CAPITOLO 6
I.D.D.A. 2.1
Integrated Dynamic Decision Analysis
6.1 Cenni generali
IDDA (Analisi Decisionale Dinamica Integrata), sviluppato dall'ing. Remo Galvagni e di proprietà di SOSE S.r.l., è uno strumento per la modellazione della logica dei sistemi: la rappresentazione del sistema si svolge delineando tutti i suoi possibili comportamenti secondo tracciati alternativi nei quali devono essere descritte le reali sequenze logico-temporali degli avvenimenti; ogni ramo si può aprire in più direzioni (fino ad otto), con probabilità condizionate dall'evoluzione degli eventi che precedono la diramazione, nella sequenza descritta.
In altri termini lo strumento, ricevuta dall'analista la descrizione del funzionamento del sistema secondo un'opportuna sintassi, la sviluppa in forma potenziata di albero degli eventi "dinamico", esplicitando tutte le sequenze di eventi compatibili con la descrizione ricevuta sia dal punto di vista della concatenazione logica sia da quello della coerenza probabilistica.
In sintesi, IDDA si occupa essenzialmente di logica dei sistemi, cioè delle connessioni logico-probabilistiche all'interno di un universo individuato, trattato dinamicamente e la cui parte logica è pienamente integrata con la sua parte fisico-fenomenologica.
Una delle maggiori potenzialità di IDDA è quella di offrire tutti gli strumenti per poter superare l'ostacolo della proliferazione binaria delle alternative, confinando il problema entro un campo dominabile con successo.
IDDA quindi è in grado di offrire un modello del sistema in esame, capace di fornire il supporto per decisioni documentate, motivate e giustificabili ricorrendo ad una presentazione analitica delle alternative possibili e del rischio (in termini di probabilità e di conseguenza) da ciascuna di esse implicato.
Più specificatamente ogni possibile scenario è sviluppato in accordo con l’approccio Cause-Conseguenze.
In questo approccio sono applicate dinamicamente sia le regole logiche che le valutazioni probabilistiche. In questo modo ogni informazione progressivamente ricevuta viene utilizzata per definire il passo logico successivo e le probabilità condizionate degli eventi successivi in accordo con l’applicazione del ragionamento induttivo fino ada arrivare a una determinata uscita coerente con le aspettative dell’analista.
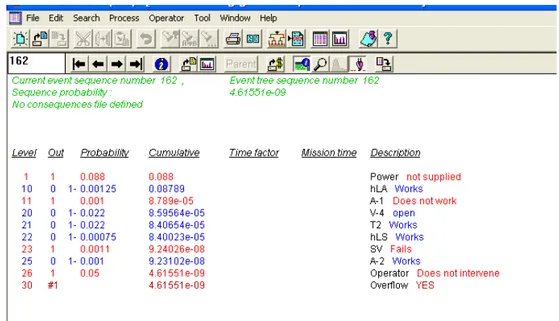
Nella figura seguente viene mostrata una possibile deviazione che porta all’uscita Overflow:
Figura 6.1 – Visualizzazione codice Idda
Ma questa analisi oltre ad essere dinamica è anche integrata in quanto studia il comportamento fisico dei fenomeni che uno studio degli eventi logici implica.
Per essere effettivo uno scenario in forma di studio logico deve essere rappresentato sia con una evoluzione della probabilità di accadimento sia con l’evoluzione fenomenologia fisica. Inoltre la conoscenza della fenomenologia degli scenari mi porta a valutare le conseguenze di questi ultimi. Le conseguenze insieme con le informazioni legate alle probabilità mi danno il rischio.
6.2 Studio della sintassi del programma
Le performance di IDDA sono basate sulla rigorosa applicazione della Logica Artificiale nell’elaborazione dei parametri per la soluzione di ogni problema esaminato. In questo ambito la logica viene definita come la scienza delle regole che garantiscono la coerenza tra premesse e conclusioni di un ragionamento.
La coerenza in Idda viene definita come assenza di contraddizioni sia che esse siano conclusioni logiche o valutazioni probabilistiche.
Come si è detto precedentemente ogni scenario alternativo è sviluppato secondo un approccio logico Causa-Conseguenza, mediante un linguaggio sintattico, che tenta di simulare il pensiero umano che può essere schematizzato secondo un grafo aperto orientato senza ricicli.
Tale grafo è orientato dal processo di acquisizione delle informazioni ed è proprio l’incremento di informazione che impedisce il riciclo.
Un esempio che porta alla comprensione della logica su cui si basa Idda è quello di considerare la semplice applicazione del grafo alla legge ebraica: “Gli animali mondi sono quelli che hanno l'unghia fessa e ruminano” dove in particolare abbiamo tre eventi:
a) animale mondo
b) animale con l'unghia fessa c) animale ruminante.
Possiamo vedere che in assenza di condizionamenti la logica che segue la partizione 2N si può schematizzare nel seguente modo:
Figura 6.2 - Rappresentazione delle possibili combinazioni dei tre eventi senza tener conto delle relazioni esistenti
Gli otto (23) termini presi insieme costituiscono la partizione, di cui si dicono i costituenti. Essi si escludono a vicenda e sono quindi incompatibili, in quanto ne è logicamente possibile uno e uno solo per volta.
Tuttavia bisogna considerare che ogni informazione logica aggiuntiva porta alla riduzione del numero teorico, 2N, dei costituenti: e questo è un potente strumento per contenere l’esplosione binaria come si può visualizzare nelle figure seguenti.
b c a
⋅ ⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
b
c
a
a
c
b
⋅
⋅
a
c
b
⋅
⋅
Figura 6.3 – Rappresentazione delle possibili combinazioni eliminando le combinazioni in contraddizione con l’enunciato
Ecco cosa otteniamo, ma non è ancora una partizione ottimizzata:
Figura 6.4 – Rappresentazione delle possibili combinazioni
b c a
⋅ ⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
b
c
a
a
c
b
⋅
⋅
a
c
b
⋅
⋅
b c a
⋅ ⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
b
c
a
P
A
R
T
I
Z
I
O
N
E
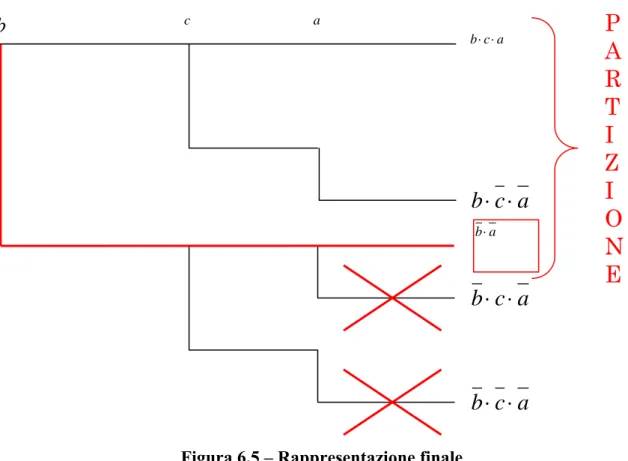
Dallo schema si vede che negli ultimi due costituenti lo stato di c è irrilevante (o in afferente).Quindi i costituenti della partizione sono infine tre.
Figura 6.5 – Rappresentazione finale
Concludendo possiamo affermare che il principio per cui la partizione di N eventi sia 2N non è quasi mai verificato. La logica del problema aiuta nella riduzione del numero dei costituenti, e più il problema è “strutturato”, cioè con molte relazioni tra eventi, e più cala la dimensione della partizione. Si noti che esistono due tipi di eventi: quelli che possono assumere valore vero e falso a causa dell’incertezza ed hanno un valore di probabilità associato e quelli che sono completamente determinati dallo stato di altri eventi e non hanno probabilità.
Un metodo efficace per rappresentare i problemi attraverso la partizione è utilizzare una logica a tre valori: vero, falso e vuoto (inafferente).
6.3 Procedura Idda
Si individuano gli eventi di interesse e si costruisce la lista dei livelli, con domande ed affermazioni (nodi dell’albero) facendo attenzione all’ordine di posizionamento dei livelli
b c a⋅ ⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
a
c
b
⋅
⋅
b
c a a b⋅P
A
R
T
I
Z
I
O
N
E
che rappresenta un fattore fondamentale per ottenere un modello di buona qualità. Si costruisce il reticolo indicando gli indirizzi da visitare a seguito di ogni risposta in ogni livello (archi). Si associano le probabilità ad ognuno dei livelli e si impongono tutti i condizionamenti.
I.D.D.A. elabora il file di input così costruito e genera la partizione completa. Bisogna porsi tutte le domande necessarie e sufficienti per descrivere il problema in modo completo, dato il nostro stato di conoscenza. Se il problema è complesso non ce la caveremo comunque con pochi costituenti, però il metodo di creazione della partizione è studiato in modo tale da sfruttare al momento della generazione dei costituenti, e non a posteriori, le armi per lo sfoltimento dell’albero: i condizionamenti logici e anche il taglio probabilistico.
Da notare che i grafi aperti, tipo Albero degli Eventi, (come quelli visti nelle figure precedenti) possono costituire strumenti logici sufficienti, specie in casi non troppo complessi, per sviluppare l’universo rappresentato dall’insieme dei costituenti della partizione; tuttavia ciò non è possibile nei casi più complessi.
In questi casi si può anche riassumere il problema in un'espressione dichiarativa, di cui occorre individuare e costruire l’universo,e dalla quale possa poi essere fedelmente sviluppata l’intera partizione.
Nel caso in esame la descrizione del sistema diventa:
1) L'animale considerato ha l'unghia fessa ? Evento B : Vero ? Falso ?
2) L'animale considerato rumina ? Evento C : Vero ? Falso ?
3) L'animale considerato è un animale puro ! Evento A : Vero ! Falso
In questo caso possiamo vedere come siano presenti due tipologie di evento: 1. eventi aleatori (domande ?)
Nella sintassi di IDDA è disponibile una serie di comandi per modificare il modello run time, in modo da adattarlo al livello attuale di conoscenza. In questo modo sia le regole logiche che le stime probabilistiche possono essere applicate dinamicamente.
Ogni informazione ricevuta progressivamente può essere utilizzata per definire i percorsi logici successivi e le probabilità condizionali degli eventi successivi, in accordo con l’applicazione del ragionamento induttivo.
Si verifica nella figura successiva lo schema riassuntivo della procedura nel caso in esame:
1 L’animale considerato ha l’unghia fessa ? [Evento B ] [Vero ] [Falso ] se [Vero ] l’Evento Successivo e’ : 2 [Evento C]-[Vero ]-[Falso ]
se [Falso ] l’Evento Successivo e’ : 3 [Evento A]-[Vero ]-[Falso ] ---
se [Falso ]: obbliga l’EVENTO 3 su: ([Evento A]-[Falso ])
2 L’animale considerato rumina ? [Evento C ] [Vero ] [Falso ] se [Vero ] l’Evento Successivo e’ : 3 [Evento A]-[Vero ]-[Falso ] se [Falso ] l’Evento Successivo e’ : 3 [Evento A]-[Vero ]-[Falso ] ---
se [Falso ]: obbliga l’EVENTO 3 su: ([Evento A]-[Falso ])
3 L’animale considerato è un animale puro ! [Evento A ] [Vero ] [Falso ] se [Vero ] allora Esce
se [Falso ] allora Esce
---
Figura 6.6 – Schematizzazione di IDDA
Il codice Idda si basa sulla Logica del Buon Senso. Secondo De Finetti (1970) l’espressione matematica del buon senso può essere rappresentata da queste condizioni di coerenza:
Per ogni evento ai si prende in considerazione quello che, per coerenza, deve essere
considerato il suo intero universo:
(ai + ¬ai) = 1
L’universo dell’insieme degli N eventi è dato dall’intersezione (prodotto logico) degli universi dei singoli eventi:
Il prodotto può essere sviluppato in una sommatoria di 2N addendi, la pertinenza di ciascuno dei quali va poi esaminata alla luce dei vincoli imposti dalle condizioni del problema.
Gli n ≤ 2N termini ottenuti costituiscono la partizione che descrive compiutamente il problema. Ogni termine è detto costituente.
Sviluppando questa logica si ottengono i seguenti costituenti:
COSTITUENTE Numero : 1
1 Evento B Vero + 3.0000E-01 7.0000E-01 2 Evento C Vero + 2.2500E-01 2.5000E-01 3 Evento A Vero + V 2.2500E-01
PROBABILITA' uguale a : 2.2500E-01
COSTITUENTE Numero : 2
1 Evento B Vero + 3.0000E-01 7.0000E-01 2 Evento C Falso - 7.5000E-02 2.5000E-01 3 Evento A Falso - V 7.5000E-02
PROBABILITA' uguale a : 7.5000E-02
COSTITUENTE Numero : 3
1 Evento B Falso - 7.0000E-01 7.0000E-01 3 Evento A Falso - V 7.0000E-01
PROBABILITA' uguale a : 7.0000E-01
Figura 6.7 – Schematizzazione Costituenti
Osservando attentamente i costituenti ottenuti dall’albero degli eventi condizionato, si può però ancora notare come:
a c
b⋅ ⋅ b⋅c⋅a
siano ridondanti, data la condizione logica imposta: infatti qualunque sia lo stato di c il b vincola già di per sé solo la conclusione a .
Quindi lo stato di c è, in questo contesto, inafferente (o vuoto) e la sua comparsa tra i costituenti, non aggiungendo alcuna informazione utile, può e deve essere evitata, riducendoli ai soli tre seguenti:
a c
b⋅ ⋅
b⋅c⋅a b⋅a
Questo è un esempio del ruolo dell'inafferenza e dello scopo di usare formalmente una logica ternaria, dotata dello stato supplementare di vuoto; scopo che sostanzialmente
consiste nel ridurre ulteriormente il numero dei costituenti ai soli essenziali per una rappresentazione logica completa.
6.4 Verifica del modello
Il modello deve subire un processo di revisione e convalida basato su una critica sistematica dei suoi risultati qualitativi e quantitativi, alla luce dell’esperienza disponibile. Le modifiche seguiranno un processo di approssimazioni successive che terminerà solo quando il risultato finale sarà giudicato pienamente in accordo con le conoscenze in possesso dell’analista.
La revisione può essere schematizzata in 4 fasi: 1. Correzione degli errori
2. Verifica della completezza degli eventi esaminati 3. Verifica dell’adeguatezza del modello
4. Verifica della congruenza delle probabilità assegnate
1. Correzione degli errori
Gli errori di sintassi vengono segnalati dal programma. Gli errori nell’impostazione della struttura del modello vengono rivelati attraverso l’ispezione delle sequenze (alternative) particolarmente significative: per esempio le più corte o lunghe, create da errori negli indirizzamenti, o altre selezionate usando criteri più complessi, dettati dalla complessità del modello o dall’esperienza.
Già in questa fase si è spinti a verificare, oltre alla correttezza della struttura, anche la chiarezza e la completezza della propria comprensione del comportamento del sistema.
2. Completezza degli eventi
Durante il processo di integrazione tra modello logico e simulatore fenomenologico, l’analista deve fare in modo che il programma che esegue i calcoli legga gli eventi e li traduca in dati d’ingresso utili.
L’analista scopre se nell’eventistica mancano informazioni rilevanti per la valutazione dei fenomeni e per il calcolo delle conseguenze.
In questa fase l’analista collauda ancora la sua comprensione del problema verificando la sua capacità nel correlare eventi e fenomeni. (data l’impossibilità di ottenere dati sufficienti riguardanti la costruzione della stazione di rifornimento idrogeno la trattazione di Idda è stata limitata al calcolo delle probabilità di guasto del sistema compressore).
3. Adeguatezza del modello
L’analista definisce i tipi di risultati che si attende dal sistema e li seleziona, estraendoli dall’insieme dei costituenti, gruppo per gruppo. La selezione può avvenire utilizzando combinazioni comunque complesse di operatori booleani.
Le sequenze appartenenti ad ogni gruppo devono essere osservate con attenzione, in particolare i costituenti più probabili e quelli meno probabili.
E’ fondamentale controllare anche la correttezza degli andamenti fenomenologici.
A volte, al termine del setacciamento progressivo, restano alternative non catalogate; queste sono sempre molto indicative e vanno esaminate con attenzione perché inattese:
- Non sono coerenti con la logica prevista (errori residui del modello) e quindi il modello deve essere corretto
Sono coerenti ma al di fuori di quanto previsto dalle capacità combinatorie o dall’immaginazione dell’analista. Sono importantissime perché costituiscono una vera acquisizione di conoscenza.
4. Congruenza delle probabilità assegnate
In questa fase l’analista deve tarare le probabilità per garantirsi che la distribuzione delle attese tra le varie alternative e tra i vari gruppi sia in accordo con il suo giudizio e la sua esperienza.
Per questo ritornerà sulle selezioni effettuate e confronterà fra loro le rispettive probabilità e i margini di incertezza. Se lo riterrà necessario le ridistribuirà prestando particolare attenzione alle sequenze che risulteranno più critiche.
6.5 Struttura della sintassi di IDDA
Ora si vedrà in dettaglio le istruzioni maggiormente utilizzate nel programma che sono servite per schematizzare la parte d’impianto studiata con il codice di calcolo:
Input Text File: descrive il modello IDDA dal punto di vista delle probabilità e della logica. È un normale file di testo ASCII che può essere compilato con qualsiasi text editor. Permette al processo di analisi dell’albero degli eventi dinamico di generare l’intero spazio degli eventi del modello previsto e deve sempre contenere una relazione con almeno un livello. Un modello logico non è una struttura statica; l’analista pone differenti domande e assegna probabilità diverse basate sulla sua conoscenza dell’evoluzione logica del sistema. Quindi la sintassi dell’Input text file fornisce alcuni comandi (chiamati constraints: vincoli) che permettono all’utilizzatore del programma di modificare il run time del
modello e di adattarlo allo stato attuale di conoscenza del sistema.
(Default: *. INP)
Struttura della sintassi dell’ Input Text File
Un’Istruzione è una sucessone di dati separati da Parentesi, Intervalli e/o Virgole. Normalmente una istruzione corrisponde ad una singola Input Line. Per una migliore comprensione del contenuto del file è possibile inserire commenti tra il testo tramite l’uso di un punto esclamativo o punto e virgola prima del testo.
Esempio:
! questa è un’istruzione su una sola linea
40 1, 0.1, 10 0, ‘Level 40’ ‘Mod 0’ ‘Mod1’; commento di fine linea
Il Livello rappresenta l’argomento elementare su cui si basa un modello logico, descrive una situazione incerta, un biforcazione dove il passo logico può seguire vie differenti. Ogni bivio ha una probabilità che rappresenta il suo grado di accadimento , un rateo di incertezza che a sua volta valuta la dispersione dei dati utilizzando la statistica del rateo di fallimento (l1,…, ln ) per calcolarne la probabilità, un nuovo indirizzo di livello
precedente e una stringa (comment string) che permette all’utilizzatore di leggere lo sviluppo logico della sequenza.
Seguendo l’esempio precedente è presente una biforcazione, la prima scelta identificata dal numero “0” e chiamata default o success mode, che non possiede un valore di probabilità ne rateo di incertezza in quanto linearmente dipendente dalla probabilità delle altre biforcazioni chiamate failure modes. La relazione è la seguente:
P Pi i m 0 1 1 = − =
∑
Un’istruzione completa di un Livello ben definito comprende diversi comandi in sequenza: • Indice di Livello (nL): viene rappresentato da un numero intero (1…4095) e
identifica il livello per la definizione del vincolo e del suo indirizzo
• Ordine di Livello (m): rappresenta il numero dei possibili modi di fallimento (1…8) in relazione al successo ( “0” ). Un livello binario che ha solo due modi possibili di scelta: un successo e un fallimento ha ordine m = 1.
• Probabilità dei failure modes (P1,…, Pm): rappresenta il grado di accadimento di uno dei possibili failure modes. È un numero reale che ha un valore compreso tra zero e uno 0≤ Pi ≤1 . Per livelli multipli aventi ordine m > 1 deve essere:
i Pi m =
∑
≤ 1 1• Rateo di Incertezza sulla probabilità dei failure modes (r1,…,rm): nei problemi di affidabilità l’analista spesso utilizza il rateo di fallimento ( l’inverso del tempo medio fra i guasti in un processo del Poisson ) per fornire la valutazione di probabilità di guasto in un dato periodo di analisi. A volte infatti non possiedo un valore preciso di incidenza guasti, ma una distribuzione log-normale di probabilità. In questo caso la nostra definizione di probabilità è basata su un valore mediano (corrisponde al 50% della zona di distribuzione) e su un rapporto di incertezza che fornisce una valutazione della dispersione di dati intorno ad esso. Il rapporto di incertezza è il rapporto fra il valore "massimo" (95% della zona di distribuzione) e
"il minimo" (5%) e deve essere un numero reale che ha valore nell’ intervallo
i
i P
r 1
1≤ ≤ in cui Pi è la probabilità mediana relativa. Il programma effettua tutta l'analisi che presuppone "la mediana" come il valore di probabilità ma fornisce inoltre una valutazione della dispersione dei dati di incertezza sulla distribuzione finale di probabilità. Se non vengono usati i dati statistici per la valutazione di probabilità, allora il rapporto di incertezza deve essere 1.
• i0, ..., im Indirizzo di Livello: indica il livello sucessivo secondo la modalità di output, quindi il relativo valore deve essere l’indice di un livello definito; un valore di indirizzo i=0 significa la conclusione della sequenza (end of the
sequence).
• ‘cmL’ titolo del livello: questa serie di caratteri fornisce una descrizione globale del livello.va uscita. Deve essere inclusa fra singoli apici.
• Hide (No print word flag): questo parametro facoltativo consente di nascondere alcune descrizioni del livello dell'uscita nella procedura di presentazione della sequenza . questo comando consente di selezionare un determinato sottoinsieme di livelli di output. Il word flag non può contenere alcun carattere in bianco ed i contrassegni dell'uscita devono essere separati dal segno (|). Per esempio il comando 0|2|4 nasconde il livello di successo (0) ed i modi di guasto livellati 2 e 4.
Esempio: 10 2, 0.3 0.4, 1 1, 20 30 40, ‘Level 10’ ‘Success’ ‘Mod 1’ ‘Mod 2’ 0|2 Nell’esempio il Livello 10 ha 2 modi di guasto che hanno probabilità 0,3 e 0,4 rispettivamente e che hanno entrambe rapporto di incertezza equivalente ad uno (sarà questo il nostro caso).
Quando una sequenza raggiunge il Livello 10 continua in caso di successo il relativo percorso che va al Livello 20, al Livello 30 quando si verifica il modo di guasto n.1 e al Livello 40 se si presenta il modo di guasto n.2. Il livello è stato identificato rispettivamente con i termini scritti tra gli apici.
Inoltre il comando View Event presentation ( 0|2 ) mostra questo livello soltanto sul modo di guasto n.1.
Questi comandi costituiscono la sintassi base del programma, tuttavia ve ne sono altri che vengono utilizzati dinamicamente per muoversi attraverso il programma. Eccone un elenco:
Vincolo per il Cambiamento di Indirizzo
Consente di cambiare il tempo di esecuzione del percorso logico seguendo un livello obbligato (definito target level), cambiando il successivo indirizzo come effetto delle uscite di un determinato livello precedente (source level). È un vincolo dinamico perché diventa attivo soltanto quando la sequenza corrente passa sopra una determinata uscita del livello sorgente.
Un'istruzione per i vincoli del cambiamento di indirizzo contiene i seguenti comandi d'informazione:
• A o a Questo carattere rappresenta il tipo di vincolo.
• Indice del Source Level (nL): identifica il livello in cui le uscite attivano il
cambiamento, quindi il relativo valore deve essere l'indice di un livello definito. • Flag identifica le uscite che attivano il cambiamento di indirizzo. Permette
di selezionare un sottoinsieme delle uscite di livello possibili.
• Indice del Target Level (kL): identifica il livello in cui gli indirizzi devono essere cambiati, quindi il relativo valore deve essere l'indice di un livello definito.
• Vincolo di intensità (ki): è un parametro opzionale che permette di definire una gerarchia sui vincolo logici e probabilistici. È un numero Integer compreso tra 1 e 255. Questo permette di attivare un vincolo logico se e solo se la probabilità del target level non è stata già modificata da un vincolo con intensità maggiore.
Esempio: A 10 0|2, 20, * 10 * 30 0 40
Quando la sequenza considera nel L. 10 il successo o il modo di guasto 2 il livello 20 si modifica cambiando gli indirizzi del modo di guasto 1 (10) e 3, 4 e 5 in 30, 0, 40 rispettivamente.
Lo zero rappresenta la fine della sequenza.
Vincolo logico
Permette di vincolare il tempo di esecuzione dell’uscita di un livello (target level) in relazione all’uscita di un altro (source level). È un vincolo dinamico perché diventa attivo soltanto quando la sequenza corrente passa sopra una data uscita del livello di sorgente. È costituito da determinati campi:
• L o l Questo carattere rappresenta il tipo di vincolo.
• Indice del Source Level (nL): identifica il livello in cui le uscite attivano il
cambiamento, quindi il relativo valore deve essere l'indice di un livello definito. • Flag identifica le uscite che attivano il cambiamento. Permette di
selezionare un sottoinsieme delle uscite di livello possibili.
• Indice del Target Level (kL): identifica il livello in cui le uscite devono essere cambiate, quindi il relativo valore deve essere l'indice del livello definito. • Vincolo di intensità (ki): è un parametro opzionale che permette di definire
una gerarchia sui vincolo logici e probabilistici. È un numero Integre compreso tra 1 e 255. Questo permette di attivare un vincolo logico se e solo se la probabilità del target level non è stata già modificata da un vincolo con intensità maggiore.
Esempi: L 10 0|1, 20, 3, 200 ! un vincolo molto forte
Nel primo esempio quando la sequenza comprende il successo o il modo di guasto uno nel livello dieci allora il livello 20 viene fortemente vincolato al modo di guasto 3 che da questo momento in poi avrà probabilità di accadimento uno (la certezza!) se non viene cambiato nuovamente da un altro vincolo con intensità maggiore di 200.
Nel secondo esempio le uscite del livello 50 costringono le uscite del livello 60 a copiarsi in modo inverso.
Vincolo probabilistico
Permette di cambiare la probabilità di accadimento dell’uscita di un livello (target level) in relazione alla probabilità di un altro (source level). È un vincolo dinamico perché diventa attivo soltanto quando la sequenza corrente passa sopra una data uscita del livello di sorgente.
È costituito da determinati comandi:
• P o p Questo carattere rappresenta il tipo di vincolo.
• Indice del Source Level (nL): identifica il livello in cui le uscite attivano il
cambiamento, quindi il relativo valore deve essere l'indice di un livello definito. • Flag identifica le uscite che attivano il cambiamento. Permette di
selezionare un sottoinsieme delle uscite di livello possibili. (0|1|2|…)
• Indice del Target Level (kL): identifica il livello in cui le uscite devono essere cambiate, quindi il relativo valore deve essere l'indice del livello definito. • Nuove probabilità dei failure modes (P1,…, Pm): rappresentano le nuove
probabilità che devono essere cambiate nel livello definito da kL.
• Nuovi ratei di Incertezza sulla probabilità dei failure modes (r1,…,rm): se non si utilizzano nel programma (come nel nostro caso) il loro rateo deve essere uno.
• Vincolo di intensità (ki): è un parametro opzionale che permette di definire una gerarchia sui vincoli logici e probabilistici. È un numero Integer compreso tra 1 e 255. Questo permette di attivare un vincolo logico se e solo se la
probabilità del target level non è stata già modificata da un vincolo con intensità maggiore.
Esempio: P 50 3|0, 20, .1 1E-12 2.32E-4 .1 1 1 1 1 1 1, 8 ! Liv.20 ordine 5
Nell’esempio quando la sequenza comprende il successo o il modo di guasto tre nel livello cinquanta allora le probabilità e i ratei di incertezza del livello venti vengono modificati con i valori scritti sopra. Successivamente tali valori potranno essere cambiati solo da vincoli con intensità maggiore di otto.
Vincolo BAYES
Consente di cambiare il tempo di esecuzione modificando secondo un determinato algoritmo la probabilità delle uscite di un determinato livello (target level) a seconda della probabilità delle uscite del livello sorgente. È un vincolo dinamico perché diventa attivo soltanto quando la sequenza corrente passa sopra una data uscita del livello di sorgente. Questo vincolo aggiorna “a priori” le probabilità di uscita del target level: P(b0), P(b1),…., P(bm) data la conoscenza del risultato di un uscita del livello sorgente: a calcolando a posteriori le probabilità condizionate secondo l’algoritmo del Teorema di Bayes: P(b0 | a), P(b1 | a),….., P(bm | a).
Teorema di Bayes: P b a
( )
P b( ) ( )
( ) ( )
P a b( )
P b P a b k P b L i i i k k k i i | | | = ⋅ ⋅ = ⋅ ⋅∑
Li = P(a|bi)Se durante il calcolo avviene che P(a) = 0, allora significa che la probabilità condizionata è in relazione ad un evento impossibile. Quindi il programma visualizza un errore logico sul tempo di esecuzione ed interrompe la generazione dinamica dell’albero degli eventi (event
tree).
• Indice del Source Level (nL): identifica il livello in cui le uscite attivano il cambiamento, quindi il relativo valore deve essere l'indice di un livello definito.
• Flag identifica le uscite che attivano il cambiamento. Permette di selezionare un sottoinsieme delle uscite di livello possibili. (0|1|2|…)
• Indice del Target Level (kL): identifica il livello in cui le uscite devono essere cambiate, quindi il relativo valore deve essere l'indice del livello definito. • Probabilità condizionata dei failure modes del target level (L0, ... , Lm): è la
probabilità legata all’evento di attivazione [a] sulle uscite [bi]. È un numero reale compreso tra zero e uno.
Nell’esempio quando la sequenza valuta il successo del livello 50 il programma aggiorna il livello 70 utilizzando l’algoritmo del teorema di Bayes.
Vincolo sul tempo di attivazione (TIME FACTOR)
Questo vincolo definisce una insieme di modi di guasto dipendenti dal tempo. È utile quando si analizza un sistema in una precisa finestra temporale; ad esempio durante il fuori servizio di un componente di un impianto riparabile. Quindi posso analizzare il comportamento del sistema durante una successione critica di guasti.
Il programma considera una relazione lineare tra il tempo e la probabilità di guasto. Questa ipotesi è possibile solo se se la finestra temporale è molto più piccola del tempo medio tra i guasti [t]che non è altro che l’inverso del rateo di guasto [l]. ∆t<<τ =1/λ
Infatti solo con questa ipotesi posso assumere localmente lineare la distribuzione della probabilità di Poisson che caratterizza il tempo tra i guasti.
Durante la generazione dinamica dell’albero degli eventi il programma immagazzina una variabile con doppia precisione chiamata mission time, che rappresenta il formato corrente
dell'intervallo di tempo su cui siamo interessati nella verifica delle uscite del livello, normalizzato rispetto al periodo di analisi.
Questa variabile, inizializzata al valore 1 all'inizio di ogni nuova sequenza, può presupporre un valore x<1, che significa che siamo localmente interessati a studiare il problema in un intervallo di tempo minore del periodo totale dell’analisi.
Misura il formato della finestra di tempo di controllo e varia secondo un valore, chiamato
time factor maggiore di zero o secondo un vincolo chiamato mission time reset.
Sulla base del valore del parametro time factor [tf ] il programma stabilisce se il modo di guasto è collegato con la relativa finestra di tempo (il tempo critico competente). Effettivamente se tf>0, questo valore rappresenta il formato della finestra di tempo relativa al modo di guasto.
In base a questo posso avere determinate situazioni nel programma che andremo ad analizzare:
1. se tf = 0 non ho finestre di tempo e il programma utilizza come probabilità di guasto il valore:
out probability mission time_ ⋅ _
e aggiunge la probabilità complementare DP all’uscita equilibrata:
(
)
∆P out probability= _ ⋅ −1 mission time_
il Complementare ∆P è la probabilità di avere un risultato del programma fuori dal tempo di missione. In questo caso il programma non modifica il valore corrente del mission time.
2. se 0 < tf < 1 siamo interessati nella verifica della sovrapposizione fra la finestra di tempo posseduta dall’uscita (il tempo critico competente) ed il tempo corrente di missione; così il programma utilizza come probabilità di guasto il valore seguente:
{
}
out_ probability⋅min ,1mission time_ +tf
e aggiunge la probabilità complementare DP all’uscita equilibrata:
{
}
(
)
in questo caso il Complementare è la probabilità per avere l'uscita del risultato senza sovrapposizione delle finestre di tempo. Di conseguenza il programma cambia il valore corrente del mission time in un tempo di sovrapposizione medio, in modo da potete ridurre il tempo di controllo alla regione di sovrapposizione:
{
}
new mission time mission time tf mission time tf _ _ _ min , _ = ⋅ + 1
Questo vincolo non ha effetto se il modo di guasto è stato forzato da un vincolo logico in quanto questo significa che il modo di guasto è stato forzato da un evento esterno e non dal proprio rateo di guasto.
Un vincolo time factor è costituito dai seguenti comandi:
• T o t Questo carattere rappresenta il tipo di vincolo.
• Indice del Source Level (nL): identifica il livello dipendente dal tempo di
missione, quindi il relativo valore deve essere l'indice di un livello definito. • Flag identifica le uscite dei guasti che utilizzano il time factor per cambiare
la loro probabilità di guasto. (1|2|…)
• Valore del time factor del livello (tf): se tf>0, esso rappresenta il tempo critico
del modo di guasto; il programma lo cambia nel tempo critico competente sul dato periodo di analisi (correzione del contorno), quindi lo immagazzina come tf · (1-tf/2).
• Ibal Indice di uscita bilanciata: l'effetto del vincolo di time factor deve regolare le probabilità di guasto dipendenti dal tempo quando vengono analizzate in una finestra di tempo (definita dal mission_time) minore del periodo di analisi; questo parametro specifica l'uscita equilibrata a cui si desidera aggiungere la probabilità complementare che rappresenta la probabilità di avere il guasto dipendente dal tempo fuori dalla finestra di tempo corrente.
Naturalmente l'uscita equilibrata non può essere tra quelle presenti nel sottoinsieme Flag (un'uscita di livello non può compensare se stessa).
• Absolute rappresenta un comando facoltativo che tiene conto del fatto che il valore di time factor è sempre il tempo critico competente su un determinato periodo di analisi. Questo inibisce le correzioni al contorno
Esempi: T 20 1|2|4, 0.2 0
t 30 2, 1.74E-3 1, Proficient ! Optional parameter
nel primo esempio i modi di guasto uno, due e quattro sono dipendenti dal tempo e hanno una finestra temporale normalizzata a un periodo di analisi uguale a 0.2. quindi il programma cambia questo valore nel competente out of service time nel periodo dell’analisi assumendo il valore 0.18 (correzione al contorno tf · (1-tf/2) ). Quando il programma attiva questo vincolo "sposta" la probabilità complementare da una uscita costretta (1, 2 o 4), aggiungendola al successo (0).
Vincolo della variazione del Time Factor
Consente di cambiare il tempo di esecuzione del time factor delle uscite dipendenti dal tempo del target level in base al comportamento delle uscite del source level. È un vincolo dinamico perché diventa attivo soltanto quando la sequenza corrente passa sopra una data uscita del livello sorgente.
Per evitare errori è possibile cambiare soltanto il fattore temporale relativo ai modi di guasto dipendenti dal tempo e quindi in relazione a qualsiasi vincolo di time factor.
Questo vincolo è costituito dai seguenti comandi:
• V o v Questo carattere rappresenta il tipo di vincolo.
• Indice del Source Level (nL): identifica il livello in cui le uscite attivano il
• Flag identifica le uscite che attivano il cambiamento. Permette di selezionare un sottoinsieme delle uscite di livello possibili.
• kL Indice del Target Level: identifica il livello in cui le uscite devono essere cambiate, quindi il relativo valore deve essere l'indice del livello definito. • Flag del time factor del target level (Kflag): identifica i modi di guasto del
target level dipendenti dal tempo che hanno bisogno di un nuovo valore di time factor.
• Nuovo valore del time factor (Ktf): se Ktf > 0 questo valore rappresenta il nuovo tempo critico del modo di guasto. Il programma lo sostituisce nel nuovo tempo critico competente e lo immagazzina come ktf · (1 – ktf/2) fino a che non viene nuovamente cancellato da altri comandi.
Esempi: V 20 0|2|3|5, 10 1|2, 1.7e-4 Proficient
v 10 0, 20 1|2|4, 7e-5 ; Level 20 ordine 5
nel primo esempio i modi di guasto due, tre e cinque e il successo [0] del livello 20 modificano le uscite uno e due del livello 10 cambiando il valore del time factor in 1.7 e-4. questo valore rappresenta il competente out of service time del periodo di analisi, allora non c’è più bisogno di correzioni al contorno.
Vincolo di Mission Time Reset
Questo vincolo permette di regolare il tempo di esecuzione (run time) al valore corrente del tempo di missione (mission time) che rappresenta il formato corrente della relativa finestra di tempo su cui noi siamo interessati nel verificare le uscite del livello. ( il valore è normalizzato in relazione all’intero periodo di analisi). Quindi all’inizio di ogni sequenza
questa variabile è x=1. Può assumere il valore x < 1, ciò significa che siamo interessati a cosa accade in un intervallo di tempo minore dell’intera analisi del sistema.
Misura il tempo di ispezione della finestra e varia a causa del vincolo di time factor ( tf>0), o può essere forzato dal mission time reset. È un vincolo dinamico perché diventa attivo soltanto quando la sequenza corrente passa sopra una data uscita del livello di sorgente. Questo vincolo è costituito dai seguenti comandi:
• R o r Questo carattere rappresenta il tipo di vincolo.
• Indice del Source Level (nL): identifica il livello in cui le uscite attivano il
cambiamento, quindi il relativo valore deve essere l'indice di un livello definito. • Flag identifica le uscite che attivano il cambiamento. Permette di
selezionare un sottoinsieme delle uscite di livello possibili.
• Nuovo tempo di missione (Mission Time): è un parametro opzionale che permette di selezionare il valore che uno vuole avere [0< tm <1]. Il valore di default è uno.
Esempio: R 25 0|2|3, 1.3E-4 ! nuovo valore opzionale del tempo di missione
Vincolo pulisci vincoli (Clear Constraints)
Permette di resettare tutti gli effetti causati dai vincoli prodotti durante la precedente sequenza . Questo vincolo ristabilisce la probabilità, il rapporto di incertezza, l'indirizzo del livello seguente ed i valori iniziali di fattore temporale di tutti i livelli vincolati. È un vincolo dinamico perché diventa attivo soltanto quando la sequenza corrente passa sopra una data uscita del livello sorgente.
Questo vincolo è costituito dai seguenti comandi:
• Indice del Source Level (nL): identifica il livello in cui le uscite attivano la
pulitura, quindi il relativo valore deve essere l'indice di un livello definito. • Flag identifica le uscite che ripristinano gli effetti dei vincoli. Permette di
selezionare un sottoinsieme delle uscite di livello possibili.
• Indice di livello di clear root (Iroot): è un parametro opzionale che permette di ripristinare gli effetti dei vincoli solo per i livello che hanno un indice ≥ iroot. Altrimenti senza questo parametro il comando ripristinerebbe i valori iniziali di tutti i livelli.
Esempio: C 10 0, 40 ! Iroot opzionale = 40
Collegamenti tra file
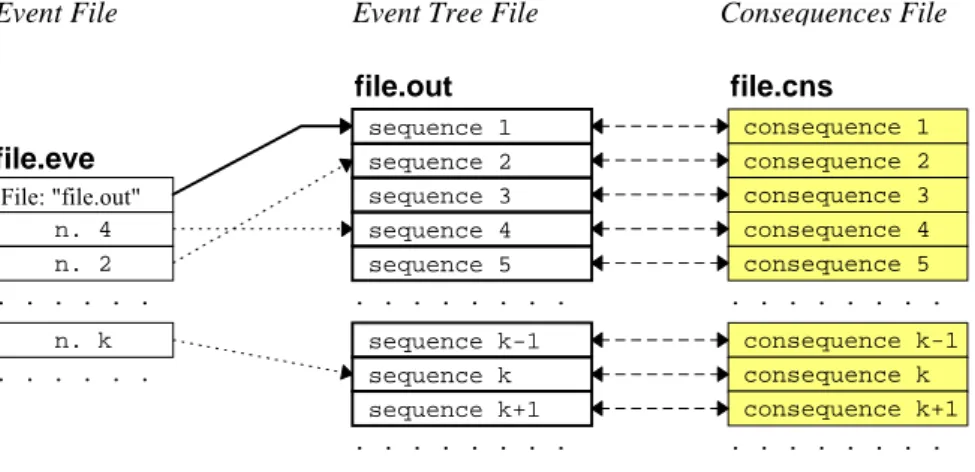
Un buon modello IDDA ha una struttura a shell; un livello rappresenta spesso il risultato di un'analisi di un sottosistema. Di conseguenza è possibile collegarlo ad un file event che spiega i valori dei parametri probabilistici e logici. In pratica questo viene fatto nel View Event Tool in quanto permette all’utilizzatore del programma di saltare da un livello al modello relativo usando il mouse. Un livello si può collegare a più di un event file.
Un esempio di collegamento è quello di figura:
Figura 6.8 – Input e Output di IDDA
file.eve ( or file.out ) file.pun file.out file.cif ( or file.cns ) file.cns Consequence Evaluation Software
IDDA
• > Questo carattere rappresenta il tipo di dichiarazione.
• nL Indice del Source Level: identifica il livello che si collega ad un altro event file, quindi il relativo valore deve essere l'indice di un livello definito.
• File name è il nome dell’event file collegato.
Esempi: > 20 c:\sose\idda\model.out; il livello 20 si collega al “model.out” > 20 c:\sose\idda\mod2.out; il livello 20 si collega anche al “mod2.out”
Struttura della sintassi di testo degli operatori
Un operators text file contiene una lista di istruzioni che permette all’utilizzatore del programma una sequenza di operatori automatici.
Quando il programma esegue un operators text file, per prima cosa analizza la congruenza della sintassi, poi esegue gli operatori seguendo l’ordine del file.
Un’Istruzione è una sucessone di dati separati da Parentesi, Intervalli e/o Virgole. Normalmente una istruzione corrisponde ad una singola Input Line. Una linea non può avere più di 255 caratteri; quindi è possibile scrivere istruzioni più lunghe usando più linee rinchiuse tra parentesi.
Per una migliore comprensione del contenuto del file è possibile inserire commenti tra il testo tramite l’uso di un punto esclamativo o punto e virgola prima del testo.
Esempi:
! questa è un’istruzione su una sola linea
file_2.eve = OR file_0.out, file_1.eve ; commento di fine linea ! questa è un’istruzione su più linee
( file_2.eve, ‘commento facoltativo’, ; commento di fine linea
! eventuale commento su un’intera linea ad esempio un titolo
file_0.out, file_1.eve
Output Binary File: quando il processo di analisi dell’albero degli eventi dinamico genera l’albero degli eventi, immagazzina tutti i dati nel Output Binary File. Quindi questo file dal punto di vista del programma è il cosiddetto spazio degli eventi.
Contiene un riassunto del Input Text File, tutte le sequenze e tutti i valori di probabilità.
( Default: *. OUT )
Event Binary File: ( Default: *. EVE): immagazzina l’evento come una lista di sequenze, selezionati in un determinato spazio di eventi.
Questo file è generato da un operatore evento e collega ad un particolare valore del OBF che immagazzina tutti i dati nello spazio degli eventi. Ogni modifica a questo ultimo file invalida tutti gli EBF collegati ( questo vuol dire che devono essere generati nuovamente e collegati al nuovo valore del output binary file.
Event Files: ogni file che definisce un evento. Dal momento che anche lo spazio degli eventi è un evento un file event può essere dia un Output Binary File oppure un Eventt Binary File.
( Default: *. EVE or OUT )
Consequence Binary File: ( Default: *. CNS): contiene i valori di conseguenze collegate agli eventi di un intero spazio degli eventi. È un file binario cstituido da records ( quattro bite ognuno ); ogni record immagazzina un valore conseguenza. Il programma coppia i file conseguenza nel file di output binario; in questo modo gli stessi file conseguenze possono essere “visualizzati” da tutti gli eventi basati sullo stesso albero degli eventi.
file.eve sequence 1 file.out sequence 2 sequence 3 sequence 4 sequence 5 sequence k-1 sequence k sequence k+1 . . . . . . . . File: "file.out" n. 4 n. 2 n. k . . . . . . . . consequence 1 file.cns consequence 2 consequence 3 consequence 4 consequence 5 consequence k-1 consequence k consequence k+1 . . . . . . . . Event Tree File
Event File Consequences File
Figura 6.9 – Collegamento files Idda
6.6 Visualizzazione e analisi degli Eventi
Nell’analisi dell’albero dei guasti è possibile identificare i possibili Incidenti (Top Event) e quantificare le probabilità di accadimento; ma nella presentazione dei Minimal Cut Sets le informazioni circa la sequenza degli eventi viene perduta.
Nel metodo IDDA invece si richiede la descrizione dell’intero impianto e si produce una serie completa di tutte le sequenze di eventi che possono accadere durante la vita dell’impianto.
La congruenza nella valutazione delle probabilità di accadimento di ogni deviazione possibile è così assicurata, in quanto si richiede che la probabilità totale sia eguale a uno considerando tutte le alternative.
Le uscite del programma Idda permettono di tenere ben presenti tutte le possibili condizioni di probabilità-conseguenza;questo lascia che le decisioni dell’analisi vengano effettuate con la piena conoscenza dell’intera distribuzione del vincolo causa-effetto. Il codice di calcolo inoltre permette una schematizzazione semplice e ben definita; come possiamo vedere in figura 6.8 la View Event window permette all’analista di leggere e verificare in dettaglio l’analisi effettuata su un singolo evento visualizzando in dettaglio il comportamento di ogni singolo componente facente parte della deviazione presa in esame.
Figura 6.10 - Sequence Presentation Mode
Nella figura sono presenti alcune informazioni importanti, dall’alto verso il basso si osserva:
1. Il numero corrente della sequenza presa in esame e la sua posizione nell’albero degli eventi (a seconda dei dati che vogliamo esaminare in ordine di preferenza: dall’evento più probabile in poi, dalle deviazioni che comprendono una determinata uscita, dagli eventi che prevedono il guasto di una valvola specificata, ecc… questi numeri possono non coincidere).
2. La probabilità di accadimento della deviazione in esame 3. Il file in cui sono visualizzate le conseguenze
4. Il valore della conseguenza analizzata (nella trattazione del sistema compressore non sono state prese in considerazione le conseguenze per l’impossibilità di ottenere dati di questo genere).
5. Il valore del rischio associato
6. I livelli che definiscono l’evento: dal primo componente considerato fino alla sua uscita. In questa presentazione sono presenti i modi di guasto, le probabilità associate singole e cumulative, una breve descrizione di ogni livello che permette all’analista una più facile visualizzazione della deviazione considerata.
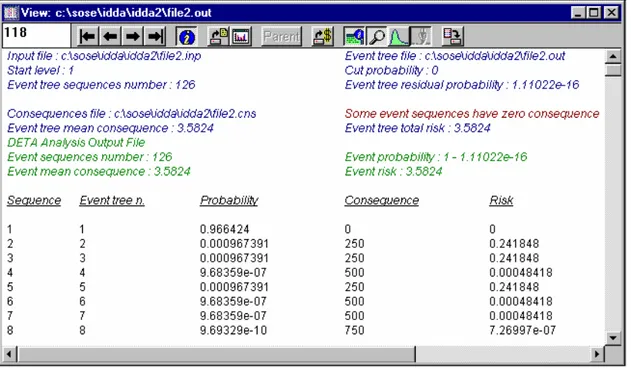
Inoltre il codice Idda ci permette di visualizzare la presentazione generale di tutti gli eventi calcolati dal programma come mostrato in figura 6.9:
Figura 6.11 - Event general data presentation mode
Da questo schema si possono ricavare dati significativi:
input file è il nome dell’input text file usato dall’analisi di processo per la generazione dell’albero degli eventi
event tree file è il nome dell’output text file che immagazzina tutti i dati degli eventi
start level è la radice dell’indice di livello usato dall’analisi dinamica del processo per la generazione
dell’albero degli eventi
cut probability è il valore di probabilità medio utilizzato dalla analisi dinamica del processo per la generazione dell’albero degli eventi per tagliare le sequenze impossibili
event tree sequences number è il numero di tutte le deviazioni dell’albero degli eventi
event tree residual probability è il contributo totale alla probabilità di tutte le sequenze che sono state tagliate. Se il valore della
probabilità residua non è zero pur avendolo nel valore della probabilità di taglio; questo avviene perché i valori delle probabilità sono rappresentate con un numero (il programma utilizza variabili a doppia precisione di 8 byte). Quindi la somma delle probabilità di tutte le sequenze non può essere 1 a causa di un errore di troncamento
consequences file è il nome del file dove sono immagazzinati i dati di tutte le conseguenze
event tree mean consequence è il valore atteso delle conseguenze di tutte le sequenze dell’evento; il programma lo visualizza solo se il cosequences file è stato definito.
event tree total risk è il valore del rischio cumulativo di tutte le sequenze dell’evento; il programma lo visualizza solo se il cosequences file è stato definito.
event comment string è una stringa di commento definita nell’event file; questa stringa permette all’analista di identificare la deviazione con un breve comento
event sequences number è il numero di tutte le sequenze dell’evento
event probability è il valore della probabilità cumulativa di tutte le sequenze dell’evento. Se il comado legato all’incertezza sulla probabilità è attivo ho una distribuzione log-normale legata alla probabilità. Il programma visualizza tre valori: 5%, 50% (probabilità mediana) e 95% del valore approssimativo
event mean consequence è il valore atteso delle conseguenze di tutte le sequenze dell’evento; il programma lo visualizza solo se il cosequences file è stato definito.
event total risk è il valore del rischio cumulativo di tutte le sequenze dell’evento; il programma lo visualizza solo se il cosequences file è stato definito.
6.7 Considerazioni sull’analisi di rischio
L’uso congiunto di un’analisi logico probabilistica e di un’analisi fisica può portare ad approfondire il problema analizzato, fino a raggiungerne una comprensione coerente e, per quanto possibile, completa. Essa è documentata appunto nello schema logico probabilistico e nella sua controparte fenomenologica.
Questo metodo permette in ogni momento di riprodurre tutte le conclusioni raggiunte e, con i loro successivi aggiornamenti, di ricostruire il filo logico del progetto.
Essi, inoltre, concorrono per la loro parte a costituire quel modello più ampio, che deve giungere a rappresentare, sistema per sistema, l’intero impianto.
Naturalmente la descrizione per eventi richiede uno sforzo di adattamento ad un linguaggio non proprio usuale, di cui bisogna acquisire, con un pò di esercizio, la padronanza.
IDDA consente di avere sempre presente nel momento delle decisioni di progetto o di processo tutte le possibili condizioni probabilità /conseguenza.
Questo consente di prendere delle decisioni basandosi sulla conoscenza dell’intera distribuzione del rischio e non solo di valori medi riferiti a situazioni particolari ed individuali.
6.8
Bibliografia
[1] IDDA 2.1; User guide copyright 1996-2000; Software Oriented System Engineering. [2] Integrated Dynamic Decision Analysis (IDDA): a new approach for risk analysis; M. Demichela, N. Piccinini SAfeR - Centro Studi su Sicurezza, Affidabilità e Rischi Politecnico di Torino; 2002
[3] Galvagni, R. and Clementel, S., “Risk Analysis as an instrument of design”, in “Safety Design Criteria for Industrial Plant”, M. Cumo and A. Naviglio (eds.), CRC Press, Boca Raton, 1989.
[4] Piccinini N. and Ciarambino I., “Operability analysis devoted to the development of logic trees”, Rel. Eng. Syst. Safety, 55, 1997, 227-241.
[5] I.D.D.A. Integrated Dynamic Decision Analysis: Uno strumento di decision-aiding basato sulla Teoria delle Probabilità secondo l’approccio soggettivo; Mariagrazia Semenza; Pisa, 13/01/2004