3. L’ALGORITMO SIFT (SCALE INVARIANT FEATURE TRANSFORM)
3.1 Premessa
In questo capitolo si prende in esame una tecnica per l’estrazione delle feature da un immagine: il SIFT, (Scalable Invariant Feature Transform), proposto recentemente (2004) da Lowe [14].
L’importanza fondamentale dell’algoritmo sta nel fatto che le feature che ne vengono estratte, risultano invarianti a variazioni di scala e rotazione dell’immagine e parzialmente invarianti a cambi di illuminazione e punti di vista 3D della telecamera. Queste risultano ben localizzate sia nel dominio spaziale che frequenziale, riducendo la probabilità di mancanza di un corrispondente (disruption probability) dovuta a occlusioni, confusione o rumore.
Dalle immagini possono essere estratte un buon numero di feature che risultano altamente distintive, il ché consente che una singola feature trovi con un’alta probabilità una corretta feature corrispondente in un’altra immagine.
In letteratura, il SIFT trova la sua principale applicazione nell’ambito della Computer Vision nel campo del riconoscimento di uno o più oggetti in un’immagine. In questo caso, si estraggono le feature che caratterizzano un oggetto, in modo da inserirlo, come modello, in database di immagini, anche di grosse dimensioni. Nell’analizzare una nuova immagine è possibile estrarne le sue feature e quindi andare a riconoscere quelle feature che caratterizzano oggetti già presenti nel database, in modo da poter riconoscere nell’immagine la presenza di oggetti “conosciuti”. Una delle applicazioni maggiormente riuscite per il SIFT è, ad esempio, in fotografia quella in cui si vuole ricostruire un’immagine a 360° componendo più foto.
In questo lavoro, il SIFT viene applicato alla Visione Stereo. Brevemente i passi fondamentali dell’algoritmo sono i seguenti:
1. Si estraggono le feature dall’immagine sinistra e dall’immagine destra tramite il SIFT. Ciascuna feature viene minuziosamente caratterizzata mediante un descrittore di feature.
2. Si trovano le corrispondenze tra le due immagini, in modo da poter individuare il maggior numero di features che caratterizzano ciascuna coppia di immagini.
3. Si esegue il matching confrontando, in termini di distanza euclidea, i vettori dei descrittori delle feature.
L’algoritmo SIFT riceve in ingresso immagini composte da un singolo canale (cioè a livelli di grigio).
Nei paragrafi successivi l’algoritmo, peraltro molto complesso, sarà illustrato nel dettaglio.
3.2 Il SIFT (Scale Invariant Feature Transform)
Nel SIFT, il costo di estrazione delle feature viene minimizzato seguendo un approccio di filtraggio a cascata, in cui le operazioni più costose in termini computazionali sono applicate solo a quei tratti salienti dell’immagine che passano un certo test iniziale, candidandoli ad essere possibili feature, dette anche keypoint.
I passi fondamentali usati per generare il set delle feature delle immagini sono:
1. Rilevamento degli estremi spazio-scalari (Scale-space extrema detection): Si analizzano i pixel dell’immagine a tutte le scale, utilizzando in modo efficiente una
funzione data dalla differenze di funzioni Gaussiane per identificare potenziali punti di interesse che sono invarianti in scala e orientazione.
2. Localizzazione dei punti chiave (Keypoint Localization): Per ciascun punto proiezione candidato ad essere una feature, un modello dettagliato viene costruito per determinare la posizione e la scala. I keypoint vengono selezionati secondo misure di stabilità.
3. Assegnamento dell’orientazione (Orientation assignment): Una orientazione viene assegnata a ciascuna posizione dei keypoint, basata sulla direzione dei gradienti locali all’immagine. Tutte le operazioni successive vengono effettuate sui dati dell’immagine che sono stati trasformati relativamente all’orientazione, alla scala e alla posizione assegnate ad ogni feature, in modo invariante.
4. Descrittori dei punti chiave (Keypoint Descriptors): I gradienti locali dell’immagine vengono misurati alla scala selezionata nella regione intorno a ciascun punto chiave. Questi sono trasformati in una rappresentazione che consente livelli significativi di distorsione locale e cambiamenti di illuminazione.
Da qui il nome: Scale Invariant Feature Transform (SIFT): trasforma i dati di un immagine in feature locali invarianti in scala. Un importante aspetto di questo approccio è il buon numero di feature che si genera e che ricopre in modo denso l’immagine su un grosso range di scala e posizioni.
La quantità di feature è molto importante nel riconoscimento di oggetti o ostacoli (object and
obstacle recognition). Senza un adeguato numero di feature e senza che esse si trovino in posizione uniforme sull’immagine, non è possibile rilevare e caratterizzare in termini di dimensioni spaziali un oggetto o un ostacolo.
Nei paragrafi successivi si entra nel dettaglio dell’algoritmo.
3.2.1 Rilevamento degli estremi scala-spaziali (Scale-space estrema detection)
Il primo passo della trasformata SIFT consiste nel rilevamento delle feature, ovvero i punti di interesse dell’immagine, chiamate anche keypoint, punti chiave.
L’approccio utilizzato è quello a filtraggio in cascata, che consente di determinare le posizioni e la scala delle feature candidate ad essere punti chiave e che, in un secondo momento, vengono caratterizzate con maggior dettaglio.
La posizione e la scala devono caratterizzare la feature in modo da poter essere assegnate in modo ripetuto anche in caso di vista differente del medesimo oggetto.
Trovare punti dell’immagine che sono invarianti a cambiamenti di scala dell’immagine può essere effettuata ricercando feature stabili su tutte le scale possibili, usando una funzione di scala nota come spazio-scala, scale space, (Witkin, 1983). Come hanno dimostrato Koenderink [20] (1984) e Lindeberg [21] (1994), l’unica possibile funzione che costituisce un Kernel Scala-Spazio è la funzione Gaussiana.
Lo Spazio-Scala di una immagine è definito come una funzione L(x,y,σ) data dalla convoluzione in x e y di una funzione Gaussiana, variabile in scala, G(x,y,σ) con l’immagine I(x,y): ) , ( ) , , ( ) , , (x y G x y I x y L σ = σ ⊗ (3.1)
Lowe [22] propone di utilizzare una funzione Spazio-Scala basata sulla funzione Differenza di funzioni Gaussiane (ottenuta dalla differenza di due Gaussiane separate in scala da un fattore k):
(
( , , ) ( , , ))
( , ) ( , , ) ( , , ) ) , , (x y σ G x y kσ G x y σ I x y L x y kσ L x yσ D = − ⊗ = − (3.3)Questa funzione è particolarmente efficiente da calcolare, perchè le immagini “smussate”,
smoothed, che corrispondono alla funzione L(.), devono comunque essere calcolate per ottenere una descrizione spazio-scalare delle feature e la funzione D(.) si ottiene facilmente mediante sottrazione di queste.
Come mostra Lindeberg (1994) [21], la normalizzazione del Laplaciano con un fattore σ è 2 necessaria per la proprietà di invarianza su giusta scala (true scale). La funzione differenza di Gaussiane costituisce un’approssimazione del Laplaciano normalizzato in scala di Gaussiane,
2 2 2 G ∇ σ :
(
)
2 2 2 ) 1 ( ) , , ( ) , , (x y k G x y k G G σ − σ ≈ − σ ∇ (3.4)Quando la funzione differenza di Gaussiane ha scala che differisce per un fattore k, il valore di scala di normalizzazione richiesto per la proprietà di invarianza in scala del Laplaciano è sempre presente. Inoltre il fattore k è costante su tutte le scale, perciò non influenza la posizione degli estremi. L’errore di approssimazione va a zero se k tende a 1; tuttavia, e Lowe [22] ha dimostrato sperimentalmente che il valore di k non ha influenza sulla stabilità delle feature rilevate, pertanto si può scegliere un valore di k del tipo: k = 2.
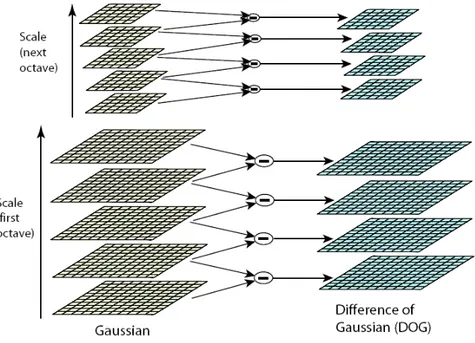
Fig. 3.1 Costruzione delle funzioni D(x, y, σ).
La figura 3.1 mostra la costruzione della funzione D(x, y, σ). L’immagine iniziale viene convoluta in modo incrementale con le Gaussiane a scale diverse, per produrre immagini separate da un fattore di scala costante k, mostrate in pila sulla colonna sinistra. Ciascuna ottava di scala in spazio viene divisa in un numero intero di intervalli, s, in modo che: k =21/s. Per ciascuna ottava, nella pila di immagini sfuocate, blurred, ci sono s+3 immagini, in modo da coprire un’intera ottava. Immagini adiacenti in scala vengono sottratte per produrre immagini Differenza di Guassiane mostrate nella pila a destra. Una volta che viene processata una ottava completa, si campiona nuovamente l’immagine Gaussiana che ha valore di deviazione standard σ
doppio rispetto a quello iniziale (ovvero la seconda immagine che si trova dalla cima della pila) e il processo viene ripetuto.
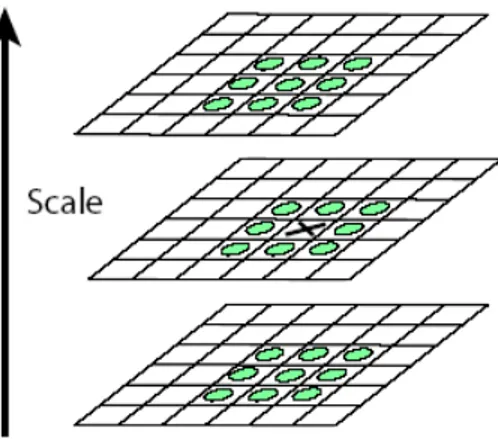
I massimi e i minimi della funzione D(x, y, σ) costituiscono i punti di interesse che vengono estratti dall’immagine di partenza. Per rilevarli, ciascun punto campione viene paragonato con gli otto vicini nell’immagine corrente e i nove punti vicini nella scala precedente e successiva, come mostrato in figura 3.2. Un punto viene considerato massimo o minimo locale, se risulta il più grosso o il più basso fra tutti i suoi vicini. Questa procedura di ricerca è molto efficiente in quanto la maggior parte dei punti campione viene eliminato dopo i primi controlli.
Figura 3.2: Rilevamento di massimi e minimi della funzione D(x, y, σ)
Sperimentalmente Lowe [14] ha trovato i valori dei parametri che massimizzano la stabilità del rilevamento degli estremi. Tali prove sono state effettuate dall’autore considerando un set di immagini sintetiche e non, le quali sono state poi opportunamente trasformate in ulteriori immagini (per effetto di rotazioni, variazioni di scala, cambiamenti di luminosità,ecc) in modo da formare un database di immagini di vario tipo. I risultati ottenuti portano a concludere che la più alta ripetibilità nel rilevare le stesse feature in immagini trasformate è ottenuta scegliendo un numero di scale campionate per ottava pari a s = 3 . Tale ripetibilità cresce al crescere del valore della deviazione standard σ, qualora venisse scelto in modo che 1<σ<2. Tuttavia scegliere un valore troppo alto di σ comporta degli svantaggi in termini di efficienza, pertanto viene scelto σ = 1.6, il chè comporta valori di ripetibilità ottimali.
Nel costruire in modo piramidale le varie immagini, viene adottato un ulteriore stratagemma: le dimensioni dell’immagine iniziale vengono duplicate, attraverso interpolazione lineare, per costruire il primo livello, perciò l’immagine viene espansa in modo da creare più punti campione di quelli presenti nell’originale. In questo modo il numero di punti chiave stabili aumenta di un fattore 4, anche se il pre-smoothing iniziale prima del rilevamento degli estremi comporta trascurare le frequenze spaziali più alte. Si assume che l’immagine iniziale abbia un rumore,
blur, caratterizzabile con una deviazione standard di al più σblur = 0.5 (il minimo che si deve avere per prevenire aliasing significativo), pertanto l’immagine doppia avrà σblur = 1 relativa allo spazio dei suoi nuovi pixel. Un’ulteriore rifinitura, smoothing, è necessaria per la creazione della prima ottava spaziale.
(che li rende più sensibili al rumore) o sono scarsamente localizzati lungo un contorno. Il metodo utilizzato è quello studiato da Brown e Lowe (per i dettagli si rimanda a [23]): viene adattata una funzione quadratica 3D ai punti campionati locali per determinare la posizione interpolata del massimo. Gli esperimenti mostrano che si ha un miglioramento in termini di matching.
Per ottenere vantaggi anche in termini di stabilità non è sufficiente rigettare i punti chiave con basso contrasto, infatti, la funzione differenza di Gaussiane ha una grossa risposta lungo i contorni, anche se la posizione lungo i contorni viene determinata con scarsa precisione e anche se risulta instabile a piccole quantità di rumore. La ragione delle curvature principali deve stare entro una certa soglia, r, in modo che:
r r Det Tr 2 ( 1)2 ) ( ) ( + < H H (3.5)
dove H è la matrice Hessiana 2x2, calcolata alla posizione e scala del punto chiave, e dove le derivate sono calcolate considerando le differenze di punti campionati vicini:
= yy xy xy xx D D D D H (3.6)
Negli esperimenti si usa una soglia r=10. 3.2.3 Assegnamento dell’orientazione
Attribuendo una giusta orientazione a ciascun punto chiave, basandosi sulle proprietà locali dell’immagine, il vettore descrittore di punti chiave può essere rappresentato relativamente alla sua orientazione e dare la proprietà alla feature di essere invariante a rotazione dell’immagine.
La scala del punto chiave viene usata per selezionare l’immagine Gaussiana smoothed, L, con la scala più vicina, in modo che tutti i calcoli vengono effettuati in modo invariante in scala. Per ciascun campione dell’immagine, L(x,y) a questa scala, l’ampiezza del gradiente, m(x,y), e l’orientazione θ(x,y), viene pre-calcolata usando differenze tra pixel:
(
)
(
)
(
) (
)
(
2)
2 2 ) , 1 ( ) , 1 ( / ) 1 , ( ) 1 , ( arctan ) , ( ) 1 , ( ) 1 , ( ) , 1 ( ) , 1 ( ) , ( y x L y x L y x L y x L y x y x L y x L y x L y x L y x m − − + − − + = − − + + − − + = θ (3.7)Si costruisce un istogramma di orientazioni dalle orientazioni del gradiente dei punti campionati in una regione attorno al punto chiave. Ciascun istogramma ha 36 barre che coprono l’intero range di 360° di orientazione. Ciascun campione aggiunto all’istogramma viene pesato con il valore dell’ampiezza del gradiente in quel punto e con una finestra circolare Gaussiana con deviazione standard pari a 1.5 volte quella della sua scala. I picchi dell’istogramma di orientazione corrispondono alle direzioni dominanti dei gradienti locali. Per determinare l’orientazione del punto chiave, si seleziona il picco più alto nell’istogramma e eventuali altri picchi locali che siano entro l’80% del valore del picco massimo. Infine per una migliore accuratezza, una parabola viene adattata ai tre valori dell’istogramma più vicini alla posizione del picco.
3.2.4 Descrittori dei punti chiave (Keypoint Descriptor)
Attraverso i passi precedenti a ciascun punto chiave è stato assegnato una posizione, una scala e un’orientazione. Questi parametri costituiscono un sistema di coordinate locali 2D, con cui è possibile descrivere localmente una regione dell’immagine e assicurare l’invarianza di tali parametri. E’ possibile, inoltre, caratterizzare ciascun punto chiave a partire da questi parametri, in modo che esso risulti invariante anche rispetto a cambiamenti di illuminazione e punti di vista 3D.
Un approccio è quello basato sull’intensità locale dell’immagine attorno ad un punto chiave alla scala appropriata e sulla corrispondenza della stessa su un'altra immagine rispetto ad una misura di correlazione. Tuttavia, questa tecnica risulta molto sensibile ai cambiamenti che causano errori nella registrazione dei campioni, come cambiamenti di punto di vista affine o 3D e trasformazioni non rigide.
Attraverso gli studi di Edelman, Intrator, Poggio [4] (1997), è stato proposto un altro modello di rappresentazione basato su un modello di visione biologica, in particolare dei neuroni complessi nella corteccia visuale primaria. Questi rispondono al gradiente ad una particolare orientazione e frequenza spaziale, ma la posizione del gradiente sulla retina può muoversi su un piccolo campo recettivo piuttosto che essere localizzato precisamente. Gli autori sopraccitati ipotizzano che la funzione di questi neuroni complessi sia consentire il matching e il riconoscimento di oggetti 3D tra un range di punti di vista. L’implementazione proposta da Lowe è ispirata a questa idea, ma consente spostamenti di posizione usando un differente meccanismo computazionale.
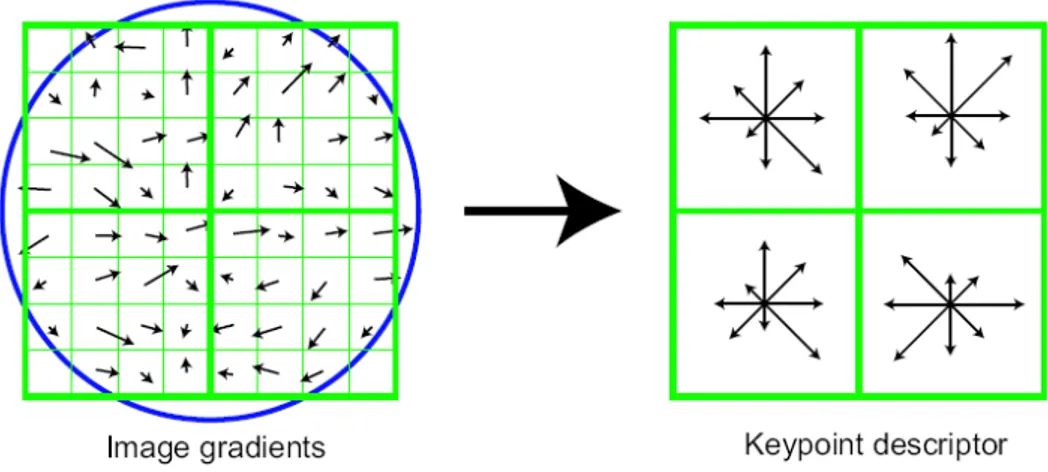
Il calcolo dei descrittori di punti chiave viene mostrato in modo icastico in figura 3.3. Innanzitutto, l’ampiezza del gradiente dell’immagine e le orientazioni vengono campionate attorno alla posizione dei punti chiave, usando la scala del punto chiave per selezionare il livello della Gaussiana per l’immagine. Per ottenere l’ invarianza alla rotazione, le coordinate del descrittore e l’orientazione del gradiente sono ruotati relativamente all’orientazione dei punti chiave. I gradienti (precalcolati come descritto nel parag. precedente) vengono illustrati sul lato sinistro della fig.3.3 come piccole frecce su ogni punto chiave.
Fig. 3.3 Creazione dei descrittori dei punti chiave
per dare meno enfasi ai gradienti che sono più lontani dal centro del descrittore, dopo che questi sono maggiormente affetti da errori.
Sul lato destro della figura 3.3 viene mostrato un descrittore di punti chiave. Un istogramma di orientazioni, su regioni di campioni 4x4, viene costruito per consentire cambi significativi del gradiente in posizione. La figura 3.3 mostra 8 direzioni per ciascuna orientazione dell’istogramma, con la lunghezza di ciascuna freccia corrispondente all’ampiezza di quell’ingresso dell’istogramma. Un campione del gradiente sulla sinistra può muovere fino a quattro posizioni di campioni intanto che contribuisce allo stesso istogramma a destra, consentendo eventuali spostamenti di posizione locale più grossi.
E’ importante evitare gli effetti che si hanno nei bordi in cui il descrittore cambia in modo brusco quando i campioni variano di poco. Inoltre, l’interpolazione trilineare viene usata per distribuire il valore di ciascun gradiente sulle barre di istogrammi adiacenti. In altri termini ciascun ingresso nella barra viene moltiplicato da un peso di 1-d per ciascuna dimensione, dove d è la distanza dal campione dal valore centrale della barra, misurata in unità di spazio per la barra dell’istogramma.
Il descrittore è formato da un vettore contenente i valori di tutte le entrate di orientazione dell’istogramma, corrispondenti alla lunghezza delle frecce in figura 3.3 Tale figura mostra array 2x2 di istogrammi di orientazione, in realtà la tecnica utilizzata si avvale di array 4x4 di istogrammi a 8 barre di orientazioni in ciascuno, perché si dimostrano dar luogo ai migliori risultati. Pertanto il vettore che descrive ciascun punto chiave consta di 4x4x8=128 elementi. In fase di test si dimostra che i risultati migliorano al crescere del numero di orientazioni possibili e della “grandezza” degli istogrammi. Scegliendo un numero maggiore per tali parametri (rispetto a quelli corrispondenti alla scelta effettuata), si può ottenere una migliore corrispondenza ma si rende il descrittore più sensibile alla distorsione. Pertanto i valori sopraccitati si rivelano i più adatti, anche perché, se il numero degli elementi del vettore può sembrare alto, si dimostra essere il più adatto per l’algoritmo più semplice che verrà utilizzato per il matching delle feature.
Infine, il vettore di feature viene modificato per ridurre gli effetti dei cambiamenti di illuminazione. Prima, il vettore viene normalizzato all’unità di lunghezza. Un cambiamento di contrasto nell’immagine in cui ciascun valore dei pixel viene moltiplicato da una costante farà moltiplicare i gradienti dalla stessa costante, cosicché il cambiamento di contrasto verrà cancellato dalla normalizzazione. Un cambiamento in illuminazione, in cui ad ogni pixel dell’immagine viene aggiunta una costante, non modifica i valori del gradiente, dato che questo viene calcolato come differenza tra pixel. Dunque il descrittore è invariante per cambiamenti di illuminazione. Tuttavia sono sempre possibili cambiamenti di illuminazione non lineari, dovuti a saturazione della telecamera o cambiamenti di illuminazione dovuti alle superfici 3D con differenti orientazioni dovute a diverse cause. Questi effetti possono causare un grosso cambiamento sull’ampiezza relativa per alcuni gradienti ma sembrano influire in misura minore sulle orientazioni. Quindi, si riduce l’influenza di gradienti più alti in ampiezza imponendo una soglia pari a 0.2 (valore trovato sperimentalmente) per gli elementi del vettore, che poi vengono successivamente ri-normalizzati alla lunghezza unitaria. Questo perché non è così importante trovar corrispondenze tra grossi gradienti quanto invece lo sia la distribuzione delle orientazioni.
3.3 Matching tra features estratte con il SIFT
Nel caso della Visione Stereo le feature SIFT vengono estratte allo stesso istante dalle immagini di una coppia di frame (sinistro e destro) e caratterizzate mediante appositi descrittori di feature, come dettagliato nei paragrafi 3.2.1-3.2.4).
L’operazione di matching si esegue nel seguente modo: ciascuna feature estratta sull’immagine sinistra viene paragonata con ciascuna feature dell’immagine destra in termini di
distanza euclidea dei vettori descrittori delle stesse. Viene utilizzato un algoritmo veloce che rintraccia il vettore descrittore di feature più vicino (nearest-neighbor algorithm), ovvero rintraccia la feature più simile (che diventa la candidata al matching) tra tutte quelle che più le “assomigliano” tra le feature dell’immagine destra.
Individuare una soglia globale sulla distanza rispetto alla feature più vicina non si rivela una buona scelta, in quanto esistono descrittori di feature più discriminanti di altri. Una misura più efficace è ottenuta confrontando la distanza che il descrittore più vicino ha rispetto al secondo descrittore di feature più vicino. Questa scelta risulta migliore della precedente perché per ottenere un matching affidabile, le corrispondenze corrette necessitano d’avere il descrittore della feature sull’immagine destra significativamente più vicino al descrittore della feature sull’immagine sinistra che quanto si avrebbe tra il secondo descrittore di feature sull’immagine destra più vicino al descrittore della feature sull’immagine sinistra. Per questo motivo, è possibile confrontare la vicinanza tra i due descrittori di feature più vicini alla feature di cui si sta cercando il corrispettivo. Si definisce allora il parametro R, rapporto delle distanze dei due vettori di descrittori, più vicino e secondo più vicino, come:
2 1
d d
R = (3.8)
dove d1 è la distanza tra descrittore della feature e descrittore della feature più vicina e d2 è la
distanza tra descrittore della feature e descrittore della seconda feature più vicina.
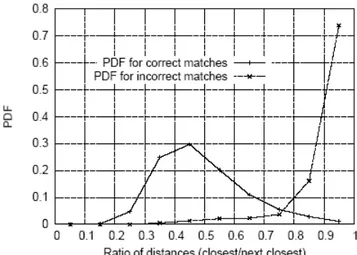
Sperimentalmente Lowe [14] ha scoperto che le corrispondenze corrette hanno una densità di probabilità (PDF) centrata ad un valore di R più basso che per quanto si ha per corrispondenze scorrette. (si veda la fig.3.4)
Fig. 3.4 Densità di probabilità in funzione del rapporto tra distanze R
D. Lowe [14] propone di considerare come giuste le corrispondenze che hanno un valore di R minore di 0.8. Tale soglia produce parecchie corrispondenze errate. Diminuire questa soglia significa diminuire le possibilità di considerare come giusta una corrispondenza errata ma, per contro, si ottiene, da una coppia di frames, un numero minore di features corrispondenti.
3.4 Studio del funzionamento dell’algoritmo SIFT mediante esperimenti
E’ stato fatto uno studio sperimentale del funzionamento dell’algoritmo SIFT di David Lowe al fine di determinarne il comportamento quando si tratta di creare una mappa di profondità di un ambiente esterno non strutturato utilizzando un sistema di visione stereo.
Vi sono due fattori critici che vanno analizzati sperimentalmente al fine di usare il SIFT per creare una mappa di profondità in tempo reale:
• Il numero di punti che hanno una corrispondenza restituiti dall algoritmo di matching per ogni coppia di frames stereo elaborata dal SIFT.
• Il tempo di esecuzione per ogni coppia di frames.
Dopo lo studio sperimentale è stata tratta la conclusione che il numero di punti trovati dall’algoritmo dipende da due fattori:
1. La struttura dell’ambiente esterno. 2. La risoluzione delle immagini.
Tra i due fattori quello che influenza di più il funzionamento dell’algoritmo è il primo, sempre a patto che le immagini rimangano ad una risoluzione accettabile (almeno 80x60).
3.4.1 Esperimenti
Di seguito saranno presentati alcuni esperimenti realizzati su video presi in ambiente esterno utilizzando il sistema di visione del robot Ulisse (paragrafo 2.2).
Il software che manda in esecuzione il SIFT sui frames ed esegue l’algoritmo di matching (paragrafo 3.3) è stato realizzato in linguaggio C++. Il codice C dell’algoritmo SIFT ci è stato fornito dal suo inventore David Lowe.
Per provare che il numero di punti trovati dipende dalla struttura dell’ambiente bisogna innanzi tutto mantenere costante la risoluzione e far vedere che il numero di punti restituiti dall’algoritmo di matching (paragrafo 3.3) dipende dalla scena inquadrata.
Fig.3.5 Coppia di frames stereo.Vengono messe in evidenza le corrispondenze trovate dall’algoritmo di matching dopo l’esecuzione del SIFT.
Risoluzione:320x240.
Numero di corrispondenze trovate:50.
Fig.3.6 Coppia di frames stereo che inquadra la stessa scena di fig.3.5. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:320x240
Fig.3.7 Coppia di frames stereo che inquadra la stessa scena di fig.3.5 e fig.3.6. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:320x240
Numero corrispondenze trovate:48.
Da fig.3.5, fig.3.6 e fig.3.7 possiamo notare che se le coppie di frames riprendono la stessa scena e la risoluzione rimane la stessa il numero di corrispondenze trovate varia di poco.
Fig.3.8 Coppia di frames stereo.Vengono messe in evidenza le corrispondenze trovate dall’ algoritmo di matching dopo l’esecuzione del SIFT.
Risoluzione:320x240. Numero corrispondenze trovate:18
Fig.3.9 Coppia di frames stereo che inquadra la stessa scena di fig.3.8. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:320x240
Numero corrispondenze trovate:22
Fig.3.10 Coppia di frames stereo che inquadra la stessa scena di fig.3.8 e fig.3.9. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:320x240
Numero corrispondenze trovate:16
Possiamo notare che, nonostante la risoluzione rimanga costante, il numero di corrispondenze trovate varia da un numero di circa 50 di fig.3.5,fig.3.6 e fig.3.7 ad un numero di circa 20 per fig.3.8,fig.3.9 e fig.3.10. Questo perché è cambiata la scena che viene ripresa dal sistema di visione.
Fig.3.11 Coppia di frames stereo.Vengono messe in evidenza le corrispondenze trovate dall’ algoritmo di matching dopo l’esecuzione del SIFT.
Risoluzione:320x240. Numero corrispondenze trovate:7
Fig.3.12 Coppia di frames stereo che inquadra la stessa scena di fig.3.11. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:320x240. Numero corrispondenze trovate:5
Fig.3.13 Coppia di frames stereo che inquadra la stessa scena di fig.3.11 e fig.3.12. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:320x240 Numero corrispondenze trovate:4
Fig.3.11, fig.3.12 e fig.3.13 mostrano il funzionamento del SIFT quando c’è un oggetto di colore uniforme che occlude il cono visivo. Il numero di corrispondenze trovate dopo l’algoritmo di matching è circa 5. Il numero di corrispondenze diminuisce parecchio rispetto alle fig. 3.5, fig. 3.6 e fig. 3.7 e fig. 3.8, fig. 3.9 e fig. 3.10 perché la scena è cambiata. Sperimentalmente è stato constatato che se davanti al cono visivo c’è un oggetto di colore uniforme vengono trovate ben poche corrispondenze dal SIFT; a volte nessuna.
Possiamo quindi concludere che il numero di punti trovati dal SIFT dipende molto dalla scena che le due telecamere hanno di fronte.
Passiamo ora ad esaminare il secondo fattore ossia la dipendenza del numero di punti trovati dal SIFT dalla risoluzione.Per fare questo si utilizzeranno immagini a risoluzione più bassa ma che riprendono le stesse tre scene delle immagini precedenti.
Fig.3.14 Coppia di frames stereo che inquadra la stessa scena di fig.3.5,fig.3.6 e fig.3.7. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120
Fig.3.15 Coppia di frames stereo che inquadra la stessa scena di fig.3.5,fig.3.6 e fig.3.7 . Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120
Numero corrispondenze trovate:44
Fig.3.16 Coppia di frames stereo che inquadra la stessa scena di fig.3.5,fig.3.6 e fig.3.7. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120
Numero corrispondenze trovate:36
Possiamo notare che a questa risoluzione il numero medio di corrispondenze trovate è leggermente inferiore a quello ottenuto con immagini 320x240. Il numero delle corrispondenze trovate a parità di scena è 45 per le immagini a 160x120, 50 per le immagini a 320x240.
Vediamo cosa accade quando la scena cambia.
Fig.3.17 Coppia di frames stereo che inquadra la stessa scena di fig.3.8,fig.3.9 e fig.3.10. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120
Fig.3.18 Coppia di frames stereo che inquadra la stessa scena di fig.3.8,fig.3.9 e fig.3.10. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120
Numero corrispondenze trovate:19
Fig.3.19 Coppia di frames stereo che inquadra la stessa scena di fig.3.8,fig.3.9 e fig.3.10. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120
Numero corrispondenze trovate:20
Alla risoluzione 160x120 si ottiene un numero medio di corrispondenze pari a 17 rispetto alle 20 ottenute alla risoluzione 320x240 a parità di scena.
Vediamo ora cosa accade quando il cono visivo è coperto da un oggetto di colore uniforme.
Fig.3.20 Coppia di frames stereo che inquadra la stessa scena di fig.3.11,fig.3.12 e fig.3.13. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120 Numero corrispondenze trovate:4
Fig.3.21 Coppia di frames stereo che inquadra la stessa scena di fig.3.11,fig.3.12 e fig.3.13. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120 Numero corrispondenze trovate: 5
Fig.3.22 Coppia di frames stereo che inquadra la stessa scena di fig.3.14,fig.3.15 e fig.3.16. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:160x120 Numero corrispondenze trovate:5
Notare che in fig.3.20, fig. 3.21,fig.3.22 il numero di corrispondenze trovate è circa uguale al numero di corrispondenze trovate alla risoluzione di 320x240 a parità di scena (fig.3.11, fig.3.12, fig.3.13).
Dalle prove sperimentali fin qui presentate, possiamo inferire che il numero di corrispondenze trovate dipende sì dalla risoluzione delle immagini ma dipende in maniera più forte dalla scena che si trova davanti al sistema di visione.
Vediamo i risultati ottenuti ad una risoluzione ancora più bassa.
Fig.3.23 Coppia di frames stereo che inquadra la stessa scena di fig.3.5,fig.3.6 e fig.3.7. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Fig.3.24 Coppia di frames stereo che inquadra la stessa scena di fig.3.5,fig.3.6 e fig.3.7. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Numero corrispondenze trovate:22
Fig.3.25 Coppia di frames stereo che inquadra la stessa scena di fig.3.5,fig.3.6 e fig.3.7. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Numero corrispondenze trovate:23
In fig.3.23 , fig.3.24 e fig.3.25 , viene inquadrata la stessa scena di fig.3.5, fig.3.6 e fig.3.7. Possiamo notare che, a parità di scena, vengono trovate un numero di corrispondenze pari alla metà.
Fig.3.26 Coppia di frames stereo che inquadra la stessa scena di fig.3.8,fig.3.9 e fig.3.10. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Numero corrispondenze trovate:10
Fig.3.28 Coppia di frames stereo che inquadra la stessa scena di fig.3.8,fig.3.9 e fig.3.10. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Numero corrispondenze trovate:11
Come vediamo in fig.3.26 , fig.3.27 e fig.3.28 il numero di corrispondenze si dimezza circa a causa della risoluzione che è diminuita. In fig.3.8,fig.3.9 e fig.3.10 a parità di scena si ha il doppio di corrispondenze.
Vediamo cosa accade quando un oggetto di colore uniforme occlude il cono visivo.
Fig.3.29 Coppia di frames stereo che inquadra la stessa scena di fig.3.11,fig.3.12 e fig.3.13 .Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Numero corrispondenze trovate:2
Fig.3.30 Coppia di frames stereo che inquadra la stessa scena di fig.3.11,fig.3.12 e fig.3.13. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Numero corrispondenze trovate:5
Fig.3.31 Coppia di frames stereo che inquadra la stessa scena di fig.3.11,fig.3.12 e fig.3.13. Vengono messe in evidenza le corrispondenze trovate.
Risoluzione:80x60
Con la scena di fig.3.29, fig.3.30 e fig.3.31 si ha un numero medio di corrispondenze trovate pari a circa 4 un numero di poco inferiore a quello che è stato ottenuto a risoluzione 320x240 (fig.3.11,fig.3.12,fig.3.13).
Possiamo concludere che il numero di corrispondenze trovate dal SIFT, dopo l’algoritmo di matching, è dipendente dalla scena che si presenta davanti al sistema di visione. In misura minore, il numero di corrispondenze è dipendente dalla risoluzione utilizzata.
La dipendenza del numero di corrispondenze trovate da com’è fatta la scena diventa un problema critico quando un oggetto di colore uniforme occlude il cono di vista. In tal caso può accadere che il numero di corrispondenze trovate sia basso o addirittura pari a zero.
Un altro fatto importante che si nota dagli esperimenti svolti è che, per immagini simili, l’algoritmo estrae features diverse. Questo è dovuto al rumore presente sulle immagini.
3.4.2 Tempo d’esecuzione
Il tempo d’esecuzione dipende dalla risoluzione delle immagini.
Se si utilizza una risoluzione 320x240 vengono elaborate circa 10 coppie di frames in 10 secondi; se si utilizza una risoluzione 160x120 vengono elaborate circa 27 coppie di frames in 10 secondi; se si utilizza una risoluzione 80x60 vengono elaborati circa 80 coppie di frames in 10 secondi.
Il tempo d’esecuzione ad alte risoluzioni è quindi abbastanza alto perché l’algoritmo possa girare in tempo reale. Ciò costituisce un problema nel caso in cui si debba evitare ostacoli in tempo reale.
In ambiente non strutturato, si dovrà considerare la possibilità di lavorare a bassa risoluzione giacché il numero di punti restituiti dall’algoritmo dipende non solo dalla risoluzione ma da com’è fatta la scena. Per contro, il tempo d’esecuzione dipendente quasi esclusivamente dalla risoluzione.
3.5 Soluzioni ai problemi presentati dal SIFT
Nel par.3.4, abbiamo visto che il principale problema del SIFT sta nel fatto che il numero di punti restituiti, dopo l’algoritmo di triangolazione, è basso se un oggetto di colore uniforme sta davanti al cono visivo. Per questo motivo, si vuole realizzare un algoritmo di appoggio al SIFT che permetta di stimare la distanza di oggetti di colore uniforme, che si trovano davanti al cono visivo. La scelta che sembra più ovvia è quella di utilizzare la segmentazione.
3.5.1 Segmentazione
Una possibile soluzione del problema può essere quella di utilizzare la segmentazione: 1. Si rileva la presenza di ampie zone in cui i pixel hanno lo stesso colore sia sull’immagine
sinistra che sulla destra. Ognuna di queste zone per noi rappresenta un oggetto. 2. Si trova il contorno di tali zone.
3. Si esegue il matching dei contorni dell’immagine sinistra con quelli dell’immagine destra 4. I pixel dei contorni di cui si ha una corrispondenza tra destra e sinistra avranno una certa
letteratura vengono spesso eseguiti su immagini provenienti da ambienti strutturati oppure su immagini artificiali.[5].
Le prove sono state eseguite utilizzando la libreria di visione OpenCv.
La tecnica di segmentazione utilizzata nelle prove pratiche è quella piramidale.[6]. Tale tecnica consiste nei seguenti passi:
1. Fare lo smoothing dell’immagine iniziale (quella che deve essere segmentata) ed abbassarne la risoluzione in modo da creare una piramide con un certo numeri di livelli L, in maniera simile a quello che fa il SIFT(par.3.2).
2. Stabilire dei collegamenti tra pixel che stanno su diversi livelli della piramide, ogni collegamento ha un peso associato che viene calcolato dall’algoritmo.
3. Segmentare l’immagine che sta nel punto più alto della piramide, cioè quella a risoluzione più bassa.
4. Propagare top-down il risultato della segmentazione sui vari collegamenti in base al peso associato ad ogni collegamento. In questo modo viene segmentata l’immagine che sta al livello più basso della piramide, cioè l’immagine iniziale.
Esistono due soglie che vengono date in ingresso all’algoritmo: T1 è una soglia che ci dice quando si può stabilire un collegamento tra pixel di diversi livelli, T2 è la differenza che ci deve essere tra i valori di due pixel adiacenti perché appartengano alla stesso segmento. Si ricorda che il valore associato ad un pixel è un numero tra 0 e 255. Nel caso di immagini a colori due pixel adiacenti appartengono allo stesso segmento se la media pesata della differenza dei tre valori di RGB sta sotto la soglia T2.
I valori delle soglie utilizzati nella seguente prova sono: T1=255 T2=14.
Fig.3.32 A sinistra: immagine originale catturata da un video girato davanti al piazzale d’Ingegneria a Pisa.
A destra: immagine segmentata. Pixel adiacenti e dello stesso colore appartengono allo stesso segmento. Notare che il ragazzo in primo piano appartiene allo stesso segmento della strada.
Risulta evidente che la tecnica non può essere utilizzata in ambiente esterno non strutturato perché c’è il rischio che il colore dell’oggetto in primo piano si confonda con quello dello sfondo
oppure con quello della strada come accade in questo caso: il ragazzo in primo piano appartiene allo stesso segmento di una parte della strada. In questo modo non è possibile effettuare il matching tra un segmento della telecamera destra e uno della telecamera sinistra perché oggetti che sono a diverse distanze appartengono alle stesso segmento. Notare che nella prova è stato scelto un valore di T2 basso ,14, se vengono scelti valori più alti i risultati sono ancora peggiori perché i segmenti saranno più grandi.
Se vengono scelti valori più bassi per la soglia T2, l’ immagine non viene segmentata in maniera così efficace da far sì che si trovi una corrispondenza tra segmenti che provengono da immagini di viste differenti dello stesso oggetto.(fig.3.33)
Fig.3.33 Immagine segmentata con la tecnica piramidale. I valori di soglia utilizzati sono T1=255, T2=14.
Fig.3.34 Coppia di immagini stereo segmentate con la tecnica piramidale. Per entrambe le immagini sono stati utilizzati gli stessi valori di soglia di fig.x.
appartengono allo stesso segmento; sull’immagine di destra il ragazzo e gli alberi sullo sfondo appartengono allo stesso segmento.
Sono stati effettuate altre prove con diversi valori di soglia ma i risultati non sono stati tali da giustificare l’utilizzo della segmentazione.
3.5.2 Template Matching
Le tecniche di template matching permettono di identificare la posizione di una patch, cioè una matrice di pixels che ha dimensioni piccole rispetto ad un immagine, all’ interno di un immagine (fig.3.35 ).
Fig.3.35 La patch di sinistra viene riconosciuta all’interno dell’immagine di destra
La posizione di una patch all’interno di un immagine è rappresentata dalla posizione (x,y) del punto in alto a sinistra della patch. Ad esempio la patch di fig.3.35 si trova in posizione (x,y)=(200,5) dove x è il numero della colonna e y il numero della riga, la risoluzione dell’immagine è 320x240.
Data un immagine I composta da un singolo canale, una patch T anch’ essa ad un singolo canale,w il numero di colonne della matrice T, h il numero di righe della matrice T,il risultato del templates matching sarà una matrice R data da:
+
+
•
+
+
−
=
∑∑
∑∑
∑∑
= = = = = = w x h y w x h y w x h yy
y
x
x
I
y
x
T
y
y
x
x
I
y
x
T
y
x
R
0 ' ' 0 2 0 ' ' 0 2 0 ' ' 0 2)
'
,
'
(
)
'
,
'
(
)]
'
,
'
(
)
'
,
'
(
[
)
,
(
(3.9)La matrice risultato R ha un numero di colonne W –w+1 e numero di righe H-h+1; dove W è il numero di colonne dell’immagine , w è il numero di colonne della patch T , H il numero di righe dell’immagine, h il numero di righe della patch.
Gli elementi della matrice R assumono valori tra 0 e 1.
Il punto (X,Y) dove la matrice R raggiunge il valore minimo corrisponde al punto in alto a sinistra della patch riconosciuta cioè al punto (x’,y’)=(0,0) relativamente alla patch.
E’ stato realizzato un programma che permette di trovare corrispondenze tra patch delle due immagini stereo, in modo da determinare la distanza degli oggetti presenti.Tale software verrà illustrato di seguito.
3.2.5.1 L’algoritmo utilizzato
L’idea di base è quella di riconoscere la corrispondenza tra patch dell’immagine destra e patch dell’ immagine sinistra allo scopo di determinare la posizione 3D degli oggetti che ci stanno davanti.
Per fare questo sì “ritagliano” una serie di patch dall’immagine sinistra e si esegue un template matching nell’immagine di destra. Il template matching viene ristretto solo alla parte di immagine destra che ha le stesse coordinate y della patch di sinistra perché è l’unica parte dell’immagine destra in cui si può avere una corrispondenza con l’immagine sinistra; questo fatto è dovuto alla geometria epipolare.
Fig.3.36 Coppia di frame stereo.
A sinistra : In rosso patch che deve essere riconosciuta nell’immagine di destra.
A destra: La zona compresa dal rettangolo in blu è l’unica zona in cui si può trovare la patch di destra corrispondente a quella sinistra a causa della geometria epipolare. I rettangoli in verde rappresentano le zone che vanno aggiunte alla zona di ricerca nel caso in cui le telecamere non
siano perfettamente allineate.
La zona di ricerca del template matching viene ingrandita come in fig.3.36 nel caso in cui le telecamere non siano perfettamente allineate.
In base alla disparità tra la posizione (x,y) della patch sull’immagine di sinistra e la posizione della patch trovata sull’immagine di destra è possibile trovare la posizione 3D (par.2.3)
Nella nostra particolare implementazione si prendono patch dall’immagine sinistra e di trova una corrispondenza con l’immagine destra.
L’algoritmo viene esplicato nei sui particolari dal flow chart di fig.3.37. Larg è la larghezza dell’immagine sinistra.
Alt è l’altezza dell’immagine sinistra.
Le variabili X e Y hanno inizialmente un valore pari a 0.
Il simbolo ‘+=’ è usato per incrementare la variabile come in linguaggio C++.
Fig.3.37 Flow-chart esplicativo del funzionamento dell’algoritmo che trova le corrispondenze
L’algoritmo è stato implementato triangolando solo il punto centrale delle 2 patch corrispondenti.Il punto centrale è il punto della patch di coordinate (w/2,h/2) dove w e h sono la larghezza e l’altezza della patch.
Fig.3.39 Punto centrale di una patch
In base a questi punti corrispondenti triangolati si può riconoscere se vi sono oggetti davanti al cono visivo.
3.2.5.2 Aspetti computazionali
Il tempo di esecuzione dell’algoritmo di template matching è troppo alto se viene fatto girare su immagini 320x240. Per ovviare a questo conveniente viene ridotta la risoluzione delle immagini fino ad ottenere delle immagini 80x60. L’algoritmo viene quindi fatto girare su immagini di dimensioni 80x60. Le patch che vengono confrontate sono di dimensione 20x20.
In questo modo il programma riesce a processare circa 20 coppie di immagini al secondo. La dimensione delle patch è grande se confrontata con le dimensione di un immagine ma ciò non crea problemi perché il nostro scopo è quello di trovare oggetti grandi che stanno davanti al cono visivo. Le patch devono essere di dimensione abbastanza grande rispetto alle dimensioni dell’immagine perché devono avere abbastanza contenuto informativo perché il risultato del template matching sia accettabile.
3.2.5.3 Risultati
Fig.3.40 Template Matching tra due immagini stereo. L’algoritmo utilizzato è quello di par. 3.2.5.1, 3.2.5.2.
Punto centrale della patch
Fig.3.41 vista dall’alto dei punti di cui si è trovato una corrispondenza in fig.3.40 e che sono stati triangolati.
Le coordinate a cui ci si riferisce nel grafico sono quelle della telecamera sinistra (Fig.2.6, Xcl,Zcl) del sistema stereo
Da fig.3.40 e fig.3.41 possiamo vedere che il ragazzo che sta davanti al cono visivo viene riconosciuto dall’insieme di punti triangolati. L’insieme di punti che si trova alla distanza di circa 2.5m rappresenta il veicolo che si trova sulla sinistra.
Possiamo notare che , anche se alcuni matching tra le aree sono errati, la maggior parte di essi sono giusti. Quindi, se un certo numero di punti vengono triangolati nella stessa posizione, possiamo inferire che, in quella posizione, c’è un oggetto che occlude il cono visivo.
La distanza degli oggetti che si trovano a meno di 4 metri di distanza viene valutata con una precisione nell’ordine del decimetro.