CAPITOLO III
3.1 Analisi del benessere
In provincia di Lucca come del resto in tutta la Toscana si percepisce e si ha una buona qualità della vita sia per coloro che investono e lavorano sul territorio sia per coloro che desiderano trascorrere un periodo di soggiorno all’insegna della cultura, del paesaggio, del mare e della logistica per visitare altri luoghi importanti della Toscana.
Gli indicatori presi in esame sono numerosi e variano a seconda del campo preso in esame: la ricchezza prodotta, i risparmi depositati in banca, l’importo medio delle pensioni, i premi assicurativi del ramo vita, la spesa per auto/moto/elettrodomestici e mobili ed il canone mensile medio di locazione per l’abitazione, indicatori occupazionali, l’ambiente, il tempo libero e cultura, la criminalità e molti altri ancora.
Analizzeremo la ricchezza prodotta stimando il PIL p.c. comunale; i consumi stimandoli a livello comunale; una breve analisi di alcune variabili di benessere sociale: gli sportelli bancari (impieghi e depositi), le assicurazioni, un’analisi degli autoveicoli, degli abbonamenti televisivi; infine per avere un quadro completo del benessere sociale ci soffermeremo sullo studio dell’ambiente e del tempo libero.
Quindi lo scopo di questa analisi è la presa conoscenza della vera qualità di vita che percepiamo nella Provincia di Lucca sia a livello economico, ma anche e soprattutto a livello non economico: sociale, culturale, ambientale...
3.1.1 Critiche al PIL
Negli ultimi anni il PIL pro capite (Prodotto Interno Lordo / popolazione residente) è stato accusato di non essere un indicatore del benessere di una nazione, ma una mera misura della produzione.
Elenchiamo i principali motivi:
Lavoro e tempo libero. Il PIL non incorpora il valore del tempo libero. Se la produzione diminuisce perché la gente preferisce lavorare di meno, questo non rappresenta un segnale che la società stia peggio. Anzi, dal momento che tale scelta è volontaria, significa che essa è stata decisa al fine di ottenere un aumento di benessere, ma, paradossalmente, il PIL diminuisce, segnalando quindi una diminuzione del benessere.
Distribuzione del reddito. Si trascurano del tutto gli aspetti della disuguaglianza economica e della povertà.
Autoconsumi e servizi esterni al mercato. Vengono trascurati i cosiddetti autoconsumi, cioè i servizi che una persona presta a se stesso o alla stessa famiglia gratuitamente (es. le casalinghe, il fai da te, il volontariato,etc.). Servizi pubblici. Altro paradosso: poiché i servizi sono valutati in base al loro
costo di produzione, il valore aggiunto della PA (Pubblica Amministrazione) viene a crescere con l’inefficienza della stessa. Vale a dire che, se per produrre una certa quantità di servizi si impiegano molti più lavoratori del necessario in un contesto di pessima organizzazione, il valore aggiunto della PA e di conseguenza del PIL risulterebbero gonfiati.
Malattia: Ancora un paradosso: chi si ammala o subisce danni fisici ed è costretto a sottoporsi a cure mediche, di tasca sua o a carico dello Stato, fa aumentare il PIL, dando quindi l’impressione che il benessere cresca.
Criminalità: Sia i privati che spendano per difendersi dalla criminalità (allarmi, vigilanza, polizze assicurative, etc.) sia lo stato che investe nelle cosiddette “spese difensive” (polizia, guerre,etc.) fa aumentare il PIL, ma non il benessere.
Inquinamento: Infine l’ultimo ed il più eclatante paradosso riguarda l’inquinamento: considerate due industrie che producono la stessa cosa, ma con la differenza che una impiega una tecnologia pulita, mentre l’altra una tecnologia altamente inquinante. Dal punto di vista del PIL, uguali quantità di prodotto apportano esattamente lo stesso contributo di benessere, dato che i danni causati all’ambiente e alla salute delle persone non sono tenuti in considerazione nel calcolo del PIL. Se non bastasse, per riparare ai danni provocati dall’inquinamento occorrono interventi preventivi e riparatori che contribuiscono ad aumentare il PIL, quindi più inquiniamo, più il PIL aumenta, ma il benessere ne subisce le conseguenze.
Però come osservano due economisti contemporanei Ekins (1995) e Fuà (1993), i teorici ed i testi economici sono consapevoli dei grossi difetti del PIL come misura del benessere, ma ciò nonostante, in pratica, fanno lo stesso riferimento al PIL pro capite come indicatore del benessere.
Questo comportamento contraddittorio può trovare alcune spiegazioni:
o Posizioni ideologiche. Si ritiene che la correlazione tra il PIL ed il benessere sia sufficientemente elevata da fare in modo che nel medio-lungo periodo la crescita del PIL porti comunque con sé anche quella del benessere.
o Consuetudine: Anche se si sa benissimo che il PIL non è un valido indicatore del benessere lo si usa lo stesso semplicemente perché così fan tutti (un certo comportamento può esser giusto solo perché è seguito dalla maggioranza).
o Interessi economici particolari: La crescita del PIL beneficia soprattutto i grandi produttori, di conseguenza appare del tutto naturale che gran parte di coloro che detengono il potere economico abbiano tutto l’interesse a che perpetui l’abitudine di identificare lo sviluppo con la crescita del PIL.
o Difficoltà tecniche: Esistono indubbie difficoltà sia teoriche che pratiche nel definire misure di benessere alternative.
3.2 Ipotesi di stima del PIL comunale
Considerata la difficoltà, quasi impossibilità, nel trovare stime del PIL pro-capite comunale della Provincia di Lucca l’unico modo per determinarli è di stimarli. In questi ultimi anni molti istituti hanno provato, senza avere grande successo, a stimare il reddito comunale, per aver così un’informazione completa e disaggregata del benessere provinciale.
L’ultimo tentativo è stato compiuto dal RuR-CENSIS che ha recentemente pubblicato un rapporto contenente la stima del reddito prodotto per tutti i Comuni d’Italia. Si tratta di un contributo importante all’informazione economico-statistica in quanto è dal 1987 che manca in Italia una stima del reddito prodotto dai singoli Comuni.
Perché questa carenza? In buona sostanza per la difficoltà metodologica di procedere ad una ripartizione del reddito provinciale sulla scorta di indicatori che in ogni caso possono risultare opinabili e, nel caso delle realtà molto piccole, presentare margini di oscillazione dei dati davvero ampi con conseguente perdita di accuratezza della stima.
Il metodo utilizzato dal CENSIS raffina e perfeziona la precedente metodologia ideata dal centro studi del Banco di Santo Spirito (poi confluito nella Banca di Roma) e che rappresentava in letteratura l’ultimo tentativo, ben 17 anni fa, di stimare la ricchezza prodotta a livello comunale. Da allora tutti gli studi fatti (ad es. uffici studi delle Camere di commercio di Padova e di Vicenza) sono rimasti limitati ai singoli ambiti provinciali, facendo ricorso peraltro ai soli dati di statistica ufficiale (popolazione, unità locali, addetti).
Questa nuova metodologia dunque risulta più raffinata. Essa considera due distinte metodologie di stima che vengono poi riunite secondo una funzione aggregatrice dei risultati ottenuti. I due metodi di riferimento sono:
a) la numerosità degli addetti per comune, sull’ipotesi di una relazione diretta tra produttività del lavoro nel territorio e ricchezza prodotta in quel territorio;
b) l’individuazione di un modello di regressione multipla, al fine di stimare il valore aggiunto provinciale come funzione di una serie di variabili disponibili a livello comunale (redditi disponibili pro-capite secondo il Ministero delle Finanze, percentuale di contribuenti oltre i 40 milioni di lire, presenze turistiche per 1000 abitanti, parco circolante pesante per 100 abitanti, percentuale del parco circolante pesante sul totale, consumi energetici delle famiglie pro-capite).
Anche questa, come tutte le metodologie, può essere soggetta a limiti ed errori.
La nostra stima ha dei punti di similitudine con quella appena mostrata: cercando un legame tra la produzione-lavoro ed il reddito e sfruttando variabili che esprimono questa relazione cerchiamo di avvicinarci il più possibile, commettendo il minor errore, a determinare il reddito pro capite provinciale INDIRETTAMENTE, cioè con l’utilizzo di variabili socio-economiche, che andremo a descrivere subito dopo aver elencato i punti che toccheremo in questo metodo di stima:
1. Ricerca di una rosa di variabili socio-economiche correlate con il reddito pro capite, le variabili devono essere reperibili a livello provinciale e comunale.
2. Scelta delle variabili più significative, cioè che meglio interpretano il modello costruito ovvero che riducano al minimo i residui e gli errori compiuti dalle stime. (utilizzo del metodo di regressione Step-wise).
3. Costruzione del modello di regressione lineare definitivo che stima il PIL pro capite a livello provinciale e verifica delle ipotesi del modello classico.
4. Assunta per buona la “regola” a livello provinciale, utilizzando i dati a livello comunale, viene infine calcolato il PIL pro capite comunale. 5. Valutazione del modello, con critiche e spunti futuri su cui riflettere.
3.2.1 Cenni teorici sui metodi ed i mezzi utilizzati
Prima di proseguire ed entrare nel vivo di questa stima sperimentale è giusto spendere alcune parole sulla teoria dei metodi e mezzi utilizzati:
I. Metodo classico della Regressione lineare multipla.
II. Test utilizzati per la valutazione della bontà della predizione (Test t di Student, test F di Fisher, indice R2 di determinazione, analisi della varianza).
3.2.1.1 Regressione lineare multipla
Il fenomeno statistico di cui si vuole spiegare il comportamento in base ad una o più variabili esplicative viene definita come variabile dipendente (o risposta) e deve essere necessariamente rappresentato da una variabile statistica quantitativa continua (o discreta approssimabile ad una continua).
Le variabili statistiche che spiegano l’andamento della variabile dipendente vengono chiamate variabile indipendenti (o predittori o regressori) e devono essere quantitative continue oppure categoriali espresse in forma binaria.
Nel modello di regressione compare anche un termine detto “errore” (identificato dal simbolo ) infatti consideriamo Yi come parte “puramente casuale”, cioè
contenente l’errore o il termine di disturbo.
L’errore può essere considerato come la somma di due componenti. Errore di misura.
Ci sono diversi motivi perché Y possa essere misurato commettendo un errore: ci possono essere delle limitazioni di precisione delle misurazioni e/o assenza di informazioni complete sulla natura del fenomeno. Per esempio nel misurare il raccolto di grano, può essersi introdotto un errore dovuto al fatto che il prodotto è bagnato o è stato pesato in modo non corretto.
Errore stocastico.
Tale tipo di errore si verifica a causa della intrinseca irriproducibilità di fenomeni sociali e biologici. L’errore stocastico può riguardarsi dunque come l’influenza di molte variabili che non consideriamo, ciascuna con piccoli effetti individuali,
Per esempio per la stima del consumo considerando come variabile esplicativa il reddito, commettiamo errore non considerando variabili come i prezzi dei beni, tassi, etc.
Quindi un modello di regressione multipla spiega la variabile dipendente Y in funzione di k variabili esplicative o regressori, con k > 2, e con l’aggiunta del “disturbo” (ε):
Yi= β1 + β2 x2 + β3 x3 + … + βkxk + εi
i=1,…,n con n = numero totale di osservazioni; si ipotizza che sia IID (indipendente identicamente distribuito) distribuito “Normalmente” con media 0 e varianza costante.
In base al criterio di ottimizzazione che rende minima la somma dei quadrati degli scarti tra variabile dipendente e modello lineare (metodo dei minimi quadrati), cioè
si ottengono i valori stimati b0, b1, …,bs di0, 1,…,s. Dal punto di vista grafico
l’equazione rappresenta un piano di uno spazio (s+1)-dimensionale per cui è difficilmente visualizzabile ed interpretabile.
Per convenzione la prima variabile esplicativa x1 assume valore 1.
Il primo coefficiente di regressione β0 rappresenta l’intercetta del modello. Gli
altri coefficienti, di pendenza, costituiscono le derivate parziali della variabile dipendente rispetto alle variabili esplicative
j j j x Y x Y per j= 2,…,k.
Di conseguenza il coefficiente βj esprime la variazione che subisce la variabile
dipendente Y in seguito a una variazione unitaria della variabile esplicativa xj ,
mentre il valore delle altre variabili esplicative rimane costante.
Prima di concludere è doveroso accennare le ipotesi di base da assumere in un modello classico di regressione lineare:
1) Forma funzionale lineare del modello: tutti i coefficienti della regressione sono di primo grado e non moltiplicativi (Yi= β1 + β2 x2 +
β3 x3 + … + βkxk + εi).
2) Media nulla dei termini aleatori: [i]0 per tutte le unità di i.
3) Omoschedasticità: [ ]2
i
Var costante e finita per ogni unità di
i.
4) Incorrelazione tra i termini aleatori: Cov[i,i]0 se i ≠ j.
5) Incorrelazione tra la variabile indipendente ed il termine aleatorio: le variabili X non sono stocastiche Cov[xi,i]0 per tutte le unità i e j.
6) Normalità dei termini di disturbo: N[0,2]
3.2.1.2 Significatività dei coefficienti: Test t di Student, Test F di
Fischer
È opportuno, dopo aver stimato un modello di regressione, sottoporre a test la significatività dei coefficienti per verificare se le singole variabili esplicative contribuiscono a spiegare le variazioni della variabili dipendente.
È infatti prassi verificare l’ipotesi nulla βj= 0 per j = 1, 2, …, k.
T Student= ( ) ) .( .S b t n p E b dove:
b è il coefficiente di regressione stimato β è ipotizzato uguale a zero (ipotesi nulla) n = numerosità campione
p= numero di parametri E.S.(b) = Errore standard di b
dove:
) ( ˆ ) .( . 2 x x S b S E i p n y y S i i
2 2 ( ˆ ) ˆse il valore T trovato è si trova nell’area critica (R.C. area verde) quindi maggiore o minore del valore critico t*n-k, 1-α/2,
allora si rifiuta l’ipotesi nulla che il coefficiente è statisticamente uguale a zero, cioè la variabile contribuisce a spiegare la variazione della variabile dipendente, altrimenti si sarebbe accettata (R.A.) l’ipotesi nulla che il coefficiente stimato sia statisticamente uguale a zero (verifica di ipotesi a due code).
Il valore critico t* dipende dal numero di gradi di libertà (n-k: numerosità del campione meno il numero delle variabili indipendenti) e dalla significatività del test, cioè dalla probabilità che l’ipotesi sia effettivamente verificata (di solito il 95%).
Si supponga di voler sottoporre a test l’ipotesi
H0: β2= β3.= … = βp = 0
contro l’alternativa che almeno uno dei parametri del modello di regressione sia diverso da zero. Di fatto questa ipotesi rappresenta una verifica della bontà di adattamento dell’intero modello. Infatti, se l’ipotesi nulla è vera, tutti i parametri del modello non spiegano in maniera significativa la variabilità della Y e quindi il modello non rappresenta una descrizione del modello. Si tratta quindi di confrontare il modello che contiene le p variabili esplicative verso un modello nullo che contiene cioè soltanto il parametro di intercetta.
Questo test può essere condotto in relazione alla scomposizione della devianza totale in devianza spiegata e varianza residua: Dev(Y ) = SSR + SSE. Un test appropriato per verificare l’ipotesi in oggetto deriva dunque dal mettere a confronto la quota di varianza spiegata dal modello di regressione con la quota di varianza residua, ovvero tramite il rapporto
) 1 , 1 ( ) 1 ( ) 1 ( Fp n p p n SSE p SSR F
Si tratta di un rapporto di coesistenza, quindi il valore di riferimento è l’unità: tanto più il rapporto da luogo a valori superiori ad uno, quanto più la devianza di regressione è maggiore di quella residua. Quindi per un buon modello di regressione si dovrà osservare un valore ”grande” della statistica F. Sotto l’ipotesi nulla, questa statistica campionaria segue una particolare distribuzione, detta F di Fisher, la quale risulta definita sulla base di una coppia di parametri, chiamati gradi di libertà, che sono direttamente legati alle due quantità messe a rapporto.
In questo caso dunque, per rifiutare l’ipotesi nulla sarà necessario osservare per il campione un valore della statistica F superiore a quello di una distribuzione di Fisher con p e (n-p-1) gradi di libertà, per un fissato livello di significatività α; quindi la regione di accettazione e la regione critica al livello di significatività α risultano:
R.A.: F Fp1,np1,1
3.2.1.3 Valutazione sulla bontà del modello
Il primo elemento da valutare è il valore di s, stima di , cioè lo standard error della regressione che misura la dispersione dei valori osservati, tanto basso è questo valore tanto capace è stato il modello a spiegare la variabilità della variabile dipendente. k n e e E s ( )
e = vettore dei residui (yi yˆi) n = numero casi
k = numero variabili
Quindi dopo aver stimato i parametri βi con i da 1…k e 2 è opportuno
Dato il modello empirico: i ki k i i x x e y ˆ1 ˆ2 2 ....ˆ ˆ ,
si indichi con yˆi ˆ1 ˆ2x2i ....ˆkxki il punto sulla funzione di regressione stimata corrispondente all’i-esima osservazione, si ha
i i
i y e
y ˆ ˆ .
Di conseguenza lo scarto di ciascuna osservazione yi dalla media campionaria osservata y è dato da i i i i i y y e y y y e y ˆ ˆ (ˆ ) ˆ .
Lo scarto di yi dalla sua media si scompone in due parti:
yˆi y cioè la variazione del valore della funzione di regressione, questa è la componente dello scarto che è possibile spiegare attraverso il modello di regressione (yi è diversa da yi perché i regressori assumono un valore diverso dalla loro media);
eˆi cioè il residuo, che costituisce la parte di variazione non spiegata dal modello di regressione
Sulla base di questa scomposizione è possibile ottenere la scomposizione della devianza della variabile dipendente. Infatti
n i i i n i i y y y e y 1 2 1 2 [(ˆ ) ˆ ] ) ( .Svolgendo il quadrato, annullando il doppio prodotto e distribuendo la sommatoria si ha residua Devianza n i i spiegata Devianza n i i n i i y y y e y
1 2 1 2 1 2 (ˆ ) ˆ ) (La devianza totale si scompone in devianza spiegata, data dalla quantità
n i i y y 1 2 ) ˆ( , e devianza residua, che coincide con la somma dei quadrati dei residui
n i i e 1 2 ˆ .L’ accostamento del modello ai dati è tanto maggiore quanto più elevata è la percentuale di devianza totale costituita dalla devianza spiegata. Di conseguenza l’adattamento può essere misurato mediante il rapporto fra la devianza spiegata e la devianza totale. Si ottiene così l’indice di determinazione:
n n i y y y y R 2 1 2 1 2 ) ( ) ˆ (L’indice di determinazione esprime qual è la percentuale di devianza della variabile dipendente spiegata dall’insieme delle variabili esplicative nel loro complesso (non dà informazioni sul contributo dei singoli regressori) Questo indice varia nell’intervallo (0,1); è uguale ad 1 quando la devianza residua è nulla ossia vi è un perfetto adattamento del modello ai dati sicché le osservazioni si trovano tutte sulla funzione di regressione stimata (yi yˆi per i= 1, 2, …,n). indice di determinazione invece è uguale a zero quando le yˆi coincidono con y. In tal caso la devianza spiegata è nulla quindi i regressori non sono in grado di spiegare le variazioni della variabile dipendente.
Un difetto dell’indice di determinazione è la difficoltà che avremo se dobbiamo scegliere tra modelli con un numero diverso di regressori, infatti risulterà sempre preferibile il modello con il maggior numero di regressori; di conseguenza l’indice R2 non consente di operare una scelta fra modelli con un diverso numero di variabili esplicative perché sarà quasi certamente più elevato nel modello con il maggior numero di regressori.
Un indice utile per confrontare modelli con un diverso numero di variabili esplicative è l’R2 corretto
n i i n i i n y y k n e R 1 2 1 2 2 ) 1 ( ) ( ) ( ˆ 1Mentre il secondo termine dell’indice R2 confronta la devianza residua con la devianza totale, il secondo termine dell’ R2confronta la stima non distorta della
varianza degli errori con la stima non distorta della varianza della variabile dipendente. Nel confronto fra diversi modelli si sceglie quello per il quale l’indice R2 è maggiore.
3.2.1.4 Analisi dei residui
Infine per verificare che il modello sia correttamente specificato, è opportuno fare un’analisi dei residui (ei yi yˆi).
Prima di tutto è necessario accertarsi che le condizioni di base siano rispettate: I. Media dei residui pari a zero
II. Distribuzione dei residui (almeno approssimatamene) seconda la variabile casuale Normale
III. Nessuna relazione con i valori della variabile dipendente
Successivamente possiamo passare ad un’analisi di natura esplorativa che si realizza ispezionando il grafico dei residui.
Di regola i residui dovrebbero disporsi in maniera casuale intorno all’asse delle ascisse.
Se i residui sono sotto l’ipotesi di normalità il 95% di essi dovrebbe essere compreso tra 1.96ˆ.
L’ispezione del grafico dei residui costituisce un’analisi preliminare ed è opportuno verificare la normalità degli errori anche mediante altri strumenti esplorativi, quali l’istogramma e il qq-plot, e con un test di normalità eseguito sui residui.
La presenza di strutture nel grafico dei residui può indicare errori di specificazione nel modello. Ad esempio se nel grafico dei residui, rispetto all’indice i o ad una variabile esplicativa o alla variabile dipendente, si modifica l’ordine di grandezza ciò può indicare la presenza di eteroschedasticità od
È opportuno tenere presente che se le ipotesi di omoschedasticità e incorrelazione non sono soddisfatte il teorema di Gauss-Markov non è più valido ed esistono stimatori più efficienti di ˆ.
Quando è possibile individuare dei gruppi nei residui ciò può indicare che si è verificato un cambiamento strutturale nella relazione fra la variabile dipendente e le variabili esplicative.
Infine residui molto distanti dagli altri possono indicare la presenza di valori anomali, ossia osservazioni distanti dalla maggioranza dei dati.
3.2.1.5 I metodi di stima per piccole aree
In una stima comunale non poteva mancare un introduzione ai metodi di stima per piccole aree. Come abbiamo sopra accennato il problema per questo genere di stime è la facile perdita di significatività e di bontà a causa di una troppa elevata oscillazione dei dati dovuta alla piccola numerosità del campione: la variabilità della stima cresce al diminuire della numerosità del campione e i modelli ed i metodi che verranno dinnanzi descritti cercano di ovviare a ciò. Prima di passare alla rassegna dei metodi di stima per piccole aree è conveniente considerare alcune definizioni di piccola area:
aree formate da un numero di unità statistiche comprese tra 1/10 e 1/100 della popolazione di riferimento (Purcell e Kish 1980).
qualunque area in cui stime accurate non possono essere derivate utilizzazioni provenienti da rilevazioni campionarie correnti, ma nuovi metodi di stima sono necessari (Brackstone 1987)
aree geografiche di piccole dimensioni come province, comuni, sezioni di censimento o sub-popolazioni con certe caratteristiche di età, sesso e razza all’interno di una più ampia area geografica (Rao 1994).
Noi faremo riferimento al termine piccola area intesa come area geografica di piccole dimensioni in senso territoriale dove le informazioni campionarie non consentono di derivare stima accurate.
Le classificazioni presenti si possano basare sulla diversità dei metodi di stima piuttosto che sulla struttura degli stimatori (metodi campionari, basati su un modello o metodi composti), mentre c’è chi gli ha suddivisi in metodi di stima diretti e indiretti sulla base della natura dei dati utilizzati.
La classificazione che invece presentiamo è basata sul tipo di inferenza:
1. Metodi basati su disegno (o campionari): la stima del parametro d’interesse di piccola area è ottenuta attraverso l’utilizzo dei metodi campionari classici basati sulla distribuzione di probabilità indotta dal disegno di campionamento. Un aspetto fondamentale di questa impostazione è costituito dal fatto che il parametro, o sue funzioni, è pensato come una costante. Inoltre gli stimatori sono corretti rispetto al disegno di campionamento applicato. Purtroppo la loro variabilità cresce al diminuire della numerosità del campione e può accadere che nessuna unità campionaria sia presente nella piccola area impedendo di ottenere una stima del parametro di interesse di piccola area.
2. Metodi assistiti da modello: metodi per i quali l’inferenza è basata sul disegno e sul modello. L’obiettivo è quello di ottenere, sfruttando l’informazione derivante dal disegno di campionamento, stimatori corretti indipendentemente dalla scelta del modello, che però assume importanza per introdurre le ipotesi
fatte dal ricercatore sul legame fra variabili ausiliarie e vettore dei parametri incogniti.
3. Metodi basati su modello: tale impostazione è nota in letteratura anche come approccio predittivo. L’aspetto saliente è costituito dal fatto che il parametro oggetto di studio, o sue funzioni, non è pensato come una costante, ma è visto, invece, come una variabile casuale. L’approccio prevede l’introduzione di un modello probabilistico di superpopolazione relativo alla distribuzione del fenomeno tra le aree da cui derivare il predittore ottimo corretto a livello di piccola area.
Noi nella nostra stima faremo riferimento a “Lo stimatore sintetico”, metodo di stima per piccole aree assistito da modello, è uno stimatore indiretto che, utilizzando la stima diretta della variabile d’interesse per una grande area, deriva stima per sub-aree assumendo che le piccole aree siano simili, per certe caratteristiche, alla grande area che le contiene.
Il più semplice stimatore sintetico è quello che si basa sull’assunzione che la media di piccola area è uguale alla media della regione che contiene la piccola area.
In questo caso non sono disponibili informazioni ausiliarie e lo stimatore indiretto “prende in prestito forza” attraverso i valori assunti dalla variabile d’interesse nella grande area. Lo stimatore sintetico della media può essere scritto come:
s j s j j i w y w N Y Y Yˆsin, ˆ ˆˆTale stimatore si basa sull’ipotesi che la media a livello aggregato sia uguale, o abbastanza prossima, a quella di piccola area (ipotesi di omogeneità); proprio per questo motivo, esso può presentare una distorsione di notevole entità quando l’ipotesi assunta non è vera. I vantaggi dello stimatore sintetico sono
rappresentati da una piccola varianza e dal fatto che non richiede complesse procedure di calcolo
Nel caso in cui siano disponibili informazioni ausiliarie a livello di piccola area Xi, la stima del totale di area Yi può essere ottenuta attraverso lo stimatore di
regressione. ˆ ˆ , sin, T i i reg X Y Con
s j T j j j s j j j jx y c w x x c w / )( / ) 1 ( ˆ Lo stimatore sintetico è generalmente distorto soprattutto per il mancato soddisfacimento dell’ipotesi di omogeneità.
La sua efficienza deve essere valutata in termini di Errore Quadratico Medio (EQM), che tuttavia è difficile da stimare; infatti la determinazione della stima della distorsione è molto complessa non essendo noti i valori veri Yi.
Possono rientrare nella classe degli stimatori sintetici anche i metodi demografici per piccole aree. Queste tecniche integrano i dati dell’ultimo censimento disponibile con le informazioni dei registri amministrativi a livello locale. I metodi utilizzano variabili “sintomatiche”, considerate cioè in stretta relazione con le variazioni di popolazione, e disponibili in banche dati delle amministrazioni locali (ad esempio, il numero dei nati e dei morti in un certo anno, il numero delle abitazioni esistenti e di quelle di nuova costruzione, il numero di iscrizioni scolastiche).
Il modello di regressione multipla che andremo ad utilizzare per la nostra stima, quando è adottato per stimare piccole aree (i comuni lucchesi) è anch’esso uno stimatore sintetico.
3.2.2 Le Variabili del modello
Questa è forse la parte più importante nella costruzione del modello regressivo, la buona riuscita del lavoro dipenderà dalla saggia ed accurata scelta delle variabili da utilizzare per spiegare il nostro fenomeno economico.
Non avendo mezzi particolari per l’approvvigionamento dei dati siamo stati costretti a riferirsi all’anno 2001, non a casa abbiamo scelto tale anno nel quale è stato compiuto il censimento sulla popolazione e sull’industria e servizi (Fonte:ISTAT).
Ricordo ancora una volta che il nostro primo vincolo è la necessità di ottenere dati a livello provinciale, per stimare il modello, ed a livello comunale per poi calcolare i PIL comunali.
3.2.2.1 Il PIL pro-capite: la variabile da spiegare
Prima di prendere in analisi la rosa di variabili esplicative è doveroso soffermarsi sullo studio della variabile da spiegare, cioè il PIL pro capite provinciale.
I 103 dati provinciali sono stati ottenuti dai Conti Territoriali dei database dell’ISTAT dove è pubblicato il Valore aggiunto ai prezzi correnti per abitante, considerando che la differenza tra il PIL pro capite ed il V.A. è minima e riguarda solo il metodo di calcolo1:, nella nostra tesi non facciamo differenza tra le due grandezze che misurano la ricchezza interna prodotta in un determinato periodo.
Il numero di casi preso in considerazione è quindi 103.
1 Il PIL nominale è la somma della quantità di beni FINALI prodotti in un'economia moltiplicate per il
loro prezzo corrente.(metodo della spesa finale). Il VA è pari al valore della sua produzione al netto del valore dei beni intermedi usati nella produzione stessa.
L’ISTAT riesce ad avere delle stime campionarie, con campioni significativi, solo a livello Regionale, i livelli sub-Regionali (province) vengano calcolati tramite stime indirette utilizzando un set di variabili di informazioni base formato da diversi archivi:
Archivio ASIA: informazioni di carattere strutturale sulle imprese a livello di unità locale.
Archivio INPS: informazioni a livello di impresa riguardanti sia le retribuzioni sia il numero di addetti distinti in diverse tipologie.
Dati regionali bastati su analisi censuaria sulle imprese: informazioni riguardanti gli addetti, il prodotto lordo, gli investimenti e le spese per il personale.
Indagine sulle unità locali del settore pubblico.
Quindi la stima del valore aggiunto è stata fatta con i dati degli archivi integrati sopra descritti e distinta per alcune branche, in ragione della particolarità dei dati di basi disponibili.
Per la branca dell’agricoltura e industria, il calcolo del valore aggiunto è stato eseguito con metodologia del tutto simile a quella dei conti regionali: stima della produzione e sottrazione dei costi intermedi. La stima della produzione si basa sul metodo di aggregazione quantità x prezzi di oltre 150 prodotti e servizi. Per i costi intermedi ci si è basati sui dati delle indagini Istat presso le industrie produttrici dei prodotti usati dal settore di interesse.
Anche per le costruzioni il calcolo segue le linee metodologiche delle stime regionali, procedendo alla stima della produzione provinciale sulla base dei dati delle indagini sull’attività edilizia e sulle opere pubbliche e utilizzando i dati
delle indagini sui conti delle imprese per la stima delle manutenzioni e dei costi intermedi della branca.
Per il credito e le assicurazioni la stima è stata effettuata, in analogia con quella dei conti regionali, con approccio dal lato della distribuzione del reddito, così come suggerito dai manuali dell’Eurostat. Ciò ha comportato la ripartizione provinciale del risultato lordo di gestione regionale sulla scorta di indicatori rappresentativi dell’attività produttiva della branca e l’assemblaggio ad esso dei redditi da lavoro dipendente.
Per il settore della pubblica amministrazione, la stima del valore aggiunto è stata effettuata attribuendo all’input di lavoro, distinto per branche e gruppi di enti, i valori pro-capite regionali.
Questa documentazione è servita per non incappare in eventuali errori di ridondanza del modello da noi proposto, in pratica se non utilizzassimo per spiegare il PIL pro capite provinciale le stesse variabili utilizzate dall’ISTAT per determinare la nostra variabili dipendente il nostro modello non avrebbe senso anche se, ovviamente, ci darebbe un indice di determinazione molto alto.
Adesso è opportuno valutare la normalità della variabile da spiegare:
Per misurare il grado di simmetria della distribuzione dei valori si utilizza la “shewness2” che assume valore 0 se c’è simmetria (in cui moda, mediana e media coincidono), nel nosro caso abbiamo un valore di -0,043951.
Mentre per misurare la concentrazione o dispersione dei dati attorno ad un valore centrale utilizziamo il valore della “kurtosis”3: il valore è 0 se la distribuzione è mesocurtica come la Normale, con valori < 3 se la distribuzione è platicurtica e
2 Il grado di asimmetria: ] ) 2 )( 1 [( ) ( 3 3
n n x x n Shewness i 3 ] ) 3 )( 2 )( 1 [( )] 1 ( 3 ) ( [ 4 2 2 4 n n n n M M M n n Kurtosis dove M j
(xj x)jpresenta una forma appiattita con valori maggiormente concentrati nelle code, mentre per “kurtosis” >3 la distribuzione è leptocurtica con picco accentuato dato dalla concentrazione dei dati intorno ad un valore massimo, nel nostro caso abbiamo un valore di -0,913757.
Infine utilizziamo anche un test non parametrico per valutare la Normalità dei dati: il test di Kolmogorov-Smirnov.
Il test di Kolmogorov-Smirnov si applica a distribuzioni continue ponendo a confronto la distribuzione cumulativa teorica con la distribuzione cumulativa osservata.
Il test si basa sulla differenza “D” che rappresenta la differenza massima, in valore assoluto, tra le due distribuzioni cumulative ed è definita come segue:
| ) ( ) ( | max F x F x D N x
Dove F(x) è la funzione cumulativa teorica e FN(x) è la funzione di distribuzione
cumulativa campionaria.
Allora l’ipotesi nulla da noi testata è la seguente: H0: F(x) = FN(x) , per ogni x
H1 : F(x) ≠ FN(x) , per ogni x
Nel nostro caso D = 0,11559 e confrontato con la tabella dei valori teorici con un α = 0,05 si accetta l’ipotesi nulla H0(p-value < 0,15).
3.2.2.2 Le variabili indipendenti
Il fallimento o la buona riuscita del nostro modello dipende dalla scelta delle variabili indipendenti che spiegheranno il PIL pro capite provinciale.
Il primo passo è stato il raccogliere più variabili possibili, correlate al reddito ed alla produzione sul territorio, ma anche correlate all’andamento socio-demografico del territorio.
È ovvio il collegamento tra il reddito e la produzione, ma sono state raccolte anche molte variabili non economiche e valutate possibili entranti nel modello. Oltre ad avere la necessità di avere i dati sia al livello provinciale che comunale, risulta non sempre di facile reperibilità l’approvvigionamento delle variabili richieste dal modello e che meglio si adatterebbero ad esso.
Essendo una trentina le variabili prese in esame le abbiamo raggruppate a seconda della branchia a cui appartengano.
Quasi tutte le variabili sono tassi oppure grandezze assolute rapportate alla popolazione, questo perché andremo a spiegare non una grandezza assoluta, bensì un valore rapportato alla popolazione residente, il PIL pro-capite.
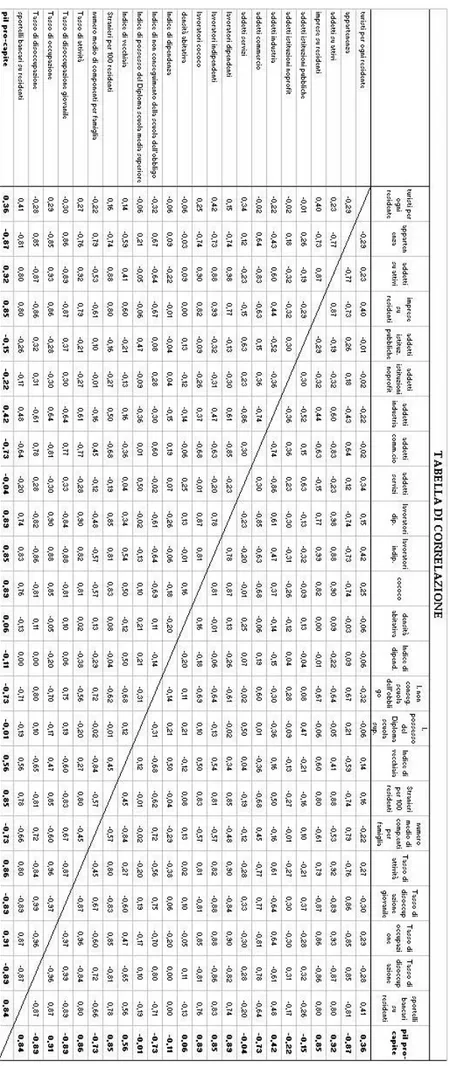
Ad ogni variabili descritta associo la sua correlazione con la variabili dipendente per valutare se ci può essere un legame fra le due variabili, anche se poi alleghiamo una tabella completa con tutte le correlazioni di tutte le variabili prese in esame.
Variabili socio-demografiche
Densità abitativa: rapporto tra popolazione residente e superficie territoriale.
( Km pop
)
A livello di benessere può essere una grandezza inversamente proporzionale con la qualità della vita, visto e considerato che a nessuno piacerebbe vivere in centri urbani troppo affollati, però economicamente sobborghi urbani con bassa densità demografica scoraggia l’insediamento di piccole attività commerciali.
Infatti vediamo che è incorrelata con il PIL pro capite.
CORRELAZIONE (0,05): non ha correlazioni degne di nota con le altre variabili ed è incorrelata con la variabili dipendente.
Appartenenza geografica: variabile policotomica che assume valore “1” se la
provincia appartiene al Nord, “2” se appartiene al Centro e “3” se appartiene al Sud. Variabile necessaria considerando il diverso modo di vivere fra Nord, Centro e Sud e soprattutto tenendo conto il maggior disagio economico che abbiamo al Sud.
CORRELAZIONE (-0,87): come abbiamo detto è una variabili molto correlata (soprattutto negativamente) con tutte le variabili prese in esame, ed ha una elevata correlazione negativa con il reddito pro capite
Considerato però la non relazione lineare non possiamo utilizzare tale variabile per la nostra stima, ma dobbiamo trasformarla in 2 variabili dicotomiche “dummy” che assumano,a seconda dell’appartenenza, il valore:
0 0 = appartenenza al Sud 1 0 = appartenenza al Nord 0 1 = appartenenza al Centro
Indice di dipendenza: misura il rapporto tra la parte di popolazione che non
lavora, bambini ed anziani (popolazione non attiva), e quella
potenzialmente attiva (15-64 anni). *100
64 15 65 14 0 Pop Pop Pop Id .
CORRELAZIONE (-0,10):è incorrelato con tutte le variabili.
Indice di vecchiaia: rapporto di composizione tra la popolazione anziana (65
anni e oltre) e popolazione più giovane (0-14 anni).
14 0 65 Pop Pop Ia .
CORRELAZIONE (0,55) : anche questo non ha una correlazione significativa con le variabili del modello, anche perché una società anche se più “anziana” può aver investito e lavorato duro negli anni per percepire i giovamenti poi in vecchiaia.
Stranieri per 100 abitanti: popolazione residente straniera ogni 1000 abitanti.
Variabile gravitazionale fondamentale perché dove essa è maggiore indica che è maggiore anche l’attrazione per quel luogo. (ricordo che tra gli stranieri residenti nella nostra provincia, e comunque vale per tutta la Toscana, molti provengono da paesi sviluppati come la Germania, UK, Francia ed USA e portano reddito e ricchezza).
CORRELAZIONE (0,85): fortemente correlata con tutte le variabili, ed come detto sopra è positivamente correlata con la variabile “reddito”.
Numero medio di componenti per famiglia: anche se non è una variabile che
oscilla molto a livello nazionale, è rilevante perché correlata con molte variabili.
CORRELAZIONE (-0,72): correlata positivamente con la variabile “appartenenza”, infatti al Sud ci sono sempre famiglie numerose, mentre negativamente correlata con l’indice di vecchiaia, a territori più “anziani” corrispondono parecchie famiglie “mono-persona”; correlazione negativa
con la variabile PIL pro capite, come si può ben pensare a famiglie più numerose corrispondono redditi minori.
Variabili lavoro
Tasso di attività: è dato dal rapporto percentuale avente al numeratore la
popolazione di 15 anni e più appartenente alle forze di lavoro e al denominatore il totale della popolazione della stessa classe di età.
anni più o 15 con e Popolazion _ lavoro Forze TassoISTAT .
CORRELAZIONE (0,86): una delle variabili con una più alta correlazione positiva con la variabile reddito, essendo una propensione al lavoro ed avendo assunto una altissima correlazione tra la produzione di lavoro ed il reddito su territorio.
È altamente correlato negativamente con la variabile di appartenenza essendo al Sud la disoccupazione è molto più numerosa.
Tasso di occupazione: è dato dal rapporto percentuale avente al numeratore la
popolazione di 15 anni e più occupata e al denominatore le forze di lavoro della stessa classe di età.
anni più o 15 con e Popolazion .occupazione Occupati T .
CORRELAZIONE (0,91):è la stessa, anzi più forte, di quello appena descritta per il T. di attività: alta correlazione col PIL pro capite spiegata dal forte legame che c’è tra il lavoro prodotto ed il reddito acquisito.
Tasso di disoccupazione: è dato dal rapporto percentuale avente al numeratore
la popolazione di 15 anni e più in cerca di occupazione e al denominatore le
forze di lavoro della stessa classe di età.
anni più o 15 con e Popolazion .disoccupati Disoccupati T .
CORRELAZIONE (-0,88): la correlazione ovviamente è inversa ai due indici sopra descritti, dove non si produce lavoro il reddito è minore. Quindi questo indice è altamente correlato positivamente con l’indice di appartenenza.
Tasso di disoccupazione giovanile: è dato dal rapporto percentuale avente al
numeratore i giovani della classe di età 15-24 anni in cerca di occupazione e al denominatore le forze di lavoro della stessa classe di età.
anni 24 -15 con e Popolazion anni 24 -15 con i Disoccupat . _
.disoccupazione giov
T
CORRELAZIONE (-0,88): uguale a sopra, anche se meno correlato con le altre variabili indipendenti.
Indicatori relativi all’istruzione
Indice di non conseguimento della scuola dell’obbligo (15-52 anni) : è dato
dal rapporto percentuale avente al numeratore la popolazione della classe d’età di 15-52 anni, che ha non conseguito il diploma di scuola media inferiore, e al denominatore il totale della popolazione della stessa classe d’età. È un indice molto negativo che segnala l’ignoranza “illegale” che ancora è presente.
CERRELAZIONE (-0,73): è correlata negativamente con il reddito pro capite, possiamo immaginare che chi non possiede neppure la licenza media non può aspirare, nella società di oggi, ad un reddito medio-alto.
Indice di possesso del Diploma di scuola media superiore: è il rapporto
percentuale avente al numeratore la popolazione della classe di età 19 anni e più, che ha conseguito almeno un diploma di scuola media (secondaria) superiore della durata di 4 o 5 anni, e a denominatore il totale della popolazione della stessa classe di età.
Questo indice si è poi rilevato di inutile aiuto all’esplicazione.
CORRELAZIONE (-0,01): praticamente incorrelato con la variabile dipendente e con tutte le variabili indipendenti.
Indici economici strutturali
Addetti ai Servizi: propensione al settore servizi; rapporto percentuale avente al
numeratore il numero di addetti del settore economico servizi ed al denominatore il totale degli addetti.
Addetti al Commercio: propensione al settore commercio; rapporto percentuale
avente al numeratore il numero di addetti del settore commercio ed al denominatore il totale degli addetti.
Addetti all’Industria: propensione al settore industriale; rapporto percentuale
avente al numeratore il numero di addetti del settore industriale ed al denominatore il totale degli addetti.
Addetti alle istituzioni pubbliche: propensione al settore pubblico; rapporto
percentuale avente al numeratore il numero di addetti alle istituzioni pubbliche4 ed al denominatore il totale degli addetti.
Addetti alle istituzioni no-profit: propensione al settore no-profit; rapporto
percentuale avente al numeratore il numero di addetti alle istituzioni no-profit5 ed al denominatore il totale degli addetti.
Quest’ultime variabili non sono importanti per la correlazione con le variabili del modello, anche perché è molto bassa, ma è importante usarne almeno una per la
4Unità giuridico - economica la cui funzione principale è quella di produrre beni e servizi non destinabili
alla vendita e/o di ridistribuire il reddito e la ricchezza e le cui risorse principali sono costituite da prelevamenti obbligatori effettuati presso le famiglie, le imprese e le istituzioni nonprofit o da trasferimenti a fondo perduto ricevuti da altre istituzioni dell’amministrazione pubblica. Costituiscono esempi di istituzione pubblica: Autorità portuale, Camera di commercio, Comune, Ministero, Provincia, Regione, Università pubblica, ecc.
spiegazione della variabile “reddito pro capite” in quanto accenna alla struttura economica di un territorio.
Lavoratori dipendenti: è il rapporto percentuale avente al numeratore i
lavoratori dipendenti ed al numeratore il totale degli attivi.
Lavoratori indipendenti: è il rapporto percentuale avente al numeratore i
lavoratori indipendenti ed al numeratore il totale degli attivi.
Lavoratori cococo: è il rapporto percentuale avente al numeratore il numero dei
co.co.co6 ed al numeratore il totale degli attivi.
Questi indici strutturali, ha differenza di quelli sopra citati, hanno tutti una forte correlazione con la variabile dipendente (poco più di 0,80) ed esprimono la propensione al tipo di lavoro svolto dagli attivi su un territorio.
Variabili gravitazionali
Addetti su attivi: forse la variabile più importante di tutto il modello. È la
propensione “al lavoro” ed indica la percentuale di addetti (residenti che effettivamente lavorano) sulle persone predisposte al lavoro (forza lavoro), e ricordando lo stretto legame tra produzione di lavoro e produzione di reddito questa variabile assume un estrema importanza.
CORRELAZIONE (0,92): come ci aspettavamo la correlazione con la variabile dipendente viene molto alta.
Turisti per ogni residente: anche questa variabile riesce a spiegare parte del
reddito, in quanto indica le presenze turistiche7 per ogni abitante residente.
6
Persona che presta la propria opera presso un’impresa o istituzione con rapporto di lavoro non soggetto a vincolo di subordinazione e che fornisce una prestazione dal contenuto intrinsecamente professionale o artistico, svolta in modo unitario e continuativo per un tempo predeterminato, ricevendo un compenso a carattere periodico e prestabilito.
Ovviamente più un territorio riesce ad attrarre turismo e più il reddito dello stesso ne guadagna.
CORRELAZIONE (0,36): non ha una correlazione degna di note con le variabile del modello.
Imprese su residenti: è il rapporto percentuale avente al numeratore il numero
di imprese su territorio ed al denominatore il totale della popolazione residente di quel territorio.
CORRELAZIONE (0,85): anche se altamente correlato e potrebbe far intendere di essere una variabile fondamentale del modello, verrà esclusa perché non è detto che le imprese sul territorio diano benefici a questo, anzi è probabile che usino le sue risorse naturali, ma i profitti non rimanghino sul territorio.
Sportelli bancari su residenti: è il rapporto percentuale avente al numeratore il
numero di sportelli bancari ed al denominatore il totale della popolazione residente di quel territorio.
CORRELAZIONE (0,84): alta correlazione con la variabile dipendente, possiamo infatti pensare che le banche preferiscano investire nelle zone più ricche.
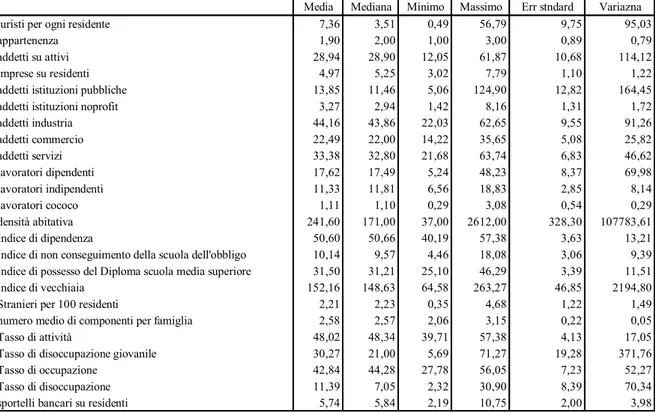
Per concludere la presentazione delle possibili variabili utilizzate nel modello le descriviamo con media, mediana, moda, errore standard e varianza.
Quindi una tabella dove riassume tutti gli indici di correlazione delle variabili sopra descritte.
7indicano l'intensità del fenomeno e si misurano con la durata del soggiorno delle persone presso le
Tabella 48. Statistiche descrittive var. dipendenti (modello PIL)
Media Mediana Minimo Massimo Err stndard Variazna
turisti per ogni residente 7,36 3,51 0,49 56,79 9,75 95,03
appartenenza 1,90 2,00 1,00 3,00 0,89 0,79
addetti su attivi 28,94 28,90 12,05 61,87 10,68 114,12
imprese su residenti 4,97 5,25 3,02 7,79 1,10 1,22
addetti istituzioni pubbliche 13,85 11,46 5,06 124,90 12,82 164,45
addetti istituzioni noprofit 3,27 2,94 1,42 8,16 1,31 1,72
addetti industria 44,16 43,86 22,03 62,65 9,55 91,26 addetti commercio 22,49 22,00 14,22 35,65 5,08 25,82 addetti servizi 33,38 32,80 21,68 63,74 6,83 46,62 lavoratori dipendenti 17,62 17,49 5,24 48,23 8,37 69,98 lavoratori indipendenti 11,33 11,81 6,56 18,83 2,85 8,14 lavoratori cococo 1,11 1,10 0,29 3,08 0,54 0,29 densità abitativa 241,60 171,00 37,00 2612,00 328,30 107783,61 Indice di dipendenza 50,60 50,66 40,19 57,38 3,63 13,21
Indice di non conseguimento della scuola dell'obbligo 10,14 9,57 4,46 18,08 3,06 9,39
Indice di possesso del Diploma scuola media superiore 31,50 31,21 25,10 46,29 3,39 11,51
Indice di vecchiaia 152,16 148,63 64,58 263,27 46,85 2194,80
Stranieri per 100 residenti 2,21 2,23 0,35 4,68 1,22 1,49
numero medio di componenti per famiglia 2,58 2,57 2,06 3,15 0,22 0,05
Tasso di attività 48,02 48,34 39,71 57,38 4,13 17,05
Tasso di disoccupazione giovanile 30,27 21,00 5,69 71,27 19,28 371,76
Tasso di occupazione 42,84 44,28 27,78 56,05 7,23 52,27
Tasso di disoccupazione 11,39 7,05 2,32 30,90 8,39 70,34
3.2.3 I modelli di regressione lineare multiplo
Per la scelta delle variabili da utilizzare, e quindi il modello finale da definire, oltre a tener conto della correlazioni delle variabili e delle considerazioni appena fatte, uno strumento che ci può venir in aiuto è il metodo ”stepwise” della regressione lineare multipla. Questo ci permetterà una prima scrematura delle variabili.
Dopo aver utilizzato uno dei 2 metodi “preliminari” Stepwise: Backward8 e Forward, si passerà alla “costruzione” del modello finale che verrà poi utilizzato per il calcolo del PIL provinciale comunale.
3.2.3.1 Modello di regressione: metodo Stepwise forward
Questo è il metodo inverso a quello backward: adesso il modello di partenza è senza coefficienti ed a ogni step viene aggiunta una nuova variabile al modello che apporta informazioni che spiegano la dipendente.
Adesso elenchiamo le variabili che sono state inserite nel modello in ordine di entrata:
8
si parte immettendo nel modello tutte le variabili indipendenti (effettivamente non è possibile immettere tutte le variabili nel modello altrimenti la matrice (x’x) verrebbe singolare e non invertibile, quindi si esclude una variabilefra addetti ai servizi-industria-commercio ed una variabile tra lavoratore
indipendente-dipendente) descritte fino ad ora e ad ogni step viene esclusa la variabile meno
significativa8. Il processo di esclusione ha termine quando tutte le variabili sono significative e l’F di Fischer8 raggiunge il suo valore massimo.
Tabella 50. Variabili entranti nel modello forward - in ordine di entrata- stima PIL
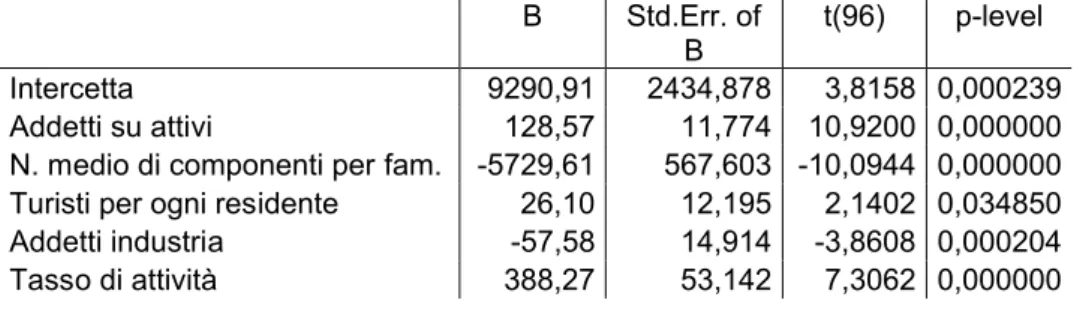
1. Addetti su attivi 3. Turisti per ogni residente 5. Tasso di attività
2. N. medio di componenti per famiglia 4. Lavoratori cocco
Il modello lineare col metodo Stepwise forward è il seguente:
i i
i i
i
i add att n med fam tur Add ind T att
Y 9290,91128,57 _ 5729,61 _ _ 26,10 57,58 _ 388,27 _
Le variabili utilizzate ed i la relativa significatività è riassunta nella tabella:
Tabella 51. Coefficienti e significatività modello forward. (modello PIL)
B Std.Err. of
B t(96) p-level
Intercetta 9290,91 2434,878 3,8158 0,000239
Addetti su attivi 128,57 11,774 10,9200 0,000000
N. medio di componenti per fam. -5729,61 567,603 -10,0944 0,000000
Turisti per ogni residente 26,10 12,195 2,1402 0,034850
Addetti industria -57,58 14,914 -3,8608 0,000204
Tasso di attività 388,27 53,142 7,3062 0,000000
Lo standard error della stima è 1017 ed abbiamo un indice R2corretto uguale al precedente di 0,94.
L’F di Fisher è 376,27 con un p-value < 0,0000, di conseguenza si rifiuta l’ipotesi nulla che tutti i coefficienti sono contemporaneamente uguali a zero.
3.2.3.2 Modello lineare di regressione definitivo
Il nostro modello finale vogliamo che oltre ad avere un alto indice di determinazione, coefficienti singolarmente e contemporaneamente significati, che abbia un significato economico, cioè che le variabili utilizzate siano altamente correlate con la variabile dipendente e che esprimano un legame socio-economico con il reddito percepito in un determinato territorio.
Il modello lineare è il seguente:
i i i i i i
i add att tur n med fam add ser t att str
Y 6252,3106,3 _ 32,4 5297,2 _ _ 66,1 _ 339,1 _ 343,1
Le variabili utilizzate ed i la relativa significatività è riassunta nella tabella:
Tabella 52. Coefficienti e significatività modello “definitivo”. (modello PIL)
B Errore
Standard t(95) p-level
Intercetta 6252,35 2858,53 2,18726 0,031152
add_att (Addetti su attivi) 106,26 13,47 7,88873 0,000000
tur (Turisti per ogni residente) 32,39 11,83 2,73911 0,007345
add_ser (Addetti servizi) 66,15 17,40 3,80200 0,000252
n_med_fam (N. medio comp.ti famiglia) -5297,22 588,89 -8,99521 0,000000
str (Stranieri per 100 residenti) 362,01 172,52 2,09830 0,038504
t_att (Tasso di attività) 339,10 52,81 6,42158 0,000000
Tutte le variabili sono singolarmente significative.
Confronto ai modelli “stepwise” abbiamo un indice di determinazione leggermente maggiore 0,95 ed un standard error minore 1007,9.
F di Fischer che è 319,7, anche se si rifiuta altamente l’ipotesi che tutti i coefficienti contemporaneamente sono uguali a zero.
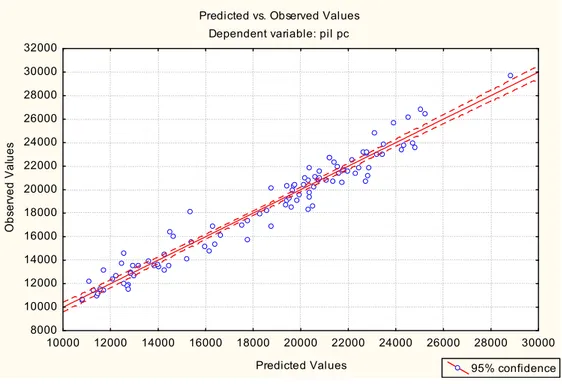
Il grafico sotto riportato ci aiuta a valutare la bontà del modello, cioè osserviamo la differenza tra i valori predetti e quelli osservati, più i valori si addensano nella sulla diagonale più il modello è ben specificato.
Figura 42. Confronto tra valori osservati e predetti (bontà del modello PIL)
Predicted vs. Observed Values Dependent variable: pil pc
10000 12000 14000 16000 18000 20000 22000 24000 26000 28000 30000 Predicted Values 8000 10000 12000 14000 16000 18000 20000 22000 24000 26000 28000 30000 32000 O b se rv e d V a lu e s 95% confidence
Infine per valutare la buona specificazione del modello è opportuno compiere l’analisi dei residui.
Dopo aver verificato che la media dei residui è pari a zero disegniamo la loro distribuzione per valutarne la normalità con 2 strumenti già utilizzati in precedenza: il QQ Plot e l’istogramma dei valori dei residui:
Figura 43. Distribuzione residui modello PIL Distribution of Raw residuals
Expected Normal -3000 -2500 -2000 -1500 -1000 -500 0 500 1000 1500 2000 2500 3000 3500 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 N o of o bs
Figura 44. QQ Plot residui modello PIL
Normal Probability Plot of Residuals
-3000 -2000 -1000 0 1000 2000 3000 Residuals -3 -2 -1 0 1 2 3 E xp ec te d N or m al V al ue
Poi verifichiamo che i residui non abbiano correlazione con la variabile dipendente:
Figura 45. Correlazione residui - variabili dipendente Raw residuals vs. pil pc Raw residuals = -874,8 + ,04766 * pil pc
Correlation: r = ,21832 8000 10000 12000 14000 16000 18000 20000 22000 24000 26000 28000 30000 32000 pil pc -3000 -2000 -1000 0 1000 2000 3000 R aw r es id ua ls 95% confidence
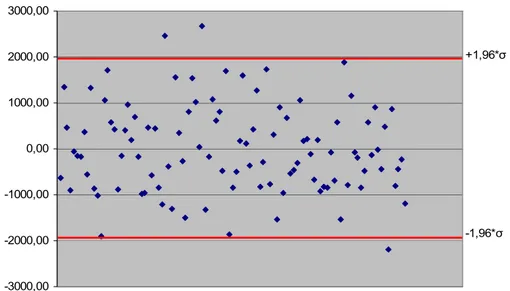
Ed infine ispezioniamo il grafico dei residui che, disponendosi in maniera casuale intorno all’asse delle ascisse, dove almeno il 95% dei valori devono essere compresi tra 1.96ˆ.
Figura 46. Scatter plot residui
-3000,00 -2000,00 -1000,00 0,00 1000,00 2000,00 3000,00 +1,96*σ -1,96*σ
Possiamo anche osservare che non c’è presenza di strutture nel grafico9 dei residui che potevano indicare errori di specificazione nel modello.
3.2.3.3 Calcolo dei PIL comunali
Dopo aver valutato la significatività e la bontà del modello e verificatone la buona specificazione possiamo calcolare i p.i.l. p.c. comunale semplicemente sostituendo alle variabili indipendenti del modello10 i rispettivi valori comunali11. Quindi riportiamo i valori calcolati nella seguente tabella dividendo i comuni per la loro appartenenza al Settore Economico Locale:
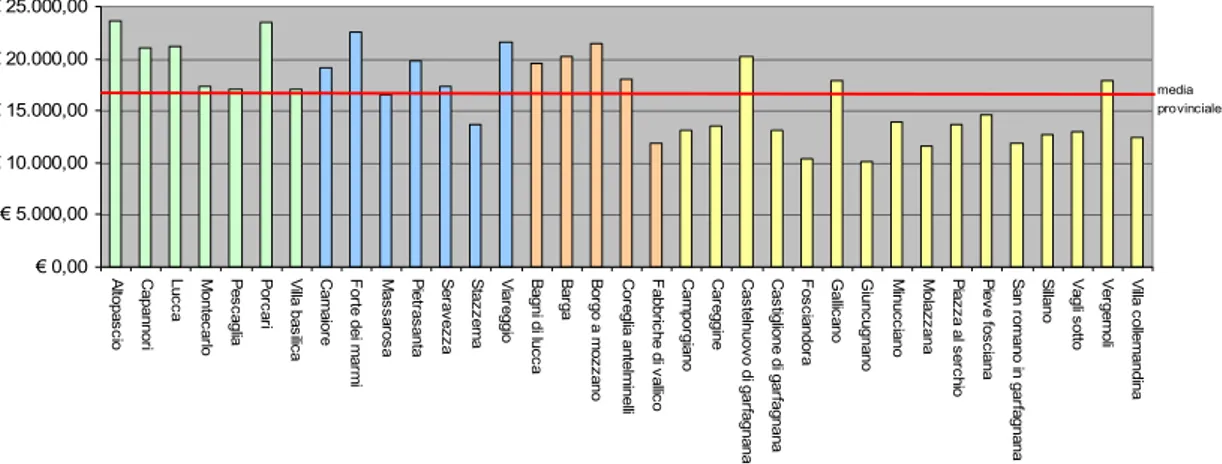
Tabella 53. Risultati stima PIL pro capite comunale - ’01
Descrizione comune PIL p.c. Descrizione comune PIL p.c.
Altopascio € 23.573,16 Camporgiano € 13.074,39 Capannori € 21.036,09 Careggine € 13.481,91 Lucca € 21.163,89 Castelnuovo di G. € 20.237,34 Montecarlo € 17.328,30 Castiglione di G. € 13.174,05 Pescaglia € 17.020,63 Fosciandora € 10.442,17 Porcari € 23.482,91 Gallicano € 17.845,30
Villa Basilica € 17.131,56 Giuncugnano € 10.072,87
Camaiore € 19.192,58 Minucciano € 13.927,93
Forte dei Marmi € 22.506,31 Molazzana € 11.570,69
Massarosa € 16.555,82 Piazza al Serchio € 13.662,69
Pietrasanta € 19.827,41 Pieve Fosciana € 14.572,90
Seravezza € 17.307,40 San Romano in G. € 11.926,97
Stazzema € 13.710,71 Sillano € 12.654,02
Viareggio € 21.592,35 Vagli Sotto € 13.037,20
Bagni di Lucca € 19.499,38 Vergemoli € 17.952,71
Barga € 20.194,32 Villa Collemandina € 12.449,65
Borgo a Mozzano € 21.466,94 Coreglia Antelminelli € 18.034,66 Fabbriche di Vallico € 11.930,09 Piana di Lucca Versilia Media Valle Garfagnana 10 i i i i i i
i add att tur n med fam add ser t att str
Y 6252,3106,3 _ 32,4 5297,2 _ _ 66,1 _ 339,1 _ 343,1
11Tutti i dati comunali e provinciali utilizzati per stimare il modello sono riportati nell’appendice del
Figura 47. Distribuzione comunale del reddito pro capite- anno 2001 € 0,00 € 5.000,00 € 10.000,00 € 15.000,00 € 20.000,00 € 25.000,00 A lto pa sc io C ap an no ri Lu cc a M on te ca rlo P es ca glia P or ca ri V illa b as ilic a C am aio re F or te d ei m ar m i M as sa ro sa P ie tra sa nta S er av ez za S ta zz em a V ia re gg io B ag ni di lu cc a B ar ga B or go a m oz za no C or eg lia a nte lm in elli F ab br ic he d i v alli co C am po rg ia no C ar eg gin e C as te ln uo vo d i g ar fa gn an a C as tig lio ne d i g ar fa gn an a F os cia nd or a G alli ca no G iu nc ug na no M in uc cia no M ola zz an a P ia zz a a l s er ch io P ie ve fo sc ia na S an ro m an o i n g ar fa gn an a S illa no V ag li s ott o V er ge m oli V illa c olle m an din a media provinciale
Figura 48. Media per S.E.L. del reddito p.c. comunale - ‘01
€ 20.105,22 € 18.670,37 € 18.225,08 € 13.755,17 € 0,00 € 5.000,00 € 10.000,00 € 15.000,00 € 20.000,00 € 25.000,00 Piana di Lucca Versilia Media Valle Garfagnana S.E.L. Piana di Lucca Versilia Media Valle Garfagnana
Il benessere dal lato economico è ora possibile valutarlo anche ad un livello disaggregato comunale. Tali risultati, come abbiamo spesso ripetuto, debbono però essere presi con cautela perché ricordiamo la difficoltà nello stimare le piccole aree.
La nostra idea è però quella di avere una visuale per territorio, per valutare le aree più povere, aree intese come insieme di comuni limitrofi, così riducendo anche l’errore di determinazione.
Quindi una prima valutazione va compiuta a livello di Settore Economico Locale:
da una prima analisi notiamo che in Piana di Lucca tutti i comuni sono sopra la media Provinciale: reddito trainato dall’alto numero di Addetti per le zone industriali (Porcari, Altopascio e Capannori):
situazione molto simile si presenta anche nella zona limitrofa alla Piana, la Media Valle: solo Fabbriche di Vallico è sotto la media Provinciale, anche in questo contesto il reddito è trainato dall’alto numero di addetti soprattutto nella zona “cartiere” di Borgo a Mozzano e Barga;
nella Versilia il reddito oltre ad essere trainato dal numero di addetti è “aiutato” dall’alto numero di turisti. Spicca fra tutte Forte de Marmi con un altissima percentuale di Addetti su Attivi e di turisti. Fanalino di coda il comune di Stazzema;
situazione completamente diversa la troviamo in Garfagnana: tasso di Attività basso e percentuale molto ridotta di Addetti su Attivi (in media 32%: meno della metà degli altri S.E.L.).
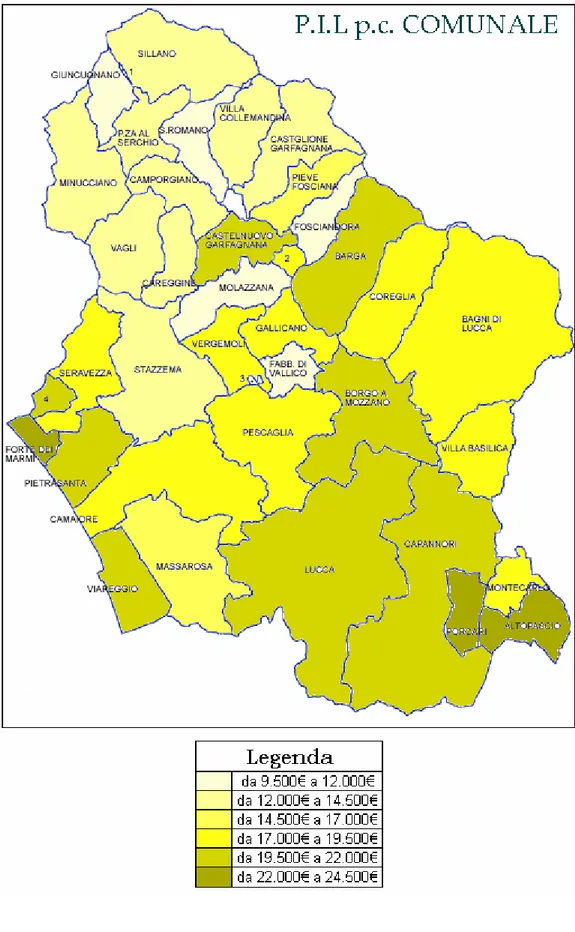
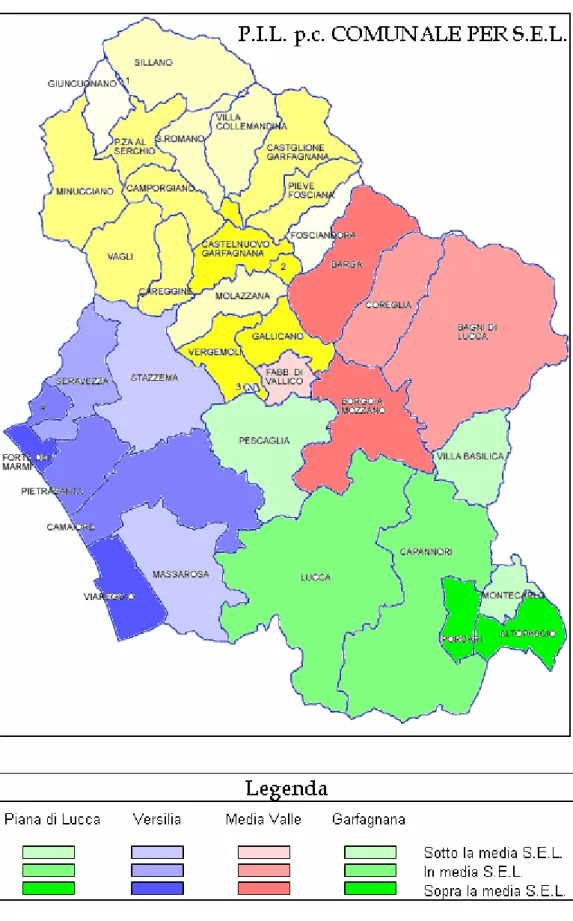
Per una più immediata consultazione proponiamo due grafici a mappa rappresentanti la distribuzione del reddito pro capite comunale all’interno della Provincia.
Il primo propone ogni comune a confronto con gli altri della Provincia, mentre il secondo ogni comune è confrontato con distretti del proprio Settore Economico Locale.
In conclusione le zone col più alto reddito pro capite sono quelle vicine ai comuni più grossi e che quindi offrono possibilità di lavoro maggiore, con insediamenti industriali notevoli ed importanti:
o lavorazione dei minerali non metalliferi: comparto lapideo versiliese
o produzioni metalliche e meccaniche (meccanica generica e cantieri navali): Lucca, Barga, Camaiore, Viareggio, Massarosa, Pietrasanta
o dall'industria cartaria, gomma e plastica: Lucca, Borgo a Mozzano, Capannori, Porcari, Villa Basilica, in misura minore, Altopascio, Bagni di Lucca, Barga, Coreglia Antelminelli, Fabbriche di Vallico
o industrie calzaturiere: Lucca, Camaiore, Capannori, Massarosa, Porcari, Altopascio e Viareggio
A tutto questo è doveroso aggiungere la forte attrazione turistica sia culturale da parte di Lucca sia naturale per quanto riguarda le colline Lucchesi e la costa Tirrenica.
Mentre le zone che hanno un reddito pro capite minore, ma che magari a livello di qualità di vita godono di molti altri privilegi, contengono quei comuni che avevamo già individuato come comuni a rischio demografico ed oltretutto fuori da ogni fulcro industriale e commerciale, dove la popolazione attiva si deve spostare per trovare lavori