Capitolo 4
Strumenti per l’analisi dei dati e soluzioni
per l’aeroporto di Pisa
In questo capitolo vengono presentati alcuni strumenti di analisi dei dati che proponiamo come sviluppo del sistema presentato nel precedente capitolo. Si tratta di tecnologie avanzate che hanno già trovato ampio spazio nelle grandi aziende e che dati i notevoli volumi di costo hanno impiegato diverso tempo per arrivare fino alle medie e piccole imprese. Data l’importanza e il vasto campo d’azione dell’argomento non sarà possibile approfondire la trattazione, limitandoci a fornirne una presentazione nonché alcuni consigli su una possibile implementazione.
4.1 Business Intelligence
Spesso manager e dirigenti d’azienda si chiedono cosa si celi dietro la mole infinita di informazioni di cui dispongono e si pongono delle domande alle
quali appare quasi impensabile rispondere se non dopo aver svolto un lavoro faticosissimo di ricerca di informazioni. Questo perché le persone che sono chiamate a dirigere un’azienda, o anche solo un ramo di essa, sono abituati a convivere ogni giorno con il compito di prendere delle decisioni in condizioni di assoluta incertezza, senza sapere quindi quali conseguenze comporteranno le proprie scelte e soprattutto lottano in continuazione con il tempo, che non gli consente di consultare come vorrebbero le infinite informazioni di cui dispongono e che provengono dal numerose fonti.
La Business Intelligence interviene proprio in questo contesto, comportando per l’azienda la possibilità, forse meglio definibile come capacità, di accedere alle informazioni, analizzarle e da esse estrapolare la conoscenza che può portare il soggetto decisore ad operare con buona prevedibilità delle conseguenze.
Ebbene, il nostro obiettivo è quello di presentare gli strumenti che vengono utilizzati a tal proposito e cercare di trovare una possibile applicazione che potrebbe rivelarsi utile per la società di gestione dell’aeroporto di Pisa.
In fig 4.1 sono state riportate sintetiche alcune caratteristiche riguardanti tutti i singoli strumenti. Nei prossimi paragrafi cercheremo di presentare nel miglior modo possibile ognuno di essi, soffermandoci in particolar modo sul Datawarehouse, ma senza entrare troppo a fondo nelle caratteristiche tecniche.
–
Datawarehouse“Magazzino di dati” centralizzato che raccoglie dati provenienti da sistemi informativi operazionali e fonti esterne, li seleziona, corregge, completa e riconcilia, li rende disponibili ai sistemi informativi decisionali.
–
Data MartDatawarehouse monotematico, in genere di uso dipartimentale p.e. data mart del marketing.
–
OLAP (On Line Analytical Processing)Sistemi per la rappresentazione e l’analisi dei dati secondo un modello multidimensionale.
–
Data MiningAnalisi complesse di dati alla ricerca di correlazioni (pattern) precedentemente sconosciute fra essi.
–
Pattern WarehouseSistema di memorizzazione e gestione dei pattern scoperti con il Data Mining.
fig 4.1 strumenti di Business Intelligence
4.2 Datawarehouse
È probabilmente l’elemento cardine di tutta la materia, anche se come vedremo più avanti alcune delle altre fasi possono essere svolte anche senza averlo realizzato. Fermo resta comunque che l’implementazione di un DW consente di lavorare con un sistema molto più complesso ma che al contempo costituisce una base di lavoro molto più redditizia. In questa fase del lavoro presentiamo il modo in cui si prepara un Datawarehouse per una sessione di lavoro, dopo aver chiaramente descritto le caratteristiche principali dello strumento. Vengono dettati i passi da affrontare ogni volta che si intende sfruttare questo potente mezzo in grado di fornire delle preziose informazioni e quindi della conoscenza.
Probabilmente il modo migliore per affrontare la descrizione del DW è quello di schematizzarne le caratteristiche, in modo da non rischiare di perdere di vista gli elementi fondamentali.
Il Datawarehouse è dunque un insieme di dati:
• Tematici, nel senso che i singoli dati sono strutturati in modo da tenere in collegamento diretto quelli riguardanti un particolare tema o soggetto (p.e. i clienti);
• Aggregati, in quanto non siamo in questo contesto interessati a lavorare sui singoli dati ma sugli aggregati di essi. Sarà quindi più utile sapere l’importo medio delle vendite di periodo che non l’importo di un singolo scontrino;
• Integrati, nel momento in cui le informazioni vengono ricostruite a partire dal flusso di dati proveniente da diverse fonti e che presentano quindi una certa eterogeneità;
• Temporali, intesa come possibilità di registrare e richiamare i dati anche a distanza di 5-10 anni, mentre nei database l’ordine temporale è molto più ristretto;
• Permanenti, perché il Datawarehouse ha una memoria read-only, non è quindi possibile apportare delle modifiche ai dati dopo averli registrati.
4.2.1 Dalla registrazione all’analisi
Il nome (magazzino di dati) è emblematico dell’utilità di questo sistema. Se per alcuni aspetti è paragonabile al classico database (al punto che in qualche caso dagli stessi database si cerca di estrapolare le informazioni necessarie, incontrando pero non poche difficoltà), in realtà, oltre che per le dimensioni, le
due strutture dati si distinguono tra esse per numerose caratteristiche, come riassunto in tabella 4.2.
È bene specificare innanzitutto il significato di Oltp ed Olap, che spesso vengono associati il primo al generico database ed il secondo al Datawarehouse. In realtà Oltp stà per on-line transaction processing, in generale uno strumento che consente di fare transazioni, mentre Olap è l’acronimo di on-line analytical processing, che permette quindi di analizzare quanto rilevato nelle transazioni.
La figura 4.2 ne contrappone le caratteristiche per quanto riguarda gli aspetti principali di una struttura dati. Le differenze sono così evidenti che una trattazione sarebbe quasi superflua, ma vediamo brevemente che sono per prima cosa contrapposti funzionalmente, in quanto un sistema di gestione delle transazioni ha una funzione operativa, registrando cioè i dati quotidianamente o comunque con una cadenza temporale continuativa ed intensa. Lo strumento che consente di analizzare i dati non può invece rilevare le informazioni in continuazione, altrimenti si correrebbe il rischio di trovarsi nell’impossibilità di effettuare delle analisi, in quanto non si avrebbe il tempo di ottenere il risultato dell’analisi che i risultati verrebbero falsati dall’incremento continuo dei dati stessi.
Come si è già detto in generale per la Business Intelligence i beneficiari dell’utilizzo di strumenti Olap sono senz’ombra di dubbio i soggetti decisori, i quali possono sfruttarlo per prendere le proprie decisioni con maggiore coscienza in quanto più informati e consapevoli di quale sia la realtà in cui si trovano ad operare.
Inquadrato in questo modo l’Olap si presenta quindi come gerarchicamente superiore al Oltp, in quanto ne sfrutta le potenzialità unendole a quelle di possibili altre fonti, quali per esempio delle altre strutture dati.
OLTP OLAP
funzione gestione giornaliera
supporto alle decisioni
progettazione orientata alle applicazioni
orientata al soggetto
frequenza gironaliera sporadica
dati recenti, dettagliati storici, riassuntivi, multidimensionali
sorgente singola DB DB multiple
uso ripetitivo ad hoc
accesso read/write read
flessibilità accesso uso di programmi precompilati
generatori di query
# record acceduti decine migliaia
tipo utenti operatori manager
# utenti migliaia centinaia
tipo DB singola multiple, eterogenee
performance alta bassa
dimensione DB 100 MB - GB 100 GB - TB fig 4.2 caratteristiche dei sistemi Oltp e Olap
4.2.2 La preparazione dei dati: ETL
Secondo quanto detto fino ad ora l’Olap fornisce quindi un’istantanea di quella che è la situazione in un determinato momento, fotografando in un certo senso il DB e consentendone una analisi approfondita, mentre lo stesso DB continua senza alcuna interruzione a rilevare e registrare le transazioni.
Data la mole dei dati da analizzare è bene che tutto quanto superfluo e che in qualche modo possa appesantire ed ostacolare le analisi sia rimosso e che le strutture dati siano integrate tra loro per raggiungere una buona coerenza delle informazioni. Queste operazioni preliminari sono tutte svolte nella fase di ETL, acronimo di Extraction Transformation Loading (estrazione, trasformazione e
caricamento). Questi sono proprio i tre passi principali che insieme costituiscono la fase di Data Staging.
Abbiamo parlato a più riprese del fatto che i dati che fluiscono nel DW vengono estrapolati da varie fonti, siano esse dei database o qualunque altra struttura dati. Ed è proprio per questo motivo che il data staging si rende indispensabile, in quanto potrebbero verificarsi delle incongruenze nei dati o delle inutili ridondanze.
La fase di estrazione può comportare un notevole impiego di tempo in quanto spesso si rende necessaria l’analisi di diversi milioni di record, e quel che è più importante è il fatto che vengono ricavati da fonti differenti.
Quando si dispone di tutti i dati necessari è possibile effettuare una vera e propria trasformazione, nel momento in cui si intende integrare le diverse informazioni, creando un’unica grande struttura dati. La diversità delle fonti non solo è rappresentata dal numero dei database, ma anche dalla natura di essi. Per esempio può accadere che vengano in questo contesto integrati il DB degli approvvigionamenti con quello delle vendite o dell’amministrazione. In tal caso potrebbe verificarsi che gli stessi dati siano stati registrati e trattati in modo differente dagli addetti dei vari reparti, come può accadere per esempio per un prodotto che viene considerato in maniera differente tra la fase di approvvigionamento e quella di vendita. Oppure ancora se sono state registrate delle persone bisogna effettuare diversi controlli di omogeneità perché per esempio una stessa persona può essere stata schedata solo con nome e cognome per esteso oppure con iniziale del nome e cognome per esteso o ancora con nome cognome ed indirizzo.
Grazie alle trasformazioni messe in atto sui dati si dispone di una massa omogenea di informazioni che possiamo finalmente caricare sul Datawarehouse. Sappiamo che per i database deve essere progettata una opportuna struttura dati in grado di accogliere i dati stessi nel modo opportuno,
in vista anche dell’utilizzo che di essi ne verrà fatto. Chiaramente questo deve avvenire anche nel Datawarehouse, altrimenti non esisterebbe alcun supporto su cui registrare i record nella fase di caricamento. In questa fase di dimostrazione di funzionamento del DW omettiamo la descrizione dei vari tipi di struttura esistenti attualmente rimandando tale trattazione alla seconda parte del capitolo, nella quale proporremo la struttura di un possibile DW che riterremo adatta quale sviluppo del sistema informativo descritto nel precedente capitolo
4.3 La rappresentazione: multidimensionalità e Datamart
Una volta inserite nel Datawarehouse, le informazioni vengono elaborate creando i valori aggregati menzionati in precedenza. Abbiamo visto però che una delle differenze tra DB e DW è insita nello stile di progettazione, essendo il primo orientato alle applicazioni ed il secondo ai soggetti. Questa importante caratteristica ci mette nelle condizioni di fornire ad ognuno il prodotto di cui necessita, nel senso che con molta probabilità il responsabile del marketing avrà delle necessità piuttosto differenti a quelle del responsabile degli approvvigionamenti o dell’amministrazione. Chiaramente chi si occupa di marketing, del rapporto con il cliente e dei suoi comportamenti sarà maggiormente interessato a studiarne i movimenti più che sapere il numero medio di difetti rilevati nei prodotti, competenza senz’ombra di dubbio dei responsabili operativi. L’orientamento al soggetto offre in questo modo la possibilità di estrapolare dalla stessa massa di dati una eterogeneità di informazioni.
Le diverse rappresentazioni di dati che in questo modo si vengono a creare prendono il nome di Datamart, ovvero dei veri e propri Datawarehouse in
miniatura, indirizzati singolarmente ad ogni responsabile di settore (Datamart del marketing, della produzione, ecc.). In questo modo il Datawarehouse si presenta come strutturato gerarchicamente, costituito da una serie di componenti più piccole, utilizzabili ed analizzabili singolarmente.
La prima necessità avvertita è quella di poter disporre di tali aggregati, perché per quanto possa essere utile l’apporto di personale specializzato ci deve comunque essere un meccanismo automatico di presentazione dei dati, in modo da offrire al soggetto decisore la possibilità di consultare dei documenti che molto sinteticamente siano in grado di fornire il giusto bagaglio informativo. A tal proposito sono state create delle strutture grafiche “navigabili” e quindi consultabili da un utente di qualsiasi livello. Si parla in questo contesto del Molap, dove la M sta per Multidimensional, ovvero una rappresentazione multidimensionale dei dati da analizzare. In tab. 4.3 vediamo un esempio di tale struttura.
Nell’esempio riportato in fig. 4.3 si tratta di un vero e proprio cubo tridimensionale e possiamo notare che sui tre assi sono identificati i tre valori da rappresentare (anno, età e tipo).
Per evitare di fare confusione è bene definire gli elementi che si trovano nel cubo, nonché l’utilità e l’impiego. Innanzitutto a cosa servono e cosa contengono i singoli quadratini? Viene scelto un parametro da ricavare a partire dagli altri, nel senso che si andrà a trovare nel Datawarehouse quale sia il valore del parametro nell’incrocio tra i valori dei tre assi. Questi tre prendono il nome di dimensioni mentre il valore da rilevare si chiama misura.
Per attenerci sempre all’esempio riportato in tabella il valore da misurare è il numero delle polizze stipulate, suddivise in questo caso in base all’anno, l’età del contraente ed il tipo di polizza (dimensioni). Per ogni combinazione di valori di questi tre parametri avremo un particolare numero di polizze. La presenza di un’interfaccia utente semplice da gestire è fondamentale per il manager, il quale potrà ottenere in pochissimo tempo tutti i valori necessari per svolgere il proprio lavoro e per prendere le proprie decisioni. È evidente l’importanza di scegliere nel modo giusto le dimensioni e le misure da rilevare, in modo da rendere strategico l’utilizzo del cubo multidimensionale, che può essere costruito con un numero qualsiasi di dimensioni, anche se solitamente si costruisce su tre dimensioni per una semplice navigazione, magari costruendone più d’uno in base alle necessità.
Le dimensioni possono poi essere strutturate in modo gerarchico, consentendo in un secondo momento di scegliere il livello di dettaglio con il quale analizzare un elemento. Per esempio per quanto riguarda la dimensione tempo, che tra l’altro è quasi sempre presente nei modelli, sarebbe possibile aggregare i dati per anno oppure, entrando più a fondo nel dettaglio, per mese o ancora per giorno e ora.
4.3.1 Utenti finali e documentazione di supporto
Abbiamo parlato di Datamart, di Cubi e dei decisori come utenti di questi potenti strumenti. In realtà spesso, in base soprattutto alla complessità del DW e di tutta la tecnologia ad esso associata i soggetti decisori non hanno né il tempo né le competenze per lavorare con questi “marchingegni”. In tal caso il manager mette a disposizione la propria competenza in termini di processi aziendali e manifesta le proprie esigenze ad un team che si occupa in modo particolare di ottenere dal sistema le risposte alle domande dei dirigenti.
Per fare un piccolo esempio un responsabile vendite della Fiat potrebbe chiedersi quante Fiat Punto siano state vendute in Toscana nel 1999. Analizzando la domanda vediamo che il parametro da ricavare (misura) è il numero di pezzi venduti, mentre le dimensioni in questo caso sono rappresentate in termini di tempo (1999), luogo (toscana) e modello di prodotto (Punto). Con molta probabilità esisterà già un modello multidimensionale in grado di rispondere alla domanda. In tal caso basterà interrogare il sistema a tal proposito e la risposta verrà trascritta direttamente in un report, ovvero un documento sintetico e di notevole impatto visivo che darà al destinatario la possibilità di risparmiare del tempo potendo risolvere i propri interrogativi in modo esaustivo e soprattutto immediato. Nel caso in cui non esista ancora un supporto multidimensionale adatto se ne potrà costruire uno senza dover fare uno sforzo eccessivo. Chiaramente ciò può avvenire se la struttura dati è stata progettata nel modo più consono e se le domande possono effettivamente trovare risposta.
Il problema della reportistica non và assolutamente sottovalutato, perché la dirigenza di un’azienda non dispone del tempo necessario per la consultazione
di documenti lunghi e complessi, dato che si trova a dover prendere delle decisioni importanti con una frequenza molto elevata.
In realtà il significato ed il sistema di utilizzo dei report è decisamente più ampio, non limitato quindi soltanto all’ambito della Business Intelligence. In generale, infatti, la reportistica comprende tutti quei documenti che fluiscono all’interno di una azienda soprattutto verticalmente, sia dall’alto verso il basso che viceversa. Nel primo caso si tratta principalmente di direttive che vengono trasmesse dalla dirigenza aziendale in merito ai compiti che i subordinati sono tenuti a svolgere. Quando i flussi informativi avvengono, invece, dal basso verso l’alto della scala gerarchica, sono dettati principalmente dalla necessità di avere un riscontro rispetto a quanto era stato previsto all’inizio del periodo. Si parla quindi di valore preventivo per il primo e consuntivo per il secondo tipo di comunicazioni.
Un altro importante aspetto riguarda i fatti che si intendono misurare e gli aspetti dell’azienda su cui si intende focalizzare l’attenzione. Questo è legato principalmente al fatto che, come ripetuto diverse volte, ogni utente del sistema si presenta con le proprie necessità e mira le proprie attenzioni verso un particolare aspetto. A tal proposito vengono identificati i fattori critici di successo (CSF), definibili anche come quegli ambiti in cui l’azienda deve obbligatoriamente eccellere per poter raggiungere (o tenere) un vantaggio competitivo nei confronti della concorrenza. Non si tratta di obiettivi che l’azienda si pone, ma delle vere e proprie aree, come per esempio i costi, la qualità, i servizi ai clienti.
Per poter in qualche modo misurare il livello di soddisfazione dei parametri di sufficienza dettati dai CSF sono necessari degli indicatori. Per fare ciò vengono definiti quelli che prendono il nome di KPI (Key Performance Indicator), che forniscono appunto degli indicatori chiave di performance, in modo da capire con certezza la situazione dell’azienda in quel campo. Un
esempio evidente è costituito dalla misurazione dei costi di produzione, per il quale è fondamentale tenere sotto controllo il costo unitario, il numero di ore di lavoro effettuate per la produzione di un singolo prodotto, sia in termini umani che come utilizzo dei macchinari.
4.4 Data Mining ed estrazione della conoscenza
Di fronte a quantità di informazioni davvero incontenibili come visto fino ad ora è naturale domandarsi se possano o meno esistere dei collegamenti tra diversi elementi che con una analisi manuale non possono in alcun modo essere rilevati. Di questo e di altro si occupa il Data Mining, il cui obiettivo principale è proprio quello di estrarre della conoscenza dai dati a disposizione, effettuando delle approfondite analisi ed elaborazioni, avvalendosi del supporto di rodati algoritmi, in grado di lavorare con milioni di record.
La struttura dati ideale in grado di preparare al meglio i dati per una analisi di questo tipo è senz’ombra di dubbio il Datawarehouse, soprattutto per applicazioni di dimensioni avanzate. Fermo resta comunque che questo strumento di Business Intelligence può essere applicato ed utilizzato anche su strutture dati di tipo differente, non necessitando quindi obbligatoriamente di un Datawarehouse dal quale attingere le informazioni.
Ciò che gli algoritmi in questione effettuano è fondamentalmente la ricerca, all’interno di una mole immensa di dati, di rapporti tra questi, di nessi non casuali. I risultati potranno rivelarsi poi fondamentali per la dirigenza di una azienda, che potrà in questo modo diminuire ulteriormente il grado di incertezza nel quale opera. A tal proposito il Data Mining fornisce un valido supporto per due differenti scopi, a seconda di quale sia la necessità dell’utenza. L’utilizzo di alcuni algoritmi, infatti, comporta la possibilità di
predire un certo comportamento, partendo dall’analisi di quanto già accaduto in passato. Per semplificare la comprensione menzioniamo un esempio pratico. Se si conoscono le caratteristiche di tutti gli evasori fiscali identificati negli ultimi dieci anni (per caratteristiche non si intende solo l’entità dell’evasione, ma anche informazioni sul nucleo familiare, sul reddito, sui possedimenti, sugli hobby, ecc), il sistema sarà in grado di suddividerli in classi omogenee (clusters) in base a qualche caratteristica ricorrente. In questo modo quando verrà sottoposto a controllo un nuovo soggetto verrà effettuata in automatico una previsione analizzando semplicemente le sue caratteristiche rispetto a quanto già registrato. Certamente il sistema può sbagliare con una percentuale che varia da caso in caso, ma che comunque gli fornisce la possibilità di apprendere automaticamente ogni qualvolta vengono inserite informazioni nuove, dato che le classi non sono statiche, ma aggiornabili. Chiaramente man mano che i dati aumentano il sistema acquista intelligenza e migliora la propria capacità predittiva, affinando sempre più il controllo delle caratteristiche fondamentali, avvicinandosi paradossalmente a quella che è la perfezione, ovvero alla capacità di dire con estrema certezza se e chi è evasore e magari anche l’entità del furto ai danni dello stato.
Ci sono poi anche altri tipi di algoritmi, che invece di predire classificano quanto realmente accaduto fino ad ora, con l’unico scopo di adottare dei provvedimenti in merito, fornendo un valido supporto ai soggetti decisori, che hanno in questo modo la possibilità di avere una visione più chiara e completa del proprio campo d’azione.
4.5 Possibili applicazioni per l’aeroporto di Pisa
Abbiamo visto fino ad ora quali siano gli strumenti per registrare le informazioni e quali altri consentano di analizzarle. Abbiamo tra l’altro affrontato tutti e tre i livelli di benefici che possono essere ricavati dall’uso di tali strumenti, partendo dalla semplice reportistica, passando per l’analisi vera e propria dei dati fino ad arrivare alla Knowledge discovery. Tutto questo ci dà la possibilità di studiare una soluzione adatta per la Sat, in funzione anche del sistema informatico consigliato nel precedente capitolo. Ricordiamo che si tratta di una bozza di struttura dati, ma che può comunque essere di aiuto come linea guida per lo studio di una sua possibile implementazione.
Nei precedenti paragrafi abbiamo volutamente omesso una descrizione dettagliata della progettazione della struttura dati nonché dell’architettura della stessa, concentrando l’attenzione soprattutto sui meccanismi di utilizzo e di lavoro del Datawarehouse. Dopo aver studiato le potenzialità di questi strumenti possiamo ora affrontare proprio questo aspetto, presentando i diversi modelli di struttura dati alla ricerca del più consono al raggiungimento dei nostri obiettivi.
4.5.1 Le differenti architetture per i Datawarehouse
Sappiamo che il Datawarehouse, a parte delle caratteristiche peculiari si presenta molto simile al Database, quantomeno per la definizione intrinseca di struttura come collezione di dati. Anche per quanto concerne l’architettura durante la fase di progettazione si possono seguire gli stessi principi visti nell’ambito relazionale, con l’unica differenza che si può optare per due
differenti tipi di architettura in base alle esigenze e caratteristiche dei dati sui cui lavorare.
Il modello più semplice, nonché il più comune è senz’ombra di dubbio lo schema a stella, il quale, come già visto anche per le rappresentazioni multidimensionali, vede come elemento cardine la tabella dei fatti (o misura) ed interno, proprio come le punte di una stella le varie dimensioni. Chiaramente ci sarà, come per i database, un meccanismo di chiavi esterne che metterà in diretto collegamento i dati delle tabelle tra loro comunicanti. Ciò che è fondamentale è il verso delle frecce, tutte uscenti dalla tabella dei fatti, in quanto, seguendo il principio già descritto ogni elemento della tabella centrale fa riferimento ad uno solo degli elementi della tabella delle dimensioni, il che non è affatto vero per il contrario. Un esempio. Se si considerano le vendite di una azienda e tra le dimensioni c’è anche il nome dei prodotti è chiaro che una vendita vede come oggetto una sola volta il prodotto, il quale pero può essere, è evidente, oggetto di più transazioni (non inteso come prodotto fisico ma come tipologia). Lo stesso discorso è valido anche per la base di dati mostrata nel capitolo tre e che potrebbe comunque rappresentare una valida base di partenza.
Esiste poi un importante modello che varia dallo schema a stella per un dettaglio in particolare. Si tratta del caso in cui una o più dimensioni possano essere strutturate gerarchicamente. È il classico esempio della variabile tempo nella quale possono essere inseriti come attributi anno, mese, giorno oppure si può creare una vera e propria gerarchia di tabelle concatenate che partendo dall’anno arrivano al giorno. Ma non è evidentemente l’unico caso, se ne potrebbero presentare diversi, a seconda dei dati a disposizione. La struttura dati così composta prende il nome di schema a fiocco di neve ed è utile in base al tipo di analisi che sui dati si vogliono fare e chiaramente all’importanza che a quegli attributi viene assegnata.
Un’ulteriore sviluppo dello schema a stella è rappresentato dallo schema a costellazione, che vede la presenza contemporanea di più tabelle dei fatti, con possibili collegamenti tra le due o anche semplicemente con riferimenti alle stesse tabelle dimensionali. In questo modo di rende possibile anche navigare tra le due tabelle, che si presentano in pratica come due (o più) stelle sovrapposte.
Di seguito è riportata la possibile struttura di uno schema a stella, che alla luce di quanto appena detto appare come il più adatto. I dati sono stati ricavati dall’elaborazione combinata dei due schemi relazionali presentati nel capitolo 3. Nella creazione delle tabelle, dimensionali in particolare, non è necessario che vengano riportati i valori nello stesso ordine e disposizione con il quale si trovano nella struttura relazionale, ma possono essere anche ristrutturate, talvolta combinando anche due o più tabelle tra loro. È questo il caso della tabella dei voli, che nel nostro lavoro è il risultato di una rielaborazione delle relative tabelle, prese da entrambi gli schemi visti in precedenza. È possibile anche includere gli attributi di una tabella tra quelli di un’altra, nel caso in cui i primi abbiano uno scarso valore se presi autonomamente. Nel nostro caso questo è successo con la tabella relativa alle compagnie aeree in quanto l’unico parametro interessante, relativo al nome della compagnia, è stato inserito tra i dati dei singoli voli, dato che il numero delle compagnie, essendo comunque ridotto per sua natura, non comporta assolutamente il moltiplicarsi del numero dei record
Dimensione : Negozi
CodTempo Ora Giorno Mese Anno
252 10 19 11 2004 566 12 25 12 2003 .. .. .. .. .. CodNegozio NomeNegozio 1 Fashion Gate 6 Oca bianca .. ..
CodVolo CodTempo CodNegozio CodAeroporto CodCl Importo
025215 252 6 Std 3211 154,00
251151 566 6 Fco 154 89,50
.. .. .. .. .. ..
CodAeroporto Città Nazione
Fco Roma Italia
Std Londra Inghilterra
.. .. ..
CodCl Tipo Sesso Nazionalità
3211 PaxPar M Italiana 154 Staff F Inglese
.. .. ..
Codvolo Data Nposti Npax NVolo Compagnia
Tabella dei fatti : vendite
Dimensione : Aeroporti Dimensione : Voli Dimensione : Clienti 025215 10/12/2004 149 130 Az578 Alitalia 251151 15/11/2003 165 141 Ba546 British .. .. .. .. .. .. Dimensione : Tempo
Sulle dimensioni possono poi essere previste delle gerarchie, che permettono di scegliere all’occorrenza la granularità dell’informazione da gestire, evitando un’elaborazione troppo onerosa nel caso in cui si renda sufficiente lavorare su aggregazioni dei dati e non sul singolo dettaglio. In fig 4.4 sono riportate delle possibili gerarchie sulle dimensioni tempo e aeroporti relative allo schema a stella precedentemente presentato.
anno nazione
città mese
giorno
ora
Fig. 4.4 esempio di gerarchia sulle dimensioni tempo e aeroporti
Nella pratica le gerarchie appena definite saranno utili nel caso in cui, per esempio, si volesse effettuare delle analisi prendendo in considerazione tutti gli aeroporti di una nazione indistintamente, aggregando dunque su questa dimensione. Nell’altro caso, invece, come accade spesso con la dimensione tempo, è possibile scegliere, in base alle esigenze, analizzare le informazioni in base all’ora di acquisto per studiarne l’andamento nell’arco della giornata, oppure controllare i volumi di vendita giornalieri, mensili o annuali.
Sappiamo, perché descritto dettagliatamente in precedenza, che le fasi di preparazione dei dati, nonché di integrazione degli stessi dalle diverse fonti comportano un lavoro piuttosto oneroso. In questo caso, però, l’aver progettato completamente il sistema, dall’inizio alla fine, ci permette di lavorare in modo più lineare, interagendo semplicemente con la struttura dati ipotizzata nel capitolo tre e contenente i dati dei voli, rapportati a quelli delle compagnie, degli aeroporti e a quelli dei singoli viaggi realmente effettuati. Chiaramente questo è possibile se gli obiettivi non variano, cioè lo studio delle vendite in modo diretto e indiretto agendo sul rapporto con le compagnie aeree. Se poi si verificassero delle variazioni nelle esigenze dell’azienda, è sempre possibile lavorare sull’integrazione con altre fonti, nel caso si avverta la necessità di informazioni non presenti tra quelle già disponibili.
A tal proposito merita un appunto particolare la trattazione delle merci dei singoli negozi, che nel nostro lavoro non è stata affrontata in maniera diretta. A primo impatto è evidente il miglioramento che subirebbe il sistema in questo modo, dato che si potrebbe avere una visione molto più approfondita, riuscendo addirittura ad identificare i gusti, in termini di prodotto e non solo di negozio, dei passeggeri delle varie compagnie o nazionalità. Il problema in questo caso è di doppia natura, dettato dal fatto che innanzitutto alcuni negozi già adottano un proprio sistema di gestione del magazzino e difficilmente potrebbero essere disposti a modificarlo adottando quello proposto in questo contesto. La seconda questione riguarda la presenza di negozi pressoché monotematici (nel senso che offrono ognuno una o comunque poche tipologie di prodotto) porta ad una certa indifferenza nei confronti del prodotto acquistato. Non è infatti importante se un negozio di prodotti gastronomici tipici della zona vende più olio di oliva extravergine o non, dato che i due prodotti sono tra loro poco differenti. In questo caso infatti è meglio lasciare questo tipo di analisi di dettaglio direttamente al commerciante, il quale vive
ogni giorno questa realtà ed è in grado di gestire al meglio le sue forniture. Diverso sarebbe se ci fossero dei grandi negozi con delle forniture piuttosto ampie perché in tal caso sarebbe compito e interesse di Sat studiare il comportamento dei clienti rispetto alla varietà merceologica dell’attività commerciale.
La semplicità della struttura è dettata anche dal fatto che come da definizione di Datawarehouse questo può essere organizzato gerarchicamente ed essere quindi visto come suddiviso in Datamart, che talvolta hanno ragion d’essere anche isolatamente (indipendenti). Nel nostro caso quello di cui stiamo parlando può essere visto come un singolo Datamart indipendente, in quanto effettivamente vengono gestiti solo alcuni aspetti dell’azienda e in particolar modo quello della vendita dei prodotti commerciali e quindi del controllo di tale attività. Se volessimo gestire parallelamente anche altri aspetti, quale per esempio l’amministrazione dovremmo integrare il sistema con nuove fonti, quali per esempio bilanci o qualsiasi altro documento in grado di fornire quanto richiesto. Il destinatario/utente del nostro sistema è quindi quasi esclusivamente il responsabile commerciale e marketing dell’azienda, che potrà consultare i risultati prima di prendere le proprie decisioni, o per verificarne l’efficacia sul mercato.
4.5.2 Una visione multidimensionale
Ora che abbiamo “disegnato” il grande contenitore per raccogliere i dati, siamo in grado di pensare ad una analisi più dettagliata, mirata a fornire quelle informazioni, successivamente tramutabili in conoscenza necessaria all’azienda per raggiungere un vantaggio competitivo.
In questa fase vedremo alcuni dei tanti cubi multidimenisionali che si possono costruire a partire dalla struttura del Datawarehouse proposto, semplicemente per mostrare le potenzialità di tale sistema. Nel prossimo capitolo ci occuperemo invece di domande e riposte, intese come esigenze informative dell’azienda e potenzialità/capacità del sistema di rispondere ai quesiti proposti.
Negozi Vendite
Voli
Tempo
fig 4.5 esempio di struttura multidimensionale
Nel modello riportato in fig. 4.5 abbiamo selezionato alcune delle tante visioni che del DW si possono avere. È un po’ come vedere un lato di una grande figura, focalizzarsi su un aspetto particolare di un argomento in realtà molto più vasto.
Per poter vedere quali siano i movimenti consentiti nell’utilizzo del cubo è bene presentare prima gli operatori messi a disposizione per plasmare la struttura in base alle caratteristiche richieste. Per far ciò ci sono di notevole aiuto le immagini mostrate di seguito che descrivono graficamente l’effetto degli strumenti in questione.
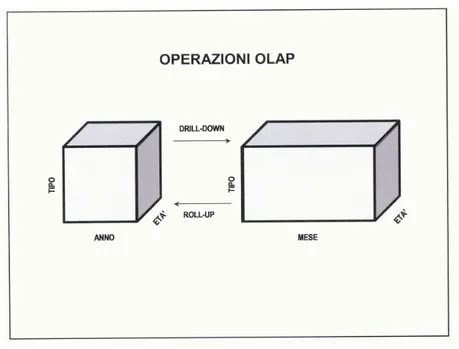
fig 4.6 operatori per cubi: drill-down e roll-up
Nel grafico riportato nella fig 4.6 vengono mostrati contemporaneamente due strumenti, il drill-dowm ed il roll-up che fondamentalmente sono, come funzionalità, opposti tra loro. Infatti, come si intuisce dal verso della freccia, il drill-down si utilizza nel caso in cui si voglia entrare a fondo nell’analisi di una dimensione con gerarchia. Nell’esempio riportato, infatti, vediamo che si passa nella dimensione tempo da un’analisi con rappresentazione annuale ad una mensile, essendo quindi ora in grado di sapere dei dati di vendita non più per anno ma per singolo mese all’interno di tutti gli anni.
Con il roll-up invece si fa il percorso inverso, in quanto, nel caso in cui non interessi andare così tanto a fondo nell’analisi, si può agevolmente
aggregare sulla dimensione, chiaramente a patto che la dimensione stessa lo consenta e che sia strutturata quindi in modo gerarchico.
Vediamo ora di seguito riportato l’operatore slice and dice il quale consente, in due fasi, di poter considerare da prima un solo elemento o comunque un sottoinsieme di una dimensione, eliminando dal computo tutti gli altri valori (slice). Partendo dalla struttura così ottenuta, permette di effettuare ulteriori selezioni sulle altre due dimensioni, ignorando ciò che non è ritenuto interessante, ottenendo in questo modo un vero e proprio sotto cubo interno.
fig 4.7 operatori per cubi: slice and dice
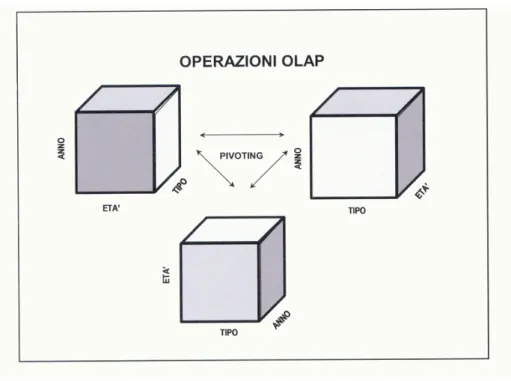
Terminiamo la presentazione dei principali operatori con un semplice strumento che facendo perno su uno spigolo consente di ruotare la struttura muovendo letteralmente il cubo stesso e invertendo dunque la disposizione delle dimensioni. Il tool che consente di far ciò prende il nome di pivot e lo troviamo ben descritto graficamente nella figura di seguito riportata.
Ovviamente l’unico scopo nell’utilizzo di questo strumento è quello di migliorare o comunque modificare l’aspetto visivo del cubo.
fig 4.8 operatori per cubi: pivot
A questo punto abbiamo inquadrato le potenzialità di queste strutture di rappresentazione grafica, che ci permettono in questo modo di avere un impatto visivo sempre più immediato in alcuni casi e in altri di lavorare su quantità di dati sicuramente ridotte rispetto all’insieme di partenza.
Tornando al cubo ottenibile dal Datawarehouse proposto da Sat potremmo usare il roll-up e il drill-down per lavorare sulla dimensione tempo, che in questo caso si presenta con una gerarchia piuttosto ampia, perché possiamo sapere i dati di vendita fino all’orario preciso e quindi per giorno, giorno della settimana, mese e così via a salire. È compito dell’utente definire il grado di dettaglio con il quale operare sui dati. Per quanto riguarda gli altri due operatori possono essere utilizzati indistintamente su tutte le dimensioni.
Chiudiamo il capitolo proponendo un altro possibile cubo di dati, che ci darà in questo modo lo spunto per poter avere più domande cui rispondere nel pro
fig 4.9 esempio di cubo multidim e
ssimo capitolo, nonché per rendere forse meglio l’idea delle potenzialità di questi modelli. È importante ricordare che le dimensioni non sono costituite sempre dall’intera tabella dimensionale, ma possono essere il risultato di una query, di una elaborazione tra attributi o di quant’altro.
Aeroporti
Tempo Vendite
Nazionalità pax