4.1. Le reti neurali
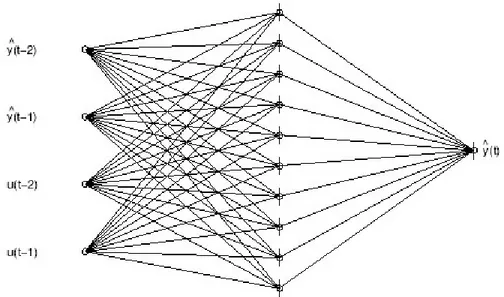
Il sistema in esame ha un comportamento non lineare, come è stato evidenziato nel § 4.2, pertanto è necessario utilizzare un metodo di identificazione adatto ai sistemi non lineari. Le reti neurali permettono l’identificazione di sistemi dinamici mediante un approccio black box, in cui l’identificazione è basata esclusivamente sui dati misurati (ingressi ed uscite), ignorando quelle che sono le dinamiche del sistema. In una rete neurale ingressi ed uscite sono detti neuroni; tra ingressi ed uscite sono inseriti uno o più strati di neuroni nascosti, collegati mediante connessioni. I neuroni che costituiscono questo tipo di reti, quindi, sono organizzati in strati (layer): uno strato di input, uno di output e un certo numero di strati intermedi tra input e output detti nascosti (hidden).
Figura 1: Schema di una rete neurale.
Ciascuna giunzione ha un determinato peso, il cui valore viene modificato iterativamente fino ad assegnare loro quei valori che consentono al sistema di rispondere ad una certa stimolazione esterna nella miglior maniera possibile, compatibilmente con i dati di ingresso/uscita a disposizione per l’addestramento del sistema. Per ottenere questo si minimizza una funzione che misura la differenza tra l’uscita desiderata (nota) e la previsione delle uscite effettuata dalla rete. Tale metodo è detto di back-propagation, cioè della propagazione all’indietro dell’errore.
Una caratteristica delle reti neurali è quella di non dare risultati completamente corretti o completamente sbagliati, ma solo approssimativamente corretti o sbagliati. Inoltre, se una rete ha imparato, ad esempio, a dare B in risposta ad A, quando le si presenta uno stimolo A’ simil e ad A, risponde automaticamente e spontaneamente in modo “sensato”. Ha, cioè, la capacità di estrapolare.
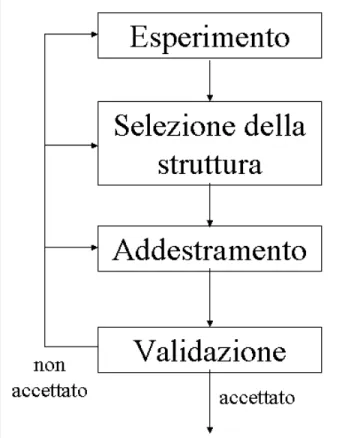
I passi necessari per la costruzione di una rete sono i seguenti:
Figura 2: Procedura per l’identificazione dei sistemi 1. Esperimento
Ha lo scopo di raccogliere un set di dati che descriva come il sistema in esame agisca nell’intero campo di funzionamento
2. Selezione della struttura del modello
Selezionare un tipo di modello che sia in grado di adattarsi al sistema da esaminare. Limitando il campo ai cosiddetti Multilayer Perceptron. In questo lavoro sono stati sperimentati 3 tipi di modelli, classificati in base agli ingressi che utilizzano, e precisamente:
a) modelli che utilizzano il segnale di ingresso e le uscite precedenti
b) modelli che utilizzano il segnale di ingresso e le previsioni delle uscite precedenti
c) modelli che utilizzano il segnale di ingresso, le previsioni delle uscite precedenti e l’errore di predizione.
3. Addestramento (training)
Scopo del training è quello di determinare il miglior modello tra il set di candidati
θˆ contenuto nella struttura. Per miglior modello si intende quello che fornisce predizioni il più possibile vicine alle uscite vere.
Il criterio maggiormente utilizzato è quello di prendere il modello che fornisce la miglior predizione della risposta del sistema al passo successivo (one step ahead
prediction), valutata in termini di minimo errore quadratico medio tra uscita
osservata e predizione.
(
)
∑
(
)
∑
= = = − = N t N t N N Z N y t yt N t V 1 2 1 2 (, ) 2 1 ) , ( ˆ ) ( 2 1 , θ ε θ θQuesto approccio appartiene alla classe dei Prediction Error Methods (PEM). L’obiettivo è quello di determinare i pesi che minimizzano l’errore. Questo viene fatto modificando iterativamente i pesi secondo un algoritmo di minimizzazione come il metodo del gradiente , il metodo di Newton o il metodo di Levenberg-Marquardt.
4. Validazione (validation)
Quando un modello è stato addestrato, è necessario verificarne la capacità di predire la risposta, non solo per il set di dati con cui il training è stato effettuato, ma anche per ingressi differenti.
4.2. Esperimento
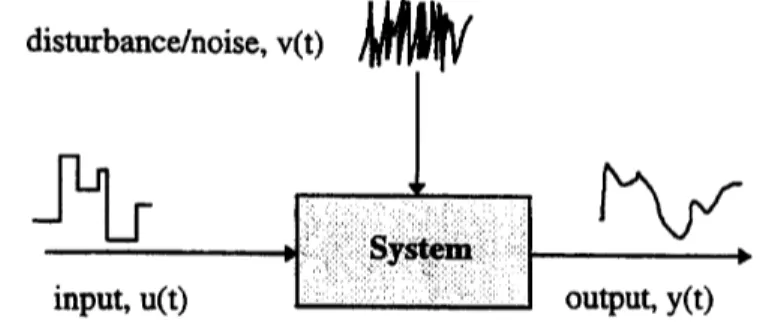
Per ottenere un set di dati che definisca il comportamento nell’intero campo operativo del sistema, lo si sollecita con un ingresso ‘u(t)’ e si misura l’effetto sull’uscita ‘ y(t)’.
Figura 3: Al sistema viene applicato un ingresso osservandone l'effetto sull'uscita In tal modo si ottiene un set di dati:
[
]
{
( ), ( ) , 1,..,}
N
che viene utilizzato per dedurre un modello del sistema.
Per poter identificare il sistema in maniera adeguata, è importante che “tutte le ampiezze e le frequenze” vengano rappresentate nel set di dati. Un tipo di ingresso che soddisfa queste richieste, è il segnale costante a tratti (N-samples-constant), generato secondo la relazione (tratta da [17]):
+ − = int 1 1 ) ( N t e t u t = 1,2,... dove:
e(t) rumore bianco con varianza 2
e
σ N numero di campioni costanti
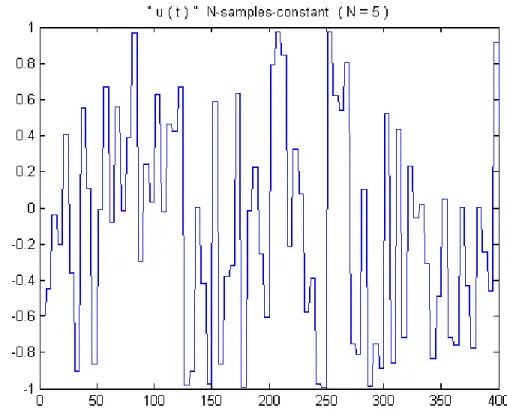
Tale funzione passa ad un nuovo valore ad ogni N° istante di campionamento. Un esempio di questo tipo di segnale è mostrato in Figura 4.
Figura 4: Segnale "N Samples Constant" con N=5
Il segnale è stato creato con Labview ed inviato al generatore di segnali LeCroy LC9100. Lo schema del programma è mostrato in appendice A.
Il segnale in tensione così ottenuto è stato utilizzato per pilotare la valvola MOOG DDV D633-717 che modula la portata di aria (vedi capitolo 2).
Le caratteristiche di tale segnale sono:
ampiezza massima [-6V +6V], frequenza di campionamento 5 kHz, numero di campioni costanti N = 5
Dalla trasformata di Fourier del segnale di comando (Figura 5), si nota che contiene tutte le armoniche di interesse. Nella figura è stato inserito anche il grafico dalla trasformata del segnale anemometrico; si osserva che la risposta è più ampia in corrispondenza di alcune frequenze, come è già stato verificato utilizzando un segnale di comando di tipo sinusoidale.
Figura 5: Trasformata di Fourier del segnale di comando e del segnale anemometrico
Come risposta del sistema si è utilizzata la velocità dell’aria all’uscita dalla lancia misurata mediante anemometro a filo caldo, come illustrato nel capitolo 2.
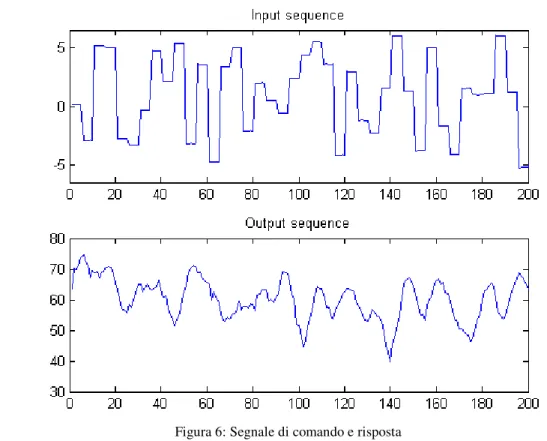
Si ottiene così un set di dati composto da due vettori, uno di ingresso ed uno di uscita (Figura 6), con cui addestrare la rete neurale.
Figura 6: Segnale di comando e risposta
Per raccogliere un set di dati che descriva il sistema in esame nell’intero campo di funzionamento, sono state effettuate misure con diverse portate e diverse lunghezze del condotto.
4.3. Scelta, Training e validazione del modello
Come famiglia di modelli è stata utilizzata quella delle reti neurali con un solo strato di neuroni nascosti. All’interno di questa famiglia, sono stati adoperati i modelli NNARX (Neural Network AutoRegressive eXogenous signal), NNARMAX (Neural Network AutoRegressive Moving Average eXogenous signal), NNOE (Neural Network Output Error).
E’ necessario inoltre stabilire il numero di ingressi da utilizzare ed il numero di neuroni nello strato nascosto. Un numero di ingressi troppo piccolo fa sì che alcune dinamiche del sistema non vengano modellate, un numero eccessivo può creare problemi nella costruzione dei controllori.
Sono disponibili in letteratura algoritmi per stimare il numero di ingressi opportuno; il metodo proposto da He & Asada [19] è basato sul calcolo dei quozienti di Lipschitz
( ) ( ) , ( ) ( ) i j ij i j y t y t q i j t t ϕ ϕ − = ≠ −
( )
t y t( )
1 , ,y t n(
a) (
,y t nk)
, ,y t n(
k nb)
ϕ = − ⋅⋅⋅ − − ⋅⋅⋅ − −
na numero di uscite precedenti utilizzate
nb numero di segnali di comando utilizzati
nk numero degli ultimi segnali di comando non utilizzati
Gli ingressi di comando utilizzati per la previsione, non sono gli ultimi nb; è necessario
ignorare gli ultimi nk valori per tener conto del tempo necessario alla fluttuazione di
portata generata dalla valvola per percorrere il condotto e raggiungere l’anemometro. Il valore di nk è diverso a seconda della lunghezza del condotto utilizzato.
Il metodo proposto prevede il calcolo dei quozienti per tutte le combinazioni di coppie ingresso-uscita e la valutazione del criterio:
( ) p ( )
( )
p k n n nq k q 1 1 =∏
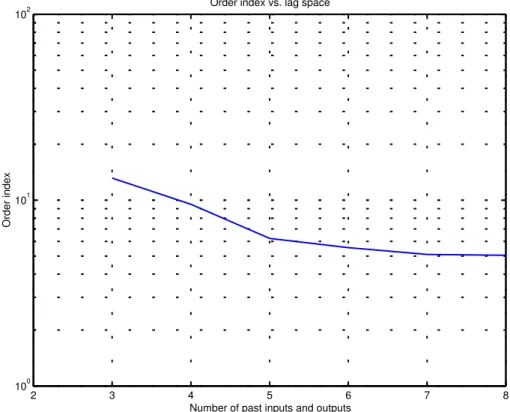
= con: n = na = nbRipetendo il calcolo per il numero voluto di ingressi e tracciando il grafico si ottiene la curva di Figura 7:
2 3 4 5 6 7 8
100 101 102
Number of past inputs and outputs
Order index
Order index vs. lag space
Il valore da scegliere è quello per cui la curva forma un “ginocchio”, perché un numero eccessivo di ingressi non porta una ulteriore riduzione di q. La leggera diminuzione oltre n=5 è probabilmente dovuta all’effetto del rumore presente nelle misure.
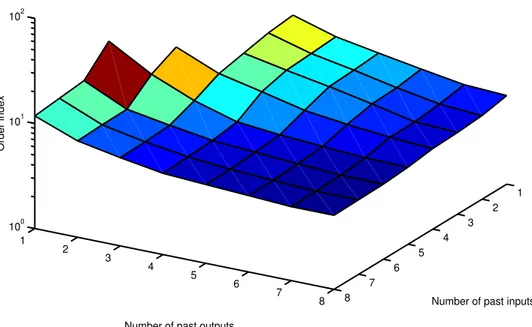
Un risultato più accurato può essere ottenuto utilizzando valori diversi di na ed nb.
1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 100 101 102
Number of past inputs Order index vs. lag space
Number of past outputs
Order index
Figura 8: Ordine del modello
La scelta di na ed nb è stata fatta basandosi sul criterio descritto e sui risultati ottenuti
sperimentalmente.
4.3.1. Modello NNARX
Il modello NNARX utilizza come ingressi il segnale di comando e le uscite del sistema al passo precedente. In questo caso si è adoperato:
na = 4 uscite precedenti,
nb = 5 segnale di comando;
Un primo set di dati viene utilizzato per addestrare il sistema (training set); i pesi di ciascuna connessione vengono modificati iterativamente in modo da minimizzare l’errore quadratico medio tra uscita osservata e predizione al passo successivo. A tale scopo è stato utilizzato il metodo di Levenberg-Marquardt.
Il set di dati ZN utilizzato per dedurre un modello del sistema è mostrato in Figura 9.
Figura 9: Set di dati utilizzato per addestrare la rete (training set)
I pesi ottenuti per questo modello e per gli altri proposti nel seguito sono riportati in appendice F.
Figura 10: Velocità misurata (in blu) e previsione (in rosso), errore di predizione
Per verificare la correttezza del modello è possibile effettuare una serie di test. Il più semplice è confrontare la risposta prevista dal modello con la risposta del sistema vero e verificare l’errore di predizione. Tale controllo si effettua non soltanto sul set di dati con cui è stato addestrato il sistema (Figura 10 e Figura 11), ma anche con un diverso insieme di dati (o una parte del primo set non utilizzata per il training), detto test set (Figura 12).
Figura 12: Velocità misurata (in blu) e previsione (in rosso), errore di predizione Il modello prevede correttamente la risposta anche per questo ingresso.
Se è possibile dire che i residui (errori di predizione) non contengono informazioni sui residui precedenti o sulle dinamiche del sistema, è ragionevole che tutte le informazioni siano state estratte dal training set e che il modello approssimi bene il sistema.
Per verificare questo, si eseguono alcuni test di auto- e cross-correlazione sull’errore di predizione (Figura 13). Auto-correlazione:
( )
(
( )
)
(
(
)
)
( )
(
)
1 2 1 ˆ ˆ , , ˆ ˆ , N t N t t t r t τ εε ε θ ε ε τ θ ε τ ε θ ε − = = − ⋅ − − = −∑
∑
≠ = = 0 , 0 0 , 1 τ τCross-correlazione:
( )
(
( )
)
(
(
)
)
( )
(
)
(
ε( )
θ ε)
τ ε θ τ ε τ τ ε = ∀ − ⋅ − − − ⋅ − =∑
∑
∑
= = − = 0 ˆ , ˆ , ˆ 1/2 1 2 2 / 1 1 2 1 N t N t N t u t u t u t u t u rSe il sistema è stato identificato correttamente, le funzioni di correlazione convergono ad una distribuzione gaussiana con valor medio nullo e varianza 1
N .
Si verifica se le funzioni, per spostamenti nell’intervallo ô∈[-25, 25], valgono 0 con una confidenza del 95%, cioè se 1.96 rˆ 1.96
N N
− < < .
Nei grafici della correlazione, tali limiti sono indicati dalle linee rosse tratteggiate.
Figura 13: Auto-correlazione e cross-correlazione
Poiché la valvola verrà tipicamente pilotata con un segnale sinusoidale, è opportuno verificare che il modello sia in grado di prevedere la risposta del sistema anche per questo tipo di segnale. Di seguito sono riportate le risposte del modello per due diverse frequenze, a cui il sistema risponde con ampiezze diverse.
Figura 14: Velocità misurata e previsione, errore di predizione; f = 180 Hz
Il modello si adatta bene a questo tipo di segnale, pur mostrando qualche limite sull’oscillazione di ampiezza maggiore ( Figura 14 e Figura 15).
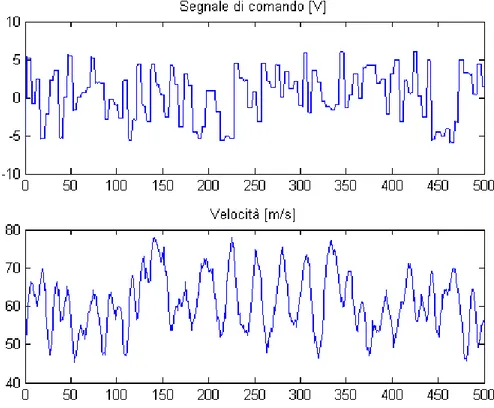
Per avere un modello del sistema sull’intero campo operativo, è necessario effettuare il training con un set di dati che includa tutte le condizione in cui il sistema si trovi ad operare. Il set di dati riportato in Figura 16 è composto da 500 valori di velocità misurati con portata di 2 gr/s ed altrettanti con portata di 4 gr/s. Al modello è stato dato in ingresso, oltre alla velocità, anche il valore della portata media.
Figura 16: Training effettuato con le misure fatte con portate di 2 gr/s e 4 gr/s
Verifichiamo la correttezza del modello ottenuto utilizzando come test la risposta del sistema per una portata di 3 gr/s (Figura 17).
Figura 17: Verifica effettuata con le misure fatte con portata di 3 gr/s
Il modello dimostra di funzionare correttamente, quindi disponiamo di un mezzo per predire la velocità al passo successivo (1-step-ahead prediction) per valori di portata intermedi tra quelli misurati.
I modelli basati sulla misura della velocità ai passi precedenti, non sono utilizzabili ai fini dell’attuazione del controllo, perché richiederebbero di misurare la velocità con il combustore in funzione, cosa impossibile da effettuare. Possiamo però utilizzare sistemi basati sulle misure di pressione anziché quelle di velocità: i sensori utilizzati per le prove sono progettati proprio per essere utilizzati in ambienti ad elevata temperatura ed hanno la possibilità di essere raffreddati.
In Figura 18 è mostrato un confronto tra le misure di velocità e pressione; anche in questo caso, come per segnali di comando sinusoidali, velocità e pressione hanno andamenti molto simili.
−10 −5 0 5 10 Comando [V] 0.2 0.4 0.6 0.8 1 Posizione Valvola −15 −10 −5 0 5 10 Pressione [mbar] 0 50 100 150 200 250 300 50 60 70 80 90 Velocità [m/s]
Figura 18: Comando, posizione valvola, pressione e velocità
I risultati del modello basato sulle misure di pressione sono riportati in Figura 19 e Figura 20.
0 50 100 150 200 250 300 350 400 450 500 −15 −10 −5 0 5 10 time (samples)
Output (solid) and one−step ahead prediction (dashed)
0 50 100 150 200 250 300 350 400 450 500 −3 −2 −1 0 1 2
3 Prediction error (y−yhat)
time (samples)
Figura 19: Modello basato sulle misure di pressione (training set)
0 50 100 150 200 250 300 350 400 450 500 −15 −10 −5 0 5 10 15 time (samples)
Output (solid) and one−step ahead prediction (dashed)
0 50 100 150 200 250 300 350 400 450 500 −6 −4 −2 0 2 4 6
8 Prediction error (y−yhat)
time (samples)
Anche con le misure di pressione è possibile costruire un modello che calcoli lo stato del sistema al passo successivo con sufficiente precisione.
Come detto in precedenza, è possibile misurare la pressione nel condotto del combustibile anche con il combustore in funzione. La posizione del sensore utilizzata per le prove, indicata nel paragrafo 2.4, creerebbe eccessiva interferenza con il flusso del combustibile e con quello dell’aria comburente, pertanto è necessario modificare la lancia combustibile in modo da collocare il sensore in una diversa posizione. Una possibile soluzione è quella di alloggiare il sensore all’interno del condotto centrale della lancia, normalmente utilizzato per il combustibile liquido. Una soluzione simile è già stata sperimentata, nel corso di prove di combustione, per alloggiare la sonda ottica per la misura delle emissioni luminose prodotte dalla combustione.
4.3.2. Modello NNARMAX
Il modello NNARMAX, per predire il valore al passo successivo, oltre al segnale di comando ed alle uscite del sistema al passo precedente, utilizza come ingresso anche l’errore di predizione ai passi precedenti.
Tale modello ha fornito risultati simili al NNARX, pertanto non se ne riportano i grafici.
4.3.3. Modello NNOE
Un modello che non richiede ulteriori modifiche al sistema di adduzione del combustibile è l’NNOE, che non utilizza le uscite precedenti per prevedere le successive e, pertanto, non richiede di misurare la pressione con il combustore in funzione. Una prova è necessaria solo per ottenere un set di dati con cui addestrare il sistema.
Il modello NNOE utilizza come ingressi, anziché le uscite misurate, le stime delle uscite precedenti calcolate dal modello stesso.
In questo caso si sono ottenuti migliori risultati utilizzando: na = 2 uscite precedenti (calcolate),
nb = 4 segnale di comando,
e 6 neuroni nello strato nascosto.
Nelle figure seguenti i valori misurati della velocità sono confrontati con quelli previsti dal modello.
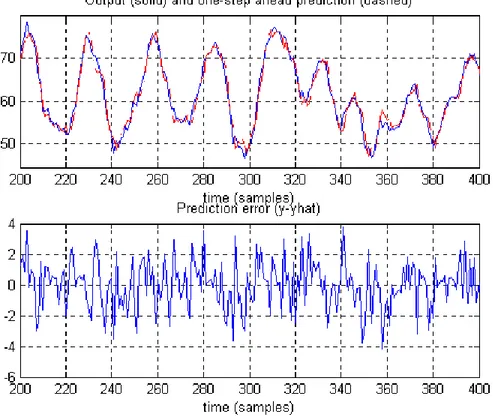
Figura 21: Training set
Figura 23:Test set (ingrandimento della precedente)
Figura 25:Test set (f = 120 Hz)
L’accuratezza del modello NNOE è minore di quella ottenuta precedentemente, ma, come si nota in Figura 23, le dinamiche principali del sistema sono modellate con sufficiente accuratezza. Rispetto al modello precedente si accentua la tendenza a sottovalutare l’effetto della maggior ampiezza dell’oscillazione in corrispondenza di alcune frequenze (Figura 26).
Da questo modello possiamo ricavare le risposte del sistema per diversi valori di portata ed ampiezza del comando.
4.4. Conclusioni
I modelli NNARX e NNARMAX, che utilizzano come ingressi il segnale di comando e le uscite del sistema misurate ai passi precedenti, hanno dimostrato di prevedere correttamente la risposta del sistema al passo successivo (1-step-ahead prediction) sia per segnali di tipo analogo a quello con cui è stato effettuato il “training” del modello (N-samples-constant), sia per segnali sinusoidali, con cui tipicamente verrà comandato il sistema.
I modelli ottenuti basandosi sulle misure di velocità non possono essere utilizzati per attuare il controllo, perché richiederebbero di misurare la velocità con l’impianto in funzione. Possiamo però utilizzare modelli basati sulle misure di pressione, infatti i sensori utilizzati per le prove sono raffreddati e possono essere utilizzati su un combustore in funzione. Per far questo è necessario modificare la lancia combustibile in modo da collocare il sensore in una posizione diversa da quella utilizzata per le prove.
Un modello che non richiede ulteriori modifiche al sistema di adduzione del combustibile è l’NNOE, che utilizza come ingressi, anziché le uscite misurate, le stime delle uscite precedenti calcolate dal modello stesso, e pertanto non richiede di misurare la pressione con il combustore in funzione.
Tale modello ha dimostrato di prevedere con sufficiente accuratezza la risposta per il segnale di tipo N-samples-constant con cui è stato effettuato il “training” del modello, mentre mostra qualche limite per gli ingressi di tipo sinusoidale: in questo caso il modello è in grado di prevedere correttamente la fase dell’uscita, ma fornisce un’indicazione meno precisa per l’ampiezza.