Una tassonomia delle risorse
Il sublime e il ridicolo sono spesso così strettamente legati, che è difficile classificarli separatamente
Tom Paine.
I tradizionali ambienti di sviluppo dei programmi, spesso vengono assunti dai loro utenti come omogenei, affidabili, sicuri e gestiti centralmente. Sempre più, tuttavia, la computazione è interessata alla collaborazione, alla condivisione dei dati, e ad altri nuovi modi di interazione che coinvolgono risorse distribuite. La Griglia computazionale entra a pieno titolo in questa nuova visione.
In una prima fase le infrastrutture di calcolo distribuite di tipo Grid sono state utilizzate, quasi esclusivamente, per supportare applicazioni scientifiche che richiedono grandi capacità di calcolo e/o il trattamento di grandi quantità di dati. In particolare, ad oggi, il settore applicativo più visibile è quello del supporto di esperimenti nel settore della fisica delle particelle o nell’astronomia. Tuttavia stanno prepotentemente emergendo nuovi scenari di utilizzo delle tecnologie Grid in ambiti diversi. Un gruppo di scienziati sparsi nel mondo potranno doversi scambiare grandi quantità di dati frutto di ricerche o di calcoli eseguiti precedentemente. Si potranno supportare in maniera efficiente l’accesso coordinato ad archivi di immagini e di dati derivanti da indagini mediche sui pazienti. Tali archivi sono aggiornati e mantenuti in centri medici (ospedali) ed in
centri di ricerca naturalmente distribuiti sul territorio. In questa nuova visione, le risorse non sono solo da intendersi come risorse di calcolo e di rete (processore, memoria, ampiezza di banda), ma qualsiasi altra cosa: dati, immagini, file musicali, database, applicazioni e quant’altro la nostra mente possa immaginare. Le infrastrutture di tipo Grid, quindi, coinvolgono molte risorse appartenenti a diversi domini amministrativi. Tali risorse sono per loro natura eterogenee. Da queste premesse si capisce quindi l’esigenza di classificare le risorse in modo da poterle inquadrare in un sistema che rispecchi il loro effettivo grado di affinità, fornendo un meccanismo per confrontare le risorse di Griglia in modo qualitativo. Inoltre da questa sistematizzazione potrà essere derivata una terminologia comune da utilizzarsi per riferire in maniera chiara ed univoca le risorse Grid.
A questo proposito, in questo capitolo svilupperemo un tassonomia con lo scopo di sistematizzare e classificare non solo le risorse fino a poco tempo fa necessarie all’infrastruttura di calcolo, ma anche le risorse che saranno introdotte in futuro. Inoltre, tenendo presente che la Griglia non contiene in maniera esplicita le informazioni che la descrivono, quali ad esempio i dettagli di implementazione del GIS, i protocolli utilizzati, etc, l’obiettivo della tassonomia qui proposta è quello di classificare non solo i dati ma anche i metadati, ovvero dati che descrivono altri dati, consentendo in tal modo di risalire alla struttura della Griglia stessa.
3.1 Lavori correlati
In questo paragrafo illustreremo le motivazioni che ci hanno indotto a sviluppare la nostra tassonomia e descriveremo alcune tassonomie sviluppate in ambito di calcolo distribuito e di Grid, confrontandole, dove possibile, con la nostra. Infine,
faremo vedere come questo lavoro sia un passo inevitabile nell’evoluzione di Grid.
Prima di iniziare è d’obbligo, comunque, citare le due tassonomie più longeve e popolari della storia dell’informatica: quelle di Chomsky e di Flynn.
Chomsky presenta alcuni modelli esplicativi della linguistica con il fine di fornire una descrizione precisa degli aspetti più singolari del linguaggio. Classifica i linguaggi in base al tipo di produzioni, o regole grammaticali, utilizzate per produrre le parole del linguaggio. Flynn, invece, presenta uno schema di classificazione per architetture parallele. Per quanto risalga ai “primordi” dell’elaborazione in parallelo esso si rivela tuttora valido ed applicabile. Altre classificazioni sono state proposte successivamente senza comunque apportare modifiche significative. La classificazione di Flynn si basa su due semplici concetti che sono il flusso di istruzioni e il flusso di dati. Si distinguono quattro possibili classi di architetture parallele a seconda della “molteplicità reale” dei flussi di istruzioni e dati.
Un sistema di calcolo di rete (Network Computing System o NCS) può essere visto come un supercomputer virtuale [KBM] formato da un insieme di reti e di sistemi di elaborazione eterogenei che permettono di condividere le proprie risorse locali con tutti gli altri sistemi di elaborazione. Una Grid è una NCS ad ampia scala. In questi ambienti di calcolo eterogeneo si presenta il problema di “mappare” task e comunicazioni in macchine e reti multiple; tale problema è stato dimostrato essere NP-arduo [BS98]. Le tassonomie sviluppate in [CK96] e [Rot] presentano un approccio al problema di gestione delle risorse discusso in termini di scheduling distribuito. La prima tratta sia scheduling statico che dinamico. Scompone il problema dello scheduling nei tre componenti principali che lo costituiscono: consumatore, scheduler (quindi politica di scheduling) e risorse, classificando le politiche di scheduling usate.
La seconda tassonomia invece tratta solo scheduling dinamico su ambiente globale. Anche qui il problema è studiato partendo dai due componenti principali: il primo che valuta lo stato, ossia recupera informazioni sullo stato della macchina, mentre il secondo componente in base a queste informazioni prende una decisione su dove schedulare il job. Sebbene i due processi sono strettamente correlati, al fine di avere un’idea più chiara delle possibili soluzioni, vengono studiati separatamente.
Uno dei componenti principali dei sistemi di calcolo su rete e di Grid è il sistema di gestione delle risorse (Resource Management System o RMS). Un RMS può essere visto, in modo molto semplificativo, come una funzione che ha lo scopo, dato l’insieme delle richieste e l’insieme delle risorse, di ‘mappare’ una richiesta su una o più risorse che soddisfano le eventuali condizioni presenti nella richiesta stessa. [KBM], in cui è presentata una tassonomia dell’architettura degli RMS, ha lo scopo di fornire un valido supporto nello sviluppo di un RMS. L’approccio seguito consiste nello studiare un modello astratto di RMS, definendone le esigenze, per determinare tutti gli aspetti importanti del sistema. Infine viene usata questa classificazione per confrontare gli RMS esistenti.
La Grid, come precedentemente detto non è solo un’infrastruttura di calcolo. Le tecnologie GRID permettono la condivisione su larga scala delle risorse all’interno di gruppi di individui e/o istituzioni. In questi ambienti, la scoperta delle risorse e dei servizi, la loro descrizione ed il loro controllo, sono problemi complessi, dovuti alla considerevole diversità dei comportamenti dinamici e delle ripartizioni geografiche delle entità alle quali un utente potrebbe essere interessato. Di conseguenza, i servizi d’informazione sono una parte vitale di ogni infrastruttura o software di Griglia, fornendo i meccanismi fondamentali per la scoperta e il controllo delle risorse e quindi per la progettazione e l’adattamento del comportamento di un’applicazione. L’interoperabilità e lo
scambio di dati sono divenuti aspetti cruciali di questi sistemi. Nasce l’esigenza di introdurre delle regole per la condivisione delle informazioni; i dati dovranno essere esportati ed importati tra applicativi o database secondo un formato standard che ne manterrà intrinsecamente la struttura e le relazioni. Sebbene XML rappresenta lo strumento standard di modellazione dei dati, c’è il problema di trovare uno schema di rappresentazione accettato da tutti. Numerosi sono i progetti che cercano di fornire uno schema semplice ed estendibile per la rappresentazione delle risorse. Uno di questi è GridML, una forma specializzata di rappresentazione XML che fornisce una descrizione flessibile delle caratteristiche osservabili di risorse di calcolo, memorie e reti [GML]. Analogo lavoro viene anche fatto in [GCX].
Attualmente lo schema adottato da Globus MDS (Monitoring and Discovery Service) e fornito come parte della release base di MDS è Grid Laboratory Uniform Environment (GLUE) [GLUE]. GLUE è nato dalla collaborazione dei team dei progetti DataTAG [Dat] e iVDGL [IVG]. Lo scopo era quello di produrre uno schema per la rappresentazione delle risorse che permettesse l’interoperabilità tra differenti middleware di Griglia. Lo schema concettuale è stato descritto con diagrammi di classi UML per favorire una struttura di informazione comune, indipendente dalla specifica tecnologia e modello dei dati. Nelle versioni 2.x di Globus MDS i dati sono memorizzati nel formato LDIF specifico di LDAP. In GT3 invece i dati sono gestiti in formato XML e memorizzati in database XML. Una Griglia computazionale, implementabile usando Globus, richiede tre tipi di risorse: risorse di calcolo, di memoria e di rete. Il punto debole di GLUE, se c’è, è quello di legarsi troppo a questo tipo di risorse e quindi non adatto a rappresentare altri tipi di risorse come vorrebbe il nostro lavoro.
Un progetto analogo a GLUE è Common Information Model (CIM) [DMTF]. CIM fornisce un modello di informazione concettuale che non si limita ad una particolare area d’implementazione ma può essere usato in differenti ambienti. Quindi oltre alle risorse di calcolo rappresenta, ad esempio, risorse di e-businness, d’impresa, etc. Il CIM fornisce una definizione consistente usando tecniche di paradigmi orientati ad oggetti: classi, proprietà, metodi e associazioni. Il linguaggio standard usato per rappresentare gli elementi è il Managed Object Format (MOF) [MOF]. Lo schema di gestione è diviso in tre livelli concettuali:
• Livello di nucleo: cattura le nozioni che sono applicabili a tutte le aree di gestione.
• Livello comune: cattura le nozioni di una particolare area di gestione, ma è indipendente dalla tecnologia o implementazione. Le aree comuni sono sistemi, applicazioni, database, reti e dispositivi. Il modello inoltre fornisce un insieme di classi base per estendere lo schema specifico all’implementazione.
• Schema di estensione: rappresenta le estensioni all’area comune. I vantaggi del CIM sono:
Flessibilità e supporto per le estensioni: questo significa che un utente può
costruire sul CIM per coprire aree di gestione particolari. Nuove sottoclassi possono essere definite e nuove istanze di classi esistenti possono essere create.
CIM è estensibile: la forza del CIM sta nella ricchezza del modello di
informazione e nella rappresentazione orientata agli oggetti che permette agli utenti di estendere classi esistenti per includere informazioni specifiche.
Lo schema CIM può essere partizionato: integrando tra loro diverse porzioni
dello schema, non si ha il bisogno di implementare lo schema CIM completo ma solo la porzione che più si adatta ai requisiti specifici di gestione.
Notiamo come gli ultimi due lavori citati, GLUE e CIM, hanno la stessa finalità ovvero quella di fornire uno schema per la rappresentazione delle risorse che favorisca l’interoperabilità tra differenti middleware di Griglia. A differenza di GLUE che si limita a fornire uno schema per un limitato numero di risorse (risorse di memoria, di calcolo e di rete), CIM è più flessibile in quanto può essere usato per rappresentare risorse appartenenti a differenti ambienti. Grid, come detto, si sta aprendo verso scenari diversi, non più solamente infrastruttura di calcolo. Ed è in questo contesto che si posiziona il nostro lavoro classificando, in accordo alla semantica dei Grid Service, le risorse di Grid.
3.2 Schema di classificazione
Uno schema di classificazione suddivide le risorse sulla base delle loro differenze permettendo una facile individuazione delle affinità. La tassonomia proposta, classifica le risorse in una struttura gerarchica che inizia con raggruppamenti ampi e relativamente non specifici, rispetto al tipo di risorsa, ed opera attraverso una serie di livelli di specificità.
La tassonomia presentata è ibrida ossia combina caratteristiche gerarchiche ben definite con caratteristiche non gerarchiche più generali per differenziare un’ampia gamma di risorse. La gerarchia deriva dal fatto che i livelli dello schema di classificazione descrivono proprietà delle risorse che sono molto diverse tra di loro. Tra le caratteristiche presenti allo stesso livello non si vuole riflettere alcun ordine di importanza.
La tassonomia è costituita da tre livelli: ontologico, proprietà ed attributi. I primi due livelli permettono di caratterizzare classi di risorse, mentre il terzo livello consente di identificare, univocamente, la risorsa che si sta classificando. Ogni livello comprende un certo numero di attributi che possono assumere diversi valori. Al primo livello, ad esempio, si hanno l’attributo “Semantica” con valori
‘Intrinseca’ ed ‘Estrinseca’, l’attributo “Localizzazione” con valori ‘Locale’ e ‘Remota’ ed infine l’attributo “Visibilità” con valori ‘Pubblica’, ‘Riservata’ e ‘Privata’.
Una risorsa viene caratterizzata scegliendo un solo valore per ogni attributo presente a ciascun livello. In alcuni casi particolari, scegliere un valore piuttosto che un altro per un determinato attributo X, presente nei primi due livelli, riduce(1) il numero dei valori che un attributo Y dei livelli successivi può assumere. Per fare un esempio, la scelta del valore ‘Locale’ per l’attributo “Localizzazione”, vincola l’attributo “Tempo di accesso”, presente al terzo livello, ad assumere zero come valore.
Segue una descrizione degli attributi presenti nei primi due livelli. Nel descrivere ognuno di questi attributi verrà fornito anche uno schema che metta in evidenza i possibili valori per quell’attributo.
3.2.1 Primo Livello: Ontologico
Questo livello è detto ontologico in quanto classifica le risorse in base alla loro natura. Sono identificate i seguenti attributi:
• Semantica • Localizzazione • Visibilità
3.2.1.1 Semantica
Una funzionalità importante dell’architettura dei Web Service è la scoperta del servizio che ci permette di trovare lo Uniform Resource Identifier (URI) del servizio che soddisfa le nostre necessità. Per fare un esempio, possiamo voler
cercare un Web Service che ci fornisca la temperatura nelle città USA. Un server UDDI(2) ci potrà essere di aiuto nella ricerca del Web Service, ma c’è qualcosa
che non può dirci? Possiamo sapere in qualche modo quale tipo di servizio offre? Cioè, di quali città fornisce le temperature e ogni quanto tempo sono aggiornate? Possiamo pensare che sarà il file WSDL(3) a darci queste informazioni, in realtà non è così. Il file WSDL dà informazioni dettagliate ma molto tecniche, ad esempio su come invocare un metodo o sul protocollo usato.
La soluzione data dai Grid Service a questo problema è costituita dai Service Data. Essi sono una collezione di informazioni, associate ai Grid Service, facilmente classificabili e indicizzabili in accordo alle caratteristiche dei Grid Service.
Figura 3.1: valori dell’attributo semantica.
La differenza tra risorsa estrinseca e intrinseca è molto simile alla differenza tra Web Service e Grid Service. Per comprendere meglio questa differenza consideriamo la seguente figura.
(2) Universal Description Discovery and Integration, utilizzato per pubblicare e ricercare informazioni sui
Web Service.
Figura 3.2: risorse intrinseche ed estrinseche.
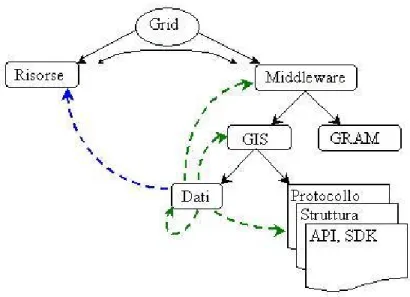
Grid è l’insieme delle infrastrutture hardware e software che consente la condivisione di risorse e la risoluzione coordinata di problemi nell’ambito di organizzazioni virtuali multi-istituzionali e dinamiche. Quindi una Griglia computazionale si basa sia su una collezione di risorse fisiche esistenti (come reti, nodi computazionali che possono essere computers, macchine parallele ad elevate prestazioni o cluster) sia su un insieme di servizi per ottenere informazioni sui componenti della Griglia, localizzare e schedulare risorse, accedere a codice e dati, autenticare utenti e risorse, assicurare la privacy delle comunicazioni e così via. Questi servizi, che sono strettamente connessi con la Griglia, sono supportati da un’infrastruttura “trasparente”, detta middleware, attraverso la quale i clienti accedono alle risorse. La Griglia, quindi, secondo una visione molto semplificata è costituita da risorse fisiche e middleware. Il Grid Information Service (GIS), uno dei servizi del middleware di Griglia, è formato sia dai dati che memorizza, quali tipo di architettura, sistema operativo, latenza e ampiezza di banda della rete, protocolli di comunicazione disponibili ed altro, sia da protocolli, API e SDK con i quali viene implementato.
Il ruolo essenziale nel concetto di risorsa intrinseca viene assunto da ciò che nella figura 3.2 chiamiamo dati. Questi vengono considerati risorse intrinseche o estrinseche se forniscono informazioni su entità che appartengono o meno a Grid. Nel caso in cui un dato fa riferimento ad una risorsa fisica (freccia blu in figura 3.2), allora il dato è estrinseco in quanto fornisce informazioni relative ad una particolare risorsa fisica che ha senso di esistere anche all’esterno di un ambiente di Griglia.
Diversamente, se un dato fa riferimento (frecce verdi in figura 3.2) ad un altro dato, ad un servizio oppure ai dettagli di implementazione di un servizio che non hanno senso di esistere all’esterno di un ambiente di Griglia, allora il dato è intrinseco in quanto l’informazione che fornisce non sarebbe di alcuna utilità al di fuori dell’ambiente di Griglia. Anche il GIS o il GRAM vengono considerati come risorse intrinseche, in quanto sono dei servizi e secondo la semantica di servizio devono fornire informazioni, attraverso i service data, su essi stessi. Vediamone l’utilità. I servizi all’interno di un sistema distribuito complesso devono essere indipendentemente espandibili. OGSA definisce le convenzioni che ci permettono di riconoscere quando un servizio cambia e quando quei cambiamenti sono compatibili all’indietro rispetto all’interfaccia e alla semantica. OGSA inoltre definisce i meccanismi per aggiornare la conoscenza che ha un cliente di un servizio, come le operazioni che supporta o quali protocolli di rete possono essere usati per comunicare con il servizio stesso. Quindi, il versionamento e la compatibilità fra i servizi devono essere gestiti ed espressi in modo che i clienti possano scoprire non soltanto le versioni specifiche di un servizio, ma anche i servizi compatibili. Inoltre, i servizi e gli hosting environment in cui funzionano devono essere espandibili senza interrompere le operazioni dei loro clienti. Per esempio, un aggiornamento dell’ambiente può cambiare l’insieme dei protocolli di rete che possono essere usati per comunicare
con il servizio e un aggiornamento del servizio in se può correggere degli errori o persino aggiungere nuove funzionalità all’interfaccia.
3.2.1.2 Localizzazione
In ambienti di Griglia non è naturale parlare di risorse locali e remote. Si è sempre cercato il modo di usare le risorse in modo indipendente dalla loro localizzazione o di rendere trasparente problemi di località al cliente. Sembra, quindi, forzata questa distinzione. Ma quale è il motivo che ci induce a considerarla?
Figura 3.3: valori dell’attributo localizzazione.
Chiariamo innanzi tutto il concetto di risorsa locale; una risorsa è considerata locale ad un’organizzazione virtuale se fa parte del suo dominio amministrativo. Le organizzazioni si stanno rendendo conto che possono ottenere significative riduzioni dei costi, utilizzando risorse e servizi messi a disposizione da altre organizzazioni. Quando un utente cerca una risorsa con determinate caratteristiche è possibile che ve ne sia più di una; in questo caso l’utente deve scegliere quale risorsa usare. Questa scelta può essere fatta in base a diversi criteri; costo o prestazioni ne sono alcuni.
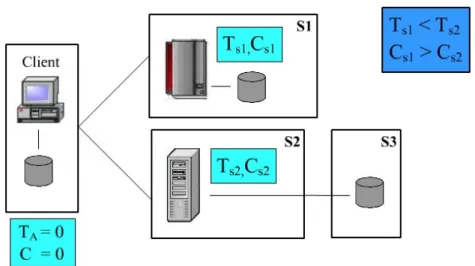
Supponiamo che il cliente ha un servizio di statistica, ma le informazioni che ha nel suo database locale non sono molto precise. Quindi il cliente potrebbe voler cercare qualche sito che offra lo stesso servizio ma con informazioni più esatte. Come mostrato in figura 3.4 ci sono due siti che offrono tale servizio con i loro costi e tempi.
Figura 3.4: risorse locali e remote.
Il cliente oltre alla soluzione locale, caratterizzata da tempo di accesso TA = 0 e
costo C = 0, ha altre due soluzioni. La soluzione offerta dal sito S1 ha tempo di servizio TS1 minore di TS2 poiché l’accesso ai dati avviene localmente, ma ha un
costo maggiore rispetto alla soluzione fornita da S2 perché offre un servizio ulteriormente più accurato, in termini di efficienza (maggiore potenza di calcolo) e di risultati (database più accurato).
Se il fattore discriminante fosse il costo il cliente sceglierebbe la soluzione locale, altrimenti potrebbe scegliere una delle soluzioni remote.
3.2.1.3 Visibilità
Il Grid computing riguarda la condivisione e l’uso coordinato delle risorse appartenenti ad organizzazioni virtuali (VO) distribuite. La condivisione alla quale siamo interessati non è solo scambio di file, ma anche accesso ai calcolatori, al software, ai dati e ad altre risorse, come è richiesto per la risoluzione di un ampio insieme di applicazioni collaborative e di strategie di brokering di risorse che emergono nell’industria, nella scienza e nell’ingegneria. Infatti, uno scenario ricorrente all’interno del Grid Computing coinvolge la formazione di VO che comprendono gruppi di individui, con risorse e servizi
associati, uniti da un obiettivo comune ma non localizzati all’interno di un singolo dominio amministrativo.
Il bisogno di supportare l’integrazione e la gestione delle risorse all’interno delle VO introduce seri problemi di sicurezza sull’utilizzo delle risorse condivise. Ad esempio, una computazione parallela che ha bisogno di risorse di calcolo multiple introduce la necessità di stabilire rapporti di sicurezza non semplicemente tra un client e un server, ma potenzialmente tra centinaia di processi che possono appartenere a molti domini amministrativi. La natura dinamica delle Griglie, però, può rendere impossibile stabilire rapporti di fiducia tra siti prima dell’esecuzione dell’applicazione. Inoltre, le soluzioni di sicurezza tra domini amministrativi devono interoperare con le diverse tecnologie di controllo dell’accesso alle risorse, utilizzate all’interno dei singoli domini. Quindi ciò che si condivide è, necessariamente, altamente controllato, con i fornitori di risorse ed i consumatori che definiscono chiaramente quali sono le risorse che è possibile condividere ed i termini sotto i quali occorre la condivisione. Ad esempio, i vincoli che un proprietario può porre sulle proprie risorse possono riguardare gli utenti autorizzati ad utilizzare queste risorse, le operazioni che possono essere effettuate su di esse, etc. L’implementazione di tali vincoli richiede meccanismi per esprimere le politiche, per accertare l’identità di un consumatore o di una risorsa (autenticazione) e per determinare se un’operazione è consistente con i rapporti di condivisione applicabili (autorizzazione).
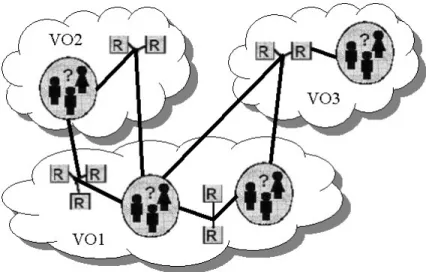
Una risorsa viene detta pubblica, rispetto ad un’organizzazione virtuale, se tutti gli utenti della VO possono utilizzare quella risorsa, seppure con le dovute restrizioni sull’insieme di operazioni che possono essere effettuate su di essa. Esempi di risorse pubbliche sono generalmente tutte le risorse fisiche, dal processore alla quantità di memoria RAM installata, o anche risorse logiche, non semplicemente file ma anche applicazioni, componenti installate quali librerie e dll. Al contrario una risorsa è detta privata, rispetto ad un’organizzazione virtuale, se l’utilizzo della risorsa non è consentito agli utenti di quella VO. Vi è comunque una situazione intermedia. Si parla di risorsa riservata, rispetto ad un’organizzazione virtuale, quando l’accesso a questa risorsa è privilegio di un numero ristretto di utenti della VO; infatti, questi ultimi possono utilizzare la risorsa solo dopo aver effettuato una procedura di identificazione e autorizzazione (basata su password od altro). Esempi tipici sono l’accesso a database o a directory che sono condivise da persone che partecipano a progetti comuni.
Figura 3.6: esempi di risorse pubbliche, riservate e private. Rispetto a VO1, le risorse di VO3 sono pubbliche, mentre quelle di VO2 sono riservate. Le risorse di VO2, rispetto a VO3, sono private.
In alcune occasioni i dati di una VO possono essere resi disponibili per l’elaborazione da parte dei programmi senza consentirne, in nessun modo, la loro visione agli utenti. Ad esempio, i dati contenuti in data warehouse aziendali
possono essere elaborati, senza permetterne la visione, con tecniche di knowledge discovery per estrapolare conoscenza o per generare statistiche.
3.2.2 Secondo Livello: Proprietà
Il secondo livello della classificazione contiene gli attributi relativi alle proprietà delle risorse. Questi sono:
• Aggregazione • Variabilità • Strutturazione • Qualità del Servizio
3.2.2.1 Aggregazione
Nell’ultimo decennio si è assistito ad un sostanziale incremento nelle prestazioni dei computer e delle infrastrutture di rete, sia grazie ad hardware sempre più veloce, sia grazie a software sempre più evoluto. Tuttavia vi sono ancora problemi in vari campi della scienza e dell’ingegneria che non si riescono a trattare efficacemente nemmeno con la generazione attuale di supercomputer. Problemi di questo genere richiedono spesso una massiccia quantità di risorse eterogenee (sia computazionali, sia dati) non sempre tutte disponibili all’interno della medesima organizzazione.
La vasta diffusione di Internet e la disponibilità di computer potenti e tecnologie di rete veloci a basso costo, hanno suggerito la possibilità di usare computer largamente distribuiti per risolvere i problemi di larga scala, conducendo a quello che oggi è comunemente noto come Grid computing. Le Grid consentono la condivisione, la ricerca e soprattutto l’aggregazione di una vasta varietà di risorse, tra cui supercomputer, sistemi di memorizzazione, sorgenti di dati,
dispositivi specializzati, distribuiti geograficamente e posseduti da diverse organizzazioni, allo scopo di affrontare problemi di larga scala in campo scientifico, ingegneristico e commerciale.
Figura 3.7: valori dell’attributo aggregazione.
Le Grid non sono quindi solo un’infrastruttura di calcolo, ma una tecnologia che può aggregare diverse risorse distribuite, da supercalcolatori paralleli a servizi di data storage allo scopo di risolvere problemi molto complessi, quali ad esempio la classificazione del genoma umano, che le risorse singole non sono in grado di risolvere in tempi ragionevoli.
È diventata, quindi, sempre più evidente la necessità di aggregare le risorse sia all’interno di un’organizzazione che tra organizzazioni diverse. Esempi di tali risorse sono cluster, database, GIS, etc.
3.2.2.2 Variabilità
Le tecnologie di Griglia permettono la condivisione su larga scala delle risorse tra gruppi di individui e/o istituzioni. In questi ambienti, la scoperta, la descrizione ed il controllo delle risorse e dei servizi sono problemi impegnativi dovuti alla considerevole diversità dei comportamenti dinamici e delle ripartizioni geografiche delle entità alle quali un utente potrebbe essere interessato. Di conseguenza, i servizi d’informazione sono una parte vitale di ogni infrastruttura o software di Griglia, fornendo i meccanismi fondamentali per la scoperta e il controllo delle risorse.
Figura 3.8: valori dell’attributo variabilità.
Ad esempio, lo scopo del GIS, il servizio di informazione di Globus, è di fornire informazioni aggiornate e valide sullo stato di tali risorse. Diciamo, quindi, che una risorsa è dinamica (o statica) se la frequenza con la quale variano le informazioni che la descrivono è alta (o bassa). Questa frequenza rappresenta il livello di dinamicità della risorsa.
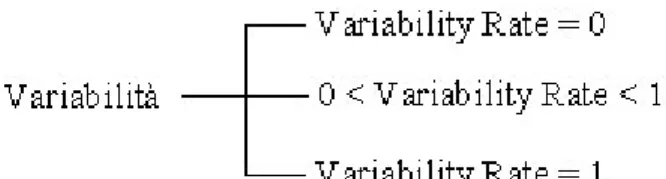
Un concetto molto importante che indica la freschezza delle informazioni di una risorsa è il Variability Rate (VR). Il GIS mantiene le informazioni nella propria cache e usa il VR per decidere quando aggiornarle in base alla seguente politica:
• VR = 0, indica che le informazioni sono statiche,
• VR = 1, indica che le informazioni sono dinamiche e quindi non ha senso memorizzarle in cache in quanto andrebbero aggiornate continuamente, • 0 < VR < 1, indica che le informazioni sono semi-dinamiche e devono
essere aggiornate ad intervalli di tempo pari a 1/VR.
Il valore del VR di una risorsa costituisce il suo livello di dinamicità.
La suddivisione tra risorse statiche e dinamiche non è puramente binaria, ma esistono diversi casi intermedi, identificati dal maggiore o minore livello di dinamicità. Esempi di risorse statiche sono processore, sistema operativo e quantità di RAM installata; al contrario le code dello scheduler, dello spooler e il traffico di rete sono risorse dinamiche. Infine come risorse semi-dinamiche
citiamo: quantità occupata di spazio disco, numero di file in una directory e applicazioni installate.
3.2.2.3 Strutturazione
Durante l’utilizzo delle risorse di Griglia, un utente può chiedere informazioni sulla disponibilità, o eventualmente sulle caratteristiche, di una particolare risorsa. I dati dai quali si estraggono queste informazioni possono essere strutturati o non strutturati.
Figura 3.9: valori dell’attributo strutturazione.
I dati strutturati, comunemente detti dati, vengono visualizzati sotto forma di campi, record, righe e colonne. Parliamo, quindi, di dati strutturati quando esiste uno “schema” che permette di interpretare in modo non ambiguo i dati.
Esempi di dati strutturati sono le basi di dati, dove i dati sono codificati in tabelle che sono accessibili tramite un apposito linguaggio di interrogazione, o le basi di conoscenza che permettono anche di eseguire inferenze (ragionamenti) usando i dati in esse memorizzati.
I dati non strutturati, invece, non possono essere ridotti a una rappresentazione di righe e colonne e vengono definiti globalmente documenti. I documenti possono riferirsi a un’immagine elettronica di testo o grafica, a un documento di un elaboratore di testi in formato ASCII, a clip audio e video, a oggetti, a file multimediali o a qualsiasi combinazione di tutto ciò all’interno di un ambiente eterogeneo. Tuttavia anche nelle basi di dati possiamo trovare dei dati non strutturati quali ad esempio i campi testuali, che vanno trattati alla stregua dei file ASCII.
Dalla fusione di dati derivanti da sorgenti diverse (che possono essere sorgenti di dati fortemente strutturate) possono originarsi dati semi-strutturati (Semi-Structure Data o SSD) in quanto lo schema di una delle sorgenti potrebbe non riuscire a catturare perfettamente la struttura dei dati dell’altra sorgente. Gli SSD possono originarsi anche in seguito alla necessità di memorizzare risultati sperimentali, i quali in generale, a causa della loro frammentarietà e parzialità, riescono difficilmente ad essere descritti tramite strutture rigide e regolari dei DBMS relazionali.
I dati semi-strutturati sono collezioni di dati che differiscono notevolmente dai dati presenti nei classici DBMS relazionali o a oggetti; innanzi tutto la loro struttura è eterogenea (la stessa informazione può essere rappresentata utilizzando tipi diversi o addirittura con strutture dati diverse, alcuni dati possono essere incompleti rispetto alla maggior parte dei dati presenti nella collezione oppure possono avere delle informazioni aggiuntive, e così via). La struttura è implicita: mentre nei sistemi relazionali o a oggetti esiste una struttura, uno schema noto a priori (che tra l’altro può essere utilizzato ad esempio durante le fasi di type checking o di ottimizzazione delle query), e l’intero database può essere visto come un’istanza di tale struttura, nei dati semi-strutturati tale schema non è noto a priori ma è presente implicitamente nei dati stessi e deve essere estratto tramite opportune elaborazioni su questi ultimi. I dati semi-strutturati sono quindi autodescrittivi ed un query language dovrebbe avere la possibilità di interrogare tanto i dati quanto lo schema. Lo schema di questo tipo di dati, inoltre, può variare: infatti, dopo l’aggiunta di ogni nuovo dato, lo schema (se presente) viene modificato di conseguenza per evolvere quindi piuttosto rapidamente (a differenza di ciò che accade nelle basi di dati relazionali o a oggetti in cui lo schema è praticamente immutabile e le modifiche sono rare e costose).
Un’altra enorme collezione di dati semi-strutturati è il web: i dati presenti sul web, infatti, non hanno quasi alcuna struttura e quindi il tentativo di vedere internet come un grosso database ha dovuto prima di tutto risolvere il problema della modellazione di tali dati. I dati semi-strutturati vengono solitamente modellati come grafi o alberi etichettati proprio per tenere conto della loro irregolarità, ed è proprio questo il modello su cui si basa lo studio dei linguaggi di interrogazione per SSD. Innanzi tutto va osservato che un qualsiasi query language per SSD deve essere abbastanza flessibile per poter catturare le caratteristiche di tale tipo di dati e si deduce quindi che i classici query language per database relazionali (come SQL), non sono adatti per i dati semi-strutturati: questo spiega il motivo per cui, negli ultimi anni, si stanno studiando modelli e linguaggi per SSD.
3.2.2.4 Supporto alla Qualità del Servizio.
Negli ultimi anni, un fattore che ha assunto un ruolo sempre più importante nelle strategie di molte organizzazioni è la “qualità del servizio” (Quality of Service o QoS). Ma cosa significa, in concreto, QoS? Certamente è possibile menzionare tutta una serie di requisiti generali che definiscono le “qualità” di un servizio ma non definiscono completamente tutte le possibili accezioni del termine qualità: in alcuni casi la stessa definizione può avere accezioni diverse per i diversi attori coinvolti nella fornitura del servizio. Ad esempio, un tipo di qualità di servizio è l’efficienza. Per l’utente, efficienza può voler dire soprattutto velocità nell’ottenere i risultati attesi. Per il gestore del servizio, diventa importante la valutazione anche del costo che deve essere sostenuto per fornire il servizio. Questi differenti punti di vista sono correlati ai diversi obiettivi che ciascun attore ha nell’osservare il servizio. L’utente è interessato ad ottenere risultati corretti in tempi brevi. Il gestore è interessato a ridurre il costo complessivo.
Altri tipi di qualità di servizio, per esempio, potrebbero essere la larghezza di banda, il costo del servizio. In quest’ultimo caso l’utente potrebbe essere interessato ad un servizio il cui costo sia inferiore ad un certo limite, indipendentemente dall’efficienza con la quale viene svolto.
Il livello di supporto per il QoS diverrà tanto più importante quanto le applicazioni diverranno più sofisticate. La nostra nozione di QoS non è limitata solo all’efficienza, al costo e alla larghezza di banda ma è estesa anche alle capacità di memorizzazione e di elaborazione dei nodi della Griglia, ai livelli di affidabilità nello svolgimento di un servizio, alla sicurezza nella trasmissione dei dati su rete e così via. Potrebbe essere molto inefficiente garantire un’adeguata larghezza di banda e insufficienti cicli di elaborazione per i componenti di applicazione che operano sulla Griglia; si pensi ad applicazioni on-demand o multimediali. Ad esempio la creazione di una sessione di videoconferenza può invocare la creazione di istanze di servizio in punti intermedi per gestire il flusso di dati tra due punti in accordo al QoS. Un altro aspetto fondamentale del QoS è la possibilità di prenotare le risorse. Una Griglia che fornisce la capacità di specificare solo a tempo di sottomissione di un job le risorse necessarie e non di riservare le risorse in anticipo dà solo una soluzione parziale al QoS.
Un’altra funzione di QoS è la capacità che un’applicazione di Griglia negozi, con il gestore, per il livello di servizio voluto. Per fornire QoS, un sistema di gestione delle risorse deve potere realizzare due aspetti critici: il controllo di ammissione e il controllo di sorveglianza. Il controllo di ammissione è il processo che determina se una richiesta di risorse può essere onorata, mentre il controllo di sorveglianza deve assicurare che il livello di servizio concordato, per l’utilizzazione delle risorse, tra il gestore delle risorse e l’applicazione richiedente sia rispettato. Cioè, il gestore da parte sua deve fornire le risorse
necessarie, quando richieste, e l’applicazione non deve usare più risorse di quelle richieste.
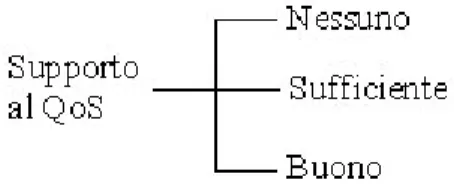
In figura 3.10 è mostrata una tassonomia, sviluppata in [KBM], per il supporto al QoS.
Figura 3.10: tassonomia del supporto al QoS e valori dell’omonimo attributo.
Un RMS che non permette alle applicazioni di specificare il livello di QoS nelle richieste di risorse non sostiene QoS. Si può dimostrare che lo scheduling fornisce una forma di controllo di ammissione ma se nella richiesta delle risorse non è possibile specificare i livelli di servizio della risorsa richiesta, lo scheduling non sostiene il QoS [KBM]. Un RMS che fornisce attributi di QoS per la richiesta delle risorse e che non impone di rispettare i livelli di servizio attraverso il controllo di sorveglianza fornisce solo un supporto sufficiente al QoS. Tutti i gestori delle risorse effettuano implicitamente un qualche livello di controllo di ammissione durante il processo di scheduling. Quasi tutti i sistemi attuali di Griglia forniscono QoS sufficiente poiché la maggior parte dei sistemi operativi non real-time non permettono la specifica del livello di servizio per i job in esecuzione e pertanto non possono far rispettare le garanzie di QoS non di rete. Il supporto buono al QoS si ha quando tutti i nodi nella Griglia possono imporre di rispettare i livelli di servizio garantiti dallo RMS.
3.2.3 Terzo Livello: Attributi
Il terzo livello della tassonomia specifica gli attributi con i quali è possibile identificare univocamente una risorsa. Considerato che la tassonomia può essere utilizzata per classificare un ampio insieme di risorse, gli attributi appartenenti a
questo livello variano di volta in volta a seconda della risorsa. Di conseguenza ci limitiamo a dare un esempio di attributi per un particolare tipo di risorsa.
Esempio 3.1
In questo esempio viene caratterizzata una componente creata, in un qualunque linguaggio, tramite ambienti visuali. Con il termine componente si vuole indicare generalmente un oggetto riusabile e che può interagire con altri oggetti. Gli ambiti d’uso, anch’essi visuali, possono essere molteplici; basti pensare al riuso del codice, non solo a livello di una singola VO ma anche a livello di Griglia. Oppure durante lo sviluppo di un progetto a livello di VO, supponendo che questa abbia un Ambiente di Sviluppo Integrato (Integrated Development Environment o IDE), il gruppo che si occupa della qualità delle interfacce, oltre a definire gli standard per le interfacce, fornisce anche le componenti base da usare al fine di avere un progetto uniforme. In questo caso si può pensare che lo IDE scopri ed integri dinamicamente queste componenti alle utility standard facilitando il lavoro degli sviluppatori e quindi velocizzando la fase di sviluppo con conseguente riduzione dei costi interni.
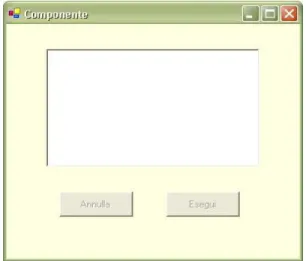
Come mostrato in figura 3.11 la componente contiene una textarea e due bottoni. Secondo la classificazione introdotta precedentemente la componente risulta essere:
• Aggregata: è costituita da ulteriori componenti quali area di testo e bottoni,
• Estrinseca: la risorsa non è strettamente correlata all’ambiente Grid, • Variability Rate = 0: le informazioni che la descrivono non variano,
• Strutturata: le informazioni che la descrivono, oltre ad essere strutturate secondo uno “schema” non ambiguo, possono essere recuperate tramite determinati metodi.
Inoltre la componente può essere sia locale che remota e sia pubblica che privata. Viene presentata adesso una descrizione XML della componente.
…
<FORM name=“form1“ title=“Componente“> <PROPERTY name=”x” value=”30” /> <PROPERTY name=”y” value=”30” /> <PROPERTY name=”height” value=”80” /> <PROPERTY name=”width” value=”60” />
<PROPERTY name=”background” value=”yellow” /> <TEXTAREA name=“textarea1“ value=““>
<PROPERTY name=”x” value=”10” /> <PROPERTY name=”y” value=”10” /> <PROPERTY name=”height” value=”40” /> <PROPERTY name=”width” value=”40” />
<PROPERTY name=”background” value=”white” /> <PROPERTY name=”foreground” value=”black” />
<PROPERTY name=”font” value=”TimesNewRoman” /> <PROPERTY name=”visible” value=”true” />
<PROPERTY name=”enabled” value=”true” /> <PROPERTY name=”editable” value=”true” /> </TEXTAREA>
<BUTTON name=”button1” value=”Annulla”> <PROPERTY name=”x” value=”10” /> <PROPERTY name=”y” value=”60” /> <PROPERTY name=”height” value=”10” /> <PROPERTY name=”width” value=”15” />
<PROPERTY name=”font” value=” TimesNewRoman” /> <PROPERTY name=”visible” value=”true” />
<PROPERTY name=”enabled” value=”false” /> </BUTTON>
<BUTTON name=”button2” value=”Esegui”> <PROPERTY name=”x” value=”35” /> <PROPERTY name=”y” value=”60” /> <PROPERTY name=”height” value=”10” /> <PROPERTY name=”width” value=”15” />
<PROPERTY name=”font” value=” TimesNewRoman” /> <PROPERTY name=”visible” value=”true” />
<PROPERTY name=”enabled” value=”false” /> </BUTTON>
</FORM> …
Esempio 3.2
Supponiamo di avere un portale che offre due servizi: vendita di componenti per PC e visione on-line dei manuali di queste componenti.
In questo esempio si vogliono classificare le pagine HTML di questi servizi. La pagina del servizio di vendita contiene le caratteristiche delle componenti disponibili, mentre la pagina di visione dei manuali contiene i link ai vari manuali.
Le pagine sono classificate come:
• Aggregate: sono costituite da ulteriori componenti quali aree di testo, bottoni, etc,
• Estrinseche: non sono strettamente correlate all’ambiente Grid, • 0 < Variability Rate < 1: possono variare sia in forma che contenuto, • Semi-strutturate: la struttura non è nota a priori ma è presente
implicitamente nei dati stessi,
• Pubbliche: possono essere consultate da tutti, • Remote: si trovano sul portale.
La qualità del servizio offerto dipende dalla frequenza di aggiornamento delle pagine, da meccanismi di pagamento on-line, etc.
Uno schema di rappresentazione potrebbe essere il seguente: …
<PAGE name=”index.html” title=”Hardware Component” link=”http://novello.cnuce.cnr.it/~tesigrid/Hardware/”> …
<COMPONENT type=”Processori”> <ELEMENT name=”Intel Pentium 4”>
<PROPERTY name=”speed” value=”2.4” units=”GHz” /> <PROPERTY name=”cacheL1” value=”512” units=”KB” /> <PROPERTY name=”cacheL2” value=”4” units=”MB” /> <PROPERTY name=”cost” value=”200” units=”€” /> <PROPERTY name=”availability” value=”100” /> </ELEMENT>
<ELEMENT name=”AMD Athlon”>
<PROPERTY name=”speed” value=”1.8” units=”GHz” /> <PROPERTY name=”cacheL1” value=”256” units=”KB” /> <PROPERTY name=”cacheL2” value=”16” units=”MB” /> <PROPERTY name=”cost” value=”84” units=”€” />
<PROPERTY name=”availability” value=”150” /> </ELEMENT>
</COMPONENT>
<COMPONENT type=”Memorie”>
<ELEMENT name=”Memoria DDR No Parity OEM”>
<PROPERTY name=”capacity” value=”256” units=”MB” />
<PROPERTY name=”bus frequency” value=”333” units=”MHz” /> <PROPERTY name=”cost” value=”50” units=”€” />
<PROPERTY name=”availability” value=”150” /> </ELEMENT>
</COMPONENT>
<COMPONENT type=”Dischi”>
<ELEMENT name=”HDD IDE Maxtor ATA133”>
<PROPERTY name=”velocity” value=”7200” units=”RPM” /> <PROPERTY name=”cost” value=”84” units=”€” />
<PROPERTY name=”availability” value=”150” /> </ELEMENT>
</COMPONENT> </PAGE>
<PAGE name=”index.html” title=”Manual Vision”
link=”http://novello.cnuce.cnr.it/~tesigrid/Manual/”> <COMPONENT>
<PROPERTY name=”link” value=”http://www.cli.di.unipi.it/~manglavi/P4.pdf” /> <DOCUMENTATION description=”Pentium 4 Manual” />
</COMPONENT> <COMPONENT>
<PROPERTY name=”link” value=”http://www.cli.di.unipi.it/~moncelli/Athlon.pdf” /> <DOCUMENTATION description=”Athlon Manual” />
</COMPONENT> <COMPONENT>
<PROPERTY name=”link” value=”http://barolo.cnuce.cnr.it/~tesigrid/Maxtor.pdf” /> <DOCUMENTATION description=”Maxtor Installation” />
</COMPONENT> </PAGE>
Esempio 3.3
In questo esempio, a differenza dei due precedenti, verrà presentata la classificazione di una risorsa intrinseca: la replica di un dato.
Una replica, o copia in sola lettura, di un dato viene spesso creata nei sistemi di calcolo allo scopo di ridurre la latenza di accesso al dato, migliorare la località dei dati e/o incrementare la scalabilità e le prestazioni delle applicazioni distribuite che ne fanno uso. Un sistema che consente la gestione delle repliche richiede necessariamente un meccanismo per localizzarle. Le informazioni relative alla locazione fisica delle repliche sono fornite dal Replica Location Service (RLS) [FKC].
In DataGrid, ad esempio, le repliche vengono utilizzate per far si che gli utenti accedano in modo efficiente ai file. Ci sono due tipi di file: i file “master” e le “repliche”. Il file master è posseduto e gestito da chi crea il file mentre le repliche sono gestite dal Grid middleware. L’uso delle repliche è trasparente all’utente; esse sono create quando necessario dal middleware stesso. Inizialmente le repliche sono per definizione di sola lettura; nel caso in cui una replica viene modificata si ha la creazione di un nuovo file master. Questo per evitare problemi di sincronizzazione molto difficili.
Un esempio di utilizzo di una replica può essere il seguente: supponiamo che un job eseguito su un sito A faccia uso di dati memorizzati all’interno di un sito B. Per migliorare le prestazioni del job, una replica, o copia di sola lettura, dei dati può essere effettuata presso il sito A. Successivamente la replica può essere usata sia dai job che saranno eseguiti sul sito A, sia dai job che saranno eseguiti sui siti che hanno con A una migliore connessione rispetto a quella che hanno con B. Per questo motivo la replica dovrebbe essere mantenuta presso il sito A il più a lungo possibile.
In base alla tassonomia introdotta in precedenza, la replica viene caratterizzata come:
• Singola: la replica non può essere vista come l’aggregazione di ulteriori risorse,
• Intrinseca: la replica è creata dal Grid middleware;
• Variability Rate = 0: la replica è una copia di sola lettura e non può essere modificata;
• Pubblica: tutti possono utilizzare la replica;
Per quanto riguarda la localizzazione, la replica può essere sia locale che remota.
3.3 Conclusioni
La crescente popolarità di Internet e l’introduzione di nuove tecnologie stanno contribuendo a rendere possibile l’integrazione tra loro di una grande varietà di risorse distribuite geograficamente, come supercomputer paralleli, sistemi di memorizzazione, fonti di dati ed altro, che possono essere impiegate congiuntamente per formare un unico ambiente complessivo che assume il nome di Grid. Queste risorse possono essere classificate in base a delle proprietà che si ritiene siano “interessanti” evidenziare ottenendo così una possibile tassonomia. In questo capitolo, in seguito alla descrizione di alcune tassonomie esistenti sia in ambito di Griglia che non, è stata sviluppata una tassonomia che classifica e caratterizza le risorse di Grid. La tassonomia proposta differisce dalle altre per il fatto che caratterizza non solo risorse di calcolo, di memoria, di rete, o comunque risorse fisiche, ma anche qualsiasi altro tipo di risorsa.