Simulazioni e risultati
4.1 Introduzione
Dopo aver presentato gli algoritmi studiati, vediamo quali risultati sono stati trovati simulando al computer situazioni diverse per tipo di canale, attenuazione, numero di utenti e di sottoportanti, ecc.
Nel capitolo verranno presentati alcuni indici di prestazioni e si cercherà di quantificare la complessità di calcolo.
Gli algoritmi presi in considerazione verranno così denominati:
• LINPROG: è l’algoritmo di programmazione lineare mediante cui si ottiene l’allocazione ottima delle sottoportanti ai vari utenti; il numero delle sottoportanti per utente è quello trovato con l’algoritmo BABS;
• RCRA: è l’algoritmo a complessità ridotta di allocazione delle risorse (Reduced Complexity Resource Allocation) che è stato studiato in questa tesi; esso trova un’allocazione subottima delle sottoportanti ai vari utenti; è composto da due algoritmi distinti: il primo calcola quante sottoportanti assegnare ad ogni utente (BABS), il secondo specifica quali sottoportanti assegnare.
•
NOALL: è l’algoritmo di “non allocazione”; le sottoportanti vengono assegnatein maniera del tutto casuale ai vari utenti, senza sfruttare alcuna conoscenza sul canale visto da ogni utente.
4.2 Parametri di simulazione
4.2.1 Canale selettivo in frequenza
La prima serie di simulazioni è stata fatta considerato il downlink di un sistema multiutente multiportante, con un numero di sottoportanti N=64. La banda complessiva è B=20MHz e, di conseguenza, la banda di ciascuna sottoportante è B N/ =312.5KHz;
il tempo di campionamento è Ts =1/B=50ns. Gli utenti sono uniformemente distribuiti in una cella esagonale di raggio 500m e il loro numero varia da simulazione a simulazione (K = 4, 8, 16). Il fading è dovuto alla pathloss, che è proporzionale alla distanza tra la BS (situata al centro della cella) e l’utente mobile; l’esponente della pathloss è α=4 e non vengono considerati gli effetti di shadowing. Il canale è selettivo in frequenza con distribuzione di Rayleigh e il profilo di ritardo di potenza è di tipo esponenziale; il delay spread è τ=0.5μs, valore tipico per un contesto urbano.
4.2.2 Canale tipico di un sistema WiLan
Per vedere come si può applicare l’algoritmo studiato a uno scenario realmente esistente, sono stati implementati i parametri tipici di un sistema WiLan; N=64 sottoportanti, banda B=20MHz, prefisso ciclico di 16 campioni, ritardo di propagazione e potenza in dB per ciascun percorso dati da vettori opportuni (vedi Appendice Software); si considera un canale con multipath e un filtro in trasmissione e in ricezione a radice di coseno rialzato con roll-off α =0.22. Come nel caso precedente il numero di utenti è variabile da simulazione a simulazione (K = 4, 8, 16).
4.3 Indici di prestazioni e risultati delle simulazioni
Vengono ora riportati i grafici relativi alle simulazioni ritenute più significative; i colori utilizzati indicano rispettivamente:
• Blu: algoritmo RCRA; • Verde: algoritmo LINPROG; • Rosso: algoritmo NOALL.
4.3.1 Consumo complessivo di potenza
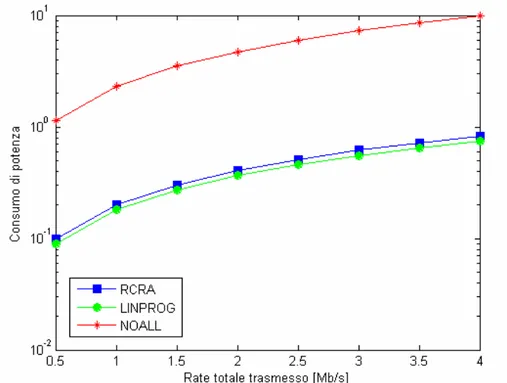
Per ognuno degli algoritmi presi in esame viene valutato il consumo totale di potenza in funzione del rate totale trasmesso nella cella in cui sono presenti K utenti attivi; si considera un rate da un minimo di 500 Kbps a 4 Mbps, con passo di 500 Kbps.
Come già esposto nel paragrafo 3.5, la formula che ci permette di valutare il consumo totale di potenza del sistema è la seguente:
1 1 ( 1) k k n R m B K T k k k e P m H = − =
∑
(4.1) dove• m è il numero di sottoportanti utilizzate dall’utente k per la trasmissione; k
• Rk =R K/ è il rate con cui trasmette l’utente k, essendo R il rate totale della cella e K il numero di utenti attivi;
• Bn =B N/ è la banda di ciascuna sottoportante, essendo B la banda complessiva a disposizione per la trasmissione e N il numero di sottoportanti
disponibili; • 2 1 ( ) N k n k H n H N =
=
∑
è il valor medio del canale visto da ogni utente, essendo2
( )
k
H n il guadagno di canale dell’utente k sulla sottoportante n.
• k k
R
m è il rate trasmesso su ciascuna delle m sottoportanti assegnate all’utente k. k
Consideriamo inizialmente uno scenario con exponential power delay profile, un numero di sottoportanti N=64 e un numero di utenti K=4, K=8 e K=16 rispettivamente.
Fig. 4.2 – Consumo complessivo di potenza in funzione del rate totale trasmesso; N=64 e K=8.
Analizzando i grafici mostrati, notiamo che l’allocazione ottenuta utilizzando un algoritmo di linear programming necessita di un minor consumo di potenza per la trasmissione; l’algoritmo RCRA ha prestazioni di poco inferiori mentre, come prevedibile, allocando le sottoportanti in maniera casuale è necessaria molta più potenza per la trasmissione.
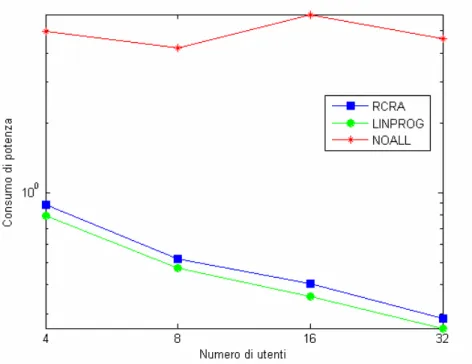
Si nota inoltre che, a parità di rate complessivo per cella, se aumenta il numero di utenti attivi, diminuisce la potenza totale consumata; questo si spiega considerando che all’aumentare degli utenti attivi aumenta la diversità; ciò significa che viene sfruttata al meglio la diversità multiutente e, di conseguenza, è necessaria meno potenza per la trasmissione.
Quanto appena esposto viene mostrato nella figura seguente, che indica come varia la potenza totale trasmessa dai tre algoritmi al variare del numero di utenti attivi, mantenendo costante il rate.
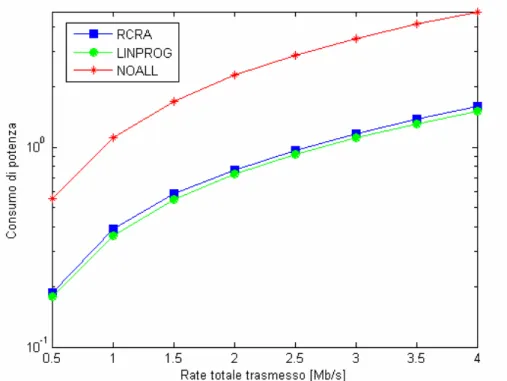
Quanto appena esposto può essere esteso ad uno scenario di tipo WiLan. La simulazione relativa a 64 sottoportanti e 16 utenti è mostrata nella figura che segue:
Fig. 4.5 – Consumo complessivo di potenza in funzione del rate totale trasmesso con canale WiLan.
Anche in uno scenario tipico della WiLan, molto più complesso rispetto a quelli precedentemente analizzati, le prestazioni dei vari algoritmi mantengono un andamento sostanzialmente simile; essendo tuttavia diverso il modello di canale, non possono essere fatti paragoni con i grafici precedenti.
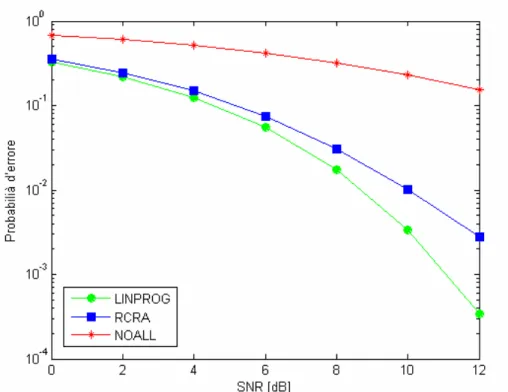
4.3.2 Probabilità d’errore
Per ognuno degli algoritmi presi in esame viene calcolata la probabilità d’errore media in funzione del rapporto segnale rumore (SNR) medio al ricevitore; il SNR considerato varia da 0 a 12 dB con passo di 2dB. In questo caso viene utilizzato un canale senza pathloss.
Se si impone che la probabilità d’errore sia uguale su tutte le sottoportanti, allora la formula che ci permette di calcolare tale probabilità d’errore su ciascuna sottoportante è la seguente:
(
)
2
e
P = Q SNR (4.2)
dove SNR è il rapporto segnale rumore medio per ogni sottoportante. Il rapporto segnale rumore sulla sottoportante n è
2 0 ( ) ( ) ( ) PTX n H n SNR n N ⋅ = (4.3)
essendo ( )PTX n la potenza trasmessa sulla sottoportante n,
2
( )
H n il guadagno di
canale della sottoportante n e N il rumore del sistema. 0
Di conseguenza il rapporto segnale rumore medio su ciascuna sottopotante è
0 TX P SNR N = (4.4)
poiché il valor medio dei guadagni di canale è H 2 =1 (avendo imposto che la pathloss
sia unitaria). P è la potenza media trasmessa su ciascuna sottoportante e il suo valore TX
è TOT
TX
P P
N
il numero di sottoportanti disponibili.
Concludendo, l’espressione che ci permette di calcolare la probabilità d’errore media per ciascuna sottoportante è la seguente
(
)
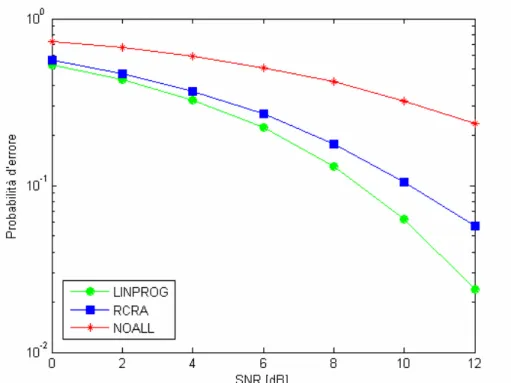
0 1 2 2 TOT e P P Q SNR Q N N ⎛ ⎞ = = ⎜⎜ ⋅ ⎟⎟ ⎝ ⎠ (4.5) Le figure che seguono mostrano la probabilità d’errore media dei diversi algoritmi in funzione del rapporto segnale rumore (SNR) medio al ricevitore. Sono considerati sistemi con 4 utenti e 4 sottoportanti, 8 utenti e 8 sottoportanti, 16 utenti e 16 sottoportanti rispettivamente.Fig. 4.7 – Probabilità d’errore in funzione del SNR;N=8 e K=8.
Le figure sopra mostrano un risultato molto interessante: sebbene l’algoritmo RCRA sia stato studiato e implementato per calcolare la particolare allocazione in cui il minimo guadagno di canale sia il più elevato possibile, tale algoritmo tende anche a minimizzare la probabilità d’errore ed ha prestazioni molto vicine a quelle dell’algoritmo di programmazione lineare.
La probabilità d’errore è infatti una funzione fortemente non lineare e i valori più bassi dei guadagni di canale hanno peso maggiore nel determinare il valore della probabilità d’errore che, di conseguenza, tende ad aumentare.
Inoltre, come già illustrato nel paragrafo precedente, le prestazioni migliorano all’aumentare del numero di utenti, in quanto la diversità multiutente viene meglio sfruttata.
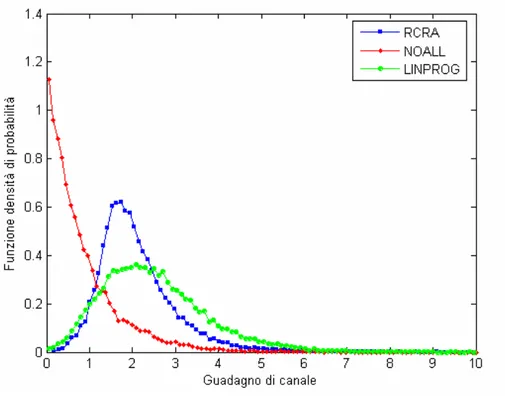
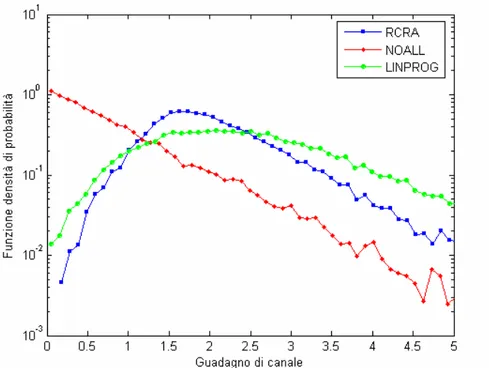
4.3.3 Istogramma dei guadagni di canale
Per ognuno degli algoritmi presi in esame viene calcolata sperimentalmente la funzione densità di probabilità dei guadagni di canale, approssimata come l’istogramma dei guadagni di canale dopo l’assegnazione.
L’istogramma è ottenuto dividendo in 100 bins il range di valori che il guadagno di canale può assumere; si stima quindi che la funzione densità di probabilità assuma valori pari a hist( )
100i .
Le figure che seguono mostrano l’istogramma dei guadagni di canale; nella prima la scala dell’asse delle ordinate è lineare, nella seconda è logaritmica, in modo da evidenziare ciò che avviene per piccoli valori dei guadagni di canale.
Fig. 4.10 – Istogramma dei guadagni di canale (scala lineare);N=16 e K=16.
Si nota che le assegnazioni con guadagno di canale più elevato sono più frequenti se si utilizza l’algoritmo di LINPROG; allo stesso tempo, tale algoritmo ha pochi valori con un basso guadagno di canale. L’algoritmo RCRA, invece, ha meno frequentemente elevati guadagni di canale ma mantiene molto bassa la probabilità che i guadagni di canale siano molto piccoli. Poiché la probabilità d’errore è una funzione concava non lineare, le assegnazioni con un basso guadagno di canale deteriorano notevolmente la prestazioni complessive del sistema ed è quindi opportuno che abbiano bassa probabilità di verificarsi. Limitatamente alla probabilità che i guadagni di canale assumano valori molto piccoli, l’algoritmo RCRA ha prestazioni migliori dell’algoritmo di LINPROG; ciò si spiega ricordando che l’algoritmo RCRA si basa proprio sulla massimizzazione del minimo dei guadagni di canale.
4.4 Complessità
Come mostrato delle simulazioni e dai grafici, l’algoritmo RCRA ha prestazioni leggermente inferiori a quelle di un algoritmo di allocazione ottima delle sottoportanti ai vari utenti; il motivo per cui esso può essere interessante per applicazioni reali, sia in ambito civile che militare, è la sua bassa complessità ed elevata velocità nell’elaborare i dati per fornire l’allocazione.
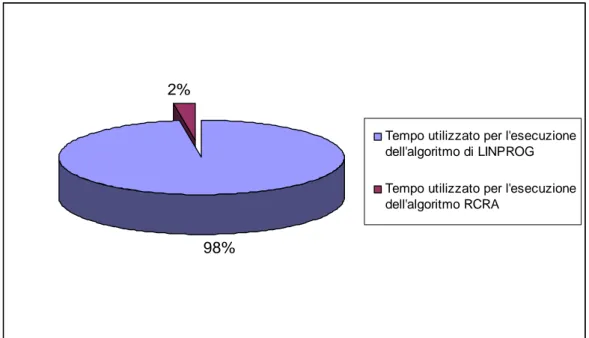
Le simulazioni con cui si confrontano le prestazioni dell’algoritmo di LINPROG e dell’algoritmo RCRA ci permettono anche di stimare il tempo necessario per trovare l’allocazione ottima con l’algoritmo di LINPROG e quella subottima con l’algoritmo RCRA; si osserva che, se si ha un basso numero di sottoportanti disponibili (N=6), il 93% del tempo totale viene impiegato per trovare la soluzione ottima, mentre la ricerca della soluzione subottima richiede solo il restante 7%. Inoltre, poiché la complessità dell’algoritmo di LINPROG cresce in maniera esponenziale all’aumentare del numero di sottoportanti, già con N=32 si ha che il tempo utilizzato per l’esecuzione del LINPROG è il 97.6% del totale, che cresce al 99% con un canale tipico della WiLan (N=64, K=16); in questo caso l’algoritmo RCRA impiega in media 0.07 secondi a trovare l’allocazione subottima, contro i 4.52 secondi necessari all’algoritmo di LINPROG per trovare l’allocazione ottima.
2%
98%
Tempo utilizzato per l'esecuzione dell'algoritmo di LINPROG
Tempo utilizzato per l'esecuzione dell'algoritmo RCRA
Fig. 4.11 – Grafico del tempo necessario all’esecuzione degli algoritmi LINPROG e RCRA;
4.4.1 Complessità dell’algoritmo di LINPROG
In generale la complessità degli algoritmi di programmazione lineare dipende da: • p: numero delle variabili.
• q: numero dei vincoli.
Se il problema LP viene risolto col metodo IPM (Interior Points Methods), allora il numero di operazioni aritmetiche da svolgere cresce in maniera polinomiale e diventa dell’ordine di 2 3
pq + . q
Nel nostro problema di allocazione dinamica delle risorse (sottoportanti, utenti e formati di modulazione) il numero delle variabili è p N K F= × × e il numero dei vincoli è
q= , dove N è il numero delle sottoportanti disponibili, K è il numero degli utenti K
attivi ed F è il numero dei formati di modulazione utilizzati. Tuttavia, ricordando che l’algoritmo di LINPROG è stato implementato assumendo come formato di modulazione quello calcolato tramite l’algoritmo BABS, possiamo assumere noto il formato di modulazione (F=1). Di conseguenza si ha p N K= × e q K= .
Inoltre, sotto l’ipotesi di formato di modulazione noto, il problema dell’allocazione risorse può essere formulato come un problema di Network Flow e può quindi essere risolto con algoritmi particolarmente efficienti, come il Network Simplex Method (NSM); esso ha una complessità di calcolo dell’ordine di pqlog2q .
La complessità dell’algoritmo di LINPROG è quindi dell’ordine di
2 2
log ( )
4.4.2 Bound superiore per la complessità di calcolo
dell’algoritmo RCRA
Valutare le effettive prestazioni dell’algoritmo RCRA è notevolmente complesso, in quanto il numero di volte in cui i vari cicli vengono svolti non è correlabile al numero N di sottoportanti disponibili e al numero K di utenti attivi. Tuttavia è possibile dare una maggiorazione della complessità dell’algoritmo, cioè effettuare un calcolo nel caso peggiore.
Si osserva che l’algoritmo RCRA richiede il maggior onere computazionale nel calcolo del minimo della matrice dei guadagni di canale; un bound superiore alle prestazioni si può allora calcolare ricercando qual è il numero massimo di tali operazioni che può essere effettuato.
Per semplicità consideriamo il caso in cui il numero N delle sottoportanti è uguale al numero K degli utenti; in uno scenario di questo tipo, infatti, l’algoritmo BABS (per il calcolo del numero di sottoportanti da assegnare ad ogni utente) non è necessario ed è noto che ad ogni utente viene assegnata una sola sottoportante. Inoltre ipotizziamo che non si verifichino mai situazioni in cui, a causa di successive cancellazioni, è necessario caricare nuovamente tutti i valori dei guadagni di canale (ciò è spiegato nel paragrafo 3.3.6 B).
Sotto tali ipotesi, il caso peggiore si ha quando nella matrice ridotta viene cancellato un numero di righe complete pari al numero degli utenti che ancora devono essere considerati; quanto appena detto viene esemplificato nella figura seguente:
In questo caso deve essere effettuato un numero di operazioni di calcolo del minimo pari a 4 (⋅ N− . Al ciclo successivo il numero delle righe (sottoportanti) e delle 4) colonne (utenti) diminuisce di 1, quindi il numero delle operazioni necessarie è
4 (⋅ N− −1 4) 4 (= ⋅ N− . Si procede in questo modo fino all’assegnazione di tutte le 5) coppie utente-sottoportante.
Di conseguenza un bound superiore per le complessità dell’algoritmo è dato dalla sommatoria 4 [(⋅ N− +4) (N− + + + = ⋅5) ... 2 1] 4 (N− ⋅4) (N− (4.7) 3) Utenti della matrice ridotta 4 Utenti ancora da considerare K - 4
4.4.3 Bound inferiore per la complessità di calcolo
dell’algoritmo RCRA
Analogamente a quanto fatto nel paragrafo precedente e sotto le stesse ipotesi, cerchiamo un limite inferiore alla complessità di calcolo dell’algoritmo presentato. In uno scenario di questo tipo, la situazione più favorevole si ha quando le celle successivamente cancellate sono corrispondenti ad un unico utente; in tal modo, dopo
N-1 cancellazioni, sarà necessario assegnare l’ultima sottoportante rimasta all’utente in
questione e, conseguentemente, cancellare tutte le celle della riga corrispondente alla sottoportante assegnata. Quanto appena detto è esemplificato nella figura seguente:
Al passo successivo, si cancelleranno N-2 celle e così via. In questo modo il costo totale in termini di operazioni svolte è
( 1)
( 1) ( 2) ( 3) ... 2 1
2
N N
4.4.4 Calcolo sperimentale della complessità dell’algoritmo
RCRA
Per verificare se i bound trovati sono sufficientemente stretti, è stata calcolata sperimentalmente la complessità dell’algoritmo RCRA, intesa come numero di cicli di ricerca del minimo. Al variare del numero di utenti e delle matrici di canale, sono state fatte numerose simulazioni e i risultati trovati sono stati opportunamente mediati.
In uno scenario con 8 utenti e 8 sottoportanti si trova sperimentalmente che il numero medio di operazioni effettuate dall’algoritmo RCRA è 42.6; tale valore è compreso tra 28 (bound inferiore, secondo l’espressione 4.8) e 80 (bound superiore, secondo l’espressione 4.7); il numero di operazioni effettuate dell’algoritmo di LINPROG per raggiungere l’allocazione ottima è invece dell’ordine di 5 10⋅ 3.
Aumentando progressivamente il numero di utenti attivi e di sottoportanti disponibili, si ottiene il grafico riportato nella pagina seguente.
Fig. 4.12 – Complessità di calcolo per gli algoritmi LINPROG e RCRA al variare del