Capitolo 5
LLCRS e architettura del sistema
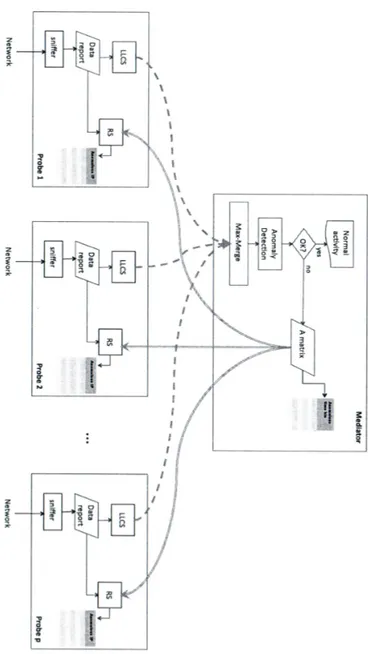
L’architettura del sistema, mostrata in figura 15, è di tipo distribuito: ogni probe, infatti, osserva il traffico che gli arriva, e, sulla base di questo, costruisce un LogLog Counting Sketch, che poi invierà al mediatore. Questa unità di centralizzazione, analizzando i dati provenienti da ogni sonda, genera gli allarmi. Inoltre, ogni probe si occupa dell’identificazione del traffico anomalo - cioè di risalire agli indirizzi IP che lo hanno generato - attraverso la struttura dati Reversible Sketch. In questo modo, associando RS e LLC, si ottiene una nuova struttura dati, i LogLog Counting Reversible Sketch.
Analizziamo adesso ogni blocco che compare in figura, in modo da comprendere il funzionamento globale del sistema.
5.1 Sniffer e Data report
Come suggerisce il nome, lo sniffer ha il compito di intercettare, in modo passivo, i dati che transitano nella porzione di rete monitorata da quel probe. Questa
funzionalità viene realizzata solitamente attraverso un software.
In uscita da questo primo strumento si hanno delle tracce che raccolgono il traffico transitato attraverso lo sniffer, suddiviso in timebin, cioè intervalli temporali di alcuni minuti. In particolare, ogni router estrae dal traffico osservato durante ogni singolo timebin alcune informazioni, che corrispondono alla quintupla {indirizzo IP sorgente, indirizzo IP destinazione, porta sorgente, porta destinazione, protocollo}; questi dati sui flussi sono memorizzati nelle tracce.
5.2 LLCS
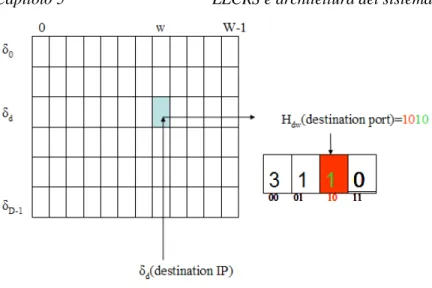
Un LogLog Counting Sketch (LLCS) è uno sketch in cui ad ogni cella è associato un LogLog Counter. Infatti, un LLCS è costituito da una matrice tridimensionale SDWm, in cui la riga d-esima (d=0,…,D-1) è legata a una funzione hash δd che può produrre in uscita solo valori nell’intervallo
0,... 1
,W
w , dove w indica la colonna dell’array. La struttura bidimensionale SDW è in realtà una normale sketch table; la terza dimensione m è stata invece introdotta
per realizzare l’algoritmo LogLog counting in ogni cella della sketch table.
Ogni LLCS, relativo a un qualsiasi router, riceve in ingresso le tracce ottenute dal passaggio attraverso lo sniffer, e le elabora come descritto nel seguito.
È innanzitutto importante osservare che la funzione δd
implementa il modular hashing della formula (8); essa prende in ingresso gli indirizzi IP di destinazione di ogni flusso, e determina in quale bucket della riga d vanno a cadere, andando cioè a fissare una colonna w dello sketch per ogni hash table d.
Se ipotizziamo di usare per il parametro q il valore 4,
δd è poi tale che a ogni parte di chiave xf (f=1,...,4) sia
applicata una funzione hash appartenente alla famiglia hash 4-universal, che ha la forma, suggerita in [2],
3 mod mod4 0 W p x a = x h = i i f idfr f r f, d,
(17)dove aidfr sono dei coefficienti scelti casualmente
nell’insieme (0,1,…,p-1) e p è un numero primo maggiore del più grande degli xf.
Se p fosse un numero primo arbitrario, questo metodo sarebbe piuttosto lento poiché il calcolo dell’operazione di modulo è oneroso; tuttavia si può ottenere
un’implementazione veloce scegliendo p come numero primo di Mersenne, nella forma 2 i 1. In questo caso, infatti, la formula (17) rappresenta la funzione hash 4-universal più veloce realizzabile su un processore che utilizzi le operazioni aritmetiche standard. Nell’hashing di interi su 32 bit, come nel nostro caso, si può ad esempio usare 261 1 = p , su 64 bit 289 1 = p .
Individuata in questo modo la cella w, viene costruito un LogLog counter, che ha la funzione di contare il numero di porte diverse di destinazione che cadono in quel bucket.
Per creare il LogLog Counter, ad ogni bucket della sketch table è associata un’altra funzione hash
3 0 mod = i i wdi dw x = a x p H (18)dove awdi sono dei coefficienti scelti casualmente
nell’insieme (0,1,…,p-1) e p è un numero primo di Mersenne maggiore di x. Hdw(x), per definizione di LLC,
con i primi k bit seleziona una cella della struttura del LogLog counter e sui bit restanti calcola la posizione del primo bit settato a 1 a partire da sinistra; questo valore va a incrementare il gruppo selezionato, secondo la formula (4). Entrambi i valori sono calcolati sulla porta di destinazione, come mostrato in figura 13.
Figura 13. Principio di aggiornamento di un LLCS.
Notare che, date le caratteristiche dell'algoritmo LogLog counting, la struttura dati LLCS mostra delle prestazioni analoghe al caso di un singolo contatore, per cui la formula approssimata per l'errore coincide ancora con la (7).
5.3 Max - Merge
Ogni probe p passa gli LLCS Sp[d][w][l] (p=0,...P),
relativi al timebin considerato, al mediatore, che realizza il “max - merge”. Infatti, il nodo centrale unisce queste informazioni prendendo i valori massimi tra i LogLog
counter dei diversi probe: in questo modo si costruisce un LLCS aggregato M[d][w][l] per ogni timebin, tale che
M d w l Sp
d w l p max ] ][ ][ [ . (19)La figura 14 mostra un'applicazione dell'algoritmo del Max-Merge, applicato ai router r e r+1.
Figura 14. Applicazione della formula (19).
Per permettere questa operazione, tutti i probe devono condividere le stesse funzioni hash Hdw, che determinano
l'indice l della terza dimensione .
A questo punto, il mediatore conta il numero di porte dei diversi flussi che collidono nello stesso bucket, applicando l'equazione (4) ad ogni cella M[d][w][l].
Notare che la presenza della massimizzazione nella tecnica del max - merge permette di andare a contare soltanto le porte diverse che cadono in quel bucket, e
risolvere quindi il problema di non contare i flussi duplicati, cioè osservati da più di un probe.
5.4 Anomaly detection e Matrix
Sulla base delle informazioni raccolte nell’LLCS globale, il mediatore può applicare un qualsiasi algoritmo di anomaly detection alla distribuzione delle chiavi memorizzate in ogni singolo bucket, per stabilire se i dati siano anomali o normali.
Il nodo centrale, osservando le uscite del blocco di anomaly detection, crea una tabella binaria A[d][w] - delle stesse (prime due) dimensioni degli sketch - nelle cui celle avrà inserito il valore 1 se il relativo bucket è risultato anomalo, 0 altrimenti.
Poi, il nodo centrale controlla se almeno un certo numero (prefissato) di righe della tabella contiene almeno un bucket anomalo: se è così, il timebin è effettivamente dichiarato anomalo e ad ogni probe viene inviata la matrice A; altrimenti essa è scartata e si decide che l’attività che caratterizza la rete è normale.
Si sottolinea che, data la natura delle funzioni hash, ogni flusso IP di traffico farà parte di D aggregati casuali
diversi che corrispondono ad altrettante funzioni hash. Questo significa che un flusso sarà controllato D volte per verificare se nasconde effettivamente un'anomalia, di conseguenza sarà più facile rilevare un flusso anomalo; infatti un flusso malevolo può essere mimetizzato in un traffico aggregato, ma essere riconoscibile in un altro.
5.5 RS
Le funzioni hash sono trasformazioni che convertono un insieme di dimensione m in uno più piccolo di dimensione n<<m. Di conseguenza, si verificheranno molte collisioni degli indirizzi IP di destinazione in uno stesso bucket, e non sarà ovvio sapere a quale indirizzo IP corrisponde effettivamente il flusso anomalo. Per questo motivo, è stata impiegata un’altra struttura, il Reversibile Sketch (RS), che, utilizzata in parallelo ai LogLog Counter, è stata denominata “LogLog Counting Reversible Sketch” (LLCRS).
Infatti, mentre crea l’LLCS, ogni probe costruisce anche un RS, nel quale sono memorizzati gli indirizzi IP di destinazione di tutti i flussi che costituiscono le tracce in ingresso.
Quando inoltre il mediatore invia ai probe la tabella A in sono indicati quali bucket sono anomali, ogni singolo probe analizza il Reversibile Sketch e, in base all'algoritmo illustrato al capitolo 3, risale agli indirizzi IP che hanno generato l'anomalia. In questo modo, il Reversibile Sketch collabora alla fase di identificazione e permette alla fine di ottenere anche una lista degli indirizzi IP anomali (e quindi non solo venire a conoscenza della presenza o meno di un’anomalia).
L'idea di costruire due strutture dati distinte, invece di un unico LLCRS è dovuta a considerazioni legate alle performance e alla privacy. Infatti, se ogni probe trasmettesse il proprio LLCRS al mediatore, gli dovrebbe inviare sia gli LLCS che le liste di chiavi associate ai bucket anomali. Questo peggiorerebbe le performance in termini di tempo di trasmissione e utilizzo di banda, inoltre implicherebbe l'invio ai probe di informazioni che possono essere sensibili, perché potrebbero compromettere la privacy degli utenti.