Capitolo 3
Algoritmo di ottimizzazione
Nella prima parte di questo capitolo è esposta la logica di funzionamento del-l’algoritmo di ottimizzazione utilizzato. Nella seconda parte è esposto come tale algoritmo è stato implementato per la nostra ricerca della traiettoria ottima in un tracciato assegnato.
3.1
Variazione genetica e selezione naturale
Un metodo di calcolo e di simulazione molto potente e versatile è rappresen-tato da quella famiglia di tecniche di ottimizzazione che vanno sotto il nome di algoritmi genetici. Gli Algoritmi Genetici (AG), proposti nel 1975 da J.H.Holland, sono un modello computazionale idealizzato dall’evoluzione na-turale darwinista. Ogni individuo ha le sue caratteristiche e proprietà speci-fiche, manifestate esternamente e “visibili”, che ne costituiscono il fenotipo. E’ il fenotipo a dettare le possibilità ed i limiti delle interazioni dell’ indivi-duo con l’ambiente in cui vive. Ma il fenotipo è determinato sostanzialmente dall’invisibile patrimonio genetico o genotipo, costituito dai geni, che sono le unità fondamentali dei cromosomi. Ad ogni gene corrisponde, in generale, un caratteristico fenotipo. Pertanto la sopravvivenza degli individui con carat-teristiche più adatte, significa in realta la sopravvivenza dei geni più adatti. I due principi fondamentali dell’evoluzione sono la variazione genetica e la
3.1 Variazione genetica e selezione naturale
selezione naturale. Affinché la popolazione possa evolvere, gli individui che la costituiscono devono anzitutto avere una ricca varietà di fenotipi e quindi di genotipi. Può allora scattare la selezione, che premia la sopravviven-za, la longevità e la riproduzione degli individui più adatti. I meccanismi generatori della varietà del genotipo sono sostanzialmente due: un proces-so combinatorio di geni, grazie ai diversi apporti dei genitori, nell’ambito della riproduzione sessuale, e le mutazioni genetiche casuali. Le mutazioni producono nuovi geni, alcuni dei quali si tramandano alle generazioni succes-sive, mentre altri scompaiono ed il cosiddetto pool di geni, nel quale “pesca” la selezione naturale, cambia continuamente. I cambiamenti che si verificano da una generazione all’altra sono molto piccoli, ma quelli positivi si accumu-lano (selezione cumulativa) e, nell’arco di tempo lunghissimi, danno origine a cambiamenti enormi. Secondo la moderna versione degli equilibri punteggiati, l’evoluzione sarebbe fortemente influenzata da eventi eccezionali e soprattut-to avverrebbe anche per salti. Ciò significa che a periodi di ristagno, che possono essere anche lunghissimi, seguono periodi di accelerazione evolutiva relativamente brevi.
Come aveva già notato Darwin, in alcuni casi bastano periodi limitati di tem-po affinché si verifichino cambiamenti notevoli. Un esempio è costituito dalla selezione degli animali domestici, guidata dall’uomo anziché dall’ambiente, che ha prodotto nel giro di poche migliaia di anni razze canine così diverse come il pastore tedesco ed il bassotto. Un esempio di rapidità evolutiva anco-ra maggiore è quello verificatosi in Inghilteranco-ra in piena eanco-ra industriale. Prima dell’avvento della macchina a vapore, esisteva una specie di farfalle di colore chiaro. Con lo sviluppo delle miniere di carbone, queste farfalle risaltavano sui tronchi d’albero, anneriti dal pulviscolo, e diventavano facile preda degli uccelli. Senonché esistevano poche ma decisive farfalle di colore alquanto scuro (variazione genetica, caso) che poterono sopravvivere e moltiplicarsi (selezione naturale, necessità), originando così in poche decine di anni una specie diversa di farfalle aventi colore decisamente nero.
3.2 Algoritmi genetici
3.2
Algoritmi genetici
Gli algoritmi genetici sono tecniche euristiche di calcolo general purpose, re-lativamente nuove, ispirate dalla meccanica della selezione naturale. Gli AG vengono applicati in un ampio spettro di problematiche: da problemi di natura prettamente controllistica per gasdotti, altiforni e la guida di missili terra-aria, a problemi di natura ottimizzatoria come quello del commesso viaggiatore, dai problemi di ingegnerizzazione come la progettazione di tur-bine e parti aerodinamiche di velivoli, alla modellazione di mercati finanziari telematici.
Dopo la prima diffusione degli AG da parte dell’università del Michigan, i ricercatori preferirono presentare i risultati in convegni specializzati invece che su convegni e riviste orientati alle applicazioni. Ciò perché la natura total-mente differente degli AG rispetto alle usuali tecniche di ottimizzazione non consente un rapporto di performance immediato con altri approcci. I proble-mi di natura implementativa derivano dalla stretta correlazione tra metodica algoritmica e fenomeno naturale, di per se alquanto complessa sia in termini fenomenici che nella terminologia. Gli AG utilizzano la sopravvivenza del-l’individuo in popolazioni di regole decisionali o di soluzioni di problemi o di valori di funzioni. Le creature (valori codificati come stringhe di informazioni logiche) che hanno successo nella popolazione hanno l’opportunità di accop-piarsi e produrre progenie, la cui struttura combina caratteristiche ereditate dalle stringhe dei loro genitori. L’evoluzione della popolazione di stringhe è casuale, ma il suo tasso di miglioramento è fortemente superiore a quello di una semplice random walk. Gli AG (come l’evoluzione biologica) impiegano l’esperienza passata per produrre una ricerca efficiente con performance ele-vate. Gli AG lavorano con popolazioni di soluzioni (parallelismo intrinseco) che tentano di guidare la ricerca attraverso miglioramenti, utilizzando il prin-cipio di sopravvivenza delle migliori soluzioni. La qualità della soluzione è misurata con la fitness (equivalente alla funzione obiettivo o alla funzione di costo nei tradizionali metodi di ottimizzazione) che è la decodifica della stringa genetica. In tal senso la stringa viene chiamata genotipo, mentre la
3.3 Rappresentazione genetica di un problema
soluzione decodificata prende il nome di fenotipo. La ricerca procede con una serie di generazioni in cui ogni individuo contribuisce alla successiva gener-azione in proporzione della sua fitness. Ciò viene realizzato selezionando gli individui in modo casuale. A tal fine viene utilizzata una funzione probabilità pesata tramite i valori della fitness, o i valori del fenotipo scalati o, ancora, un semplice rango.
3.3
Rappresentazione genetica di un problema
Gli algoritmi genetici risolvono un determinato problema ricorrendo ad una popolazione di soluzioni che, inizialmente casuali e quindi con fitness bassa, vengono poi fatti evolvere per un certo numero di generazioni successive, sino all’apparizione di almeno una soluzione con fitness elevata. Per poter applicare l’algoritmo genetico, occorre anzitutto codificare numericamente le soluzioni ed individuare una opportuna funzione di fitness.
3.3.1
Codifica numerica
La codifica numerica è una operazione che ci permette di esprimere i valori dei parametri da ottimizzare in forma binaria in modo da essere utilizzabili dall’algoritmo genetico.
Come prima cosa viene scelto il numero di bit qj utilizzato per rappresentare
ogni variabile.
Una volta scelto il numero di bit è possibile calcolare, con la seguente formu-la, il grado di risoluzione Rj con cui viene espressa una variabile all’interno
del suo intervallo di definizione
Rj =
2qj −1
bj −aj (3.1) dove la singola variabile kj ∈Dj = [aj bj].
Ogni cromosoma xi, cioè ogni potenziale soluzione del problema, sarà
3.4 Operazioni genetiche q= m X j=1 qj
I primi q1 bits mapperanno un valore dell’intervallo [a1 b1], il successivo
gruppo di q2 bits mapperà un valore in [a2 b2] e così via fino all’qm-esimo
gruppo di bits, che mapperà un valore in [am bm].
Si crea infine un vettore, vedi equazione 3.2, contenente la sequenza ordinata in j delle codifiche binarie.
k1 z }| { 1 0 1 1 1 0 0 k2 z }| { 1 0 0 1 0 1 1 0 0 1 ... z }| { 1 1 0 0 km z }| { 0 1 1 0 1 0 1 1 0 (3.2)
3.3.2
Scelta della funzione di fitness
La funzione di fitness è la misura numerica della “bontà” di una soluzione, ge-neralmente normalizzata tra 0 ed 1, e fortemente dipendente dal problema che occorre risolvere. Come già affermato in precedenza corrisponde alla funzione obiettivo o alla funzione costo dei tradizionali metodi di ottimizzazione.
3.4
Operazioni genetiche
La popolazione che evolve ha un numero M di individui (M ≪ 2N), tale
nu-mero viene mantenuto costante da una generazione all’altra. Ad ogni genera-zione, vengono eseguite opportune operazioni genetiche che producono nuovi individui e quindi varietà. Per mantenere costante M , occorre riprodurre nella generazione successiva solo M individui ed essi vengono selezionati con criteri probabilistici, premiando tendenzialmente quelli dotati di maggiore fitness. Le operazioni genetiche più importanti sono il cross-over, la mu-tazione e l’inversione.
Il cross-over (incrocio) assicura, assieme alla duplicazione, il mantenimento di buoni individui per migliorare le soluzioni, mentre la mutazione e l’inversione
3.4 Operazioni genetiche
mantengono la diversità nella popolazione e permettono di ampliare l’esplo-razione. Tutti e tre gli operatori dipendono dal caso ossia dalla probabilità di incrocio, di inversione e di mutazione.
3.4.1
Cross-over (incrocio)
Questa operazione coinvolge 2 stringe “genitrici” < A1, A2, . . . , An >
< B1, B2, . . . , Bn >
e, dopo la scelta casuale di una posizione k (1 ≤ k ≤ n), o punto di cross-over, effettua lo scambio di geni che produce le stringhe “figlie”
< A1, A2, . . . , Ak, Bk+1, Bk+2, . . . , Bn>
< B1, B2, . . . , Bk, Ak+1, Ak+2, . . . , An>
Una variante di questa operazione sceglie casualmente due punti di cross-over k, l (k ≤ l) nelle due stringhe genitrici
< A1, A2, . . . , Ak, . . . , Al, . . . , An >
< B1, B2, . . . , Bk, . . . , Bl, . . . , Bn >
ed effettua lo scambio
< A1, A2, . . . , Ak, Bk+1, . . . , Bl−1, Al, . . . , An>
< B1, B2, . . . , Bk, Ak+1, . . . , Al−1, Bl, . . . , Bn>
Una altra variante considera ogni stringa come un anello chiuso diviso, da k punti di cross-over, in k segmenti che vengono scambiati tra le due stringhe in modo alternato. Un’ altra tecnica per l’evoluzione della specie è quella dello uniform cross-over, vedi equazione (3.3).
Questa tecnica è completamente differente dalle precedenti. Per ogni coppia di genitori si genera casualmente una stringa binaria della stessa lunghez-za l chiamata maschera di cross-over. Ogni bit della stringa discendente
3.4 Operazioni genetiche
(corrispondente ad un gene del figlio) viene creato tramite una coppia del corrispondente bit di una delle due stringhe genitori, scelta in accordo alla maschera. Dove c’è 1 nella maschera, il bit viene copiato dal primo genitore, dove c’è 0 il bit è copiato dal secondo.
M aschera di cross − over 1 0 0 1 0 1 1 1 0 0 Genitore1 1 0 1 0 0 0 1 1 1 0 ↓ ↓ ↓ ↓ ↓ F iglio1 1 1 0 0 0 0 1 1 1 1 ↑ ↑ ↑ ↑ ↑ Genitore2 0 1 0 1 0 1 0 0 1 1 (3.3)
Quando due cromosomi sono simili, i segmenti scambiati con un eventuale taglio, è probabile che siano identici, e portano a creare figli che sono identici ai genitori. Questo è meno probabile che succeda con l’uniform cross-over.
3.4.2
Mutazione
La mutazione riguarda un singolo bit di una stringa che viene cambiato nel valore opposto, con una probabilità prefissata. Si potrebbe così avere, scegliendo a caso il k−esimo bit
< A1, A2, . . . , Ak = 0, . . . , An> → < A1, A2, . . . , A′k = 1, . . . , An>
3.4.3
Inversione
L’inversione riguarda una sola stringa; scegliendo a caso un punto k di inversione, si ha
< A1, A2, . . . , Ak, Ak+1, . . . , An > → < A1, A2, . . . , Ak, An, An−1, . . . , Ak+1
Anche per l’inversione, come per il cross-over, esistono varianti a due o più punti di inversione.
3.5 Algoritmo genetico di base
3.5
Algoritmo genetico di base
Lo sviluppo di un algoritmo genetico nella risoluzione di un particolare pro-blema coinvolge due tipi di decisione. La prima riguarda il modo in cui il problema deve essere modellato e include la definizione dello spazio delle soluzioni ammissibili, la forma della funzione di fitness ed il modo in cui gli individui devono essere presentati come stringhe. La seconda concerne i parametri dell’algoritmo genetico stesso e include le proporzioni della popo-lazione da riprodurre, da incrociare e mutare, la procedura di selezione, la grandezza della popolazione, il numero di generazioni, e decisioni relative a variazioni rispetto l’algoritmo di base.
L’algoritmo genetico di base, di cui esistono molte varianti, è il seguente
1. Inizializzazione casuale di una popolazione di M cromosomi e calcolo delle fitness fi;
2. Scelta di due cromosomi, ciascuno con probabilità proporzionale a fi,
ed esecuzione dell’operazione di cross-over con probabilità Pcross,
otte-nendo due nuovi cromosomi (dei quali si calcola la fitness);
3. Scelta casuale di una stringa e di un suo bit, esecuzione quindi della operazione di mutazione con probabilità Pmut ≪ Pcross, ottenendo un
nuovo cromosoma (di cui si calcola la fitness);
4. Riproduzione di M cromosomi (eliminando quindi i 3 soprannumerati) con probabilità proporzionale a fi; generalmente il cromosoma migliore
viene comunque riprodotto nella generazione successiva, per non rischiare di perderne il prezioso patrimonio genetico;
3.5 Algoritmo genetico di base
5. Ritorno al precedente punto 2, sino al soddisfacimento di un criterio prefissato, come l’avvenuta esecuzione di un determinato numero di cicli, l’ottenimento di almeno un cromosoma con fitness superiore a un valore prefissato o il conseguimento di un prefissato grado di omogeneità nella popolazione;
La scelta di un cromosoma con probabilità proporzionale a fi (compreso tra
0 e 1) può realizzarsi mediante la generazione di un numero a caso ǫ con distribuzione uniforme tra 0 e 1 e la verifica che esso sia inferiore a fi. Un
metodo analogo è quello della roulette
1. La circonferenza di un immaginario cerchio viene divisa in M segmenti con apertura angolare
Ai = 2πfi P(fi) quindi con X i (Ai) = 2π
2. Per ogni fi si genera un numero a caso k, con distribuzione uniforme
tra 0 e 2π;
3. Il cromosoma (i) viene scelto se k cade nel relativo settore Ai;
Generalmente la popolazione comprende da 30 a 200 individui, la probabilità di cross-over varia da 0.5 a 1 e la probabilità di mutazione da 0.001 a 0.05. Secondo un criterio empirico, suggerito dall’esperienza, se la popolazione è piccola, entrambe le probabilità dovrebbero essere più grandi che nel caso contrario.
3.6 Teorema fondamentale degli algoritmi genetici
popolazione, ossia quando la varianza della popolazione è inferiore ad un dato valore fissato ǫ.
3.6
Teorema fondamentale degli algoritmi
ge-netici
Per gli algoritmi genetici non esiste una teoria completa e rigorosa che spieghi tutto, suggerisca i parametri più opportuni da adottare ecc. Esiste tuttavia un Teorema di Holland che assicura la convergenza dell’algoritmo genetico verso una soluzione ottimale.
Nell’ambito di una stringa ci possono essere dei segmenti che contribuiscono molto alla soluzione ottimale come, supponiamo, i blocchi (011) e (110) nei due schemi seguenti a 8 bit (il simbolo * indica qualunque valore)
011 ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗110
Le operazioni genetiche favoriscono generalmente, ma non sempre, il “mon-taggio” dei building blocks in schemi di fitness crescente come, supponiamo
011 ∗ ∗110
Il teorema di Holland dimostra appunto che, sotto certe condizioni, gli schemi con fitness superiore alla media tendono a crescere esponenzialmente nella popolazione. Quanto sopra implica che le “bontà” dei building blocks siano additive.
Esiste però talvolta un fenomeno di interazioni non lineari tra i bit di una stringa (epistaticità) per il quale non è detto che abbinando building block di per sé “buoni” si ottenga una stringa “più buona”. Non sempre quindi l’operazione genetica di cross-over produce buoni risultati e talvolta da due cromosomi relativamente “buoni” se ne produce uno decisamente “cattivo”. Nonostante la mancanza di una solida teoria globale e il permanere di alcune questioni controverse, gli algoritmi genetici si sono dimostrati molto utili per
3.7 Modellazione del problema di ottimizzazione delle traiettorie
le applicazioni pratiche, dove rivaleggiano validamente o collaborano con le reti neuronali, le euristiche fondate su criteri di scelta, gli algoritmi evolutivi.
3.7
Modellazione del problema di ottimizzazione
delle traiettorie
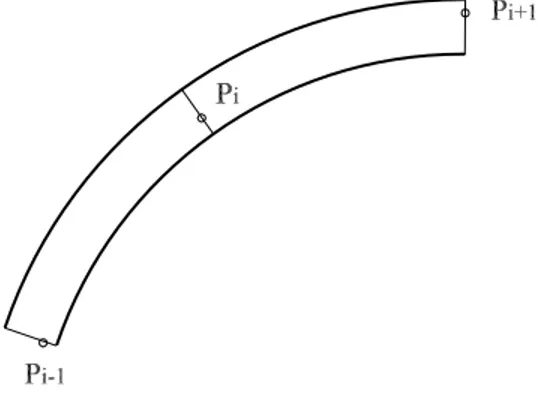
Come scritto nel paragrafo 2.3, una traiettoria viene determinata attraverso la definizione di una serie di n punti di passaggio. Per assegnare tali punti si è operato nel modo seguente:
Definiamo tracciato due linee parallele, in modo che possa essere definita
Figura 3.1: Assegnazione dei punti di passaggio per il tracciamento di una generica traiettoria
una normale comune, dette rispettivamente bordo destro e bordo sinistro. Assegnato un tracciato, si individuano n perpendicolari alla linea media della carreggiata (vedi figura 3.1). Il generico punto di passaggio Pi viene fatto
variare lungo tale perpendicolare per generare una famiglia di traiettorie. La posizione di tale punto è quindi funzione di una sola variabile. Se il valore di tale variabile è uguale a 0, il punto si trova sul bordo interno della corsia, mentre se è pari ad 1 il punto di passaggio è localizzato sul bordo esterno.
3.7 Modellazione del problema di ottimizzazione delle traiettorie
Una generica traiettoria è quindi indentificata da un vettore di n componenti, ognuna delle quali rappresenta la posizione del generico punto di passaggio su ciascuna delle perpendicolari tracciate. Il processo di ottimizzazione tenderà quindi a trovare la “migliore serie” di tali variabili, ovvero quella combinazione di valori compresi tra 0 ed 1 che realizza il minor tempo di percorrenza.
3.7.1
Scelta del numero di variabili
E’ necessario stabilire un criterio per assegnare le n perpendicolari che an-dranno ad identificare i punti di passaggio per il tracciamento della traiet-toria. Come è stato evidenziato in precedenza, tale numero di “raggi” cor-risponde al numero di variabili che bisogna ottimizzare. Come facilmente intuibile, è bene limitare il più possibile tale numero, in modo da poter rag-giungere la convergenza dell’algoritmo di ottimizzazione sviluppato in tempi ragionevoli. D’altra parte è necessario che la traiettoria ottimale risultante rimanga all’interno del tracciato stradale. Affinchè ciò avvenga è necessario incrementare il numero di perpendicolari che rappresentano la traiettoria. Infatti non si ha alcun controllo sul percorso generato nelle zone comprese tra due perpendicolari, quindi un numero insufficiente di queste comporta un elevata probabilità che tale percorso esca dal limite del tracciato. Altra caratteristica importante che il nostro processo deve garantire è l’esplorazione di tutte le parti della carreggiata per garantire la generalità dell’algoritmo. L’ottimizzazione deve infatti garantire la migliore traiettoria possibile, non la migliore tra quelle rappresentabili con la particolare schematizzazione scelta. Per essere sufficientemente confidenti che tutte le zone del tracciato siano analizzate è necessario incrementare il numero di raggi per la rappresen-tazione.
Per poter trovare un criterio di scelta del numero di raggi da tracciare sono state effettuate varie prove sulle curve di esempio presentate nel paragrafo 1.4. A seguito di tali prove si è potuto concludere che è necessario inserire una perpendicolare al tracciato stradale, lungo una curva, ogni 20-30 gradi.
3.7 Modellazione del problema di ottimizzazione delle traiettorie
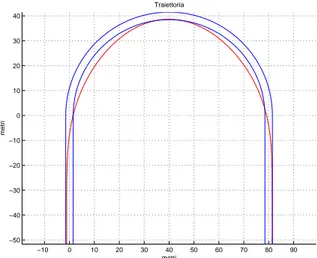
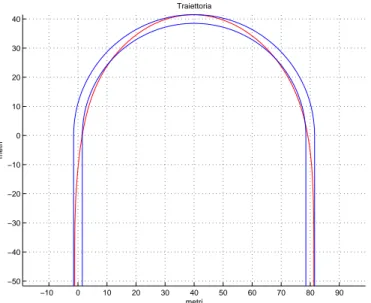
Si riportano in seguito i risultati ottenuti nel caso di un tornante di raggio 40 metri al variare del numero di raggi di rappresentazione.
−10 0 10 20 30 40 50 60 70 80 90 −50 −40 −30 −20 −10 0 10 20 30 40 Traiettoria metri metri
Figura 3.2: Traiettoria ottenuta imponendo il passaggio per tre punti (uno ogni 90 gradi) −10 0 10 20 30 40 50 60 70 80 90 −50 −40 −30 −20 −10 0 10 20 30 40 Traiettoria metri metri
Figura 3.3: Traiettoria ottenuta imponendo il passaggio per quattro punti (uno ogni 60 gradi)
3.7 Modellazione del problema di ottimizzazione delle traiettorie −10 0 10 20 30 40 50 60 70 80 90 −50 −40 −30 −20 −10 0 10 20 30 40 Traiettoria metri metri
Figura 3.4: Traiettoria ottenuta imponendo il passaggio per cinque punti (uno ogni 45 gradi) −10 0 10 20 30 40 50 60 70 80 90 −50 −40 −30 −20 −10 0 10 20 30 40 Traiettoria metri metri
Figura 3.5: Traiettoria ottenuta imponendo il passaggio per sette punti (uno ogni 30 gradi)
3.8 Scelta dei parametri caratteristici dell’algoritmo genetico
3.8
Scelta dei parametri caratteristici
dell’al-goritmo genetico
3.8.1
Funzione di fitness
La funzione di fitness che determina la “bontà” di un generico “individuo” è chiaramente rappresentata dal valore del tempo di percorrenza della traiet-toria interpolante i punti derivanti dalla decodifica del cromosoma. A dif-ferenza dell’algoritmo generale presentato nel paragrafo 4.5, l’ottimizzazione deve tendere a minimizzare tale valore, anziché massimizzarlo come esposto in precedenza.
3.8.2
Codifica numerica
Per la rappresentazione dei valori assunti dal vettore di variabili si è scelta una codifica binaria a 10 bit. Il generico cromosoma risulta quindi formato da sequenza di 10n geni. Una tale codifica permette di identificare 210
valori distinti per ogni singola variabile. Poichè la larghezza della corsia è pari a tre metri, ciò significa che la distanza tra due posizioni successive che può assumere il generico punto Pi (risoluzione), calcolata attraverso l’equazione
3.1 è inferiore a tre centimetri.
3.8.3
Probabilità di cross-over, mutazione ed inversione
La probabilità di cross-over è posta pari a 0.8, quella di mutazione 0.04, mentre non è prevista la possibità di inversione all’interno di un singolo cro-mosoma. Il tipo di cross-over scelto è l’uniform cross-over. Le probabilità scelte sono volutamente elevate per poter limitare il più possibile il numero di generazioni, in accordo a quanto affermato nel paragrafo 3.5. La probabi-lità associata al singolo cromosoma è considerata proporzionale al valore di fitness, secondo il metodo della roulette prima esposto.