'applicazione software una gestione della sicurezza e degli account indipendentemente se questa sarà gestita da noi o meno. Un esempio di account utente potrebbe essere il seguente, dove si fa distinzione tra un utente che fornisce i propri permessi legati a un social network per effettuare il login e un utente che non li ha o non li fornisce:
Account utente nome
cognome indirizzo email
recapito telefonico (cellulare o abitazione) *
indirizzo * username password
I campi contrassegnati con * sono campi opzionali, gli altri sono obbligatori
Account utente social network nome cognome indirizzo email recapito telefonico (cellulare o abitazione) * indirizzo * username password
username social network password social network
1.4.2 Funzionalità Utente
L'utente è l'utilizzatore finale dei servizi messi a disposizione dall'applicazione, ovvero sarà in grado di scaricare una lista di tweet in base a dei parametri di ricerca, di ottenere i risultati della classificazione di tali tweet e di venire a conoscenza della presenza o meno di eventi nei punti di interesse da lui specificati.
1.4.3 Funzionalità Amministratore Modulo Classificazione
Con il ruolo di amministratore del modulo di classificazione si intende tutto il team di sviluppatori e ingegneri di knowledge discovery in database. Principale compito dell'amministratore del modulo classificazione è creare e gestire i modelli di classificazione. Carica i nuovi modelli allenandoli con
distinti dataset di training, aggiorna ed edita i modelli qualora necessario cambiando ad esempio il classificatore usato e associato al modello, elimina vecchi modelli qualora siano divenuti obsoleti per l'applicazione software.
1.5 Requisiti non funzionali
Per quanto concerne le specifiche non funzionali, il sistema:
• Deve garantire elevate prestazioni di risposta riguardo i servizi che espone agli utenti tramite web service. Questo per far sì che l'utente non si annoi nell'attendere il risultato di un elaborazione e per far si che in futuro sia possibile integrare i servizi con applicazioni orientate all'interazione diretta con gli utenti, come ad esempio delle App per smartphone.
• Deve avere un database che sia in grado di gestire una grande quantità di dati. Per tale motivo questo deve essere progettato in maniera acconcia con ottimizzazioni di codice sql e scalabilità architetturale massima. Si deve inoltre garantire uno spazio di memorizzazione sufficiente di almeno 1 Tera.
• Dato che è orientato all'esportazione di servizi, è necessario che questi rimangano online il maggior tempo possibile. Questo si ottiene proteggendo il sistema con gruppi di continuità per salvaguardarlo in caso di blackout e implementando una server farm (avere più copie del server in posti differenti e distanti per proteggerlo da catastrofi naturali e attacchi informatici).
Capitolo 2: Studio di Fattibilità
Lo studio di fattibilità ha lo scopo di stabilire se un determinato progetto può essere realizzato dal punto di vista tecnico e se risulta conveniente dal punto di vista economico.
In questo capitolo vengono introdotti sia il social network oggetto della prima release relativa alla piattaforma software; ovvero Twitter, sia tutte le API e i programmi utilizzati al fine dei servizi esportati agli utenti. Questo viene fatto per valutare costi e benefici inerenti.
2.1 Analisi contesto
2.1.1 Introduzione a Twitter
Twitter è un social network gratuito che si occupa di microblogging, ideato
dallo statunitense Jack Dorsey e sviluppato dalla Obvious Corporation di San Francisco. Il servizio offerto agli iscritti è l’inserimento di messaggi, chiamati in gergo tweet, composti da un massimo di 140 caratteri. Fin dalla sua creazione e messa in rete nel marzo 2006, Twitter ha assunto un ruolo di rilievo all’interno dell’insieme dei social network, raggiungendo nel 2012 oltre 500 milioni di utenti iscritti [15]. Giornalmente vengono inviati in media 55 milioni di messaggi, con punte che sfiorano i 3-4 mila tweet al secondo in casi eccezionali solitamente legati a eventi di cronaca di carattere internazionale (disastri ambientali, attentati, eventi e ricorrenze religiose o civili), ma anche
eventi sportivi e politici. Twitter ha assunto in questo caso anche un ruolo di rilievo per la diffusione di notizie [16]: ne sono esempi la cosiddetta Iran’s Twitter revolution, avvenuta durante le elezioni politiche in Iran nel giugno 2009, l’attacco terroristico a Mumbai nel 2008, il terremoto ad Haiti nel gennaio 2010 o, rimanendo sul suolo italiano, il terremoto in Abruzzo dell’aprile 2009, durante il quale gli utenti di Twitter segnalarono prima dei media tradizionali quanto stava accadendo. Di notevole importanza su Twitter è anche l’iscrizione al servizio da parte di numerosi personaggi celebri, fra cui è possibile trovare oltre a innumerevoli personalità dello spettacolo e del mondo della musica, politici, ma anche testate giornalistiche, aziende di importanza mondiale, associazioni e molti che hanno trovato nel servizio offerto da questo social network un metodo veloce per interagire con il resto del mondo. Oltre che semplice testo, all’interno dei tweet è possibile inserire delle parole chiave, dette hashtag, precedute dal carattere #, e link ad altri siti, solitamente abbreviati tramite servizi di URL shorting. I messaggi inseriti dagli iscritti vengono di default resi visibili a chiunque, sia esso iscritto o meno al servizio, mentre è possibile rendere i propri tweet privati per fare in modo che possano essere letti solamente da persone autorizzate. L’inserimento dei messaggi è reso possibile non solo tramite il sito del social network, ma anche da una serie di applicazioni esterne e, limitatamente ad alcuni paesi, tramite SMS. La possibilità di inviare messaggi tramite diversi dispositivi e applicazioni è uno dei punti di forza del social network: il 60% dei messaggi vengono infatti inseriti su Twitter tramite applicazioni realizzate da terze parti, mentre il 37% degli utenti iscritti inserisce i propri tweet tramite cellulare. Gli iscritti al servizio hanno la possibilità di seguire altri utenti registrati: essi assumono in questo caso il nome di follower e hanno la possibilità di visualizzare nella propria home page i messaggi inseriti da tali utenti. È
inoltre possibile seguire liste di utenti, ovvero liste create da altri iscritti in cui è incluso un numero variabile di utenti. Un iscritto può inoltre ripostare un messaggio di un altro utente, in modo che esso sia visibile anche a tutti i propri follower. Questa tecnica è definita retweet e viene segnalata nei messaggi anteponendo i caratteri RT al testo originale.
Come descritto da Ryan Kelly [17] (Analista e web designer per Twitter), i contenuti inseriti dagli utenti su Twitter sono riconducibili principalmente a sei categorie, qui di seguito ordinate in modo decrescente per frequenza: status personali, conversazioni, retweet, self-promotion, spam e news. È bene notare che le conversazioni e gli status personali, calcolati su un campione di tweet raccolti dal social network, raggiungono sommati quasi il 90% totale dei messaggi, mentre il 37.55% del totale è composto da messaggi in risposta ad altri tweet. Per quanto riguarda lo spam e i messaggi di self-promotion (ovvero tweet a solo scopo pubblicitario inseriti da aziende) essi sono limitati al 9.6%. Da queste statistiche è possibile dedurre come Twitter sia divenuto uno dei mezzi più efficaci per condividere le proprie esperienze e di come gli utenti lo utilizzino anche per comunicare fra di loro, riconducendosi all’idea originale di Jack Dorsey di realizzare un servizio simile agli SMS, ma applicato a gruppi di persone e disponibile sul web.
Per questi motivi lo studio di Twitter si è rivelato fin dal principio di enorme interesse essendo un social network molto frequentato, dinamico e in cui gli utenti tramite i loro tweet, contribuiscono a tenere informato il pubblico di quanto stia accadendo attorno ad essi. Si parla difatti in questo caso di Social-Sensors; ovvero di sensori fatti da persone reali che tramite i loro tweet rendono noto alla rete cosa stia accadendo attorno a loro.
2.1.2 Introduzione alla Pre-Elaborazione dei dati
In contesti reali in cui si vogliono applicare tecniche di Data Mining [18] per estrarre conoscenza dai dati, ci si trova spesso davanti ad una notevole quantità di informazioni a disposizione. Tali informazioni provengono da numerose sorgenti, distinte ed eterogenee, per cui, frequentemente i dati con cui ci si trova a lavorare sono caratterizzati da inconsistenze, rumore e inesattezze. Di conseguenza, tali dati risultano essere di bassa qualità e la loro successiva analisi potrebbe essere poco soddisfacente. Per migliorare la qualità, è necessario effettuare un’accurata pre-elaborazione su questi dati allo scopo di rimuovere possibili inconsistenze, ridurre il rumore, gestire valori mancanti, normalizzare e nel caso trasformare i dati, estrarre delle caratteristiche ed eventualmente selezionarle.
I principali fattori che caratterizzano la qualità dei dati sono:
• Accuratezza: determina la correttezza di un dato. Vi sono varie ragioni per cui un dato può risultare inaccurato. Ad esempio, un dato potrebbe essere stato memorizzato con un valore errato a causa di un malfunzionamento del sensore che lo registra oppure a causa di un errore umano nell'inserimento dello stesso all'interno del database. Errori di memorizzazione potrebbero anche essere causati da problemi tecnici nella linea di trasmissione.
• Completezza: valuta se i dati analizzati sono completi o meno. Un insieme di dati, infatti, può essere incompleto a causa, per esempio, della perdita di qualche valore nella trasmissione dei dati o del parziale malfunzionamento di un sensore di acquisizione.
• Consistenza: verifica la consistenza dei dati. Un dato può essere inconsistente a causa di errori, di diverse convenzioni adottate nella
sua memorizzazione, oppure per via dell'integrazione di differenti sorgenti informative.
• Tempo invarianza: valuta il livello di aggiornamento dei dati. Anche tale fattore influisce sulla qualità dei dati, specialmente quando si integrano differenti sorgenti informative.
• Credibilità: riflette quanto i dati siano ritenuti veritieri dagli utenti.
• Interpretabilità: rispecchia la facilità di comprensione dei dati da parte degli utenti.
I principali passaggi che caratterizzano la pre-elaborazione dei dati sono [13]:
• Data Cleaning: vengono utilizzate delle routine di lavoro per “pulire” i dati. Ad esempio, si riempiono con dei valori opportunamente scelti i dati mancanti, vengono filtrati i dati rumorosi, si identificano e rimuovono gli outlier (dati con valori molto distanti da quelli di tutti gli altri dello stesso tipo), si risolvono le inconsistenze trovate.
• Data Integration: si effettua un'integrazione multipla delle sorgenti d'informazione eterogenee che si hanno, come per esempio database, file, e data cube. Vi sono dei problemi che possono nascere dopo tale fase. Dal momento che uno stesso concetto può essere espresso con nomi distinti all'interno di due sorgenti informative diverse, si possono generare inconsistenze e ridondanze (per esempio NomeCliente e Cliente o Id_Cliente e ID_Cli). Può anche accadere che il valore di un attributo sia diverso in due sorgenti distinte, sebbene il concetto espresso da tale valore sia lo stesso (ad esempio, in un database si ha NomeCliente: “Bill Clinton”, in un altro NomeCliente appare: “William Clinton”).
• Data Reduction: i dati raccolti nel mondo reale sono molto numerosi e potrebbe essere estremamente difficile gestirli nelle varie fasi di analisi. Per la riduzione dei dati vengono utilizzate delle tecniche specifiche che mirano a diminuirne il numero individuando una nuova e più efficiente rappresentazione. Questa deve consentire di ottenere risultati similari a quelli che si otterrebbe utilizzando tutti i dati a disposizione. Si parla di riduzione dimensionale quando vengono applicate delle tecniche per codificare i dati secondo degli schemi precisi al fine di ottenere una rappresentazione compressa o ridotta dei dati originari (Trasformata Discreta Wavelet, Principal Component Analysis PCA, tecniche di selezione di attributi). Quando i dati sono sostituiti da delle rappresentazioni di più piccole dimensioni si parla di riduzione della numerosità. Le rappresentazioni possono essere non parametriche, come per esempio istogrammi, cluster, aggregazioni e campionamenti, o basate su modelli parametrici come per esempio regressori o modelli log-lineari.
• Data Trasformation and Discretization: si tratta di tecniche di trasformazione dei dati per garantirne un'analisi e un processo di data mining più efficiente e di qualità. Per esempio, la normalizzazione dei dati è spesso necessaria quando si utilizzano modelli basati sulle reti neuronali e la discretizzazione è utile quando si vuole generare classificatori basati su regole associative.
In conclusione, effettuare operazioni di pre-eleborazione dei dati agevola enormemente il successivo processo di analisi e garantisce risultati migliori. Infatti, rimuovere le anomalie il prima possibile e diminuire il numero dei dati da processare, riduce la possibilità che questi possano generare errori e
produrre risultati falsati.
2.1.3 Introduzione all'apprendimento automatico
La piattaforma software che abbiamo intenzione di realizzare ha tra gli scopi principali quello di fornire agli utenti una panoramica sugli eventi che si generano in base all'analisi dei tweet scaricati dal social network. Come descritto in precedenza (paragrafo 2.1.1) ci si aspetta che la quantità di dati che sarà da analizzare sarà molto alta, per cui avremo necessariamente bisogno di un programma per l'apprendimento automatico dai dati estrapolati [19], ovvero un programma che consenta di effettuare operazioni di data mining.
2.1.4 Introduzione al Text Mining
Il text mining è un particolare tipo di data mining [20] che consiste nell'estrazione di informazioni significative da documenti testuali non strutturati attraverso l’applicazione di tecniche di data mining e il trattamento del linguaggio naturale (Natural Processing Language), allo scopo di:
• individuare i principali gruppi tematici nei documenti e le relazioni tra i gruppi,
• classificare i documenti in categorie predefinite, • scoprire associazioni nascoste,
• estrarre specifiche informazioni (information extraction).
Quando si parla di analisi dei testi, si distingue tra information extraction e text mining vero e proprio. Il primo produce una rappresentazione strutturata della informazione testuale e richiede la definizione di parole chiave da cercare nei documenti o la composizione di query, in modo da produrre un sottoinsieme di documenti su cui effettuare l’elaborazione. Il secondo sfrutta
tecniche proprie di data mining per estrarre automaticamente nuovi concetti o relazioni.
Il text mining si riferisce al processo di estrazione automatica di informazioni significative e conoscenza da documenti testuali non strutturati. Si tratta di una disciplina relativamente giovane che sta ottenendo un elevato interesse dato che circa l’80% dei documenti prodotti ogni giorno dalla società moderna è memorizzato in forma testuale non strutturata (testi liberi) o semi-strutturata (email, documenti html), rendendo quindi di fondamentale importanza gli strumenti automatici di analisi dei testi [21].
Il text mining (o text data mining) può essere definito come una sotto categoria di data mining. Entrambi estraggono informazione significativa e conoscenza da dati, ma si differenziano per il formato dei dati su cui lavorano: il data mining opera essenzialmente su informazioni di tipo strutturato contenute nei database [22], il text mining lavora invece su testi scritti in linguaggio naturale e necessita quindi di una fase di pre-elaborazione dei dati prima dell’effettiva fase di estrazione delle informazioni.
La maggiore difficoltà incontrata nell’affrontare problemi di text mining è proprio causata dall’imprecisione del linguaggio naturale. Infatti, le persone, a differenza dei computer, sono perfettamente in grado di comprendere dialetti, variazioni grammaticali, espressioni gergali, o contestualizzare una data parola. Tuttavia, i computer possiedono l’abilità, mancante negli essere umani, di elaborare velocemente grandi quantità di informazioni.
Il text mining è anche noto in letteratura come Knowledge Discovery in Text (KDT) [23] o Intelligent Text Analysis e sfrutta tecniche caratteristiche di settori di ricerca quali il Data Mining (DM), la Information Retrieval (IR), la Information Extraction (IE), il Machine Learning, la statistica, e
l’elaborazione del linguaggio naturale (Natural Language Processing, NLP). Alcuni degli obiettivi tipici del text mining [24] sono: i) la classificazione di documenti, ii) il raggruppamento di documenti simili (clustering), iii) la scoperta di associazioni nascoste, iv) l’identificazione di entità (nomi), v) l’estrazione di concetti o informazioni, vi) il riassunto di documenti, vii) la categorizzazione di un insieme di documenti (topic tracking), viii) l’individuazione di legami tra argomenti diversi (concept-linkage).
Un processo di text mining si struttura tipicamente in 3 fasi:
• pre-elaborazione e indicizzazione,
• information mining,
• valutazione e interpretazione.
Nella prima fase, viene effettuata una analisi linguistica per arrivare ad una rappresentazione vettoriale (strutturata) del documento. Sotto fasi di questa prima fase sono l’identificazione e la selezione dei termini, la lemmatizzazione, la ponderazione, la definizione delle stop-words, la riduzione della dimensionalità, l’integrazione con meta informazioni. Nella seconda fase, un algoritmo di data mining (di clustering oppure di classificazione) viene applicato ai documenti vettoriali. Il classificatore impara ad individuare, a partire da un insieme di documenti pre-classificati, la classe di appartenenza (categoria) di un nuovo documento. La terza fase consiste nel valutare i risultati ottenuti mediante misure di efficacia.
La fase di pre-elaborazione è necessaria per portare il contenuto informativo del documento in una forma strutturata (vettoriale). La maggior parte delle tecniche di text mining si basa sull’idea che un documento possa essere fedelmente rappresentato dall’insieme di parole contenute in esso (rappresentazione bag-of-words). Ad ogni parola viene poi assegnato un valore
numerico che ne indica l’importanza.
La fase di pre-elaborazione può essere organizzata in due sotto-fasi:
a) Information retrieval: questa fase consiste nella selezione o ricerca di testi/documenti rilevanti in base all’obiettivo prefissato per mezzo di parole chiave, query, tecniche di indicizzazione e tecniche statistiche. Un semplice metodo impiegato per la selezione delle parole chiave è quello basato sul calcolo dell’entropia per stabilire l’importanza di una parola in un certo contesto. Il risultato della fase è un sottoinsieme dei documenti iniziali.
b) Information extraction: questa fase ha come scopo l’estrazione di informazione dall’insieme di documenti selezionati nella fase precedente. Per prima cosa viene effettuata una analisi del testo dei singoli documenti mediante l’applicazione di tecniche di NLP. Successivamente le informazioni estratte dai singoli documenti vengono integrate e considerate globalmente mediante analisi di coreferenza. Infine, i dati vengono rappresentati nel formato vettoriale, tipicamente compilando un template. Al termine di questa fase i documenti sono trasformati in un formato strutturato, secondo un template dipendente dallo specifico problema. Una possibile sequenza di passi per la fase di information extraction può essere la seguente:
• Tokenization: è l’estrazione di tutte le parole (token) presenti nel testo da analizzare mediante la rimozione della punteggiatura e di altri caratteri non testuali e può richiedere una operazione di normalizzazione di simboli quali accenti, apostrofi, trattini e spazi. Il processo è ripetuto su tutti i documenti da analizzare e l’insieme
di token ottenuto è in genere chiamato dizionario dell’insieme di documenti e rappresenta l’insieme di parole che descrivono i documenti considerati e viene generalmente ridotto, in modo da ridurre la dimensionalità del problema, mediante tecniche di filtraggio, lemmatizzazione e stemming.
• Identificazione della parte del discorso (part of speech) (Pos-tagging): è una analisi che serve ad associare ad ogni parola individuata nel testo una meta-informazione (tag) che indica quale parte grammaticale del discorso la parola rappresenta (sostantivo, verbo, aggettivo, ecc.).
• Riconoscimento di nomi: si individuano nel testo nomi propri, nomi noti di persone o luoghi, acronimi, date presenti in un dizionario specifico.
• Word Sense Disambiguation (WSD): questa fase serve a risolvere l’ambiguità creata da parole o frasi che hanno molteplici significati. • Chunking: è l’operazione che individua sequenze di parole adiacenti
nelle frasi del testo che formano una unità strutturale di base (nominale, verbale o aggettivale), detta chunk. Esempi di chunk sono: estratto conto, lavoro nero, carta bianca, capo dello stato. • Filtraggio di parole di tipo stop-word: consiste nell’eliminare dal
dizionario dell’insieme di documenti (e quindi dai documenti) le parole dette stop-word, cioè quelle che apportano poca o nessuna informazione, come articoli, congiunzioni, preposizioni, pronomi, ecc.. Vengono considerate stop-word anche le parole che non hanno rilevanza statistica, cioè quelle che tipicamente appaiono molto spesso nelle frasi della lingua considerata o nell’insieme di
documenti oggetto di analisi e che possono quindi essere considerate rumore. Gli autori in [25] indicato che le 10 parole più frequenti nei testi/documenti di lingua inglese costituiscono ben il 20%-30% dei token di un documento sottoposto ad analisi. Quindi, questo filtraggio permette di ridurre la dimensione dello spazio delle feature (testuali) semplificando il problema, velocizzando le operazioni di analisi e migliorando l’efficienza del processo di text mining. Esistono diverse tecniche per l’individuazione di parole di tipo stop-word in un insieme di documenti, e si distinguono in tecniche di estrazione automatica e tecniche di costruzione artificiale di liste di parole di tipo stop-word. Il metodo più utilizzato consiste nel calcolare la frequenza di una parola e associare un rumore elevato alle parole con frequenza elevata.
• Lemmatizzazione: è il processo che, sfruttando l’analisi POS-tagging, associa alle parole in forma flessa la corrispondente forma canonica (detta lemma o radice morfologica), cioè quella per cui esiste una voce nel vocabolario della lingua considerata. Tipicamente la parola viene etichettata con la meta-informazione inerente il lemma associato. Esempi di lemmatizzazione sono i verbi coniugati riportati alla forma infinita (camminai, cammina, ecc. -> camminare), o le parole plurali riportate alla forma singolare (viaggi -> viaggio).
• Stemming: è il processo che associa alle parole in forma flessa il corrispondente tema (che non necessariamente coincide con la radice morfologica) con lo scopo di raggruppare parole con lo stesso tema aventi una semantica strettamente correlata. Un
esempio di stemming consiste nel riportare le parole gatto, gatta, gattino, gattaccio al tema comune gatt impiegando una tecnica di rimozione del suffisso.
• Pattern matching: consiste nel cercare nel testo sequenze di parole predefinite o pattern noti (numeri di telefono, indirizzi, parole composte di senso compiuto...)
• Analisi di coreferenza: consiste nella risoluzione dei riferimenti (ambigui) dei pronomi in un frase.
Segue poi la fase di Information Mining: in questa fase i noti algoritmi di data mining e machine learning vengono applicati per raggiungere l’obiettivo prefissato (classificazione automatica di documenti, clustering tematico di documenti, scoperta di associazioni/pattern tra i testi/documenti).
Un classificatore automatico addestrato su un insieme di documenti pre-classificati, impara a distinguere le caratteristiche delle classi di interesse ed è in grado di individuare la classe di appartenenza di un nuovo documento.
Infine abbiamo la fase di Interpretazione e valutazione dei risultati in cui si ha un'analisi e interpretazione dei risultati ottenuti mediante misure di efficacia con lo scopo di verificare l’esattezza dell’analisi effettuata o dei pattern estratti. Per migliorare i risultati ottenuti è poi possibile ripetere la fase di pre-elaborazione, completamente o solo in parte, andando a modificare i parametri interessati (ad esempio, ampliare la lista delle stop-words, ampliare i dizionari utilizzati, ecc.).
2.1.6 Introduzione ai problemi del linguaggio naturale della lingua Italiana
Dato che la piattaforma software ha come obiettivo l'estrazione di conoscenza dai tweet postati dagli utenti italiani è stato necessario condurre un'analisi sulla lingua Italiana e evidenziare fin da subito le differenze con l'Inglese dato che per quest'ultimo è ampia e ricca la letteratura a riguardo [26] [27] [28].
Quando si effettua text mining in lingua Italiana, bisogna prestare particolare attenzione alle features che dobbiamo andare a garantire ed implementare. Le differenze tra l'italiano e l'inglese difatti, sono enormi. Basti pensare che il dizionario inglese ha circa 490.000 parole, mentre quello italico ne contiene circa 300.000. La differenza che sta tra l'uno e l'altro deriva da diversi fattori:
• Anzitutto l'alfabeto inglese consta di un numero maggiore di consonanti e vocali, rispettivamente 24 e 23 contro le 16 e 5 della lingua italiana. Questo implica che in generale gli inglesi utilizzano un'unica parola per definire un ben determinato contesto mentre in italiano un'unica parola viene spesso utilizzata per differenti contesti e assume
significati diversi (“pesca” viene utilizzata sia per indicare il frutto, sia per indicare lo sport della pesca).
• In Italiano, allo stesso modo delle parole, aggettivi e avverbi cambiano il senso di una frase e/o di un verbo (portando quindi ad avere un numero maggiore di token e problemi legati alla contestualizzazione automatica durante il text mining) :
Italiano Inglese
girare per negozi to go around
girare una cambiale to endorse
girare un film to shoot
girare a destra to turn
• Oltre a considerare quindi le singole parole e frasi in italiano, bisogna considerare anche le varie possibili abbreviazioni o sigle.
• Si deve inoltre ricordare che essendo il contesto quello di internet, sarà possibile trovare nel testo dei tweet anche un alto numero di parole straniere, entrate oramai di diritto nell'alfabeto degli utenti. (come ad esempio Windows, post, tweet, tag, hashtag, selfie, ecc...)
• In italiano vi sono numerosi dialetti, la classificazione più recente (1975) e anche quella più seguita oggi è quella di Giovan Battista Pellegrini fondata sul concetto di italoromanzo [29]. ovvero considera solo le parlate che hanno come lingua guida l'italiano (escludendo quindi il latino) e sono: dialetti settentrionali, friulano, toscano, dialetti centromeridionali e sardo.
• Molti nomi prendono significati diversi a seconda degli aggettivi a cui sono riferiti: ad esempio terremoto (sisma), terremoto finanziario (brusco cambiamento in borsa).
2.1.5 Situazione attuale
La macchina è il mezzo di trasporto più popolare e in uso attualmente. Le congestioni di traffico causano perdite di denaro, tempo e pazienza da parte delle persone. Ad esempio le perdite di denaro in America a causa del Traffico superano i 100 miliardi di dollari [30]. Per tali motivi l'implementazione di un sistema software che riesca ad individuare eventi critici legati alla viabilità è di enorme interesse. Da una ricerca fatta tramite vari canali è emerso che non esistono applicazioni in commercio che soddisfino i requisiti funzionali richiesti. La piattaforma software deve essere quindi realizzata ex-novo dal
punto di vista implementativo, ma si basa su uno studio che è stato effettuato fondando le proprie radici in numerosi articoli di interesse internazionale inerenti l'information extraction da twitter (o da social network in generale) [31] [32] [33] [34] [35] e su numerosi studi effettuati all'interno del Dipartimento di Ingegneria dell'Informazione di Pisa relativi al data mining e all'estrapolazione di dati tramite sensori sociali.
2.2 Possibili soluzioni riguardanti aspetti legati
all'Implementazione
2.2.1 Architettura software
Il sistema informatico in questione potrebbe essere implementato utilizzando una semplice architettura client-server oppure un’architettura SOA che permetterebbe una maggiore flessibilità, associata ad una applicazione web. Analizziamo entrambe le soluzioni per poter stabilire quale delle due risulta più idonea per il sistema da realizzare.
- Architettura client-server: Questo tipo di architettura permette di avere un server centrale che gestisce i dati usando data base relazionali (DBMS, acronimo inglese di database management system) e un server che gestisce l’applicazione che può essere acceduta da client. In questo caso il server è di tipo web e quindi potrebbe accettare richieste da client tipo browser. Questa architettura risulta abbastanza veloce nell’implementazione, ma limita gli utenti ad utilizzare un solo tipo di
client e oltretutto potrebbe risultare difficile l’integrazione con altri sistemi.
- Architettura SOA: Un’ architettura SOA (acronimo inglese di Service Oriented Architecture) è in grado di fornire servizi (funzionalità), tramite i cosiddetti web service, ad applicazioni o utenti e di rappresentare le singole componenti di un processo di business in termini di servizi offerti. Pertanto nell’ambito di una SOA è possibile gestire la combinazione ottimale di servizi utilizzati in un processo di business, rendendo questo servizio riutilizzabile e configurabile a seconda delle specifiche esigenze. In questo caso il software sarebbe composto da un database, dall’insieme dei servizi web, e dai vari client che accedono ai servizi. Si tratta di un sistema software progettato per supportare l'interoperabilità tra diversi elaboratori su una stessa rete. All'applicazione è associata un'interfaccia software, descritta in un formato chiamato WSDL (Web Service Description Language) utilizzandolo, altri sistemi possono interagire con il web service, attivando le operazioni descritte nell'interfaccia attraverso appositi messaggi di tipo SOAP [36]. I client potrebbero essere sia applicazioni stand-alone sia applicazioni web.
I punti più interessanti di una SOA sono:
- il fatto che non sia legata ad una specifica tecnologia, consente di potersi interfacciare in maniera più o meno semplice a qualsiasi altra realtà aziendale o commerciale anche se questa gestisce i propri processi di business in maniera differente.
- il fatto di garantire l’indipendenza dei servizi offerti dall’applicazione chiamante viene effettuato tramite un’ interfaccia specifica
implementata seguendo il pattern architetturale MVC (Model-View-Control), il servizio non deve essere a conoscenza dell’applicazione chiamante e l’applicazione chiamante non deve sapere quale servizio soddisferà le proprie necessità.
- il fatto di garantire l’interoperabilità dei servizi tramite protocolli indipendenti dalla piattaforma che ospita la SOA e dalla tecnologia utilizzata per realizzare le applicazioni. Ad esempio in una SOA possono comunicare servizi scritti in differenti linguaggi di programmazione.
2.2.2 Gestione server
L'hardware necessario all'implementazione della piattaforma software consiste quasi unicamente in un server. La macchina server che eseguirà il software può essere installata direttamente all’interno dell’azienda oppure si può scegliere di affittare una macchina server all’interno di una “Server Farm” stipulando un contratto di locazione. Attualmente la macchina server che espone i servizi è presente all'interno del “Dipartimento di Ingegneria dell'Informazione”, Via Diotisalvi 1, Pisa.
Per quanto concerne l'uso futuro dell'applicazione, si analizzano le due possibili soluzione riguardanti il server per evidenziarne pregi e difetti:
- Server locale: Installare l’applicazione su un server locale ha il vantaggio di poterlo configurare ad hoc sulla base delle specifiche richieste e oltretutto consente di tenere tutti i dati sensibili inerenti all'applicazione in privato; questo tipo di soluzione prevede però di effettuare una serie di accorgimenti che possano garantire la stabilità e l’usabilità dell’applicazione stessa. Dato che l'applicazione necessita
di un uso costante della rete internet per poter scaricare da Twitter i tweet e per poter fornire ai client i risultati relativi ai servizi richiesti, si richiede la stipulazione di un contratto ADSL che garantisca una banda necessaria a gestire il volume di dati gestito. Inoltre si deve effettuare richiesta di un indirizzo IP statico al provider ADSL in modo da poter localizzare il server da remoto. Infine è necessario l’acquisto o il noleggio di un gruppo di continuità in grado di alimentare il server per garantirne la continuità d'uso anche in casi di mancanza di corrente. A livello economico questo tipo di scelta può risultare più costosa in un primo momento (rispetto ovviamente ad un server in affitto) ma può essere conveniente valutando l’utilizzo di tale macchina almeno per qualche anno in modo da ammortizzare i costi. Infatti, l’unico costo fisso che si protrae per tutta la durata di utilizzo dell’applicazione è quello legato al contratto di connessione ADSL stipulato col provider (un contratto ADSL orientato alle attività aziendali può essere sufficiente, come ad esempio Vodafone ADSL business o TIM Impresa semplice) e alla manutenzione della macchina.
- Server in affitto: Installare il software su un server in affitto ha il vantaggio di poter delegare ad una ente esterno la gestione inerente alla connessione di rete e all'alimentazione del server rimanendo estranei anche ai relativi problemi che possono verificarsi (congestione di rete, blackout vari, ecc..). Inoltre l'uso di server farm ci pone ad un maggiore livello di sicurezza a rischi inerenti attacchi hacker ed eventi catastrofici che potrebbero distruggere il server. La
scelta di questa opzione ha però il grosso svantaggio di non avere il sistema in locale e dunque di avere una minor riservatezza dei dati contenuti (problema non da poco se si deve garantire la privacy degli utenti) nel sistema, nonché una minore configurabilità e flessibilità del server nel rispondere a modifiche e aggiornamenti. Questo tipo di soluzione prevede dei costi fissi per tutta la durata di utilizzo dell’applicazione (tali costi aumentano proporzionalmente al numero di server che si intende utilizzare sia come server principali sia come server di backup); a differenza della soluzione precedente non sono previsti investimenti iniziali, ma a lungo termine potrebbe risultare la soluzione più costosa.
2.2.3 Connessione tra host
La rete che permetterà lo scambio di dati tra i vari host che compongono il sistema sarà la rete Internet. Infatti, questa permette la trasmissione di dati senza dover creare reti dedicate. Dato che i dati inerenti la nostra applicazioni non sono dati “sensibili” (ovvero non contengono informazioni riservate degli utenti riguardanti ad esempio denaro o contratti commerciali) non sono necessari particolari requisiti legati alla sicurezza del sistema, per cui la rete internet risulta ottimale.
2.2.4 Linguaggi di programmazione
Esistono diversi linguaggi di programmazione che possono essere utilizzati in fase di implementazione della piattaforma software. Consideriamo unicamente i linguaggi di programmazione orientati agli oggetti dato che sono i più indicati per lo sviluppo di un'applicazione distribuita. Questi, consentono
di definire oggetti in grado di interagire gli uni con gli altri attraverso lo scambio di messaggi. Risultano particolarmente adatti nei contesti in cui si possono definire delle relazioni di interdipendenza tra i concetti da modellare (contenimento, uso, specializzazione).
• Alcuni dei vantaggi della programmazione orientata agli oggetti di particolare rilevanza sono:
• semplicità nell’organizzare le strutture dati come oggetti da manipolare attraverso i metodi proprietari;
• gestione semplice e manutenzione di progetti di grandi dimensioni; • l'organizzazione del codice sotto forma di classi favorisce la modularità
e il riuso di codice. Dato che lavoriamo su una piattaforma software che subirà mutevoli e continue release, andando a integrare nuovi servizi e nuove applicazioni il riuso e la modularità sono fondamentali.
Tra i linguaggi di programmazione orientati agli oggetti ci sono ad esempio Java e C++. Il C++ è un linguaggio che produce un codice che deve essere compilato, ovvero elaborato da un compilatore che dovrà generare il file binario da eseguire su uno specifico processore. Questo aspetto rende la sua esecuzione strettamente connessa all’architettura nella quale avverrà l’esecuzione. Il Java è invece un linguaggio che ha delle caratteristiche particolari. Al fine di ottenere indipendenza dalla piattaforma e una totale portabilità, viene utilizzato uno strato software intermedio che maschera l’architettura sottostante in maniera tale da avere la stessa esecuzione a prescindere da quale sia il calcolatore e il sistema operativo nel quale è in esecuzione. Il codice scritto dal programmatore viene compilato per ottenere il byte code Java interpretabile dalla JVM (Java Virtual Machine). Inoltre, in
Java la gestione della memoria dinamica risulta più semplice rispetto al C++. Per quanto riguarda invece la velocità di esecuzione, un programma Java potrebbe essere più lento rispetto ad un programma scritto in C++. In realtà, vista l’attuale disponibilità di calcolatori equipaggiati con processori e memorie molto veloci spesso le differenze in termini di velocità di esecuzione sono minime.
Per i motivi sopra elencati l'applicazione software sarà programmata utilizzando il linguaggio Java per garantire una interoperabilità massima. L'uso di Java rende inoltre più immediato sia l'utilizzo delle API fornite da Weka (totalmente scritto in linguaggio Java) sia delle API utilizzate relativamente per la comunicazione con Twitter e GoogleMap.
2.2.5 Sicurezza informatica
La piattaforma in questione non ha bisogno di particolari misure di sicurezza; l’unico aspetto che riguarda la sicurezza è quello di dover garantire l'accesso da parte degli utenti a servizi a loro rivolti (ad esempio un utente può accedere unicamente ai servizi esportati per gli utenti, mentre uno sviluppatore ha accesso anche ai servizi relativi agli sviluppatore oltre a quelli utente). Questo può essere effettuato con un sistema di gestione dei vari utenti del sistema basato su un'assegnazione di vari livelli di privilegio basati sul tipo dell'utente. Così facendo si riesce ad offrire accessi controllati alle varie sezioni di dati, sulla base dei ruoli degli utenti stessi. Anche l'aspetto riguardante la sicurezza però non è un focus del progetto attuale, indi per cui anch'esso viene dato per scontato unitamente alla gestione degli utenti che si ha a monte del sistema stesso.
2.3 Soluzione proposta
Per poter proporre una soluzione è necessario andare ad analizzare i punti discussi nei paragrafi precedenti, cercando una soluzione che possa adattarsi nel modo più consono al progetto in questione.
Per quanto riguarda il tipo di piattaforma si è scelto di utilizzare una architettura SOA in modo che l’applicazione possa essere quanto più scalabile e facile da manutenere possibile (nel tempo possono essere aggiunte nuove funzionalità), indipendente dai vari tipi di client e possa interagire con altri sistemi simili (utilizzo di altri web service). L’insieme dei servizi web faranno da “motore” ad una applicazione web che verrà usata dagli utenti. I web service dunque, saranno completamente trasparenti agli utenti.
Per quanto riguarda la scelta del linguaggio di programmazione, si ritiene opportuno utilizzare il linguaggio Java in ambiente J2EE; il linguaggio Java, a differenza degli altri, offre i seguenti vantaggi:
• Ambiente di sviluppo totalmente gratuito (non proprietario)
• Portabilità del software: possibilità di installare l’applicazione su vari tipi di server (server Windows o server UNIX-based)
Il linguaggio Java sarà utilizzato sia per lo sviluppo dei web service sia per lo sviluppo dell’applicazione web. Per l’implementazione dei web service verranno utilizzati gli EJB che andranno a contenere le effettive attività da svolgere (business) dell'applicazione. Gli EJB si occupano di interfacciarsi con il database che memorizza tutti i dati inerenti all'applicazione tramite dei connettori JDBC. L’intera applicazione sarà sviluppata utilizzando come ambiente di sviluppo il software Eclipse (Uno degli IDE più usati a livello internazionale per lo sviluppo di software, consigliato anche dalla SUN