Appendice B
Protocollo IP
B.1
Protocolli Ipv4 - Ipv6
B.1.1
Ipv4
IPv4 `e la versione di rappresentazione di indirizzi IP attualmente in uso dell’Internet Protocol. Esso `e descritto nell’IETF RFC 791 pub-blicato per la prima volta nel settembre 1981. Il diagramma seguente mostra come `e fatto l’header del protocollo IPv4: Notare che la larghezza della cella `e proporzionale alla lunghezza del campo. L’ind-irizzo IPv4 `e formato da 32 bit, esso `e univoco sulla rete di cui fa parte. Tale indirizzo, inoltre, non va assegnato all’host, ma alle connessioni fisiche alla rete che l’host possiede (nel cast di host multicollegati o di dispositivi di rete). Concettualmente l’indirizzo IP si compone di due parti:
• identificatore di rete e precisamente della sottorete
Fig. B.2: example caption
Per semplificarne la lettura, ogni indirizzo IP viene descritto con 4 numeri decimali in modo che ognuno rappresenti un byte (quindi ogni numero varia da 0 a 255) separati dal simbolo ’punto’; un esempio di indirizzo IPv4 `e 192.0.34.166. Ogni indirizzo in cui l’identificati-vo host presenta tutti 0 ci si riferisce alla rete, mentre se tutti i bit di questo identificativo sono a 1 ci si riferisce ad una trasmissione broadcast diretta.In pratica quando ad un router arriva un pacchetto con un indirizzo host con tutti bit a 1, questo esegue un broadcast a tutti gli host della sottorete. Se un host deve comunicare con un altro host della stessa sottorete, user`a il protocollo di livello 2 della rete a cui `e collegato, altrimenti dovr`a inviare i pacchetti ad un gateway o router, che sar`a connesso ad altre reti e si occuper`a di inoltrare i pacchetti ricevuti. La comunicazione tra i router avviene mediante indirizzi IP utilizzando delle tecniche particolari di indirizzamento per individuare la sottorete e l’host. Originariamente lo schema delle
suddivisione delle due componenti era a classi per cui un indirizzo IP aveva una delle seguenti forme: Con questi schemi l’indirizzo ´e ad
Fig. B.3: example caption
autoidentificazione perch´e il confine tra le due componenti si pu´o de-terminare con i bit pi´u significativi. Per maggiore chiarezza di seguito riportiamo le caratteristiche di ogni classe:
• classe A: il primo byte rappresenta la rete, gli altri l’host; [0-127].x.x.x. La maschera di sottorete ´e 255.0.0.0, o /8. Questi indirizzi iniziano tutti con un bit a 0.
• classe B: i primi due byte rappresentano la rete, gli altri l’host; [128-191].y.x.x (gli y sono parte dell’indirizzo di rete, gli x del-l’indirizzo di host). La maschera di sottorete ´e 255.255.0.0, o /16. Questi indirizzi iniziano con la sequenza 10
• classe C: i primi 3 byte rappresentano la rete, gli altri l’host; [192-223].y.y.x. La maschera di sottorete ´e 255.255.255.0, o /24. Questi indirizzi iniziano con la sequenza 110
• classe D: riservata agli indirizzi multicast: [224-255].x.x.x Il problema principale del protocolli Ipv4 e’ rappresentato dal numero di indirizzi univoci disponibili, che per tale protocollo vale:
232= 2564 = 4.294.967.296 ∼= 4.3 · 109 (B.1)
Bisogna tener presente che non vengono usati tutti, perch´e alcu-ni sono riservati a un particolare utilizzo (ad esempio gli indirizzi 0.0.0.0, 255.255.255.255, 192.0.34.166 e la classe 192.168.0.1/16) e perch´e certe classi non vengono sfruttate interamente per via della suddivisione interna in classi pi´u piccole. L’indirizzamento a classi, proprio per questo, presenta diversi limiti dovuti soprattutto al nu-mero di host gestibili dalle diverse classi. In pratica se si esauriscono gli indirizzi univoci resi disponibili da una classe, ad esempio la C connettendo pi´u di 255 host, occorre fare ricorso ad un indirizzo di classe superiore. Il cambiamento di indirizzo non ´e indolore con questa tecnica perch´e il software di rete va aggiornato con i nuovi indirizzi e non consente una transizione graduale. In pratica l’indicatore di rete univoco non poteva adempiere alle esigenze della crescita che negli anni ’80 ebbero le reti LAN. Quindi per risparmiare i prefissi di rete si dovettero escogitare altre tecniche come quella del mascheramento
per continuare a fare in modo che IPv4 potesse adempiere al suo ruo-lo prima dell’entrata di IPv6. L’indirizzamento in classi ´e considerato obsoleto, e per permettere un migliore sfruttamento degli indirizzi IP disponibili, ´e stato introdotto l’indirizzamento senza classi, o CIDR (Classless Inter-Domain Routing). La modifica introdotta dal CIDR consiste essenzialmente nell’utilizzare maschere di sottorete (subnet mask) di lunghezza arbitraria, mentre l’indirizzamento con classi am-metteva solo tre lunghezze della maschera di sottorete: /8, /16 e /24. La maschera della vecchia classe C (/24) ´e ancora popolare, ma si usano anche maschere pi´u corte per reti grandi (/23 o /22) o pi´u lunghe per reti piccole (/25, /26, fino a /30 per reti punto-punto). I bit che nella maschera di sottorete sono a 1 fanno parte dell’indi-rizzo della sottorete, gli altri sono l’indidell’indi-rizzo dell’host. Normalmente, la maschera di sottorete ´e costituita da N bit a 1 seguiti da (32-N) bit a 0, e pu´o essere abbreviata nella forma /N. In questo modo non si ´e vincolati a un numero fisso di bit per determinare l’indirizzo di rete, ma i bit utili a rappresentare la rete, piuttosto che l’host, sono fissati liberamente. Gli indirizzi IP sono univoci a livello mondiale, e vengono assegnati in modo centralizzato da una gerarchia di enti ap-positi. Sono considerati una risorsa preziosa da gestire con cura. Per rafforzare questo concetto, si parla di indirizzi IP pubblici. Inizial-mente l’autorit´a preposta era la IANA (Internet Assigned Number Authority), dopo il 1998 venne creato l’ICANN (Internet corporation for Assigned Names and Numbers) che opera tuttora. Essa ´e respon-sabile della gestione degli indirizzi IP in base alle direttive dell’ RFC 2050.
B.1.2
Ipv6
Le novita’ apportate da IPv6 rispetto a IPv4 riguardano:
• Estensione dello spazio degli indirizzi: la dimensione dell’IP ad-dress passa da 32 a 128 bits in modo da poter supportare diversi livelli gerarchici e allo stesso tempo un numero molto maggiore di nodi rispetto a IPv4. E’ stato introdotto anche un nuovo tipo di indirizzo l’Anycast usato per spedire un pacchetto ad un nodo qualsiasi di un gruppo di nodi selezionati come destinazione.
• Semplificazione del formato degli header: alcuni campi degli header di IPv4 sono stati eliminati o resi opzionali in modo da ridurre il tempo di elaborazione del singolo pacchetto nei casi di default, con un conseguente beneficio sulla velocita di trasmis-sione, infatti nonostante la dimensione degli indirizzi in IPv6 sia quadruplicata l’header di IPv6 e’ solo il doppio di quello di IPv4.
• Miglior trattamento delle estensioni e delle opzioni: la codifica delle opzioni nell’ header e’ cambiata in modo da rendere pi-u’ efficiente il forwarding.?Limiti meno stringenti sulla lunghez-za delle opzioni e inoltre maggiore flessibilita’ per facilitare l’introduzione di nuove opzioni in futuro.
• Introduzione di meccanismi per garantire qualita’ del servizio: e’ possibile etichettare pacchetti appartenenti ad uno stesso ”flus-so di traffico” per i quali il mittente richiede una qualita’ di servizio speciale, ad esempio la garanzia di una quantita‘ minima di banda costante. Questo e’ essenziale per servizi “real-time”.
• Introduzione di meccanismi di sicurezza: IPv6 definisce esten-sioni che permettono l’uso di meccanismi di autenticazione, integrita’ dei dati e segretezza a livello di network.
Inoltre in IPv6 le funzionalita’ di ICMPv4 e IGMP sono state rag-gruppate in un solo protocollo l’ICMPv6. ICMPv6 e’ usato per ri-portare errori incontrati nell’elaborazione dei pacchetti e nell’ese-cuzione di altre funzioni di livello di rete (es funzioni diagnostiche quali ping).
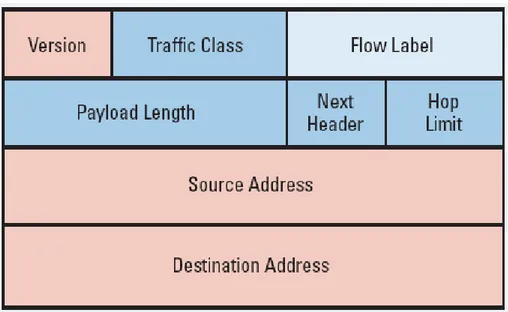
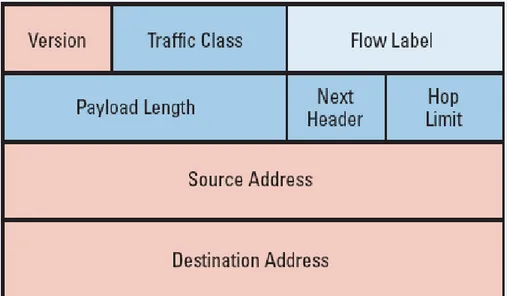
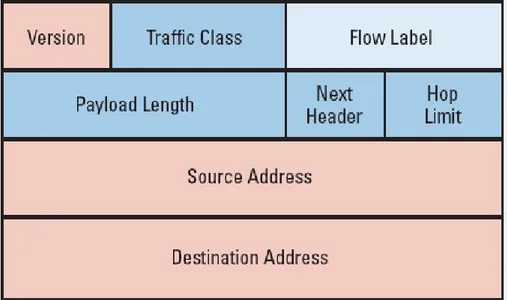
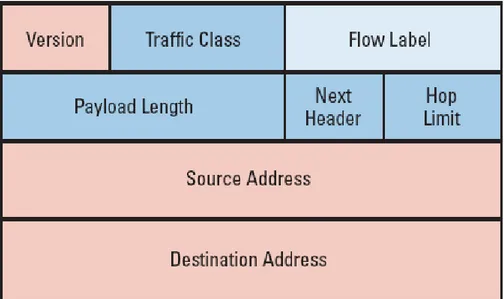
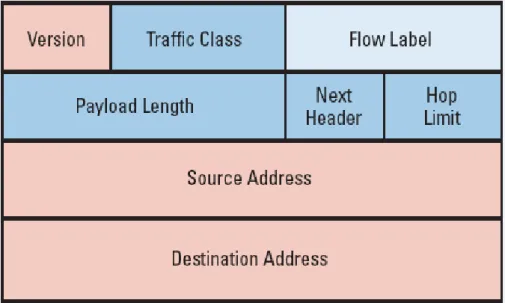
Formato del pacchetto - Header
Fig. B.4: example caption
In dettaglio si ha:
• Version: intero di 4 bit
• Priority: 4 bit
• Payload Lenght: 16 bit intero senza segno. Per dati si intende la lunghezza del pacchetto meno l’header.
• Next Header: 8 bit, identifica il tipo di header che segue l’header IPv6. I valori sono gli stessi di IPv4.
• Hop Limit: 8 bit intero senza segno. Viene decrementato di 1 ad ogni nodo attraversato dal pacchetto. Il pacchetto viene scartato da un nodo che trova il valore zero in questo campo.
• Source Address: 128 bits
• Destination Address: 128 bits
L’header di IPv6 consente di avere pacchetti con una lunghezza mas-sima di 65535 byte. Pacchetti di dimensione piu’ grande possono comunque essere spediti mediante una particolare modalita’.
Estensione dello spazio degli indirizzi
Gli indirizzi IPv6 sono lunghi 128 bit e servono ad identificare a dif-ferenza di IPv4 interfacce o insiemi di interfacce e non nodi. Lo spazio degli indirizzi ´e quattro volte quello di IPv4. Anche se pu´o sembrare enorme, la possibile richiesta di creazione di diversi livelli gerarchi-ci ridurr´a notevolmente il numero di indirizzi realmente utilizzati a causa di un calcolato spreco di indirizzi simile a quello avvenuto con il formato a classi di IPv4. Poich´e ogni interfaccia pu´o appartenere ad un solo nodo, qualsiasi indirizzo unicast di un’interfaccia apparte-nente ad un nodo pu´o essere usato per identificare il nodo. IPv6 definisce tre tipi di indirizzi:
• Unicast: Indirizzo per una singola interfaccia. Un pacchetto spedito ad un indirizzo unicast verra’ consegnato all’ interfaccia identificata dall’indirizzo.
• Anycast: Indirizzo per un insieme di interfacce (tipicamente ap-partenenti a nodi diversi). Un pacchetto spedito ad un indiriz-zo anycast sara’ consegnato ad una delle interfacce identificate dall’indirizzo.
• Multicast: Indirizzo per un insieme di interfacce. Un pacchetto spedito ad un indirizzo multicast sara’ consegnato a tutte le interfacce definite da quell’indirizzo
In IPv6 non ci sono piu’ gli indirizzi broadcast di IPv4, perch´e ´e una funzionalit´a coperta dalla modalit´a multicast. L’ indirizzo ´e composto da due campi il cui primo di lunghezza variabile, chiamato Format Prefix (FP) indica il tipo di indirizzo, il secondo ´e l’indirizzo vero e proprio. Inizialmente parte dello spazio degli indirizzi (circa il 15las-ciato ad allocazioni future.Gli indirizzi unicast e anycast sono sintat-ticamente uguali e per questo non ci sono due sottospazi diversi per l’allocazioni di questi tipi. Gli indirizzi multicast distinguono da quel-li unicast per il fatto di avere il valore dell’ottetto piu’ significativo uguale a FF. Gli indirizzi sono rappresentati mediante stringhe testo con il seguente formato: x:x:x:x:x:x:x:x
A causa dell’ allocazione dello spazio degli indirizzi, alcuni indirizzi avranno diversi campi con il valore zero. Per fornire una rappresen-tazione piu’ coincisa campi di zero possono essere rappresentati con ‘::’ 1080::8:800:200C:417A
Indirizzi IPv4 compatibili
Per gestire la fase di transizione con IPv4 sono stati definiti due diver-si tipi di indirizzi. Il primo definito ‘IPv4 compatibile’ che permette a nodi e router IPv6 di gestire indirizzi IPv4, inserisce nei 32 bit meno significativi dell’indirizzo IPv6, l’indirizzo IPv4.
Indirizzo Unicast IPv4 compatible
Il secondo definito ‘IPv4 mappato’ e’ usato per utilizzare IPv6 anche in presenza di nodi e/o router che non implementano IPv6. Indirizzo Unicast IPv4 mappato
Indirizzi Anycast Un indirizzo Anycast e’ un indirizzo assegnato a pi-u’ di un interfaccia con la proprieta’ che un pacchetto spedito ad un indirizzo anycast e’ instradato e consegnato all’interfaccia piu’ vicina avente quell’indirizzo. Dove la definizione di distanza dipende dalla politica di routing adottata. Questo tipo di indirizzi e’ stato pensato per risolvere in modo efficiente problemi come la gestione di siti mir-ror. Alcune aziende che operano a livello mondiale mantengono piu’ copie dello stesso archivio di informazioni fornite ai clienti. Le copie (mirrors) possono essere distribuite ad esempio geograficamente in modo da facilitare l’accesso dell’utenza distribuita in tutto il mondo. Con la modalita’ anycast si puo’ assegnare lo stesso indirizzo logico a tutti i siti ed e’ poi compito del router contattare la copia piu’ ‘vicina’ quando un pacchetto e’ spedito a questo indirizzo anycast, il tutto in modo trasparente dall’utente. Con IPv4 questa modalita’ puo’ essere ottentuta ma con l’intervento manuale da parte dell’utente del nodo che spedisce il pacchetto.?La modalita anycast consentira’ anche di poter selezionare, durante l’instradamento, a quale fornitore di servizi rivolgersi per ottenere la consegna del pacchetto. Lo stesso indirizzo
puo’ essere infatti assegnato ad un insieme di fornitori di servizio a cui ci si affida. Questa funzionalita’ e’ essenziale per consentire un pagamento della connessione di rete da parte dell’utente basata sul-l’efficienza con cui i propri pacchetti vengono consegnati. Indirizzi Multicast Un indirizzo multicast identifica un insieme di interfacce. Un pacchetto spedito ad un indirizzo multicast viene consegnato a tutte le interfacce corrispondenti a quell’indirizzo. I primi 8 bit
set-Fig. B.5: Indirizzo Multicast
tati a 1 indicano che si tratta di un indirizo multicast. Il campo FLAG di 4 bit, ha i primi 3 bit settati a 0 per usi futuri, mentre il quarto bit se e’ settato a 0 indica che l’indirizzo di multicast corrisponde ad un gruppo di interfacce fissato. Si tratta cioe’ di un indirizzo multicast definito e riservato dalle autorita’ competenti per un preciso scopo e non puo’ essere ridefinito. Se il quarto bit e’ settato al valore 1 indica un normale indirizzo multicast, quindi ridefinibile se inutilizzato. Un indirizzo ridefinibile ha anche sempre una scadenza associata. Il
cam-po SCOPE serve per definire il dominio in cui l’indirizzo di multicast e’ definito. Posso infatti avere indirizzi multicast locali, aziendali o mondiali. Infine il campo GROUP id server ad identificare l’insieme multicast. ?
Semplificazione del formato degli header Rispetto a IPv4, IPv6 ha migliorato il trattamento degli header opzionali. Oltre all’header IPv6, presente in tutti i pacchetti, infatti ci possono essere altri head-er (specificati nella tabella II) i quali sono posizionati tra l’headhead-er IPv6 e l’header del livello di trasporto (es. TCP). Tutti questi
head-Fig. B.6: Extension Headers
er, ad eccezione di uno (l’Hop-by-Hop) sono individuati e processati solo dal nodo destinazione e non dai router intermedi. In IPv4 in-vece la presenza di una qualsiasi opzione deve essere processata dai router intermedi con conseguenze sulle prestazioni. Altra differenza e’ la possibilita’ di avere header opzionali di lunghezza arbitraria e non limitata a un totale di 40 byte come prevede IPv4. Questo permette
Fig. B.7: Extension Headers
funzionalita’ non realizzabili con la vecchia versione di IP come alcuni servizi di sicurezza. Infine i campi di IPv6 sono sempre multipli interi di ottetti per facilitare l’allineamento.
RoutingHeader
E’ usato dal nodo che spedisce il pacchetto per specificare uno o piu’ router intermedi che devono essere attraversati. Fornisce una funzionalita simile all’opzione ‘source route’ di IPv4. Il routing in IPv6 e molto simile a quello di IPv4, a parte la differenza di lunghezza degli indirizzi. Tutti i metodi di routing di IPv4 (OSPF,RIP,IDRP e ISI per esempio) sono supportati da IPv6. Le nuove funzionalita’ introdotte riguardano invece:
• selezione del provider in base a prestazioni, costi, politiche adottate.
• possibile mobilita’ dell’host (instradamento alla corrente locazione)
• auto-reindirizzamento (instradamento al nuovo indirizzo) Fragment Header Una della differenze maggiori tra IPv6 e IPv4 rigur-da la frammentazione. In IPv6 un pacchetto puo’ essere frammentato solo dal nodo che l’ha originato. La responsabilita’ e il costo del con-trollo della dimensione del pacchetto non ricadono quindi sui router ma su chi genera il traffico. Il nodo sorgente prima di spedire un pac-chetto deve assicurarsi che sia di dimensioni che consentano il suo trasporto su tutti i link che attraversa per giungere a destinazione, dove ogni link puo’ avere differente MTU. Per facilitare questo cal-colo IPv6 prevede che tutti i link garantiscano un MTU di almeno 576 byte, invece dei 68 previsti da IPv4. Un nodo puo’ usare questo come limite per la dimensione del proprio pacchetto e prevedere che se non e’ superata il suo pacchetto e’ sufficientemente piccolo da rag-giungere a destinazione senza essere scartato. L’ MTU minimo di un cammino tra due nodi e’ detto Path MTU e puo’ essere maggiore di 576. In questi casi per non sprecare banda IPv6 fornisce un pro-tocollo per calcolare il path MTU in modo da definire la lunghezza del pacchetto pari a questa dimensione e sfruttare nel miglior modo possibile la banda disponibile. Se un pacchetto ha una dimensione maggiore del path MTU disponibile, deve essere frammentato prima di poter essere spedito. I vari pacchetti verranno poi riassemblati nel pacchetto di partenza dal nodo destinatario. A differenza di IPv4, l’-header di IPv6 non contiene un campo specifico per questo scopo. Le informazioni sulla eventuale frammentazione sono invece contenute in un speciale header, il fragment header appunto. Il fragment
head-Fig. B.8: Fragment Header
er contiene un campo per identificare tutti i frammenti appartenenti allo stesso pacchetto e un indicatore (M) per individuare l’ultimo frammento. L’offset, espresso in ottetti, indica l’offset dei dati con-tenuti nel sotto-pacchetto relativo all’inizio dei dati frammentabili del pacchetto originale. Nel pacchetto originale alcuni dati sono fram-mentabili e altri no. La prima operazione fatta e’ quella di distinguere le due parti. La parte che non puo’ essere frammentata e’ rappresen-tata da tutti gli header contenuti nel pacchetto originale. La parte frammentabile sono i dati veri e propri contenuti nel pacchetto. Una copia della parte non frammentabile e’ appesa a tutti i frammenti. ? Il nodo ricevente ricostruisce, a livello di network, il pacchetto indi-viduando tutti i pacchetti con lo stesso IP source address, gli stessi header e lo stesso identificatore e lo fornisce poi ai livelli superiori. Ovviamente una sola parte non frammentabile viene ricostruita.
Fig. B.9: Frammentazione
Destination Header
Questo header e’ usato per trasportare informazioni aggiuntive che devono essere processate solo dal nodo destinatario del pacchetto.
Introduzione di meccanismi per garantire qualita’ del servizio
Come abbiamo gia’ detto IPv6 introduce in Internet anche meccan-ismi per poter garantire una qualita’ di servizio (QoS) intesa come la garanzia di poter usufruire certamente di una larghezza di banda negoziata e (possibilmente pagata) per tutto l’arco della particolare trasmissione. IPv4 e’ basato sulla politica ‘best effort’ per cui se si verifica una congestione IPv4 distribuisce democraticamente il degra-do del servizio peggiorandegra-do la qualita’ media di tutte le comunicazioni coinvolte. Alla base di questa scelta di progettazione ci sono due
mo-tivi essenziali: quando nacque Internet essenzialmente il traffico era di un solo tipo e cioe’ dati mentre oggi si hanno dati, segnali video e/o audio di diversa qualita’.?La comunita’ degli utenti di IPv4 erano uni-versita’ e istituti di ricerca soprattutto, oggi invece si ha una grande diffusione nel mondo commerciale e gli utenti sono diversi con diverse esigenze e diverse disponibilita’ economiche per soddisfare queste es-igenze. Ecco quindi la necessita’ di introdurre il concetto di QoS in Internet, (in ATM la QoS e’ una scelta caratterizzante) per fornire lo strumento necessario per introdurre banda a pagamento. La QoS in IPv6 e’ realizzata mediante due maccanismi le ‘flow labels’ e le prior-ita’. Oltre a questi meccanismi a livello di rete, e’ in fase di sviluppo un protocollo a livello di trasporto, il ReSerVation Protocol (RSVP) che ha il compito di gestire la QoS nel routing di un pacchetto.
Flow Labels
Il Flow Label e’ un campo di 24 bit definito nell’header di IPv6 ed e’ utilizzato per identificare flussi di traffico tra due nodi. Un flusso e’ costituito da una sequenza di pacchetti che hanno la stessa sorgente e la stessa destinazione e che necessitano un servizio ‘speciale’ per essere trasportati. Tipico esempio e’ il caso di servizi real-time per i quali una politica best-effort in caso di congestione non e’ adeguata. Og-ni flusso richiede quindi un ‘particolare trattamento’. La descrizione specifica di questo trattamento a cui i routing devono attenersi puo’ essere contenuta o nei pacchetti stessi facenti parte del flusso, usando l’opzione hop-by-hop oppure se piu’ complesse dal protocollo RSVP. Ci possono essere piu’ flussi attivi tra due nodi, cosi come pacchetti trattati normalmente. Un flusso e’ identificato in modo univoco dalla
combinazione dell’indirizzo sorgente e da una etichetta di flow diver-sa da zero. I pacchetti che non appartengono a nessun flusso hanno l’etichetta uguale a zero.
Priorita’
Il campo priotita’ di 4 bit permette ad un nodo di distinguere al suo interno diversi livelli di priorita’ con cui spedire i propri pacchetti. I valori di priorita’ sono divisi in due classi. La prima (con valori da 0 a 7) e’ usata per specificare la priorita’ del traffico per cui il nodo fornisce meccanismi di controllo della congestione. Esempio di traffico di questo tipo sono i pacchetti TCP che se c’e’ congestione vengono scartati. I valori da 8 a 15 invece sono usati per il traffico che non puo’ essere scartato in presenza di congestione, ad esempio pacchetti spediti in real-time ad un tasso costante. Il valore piu’ basso (8) dovrebbe essere usato per identificare il traffico che il nodo sor-gente vorrebbe scartare per primo in caso di congestione (es. video ad alta definizione) e il valore piu’ alto (15) usato per quello che piu’ non verrebbe fosse scartato (es. audio a bassa definizione) in caso di congestione.
Introduzione di meccanismi di sicurezza
IPv6 prevede due servizi di sicurezza che possono essere usati sep-aratamente, congiuntamente, o non utilizzati dipendentemente dalle esigenze. Sono previsti a questo scopo due diversi header. IPv6 sepa-ra authenticazione e segretezza definendo due header diversi perche’ mentre la prima puo’ essere implementata senza problemi, la
seg-retezza deve invece sottostare a stringenti norme anti-esportazione (soprattutto riguardanti gli Stati Uniti).
Authentication Header
L’Authentication header e’ utilizzato per fornire autenticazione e in-tegrita’ ai pacchetti IPv6. I servizi di sicurezza al contrario di IPv4 che ne era completamente sprovvisto sono previsti in tutte le imple-mentazioni di IPv6. Il campo Authentication Data Lenght specifica
Fig. B.10: Authentication Header
la lunghezza del campo Authentication Data. Il campo SPI specifi-ca i parametri per poter instaurare un’asociazione che faccia uso dei servizi di sicurezza. Questi non sono fissi ma variano in base all’algo-ritmo utilizzato anch’esso specificato. Per default viene utilizzato l’al-goritmo MD5 con chiave. La funzione calcolata da MD5 e’ la seguente: MD5(chiave,dati)=authentication data. La chiave e’ segreta e condi-visa dal nodo destinatario e dal nodo ricevente. IPv6 non definisce
come i nodi acquisiscono la chiave. Poiche’ l’algoritmo e’ calcolato dal nodo che spedisce il pacchetto esso viene applicato solo sui dati che non cambiano durante il cammino per raggiungere il destinatario. I campi che possono essere soggetti a variazioni per assunzione han-no tutti valore zero. L’autenticazione dei han-nodi permette di eliminare una classe importante di possibili attacchi alla rete, ed in particolare impedisce il mascheramento di un nodo. L’uso dell’autenticazione e’ particolarmente importante quando si usa il ‘source routing’, in cui il rischio di poter mascherare router e’ piu’ alta che in altre situazioni.
Encapsulation Security Payload(ESP)
ESP fornisce integrita’ e segretezza. Dipendentemente dall’esigenze dell’host questo meccanismo puo’ essere usato per cifrare sia segmen-ti di informazionia livello di trasporto (es. UDP, TCP) sia un intero pacchetto IP. L’uso di questa funzionalita’ aumenta i costi e la latenza a causa delle operazioni di cifrature/decodifica dei pacchetti. Questo header ha un formato differente dagli altri come mostrato in figura: L’ESP puo’ essere in qualunque posizione dopo l’IP header e prima della fine del segmento di trasporto (?). ESP e’ costituito da due campi: SPI che e’ un header in chiaro che descrive le modalita’ (al-goritmo, modalita’, informazioni sulla chiave) con cui il ricevente, se autorizzato, deve decifrare i dati. Il secondo campo contiene i dati cifrati che possono essere i dati del pacchetto IP vero e proprio piu’ dati propri dell’algoritmo di cifratura applicato che devono comunque restare confidenziali. In caso di frammentazione l’ESP e’ processato prima della frammentazione e dopo il riassemblaggio. Ci sono due modalita per usare ESP: Tunnel-mode e Transport-mode.
Fig. B.11: esp
• Tunnel-mode: il pacchetto IP e’ contenuto nella parte cifrata dell’ESP e l’intero ESP e’ contenuto in un pacchetto avente headers IP in chiaro. Questi header sono usati per instradare il pacchetto dalla sorgente alla destinazione.
• Transport-mode:L’ESP header in questa modalita’, e’ inserito nel pacchetto IP immediatamente prima dell’header del proto-collo di livello di trasporto. In questo modo si risparmia banda di trasmissione perche’ non ci sono header o opzioni IP cifrate.
B.1.3
Migrazione da Ipv4 a Ipv6
L’ enorme dimensione di Internet e il grandissimo numero di utenti di IPv4 (la versione del protocollo IP attualmente utilizzata su In-ternet) rendono impossibile una migrazione totale da IPv4 a IPv6 (la nuova versione del protocollo IP) in un preciso istante di tempo.
Inoltre molte organizzazioni hanno una sempre maggiore dipenden-za da Internet per il loro lavoro quotidiano e quindi non possono tollerare periodi di inattivit´a dovuti alla sostituzione del protocollo IP. Quindi non ci sar´a nessun D-day in cui spegnere IPv4 e accen-dere IPv6, poich´e i due protocolli possono coesistere senza problemi. La migrazione da IPv4 a IPv6 potr´a essere fatta nodo per nodo. Questo consentir´a di approfittare immediatamente dei molti vantaggi di IPv6 pur conservando le possibilit´a di comunicare con utenti o per-iferiche IPv4. Esistono caratteristiche di IPv6 pensate esplicitamente per semplificare la migrazione. Per esempio, gli indirizzi IPv6 pos-sono essere ricavati automaticamente dagli indirizzi IPv4, si pospos-sono costruire tunnel IPv6 su reti IPv4 e almeno in fase iniziale tutti i no-di IPv6 seguiranno la filosofia ’dual stack’, saranno cio´e in grado no-di utilizzare contemporaneamente IPv4 e IPv6. Questa buona compat-ibilit´a tra IPv4 e IPv6 pu´o anche spingere qualche utente a pensare che sia inutile migrare ad IPv6. Questa scelta in prospettiva sar´a penalizzante in quanto non permetter´a di accedere ai nuovi sviluppi che a partire dal 2000 riguarderanno unicamente IPv6. IPv6 ´e sta-to accuratamente progettasta-to, approfonditamente discusso e provasta-to in campo dallo IETF (l’organismo tecnico che gestisce Internet) e da molte istituzione di ricerca. Esiste un progetto denominato 6bone che permette di acquisire esperienza e provare subito i protocolli della famiglia IPv6. Gli anni dal 1997 al 2000 saranno caratterizzati dal-l’adozione di IPv6 da parte degli ISP e degli utenti. Nel 1997 potranno ancora esserci problemi legati alla giovent´u dei prodotti, ma a partire dal 1998 IPv6 far´a parte dei protocolli distribuiti di serie sui router, sulle workstation e sui PC. Le organizzazioni potranno iniziare a quel
punto a migrare pi´u o meno gradualmente a IPv6. Gli obiettivi chiave della migrazione sono:
• gli host IPv6 e IPv4 devono poter interoperare;
• gli host e i router IPv6 devono potersi diffondere su Internet in modo semplice ed incrementale, con poche interdipendenze;
• i gestori delle reti e gli utenti finali devono percepire la migrazione come semplice da comprendere e realizzare.
Per semplificare la migrazione sono stati messi a punto una serie di meccanismi a livello di protocolli e di regole operative che pren-dono il nome di SIT (Simple Internet Transition). Le caratteristiche principali di SIT sono:
• Possibilit´a di transizione progressiva e non traumatica. Gli host e i router IPv4 possono essere aggiornati ad IPv6 uno alla volta senza richiedere che altri host o router siano aggiornati contemporaneamente.
• Requisiti minimi per gli aggiornamenti. L’unico requisito per poter aggiornare gli host a IPv6 ´e che deve essere disponibile un server DNS in grado di gestire gli indirizzi IPv6. Non ci sono requisiti per i router.
• Semplicit´a di indirizzamento. Quando un router o un host sono aggiornati ad IPv6 possono comunque continuare ad usare anche gli indirizzi IPv4.
• Basso costo iniziale. Non occorre effettuare un particolare lavoro preparatorio per iniziare la migrazione ad IPv6.
• Una struttura degli indirizzi IPv6 che permette di ricavare questi ultimi a partire dagli indirizzi IPv4.
• La disponibilit´a del dual stack sugli host e sui router durante la fase di transizione, ossia la presenza contemporanea degli stack di protocolli IPv4 e IPv6.
• Una tecnica per incapsulare i pacchetti IPv6 all’interno di pac-chetti IPv4 (tunneling) per permettere ai pacpac-chetti IPv6 di attraversare isole non ancora aggiornate ad IPv6.
• Una tecnica opzionale che consiste nel tradurre gli header IPv6 in IPv4 e viceversa per permettere, in una fase avanzata della migrazione, di far comunicare nodi che utilizzano solo IPv4 con nodi che utilizzano solo IPv6.
L’approccio SIT garantisce che gli host IPv6 possano interoperare con gli host IPv4 inizialmente sull’intera Internet. A migrazione comple-tata tale interoperabilit´a sar´a garantita ancora per un lungo periodo di tempo su base locale. Questo permette di salvaguardare gli inves-timenti fatti su IPv4: dispositivi semplici che non potranno essere aggiornati ad IPv6, ad esempio stampanti di rete e terminal server, continueranno a funzionare in IPv4 sino al termine della loro esisten-za. La possibilit´a di una migrazione graduale permette a chi realiz-za router, sistemi operativi e software di rete di integrare IPv6 nei prodotti quando ritiene che le realizzazioni siano stabili e agli utenti di iniziare la migrazione nell’istante considerato pi´u opportuno. Tunneling Le tecniche di tunneling consentono di utilizzare il routing IPv4 per trasportare il traffico IPv6. Gli host e i router dotati del dual stack (detti anche IPv4/IPv6) possono utilizzare i tunnel per
instradare i pacchetti IPv6 su porzioni di rete dotate unicamente di routing IPv4, come mostrato nell’esempio di Figura 1. Nell’esempio,
Fig. B.12: example caption
l’host A invia il pacchetto IPv6 nativo al router R1 che lo ritrasmette in un tunnel IPv4 al router R2 che lo trasmette infine come pacchetto IPv6 nativo all’host B. In questo caso il tunnel ´e gestito da R1 e R2. Dal punto di vista dell’incapsulamento realizzare un tunnel significa incapsulare un pacchetto IPv6 in un pacchetto IPv4, come mostrato in Figura 2. Nell’esempio precedente l’header IPv6 conterr´a gli indi-rizzi A e B, mentre quello IPv4 gli indiindi-rizzi R1 e R2. Approccio Dual
Stack
L’ approccio dual stack consiste nel dotare gli host e i router degli stack di protocollo IPv6 e IPv4. Nel caso di un host IPv6/IPv4 una possibile organizzazione degli stack di protocollo ´e illustrata in Figura 3. Si noti che l’approccio dual stack non richiede necessariamente la capacit´a di creare tunnel, mentre la capacit´a di creare tunnel richiede l’approccio dual stack. In generale i due approcci sono entrambi for-niti dalle realizzazioni IPv6/IPv4. Una spiegazione semplicistica del modo di operare dell’approccio dual stack ´e la seguente:
• se l’indirizzo di destinazione utilizzato dall’applicazione ´e IPv4 allora si utilizza lo stack di protocolli IPv4;
• se l’indirizzo di destinazione ´e IPv6 compatibile IPv4 allora si utilizza IPv6 incapsulato in IPv4;
• se l’indirizzo di destinazione ´e un indirizzo IPv6 di altro tipo si utilizza IPv6 eventualmente incapsulato nel default configured tunnel.
In realt´a i casi da prendere in considerazione sono molti di pi´u. Inoltre occorre considerare che l’utente normalmente fornisce all’applicazione un nome e non un indirizzo. Tale nome deve essere tradotto in un in-dirizzo utilizzando il DNS. Nel DNS per ogni nome possono essere memorizzati solo l’indirizzo IPv4 (record A), solo quello IPv6 (record AAAA) oppure entrambi. Nell’ultimo caso decidere se utilizzare l’ind-irizzo IPv4 oppure quello IPv6 non ´e assolutamente banale e dipende da una serie di considerazioni. In primo luogo occorre determinare se il nodo ha connettivit´a diretta IPv6 oppure no. In caso negativo l’utilizzo dell’indirizzo IPv6 richieder´a la trasmissione di un
pacchet-to IPv6 in un tunnel IPv4. Quespacchet-to pu´o essere meno conveniente che l’utilizzo di IPv4 in modalit´a nativa o addirittura impossibile se il nodo non ´e in grado di utilizzare i tunnel. 6bone Il progetto 6bone ´e una emanazione spontanea del gruppo di lavoro IPng dello IETF e mira a realizzare e provare i protocolli IPv6 con lo scopo finale di rimpiazzare IPv4 con IPv6 in Internet. 6bone ´e una collaborazione informale tra varie istituzioni di ricerca localizzate nell’America del Nord, in Europa e in Giappone. Una fase essenziale della migrazione da IPv4 a IPv6 ´e lo sviluppo di un backbone IPv6 che copra l’intera Internet e che possa trasportare pacchetti IPv6. Come nel caso del-l’attuale backbone IPv4 di Internet, il backbone IPv6 sar´a costituito da molti ISP e dalle reti degli utenti collegate tra loro a realizzare la nuova Internet. Finch´e i protocolli della famiglia IPv6 non saranno ampiamente disponibili e collaudati con particolare riferimento al-l’interoperabilit´a delle realizzazioni, gli ISP e gli utenti non vorranno migrare i router IPv4 di produzione per non incorrere in inevitabili rischi. Occorre quindi identificare un modo per fornire una connettiv-it´a IPv6 sull’intera Internet senza modificare l’Internet attuale IPv4, in modo da collaudare i protocolli IPv6 e da poterli utilizzare al pi´u presto. 6bone ´e una rete virtuale che si appoggia sull’attuale Inter-net IPv4 e che fornisce il routing ai pacchetti IPv6, poich´e ad oggi non tutti i router sono in grado di gestire correttamente il routing IPv6. La rete ´e composta da isole che forniscono una connettivit´a diretta IPv6 (tipicamente LAN) collegate tra loro da canali virtuali punto-punto (tunnel). I punti terminali dei tunnel sono inizialmente workstation con IPv6 e in prospettiva dei router con IPv6. 6bone ´e un progetto a termine. Infatti, con il passare del tempo e con l’aumentare
della confidenza nel trasporto in modalit´a nativa di pacchetti IPv6 sui router, IPv6 verr´a installato a bordo dei router di produzione e 6bone scomparir´a per accordo comune tra i suoi realizzatori. Essa sar´a sostituita in modo trasparente da una connettivit´a globale IPv6 offerta dagli ISP e dalle reti degli utenti. 6bone mira quindi a fornire un ambiente dove collaudare il trasporto di pacchetti IPv6 e perme-ttere agli utenti di crearsi l’esperienza necessaria. Non mira a creare una nuova architettura di interconnessione da usarsi a regime. 6bone cerca di coinvolgere il maggior numero di ISP e di utenti in modo da diffondere il pi´u possibile l’esperienza su IPv6 e creare una migrazione dolce verso IPv6 stesso.
B.2
Standard ISO
Open Systems Interconnection (meglio conosciuto come Modello ISO/OSI) `e uno standard stabilito nel 1978 dall’International Orga-nization for Standardization, il principale ente di standardizzazione internazionale, (ISO), che stabilisce una pila di protocolli in 7 livelli. L’organizzazione sent`ı la necessit`a di produrre una serie di standard per le reti di calcolatori ed avvi`o il progetto OSI (Open Systems Interconnection), un modello standard di riferimento per l’intercon-nessione di sistemi aperti. Il documento che illustra tale attivit`a `e il Basic Reference Model di OSI, noto come standard ISO 7498. Il mod-ello ISO/OSI `e costituito da una pila (o stack) di protocolli attraverso i quali viene ridotta la complessit`a implementativa di un sistema di comunicazione per il networking. In particolare ISO/OSI `e costituito da strati (o livelli), i cosidetti ’layer’, che racchiudono uno o pi`u
as-petti fra loro correlati della comunicazione fra due nodi di una rete. I layers sono in totale 7 e vanno dal livello fisico (quello del mezzo fisi-co, ossia del cavo o delle onde radio) fino al livello delle applicazioni, attraverso cui si realizza la comunicazione di ’alto livello’. Lo stack `e costituito dai seguenti layers (in ordine decrescente):
• 7 - protocollo/livello applicativo (application layer);
• 6 - protocollo/livello di presentazione (presentation layer);
• 5 - protocollo/livello di sessione (session layer);
• 4 - protocollo/livello di trasporto (transport layer);
• 3 - protocollo/livello di rete (network layer);
• 2 - protocollo/livello di collegamento dati (data-link layer);
• 1 - protocollo/livello fisico (physical layer). In dettaglio si ha
• Livello 1: fisico
Obiettivo: trasmettere un flusso di dati non strutturati attraverso un collegamento fisico, occupandosi della forma e del voltaggio del segnale. Ha a che fare con le procedure meccaniche e elettroniche necessarie a stabilire, mantenere e disattivare un collegamento fisico.
• Livello 2: datalink
Obiettivo: permettere il trasferimento affidabile di dati attraverso il livello fisico. Invia trame di dati con la necessaria sincronizzazione ed effettua un controllo degli errori e delle perdite di segnale.
fisico, incapsulando i dati in un pacchetto provvisto di header (intes-tazione) e tail (coda), usati anche per sequenze di controllo. Per ogni pacchetto ricevuto, il destinatario invia al mittente un pacchetto ACK (acknowledgement, conferma) contenente lo stato della trasmissione: il mittente deve ripetere l’invio dei pacchetti mal trasmessi e di quelli che non hanno ricevuto risposta. Per ottimizzare l’invio degli ACK, si usa una tecnica detta Piggybacking, che consiste nell’accodare ai messaggi in uscita gli ACK relativi ad una connessione in entrata, per ottimizzare l’uso del livello fisico. I pacchetti ACK possono an-che essere raggruppati e mandati in blocchi. Questo livello si occupa anche di controllare il flusso di dati: in caso di sbilanciamento di ve-locit`a di trasmissione, si occupa di rallentare l’opera della macchina pi´u veloce, accordandola all’ altra e minimizzando le perdite dovute a sovraccarico. La sua unit`a dati fondamentale `e la trama.
• Livello 3: rete
Obiettivo: rende i livelli superiori indipendenti dai meccanismi e dalle tecnologie di trasmissione usate per la connessione. Si occupa di sta-bilire, mantenere e terminare una connessione.
´
E responsabile del routing (instradamento) dei pacchetti. La sua unit´a dati fondamentale ´e il pacchetto.
• Livello 4: trasporto
Obiettivo: permettere un trasferimento di dati trasparente e affidabile (implementando anche un controllo degli errori e delle perdite) tra due host
A differenza dei livelli precedenti, che si occupano di connessioni tra nodi contigui di una rete, il Trasporto (a livello logico) si occupa
solo del punto di partenza e di quello di arrivo. Si occupa anche di effettuare la frammentazione, di ottimizzare l’ uso delle risorse di rete e di prevenire la congestione. La sua unit`a dati fondamentale ´e il messaggio.
• Livello 5: sessione
Obiettivo: controllare la comunicazione tra applicazioni. Stabilire, mantenere e terminare connessioni (sessioni) tra applicazioni cooper-anti.
Esso consente di aggiungere, ai servizi forniti dal livello di trasporto, servizi pi`u avanzati, quali la gestione del dialogo (mono o bidi-rezionale), la gestione del token (per effettuare mutua esclusione) o la sincronizzazione (inserendo dei checkpoint in modo da ridurre la quantit`a di dati da ritrasmettere in caso di gravi malfunzionamenti). Si occupa anche di inserire dei punti di controllo nel flusso dati: in caso di errori nell’invio dei pacchetti, la comunicazione riprende dall’ ultimo punto di controllo andato a buon fine.
• Livello 6: presentazione
Obiettivo: trasformare i dati forniti dalle applicazioni in un forma-to standardizzaforma-to e offrire servizi di comunicazione comuni, come la crittografia, la compressione del testo e la riformattazione.
Esso consente di gestire la sintassi dell’informazione da trasferire. E sono previste tre diverse sintassi: astratta (definizione formale dei dati che gli applicativi si scambiano), concreta locale (come i dati sono rappresentati localmente) e di trasferimento (come i dati sono codificati durante il trasferimento).
• Livello 7: applicazione
Obiettivo: interfacciare utente e macchina.
Ogni layer individua un protocollo di comunicazione del livello medes-imo. ISO/OSI realizza una comunicazione per livelli, ovvero dati due nodi A e B, il livello n del nodo A pu`o scambiare informazioni col livello n del nodo B ma non con gli altri: ci`o conferisce modularit`a al sistema e semplicit`a di implementazione e reimplementazione. Inoltre ogni livello realizza la comunicazione col livello corrispondente su al-tri nodi usando il PoS (point of service) del livello immediatamente sottostante. Sicch´e ISO/OSI incapsula i messagggi di livello n in mes-saggi del livello n-1. Cos`ı se A deve inviare, ad esempio, una e-mail a B, l’applicazione (liv. 7) di A propagher`a il messaggio usando il layer sottostante (liv. 6) che a sua volta user`a il PoS del layer inferiore, fino ad arrivare alla comunicazione sul mezzo fisico. In tal modo si realizza una comunicazione multilivello che consente, ad esempio, di implementare algoritmi diversi per l’instradamento in rete pur dispo-nendo di protocolli di trasporto connessi. ISO/OSI `e stato progettato per permettere la comunicazione in reti a ’commutazione di pacchet-to’, del tutto simili al paradigma TCP-UDP/IP usato in Unix e nella rete ARPAnet, poi divenuta Internet. La differenza sostanziale fra TCP/IP e ISO/OSI consiste nel fatto che nel TCP/IP il layer ap-plicativo `e esterno alla pila di protocolli (ovvero `e una applicazione stand-alone che ’usa’ TCP/IP per comunicare con altre applicazioni) , i layer sono dunque solo 5 (applicazione, trasporto, rete, data-link, fisico) e i livelli sessione, presentazione sono assenti perch´e imple-mentati (eventualmente) altrove, cio`e nell’applicazione stand-alone esterna. ISO/OSI `e uno stack di protocolli incapsulati, che
sicura-mente `e pi`u flessibile rispetto al paradigma di TCP/IP, ma soltanto perch´e risulta pi`u astratto rispetto a questo. In pratica non esistono implementazioni ’complete’ di ISO/OSI , a parte quelle proprietarie (ad esempio DECNET della Digital) e di interesse accademico.