Sezione di Ingegneria dell’Elettronica Biomedica, dell’Elettromagnetismo e delle Telecomunicazioni
“TECNICHE DI CLASSIFICAZIONE E
PREDIZIONE DELLE ATTIVITÀ MOTORIE PER
TELEMONITORAGGIO E TELERIABILITAZIONE”
Rossana Muscillo
Docente-guida
Prof. Tommaso D’Alessio
Università degli Studi di Roma TRE
Coordinatore: Prof. Lucio Vegni
Università degli Studi di Firenze
Tesi sottomessa
all’Università degli Studi Roma Tre
Dipartimento di Elettronica Applicata
per il conseguimento del titolo di
DOTTORE DI RICERCA
A suor Teresa
per il suo insegnamento
Indice
Introduzione……….. Capitolo 1 Il tele monitoraggio e la tele riabilitazione………..
1.1La classificazione come problema teorico di fondo……… 1.2La sensoristica utilizzata………..
Capitolo 2 Il problema della classificazione………...
2.1 Il template matching e le tecniche di clustering………... 2.1.1 Il Dynamic Time Warping (DTW)……… 2.1.2 Il Derivative Dynamic Time Warping (DDTW)………... 2.1.3 Le tecniche di clustering……… 2.2 La classificazione bayesiana……… 2.2.1 Stima della densità di probabilità condizionata: metodi parametrici e non parametrici
2.3 Le SVM……… 2.4 Gli alberi di decisione e la classificazione precoce………..
Capitolo 3 Le tecniche di classificazione proposte………
3.1 La classificazione gerarchica……… 3.2 La classificazione cooperativa……….
3.2.1 Il classificatore bayesiano e il DTW………. 3.2.2 Un classificatore bayesiano a n dimensioni: la riduzione dello spazio delle features………... 3.2.3 Una classificazione adattiva: Bayes e il filtro di Kalman…….. 3.3 La classificazione precoce……… 3.3.1 Il real-time DTW………...
Capitolo 4: L’attività progettuale e realizzativa………...
4.1 Realizzazione sistema di acquisizione dati per Pc e Pocket Pc…………. 4.2 Interfaccia LAbView per acquisizione ed elaborazione dai in real time da sensori della MicroStrain……… 4.3 Sistema di acquisizione di dati in tempo reale con Matlab………..
Capitolo 5: L’estrazione di caratteristiche………
5.1 Il cammino e le variabili di interesse……… 5.1.1 Valutazione dei parametri della camminata tramite sensori accelero metrici……….. 5.1.2 Applicazione su soggetti anziani………... 5.1.3 Applicazione su soggetti giovani……….….. 5.1.3 Un nuovo metodo per il calcolo della step length………. 5.2 Algoritmi di separazione del tremore dal movimento volontario su segnali accelerometrici………... 5.3 Possibilità di ricostruzione della posa da dati provenienti da sensori inerziali……….. 5.4 Estrazione di caratteristiche per la riabilitazione della pelvi.…………...
Pag. 5 Pag. 8 Pag. 8 Pag. 14 Pag. 17 Pag. 22 Pag. 25 Pag. 30 Pag. 31 Pag. 33 Pag. 38 Pag. 43 Pag. 45 Pag. 49 Pag. 49 Pag. 52 Pag. 52 Pag. 56 Pag. 60 Pag. 63 Pag. 64 Pag. 69 Pag. 69 Pag. 74 Pag. 77 Pag. 79 Pag. 79 Pag. 83 Pag. 87 Pag. 91 Pag. 96 Pag. 98 Pag.100 Pag.101
Capitolo 6: Le applicazioni per il monitoraggio e la riabilitazione domiciliare.
6.1 Il template matching applicato su segnali accelerometrici………... 6.1.1 Il DTW per il riconoscimento di task motori effettuati con gli arti superiori……… 6.1.1.1 I diversi metodi per la fase di calibrazione………… 6.1.2 Il DTW e il DDTW per il riconoscimento di attività motorie quotidiane……….. 6.2 La classificazione gerarchica: applicazione alle ADL……… 6.3 La classificazione cooperativa:applicazione su attività relative agli arti inferiori………... 6.4 La classificazione cooperativa: riconoscimento di attività su giovani e anziani tramite bayesiano a n dimensioni………..
6.41 Confronto con le SVM……….. 6.5 La classificazione adattiva: riconoscimento di attività su giovani e anziani………. 6.6 La classificazione precoce: riconoscimento di gesti dell’arto superiore.. 6.6.1 Applicazione per il riconoscimento di attività in tempo reale tramite alberi di decisione………...
Conclusioni………. Bibliografia………. Pag.106 Pag.107 Pag.107 Pag.110 Pag.111 Pag.113 Pag.117 Pag.120 Pag.123 Pag.125 Pag.130 Pag.137 Pag.139 Pag.142
INTRODUZIONE
A seguito dell’aumento dell’età media della popolazione e della possibilità delle tecnologie attuali di fornire servizi innovativi, nel mondo della ricerca si stanno esplorando soluzioni che consentano all’utente di poter usufruire di servizi sanitari direttamente stando a casa propria, limitando così le spese del servizio sanitario nazionale e riducendo il disagio per il paziente che altrimenti dovrebbe spostarsi per ottenere assistenza .
Il presente lavoro di ricerca si inserisce infatti tra i concetti di tele riabilitazione e di tele monitoraggio, approfondendone degli aspetti a nostro avviso cruciali, tra la vastità delle implicazioni che i due concetti inevitabilmente portano con sé.
Per tele monitoraggio si intende la possibilità di trasmettere a distanza parametri di interesse per la valutazione clinica di pazienti che necessitano di un controllo continuo della loro condizione di salute. La tele riabilitazione invece consente ad un
paziente, a seguito di un evento traumatico, di ricevere a domicilio terapie, indicazioni e ausilio durante la fase di riabilitazione.
Ambedue gli aspetti richiedono innanzitutto uno studio a monte delle problematiche da affrontare, relativo alla sensoristica da utilizzare e alla combinazione più opportuna di soluzioni versatili e innovative, che consentano al paziente facilità di utilizzo e naturalità nei movimenti.
La nostra analisi a questo proposito si è concentrata sui sensori inerziali dato che tramite essi è possibile acquisire informazioni riguardanti la velocità, l’accelerazione e la posizione dei segmenti corporei a cui il sensore viene rigidamente collegato. L’accelerometria, in particolare, è infatti una tecnica a basso costo, minimamente invasiva, che permette l’estrazione di parametri significativi dell’attività motoria. La rilevanza di tale tecnica va dalla classificazione delle attività, all’individuazione di parametri predittivi di cadute, alla stima del consumo metabolico e alla valutazione di parametri indicativi della funzionalità del movimento. Subito a valle della problematica suddetta un aspetto fondamentale, e cuore della nostra analisi, riguarda l’integrazione dei dati a disposizione e la possibilità di interpretare in modo consono le informazioni che da essi ne derivino. E’ infatti necessario classificare le situazioni di interesse e scartare quelle che non producono alcun tipo di conseguenza così come è necessario classificare un tipo di movimento rispetto ad un altro quando la problematica richiede un monitoraggio delle attività motorie quotidiane, che vengono analizzate in tutti i contesti medico/riabilitativi considerando l’impatto che esse hanno sulla qualità della vita. Un tale approccio risulta particolarmente interessante per monitorare le azioni di persone anziane autosufficienti o con disabilità motorie lievi/moderate, in modo da individuare se l’azione svolta ad un dato istante di tempo rientra nella normalità delle azioni quotidiane, oppure se se ne discosta in modo significativo, rappresentando quindi una situazione di potenziale o effettivo pericolo. Ciò implica la necessità di creare un modello di interpretazione delle azioni del soggetto nell’ambiente in cui vive.
La classificazione diviene poi il cuore dell’analisi anche se stiamo parlano di tele riabilitazione, in quanto l’esecuzione della terapia riabilitativa, richiede il riconoscimento del task effettuato prima di poterne valutare la bontà di esecuzione. La teoria della classificazione è un aspetto enorme della conoscenza scientifica e il presente lavoro non ha la pretesa di affrontare il tema a tutto tondo ma di approfondirne criticamente gli aspetti ritenuti più opportuni rispetto ai problemi da noi posti inizialmente.
Tra le innumerevoli tecniche, in una prima fase, ci si è concentrati sulle tecniche di Template Matching, tecniche che consentono il confronto tra il segnale da classificare e un segnale di riferimento, detto template, tipico della classe da riconoscere. Il confronto avviene tramite misure di distanze ed è stato applicato su serie temporali accelerometriche. In una seconda fase sono stati approfonditi gli aspetti relativi alla classificazione bayesiana, concentrandosi sia sulla scelte delle features caratteristiche che sul tipo di densità di probabilità condizionata, fattori che condizionano la forma del classificatore. Inoltre si è esplorato un approccio innovativo che, tramite l’utilizzo delle catene di Markov e del filtro di Kalman, implementi un classificatore bayesiano di tipo adattativo, variando la probabilità a priori al passo k in funzione dell’attività riconosciuta al passo k-1.
Diversi approcci di classificazione sono stati implementati cercando la cooperazione di tecniche differenti, valutando i maggiori benefici che eventualmente ne derivino. Un ulteriore contributo alla classificazione è stato dato esplorando l’idea di classificare il gesto compiuto in maniera precoce, ovvero prima del termine del gesto stesso. A questo proposito è stata implementata una versione real-time dell’algoritmo del Dynamic Time Warping. Tutte le tecniche menzionate sono state applicate per il riconoscimento di attività motorie quotidiane, sia riferite agli arti inferiori che a quelli superiori e le diverse campagne sperimentali condotte hanno interessato sia popolazione giovane che anziana, in molteplicità di protocolli applicati e di set-up sperimentali.
Capitolo 1
Il Telemonitoraggio e la Teleriabilitazione
1.1
La classificazione come problema teorico di fondo
Per tele monitoraggio si intende la possibilità di trasmettere a distanza parametri di interesse per la valutazione clinica di pazienti che necessitano di un controllo continuo della loro condizione di salute. Queste soluzioni consentono al paziente di continuare a svolgere, nella maggior parte dei casi, le loro occupazioni quotidiane ma offrono loro la possibilità di controllare attivamente parametri vitali quali il battito cardiaco, la pressione arteriosa, la temperatura corporea, la glicemia, ecc..
• Di far viaggiare i dati e non i pazienti
• Di poter fronteggiare tempestivamente situazioni di allarme
• Di migliorare la qualità di vita dei pazienti
• Di sfoltire il lavoro dei presidi sanitari
• Effettuare un’azione sanitaria capillare sul territorio
• Fornire assistenza continua anche 24h/24h
Agli indubbi benefici si associa un grande lavoro di background tecnologico e teorico, che deve indagare, tra le innumerevoli possibilità, le soluzioni ottimali rispetto ai requisiti e adattarle al problema in questione.
Una prima questione da affrontare riguarda la sensoristica da utilizzare, soprattutto tenendo in considerazione non solo la finalità del progetto quanto i requisiti di basso costo, versatilità e facilità di utilizzo.
L’impianto teorico di fondo invece deve considerare il progetto nel suo complesso, le finalità, la gestione delle informazioni, la varietà dei dati a disposizione, l’integrazione di essi e l’estrazione delle informazioni utili tra le innumerevoli informazioni grezze che si hanno a disposizione.
Monitorare una patologia, monitorare un parametro clinico o semplicemente un paziente durante una giornata vuol dire classificare e distinguere le situazioni normali da quelle patologiche lievi/gravi, e vuol dire anche saper distinguere quali tipologie di attività il soggetto sta svolgendo, eventualmente rilevando situazioni di rischio, come una caduta. I sistemi di tele monitoraggio consentono quindi di classificare le informazioni di cui disponiamo in forma grezza o più spesso sotto forma di features estratte da questi dati, sia in loco, consentendo rapidità nell’azione da svolgere e gestione in tempo reale delle situazioni di rischio, sia in remoto, dove una unità di controllo può decidere autonomamente strategie di intervento differite.
I sistemi di tele monitoraggio classico hanno l’obiettivo di monitorare parametri fisiologici e trasmettere a distanza le informazioni relativi all’intero segnale, che possa essere così analizzato da personale competente, oppure di trasmettere il segnale
già classificato in base a diversi parametri. E’ il caso ad esempio dell’invio del segnale ECG, che raramente viene trasmesso per intero, ma di cui vengono inviate le informazione di interesse, quali la frequenza cardiaca, oppure le situazioni ritenute di anomalia.
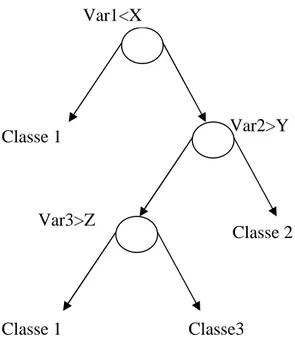
Tra le applicazioni di tele monitoraggio più recenti, il riconoscimento delle attività quotidiane in questi anni ha visto un fiorire di tecniche e applicazioni tra le più svariate, applicate principalmente a tecniche video e a sensori indossabili. Per distinguere tra attività statiche e dinamiche le tecniche hanno fatto spesso uso degli alberi di decisione [1,2,3] in cui la decisione viene presa muovendosi lungo un albero di possibilità e riducendo ad ogni passo lo spazio di decisione, partendo appunto dalla decisione iniziale di distinguere tra attività statiche e dinamiche.
Altri studi hanno classificato le attività motorie usando tecniche di clustering (k-NN) esplorando la possibilità di una classificazione non supervisionata e confrontandola con la maggior parte delle tecniche supervisionate [4,5]. Molti di questi lavori hanno analizzato anche la bontà delle diverse features, ricavate per lo più, in queste applicazioni citate, da segnali accelerometrici, e anche la possibilità di differenziarle a seconda della tecnica usata e in base alla possibilità di combinarle con tecniche diverse [5,6]. Il riconoscimento dell’atto motorio può essere poi effettuato con i classificatori Bayesiani, in cui, in una preliminare fase di training, viene stimata la densità di probabilità condizionata e anche ipotizzata una probabilità a priori [1,2,7,8]. A questo proposito anche nel corso del nostro lavoro sono state effettuate diverse valutazioni in base alle diverse probabilità a priori [9,10]. Le probabilità di compiere una determinata azione prima/dopo di un’altra sono state sfruttate nel riconoscimento di attività qualora si riconosca la sequenza della attività come un processo markoviano e si sfruttino le probabilità di transizione e la teoria dei modelli markoviani [11,12,13,10]. Altre tecniche di classificazione che hanno dati risultati soddisfacenti utilizzano le reti neurali, dove lo strato di uscita classifica l’attività, avendo a disposizione come strato di ingresso tutte le features ritenute utili [14].
Il monitoraggio dei dati fisiologici umani e il riconoscimento delle attività compiute, sia in situazioni normali che anormali di attività, diviene interessante anche ai fini della rilevazione di eventi di emergenza, soprattutto nel caso di persone anziane che vivono da sole. Diverse tecniche sono state proposte per l'identificazione di situazioni di pericolo, ad esempio utilizzando il movimento, l’audio o i video relativi ai dati del soggetto oppure analizzandone l'ambiente circostante.
Per classificare situazioni di pericolo gli impianti teorici che sono stati proposti analizzano il segnale in tempo reale e, tramite features caratteristiche, estratte sulle diverse tipologie di dati a disposizione, identificano immediatamente la situazione di anomalia. Numerosi sistemi di gestioni della situazione di rischio usano classificazione tramite sistemi video, ad esempio analizzando con algoritmi di tracking i contorni delle figure analizzate e classificando le diverse situazioni tramite analisi delle componenti principali o algoritmi di clustering come i k-nearest neighboors [15]. Altri sistemi utilizzano entrambe le tecniche menzionate, usando gli accelerometri per rilevare immediatamente la variazione di situazione che viene poi confermata dall’analisi video che consente l’identificazione della situazione di emergenza [16].
Tra le situazioni di rischio più diffuse e che meritano interesse nell’ambito del monitoraggio quotidiano delle attività motorie c’è il pericolo delle cadute. La caduta è un evento traumatico soprattutto per la popolazione anziana, non solo per le ovvie possibili conseguenze di ordine traumatico, ma anche per le ripercussioni di ordine psicologico, caratterizzate dall’insicurezza e quindi dalla tendenza ad un progressivo isolamento ed alla riduzione delle attività quotidiane e dei rapporti interpersonali. Le cadute nei soggetti anziani infatti sono rovinose non solo per ragioni neurologiche, ma anche per le conseguenze sull’apparato muscolo-scheletrico. L’approccio più utilizzato per la rilevazione delle cadute prevede [17,18] che un cambiamento di orientazione dell’asse del corpo da eretto a steso che si verifichi subito dopo una grande, improvvisa accelerazione negativa, prodotta dall’impatto, sia indicativo di una caduta. Entrambe queste considerazioni possono essere determinate
usando un accelerometro che ha una risposta in continua, ovvero utilizzandolo cioè come inclinometro, e rilevate con diverse metodologie [19, 20, 21, 22, 23, 24]. Più specificamente per il rischio di cadute sono stati implementati molti sistemi di classificazione delle situazioni di rischio, che necessitano di una notevole fase di training per evitare situazioni di falsi positivi. Ad esempio, tramite l’utilizzo di reti neurali e features estratte da sensori inerziali quali accelerometri e giroscopi, sono stati addestrati classificatori con campioni di circa 30 soggetti anziani con diversi fattori di rischio di cadute, identificate tramite la scala di Tinetti, e testati su 100 soggetti altrettanto diversificati. La classificazione della situazione di rischio cadute fornita dalla rete ha fornito dati incoraggianti, addirittura superiori a sistemi addestrati grazie alle stime delle densità di probabilità a priori in un classificatore di Bayes classico [25]. Altri sistemi di classificazione del rischio di cadute prevedono l’utilizzo di un accelerometro triassiale posizionato sulla cintura che estrapoli, in una acquisizione a lungo termine, i parametri del cammino ritenuti utili in un’analisi di tipo quantitativo del cammino, e tramite essi produca in uscita una identificazione del rischio di caduta/non rischio di caduta. In questo caso sono stati utilizzati classificatori basati sugli alberi di decisione [26].
Metodi alternativi sono stati proposti grazie all’utilizzo del suono come una soluzione alternativa al video tele monitoraggio, grazie all'individuazione e la classificazione dei suoni allarmanti in un ambiente rumoroso. Il sistema di analisi audio è diviso in due fasi: individuazione del suono e classificazione. La prima fase di analisi (individuazione del suono) consiste nell’estrazione di suoni significativi da un flusso continuo del segnale audio proveniente dall’ambiente, di solito rumoroso, ed è costituito da un algoritmo di rilevazione basato sulla trasformata discreta wavelet. La seconda fase del sistema è la corretta classificazione, che utilizza un approccio statistico per individuare i suoni sconosciuti, tramite parametri ricavati dalle wavelet. Il sistema proposto presenta un 3% di tasso di mancato allarme e gli autori lo propongono come sistema che può essere fuso con altri sensori biomedici per
migliorare le prestazioni generali di un sistema di classificazione di parametri ambientali e di situazioni di anomalie [27].
Se parliamo invece di tele riabilitazione i metodi di classificazione assumono un ruolo leggermente diverso perché influenzano direttamente la terapia da seguire e consentono un ausilio in tempo reale per la realizzazione dell’esercizio riabilitativo. Infatti la tele-riabilitazione offre ad un paziente la possibilità di ricevere a domicilio sia la terapia che l’ausilio sulla fase di riabilitazione post-trauma, consentendogli di svolgere un programma riabilitativo personalizzato attraverso un computer, una web-cam, sensori indossabili e interfacce ad hoc. In questo caso perciò l’approccio metodologico di fondo consente sia l’identificazione del task motorio eseguito o di una parte di esso, che la valutazione del task eseguito in termini di bontà del gesto eseguito. Tramite la tele riabilitazione esiste la possibilità di una interazione diretta e immediata tra il paziente e lo strumento che ha direttamente a disposizione per la terapia [28].
E’ possibile ad esempio valutare se un determinato task motorio è stato eseguito in maniera corretta o meno confrontando i parametri estratti dal segnale a disposizione con gli stessi parametri estratti su una popolazione sana, oppure valutando la correlazione tra i dati a disposizione e le più comuni scale di valutazione funzionale. [29, 30, 31]. A questo proposito sono state utilizzate tecniche di classificazione basate sui Template Matching, che confrontano pattern di segnali in ingresso con andamenti dello stesso segnale in movimenti eseguiti da persone sane o, in fase di training dell’applicazione, dal soggetto stesso. Le stesse tecniche, da noi ampiamente trattate, sono state perfezionate per effettuare classificazioni dell’atto motorio in tempo reale [32], in modo da consentire un più rapido intervento dell’ausilio al movimento in tutte le tipologie di tecnologie assistive.
1.2
La sensoristica utilizzata
Come già ampiamente discusso, le problematiche di tele monitoraggio e tele riabilitazione sono state implementate in contesti applicativi tra i più svariati e anche con diversi apparati sperimentali. Molte applicazioni utilizzano i sistemi video per monitorare le attività quotidiane, estrapolare le situazioni di rischio e classificare le performance motorie [33, 34]. Tutti questi sistemi utilizzano telecamere, posizionate in diverse posizioni dell’abitazione, che consentono un videocontrollo quasi totale del paziente e dell’ambiente in cui normalmente vive. Soprattutto in ambito riabilitativo sono stati implementati sistemi più complessi di robotica o di realtà virtuale, ad esempio in cui, tramite ambiente virtuale, i pazienti eseguono gli esercizi proposti usando una workstation con sensori di forza che forniscono un feedback tattile in tempo reale. Al sistema viene anche fornita una webcam per il monitoraggio della seduta di riabilitazione [35]. Questi sistemi però hanno diverse problematiche, sono più costosi, esigono calibrazioni molto raffinate e non consentono di rilevare alcune situazioni in tempo reale.
Per questo nel corso degli anni si sono studiate situazioni alternative che superassero le difficoltà sopra poste e esplorassero settori più versatili, più economici e soprattutto indossabili, che sfruttassero le nuove tecnologie e consentissero facilità di utilizzo, libertà di movimento del paziente e nello stesso tempo garantissero rigorosità nei risultati.
Molto lavori hanno utilizzato, tra questi, i sensori inerziali sia per la classificazione delle attività motorie, identificando le situazioni di rischio, sia per la valutazione della bontà del gesto motorio in applicazioni più strettamente di riabilitazione. Nel corso dell’attività di ricerca svolta la nostra attenzione si è concentrata su questa tipologia di sensori per le caratteristiche che essi presentano e che da noi sono state ritenute rilevanti rispetto alle nostre priorità.
I sensori inerziali sono dispositivi a basso costo che consentono di rilevare la cinematica del segmento corporeo a cui sono rigidamente collegati. Gli accelerometri in particolare misurano l’accelerazione lungo l’asse corporeo a cui sono rigidamente collegati, e possono essere di diverse tipologie in base al principio di funzionamento e al numero di assi rispetto ai quali misurano l’accelerazione.
Il monitoraggio di attività quotidiane, tramite l’uso di sensori inerziali, ha diverse applicazioni sia in ambito riabilitativo che nella ricerca e nello sviluppo, e diviene fondamentale anche per ottenere importanti parametri, relativi sia alle attività funzionali sia indicativi di situazioni patologiche. Misurazioni, ad esempio, dell’andamento e della velocità del passo producono informazioni sul rischio di cadute [36, 37, 38, 39, 40, 41]. Movimenti come il sit-to-stand (alzarsi da una sedia) e il cammino risultano importanti per poter valutare l’autosufficienza [42, 43]. Gli accelerometri risultano essere anche appropriati nelle determinazione di eventi come appunto le cadute, di cui abbiamo già ampiamente parlato nel paragrafo precedente, e metodi sempre più raffinati sono stati implementati per rivelare le cadute utilizzando solamente gli accelerometri. Negli ultimi anni vari autori hanno proposto l’uso di accelerometri per la misura dell’oscillazione posturale ad uso clinico [40, 44, 45]. L’accelerometro, tra la gamma dei sensori inerziali, offre un metodo indiretto anche per accertare e valutare attività fisiche in ambiente di vita quotidiana che funziona bene quando viene comparato con altri metodi indiretti come il self-report [46, 47] e le misurazioni del battito cardiaco [48, 49].
Un altro importante utilizzo degli accelerometri monoassiali e triassiali riguarda la possibilità di misurare i livelli dell’attività motoria quotidiana: essi si sono dimostrati affidabili e stabili quando vengono comparati con altri indicatori della capacità funzionale. Tali studi sono stati numerosi e hanno interessato soggetti giovani e sani [50, 51], soggetti anziani [52, 53], pazienti con sclerosi multipla [47], pazienti con malattie ostruttive polmonari croniche (COPD) [46] e bambini obesi [54, 55, 56]. Per la valutazione dei livelli di attività motoria un approccio molto studiato è quello relativo alla stima del livello di energia speso durante le attività compiute.
I sistemi accelerometrici si basano tipicamente sul modello secondo il quale l’area sottesa dalla curva che indica le tre accelerazioni del corpo lungo i tre assi principali, è direttamente proporzionale al consumo energetico metabolico (CEM ). Tale ipotesi è stata verificata tramite l’utilizzo di accelerometri triassiali [57, 58, 46] e anche stimata mediante accelerometri monoassiali [59]. In uno studio con 11 soggetti sani che indossavano un accelerometro triassiale posizionato in vita, è stato dimostrato però che il miglior indicatore di CEM durante la camminata è rappresentato dall’integrale dell’ampiezza dell’accelerazione nella direzione antero-posteriore mentre il miglior stimatore per il dispendio energetico nelle totalità delle attività quotidiane risulta essere la somma degli integrali delle ampiezze di ognuna delle tre accelerazioni [60].
Alla luce dei risultati riguardanti il dispendio energetico, sono stati misurati anche alti livelli di correlazione (0,86) tra il livello di MET, che è un multiplo del metabolismo basale che identifica il dispendio energetico per una determinata attività, cioè un multiplo del consumo di ossigeno a riposo necessario per mantenere il metabolismo basale, e conteggio di attività motoria del (CSA) [56].
Molti studi hanno utilizzato accelerometri per classificare attività motorie e per stimare mediamente l’attività motoria compiuta, tramite stime di conteggi di attività per minuto (mediamente all’ora) su periodi che vanno da tre giorni a due settimane [61, 62, 63, 64, 46, 65]. A tutti questi impieghi, che sfruttano le molteplici potenzialità di questi sensori, si affianca il riconoscimento delle attività motorie di cui abbiamo ampiamente parlato nel paragrafo precedente che è la applicazione basilare fondamentale di un sistema di tele monitoraggio e di teleriabilitazione, affiancata alle diverse tecniche di classificazione applicabili. Molteplici studi hanno interessato questo settore e hanno esplorato le diverse possibilità di riconoscere il gesto motorio tramite queste tipologie di sensori, sfruttandone sia diverse tipologie di set up sperimentali sia diverse modalità di analisi dei dati a disposizione [ 66, 67, 68, 69, 70]
Capitolo 2
Il problema della classificazione
Lo studio affrontato sul problema della classificazione ha cercato di affrontarne il problema a tutto tondo, cercando di farne emergere delle linee di studio che fossero anche linee di pensiero, tali da poterci guidare nel corso degli anni di studio e che fossero tali da consentirci un approccio critico ai quesiti in questione . In particolare il contesto studiato ha fatto emergere alcune linee principali del problema della classificazione che possono essere così riassunte:
- Le tecniche di classificazione basate sul teorema di Bayes
• I metodi non parametrici - Le tecniche di clustering
- Le tecniche mutuate dal soft computing
• Il percettrone e le reti neurali
• La logica fuzzy e i sistemi neuro-fuzzy
• Le euristiche
- Le tecniche di template matching ( DTW – Dynamic Time Warping)
L’obiettivo generale della classificazione è quello di assegnare un campione, tramite un opportuno set di informazioni, ad una specifica classe in base a determinate regole di interpretazione. Nel caso del nostro lavoro le diverse classi sono i differenti movimenti che si vogliono monitorare/riconoscere/analizzare.
La classificazione si basa sulle seguenti ipotesi:
– per ogni campione si dispone di un insieme di misure detto vettore di caratteristiche (feature). Si suppone che le caratteristiche dei segnali a disposizione possano essere misurate tramite sensori che siano in grado di fornire dati in forma grezza, oppure caratteristiche ottenute dalle misure stesse mediante opportune elaborazioni;
– le classi di appartenenza del nostro campione sono in numero finito. E, nella caso della classificazione supervisionata:
– si possiede una sufficiente conoscenza a priori sulle classi oppure si ha a disposizione un insieme di campioni di training di cui si conosce l’appartenenza alla classe.
In generale per classificare un insieme di dati si lavora su features caratteristiche estratte a partire dai dati Una feature, come abbiamo detto, può essere il risultato di una misura (numero reale o intero) o una risposta binaria (sì/no) a date domande o un andamento del segnale opportunamente pre-elaborato.
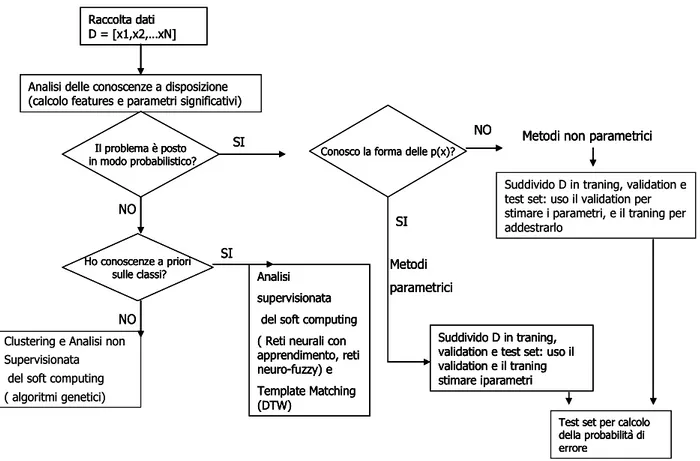
Il problema della scelta del classificatore si articola secondo uno schema riassuntivo mostrato in Figura 1, in cui la prima domanda da porsi è se è possibile o meno porre il problema in forma probabilistica. A seguito di una risposta affermativa ci addentriamo nei classificatori bayesiani di cui parleremo diffusamente più avanti, con la prima problematica da affrontare che riguarda la conoscenza o meno della densità di probabilità della variabile in questione (metodi parametrici/non parametrici). Nell’altro caso ci troviamo di fronte alla possibilità di definire il nostro classificatore in base alla conoscenza a priori di cui disponiamo. Da questo punto in poi il problema diviene quello relativo ad una classificazione supervisionata/non supervisionata. La classificazione non supervisionata ha la particolarità che non richiede alcuna conoscenza a priori e sfrutta le similitudini naturali tra gruppi di dati, limitando però il controllo dell’operatore sul procedimento e sui risultati.
Nei classificatori non supervisionati:
– non viene utilizzato l’insieme dei dati di training (training set). Gli algoritmi devono pertanto essere in grado di raggruppare in classi naturali i diversi campioni a disposizione in base a delle caratteristiche di similitudini naturali tra gli oggetti stessi. – la complessità è di solito maggiore rispetto classificatori supervisionati ed il risultato necessita di una ulteriore validazione.
Talora la classificazione non supervisionata non viene considerata classificazione vera e propria, essendo in realtà un processo di individuazione delle classi naturali. Tale processo si indica, in inglese, col termine “clustering”, dove “cluster” denota il raggruppamento di elementi con caratteristiche simili.
Le fasi di un processo di classificazione supervisionata invece sono diverse e richiedono ognuna la definizione di un differente insieme di dati su cui operare:
– addestramento (training): il sistema opera su un insieme di dati di addestramento (training set), cioè su un insieme di campioni di cui si conosce a priori l’appartenenza o meno ad una determinata classe, in base ai quali vengono ottimizzati sia la struttura che tutte le variabili di interesse del classificatore, fino a raggiungere una corretta classificazione. La scelta dei dati di training e di test è molto importante e
teoricamente essi dovrebbero rappresentare tutte le varie casistiche, ossia dovrebbero essere “statisticamente eterogenei”.
– test: tale fase è svolta operando su un test set composto da dati anch’essi preclassificati, ma che sono differenti da quelli utilizzati in fase di training; ottenute buone prestazioni sul test set, si può operare su dati incogniti.
In questo contesto noi ci siamo occupati rispettivamente delle tecniche di clustering, per quanto riguarda l’analisi non supervisionata, e di quelle Template Matching per quanto riguarda le tecniche supervisionate.
Queste diverse tecniche sono state analizzate per valutarne l’applicabilità alle tipologie di dati a nostra disposizione e per i requisiti di nostro interesse. Il nostro studio ha posto l’accento sulle peculiarità degli approcci, sulle possibilità di innovazione e soprattutto sulle possibilità di utilizzo in un contesto come il nostro, fatto di sensori indossabili e di requisiti differenti a seconda dell’applicazione.
In una prima fase del nostro lavoro ci siamo concentrati sulle tecniche di Template Matching e sull’ipotesi di fondere tecniche accreditate di clustering (ad esempio, algoritmo del k-means) con analisi di tipo DTW (Dynamic Time Warping) per una classificazione non supervisionata utilizzabile in ambito di telemonitoraggio con obiettivi adattativi e di apprendimento del contesto: tale tecnica può risultare valida, in quanto entrambi gli algoritmi fanno uso della nozione di distanza per stabilire l’appartenenza ad uno stesso cluster o ad una stessa classe. In una seconda fase del nostro lavoro ci siamo occupati di classificatori bayesiani, esplorati in diversi contesti teorici e di applicazione, anche volgendo uno sguardo approfondito all’analisi delle features, che è il primo passo nella costruzione di un classificatore di questo tipo. I classificatori bayesiani sono stati implementati supponendo di conoscere la forma della densità di probabilità condizionata delle features.
Figura 1 – Schema di massima del problema della classificazione
Sono state esplorate poi le possibilità di integrazione di tecniche differenti che hanno interessato i classificatori bayesiani, in differenti modalità, sia con le tecniche quali il Dynamic Time Warping che con strumenti teorici quali il filtro di Kalman e le catene di Markov. Inoltre abbiamo dato uno sguardo ai metodi decisionali basati sulle SVM e sugli alberi di decisione, con cui ci siamo confrontati sia in ottica di valutazione di performance che in ottica di integrazioni di sistemi. Un’ultima fase del lavoro sulla classificazione ha interessato le tecniche di classificazione precoce, sia con approcci innovativi per l’algoritmo del DTW in tempo reale, sia tramite l’utilizzo degli alberi di decisione.
Suddivido D in traning, validation e test set: uso il validation per stimare i parametri, e il traning per addestrarlo
Clustering e Analisi non Supervisionata
del soft computing ( algoritmi genetici)
Analisi delle conoscenze a disposizione (calcolo features e parametri significativi)
Raccolta dati D = [x1,x2,…xN]
Il problema è posto
in modo probabilistico? Conosco la forma delle p(x)?
NO Metodi non parametrici
Ho conoscenze a priori sulle classi? SI SI SI NO NO Suddivido D in traning, validation e test set: uso il validation e il traning stimare iparametri Metodi parametrici Analisi supervisionata del soft computing ( Reti neurali con apprendimento, reti neuro-fuzzy) e Template Matching (DTW)
Test set per calcolo della probabilità di errore
Suddivido D in traning, validation e test set: uso il validation per stimare i parametri, e il traning per addestrarlo
Clustering e Analisi non Supervisionata
del soft computing ( algoritmi genetici)
Analisi delle conoscenze a disposizione (calcolo features e parametri significativi)
Raccolta dati D = [x1,x2,…xN]
Il problema è posto
in modo probabilistico? Conosco la forma delle p(x)?
NO Metodi non parametrici
Ho conoscenze a priori sulle classi? SI SI SI NO NO Suddivido D in traning, validation e test set: uso il validation e il traning stimare iparametri Metodi parametrici Analisi supervisionata del soft computing ( Reti neurali con apprendimento, reti neuro-fuzzy) e Template Matching (DTW)
Test set per calcolo della probabilità di errore
Analisi delle conoscenze a disposizione (calcolo features e parametri significativi)
Raccolta dati D = [x1,x2,…xN]
Il problema è posto
in modo probabilistico? Conosco la forma delle p(x)?
NO Metodi non parametrici
Ho conoscenze a priori sulle classi? SI SI SI NO NO Suddivido D in traning, validation e test set: uso il validation e il traning stimare iparametri Metodi parametrici Analisi supervisionata del soft computing ( Reti neurali con apprendimento, reti neuro-fuzzy) e Template Matching (DTW)
Test set per calcolo della probabilità di errore
Raccolta dati D = [x1,x2,…xN]
Il problema è posto
in modo probabilistico? Conosco la forma delle p(x)?
NO Metodi non parametrici
Ho conoscenze a priori sulle classi? SI SI SI NO NO Suddivido D in traning, validation e test set: uso il validation e il traning stimare iparametri Metodi parametrici Analisi supervisionata del soft computing ( Reti neurali con apprendimento, reti neuro-fuzzy) e Template Matching (DTW)
Test set per calcolo della probabilità di errore
2.1
Tecniche di Template Matching e di Clustering
Da una serie di considerazioni critiche sull’argomento, è parso utile concentrarsi dapprima su alcuni aspetti in particolare, legati all’approccio cosiddetto del template matching e degli algoritmi di clustering.
L’indecisione sull’uso di classificatori supervisionati e non supervisionati è stata superata in quanto disporre di segnali di training, la cui classe di appartenenza è nota, non è apparsa una criticità nei nostri tipi di applicazioni. La particolarità di questo approccio sta nel fatto che si lavora non su features caratteristiche ma su andamenti completi del segnale accelerometrico, opportunamente pre-elaborato, per cui è stato ritenuto più utile lavorare su funzioni di distanze tra pattern associati alle diverse attività motorie.
Le tecniche di classificazione che fanno uso di metriche di similarità/dissimilarità tra patterns sono quelle che vanno sotto il nome di template matching oppure tutte le varie forme di clustering. La caratteristica del primo approccio sta nella possibilità di confrontare il segnale in ingresso da classificare con un segnale caratteristico della classe da riconoscere. Questo segnale caratteristico viene definito Template e di solito viene stimato in una fase di training iniziale.
Esistono a questo proposito innumerevoli tecniche di Template Matching che sfruttano diverse definizioni di distanza: euclidea, di Minkowski, Mahalanobis ecc.. Una distanza o metrica nello spazio delle features è una funzione d(·, ·) definita dalle seguenti proprietà:
– d(x, x) = 0;
– d(x, y) = d(y, x) > 0 per ogni x≠y;
– d(x, z) ≤ d(x, y) + d(y, z) (disuguaglianza triangolare)
o Distanza euclidea: è la distanza più conosciuta ed è espressa da: 1/ 2 2 1
( , )
(
)
n i i id x y
x
y
=
=
−
∑
o Distanza di Minkowsky: è una forma di distanza più generale che contiene come caso particolare la distanza euclidea, e utilizza un generico esponente
λ≥1: 1/ 1
( , )
(
)
n i i id x y
x
y
λ λ =
=
−
∑
o Distanza matrice quadrata: data una matrice quadrata (n×n) Q simmetrica e definita positiva:
( , )
(
)
T(
)
d x y
=
x
−
y Q x
−
y
o Distanza di Chebychev: corrisponde alla massima distanza delle componenti (feature) dei due campioni
1,2,..,
( , )
max |
i i|
i nd x y
x
y
==
−
Tra le diverse tecniche di template matching presenti in letteratura, si inserisce la classificazione a distanza minima effettuata con l’algoritmo del DTW (Dynamic Time Warping) da noi implementato e adattato ai nostri requisiti.
Le tecniche di clustering consentono invece di suddividere un insieme di dati in una serie di gruppi o cluster che risultino avere delle similarità. Le tecniche di classificazione baste sugli algoritmi di clustering fanno dunque anch’esse uso di calcoli di distanze o similarità e sembrano collocarsi bene in un approccio non supervisionato. Naturalmente le modalità con cui vengono definite le distanze influiscono direttamente sull’appartenenza o meno di un elemento ad un determinato cluster e divengono l’elemento chiave degli algoritmi.
L’obiettivo di questa prima analisi è stato quello cercare di trovare una possibile integrazione tra queste due tecniche nell’ottica di sviluppare un algoritmo di clustering di tipo partitivo/gerarchico che utilizzi, tra gli altri, il metodo del DTW
come criterio di similarità, e approfondire le possibilità di utilizzo di queste tecniche non supervisionate per il riconoscimento dei gesti tramite i segnali accelerometrici.
2.1.1 Dynamic Time Warping (DTW)
L’algoritmo del DTW si basa sul principio di ricercare similarità tra segnali relativi a due istanze della stessa attività.
Esso viene usato per riconoscere pattern in sequenze di dati anche non perfettamente allineate che si riferiscono sostanzialmente alla stessa “forma” di segnale; un tipico esempio è quello di uno stesso movimento o di una stessa parola effettuato/pronunciata a differente velocità.
Il buon fine del riconoscimento è legato ai possibili criteri di “distanza” tra due sequenze e, più in particolare, a tutte le difficoltà derivanti da imperfetti allineamenti temporali tra le due sequenze e/o effetti di distorsione. In realtà, più che riferirsi a due generiche sequenze, occorre considerare il confronto di una sequenza di dati con una sequenza di riferimento genericamente ottenuta con una procedura di calibrazione. Con calibrazione si intende il procedimento che, in generale, prevede una serie di misurazioni iniziali e che nel nostro caso consente la determinazione del segnale di riferimento detto template.
L’algoritmo in questione si propone di risolvere il problema considerando le possibili distorsioni nel tempo del segnale d’ingresso e confrontandolo con il segnale di riferimento. Il confronto avviene considerando i due segnali come se fossero due vettori.
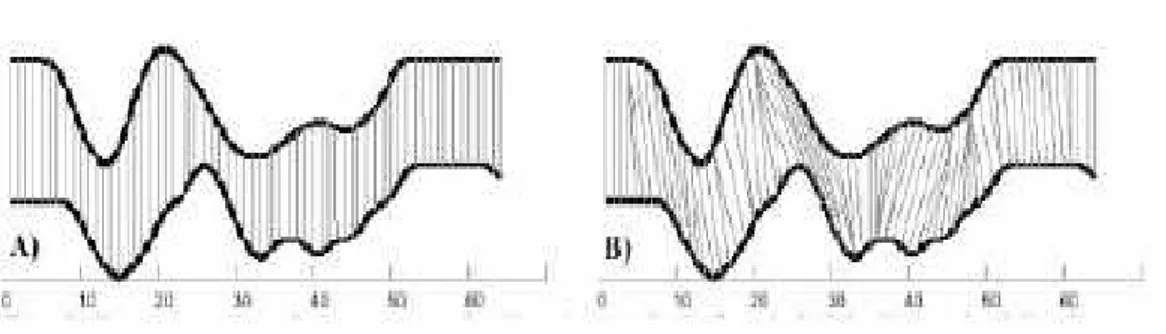
Figura 2 – Il concetto di “warp”
In Figura 2 viene illustrato il concetto appena esposto dove il segnale tratteggiato rappresenta l’ingresso, mentre quello a tratto continuo un campione di un ipotetico database contenente i segnali di riferimento.
Figura 3-Confronto tra DTW e calcolo della distanza euclidea
Consideriamo il segnale in ingresso come una sequenza di n campioni X(k) k=1,2,..,N e il segnale di riferimento (template) come una sequenza di m campioni Y(k) k=1,2,…M. Il DTW “allinea” il segnale di ingresso con quello di riferimento mediante una variazione temporale non lineare. Tale variazione temporale avviene secondo quanto illustrato dal grafico B di Figura 3. Come si vede dalla figura, anche la distanza euclidea tra due serie temporali può essere considerata una tecnica di Template Matching, ma non consente di tenere conto delle differenze “temporali”
delle due serie numeriche limitandosi ad effettuare un calcolo di distanza tra punti corrispondenti.
Ogni punto del segnale di ingresso (traccia superiore), X(k), non viene confrontato con il corrispondente omologo temporale del segnale di riferimento (traccia inferiore) Y(k), come avverrebbe in un confronto classico e illustrato nel grafico (A) della Figura, ma con diversi punti del segnale di riferimento appartenenti ad un intorno temporale di dimensione 2N+1 del k-mo punto del segnale di riferimento. Il confronto uno a molti del DTW, permette di individuare un punto ottimo (secondo un criterio di distanza minima), chiamiamolo Y(kott), nel segnale di riferimento e quindi
permette un “allineamento” di k con kott.
Il confronto di tutti i punti dà luogo alla costruzione di un percorso minimo, mediante la procedura che si articola nei seguenti passi:
1) Costruzione della matrice d ([NxM]) in cui ogni elemento di posizione (i,j) rappresenta la distanza tra l’elemento i-esimo della sequenza X(k) e l’j-esimo elemento della Y(k). La distanza scelta è quella euclidea. La matrice d ha la seguente forma: 1 1 1 2 2 1
( , )
( , )
...
( , )
...
...
( ,
)
( , )
...
( ,
)
M N N Md x y
d x y
d i j
d x y
d x y
d x y
=
2) Calcolo, secondo un approccio ricorsivo, di una nuova matrice D(i,j) (sempre di dimensione [NxM]), detta matrice delle distanze globali, definita nel seguente modo:
[
]
( , )
( , ) min
(
1,
1), ( ,
1), (
1, )
Ogni elemento di questa nuova matrice è calcolato come la somma tra la distanza locale d(j,i) e il minimo delle distanze globali degli elementi immediatamente circostanti.
3) Calcolo, a partire dalla matrice D(i,j), del percorso di minimizzazione (Warp-path ) procedendo come in Figura 4 e cioè muovendosi dal punto (1,1) al punto (N,M) (o viceversa ).
Figura 4- Vincoli al percorso
Il percorso è costituito da un insieme W di k coppie di punti che vengono presi nella matrice D(i,j) compiendo un percorso soggetto alle seguenti regole (figura5):
• non è possibile un’inversione di direzione nel tempo ;
• l’andamento nel tempo deve essere monotono non decrescente; • il segnale d’ingresso deve essere continuo nel tempo;
• al fine di ottenere una distanza globale, ogni nuovo elemento del percorso deve essere frutto della somma di distanze locali.
La mancanza di una precisa delimitazione del segnale d’ingresso e il mancato allineamento del punto d’inizio dei segnali che formano il database fa sì che il percorso prenda una direzione parallela all’asse temporale relativo alla sequenza dove l’inizio del segnale è ritardato.
Come ulteriore condizione, ogni percorso della matrice D parte da j=1, i=1 e termina una volta calcolato l’(N,M)-esimo (o viceversa
Infine notiamo che per il calcolo di D(1,1) sono necessari valori di D corrispondenti ad indici negativi, e così anche per tutti gli elementi della prima riga e della prima colonna. Per risolvere il problema si pongono precise condizioni al contorno:
• D(1,1) = d(1,1)
• D(1,i) = d(1,i) + D(1,i
• D(j,1) = d(j,1) + D(j-1,1)
Il percorso sarebbe la diagonale di una matrice di dimensione [ segnali fossero perfettamente allineati.
riallineare un segnale rispetto all’altro e consentire il calcolo ottimale della distanza tra di loro (figura6)
Figura 5 –Il warp path
ogni percorso della matrice D parte da j=1, i=1 e termina esimo (o viceversa ).
Infine notiamo che per il calcolo di D(1,1) sono necessari valori di D corrispondenti ad indici negativi, e così anche per tutti gli elementi della prima riga e della prima
Per risolvere il problema si pongono precise condizioni al contorno:
D(1,i-1) 1,1)
l percorso sarebbe la diagonale di una matrice di dimensione [
segnali fossero perfettamente allineati. Tramite questo warp-path è possibile allora rispetto all’altro e consentire il calcolo ottimale della distanza ogni percorso della matrice D parte da j=1, i=1 e termina
Infine notiamo che per il calcolo di D(1,1) sono necessari valori di D corrispondenti ad indici negativi, e così anche per tutti gli elementi della prima riga e della prima
Per risolvere il problema si pongono precise condizioni al contorno:
l percorso sarebbe la diagonale di una matrice di dimensione [N x M] se i due path è possibile allora rispetto all’altro e consentire il calcolo ottimale della distanza
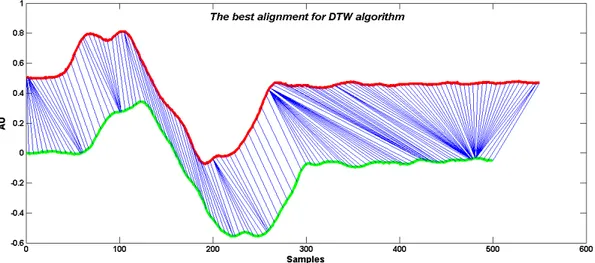
Figura 6: Allineamento ottimale di due segnali tramite il DTW
Il termine D(N,M) rappresenta il punteggio associato al percorso minimo tra l’elemento X(N) e l’elemento Y(M) e dunque la distanza tra le due forme d’onda:
DistDTW(X,Y) = D(N,M).
2.1.2 Derivative Dynamic Time Warping (DDTW)
Il Derivative Dynamic Time Warping (DDTW) è una variante del DTW e considera, al posto della matrice d(i,j) delle distanze euclidee tra i campioni, una nuova matrice d che è la matrice data dalla differenza tra le stime della derivata:
( )
(
1) (
1 1) / 2
2
i i i i
X
X
X
X
Questo algoritmo risulta essere più robusto del precedente nell’allineamento dei due segnali sia rispetto a variazioni dei due segnali lungo l’asse delle ordinate (cioè variazioni in ampiezza), sia rispetto ad alcuni punti di singolarità come mostrato in Figura 7 :
2.1.3 Le tecniche di clustering
Le tecniche di clustering nascono dalla necessità di partizionare un insieme di dati in gruppi (o clusters) omogenei, tali da rappresentare una classe rispetto ad un’altra o da isolare una particolare proprietà rispetto ad un’altra.
Essi infatti sono costituiti da algoritmi che hanno come obiettivo la ricerca di clusters omogenei minimizzando una particolare funzione di costo definita attraverso misure di distanza di tipo euclideo fra i punti del nostro spazio e le medie dei gruppi.
Le tecniche di clustering si dividono essenzialmente in due tipologie:
• Dal basso verso l'alto (Bottom-Up):
Questa filosofia prevede che inizialmente tutti gli elementi siano considerati come cluster e poi l'algoritmo continua ad agglomerare i dati unendo via via i cluster omogenei fino ad ottenere un numero prefissato di cluster, oppure fino a che la distanza minima tra i cluster non supera un certo valore.
• Dall'alto verso il basso (Top-Down):
All'inizio tutti gli elementi costituiscono un unico cluster e poi l'algoritmo inizia a dividere il cluster in tanti cluster di dimensioni inferiori. Il criterio che guida la divisione è sempre quello di cercare di ottenere elementi omogenei. L'algoritmo procede fino a che non ha raggiunto un numero prefissato di cluster.
Una tra i più noti e più usati algoritmi di clustering è l’algoritmo del k-means.
L’algoritmo del k-mean minimizza la varianza totale tra i cluster. Ogni cluster viene
identificato mediante un centroide o punto medio. L'algoritmo segue una procedura iterativa che inizialmente crea K cluster ognuno con uno degli elementi da classificare. Per ogni cluster viene stimato anche il suo centroide (zi) .
Al passaggio successivo associa ogni punto d'ingresso al cluster il cui centroide è più vicino ad esso ed identifica iterativamente i K cluster S1, S2, …, SK che minimizzano il funzionale sum-of-squared error (SSE):
2 1
||
||
i K i i x SSSE
x
z
= ∈=
∑ ∑
−
Quindi vengono ricalcolati i centroidi per i nuovi cluster e così via, finché l'algoritmo non converge.
Si dimostra che l’algoritmo converge sempre in un numero finito di passi, ossia che, dopo un certo numero i di iterazioni, i centri-cluster non si spostano più (coincidono con quelli dell’iterazione precedente). Il numero i di iterazioni necessario a raggiungere la convergenza dipende dai dati e dalla scelta dei centri-cluster iniziali (schema dell’algoritmo in figura 8):
2.2
La classificazione bayesiana
Per introdurre la classificazione bayesiana è necessario introdurre alcuni concetti di probabilità e il teorema di Bayes.
Sappiamo che con la notazione p(A | B) si denota la probabilità condizionata dell’evento A dato B, che in uno spazio degli eventi che non è quello originario, ma è ristretto a B, identifica la probabilità che A si verifichi negli stati del mondo nei quali B si verifica. Potremmo anche dire “la probabilità che l’enunciato A sia vero negli stati del mondo in cui l’enunciato B è vero”.
Un caso particolare è p(A | B) = 1: sapendo che B si è verificato, sappiamo che A è certo. Se invece p(A | B) = 0: sapendo che B si è verificato, sappiamo che A è impossibile. Se p(A | B) > p(A) allora il verificarsi di B facilita, rende più probabile il verificarsi di A. Se le due probabilità sono uguali, allora l’informazione su B è irrilevante per prevedere A, B non facilita né ostacola A: in tal caso si dice che i due eventi sono indipendenti.
Vale la seguente relazione (il cosiddetto teorema delle probabilità composte):
(
)
( | ) ( )
p A
∪
B
=
p A B p B
Il teorema delle probabilità composte, come si è visto, porta immediatamente alla seguente identità
( | ) ( )
( | ) ( )
p A B p B
=
p B A p A
poiché entrambi i membri uguagliano
p A
(
∪
B
)
Questa identità si trova in genere scritta in questo modo ( Teorema di Bayes):( | ) ( )
( | )
( )
p A B p B
p B A
p A
=
mettendo in evidenza una delle due probabilità condizionate. Si vuole così suggerire che, conoscendo le due probabilità a priori, non condizionate, e una delle due probabilità condizionate, si riesce a calcolare l’altra probabilità condizionata. Dato il teorema di Bayes sopra menzionato, possiamo introdurre la classificazione di Bayes. Supponiamo, per semplicità di esposizione, di avere due classi ω1 e ω1, e ipotizziamo di conoscere le probabilità a priori delle classi (P(ω1) e P(ω2)).
• La teoria della decisione assume nota la densità di probabilità (ddp) p(x|ωi)del vettore delle feature x condizionate all’appartenenza a ciascuna classe ωi (i = 1, 2, ..., M).
• Un campione incognito xi è assegnato ad una delle classi ω1, ω2, ..., ωM
sfruttando l’informazione statistica contenuta nelle ddp condizionate alle classi p(x|ωi) (i = 1, 2, ..., M) e la conoscenza della probabilità a priori di tutte le classi ωi.
Criterio di decisione MAP (Massima Probabilità a Posteriori):
• un campione x è assegnato alla classe che presenta la massima probabilità a posteriori P(ωi| x):
• Le probabilità a posteriori vengono stimate applicando il teorema di Bayes (la definizione di probabilità condizionata).
Ad esempio per la classe 1, detto x il vettore di dati a disposizione (features), si definisce la probabilità condizionata come la densità di probabilità di x appartenente alla data classe ω1, p (x | ω1). Si utilizza quindi il Teorema di Bayes:
dove, per N condizioni mutuamente esclusive ω1. . . ωN, la probabilità (totale) di una osservazione x si calcola come:
P(x) = Σ p(x | ωj)P(ωj) con j=1,2,..N
P(ω1|x) è indicata come probabilità a posteriori. La probabilità a posteriori esprime dunque la probabilità che, dato un determinato vettore caratteristico in ingresso, esso appartenga ad una determinata classe. La teoria della decisione vuole che, se le densità di probabilità sono note, la regola di decisione più razionale è quella della massima probabilità a posteriori (MAP):
Se le probabilità a priori sono uguali (P(ω1) = P(ω2)) è possibile decidere in base alle sole verosimiglianze (ML maximum likelihood), ovvero solo in base alle densità di probabilità condizionata, in quanto il denominatore sarebbe lo stesso per le diverse espressioni e la formula verrebbe per le due classi identificata solo dalla densità di probabilità a priori.
Inoltre è possibile esprimere valutare la accuratezza dei nostri risultati valutando la probabilità di errore che si compie con questo tipo di classificazione. La probabilità di errore si esprime nel modo seguente:
1
(
)
(
|
) (
)
M e i i iP
P err
P err w P w
==
=
∑
Se P(w1|x) > P(w2|x) è più razionale scegliere w1 Altrimenti w2
Si dimostra che il classificatore MAP minimizza la probabilità di errore, note le ddp condizionate alle classi e le probabilità a priori delle classi stesse.
Il criterio MAP non tiene conto degli eventuali costi associati ai diversi errori di classificazione. A questo proposito accenniamo brevemente alla teoria generale del minimo rischio, di cui il criterio della massima probabilità a posteriori diviene un caso particolare.
La teoria del minimo rischio è basata anch'essa sulla definizione e sulla massimizzazione di una misura di natura probabilistica e tiene conto dei costi associati alle azioni che si possono intraprendere in seguito alla decisione e ai rischi associati ad esse.
I costi delle azioni che è possibile intraprendere dipendono dalle classi e sono definiti da una matrice dei costi Λ:
1 1 1 2 1 2 1 2 2 2 1 2
(
|
)
(
|
)
...
(
|
)
(
|
)
(
|
)
...
(
|
)
...
...
...
...
(
|
)
(
|
)
(
|
)
M M R R R Mw
w
w
w
w
w
w
w
w
λ α
λ α
λ α
λ α
λ α
λ α
λ α
λ α
λ α
∆ =
L’elemento λij= λ(αi | ωj) è il costo dell’azione αi data la classe ωj ed è, in genere, un
numero reale e positivo (qualora fosse negativo, denoterebbe un “guadagno”).
Per ogni pattern x, introduciamo il rischio condizionato R(αi | x) di effettuare l’azione
αi dato il pattern x:
{
}
1(
| )
(
|
) (
| )
(
| ) |
M i i j j w i jR
α
x
λ α
w P w x
E
λ α
w
x
∈Ω ==
∑
=
Il rischio condizionato può essere visto come un costo medio (rispetto alla distribuzione di probabilità a posteriori delle classi) che si ha se, osservato un campione x, si decide per un’azione αi
Dato il pattern x viene scelta l’azione αj cui è associato il minimo rischio
condizionato:
(
| )
(
| )
1, 2..
i i j
x
→ ⇔
α
R
α
x
≤
R
α
x
∀ =
j
R
Anche mediante l’approccio globale, si può verificare che il classificatore MAP è un caso particolare del classificatore a minimo rischio.
Nel caso di matrice dei costi:
0 1
0
1
1
0
P
C
P
η
=
⇒
=
Pertanto il classificatore a minimo rischio basato su tale matrice dei costi è:
0 1
( | 1)
( )
( | 0)
P
p x w
x
MAP
p x w
<P
∆
=
>
⇒
Inoltre, in questo caso particolare, il rischio coincide con la probabilità di errore. È pertanto confermato che il classificatore MAP minimizza la probabilità di errore anche in senso globale.
2.2.1 Stima della densità di probabilità condizionata: metodi
parametrici e non parametrici
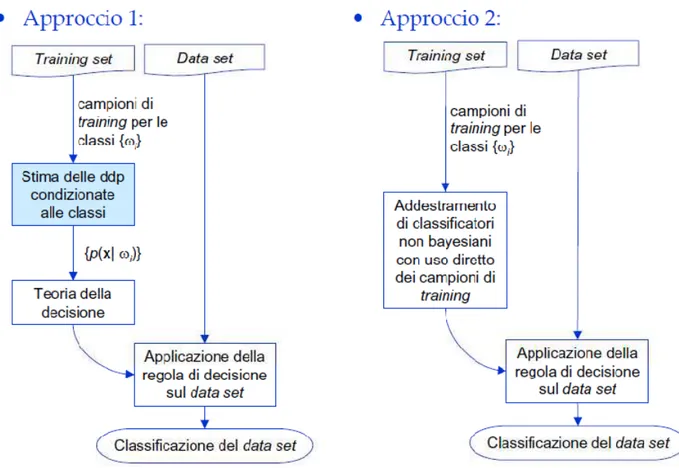
Il primo problema da affrontare nella costruzione di un classificatore bayesiano è quello di stimare la densità di probabilità condizionata della nostra variabile rispetto all’appartenenza ad una classe. Esistono metodi parametrici, che suppongono nota la forma della densità di probabilità e si riconducono ad una stima dei parametri, e metodi non parametrici, che non ipotizzano informazioni a priori sulle caratteristiche della densità di probabilità (Figura 9)
Figura 9 – Schema degli approcci parametrici e non parametrici
Tra i metodi parametrici quello classico, e anche da noi implementato, suppone nota la forma della densità di probabilità come una gaussiana ( n-dimensionale ) e la fase
di training prevede dunque la stima dei soli parametri che in questo caso sono la media e matrice di covarianza.
In generale, una giustificazione della grande diffusione dei modelli gaussiani è rappresentata dal teorema del limite centrale, secondo cui la somma di N variabili aleatorie indipendenti converge in distribuzione ad una gaussiana per N→+ ∞.
Da questo se ne deduce che un grande numero di fenomeni stocastici possono essere descritti con un modello di tipo gaussiano che può essere espresso nella seguente forma: 1 / 2 1/ 2
1
1
( )
exp
(
)
(
)
(2 )
|
|
2
t np x
x
m
x
m
π
−
=
−
−
∑
−
∑
Una volta definita la forma della densità di probabilità, tramite i dati di training è possibile fare una stima dei parametri della forma d’onda. Nel caso in questione, tramite i nostri dati a disposizione, possiamo stimare la media e la matrice di covarianza, che risulteranno anch’essi delle variabili aleatorie. Date N osservazioni aleatorie indipendenti, si può dimostrare che le stime a massima verosimiglianza di media e matrice di covarianza sono:
1
1
ˆ
N k km
x
N
==
∑
11
ˆ
N(
ˆ
)(
ˆ
)
t k k kx
m x
m
N
=∑
=
∑
−
−
Invece in un contesto non parametrico non si suppone nessuna forma per la densità di probabilità condizionata e si stima direttamente dai dati di training. Supponiamo che xi sia uno di questi campioni e che sia contenuto in una regione dello spazio delle
{
}
ˆ
( )
( )
S i
S
P
=
P x
∈
S
=
∫
p x dx
≃
p x V
dove V è il volume n-dimensionale (misura) di S.
Una stima consistente della probabilità P è data dalla frequenza relativa:
ˆ
SK
P
N
=
Con K numero di campioni di training che cadono nella superficie S. Dalla stima della probabilità che un punto appartenga ad S ne deduco una stima della ddp per il punto xi
Osservazioni
– S deve essere abbastanza “grossa” da contenere un numero di campioni di training che giustifichi l’applicazione delle legge dei grandi numeri;
– S deve essere abbastanza “piccola” da giustificare l’ipotesi che p(x) non vari apprezzabilmente in S.
Come tutte le situazioni in cui sembrano esserci condizioni contrastanti è necessario un compromesso fra queste due esigenze, per fare in modo che la stima della ddp sia consistente. E’necessario comunque che il numero totale N di campioni di training sia abbastanza numeroso.
A seconda delle grandezze K e V, ci sono diverse possibilità di approccio alla stima non parametrica, di cui noi accenniamo a due metodi in particolare :
– metodo dei “K-punti vicini”: si fissa K e si determina la regione R in base al training set, se ne calcola l’ipervolume V e se ne deduce la stima delle ddp;
– metodo di Parzen: fissata la regione S (e fissato quindi anche il suo ipervolume V), si calcola K a partire dal training sete se ne deduce la stima.
– Il metodo dei “K-punti vicini” (K-nearest neighbors, K-NN) espande la cella finchè essa non contenga esattamente K campioni di training: sia VK(x*) il volume della cella risultante. La ddp nel punto xi è stimata allora come segue:
ˆ ( )
(
)
i k iK
p x
NV x
=
Si può dimostrare che, scelto K in funzione di N(K= KN), condizione necessaria e
sufficiente affinché la stima K-NN sia consistente in tutti i punti in cui p(x) è continua è che KN→+ ∞per N→+ ∞, ma di ordine inferiore ad 1
In parole semplici il nuovo campione da classificare viene assegnato alla classe, se questa è la più frequente tra i k esempi più vicini al nuovo elemento. Il nuovo campione, una volta classificato, può far parte o meno della decisione certa e contribuire alla classificazione dell’elemento successivo. Il procedimento è illustrato in figura 10:
Figura 10
In figura 10 abbiamo cercato di esemplificare il procedimento dell’algoritmo di KNN. Supponiamo di ricevere il campione rappresentato dal simbolo + . Abbiamo a disposizione due classi, quelli dei pallini e quella degli asterischi.