CAPITOLO III
STATO DELL’ARTE
La pila di protocolli usata dal nodo Sink e da tutti i nodi sensori è mostrata in Figura 3.1. Tale pila è composta da diversi livelli:
• Application layer: dipendente dal tipo di applicazione;
• Transport layer: aiuta a mantenere il flusso di dati se l’applicazione lo richiede;
• Network layer: si occupa di instradare i dati forniti dal transport la-yer;
• Data-link layer: poiché l’ambiente è rumoroso ed i nodi possono spostarsi il MAC protocol deve essere power-aware e capace di minimizzare le collisioni con le trasmissioni dei nodi vicini;
• Physical layer: richiede una semplice ma robusta modulazione e delle tecniche di trasmissione e di ricezione.
Il power, task e mobility planes effettuano il monitoraggio dell’energia, mobilità e la distribuzione dei task sui vari nodi.
• Power management plane: gestisce come il nodo deve usare la po-tenza; ad esempio il Nodo Sensore potrebbe spengere il ricevitore dopo che ha ricevuto un messaggio da un vicino; inoltre, quando il livello di energia di un nodo è basso il nodo può inviare un messag-gio ai vicini per comunicare il suo stato e che non può più parteci-pare al routing dei messaggi;
• Mobility management plane: rileva e registra i movimenti dei Nodi Sensore in modo che una route verso l’utente sia sempre mantenu-ta e che ogni nodo possa tenere traccia di chi sono i propri vicini; • Task management plane: bilancia e schedula i task assegnati ad
una regione specifica; questo perché non tutti a tutti nodi (in una regione) in contemporanea è richiesto di eseguire un task di sen-sing.
Figura 3.1 Architettura di rete per una Rete di Sensori
Tramite questi livelli di gestione i nodi di una rete possono lavorare tutti insieme in modo da risparmiare energia, instradare dati e condividere risorse. Senza questi livelli ogni nodo lavorerebbe individualmente.
2.1 PROTOCOLLI PER LA RELIABILITY E PER IL
CON-TROLLO DELLA CONGESTIONE
Essenzialmente sono due i flussi di dati che è possibile distinguere all’interno di una Rete di Sensori: un flusso è quello che parte dai nodi e
arriva al Sink (forward path) mentre l’altro è quello contrario che instrada i dati dal Sink verso i nodi della rete (riverse path).
Mentre i dati che transitano nella forward path hanno caratteristiche forte-mente periodiche, quelli inviati dal Sink possono essere considerati asin-croni. Inoltre, anche per quanto riguarda la reliability, i dati che transitano sui due path hanno vincoli diversi.
3.1.1 TCP
Il TCP è il protocollo di trasporto usato in Internet ma sicuramente un suo impiego nelle Reti Sensoriali non risulterebbe efficiente.
Il motivo è essenzialmente che questo protocollo richiede una considere-vole impiego di memoria nei nodi in quanto i pacchetti devono restare sul nodo fino a quando non è stato ricevuto l’ack (i Nodi Sensore invece han-no una memoria limitata, ad esempio i Mica motes hanno meno di 4 KBytes).
Quindi la limitata capacità dei sensori rende inapplicabile ad una Rete di Sensori il protocollo TCP ed anche il meccanismo per il controllo della congestione.
3.1.2 ESRT
[Akyildiz] È un protocollo per gestire la reliability sulla forward path.
L’affidabilità degli eventi rilevati dal nodo Sink è basata sull’informazione collettiva fornita dai Nodi Sensore e non su ciscun individuale report: è per questo che un protocollo di trasporto convenzionale, cioè basato sull’affidabilità di tipo end-to-end, è inapplicabile in una Rete di Sensori in quanto porta solo ad uno spreco di energie sui Nodi Sensore . Invece il paradigma per una Rete di Sensori deve essere di affidabilità di tipo e-vent-to-Sink. ESRT è un protocollo di trasporto che viene in contro a que-sto nuovo paradigma ed ha le seguenti caratteristiche:
• garantisce il minimo consumo di energia;
• comprende anche un meccanismo per il controllo della congestione
che permette sia di raggiungere l’affidabilità che il risparmio energe-tico.
L’algoritmo ESRT viene per la maggior parte eseguito sul Sink mentre sui Nodi Sensore sono richieste funzionalità minime.
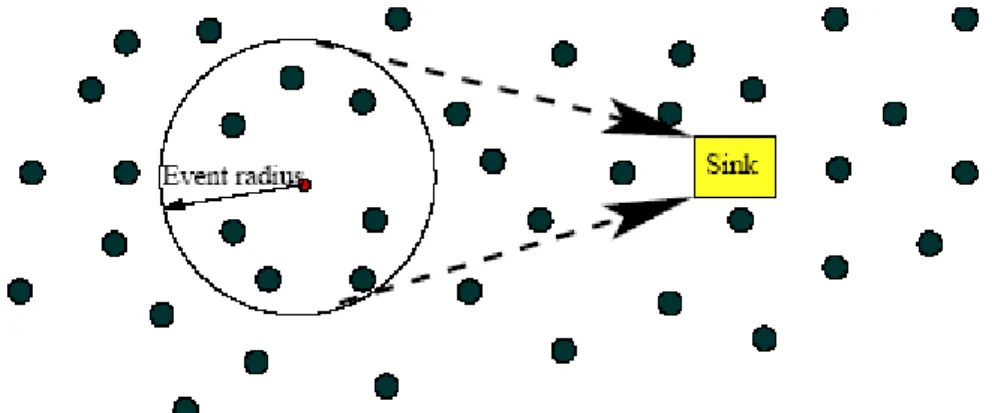
ESRT è quindi un nuovo protocollo di trasporto che permette una rileva-zione affidabile di un evento con il minimo consumo di energia e con una risoluzione del problema della congestione. (Figura 3.2)
Figura 3.2 Rilevazione dell’evento da parte del nodo Sink
ESRT viene incontro ai vincoli imposti da una WSN:
• Auto-configurazione: la rilevazione affidabile di un evento deve es-sere garantita e mantenuta anche a fronte dei cambiamenti della topologia di una WSN (dovuti al fallimento di alcuni nodi);
• Energy awareness: l’obiettivo della rilevazione affidabile di un even-to deve essere raggiuneven-to con il minor consumo di energia possibile; • Controllo Congestione: la perdita di pacchetti dovuta alla conge-stione può compromettere la rilevazione di un evento sul Sink an-che se dai nodi sono inviate un numero sufficiente di informazioni. Un meccanismo di controllo della congestione aiuta sia a risolvere il
problema della rilevazione affidabile di eventi sul Sink sia quello del risparmio energetico (in quanto non si perdono pacchetti per la congestione);
• Identificazione Collettiva: in una tipica applicazione sensoriale il Sink è interessato sull’informazione collettiva fornita da numerosi nodi e non sui singoli report: ESRT non richiede, per le operazioni, un ID per individuare ciascun nodo;
• Implementazione: ESRT viene eseguito maggiormente sul nodo
Sink e solo funzionalità minime devono essere presenti sui Nodi Sensore.
Supponiamo che il Sink debba prendere una decisione, riguardo gli eventi rilevati dai Nodi Sensore, ogni T unità di tempo (intervallo di decisione): il nodo può ritenere le informazioni ricevute affidabili solo se il numero di pacchetti ricevuti è superiore ad una certa soglia imposta dall’applicazione.
Definiamo
• n = numero di pacchetti ricevuti dal Sink nell’i-esimo intervallo deci-sionale;
• R = numero di pacchetti richiesto per la rilevazione affidabile di un e-vento .
Se n >R allora l’evento è giudicato affidabile, altrimenti sono necessarie delle azioni appropriate per raggiungere il livello in cui n =R.
Viene definito come reporting rate,f , di un Nodo Sensore, il numero di pacchetti per unità di tempo che escono dal Nodo Sensore. È necessario configurare in modo opportuno il valore di f in modo che si arrivi ad avere n =R con un consumo minimo di risorse.
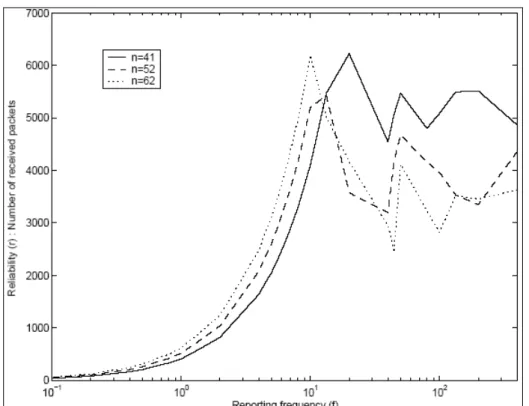
Nella Figura 3.3 di sotto sono riportati gli andamenti, al variare del numero di nodi presi in considerazione, del numero di pacchetti ricevuti dal nodo Sink in funzione della frequenza f di invio dei pacchetti da parte di ogni nodo. Questi grafici sono stati costruiti considerando una rete in cui i nodi sono disposti in modo random e in cui sia stato usato il protocollo CSMA/CD e un generico protocollo di routing.
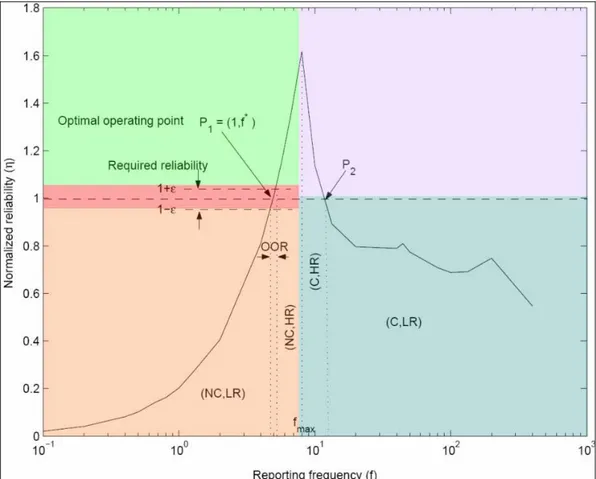
Figura 3.3 Andamento della Reliability al variare della frequenza di reporting dei nodi Dalla Figura 3.3 di sopra è facile notare che tutte le curve presentano un andamento simile. È possibile individuare delle regioni caratteristiche all’interno del grafico. Tali zone sono riportate nella Figura 3.4 sotto in cui è stata considerata una affidabilità normalizzata. η=n/R.
Perciò l’obiettivo del protocollo è quello di lavorare il più vicino possibile ad η=1.
Analizziamo le cinque zone:
(NC,LR): f<fmax e η<1-ε No congestione, bassa affidabilità;
(NC,HR): f<=fmax e η>1-ε No congestione, alta affidabilità;
(C,HR) : f>fmax e η>1 Congestione alta affidabilità;
(C,LR) : f>fmax e η<=1 Congestione, bassa affidabilità;
OOR : f<fmax e 1-ε ≤η ≤1+ε Zona Ottima
Da notare che η=1 interseca la curva in due punti distinti P1 e P2. Però in P2 la rete è congestionata e, sebbene il numero di informazioni che arri-vano al nodo Sink siano sufficienti c’è uno spreco di energia (molti pac-chetti vengono eliminati dalla rete a causa della congestione).
Figura 3.4 ESRT: suddivisione a zone
L’obiettivo dell’ESRT è quello di raggiungere e mantenere la zona di lavo-ro OOR. È quindi necessario configurare la reporting frequency f dei Nodi Sensore in modo da raggiungere questa zona. In generale la rete può es-sere in uno dei cinque stadi sopra elencati. A seconda dello stato Si
cor-rente della rete l’algoritmo calcola una nuova reporting frequency, fi+1, che
viene poi inviata in broadcast ai Nodi Sensore. Facciamo l’ipotesi che il nodo Sink sia abbastanza potente da poter raggiungere in broadcast diret-tamente tutti i nodi. L’algoritmo ESRT principalmente gira sul Sink e solo funzioni minimali sono sui Nodi Sensore. In particolare i nodi devono ave-re solo queste due funzionalità addizionali:
• ascoltare il nodo Sink quando trasmette in broadcast alla fine di o-gni intervallo di decisione e aggiornare la loro reporting frequency ;
• implementare un semplice e locale meccanismo di rilevamento del-la congestione.
Se la zona di lavoro attuale è la(NC,LR) allora non ho congestione e l’affidabilità è bassa. Questa situazione potrebbe essere dovuta a:
• Fallimento o power-down di qualche nodo intermedio necessario per il routing: esistono comunque protocolli di routing che sonotolle-ranti ai guasti;
• Perdita di pacchetti dovuta all’alto tasso di errore del mezzo tra-smissivo. Questa perdita è linearmente dipendente alla reporting frequency f ;
• Inadeguato numero di informazioni inviate dai nodi. È l’unico punto su cui è possibile agire : aumentiamo la repoting frequency in mo-do aggressivo per raggiungere l’affidabilità richiesta il prima possibi-le. In assenza di congestione abbiamo visto che r cresce in modo lineare al crescere di f.
Quindi in questa situazione l’algoritmo ESRT aggiorna la frequenza di re-porting dei nodi nel seguente modo:
i i i f f η +1 = (3.1)
Se la zona di lavoro attuale è (NC,HR) allora non ho congestione ma ho
alta affidabilità. Abbassiamo la reporting frequency in modo da avere un risparmio energetico; comunque questa riduzione non deve compromette-re l’affidabilità ; perciò la fcompromette-requenza viene ridotta in modo più dolce rispetto all’approccio precedente: ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + = + i i i f f η 1 1 2 1 (3.2)
Se invece la zona di lavoro attuale è (C,HR) si ha congestione insieme ad alta affidabilità: si diminuisce la reporting frequency in modo da evitare la congestione e da conservare l’energia. Questo decremento deve essere effettuato in modo attento per cercare di mantenere l’affidabilità:
i i i f f η = +1 (3.3)
Se mi trovo nella zona (C,LR) allora siamo in presenza di Congestione e di bassa affidabilità: questo è il caso peggiore in quanto l’affidabilità è bas-sa, c’è congestione e c’è speco di energia. Quindi è necessario ridurre in modo drastico la reporting frequency per raggiungere il prima possibile lo stato OOR. Nello stato (C,LR) la curva dell’affidabilità è non lineare; è quindi necessario un decremento esponenziale della frequenza:
) ( 1 i k i i f f η = + (3.4) Infine nel caso in cui si nella zona OOR allora non devo far altro che
man-tenere la reporting frequence attuale, quindi: i
i f
f +1 = (3.5)
Affinché ESRT determini lo stato Si corrente è necessario che sia capace di rilevare la congestione nella rete. Una soluzione del tipo ACK/NACK non può essere applicata in questo contesto (vogliamo un’affidabilità del tipo event-to-Sink e non end-to-end ed inoltre questa strategia porterebbe ad uno spreco di energia). Perciò l’ESRT usa un meccanismo di rilevazio-ne della congestiorilevazio-ne basato sul monitoraggio della livello del buffer locale di ogni nodo. Ogni sensore il cui buffer va in overflow è detto congestiona-to e informa il Sink di questa cosa.
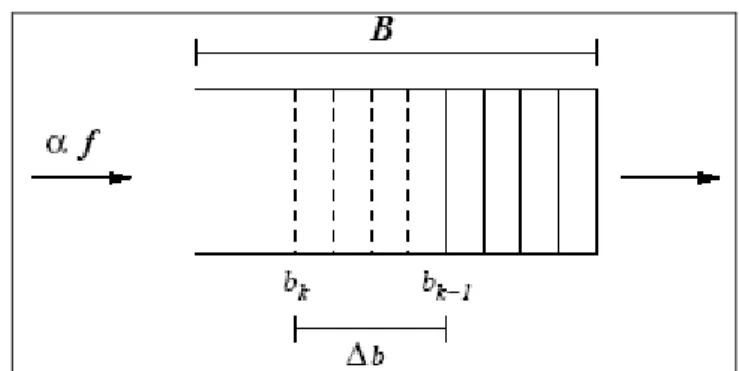
La congestione su un nodo viene rilevata nel seguente modo (Figura 3.5) : ipotizziamo che bk e bk-1 siano il livello di riempimento del buffer alla fine
del k-esimo e del (k-1)-esimo intervallo di reporting e B la dimensione del buffer. Per un Nodo Sensore, dato Δb incremento della lunghezza del buffer osservato alla fine dell’ultimo reporting period :
1 − − =
∆b bk bk (3.6)
Figura 3.5 ESRT: rilevazione della Congestione
Se abbiamo che bk + Δb>B allora il nodo conclude che sta andando a
spe-rimentare congestione. Perciò segnale questo al Sink tramite il settaggio del bit CN (congestion notification) nell’intestazione del pacchetto che tra-smette al Sink (Figura 3.6)
Figura 3.6 ESRT: paccheto 3.1.3 PSFQ
[Cambpbell 02] È un protocollo per gestire la reliability sulla reverse path. I dati che fluiscono dal nodo Sink comprendono files di programmazione o di riprogrammazione dei nodi, interrogazioni per i nodi etcc… La dissemi-nazione di questo tipo di dati richiede la maggior parte delle volte un’affidabilità del 100 %. Quindi, l’approccio introdotto in precedenza per
una reliability di tipo event-to-Sink non è sufficiente per risolvere questo ti-po di problema.
In PSFQ non viene realizzata una affidabilità di tipo end-to-end. Il maggior problema con un recupero dell’errore di tipo end-to-end ha a che fare con le caratteristiche fisiche del mezzo di trasmissione: le Reti di Sensori soli-tamente operano in ambienti con molti disturbi e, poiché gli errori si accu-mulano esponenzialmente, in una trasmissione multihop un approccio di questo tipo risulterebbe impraticabile. Un approccio di questo tipo risulte-rebbe conveniente solo per canali il cui errore di trasmissione risulti al di sotto dell’1% che sicuramente non è il caso di una Rete di Sensori. È quindi preferibile usare un approccio con ritrasmissioni locali (hop-by-hop error recovery) assieme alla tecnica dei negative acknolegment. In questo modo essenzialmente si segmenta un cammino multihop in una serie di trasmissioni a singolo hop eliminando così il problema dell’accumulo dell’errore accennato in precedenza. L’approccio del recupero dell’errore hop-by-hop perciò risulta più scalabile e più tollerante agli errori.
Il protocollo PSFQ (Pump Slowy Fetch quickly) è basato sull’iniettare pac-chetti nella rete con un basso rate (Pump Slowy) ma sull’eseguire, in caso di perdita di un pacchetto, un recupero dell’errore aggressivo (Fetch quickly).
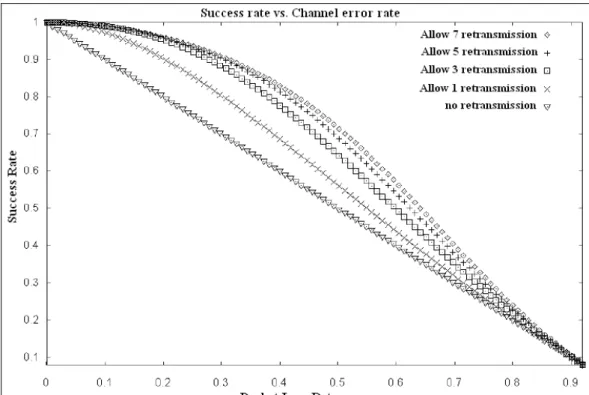
In PSFQ, l’operazione di pump viene realizzata tramite un flooding control-lato e richiede che ciascun nodo intermedio crei e mantenga una data cache da essere usata per il recupero di eventuali perdite. Infatti è neces-sario poter permettere ritrasmissioni multiple del pacchetto n prima dell’arrivo del pacchetto n+1. In altre parole vogliamo svuotare la CODA del ricevitore prima dell’arrivo di un nuovo pacchetto. Il problema è deter-minare il numero ottimo di ritrasmissioni che devono essere permesse per ogni pacchetto.
Dalla Figura 3.7 è possibile notare che le prestazioni incrementano sensi-bilmente fino a quando non si raggiungono un numero di ritrasmissioni pa-ri a 5. Quindi, il rapporto ottimale tra il tasso di trasmissione (operazione di pump) e quello di fetch deve essere approssimativamente pari a 5.
La consegna dei pacchetti deve avvenire in sequenza in quanto questo minimizza il numero di pacchetti che ogni nodo deve mantenersi nella propria data cache.
Figura 3.7 Probabilità di successo nella consegna di un messaggio permettendo ritrasmis-sioni multiple prima dell’arrivo del messaggio successivo
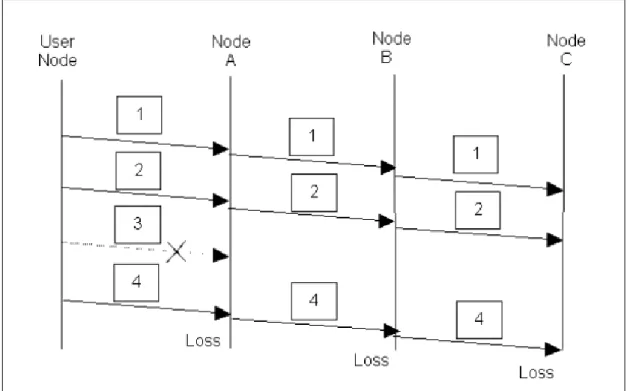
La Figura 3.8 mostra come la propagazione di un errore di trasmissione porti ad un vasto spreco di energia: i nodi A,B e C di figura si accorgono della mancata ricezione del pacchetto 3 solo quando ricevono il pacchetto 4. Se quando il nodo C invia il nack al nodo B quest’ultimo non ha il pac-chetto e quindi l’errore non può essere recuperato. È quindi necessario assicurarsi che i nodi intermedi consegnino pacchetti con sequence num-ber continui. Ritornando all’esempio di Figura 3.8, il nodo A non deve tra-smettere il pacchetto 4 fino a quando non ha ricevuto correttamente il pacchetto 3. La data cache deve contenere sia il messaggio 3 che il mes-saggio 4.
Figura 3.8 PSFQ:trasmissione sequenziale
3.1.4 CODA
[Campbell 03] CODA è un protocollo per la rilevazione e per la gestione della congestione sulla forward path ( cioè dai nodi verso il Sink) di una Rete di Sensori.
Il protocollo può essere suddiviso in 3 parti:
• Rilevazione della Congestione: ogni nodo sorgente è in grado di ri-levare condizioni di congestione locale. Questo viene fatto analiz-zando sia lo stato attuale del buffer di trasmissione ma anche in base alle condizioni presenti e passate del mezzo di trasmissione. In pratica viene fatto un sensing del mezzo di trasmissione e per ovvi motivi energetici il sensing non viene fatto in continuo ma solo per brevi istanti di tempo. Quando un nodo rileva una condizione di congestione locale prende dei provvedimenti locali per limitare il ca-rico del mezzo di trasmissione ed inoltre invia in broadcast dei messaggi di backpressure per segnalare la congestione rilevata; • Open-Loop hop-by-hop backpressure: quando un nodo riceve un
messaggio di backpressure può decidere di rallentare il proprio tas-so di invio oppure di cancellare dei pacchetti pronti per la
trasmis-sione. Inoltre, in base alle condizioni di congestione rilevate, può decidere se a sua volta inviare il messaggio di backpressure in bro-adcast oppure no. Quando un nodo invia un messaggio di ba-ckpressure non abbiamo la garanzia che tutti i vicini ricevano quel messaggio anche se dal punto di vista probabilistico possiamo con-siderare questa ipotesi veritiera. Un nodo continua ad inviare in broadcast messaggi di backpressure a intervalli regolari fino a quanto la congestione persiste;
• Closed-Loop Multi-Source Regolation : mentre le prime due fasi de-scritte in precedenza servono per rilevare e gestire la congestione
locale, CODA prevede un meccanismo per regolare le congestioni
persistenti e su larga scala. Sotto normali condizioni le sorgenti si auto-regolano imponendosi un rate di trasmissione predefinito dall’applicazione e senza la supervisione del nodo Sink: questo av-viene quando il rate r di trasmissione risulta minore di una frazione η del massimo throughput teoretico del canale Smax. Quando inve-ce questo valore viene superato (r >= η Smax) allora è probabile che la sorgente stia contribuendo alla congestione e quindi si aziona il controllo di tipo closed-loop: da questo momento in poi la sorgente richiede dei feedback dal Sink per regolare il rate di trasmissione. Per fare questo la sorgente imposta ad uno un particolare bit nel pacchetto che contiene l’evento rilevato e che viene inviato verso il Sink. La ricezione da parte del Sink di un pacchetto col bit imposta-to ad uno forza il Sink ad inviare degli ack (ad esempio un ack ogni 100 eventi ricevuti dal Sink) per regolare tutte le sorgenti associate ad un certo evento. Una sorgente che ha azionato il meccanismo di closed-loop si aspetta di ricevere un ack entro un certo periodo di tempo oppure l’arrivo di ack con un determinato tasso. Se non c’è congestione allora gli ack arrivano in modo regolare e quindi la sor-gente mantiene il proprio rate di trasmissione altrimenti è costretta a rallentare. Se ad esempio il Sink rileva una congestione allora può decidere di non inviare ack e di conseguenza le sorgenti sono
co-strette a cancellare i pacchetti in CODA di trasmissione. Quando la congestione sparisce allora il Sink ricomincia ad inviare ack. Quan-do il rate di trasmissione di una sorgente riscende sotto la soglia cri-tica (r < η Smax) allora il closed-loop viene interrotto e la sorgente invia pacchetti senza attendere ack da parte del Sink.
2.2 PROTOCOLLI DI ROUTING
Così come gli altri protocolli, anche quelli di routing devono essere effi-cienti dal punto di vista energetico.
Passiamo ora in rassegna le caratteristiche di alcuni protocolli per Reti di Sensori proposti in letteratura.
3.2.1 ENERGY EFFICIENT ROUTE
Uno degli approcci che può essere seguito è quello di scegliere il cammi-no più efficiente dal punto di vista energetico. Per fare questo prendiamo in considerazione la rete di Figura 3.9 sotto, dove il nodo T è il nodo sor-gente. Ci sono 4 possibili vie per poter comunicare con il nodo Sink: • Percorso 1: Sink-A-B-T; total PA=4, total α=3;
• Percorso 2: Sink-A-B-C-T; total PA=6, total α=6; • Percorso 3: Sink-D-T; total PA=3, total α=4; • Percorso 1: Sink-E-F-T; total PA=5, total α=6.
Dove con PA abbiamo indicato la potenza disponibile mentre con α= e-nergia necessaria per trasmettere un pacchetto lungo il link.
Gli algoritmi che possono essere applicati sono
• MAXIMUN AVAIBLE POWER ROUTE: si sceglie il percorso che ha il total PA maggiore. In base alla definizione si ha che il percorso 2 è il migliore; ma poiché il percorso 2 include tutti i nodi del percorso 1 non deve essere considerato. In pratica è importante non considerare per-corsi derivati estendendo altri perper-corsi. È quindi necessario eliminare il percorso 2. Il percorso da selezionare è perciò il percorso 4 (che chia-miamo PA route);
• MINIMUM ENERGY ROUTE: si sceglie il percorso che comporta un minimo consumo di energia per la trasmissione dei dati. Quindi il per-corso1 è il percorso migliore (ME route);
• MINIMUM HOP ROUTE: si sceglie il percorso che comporta un attra-versamento minimo di nodi. Nel nostro esempio il percorso 3 è il mi-gliore (MH route).Da notare che la minimum hop route risulta la stessa della minimum energy route quando il costo di trasmissione sui link è sempre lo stesso (cioè è costante);
• MAXIMUM MINIMUM NODE ROUTE: si sceglie il percorso in cui il PA minimo è il maggiore di tutti i PA minimi degli altri percorsi. Nel nostro caso scegliamo il percorso 3.
3.2.2 DATA-CENTRIC ROUTE
In questo tipo di routing la diffusione di una interrogazione è effettuata in modo da assegnare i task di sensing ai Nodi Sensore.
Gli approcci usati sono due:
• I Sink effettuano la trasmissione in broadcast della interrogazione; • I Nodi Sensore inviano un messaggio per notificare la disponibilità di
dati e aspettano una richiesta dai Sink interessati.
Un routing di tipo data-centric richiede un naming basato sugli attributi. Gli utenti sono più interessati nel conoscere l’attributo di un fenomeno piutto-sto che ad interrogare un singolo nodo. Ad esempio “la zona in cui la tem-peratura è maggiore di 30°” (attribute-based naming) è una interrogazione più usata e più utile di “la temperatura letta da un determinato nodo”.
Figura 3.9 Energy Efficient Route: rete di riferimento
3.2.3 DATA AGGREGATION ( o DATA FUSION)
Serve per risolvere il problema dell’implosione e supera i problemi presenti nel data centric routing:
Prendiamo come esempio il caso in cui il nodo Sink chiede ai nodi di rile-vare la temperatura di un ambiente.
Con riferimento alla Figura 3.10 il nodo E aggrega le informazioni di A e B e le combina in un set di informazioni concentrate.
Quando si effettua l’aggregazione dei dati è necessario non perdere in-formazioni importanti per l’applicazione (ad esempio la zona di cui è relati-va l’informazione)
3.2.4 FLOODING
È una vecchia tecnica che può essere usata anche per il routing nelle Reti di Sensori. In questa tecnica un nodo che riceve dati o pacchetti di gestio-ne li ritrasmette in modo broadcast (a meno che il pacchetto abbia
rag-del pacchetto). Il flooding è una tecnica reattiva e che non richiede un mantenimento della topologia. Comunque presenta alcuni problemi:
• Implosion :situazione in cui duplicati di un messaggio siano inviati allo stesso nodo. Ad esempio se il nodo A ha N vicini che a loro volta han-no il han-nodo B come vicihan-no allora il Nodo Sensore B riceve N copie del messaggio inviato da A;
• Overlap : se due nodi condividono la stessa regione di osservazione, entrambi potrebbero rilevare gli stessi stimoli agli stessi istanti. Quindi i nodi vicini ricevono messaggi duplicati;
• Resource Blindness : questo protocollo non tiene di conto della risorsa energia disponibile.
Figura 3.10 Esempio di aggregazione di dati
3.2.5 GOSSIPING
È una derivazione del flooding. In questo protocollo i nodi non fanno l’inoltro dei messaggi ma inviano i pacchetti ad un solo nodo selezionato in modo random tra tutti i vicini. Questo approccio evita il problema dell’implosione ma impiega molto tempo per propagare un messaggio a tutti i nodi.
3.2.6 SPIN (Sensor Protocols for Information via Negotiation)
È una famiglia di protocolli adattivi ideati per risolvere i problemi del floo-ding tramite una negoziazione e un adattamento delle risorse. Il protocollo si basa sull’idea che i nodi operano in modo più efficiente se, invece di in-viare i dati, inviano prima una descrizione dei dati ( e poi eventualmente i dati).
Figura 3.11 Il protocollo SPIN
Come è possibile vedere nella Figura 3.11 lo SPIN prevede tre tipi di mes-saggi: ADV,REQ,DATA. Prima di inviare i dati (DATA ), il nodo invia in broadcast un messaggio ADV contenente una descrizione (ad esempio meta-dati) dei dati. Se un vicino è interessato ai dati manda un messaggio di REQ ed in seguito riceve un messaggio di tipo DATA.
Da notare che il protocollo SPIN è basato sul data-centric routing.
3.2.7 SAR (Sequential Assignment Routing)
È un set di algoritmi che implementano operazioni di organizzazione , e gestione della mobilità di una Rete di Sensori.
Due algoritmi appartenenti a questa famiglia sono:
• SMACS (self-organizing MAC for sensor networks) : è un protocollo di-stribuito che permette ad un insieme di Nodi Sensore di scoprire i loro
vicini e di stabilire dei piani di ricezione/trasmissione senza il bisogno di un sistema centrale di gestione.
• EAR (eavesdrop and register protocol) è un protocollo basato sui mes-saggi di invito e sulla registrazione di nodi mobili presso nodi stazionari (vedi Figura 3.12)
BI -invito Broadcast
MI -invito Mobile
MR -Risposta Mobile
MD -Disconnessione Mobile
Figura 3.12 Algoritmo EAR
Gli algoritmi della famiglia SAR creano più alberi in cui la radice di ogni al-bero è un vicino (one hop neighbor ) del nodo Sink. Ogni alal-bero viene co-struito a partire dal Sink e vengono evitati i nodi con una bassa QoS (ad esempio un basso throughput) e una bassa riserva di energia. Alla fine di questa procedura la maggior parte dei nodi appartengono a più di un albe-ro. Questo permette ad un Nodo Sensore di scegliere un albero per man-dare le sue informazioni al nodo Sink. Ci sono due parametri associati ad ogni percorso che lega un nodo al nodo Sink:
• Risorse energetiche: sono calcolate in base al numero di pacchetti che il Nodo Sensore può mandare ed in base al fatto se il Nodo Sensore ha un uso esclusivo del cammino o meno;
• Metrica additiva della QoS : se risulta alta allora la QoS è bassa.
Tramite questi due parametri e il livello di priorità del pacchetto da inviare, ciascun nodo sceglie il cammino su cui inviare i pacchetti fino al nodo Sink.
3.2.8 LEACH (Low-Energy Adaptive Clustering Hierarchy)
È un altro protocollo che gestisce i task di segnalazione e di trasferimento dati di processi che richiedono la collaborazione di più nodi
È un protocollo basato sul clustering e che minimizza la dissipazione di energia in una Rete di Sensori. Lo scopo di questo protocollo è quello di scegliere in modo random alcuni nodi ed eleggerli capo-cluster. Gli altri nodi, invece, si associano ad un cluster in modo da minimizzare la dissi-pazione di energia.
Vediamo come viene eletto un capo-cluster: ogni nodo, durante la fase di setup, sceglie un numero random compreso tra 0 e 1. Se questo numero è minore della soglia T(n) allora il nodo viene eletto capo-cluster. T(n) viene calcolato nel seguente modo:
[
]
⎪⎩ ⎪ ⎨ ⎧ ∈ − = altrimenti 0 G n se ) / 1 mod( 1 ) ( P r P P n T (3.7)Dove: P è il desiderio di diventare un capo-cluster (random) , r è il round corrente e G è il set di nodi che non sono ancora stati selezionati come capo-cluster negli ultimi 1/P round.
Dopo che sono stati scelti i capo-cluster, ciascun capo-cluster invia un messaggio a tutti gli altri nodi della rete per avvertirli della propria promo-zione. Dal momento che i Nodi Sensore ricevono il messaggio, stabilisco-no il cluster a cui ogni stabilisco-nodo vuole appartenere (questo calcolo è basato sulla potenza del segnale ricevuto da ciascun capo-cluster). A questo pun-to ciascun Nodo Sensore si registra presso il proprio capo-cluster. In se-guito il capo-cluster assegna il periodo di tempo durante il quale ciascun Nodo Sensore appartenente a quel cluster può inviare dati al capo. Il ca-po-cluster riceve e aggrega i dati dei nodi appartenenti al cluster prima di inviare questi dati alla stazione base.
Dopo un certo periodo di tempo la rete entra nuovamente in fase di setup (nuovo round) e inizia nuovamente la fase di selezione dei capo-cluster.
3.2.9 DIRECTED DIFFUSION
È un protocollo per la diffusione di Interrogazioni e per il recupero dei risul-tati da una Rete di Sensori. Questo meccanismo risulta scalabile rispetto al numero di sensori che compongono la rete (anche milioni); inoltre tiene di conto che i nodi sensori possono fallire, finire la batteria o essere tem-poraneamente incapaci di comunicare a causa di fattori ambientali.
Questo meccanismo cerca di minimizzare il consumo energetico
Nel direct Diffusion la descrizione dei task viene fatta tramite una lista di coppie attributo-valore.
Ad esempio il task: “Per i prossimi 10 secondi e ogni 20 ms inviami una stima della posizione di qualsiasi animale a quattro zampe se avvistato all’interno della regione rettangolare di cOORdinate [-100,100,200,400] “ viene tradotto con questa descrizione (chiamata interest) :
type= four-legged animal interval = 20 ms
duration = 10 seconds rect = [-100, 100, 200, 400]
la risposta che verrà inviata dai Nodi Sensore (dotati di gps per conoscere la propria posizione) sarà del tipo:
type = four-legged animal instance = elephant
location = [125, 220] intensity= 0.6
confidence = 0.85 timestamp = 01:20:40
Passiamo ora alla descrizione del funzionamento dell’algoritmo, vedendo come vengono propagate gli Interest e come sono generati i gradienti. Se il Sink vuole diffondere nella rete il seguente interest:
type = four-legged animal interval = 10 ms
duration = 10 min
rect = [-100, 100, 200, 400]
Allora invia periodicamente in broadcast, a tutti i suoi vicini, il seguente in-terest:
type = four-legged animal interval = 1s
rect = [-100, 200, 200, 400] timestamp = 01:20:40 expiresAt = 01:30:40
Questo Interest può essere pensato come esplorativo. Serve per vedere
se esiste veramente qualche nodo in grado di rilevare un animale a quat-tro zampe (ecco perché viene specificato un tasso più basso di quello rea-le). L’Interest viene poi periodicamente rinfrescato dal Sink tramite ulteriori trasmissioni del medesimo ma con un timestamp aggiornato (questo è ne-cessario perché gli Interest non sono diffusi in modo affidabile per tutta la rete ).
Ogni nodo si mantiene una Interest cache del tipo riportato in tabella 3.1 . Type Rect Gradiente1 ….. GradientN
Id vicino1 … Id vicinoN
Data rate1 … Data rateN
Durata1 …. DurataN
Tabella 3.1 Directed Diffusion:Interest cache
Di campi di tipo gradiente al massimo ce n’è 1 per ogni vicino del nodo. Ogni nodo, quando riceve un Interest prima lo memorizza nella Interest cache (o inserisce un nuovo Interest o effettua il refresh di un vecchio inte-rest) e dopo decide di fare il re-direct dell’Interest ad un sott’insieme dei
vicini (questa cosa può essere fatta in broadcast e quindi viene effettuato
un flooding oppure ad esempio tramite un geographic routing
etc…).Nell’Interest non ci sono informazioni riguardanti il Sink che ha in-viato l’interest: ai vicini l’Interest appare come generato dal nodo che ha effettuato il l’inoltro dell’Interest e non dal Sink.
Alla fine della disseminazione dell’Interest si crea una rete di gradienti co-me è possibile vedere nella Figura 3.13 di sotto. Da notare che i gradienti sono bidirezionali : questo perché, quando un nodo riceve un Interest da un suo vicino, non ha modo di sapere se l’Interest ricevuto era già stato inviato in precedenza da lui stesso oppure se è un Interest identico a quel-lo inviato in precedenza ma che è sta inviato da un altro Sink (nota: nella figura l’Interest è stato diffuso tramite un flooding).
Figura 3.13 Directed Diffusion: Creazione di gradienti dopo la diffusione degli interest Passiamo ora ad analizzare come avviene la propagazione dei dati dai nodi verso il Sink.
Un Nodo Sensore campiona e genera dati (per ogni task) ad un rate che è il massimo tra i rate indicati nei campi gradiente della propria Interest cache. Il nodo sorgente invia, in unicast, gli event description, a tutti i vicini per cui ha installato un gradiente nella Interest cache.
Un nodo, quando riceve un event description controlla la propria Interest cache:
• Se non ci sono match allora l’event description viene cancellato; • Se c’è un match allora controlla la data cache associata a
quell’Interest (la data cache associata ad un Interest contiene tutti i dati ricevuti e inviati riguardanti quell’interest). Se l’Interest descrip-tion ricevuto è già presente nella data cache allora il nodo elimina il messaggio (in questo modo è possibile evitare eventuali loop). Al-trimenti il messaggio è inserito nella data cache e viene inviato ai vicini del nodo (che hanno una entry nella Interest cache).
Consultando la data cache un nodo può determinare anche il tasso con cui ha ricevuto gli event description : quindi, quando un nodo riceve un event description va a consultare la sua Interest cache e:
• Se tutti i rate (di tutti i gradienti) sono maggiori o uguali al rate con cui sta ricevendo gli event description allora invia l’event description ai vicini opportuni;
• Se qualche gradiente ha un rate minore rispetto al rate con cui sta ricevendo igli event description allora a quel nodo è necessario trasmettere ad un rate minore (alimino alcuni pacchetti oppure in-terpolo 2 eventi successivi).
Per quanto detto finore il Sink diffonde un Interest con rate più basso di quello richiesto dall’applicazione. Una volta che un nodo rileva un animale inizia a inviare dati a basso rate. I dati arrivano al Sink di solito tramite più percorsi. Dopo che il Sink ha iniziato a ricevere questi eventi a basso rate rinforza un particolare vicino in modo da ricevere dati ad alta qualità (cioè con il rate voluto). Ad esempio è ragionevole rinforzare il vicino che per primo ha inviato l’evento. Per fare questo il Sink invia nuovamente l’Interest originale ma con un tasso più alto:
type = four-legged animal interval = 10ms
rect = [-100, 200, 200, 400] timestamp = 01:22:35 expiresAt = 01:30:40
Quando il nodo vicino riceve questo Interest nota che ha già un gradiente ricevuto dal nodo Sink: poiché questo Interest ha un rate maggiore del precedente allora il vecchio gradiente viene soprascritto. Se questo nuovo data rate è inoltre maggiore dei data rate degli altri gradienti allora il nodo deve a sua volta rinforzare almeno un vicino: ad esempio può scegliere di rinforzare il nodo da cui ha ricevuto per primo l’ultimo evento. Tramite questa sequenza di interazioni locali viene stabilito un percorso ad alto ra-te tra il Sink e la sorgenra-te (vedi Figura 3.14).
L’algoritmo appena descritto potrebbe portare alla necessità di rinforzare più di un percorso. Se il Sink rinforza il vicino A ma dopo riceve un nuovo evento dal nodo B allora è necessario rinforzare il nodo B. Se il percorso tramite il nodo B risulta migliore è necessario un meccanismo per rinforza-re in negativo (indebolirinforza-re) il percorso tramite A. Ci sono vari metodi:
• Associare un timeout a tutti i gradienti con alto data rate:il Sink deve rinforzare periodicamente il vicino B mentre basta che non rinforzi più il vicino A;
• Indebolire esplicitamente il nodo A inviandogli un Interest con un basso rate. Quando A riceve l’Interest allora effettua il refresh del gradiente nella Interest cache e, se tutti gli altri gradienti hanno tutti un rate basso, A a sua volta rinforza in negativo tutti i vicini che gli stanno inviando dati ad un alto rate.
Vediamo quali sono le possibili regole che un nodo può seguire per deci-dere di rinforzare negativamente un nodo vicino:
• Rinforzare negativamente il vicino dal quale non sono stati ricevuti nuovi eventi ( ad es. gli altri vicini hanno costantemente inviato nuovi eventi prima di questo nodo) considerando una finestra di N eventi o di T secondi;
• Rinforzare negativamente il vicino che ha inviato il numero minore di nuovi eventi.
Vediamo ora il caso in cui, invece di avere una sola sorgente, abbiamo più sorgenti (Figura 3.15 ). Assumiamo che inizialmente tutti i gradienti abbia-no un basso rate: in questo modo i dati delle sorgenti A e B raggiungoabbia-no il Sink sia tramite il nodo C che tramite il nodo D. Se ad esempio C ha co-stantemente un ritardo minore rispetto a D allora in base alle regole appe-na viste il percorso attraverso C viene rinforzato.
Figura 3.15 Directed Diffusion: 2 sorgenti
Se invece il Sink sente gli eventi di A provenire prima da C mentre gli e-venti di B provenire prima da D allora il Sink rafforza entrambi i percorsi : in questo caso il Sink riceve gli eventi di entrambe le sorgenti da entrambi i vicini (C e D) e questo è fonte di spreco di energia. Sarà necessario ,in futuro, trovare un metodo per evitare questo spreco.
Nel il caso in cui due nodi Sink diffondono lo stesso Interest nella rete tut-to funziona regolarmente (Figura 3.16 ).
Figura 3.16 Directed Diffusion: due Sink
Se all’inizio è attivo solo il Sink Y (e il Sink X funziona da nodo) allora il Sink Y rinforza un percorso per ricevere eventi ad alto rate; quando anche il Sink X è interessato allo stesso task iniettato da Y allora può direttamen-te rinforzare un percorso senza dover aspettare l’arrivo di alcuni eventi a basso rate e andando a consultare direttamente la propria data cache. Fino ad ora abbiamo analizzato il caso in cui il rinforzo di un percorso sia triggerato da un Sink. Comunque nella directed Diffusion anche i nodi in-termedi possono applicare un rinforzo sui percorsi che però devono esse-re già stati rinforzati in pesse-recedenza.Questa cosa è utile per permetteesse-re ri-parazioni locali di percorsi che falliscono o che risultino degradati. Nell’esempio di Figura 3.17 assumiamo che la qualità del link tra la sor-gente e C degrada e gli eventi risultano frequentemente corrotti. Quando C rileva questo degrado (notando che la frequenza con cui gli eventi arri-vano è bassa) allora può rinforzare negativamente il link tra se stesso e la sorgente.
3.3 PROTOCOLLI PER L’ACCESSO AL MEZZO
TRA-SMISSIVO
Il MAC protocol in una Rete di Sensori deve raggiungere diversi obbiettivi: • Creare l’infrastruttura della rete. Poiché migliaia di sensori sono sparsi
in modo denso in una zona, il MAC deve stabilire un link di comunica-zione per il trasferimento dei dati. Questo crea l’infrastruttura di base necessaria per la comunicazione wireless di tipo hop-by-hop e dà, alla Rete di Sensori, la capacità di auto organizzarsi;
• Condividere in modo equo ed efficiente le risorse di comunicazione tra i nodi sensori;
• Limitare il consumo di energia. È necessario usare modalità di rispar-mio di energia (ad esempio permettendo lo spengimento degli appa-recchi durante i periodi di idle); inoltre è preferibile usare, dove è pos-sibile, i timeouts agli acknoledgements. Anche l’accesso al mezzo tra-mite la contesa è giudicato inadatto a causa alla necessità di monitora-re il canale costantemente;
• Gestione della mobilità.
• Strategie di recupero da fallimento
Di solito i MAC protocol vengono classificati in base al meccanismo usato per la condivisione di risorse (possono essere assegnate in modo statico, in accordo alle richieste dell’utente oppure in base alla contesa sul canale trasmissivo quando c’è bisogno di trasmettere un pacchetto).
Non è possibile utilizzare i MAC protocol esistenti in quanto, nelle altre re-ti wireless, il principale obiettivo è il rispetto della QoS mentre i consumi assumono solo un ruolo secondario. Fra tutte le reti wireless quelle blue-thoot e quelle ad hoc sono sicuramente quelle più simili alle Reti Sensoria-li.
3.3.1 SMACS
È un protocollo distribuito che permette ad un insieme di Nodi Sensore di scoprire i loro vicini e di stabilire dei piani di ricezione/trasmissione senza il bisogno di un sistema centrale di gestione.
In questo protocollo la fase di scoperta dei vicini e quella di assegnazione del canale sono combinate in modo che, dal momento in cui i nodi ascol-tano tutti i loro vicini, formano una rete connessa.
Un link di comunicazione consiste in una coppia di time slot (uno per l’invio e uno per la ricezione) che entrano in esecuzione ad un tempo scel-to in modo random ma ad una frequenza stabilita: questa cosa (avere 2 slot, uno per l’invio e uno per la ricezione) è possibile in quanto si suppone che la banda disponibile sia più grande del massimo rate di invio dei dati. Questo schema richiede la necessita di una sincronizzazione tra i nodi. Il risparmio di energia è effettuato spengendo la radio durante i periodi di i-dle.
Descrizione del protocollo: nella Figura 3.18-b Il nodo A ed il nodo D si svegliano agli istanti Ta e Td rispettivamente. I due nodi si riconoscono l’uno con l’altro e concordano una coppia di time slot per scambiarsi dati (uno slot per trasmettere e uno per ricevere). Questa coppia di slot (tx/rx) viene ripetuta periodicamente ogni tempo Tframe. I nodi B e C si svegliano in un secondo momento (all’istante Tb e Tc rispettivamente). Analogamen-te a quanto descritto in precedenza i due nodi si riconoscono e stabilisco-no un’altra coppia di slot per la trasmissione/ricezione dei dati.
Da notare che, se tutti i nodi comunicano alla stessa banda di frequenza, allora è possibile che qualche trasmissione, nello schema appena descrit-to, vada in contro a collisione. Ad esempio, in base alla topologia della re-te mostrata nella Figura 3.18-a, una trasmissione dal nodo D al nodo A colliderebbe con una dal nodo B al nodo C. Se invece sono assegnate a diversi link diverse bande di frequenza, allora le trasmissioni non collidono più. Quindi, se la banda di trasmissione viene scelta in modo random tra un set di bande disponibili, la probabilità che due link adiacenti scelgano la stessa banda risulta molto bassa.
(a) Topologia Rete
(c) Fase di scoperta dei Nodi (b) Comunicazione NonSincrona
Figura 3.18 Fasi del protocollo SMACS Il tempo Trame è un parametro fisso del protocollo MAC.
Vediamo ora il meccanismo tramite il quale un nodo trova un altro nodo. Prendiamo in considerazione la Figura 3.18-c in cui sono valutati i nodi A, B e G. Questi nodi sono coinvolti nel processo di ricerca di nodi vicini. I nodi si svegliano ad istanti diversi (random). Appena sveglio, ciascun nodo si mette in ascolto sul canale, su una banda di frequenza fissata, per un tempo di durata random. Se alla fine di questo periodo il nodo non ha rice-vuto nessun invito dagli altri nodi allora decide lui stesso di trasmettere un invito. Questo è quello che accade al nodo C che invia in broadcast un messaggio di tipo1 (o invito). I nodi B e G, che nel frattempo si sono
sve-gliati e sono nella fase di ascolto, ricevono il messaggio di tipo1. Ciascun nodo, trascorso un periodo random di tempo dalla ricezione del messag-gio di tipo1, invia un messagmessag-gio di tipo 2 indirizzato al nodo C. Se i due messaggi di tipo2 non collidono il nodo C ascolta entrambi. Il nodo C deve scegliere un solo nodo a cui rispondere. Sceglierà il nodo B perché è quel-lo che ha risposto per primo ( un altro criterio di scelta che può essere u-sato è quello di scegliere il nodo più vicino oppure quello con il più alto li-vello di segnale ricevuto). Il nodo C invia un messaggio di tipo3 per notifi-care a tutti i nodi quale nodo è stato scelto. Il nodo G, che non è stato scelto, spenge il transceiver per un certo periodo e dopo riinizia nuova-mente la procedura appena descritta.
Se il nodo C sta già partecipando ad un’altra comunicazione con un altro nodo allora trasmette le informazioni riguardanti il suo attuale schedule nel body del messaggio di tipo3. Il nodo B legge queste informazioni, e si cal-cola due slot liberi per la comunicazione con il nodo C: tutte queste infor-mazioni sono inviate al nodo C nel body del messaggio di tipo4 (mostrato in Figura 3.18-c).
3.3.2 EAR
È un protocollo che cerca di offrire un servizio continuo ai nodi mobili in condizioni sia statiche che di mobilità. Questo protocollo è trasparente allo SMACS in modo che lo SMACS è funzionante fino all’introduzione di nodi mobili nella rete.
3.3.3 CSMA
I protocolli CSMA tradizionali sono da scartare perché partono dall’assunzione che il traffico sia stocasticamente distribuito e tendono a supportare flussi point-to-point indipendenti. Invece, un MAC protocol per una Rete di Sensori deve essere capace di supportare traffici variabili ma fortemente correlati.
IEEE 802.11
Lo standard IEEE 802.11 definisce un Livello MAC e diversi Livello Fisici ( Figura 3.19) , che servono ad agevolare la presenza di più tipi di canali e modulazioni utilizzate in virtù dalle differenti caratteristiche di sensing del mezzo.
Per quanto concerne il livello MAC, permette la sovrapposizione di più servizi rendendo il sistema robusto all’interferenza ed al problema della stazione nascosta. In generale, il metodo di accesso di base nell’IEEE 802.11 è il Distribuited Control Function (DCF) il cui nucleo è basato su un protocollo specifico detto Carrier Sense Multiple Access with Collision A-voidance (CSMA/CA). Oltre al DCF, lo standard 802.11 incorpora anche un metodo di accesso chiamato Point COORdination Function (PCF), che opera tramite una tecnica a Polling, utilizzando un nodo cOORdinatore (spesso un Access Point: nodo appartenete ad un infrastruttura fissa) per determinare quale stazione ha il diritto di trasmettere. Poiché quest’ultimo metodo di accesso può essere applicato solo in una rete completamente connessa e quindi non può essere adottato nella costituzione della Rete di Sensori, nelle descrizioni presenti nel seguito considereremo solamente il metodo di accesso DCF.
Ciascuna stazione, prima di iniziare a trasmettere, ascolta il canale per de-terminare se un’altra stazione sta trasmettendo. Se il canale è percepito libero per un intervallo di tempo pari ad un valore detto Distribuited Inter-Frame Space (DIFS) la stazione inizia la trasmissione.
Se invece il canale risulta occupato, la trasmissione è rimandata almeno fino alla fine della corrente trasmissione che sta occupando il mezzo fisico. La stazione, alla fine di questo tempo, genera un intervallo di tempo ca-suale, noto come Backoff Interval, è lo utilizza per inizializzare un contatore detto Backoff Timer. Il Backoff Timer è decrementato per tutto il tempo che il canale resta libero, congelato quando eventualmente una nuova trasmis-sione viene rilevata sul mezzo fisico e nuovamente decrementato quando il canale è nuovamente sentito idle per più di un DIFS. La stazione tra-smette quando il Backoff Timer raggiunge zero (Figura 3.20).
Figura 3.19 Architettura IEEE 802.11
Figura 3.20 IEEE 802.11 DCF:Meccanismo Base di accesso
Il backoff time è slottizzato, in particolare il tempo immediatamente suc-cessivo ad un intervallo DIFS libero è suddiviso in slot, ed una stazione è abilitata a trasmettere solo all’inizio di uno slot, la cui durata temporale è uguale a quella necessaria e sufficiente a rilevare la trasmissione di un pacchetto da parte di un'altra stazione. Quindi il backoff time è un numero intero (da intendere come numero di slots) scelto da un intervallo unifor-me (0,CW-1). CW è definita counifor-me Backoff Window (anche detta
conten-tion window). Alla prima trasmissione CW=CWmin e il suo valore viene raddoppiato per ogni ritrasmissione fino a raggiungere CWmax. CWmin e CWmax dipendono dal physical layer adottato.
Per garantire equità di accesso al mezzo condiviso, una stazione che ha già trasmesso un pacchetto, e possiede un ulteriore pacchetto da inviare, applica la procedura di backoff prima di iniziare un’altra trasmissione. Naturalmente, può accadere che due o più stazioni inizino a trasmettere in contemporanea, portando quindi a collisione. Tramite il CSMA/CA le sta-zioni non sono capaci di rilevare una collisione ascoltando le loro trasmis-sioni (questo è possibile nel CSMA/CD) . Quindi è necessario che un im-mediato Acknowledge di ricezione corretta sia inviato dal ricevitore per in-formare il trasmettitore dell’avvenuta corretta ricezione. In relazione alla Figura 3.21, immediatamente dopo la ricezione del pacchetto dati, il ricevi-tore inizia la trasmissione dell’Acknoledge (ACK) dopo un intervallo di tempo denominato Short InterFrame Space (SIFS), di durata inferiore al DIFS. Se un Acknowledge non è ricevuto, il frame dati si suppone essere perso, e quindi viene attivata una nuova ritrasmissione dello stesso. Il SIFS è più piccolo del DIFS per poter dare priorità alla stazione ricevente rispetto ad altre possibili stazioni che sono in attesa per trasmettere.
Figura 3.21 IEEE 802.11 DCF: meccanismo di acknoledgment
L’ACK non viene trasmesso nel caso che il codice a rilevazione di errore Cyclic Redundancy Check (CRC) rilevi che il pacchetto dati è corrotto o se il pacchetto non viene del tutto rilevato.
Il problema della stazione nascosta
Lo schema appena descritto funziona correttamente se le tutte le stazioni sono in grado di riceversi reciprocamente. Questo vincolo non sempre è soddisfatto. Ad esempio, la Figura 3.22 mostra un tipico scenario delle “stazioni nascoste”. Assumiamo che la stazione B si trovi nel raggio di tra-smissione sia della stazione A che della stazione C ma che A e C non possano ascoltarsi l’un l’altra. Assumiamo l’ipotesi che A deve trasmettere a B. Se anche C ha un frame da trasmettere a B, in base al protocollo DFC, effettua il sensing del mezzo e trova questo libero; quindi C inizia la trasmissione ma il frame sperimenta interferenza.
Questo problema può essere superato imponendo una leggera modifica al metodo di accesso. Il protocollo con la nuova caratteristica, consiste nell’estendere il meccanismo del Carrier Sense attraverso un meccanismo di “acquisizione” di informazione chiamato Request To Send (RTS) / Clear To Send (CTS). In questo caso, una stazione dopo aver guadagnato l’accesso al mezzo e prima di iniziare la trasmissione del pacchetto dati, invia un breve pacchetto di controllo, chiamato RTS, al destinatario, an-nunciandogli l’imminente trasmissione di un frame di dati; il destinatario quindi, rispondecon un breve pacchetto CTS che è pronto a ricevere i da-ti. Quindi, in risposta al CTS, dopo un ulteriore tempo SIFS comincia la trasmissione dati (si veda Figura 3.23).
I pacchetti RTS e CTS contengono anche la durata stimata della trasmis-sione. Il vantaggio consiste nel fatto che quest’informazione può essere letta da ogni stazione nell’area di ricezione dei pacchetti del trasmettitore e del ricevitore e quindi può memorizzata da tutte le stazioni in un Network Allocation Vector (NAV) il quale contiene l’informazione sul periodo di tempo per il quale il canale rimarrà occupato. Per questo, tutte le stazioni nell’area di copertura di almeno una delle due stazioni comunicanti, sono a conoscenza di quanto tempo il mezzo fisico sarà occupato per tale tra-smissione dati (si veda Figura 3.23) e quindi evitano di trasmettere.
Figura 3.23 IEEE 802.11 DCF Meccanismo del Virtual Carrier Sensing
Problema della stazione esposta
Esiste anche il problema inverso a quello della stazione nascosta: si sup-ponga, come riportato in Figura 3.24 che B stia trasmettendo ad A e che C voglia trasmettere a D:
Ascoltando il mezzo, C sentirà la trasmissione di B e concluderà erronea-mente di non poter trasmettere; invece, essendo D fuori della portata di B, ed A fuori della portata di C, le due trasmissioni potrebbero avvenire paral-lelamente senza interferenze.
Figura 3.24: problema della stazione esposta Sincronizzazione
All’interno dello standard IEEE 802.11, una rete distribuita senza infra-struttura fissa è chiamato Indipendent Basic Service Set (IBSS) ed è costi-tuito da due o più stazioni IEEE 802.11 comunicanti direttamente senza l’intervento di un Access Point o di altra infrastruttura fissa.
Le due principali funzioni implementate nell’IEEE802.11 per la sincroniz-zazione delle stazioni dell’IBSS sono:
i) acquisizione della sincronizzazione (Synchronization Acquirement)
ii) mantenimento della sincronizzazione (Synchronization
Maintenan-ce).
Syncronization Acquirement. Questa funzionalità è necessaria per parte-cipare ad un IBSS. L’individuazione di una IBSS esistente è il risultato di una procedura di scansione del mezzo fisico da parte della stazione, nel quale la stessa si sintonizza su diverse frequenze radio, alla ricerca di par-ticolari pacchetti di controllo. Altrimenti,se la procedura di scansione non da risultati nella ricerca di una IBSS già esistente, la stazione può inizializ-zarne una nuova. L’inizializzazione può essere quindi sia attiva sia passi-va.
Synchronization maintenance. Questa funzionalità è presente per sopperi-re alla mancanza di una stazione centrale che fornisca il proprio riferimen-to temporale a tutte le altre. Il meccanismo di mantenimenriferimen-to della sincro-nizzazione è realizzato attraverso un algoritmo distribuito che è eseguito
da tutte le stazioni partecipanti all’IBSS. Questo algoritmo è basato sulla trasmissione di pacchetti di segnalazione ad un tasso nominale noto. L’intervallo fra l’invio di due pacchetti di segnalazione è quindi il parametro Beacon Period che è adottato da ogni stazione quando partecipa all’IBSS (intervallo che è deciso dalla stazione che ha inizializzato l’IBSS). All’inizio del Beacon Period ciascuna stazione intraprende le seguenti azioni:
• Interrompe il decremento del backoff timer per qualsiasi trasmissio-ne pendente (non-beacon)
• Genera un delay random uniformemente distribuito in un intervallo di estremi zero e due volte il valore minimo della Contention Window.
• Aspetta che si esaurisca il delay random;
• Se un pacchetto di tipo Beacon arriva prima che il delay random si sia esaurito allora interrompe il delay random, cancella la trasmis-sione pendente del pacchetto beacon e riattiva il backoff timer; • Se il random delay termina e non sono stati ricevuti nessun
pac-chetto beacon allora invia un frame di tipo beacon.
Quando viene trasmesso un beacon frame la stazione setta il time-stamp del beacon con il valore del proprio orologio interno. Quando una stazione riceve un beacon prende in considerazione il suo time-stamp. Se il timestamp del beacon è successivo al clock della stazione allora la stazione setta il proprio orologio al valore del timestamp rice-vuto. In pratica, le stazioni sincronizzano il loro orologio con l’orologio più veloce tra tutte le stazioni.
POWER MANAGEMENT
Nel contesto della mobilità, infine, le funzioni di Power Managment, rive-stono una particolare importanza dovuta alla poca energia che deve esse-re richiesta ai terminali portatili (i quali sono alimentati a batteria).
In particolare, una stazione può essere dal punto di vista del Power Sa-ving (PS) in due possibili stati: awake, se la stazione è completamente a-limentata, e doze, se la stazione non è in grado di trasmettere e ricevere.
Figura 3.25 IEEE 802.11 DCF Scambio di dati tra stazioni operanti in modalità PS
Ogni qualvolta, un pacchetto diretto o multicast sta per essere trasmesso, prima della trasmissione è annunciato attraverso un messaggio chiamato Ad-hoc Traffic Indication Message (ATIM), il quale deve essere inviato quando tutte le stazioni sono nello stato awake. Per cui è definita una fi-nestra ATIM di una certa durata, susseguente l’inizio di un intervallo di se-gnalazione, durante la quale possono essere trasmessi solamente pac-chetti di segnalazione o ATIM. Se una stazione non riceve nessun ATIM frame durante l’ATIM Window allora, alla fine della ATIM Window può en-trare nella stato dooze (Figura 3.25) .