Dipartimento di Ingegneria dell'Informazione
Corso di Laurea Specialistica in Ingegneria Informatica
Progettazione e realizzazione di un sistema multi-agente
per il riconoscimento di aree parcheggio basato su tecnologia GPS
Tesi di Laurea Specialistica
Anno Accademico 2012/2013
RELATORIProf. Gigliola Vaglini Ing. Mario G.C.A Cimino
CANDIDATO Giovanni Pelosi
1
Indice
1 Introduzione ... 3 2 Concetti base ... 4 2.1 Sistema multi-agente ... 4 2.2 Swarm Intelligence ... 7 2.3 Stigmergia ... 8 3 Stato dell’arte ... 10 4 Realizzazione ... 12 4.1 Modello... 12 4.2 Marking Agent ... 14 4.3 Event Agents ... 174.3.1 Driving Agent e Walking Agent ... 17
4.3.2 Stopping Agent ... 22
4.4 Situation Agent ... 25
4.5 Area Agent ... 27
5 Tecnologie ... 31
5.1 Introduzione a Repast Symphony ... 31
5.2 Repast Scheduler ... 31
5.3 Elementi di Repast ... 33
5.4 Repast Simphony 2.0 ... 36
5.4.1 Miglioramenti dello scheduler ... 36
5.4.2 Geographical System Information ... 37
2 6 Implementazione ... 38 6.1 Package Area_park.agents ... 38 6.1.1 Marking Agent ... 40 6.1.2 Driving Agent ... 41 6.1.3 Walking Agent ... 41 6.1.4 Stopping Agent ... 42 6.1.5 Area Agent ... 43 6.1.6 Situation Agent ... 44 6.1.7 Diary ... 45 6.2 Package.core ... 45 6.2.1 Areaparkcontext... 46 6.3 Package.mfun ... 47 6.3.1 Membership Function ... 47 6.4 Package Area_park.services ... 49 6.4.1 Diffuse Service ... 49
7 Uso del simulatore ... 51
7.1 Configurazione del simulatore ... 51
7.2 Interfaccia grafica ... 54
8 Risultati Sperimentali ... 58
8.1 Scenario 1 ... 59
8.2 Scenario 2 ... 65
8.3 Prestazioni del sistema... 71
9 Conclusioni ... 72
3
1 Introduzione
Il problema del riconoscimento delle aree parcheggio, allo stato attuale, viene affrontato con scarso successo e con soluzioni molto lontane dall’individuazione di un meccanismo che in maniera automatica riesca a rilevare aree adibite a sosta, di cui non si ha una conoscenza a priori. In letteratura i sistemi che si possono trovare sono orientati più alla implementazione di grandi basi di dati, sfruttando la collaborazione attiva di utenti o “gestori” delle aree, che alla ricerca di sistemi e algoritmi che riescano a riconoscerle attraverso un qualche tipo di analisi. Si evidenzia, comunque, che la maggior parte delle soluzioni attuali, ampiamente descritte in seguito, trovano collocazione e utilizzo in applicativi per dispositivi cellulari di ultima generazione. Strumento, chiaramente molto efficace per supportate un automobilista. La proliferazione degli smartphone negli ultimi anni ha mostrato parimenti lo sviluppo del mercato degli applicativi per terminali mobili. Questi riescono a coprire, oggigiorno, svariati campi di utilizzo, non ultimo quello dei servizi detti recommender, ossia di suggerimento a problemi comuni per l’utente in mobilità. Molti di questi applicativi sviluppati negli ultimi anni possono essere classificati in una particolare categoria cioè quella dei sistemi Situation-Aware. Questi tipi di applicazioni rilevano e analizzano le situazioni in cui si trova l’utente in un particolare momento, fornendo in questo modo supporto e informazioni puntuali in risposta a specifiche richieste [1]; ad esempio luoghi di interesse culturale, di ristorazione o di servizi specifici in base alla posizione corrente. Lo strumento che permette di individuare la situazione in cui si trova un utente è il contesto, i cui dati possono essere raccolti da un sistema fisico o logico. La raccolta delle informazioni di contesto dovrebbe però avvenire in maniera implicita, in seguito ai cambiamenti dell’ambiente in cui opera l’applicativo. In questo modo il sistema diventerebbe efficace, semplice e poco invasivo. Per riuscire ad ottenere in maniera implicita questi tipi di dati, di seguito proporremo un sistema basato sul paradigma emergente. Il paradigma emergente si fonda sul principio dell’auto-organizzazione, dove un sistema, costituito da entità elementari, dà origine a comportamenti complessi fornendo allo stesso proprietà particolari che senza un approccio collaborativo non sarebbero emerse. In letteratura il meccanismo utilizzato per organizzare questi tipi di sistemi è conosciuto come Swarm Intelligence [2]. Questo concetto è versatile e applicabile a svariati campi: dalla fisica all’economia. Negli ultimi anni si è visto però che il concetto di comportamento emergente può risultare utile anche nel settore dei sistemi mobili e pervasivi [2]. In questo lavoro, infatti, ci proponiamo di sviluppare un sistema multi-agente basato
4 sul paradigma emergente finalizzato all’individuazione di punti d’interesse per l’utente in mobilità. Nello specifico questo studio permetterà l’individuazione di aree di parcheggio, da consigliare a un utente alla guida. Il sistema sarà strutturato secondo tre livelli in cui verranno processati e analizzati i dati del contesto. Nel primo livello, secondo il paradigma di stigmergia, sfruttando i dati di localizzazione dell’utente e tramite agenti specifici, verranno realizzate delle tracce di posizione attraverso i cosiddetti mark informativi, definiti nei capitoli seguenti. Nel secondo livello invece l’accumulo dei mark informativi verrà analizzato da ulteriori agenti, in modo da poter individuare una serie di eventi emergenti. Infine, nel terzo livello, il processing degli eventi individuati permetterà di dedurre situazioni specifiche in cui un utente alla guida può trovarsi. L’applicativo finale, di cui questo sistema sarà il nucleo, in questa prima versione è stato pensato per un utilizzo limitato a una cerchia di utenti ristretti: utenti di una ZTL cittadina. Questi utenti faranno tutti uso del servizio, poiché lo stesso sarà sfruttato anche per il pagamento orario della sosta. Con le ipotesi appena descritte non avremo, quindi, la presenza di utenti “invisibili” (che si servono dell’area di sosta ma non utilizzano l’applicativo) e dunque le classificazioni finali delle nostre analisi risulteranno attendibili. Il sistema appena descritto verrà implementato attraverso Repast Simphony, una piattaforma di progettazione e simulazione agent-based.
2 Concetti base
2.1 Sistema multi-agente
I sistemi ad agenti sono un paradigma di progettazione e implementazione del software sviluppatosi negli ultimi anni, particolarmente efficace in ambienti distribuiti e open source come può essere il software reperibile in rete. Un sistema multi-agente è un sistema composto da un insieme di agenti, entità indipendenti e autonome, capaci di interagire con l’ambiente circostante (contesto). Un sistema di questo tipo è utilizzato per approcciare problemi difficilmente risolvibili attraverso un sistema monolitico o a singolo thread (agente). Il problema complesso viene scomposto in sotto problemi più semplici che vengono affidati ad uno o più agenti, questi eseguendo le operazioni per i quali sono stati progettati e interagendo tra loro, porteranno alla risoluzione del problema finale. Ogni agente è un oggetto software con un suo flusso privato di esecuzione, che compie operazioni in relazione al suo compito specifico predefinito.
5 È possibile introdurre anche una classificazione degli agenti secondo due criteri:
Agenti Cognitivi o Reattivi
Comportamento Teleonomico o Riflesso
La distinzione tra cognitivo e reattivo si riferisce sostanzialmente alla rappresentazione del “mondo” di cui dispone l'agente. Se il singolo agente è dotato di una rappresentazione simbolica del “mondo” a partire dalla quale è in grado di formulare ragionamenti, si parlerà di agente cognitivo, mentre se non dispone che d'una rappresentazione sub simbolica, vale a dire limitata alle percezioni, si parlerà di agente reattivo. Tale distinzione corrisponde a due scuole di pensiero relative ai sistemi multi-agente: la prima sostiene un approccio basato su insiemi di agenti "intelligenti" collaborativi, da una prospettiva più sociologica; la seconda studia la possibilità dell'emergere di un comportamento "intelligente" di un insieme d'agenti che non lo sono.
La seconda distinzione tra comportamento teleonomico o riflesso divide i comportamenti intenzionali (perseguire scopi espliciti) dai comportamenti legati a delle percezioni [3].
6 Fig. 2.2 Comportamento Teleonomico Un agente può implementare diversi tipi di meccanismi:
Collaborazione: dove diversi agenti collaborano o condividono risorse per raggiungere uno scopo finale comune.
Coordinamento: dove avvengono negoziazione di risorse e coordinamento di azioni specifiche
Competizione: dove gli agenti competono in situazioni in cui si trovano a condividere risorse essenziali allo scopo finale.
Gli agenti all’interno di un sistema di questo tipo devono possedere inoltre alcune importanti caratteristiche[4][5] :
Autonomia : devono essere quantomeno parzialmente autonomi
Visione locale : non hanno piena visione del sistema globale, ma rispondo solo alle regole singole di comportamento pre-impostate al momento della progettazione del sistema
Decentralizzazione : Non sono previsti, inoltre, agenti designati al controllo delle singole entità
Nei sistemi multi-agente troviamo generalmente tre tipi di utilizzo:
possono essere utilizzati per simulare fenomeni complessi
7
per la progettazione di software articolato
I campi della ricerca in cui vengono utilizzati sono invece svariati. Si utilizzano i sistemi multi-agente per simulare le interazioni esistenti tra agenti autonomi. Si cerca di determinare l'evoluzione del sistema (fenomeno complesso) al fine di prevederne l'organizzazione risultante. Per esempio, in sociologia, si possono modellare i differenti agenti che compongono una certa comunità. Le applicazioni esistenti hanno riguardato anche la fisica delle particelle (agente = particella elementare), la chimica (agente = molecola), la biologia cellulare (agente = cellula),
l'etologia (agente =animale), la sociologia e l'etnologia (agente = essere umano).
L'intelligenza artificiale distribuita è nata per risolvere i problemi di complessità dei grossi
programmi monoblocco dell'intelligenza artificiale: l'esecuzione è pertanto non concentrata ma
distribuita, ma il controllo rimane centralizzato. Al contrario, nei sistemi ad agenti multipli, ciascun agente possiede un controllo totale sul suo comportamento. Per risolvere un problema complesso, talvolta è, in effetti, più semplice concepire programmi relativamente piccoli (gli agenti) interagenti con un unico grosso programma monoblocco. L'autonomia permette al sistema di adattarsi dinamicamente ai cambiamenti imprevisti che intervengono nell'ambiente.
L'ingegneria del software si è evoluta, dunque, in direzione di componenti sempre più autonomi. I sistemi ad agenti multipli possono essere visti come un raccordo tra ingegneria del software ed intelligenza artificiale distribuita, con l'apporto rilevante dei sistemi distribuiti. In rapporto ad un oggetto, un agente può prendere iniziative, può rifiutarsi di obbedire ad una richiesta, può spostarsi, etc.: l'autonomia consente al progettista di concentrarsi sul lato umanamente
comprensibile del software [6].
2.2 Swarm Intelligence
La swarm intelligence trae origine dall’osservazione di sistemi naturali come colonie d’insetti (formiche, api, termiti),branchi di pesci, stormi di uccelli oppure di sistemi biologici (sistema immunitario); in questi tipi di sistemi un’azione complessa deriva da un’intelligenza collettiva. Lo stesso cervello umano possiede un comportamento intelligente riconducibile al comportamento collettivo intelligente di un numero elevato di semplici neuroni che collaborano attivamente. Secondo la definizione di Beni e Wang [7] questo tipo di paradigma può essere definito come: “Proprietà di un sistema in cui il comportamento collettivo di agenti (non sofisticati) che
8 interagiscono localmente con l’ambiente produce l’emergere di pattern funzionali globali nel sistema”. Uno sciame (swarm) è appunto definito come l’insieme di entità autonome (agenti), distribuite nello spazio, che agiscono sul loro ambiente locale e interagiscono tra loro. Le caratteristiche che identificano un sistema di questo tipo sono :
Capacità limitate di ogni individuo del sistema
Conoscenza limitata e non globale dello stato del sistema
Assenza di un’entità coordinatrice
Le interazioni fra i vari agenti, come già ampiamente descritto, fa emergere un comportamento globale intelligente riferito come comportamento emergente.
2.3 Stigmergia
La stigmergia è un meccanismo di coordinamento indiretto tra agenti o azioni, anch’esso ispirato a sistemi naturali-animali. Questa forma di comunicazione avviene alterando lo stato dell’ambiente in modo tale da influenzare il comportamento degli altri individui per i quali l’ambiente stesso è uno stimolo [8]. Il principio che vi è alla base, dunque, consiste nel lasciare una traccia iniziale nel sistema in modo da stimolare altri individui a fare lo stesso e rafforzare questa, innescando un meccanismo di feedback positivo che porterà alla comparsa di attività coerenti apparentemente sistematiche. Si evince, dunque, che la stigmergia è una forma di auto-organizzazione, producendo strutture anche complesse senza il bisogno di una pianificazione o di entità di coordinamento. Sistemi che sfruttano questo tipo di meccanismo sono scalabili, adattabili, veloci e tolleranti ai guasti. Un tipico esempio di auto-organizzazione e stigmergia è quello della ricerca di alimenti di una colonia di formiche.
9 Fig. 2.3 Colonia di formiche nella scelta di un percorso
Ogni formica, dopo aver individuato il luogo in cui si trova del cibo, rilascia nell’ambiente una traccia di feromoni (che gradualmente scompare nel tempo), nel tragitto di ritorno al nido. Le altre formiche, anch’esse alla ricerca di cibo non seguiranno più un percorso casuale nella loro ricerca ma saranno guidate dalla scia rilasciata in precedenza. La scelta del percorso da seguire è guidata dall’intensità della scia: più essa è intensa più è probabile che venga scelta come percorso. Se quindi quel percorso è utilizzato da molte formiche (molti feedback positivi) l’intensità si rinforzerà a ogni passaggio e questo sarà, molto probabilmente, scelto come percorso preferenziale anche dal resto della colonia. Quando si sarà esaurita la fonte di cibo, l’intensità del percorso, considerando la scarsa percorrenza di questo, andrà a decadere con il passare del tempo. Si vede chiaramente anche in questo esempio come non sia presente alcuna forma di controllo centralizzato che vada a coordinare le formiche (agenti del sistema) nell’attuazione del processo “ricerca cibo”.
10
3 Stato dell’arte
Nel vasto settore dei servizi all’utente in mobilità, come già anticipato, troviamo soluzioni tecnologiche, soprattutto negli ultimi tempi, nel campo degli applicativi per smartphone. I dispositivi attuali in commercio ormai dotati di una sensoristica completa e di alto livello come localizzatori GPS, giroscopi, accelerometri ecc. riescono a fornire all’utente informazioni precise e utili a seconda dell’occorrenza. Nel campo che ci accingiamo ad analizzare, cioè quello dei sistemi per l’individuazione delle aree di parcheggio, la loro classificazione e l’analisi del loro stato, troviamo diverse soluzioni utili sia nel campo degli applicativi per smartphone, a cui rivolgiamo particolare interesse, sia in altri tipi di sistemi che utilizzano tecnologia e hardware non di largo consumo, come satelliti o sensori specifici. Nel campo delle app-mobile ci troviamo di fronte a soluzioni che fanno largo uso di banche dati centralizzate, preimpostate, e che necessitano di aggiornamento manuale [9][10]. Questi sistemi sono spesso statici [10], non essendoci condivisione d’informazioni e inoltre non forniscono indicazioni sulla disponibilità o meno di postazioni di parcheggio libere nelle aree che vanno a consigliare all’utente. In altri tipi di sistemi invece, social
style, viene superata la staticità condividendo un gran numero di informazioni tra gli utenti della social-app: segnalazioni della presenza di aree di parcheggio free e a pagamento, segnalazioni di
postazioni libere in aree già individuate, segnalazione di inizio e fine parcheggio e possibilità di “prenotazioni di una postazione” ecc. [11][12][13]. E’ evidente che la condivisione attiva delle informazioni è efficace ma fa affidamento al buon senso delle persone, perché un utente “distratto” potrebbe non segnalare il posto auto appena liberato rendendo così l’applicazione non sempre funzionale. Sistemi dunque che non si affidano all’intraprendenza e collaborazione dell’utente devono necessariamente sfruttare la tecnologia sotto un’altra forma come ad esempio quella dei sensori. Esistono infatti progetti che si basano esclusivamente sull’installazione di sensori nelle aree parcheggio in modo da poter sfruttare le informazioni, evidentemente certe e puntuali, per fornire all’utente indicazioni sempre corrette, come la presenza o meno di una postazione libera o come il suggerimento del percorso più veloce (evitando traffico e ingorghi) verso il parcheggio con più postazioni libere. Nella prima tipologia, l’installazione dei sensori nelle strisce di parcheggio ha ovviamente come vantaggio l’indicazione sempre corretta dell’informazione di “presenza parcheggio” ma come svantaggio ha la necessità dell’installazione del sensore in loco (soluzione non certo economica e scalabile) [14]. Nella seconda tipologia invece l’installazione massiccia di sensori in loco è ridimensionata dotando il centro cittadino solo di alcune “unità di sensing” in punti strategici, a discapito però della necessità di dover dotare le automobili di dispositivi di
11 comunicazione wireless [15]. Infine possiamo trovare anche sistemi più complessi che eliminano l’utilizzo dei sensori in loco e sfruttano il processing d’immagini provenienti da videocamere di sorveglianza o da vedute aeree (anche satellitari). Questi sistemi analizzano il variare dell’intensità della luce nelle immagini e la sua non uniformità, analizzando i pixel; attraverso questo processing riescono a fornire indicazioni su disponibilità o meno di zone di parcheggio libere in aree già parzialmente utilizzate da altri automobilisti [16][17].
12
4 Realizzazione
4.1 Modello
Lo scopo dell’applicazione è quello di rilevare implicitamente, tramite le sole informazioni ottenute dal dispositivo mobile degli utenti, se una qualsiasi area (utilizzata per sostare con l’auto) può essere definita, con un certo grado di certezza, area parcheggio. L’applicazione raccoglierà i dati provenienti dai singoli utenti (posizione e tempo) e li processerà ottenendo in maniera emergente: in prima analisi le situazioni di sosta (parcheggio di un’auto) e relativo rilascio del singolo utente, in seconda analisi quali delle aree interessate dalle precedenti situazioni sosta/rilascio possono essere classificate come aree parcheggio. Entrambi i due tipi di analisi vengono espletati all’interno di un
sistema multi-agente basato su uno schema di collaborazione situation-aware (Fig.4.1).
Le proprietà chiave di questo schema possono essere individuate negli “stati”: l’utente si muove
nell’ambiente, l’utente si trova in una situazione. Queste due proprietà (rappresentate dalla linea
tratteggiata) non possono essere individuate direttamente dai sensori del dispositivo, ma emergono
in maniera indiretta, dal contesto informativo a cui collaborano gli utenti con i loro dispositivi. I
dispositivi, entrando più nel dettaglio, forniscono come dati informativi la loro posizione e l’ora utilizzando rispettivamente i moduli GPS e orologio, integrati negli smartphone.
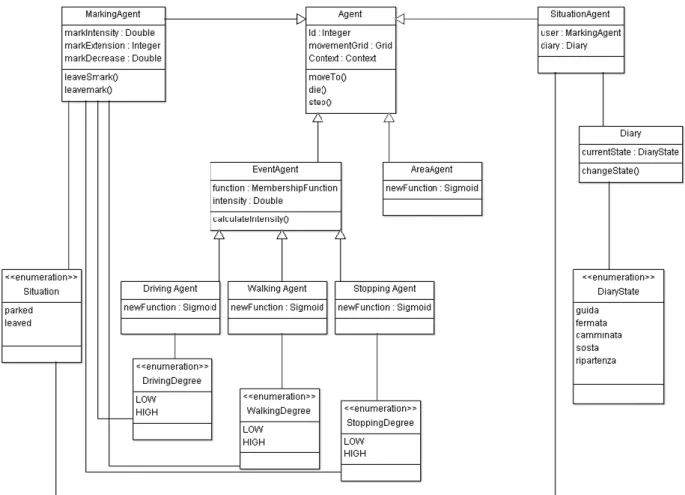
13 Gli Agenti che andranno ad utilizzare i dati informativi citati sopra sono il Marking Agent, gli Event
Agent e in maniera indiretta il Situation Agent e lo User Agent.
Il Marking Agent è l’agente più a basso livello del sistema ed è utilizzato principalmente per tenere traccia dei movimenti dell’utente nell’ambiente. Man mano che l’utente cambia posizione nello spazio in cui si muove (comunicando al sistema la sua nuova posizione in coordinate GPS), questo agente rilascerà all’interno dell’ambiente un mark (o impronta) in corrispondenza della posizione attuale dell’utente. Il rilascio del mark avviene con una frequenza regolare a ogni nuova coordinata GPS ricevuta dal dispositivo. I mark, sono caratterizzati oltre che dalla posizione, in cui vengono rilasciati, anche da una certa intensità (come verrà dettagliato nel prossimo paragrafo), e permarranno nell’ambiente per un certo lasso di tempo. La loro presenza nel sistema è sfruttata dagli Event Agent che valutandone l’intensità riescono a individuare ,con un certo grado di certezza, gli eventi di guida, di camminata e di stop. Quando un utente permane in un luogo o riduce la sua velocità di spostamento i mark rilasciati in una posizione si sovrapporranno, col passare del tempo, a quelli già presenti nell’ambiente nel medesimo luogo andando in questo modo a modificarne le intensità. In particolare il Driving Agent stabilirà se è possibile individuare un evento di guida. Il
Walking Agent se è presente un evento di camminata e lo Stopping Agent se è possibile individuare
un evento di stop (fermata o sosta). L’identificazione di questi eventi però non ci permette di definire se l’utente è in una situazione diversa oltre quelle evidenti di guida, camminata e generico
stop. Dunque per individuare ulteriori condizioni come per esempio quella di fermata breve oppure
di sosta prolungata (come quella di un parcheggio) o ancora la situazione di ripartenza (rilascio del parcheggio), ci sarà bisogno di un ulteriore agente che ne studi la comparsa, deducendola dal contesto informativo opportunamente aggiornato . Il Situation Agent sarà adibito esattamente a questo scopo, attraverso l’osservazione degli eventi suddetti e la costruzione di determinare regole da seguire effettuerà le deduzioni che gli permetteranno di stabilire se l’utente si trova o meno nei seguenti ben definiti stati: guida, fermata, a_piedi, sosta, ripartenza. La conoscenza delle precedenti condizioni, che completa la prima fase di analisi, non permette di poter stabilire ancora se la sosta (parcheggio) e ripartenza da un luogo possano identificare quel luogo come area
parcheggio. Lo User Agent (Area Agent) ,allora, osserverà le situazioni individuate dal Situation Agent in particolare quelle di sosta e ripartenza, andandone ad utilizzare le informazioni di
localizzazione e di tempo, e a completamento della seconda fase di analisi stabilirà se l’area (individuata da una coordinata di posizione) può essere definita o meno area parcheggio. Per giungere a questo tipo di conclusione si è pensato di analizzare la seguente condizione: Utenti
diversi, in istanti diversi, effettuano una sosta (parcheggio) nella stessa "postazione”. E’ questo
14 considerata area parcheggio, proprio perché utilizzata da diversi utenti, a differenza di una postazione utilizzata da un singolo utente nel caso di una sosta breve in una zona non adibita a parcheggio (sosta a bordo strada, semaforo ecc.). Per permettere all’Area Agent di poter fare dunque deduzioni di questo tipo abbiamo bisogno di un ulteriore rilascio di mark (impronte) nell’ambiente che differiscano dai primi e che quindi non si vadano a sovrapporre a questi. Il Marking Agent quindi si preoccuperà di rilasciare questo “nuovo” mark (con una intensità pari alla durata del parcheggio) nella postazione di sosta utilizzata dagli utenti, a sosta terminata. Se la postazione è la medesima o comunque appartenente alla stessa area per n-utenti anche in questo caso avremo (col passare del tempo) sovrapposizione di mark e conseguentemente intensità modificata. L’analisi dell’intensità di queste nuove “impronte di secondo livello”, così come accadeva nel caso dell’evento di sosta, permetteranno all’Area Agent di individuare con un certo grado di certezza se la postazione è adibita ad area parcheggio oppure no. Più utenti parcheggeranno nell’area in un breve arco temporale (più impronte verranno rilasciate), maggiore sarà il grado di certezza legato a quell’area. Mentre se avverranno pochi parcheggi e saranno diradati nel tempo il grado associato all’area tenderà a zero e quindi a scomparire. Le aree di parcheggio risalteranno quindi, anche in questo caso, in modo emergente sulla base delle informazioni cumulate dagli utenti (luogo e durata del parcheggio).
4.2 Marking Agent
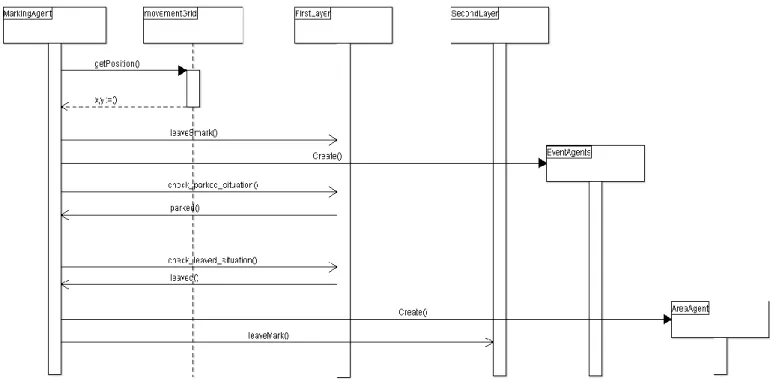
Il Marking Agent è associato al singolo utente. Questo agente seguirà posizione dopo posizione l’utente nei suoi spostamenti e rilascerà in ognuna di queste un’impronta (mark). In questo modo si terrà traccia degli spostamenti dell’utente all’interno dell’ambiente. Nello specifico di questo modello di simulazione, l’ambiente in cui si muoverà l’utente sarà rappresentato da una griglia di dimensioni LxM, dove ogni cella è identificata da una coppia di coordinate (x,y) con x ϵ[1,….,L] e y ϵ [1,….M].
Un mark è caratterizzato dai seguenti attributi:
Intensità del Mark – E’ il valore che inizialmente ha ogni mark, nella sua cella centrale. La cella centrale è quella a valore più alto.
15
Estensione del Mark – E’ il numero di celle con cui si estende il mark oltre la cella centrale. L’estensione spaziale permette di coprire sia il movimento dell’utente tra un mark e l’altro, che l’incertezza sulla localizzazione precisa dovuta all’errore del GPS.
Decremento del Mark – rappresenta la diminuzione percentuale del mark per ogni cella della griglia. L’intensità degrada con l’incrementare della distanza dal centro del mark.
Fig. 4.2 Rappresentazione di una singola impronta (mark)
Come si può facilmente vedere dalla figura 4.2 l’intensità del mark non sarà uniforme e inoltre non sarà la stessa col passare del tempo. Ci sarà un decadimento temporale che verrà applicato uniformemente all’impronta secondo un Evaporation Rate che la porterà a dissolversi man mano che passa il tempo. In questo modo è evidente che se l’utente si muoverà, localizzandosi in posizioni sempre diverse nell’ambiente, le impronte rilasciate si collocheranno sempre in posti diversi senza sovrapporsi e così decadranno nel tempo fino a scomparire, mentre se l’utente stazionerà in un posto le impronte si sovrapporranno e l’intensità tenderà a crescere fino a un valore limite (fig 4.3). E’ chiaro dunque che in fase di progettazione particolare cura va riservata allo studio e settaggio di questi parametri, che soltanto nelle giuste configurazioni riusciranno a produrre condizioni tali da permettere uno studio con relativi risultati utili.
16 Fig. 4.3 Utenti in movimento e relativo rilascio di impronte al passare del tempo
In particolar modo, e per quelli che sono gli interessi specifici del progetto, possiamo anticipare che è presente una chiara relazione tra la velocità di movimento dell’utente e il sovrapporsi dei mark. Si può evidenziare ad esempio che in situazioni di guida dove le velocità sono chiaramente più elevate di quelle in situazioni di camminata o parcheggio, le impronte rilasciate non si sovrapporranno, a differenza della seconda situazione in cui si andranno a sovrapporre parzialmente o quasi del tutto, decadendo nel tempo più lentamente. Entrando nel dettaglio di come evolve l’intensità di un mark da quando viene rilasciato a quando “evapora”, possiamo capire meglio come poter dedurre le
situazioni ,in cui si trova l’utente, descritte poco prima.
Un Marking Agent rilascia ad ogni istante ̅ ̅= 0, TM, 2 TM, …. nella cella Q(x,y) con x ϵ[1,….,L]
e y ϵ [1,….M] un mark di intensità I (x,y, ̅) definito come :
̅( ̅ ) ( (| | | |) )
con e coordinate del centro del mark e decremento del mark
ogni TD secondi l’intensità del mark decade di una percentuale rispetto al valore attuale che è:
̅( ̅ ) ̅( ) con ̅ ̅
Per ogni cella Q(x,y) il valore dell’intensità attuale ( ) è ottenuto sommando le intensità dei
mark precedenti, se sono stati rilasciati :
( ) ∑ ̅( )
̅ ( ̅)
Se supponiamo che un utente rimane fermo in una postazione si può dedurre che dopo Z* TD
17 ( ) ̅( ̅) ̅( ̅) ̅( ̅)
Se dunque Z>>1 ( ) ̅
( ̅)
Sfruttando la precedente osservazione, nei prossimi paragrafi, discuteremo com’è possibile riconoscere i tre eventi (guida, camminata e stop).
4.3 Event Agents
Le intensità dei mark rilasciati nell’ambiente saranno, a questo punto, sfruttate dal Driving Agent, dal Walking Agent e dallo Stopping Agent per individuare rispettivamente l’evento di guida, di
camminata e di stop. Questi tre tipi di agenti sono associati al singolo utente e vengono creati
contemporaneamente all’attivazione del Marking Agent.
4.3.1 Driving Agent e Walking Agent
Il Driving Agent e il Walking Agent sono utilizzati per il riconoscimento degli eventi di guida e di
camminata. Questi tipi di agenti si serviranno, come anticipato, delle impronte rilasciate dal Marking Agent nell’ambiente e sfrutteranno le due seguenti condizioni: sovrapposizione dei mark e non sovrapposizione dei mark. Una volta definito il valore della frequenza di acquisizione della
posizione dell’utente (dati GPS) e conseguentemente il valore di estensione del mark , in una fase inziale di progettazione del sistema, e avendo presente che la velocità di un utente alla guida è molto più alta di quella di un utente a piedi, possiamo facilmente individuare le precedenti condizioni (sovrapposizione e non sovrapposizione) rispettivamente in un evento di guida e in un evento di camminata (fig. 4.4). E’ evidente dunque che se le coordinate di posizione dell’utente automobilista vengono ottenute, ad esempio, ogni 30 secondi e i mark rilasciati con la stessa frequenza, maggiore sarà la velocità di movimento dell’utente maggiore sarà la distanza tra un’impronta e l’altra. Allo stesso modo dunque, minore sarà la velocità di spostamento maggiore sarà la porzione di impronta che andrà a sovrapporsi a quella già presente nel sistema.
18 Fig. 4.4
utente alla guida, mark spazialmente e temporalmente distanziati
utente a piedi, mark spazialmente e temporalmente ravvicinati tali da sovrapporsi parzialmente
L’elemento di cui si serviranno i due agenti per riuscire a distinguere i rispettivi eventi sarà ovviamente l’intensità dei mark e le loro differenze in seguito alle variazioni di velocità e dunque al susseguirsi degli eventi di guida e di camminata a piedi. Per poter verificare in che modo i valori di intensità oscillano, sono stati ricavati due grafici in cui vengono rappresentate le intensità delle impronte al variare del tempo e degli spostamenti dell’utente nell’ambiente. In questo modo si possono individuare i range d’intensità che corrispondo al verificarsi degli eventi di guida (intensità
minore) e di camminata (intensità maggiore). I dati con i quali sono stati realizzati i grafici sono
stati ottenuti simulando in ambiente Repast gli spostamenti di un utente alla guida e di un utente a piedi, utilizzando dati di localizzazione reali ottenuti tramite smartphone.
Per avere una visione più tecnica di come il sistema è stato sviluppato in termini di parametri e relativi valori, in base ai dettagli dello stesso che sono stati descritti in precedenza, possiamo sottolineare che nei seguenti due test sono stati utilizzati i seguenti parametri :
Intensità del mark = 10
Estensione del mark = 2 celle
Fattore di decrescita dal centro del mark = 2
19 Nel primo caso è stato testato un percorso di pochi km in auto, nel traffico urbano di Pisa. Sono state registrate, sul dispositivo cellulare, le coordinate GPS dell’intero percorso, poi queste sono state utilizzate all’interno dell’ambiente Repast, preventivamente normalizzate (come verrà dettagliato in seguito). In questo caso le velocità rilevate in questo tratto di strada urbana hanno oscillato in un intervallo che va dai 15 km/h ai 30 km/h. Di seguito vediamo dunque come l’intensità delle impronte varia durante il percorso.
Fig. 4.5 Percorso su google maps e tracciato dell’intensità delle impronte relative
Nel secondo caso invece è stato testato un percorso, a piedi, nel centro abitato di Pisa. Anche in questo caso i dati sono stati ottenuti tramite smartphone e utilizzati all’interno dell’ambiente di simulazione. In questa situazione le velocità rilevate nel tratto di strada hanno oscillato in un intervallo che va dai 2 km/h ai 4 km/h. Di seguito vediamo dunque come l’intensità delle impronte varia durante il percorso.
20 Nel primo caso, rappresentativo di un evento di guida, possiamo vedere che l’intensità dei mark rilasciati nell’ambiente, che tendono a non sovrapporsi, oscillano in un range di valori che va da 81 a 164
Nel secondo caso invece, rappresentativo di un evento di camminata, possiamo vedere che l’intensità dei mark rilasciati nell’ambiente, che tendono a sovrapporsi parzialmente, oscillano in un range di valori che va da 116 a 300
Di seguito mostriamo invece il caso in cui un utente si trova prima in una situazione di guida e poi in una situazione di camminata, in modo da ottenere un unico grafico in cui è possibile evidenziare i cambiamenti nei valori di intensità relativi al passaggio tra l’evento di guida e l’evento di
camminata.
Fig. 4.7 Tracciato delle intensità delle impronte per un unico utente
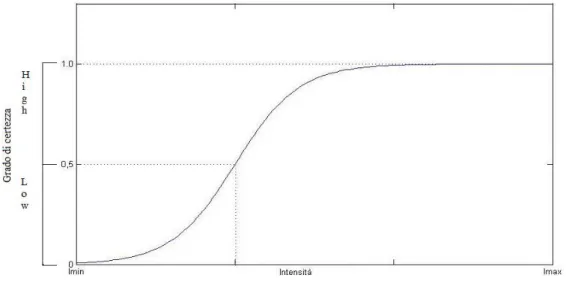
Il grado di certezza dunque associabile all’individuazione dell’evento di guida e di camminata verrà valutato sull’evoluzione di una funzione di attivazione (tipica delle reti neurali) a cui passeremo come parametro le intensità dei mark ad ogni istante. Nello specifico la funzione che metterà in relazione l’intensità delle impronte al grado di certezza della presenza degli eventi, sarà una funzione sigmoidea per la quale assoceremo al valore (grado) 0 l’estremo minore del range delle intensità del relativo evento e al valore (grado) 1 l’estremo maggiore dello stesso range di intensità. Il valore ottenuto da questa interpolazione sarà per l’appunto il grado di certezza associabile a quell’evento. Il valore soglia invece sarà identificato in 0.5 e collocato in prossimità del punto medio tra e
21 Fig. 4.8 Funzione sigmoidea usata per modellare il Driving Agent
Nel caso del Driving Agent, in base ai grafici di Fig. 4.5 e 4.6, assoceremo al valore = 81 e al valore = 164. Nel caso dunque le intensità si manterranno su valori molto bassi ne dedurremo
che le impronte saranno parecchio distanziate nello spazio dunque si sarà verificato un evento di
guida. Dalla funzione sigmoidea, infatti, si evince che ad intensità ridotte corrisponderà un grado di
certezza HIGH mentre a intensità maggiori corrisponderà un grado di certezza LOW (Fig.4.8).
Fig. 4.9 Funzione sigmoidea usata per modellare il Walking Agent
Nel caso del Walking Agent, in base ai grafici di Fig. 4.5 e 4.6, assoceremo al valore = 116 e al
valore = 300. Nel caso dunque le intensità iniziano ad assumere valori sempre più alti ne dedurremo che le impronte cominciano a sovrapporsi, dunque si sarà verificato un evento di
22
camminata. Dalla funzione sigmoidea, infatti, si evince che ad intensità elevate corrisponderà un
grado di certezza HIGH mentre a intensità ridotte corrisponderà un grado di certezza LOW (Fig. 4.9).
Risulta chiaro come questi range di valori evidenziati possano subire anche variazioni non previste nei loro rispettivi casi. Possono presentarsi, infatti, situazioni in cui un utente sviluppa una camminata con velocità superiori a quelle indicate, oppure si trovi nella condizione di dover guidare molto lentamente (quasi a passo d’uomo). Nel primo caso, com’è facile immaginare, i mark rilasciati nell’ambiente si collocheranno a distanze maggiori rispetto a quelle riconosciute nei test, e dualmente nel secondo caso i mark si collocheranno a distanze minori. Queste “anomalie”, quindi, si rifletteranno sui valori di intensità delle impronte che di conseguenza non rientreranno più nei range individuati in precedenza. Nel caso specifico di una camminata con passo veloce, il sistema sicuramente vedrà impronte con intensità minori rispetto a quelle del relativo test (fig. 4.6). Affinché il sistema “scambi” un evento di camminata con uno di guida, le differenze nei range devono essere, però, molto sensibili. Tenendo presente che i range individuati nei test, erano relativi a velocità di guida che andavano dai 15 km/h ai 30 km/h e per le camminata dai 2 km/h ai 4 km/h, variazioni sensibili ,tali da produrre errore, si possono verificare solo se si presenta una condizione di camminata con velocità almeno doppia, una situazione che è evidentemente più rara che comune. Maggiore attenzione invece necessiterebbe il caso duale, cioè di guida molto lenta, dovuta ad esempio a cause di forza maggiore come il traffico. In questa situazione il sistema effettivamente potrebbe andare a riconoscere l’evento di camminata al posto di quello di guida, rientrando nei range di intensità relativi non al proprio caso specifico. Come sarà più chiaro in seguito, però, questo tipo di anomalia verrà facilmente assorbito dal secondo livello di analisi, e non porterà alla produzione di dati poco attendibili.
4.3.2 Stopping Agent
Lo Stopping Agent è utilizzato per il riconoscimento dell’evento di stop da parte di un utente alla guida. Questo Agente viene attivato in contemporanea al Marking Agent seguendo passo dopo passo anch’esso i movimenti dell’utente. In questo modo può valutare ad ogni movimento le tracce lasciate dal Marking Agent nell’ambiente e individuare quale sia il grado di certezza che è possibile associare a questo tipo di evento. Il meccanismo che permette all’agente di individuare l’evento di
stop generico si basa sulla stessa analisi fatta con i precedenti Event Agent: un utente che staziona
23 di diversi mark e le intensità di questi andranno a sommarsi. Con il passare del tempo e delle sovrapposizioni l’intensità finale tenderà a un valore stazionario che potrebbe essere individuato in un valore ben preciso come evidenziato analiticamente anche nel paragrafo relativo al Marking
Agent :
( ) ̅
( ̅)
Progettando dunque un agente che vada ad analizzare l’evolvere delle intensità delle impronte e in particolare il valore sul quale queste si assestano in corrispondenza dell’evento, si riuscirà anche in questo caso ad individuare il caso di stop (generico).
Procedendo per via sperimentale, simulando situazioni in cui si verificano eventi di stop , possiamo anche in questa circostanza andare a stabilire qual è l’intervallo di intensità che l’agente in questione dovrà studiare, sfruttando grafici descrittivi dell’evoluzione delle intensità delle impronte. Nelle figure seguenti vengono mostrati due di questi grafici di test realizzati andando a plottare le intensità delle tracce, al passare del tempo, rilasciate da due utenti diversi. I dati di localizzazione sono stati ottenuti tramite smartphone e utilizzati all’interno dell’ambiente Repast.
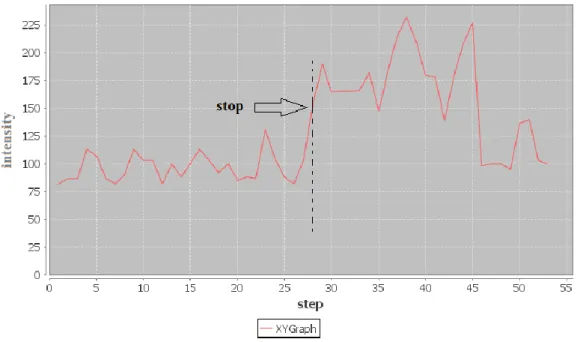
Nel primo caso evidenziamo uno stop dovuto ad un parcheggio. Nel secondo caso evidenziamo uno stop in seguito ad un semaforo. Il valore dell’intensità in questi casi non è detto che sia sempre differente o tale da permetterci di distinguere quale dei due eventi si sia verificato. In linea generale lo stop a un semaforo ci si aspetta sia di durata minore a quello nella situazione in cui un utente si trova a parcheggiare l’auto. Questa disparità di tempo si rifletterebbe sulla sovrapposizione delle impronte e dunque sul valore dell’intensità. Ma poiché anche la durata di un semaforo può essere variabile (spesso adattabile alle condizioni di traffico) e le stesse operazioni di parcheggio potrebbero essere più o meno rapide, non possiamo basare la nostra analisi su un tipo di ragionamento del genere. Pertanto in questo livello di analisi l’individuazione dello stop fatta dallo Stopping Agent sarà sempre quella di un evento di generico stop. Vedremo in seguito come sarà possibile invece individuare la specificità dello stop.
24 Fig. 4.10 Tracciato dell’intensità delle impronte per un utente ed evidenza dell’evento di stop in parcheggio In questo caso lo stop avviene allo step 28 e il valore dell’intensità dell’impronta in questo punto è 150
Fig. 4.11 Tracciato dell’intensità delle impronte per un utente ed evidenza dell’evento di stop al semaforo
In questo caso lo stop avviene allo step 10 e il valore dell’intensità dell’impronta in questo punto è 219
25 Il grado di certezza dunque associabile all’individuazione dell’evento di stop verrà valutato, come in precedenza, sull’evoluzione di una funzione di attivazione a cui passeremo come parametro le intensità dei mark ad ogni istante. La funzione che metterà in relazione l’intensità delle impronte al grado di certezza della presenza degli eventi sarà una funzione sigmoidea per la quale collocheremo in corrispondenza del valore soglia di 0.5 il valore minore delle intensità significative individuate nei due test precedenti. Il valore ottenuto dall’interpolazione delle intensità se andrà a collocarsi sotto il valore soglia sarà associato a un grado di certezza LOW mentre al di sopra sarà associato a un grado di certezza HIGH.
Fig. 4.12 Funzione sigmoidea usata per modellare lo Stopping Agent
Anche nel caso dello Stopping Agent possiamo analizzare una condizione in cui il valore di riferimento individuato tramite i test, risulterà differente. In uno scenario di utilizzo reale, è molto facile che si verifichino situazioni in cui il parcheggio o il generico stop (ad esempio ad un semaforo) siano caratterizzati da durate molto prolungate. In questo caso le impronte, che avranno la possibilità di accumularsi, saranno maggiori, e quindi la relativa intensità sensibilmente più alta di quella indicata nei test. Questa condizione non risulta compromettere l’individuazione dell’evento di stop, poiché a intensità maggiori potrà solo che corrispondere un grado di certezza maggiore, come spiegato in precedenza (fig. 4.12). La deduzione del tipo di stop (parcheggio, semaforo, sosta occasionale ecc.), a partire dallo stop generico, non avviene andando a discriminare le durate delle soste, ma come si vedrà in seguito emergerà da una concatenazione di eventi.
4.4 Situation Agent
Il processo di deduzione delle situazioni specifiche di sosta e ripartenza oltre quelle di guida, stop
26 degli istanti e luoghi in cui avvengono gli eventi individuati dagli agenti descritti in precedenza non è sufficiente. È chiaro che l’identificazione dell’evento di stop non ci assicura che l’utente si trovi effettivamente in una situazione di “parcheggio dell’auto” e tantomeno ci permette di riconoscere quando lo stesso si troverà nella situazione di “ripartenza dal parcheggio”. L’evento di stop descritto finora è un evento generico e può essere associato tanto alla situazione di nostro interesse, parcheggio auto, tanto a una fermata breve a bordo strada (ad. esempio per chiedere informazioni) o alla fermata di un semaforo o ad altre situazioni simili. Il Situation Agent quindi sfrutterà le combinazioni di eventi fornite dai precedenti agenti e riuscirà a riconoscere le seguenti situazioni:
parked, l’utente ha parcheggiato l’auto
leaved, l’utente lascia la postazione di parcheggio occupata in precedenza
Il Situation Agent utilizzerà i gradi di certezza degli eventi, descritti dalle nomenclature LOW e HIGH, forniti dai rispettivi Event Agent per individuare le situazioni in cui gli utenti sono coinvolti. Non sarà però questo l’unico elemento sfruttato dal seguente agente nel processo di deduzione. Si farà uso anche di un meccanismo di cronologia degli eventi, relativo al singolo utente, in cui andremo a tenere memoria delle condizioni che vengono individuate al passare del tempo. È quest’ultima struttura che ci permetterà effettivamente di dedurre se l’utente è in una certa situazione o meno. La considerazione che viene fatta è quella per la quale le situazioni di nostro interesse (sosta parcheggio e rilascio parcheggio) si verificheranno soltanto se il sistema è già riuscito ad individuare la seguente sequenza ordinata di condizioni:
Guida -> Fermata -> Camminata -> Sosta -> Ripartenza
Gli stessi singoli eventi della sequenza precedente verranno riconosciuti solo e soltanto in quel determinato ordine. Il sistema non indicherà mai una condizione di Camminata se in precedenza non ha individuato una condizione di Fermata, così come non riconoscerà una condizione di
Fermata se prima non ha individuato un condizione di Guida. In questo modo, dedurrà la situazione parked (associata alla condizione Sosta) se prima ha individuato la condizione di Camminata e
conseguentemente dedurrà la situazione di leaved (associata alla condizione Ripartenza) se prima ha individuato la condizione Sosta.
Nello specifico il seguente sistema, implementerà il meccanismo di cronologia utilizzando una struttura di memorizzazione che chiameremo Diary, questa struttura verrà quindi utilizzata per tenere traccia delle condizioni individuate e la loro sequenza temporale e verrà aggiornata secondo le seguenti regole predeterminate:
27 partendo da una condizione iniziale di Guida, in cui si presume che l’utente si trovi quando avvia il sistema
- Se lo Stopping Degree è HIGH e il Diary contiene la condizione Guida, allora comincerà e sarà memorizzata la condizione Fermata
- Se il Driving Degree è HIGH e il Diary contiene la condizione Fermata allora verrà memorizzata di nuovo la condizione Guida
- Se il Walking Degree è HIGH e il Diary contiene la condizione Fermata allora comincerà e sarà memorizzata la condizione Camminata
- Se il Walking Degree è HIGH e il Diary contiene la condizione Camminata allora comincerà e sarà memorizzata la condizione Sosta
- Se il Driving Degree è HIGH e il Diary contiene la condizione Sosta allora comincerà e sarà memorizzata la condizione Ripartenza
4.5 Area Agent
Questo nuovo agente ha il compito di completare la seconda e ultima fase di analisi, come anticipato all’inizio del capitolo, e permetterà di definire se una particolare area (geo-localizzata) può essere definita o meno Area parcheggio. L’Area Agent verrà attivato in relazione all’individuazione della coppia di situazioni sosta-ripartenza. In corrispondenza di questo istante il Marking Agent che fino ad allora era dedicato a rilasciare mark su unico livello (per tenere traccia degli spostamenti dell’utente) ora verrà impiegato per rilasciare un ulteriore tipo d’impronta, un’unica impronta di intensità proporzionale alla durata della sosta e di estensione tale da poter coprire una possibile area di sosta. Le coordinate di localizzazione del parcheggio e l’istante temporale in cui è avvenuto e in cui è stato abbandonato, vengono memorizzate dal Situation Agent in corrispondenza dell’individuazione delle relative condizioni (parked e leaved). È in questo modo che gli utenti di una determinata area parcheggio, avvicendandosi nel tempo, realizzeranno nel nostro sistema una sovrapposizione d’impronte (nella medesima area) d’intensità variabile. Queste impronte dovranno avere ovviamente un decadimento temporale molto dilatato in modo da permettere la loro sovrapposizione anche a distanza di parecchi minuti. È ipotizzabile che per permettere il riconoscimento di un’area parcheggio al sistema, la completa evaporazione di unica
28
impronta parcheggio avvenga solo dopo 24H, in questo modo avremo certezza che in questo arco di
tempo ,se l’area parcheggio ha un minino di utenti, i loro mark si saranno sovrapposti. Dunque più utenti si avvicenderanno in un breve arco temporale, maggiore sarà l’intensità d’impronte che si potrà trovare in quella particolare area geo-localizzata, mentre se i parcheggi si susseguiranno parecchio distanziati nel tempo le impronte cumulate tenderanno a scomparire con un’intensità molto bassa. Anche in questo caso, come avveniva per i precedenti Event Agent, il grado di certezza associabile all’area parcheggio verrà dunque valutato sull’evoluzione di una funzione di attivazione opportunamente associata alle intensità delle impronte relative a questa situazione (avvicendarsi dei parcheggi nel tempo in un'unica area di sosta).
Per analizzare in che modo i valori d’intensità delle impronte oscilleranno dalla situazione in cui un unico utente utilizza un’area parcheggio a quella in cui n-utenti utilizzano l’area parcheggio, in un certo intervallo di tempo, sono stati ricavati dei grafici che ci permettono di individuare un range d’intensità da poter associare alla funzione che valuterà il grado di certezza dell’area parcheggio. Nel realizzare questo scenario di test per l’individuazione del range si sono considerati utenti che si avvicendavano nell’occupazione della postazione parcheggio a breve distanza di tempo e le loro soste hanno una durata media di 30 min. Una durata media di questo tipo copre casi di soste di breve durata tipo 15 minuti , di durata media tipo 30 minuti e di durata lunga ad esempio 60 minuti. In questi casi, con soste della durata media sopracitata, ci sarà bisogno che la postazione venga utilizzata da un buon numero di utenti prima che si possa avere un grado di certezza positivo. Soste di durata maggiore, rilasciando un’impronta con intensità più elevata (l’intensità è direttamente proporzionale alla durata della sosta) permetterebbero di far emergere ancora prima la certezza che quella sia un’area parcheggio.
Nella figura seguente viene mostrato uno di questi grafici di test realizzati andando a graficare le intensità delle tracce, al passare del tempo, rilasciate da 4 utenti diversi nell’istante in cui abbandonano la postazione di parcheggio. Gli utenti hanno tutti utilizzato la stessa area parcheggio. Anche in questo caso i dati sono stati ottenuti tramite smartphone e utilizzati all’interno dell’ambiente di simulazione.
Nel seguente test sono stati utilizzati i seguenti parametri :
Intensità del mark = 10
Estensione del mark di secondo livello = 4 celle
Fattore di decrescita dal centro del mark = 2
29 Fig. 4.13
Il valore minimo (che corrisponde all’utilizzo dell’area da parte di un unico utente, post evaporazione parziale dell’impronta) individuato è pari circa a 4200
Il valore massimo (che corrisponde all’utilizzo dell’area da parte di tre utenti), invece, individuato è pari circa a 16000
Utilizzeremo una funzione sigmoidea, anche in questo caso, alla quale assoceremo al grado di certezza di 0,5 il valore massimo individuato in precedenza. La scelta di questo valore soglia è stata fatta considerando che in corrispondenza di questa intensità si sono avvicendati nella stessa area almeno tre utenti a parcheggiare, quindi con una buona probabilità quella sarà un’area di parcheggio autorizzata. È evidente come l’aumentare del numero di utenti e quindi del valore d’intensità (rispetto al valore soglia) faccia corrispondere un grado di certezza della condizione di area
parcheggio, ancora maggiore. Il valore ottenuto in corrispondenza di una certa d’intensità sarà il
grado di certezza da associare alla presenza della rispettiva area parcheggio. Si evince chiaramente a questo punto che il sistema fornirà un’indicazione precisa relativa ad un’area parcheggio se l’applicazione finale verrà utilizzata da un cospicuo numero di utenti.
30 Fig. 4.14 Funzione sigmoidea usata per modellare l’Area Agent
31
5 Tecnologie
5.1 Introduzione a Repast Symphony
Repast è un ambiente di simulazione basato su agenti implementati in linguaggio Java. Esso fornisce una raccolta integrata di classi per la creazione, l'esecuzione, la visualizzazione in 2D - 3D e la raccolta di dati da simulazioni; comprende inoltre diverse varietà di grafici per la visualizzazione di dati (es. istogrammi e grafici di sequenza) permettendo inoltre di ottenere snapshot durante il funzionamento delle simulazioni oppure filmati dell’esecuzione. [18]
Una simulazione in Repast è principalmente una raccolta di agenti programmabili dall’utente, il quale ha piena flessibilità di specificarne le proprietà e il comportamento.
5.2 Repast Scheduler
Lo scheduler Repast è il nucleo del sistema. Questo supporta in maniera concorrente simulazioni a eventi sia con operazioni sequenziali che parallele.
E’ uno scheduler ad eventi discreti e l’unità di tempo utilizzata è nota come tick. Lo scheduler dunque andrà a eseguire le azioni del modello a ogni tick secondo un ben preciso ordine di priorità e una determinata frequenza. Lo schedulatore non controlla solo le azioni degli agenti, ma anche le azioni all’interno del modello stesso, come l’aggiornamento del display e la raccolta dei dati.
Esistono tre modalità con cui poter schedulare le azioni:
Schedulazione diretta di un’azione
Schedulazione con annotazione
32 Schedulazione diretta di un’azione: in questo caso si ottiene prima uno schedulatore e gli si dice quando e cosa mandare in esecuzione. Un esempio di questo caso :
//Si specifica che l’azione comincerà al tick 1 e sarà eseguita ad ogni altro tick ScheduleParameters params = ScheduleParameters.createRepeating(1, 2); //Schedula myAgent ad eseguire il metodo move secondo i parametri specificati schedule.schedule(params, myAgent, "move");
Schedulazione con annotazione: in questo caso si sfruttano le annotazioni Java che un modo per aggiungere metadati al codice sorgente. Un esempio di schedulazione di questo tipo :
@ScheduledMethod(start = 1, interval = 1, priority = 3) public void step(){} //comportamento dell’agente
La notazione è facilmente comprensibile: si va ad individuare lo tick di inizio esecuzione delle azioni dell’agente con start mentre la frequenza di esecuzione con interval e la priorità con
priority
Schedulazione con Watcher: I Watcher sono progettati per essere utilizzati nella schedulazione dinamica, dove il workflow è ben noto al programmatore. Un osservatore fa si che ad un agente venga notificato un cambiamento di stato in un altro agente e scheduli un evento che avvenga di conseguenza. Un esempio di notazione in questo caso:
@Watch(watcheeClassName = "repast.demo.simple.SimpleHappyAgent", watcheeField-Name = "happiness", query = "linked_from", whenToTrigger = WatcherTriggerSchedule.LATER,
scheduleTriggerDelta = 1, scheduleTriggerPriority = 0) public void friendChanged(SimpleHappyAgent friend) {
if (Math.random() > .25) { this.setHappiness(friend.getHappiness()); } else { this.setHappiness(Random.uniform.nextDouble()); } System.out.println("Happiness Changed"); }
33
5.3 Elementi di Repast
Un progetto in Repast deve avere caratteristiche specifiche in maniera tale che l’ambiente di simulazione le possa gestire in modo appropriato. Prima di tutto deve essere creato un file di configurazione nel quale si devono indicare gli elementi di base che sono :
contesto
proiezioni
agenti
data layer
Contesto: è il nucleo di un progetto in Repast Simphony. Esso fornisce una struttura dati per organizzare gli agenti sia da una prospettiva di modellazione, sia da un punto di vista dell’implementazione software. Il contesto di fatto è un contenitore pieno di agenti. Può contenere anche altri contesti, creando una struttura gerarchica. Per controllare il processo di creazione del modello è necessario implementare un ContextBuilder ed estendere il DefaultContext
Proiezioni: mentre il contesto è un raccoglitore di agenti e informazioni, le proiezioni permettono di imporre una struttura sugli stessi agenti. Permettono di creare una struttura che definisce relazioni, che possono essere spaziali, di rete o geografiche.
34 Una proiezione collegata ad un contesto viene applicata a tutti gli agenti contenuti in tale contesto; ovviamente un oggetto deve esistere prima che possa essere utilizzato in una proiezione.
Repast fornisce quattro tipi di proiezioni :
Continuos Space Projection: L’ambiente in cui gli agenti sono inseriti è uno spazio continuo n-dimensionale con valori reali. La localizzazione di un agente è rappresentata da coordinate in virgola mobile.
Grid Space Projection: L’ambiente in cui gli agenti sono inseriti è uno spazio discreto n-dimensionale. Le celle della griglia sono riferite con coordinate intere. In altre parole la griglia è una matrice n-dimensionale. La griglia può essere utilizzata per simulare gli spazi e creare relazioni altamente strutturate tra gli agenti
GIS Projection: o proiezione Geografica. E’ essenzialmente uno spazio in cui gli agenti sono associati con geometrie spaziali.
Network Projection: L’ambiente è caratterizzato da connessioni tra gli agenti che non hanno una localizzazione spaziale. Queste connessioni possono rappresentare connessioni sociali, connessioni tra infrastrutture fisiche o qualche altra connessione astratta.
35 In generale, le proiezioni sono create usando le factory fornite da repast; ogni factory crea una proiezione di uno specifico tipo e richiede il contesto a cui viene associata. Questo è un esempio di come viene creata una proiezione:
Grid<Object> grid = GridFactoryFinder.createGridFactory(null).createGrid("Grid", context, new GridBuilderParameters<Object>(new WrapAroundBorders(),
new SimpleGridAdder<Object>(), true, gridWidth, gridHeight));
Agenti: gli agenti sono implementati utilizzando dei semplici Plain Old Object Java. Quando viene creato un agente bisogno aggiornare anche il file di configurazione del progetto in modo che venga riconosciuto dall’ambiente. Quando si progetta un agente oltre a definire i suoi parametri e metodi bisogna definire il suo ciclo di vita e il suo comportamento (le azioni messe in esecuzione dallo schedulatore). Tutti i comportamenti dei vari agenti hanno una certa frequenza di esecuzione e una priorità. Il programmatore come detto precedentemente può schedulare questi metodi attraverso l’uso delle annotazioni oppure negli altri modi visti prima.
Data layers: rappresentano dati numerici che possono essere acceduti utilizzando un set di coordinate. Permettono ai progettisti del modello di fornire valori numerici con cui i loro agenti possono interagire. I data layers per un dato contesto sono separati dai layers di altri contesti, permettendo agli agenti di orientarsi rispetto ad un insieme di dati a seconda del contesto in cui si utilizza. In un contesto, un data layers può essere collegato a una proiezione particolare, a più proiezioni o a nessuna.
Un esempio di come viene creato un data layer:
GridValueLayer marks = new GridValueLayer("Marks", true, new WrapAroundBorders(), gridWidth, gridHeight);
36
5.4 Repast Simphony 2.0
La versione 2.0 di Repast Simphony è particolarmente interattiva rispetto alle versioni iniziali, e la progettazione di software Java-based, per cluster e workstation, semplice da imparare.
5.4.1 Miglioramenti dello scheduler
Nelle precedenti versioni di Repast, lo scheduler era stato progettato come un simulatore a tempo discreto, dove ogni tick veniva controllato per vedere se era stata programmata in sua corrispondenza una qualche azione. In questo modo il tick count procedeva in maniera sequenziale (es. 1,2,3,4…) . Questa scelta però crea confusione nella natura dei tick poiché verrebbero considerati semplicemente come indici per eseguire in ordine un certo numero di operazione in Repast.
In Repast 2.0 gli sviluppatori hanno pensato di cambiare lo schedulatore creando un vero simulatore a eventi discreti. In questo modo il tick count ora riflette in maniera corretta la vera natura del tick. Ad esempio se avessimo tre azioni schedulate al tick 1,5 e 10 rispettivamente, il tick count incomincerà ad 1 , poi salterà al 5 e infine al 10 senza iterare attraverso i tick intermedi. Questi cambiamenti rendono più semplice la scrittura di modelli complessi, poiché più vicino al comportamento osservabile di una simulazione, con le semantiche dello scheduling.
Un altro aspetto importante introdotto in questa versione è la possibilità di schedulare azioni, qualora fosse necessario, in corrispondenza di fractional ticks. Un fractional tick è un tick il cui indice numerico è un numero floating point. In questo modo si fornisce la possibilità di modellare facilmente processi che vanno in esecuzione in diversi contesti temporali. Per esempio se vogliamo modellare un processo dove alcune azioni arrivano al tempo 5 per ogni singola occorrenza di un altro processo, allora possiamo schedulare la prima azione con un intervallo di 0.2 e la seconda con un intervallo di 1. In questo modo se avviamo il primo processo allo step 2 questo eseguirà allo step 0.2, 0.4,0.6,0.8 ecc. Se avviamo la seconda azione allo step 1.1 questa eseguirà a 1.1, 2.1,3.1 ecc. In aggiunta alle precedenti modifiche, è possibile adesso specificare anche la durata dell’esecuzione di un’azione, introducendo maggiore flessibilità nello scheduling. Ad esempio un evento che per natura viene progettato come azione di background, potrà eseguire per un certo lasso di tempo senza dover bloccare necessariamente l’esecuzione di altre azioni quando la sua esecuzione è terminata.
37
5.4.2 Geographical System Information
Un’altra caratteristica importante introdotta in Repast Simphony 2.0 è la possibilità di utilizzare il sistema di informazioni geografiche GIS. Un sistema GIS è un sistema utilizzato per creare, memorizzare, analizzare e manipolare dati spaziali e relativi attributi. Grazie a questa nuova introduzione adesso gli Agenti Repast possono operare su paesaggi e vedute importati direttamente da sistemi GIS. Gli stessi paesaggi e vedute possono adesso agire e comportarsi come agenti all’interno dell’ambiente. Nello specifico i dati provenienti da sistemi GIS possono essere importati da shapefiles, gml e postgis [19].
5.4.3 Ulteriori miglioramenti
In aggiunta sono state introdotte anche le seguenti caratteristiche :
Miglioramento nel caricamento dei modelli attraverso la toolbar Repast
Miglioramento nel tracciamento delle reti
Creazione automatica dei link di rete
Creazione più agile di grafici e istogrammi
Ridimensionamento automatico delle superfici
Dimensione e posizione delle finestre persistente attraverso le varie istanze di esecuzione
Rivisitazione delle classi del nucleo che permette ai programmatori esperti di potere estendere più agilmente Repast
38
6 Implementazione
Il simulatore è stato implementato attraverso quattro package Java: Area_park.agents, Area_park.core, Area_park.mfun, Area_park.services. Alcune delle seguenti componenti sono state riutilizzate e adattate da un precedente lavoro su un sistema multi-agente [20].Di seguito verranno presentati nel dettaglio i singoli package descrivendo la struttura del codice e le scelte effettuate.
6.1 Package Area_park.agents
Il package contiene tutti gli Agenti utilizzati nel sistema: Marking Agent, Driving Agent, Walking Agent, Stopping Agent e Area Agent. Per ottenere un codice strutturato e facilmente modificabile, si è fatto largo uso del meccanismo di ereditarietà di Java.
39 Anzitutto è stato creata una classe Agent in modo da raggruppare le caratteristiche comuni ai sopracitati agenti come il Contesto dell’ambiente Repast, l’ID agente e la Griglia di Movimento. In questo modo si sono potuti realizzare gli agenti Marking, Walking, Driving, Stopping e Area andando a specializzare la classe Agent prima citata.
Il Marking Agent avrà il compito di seguire i movimenti dell’utente all’interno della griglia di movimento e rilascerà due tipi di marks uno su un primo livello e uno su un secondo livello, quest’ultimo solo in determinate condizioni. Il Marking Agent possiederà gli attributi mark
Intensity, mark Extension e mark Decrease che verranno utilizzati nei metodi che implementeranno
il rilascio del mark sul rispettivo livello.
L’Event Agent invece sarà costituito da una Membership Function, la funzione di attivazione citata nei precedenti capitoli, che verrà sfruttata nella implementazione del Driving Agent, Walking Agent, Stopping Agent e Area Agent; rispettivamente utilizzati per individuare il grado di certezza di un evento di guida, camminata e stop e il grado di certezza dell’utilizzo di un’area come area parcheggio. Agli Event Agent sono stati associati inoltre gli enumerati Degree HIGH e LOW attraverso i quali poter definire i gradi associati agli eventi corrispondenti. Infine il Situation Agent associato a ogni utente, e fornito di una struttura dati Diary che utilizzerà per tenere memoria delle condizioni di guida, stop, camminata ecc. da lui riconosciute con il passare del tempo. La strutttura dati Diary come si vede in figura è un enumerato e definisce le cinque condizioni che il Situation Agent è in grado di riconoscere : guida, fermata, camminata, sosta, ripartenza
La logica di ogni Agente, descritta nei paragrafi successivi, è contenuta all’interno del metodo step() proprio dell’ambiente Repast. Lo schedulatore dell’ambiente di simulazione si preoccuperà di mandare in esecuzione in maniera concorrente il metodo step() di ogni Agente così come definito nella direttiva Repast :
@ScheduledMethod ( start=1, interval=1, priority=2) public void step ( ) { // Comportamento dell’Agente }