Capitolo 1 - Architetture di rete per la garanzia del servizio
In questo capitolo vengono affrontate le problematiche di qualità del servizio (QoS), in relazione ad un servizio di streaming multimediale, e vengono illustrate le architetture di rete che allo stato attuale di sviluppo costituiscono uno strumento per garantire il corretto funzionamento di tale applicazione.Garanzie di QoS richieste da uno
streaming multimediale
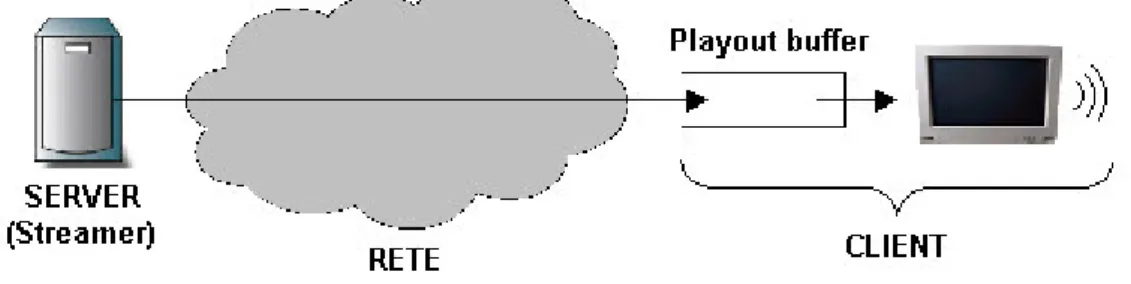
La Figura 1-1 presenta la struttura funzionale di un’applicazione di streaming multimediale, in particolare è stato messa in evidenza la struttura a lato client di una generica applicazione: i dati vengono ricevuti dalla rete e inviati in un buffer (playout buffer) prima di essere elaborati per la riproduzione del contenuto multimediale. Il buffer, pur introducendo un ritardo temporale tra la ricezione dello streaming e la sua riproduzione, permette di regolare e annullare fluttuazioni sul breve termine del livello di servizio offerto dalla rete: infatti la riproduzione continua del contenuto multimediale è garantita fintanto che nel playout buffer sono presenti dei dati.
Figura 1-1: Streaming
E’ da far notare che al pari di tutte le applicazioni multimediali non interattive, un’applicazione di streaming rientra nella categoria delle applicazioni insensibili al ritardo end-to-end; un valore elevato di tale parametro si traduce in un analogo sfalsamento temporale della riproduzione dei dati al client, rispetto al momento in cui essi sono inviati sulla rete dal server, senza tuttavia pregiudicare la continuità e la fruibilità del servizio all’utente finale. Questo permette tra le altre cose di utilizzare un playout buffer di notevole lunghezza (decine di secondi) allo scopo di annullare gli effetti negativi sulla riproduzione di
un deterioramento del livello di servizio offerto dalla rete, anche di notevole lunghezza temporale.
E’ stato dimostrato [1] che il corretto funzionamento di un’applicazione di questo tipo richiede due vincoli sulla garanzie di QoS end-to-end:
1. Un throughput medio maggiore o uguale del bit-rate richiesto in ingresso al decoder del contenuto multimediale da riprodurre.
2. Una variazione del ritardo end-to-end (jitter) finita e quanto più piccola possibile.
La prima condizione risulta necessaria per la riproduzione continua e senza interruzioni del contenuto audio video al decoder: un throughput insufficiente porterebbe infatti l’applicazione al lato client a leggere dati dal playout buffer più velocemente di quanto essi non pervengano dalla rete, portando inevitabilmente all’ underflowing del buffer e quindi all’inte rruzione della riproduzione.
La seconda condizione è necessaria per limitare le dimensioni del playout buffer al decoder. Tuttavia il parametro di jitter può essere considerato un parametro secondario, poiché i valori sperimentati sulle attuali reti di telecomunicazioni sono da considerarsi di modesta entità, e ampiamente accettabili anche in casi di architettura di rete best-effort.
Un parametro che deve essere considerato a parte è quello della Bit Error Rate (BER) sperimentata al client: i moderni standard di compressione audio-video (di cui il più comune è lo standard MPEG [2] nelle sue diverse versioni), a fronte di una elevata compressione del volume di dati con conseguente riduzione del bit rate, richiedono per funzionare correttamente un bassissimo valore di BER al decoder. A titolo di esempio il più recente standard MPEG-4 a fronte di una richiesta di throughput pari a meno di 5 Mb/s per una trasmissione di qualità televisiva, richiede un valore di BER al decoder inferiore a 10-10; si parla di una trasmissione Quasi Error Free. Nel caso di un servizio ad alta affidabilità, risulta necessario garantire a livello di trasporto un inoltro affidabile dello stream al decoder.
In conclusione per supportare un servizio affidabile di streaming multimediale si deve implementare un’architettura per la qualità del servizio che sia in grado di allocare dinamicamente connessioni a banda garantita. Negli ultimi anni sono stati proposti vari protocolli ed architetture, da affiancare all’ar chitettura IP, con lo scopo di fornire garanzie di QoS, specificatamente le architetture IntServ, DiffServ e MPLS.
Architettura
Integrated Service
identificati nella rete, ed a ciascuno la rete stessa riserva tutte le risorse necessarie per garantire parametri di QoS richiesti dall’applicazione stessa. Per far ciò c’è bisogno di introdurre nuove funzionalità e protocolli.
Come primo aspetto le applicazioni che richiedono determinati parametri di QoS per il proprio flusso di traffico hanno bisogno di comunicare alla rete tale richiesta (connection request), che deve essere sottoposta ad una procedura di admission control. C’è la necessità allora di una procedura di segnalazione che viene garantita dal protocollo RSVP [4]: si tratta di un protocollo di segnalazione che consente la comunicazione host/rete e fra i nodi di rete allo scopo di instaurare connessioni con parametri di QoS garantiti end-to-end.
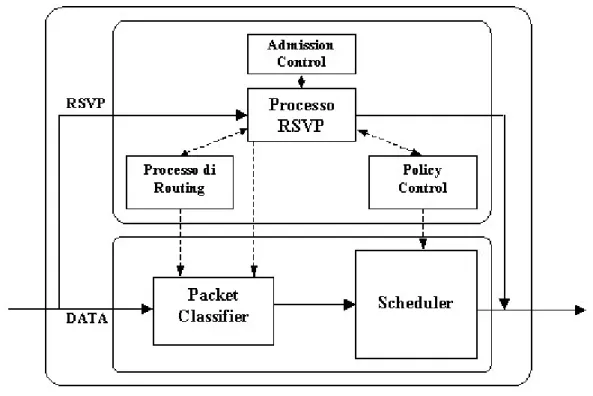
L’altro aspetto nuovo di IntServ è quello di richiedere la messa in campo di politiche di forwarding su ciascuno dei nodi di rete, allo scopo di garantire hop-by-hop il rispetto di quelle garanzie di QoS concordate in fase di connection setup, richiedendo ai router l’introduzione di funzionalità totalmente nuove (vedi Figura 1-2).
Figura 1-2: Struttura funzionale di un router in ambito IntServ
Il router da una parte deve gestire la segnalazione RSVP, una per ogni microflusso che lo attraversa. In fase di connection setup ciascuna richiesta è sottoposta alla procedura di admission control, allo scopo di verificare la presenza delle risorse necessarie a garantire le garanzie di QoS richieste. Una volta stabilita la connessione i pacchetti dati che arrivano al router vengono prima passati ad un packet classifier che identifica il microflusso di appartenenza, poi allo scheduler, il quale controllato da un processo di policy control, attua ai
pacchetti appartenenti a ciascun microflusso le discipline di forwarding appropriate per garantire i parametri di QoS concordati in fase di segnalazione RSVP.
Si tratta di una vera e propria “rivoluzione copernicana”: si introducono cioè nell’architettura di rete IP, che è un’architettura di rete tipicamente connectionless, caratteristiche proprie di un’architettura connection oriented, che prevede cioè meccanismi di connection setup e tear-down, nonché di admission-control atte a fornire garanzie di QoS stringenti. Tali modifiche minano tuttavia i principali fattori di vantaggio dell’architettura IP, vale a dire l’elevata scalabilità; questo perchè le nuove funzionalità che i nodi di rete devono supportare risultano non scalabili al crescere del numero di microflussi che devono gestire. Questo accade per due ordini di motivi:
1. I nodi di rete devono gestire una procedura di segnalazione per ciascun microflusso da cui è attraversato, il che implica una complessità proporzionale al numero di microflussi che attraversano il nodo stesso.
2. Il motore di forwarding deve applicare delle discipline di scheduling atte a garantire i parametri prestazionali concordati a ciascun microflusso, il che equivale alla gestione di una coda di uscita per ciascuno di essi. Questo comporta una complessità della gestione dei pacchetti proporzionale non solo al numero dei flussi, ma anche al volume di traffico che attraversa il nodo di rete.
Il fattore limitante risulta perciò non tanto la gestione dei protocolli di segnalazione, quanto piuttosto la velocità di calcolo richiesta al motore di forwarding nei nodi di core attraversati da elevati volumi di traffico. Per questo motivo l’architettura Intserv risulta tuttora poco supportata nella maggioranza dei router IP commerciali.
Architettura
Differentiated Service
L’idea che sta alla base dell’architettura Differentiated Service (DiffServ) [5] è quella di fornire garanzie sulla QoS non più sulla base di singole connessioni, ma sulla base di macroflussi costituiti dall’aggregazione di più microflussi, questo allo scopo di limitare le problematiche di scalabilità cha affliggono l’ar chitettura IntServ. Si tratta di definire un numero limitato di “classi di servizio”, mentre ciascun pacchetto viene assegnato ad una delle possibili classi di servizio nel momento in cui entra nel dominio DiffServ, secondo le richieste di QoS del microflusso di traffico a cui appartiene. I pacchetti vengono poi gestiti diversamente dai router di rete secondo la classe di servizio a cui appartengono.
1. I pacchetti IP devono essere assegnati ad una classe di servizio nel momento in cui entrano nel dominio DiffServ (packet classification).
2. I nodi di rete (router) devono mettere in campo delle politiche di forwarding che permettano di gestire diversamente i pacchetti IP a seconda della classe di servizio a cui appartengono (forwarding policies)
E’ da notare che mentre la funzionalità di policing deve essere effettuata da tutti i router della rete, quella di marking viene effettuata solo da quei router che si affacciano al di fuori del dominio DiffServ. Mentre questi ultimi sono detti edge router, gli altri vengono chiamati core router.
Ingresso nel dominio DiffServ
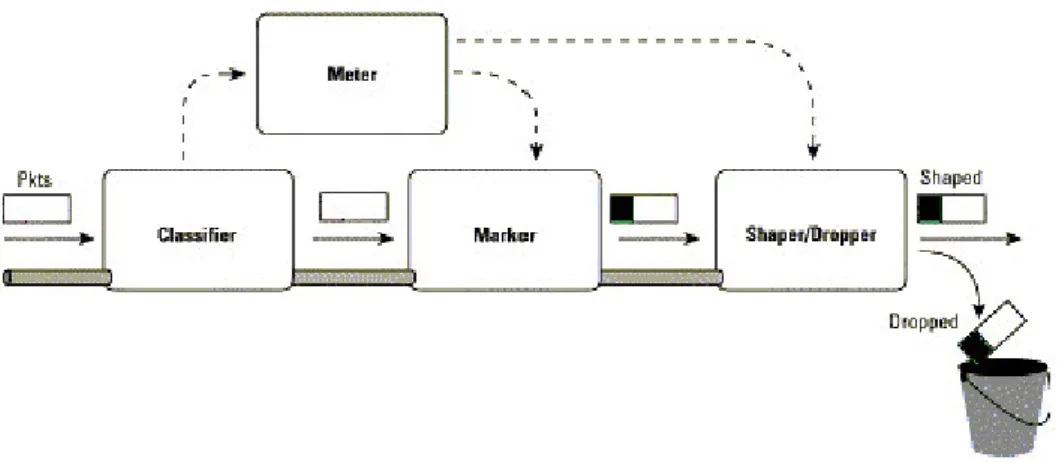
Figura 1-3: ingresso del pacchetto IP nel dominio DiffServ
All’ingesso del dominio DiffServ, i pacchetti vengono sottoposti dall’ edge-router ad operazioni di classification / marking / shaping, che sono illustrate in figura Figura 1-3 , e di cui in seguito si va a dare una descrizione:
1. Packet classification
La classificazione dei pacchetti avviene sulla base di criteri definiti su base semistatica. Il classificatore in particolare effettua la classificazione sulla base di alcuni campi dell’ header IP o dell’ header di livello 4, in particolare:
• Source / destination address • Protocol type
• ToS
Sulla base di questi parametri viene individuato a quale microflusso in ingresso il pacchetto appartiene.
2. Traffic monitoring
A ciascun microflusso vengono accordati dei profili di traffico su base semistatica. Compito del Meter è quello di verificare che il traffico in arrivo su ciascun microflusso sia in-profile, cioè non ecceda le specifiche concordate.
3. Packet marking
Il Marker procede quindi ad assegnare a ciascun pacchetto una classe di servizio, sulla base del microflusso di appartenenza, ma anche in rapporto alle specifiche di traffico: qualora il traffico offerto dal microflusso sia out-profile, è opportuno assegnare i pacchetti in eccesso a classi di traffico meno convenienti. La classe di traffico viene stabilita dal campo DSCP (DiffServ Code Point) del pacchetto IP.
4. Traffic shaping / dropping
Lo Shaper / Dropper provvede infine a far sì che il traffico relativo a ciascun microflusso in ingresso al dominio DiffServ rispetti le specifiche di traffico concordate, eventualmente scartando i pacchetti out-profile.
Politiche di forwarding
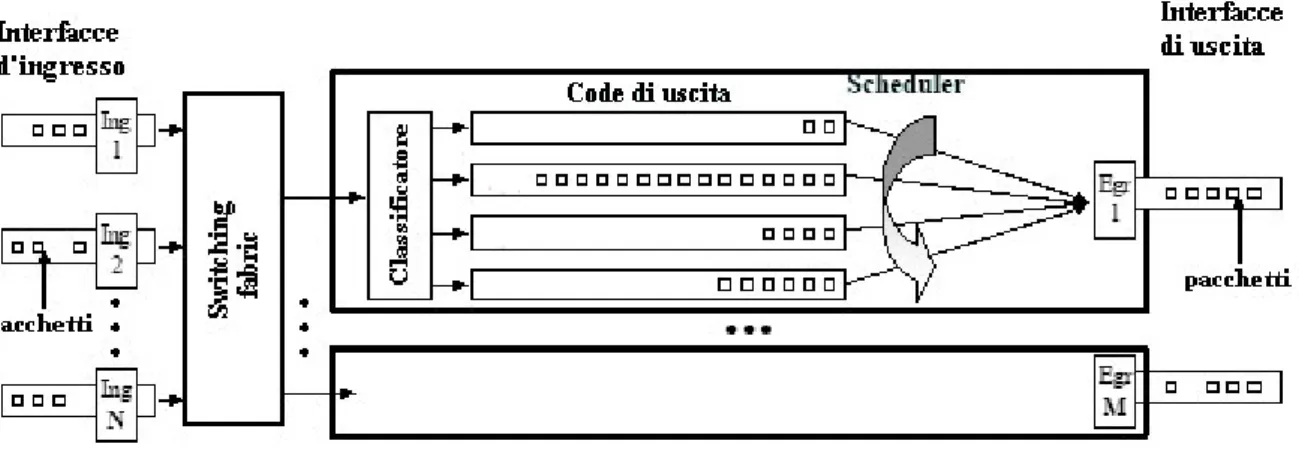
Nel momento in cui ciascun pacchetto lascia l’ edge router esso non appartiene più al microflusso di partenza, ma ad un macroflusso che viene definito dalla sua destinazione e dalla classe di servizio alla quale è stato assegnato. Per capire il trattamento che ciascun nodo di rete, e in particolare i core router, riserva ai pacchetti in transito si consideri la Figura 1-4, che mostra il diagramma funzionale di un core router in ambito DiffServ.
Il pacchetto in ingresso al core router viene inviato alla switching fabric, che provvede ad indirizzarlo sulla porta di uscita appropriata, in base alla sua destinazione (IP destination address): in questo modo il percorso che ciascun pacchetto effettua per attraversare il dominio DiffServ fino all’ edge router di uscita dipende soltanto dalla sua destinazione (IP destination address), cioè il pacchetto viene inoltrato hop-by-hop secondo le normali tabelle di forwarding, che ciascun router compila secondo le indicazioni fornite dall’ IGP e dal EGP. Tale approccio è del tutto identico al normale forwarding basato su IP. La differenza sostanziale risiede nel differente trattamento che ciascun pacchetto subisce nella coda di uscita, che varia a seconda della classe di servizio a cui appartiene, che viene indicato nel campo DSCP dell’header IP.
Figura 1-4: Diagramma funzionale di un router in ambito DiffServ
La Figura 1-4 mostra nel dettaglio la struttura funzionale della prima interfaccia di uscita. Su ciascuna il router implementa un numero limitato di code FIFO, ciascuna associata ad una delle classi di servizio implementate nel dominio DiffServ; un classificatore provvede a inviare ciascun pacchetto che entra nell’interfaccia di uscita sulla coda appropriata, semplicemente esaminando il campo DSCP. Uno scheduler provvede quindi a servire le differenti code di uscita, secondo una disciplina di scheduling [6] che ovviamente deve privilegiare le classi di servizio a specifiche di QoS più stringenti. La discipline di queueing / scheduling definite per ogni classe di servizio ad ogni nodo, costituiscono il cosiddetto Per-Hop Behaviour (PHB), che ovviamente influirà in modo determinante sul Per-Domain Behaviour (PDB), cioè il comportamento sperimentato dal generico pacchetto appartenente ad una classe di servizio, nell’attraversamento dell’inte ro domino DiffServ.
Vantaggi e limitazioni dell’architettura DiffServ
L’architettura DiffServ risulta vantaggiosa dal punto di vista della scalabilità, requisito nevralgico per qualsiasi architettura che debba agire su reti di dimensioni medio-grandi. Tale considerazione è conseguenza di due fattori:
• Assenza di procedure di segnalazione, che libera risorse di computazione; il vantaggio
rispetto all’architettura IntServ è decisivo, se si tiene conto che questa prevede la gestione di una procedura di segnalazione per ogni microflusso attivo.
• Limitazione del numero di classi di servizio, nonché l’adozione di flussi aggregati di
traffico, che consentono di limitare la complessità delle operazioni di forwarding: visto che secondo standard le classi di servizio sono limitate a 4, i nodi di rete su ciascuna porta di uscita si possono limitare alla gestione di un analogo numero di code su ciascuna porta di uscita. Questa limitazione risulta fondamentale soprattutto nella limitazione di
complessità nei router ad alte prestazioni, in quanto la complessità della gestione delle code in uscita è proporzionale al numero di code implementate.
Tuttavia DiffServ presenta anche svantaggi, e per certi versi presenta un passo indietro rispetto all’architettura IntServ. In partic olare:
• Difficile derivazione delle garanzie end-to-end: mentre IntServ consente garanzie
stringenti di QoS per ogni microflusso non altrettanto si può dire di DiffServ che opera strettamente su flussi di traffico aggregati; di conseguenza non è possibile derivare facilmente i parametri di QoS end-to-end a partire dal PHB che è stato stabilito su ciascun router.
• Distribuzione delle risorse e soluzione delle problematiche di traffic engineering: La
suddivisione del traffico in classi di servizio, è condizione necessaria ma non sufficiente ad ottenere determinate garanzie di QoS a livello end-to-end, anche per le classi di servizio “privilegiate”. Se un macroflusso di traffico segue un percorso di rete con risorse inadeguate (in termini di banda o di buffer ad esempio), può incorrere in parameri di QoS non corrispondenti alle specifiche richieste. Ciò avviene principalmente a causa dell’insorgere della congestione, la quale porta alla perdita di pacchetti per l’ overflowing dei buffer di uscita, che alla fine portano ad una drastica decadenza dei parametri di QoS. La soluzione del primo inconveniente risulta relegata all’adozione di discipline di queueing / scheduling che possano portare, attraverso un’opportuna trattazione matematica, a dei modelli che possano risultare in almeno dei bound sulle garanzie end-to-end.
La soluzione del secondo problema potrebbe essere riconducibile ad una progettazione accurata della rete, che tenga conto di tutti i flussi di traffico e verifichi che non vi siano nodi o link che possano venire congestionati. Questo approccio presenta però pesanti inconvenienti:
• si potrebbero evitare eventuali problemi di congestione o resource contention attraverso
un overprovisioning delle risorse di rete (in termini ad esempio di banda dei link), con l’evidente controindicazione di un aumento non necessario di costo della rete.
• si incorre comunque in un problema di eccessiva staticità della rete, in quanto qualsiasi
parametro calcolato in fase di progettazione, andrebbe rivisto in caso di modifica, anche minima, della rete; si incorrerebbe quindi in problematiche serie sia in termini di costi di gestione, nel momento in cui si volesse apportare modifiche, come ad esempio incrementi nei flussi di traffico o cambiamenti di topologia, per non parlare di effetti disastrosi che potrebbe avere un eventuale guasto di link o di nodo. La mancanza di qualsiasi protocollo
di segnalazione/controllo rende impossibile l’allocazione dinamica delle risorse e quindi la possibilità di offrire servizi dinamici on-demand come uno streaming multimediale. Occorre quindi introdurre nella rete funzionalità dinamiche di traffic engineering, allo scopo di ottenere un utilizzo sempre ottimale delle risorse e una garanzia più precisa delle prestazioni a livello di parametri di QoS garantiti end-to-end.
Traffic engineering con MPLS
La combinazione dell’architettura per la QoS DiffServ, con le funzionalità di traffic engineering offerte dal protocollo MPLS (Multi Protocol Label Switching) [7] costituisce una soluzione almeno parziale delle problematiche che affliggono DiffServ.
Forwarding MPLS
La limitazione principale della modalità di routing messa in campo da IP, e che di conseguenza affligge anche l’architettura DiffServ, consiste nel fatto che ciasc un pacchetto viene instradato hop-by-hop in modo indipendente da ciascun nodo di rete (router), sulla base della sola destinazione finale, secondo le tabelle di routing/forwarding che vengono compilate attraverso i protocolli di routing dinamico e distribuito. IP è infatti una tipica architettura di rete connectionless in modalità datagramma. Ciò porta necessariamente ad una limitazione alla possibilità di effettuare qualsiasi politica di gestione del traffico: infatti tutti pacchetti IP destinati al medesimo indirizzo IP, si trovano forzatamente a dover seguire lo stesso percorso nella rete (path).
Al contrario MPLS si basa su una architettura connection oriented, in cui i singoli pacchetti vengono ancora instradati hop-by-hop, non più però sulla base della loro destinazione, ma sulla base di una label a loro associata, che identifica univocamente a ciascun nodo di rete il Label Switched Path (LSP) sul quale il pacchetto è instradato; naturalmente i LSP devono essere preventivamente stabiliti attraverso la rete mediante protocolli di segnalazione opportuni, come RSVP [9] o LDP (Label Distribution Protocol) [10].
In questo modo il percorso seguito da un pacchetto nella rete non dipende unicamente dalla sua destinazione IP, ma dal LSP su cui viene instradato; ciò comporta che tutti i pacchetti instradati sul medesimo LSP condividono la stessa Forwarding Equivalence Class (FEC), cioè vengono trattati indistintamente ad ogni nodo di rete.
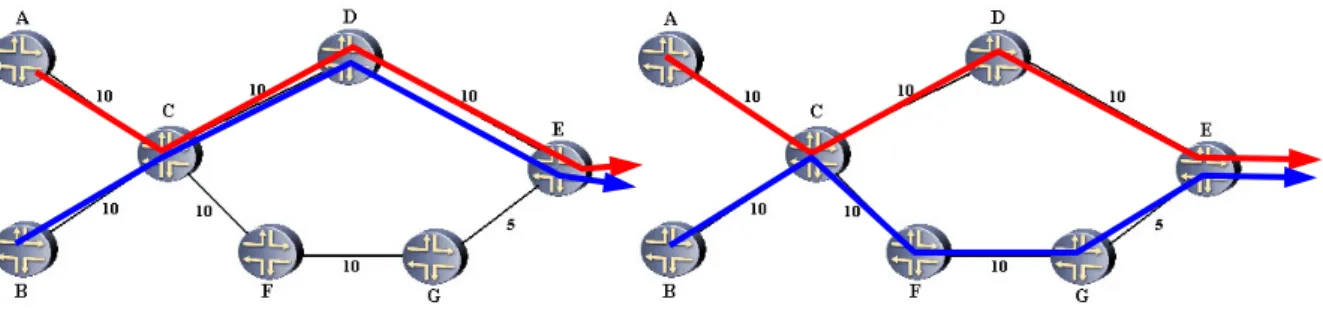
Figura 1-5: Esempio di routing IP (a sinistra) e di MPLS traffic engineering (a destra)
Le due frecce rappresentano due distinti flussi di traffico che devono uscire dalla rete attraverso il router E. Si supponga che entrambi i flussi richiedano 100 Mb/s e tutti i link abbiano banda pari a 150 Mb/s. Nel caso di routing IP (a sinistra) entrambi i flussi vengono instradati hop-by-hop attraverso il cammino di costo minimo, vale a dire attraverso il router D, andando inevitabilmente a congestionare i link C-D e D-E. Al contrario in caso di routing MPLS (a destra) è possibile instradare i due flussi su due LSP diversi, uno attraverso D, l’altro attraverso il percorso subottimo F -G, evitando così l’insorgere della congestione. E’ evidente quindi come la modalità di forwarding di MPLS basata sul meccanismo delle LABEL/LSP sia uno strumento fondamentale per permettere la messa in atto qualsiasi politica di traffic-engineering.
Traffic engineering con MPLS
Una volta stabilita la modalità di forwarding che permette ai pacchetti di seguire determinati path piuttosto che altri, resta da stabilire quali siano i criteri per effettuare il routing dei LSP dal nodo sorgente (ingress router) a quello destinazione (egress router). MPLS DiffServ fa affidamento ai meccanismi di traffic engineering propri di MPLS (MPLS Traffic Engineering)[8]..
MPLS-TE mette in campo degli algoritmi che hanno come finalità quella di evitare la congestione dei link, che è la causa principale della degradazione delle prestazioni di rete. Come primo elemento vengono associati a ciascun LSP dei parametri (constraint) che vengono definiti prima dell’instaurazione; tra i più significativi si possono citare i seguenti:
• Banda
E’ il parametro fondamentale, in quanto gli algoritmi di routing messi in campo da MPLS-TE, si preoccuperanno di garantire su ciascun link attraversato dal LSP un parametro di banda. In altre parole la somma dei parametri di banda di tutti i LSP che
• Priorità
Serve a stabilire delle precedenze tra LSP che si contendono delle risorse di rete. Il concetto è che un LSP a priorità maggiore può forzare l’abbattimento di un LSP a più bassa priorità (LSP preemption) qualora ve ne sia la necessita (si veda Capitolo 2 - LSP preemption).
Gli algoritmi di routing si preoccupano che i LSP siano instradati lungo percorsi che permettono di soddisfare tutti i constraint, mentre nel caso non esista alcun path da ingress a egress router che permetta di soddisfarli tutti, il LSP viene abbattuto o non viene stabilito. L’algoritmo di routing Constraint Shortest Path First (CSPF) è l’algoritmo utilizzato in sede di path computation: si tratta di uno sviluppo degli algoritmi Shortest Path First, del tipo di quelli già utilizzati negli algoritmi di routing Link State, che consentono di calcolare il percorso più breve tra due nodi, secondo una stabilita metrica di ramo. L’algoritmo CSPF in particolare è in grado di trovare il percorso più breve che congiunge ingress e egress router, sempre secondo la metrica di link propria dell’IGP, scelto però solo tra i percorsi che soddisfano tutti i LSP constraint.
Dal punto di vista strettamente funzionale l’algoritmo CSPF sfrutta un qualsiasi algoritmo SPF, applicato alla topologia di rete preliminarmente elaborata escludendo tutti i link che non possono essere attraversati dal LSP (ad esempio vengono esclusi tutti i link con banda disponibile non sufficiente) quindi viene computato un normale algoritmo SPF per il calcolo del path.
L’algoritmo CSPF vien e eseguito dall’ ingress router ogniqualvolta venga stabilito un LSP, o qualora in caso di cambiamenti nella topologia di rete vada effettuato il rerouting (vedi Capitolo 2 - Path Recovery dinamico). L’algoritmo CSPF , al pari degli algoritmi SPF, richiede che in ciascun router sia presente un database che contenga oltre a tutte le informazioni circa la topologia della rete (informazioni di Link State), anche dei parametri di traffic engineering associati a ciascun link, come la banda allocabile. Un IGP “tradizionale”, come ad esempio OSPF [11] che prevede la distribuzione della sola metrica di ramo, non è sufficiente; l’architettura MPLS -TE prevede allora l’utilizzo di OSPF Traffic Engineering [12] come IGP all’interno del dominio MPLS, il quale provvede ad estendere OSPF con nuovi Link State Advertisement (LSA) che possono trasportare i parametri di traffic engineering necessari all’algoritmo CSPF per funzionare.
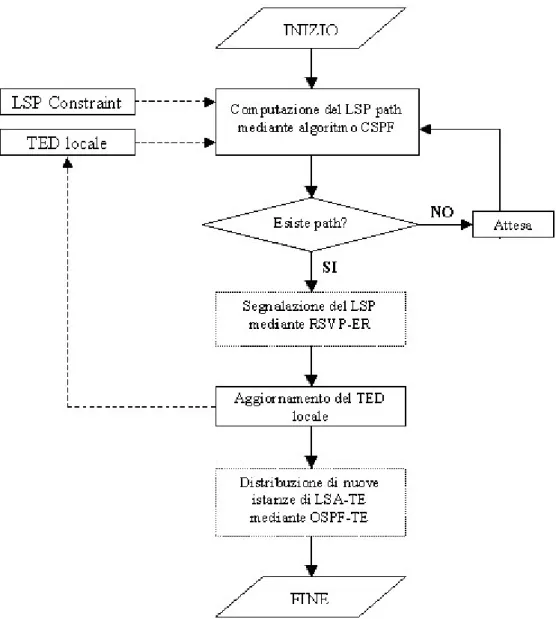
E’ importante notare come tali estensioni al protocollo IGP consentono la compilazione dell’algoritmo CSPF localmente all’ ingress router, senza l’ausilio di alcuna comunicazione con altri router, questo perché le informazioni contenute nel Traffic Engineering Database
(TED) sono sufficienti alla compilazione del CSPF. Il diagramma di flusso di Figura 1-6 mostra le operazioni compiute dall’ ingress router per instaurare un nuovo LSP.
Figura 1-6: Instaurazione dei un LSP da parte dell’ingress router
Una volta che l’ ingress router ha effettuato il calcolo del path attraverso l’algoritmo CSPF, c’è bisogno di una procedura di segnalazione che provveda a stabilire il LSP in tutti i router che sono attraversati. A tal fine l’architettura MPLS -TE prevede l’utilizzo del protocollo RSVP-TE [9], un’estensione al protocollo RSVP già utilizzato nell’architettura IntServ, provvisto di estensioni per la gestione degli MPLS-LSP, nonché delle estensioni di Explicit routing.
Se non si incorre in errori la segnalazione RSVP-ER porta alla corretta instaurazione del LSP attraverso la rete; da quel momento il LSP è attivo e può essere utilizzato dall’ ingress router
Infine è necessario un aggiornamento del TED localmente all’ ingress router che porta alla distribuzione attraverso OSPF-TE di nuovi LSA-TE in tutti i router di rete, allo scopo di sincronizzare i TED.
Al contrario se l’algoritmo CSPF rilev a l’impossibilità di stabilire il LSP, nessuna segnalazione ha luogo; l’ ingress router può ritentare la procedura dopo un certo tempo di attesa, che può essere fissato staticamente, oppure può attendere che avvengano dei cambiamenti nel TED.
Architettura
MPLS-DiffServ
I meccanismi di traffic engineering permettono di instradare ciascun flusso di traffico in maniera efficiente rispetto all’utilizzo delle risorse di rete e in modo da evitare l’insorgere della congestione. Nonostante le funzionalità messe a disposizione da MPLS-TE, questo da solo non è in grado di per sé di garantire alcuna specifica di QoS, poiché l’architettura MPLS è in grado di influenzare solo il routing dei flussi di traffico, senza alcuna possibilità di influire sulle dinamiche di forwarding, che in definitiva sono quelle che consentono una differenziazione del traffico. Per questo l’integrazione dell’architettura DiffServ con quella MPLS-TE risulta fondamentale per garantire un’architettura per la QoS quanto più completa ed affidabile possibile. Si può dire cioè che mentre MPLS espande il piano di controllo con funzionalità di traffic engineering che IP non prevede, a livello di piano dati viene mantenuto quello di IP DiffServ.
Ingresso nel dominio MPLS-DiffServ
Il traffico IP in ingresso al dominio MPLS-DiffServ può essere instradato su un LSP (definendo la FEC di appartenenza), secondo criteri non dissimili a quelli illustrati nel paragrafo Ingresso nel dominio DiffServ. L’instradamento di un pac chetto su un LSP ne stabilisce anche la classe di traffico DiffServ (vedi paragrafo seguente). Si noti che a differenza di DiffServ, in cui la limitazione delle classi di servizio limitano necessariamente il livello di granularità, le specifiche di MPLS-DiffServ non stabiliscono il livello di granularità con cui i microflussi devono essere mappati nei LSP; al limite è possibile far coincidere un singolo LSP con un singolo microflusso in ingresso.
Si fa notare che la totalità del traffico in ingresso ad un LSP non può mai eccedere il parametro di banda del LSP stesso; si è visto come le funzionalità di traffic engineering permettano di instradare i LSP secondo le specifiche di banda, allo scopo di evitare la congestione dei link che potrebbe verificarsi qualora i parametri di banda di tutti i LSP che transitano su un link eccedessero la capacità trasmissiva del link stesso. Sarebbe allora
compromettente inviare su un LSP un traffico che ecceda il parametro di banda del LSP, poiché questo potrebbe portare alla congestione di uno o più link attraversati, con conseguente overflowing delle code di uscita, con conseguenze negative sui parametri di packet loss / delay / throughput non solo del traffico che transita dal LSP che ha portato la congestione, ma anche sul traffico inoltrato su tutti i LSP che attraversano lo stesso link / coda congestionata.
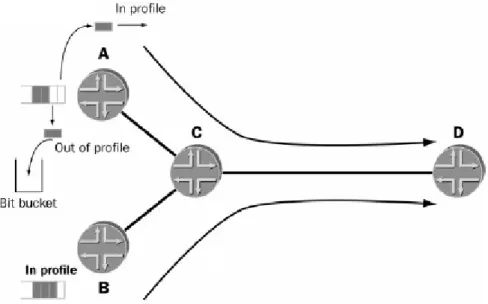
Il rimedio naturale ad un inconveniente di questo tipo è semplicemente quello di adottare politiche di shaping / dropping all’ingresso di ciascun LSP, allo scopo di as sicurarsi che il traffico in ingresso non ecceda le specifiche di banda del LSP, evitando così l’insorgere della congestione nei core-router (Figura 1-7). D’altra parte ciò fa sì che su un LSP non sia possibile inviare mai un volume di traffico che ecceda la banda garantita, anche qualora le condizioni complessive del carico di rete lo consentano.
Figura 1-7: Limitazione del traffico in ingresso ai LSP a banda riservata
Politiche di questo tipo possono essere prese sia sulla base dei singoli microflussi in ingresso al dominio MPLS, come già previsto da DiffServ, sia sulla base dell’intero flusso di traffico in ingresso al singolo LSP.
Politiche di forwarding
I meccanismi di forwarding delle varie classi di traffico messe a disposizione di DiffServ possono essere facilmente integrati al forwarding MPLS allo scopo di garantire trattamenti
Il traffico che all’ingresso del dominio MPLS viene inoltrato sul medesimo LSP è assegnato alla medesima FEC, il che significa:
• tutti i pacchetti seguiranno il medesimo path verso l’egress router del LSP, grazie al
meccanismo del label based forwarding.
• tutti i pacchetti subiranno il medesimo trattamento alle code di uscita, secondo la classe di
servizio DiffServ assegnata al LSP.
Come visto in precedenza nell’ambito DiffServ il campo DSCP del pacchetto IP stabilisce il PHB del pacchetto; nell’integrazione MPLS -DiffServ esistono due possibilità:
• la classe di servizio a cui un pacchetto fa riferimento è mappato nei 3 bit del campo EXP
della label MPLS (E-LSP): all’ingresso del dominio MPLS l’ ingress router provvede sia alla label pushing del pacchetto, sia a settare opportunamente gli EXP bit per identificare il PHB a quale il pacchetto MPLS fa riferimento. Si possono identificare in questo modo fino a 8 PHB.
• in caso che il numero di classi di servizio che si vuole implementare ecceda questo
numero, è possibile che in fase di instaurazione del LSP, sia segnalato ai router a quale classe di servizio deve essere assegnato tutto il traffico inoltrato su LSP (L-LSP). I 3 bit del campo EXP possono essere utilizzati per settare la drop preference associata a ciascun pacchetto.
In definitiva la combinazione delle politiche di traffic engineering messe in campo da MPLS, con quelle di forwarding previste da DiffServ, consentono di stabilire sulla rete delle connessioni (LSP) con parametri di QoS garantiti. Le specifiche modalità implementative non sono strettamente definite dallo standard. Nel Capitolo 3 - Architettura di rete è illustrata una possibile implementazione di MPLS-DiffServ, che è stata utilizzata nelle prove sperimentali per garantire una connessione a banda garantita end-to-end al flusso di streaming. Nel seguente capitolo verranno esaminate invece le tecniche di ripristino che consentono la sopravvivenza dei LSP in caso di cambiamenti nello stato della rete.