2 Progettazione a bassa potenza per circuiti
CMOS.
Un obiettivo importante nel signal-processing e in altre applicazioni dedicate è il mantenimento del throughput al minimo necessario; infatti non ci sarebbero vantaggi nell’elaborare i segnali il più veloce possibile se poi vengono inseriti dei cicli di wait finchè è richiesta una nuova elaborazione. Se ad esempio si usa una tecnica di voltage-scaling per ridurre la potenza, contemporaneamente ciò introdurrà una diminuzione di velocità dei circuiti logici e per mantenere il throughput iniziale si possono introdurre delle strutture parallele oppure delle strutture in pipeline.
Qualche tecnica per ridurre la potenza può avere come conseguenza un aumento di area, bisognerà perciò trovare una soluzione di compromesso che non penalizzi troppo né l’uno né l’altro aspetto. Spesso però un piccolo aumento dell’area, può avere un sostanziale impatto sulle richieste in termini di potenza.
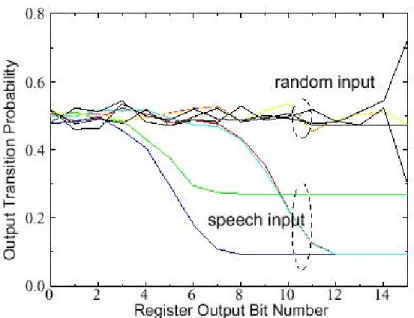
In generale, i circuiti CMOS dissipano in condizioni statiche una potenza trascurabile, quindi bisognerà ridurre la switching activity (attività di commutazione) ai minimi livelli richiesti per l’elaborazione. A questo scopo si potrebbe privare del segnale di clock i moduli che restano inattivi per lunghi periodi di tempo (clock gating) oppure si potrebbe modificare l’architettura circuitale per ridurre il numero di transizioni a parità di funzione realizzata. Il numero di commutazioni dipende anche dalla correlazione tra i valori della sequenza temporale dei dati da elaborare: se la correlazione è alta allora i dati cambiano molto lentamente e la switching activity diminuisce. Ad esempio in Figura 2-1 si prende in considerazione un filtro FIR e viene rappresentata la probabilità di transizione dell’uscita in funzione del numero di bit del registro d’uscita, nei due casi di random input e di segnale vocale. Si nota che nel caso di segnale vocale (alta correlazione) si ha una probabilità di transizione più piccola dell’80% [1].
Figura 2-1 Dipendenza delle commutazioni dalla statistica in ingresso.
Inoltre anche la sequenza delle operazioni eseguite può influire molto sul numero di commutazioni complessive.
Le tecniche di riduzione in potenza possono agire a quattro livelli di ottimizzazione che vengono elencati di seguito (partendo dal livello di astrazione più basso):
• Ottimizzazione a livello tecnologico.
• Ottimizzazione a livello circuitale e logico.
• Ottimizzazione a livello architetturale.
• Ottimizzazione a livello algoritmico.
2.1 Ottimizzazione a livello tecnologico.
Come si è giá visto nel Paragrafo 1.1, il maggior contributo per la potenza (componente di switching) è proporzionale al quadrato della tensione di alimentazione. Quindi una possibile soluzione per una notevole diminuzione della potenza, è rappresentata dalla riduzione di Vdd. Il prezzo da pagare è l’aumento
dei ritardi. Infatti approssimando un transistore MOS come un generatore di corrente costante I, il tempo impiegato dalla tensione di uscita per variare da 0 V a
dd V (e viceversa) è: 2 ) ( 2 dd t o x dd L dd L d V V L W C V C I V C T − × = × = µ
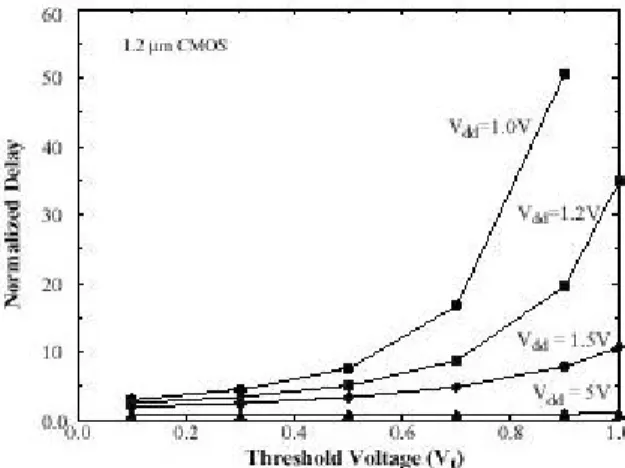
Si può vedere c he al tendere di Vdd a Vt, il ritardo aumenta notevolmente a causa dell’effetto quadratico di Vdd −Vt al denominatore.
Per compensare l’introduzione di questi ritardi e mantenere il throughput costante si potrebbero introdurre delle architetture parallele o pipelined come si vedrà più tardi nel Paragrafo 2.3.1. Una soluzione a livello tecnologico consiste nel diminuire la tensione di soglia. Infatti la dipendenza Td = f(Vdd,Vt) è di tipo seguente:
Figura 2 -2 Effetto della riduzione della tensione di soglia per varie tensioni di alimentazioni.
Si possono cioè trovare dei punti in cui:
) , ( ) , ( dd1 t1 d dd2 t2 d V V T V V T =
con: 2 1 dd dd V V < 2 1 t t V V <
Dall’altro lato c’è un limite inferiore alla diminuzione di Vt fissato dalla necessità di mantenere basse le correnti sotto-soglia; esse infatti potrebbero causare un aumento della potenza statica non trascurabile. Quindi muovendoci lungo una curva a throughput costante e diminuendo gradualmente sia Vdd che Vt si troverà infine un punto di minimo della potenza totale (pote nza statica + dinamica) in cui conviene lavorare.
2.2 Ottimizzazione a livello circuitale e logico.
A questo livello si hanno le seguenti soluzioni: placement e routing, dimensionamento dei transistori, riduzione della dinamica, circuiteria di supporto per il low-voltage, minimizzazione della logica e mappaggio tecnologico, livello logico.
2.2.1 Placement e Routing.
A livello di layout, si deve fare in modo che ai segnali che hanno un’alta switching activity (ad esempio il clock) siano assegnate delle connessioni più corte possibili in modo che essi pilotino capacità non troppo elevate.
2.2.2 Dimensionamento dei transistori.
Si potrebbe ad esempio aumentare il rapporto W/L dei transistori: in questo modo si hanno dei dispositivi più veloci e ciò può permettere una riduzione della tensione di alimentazione e nello stesso tempo si mantiene il throughput iniziale. Vediamo un esempio:
Figura 2-3 Modello circuitale per analizzare l’effetto di W/L sui ritardi.
Nel caso in Figura 2-3 si è sovradimensionato W/L dell’inverter 1 e dell’’inverter 2 in modo che W/L = N (W/L)ref. Dove si è indicato con (W/L)ref il
minimo rapporto consentito tra larghezza e lunghezza di canale. Ció provoca 2 effetti:
1. La capacità d’ingresso (Cg) dell’inverter 2 diventa N volte più grande rispetto al caso in cui W/L = (W/L)ref.
2. La corrente (I) erogata dall’inverter 1 diventa N volte più grande rispetto al caso in cui W/L = (W/L)ref.
Si è inoltre considerata la capacità parassita (Cp) dovuta alle interconnessioni e all’accoppiamento capacitivo col substrato. In generale il ritardo per caricare la capacità Cp + Cg è pari a:
I V C C
Contemporaneamente all’aumento di W/L, si puó diminuire Vdd dal valore iniziale Vref al valore VN in modo che Td rimanga costante, avremo:
2 2 ( ) ) ( ) )( ( ) ( t ref ref ref ref p t N ref N ref p V V KC V C C V V NC K V NC C − × + = − × +
Nel caso in cui VN,Vref >>Vt si ha:
ref ref p ref p N V C C NC C V ) / 1 ( ) / 1 ( + + =
L’energia consumata per una transizione 0→VN sarà:
3 2 ) 1 ( ) ( ) ( ref p N ref p NC C N V NC C N E = + ∝ + allora: 3 3 ) / 1 ( ) / 1 ( ) 1 ( ) ( ref p ref p C C NC C N N E N E + + = =
Quindi non sempre conviene sovradimensionare W/L per ottimizzare in potenza: ad esempio se Cp <<Cref conviene avere N più piccolo possibile (N = 1). Se invece Cp >>Cref allora conviene il sovradimensionamento.
2.2.3 Riduzione della dinamica.
Supponiamo che la dinamica d’uscita non sia di tipo rail-to-rail. Si consideri ad esempio un pull-up a singolo pass -transistor NMOS come in Figura 2-4:
Figura 2-4 Esempio di un circuito con dinamica di uscita ridotta.
Allora la tensione di uscita varia da 0 V a Vdd−Vt, infatti quando l’uscita raggiunge questa tensione allora l’NMOS si interdice. L’energia consumata per una transizione 0→Vdd −Vt non sarà più E =CLVdd2 ma:
) ( dd t dd LV V V C E = −
Usando questa tecnica si hanno però due conseguenze negative:
• Riduzione del Noise-Margin sul livello alto (NMH).
• Quando l’uscita si trova al livello alto Vdd −Vt, allora la porta successiva può consumare una potenza statica non più nulla.
2.2.4 Circuiteria di supporto per il low-voltage.
Si è visto nel Paragrafo 2.1 che il low-voltage permette una notevole riduzione della potenza dissipata. Spesso i sistemi portatili sono costituiti da
diverse parti che richiedono di lavorare ognuno con la propria Vdd ottimale (in base ai ritardi e alla potenza dissipata). In questi casi per generare le diverse tensioni di alimentazione sono richiesti appositi circuiti low -voltage dc/dc converter ad alta efficienza (es. buck converter).
2.2.5 Minimizzazione della logica e mappaggio tecnologico.
Queste tecniche consistono nell’opportuna scelta di logica che minimizzi il numero di commutazioni, nel riposizionare i registri (retiming) per ridurre il glitch, nello scegliere componenti da una libreria di tipo low -power. In questo modo la potenza può essere ridotta di circa 25 %.
2.2.6 Livello logico.
A questo livello, la switching activity può essere ridotta notevolmente usando qualche circuiteria di controllo addizionale. Una possibile soluzione potrebbe essere il clock gating (di cui si parlerà più in dettaglio nel Paragrafo 5.6.1).
Nelle macchine a stati si cerca di realizzare un assegnamento degli stati in modo da minimizzare l’attività di commutazione. Per far ciò, si completa l’STG (State Transition Graph) aggiungendovi la probabilità di ogni stato e la probabilità di transizione fra gli stati. In base a questi dati, si sceglie una codifica binaria adiacente tra stati con alta probabilità di transizione. Per cercare di non penalizzare troppo l’area, si può scegliere tra le diverse codifiche che hanno pari switching activity, quella che presenta area minore.
In circuiti sequenziali, usando entrambi i fronti in salita e in discesa del clock per aggiornare i registri, si riesce a lavorare con una frequenza pari a metà di quella originale e inoltre si mantiene il throughput di partenza. In questo modo si usano dei DETFF (Double Edge Triggered Flip Flop): si dovrebbe avere un risparmio del 50 % nella potenza consumata dalla rete di distribuzione del clock
[2]. Però in generale i DETFF occupano un’area maggiore e presentano delle capacità più elevate rispetto ai normali DFF (D Flip Flop). Un altro difetto del double edge clocking rispetto al single edge clocking, è la necessità di usare un duty cycle del clock di 1/2 (per evitare violazioni di timing nei percorsi critici), inoltre le specifiche sul jitter del clock sono più stringenti e quindi diventa più difficile la progettazione della rete di generazione del clock [19].
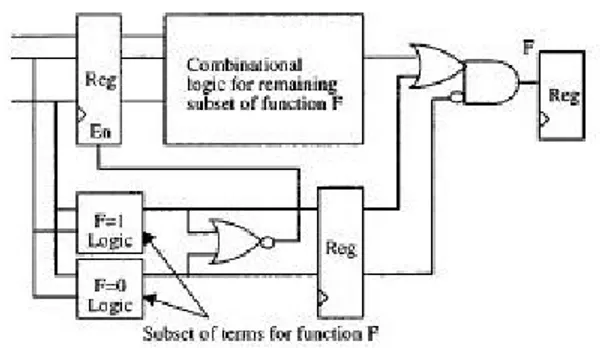
La precomputazione è una tecnica di ottimizzazione per circuiti sequenziali: è usata per precalcolare, in modo molto facile, l’uscita di un circuito logico prima che questa sia richiesta. Poi gli ingressi del circuito logico vengono disabilitati (si usano dei registri con abilitazione) e l’uscita viene aggiornata al valore precalcolato.
Figura 2 -5 Struttura per la precomputation.
La logica di precomputazione è molto semplice e usa un numero ridotto di ingressi per stabilire se la funzione F è ver a o falsa. Inoltre la funzione logica originale può essere semplificata perché se gli ingressi attivano la logica di precomputazione allora l’uscita della logica originale può essere non specificata. In questo modo si riescono ad ottenere risparmi in potenza dell’ordine di 11% - 66%.
Altre tecniche sono le seguenti: operand isolation e guarded evaluation. La prima sarà trattata più in dettaglio nel Capitolo 5 e consiste nell’aggiungere delle porte AND (o OR) agli ingressi di un generico operatore inserito all’interno di un datapath. Viene inoltre prodotto un Activation Signal (AS) che va a livello logico basso (o alto se vengono usate delle porte OR) quando l’uscita dell’operatore non
serve. In questo modo gli ingressi dell’operatore vengono mantenuti costanti quando l’uscita non è usata e non si hanno commutazioni all’interno dell’operatore. Un’altra tecnica di ottimizzazione in potenza a livello logico è chiamata “guarded evaluation”. Come altre tecniche già viste, anche ora bisogna individuare quali parti di un circuito logico sono usate oppure no, e poi si fa in modo che non si propaghi nessuna transizione attraverso la logica combinatoria che non è usata. Una soluzione per far ciò è quella di usare il clock gating sui registri che forniscono gli ingressi a questa logica combinatoria. Però questa soluzione non va bene quando i registri di cui si è parlato forniscono dei dati in ingresso anche ad altre logiche combinatorie che invece sono utilizzate. In questo caso non si può fare il clock gating e questi registri devono necessariamente essere aggiornati: ciò provoca delle commutazioni anche sulla logica non utilizzata. Si consideri ad esempio il caso in figura:
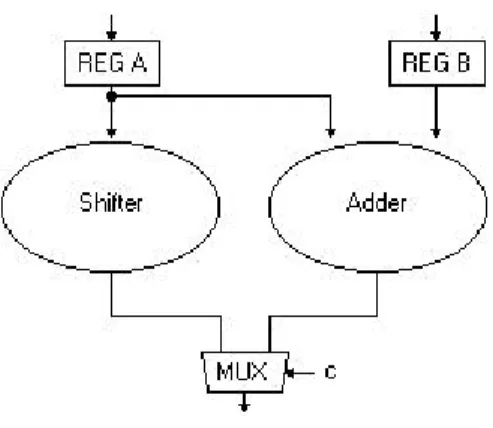
Figura 2-6 Dual ope ration ALU.
Quando lo shifter non è utilizzato (ad esempio con c = 0), il registro A deve continuare a essere clockato perché il suo valore serve anche all’adder. Si potrebbe pensare ad esempio di duplicare il registro A ed applicare il clock gating solo al registro in ingresso allo shifter, ma spesso questa soluzione è troppo costosa in termini di area.
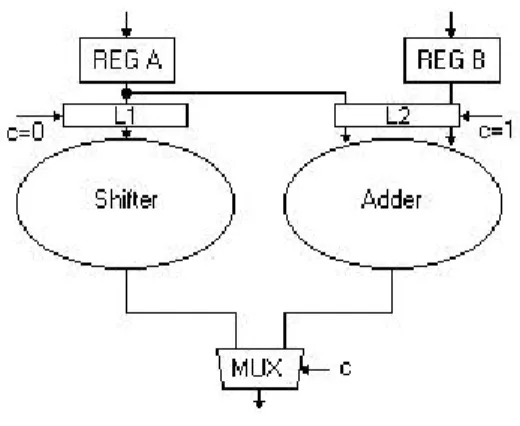
La tecnica chiamata “guarded evaluation” risolve questo problema inserendo dei latch trasparenti agli ingressi di quelle parti del circuito che necessitano di essere spente in modo selettivo. Infatti se il segnale di enable di
questi latch è attivo, allora vengono eseguite le normali operazioni altrimenti il latch conserva il suo valore e non permette la propagazione di commutazioni attraverso il modulo inattivo. Quindi la ALU di sopra si modifica in questo modo:
Figura 2 -7 Dual operation ALU con guard logic.
La guarded evaluation si propone anche lo scopo di bloccare le commutazioni di nodi all’interno di una rete combinatoria qualora esse non ne influenzino l’uscita. Ad esempio, se al variare degli ingressi della rete combinatoria si generano delle commutazioni su un ingresso di una porta AND in cui l’altro ingresso è costantemente al valore logico basso, bisognerà eliminare queste commutazioni perché esse non influenzano l’uscita della rete. L’uso di una barriera di latch evita inoltre la propagazione di glitch indesiderati attraverso la logica combinatoria. Questi latch vengono abilitati dopo un certo intervallo di tempo dall’ultimo fronte del clock e sono controllati da specifiche condizioni logiche.
Vediamo come si può implementare la guarded evaluation. Si consideri un circuito logico combinatorio C, sia x un segnale nel circuito e sia F l’insieme delle celle usate per generare x (e non altri segnali). Si dovrà trovare un segnale s all’interno di C tale che quando s = 1, x non è necessario per calcolare il valore delle uscite di C. Come si vede in Figura 2-8, si possono aggiungere dei latch in ingresso alla rete F che saranno abilitati solo quando s = 0.
Figura 2 -8 Pure Guarded Evaluation.
Se si vuole un risparmio di potenza massimo si deve fare in modo che “s” si stabilizzi al valore “1” prima che commutino gli ingressi della rete. In questo modo si realizza una “pure-guarded-evaluation” cioè il circuito che si ottiene è diverso da quello di partenza solo per l’aggiunta dei latch (cioè non è aggiunta nessuna logica di controllo perché il segnale s è già esistente all’interno della rete C). Spesso il segnale s che verifica la condizione di sopra non può essere trovato: sarà necessaria l’aggiunta di altra logica oltre ai latch (“extended-guarded-evaluation”). In [3] è descritta una tecnica automatica per determinare quali parti di un circuito possono essere disabilitate in differenti cicli di clock.
2.3 Ottimizzazione a livello architetturale.
Di seguito vengono proposte le seguenti soluzioni: modifiche architetturali per il voltage scaling, scelta della rappresentazione dei numeri, modifica dell’ordine delle operazioni sui segnali in ingresso, minimizzazione del glitch, condivisione delle risorse.
2.3.1 Modifiche architetturali per il voltage scaling.
Si è visto che il voltage -scaling comporta un aumento dei ritardi. Per mantenere il throughput al valore minimo richiesto, verranno utilizzate delle strutture ottimizzate: ad esempio architetture parallele o architetture pipelined.
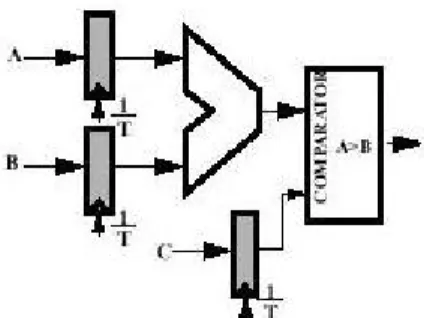
Analizziamo ad esempio la situazione in figura:
Figura 2 -9 Un semplice datapath.
Supponendo di dover lavorare alla massima frequenza consentita e sapendo che, quando la tensione di alimentazione vale 5 V, il ritardo introdotto dalla rete adder + comparatore vale 25 ns allora deve essere: T = 25 ns. In queste condizioni la rete del clock consuma:
ref ref ref ref C V f
P = 2
Dove Cref è la capacità di ingresso dei 3 flip flop vista dal segnale di clock, Vref =5V ,
T fref = 1 .
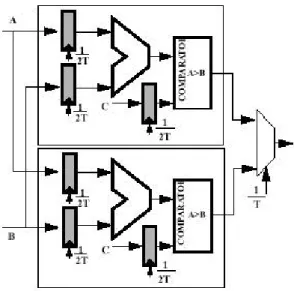
Una soluzione per mantenere il throughput e contemporaneamente ridurre la tensione di alimentazione, è di utilizzare un’architettura parallela come in Figura 2-10. Poiché vengono utilizzati 2 identici adder-comparator, allora per mantenere il throughput iniziale, ciascuna unità può lavorare con un periodo di clock raddoppiato (50 ns) rispetto alla soluzione di Figura 2-9. Ciò consente di
abbassare la tensione di alimentazione fino ad una valore in cui il ritardo della rete adder-comparator raddoppia: se per il ritardo si usa il modello trattato nel Paragrafo 2.1 allora si può calcolare che la tensione di alimentazione può essere ridotta al valore 2.9 V.
Figura 2-10 Implementazione parallela del datapath di partenza.
La potenza consumata dalla rete del clock in questa struttura parallela sarà:
ref ref ref ref par par par par C V f C V f P P = 2 =(2 )(0.58 )2( /2)≈0.34
Infatti la capacità pilotata dalla rete del clock raddoppia. Il difetto principale dell’architettura parallela è il grande aumento della complessità.
Un'altra soluzione è quella di usare una struttura in pipeline come in Figura 2-11:
Figura 2-11 Implementazione pipelined del datapath di partenza.
Ora il critical path non è più Tadder +Tcomparator come prima ma è pari a )
,
max(Tadder Tcomparator . Supponiamo Tadder =Tcomparatore. Se in questo caso si riduce la tensione di alimentazione da 5 V a 2.9 V, i ritardi sia dell’adder sia del comparatore raddoppiano (da 12.5 ns a 25 ns), ma si può ugualmente usare un periodo di clock pari a 25 ns. Quindi il throughput si conserva e la potenza diventa: ref ref ref ref pipe pipe pipe pipe C V f C V f P P = 2 =(1.67 )(0.58 )2 ≈0.56
Questa seconda soluzione presenta però un minor incremento in area rispetto alla soluzione precedente e minor contributo in potenza dovuto ai glitch (infatti i livelli di logica tra un registro e l’altro sono diminuiti). Ovviamente si possono anche usare soluzioni miste pipelined-parallel che consentono di ottenere risparmi in potenza (ma anche aree occupate) maggiori rispetto alle singole soluzioni.
Il concetto del parallelismo si può usare anche per la lettura in una memoria. Supponiamo ad esempio di avere una memoria in cui ogni locazione è formata da 8 byte. Si può usare un accesso in memoria seriale cioè si seleziona una locazione tramite l’indirizzo di riga e poi un byte di quella locazione tramite l’indirizzo di colonna, infine si campiona a frequenza f. Se l’accesso in memoria è sequenziale conviene invece campionare una locazione intera a frequenza f/8 (lettura di 8 byte in parallelo) e poi selezionare con un MUX a frequenza f il byte che ci interessa in quella locazione. In questo caso la memoria è clockata a
frequenza f/8 e perciò la tensione di alimentazione può essere abbassata notevolmente senza perdere in prestazioni.
2.3.2 Scelta della rappresentazione dei numeri.
Spesso in molte applicazioni signal-processing viene scelta la rappresentazione in complemento a 2 a causa della facilità con cui si fanno le operazioni di somma e sottrazione. Un difetto di questa rappresentazione è l’alta attività di commutazione. Questo difetto è particolarmente evidente quando il segnale è non correlato (quindi cambia segno frequentemente) e inoltre è a dinamica ridotta. Ad esempio se il segnale passa continuamente dal valore – 1 al valore 0 si ha una commutazione di tutti i bit. Se invece si usa una rappresentazione in modulo e segno, si ha un bit per il segno e i rimanenti bit per il valore assoluto. Perciò quando il segnale cambia segno e mantiene costante il suo valore assoluto, ora commuta un solo bit (invece nella rappresentazione in complemento a 2, il valore di segno opposto si ottiene complementando tutti i bit e aggiungendo 1). In generale se si vuole ridurre il numero totale di commutazioni, è sempre preferibile la rappresentazione in modulo e segno rispetto a quella in complemento a 2; se poi il segnale è anche a dinamica ridotta ed è non correlato, i vantaggi nell’usare la rappresentazione in modulo e segno sono ancora più evidenti. Però come si è già detto, se si usa una rappresentazione in modulo e segno è più difficile (in termini di area) implementare le operazioni di addizione e sottrazione. Per questo motivo possono aumentare le capacità da pilotare, quindi spesso la scelta tra queste 2 soluzioni non è così banale come può sembrare.
2.3.3 Modifica dell’ordine delle operazioni sui segnali in ingresso.
L’attività di commutazione può essere ridotta scambiando l’ordine delle operazioni da eseguire sui dati in ingresso. Se ad esempio si deve eseguire una
signal-processing), essa può essere scomposta in operazioni di shift-add. Si consideri l’esempio in cui una moltiplicazione per una certa costante è così scomposta: ) 8 ( ) 7 ( ) 2 2 1 ( + 7 + 8 = + >> + >> × − − IN IN IN IN
Dove si è indicato con “>>” lo shift aritmetico a destra. Si considerino le seguenti soluzioni:
1. (IN + IN>>7) + IN >>8 2. (IN>>7 + IN>>8) + IN
Figura 2-12 Possibili implementazioni di una moltiplicazione per una costante.
La soluzione 1 e la soluzione 2 sono funzionalmente equivalenti. L’unica differenza sta nella switching activity di SUM1. Infatti nella soluzione 1, SUM1 si ottiene sommando IN con IN>>7; in questo caso SUM1 ha caratteristiche di
transizione simili a quelle di IN (infatti (IN >> 7) + IN è circa uguale a IN ). Nella soluzione 2, invece SUM1 ha caratteristiche di transizione simili a quelle di IN >> 7 (infatti (IN >> 7) + (IN >>8) è circa uguale a IN >>7) e quindi presenta una switching activity più bassa. Con la soluzione 2 si possono ottenere risparmi in potenza fino al 30 % [1].
2.3.4 Minimizzazione del glitch.
A causa dei ritardi di propagazione da un blocco logico ad un altro, un qualsiasi nodo può avere delle transizioni spurie prima di stabilizzarsi al valore di regime: ciò provoca un consumo di potenza non desiderato. Per risolvere questo problema bisogna bilanciare tutti i percorsi logici e ridurre i livelli di logica. Supponendo ad esempio di avere un adder a 4 ingressi: se gli ingressi commutano contemporaneamente è preferibile un’implementazione ad albero piuttosto che a catena. Però non bis ogna esagerare nella riduzione dei livelli di logica perché in questo modo vengono introdotti più registri e quindi altre capacità da pilotare.
2.3.5 Condivisione delle risorse.
Quando non sono richieste elevate prestazioni, per risparmiare in termini di area si sceglie un’architettura di tipo time-multiplexed (in cui più operazioni sono eseguite da un’unica unità hardware) piuttosto che un’architettura di tipo parallela. Ma fra queste, qual è la soluzione che presenta la minore attività di commutazione? Conf rontiamo ad esempio i due casi seguenti:
Figura 2 -1 3 Parallel architecture o time -multiplexed architecture.
Supponiamo che i due contatori (ognuno ad 8 bit) incrementino il loro valore ogni ciclo di clock. Allora nel caso di bus separati avrò:
= + + + + + + + = CV f CV f Pno bus sharing 2 2 _ _ (1/2 1/4 ... 1/256) (1/2 1/4 ... 1/256) f CV2 2 =
Dove C è la capacità di carico associata ad ogni bit. Infatti il bit 0 (LSB) di ciascun contatore commuta (dal livello basso al livello alto) una volta ogni 2 cicli di clock, ed in generale il bit n-esimo commuta (dal livello basso al livello alto) una volta ogni 2n+1 cicli di clock.
Invece nel secondo caso, per mantenere la stessa funzionalità, il bus commuta a frequenza 2f. Quindi facendo la somma su tutti gli 8 bit del bus, si ha:
) 2 ( ) ( 2 7 0 _ CV f P i i sharing bus
∑
= = αSi nota che solo se i due contatori hanno istantaneamente la stessa uscita allora conviene la seconda soluzione; infatti in questo caso quando il mux passa da counter 1 a counter 2 e viceversa non si verificano commutazioni su alcun bit del bus (tranne i casi in cui entrambi i contatori vengono incrementati) e la potenza è:
f CV f CV Pbus sharing 2 2 _ =(1/2+1/4+...+1/256) =
Però appena le uscite dei due contatori hanno uno skew diverso da zero a llora conviene la prima soluzione. In questo caso il bus commuta a causa degli incrementi di counter 1, a causa degli incrementi di counter 2 e a causa del passaggio da counter 1 a counter 2 e viceversa, tramite il mux. Il confronto del numero totale di tra nsizioni tra bus-sharing e no-bus-sharing si può osservare in Figura 2-14 (in cui si considera nel numero di transizioni, entrambi le commutazioni 0 ? 1 e 1? 0):
Figura 2-1 4 Numero di commutazioni vs skew dei contatori.
Consideriamo ora un secondo esempio. Si vuole implementare il filtro FIR seguente: C B A t X a t X a t X a Y = 0 ( )+ 1 ( −1)+ 2 ( −2)= + +
Figura 2 -1 5 Parallel architecture o time -multiplexed architecture.
In entrambi i casi viene eseguita nel primo ciclo di clock l’operazione O1 = A + B e poi nel secondo ciclo di clock viene eseguita l’operazione O1 + C. Se si fa qualche simulazione, si può vedere che la soluzione parallela ha una switching activity minore. Questo risultato si spiega nei seguenti termini: nella soluzione time-multiplexed gli ingressi dell’adder non provengono da sorgenti fisse (ad esempio IN2 nel primo ciclo coincide con B e nel secondo ciclo coincide con C) come invece avviene nella soluzione parallela. Perciò anche se X(t) è lentamente variabile, B e C possono essere anche di segno opposto (dipende se sono di segno opposto i coefficienti a1 e a2): ne segue che il nodo IN2 dell’implementazione time-multiplexed può avere un attività di commutazione piuttosto elevata.
2.4 Ottimizzazione a livello algoritmico.
2.4.1 Riduzione della tensione di alimentazione usando
trasformazioni dell’algoritmo.
Si cerca di ridurre la tensione di alimentazione mantenendo il throughput costante. Si è già visto come creare una struttura di tipo parallela: ma spesso in applicazioni che presentano un feedback (es. YN =XN + AYN−1), questa soluzione non è facile da applicare. Si ricorre allora all’uso del “loop-unrolling” [1], cioè il loop del feedback viene in qualche modo modificato (“to unroll” = srotolare) e la potenza consumata può addirittura aumentare; in seguito si possono realizzare delle trasformazioni dell’algoritmo (sfruttando proprietà come la distributività,
l’associatività, il pipelining ecc.) che consentono di ridurre il critical path: ciò permette di abbassare la tensione di alimentazione senza perdere in prestazioni. Sfortunatamente si può avere un aumento delle capacità che però è controbilanciato dall’effetto quadratico della tensione di alimentazione sulla potenza. Un esempio di loop-unrolling riferito al caso (YN =XN + AYN−1) con le susseguenti trasformazioni dell’algoritmo è mostrato in Figura 2-16:
Figura 2-1 6 Riduzione della tensione usando trasformazioni dell’algoritmo.
Il caso in Figura 2-16 è un caso un po’ particolare in quanto il cr itical path finale della struttura (d) è uguale a quello iniziale della struttura (a), pari a 2 (se si assume che ciascun operatore impiega un’unità di tempo). Però nella struttura (d) si può lavorare con un periodo di clock doppio rispetto alla struttura (a): infatti vengono processati 2 campioni in parallelo. Ciò consente di abbassare la tensione
di alimentazione da 5 V a 2.9 V (valore in cui i ritardi raddoppiano come si è già visto nel Paragrafo 2.3.1). Considerando anche l’aumento della capacità Ceff, si
ottiene un risparmio in potenza totale del 50 %.
2.4.2 Minimizzazione del numero delle operazioni.
Spesso si hanno a disposizione diversi algoritmi per svolgere una data funzione. Fra di essi bisogna scegliere l’algoritmo che minimizzi il numero di operazioni (ad es. accessi in memoria, moltiplicazioni, addizioni e sottrazioni): così si riesce ad ottenere una notevole riduzione della switching activity globale.
2.4.3 Minimizzazione del numero delle operazioni:
moltiplicazione per una costante.
In genere la moltiplicazione per un coefficiente costante si traduce in un numero di shift e somme indicato dal numero di uni (‘1’) presenti nel coefficiente. Bisogna cercare di minimizzare il numero di queste operazioni di shift e somme. Si consideri ad esempio il caso in Figura 2-17:
Figura 2 -1 7 Esempio di condivisione delle espressioni comuni.
La seconda soluzione è da preferire in quanto viene calcolato prima A e poi esso è sfruttato per calcolare B. Si risparmia così il calcolo di due shift e una somma.