Capitolo 3
Gli strumenti per la simulazione
3.1 INTRODUZIONE
La grande novità degli anni ‘90 nel campo dello sviluppo software è stata la programmazione ad oggetti (OOP, Object Oriented Programming), il cui principale vantaggio consisteva nella possibilità di definire delle CLASSI che implementavano una certa funzionalità e/o struttura dati. Il programmatore che utilizzava una certa classe doveva semplicemente richiamare i suoi metodi senza preoccuparsi di come questi implementassero al proprio interno le funzionalità della classe. Questo rendeva un programma modulare, e una classe poteva anche essere interamente riprogrammata (per esempio con un'implementazione più efficiente) senza toccare una sola riga del resto del programma, purché la nuova versione mantenesse gli stessi nomi per metodi e proprietà pubblici della vecchia. Dal punto di vista opposto, una stessa classe poteva essere riusata in più programmi senza modifica alcuna, e questo ha portato alla nascita di una filosofia di programmazione per componenti, e quello dello sviluppo di classi specializzate nella soluzione di certi problemi o nell'implementazione di certe funzionalità è diventato un mercato vero e proprio. Nuovi linguaggi di programmazione sono nati, alcuni come estensione di linguaggi tradizionali (come il C++, derivato dal C e che permette anche una programmazione «mista», o il CLOS, estensione a oggetti del Lisp), altri ex-novo (come Java, anch'esso derivato dal C ma impostato totalmente sulla filosofia OOP).
Ora, a qualche anno di distanza, una nuova filosofia di programmazione sta emergendo, grazie soprattutto alla crescente diffusione di macchine sempre più potenti e di sistemi operativi multitasking, e soprattutto di ambienti distribuiti (reti locali, Internet). Questo scenario, infatti, permette di superare sia la programmazione tradizionale, in cui un programma gira su una macchina, sia la programmazione con approccio client-server, in cui un'applicazione è suddivisa in due o più moduli, che possono risiedere su macchine diverse e dialogano tra loro conservando però una gerarchia ben definita. Infatti, avendo a disposizione un ambiente di rete (sia locale che globale), si possono concepire applicazioni distribuite, formate da una comunità di componenti detti agenti che non solo comunicano fra loro, ma possono anche essere in grado di spostarsi da un computer a un'altro insieme con i propri dati.
La programmazione ad agenti, in effetti, può essere considerata l'applicazione pratica di quei concetti, come la programmazione concorrente e/o distribuita, che per troppo tempo sono rimasti pura teoria, confinata ai corsi universitari o in alcuni centri di ricerca. Un'applicazione realizzata tramite una popolazione di agenti, infatti, è concorrente in quanto ogni agente può essere composto da più processi o thread (sfruttando le capacità multithread di sistemi operativi come Linux, Windows95/NT, o i prossimi BeOS e Freedows), ma anche distribuita, in quanto l'insieme degli agenti, che girano su macchine diverse di una rete, concorrono a risolvere il problema generale (che può essere di Information Retrieval in ambito Internet/Intranet, di simulazione di processi vari, di monitoraggio, ecc.).
Come risultato del lavoro di molti ricercatori, nell'ambito delle Università e di grandi aziende, sono già apparse diverse librerie utilizzabili per creare applicazioni multiagente. La programmazione ad agenti è basata strettamente su quella a oggetti, in quanto un agente può essere definito in modo molto naturale come un oggetto, o meglio come una classe che incapsula le funzionalità implementate dall'agente, i cui metodi e proprietà pubblici definiscono i servizi che esso mette a disposizione degli altri agenti, servizi realizzati tramite metodi e proprietà privati o protetti. Si può ovviamente usare un qualunque linguaggio a oggetti, ma la natura distribuita di un'applicazione multiagente e l'eterogeneità a livello hardware e di sistema operativo che si può incontrare in una rete di computer fanno preferire il linguaggio che per definizione è nato per programmare in ambienti con tali caratteristiche: Java.
Nel seguito si descriveranno alcuni toolkits per la programmazione multiagente, ossia quegli ambienti applicativi o di sviluppo che forniscono gli strumenti per creare agenti, con un livello sufficiente di astrazione da permettere l’implementazione di agenti intelligenti con attributi desiderati, caratteristiche e regole.
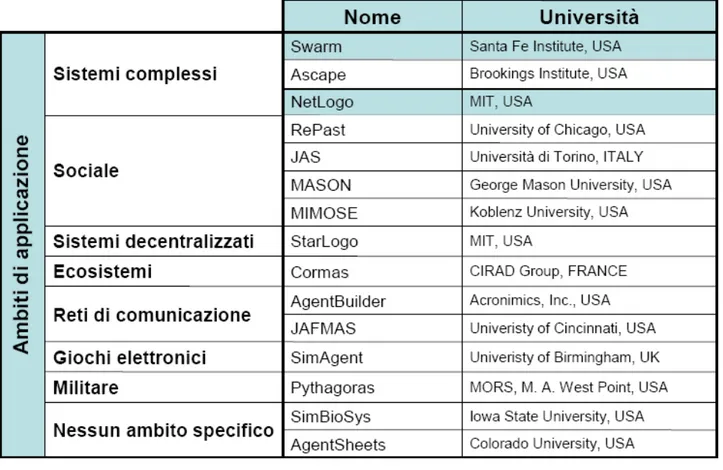
In figura 3.1 possiamo osservare una classificazione dei toolkits con le loro università di provenienza in base agli ambiti di applicazione.
Particolare attenzione sarà riservata all’ambiente di sviluppo utilizzato per le simulazioni di questo lavoro di tesi, ossia NetLogo nella versione 4.0.2 (Dicembre 2007).
3.2 NETLOGO
NetLogo è uno strumento di modellazione programmabile che permette di simulare fenomeni di tipo naturale e sociale. Con questo strumento è possibile passare delle istruzioni a centinaia e/o migliaia di agenti indipendenti in grado di operare in modo concorrente e collaborativo.
L'ambiente che mette a disposizione NetLogo rende possibile l'esplorazione della connessione tra il livello micro del comportamento dell'individuo con quello macro dei pattern che emergono dall'interazione di molti individui singoli.
NetLogo permette a chi lo usa simulazioni libere e di giocare esplorando il proprio comportamento in condizioni diverse. Ogni persona che lo usa può creare il proprio modello di riferimento e può essere utilizzato da utenti inesperti quali possano essere degli studenti o esperti quali sono solitamente docenti e ricercatori.
3.2.1 Introduzione
Il software NETLOGO, sviluppato originariamente da Uri Wilensky nel 1999 presso il Center for Connected Learning and Computer-Based Modeling della Northwestern University (http://ccl.northwestern.edu/netlogo/), offre un ambiente di sviluppo ideale per la realizzazione di modelli di simulazioni ad agenti, di networks e di sistemi dinamici.
All’interno di NETLOGO é possibile riprodurre molte delle caratteristiche di un sistema complesso, studiare la sua evoluzione nel tempo e visualizzarla in tempo reale all’ interno di un laboratorio virtuale 2D o 3D.
NETLOGO é stato scritto in JAVA ma é completamente programmabile per mezzo di un meta-linguaggio ad oggetti semplificato basato sulla sintassi del Logo (S.Papert, anni ‘60) ed introdotto originariamente nell’ambiente Starlogo, il progenitore di Netlogo creato all’MIT nel 1990 (M.Resnick).
L’ambiente di sviluppo di NETLOGO interpreta direttamente il codice senza bisogno di compilarlo, quindi al suo interno é possibile, in tempo reale:
- interagire con il sistema attraverso pulsanti e sliders per modificare i parametri di controllo; - visualizzare variabili, grafici e istogrammi relativi alla simulazione;
E’possibile inoltre:
- effettuare set di esperimenti al variare delle condizioni iniziali o dei parametri di controllo; - lanciare le simulazioni più pesanti in modalità off-line su computer remoti;
- usufruire di una ricca libreria di modelli di esempio da cui prendere spunto e di un help pratico ed ipertestuale;
- salvare le proprie simulazioni come applet JAVA e visualizzarle immediatamente dentro un web browser.
Come detto sopra, NetLogo nasce dall'unione di StarLisp e Logo. Dal primo, un parallelo del Lisp, eredita la struttura a più agenti, mentre dal secondo deriva la possibilità di controllare una “tartaruga” (turtle); Logo era molto popolare per l'ottima grafica, ma aveva il difetto, superato da NetLogo, che nel modello poteva esserci una sola tartaruga. NetLogo rappresenta inoltre il risultato degli studi su StarLogoT fatti dai suoi creatori, che hanno riscritto completamente il linguaggio e ridisegnato l'interfaccia grafica.
Figura 3.2 - Logo di NetLogo
Gli utilizzatori possono inserire istruzioni per gli agenti indipendenti che operano in parallelo nel modello; questo rende possibile l'analisi delle connessioni tra i comportamenti individuali degli agenti e la caratteristiche che emergono dall'interazione di popolazioni di individui.
Gli studi di fenomeni complessi effettuati con NetLogo possono interessare una grande varietà di ambiti di studio, quali, per esempio, le scienze naturali, la biologia, la medicina, la matematica, le scienze sociali, l'economia e la psicologia.
3.2.2 L’ambiente di NetLogo
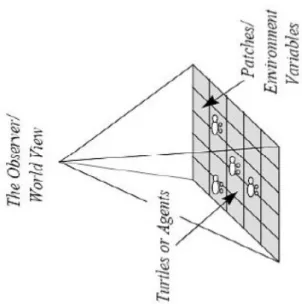
Il mondo di NetLogo è popolato da agenti che seguono le istruzioni impartite dall'utilizzatore. Nel modello possono esserci tre tipi di agenti (Wilensky, 1999):
le tartarughe, turtles, che si muovono ed interagiscono tra loro nel mondo in cui si trovano; si possono anche definire diversi tipi di tartarughe, in modo da associare ad essi differenti variabili e comportamenti e valutare i fenomeni che emergono dalla loro interazione;
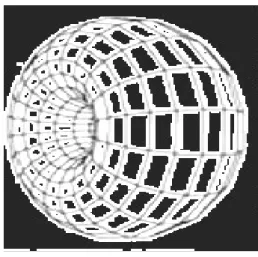
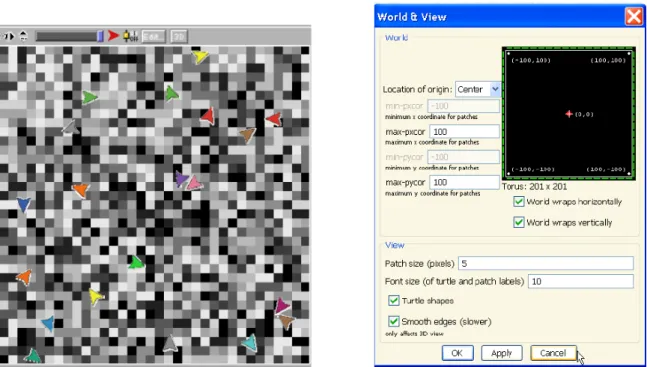
i patch, che sono delle sezioni quadrate di uno spazio continuo a due dimensioni in cui le tartarughe si possono muovere. I patch hanno delle coordinate chiamate pxcor, per la dimensione orizzontale, e pycor, per la dimensione verticale; il patch al centro del mondo ha coordinate (0; 0). Il mondo in cui si trovano le tartarughe non è limitato, è un toroide (fig. 3.3), perciò se una tartaruga si muove oltre il limite sinistro del mondo scompare per poi riapparire all'estremo destro della zona che rappresenta il mondo;
l'observer, che osserva ciò che accade nel modello; quando si avvia il modello non esistono tartarughe ed è compito dell'observer crearne nuove.
Figura 3.3 -Toroide, mondo in cui si muovono le tartarughe
Un'importante e nuova caratteristica del linguaggio di NetLogo è l'introduzione dell'agentset, o collezione di agenti, che permette la definizione di un insieme di agenti aventi le stesse caratteristiche e lo stesso comportamento.
Un agentset può essere costituito da un insieme di più tartarughe o di più patch di un certo tipo, ad esempio solo tartarughe rosse oppure una colonna di patch, cioè una serie di patch con la stessa coordinata per l'ascissa.
Oltre alle speciali strutture che supportano il modelli formati da più agenti, NetLogo prevede anche le altre possibilità della programmazione standard come ad esempio i cicli, le condizioni, le recursioni e le liste.
Quando si avvia NetLogo, ci si trova di fronte un’interfaccia che si divide in tre parti (fig. 3.4): 1. Interface, la prima che si apre quando si avvia il programma, è l’interfaccia grafica vera e
propria, dove si trova l’ambiente in cui si muovono le tartarughe; 2. Information, è una sorta di guida al programma;
3. Procedures, è la parte dove è contenuto il codice Logo che definisce il modello.
3.2.3 Interface tab
Nell’Interface, o interfaccia grafica:
gli agenti sono rappresentati come tartarughe;
lo spazio all’interno del quale si muovono gli agenti è un insieme di patch; è possibile inserire grafici per visualizzare in tempo reale i parametri desiderati; è possibile inserire bottoni per modificare alcune delle variabili;
ci sono dei modelli di simulazione già inclusi per iniziare.
Procedendo passo per passo, iniziamo con la descrizione dell’ambiente di simulazione.
Esso, come abbiamo già detto, è popolato da agenti, ossia da entità che seguono delle istruzioni ben precise. Ogni agente può portare avanti la propria attività, tutti simultaneamente. In NetLogo ci sono tipologie diverse di agenti: i turtles, i patch e l’osservatore ( Figura 3.5 ). In più ci sono anche i links.
Andando più nel dettaglio, le tartarughe sono agenti in grado di muoversi nel mondo, di cambiare colore, forma e proprietà, sotto forma di variabili proprietarie. Il mondo è bidimensionale ed è diviso in una griglia di patch. Ogni patch è un quadretto sul quale le tartarughe possono muoversi; corrispondono ai pixel del mondo virtuale e quindi sono immobili. Possono anch’essi cambiare colore o contenere informazioni sotto forma di variabili proprietarie. I link invece sono agenti che connettono due tartarughe. L’osservatore infine, non ha una locazione; lo si può immaginare che controlla dall’alto il suo mondo costituito da patch e turtles.
Quando si avvia NetLogo, nell’interfaccia utente, non viene ancora rappresentata nessuna tartaruga, dunque l’osservatore ne può costruire di nuove. Anche i patch possono farlo; infatti essi non si possono muovere, ma sono ‘vivi’ come le turtles e, come quest’ultime, hanno coordinate. Il patch con le coordinate (0,0) è chiamato origine mentre le coordinate degli altri patch sono le distanze orizzontali e verticali dall’origine stessa. Le coordinate dei patch si chiamano pxcor e pycor. Proprio come nel piano cartesiano standard, pxcor aumenta quando ci si muove verso destra, mentre pycor aumenta quando ci si muove verso l’alto.
Il numero totale di patch è determinato dai settaggi min-pxcor, max-pxcor, min-pxcor, max-pycor. Quando si avvia NetLogo, queste sono -16, 16, -16 e 16 rispettivamente. Questo vuol dire che sia
pxcor che pycor hanno un range che va da -16 a 16; ci sono dunque 33 x 33, quindi 1089 patches in
totale. Il numero di patch si può naturalmente cambiare con il bottone di Setting.
Figura 3.6 - A sinistra, l’ambiente di sviluppo con i patch e le tartles; a destra il settaggio delle coordinate dei patch, del numero totale e della dimensione.
Anche le tartarughe hanno coordinate xcor e ycor. Le coordinate dei patch sono sempre numeri interi, mentre quelle delle tartarughe possono avere numeri decimali. Questa sta a significare che una tartaruga può essere posizionata in ogni punto all’interno del suo patch; non deve essere nel centro del patch.
I link invece non hanno coordinate, ma hanno due punti finali (ognuno per turtle). Essi appaiono tra due punti finali, lungo il percorso più corto possibile.
Il modo in cui il mondo dei patch è connesso può cambiare. Per default il mondo è un toroide, ciò sta ad indicare che esso non è delimitato; infatti quando una tartaruga si muove al di là del limite del mondo, questa scompare e riappare nel contorno opposto ed ogni patch ha lo stesso numero dei patch vicini; cioè se sei un patch sul contorno, alcuni dei tuoi “vicini” stanno sul contorno opposto. Tuttavia, si può cambiare il settaggio del mondo virtuale con il bottone ‘Setting’ che sta in alto a destra dell’interfaccia utente. Si può rendere impossibile questo avvolgimento in una data direzione ( x o y ), e allora si dirà che in quella direzione il mondo è delimitato. I patch lungo quel confine avranno meno di 8 ‘vicini’ e le tartarughe non si muoveranno aldilà del contorno.
In NetLogo, mentre i patch possono cambiare solo il colore, le tartarughe possono avere diverse forme, costruite a partire da forme geometriche di base, come cerchi, quadrati e linee. Esse sono scalabili e ruotabili; possono avere dimensioni di 1, 1.5 o 2 a seconda della velocità di esecuzione. La forma di una tartaruga è immagazzinata nella sua variabile shape e può essere modificata usando il comando set. Le tartarughe ‘nuove’ hanno una forma di ‘default’.
In molti modelli NetLogo, il tempo passa in step discreti, chiamati “ticks”. NetLogo include un contatore di tick con lo scopo di farci render conto dei tick che stanno passando. Il valore corrente del contatore viene mostrato sopra la ‘view’. Si può usare il bottone di ‘Setting’ per nascondere il contatore o per cambiarlo in qualcos’altro.
La ‘view’ in NetLogo ci fa vedere gli agenti nel modello sul tuo schermo del computer. Quando gli agenti si muovono e cambiano, li puoi vedere muoversi e cambiare nella ‘view’. Naturalmente non si possono realmente vedere gli agenti direttamente. La ‘view’ è un’immagine che NetLogo disegna, che ci mostra come gli agenti appaiono in un particolare istante. Una volta che questo istante passa, e che gli agenti si muovono e cambiano, quell’immagine ha bisogno di essere ridisegnata per raffigurare il nuovo stato del mondo virtuale. Questo si chiama ‘updating the view’, ossia aggiornare la vista. Ma quando bisognare aggiornare l’immagine?
NetLogo offre due metodi di aggiornamento, “continuo” e “basato sui tick”. Si può selezionare uno dei due modi usando il popup menù in alto nell’Interface. Gli aggiornamenti ‘continui’ sono di default quando si avvia NetLogo, quasi tutti i modelli nella libreria, tuttavia, usano l’aggiornamento basato sui tick. Mentre il primo modo è il più semplice, il secondo ci da più controllo sul quando e il come avvengono gli aggiornamenti.
Come già precedentemente accennato, nell’Interface è possibile inserire dei grafici che poi possono essere esportati come file, che servono ad aiutarci a capire come sta andando il modello o come si sta comportando un certo parametro all’avanzare dei tick.
Naturalmente c’è bisogno prima di tutto di crearli nell’Interface, e questo avviene cliccando sul bottone ‘Button’ nel toolbar e selezionando poi l’item ‘plot’ (Fig. 3.7 ). Ogni grafico deve avere un solo nome. Si userà questo nome per riferirci al codice nella Procedures.
Figura 3.7 - Il bottone Button sul toolbar e le possibli scelte a sinistra, e come appare il grafico nell’interfaccia a destra.
Quando si crea un grafico, appare automaticamente la seguente finestra di settaggio del grafico.
Per specificare un grafico bisogna usare nella sezione ‘Procedures’ il comando set-current-plot seguito dal nome del grafico stesso racchiuso nelle virgolette (ad esempio set-current-plot
“Distanza vs tempo”). Se si cambia il nome del grafico si dovrà anche aggiornare il set-current-plot in modo che il modello usi il nuovo nome.
Quando si fa un nuovo grafico, in esso inizialmente c’è un solo parametro. Se il grafico corrente ha un solo parametro, allora si può iniziare a graficarlo immediatamente. Ma si può anche avere più di un parametro. Si possono infatti creare dei parametri addizionali usando la sezione “Plot pens” in fondo alla finestra di dialogo ( figura ). Ogni parametro deve avere un unico nome al quale ci si riferirà anche nel codice nella sezione ‘Procedures’.
Per un grafico con molti parametri, si deve specificare quale di questi si vuole graficare. Se non si specifica un parametro, automaticamente verrà graficato il primo parametro. Per graficare un differente parametro, bisogna usare il comando set-current-plot-pen seguito dal nome del parametro tra virgolette ( ad sempio set-current-plot-pen “distanza”).
I due comandi base per graficare sono plot e plotxy. Con il primo comando si ha bisogno solamente di specificare il valore y che si vuole graficare. Il valore x sarà automaticamente 0 per il primo punto, 1 per il secondo e così via. Il comando plot è pratico soprattutto quando si vuole graficare un nuovo punto ad ogni passo di tempo. Ad esempio:
to setup ...
plot count turtles end
to go ...
plot count turtles end
Se si vuole specificare sia il valore x che quello y del punto che si vuole graficare, si deve usare il commando plotxy.
Per default, NetLogo grafica I parametric in modo lineare; così i punti graficati sono connessi da una linea. Se si vuole muovere il parametro senza graficarlo, si può usare il comando plot-pen-up. Così i comandi plot e plotxy muovono il parametro ma in realtà non viene raffigurato niente. Una volta che il parametro si trova nel punto che volevamo, si usa il comando plot-pen-down per portarlo indietro.
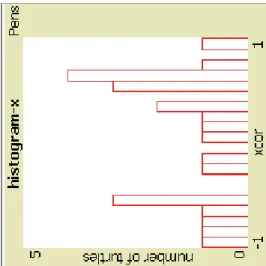
Se si vuole graficare punti individuali invece di linee, o si vuole raffigurare sbarre, lo si può fare cambiando la modalità di graficare i parametri; ci sono tre modi disponibili: linee, sbarre o punti. C’è anche un altra tipologia di grafico che mostra la distribuzione di frequenza dei valori della variabile proprietaria di un certo agentset: l’istogramma. L’altezza delle barre rappresenta il numero di agenti con valore della variabile compreso in un dato range.Ad esempio, se le tartarughe hanno un’età variabile, si può creare un’istogramma della distribuzione dell’età tra le tartarughe con il comando histogram, in questo modo: histogram [age] of turtles ( Figura 3.8 ).
Figura 3.8 – Istogramma, come viene raffigurato in NetLogo
Esistono dei comandi di clear e di reset. Il primo permette di ‘pulire’ il grafico corrente con il comando clear-plot, oppure tutti i grafici del modello con il comando clear-all-plots. Il comando
clear-all invece cancella tutti i grafici, ed in aggiunta anche ogni altra cosa presente nel modello. Se
si vuole rimuovere solamente i punti che ha raffigurato il parametro corrente, si deve usare
plot-pen-reset.
Si può mostrare la legenda di un grafico selezionando “Show legend” nella finestra che si apre per elaborare il grafico. Se non si vuole mostrare un particolare parametro nella legenda, questo può essere rimosso.
I bottoni nell’Interface forniscono un modalità più semplice per controllare il modello. Tipicamente un modello avrà almeno un bottone di “Setup”, per assegnare uno stato iniziale al mondo virtuale, ed un bottone “Go” per far girare il modello continuamente. Alcuni modelli avranno dei bottoni addizionali per compiere altre azioni. Ogni bottone contiene del codice NetLogo, che comincerà a girare quando lo si preme. Esso può essere un “once button” oppure un “forever button”; si può controllare questo cliccando o no il box forever. Il primo bottone fa girare il codice una volta sola e poi si ferma, il secondo fa girare il codice fino a che non si preme il comando di stop. Quando si preme il bottone di stop, il codice non viene interrotto, ma il bottone aspetta che il codice abbia finito. Normalmente, un bottone viene etichettato con il codice che fa girare, quindi uno che dice “go” di solito contiene il codice “go” che sta a significare “fai girare la procedura go”. Ma si può anche metterci un nome a proprio piacimento.
Quando si mette del codice in un bottone, si deve anche specificare a quali agenti vogliamo riferirci, ossia quali agenti devono compiere le azioni dettate dal codice. Si può scegliere di far girare il codice ad un osservatore, a tutte le tartarughe, ai patch o ai link.
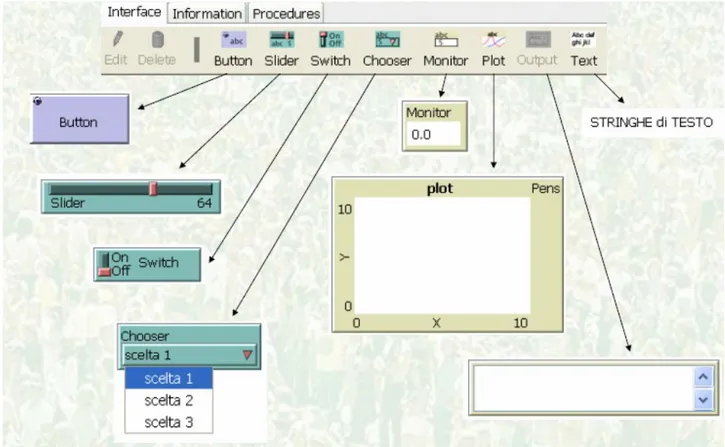
Oltre ai bottoni, o meglio i “button”, nell’Interface toolbar ci sono anche altri elementi che si possono scegliere cliccando sul pulsante “button”, tra questi abbiamo: slider, switch, chooser, imput, monitor, plot, output, note (figura 3.9 ).
Figura 3.9 – Elementi dell’Interface toolbar
Gli slider sono variabili globali, accessibili da tutti gli agenti. Sono utilizzati nei modelli come una modo più veloce per cambiare una variabile senza dover riscrivere il codice nella procedura tutte le volte. In questo modo, l’utente muove lo slider verso un valore ed osserva che cosa accade nel modello.
Gli switches sono invece la rappresentazione visiva di una variabile vero/falso. L’utente deve settare la variabile su on (vero) oppure off (falso) spostando lo switch.
I choosers fanno in modo che l’utente possa scegliere una variabile globale dalla lista di scelte possibili presentata in un piccolo menù.
Gli input sono variabili globali che contengono stringhe o numeri. L’autore del modello sceglie che tipologia di valore da immettere.
I monitors visualizzano i valori di ogni espressione. L’espressione può essere una variabile, un’espressione complessa, oppure una chiamata. Si aggiornano automaticamente tante volte ogni secondo.
I plot, come già precedentemente detto, sono grafici in tempo reale dei dati che il modello sta generando.
L’area degli output è un’area di testo scorrevole che può essere utilizzata per creare un registro di attività del modello. Un modello può avere solamente un’area output.
Le notes servono ad aggiungere etichette di testo informative all’interfaccia. Il contenuto delle notes non cambia nel momento in cui il modello viene compilato.
3.2.4 Information tab
Questa sezione è una sorta di guida al programma, fornisce un’introduzione al modello, una spiegazione di come usarlo, le cose da esplorare, le possibili estensioni e le caratteristiche di NetLogo. Risulta molto utile quando si sta analizzando il modello per la prima volta.
Figura 3.10 – Infromation tab
L’infromation tab dunque spiega i principi che sono stati modellati e come il modello stesso è stato creato. Ci sono varie sezioni, tra cui quella in cui ci sono dei nomi di modelli presenti nella NetLogo Library che possono essere correlati al modello corrente.
Non si possono fare elaborazioni sul display, per farle bisogna cliccare il tasto “Edit” o fare un doppio click su una parola.
3.2.5 Procedures tab
Questa sezione rappresenta lo spazio di lavoro in cui viene immagazzinato il codice del modello. Per i comandi che si vogliono usare immediatamente si usa il Command Center sul’Interface, mentre quelli che si vogliono salvare ed usare poi in seguito si scrivono nella sezione delle Procedures.
Per controllare se il codice ha degli errori, bisogna cliccare sul bottone “Check”; se ci sono errori di sintassi, il Procedures tab diventerà rosso ed il codice che contiene gli errori sarà evidenziato, mentre un commento apparirà in una finestra.
Figura 3.11 – Procedures tab
Se si vuole cercare un frammento di codice nella procedura, si clicca sul bottone “Find” ed apparirà una finestra Find.
Si può inserire o una parola od una frase da cercare oppure una parola od una frase con la quale voglio sostituirla.
3.2.6 Il linguaggio di programmazione
In NetLogo ci sono tre tipi di variabili: Globali
Locali Proprietarie.
Le variabili globali esistono in esemplari unici e sono visibili da qualunque punto del codice. Vengono dichiarate fuori da ogni altra procedura e aggiornate col comando “set nome_var valore” oppure direttamente dall’interfaccia di sviluppo attraverso gli sliders, gli switch o i chooser.
Anche le variabili locali esistono in esemplari unici e sono visibili solo all’interno della routine dove sono state dichiarate con “let nome_var valore”.
Le variabili proprietarie appartengolo alle turtles (turtles-own) o alle patches (patches-own) e sono replicate per ciascuna di esse (in JAVA sarebbero attributi degli oggetti appartenenti alle classi ‘turtles’ e ‘patches’).
Le dichiarazioni avvengono prima delle procedure vere e proprie ed il loro corpo è delimitato dalle parentesi quadre.
In NetLogo tutto il codice del modello risiede nello stesso listato, suddiviso in procedure che possono essere destinate all’esecuzione da parte del modello, delle patches o delle turtles.
Le procedure possono essere di due tipi diversi:
Subroutines Sono richiamate da altre subroutines oppure direttamente dall’interfaccia grafica per mezzo della pressione di un ‘button’. Possono prendere valori in ingresso ma non restituiscono alcun valore in uscita. Iniziano sempre con la parola chiave “to” e finiscono con “end”.
Reporters Sono chiamati da altri reporters o subroutines. Possono prendere valori in ingresso e restituiscono sempre un valore in uscita, attraverso il comando ‘report’. Iniziano sempre con la parola chiave “to report” e finiscono con “end”.
Le due principali subroutines, presenti in quasi tutte le simulazioni create con Netlogo sono:
a. Setup: chiamata dal relativo pulsante sull’interfaccia grafica, serve ad inizializzare le variabili, lo spazio virtuale e gli eventuali grafici. Serve anche:
- a creare le turtles che verranno usate nella simulazione e a fissarne le condizioni iniziali; - ad inizializzare le patches e gli altri elementi dell’ambiente.
b. Go: chiamata dal relativo pulsante sull’interfaccia grafica, serve a fare partire la simulazione, a far muovere le turtles o a cambiare stato alle patches. In realtà di solito contiene le istruzioni per eseguire un singolo run della simulazione. Attivando però la casella ‘Forever’ si impone alla routine di ripetersi fino a quando non venga nuovamente premuto il pulsante GO.
Figura 3.12 – Come funzionano le subroutine
Uno dei comandi principali di NetLogo è la parola chiave “ask”, applicabile sia alle turtles che ai patches. Il programma usa questo comando per dare ordini alle tartarughe, ai patch ed ai link. Tutto il codice che deve essere compilato dalle tartarughe deve essere localizzato in un contesto. Si può stabilire questo contesto in uno dei tre modi:
I. In un bottone, scegliendo “Turtles” dal menù. Il codice inserito nel bottone sarà compilato da tutte le tartarughe;
II. nel Command Center, scegliendo “Turtles” dal menù. Ogni comando inserito sarà compilato da tutte le tartarughe;
III. utilizzando la formula ask turtles.
Lo stesso vale per i patch, i link e l’osservatore, tolto il fatto che non si può dare un ordine con il commando ask all’osservatore. Il codice che non si trova all’interno degli ordini ask è, per default, codice dell’osservatore. Qui di seguito verrà mostrato un esempio dell’uso del comando ask in una procedura di NetLogo:
to setup clear−all
crt 100 ;; crea 100 turtles ask turtles
[ set color red ;; le fa diventare rosse
rt random−float 360 ;; gli si da delle direzioni random
fd 50 ] ;; vengono sparsi nel loro ambiente di sviluppo ask patches
[ if pxcor > 0 ;; fa diventare verdi le patch [ set pcolor green ] ] ;; sul lato destro della view end
Per complicare ulteriormente i comportamenti degli agenti tuttavia, ci mancano ancora degli importanti elementi di programmazione indispensabili per consentire agli agenti di compiere delle scelte: questi elementi sono le “strutture per il controllo di flusso”.
Tra le più importanti ci sono:
if condizione [comando] ;
ifelse condizione [comando1] [ comando2] ; ifelse-value condizione [valore1] [valore2] ; loop [comando] ;
repeat numero [ comando ] while [condizione] [ comando ] foreach lista [ comando ]
3.2.7 Il Behaviour Space
È lo strumento che permette di programmare ed effettuare i cicli di esperimenti variando sistematicamente le impostazioni e registrando i risultati. Ci si può arrivare dal menù principale dell’interfaccia grafica, cliccando su Tool e scegliendo la voce BehaviourSpace (Figura 3.13 ).
Figura 3.13 – Finestra del Behaviour Space
Behaviour Space è uno strumento software integrato con NetLogo che ci permette di compiere degli esperimenti con i modelli. Infatti fa girare il modello molte volte, variando sistematicamente il settaggio del modello e registrando i risultati ad ogni compilazione di quest’ultimo. Questo è il processo che a volte viene chiamato “parameter sweeping”. Permette di esplorare lo spazio dei possibili comportamenti e di determinare quali combinazioni di settaggi portano ai comportamenti di interesse.
Il bisogno di questo tipo di esperimenti è rilevato dalle seguenti osservazioni. I modelli spesso hanno molti settaggi, ognuno dei quali può prendere un range di valori. Insieme formano quello che in matematica è chiamato uno spazio del parametro per il modello, le cui dimensioni sono il numero di settaggi, ed in cui ogni punto rappresenta una particolare combinazione di valori. Far girare un
modello con differenti settaggi ( a volte anche gli stessi settaggi) può portare a comportamenti drasticamente differenti l’uno dall’altro nel sistema modellato. Così, come si fa a conoscere la particolare configurazione di valori, o il tipo di configurazioni che realizzeranno proprio il comportamento a cui si è interessati? E poi, dove il modello nello spazio multi dimensionale dei parametri ottiene la migliore prestazione?
Behaviour Space offre un modo migliore per risolvere il problema. Se viene specificato un sottoinsieme di valori dal range di ogni slider, girerà il modello con ogni possibile combinazione di questi valori e, durante ogni compilazione del modello, registrerà i risultati. Dopo aver fatto girare il modello per tutte le volte che vogliamo, viene generato un dataset che si può aprire in un tool differente e si può esplorare. Esplorando l’intero spazio dei comportamenti, BehaviourSpace può essere un assistente perfetto per il modellista.
3.3 ALTRI TOOLKIT PER LA SIMULAZIONE
In questo capitolo si presentano Swarm e RePast, due strumenti con i quali, insieme a NetLogo, è possibile costruire all'interno del computer modelli di simulazione ad agenti.
Tra i due Swarm è quello che vanta la maggior diffusione e la maggior robustezza del codice ed è presentato in modo più approfondito, perché è il protocollo di programmazione su cui si basa jES (java Enterprise Simulator).
Su RePast sono fornite soltanto alcune informazioni che consentono di comprendere come è strutturato l'ambiente di simulazione.
3.3.1 Swarm
Il progetto Swarm nasce nel 1994 dall'idea di Chris Langton ed è successivamente sviluppato all'interno dell'Istituto degli Studi sulla Complessità di Santa Fe.
Swarm è una piattaforma informatica con cui è possibile effettuare simulazioni di sistemi complessi adattivi; l'unità base della simulazione è lo sciame, che è definito come un insieme di agenti che eseguono una serie di azioni.
Swarm offre delle librerie di componenti con le quali si possono costruire modelli e analizzarli.
Figura 3.14 – Logo si Swarm
Uno dei principali motivi della nascita del progetto Swarm è l'esigenza di disporre di uno strumento versatile per lo studio dei sistemi complessi che possa essere facilmente comprensibile ed
utilizzabile dai ricercatori di diverse discipline; il progetto deve pertanto la sua nascita al lavoro congiunto di più studiosi, che hanno avuto come obiettivo primario la creazione di una ``lingua franca della simulazione ad agenti.
Prima della sua creazione nell'ambito dello studio dei sistemi complessi era presente un grande numero di modelli di simulazione, che risultavano di difficile interpretazione e comprensione per chi tentasse di avvicinarsi allo studio di un particolare fenomeno. Il motivo principale è che le piattaforme di simulazione esistenti erano molto specifiche e contenevano un numero di assunzioni implicite che erano chiare soltanto ai creatori del software.
Swarm presenta il vantaggio di poter essere utilizzato in diverse area di ricerca, ad esempio nella chimica, nell'ecologia, nell'economia e nelle scienze sociali, grazie al fatto che il codice informatico relativo al comportamento degli agenti deve essere integralmente scritto dall'utilizzatore; il progetto infatti fornisce soltanto le funzioni generiche di gestione del tempo, dei cicli di funzionamento e di interazione grafica con l'utente.
Sviluppo di una simulazione
Il formalismo adottato da Swarm prevede un insieme di agenti che interagiscono tra loro mediante eventi. L'agente è l'oggetto principale all'interno di una simulazione e può generare eventi che interessano se stesso o altri agenti.
Il verificarsi degli eventi è regolato da un calendario interno che descrive le azioni nel preciso ordine in cui devono essere eseguite; il tempo avanza solo nel momento in cui gli eventi inseriti nella sequenza sono stati eseguiti.
La componente che organizza gli agenti è detto sciame (o swarm) e rappresenta un intero modello, in quanto contiene gli agenti e la rappresentazione del tempo, vale a dire una sequenza di attività che devono essere eseguite.
Gli sciami possono essere anche agenti, oltre che i loro contenitori; un agente per definizione è costituito da un insieme di regole e di capacità di risposta agli stimoli ma può essere allo stesso tempo anche uno sciame, cioè una collezione di oggetti e di sequenze di azioni da svolgere. In questa situazione il comportamento dell'agente è definito dalle interazioni che si svolgono all'interno dello sciame.
Per effettuare una simulazione in qualsiasi ambito di ricerca occorre portare a termine una serie di azioni che possono essere riassunte in uno schema generale:
l'utilizzatore deve definire gli agenti e stabilire le regole che definiscono il loro comportamento; inoltre deve decidere quali relazioni intercorrono tra loro;
in seguito deve inserire tutti gli agenti all'interno di uno sciame, descrivendo un elenco di attività da svolgere con l'indicazione dei tempi in cui devono essere portate a termine;
il ricercatore deve anche definire quali strumenti utilizzare per osservare l'andamento della simulazione (grafici, statistiche, ...); essi sono messi a disposizione dalle librerie di Swarm e sono anch'essi agenti appartenenti ad uno sciame, detto observer. Il motivo del ricorso a questa opzione dipende dal fatto che il fine ultimo dei ricercatori non è far funzionare il modello, ma analizzare la nascita e l'evoluzione dei fenomeni complessi nei mondi da loro costruiti;
dopo aver definito e combinato il model e l'observer, l'apparato di simulazione è completo ed è possibile far `”funzionare” l'universo creato.
Dallo schema proposto risalta il fatto che la struttura di Swarm è composta da due livelli differenti: al primo livello si ha il modello (model ), che rappresenta il fenomeno che si vuole analizzare, al secondo l'osservatore, (observer) che considera il modello come un unico oggetto con il quale interagisce per ottenere i risultati richiesti dagli strumenti che il ricercatore utilizza per analizzare il mondo creato.
Riprendendo l'esempio precedente sul distretto industriale, nella figura 3.15 è mostrato un esempio sintetico della struttura della simulazione. Nel model sono presenti gli agenti, cioè le industrie, e un gestore del tempo che contiene le azioni da svolgere; nell'observer vi sono altri tipi di agenti, vale a dire gli strumenti di controllo del modello, e un altro gestore del tempo. Sia il model sia l'observer sono sciami.
Caratteristiche principali
La struttura di Swarm è realizzata con il linguaggio di programmazione ad oggetti Objective C. Questo stile di programmazione consiste nella definizione di varie classi di oggetti; un oggetto è la combinazione di variabili di stato, che ne definiscono le caratteristiche interne, e di metodi, che ne rappresentano il comportamento.
Dalla versione 2.0 di Swarm gli utilizzatori possono scrivere i modelli con il linguaggio Java, creato dalla Sun Microsystem; i vantaggi principali di questo linguaggio sono la scarsa possibilità di creare errori all'interno del modello e la sua grande diffusione.
Le caratteristiche più importanti della programmazione object-oriented dal punto di vista dell'utilizzo di Swarm sono l'incapsulamento e l'ereditarietà, che permettono di creare software utilizzabili in più situazioni richiamando semplicemente la classe di una libreria che si vuole utilizzare.
Secondo il principio dell'incapsulamento i dettagli interni di un oggetto sono protetti e non possono essere messi a disposizione dell'utente, ad eccezione di quei metodi che sono scritti con l'obiettivo di trasmettere informazioni all'esterno. la programmazione object-oriented applica all'informatica dei concetti che sono comuni nel modo in cui le persone considerano gli oggetti fisici. Prendendo una semplice radio come esempio di oggetto, possiamo notare che presenta la caratteristica di essere incapsulato: infatti, per poterla utilizzare non occorre essere esperti di elettronica, è sufficiente agire sui pulsanti; la stessa cosa avviene nel caso degli oggetti informatici, dal momento che gli utenti possono agire solo sui metodi che sono messi a loro disposizione dall'oggetto, senza dover conoscere le sue caratteristiche interne.
L'ereditarietà permette che ogni sottoclasse erediti le variabili ed i metodi della classe base, che è chiamata superclasse. In questo modo si può creare una classe che contiene i metodi della classe di livello superiore e ne aggiunge di nuovi. Tornando all'esempio della radio, possono essercene di diverse tra loro che hanno una maggiore ricezione o un altoparlante più potente; queste ultime ereditano le caratteristiche di base dalla radio normale, che, con una metafora informatica, potrebbe essere definita la superclasse delle radio.
Le “sonde”
Le sonde, o probes, permettono all'utilizzatore di interagire con gli oggetti della simulazione osservando e modificando i valori delle variabili; il loro maggior vantaggio sta nel non dover aggiungere nuovo codice informatico per poterle utilizzare.
Una sonda è una finestra rettangolare nelle cui righe sono descritti gli attributi dell'oggetto preso in considerazione; i dati mostrati possono riguardare il modello in generale oppure possono rappresentare le informazioni di un semplice agente che opera all'interno del modello. Tutti i progetti costruiti con Swarm hanno almeno due sonde: quella del ModelSwarm, che indica i parametri del modello, e quella dell'ObserverSwarm, che contiene le caratteristiche degli strumenti utilizzati per analizzare l'andamento della simulazione nella figura 3.16 sono mostrati due esempi di sonde di model e observer.
Figura 3.16 – Esempi di sonda
Le librerie di Swarm
Le librerie di Swarm hanno due funzioni principali: elencano una serie di classi che i costruttori del modello possono utilizzare e sono impiegate per creare delle sottoclassi più specifiche per le particolari finalità della simulazione.
Le librerie sono suddivise in due gruppi: da un lato quelle fondamentali per ogni modello di simulazione, swarmobject, activity e simtools, dall'altro le librerie di supporto, utili per la creazione di modelli che rispondano a particolari esigenze, defobj, collections, random, tkobjc.
La libreria swarmobject contiene le classi principali su cui si basano gli agenti creati nel modello. Questa libreria contiene la classe SwarmObject, dalla quale tutti gli agenti ereditano il loro comportamento, e la classe Swarm, che è utile per la scrittura del ModelSwarm e dell'ObserverSwarm.
La libreria activity permette la definizione del calendario degli eventi e supporta l'esecuzione della simulazione.
Infine, l'ultima libreria specifica è simtools, un insieme di classi che controllano l'intero svolgimento della simulazione. Le classi contenute in questa libreria possono, ad esempio, creare grafici riassuntivi ed elaborare statistiche.
Passando al secondo gruppo di liberie, defobj definisce le indicazioni standard per la creazione degli oggetti, per l'archiviazione di dati e per il trattamento degli errori.
La libreria collections mette a disposizione le classi utili per seguire gli oggetti, per esempio mappe e liste. La libreria random offre all'utente una serie di classi che generano numeri casuali e che possono trasformare sequenze di numeri casuali in numerose distribuzioni di probabilità. Nella simulazione al computer la fase della generazione di numeri casuali è molto importante, in quanto influenza i risultati finali, pertanto è fondamentale evitare di utilizzare generatori di numeri con distorsioni o correlazioni tra loro.
L'ultima libreria del supporto di base di Swarm è tkobjc, che contiene gli oggetti base per la creazione di un'interfaccia per l'utente; con le sue classi è possibile creare bottoni, istogrammi e grafici.
In aggiunta alle librerie base richieste per la simulazione ci sono molte altre librerie che possono essere utilizzate per la costruzione di particolari modelli.
Esistono librerie che supportano gli spazi bidimensionali, gli algoritmi genetici e le reti neurali. La libreria space è utile nella costruzione di ambienti in cui gli agenti interagiscono tra loro; è prevista la definizione di uno spazio a due dimensioni, simile ad una griglia di punti nella quale sono collocati gli oggetti della simulazione.
Infine, si rappresenta la prima libreria creata dal gruppo di utilizzatori di Swarm e consente l'uso di algoritmi genetici, mentre neuro permette di utilizzare le reti neurali artificiali.
3.3.2 RePast
RePast, acronimo per REcursive Porous Agent Simulation Toolkit, è uno strumento per la simulazione ad agenti scritto completamente in Java e simile a Swarm creato dal Social Science Research Computing dell'Università di Chicago.
Questo software offre una libreria di classi utili per creare e far funzionare i modelli di simulazione e per l'uso di grafici che visualizzino i risultati.
Figura 3.17 - Logo di RePast
Inizialmente RePast era stato concepito con l'idea di creare una serie di librerie Java da affiancare a Swarm per semplificarne l'utilizzo; tuttavia questo progetto venne abbandonato nel momento in cui uscì la versione Java di Swarm, in quanto RePast rappresentava soltanto un doppione. Pertanto lo sviluppo di questo software è continuato in modo indipendente da Swarm all'interno dell'Università di Chicago ed anche in altri ambienti di ricerca.
Obiettivi
Gli obiettivi principali dei creatori di RePast sono il raggiungimento di un buon livello di astrazione della struttura della simulazione, l'estendibilità, e la performance “good enough”.
L'astrazione è una delle caratteristiche più importanti di RePast, che astrae la maggior parte degli elementi chiave della simulazione ad agenti e li rappresenta in classi Java.
L’estendibilità è resa possibile dall'uso del linguaggio Java, in quanto la programmazione ad oggetti permette la creazione di strutture estendibili grazie alle proprietà dell'ereditarietà e dell'incapsulamento.
Il concetto della performance “good enough” si riferisce al livello delle prestazioni di RePast in rapporto agli altri benefici di questo strumento di analisi. L'attenzione maggiore dei creatori di RePast è concentrata sulla minimizzazione del numero di oggetti creati e sulla velocità della simulazione, che si basa principalmente sui miglioramenti che saranno portati alla Java Virtual Machine.
Caratteristiche della simulazione
Con RePast è possibile realizzare una simulazione concepita come una state machine costituita dagli stati di tutte le sue componenti; queste ultime possono essere divise in due gruppi, l'infrastruttura e la rappresentazione.
L'infrastruttura rappresenta tutti i meccanismi che permettono di far funzionare la simulazione, come ad esempio mostrare e raccogliere dati. Lo stato dell'infrastruttura è lo stato dei grafici e degli oggetti che raccolgono dati.
La rappresentazione è ciò che l'utilizzatore della simulazione costruisce, cioè il modello. Lo stato della rappresentazione è lo stato degli agenti appartenenti al modello, indicato dai valori delle loro variabili e dello spazio in cui operano.
Qualsiasi modifica agli stati dell'infrastruttura e della rappresentazione sono realizzati attraverso un calendario; questo meccanismo permette una grande flessibilità per l'utilizzatore della simulazione. L'unità di tempo usata dal simulatore è, come in Swarm e in NetLogo, il tick e il passare del tempo è scandito dall'esecuzione delle attività programmate nel calendario; durante la simulazione si passa al tick successivo solo nel momento in cui l'azione programmata per un dato tick si è conclusa, perciò in RePast i tick rappresentano soltanto un modo per far trascorrere gli eventi in un certo ordine.
Una tipica simulazione costruita con RePast è composta da una serie di agenti, che possono essere omogenei oppure inseriti all'interno di una gerarchia, e da un modello che controlla che gli agenti eseguano i loro comportamenti secondo il calendario interno. Il calendario ha anche il compito di controllare gli eventi all'interno del modello, ad esempio aggiornando il monitor e raccogliendo dati, e può essere creato internamente al modello o esternamente da parte dell'utilizzatore.
Nel formalismo di RePast gli eventi sono chiamati azioni. Le librerie
RePast è composto da 210 classi Java organizzate nelle seguenti librerie:
la libreria analysis contiene le classi che sono usate per raccogliere dati e rappresentarli su grafici;
le classi contenute nel pacchetto engine sono responsabili dell'organizzazione e del controllo di una simulazione;
le classi del pacchetto event sono usate internamente da RePast e sono incaricate, insieme ad alcune della libreria engine, della comunicazione tra le parti interne del modello non di competenza del calendario della simulazione;
la libreria games contiene le classi utili a simulare giochi cooperativi come il dilemma del prigioniero;
le classi gui sono responsabili della visualizzazione grafica della simulazione e della possibilità di creare delle animazioni del modello con QuickTime;
la libreria network contiene le classi incaricate di creare la rete della simulazione; la classe interna NetworkFactory è usata per creare il network o per caricarlo da un file;
il pacchetto space contiene le classi che si occupano delle relazioni spaziali e possono rappresentare vari tipi di spazio;
la libreria util contiene classi che possono essere sfruttate sia internamente da RePast sia dall'utilizzatore; le più importanti sono la classe Random, che contiene un grande numero di distribuzioni casuali, e SimUtilities, in cui ci sono metodi per creare sonde e liste.