Capitolo 2
KDDML
Questo capitolo vuole essere una descrizione breve ma esaustiva del linguaggio e del sistema KDDML in modo tale da poter comprendere meglio quali sono i punti in cui il sistema è stato modificato e quali sono i passaggi necessari per estendere e/o modificare KDDML. Verrà data inoltre una breve descrizione del linguaggio di markup XML per avvicinarci meglio a capire il modo in cui sono strutturate le KDDML query.
2.1 XML
2.1.2 Introduzione a XML
XML è un meta-linguaggio per definire la struttura di documenti e dati. Il termine documento ricorre spesso nella terminologia XML. Anche se esso può far pensare pagine Web o altri prodotti dell'elaborazione di testo, è utilizzato nella sua accezione più ampia di contenitore di informazioni.
Concretamente, un documento XML è un file di testo che contiene una serie di tag, attributi e testo secondo regole sintattiche ben definite.
Analizziamo ora XML dal punto di vista logico e sintattico e i documenti che con esso si possono creare dando uno sguardo alla struttura logica. Introduciamo alcuni concetti fondamentali per la corretta comprensione di questo meta-linguaggio.
Un documento XML è intrinsecamente caratterizzato da una struttura gerarchica. Esso è composto da componenti denominati elementi. Ciascun elemento rappresenta un componente logico del documento e può contenere
altri elementi (sottoelementi) o del testo.
Gli elementi possono avere associate altre informazioni che ne descrivono le proprietà. Queste informazioni sono chiamate attributi.
L'organizzazione degli elementi segue un ordine gerarchico o arboreo che prevede un elemento principale, chiamato root element o semplicemente root o radice.
La radice contiene l'insieme degli altri elementi del documento. Possiamo rappresentare graficamente la struttura di un documento XML tramite un albero, generalmente noto come document tree.
Prima di proseguire e di capire meglio, ecco un esempio tipico di file XML. Lo si può visualizzare su un browser qualsiasi semplicemente salvandolo in un file di testo, poi rinominandolo con estensione .xml.
<?xml version="1.0" encoding="ISO-8859-1"?> <utenti> <utente> <nome>Luca</nome> <cognome>Ruggiero</cognome> </utente> <utente> <nome>Max</nome> <cognome>Rossi</cognome> </utente> </utenti>
La prima riga indica la versione di XML in uso e specifica la codifica ISO per la corretta interpretazione dei dati. L'XML non riconosce i caratteri speciali all'interno di una sua struttura: le lettere accentate, la & (e commerciale) ed altri vanno quindi sostituiti con le rispettive sequenze Unicode.
un database, viene chiamato nodo ed ogni tag può essere corredato da attributi. Ad esempio, la struttura precedente può essere modificata come segue:
<?xml version="1.0" encoding="ISO-8859-1"?> <utenti>
<utente nome="Luca" cognome="Ruggiero" /> <utente nome="Ruggiero" cognome="Rossi" /> </utenti>
I tag che non hanno l'omonimo tag di chiusura vanno chiusi con uno slash ( / ) finale, prima della fine del tag stesso. Per maggiore compatibilità con i browser più vecchi è preferibile far precedere lo slash da uno spazio, come indicato nell'esempio qui sopra.
2.1.3 XML : Documento ben Formato
Per poter essere correttamente interpretato da un browser, un documento XML deve essere ben formato, deve cioè possedere le seguenti caratteristiche:
Un Prologo, che è la prima istruzione che appare scritta nel documento. Nel nostro caso: <?xml version="1.0" encoding="ISO-8859-1"?>
Un unico Elemento radice (ovvero il nodo principale) che contiene tutti gli altri nodi del documento. Nel nostro esempio: <utenti> .
All'interno del documento tutti i Tag devono essere chiusi. Per esempio: il tag <html> va chiuso con </html>, anche il tag <br> deve essere chiuso con </br>, o in questo caso più semplicemente possiamo
scrivere <br/>.
XML è dunque un sottinsieme di SGML semplificato ed ottimizzato specificamente per applicazioni in ambiente Word Wide Web. Le caratteristiche dell’XML sono quindi molto simili a quelle dell’SGML (sia per quanto riguarda i principi di codifica che per quello che concerne le specifiche della DTD). Si tratta dunque di un vero metalinguaggio, che permette di specificare molteplici classi di linguaggi di marcatura, e non una semplice applicazione SGML come HTML (che si configura come uno dei possibili linguaggi di codifica conformi alla sintassi SGML).
2.1.4 Strutturazione di un documento XML
La grande novità che caratterizza XML, in antitesi a HTML, orientato alla descrizione della struttura fisica del documento e della rappresentazione “visiva” dello stesso, è la propensione alla descrizione delle informazioni testuali in un formato leggibile e comprensibile dall’utente, prescindendo dalle indicazioni relative a come i dati devono essere visualizzati. XML è un database-neutral e un device-neutral format; solo in un secondo momento i dati codificati in XML potranno essere indirizzati a differenti devices, usando l’Extensible Style Sheet Language (XSL). Essendo XML extensible, rispetto a HTML (che prevede il solo utilizzo di prefissati set di elementi) il suo utilizzo eliminerà il bisogno da parte dei produttori di browser di aggiungere specifici tag HTML incompatibili (le “extensions” di cui si diceva).
Questo è possibile perchè XML è un metalinguaggio impiegato per realizzare altri linguaggi specifici, denominati anche “vocabolari”. Ogni vocabulary può essere costruito mediante il ricorso ad una DTD che fornisce le regole necessarie alla definizione degli elementi e della struttura del nuovo linguaggio. Dunque anche un singolo documento XML valido, un singolo esemplare di
documento conforme a XML, deve essere associato ad una DTD che ne specifica la grammatica. Tuttavia a differenza di SGML, XML consente la distribuzione anche di documenti privi di DTD, documenti well-formed, dotati di una sintassi più rigida rispetto a quella di un documento SGML (per esempio è sempre obbligatorio inserire i marcatori di chiusura negli elementi non vuoti). Per questa ragione alcune delle più complesse caratteristiche di SGML, che ne accrescono la complessità computazionale, sono state eliminate in fase di realizzazione. Sono state dunque introdotte novità nella sintassi, giungendo ad una consistente riduzione della complessità di implementazione di un browser XML e facilitando di molto l’apprendimento del linguaggio. La semplificazione poi non comporta alcuna incompatibilità: un documento XML valido è sempre un documento SGML valido; ne deriva che il passaggio e quindi la trasformazione di un’applicazione o di un documento SGML in uno XML è una procedura quasi sempre automatica.
In termini opposti alla tendenza ora dominante nell’ambito delle recenti tecnologie Web, XML è orientato alla descrizione della struttura del testo e non alla rappresentazione visiva del documento. Un file HTML riflette il privilegio accordato alla rappresentazione della struttura del documento ma non ad un altrettanto adeguata descrizione della struttura dei dati. Un markup HTML si limita a fornire informazioni necessarie a comprendere come gli elementi testuali sono disposti all’interno della pagina, ma non fornisce alcuna informazione utile a comprendere il significato degli elementi codificati, in quanto ogni singolo tag non apporta nessuna nozione relativa al blocco di testo cui è affiancato. Quando un documento HTML viene processato dal browser, la semantica viene ignorata, la macchina non comprende quale tipo di informazione deve essere resa, il contenuto di informazioni del testo non è oggetto di indagine.
Viceversa una codifica XML presta attenzione non all’aspetto degli elementi testuali, cioè alla loro distribuzione fisica, ma al contenuto di ogni singola partizione; esprime quindi, tramite il ricorso a marcatori alfabetici, il significato
della stringa di caratteri cui il tag è associato. Diremo che XML focalizza la codifica sulla semantica e sulla struttura dei dati, mantenendo altresì l’ordinamento gerarchico che sovrintende l’organizzazione degli elementi della fonte. Ne deriva un assoluto parallelismo con la distribuzione dei record all’interno di una base di dati.
L’insieme delle specifiche del progetto XML permette dunque di creare, gestire, manipolare e mantenere applicazioni complesse in rete. XML si configura dunque come un potente metalinguaggio in grado di superare quella molteplicità di limitazioni di una delle più note applicazioni SGML, HTML. La possibilità di introdurre tag custom per codificare ogni tipo di fenomeno testuale o di elemento documentale fa di XML uno strumento innovativo. Senza dimenticare che l’attenzione accordata all’analisi della struttura dei dati, con la possibilità fornita all’utente di comprendere il significato delle componenti testuali grazie all’utilizzo personalizzato dei marcatori, costituisce una imprescindibile potenzialità di XML. L’essere XML un sottinsieme di SGML, compatibile con HTML, consente spesso di non dover ricorrere all’elaborazione di nuovi tool per la gestione e la manipolazione dei documenti codificati secondo le specifiche del W3C; molteplici parser e conversion tool nati per HTML e SGML funzionano in modo ottimale anche con XML.
2.2 KDDML
2.2.2 Un linguaggio di mark-up per il processo KDD
KDDML è stato progettato con l’obiettivo di fornire differenti tools di DM e con la possibilità di interagire con il processo KDD attraverso un QL. Per
mezzo dell’interfaccia grafica l’utente ha poi la possibilità di seguire il processo di estrazione di conoscenza in modo interattivo.
Come mostrato in precedenza, il linguaggio di markup KDDML definisce e formalizza una serie di oggetti utilizzati all’interno del processo KDD. Ognuno è stato definito sfruttando XML come linguaggio di markup che, come già detto, fornisce per ognuno di essi una rappresentazione univoca. Per ogni singolo oggetto componente la gerarchia è stata quindi definita una DTD che ne rappresenta la struttura e che ne stabilisce la validità.
2.2.3 Introduzione a KDDML
KDDML ( KDD Markup Language ) è un linguaggio di Markup basato su XML sia per quello che riguarda i la rappresentazione dati sia per la sintassi delle query, sia per la rappresentazione dei modelli.
La sintassi del linguaggio è basata su XML in modo tale da rendere semplice l’interazione con il calcolatore, ogni tag modella un operatore del linguaggio. L’obiettivo di KDDML è quello di fornire un linguaggio (ed un sistema) middleware per supportare lo sviluppo di applicazioni che necessitano di usufruire di strumenti per l’accesso ai dati, e di algoritmi per il preprocessing ed il DM.
I modelli sono rappresentati utilizzando una particolare estensione dello standard PMML.
2.3 Il linguaggio KDDML
Il linguaggio è stato costruito in modo tale da poter essere completamente indipendente dall’implementazione a basso livello degli algoritmi di mining. Le query KDDML, come detto in precedenza, sono documenti XML-based. I tag del documento corrispondono ad operazioni su dati e/o modelli.
KDDML assume la presenza di un data repository che contiene le tabelle relazionali, un model repository, che contiene i modelli di minino, e un query repository che contiene le query.
E’ importante tenere presente che KDDML è un linguaggio completamente tipato, quindi gli argomenti di un determinato operatore devono essere dell’appropriato tipo e sequenza come richiesto dalla signature dell’operatore stesso.
Quindi le query KDDML rappresentano termini dell’algebra degli operatori che sono soltanto sintatticamente rappresentati attraverso documenti XML.
In generale c’è un tipo per le sorgenti di dati, un tipo per ogni modello di minino, un tipo per le gerarchie un tipo per gli operatori che restituiscono uno scalare e un tipo generico per denotare elementi xml che devono essere valutati dall’operatore.
Il linguaggio soddisfa il principio di chiusura, nel senso che un operatore che restituisce un tipo “t” può essere usato come argomento di un altro operatore che richiede come parametro un argomento di tipo “t”.
Consideriamo un piccolo frammento di un file contenente una query KDDML: Esempio 1:
<OPERATOR_NAME xml_dest="results.xml" att1="v1" ... attM="vM">
...
<ARGn_NAME> .... </ARGn_NAME> </OPERATOR_NAME>
La valutazione di questo frammento consiste :
1. Valutazione ricorsiva di <ARG1_NAME>…</ARG1_NAME> … <ARGn_NAME>…</ARGn_NAME>.
2. Valutazione degli attributi att1… attM che restituiscono un insieme discalari;
3. Chiamata ad un operatore OPERATOR_NAME che prende come input la valutazione dei punti 1 e 2.
L’attributo xml_dest è opzionale e se specificato il risultato finale viene memorizzato nel repository.
Come abbiamo precedentemente accennato il linguaggio KDDML soddisfa un principio di chiusura, vale a dire che qualunque operatore che ritorna il tipo t può essere usato ogni volta che un argomento di tipo t sia richiesto. Per soddisfare il principio di chiusura, viene definita una entità per ogni tipo restituito dagli operatori; ogni entità raggruppa tutti gli operatori che restituiscono lo stesso tipo. La convalida delle query, come documenti XML, con il DTD, corrisponde ad un controllo statico del tipo degli operatori nelle query.
Esempio 2 (Operatore di data mining).
<SEQUENCE_MINER>
<ARFF_LOADER arff_file_path="repository/data/ARFF/" arff_file_name="coop_timestamp.arff"/>
<PARAM name="min_support" value="0.9"/> </ALGORITHM>
</SEQUENCE_MINER>
Come si è già detto KDDML è un linguaggio completamente tipato e per completezza riportiamo brevemente i tipi degli operatori KDDML con un breve descrizione :
Relational table (table)
Questa entità rappresenta una tabella relazionale. Una tabella KDDML è composta da:
uno schema, che contiene i tipi degli attributi ed alcune statistiche sui valori;
i dati sotto forma di file di testo in formato CSV (Comma Separated Value);
I dati fisici possono essere rappresentati in diversi formati: relazionale, transazionale, e timestamp.
Formato relazionale Ogni colonna di dati corrisponde ad un attributo logico, ed ogni riga ad un record (transazione).
Formato transazionale I dati hanno un numero variabile di attributi logici (items) tra tutti quelli possibili; per ottenere una rappresentazione più compatta, vengono rappresentati solo gli items presenti.
Una tabella transazionale ha un attributo transaction che identifica la transazione e un attributo event che contiene il singolo item. Le transazioni sono ordinate rispetto all’attributo transaction. La tabella può contenere altri attributi, ma, a seconda del contesto, possono essere ignorati dall’operatore.
Formato timestamp Simile alla tabella transazionale, ma con un attributo timestamp.
Questo attributo definisce un ordinamento parziale fra le transazioni e gli item.
Preprocessing table (PPtable)
Rappresenta le tabelle utilizzate nella fase di preprocessing. Una tabella di pre- processing è composta da:
uno schema, che contiene i tipi degli attributi ed alcune statistiche sui valori;
i dati sotto forma di file di testo in formato csv (Comma Separated Value);
i dati di preprocessing che includono le informazioni di preprocessing.
PMML models (rda, cluster, tree, sequence, hierarchy)
Questa entità è definita per rappresentare i modelli estratti: regole d’associazione, clusters, alberi di classificazione, pattern sequenziali e gerarchie di items.
I modelli KDDML sono rappresentati come estensione dei modelli PMML.
Ogni modello è composto da:
un data dictionary, che contiene le meta-informazioni sui dati utilizzati per estrarre il modello;
un mining schema, indica quali dati sono stati utilizzati per estrarre il modello, ed in che modo;
Scalar (scalar)
Uno scalare contenente una costante numerica o una stringa.
Algorithm (alg)
Questa entità è utilizzata per specificare un algoritmo di data mining o preprocessing; l’attributo algorithm_name identifica l’algoritmo, mentre l’elemento PARAM permette di specificare una lista di parametri (name, value) che possono essere passati all’algoritmo.
Condition (cond)
Questa entità è definita per rappresentare la specifica di una condizione. Una condizione può essere utilizzata per valutare operatori booleani (come di una tabella (relazionale o di preprocessing) o su proprietà del modello (per es. il supporto di un pattern sequenziale). L’elemento CONDITION (Vedi descrizione seguente) è una combinazione booleana (AND, OR, NOT) di casi base (elemento BASE COND). Ogni condizione base è espressa utilizzando l’attributo op type, che rappresenta l’operatore booleano.
I parametri dell’operatore vengono passati utilizzando gli attributi XML dell’elemento BASE COND (term1, term2 e term3)
Expression (expr)
Questa entità è utilizzata per rappresentare delle espressioni nel linguaggio. Di seguito è riportato un semplice esempio che mette in evidenza le definizioni appena espresse.
Esempio 3 : rappresentazione dei dati. <?xml version="1.0" encoding="UTF-8"?>
<KDDML_OBJECT>
<KDDML_TABLE data_file="market_timestamp.csv">
<SCHEMA logical_name="market" number_of_attributes="5" number_of_instances="38">
<ATTRIBUTE name="transaction" number_of_missed_values="0" type="string"> <STRING_DESCRIPTION/> </ATTRIBUTE> <ATTRIBUTE name="timestamp" number_of_missed_values="0" type="numeric"> <NUMERIC_DESCRIPTION mean="3.079"
variance="3.53" min="1.0" max="7.0"/> </ATTRIBUTE> <ATTRIBUTE name="event" number_of_missed_values="0" type="string"> <STRING_DESCRIPTION/> </ATTRIBUTE> <ATTRIBUTE name="price" number_of_missed_values="0" type="numeric"> <NUMERIC_DESCRIPTION mean="7.34"
variance="10.99" min="2.0" max="15.0"/> </ATTRIBUTE>
<ATTRIBUTE name="quantity"
number_of_missed_values="0" type="numeric"> <NUMERIC_DESCRIPTION mean="2.32"
variance="2.65" min="1.0" max="6.0"/> </ATTRIBUTE>
</SCHEMA> </KDDML_TABLE> </KDDML_OBJECT>
Vediamo ora come sono fatti gli elementi Algorithm, Condition ed Expression:
<!ELEMENT ALGORITHM (PARAM)*>
<!ATTLIST ALGORITHM algorithm_name %string; #REQUIRED> <!ELEMENT PARAM EMPTY>
<!ATTLIST PARAM name %string; #REQUIRED> <!ATTLIST PARAM value %any_type; #REQUIRED>
<!ELEMENT CONDITION
(TRUE|FALSE|OR_COND|NOT_COND|AND_COND|BASE_COND)> <!ELEMENT TRUE EMPTY>
<!ELEMENT FALSE EMPTY>
<!ELEMENT OR_COND ((OR_COND|NOT_COND|AND_COND|BASE_COND), (OR_COND|NOT_COND|AND_COND|BASE_COND)+)> <!ELEMENT AND_COND ((OR_COND|NOT_COND|AND_COND|BASE_COND), (OR_COND|NOT_COND|AND_COND|BASE_COND)+)> <!ELEMENT NOT_COND ((OR_COND|NOT_COND|AND_COND|BASE_COND))> <!ELEMENT BASE_COND EMPTY>
<!ATTLIST BASE_COND op_type %string; #REQUIRED term1 %any_type; #REQUIRED
term2 %any_type; #IMPLIED term3 %any_type; #IMPLIED>
<!ELEMENT EXPRESSION (BASE_TERM|SEQ_TERM|IF_TERM)> <!ELEMENT SEQ_TERM ((BASE_TERM|SEQ_TERM|IF_TERM),
(BASE_TERM|SEQ_TERM|IF_TERM)+)> <!ATTLIST SEQ_TERM op_type
(concat|equal|sum|multiply|subtract|divide) #REQUIRED> <!ELEMENT BASE_TERM EMPTY>
<!ATTLIST BASE_TERM value %any_type; #REQUIRED> <!ELEMENT IF_TERM (CONDITION,
(BASE_TERM|SEQ_TERM|IF_TERM),
(BASE_TERM|SEQ_TERM|IF_TERM)?)>
2.4 Architettura del sistema
Il sistema, fin dall’inizio, è stato pensato come una creatura in costante evoluzione e per questo KDDML è stato progettato e realizzato in modo da poter essere esteso in maniera semplice e senza dover apportare modifiche al core del sistema.
1. Data Source: si può aggiungere una nuova sorgente di dati. Questo lo si può fare semplicemente aggiungendo un nuovo tag con appropriati attributi e sottoelementi. Come conseguenza il sistema deve prevedere di aggiungere un nuovo wrapper per la nuova sorgente di dati in modo da trasformare la nuova sorgente in tabelle interne al sistema.
2. Algoritmi: aggiungere un nuovo algoritmo di estrazione di conoscenza deve essere il più semplice possibile. Si segue la stessa idea valida per l’aggiunta di data source nel senso che nuovi algoritmi devono essere facilmente inclusi nel linguaggio e nel sistema, infatti il nome degli algoritmi e il numero e il tipo di parametri non sono codificati nel sistema.
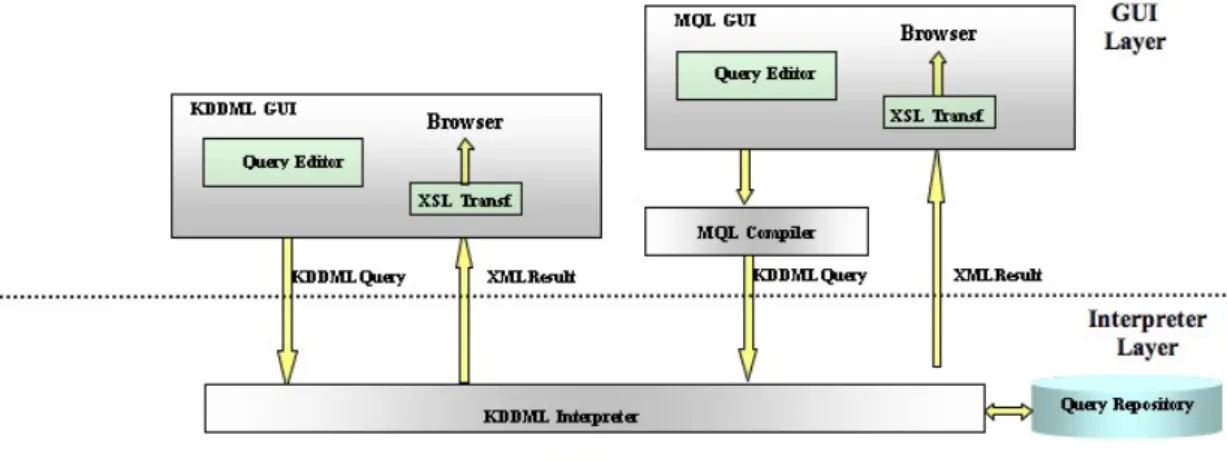
3. Modelli: anche l’aggiunta di nuove forme di conoscenza è alla base del progetto diestensibilità del sistema. Infatti aggiungere un nuovo modello al sistema significa semplicemente aggiungere un tipo che vuol dire semplicemente effettuare delle modifiche alla DTD degli operatori. Come si può vedere dalla figura 13, il sistema è diviso in livelli e ogni livello implementa una funzionalità del sistema.
Nel seguito daremo una breve descrizione delle caratteristiche di ogni layer del sistema (per maggiori informazioni e chiarimenti vedi [TESI_1]).
Livello Repository Livello Repository
Gestisce gli accessi in lettura e scrittura ai repository di dati e modelli.
Questo è il livello più in basso e costituisce il nucleo del sistema. Infatti, oltre a fornire un’interfaccia di gestione (Manager) per dati e modelli, fornisce dei moduli (factory) per accedere a dati e modelli.
figura 13 : architettura KDDML
Esistono inoltre, dei moduli factory per l’accesso a dati e modelli in formato non proprietario, che si occupano di trasformare dati e modelli importati, nel formato richiesto dal sistema.
In pratica questo livello racchiude tutte le funzionalità necessarie ai livelli superiori per la gestione di dati e modelli:
acesso, creazione e gestione;
Data and Models manager Data and Models manager
Quando si accede ad un modello questo layer rende possibile lettura e scrittura sui contenuti del modello stesso poiché L’accesso ad una tabella produce un oggetto che soddisfa l’interfaccia interna InternalTable.
Allo stesso modo quando si accede ad una tabella il layer fornisce il servizio di accesso alle righe e colonne della tabella e disponibilità di metadati e statistiche sulle colonne.
Dat
Dat a and Models Factorya and Models Factory
Include moduli wrapper per per l’accesso e l’importazione di tabelle e modelli da sorgenti esterne. I wrapper in questo caso si occupano di trasformare le tabelle esterne in tabelle riconosciute dal sistema ( InternalTable).
Operato
Operato rs and algorithm layerrs and algorithm layer
A questo livello è realizzata l’implementazione degli operatori del linguaggio. Infatti ogni possibile risultato di un operatore è una sottoclasse di un tipo generico KDDMLObject in modo da distinguere tra dati ed operatori.
Alcuni operatori come <TREE_MINER> o <RDA_MINER> chiamano un algoritmo esterno per applicare il modello o estrarlo da una sorgente . Di solito questo algoritmo è un programma esterno che richiede un proprio tipo di input, quindi una tipica procedura execute_algorithm() è fatta in modo tale da scandire i dati , trasformarli nel formato desiderato e chiamare l’algoritmo.
Un operatore <operator name> è implementato come una classe Java che soddisfa l’interfaccia KDDMLOperator, che richiede i seguenti metodi:
boolean runtimeCheckNeeded() :
restituisce true se il tipo del risultato del metodo execute() non è determinato a tempo di compilazione, ma deve essere controllato a run-time;
boolean abortIfIsEmpty()
dice all’interprete di interrompere l’esecuzione della query se il risultato prodotto è vuoto;
KDDMLObjectType getParamType(int i)
restituisce il tipo dell’i-esimo argomento dell’operatore; boolean checkAttributes(Hashtable atts)
esegue un controllo di correttezza sui parametri (attributi) dell’operatore.
KDDMLObject execute(Vector arguments)
restituisce il risultato dell’esecuzione dell’operatore sugli argomenti dati.
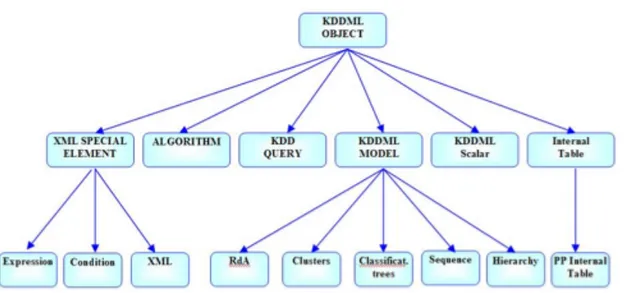
Per una maggiore completezza viene mostrata nella figura seguente tutta la gerarchia degli oggetti KDDML:
A seconda che si tratti di un operatore di accesso ai dati o ai modelli, o che si consideri un operatore per preprocessing o post-processing o un operatore di data mining esistono delle realizzazioni differenti per il metodo che esegue l’operatore (execute() ).
Operatori di accesso a dati e modelli : utilizzano direttamente le funzionalità
del Repository per caricare e salvare dati e modelli.
Operatori di data mining : utilizzano un algoritmo per estrarre e applicare un
modello dai dati in input. Solitamente, l’algoritmo è un programma esterno, che richiede/fornisce in input/output il proprio formato. Quindi, normalmente, il metodo execute() trasforma l’input nel formato richiesto dall’algoritmo, richiama l’algoritmo e trasforma l’output nell’appropriato KDDMLObject.
Operatori di pre/post processing : hanno un pattern simile a quello degli op-
eratori di data mining quando l’operatore è implementato da un algoritmo esterno.
Differentemente dagli operatori di data mining, gli operatori di pre/ post processing sono implementati principalmente nel sistema KDDML, per evitare le trasformazioni del formato dell’input/output. Questa scelta è dettata dal fatto che solitamente gli operatori che fanno parte di questa categoria trasformano dati. In tale trasformazione, che in genere è time-consuming, deve pertanto essere maggiore efficienza.
Interpreter Lay er Interpreter Lay er
Questo livello è stato pensato per poter essere più semplice possibile. Infatti l’interprete del sistema, accetta delle query KDDML validate, le esegue e salva
i risultati nel repository.
A partire da un file XML o da un DOM, l’interprete costruisce attraverso i metodi forniti dal livello operator factory, degli operatori con tipo KDDMLObject e valuta tutti gli attributi inserendoli in un vettore di KKDMLScalar.
L’interprete è stato concepito in modo da non dover essere modificato se il sistema venisse esteso (per esempio con nuovi algoritmi). In fatti se si aggiungesse un nuovo algoritmo, l’unica parte a dover essere modificata sarebbe la KDDMLFactory.
Anche considerando un’estensione del sistema con nuovi modelli di mining si deve notare che l’interprete non subisce particolari modifiche. Infatti è modificato solo il livello relativo al repository, il layer degli operatori e alcune modifiche alle DTD del linguaggio necessarie per il controllo statico sui tipi. Tutte le operazioni svolte dall’interprete, fanno uso delle interfacce definite da KDDMLObject e KDDMLOperator.