Capitolo 3
Ambiente ASSIST e Deployment
delle applicazioni
Introduzione
In questo capitolo introdurremo l’ambiente di sviluppo ASSIST ed il suo modello a componenti. In seguito vedremo brevemente gli strumenti messi a disposizione del linguaggio di coordinamento di ASSIST per la programmazione della parte funzionale dei componenti. Successivamente mostreremo il meccanismo di Application Management e del contratto di performance. Dopo un accenno alla fase di compilazione dei sorgenti ASSIST e l’interpretazione del contratto di performance vedremo più in dettaglio il funzionamento del Grid Execution Agent. Subito dopo introdurremo le caratteristiche del Broker System e la sua integrazione con il GEA ed il supporto fornito in fase di esecuzione.
3.1 Assist
Assist è un ambiente di programmazione integrato che fornisce un’insieme di strumenti a supporto dello sviluppo di applicazioni parallele e distribuite. Una caratteristica dell’ambiente di sviluppo è quella di offrire un approccio omogeneo alla programmazione delle applicazioni di cui sopra, permettendone l’esecuzione su un’ampia gamma di architetture che include cluster a parallelismo massiccio, reti di workstation e piattaforme Grid. Le applicazioni sono espresse come grafi generici i cui nodi sono componenti e gli archi rappresentano i meccanismi che regolano la loro composizione ed interazione. L’applicazione quindi può sfruttare sia il parallelismo inter-componente che quello intra-inter-componente, quest’ultimo offerto dai componenti stessi che possono, al loro interno, avvalersi di varie forme di parallelismo. Assist, inoltre, supporta lo sviluppo di applicazioni dinamicamente adattive permettendo di creare codice eseguibile per architetture differenti e fornendo i meccanismi per guidare, a runtime, l’eventuale processo di ristrutturazione dei componenti paralleli (es. modifica del loro grado di parallelismo), aggiunta di risorse, de-allocazione di componenti e loro rescheduling su nodi di calcolo alternativi.
3.2 Componenti Assist
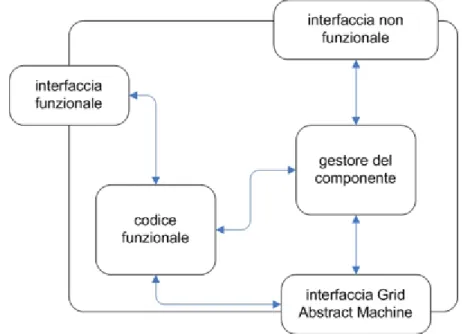
Un componente Assist ha la struttura riportata in figura 3.1; descriviamo brevemente le sue caratteristiche. L’interfaccia funzionale viene utilizzata per esprimere le modalità di interazione del componente con gli altri componenti dell’applicazione; possono essere definite interfacce di tipo
uses/provides (es. CORBA14 – CCM15, DCOM16), oppure di tipo stream.
Figura 3.1 Struttura di un componente ASSIST. Sono visibili le interfacce messe a disposizione e la logica interna.
L’interfaccia non funzionale invece serve a fornire metodi standard di interazione fra i meccanismi a supporto dell’adattività interni al componente e l’application manager che ha il compito di gestire a runtime il comportamento dell’applicazione. I metodi messi a disposizione dall’interfaccia non funzionale possono essere divisi in due gruppi: i metodi del primo gruppo servono ad esportare all’esterno del componente informazioni relative alla sua performance ed alle sue capacità di adattamento; quelli del secondo gruppo danno la possibilità di regolare dall’esterno gli obiettivi di performance del componente e possono essere utilizzati anche per riconfigurarlo direttamente. Il gestore del componente si preoccupa di prendere decisioni sulla base delle informazioni di monitoring locali per eventualmente indirizzare la propria riconfigurazione allo scopo
14 Common Object Request Broker Architecture. 15 CORBA Component Model.
di rispettare il proprio contratto di performance. L’altra interfaccia presente in un componente è quella denominata GAM 17 Interface; questa è l’interfaccia utilizzata per comunicare verso il livello sottostante dell’architettura della piattaforma grid, nel caso fosse necessario utilizzare i servizi del middleware.
I componenti possono essere semplici o aggregati: quelli semplici sono considerati unità base di composizione e rappresentano il componente minimo che può essere gestito dal runtime o alternativamente la classe più piccola di applicazioni che può essere eseguita, quelli aggregati invece cono creati istanziando al loro interno altri componenti (semplici o a loro volta aggregati), detti subcomponenti. Entrambe le tipologie di componenti presentate espongono all’esterno le stesse interfacce e pertanto sono, da un punto di vista esteriore, indistinguibili.
3.3 Codice funzionale
La parte funzionale di un componente è espressa usando il linguaggio di coordinamento ASSIST-CL. Questo linguaggio offre la possibilità di definire programmi in termini di moduli di vario genere interconnessi tramite stream (figura 3.2). Uno stream è una sequenza ordinata, anche infinita, di valori tipizzati. I moduli possiedono un certo numero di stream in ingresso ed in uscita; la computazione definita al loro interno è attivata alla ricezione dei valori sugli stream d’ingresso; in maniera dipendente dal tipo di modulo e dal comportamento desiderato è possibile far sì che la computazione sia attivata solo quando tutti gli stream d’ingresso presentano
un valore, oppure accettarli non deterministicamente. E’ possibile definire il nucleo algoritmico del modulo in uno qualsiasi dei
Figura 3.2 Rappresentazione di un grafo ASSIST. Sono visibili i moduli (M1 .. M5) e gli
stream che li connettono (Si,j)
linguaggi ospitati (Fortran, C, C++), caratteristica che permette così il riuso di codice legacy. I moduli possono essere essenzialmente di due tipi: sequenziali oppure paralleli. Il modulo più semplice che è possibile esprimere è quello sequenziale (seqmod) : possiede uno stato interno e la computazione viene attivata dai valori presi dagli stream in ingresso (non è possibile il comportamento non deterministico). I moduli paralleli (figura 3.3), in ASSIST chiamati parmod, sono più complessi e possono essere usati per implementare algoritmi che sfruttano forme di parallelismo di vario genere, come per esempio pipeline, farm, data parallel con e senza stencil, data flow, dividi et impera così come programmi MPMD18. Un parmod può essere visto come un pipeline a tre stadi: Stadio di ingresso, Processori Virtuali (VP19), Stadio di uscita. Il primo e l’ultimo sono i gestori degli stream in ingresso ed in uscita dal modulo, la computazione viene effettuata dallo stadio centrale da uno o più VP. Ai VP e’ possibile associare una topologia e fare in modo che scambino dati fra loro
18 Multiple Program Multiple Data. 19 Virtual Processor.
utilizzando uno stencil di comunicazione (fisso o variabile) definibile dal programmatore. Il grado di parallelismo di un parmod può essere modificato a runtime, caratteristica questa, che va a supporto delle capacità di riconfigurazione del componente/modulo. Un’altra caratteristica offerta dai moduli ASSIST è quella di permettere di riferire oggetti esterni; l’interazione sarà attuata in accordo con l’interfaccia esportata da quest’ultimi. Questo meccanismo estende ulteriormente le potenzialità dei moduli permettendo, per esempio, l’utilizzo di librerie per la DSM20 variabili condivise oppure oggetti remoti (es. CORBA).
Figura 3.3 Rappresentazione di un parmod. Sono visibili gli stream di ingresso e di uscita
con le relative interfacce, l’insieme dei processori virtuali (VP) e l’interfaccia verso gli oggetti esterni.
Utilizzando il costrutto generic e’ poi possibile collegare più moduli fra di loro realizzando un grafo di moduli ed utilizzarlo all’interno di un componente per la realizzazione di una applicazione più complessa.
3.4 Contratto di performance
Ad ogni componente ASSIST viene associato un contratto di performance. Questo è così definito [Z05]:
- modello di performance - requisiti di performance - annotazioni di deployment - per ogni subcomponente:
- contratto di performance per il subcomponente
- un mapping delle capacità prestazionali del componente aggregato a quelle del subcomponente
Il modello di performance viene generato dal compilatore sfruttando alcune informazioni presenti nel codice del componente (annotazioni di performance), fornite dal programmatore del componente stesso. Un contratto di performance è considerato valutato (assessed) quando associa ad ogni componente il valore atteso della sua performance in maniera tale da soddisfare nella loro totalità i vincoli dell’applicazione. La valutazione del contratto di performance viene effettuata in modo automatico tramite un algoritmo specifico. In caso di componenti aggregati l’algoritmo di valutazione viene applicato in maniera ricorsiva ai subcomponenti. Le annotazioni di deployment, oltre ad altre informazioni riguardanti il peso delle computazioni effettuate dai moduli, specificano i requisiti minimi che deve possedere l’hardware per eseguire ogni modulo; queste informazioni, opportunamente trattate, verranno poi utilizzate dal GEA in fase di lancio dell’applicazione e per tutte le fasi che coinvolgono la ricerca, il filtraggio e la selezione delle risorse.
3.5 Processo di compilazione e valutazione del contratto di performance
Il processo di compilazione e valutazione del contratto procede attraverso le fasi descritte in figura 3.4. Il codice sorgente annotato con le informazioni relative alla performance viene trasformato nei file binari che realizzeranno, una volta in esecuzione, la rete di processi che rappresenta l’applicazione. Più in dettaglio un componente ASSIST semplice, costituito da un grafo di moduli, viene tradotto in una rete di processi; i moduli sequenziali verranno tradotti in singoli processi, mentre i moduli paralleli saranno tradotti in una rete di processi parametrica rispetto al grado di parallelismo che esprime. Le annotazioni relative alla performance presenti nei file sorgenti vengono tradotte nel contratto di performance iniziale; questo è espresso in un formalismo xml ed è possibile, dopo la sua generazione, modificarlo per adattarlo ulteriormente alle proprie esigenze.
Figura 3.4 Il processo di compilazione e di valutazione del contratto di performance.
La fase successiva al processo di compilazione effettua la valutazione del contratto e produce la descrizione dell’applicazione e delle risorse
necessarie a garantire, almeno inizialmente, il rispetto del livello prestazionale specificato. Anche la descrizione dell’applicazione è realizzata utilizzando un linguaggio con sintassi xml ALDL 21 ed è interpretata dal GEA per guidare le fasi di Resource Discovery e Resource Selection.
3.6 Application Management
La gestione dell’applicazione a tempo di esecuzione viene effettuata dall’Application Manager. Questa entità logicamente è considerata centralizzata, ma la sua realizzazione è distribuita: ogni componente possiede un proprio gestore detto CAM22 che ne implementa l’interfaccia non funzionale; questa, come illustrato precedentemente, fornisce sia metodi per effettuare il monitoring dello stato del componente, sia metodi per la gestione della sua configurazione. I CAM sono organizzati in modo da riflettere la struttura dell’applicazione; i CAM appartenenti a componenti aggregati sfruttano le interfacce non funzionali dei componenti al loro interno per guidare la loro riconfigurazione basandosi sulle informazioni di monitoring che quest’ultimi rendono disponibili. All’atto del lancio dell’applicazione l’Application Manager legge il contratto di performance ed incomincia ad eseguire il monitoring dei componenti, controllando che non vengano violati i vincoli prestazionali imposti. In caso di violazione l’AM reagisce in base a strategie selezionabili dall’utente. Durante questa fase è possibile che sia necessario comunicare con il GEA per la scoperta delle risorse, per il loro filtraggio e per effettuare le eventuali prenotazioni.
21 Application Level Description Language. 22 Component Adaptation Manager.
3.7 Grid Execution Agent
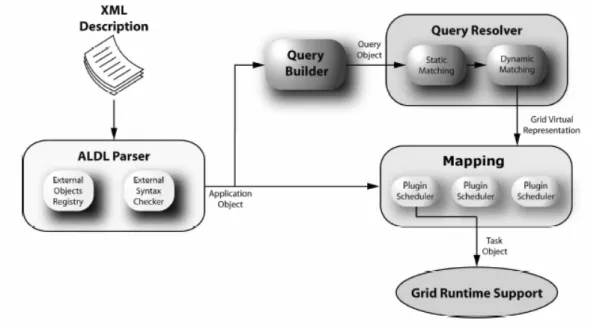
Il GEA23 è il tool che si occupa del lancio delle applicazioni Grid in maniera del tutto automatizzata. Il GEA è in grado di appoggiarsi a middleware diversi ed è realizzato in maniera da permettere l’utilizzo di plug-in rendendolo così di facile espandibilità. L’architettura logica è riportata in figura 3.5.
Figura 3.5 Architettura del GEA.
Il GEA prende in input i file eseguibili più la descrizione dell’applicazione prodotti dalla fase di compilazione e valutazione del contratto. Una applicazione consiste in un insieme di istanze di moduli legate da relazioni;
all’interno del file di descrizione dell’applicazione sono specificate le richieste, specifiche per ognuna delle istanze. Queste richieste descrivono i vincoli che dovranno essere considerati dal sistema in fase di selezione delle risorse. Il processo di lancio di una applicazione grid tramite il GEA può quindi essere scomposto in quattro fasi (figura 3.6).
Figura 3.6 Fasi attraversate dal GEA per effettuare il lancio di una applicazione, con dettaglio della fase di Running.
Una prima fase prevede il parsing del file di descrizione dell’applicazione e la creazione di una sua rappresentazione in memoria (Application Object) che sarà disponibile durante le altre fasi. Successivamente inizia la fase di Resource Discovery che ha per obiettivo la creazione di una vista logica della griglia disponibile e adatta al deployment dell’applicazione; questa fase si compone di due differenti passi. Il primo passo è quello di comporre una interrogazione con una sintassi indipendente dalle particolari istanze di GIS offerte dal middleware sottostante; questo compito viene effettuato dal modulo chiamato Query Builder il quale, prendendo in ingresso l’Application Object restituisce in uscita il Query Object. Il secondo passo prevede la ricerca vera e propria delle risorse: il Query Object viene quindi tradotto dal Query Resolver nel linguaggio di interrogazione proprio dei GIS disponibili e inoltrato a questi ultimi. I GIS eseguono l’interrogazione in parallelo e restituiscono le risposte al Query Resolver che combinandole
incrementalmente produce la rappresentazione virtuale della griglia24. La terza fase del processo riguarda la Resource Selection ed il Mapping. Durante questa fase verranno sfruttate le informazioni espresse dal contratto di performance allo scopo di selezionare un numero adeguato di risorse da associare ai moduli paralleli determinando quindi il loro grado di parallelismo ottimo; in modo simile verranno selezionate le risorse adeguate per l’esecuzione dei moduli sequenziali e successivamente verranno mappati i processi sulle risorse tenendo conto dei vincoli imposti dalla topologia dell’applicazione e dalla capacità delle reti che connettono le risorse. Invece di fornire un algoritmo di mapping generico, il GEA è pensato per poter offrire una serie di algoritmi di mapping, ognuno adatto ad una specifica classe di programmi, e lasciare la scelta di quale usare all’utente che può specificarlo nella descrizione dell’applicazione. Per schedulare i processi il GEA attualmente non sfrutta gli eventuali Resource Manager locali di tipo batch o basati su code in quanto è principalmente finalizzato al lancio di applicazioni fortemente accoppiate che necessitano quindi di co-allocazione delle componenti. Allo stato attuale il GEA sfrutta quindi lo schedulatore locale del sistema operativo. La quarta ed ultima fase è la messa in esecuzione vera e propria dell’applicazione; questa prevede l’esecuzione di tre attività principali:
• stage in
• esecuzione (running) • stage out
Il primo passo è quello di creare una rappresentazione astratta delle attività
da compiere per organizzarle al meglio, attenendosi alle informazioni fornite dalla fase precedente. Le operazioni pianificate andranno poi eseguite tentando di eseguire contemporaneamente tutte quelle non interdipendenti (per esempio i trasferimenti di file pre e post esecuzione), e rispettando i meccanismi di sincronizzazione propri del supporto per la fase di esecuzione.
L’attività di stage in prevede tutte le operazioni necessarie per operare il trasferimento (parallelo ove possibile) dei file necessari all’esecuzione; durante questa attività verranno quindi trasferiti gli eseguibili, le librerie necessarie e gli eventuali file di input. Unitamente ai trasferimenti dei file è sempre durante lo stage in che vengono configurati (se necessario installati) gli eventuali servizi di supporto. Il comportamento in fase di esecuzione dipende dal particolare meccanismo di sincronizzazione utilizzato dal supporto a run-time. Nel caso di applicazioni ASSIST si ha il seguente comportamento: un processo da eseguire viene nominato master e gli altri slave. Il master deve essere in esecuzione prima degli slave in quanto ha la responsabilità di sincronizzare gli slave e di costruire la topologia dell’applicazione. Gli slave necessitano di sapere la locazione del master, informazione che viene fornita dal GEA. Dopo questa fase di inizializzazione i processi sono in grado di comunicare fra di loro senza l’ausilio del master. Nel caso di altri tipi di applicazione il comportamento potrebbe essere diverso ed il particolare schema di lancio potrebbe essere implementato e messo a disposizione del GEA. Lo stage out rappresenta l’insieme di operazioni necessarie per organizzare e trasferire i risultati della computazione, eliminare gli eventuali file temporanei, ed in generale riportare le risorse utilizzate nelle condizioni iniziali. Il comportamento descritto è implementato nel GEA facendo uso della sua architettura a
plugin riportata in figura 3.7. Descriviamone brevemente il funzionamento. Il Gea Engine istanzia un Plug Manager per ogni applicazione da lanciare ed associa a questa un identificativo unico chiamato runHandler . Il Plug Manager riceve quindi il risultato della precedente fase di Mapping e carica i plugin (detti Plug Gear) necessari per attuare le tre attività precedentemente elencate con le modalità proprie della classe dell’ applicazione da lanciare. Per il lancio di applicazioni ASSIST, per esempio, viene caricato il plugin AssistGear che opera come descritto precedentemente.
Figura 3.7 Struttura a plugin del GEA. In figura si vede il GEA Engine che istanzia i Plug Manager ognuno con il suo gruppo di Plug Gear.
Il GEA dispone anche di un meccanismo di gestione degli eventi25, questo provvede a ricevere le eventuali comunicazioni da tutti i processi lanciati dai PlugGear ed in particolare i messaggi provenienti dagli application manager. Il gestore degli eventi è in grado di riconoscere il processo da cui proviene l’evento e può farlo corrispondere (grazie al runHandler presente
nel messaggio) al Plug Manager e conseguentemente al GEA Engine da cui (logicamente) dipende. Con questo meccanismo L’Event System può far pervenire gli eventi sia al GEA Engine sia al Plug Manager per la gestione più appropriata.
3.8 Broker System
Il Broker System26 è un sistema studiato per fornire supporto a strumenti di deployment di applicazioni parallele. In particolar modo è stato integrato nel tool GEA allo scopo di dare la possibilità di effettuare la raccolta delle informazioni sulle risorse nella fase di Discovery e le successive prenotazioni nella fase di Resource selection.
Il Broker System logicamente è composto da due sottosistemi fortemente interrelati:
5) Information Gathering System27 6) Advance Reservation System28
Lo Information Gathering System Gathering System offre le seguenti caratteristiche:
• Permette di catalogare e pubblicare le risorse appartenenti ad un dominio amministrativo che si vogliono mettere a disposizione della piattaforma Grid. Questo tool offre un linguaggio di descrizione delle risorse espandibile. Attualmente è in grado di descrivere risorse di tipo computazionale.
26 In seguito anche abbreviato BS. 27 Abbreviato in seguito IGS. 28 Abbreviato in seguito ARS.
• Interrogazione del catalogo tramite un meccanismo basato su filtri. L’utente del IGS potrà specificare all’interno di un filtro un’insieme di vincoli. Il sistema provvederà a restituire solo le risorse che rispetteranno i vincoli espressi nel filtro. E’ possibile anche richiedere, specificando alcuni parametri nel filtro, l’ordinamento delle risorse filtrate rispetto ai loro attributi; l’ordine di precedenza tra questi è definibile a piacere. L’approccio utilizzato per il matchmaking è quello simmetrico: il formalismo usato per la descrizione delle risorse viene utilizzato anche per esprimere le interrogazioni.
• I risultati delle interrogazioni vengono restituiti dal BS tramite un iteratore. L’iteratore permette di scorrere l’insieme di risorse che soddisfa i vincoli impostati nel filtro. E’ possibile richiedere l’iteratore in due versioni differenti: locale o remoto; il primo consente di scorrere più velocemente l’insieme delle risorse e tende ad ammortizzare maggiormente l’overhead delle comunicazioni, il secondo, fornisce risultati più aggiornati.
• Possibilità di adattare la morfologia dell’IGS alla struttura di rete del dominio amministrativo. In particolare è possibile gestire le risorse raggruppandole in insiemi di cardinalità compresa nel seguente intervallo [1 .. ∞).
• Facilità di integrazione con le politiche di sicurezza di rete esistenti (regole di firewalling).
Lo Advance Reservation System è il sottosistema che si occupa effettivamente della gestione delle prenotazioni. Il sistema è realizzato in maniera distribuita ed ha le seguenti caratteristiche:
• Associa ad ogni risorsa gestita dall’IGS una lista di prenotazioni • Possibilità di associare alle prenotazioni una classe di priorità. • E’ possibile prenotare frazioni di risorse (storage, cpu, etc.).
• Possibilità di rappresentare sia prenotazioni definite che indefinite. Le prenotazioni definite sono attive in un arco di tempo ben precisato; quelle indefinite sono attive dall’istante iniziale specificato in poi.
• L’intervallo di tempo rappresentato dalle prenotazioni può essere definito con la precisione di un secondo.
La mancanza di un sistema di information gathering nativo del GEA, la necessità di dover creare una rappresentazione delle risorse ai fini della advance reservation e l’esigenza di una struttura modulare e distribuita ha portato alla progettazione del Broker System dove l’IGS e l’ARS condividono, logicamente ma anche fisicamente, la stessa rappresentazione delle risorse e gli stessi meccanismi di comunicazione. Il Broker System viene descritto in dettaglio nel capitolo 4.
3.9 Integrazione con il GEA
L’integrazione con il GEA è stata effettuata apportando alcune modifiche al Query Resolver ed al Mapper. Le modifiche apportate al primo dei due moduli servono ad operare la traduzione dei vincoli presenti nell’oggetto query (prodotto dal Query Builder) nei filtri necessari al Broker System per eseguire l’interrogazione. Il modulo del mapper è stato modificato in modo
da utilizzare l’iteratore sull’insieme di risorse prodotto dall’interrogazione ed effettuare la prenotazione di queste una volta trovata una allocazione soddisfacente per i processi da mettere in esecuzione. L’algoritmo di mapping è stato lasciato invariato in quanto non di diretto interesse per fini della nostra realizzazione. Per l’interazione con il Broker System è stata utilizzata l’API implementata dalla brokerLib; questa include tutti i metodi necessari per l’interazione con il Broker System.
3.10 Broker System e supporto in fase di esecuzione
Durante la fase di esecuzione dell’applicazione può verificarsi la necessità di dover allocare nuove risorse; per esempio l’application manager potrebbe rilevare un calo prestazionale dell’applicazione che porterebbe alla violazione del contratto di performance; in un caso simile l’application manager, tramite l’Event System, potrebbe richiedere al GEA di avviare nuovamente il processo di discovery per trovare e prenotare risorse da affiancare o da sostituire, come nel caso della migrazione di processi, a quelle già sfruttate dall’applicazione. Questa eventualità potrebbe verificarsi anche nel caso di fault dei nodi qualora l’applicazione si avvalesse di meccanismi di fault tolerance. Il Broker System supporta attivamente questo genere di interazione tramite il meccanismo delle sessioni. Una sessione è una connessione persistente tra il GEA e il Broker System a cui viene associato un identificativo unico ed uno stato. Il meccanismo delle sessioni, realizzato con modello multithreaded, prevede un thread per ogni sessione che rimane attivo e gestisce le richieste del
cliente a cui è associato fino alla chiusura della sessione; questo permette di migliorare il tempo di risposta del sistema; inoltre, associando l’identificativo di sessione del Broker System al runHandler di ogni applicazione lanciata, permetterebbe al GEA di identificare, in caso di ricezione di eventi per la richiesta di nuove risorse, la sessione da utilizzare per interrogare il Broker System. Questo permette di sfruttare un’ottimizzazione sul filtraggio: lo stato associato alla sessione comprende infatti una struttura dati contenente i risultati dell’ultimo filtraggio richiesto dal cliente. In caso di una nuova richiesta di filtraggio viene controllato se il nuovo filtro richiesto è una ulteriore restrizione dell’ultimo filtro calcolato; in caso positivo il nuovo filtro richiesto viene applicato all’insieme di risultati precedentemente calcolato. Il meccanismo illustrato potrebbe essere utile, soprattutto se consideriamo che spesso gran parte dei vincoli espressi dalla stessa applicazione in due richieste di filtraggio distinte potrebbero coincidere (es. l’architettura, il sistema operativo, le librerie software, etc.).