Capitolo 4 - Implementazione e valutazione di uno schema
di migrazione del server integrato a livello di rete
Tenendo conto delle problematiche di ottimizzazione presentate alla fine nel capitolo precedente, di seguito si andrà a presentare uno sviluppo dell’integrazione dello schema di migrazione a livello di applicazione e del recupero del fault a livello di rete.
Approccio alla migrazione integrato con la rete
Si è visto nel capitolo precedente come lo schema di migrazione proposto, rispetto alla sua funzionalità e velocità, possa essere ottimizzato rispetto all’utilizzo delle risorse di rete, in particolare in relazione all’utilizzo contemporaneo di due LSP, uno con la funzione di trasportare lo streaming, l’altro di backup, da utilizzare in caso di migrazione.
Per ottimizzare l’aspetto di utilizzo delle risorse una soluzione può consistere in un approccio della migrazione integrato alla rete; lo schema presentato nel capitolo precedente non prevede alcuna interazione tra applicazione e rete nei meccanismi di ripristino e recupero da fault; la procedura di elezione del server di backup e di instaurazione della connessione viene effettuata preventivamente, per completare velocemente il ripristino in caso di fault. Nel caso di un fault che la rete non è in grado di recuperare, la perdita di QoS porta l’applicazione a lato client a effettuare la migrazione verso il server di backup, limitando la coordinazione ai diversi tempi di detection del fault.
In un approccio integrato invece applicazione e rete collaborano nel corso della procedura di migrazione. In particolare ciò permette che il server di backup sia designato dopo il fault, e che la connessione a banda garantita tra server di backup e client sia messa in atto dalla rete nel corso della procedura di migrazione e non prima.
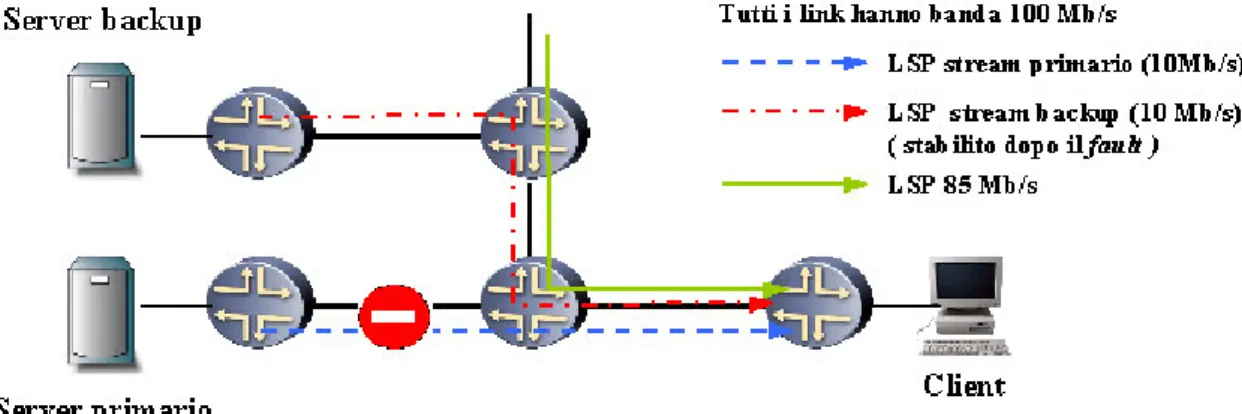
Per capire le conseguenze di tale approccio si può fare riferimento alla Figura 4-1: il link che collega il router del client è già occupato da una connessione a 85 Mb/s ad alta priorità che permette l’instaurazione di un solo LSP da 10 Mb/s; in una situazione del genere lo schema di migrazione presentato nel capitolo precedente si rivela inadeguato, poiché è impossibile instaurare contemporaneamente due LSP verso il client.
In un approccio integrato invece, l’abbattimento del LSP primario libera le risorse necessarie alla creazione di un altro LSP dal server di backup, che può avvenire durante la procedura di migrazione.
Figura 4-1: Esempio di approccio di migrazione integrata alla rete
E’ chiaro che un approccio di questo tipo, se da un lato può risolvere alcune problematiche, dall’altro comporta un appesantimento dello schema globale, in cui sono necessarie funzionalità nuove che operino l’integrazione con la rete, nonché un allungamento dei tempi di recupero, soprattutto in relazione al fatto che la procedura di fault recovery, a differenza di prima, adesso richiede una procedura di segnalazione, che porta sia all’elezione del server di backup, nonché all’instaurazione della nuova connes sione garantita.
Il
resource broker
Al fine di implementare uno schema di migrazione integrato, occorre mettere in campo una funzionalità nuova con compiti di interfaccia tra applicazione e rete. Tale interfaccia, che d’ora in poi verrà indicata con il nom e di resource broker (RB), comunica con il client e la rete allo scopo di avere garanzia di qualità e affidabilità del servizio dal server al quale si trova attualmente connesso. Per maggiore chiarezza si veda la Figura 4-2.
Come è noto client e server si scambiano dati e richieste attraverso il piano dati, in particolare il server deve essere in grado di trasmettere il flusso di streaming al client attraverso una connessione a banda garantita.
A tale scopo il RB interagisce con la rete, in particolare esso deve avere accesso al piano di controllo, in quanto deve essere in grado sia di supervisionare le connessioni protette su cui sono inoltrati i flussi di streaming, sia di richiedere la loro instaurazione e il loro abbattimento, secondo la necessità e le richieste del client.
Il client interagisce con il RB principalmente allo scopo di richiedere il servizio: per tutta la sua durata il RB si preoccupa della supervisione della connessione protetta tra client e server; all’inizio si preoccupa della sua instaurazione, mentre in caso di migrazione, si fa carico della parte relativa alla rete della procedura di fault recovery, operando l’elezione di un server con il quale è possibile instaurare un connessione protetta verso il client.
Il RB può essere localizzato al client host, implementato come thread dell’applicazione, oppure può essere un applicativo separato che gira sul client host, inoltre può essere delocalizzato allo scopo di funzionare come server centralizzato, al quale affluiscono le richieste di molteplici client.
Un’implementazione localizzata al client host, pone problematiche si sicurezza, in quanto il RB ha privilegio di accesso al controllo della rete. Al contrario un server delocalizzato pone problematiche di affidabilità, in quanto un fault di rete può interrompere la connettività verso il client e pertanto minare l’affidabilità del servizio. Una soluzione intermedia, vale a dire un RB localizzato su un host diverso dal client, ma direttamente connesso al medesimo router, e in grado di servire i client che si connettono a questo, può rappresentare un valido compromesso tra sicurezza e affidabilità.
Un esempio di implementazione
In appendice C si riporta il codice che implementa il RB come applicativo indipendente, nonché le modifiche all’applicativo VLC per interagire con esso. Al pari del capitolo precedente si è ancora fatto riferimento all’architettura di rete MPLS -DiffServ. Di seguito si va ad illustrare in che modo avviene la comunicazione tra RB e piano di controllo, tra RB e client, per poi soffermarsi su come sono state implementate le tre fasi di fault detection, fault notification e fault recovery.
Interazione tra resource broker e piano di controllo
Si è visto nei capitoli precedenti come l’architettura MPLS DiffServ sia in grado di fornire connessioni a banda garantita attraverso l’instaurazione di LSP. Il RB, avendo il compito di
supervisionare lo stato delle connessioni sulle quali sono trasportati i flussi di streaming, ha perciò bisogno di verificare il loro stato, nonché di comandarne l’instaurazione o l’abbattimento. A tale scopo il RB per modificare e verificare lo stato di un LSP ha bisogno di comunicare con il relativo ingress router.
Si è già notato come gli ingress router di un LSP che trasporti un flusso di streaming sia sempre il router al quale si connette il server, di conseguenza il RB dovrà essere in grado di comunicare costantemente con tutti gli edge router ai quali si connette un server. Il RB deve essere in grado allora di effettuare le seguenti operazioni:
• Richiedere al router l’instaurazione di un LSP: tale richiesta verrà soddisfatta solo se sulla rete sono presenti le risorse necessarie. L’ ingress router provvede a informare il RB sull’ esito della sua richiesta (LSP Up o Down).
• Ordinare al router l’abbattimento di un LSP, qualora esso non sia più utilizzato dal servizio di streaming.
• Richiedere al router lo stato di un LSP, allo scopo di rilevare un fault di rete; tale richiesta comporta che l’ ingress router riporti lo stato attuale del LSP (Up o Down).
Interazione tra client e resource broker
La comunicazione tra client e RB avviene essenzialmente in due occasioni:
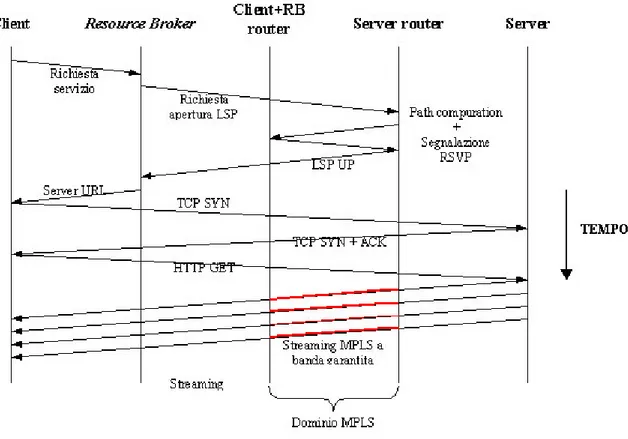
• Accesso al servizio: la procedura messa in atto all’inizio del servizio è mostrata in Figura 4-3: al momento di accedere al servizio il client invia una richiesta al RB, con il quale richiede il particolare contenuto multimediale del quale vuole ricevere lo streaming. Si ricordi che si è posto che RB e client si connettano al medesimo edge router, indicato in figura con l’acronimo client+RB router. Come si è visto in precedenza il RB è in possesso di una lista dei router ai quali si connettono i server; è allora logico fornire al RB una lista dei server sui quali il contenuto richiesto dal client è disponibile.
In questa fase, in cui non sussistono esigenze di tempestività, il RB può mettere in campo diverse politiche per l’elezione del server, tenendo conto anche esigenze di risparmio di risorse. In ogni caso tale procedura dovrà portare all’instaurazione di una connessione con banda sufficiente a trasportare lo streaming dal server al client.
Figura 4-3: accesso e inizio del servizio
Dopo che un server è stato scelto e un LSP a banda garantita è stato instaurato sul dominio MPLS, il RB comunica al client l’URL della risorsa richiesta. Il client può quindi instaurare la connessione TCP, richiedere tramite un messaggio HTTP GET (vedi capitolo 3) lo streaming del contenuto di interesse, che verrà trasportato nel dominio MPLS su un LSP a banda garantita.
• Migrazione: in caso di migrazione al termine della fase di fault recovery il server ha bisogno di conoscere l’URL verso il quale deve effettuare la migrazione. Al termine d el fault recovery il RB provvede sempre a notificare al client tale informazione (vedi fault recovery).
Fault detection
I meccanismi di fault detection presentati nel capitolo precedente possono essere utilizzati anche nella presente implementazione, in quanto si sono dimostrati sufficientemente affidabili. Tuttavia le funzionalità presenti sul RB introducono ulteriori possibilità, soprattutto per quanto riguarda fault dovuti a preemption della connessione a banda garantita. Tale fault,
nello schema presentato nel capitolo precedente, viene rilevata nel client dal meccanismo di underflowing del buffer del decoder, in un tempo prossimo al secondo.
In un ottica di integrazione, e visto che il RB svolge un compito di supervisione e controllo della rete, può essere uno sviluppo naturale liberare il client dal compito di rilevare l’abbattimento della connessione protetta per affidarlo alla nuova funzionalità.
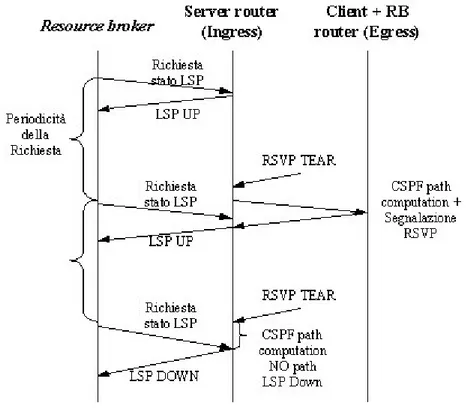
La supervisione dello stato del LSP che trasporta lo streaming è stato implementato tramite un meccanismo di polling, attraverso il quale il RB periodicamente interroga l’ ingress router circa lo stato del LSP. L’ ingress router riporta lo stato down del LSP solo dopo essersi accertato che i meccanismi di ripristino a livello di rete, quale il dynamic path recovery, non siano in grado di recuperare il fault.
Figura 4-4: supervisione dello stato del LSP da parte del RB (fault detection)
Qualora dopo un’interrogazione lo stato del LSP risultasse Down, significa allora che si è verificato un fault che implica necessariamente una migrazione per essere ripristinato.
Il servizio non richiede che la periodicità dell’operazione di polling sia eccessivamente ristretta: per garantire la scalabilità dello schema è sufficiente utilizzare una periodicità vicina al secondo, o al massimo ad una frazione di secondo. Valori troppo elevati pregiudicano invece il rilevamento tempestivo di un malfunzionamento del LSP.
Viene mantenuto il meccanismo di fault detection basato sulla mancata lettura da socket, implementato sul client; tale meccanismo rimane valido per l’interruzione totale della
connettività end-to-end tra client e server (guasti di rete), nonché per rilevare fault localizzati sul server.
Fault notification
La fault detection può essere effettuata sia dal client, sia dal RB. In ogni caso la procedura di fault notification deve provvedere a richiedere l’inizio del fault recovery al RB, il quale deve provvedere in prima battuta all’elezione del server di backup.
Se la fault detection viene effettuata dal client (guasti di rete, fault localizzati sul server) è necessario una pronta comunicazione al RB; in caso contrario, se è l’RB a rilevare il fault (preemption) questi deve provvedere velocemente a dare inizio alla fase di fault recovery. Fault recovery
La fase di fault recovery in caso di migrazione è operata inizialmente dal RB. L’obiettivo è di giungere nel più breve tempo possibile a stabilire un nuovo LSP a banda garantita da uno dei server in grado di erogare lo streaming del contenuto multimediale riprodotto al client. Come visto in precedenza il RB è in possesso della lista completa dei server che possono erogare tale servizio.
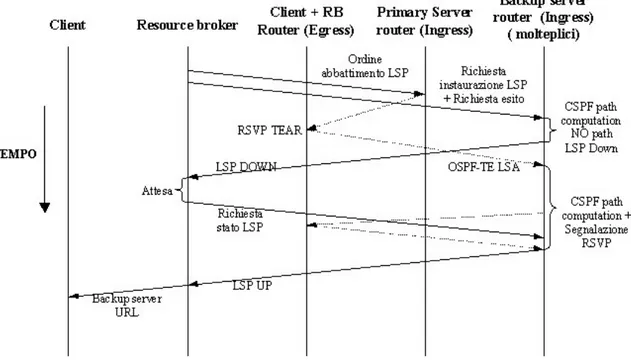
La procedura prevede la comunicazione tra RB e il vecchio server, nonché tra RB e tutti i server eleggibili a backup server. La prima provvede a sollecitare l’ ingress router del LSP abbattuto dal fault, a liberare il più velocemente possibile le risorse di banda occupate: tali risorse non vengono annunciate OSPF-TE LSA come nuovamente disponibili, fintanto che l’ ingress router non provvede a inviare un messaggio RSVP PATH TEAR. Da alcune prove è risultato che l’invio di tale messaggio, può essere ritardato di vari secondi dal momento in cui l’ ingress router riceve la notifica dell’abbattimento del LSP tramite mess aggio RSVP RESV TEAR. La richiesta di abbattimento dal RB all’ ingress router ha un duplice scopo:
• Evitare che l’ ingress router tenti di reinstaurare il LSP abbattuto che non sarà più utilizzato
• Velocizzare la procedura che libera le risorse di banda occupate dal LSP abbattuto, perché possano essere eventualmente occupate dal LSP di backup.
Quest’ultimo punto rappresenta un nodo nevralgico dello schema; si è visto infatti come il LSP primario e quello di backup tendano ad essere inoltrati sui medesimi link nelle vicinanze dell’ egress router; la non tempestiva liberazione delle risorse che erano occupate dal LSP primario può pregiudicare l’instaurazione del LSP di backup.
La comunicazione tra RB e tutti i router che si connettono a server eleggibili (cioè quelli in grado di erogare il contenuto riprodotto al client) è funzionale all’elezione di un router di
backup, scelto tra tutti quelli da cui è possibile instaurare un LSP verso il client. La comunicazione con ciascuno avviene in parallelo, e l’implementaz ione proposta, porta all’elezione del server dal quale è possibile instaurare più velocemente un LSP.
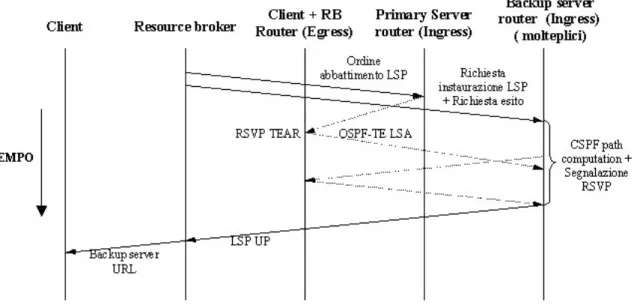
La Figura 4-5 mostra la prima parte della fase di fault recovery nel cosiddetto caso migliore, cioè qualora sussistano nella rete le condizioni per instaurare un LSP da uno dei server di backup, a prescindere dalle risorse precedentemente occupate dal LSP abbattuto (si veda dopo test1). La situazione è quella considerata nel capitolo precedente, in cui era considerata la situazione in cui il LSP di backup venisse prima del fault, mentre adesso invece si procede all’instaurazione del LSP di backup dopo il fault.
Figura 4-5: Fault recovery in caso di migrazione (caso migliore)
Dopo le fasi di fault detection e notification, la fase di fault recovery si apre con il RB che ordina il completo abbattimento del LSP, e richiede a tutti i router connessi a server eleggibili di aprire un LSP verso il client. Se sulla rete sono presenti già le risorse per instaurare un LSP da uno dei server eleggibili, questo può venire segnalato ancora prima che le risorse occupate dal LSP abbattuto, limitando così la durata complessiva della migrazione.
L’ ingress router che è riuscito per primo ad instaurare il LSP, notifica l’e sito della richiesta al RB, il quale a sua volta provvede a notificare al client l’URL della risorsa verso il quale deve effettuare la migrazione.
Questa si completa al lato client con la chiusura della connessione con il server primario e la nuova connessione verso quello di backup (non mostrata in figura, vedi Capitolo 3 - Fault recovery: migrazione su server di backup).
La Figura 4-6 mostra invece la prima parte della procedura di migrazione, nel caso peggiore, qualora cioè l’instaurazione di un LSP da uno dei server eleggibili necessiti delle risorse occupate dal LSP abbattuto (vedi test 2).
In questa evenienza è probabile che la prima risposta che tutti gli ingress router inviano al RB dia esito negativo, poiché la disponibilità delle risorse non è stata ancora notificata attraverso le nuove istanze di OSPF-TE LSA. E’ allora necessario che il RB proceda a inviare nuove richieste allo scopo di verificare che l’instaurazione del LSP sia effe ttivamente possibile. Questo ovviamente comporta un allungamento dei tempi di ripristino, che in ogni modo dipendono strettamente dall’architettura della rete.
Figura 4-6. procedura di fault recovery (caso peggiore)
Tale procedura continua in parallelo verso tutti i router dei server eleggibili, fintanto che uno di essi non conferma l’avvenuta instaurazione del LSP; quando ciò avviene il server relativo viene eletto come server di backup, e il RB può inviare al client il nuovo URL sul quale effettuare la migrazione, in modo non dissimile a quanto visto in precedenza.
Per completare la procedura è necessario che il RB provveda ad ordinare l’abbattimento dei LSP da tutti i server che sono stati coinvolti nella procedura di elezione ma non sono stati eletti, allo scopo di liberare le risorse eventualmente occupate da LSP non necessari.
Valutazione sperimentale
Di seguito si va a presentare la valutazione dello schema implementato; i test mirano in particolare a valutare la funzionalità, nonché la lunghezza temporale della procedura di migrazione.
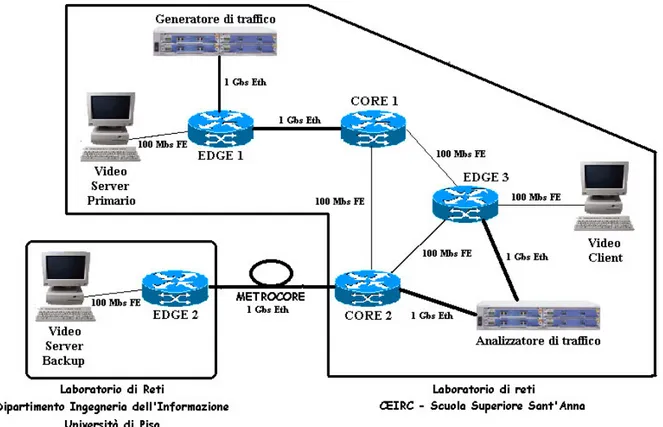
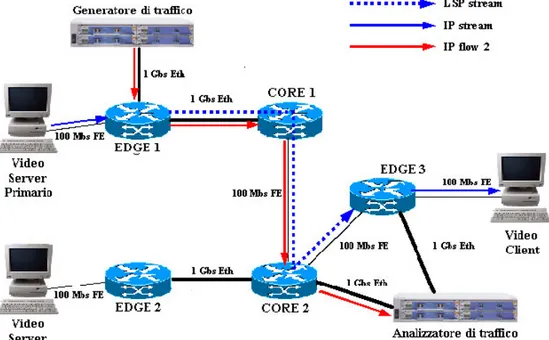
La topologia complessiva, l’architettura e gli apparati inseriti nel testbed non differiscono significativamente da quello utilizzato nel capitolo precedente. Questa volta però è stato utilizzato un testbed distribuito tra il laboratorio di reti dell’istituto CEIRC – Scuola Superiore Sant’Anna di Pisa e il laboratorio di reti del Dipartimento di Ingegneria dell’Informazione, Università degli studi di Pisa (Figura 4-7). Il collegamento tra le due parti è avvenuto mediante interfacce Gigabit Ethernet connesse attraverso l’anello metropolitano in fibra ottica denominato Metrocore [24].
Figura 4-7: Il testbed distribuito
Il contenuto multimediale utilizzato ha caratteristiche di rate e qualità del tutto simili a quello utilizzato nel capitolo precedente (Rate = 10 Mbit/s ; Qualità DVD). Il RB è stato implementato come applicativo indipendente, che nel corso dei test è stato eseguito direttamente sul client host. Nel corso delle esperienze esso provvedeva ad interagire, oltre che con il client, anche con i router Edge1 e Edge2 allo scopo di instaurare, supervisionare o abbattere il LSP Stream, il quale veniva configurato secondo i seguenti parametri:
LSP Stream Parametro di banda 10 Mb/s
ingress router Edge1 o Edge 2
Egress Router Egde3
Setup / Hold Priority 4 / 4
Tabella 4-1. Parametri del LSP stream configurati dal RB Altri parametri di funzionamento utilizzati nelle esperienze sono i seguenti: • Lunghezza buffer al Video client: 15 sec
• Frequenza di polling (interrogazione stato LSP): 1 sec
I LSP e i flussi di traffico utilizzati saranno descritti in ciascuna esperienza. Si noti che rispetto al capitolo precedente, in cui per ciascun test sono stati riportati i risultati di una sola prova, nei test descritti in seguito si è utilizzato un criterio di diverso, in cui si sono riassunti in tabella i risultati di tutte le esperienze svolte, mentre i grafici fanno ancora riferimento ad una singola prova.
Come ultima osservazione si noti che le latenze end-to-end sperimentate nel testbed, presentano valori tipici molto bassi (nell’ordine dei millisecondi); di conse guenza tutte le valutazioni di ordine temporale non tengono conto delle latenze, che in generale vengono a dipendere dalla dimensione e dalla topologia della rete, piuttosto che dall’architettura dello schema che si sta valutando.
Test 1: LSP rerouting in seguito a preemption
Questo test riprende la modalità di svolgimento del test 3 (LSP rerouting in seguito a preemption) del precedente capitolo, ed in particolare mira a verificare la coordinazione dei meccanismi di ripristino a livello di rete e la procedura di migrazione.
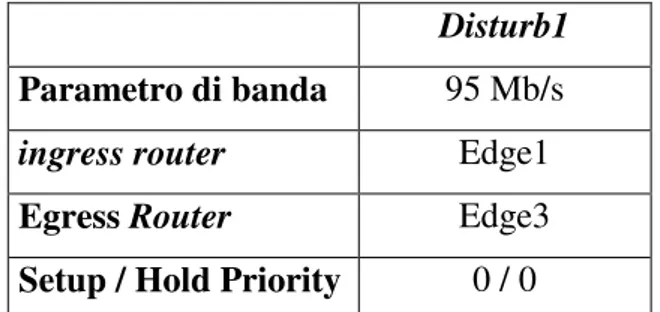
La Figura 4-11 mostra la configurazione iniziale del test, in cui il LSP Stream è instradato attraverso C1, quando l’instaurazione del LSP Disturb1 (la cui configurazione è riportata in Tabella 4-2) provoca la preemption e costringe la rete ad effettuare il rerouting del LSP Stream mediante la procedura di dynamic path recovery (Figura 4-12.).
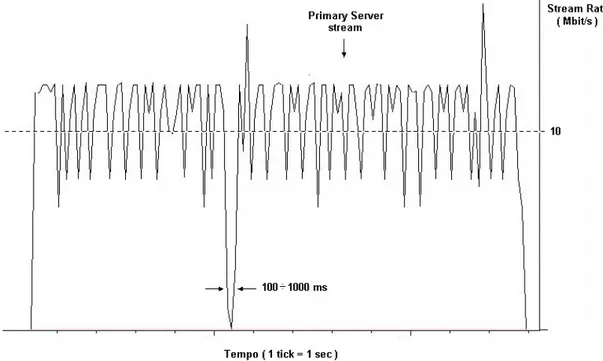
Ciò comporta, come già visto nel capitolo precedente, una breve interruzione dello stream al client (Figura 4-9), dalla durata che è risultata variabile tra 100 e 1000 millisecondi, a seconda del numero di LSP sei quali deve essere eseguito il rerouting. Tale interruzione non è tale da
Disturb1
Parametro di banda 95 Mb/s
ingress router Edge1
Egress Router Edge3
Setup / Hold Priority 0 / 0 Tabella 4-2: Configurazione del LSP Disturb 1
Figura 4-8: Configurazione iniziale del test 1
Figura 4-10: esempio di stream rate ricevuto al client nel corso del test 1
poter pregiudicare il corretto funzionamento dell’applicazione al lato client, nel caso di un buffer di lunghezza superiore a qualche secondo.
In nessuna prova sì è assistito al ricorso alla migrazione: ciò è coerente con l’ipotesi fatta nel pragrafo relativo alla fault detection, cioè il router riporta lo status down del LSP al RB solo dopo aver constatato l’impossibilità di effettuare il re routing del LSP su un path alternativo. Test 2: Migrazione in seguito a preemption 1
Questo test riprende la modalità di svolgimento del test 4 ( Migrazione dopo la preemption del LSP Stream ) del precedente capitolo. La Figura 4-11 mostra la configurazione iniziale del test; si noti come rispetto alla topologia originale del testbed sia stato interrotto volontariamente il link Core1-Edge3, unicamente allo scopo di far condividere ai LSP primario e di backup l’ultimo link Core2-Edge3; questo permette tra le altre cose di effettuare una lettura dei messaggi che transitano su tale link, allo scopo di verificare come si svolgono le procedure di segnalazione dei due meccanismi di ripristino, nonchè analizzarne più in dettaglio le tempistiche.
Inizialmente il LSP Stream è instradato attraverso i router C1-C2. L’instaurazione del LSP Disturb1 (analogo a quello utilizzato nel test precedente) provoca necessariamente l’abbattimento del LSP Stream, essendo la rete impossibilitata ad effettuarne il reroutimg, richiedendo quindi l’intervento della migrazione ( Figura 4-12).
Figura 4-11: Configurazione iniziale del test 2
Figura 4-12: Configurazione del test 2 dopo la migrazione
In particolare si noti come la configurazione di rete permetta l’instaurazione d el LSP di backup indipendentemente dalle risorse occupate dal LSP abbattuto; in questo caso la durata complessiva della procedura di migrazione dovrebbe risultare minima.
La Tabella 4-3 riporta un elenco dei pacchetti coinvolti nella segnalazione della migrazione, rilevati in particolare sul link C2-E3 nel corso di varie prove; in particolare nella colonna ∆T è riportato il tempo minimo e massimo che trascorre dalla rilevazione del messaggio
immediatamente precedente. In scuro sono evidenziate i messaggi fra RB e ingress router del LSP abbattuto, mentre in chiaro quelli tra RB e ingress del LSP di backup.
No ∆∆T
(sec) Sorgente Destinazione Protocollo Commento
1 0 RB Egress (Edge 3) TCP LSP Stream status request
2 0 Ingress RB TCP LSP Stream status = Down
3 0 RB Ingress primary TCP Req LSP Stream tear-down
4 0 RB Ingress backup TCP Req LSP Stream setup
5 0 RB Ingress backup TCP LSP Stream status request
6 1.6 ÷1,8 Ingress backup Egress RSVP PATH Segnalazione LSP stream 7 0 Egress Core2 RSVP RESV Segnalazione LSP stream
8 0,2 Ingress backup RB TCP Configurazione caricata
9 0,4 Ingress Backup RB TCP LSP Stream UP
10 0 Client Backup server HTTP GET Richiesta contenuto
11 0 Backup Server Client HTTP Inizio streaming
Tabella 4-3: Sommario dei pacchetti rilevati su link Core2 – Edge3
Per primo si notare la congruenza tra le specifiche della segnalazione descritta nel paragrafo relativo alla fault recovery e la procedura di segnalazione rilevata.
In seconda battuta si fa notare che a fronte di una latenza end-to-end trascurabile, la maggior parte del tempo impiegata dalla procedura di viene spesa dal ingress router di backup nella fase di riconfigurazione/ segnalazione/ notifica del LSP, in particolare:
• Tra 1,6 e 1,8 secondi sono impiegati dall’ ingress router per caricare la configurazione del nuovo LSP e calcolare il path mediante l’algoritmo CSPF, prima di dare il via alla segnalazione RSVP (messaggio 6).
• Circa 0,6 secondi trascorrono tra il completamento della segnalazione del LSP e la notifica al RB (messaggi 8 e 9).
Mentre il primo intervallo di attesa era prevedibile, considerando che il router deve riconfigurarsi, nonché calcolare il LSP path mediante CSPF, il secondo intervallo di attesa non era stato previsto prima di effettuare le prove.
La procedura di migrazione si completa con la segnalazione da parte del RB al client del backup server (vedi fault recovery) che si completa in un tempo trascurabile se si considerano latenze di rete risibili.
La fase di fault recovery in caso di migrazione si completa allora in un tempo compreso tra 2,2 e 2,4 secondi. Tuttavia, mentre si può trascurare il tempo impiegato dalla fault notification, non lo è quello di fault detection, che può impiegare un tempo massimo pari alla frequenza con cui il RB interroga il router circa lo stato del LSP (frequenza di polling). Poiché nelle prove effettuate si è scelto una frequenza di polling pari ad 1 secondo, la durata
complessiva della procedura di ripristino in caso di migrazione impiega un tempo complessivo compreso tra 2,2 e 3,4 secondi.
La Figura 4-13 mostra lo stream rate ricevuto al client nel corso di una delle prove relative a questo test. In particolare si è evidenziato l’intervallo tem porale tra il fault (abbattimento del LSP Stream) e il completamento della procedura di migrazione che porta allo streaming dal server di backup. Nel corso della prova analizzata si può vedere come il tempo di ripristino sia molto vicino a 3 secondi. Si fa notare inoltre come in questo intervallo lo streaming continui a raggiungere il client dal server primario, ma in qualità di traffico IP best-effort; poiché tale flusso viene limitato dal traffico trasportato dal LSP Disturb1 su link C1-C2, ciò comporta una riduzione del throughput fintanto che il ripristino del servizio non si completa.
Figura 4-13: esempio di stream rate ricevuto al client nel corso del test 2
Test3: Migrazione in seguito a preemption 2
Questo test utilizza una configurazione simile al precedente: la Figura 4-14 mostra la configurazione iniziale del test; si noti come rispetto al test precedente sia stato inserito il nuovo LSP Disturb2, le cui impostazioni sono riportate in Tabella 4-4.
LSP Disturb1 Parametro di banda 85 Mb/s
ingress router Edge2
Egress Router Edge3
Setup / Hold Priority 0 / 0 Tabella 4-4: Impostazione del LSP Disturb2
Figura 4-14: Configurazione iniziale del test 3
In particolare si noti come questa volta la configurazione di rete non permetta l’instaurazione del LSP di backup prima che la rete abbia liberato le risorse occupate dal LSP abbattuto, poiché sul link C2-E3 il LSP Disturb2 da 85 Mb/s non lo permette: si tratta della situazione già considerata nel paragrafo relativo alla fault recovery, in cui la durata complessiva della procedura di migrazione dovrebbe risultare massima.
Le esperienze hanno avuto una sequenza di svolgimento identica al test precedente, con l’instaurazione del LSP Disturb1 a causare la preemption del LSP Stream dal server primario, e il conseguente ricorso alla migrazione, vista l’impossibilità da parte della rete di eseguire il ripristino tramite rerouting (Figura 4-15).Anche questa volta è stato effettuato la rilevazione dei messaggi che transitano sul link C2-E3, relativi all’operazione di migrazione. I risultati sono mostrati in Tabella 4-5. Rispetto al test precedente in questo caso si è utilizzato un criterio temporale assoluto, dove nella colonna T si ripora l’intervallo temporale minimo e massimo dal primo messaggio rilevato.
No T (sec) Sorgente Destinazione Protocollo Commento
1 0 RB Egress (Edge 3) TCP LSP Stream status request
2 0 Ingress primary RB TCP LSP Stream status = Down
3 0 RB Ingress primary TCP Req LSP Stream tear-down
4 0 RB Ingress backup TCP Req LSP Stream setup
5 0 RB. Ingress backup TCP LSP Stream status request
6 1,8 ÷ 2,0 Ingress backup RB TCP Configurazione caricata 7 2,2 ÷ 2,6 Ingress backup RB TCP LSP Stream Down 8 2,0 ÷ 2,5 Ingress primary Egress RSVP TEAR Libera risorse
9 2,0 ÷ 2,5 Core2 Core3 OSPF LSA Annuncia risorse libere 10 3,0 ÷ 3,5 Ingress backup Egress RSVP PATH Segnalazione LSP stream 11 3,0 ÷ 3,5 Egress Core2 RSVP RESV Segnalazione LSP Stream 12 3,4 ÷ 4,6 RB Ingress backup TCP LSP Stream status request 13 3,4 ÷ 4,6 Ingress backup RB TCP LSP Stream Up
14 3,4 ÷ 4,6 Client Backup server HTTP GET Richiesta contenuto 15 3,4 ÷ 4,6 Backup server Client HTTP Inizio streaming
Tabella 4-5: Sommario dei pacchetti rilevati su link Core2 – Edge3 In merito ai risultati riportati in tabella si possono fare le seguenti osservazioni:
• A differenza del test precedente, l’esito riportato dal router di backup dopo la richiesta di instaurazione del LSP è negativa (messaggio 7); poiché le risorse occupate dal LSP primario non sono ancora state rilasciate dalla rete, la computazione del CSPF localmente porta esito negativo. Il tempo impiegato dal router per fornire la risposta è consistente con quello riscontrato nel corso del test 2.
• Il messaggio RSVP TEAR (messaggio 8) inviato dall’ ingress router primario, che sollecita i router attraversati dal LSP abbattuto a rilasciare le risorse, viene rilevato da 2,0 a 2,5 secondi dopo la richiesta inviata dal RB (messaggio 3). Questo porta all’immediata generazione da parte di tutti i transit router del LSP primario di una nuova istanza di OSPF-TE LSA, che annuncia in tutto il dominio la liberazione delle risorse (messaggio 9). • Dopo circa un secondo l’ ingress backup è in grado di portare a termine la segnalazione
del LSP di backup (messaggi 10 e 11).
• Esattamente un secondo dopo aver ricevuto il primo esito negativo, il RB procede a verificare nuovamente lo stato del LSP (messaggio 12). Il backup ingress è in grado di annunciare il LSP up circa 0,4 secondi dopo il completamento della segnalazione (RSVP RESV, messaggio 11).
Al pari del test precedente la procedura si conclude con la notifica del nuovo server al client, il quale provvede a completare la migrazione (messaggi 14 e 15). Il tempo complessivamente impiegato dalla fase di fault recovery varia quindi tra 3,4 e 4,6 secondi. Se si tiene conto che la fase di fault detection può variare tra 0 e 1 secondo (frequenza di polling), il tempo completo di ripristino dopo il fault può variare quindi tra 3,4 e 5,6 secondi.
La Figura 4-16 mostra lo stream rate ricevuto al client nel corso di una delle prove relative a questo test.
In particolare si è evidenziato l’intervallo temporale tra il fault (abbattimento del LSP Stream) e il completamento della procedura di migrazione che porta allo streaming dal server di backup. Nel corso della prova analizzata si può vedere come il tempo di ripristino sia di circa 4,7 secondi. Al pari del test precedente si fa notare la riduzione del throughput nel corso della procedura di ripristino.
Commenti ai test
I test dimostrano che l’implementazione dello schema è consistente con le specifiche preposte:
• Il test 1 dimosta che qualora, in seguito a preemption, la rete sia in grado di ricorrere a meccanismi di dynamic path recovery, sia possibile effettuare il rerouting della connessione protetta, la migrazione non interviene.
• Il test 2 e 3 dimostano invece che in caso di perdita della garanzia del servizio, sul quale la rete non è in grado di intervenire, lo schema di migrazione proposto è in grado di procedere all’instauraz ione di un LSP da un server di backup e di completare la procedura di migrazione.
Per ciò che riguarda i tempi di ripristino, la procedura di migrazione così come implementata è in grado è stata in grado di completarsi in tempo compreso tra 2,2 e 5,6 secondi, a seconda anche della configurazione globale della rete. Tale valutazione è veritiera in presenza di latenze di rete trascurabili (nell’ordine di grandezza del millisecondo), e tiene conto solo dei tempi di riconfigurazione e computazione impiegati dagli apparati di rete che sono stati utilizzati.
Tali valori richiedono una maggiore lunghezza del buffer al lato client (almeno 10 secondi) allo scopo di garantire la continuità del servizio nel corso del ripristino. Utilizzando un buffer al video client di 15 secondi non si è verificata la perdita di frame in fase di visualizzazione, in nessuna delle prove effettuate.
Confronto tra schema integrato e coordinato
La Tabella 4-6 presenta un confronto sommario tra i due schemi di migrazione presentati. Per ciò che riguarda l’utilizzo delle risorse di rete, lo schema non integrato presenta un utilizzo non ottimale delle risorse di rete, in quanto richiede l’instaurazione del LSP di backup prima del fault, a differenza dello schema integrato, il quale, mantenendo attivo solo il LSP utilizzato dallo streaming, utilizza in modo ottimale le risorse di rete.
Schema coordinato Schema integrato Utilizzo risorse di rete Spreco (2 LSP) Ottimale Garanzia di ripristino Non sempre Sempre, se possibile
Tempo di ripristino Circa 1 secondo 2,2 ÷ 5,6 secondi
Occupazione memoria client Limitata (buffer pochi secondi)
Maggiore
(buffer di almeno 10 secondi) Tabella 4-6: Confronto tra schema di migrazione integrato e non integrato
Inoltre il fatto che lo schema di migrazione non integrato richieda l’instaurazione del LSP di backup prima del fault, pone problematiche di garanzia, in quanto il fault potrebbe abbattere anche quest’ultimo, oppure la contesa di risorse tra LSP primario e di backup potrebbe impedirne l’instaurazione. Al contrario lo schema integrato garantisce il ripristino del servizio, sempre che esista almeno un server dal quale è possibile instaurare un LSP a banda garantita.
Naturalmente lo schema integrato richiede l’interazione della rete dopo il fault, allo scopo di instaurare il LSP di backup, il quale richiede la riconfigurazione dei router, con conseguente allungamento del tempo complessivo di ripristino, che da circa un secondo dello schema non integrato, passa a valori fino a 5-6 secondi. Si tenga poi in conto, che tale divario tende ad aumentare con le latenze end-to-end (che nelle prove fatte sono risultate trascurabili), in quanto la procedura di segnalazione prevista dallo schema integrato risulta notevolmente più lunga e complessa che nello schema integrato.
Questo allungamento richiede un aumento della dimensione del buffer al client, che da una lunghezza minima di pochi secondi nel caso di schema non integrato, passa a circa 10 secondi, con conseguente aumento della memoria occupata dall’applicazione sul client host.