Capitolo 2
Piattaforme Grid e applicazioni
Grid-Aware
Introduzione
In questo capitolo introdurremo i temi necessari per comprendere il contesto in cui è immerso il nostro lavoro. A questo scopo introdurremo le piattaforme Grid come tecnologia nell’ambito del calcolo parallelo e distribuito. Tratteremo quindi i problemi fondamentali che è necessario affrontare quando si considerano le applicazioni Grid e il loro sviluppo, con particolare attenzione verso il modello a componenti. In seguito verrà presentata l’architettura della piattaforma Grid a cui faremo riferimento nel corso della tesi. Nei paragrafi seguenti verranno introdotte le problematiche relative alla gestione delle risorse in una piattaforma Grid e parleremo delle fasi di scheduling e mapping sia in maniera generale sia in relazione alla piattaforma di riferimento; inoltre verrà introdotta la nozione di matchmaking come sottoproblema in alcune fasi della gestione delle risorse. In seguito sarà data una definizione di Qualità del Servizio e verranno considerati alcuni strumenti per la sua specifica e gestione. Infine verrà presentata una rassegna degli strumenti che rappresentano lo stato dell’arte in questo contesto.
2.1 Le piattaforme Grid
Una piattaforma grid [FK98] è una infrastruttura per il calcolo basata su un sistema distribuito in cui i nodi di elaborazione possono essere macchine di varia natura (supercomputer, cluster di pc,workstation etc.) interconnessi tramite reti estese anche geograficamente; oltre ai nodi di calcolo, la piattaforma può includere altre classi di risorse, come per esempio, sottosistemi di archiviazione di vario genere o apparecchiature scientifiche specializzate. La piattaforma grid deve fornire un’astrazione tale da permettere una modalità di accesso uniforme alle risorse che la compongono e deve rendere possibile aggregarle dinamicamente al fine di utilizzare l’insieme così ottenuto come infrastruttura a supporto dell’esecuzione delle applicazioni. Oltre l'eterogeneità delle risorse un'altra caratteristica importante delle piattaforme grid è la loro dinamicità. Per dinamicità si intende che la piattaforma potrebbe essere, in generale, in continuo mutamento; le risorse che compongono la piattaforma, infatti, potrebbero essere aggiunte e rimosse con grande libertà e la natura anche non dedicata di queste si traduce in ulteriori incertezze riguardo alla loro disponibilità nel tempo. Grazie alla flessibilità della loro struttura e del numero potenzialmente alto di risorse che è possibile integrare in una singola piattaforma le griglie trovano impiego come strumenti per il calcolo in molte aree dell'ingegneria, della fisica e della ricerca scientifica in genere.
2.2 Applicazioni abilitate alla griglia
A causa dell'eterogeneità e della dinamicità della piattaforma è importante dare alle applicazioni la possibilità di gestire in maniera corretta ed efficiente le situazioni eccezionali che queste due caratteristiche possono comportare. Una applicazione grid-aware potrebbe quindi possedere le seguenti capacità:
• Fault tolerance:
Insieme di meccanismi e politiche che servono a garantire il corretto comportamento dell'applicazione anche in caso di fallimenti hardware/software.
• Adattività:
Consiste nella capacità che l'applicazione ha di riconfigurarsi in seguito alla rilevazione di alcuni eventi, per esempio lo sbilanciamento del carico di lavoro sui nodi di elaborazione.
• Gestione dell'eterogeneità
L'applicazione ha la capacità di andare in esecuzione su un'insieme di macchine con architetture differenti fra loro. Questo in genere è
ottenuto tramite utilizzo di rappresentazioni dei dati XDR 5 e
predisponendo varie forme di eseguibili.
2.3 Modello a componenti
La crescente complessità delle applicazioni distribuite, rende il loro
sviluppo una attività complessa e facilmente esposta ad errori sia in fase di progettazione sia in fase di realizzazione. L'approccio che prevede soluzioni ad hoc (basate per esempio su librerie a scambio di messaggi) porta inevitabilmente a conseguenze che sarebbe auspicabile evitare:
• tempi di sviluppo elevati
• bassa possibilità di riutilizzo del codice prodotto • scarsa manutenibilità del prodotto finale
Questo genere di problemi si verifica anche in progetti medio-piccoli che fanno uso di piattaforme dedicate e che quindi rendono molto più agevole l'implementazione dei meccanismi di gestione dell'eterogeneità (spesso non necessari in tali ambienti) e soprattutto di tolleranza ai guasti.
Il modello a componenti si propone come soluzione efficace a tali problematiche, permettendo una strategia di sviluppo solida e modulare basata appunto sul concetto di componente [SGM02]:
“Un componente software e' una unità di composizione con interfacce ben definite che può essere utilizzato indipendentemente e può essere soggetto a composizione da parte di terzi”.
Questa definizione, di carattere molto generale, permette di identificare alcune delle caratteristiche fondamentali dei componenti:
tipo use/provide; Questa caratteristica porta ad una efficace modularizzazione del codice che si riflette positivamente sugli aspetti tipici delle fasi di progettazione, sviluppo e manutenzione. • composizione. Le applicazioni sono il risultato della composizione di
uno o più componenti più semplici. La restrizione al paradigma composizionale permette di eliminare molti dei problemi indotti da una poco accorta utilizzazione di mezzi potenti ma difficilmente controllabili come l'ereditarietà multipla.
• opacità. L’implementazione di un componente è nascosta ai programmatori delle applicazioni che ne ignorano qualsiasi dettaglio realizzativo. Questa caratteristica isola completamente i programmatori dei componenti dai programmatori delle applicazioni i quali non possono estendere o modificare le funzionalità dei componenti mediante i meccanismi di ereditarietà e sovraccaricamento dei metodi.
Il modello a componenti classico prevede che un componente venga associato dal suo sviluppatore ad una serie di risorse che verranno utilizzate da questo in fase di esecuzione; per sfruttare tecniche di allocazione a tempo di esecuzione e per adattare meglio il modello alle piattaforme grid è necessario arricchire il componente con tutte le informazioni necessarie al modulo che effettua l’installazione ed il lancio dell'applicazione. Il modulo di deployment utilizzerà le informazioni del componente per la ricerca e la selezione delle risorse sui cui verranno successivamente messi in esecuzione i processi costituenti l’applicazione. Un ambiente di sviluppo a componenti è essenzialmente un framework che permette l'attuazione del modello di sviluppo sopra brevemente presentato isolando efficacemente il
programmatore dai meccanismi utilizzati per la realizzazione delle caratteristiche sopraelencate (cooperazione fra componenti, tolleranza ai guasti, adattività etc.) che sono realizzati dalla infrastruttura di supporto.
2.4 Applicazioni parallele ad alte prestazioni basate su componenti Tutti i vantaggi dell’approccio basato sui componenti possono essere sfruttati anche nell’ambito della programmazione di applicazioni parallele ad alte prestazioni. Tali applicazioni sono ottenute sempre mediante composizione di componenti, ma quest’ultimi saranno in grado di fornire un livello prestazionale ben definito ed aderente ad un modello formale che ne descrive in dettaglio il comportamento. Il programmatore dell’applicazione potrà quindi scegliere fra i componenti a disposizione quelli che meglio soddisfano le proprie esigenze tenendo conto delle loro caratteristiche prestazionali. Generalmente una applicazione parallela basata su componenti può sfruttare due livelli di parallelismo [DVZ04], quello intercomponente (esterno) e quello intracomponente (interno). Il primo livello è rappresentato dall’esecuzione contemporanea, e possibilmente su nodi di calcolo distinti, delle componenti dell’applicazione; il secondo è offerto dal componente stesso che all’interno potrebbe essere costituito da moduli software interoperanti che realizzano una computazione parallela. Anche i moduli contenuti in un componente potrebbero essere messi in esecuzione su nodi distinti. La caratteristica precedentemente descritta porta a dover risolvere alcuni problemi riguardanti l’allocazione dei componenti e, allo scopo di mantenere la performance globale desiderata anche in caso
componenti ad alte prestazioni sfruttano i già citati meccanismi di adattività.
2.5 Architettura di riferimento
L’architettura della piattaforma grid a cui si fa riferimento in questa tesi è quella proposta in [ACDVZ05]; questa è suddivisa nei livelli riportati in figura 2.1.
Figura 2.1 Architettura stratificata della griglia.
Al livello più alto troviamo le applicazioni, queste saranno sviluppate con l'ambiente di programmazione direttamente sottostante; nel nostro caso si tratterà di applicazioni parallele realizzate con componenti ad alte
prestazioni. Il livello denominato GAM6 fornisce tutte le funzionalità
necessarie per effettuare la preparazione, il lancio e l'esecuzione delle applicazioni. Il livello include anche alcuni servizi che, generalmente, sono forniti dal middleware. Per middleware si intende [ACCF00] “the services
needed to support a common set of applications in a distributed network environment”; riferendosi alle piattaforme grid il middleware è lo strato software che fornisce le astrazioni necessarie per la programmazione delle applicazioni abilitate alla griglia. Nella visione tradizionale dell'architettura grid questo strato è composto da più livelli:
• Fabric Fornisce una astrazione delle risorse adatta al loro trattamento omogeneo da parte del livello superiore; l'interfaccia esportata nasconde quindi qualsiasi dettaglio specifico della risorsa. Rappresenta il livello più basso dell'architettura.
• Connectivity Definisce l'insieme minimo di protocolli per l'autenticazione e la comunicazione necessari per abilitare le comunicazioni fra le risorse virtualizzate dal livello Fabric e l'autenticazione degli utenti.
• Resource Definisce una serie di protocolli per la negoziazione, il controllo ed il monitoring della singola risorsa; comprende due tipi di protocolli: protocolli informativi e protocolli di gestione. I primi servono a recuperare le informazioni relative allo stato della risorsa, mentre gli altri sono usati per negoziare la risorsa specificandone per esempio le caratteristiche desiderate.
• Collective Offre i protocolli per coordinare risorse multiple. Le funzionalità di Scheduling e allocazione congiunta delle risorse sono realizzate a questo livello.
Nel nostro caso la GAM include i servizi forniti dai livelli Connectivity, Resource e Collective. La GAM sfrutta un sottoinsieme dei servizi offerti
programmazione adottato ed evita che le applicazioni utilizzino direttamente i servizi del middleware. Le funzionalità aggiuntive che la GAM realizza comprendono un'adeguata gestione delle risorse ed i meccanismi a supporto dell'adattività delle applicazioni. La GAM attualmente può sfruttare sia i servizi di middleware offerti da suite standard come Globus [GLOBUS], sia quelli nativi.
2.6 Gestione delle risorse
Il sistema di gestione delle risorse (o RMS7) può essere visto come un insieme di servizi a supporto delle fasi di lancio ed esecuzione dell’applicazione grid. Il gestore delle risorse, inteso come entità logica, è uno degli elementi chiave dell’intera architettura grid ed è tuttora oggetto di ricerca.
Nella definizione in [NSW05] si legge:
“Resource Management is the process of identifying requirements, matching resources to applications, allocating those resources, and scheduling and monitoring Grid resources over time in order to run grid applications as efficiently as possible”
Un RMS deve fornire i meccanismi per poter effettuare le seguenti macro operazioni:
1 Raccolta di informazioni sia statiche che dinamiche sulle risorse.
2 Mapping/Scheduling delle componenti software costituenti l’applicazione sulle risorse.
Il primo punto viene espletato appoggiandosi a servizi che forniscono informazioni riguardo allo stato delle risorse che compongono la griglia; questi servizi agiscono da interfaccia verso una base di dati, generalmente distribuita, mantenuta aggiornata utilizzando le informazioni provenienti dai vari sottosistemi di monitoraggio. In letteratura questo insieme di servizi prende il nome di Grid Information Services o GIS.
Il secondo punto prevede che i moduli software che compongono l’applicazione vengano assegnati alle risorse in base a strategie finalizzate al raggiungimento di un certo tipo di obiettivo; una volta trovato l’assegnamento voluto è possibile avviare l’esecuzione dell’applicazione. Durante la fase di Mapping/Scheduling vengono utilizzati i GIS per la raccolta delle informazioni necessarie.
Uno degli aspetti che è necessario considerare quando si parla di gestione delle risorse ed in generale delle problematiche proprie dell'utilizzo delle risorse di griglia è quella inerente ai domini amministrativi. In [RFC1136] si definisce un Dominio Amministrativo come:
"A collection of End Systems, Intermediate Systems, and
subnetworks operated by a single organization or administrative authority. The components which make up the domain are assumed to interoperate with a significant degree of mutual trust among themselves, but interoperate with other Administrative Domains in a mutually suspicious manner"
Un dominio amministrativo rappresenta quindi un'insieme di risorse eterogeneo gestite da una organizzazione secondo politiche locali. Le entità che compongono un AD interoperano fra di loro con un alto grado di mutua fiducia, ma possono adottare politiche di sicurezza più restrittive quando collaborano con altri AD. Dato il carattere multi istituzionale che potrebbe avere una piattaforma grid, è possibile che le risorse che la compongono siano appartenenti fisicamente a più Domini Amministrativi; è necessario quindi che gli strumenti utilizzati per realizzare le funzionalità di base della piattaforma forniscano i mezzi per potersi integrare con la struttura esistente tenendo conto delle politiche di gestione locale al fine di agire nel loro rispetto. La visione sopra presentata è volutamente semplificata, ma sufficiente per i nostri scopi; focalizzeremo quindi la nostra attenzione sulla fase di Mapping/Scheduling dettagliandone ulteriormente i vari aspetti.
2.7 Mapping e Scheduling su piattaforme grid
Per chiarezza riportiamo le seguenti definizioni date in [RZW02] : Mapping: The allocation of computation and data “in space”
In seguito utilizzeremo il termine mapping in riferimento alla fase in cui viene stabilita una corrispondenza fra task e risorse.
Scheduling: The process of ordering tasks on compute resources and
ordering communication between tasks. Also, known as the allocation of computation and communication “over time”
La fase di mapping è quindi parte integrante della più ampia fase di scheduling.
Le applicazioni grid sono generalmente costituite in ultima analisi da una serie di moduli software fra loro cooperanti,detti task; obiettivo dello schedulatore di griglia è fornire una allocazione dei task finalizzata ad ottimizzare uno o più aspetti relativi all'applicazione (non necessariamente relativi soltanto alla performance) e di mettere quest'ultima in esecuzione. Lo schedulatore in una piattaforma grid deve gestire una grande quantità di risorse, eterogenee e distribuite, generalmente non possedendone il controllo diretto. In un simile scenario è possibile che si venga a creare una gerarchia di schedulatori; quelli ai livelli più alti sono più astratti ed in generale non possiedono il controllo diretto delle risorse; più si scende di livello, più elevato sarà il controllo della risorsa posseduto dallo schedulatore. Per fare un esempio concreto possiamo pensare ad una griglia i cui nodi siano cluster dedicati, ognuno con il proprio schedulatore locale, ed appartenenti a domini amministrativi differenti; in un caso come questo avremmo due livelli di scheduling (non considerando lo schedulatore del sistema operativo su ogni nodo dei cluster) come riportato in figura 1.2.
Figura 2.2 Vari livelli di scheduling in una griglia composta da due domini
amministrativi.
Generalmente uno schedulatore di griglia opera come superscheduler. In [RZW02] viene data la seguente definizione di superscheduling :
Superscheduling: ”The process that will (1) discover available resources allocation for a job, (2) select the appropriate systems(s), and (3) submit the job. Each system would then have its own local scheduler to determine how job queue it is processed.”
Secondo la definizione il processo di schedulazione passa attraverso le seguenti fasi (espanse secondo [SCH02]) :
a) Resource Discovery
disponibili all'interno della griglia. Può essere composta dalle seguenti sotto-fasi:
(1) Authorization Filtering
(2) Application Requirement Definition (3) Minimal Requirement definition b) System Selection
In questa fase vengono selezionate le risorse più adatte per l'esecuzione dell'applicativo, in base a criteri definiti nell'applicativo stesso e dalle informazioni di dettaglio delle risorse.
Comprende i passi di: (1) Information Gathering (2) Select the system(s) to run on c) Run Job ( Submit the job )
Fase di lancio dell'applicazione e controllo della stessa a tempo di esecuzione. Comprende le seguenti:
(1) Make an advance reservation (prenotazione) (2) Submit the job to resource
(3) Preparation Tasks (4) Monitor Progress (5) Find out if job is done (6) Completion tasks
2.8 Mapping e Scheduling di programmi paralleli ad alte prestazioni basati su componenti
I passi generali descritti nel paragrafo precedente valgono anche nel caso in cui si debba effettuare lo scheduling di programmi paralleli; esistono tuttavia alcuni vincoli da rispettare. Una applicazione parallela necessita che tutti i task che la compongono vengano allocati ed eseguiti nella stessa finestra temporale, in un caso come questo si dice che l’applicazione necessita della co-allocazione e della co-schedulazione delle risorse; nel caso di applicazioni ad alte prestazioni è anche auspicabile che le risorse selezionate per l’esecuzione siano prenotabili, questo per evitare che la performance dell’applicazione subisca degradazioni dovute, per esempio, al sovraccaricamento di un nodo da parte di applicazioni lanciate da altri utenti della griglia. Il sistema di prenotazione dà al mapper la possibilità di riservare alcune risorse e metterle a disposizione del programma in fase di mapping per la futura fase di esecuzione; le risorse prenotate quindi non saranno sfruttabili dagli altri programmi che girano sulla piattaforma grid, almeno per il lasso di tempo specificato nella prenotazione stessa. Il metodo della prenotazione non è l’unico strumento in grado di supportare in maniera efficace il controllo delle prestazioni, ma permette in certi casi di limitare l’intervento di meccanismi più complessi e potenzialmente costosi in termini computazionali come i già citati meccanismi di adattività che rimangono comunque i metodi di elezione per far fronte ai repentini cambiamenti di stato delle risorse tipici delle piattaforme grid (guasti hardware, disservizi di rete, modificate capacità di una risorsa etc.). Anche nel caso di applicazioni basate su componenti ad alte prestazioni valgono le considerazioni fatte sulla necessità di co-allocazione, co-schedulazione e
prenotazione delle risorse.
In questa testi tratteremo alcuni aspetti specifici riguardo alla schedulazione restringendoci alla classe di programmi paralleli ad alte prestazioni basati su componenti, in particolare, riferendosi ai punti elencati nel paragrafo precedente, ci occuperemo delle fasi di Resource Discovery e System Selection, in seguito chiamata Resource Selection. Nell’architettura a cui facciamo riferimento tutti i passi necessari per la messa in esecuzione di una applicazione sono effettuati da un tool, il Grid Execution Agent o GEA, che si occupa di effettuare il deployment dell’applicazione sulla piattaforma grid.
Il GEA svolge le seguenti attività: Application Submission
Per effettuare questa operazione il GEA necessita in input di tutte le informazioni necessarie per guidare le fasi successive. Queste informazioni sono fornite in un file che contiene una descrizione delle componenti dell’applicazione, della loro interazione e delle caratteristiche delle risorse necessarie per la loro corretta esecuzione.
Resource Discovery
Questa fase ha lo scopo di trovare le risorse con le caratteristiche adatte per l’esecuzione dell’applicazione. Nel file che contiene la descrizione dell’applicazione possono essere specificate varie richieste concernenti, per esempio, caratteristiche hardware (cpu, memoria disponibile, spazio disco, etc.), caratteristiche software come librerie disponibili, sistemi operativi e compilatori, ma
trasferimento file, possibilità di eseguire script) e servizi necessari
all’esecuzione dell’ambiente a supporto dell’applicazione.
Resource Selection
In questa fase vengono valutate le varie possibilità di assegnamento dei moduli costituenti i componenti alle risorse scoperte nella fase precedente. Per effettuare questa operazione è necessario considerare anche le richieste dell’applicazione che specificano rapporti fra più risorse ( requisiti aggregati ), per far questo è quindi necessario interagire nuovamente con il Grid Information Service.
Deployment Planning
L’applicazione che deve essere messa in esecuzione potrebbe aver bisogno di servizi accessori durante il suo funzionamento; questa fase che precede il deployment vero e proprio serve a pianificare come effettuare la configurazione e l’attivazione di tali servizi. Inizialmente viene prodotto un piano di deployment astratto che viene poi trasformato nel piano di deployment concreto. Durante questa fase potrebbe essere necessario tornare più volte alle fasi di Resource Discovery e Selection a causa dell’impossibilità di operare la trasformazione sopra menzionata con le risorse a disposizione.
Deployment Enactment
In questa fase viene effettuato il deployment vero e proprio, di fatto preparando l’applicazione per la successive fase di esecuzione.
Questa attività deve poter interoperare con vari middleware differenti selezionando quelli necessari in base alle richieste specificate nel
piano di deployment concreto. E’ possibile che mutamenti nello stato delle risorse interessate dal deployment portino a dover tornare nuovamente alla fase precedente.
Application Execution
L’applicazione viene lanciata e durante l’esecuzione vengono effettuate molte attività necessarie per gestirne correttamente il ciclo di vita.
Queste attività di monitoring e controllo sono orchestrate in cooperazione con il supporto al deployment.
2.9 Matchmaking
Il matching è un'operazione comune in molte aree dell'informatica, a noi interessa studiarne l'utilità applicata al campo del grid computing e in particolar modo alle fasi di resource discovery e resource selection. In letteratura, il termine matching [BYJM04] si riferisce al processo di valutazione del grado di somiglianza tra due oggetti. Per effettuare tale valutazione è necessario che ogni oggetto da confrontare sia caratterizzato da un'insieme di proprietà e/o attributi. Ogni attributo è rappresentato da un a coppia (nome, valore), dove il nome è una stringa di caratteri e il valore è una costante (di tipo intero, reale, stringa o booleano) oppure un'espressione che ritorna una costante. Solitamente si usa il termine matching degree per indicare il grado di somiglianza tra due oggetti e viene rappresentato da un numero reale m. Tipicamente m viene fatto variare tra 0 e 1, quando m
assume valore 1 invece uguaglianza perfetta (perfect match). Spesso ci si trova nella condizione di dover confrontare un ben preciso oggetto con un insieme di oggetti di riferimento al fine di identificare l'oggetto stesso oppure individuare il sottoinsieme di oggetti che meglio corrispondono all'oggetto indicato. In questo caso l'operazione è riferita con il nome di matchmaking. La logica dello scenario del matchmaking comprende l'esistenza di un'entità richiedente, che effettua le richieste di matching, di uno o più oggetti, in un adeguato linguaggio e un'entità che offre il servizio di matchmaking la quale possiede una base di conoscenza, contenente gli oggetti confrontabili, descritti in un linguaggio non necessariamente identico a quello del richiedente.
2.10 Definizione di QoS
Il concetto di Qualità del Servizio (QoS8) è ampio e viene utilizzato in numerosi campi applicativi molto differenti fra loro; valutazione dell' usabilità delle interfacce grafiche, definizione di standard qualitativi per le prestazioni delle reti, prestazioni di processori, in ognuno di questi settori esiste un concetto preciso di QoS. In generale possiamo dire che le specifiche di QoS condividono le seguenti caratteristiche:
• Sono specifiche del dominio applicativo
• Possiedono un formato appositamente progettato tenendo conto del particolare impiego
• Necessitano di essere tradotte dal linguaggio a livello applicativo in
parametri di QoS a livello di sistema interpretabili dal middleware sottostante
Ecco alcune definizioni di qualità del servizio presenti in letteratura: [ISOX641]
"La qualità del servizio è l'insieme delle caratteristiche relative al comportamento collettivo di uno o più oggetti "
[F96]
"La qualità del servizio è la prestazione del sistema percepita e le impressioni di utilizzo dell'applicazione dal punto di vista dell'utente"
[P806]
"Il QoS è il grado di conformità del servizio fornito rispetto all'accordo stipulato fra l'utente ed il fornitore dello stesso"
Queste definizioni sono del tutto generali e non danno indicazioni su come ottenere la qualità desiderata, ma pongono l'attenzione sul fatto che la qualità è qualcosa che deve poter essere percepita e misurata, con le metriche specifiche del dominio di applicazione. A livello utente vengono valutati principalmente gli aspetti direttamente percepibili delle applicazioni (es. tempo di risposta, usabilità etc.), a tutti i livelli sottostanti i criteri di valutazione della qualità del servizio sono specifici delle risorse coinvolte.
2.11 Livelli di specifica del QoS
La definizione degli standard qualitativi attesi da una applicazione grid-aware e' un obiettivo complesso da raggiungere a causa del grande numero di parametri che vanno considerati. Per tentare di diminuire la complessità nello specificare il QoS sembra essere oramai comune l'approccio a livelli sovrapposti.
Esistono quindi tre livelli principali da considerare: • Livello utente
• Livello applicazione • Livello risorsa
Ad ognuno di questi livelli corrisponde un tipo di specifica diverso; a livello utente la specifica sarà basata su parametri di semplice comprensione, se si tratta per esempio di definire la qualità del servizio atteso da una applicazione di compressione audio-video potremmo esprimere la specifica attraverso parametri complessi come accuratezza della compressione, quantitativo di tempo a disposizione per l'elaborazione e la dimensione desiderata dei fotogrammi. A questo livello il linguaggio utilizzato è dipendente dal contesto applicativo. A livello applicazione si scende più in dettaglio; qui è possibile specificare richieste di due tipologie distinte: relative alla performance oppure relative al comportamento a tempo di esecuzione. Sotto la prima delle due classi possono essere raggruppati tutti quei requisiti che servono al raggiungimento delle prestazioni desiderate, per esempio in una applicazione high performance distribuita questi parametri sono finalizzati al raggiungimento di uno
stabilito tempo di servizio dei singoli moduli e quindi di tutta l’applicazione; nella seconda classe finiscono invece tutti i requisiti che determinano il comportamento in fase di esecuzione dei componenti dell'applicazione; quindi capacità di adattività e riconfigurazione dinamica in caso di violazione della performance richiesta, caratteristiche di tolleranza ai guasti, riservatezza dei dati mediante utilizzo di crittografia, sono tutti aspetti che ricadono in questa classe. Il linguaggio utilizzato a questo livello è specifico dell'applicazione ma indipendente dalla risorsa. Nel terzo livello infine, vengono espressi vincoli riguardanti le risorse in maniera specifica come le loro caratteristiche architetturali, le librerie installate, la dimensione dei dischi etc. A questo livello è anche possibile specificare il quantitativo di risorsa necessaria e opzionalmente la prenotazione della stessa per un intervallo di tempo specificato.
2.12 Contratto di Performance
Considerando gli strumenti per la gestione del QoS a livello applicazione introduciamo il concetto di contratto di performance (performance contract). Il contratto di performance è un mezzo efficace per consentire il controllo della qualità del servizio. La definizione data in [V02] dice:
“A performance contract states that given a set of resources with certain capabilities, for a particular problem parameters, the application will exhibit a specified, measurable performance.”
in esecuzione; tramite il contratto di performance ed un modello delle prestazioni è possibile generare previsioni sul rendimento di una applicazione una volta specificate le risorse, le capacità di queste ed i parametri fondamentali del problema (es. grandezza dell’input). Il contratto di performance in sé non fornisce mezzi per far rispettare il QoS richiesto all’applicazione, ma permette, tramite una attività di monitoring a runtime, di verificare costantemente il rispetto o meno dei vincoli di performance specificati. Qualora uno dei vincoli esplicitati nel contratto dovesse essere violato sarebbe necessario attivare meccanismi di riconfigurazione dinamica (es. migrazione di processi, allocazione di nuove risorse etc.) per riportare le prestazioni dell’applicazione ad un livello accettabile. L’interpretazione del contratto di performance da parte del sistema a supporto dell’esecuzione produce una specifica di QoS a livello risorsa, utilizzata per guidare le fasi immediatamente precedenti il lancio dell’applicazione.
2.13 Prenotazione delle risorse
La prenotazione delle risorse è un altro dei meccanismi utilizzati per controllare il QoS ed in letteratura è noto come Advance Reservation.
Riportiamo la seguente definizione [ML03] a cui ci atterremo :
“An advance reservation is a possibly limited or restricted delegation of a particular resource capability over a defined time interval, obtained by the requester from the resource owner through a negotiation process”
Generalmente la prenotazione delle risorse viene effettuata durante la fase di mapping/scheduling utilizzando i protocolli messi a disposizione dal resource manager con supporto dell’Advance Reservation.
Una generica prenotazione può assumere i seguenti stati:
Richiesta: La risorsa è stata richiesta per essere prenotata. Se la prenotazione finisce a buon fine allora la risorsa è considerata prenotata, altrimenti viene rifiutata.
Rifiutata: La prenotazione non è andata a buon fine.
Prenotata: La prenotazione è stata effettuata. Da questo stato è possibile che la prenotazione diventi successivamente Attiva,Cancellata o Attivata con Richiesta di Modifica.
Prenotata con Richiesta di Modifica: La risorsa di una prenotazione è soggetta alla modifica da parte di un utente; lo stato successivo in cui si può trovare la prenotazione e’ Prenotata sia in caso di fallimento della modifica che di successo.
Cancellata: Un utente cancella la prenotazione prima della sua attivazione. Attivata: La prenotazione è iniziata, ma non ancora terminata.
Terminata: La prenotazione attiva viene terminata prima della sua fine. Completata: La prenotazione è finita regolarmente.
Attivata con Richiesta di Modifica: La risorsa è soggetta alla modifica mentre la prenotazione è attivata. Lo stato successivo in cui si potrà trovare la prenotazione è Attivata sia in caso di fallimento che di successo.
- Servizio garantito
- Servizio al meglio (Best effort)
Il primo viene richiesto specificando la risorsa e la quantità desiderata in maniera esatta; in caso di successo la risorsa viene riservata per il periodo temporale specificato nella richiesta ed esattamente nella quantità indicata. Il servizio al meglio equivale a non riservare le risorse.
E’ importante notare che i meccanismi di prenotazione riescono a dare la garanzia della qualità del servizio offerto quando sono abbinati a gestori di risorse per ambienti dedicati, come i cluster, dove la presentazione dei job viene fatta passando per un punto di centralizzazione; In un ambiente dove le risorse di calcolo sono workstation o pc sottoposti al normale utilizzo da parte degli utenti locali (es. pc in una lan aziendale) la prenotazione delle risorse non può essere fatta rispettare a causa della mancanza del supporto del sistema operativo. In un caso come questo gli aspetti relativi al QoS di una applicazione possono soltanto essere gestiti utilizzando tecniche di riconfigurazione dinamica.
2.14 Stato dell’arte
In questo paragrafo presenteremo una panoramica sugli strumenti attualmente utilizzati in ambienti di produzione o in avanzato stadio di sviluppo che utilizzano tecniche di advance reservation nella loro gestione del QoS.
GARA
GARA9 è un framework con architettura modulare che permette agli utenti di effettuare prenotazioni di diverse tipologie di risorse.
GARA possiede le seguenti caratteristiche:
- Interfaccia uniforme per rendere semplice lo sviluppo di nuove funzionalità costruite sopra GARA (per esempio prenotazioni coordinate di più risorse)
- Possibilità di effettuare prenotazione delle risorse (Advance Reservation)
- Architettura stratificata per permettere una semplice espansione dei meccanismi di prenotazione
- Integrato con il Globus Toolkit di cui sfrutta l’infrastruttura di sicurezza
L’architettura proposta si basa su quattro livelli distinti (figura 2.3); il livello più alto è quello costituito dalle applicazioni che utilizzano, tramite una API, lo strato sottostante detto GARA Layer. Il Gara Layer offre accesso remoto uniforme alle funzionalità di prenotazione delle risorse; questo livello comunica con il LRAM Layer che fornisce funzionalità basilari di autenticazione e autorizzazione accessi e si preoccupa di tradurre le richieste provenienti dal livello superiore in una serie di richieste comprensibili dallo strato sottostante, il Resource Manager Layer. L’ultimo
livello è responsabile di tenere traccia delle prenotazioni e di imporre il rispetto di queste comunicando con la risorsa gestita; sempre a questo livello sono demandate funzionalità di autorizzazione accessi, ma ad una grana più fine rispetto allo strato superiore. Il framework utilizza il Globus Resource Specification Language per rappresentare le richieste di prenotazione; si tratta di un linguaggio privo di schema, ma GARA richiede la presenza di alcuni attributi standard.
Figura 2.3 L’architettura a livelli di GARA.
L’esempio seguente propone una tipica richiesta di prenotazione relativa alla rete. &{(reservation-type=network) (start-time=953158862) (duration=3600) (endpoint-a=140.221.48.146) (endpoint-b=140.221.48.106) (bandwidth=150)}
I primi tre campi sono obbligatori e caratterizzano il tipo di richiesta (network), l’istante iniziale della prenotazione e la durata. Gli ultimi tre campi invece sono specifici delle richieste di prenotazione relative alla rete. E’ inoltre previsto anche un sistema di notifiche asincrone per mantenere informata l’applicazione riguardo allo stato delle prenotazioni; tipici eventi segnalati sono l’attivazione della prenotazione oppure il sovrautilizzo di una risorsa rispetto a quanto stabilito nella richiesta.
Silver
Silver è un metascheduler orientato alla griglia con supporto per l’advance reservation ed agisce come singolo punto d’accesso a più sistemi high performance gestiti indipendentemente.
Il tipo di prenotazioni che sono permessi da Silver sono due: - Job Reservation
Permette di garantire la disponibilità delle risorse per una
applicazione specifica.
- User reservation
Garantisce la disponibilità delle risorse ad uno o più utenti, gruppi o progetti.
Silver è in grado di interfacciarsi con resource manager/scheduler locali come Maui, Load Leveler,Sun Grid Engine, OpenPBS, PBS Pro, LSF, SGE Enterprise Edition.
che offre la prenotazione delle risorse. Il sistema di prenotazione di Maui prevede che la richiesta di risorse venga effettuata tramite la descrizione del task. Nella terminologia adottata da Maui un task rappresenta un’insieme di risorse considerata atomica; un task può includere processori, memoria, spazio di swap, spazio disco etc. Un task deve essere allocato all’interno dello stesso nodo. E’ possibile allocare più task all’interno dello stesso nodo, a patto che ci siano sufficienti risorse. Una prenotazione consiste in uno o più task.
Ad ogni prenotazione viene associato un timeframe che serve a specificare la finestra temporale in cui la prenotazione ha effetto. Oltre al timeframe ad ogni prenotazione viene associata una ACL10; questa serve a controllare se il job da eseguire sulle risorse prenotate ha i requisiti necessari per farlo. All’interno di una ACL è possibile utilizzare vari criteri per il controllo degli accessi, basandosi su utenti, gruppi,clienti, classi, QoS e durata del job. Il sistema permette di effettuare due tipi di prenotazioni, dette rispettivamente Administrative Reservation e Standing Reservation; la prima classe rappresenta le prenotazioni effettuate una tantum in caso di occasioni particolari e possono essere create soltanto dagli amministratori, la seconda classe rappresenta le prenotazioni di risorse effettuate su base regolare, le quali possono essere effettuate anche dagli utenti del sistema. Allo scopo di evitare che un utente possa prenotare le risorse in una maniera tale da costringere lo scheduler ad un’utilizzo unfair e improduttivo delle risorse, maui prevede meccanismi per limitare il numero di risorse prenotabile, permettendo di intervenire su utenti, gruppi, clienti e fasce orarie. Infine è possibile associare ad ogni prenotazione un profilo per l’addebito dei costi per l’utilizzo delle risorse. Il profilo è associabile agli
utenti/gruppi dall’amministratore, l’utente finale può effettuare e modificare le prenotazioni ma non modificare il profilo a lui associato.
Condor matchmaker
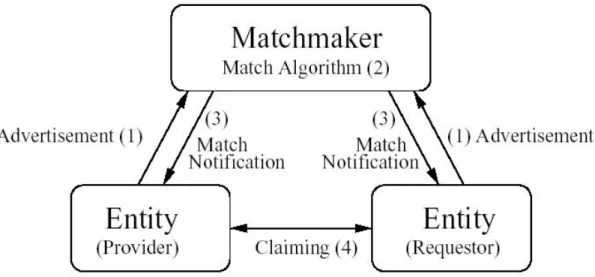
In [RSL98] viene presentato il matchmaker system di Condor [COND]. Essenzialmente si tratta di un matchmaking framework per la gestione di risorse in ambiente distribuito. Il framework risulta composto da tre entità (fig. 1):
• provider: il proprietario e fornitore delle risorse, queste entità pubblicano la descrizione delle risorse e ne aggiornano periodicamente lo stato, un provider potrebbe essere anche un singolo host.
• requester: i richiedenti delle informazioni sulle risorse, l’entità che effettua una richiesta ed esprime i vincoli per l’esecuzione di un job, un requester potrebbe essere un mapper o uno scheduler.
• matchmaker: pubblica le informazioni sulle risorse fornite dai provider ed esegue l'algoritmo di matchmaking sulle richieste dei requester.
Sia le descrizione delle risorse effettuate dai provider, sia le richieste inoltrate dai requester, sono espresse nel medesimo linguaggio e vengono spedite tramite messaggi al matchmaker. Tali messaggi prendono lo stesso nome del linguaggio con cui sono scritti, il classified
vogliono pubblicare al matchmaker che le memorizza. Il matchmaker confronta i classads dei requester con quelli memorizzati, verifica il soddisfacimento dei vincoli richiesti, e informa il requester dei risultati ottenuti.
Figura 2.4 Le tre entità nel framework di matchmaking, le frecce rappresentano le azioni
intraprese dalle entità.
Tali caratteristiche consentono al matchmaker di offrire il cosiddetto bi-latreral match, permettendo ad ognuna delle entità provider e requester di esprimere i propri vincoli di matching, per esempio descrivendo le caratteristiche desiderate dalle risorse per i requester, e le politiche di accesso per i provider. Il sistema può essere decomposto nei seguenti elementi:
1) classified advertisements, un linguaggio per specificare sia le
caratteristiche delle risorse da pubblicare, sia i vincoli per le richieste. Inoltre fornisce una semantica per valutare questi attributi.
2) matchmaking algorithm, è usato dal matchmaker per creare
classads da un requester e lo stato del sistema dato dall'insieme delle risorse pubblicate dai provider, in output fornisce un insieme di corrispondenze tra oggetti classads.
3) matchmaking protocol, descrive le modalità con cui le entità provider e
requester comunicano con il matchmaker per pubblicare nuove risorse e ricevere notifiche.
4) claiming protocol, è utilizzato tra i requester e i provider per confermare
il match, per effettuare l'allocazione e utilizzare le risorse. Ognuna delle due parti può abortire la richiesta, per esempio nel caso in cui lo stato della risorsa sia cambiato.
Tale approccio al problema è detto symmetric attribute-based matching. Le caratteristiche salienti che contraddistinguono il framework sono dovute al linguaggio utilizzato, il già citato classads. Classads fornisce la sintassi e la semantica necessaria per un modello dei dati semi-strutturato, con il quale è possibile esprimere vincoli formati da coppie (nome, espressione), un'insieme di vincoli prende il nome di attribute list. Il linguaggio fornisce valori speciali come undefined e error e speciali operatori semantici per operare in un ambiente eterogeneo e semi-strutturato. Inoltre è possibile utilizzare l’attributo rank il quale serve per dare un ordinamento nel caso in cui il matching produca più di un risultato. Di seguito presentiamo un esempio di richiesta e uno di pubblicazione espresse con la sintassi di ClassAds:
Request ClassAd:
[ Type = “Job”; Owner = “user1”;
Resource ClassAd:
[ Type = ”Machine”; Name = “m1”; Disk = 30000; Arch = “INTEL”; OpSys = “SOLARIS”; ResearchGrp = “user1”, “user2”;
Constraint = member(other.Owner,ResearchGrp) && DayTime _ 18*60*60;
Rank = member(other.Owner,ResearchGrp) ]
La prima implementazione del matchmaker di condor eseguiva unicamente un matching binario. Per ovviare a questa limitazione in seguito è stato introdotto il gang-matching [SRL00]. Tale estensione consente di specificare in una richiesta classad una lista di bi-lateral matches. Per esempio una richiesta potrebbe comprendere una o più macchine, ognuna delle quali dovrà soddisfare indipendentemente i vincoli richiesti. Qui di seguito è riportato un classad in cui è utilizzata la sintassi messa a disposizione dall’estensione gang-matching, sono presenti due elementi nella lista descritta con Ports.
[ Type = "Job"; Owner = "raman"; Cmd = "run_sim"; Ports = { [ // request a workstation Label = "cpu"; ImageSize = 28M;
Rank = cpu.KFlops/1E3 + cpu.Memory/32; Constraint =
cpu.Type=="Machine" && cpu.Arch=="INTEL" && cpu.OpSys=="LINUX" && cpu.Memory>=Imagesize; ],
[ // request a license Label = "license";
Host = cpu.Name; // cpu name Rank = 0;
license.Type=="License" && license.App==Cmd; ] }
]
L’attributo Ports è una lista che rappresenta i matches richiesti per soddisfare la richiesta, in pratica, il bilateral matching invece di essere effettuato sull’intero classads è effettuato tra gli elementi descritti nella lista dall’attributo Ports.
Una successivo ampliamento della semantica di classads è stata introdotto grazie all’espansione fornita dal set-matching [LYFA02]. In tale modello una singola richiesta di un requester è soddisfatta se l’algoritmo di matching trova un insieme di risorse le cui caratteristiche aggregate risultino soddisfare certi vincoli. La sintassi adottata dell’estensione set-matching risulta identica al normale classad, arricchita dalla possibilità di utilizzare i costrutti set expressions e individual expressions. Il primo costrutto consente di specificare i vincoli da verificare sull’aggregazione dei valori delle proprietà dell’intero insieme di risorse. Per esempio la dimensione totale della memoria. Il secondo costrutto, invece, serve per indicare i vincoli da verificare individualmente, su ogni risorsa nell’insieme individuato. L’algoritmo di set-matching cerca di costruire un insieme di risorse che soddisfi i requisiti imposti da entrambi i costrutti.
Redline system
Un approccio alternativo al problema del matching è stato presentato in Redline matching system [LF03]. Come il matchmaker di Condor, Redline
linguaggio utilizzato da Redline supporta sia il gang-matching che il set-matching, ma in generale appare essere più espressivo di quello di utilizzato da Condor. La differenza sostanziale sta nel tipo di algoritmo utilizzato per il matching. In questa soluzione il matching viene trasformato in un problema di soddisfacimento di vincoli, meglio conosciuto come CSP (constraint satisfaction problem), infatti tale approccio è anche classificato come constrain-satisfaction-based matching. Un CSP è comunemente definito come un insieme di variabili, ognuna associata ad un dominio finito, e un insieme di vincoli sui valori che posso assumere tali variabili. La soluzione del problema è un assegnamento di valori alle variabili tale che vengano soddisfatti tutti i vincoli. Formalizzare il matching come un problema CSP significa associare una variabile per ogni risorsa richiesta. Il dominio di ogni variabile sarà dato dall’insieme di tutte le risorse disponibili. I vincoli sulle variabili devono descrivere i requisiti desiderati da ogni risorsa, compreso, per esempio, la politica di accesso. Prima di risolvere il sistema creato bisogna epurare i vincoli da possibili conflitti, in seguito potrà essere trattato con algoritmi di constraint solving, come quelli usati nella programmazione intera [MP98].
Di seguito vengono riportati alcuni esempi della sintassi del linguaggio: [user="globus-user";
group="dsl-uc";
computation ISA SET[type="computation"]; storage ISA [ type="storage”];
Forall x in computation; x.cpuspeed > 150;
x.bandwidth[storage.hn] > 30; x.accesstime > 18;
Sum(computation.memory) > 300; storage.space > 80;
storage.accesstime > 18 ]
Questa è una descrizione che specifica la richiesta di più risorse. Le risorse dovranno essere sia di tipo computational, un insieme di processori ognuno avente un clock superiore a 150Mhz e un memoria aggregata totale di 300Mb, sia di tipo storage, uno spazio disco pari a 80Mb.
R1= [type="computation"; hn="ucsd1"; cpuspeed=200; bandwidth=DICTIONARY[{"s1", 20}, {"s2", 40}]; accesstime > 17 ]
R2= [type="computation"; hn="ucsd2"; cpuspeed=200; bandwidth=DICTIONARY[{"s1", 20}, {"s2", 40}]; accesstime > 17]
R3= [type = "storage"; hn="s1"; space=100] R4= [type = "storage"; hn="s2"; space=200]
Questo secondo esempio mostra una descrizione di risorse pubblicate: due computer (R1 e R2) e due storage system (R3 e R4). Si può notare come vengano espresse sia le caratteristiche delle risorse (cpuspeed), sia politiche di accesso (accesstime > 17).
Ontology-based matchmaker
Nel symmetric attribute-based matching, precedentemente illustrato, i valori degli attributi pubblicati dalle risorse sono confrontati con quelli presenti nelle varie richieste, quindi i producer e i requester devono accordarsi sui nomi degli attributi e su quale sia il range di valori accettabile. Questa
dovute sia all’eterogeneità della griglia che all’ambiente multi-istituzionale, rendono il symmetric attribute-based matching poco flessibile ed estensibile. Le critiche precedenti sono il punto di partenza per un approccio radicalmente diverso al problema del matchmaking; nato dall’incrocio delle teorie sul semantic-web e degli agenti, viene comunemente denominato ontology-based matchmaking, o per contrapposizione al precedente metodo, asymmetric matching. Alla base di questa tecnologia c’è il concetto di ontologia. Nel campo informatico, un’ontologia è uno schema concettuale esaustivo e rigoroso nell'ambito di un dato dominio; si tratta generalmente di una struttura dati gerarchica che contiene tutte le entità rilevanti, le relazioni esistenti fra di esse, le regole, gli assiomi, ed i vincoli specifici del dominio. In contrasto con i linguaggi basati su schemi, per esempio XML, le ontologie cercano di catturare la semantica del dominio di interesse, utilizzando le basi di conoscenza nel tentativo di automatizzare la comprensione delle relazioni tra i concetti del dominio. I lavori più interessanti in questo ambito sono [LH03], incentrato sull'argomento dei web services e [TDK03], che invece è focalizzato sul resource selection in ambiente di griglia. Proprio quest'ultimo descrive una serie di caratteristiche desiderabili da un sistema di matchmaking di tipo asimmetrico:
• Descrizione asimmetrica delle richieste e delle risorse: La descrizione delle risorse e delle richieste sono modellate e descritte separatamente. • Condivisione e manutenzione: Le ontologie sono condivisibili e facili
da mantenere aggiornate rispetto alle liste di attributi.
specificare i vincoli e allo stesso tempo ogni descrizione di risorsa può indipendentemente esprimere vincoli sulle politiche di utilizzo. Per esempio specificare chi ha il permesso di accesso. L'algoritmo di matching terrà conto sia dei vincoli delle richieste che di quelli delle risorse.
• Matching multi-laterale: Si possono effettuare delle richieste che richiedono risorse multiple e simultanee.
• Controllo di integrità: Il matchmaker può usare il dominio di conoscenza per identificare le inconsistenze presenti nella descrizione delle risorse prima che queste vengano accettate e pubblicate tra quelle disponibili. Un controllo di integrità può anche essere sulle richieste per assicurarsi che non ci siano conflitti tra i vincoli.
• Flessibile ed estensibile: Nuovi concetti possono essere facilmente aggiunti all'ontologia grazie all'introduzione di nuove regole.
L'ontology-base matchmaker può essere suddiviso in:
• ontologies: catturano il modello del dominio e forniscono il vocabolario necessario per esprimere le richieste dei job e descrivere le caratteristiche delle risorse. Per descrivere le ontologie viene usato RDF11.
• domain background knowledge: cattura conoscenza addizionale sul dominio, in pratica, quella che viene espressa tramite le ontologie. • matchmaking rules: definiscono quando una richiesta di un job è
soddisfatta dalle caratteristiche di una risorsa.
Il background knowledge usa il vocabolario messo a disposizione dalle ontologie per acquisire la base informativa. Le matchmaking rules usano sia le ontologie che la background knowledge per effettuare i confronti tra richieste e descrizioni delle risorse. Inoltre, il matchmaker si appoggia sul linguaggio TRIPLE per esprimere le rules e sul database deduttivo XBS. L'ontology-base matchmaker è parte integrante del servizio di machmaking
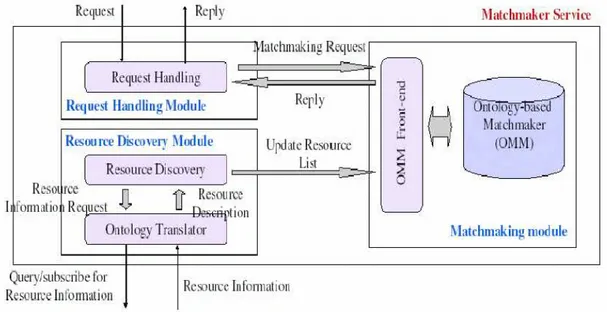
e brokering messo a disposizione dal framework denominato OMMS12
[HHTDK04]. L'architettura del framework è composta da tre moduli (figura 2.5), ed è implementata per mezzo della tecnologia grid sercices, una estensione de lla tecnologia web services, conforme alle specifiche dettate nel OGSI13.
11 Resource Description Format.