Capitolo 5
Realizzazione di un linguaggio grafico per KDDML
Introduzione
In questo capitolo verranno mostrate tutte le scelte legate all’implementazione della metafora grafica in relazione alle molteplici osservazioni che sono venute ala luce nel capitolo precedente.
Proprio i requisiti a cui facciamo riferimento, saranno considerati lo zoccolo duro su cui costruire la nostra interfaccia grafica. Naturalmente ogni problematica verrà analizzata in dettaglio, rimandando ove necessario riferimenti ai package e a specifiche classi relative al progetto software.
In tal senso quindi, tenendo conto della attuale architettura del sistema, si cercherà di capire se c’è bisogno di modifiche agli elementi esistenti e in che modo effettuare le modifiche, per fornire al sistema un’interfaccia grafica che non sia solo una guida text-oriented alla scrittura di query KDDML, ma che si configuri come un mezzo potente per rappresentare in maniera semplice ed intuitiva la maggior parte delle potenzialità offerte dal sistema KDDML.
In questo lavoro infatti, noi proponiamo un sistema per interrogare un motore di estrazione di conoscenza attraverso query rappresentate con diagrammi ( più precisamente con un grafo), tenendo presente il concetto di processo KDD e un linguaggio di markup per tale processo (KDDML).
Nel seguito faremo riferimenti ai livelli del sistema e per tale motivo è utile tenere presente la figura e la collocazione del livello GUI in tale schema.
5.1 Rappresentazione di una query KDD
sicuramente una scelta che condiziona la concezione dell’intero sistema grafico. Naturalmente lo scopo di una rappresentazione più “user-friendly” ha lo scopo di facilitare la modo di vedere una query KDD e quindi poter disporre di un meccanismo con cui astrarre l’intero processo di estrazione di dati.
Naturalmente dal punto di vista dell’utente, la scelta di rappresentare una query che per sua natura è testuale, in un diagramma porta una serie di vantaggi :
- l’utente ha a che fare con un semplice, e allo stesso tempo potente formalismo per capire il processo di estrazione di dati. I concetti utilizzati nel formalismo grafico sono sicuramente più espressivi rispetto al modello che c’è al livello sottostante. Basti pensare che per ogni operatore del linguaggio KDDML, nella GUI è possibile accedere a tutte le informazioni che caratterizzano tale operatore (ad esempio il tipo restituito, numero e tipo di parametri, numero di attributi).
- Il formalismo grafico utilizzato per rappresentare lo schema concettuale, semplifica l’esecuzione di alcuni task che sono tipici della formulazione della query, come l’estrazione di uno schema che rappresenta una query parziale o il controllo dei parametri prima dell’esecuzione.
Naturalmente una trattazione grafica del processo di querying deve possedere almeno lo stesso potere espressivo del formalismo testuale. In tal senso, si può dire che tale requisito è stato soddisfatto (vedi sezione 4.2) creando semplicemente una associazione univoca tra gli operatori KDDML e gli oggetti grafici. Questi ultimi infatti ereditano tutte le caratteristiche del linguaggio e le potenzialità di formulazione delle query sono pressoché identiche.
Per ciò che concerne il modello di rappresentazione dei dati, come abbiamo detto nel capitolo precedente, la scelta è caduta sul grafo. Sebbene una query KDDML sia più facilmente assimilabile ad un modello di
rappresentazione ad albero, pensiamo che dal punto di vista dell’espressività e semplicità di manipolazione il grafo rappresenti la scelta più sensata.
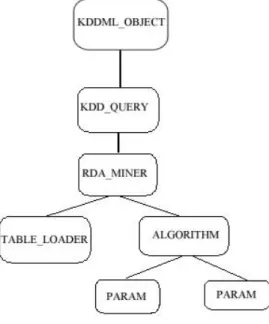
Per capire meglio quanto detto si consideri un esempio di query KDDML :
<?xml version="1.0" encoding="UTF-8"?> <KDDML_OBJECT> <KDD_QUERY name="mine_rule"> <RDA_MINER xml_dest="weather_rda.xml"> <TABLE_LOADER xml_source="weather.xml"/> <ALGORITHM algorithm_name="DCI">
<PARAM name="min_support" value="0.3"/> <PARAM name="min_confidence" value="0.3"/> </ALGORITHM>
</RDA_MINER> </KDD_QUERY> </KDDML_OBJECT>
figura 22 : esempio di query KDDML
Come si può notare, la query è rappresentata da un documento XML, e come nel caso del linguaggio di markup XML, anche per una query KDDML è possibile costruire l’albero DOM ad essa associato.
Se consideriamo la situazione sotto questo punto di vista si capisce che il modo più immediato per rappresentare graficamente la query è attraverso un albero. (vedi figura 23).
Ma le motivazioni per utilizzare un grafo come metafora grafica sono molteplici e le abbiamo già trattate nel capitolo precedente. Di conseguenza abbiamo fornito il sistema grafico di un semplice “compilatore” che trasforma la query dal linguaggio visuale al linguaggio KDDML.
Se analizziamo bene la query di figura 22, possiamo notare come sia abbastanza immediato ricavare il grafo corrispondente dall’albero della query KDDML. Infatti, se si effettua una visita di tale albero a partire dalle foglie, si ottiene un flusso di operatori che si può associare senza molti problemi ad un grafo (vedi figura 24).
Naturalmente bisogna utilizzare alcuni accorgimenti nel processo di ricodifica. Basti pensare che alcuni di quelli che nel modello ad albero sono dei nodi (e nelcaso di una query testuale sono tag), nel modello di rappresentazione a grafo
Figura 23. Albero per una query KDDML
diventano degli attributi del nodo genitore. Ma chiariamo tutto con un esempio. Consideriamo la query rappresentata in figura 22. In questo caso il processo di trasformazione in grafo prevede la marcatura del nodo ALGORITHM come attributo del nodo RDA_MINER (vedi figura 20).
Chiaramente da un punto di vista logico non vi sono differenze tra le query ma, in alcuni casi, non bisogna perdere di vista tali considerazioni.
In ogni caso, durante il processo di stesura della query, ci troviamo ad affrontare il problema inverso, vale a dire trasformare una query grafica in una query valida per l’interprete KDDML. In tal caso bisogna effettuare una visita del grafo a partire dalle foglie fino alla radice.
E’ importante notare come ad ognuna delle foglie del grafo corrisponda la radice di una query. Le foglie del grafo infatti sono i task che identificano l’intero processo e i nodi che non hanno nessun collegamento in input identificano le sorgenti di dati del nostro processo. Per capire meglio quanto detto fino ad ora consideriamo una query grafica del tipo :
figura 25 : esempio query grafica.
In questo caso assumiamo che il grafo non sia orientato, le motivazioni per una tale rappresentazione verranno mostrati nel paragrafo successivo.
A questo formalismo grafico, possono essere associate due query KDDML completamente distinte : <KDDML_OBJECT> <KDDML_OBJECT> <KDD_QUERY> <KDD_QUERY> <RDA_MINER > <RDA_MINER > <ARFF_LOADER> <ARFF_LOADER> </ALGORITHM> </ALGORITHM> </RDA_MINER> </RDA_MINER>
</KDD_QUERY> </KDD_QUERY> </KDDML_OBJECT> </KDDML_OBJECT>
(a) (b)
La query (a) si riferisce al cammino 1-2, mentre la query (b) si riferisce al cammino 1-3. Facciamo notare che in questo esempio per semplicità sono stati omessi gli attributi per gli operatori di entrambe le query, per tale motivo le query non sono da considerarsi valide ma rappresentano solo un la gerarchia di operatori in grafo.
Da un punto di vista grafico quindi, abbiamo scelto di dare la possibilità all’utente di formulare più query a partire da uno stessa sorgente di dati, ma come abbiamo fatto notare nell’esempio precedente, una query grafica non identifica univocamente una query KDDML, e l’utente nel comporre una query potrebbe far riferimento a due schemi separati. Questa scelta è stata presa in base a motivazioni puramente grafiche, onde evitare di inserire due operatori con identiche caratteristiche. Naturalmente nel caso in cui nell’ambiente grafico siano state costruite più query, si può procedere alla loro validazione ed esecuzione in maniera completamente separata. Le scelte precedenti sono state fatte solo per favorire l’utente, almeno quando si considerano query abbastanza piccole, nell’inserimento dei parametri, ma nulla vieta a chi utilizza l’interfaccia grafica di creare nello stesso pannello due query “parallele” e scegliere solo in seguito quale mandare in esecuzione.
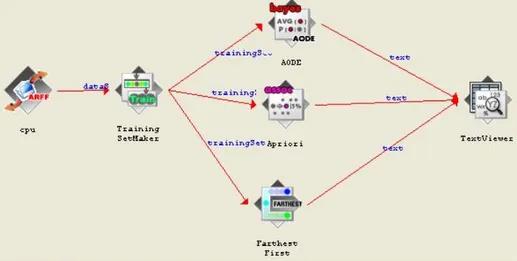
Facciamo notare che tale scelta in qualche modo vincola l’utente rispetto alle funzionalità proposte da altri tools. Per esempio consideriamo la query grafica di WEKA mostrata in figura 24.
Questa prevede l’estrazione di tre modelli da uno stesso dataset e non comporta alcuna ambiguità poiché il TextViewer di WEKA prevede la visualizzazione di risultati multipli provenienti da query differenti. Poiché ad oggi KDDML non prevede operatori per la visualizzazione, nell’implementazione dell’interfaccia grafica abbiamo evitato la sottomissione di query di questo tipo e quindi in tal senso non è presente nessuna ambiguità. Per completezza, supponiamo che
l’interfaccia di KDDML abbia la possibilità di visualizzare l’output dopo l’estrazione del modello. Lo schema grafico risultante sarebbe quello di figura 26.
figura 26: WEKAWork flow
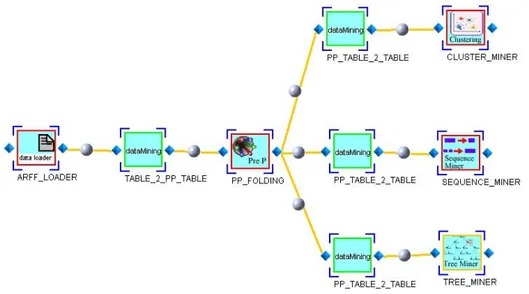
Guardando la figura 25, immediatamente saltano all’occhio alcune differenze sostanziali rispetto al “Weka Work Flow”. Oltre agli operatori TABLE_2_PPTABLE e PP_TABLE_2_TABLE il cui significato verrà spiegato in seguito e il cui inserimento è del tutto automatico, si possono notare due particolari interessanti :
(1) gli archi non sono orientati;
(2) non si possono connettere più input allo stesso operatore. Il punto (1) è una conseguenza diretta del punto (2) poiché, data l’impossibilità di connettere all’input di un operatore KDDML più di un arco (a parte nel caso in cui l’operatore stesso preveda più di un parametro di input), non vi è la possibilità di creare query che graficamente appaiano ambigue.
Ci teniamo a precisare che nel caso di figura 23 anche se si tratta di un singolo grafo, sono rappresentate 3 query completamente distinte che però hanno in comune la stessa sorgente di dati. Facciamo notare che anche dal punto di vista della traduzione necessaria per poter sottomettere la query all’interprete KDDML è necessario selezionare la query che si ha intenzione di eseguire e a quel punto il sistema provvederà ad effettuare la traduzione da query grafica a
query XML.
Naturalmente da un punto di vista implementativo sono state necessarie apposite strutture dati per contenere la query e tutte le informazioni relative agli operatori. Facendo riferimento ai Pakage (vedi appendice) diamo una breve descrizione di come è stata realizzata la traduzione di un query grafica in una query KDDML.
figura 27: KDDML work Flow
Il pakage GraphCompiler fornisce una serie di classi utilizzate per la manipolazione e l’analisi delle query visuali. Per ciò che riguarda la costruzione delle query, sono stati realizzati dei metodi nella classe GraphModifier che permettono di riempire le strutture dati utilizzate per contenere le query.
Come abbiamo precisato nel paragrafo precedente, per poter identificare una query da un grafo è necessario visitare il grafo a partire dalle foglie. Considerando l’esempio precedente la visita del grafo è effettuata partendo dal nodo TREE_MINER, dal nodo SEQUENCE_MINER, e da nodo CLUSTER_MINER. Anche se graficamente non è mostrato all’utente, gli archi del grafo sono comunque memorizzati come archi orientati, quindi prima di visitare il grafo è necessario invertire l’orientamento dei nodi. Ad ogni modo queste fasi del processo di costruzione della query sono del tutto trasparenti all’utente. Il processo di visita del grafo inserisce tutte le query presenti nel pannello di lavoro in una struttura ad albero in cui è memorizzato livello per
livello l’ordine degli operatori. Il nucleo principale di questo package è sicuramente rappresentato dal metodo builtXMLQuery() nella classe GraphModifier che procede con il salvataggio in formato XML della query grafica. In questo caso l’albero che rappresenta la query viene esplorato livello per livello e a ciascun operatore grafico, viene associato un operatore testuale. Tutti i parametri dell’operatore vengono inseriti come attributi del nodo XML corrispondente e se l’operatore prevede tra i suoi tipi di input CONDITION oppure ALGORITHM (vedi sezione 2.3) vengono aggiunti nel DOM gli appositi tag per l’identificazione di queste proprietà utilizzando delle procedure ricorsive.
Questa soluzione è resa necessaria poiché il linguaggio KDDML prevede che questi due tipi siano identificati tra gli Input degli operatori che li prevedono e non tra i parametri. Si potevano pensare due soluzioni differenti per risolvere graficamente il problema.
Per il tipo ALGORITHM si poteva pensare di duplicare l’operatore che contiene un algoritmo, ad esempio, l’operatore CLUSTER_MINER ha una signature del genere:
CLUSTER_MINER : table × algorithm → cluster
E tra gli algoritmi di clustering presenti nel sistema vi sono KMeans e Expectation Maximization. Si potrebbe pensare di creare due diversi operatori grafici (ad esempio KM_CLUSTER_MINER e EM_CLUSTER_MINER), che però da un punto di vista semantico fanno riferimento allo stesso operatore con parametri differenti. La scelta su cui abbiamo puntato, è stata diversa, vale a dire mantenere un solo operatore e dare la possibilità all’utente di selezionare tra i propri parametri di impostazione l’algoritmo e i parametri correlati. Abbiamo optato per questa scelta poiché pensiamo che in una futura espansione del sistema, l’aggiunta di un algoritmo non comporterebbe alcun cambiamento al livello dell’interfaccia grafica (vedi paragrafo 5.3), mentre in una soluzione
come quella precedente sarebbe necessario realizzare un oggetto grafico differente, ed estendere (ad esempio), un’apposita classe per specializzare il comportamento di tale operatore con il nuovo algoritmo.
5.2 Formulare una Query
La formulazione di una query grafica può essere vista in senso metaforico, come la navigazione del processo di KDD. L’idea di base è quella di decomporre la query in diversi step, rappresentati dalle fasi del processo di estrazione dei dati che comprendono vari operatori del sistema, e guidare l’utente nella stesura della stessa attraverso l’interfaccia grafica.
Il concetto di base su cui si poggia l’interfaccia grafica è quello di “non permettere all’utente di fare ciò che non può fare”. Ciò vuol dire che da un punto di vista della formulazione della query e dell’immissione dei parametri per gli operatori grafici, l’utente deve essere molto guidato dal sistema, onde evitare di mandare in esecuzione una query non valida e generare un errore a livello interprete.
Per realizzare tali funzionalità è necessario tenere presente come si evolve il processo di KDD (vedi sezione 1.7 figura 2). Il processo di KDD infatti è iterativo e diviso in fasi ben precise, quindi un primo modo per guidare l’utente del sistema allo sviluppo di una corretta query KDD è quella di mappare ogni operatore su una fase del processo KDD (quella a cui si riferisce ) e mostrare nell’interfaccia grafica solo gli operatori che sono compatibili con il passo successivo del processo. Dobbiamo precisare che sono state necessarie alcune modifiche al sistema sottostante, poiché le informazioni utilizzate per gestire la divisione in fasi della query, non era stata prevista al momento della realizzazione di KDDML; tuttavia, non è stata necessaria nessuna modifica all’interprete del linguaggio. L’architettura di KDDML essendo stata progettata ”a livelli”, ha permesso una agevole modifica a quelle che sono le caratteristiche principali degli operatori. Questo vuol dire che ad ogni operatore
è stata assegnata la fase relativa al processo KDD in cui esso si colloca. Ad esempio, tutti gli operatori che vanno sotto la categoria di data-source sono stati divisi in due gruppi : Data Loader e Model Loader. Questi sono stati inseriti nello step che chiameremo data-source. Per gli operatori di PreProcessing è stata fatta la stessa distinzione, assegnando a tutti gli operatori del sistema di pre-processing un meccanismo che permetta di recuperare staticamente la fase di appartenenza di un operatore. Lo stesso processo di “marcatura” è stato effettuato per gli operatori di data mining, di post-processing e di visualizzazione.
In questo modo si possono definire delle regole di visualizzazione ben precise attraverso cui direzionare l’utente nell’inserimento dei vari operatori. Per chiarire quanto detto facciamo un semplice esempio (vedi figura 26): supponiamo che l’utente abbia inserito tre operatori : ARFF_LOADER che provvede a caricare un file con estensione .arff dal repository, TABLE_2_PP_TABLE il cui inserimento è completamente automatico ed il cui comportamento verrà discusso in seguito, e PP_SAMPLING che prende in input una tabella e restituisce una nuova tabella su cui è stato applicato un algoritmo di sampling per ridurre la dimensione del data-set. In questo caso, se l’utente “clicca” con il mouse sull’operatore PP_SAMPLING quello che ottiene è un filtraggio automatico delle fasi che non sono considerate compatibili con quella corrente. In tal caso, come si può vedere dalla figura, vengono rese inaccessibili le fasi di DataLoader, PostProcessing e ModelLoader.
Quindi, seguendo quello che è il processo iterativo del KDD l’utente può pensare di proseguire nella stesura della query inserendo un altro operatore. A partire da PP_SAMPLING quindi, l’utente può scegliere di applicare ancora un altro operatore di PreProcessing, passare alla fase di DataMining, oppure registrare la tabella su disco applicando un operatore di DataWriter.
Dobbiamo precisare, che a differenza dei tool analizzati nel terzo capitolo, la nostra metafora grafica non prevede la possibilità da parte dell’utente di collegare i vari elementi grafici in maniera autonoma ma il sistema assiste chi compila la query, per ciò che riguarda l’inserimento dei collegamenti tra gli elementi grafici. Il collegamento tra un nodo ed un altro del grafo quindi, può avvenire in due maniere differenti. Quando l’utente seleziona con il mouse un elemento grafico, quest’ultimo cambia colore per segnalare che è stato selezionato ed automaticamente le liste degli operatori compatibili e delle fasi disponibili (chiariremo nel prossimo paragrafo questo concetto) vengono aggiornate. A questo punto basta selezionare l’operatore che si vuole agganciare e il collegamento viene creato in maniera automatica. Naturalmente è il sistema a gestire il posizionamento nello spazio dell’operatore e in generale all’utente dal punto di vista del posizionamento sul canvas, sono imposti alcuni vincoli. Ogni elemento grafico infatti, per quanto riguarda l’asse delle ascisse viene limitato tra due vincoli che sono rappresentati dall’operatore che sta alla sua sinistra e quello che sta alla sua destra. Ciò vuol dire che l’utente in tale area può spostare l’elemento grafico a suo piacimento senza il rischio di sovrapporre i nodi del grafo. Abbiamo scelto questa soluzione per non subire le stesse ristrettezze di una rappresentazione ad albero,ma parallelamente abbiamo scelto di lasciare libero l’utente di spostare i nodi in senso verticale per non limitare del tutto la possibilità di organizzare il flusso di lavoro in maniera indipendente. In questo modo, a nostro avviso, si mantiene una certa rigidità di rappresentazione e quindi si evitano rappresentazioni di query confuse, ma allo stesso tempo si lascia l’utente “abbastanza” libero nella scelta del
posizionamento grafico degli operatori.
Esiste un altro modo per collegare due operatori sul grafo e rimandiamo la descrizione di tale meccanismo ai paragrafi successivi(in particolare vedi il paragrafo 5.4).
5.3 Funzione filtro su un operatore
Come già discusso formalmente nella sezione 4.2, si può definire una funzione che permetta in maniera abbastanza immediata di associare ad ogni operatore l’insieme di tutti gli altri elementi del linguaggio che possono risultare con esso compatibili. Questa compatibilità, come precedentemente descritto, può dipendere sia dalla fase del processo di KDD associata con l’operatore stesso che dal tipo restituito dall’operatore corrente. Infatti ricordiamo che ogni operatore del linguaggio , formalmente ha uno o più input e un output.
Come si poteva immaginare l’introduzione dell’interfaccia grafica ha reso necessarie alcune piccole modifiche al sistema a causa di alcune funzionalità che abbiamo scelto di realizzare. In questo caso un’altra modifica al livello sottostante è stata necessaria. Infatti anche se per gli operatori i tipi (input ed output ) vengono definiti al momento dell’inserimento nel sistema inserendo opportune keyword nelle DTD di riferimento, non era stata prevista la funzionalità di recupero del tipo restituito da ognuno di essi.
A questo punto, conoscendo sia il tipo(i) di input che quello di output di ogni singolo elemento, possiamo facilmente definire una funzione che dato un operatore, la fase del processo KDD a cui appartiene e il proprio tipo di output restituisce un insieme di operatori che possono essere collegati ad esso con un arco. Facciamo notare la potenzialità di tale funzionalità. In questo modo infatti l’utente non corre il rischio di collegare operatori non compatibili tra loro. Se pensiamo che è possibile dare in pasto all’interprete KDDML anche dei file xml
lanciandolo da linea di comando, capiamo bene che tale formalismo grafico effettuando un’analisi statica sui tipi degli operatori permette di evitare di incorrere in errori a run time.
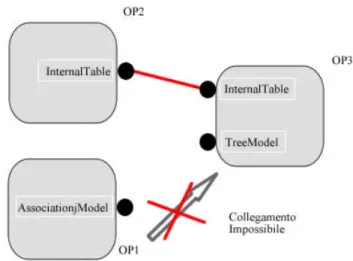
Non tutto però risulta così semplice e sicuramente vengono alla luce altre problematiche con questo tipo di soluzione. Consideriamo il caso in cui un operatore del linguaggio abbia la signature OP : input1 × input2 → output. Ciò vuol dire che in qualche maniera si deve fornire all’utente il modo di collegare all’operatore OP due archi in entrata. Date le nostre osservazioni precedenti riguardo all’inserimento automatico dei collegamenti tra i nodi del grafo, sembra che il requisito legato all’automatizzazione di tale azione possa venir meno. Ma consideriamo la figura seguente, in cui i collegamenti in ingresso ad un nodo vengono intesi come “segnali” di input e le etichette InternalTable e TreeModel sono dei tipi di dato specificati nel sistema KDDML.
figura 29 : esempio di collegamento tra operatori
In questo caso il nodo OP3 necessita di due segnali di input e da un punto di vista grafico, prevede il collegamento con due nodi. Dato che non è prevista la possibilità di inserire “manualmente” dei collegamenti tra gli elementi grafici del grafo, abbiamo previsto una modalità equivalente per il collegamento.
Infatti tutti i nodi che hanno un segnale di input non ancora assegnato, vengono inseriti in una lista che contiene tutti i nodi del grafico che possono essere
collegati. Facciamo notare che l’inserimento avviene o quando è inserito un nuovo elemento grafico che ha ancora un segnale non assegnato o quando si procede con l’eliminazione di uno o più nodi dal grafo. In questo caso infatti tutti gli archi entranti ed uscenti del nodo da eliminare vengono cancellati e a seconda del nodo eliminato si può avere una query valida o meno (vedi paragrafo successivo per maggiori dettagli). Naturalmente anche su questa lista viene fatto un filtro sui tipi di segnali. Ad esempio se il tipo di OP2 fosse stato AsssociationModel non sarebbe stato possibile collegare i nodi OP1 ed OP3 (vedi figura 28).
Questa soluzione è stata possibile poiché senza eseguire la query siamo in grado di conoscere sia il tipo restituito che la tipologia di input (o segnali) richiesti da un operatore. In tal modo si riesce guidare completamente l’utente anche in questo senso, permettendo di collegare tra loro solo nodi compatibili.
figura 30 : incompatibilità tra i segnali di input/output degli operatori
5.4 Inserimento degli attributi
Un altro problema che abbiamo evidenziato anche in precedenza, riguarda sicuramente la modalità di inserimento dei parametri per gli operatori. Infatti se
all’interprete KDDML fosse data in pasto una query scritta in modalità testuale non si potrebbe avere alcuna garanzia sulla correttezza dei parametri inseriti (in realtà nemmeno sul corretto formato degli operatori). Con l’introduzione dell’interfaccia grafica però, si ha il grosso vantaggio di riuscire a guidare l’utente del sistema anche attraverso delle modalità di input per ogni singolo operatore che dipendono direttamente sulla tipologia di input degli operatori. In questa analisi siamo avvantaggiati dal fatto che i tipi di input degli attributi degli elementi del linguaggio sono finiti, quindi è possibile costruire un dialogo per l’immissione dei parametri completamente indipendente dal tipo di operatore a cui si fa riferimento.
Consideriamo ad esempio un operatore come quello seguente:
<!ELEMENT OPERATOR ((%kdd_query_trees;), (%kdd_query_trees;)+)> <!ATTLIST OPERATOR xml_dest %string; #IMPLIED>
<!ATTLIST OPERATOR combination_type (false|true) #REQUIRED> <!ATTLIST OPERATOR positive_int %integer; #REQUIRED>
<!ATTLIST OPERATOR min_confidence %prob_number; #IMPLIED>
Chiaramente in questo caso non è possibile lasciare totalmente all’utente la possibilità di inserire per tutti gli attributi dei valori attraverso input di testo. Questo infatti porterebbe l’input grafico degli attributi allo stesso livello della compilazione in forma testuale della query. Quindi a seconda che l’input di un operatore sia integer o string l’utente si troverà a selezionare il valore per uno spinner o a riempire un campo di testo. Naturalmente se ad esempio per l’operatore precedente l’attributo min-confidence prevede un valore nell’intervallo (0,1] saranno considerati corretti solamente valori compresi in quell’intervallo. Lo stesso discorso si ripete nel caso in cui vi sia un attributo di tipo combination_type. In tal caso infatti non si lascia all’utente la possibilità di inserire valori di tipo stringa ma vengono mostrate automaticamente le possibili
scelte per quell’attributo e l’utente è costretto quindi a selezionare un campo dalla lista che sicuramente è compatibile con la relativa DTD.
E’ stato necessario realizzare un ulteriore passo di controllo di correttezza sugli attributi obbligatori. Nel caso precedente ad esempio, l’elemento OPERATOR presenta due attributi, che sono positive_int e combination_type, che è necessario specificare nella query se si vuole considerare valido l’input per l’operatore. In tal caso l’utente può scegliere se inserire i parametri in seguito o completare la lista dei valori obbligatori in maniera corretta. Facciamo notare che nella costruzione del dialogo di input il numero ed il tipo dei parametri viene recuperato in maniera dinamica a seconda dell’operatore selezionato. Lo stesso discorso vale se si considera la selezione di un particolare algoritmo per l’elemento. In tal senso si può dire che il sistema grafico è completamente indipendente da quello che accade al livello inferiore del sistema. Per chiarire meglio quanto detto si consideri lo pseudo-codice del dialogo di input per gli operatori di DataMining.
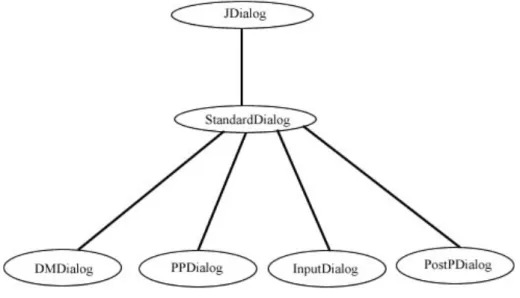
Precisiamo che anche per i dialoghi di input è stata creata una gerarchia (vedi figura 29). Quando si inserisce un nuovo operatore nel linguaggio quindi, basta implementare il metodo (che in un operatore generico è abstract) getOperatorPhase() in cui viene specificata la fase del processo di KDD a cui l’operatore appartiene e, a seconda della collocazione dell’operatore nel processo KDD viene chiamato un dialogo specializzato per l’immissione degli input. In questo modo quindi si evita di dover costruire un elemento grafico ad hoc per ogni nuovo elemento inserito nel sistema.
figura 32 : gerarchia di dialoghi
5.4.1 Supporto all’inserimento degli attributi
Oltre alle modalità descritte nel paragrafo precedente, che prevedono in qualche modo di “guidare” l’utente attraverso l’inserimento dei parametri, vogliamo segnalare la presenza nel tool grafico di composizione di query, la possibilità di usufruire di informazioni supplementari senza bisogno di consultare la documentazione del sistema KDDML.
guida per la stesura delle query. Ad esempio se si sposta il mouse su uno degli operatori della lista, appare un tooltip che sintetizza tutti i parametri che è necessario inserire per quel determinato operatore con una breve descrizione. Naturalmente oltre ai parametri sono presenti anche tipo restituito dall’elemento e possibili tipi di input. Ciò permette sicuramente all’utente di capire meglio cosa sta facendo evitando inserzioni ed eliminazioni inutili di elementi grafici. Oltre a questo accorgimento vi è la possibilità di capire il tipo restituito da un elemento grafico semplicemente cliccando con il pulsante sinistro del mouse sulla sfera che c’è sugli archi che collegano i nodi del grafo.
Segnaliamo inoltre, la possibilità di vedere il tipo dei parametri degli algoritmi di ogni operatore (ove previsto) aprendo la finestra per l’immissione dei parametri e cliccando sul pulsante adiacente alla Form di input.
Un ulteriore tooltip è stato inserito su tutti i pannelli per l’input degli operatori, quindi se si apre la finestra per l’immissione dei parametri e si lascia il puntatore del mouse fermo accanto alla form di input per un determinato parametro, apparirà un tooltip che fornisce una breve descrizione sul parametro. Queste caratteristiche sono state considerate necessarie affinché chi compone la query abbia un adeguato grado di assistenza durante il processo di KDD.
5.5 Validazione di una query grafica, una guida per l’utente
Uno dei requisiti principali che abbiamo individuato per il nostro sistema grafico, è sicuramente quello di individuare eventuali errori prima che la query sia interpretata evitando così errori a tempo di esecuzione. Con le restrizioni elencate nel capitolo precedente una parte dei possibili errori introdotti viene limitata ma rimangono alcune problematiche legate all’inserimento dei parametri dei singoli operatori. Alcuni operatori del linguaggio infatti,
presuppongono di avere informazioni che riguardano le fasi precedenti, quindi con una pura analisi statica sugli input ed sui parametri non si riesce a gestire queste situazioni.
Per chiarire meglio questo concetto consideriamo un semplice esempio (figura 30) in cui, uno degli attributi di un operatore dipende in maniera stretta dal nodo figlio.
<?xml version="1.0" encoding="UTF-8"?> <KDDML_OBJECT>
<KDD_QUERY name="casting">
<PP_CHANGE_TYPE attributes_list="temperature, humidity” new_type="string"> <PP_TABLE_LOADER xml_source="pp_weather.xml"/>
</PP_CHANGE_TYPE> </KDD_QUERY>
</KDDML_OBJECT>
figura 33 : esempio di query
L’esempio in figura è una semplice query KDDML in cui è applicato un operatore di preprocessing ad una tabella. In questo caso il tipo degli attributi della tabella “pp_weather” temperature ed humidity , vengono trasformati da Integer in string. Capiamo bene che se la tabella “pp_weather” non contenesse gli attributi temperature ed humidity, verrebbe sollevato un errore a tempo di esecuzione. I dati sugli attributi della tabella “pp_weather” non si conoscono fin quando la query non è mandata in esecuzione, quindi al momento della scrittura della query grafica staticamente non si può fare alcun tipo di analisi. E’ necessario quindi un altro meccanismo per fornire ulteriori informazioni all’utente.
Nel tool grafico infatti, abbiamo inserito uno strumento che in casi come questi può essere sicuramente d’aiuto. A partire da una sorgente di dati, che sia un file “arff” o un modello, si può interagire con il livello sottostante in maniera da rendere disponibili alcune statistiche riguardo ad una tabella o un modello. Dal
punto di vista della nostra implementazione, diciamo che quello che si fa è costruire una query fittizia e inserire in un buffer (poi visualizzato a video) le informazioni che l’interprete fornisce a tempo di esecuzione. Questo avviene in maniera completamente trasparente all’utente che può continuare a comporre il proprio schema. Quando questi attributi sono stati recuperati, vengono inseriti in opportune strutture dati e viene data quindi la possibilità all’utente di prenderne visione. Considerando l’esempio precedente, l’utente sarebbe stato capace di individuare il tipo, il numero, e il nome degli attributi presenti nella tabella “pp_weather” in maniera tale da evitare di inserire il nome di uno o più attributi non fisicamente presenti all’interno della tabella stessa. Questo a nostro avviso rappresenta un miglioramento significativo rispetto alla rappresentazione testuale di una query KDD che va ben oltre alla possibilità di rappresentare il processo in maniera grafica. Capiamo bene che con l’aggiunta di questa ulteriore funzionalità la probabilità di inserire parametri erronei decresce ulteriormente.
Nonostante questi accorgimenti, ci sono alcune situazioni che fino ad ora non abbiamo trattato e per cui forniamo una ulteriore soluzione. Oltre all’immissione dei parametri e al controllo statico sul loro tipo e numero, è necessario considerare anche il caso in cui l’utente non fornisca tutti gli input necessari per un operatore che ne prevede più di uno. Consideriamo l’esempio seguente (figura 31): <KDD_QUERY name="fff"> <PP_ADD_HIERARCHY attribute_name="event"> <TABLE_2_PP_TABLE> <ARFF_LOADER arff_file_name="coop_timestamp.arff"/> </TABLE_2_PP_TABLE> <HIERARCHY_LOADER xml_source="coop_taxonomy.xml"/> </PP_ADD_HIERARCHY </KDD_QUERY>
Per l’operatore PP_ADD_HIERARCHY, che provvede ad assegnare un “oggetto gerarchia” alle colonne di una tabella sotto forma di meta-dati, sono previsti due input differenti: una PPTable e un HierarchyModel. Da come abbiamo descritto la costruzione della query nel paragrafo precedente, il collegamento di questo operatore agli input avviene in due passi e può essere attuato in due maniere differenti: collego prima l’elemento TABLE_2_PP_TABLE al proprio input e poi a partire da HIERARCHY_LOADER inserisco un nuovo arco verso il nodo
PP_ADD_HIERARCHY oppure collego per primo il nodo
HIERARCHY_LOADER e in seguito faccio un collegamento con l’altro operatore TABLE_2_PP_TABLE. Precisiamo che queste due differenti situazioni si possono verificare perché, per come è stata concepita la metafora grafica, è possibile connettere, qualora i tipi di input/output siano compatibili tra loro, due grafi separati rappresentati sul canvas.
E’ evidente quindi come da pare dell’utente vi sia la possibilità di connettere l’operatore con un numero inferiore di input rispetto a quelli che sarebbero necessari. Queste informazioni, sono note staticamente e non è necessario rimandare i controlli sul corretto inserimento di input a tempo di esecuzione. Perciò direttamente dall’interfaccia grafica si può tranquillamente interagire con questo livello del sistema in modo da rilevare anche questo tipo di errori. Abbiamo predisposto un tool che scandisce la query grafica e rilevando, ove ve ne siano, errori di vario tipo. Più precisamente i controlli che vengono effettuati riguardano :
1) controllo di correttezza degli attributi degli algoritmi; 2) controllo inserimento degli attributi obbligatori; 3) controllo inserimento corretto del numero di input.
relativo agli attributi dell’algoritmo selezionato. Ad esempio se l’algoritmo prevede un parametro min_confidence che deve essere un numero reale positivo nell’intervallo (0,1], e per quel parametro l’utente immette un valore string, il tool di validazione si accorge del valore erroneo e lo segnala all’utente nella apposita finestra degli errori marcando perciò l’operatore come “non disponibile per l’esecuzione”. Per quanto riguarda il controllo sui parametri che sono obbligati per un determinato algoritmo, si può dire che non è necessario esplicitamente verificarne l’inserimento poiché questo controllo è già effettuato quando l’utente tenta di inserire i parametri dall’apposito dialog box. Infatti se chi costruisce lo schema non inserisce tutti i parametri per un determinato operatore, non può procedere con la convalida degli stessi. Ciò vale solo per i parametri obbligatori, mentre per tutti gli altri si può procedere con l’inserimento anche in momenti separati.
Chiaramente quando si procede con la validazione di una query, nella finestra in cui vengono mostrati gli errori, è precisato l’operatore in cui si è verificato l’errore e il tipo di inesattezza che c’è stata. In questo modo l’utente è maggiormente guidato nella correzione.
Il processo di validazione è attivato in maniera automatica quando si tenta di eseguire una query. In questo modo l’esecuzione viene bloccata se vengono riscontrati degli errori e all’utente viene mostrata una finestra in cui vengono elencati tutti i problemi incontrati in fase di “compilazione” della query grafica. In alternativa si può scegliere di validare la query in maniera indipendente dall’esecuzione, scegliendo di verificare se vi sono errori man mano che si procede con la rappresentazione dello schema. In tal modo è possibile conoscere in maniera abbastanza dinamica le informazioni sullo stato della query e tale tool risulta indispensabile soprattutto quando si ha a che fare con schemi abbastanza complessi.
5.6 Esecuzione parziale della query
Come abbiamo analizzato nei capitoli precedenti, il processo di KDD è iterativo, quindi, la possibilità di visualizzare i dati intermedi, tra uno step e l’altro risulta molto importante. A tale scopo il linguaggio KDDML prevede già per ogni operatore un attributo chiamato xml_dest tramite il quale è possibile specificare il nome di un file in cui salvare i risultato intermedio per poterlo poi visualizzare successivamente.
Tale procedimento però, se considerato in questo modo risulta non molto interattivo e quindi è stato necessario realizzare una soluzione che sia in qualche modo di aiuto a quella già esistente. Direttamente dall’interfaccia grafica è possibile quindi eseguire anche solo una parte dell’intera query rappresentata, marcando un operatore come “breakpoint” (per un esempio dettagliato vedi capitolo successivo). In questo modo chi realizza lo schema, può prima definire l’intera query, e poi decidere di eseguire solo una parte di essa. Da un punto di vista di rappresentazione ciò comporta l’esecuzione di un sottoalbero del DOM relativo alla query KDDML. Tutti gli archi uscenti dal nodo selezionato vengono marcati, e il nodo è indicato come foglia nell’albero di rappresentazione.
Precisiamo che questa funzionalità risulta ragionevole quando il dataset su cui si lavora è ragionevolmente piccolo da poter permettere un’esecuzione in un tempo limitato. Se si stanno effettuando processi di mining che necessitano di molto tempo di elaborazione, l’utilità dell’esecuzione parziale viene messa in discussione. Ciò nonostante, il sistema è stato predisposto per marcare più di un nodo e quindi effettuare una sorta di “debugging” della query nel senso che si può prevedere di eseguire lo schema passo dopo passo e quindi terminare l’esecuzione se ad esempio, ad un certo punto non sono emersi dei risultati che consideriamo rilevanti.
Naturalmente il processo di validazione non viene disabilitato quando si manda in esecuzione una query parziale, quindi i controlli su tipi ed attributi vengono
eseguiti regolarmente solo sul sotto-grafo delimitato dal marcatore.
5.7 Salvataggio e caricamento di una query
Quando si ha a che fare con schemi che rappresentano query abbastanza complesse, la necessità di salvare lo schema disegnato risulta a dir poco fondamentale. Per questo motivo uno dei requisiti elencati nel capitolo precedente è sicuramente il salvataggio, e di conseguenza anche il caricamento, delle query.
Nel tool grafico quindi, è possibile scegliere di salvare la query conservando tutte le impostazioni ed i parametri immessi fino a quel momento.
Naturalmente, oltre che a tutte le informazioni relative alla query KDDML vera e propria, è necessario sicuramente salvare insieme ad esse ulteriori indicazioni che possono permettere di identificare gli elementi a livello grafico.
Quindi per il salvataggio dei documenti è stato necessario affrontare un’ulteriore problematica. Abbiamo dovuto considerare se fosse più conveniente salvare il processo in un formato proprietario oppure salvarlo in un formato “aperto” e quindi leggibile anche al di fuori dell’interfaccia del sistema. La nostra scelta è stata quella di avere un formato visionabile anche con altre applicazioni. Sono stati aggiunti opportuni tag all’interno della query salvata che identificano esclusivamente gli elementi grafici e altre informazioni legate strettamente alla rappresentazione e alla gestione dei nodi del grafo. In questo modo quando si desidera caricare la query, bisogna però creare una sorta di filtro che scorra l’albero DOM e mantenga solo i tag significativi per l’interprete KDDML onde evitare di mandare in esecuzione una query non valida. Scendendo nei particolari, quando si effettua il salvataggio vengono aggiunti dei tag all’inizio della query KDDML che identificano gli archi del grafo :
<KDDML_OBJECT>
<KDD_QUERY name="aaa"> <ARCS>
<ARC from_index="0" to_index="1" has_breakpoint="false" /> <ARC from_index="1" to_index="2" has_breakpoint="false" /> <ARC from_index="3" to_index="2" has_breakpoint="false" /> </ARCS>
….
</KDD_QUERY> </KDDML_OBJECT>
Il tag “<ARCS>” prevede una serie di tag figli che identificano univocamente gli archi della query salvata. Infatti, gli attributi from_index e to_index sono gli identificativi dei nodi collegati da un arco nel grafo e l’attributo has_breakpoint ci dice se, quando la query è stata salvata sull’arco, era previsto un marcatore per l’esecuzione parziale. La presenza o meno di questi tag ci permette anche di dire se la query che si tenta di caricare nell’interfaccia è o no in un formato valido. In ogni modo, in aggiunta alle informazioni sul numero e sulla tipologia di archi presenti, sono sicuramente necessarie altre informazioni legate strettamente alla rappresentazione di ogni singolo operatore. Elenchiamo di seguito tutti gli attributi aggiuntivi per gli elementi della query e forniamo un esempio di formato di salvataggio in figura 32.
- x : posizione sull’asse delle x dell’elemento grafico; - y : posizione sull’asse delle y dell’elemento grafico;
- constraint_left : vincolo di movimento alla sinistra dell’operatore; - constraint_right : vincolo di movimento alla sinistra dell’operatore; - icon_path : path del file immagine che rappresenta il nodo;
- panel_index : rappresenta il pannello grafico in cui è l’operatore quando viene inserito nel grafo.
- operator_graph_index : identificativo dell’oggetto nella struttura dati grafo;
- label : etichetta assegnata dall’utente all’elemento grafico.
figura 35 : esempio di formato per il salvataggio immagini
Queste sono tutte le informazioni necessarie per gestire il caricamento di una query a al livello dell’interfaccia, ma qualora vi siano sviluppi futuri,e quindi la necessità di informazioni addizionali, non vi è nessuna difficoltà a modificare questo formato. Infatti nel package GraphCompiler vi sono le interfacce QuerySaverInterface e QueryLoaderInterface che rappresentano le linee guida per gestire il salvataggio e il caricamento di un file che identifica il processo. Naturalmente l’implementazione fornita rispecchia le necessità del sistema in questo momento e quindi se ci saranno alcune modifiche da effettuare, ad esempio con l’aggiunta di un vero e proprio tool per l’esecuzione step-to-step,
le modifiche a questa parte del sistema grafico saranno sicuramente minime. Precisiamo che, come ci si dovrebbe aspettare, quando si carica uno schema tutti i parametri inseriti al momento del salvataggio vengono mantenuti e quindi si ha la possibilità di interagire con il sistema grafico come se il processo fosse stato costruito da zero .
5.8 Gli operatori PP_TABLE_TO_TABLE e
TABLE_2_PP_TABLE
Sicuramente una descrizione a parte meritano questi due operatori del linguaggio KDDML. Diciamo subito che il loro utilizzo potrebbe risultare in alcuni casi poco chiaro e soprattutto ripetitivo all’occhio dell’utente. Gli operatori TABLE_2_PP_TABLE e PP_TABLE_TO_TABLE , rispettivamente rappresentano la possibilità di effettuare una conversione tra tabelle che hanno tipo InternalTable in tabelle di tipo InternalPPTable e viceversa.
L’operatore TABLE_2_PP_TABLE ad esempio risulta indispensabile quando, caricata una sorgente di dati, si vuole procedere con la fase di Pre-Processing. Tutti gli operatori di Pre-Processing prevedono come input una InternalPPTable e tutti i Data-Source restituiscono un tipo InternalTable; è necessaria quindi una conversione. L’utente quindi se vuole compiere il passo di preprocessing deve inserire necessariamente l’operatore TABLE_2_PP_TABLE a meno che non carichi direttamente dal repository una tabella di preprocessing (PP_TABLE_LOADER). Questo passaggio può quindi risultare indispensabile e un utente, se desidera utilizzare questa funzionalità ogni volta ha la necessità di inserire questo operatore “manualmente” per poter proseguire nel disegno del proprio schema. Per ovviare a questo problema abbiamo pensato di guidare l’utente anche in questo compito. Infatti è possibile attivare una opzione che permette all’utente di essere aiutato dal sistema in questo compito. Il sistema grafico quindi provvederà ad inserire questi operatori
in maniera completamente trasparente all’utente. Sostanzialmente le situazioni “critiche” in tal senso possono essere raggruppate in due insiemi : quando si parte da un data-source e si vuole procedere con il passo di Mining oppure quando si termina il passo di pre-processing e si vuole fare il passo di Mining (in tal caso a dover essere inserito è l’operatore PP_TABLE_2_TABLE).
Da un punto di vista prettamente grafico, quando ad esempio si seleziona un operatore di data-source e si vuole passare alla fase si pre-processing inserendo un nuovo elemento che appartiene a quella fase, il sistema automaticamente provvede a concatenare al nuovo elemento inserito l’operatore di conversione esonerando così l’utente da inserirlo in maniera manuale. Lo stesso accade nel caso si voglia passare dalla fase di preprocessing a quella di Mining vera e propria. In ogni caso a riguardo verranno forniti esempi significativi nel prossimo capitolo.
5.9 Ulteriori problematiche e funzionalità
Anche se da un punto di vista prettamente grafico, la query che rappresenta il processo è raffigurata attraverso un grafo in realtà quando si chiama l’interprete KDDML essa viene trasformata in un albero XML. Poiché in questo caso nella visualizzazione a cambiare sono sia il modello di rappresentazione (da grafo ad albero ) che la vista (il primo sotto forma schematica, il secondo attraverso un documento xml) è sicuramente auspicabile che il tool grafico abbia la possibilità di visualizzare il documento xml prodotto ad un certo punto della stesura della query grafica. Proprio per questo abbiamo integrato la possibilità di visualizzare in un frame separato da quello principale, il file xml prodotto dal processo di costruzione dello schema in modo che anche l’utente più esigente possa rendersi conto di come si evolve il proprio lavoro al livello sottostante. Una ulteriore problematica che abbiamo dovuto affrontare nella implementazione della metafora grafica è strettamente collegata con il
collegamento degli elementi grafici. Infatti l’input degli operatori, definiti attraverso opportune DTD, deve rispettare l’ordine elencato nel file che ne descrive le caratteristiche. Consideriamo ad esempio la DTD in figura 33.
figura 36 : esempio di DTD di un operatore
In questo caso, l’operatore RDA_SATISFY prende in input due tabelle differenti e più precisamente un AssociationModel e una InternalTable. Il problema che si pone ora è l’inserimento nel corretto ordine di entrambe le tabelle, vale a dire che nell’albero DOM che rappresenta la query tale operatore deve avere necessariamente come primo figlio un AssociationModel e solo per secondo una InternalTable. Questo chiaramente è troppo vincolante per l’utente che utilizza il tool grafico e non si può pensare di chiedere all’utente di inserire gli input nella corretta sequenza poiché questi non dipendono dalla fase del processo KDD ma chiaramente da come si evolve lo schema che si sta costruendo.
Per questo motivo abbiamo dovuto pensare e realizzare un modo per fare un refactoring della query ove si presenti questa eventualità. Tutti gli operatori che hanno più di un input (differente l’uno dall’altro), vengono marcati come possibili parametri da mandare in pasto ad una funzione di refactoring.
Al momento di mandare in esecuzione la query, sono effettuati una serie di controlli sui tipi che permettono di rendere la query valida per essere eseguita (vedi figura 34). In particolare viene controllato il corretto ordine dei figli del DOM della query KDD. In caso venga riscontrato un problema viene chiamata la funzione per il refactoring dell’albero. In questo modo si evitano errori a run-time lanciati dall’interprete a causa del formato non corretto dello schema. Attraverso questa procedura infatti, si riesce a svincolare chi sta costruendo lo schema dal compito di inserire nel corretto ordine tutti gli elementi, rimandando tale task ad una procedura completamente automatizzata.
Una procedura come quella mostrata in figura 34 può avere senso poiché si assume che tra gli input agganciati ad un determinato elemento, vi sono sicuramente legami con oggetti compatibili per quell’operatore altrimenti non vi sarebbe proprio stata la possibilità di collegarli durante la costruzione della query grafica.
Questa situazione rappresenta lo spunto per fare un’altra osservazione importante. Infatti, abbiamo visto come anche in questo caso una corretta analisi statica al momento della costruzione della query possa garantire un enorme vantaggio quando si scende al livello più basso. In questa occasione abbiamo risparmiato moltissimi controlli sulla correttezza della query poiché, abbiamo assunto che dalla fase precedente la query sia arrivata già in uno stato consistente.