Capitolo IV 107
CAPITOLO IV
APPLICAZIONE
DEL
MODELLO
DI
REGRESSIONE
LINEARE
MULTIPLA:
IL
CASO DI AMBIENTE S.C.
La fase di definizione degli obiettivi di un’attività di DM è molto delicata, in quanto è proprio durante questo step che prenderà forma tutto il progetto di indagine. Nel nostro caso sono state le tecniche di ricerca qualitativa a mettere in luce problematiche e relazioni nascoste che sarebbero interessanti da analizzare più nel profondo.
Per giungere a conclusioni significative, rigorose, e credibili si sono seguiti in modo scrupoloso tutti i passi dell’iter operativo già esplicitato nel capitolo secondo, cercando di attenersi il più possibile a quelle che sono le diverse fasi di questo delicato processo.
4.1. FASE PRELIMINARE: ESPLORAZIONE DEI DATI E LORO
ORGANIZZAZIONE
Tutta l’indagine si è articolata attraverso due grandi percorsi, il primo ha riguardato la ricerca e la comprensione delle variabili che vanno ad influire sul fatturato realizzato da Ambiente S.C. relativamente a ciascun cliente; una volta isolate tali variabili si è cercato di chiarificare come ciascuna intervenga sul risultato finale.
Definitigli obiettivi, è necessario comprendere quali possano essere i dati necessari a conseguirli, dove si possano individuare, e se sia possibile un’eventuale e coerente elaborazione degli stessi. Spesso, infatti, i dati aziendali sono presenti, ma sono difficilmente accessibili per motivi tecnici o di segretezza. Nel nostro caso è stato possibile costruire un datamart, ovvero un data base tematico di interesse, che contenesse i dati
Capitolo IV 108
necessari. Il punto di partenza è stato il data warehouse aziendale, contenente molte informazioni sui clienti di Ambiente S.C., i dati su quanto viene loro fatturato e come tale fatturato è ripartito tra i diversi centri di ricavo. Attraverso il software contabile di Ambiente S.C., tutti le informazioni, contabili e non, provenienti dai vari settori di attività, sono state sintetizzate in un unico grande database, che è stato poi integrato con le variabili caratterizzanti le aziende clienti. La disponibilità di un data warehouse di partenza ha comportato molteplici vantaggi in termini di risparmio di tempo, costi e affidabilità; per rendere poi tali informazioni più adatte agli scopi di ricerca sono state selezionate solo le informazioni di interesse, ottenendo così un datamart completo e pertinente.
La matrice dei dati realizzata è formata da 78 unità statistiche, ovvero le aziende-clienti di Ambiente S.C. selezionate in base ad alcune caratteristiche. Infatti, sono state considerate solo quelle aziende a cui è stato fatturato nel 2008 un ammontare uguale o superiore a 10.000 euro, e che hanno natura privata. Si è ritenuto, infatti, che le leggi di mercato che regolano domanda e offerta per le realtà private non valgano anche nel caso di amministrazioni ed entità pubbliche, che generalmente scelgono i loro fornitori attraverso gare di appalti.
Sono stati isolati così 78 clienti; la variabile dipendente è data da quanto è stato fatturato a ciascuno di questi clienti nel 2008; le altre colonne della matrice dei dati sono date dalle variabili che influiscono su questo aspetto. In seguito alle valutazioni da parte del management, sono state individuate le variabili, caratterizzanti le aziende clienti stessi, che si ritiene possano essere determinati.
Sono state evidenziate 14 variabili indipendenti, sia di carattere quantitativo che di carattere qualitativo:
1. Fatturato realizzato nel 2007 dall’azienda-cliente nella propria attività.
2. Ragione sociale dell’azienda-cliente, che presenta 3 modalità: consorzi e cooperative, s.p.a. o s.r.l, corporation.
3. Numero di dipendenti dell’azienda-cliente nel 2007. 4. Numero anni di attività dell’azienda-cliente al 2007.
Capitolo IV 109
6. Area geografica di attività dell’azienda-cliente, che presenta 4 modalità: nord ovest, nord est, centro, sud e isole.
7. Settore di attività dell’azienda-cliente, che presenta 5 modalità: edilizia e costruzioni, produzione industriale, settore chimico, consulenza e tecnologie ambientali, servizi vari.
8. Fatturato prodotto dall’azienda-cliente nell’area Ambiente S.C. 9. Fatturato prodotto dall’azienda-cliente nell’area Bonifiche.
10. Fatturato prodotto dall’azienda-cliente nell’area Fisica ambientale. 11. Fatturato prodotto dall’azienda-cliente nell’area Laboratorio. 12. Fatturato prodotto dall’azienda cliente nell’area Sicurezza.
13. Fatturato prodotto dall’azienda-cliente nell’area Studi e pianificazione. 14. Fatturato prodotto dall’azienda-cliente nell’area Formazione.
Una volta costruito il datamart, si è proceduto a un controllo sostanziale e formale dei dati, verificando che questi fossero corretti e coerenti tra loro, e controllando la presenza di dati mancanti. Alcune osservazioni presentavano dei dati mancanti in corrispondenza di alcune variabili, si è sopperito a questa mancanza cercando le informazioni su web, visitando i siti aziendali, e prendendo contatti direttamente con il personale delle aziende clienti così da assicurarsi dati affidabili.
Avendo a disposizione un data base completo in ogni sua parte, si è cominciato ad “esplorarlo” iniziando con aspetti di carattere descrittivo, prima attraverso un’analisi esplorativa uni variata e proseguendo con un’analisi multivariata.
Utilizzando la funzione “Statistica descrittiva” del programma Excel, applicata ai dati relativi alla variabile dipendente, si sono tenuti i seguenti risultati:
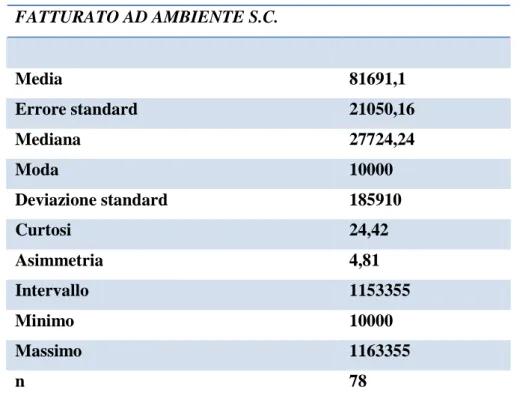
Capitolo IV 110 FATTURATO AD AMBIENTE S.C. Media 81691,1 Errore standard 21050,16 Mediana 27724,24 Moda 10000 Deviazione standard 185910 Curtosi 24,42 Asimmetria 4,81 Intervallo 1153355 Minimo 10000 Massimo 1163355 n 78
Figura 1: Tabella riassuntiva “Statistica descrittiva della variabile Fatturato”
Si nota come l’intervallo dei valori assunti dalla varabile sia piuttosto ampio, la media supera la mediana, si parla pertanto di asimmetria positiva, l’indice di asimmetria assume valore 4,81; il valore di riferimento per questo indice è 3, nel caso di perfetta simmetria, ciò conferma quindi la presenza di una forte asimmetria positiva, si riscontra infatti una frequenza maggiore per ammontari di fatturato con valore superiore a quello medio rispetto a quelli con valore inferiore. Con riguardo invece all’indice di curtosi, si nota come questo abbia valore maggiore di 3 pertanto la distribuzione è ipernormale, cioè rispetto alla distribuzione normale ha frequenza maggiore per i valori molti distanti dalla media1. Si parla in questo caso di distribuzione leptocurtica in quanto presenta un maggiore allungamento verso l’alto rispetto alla distribuzione normale.
1nota: la variabile è stata standardizzata ai fini del calcolo dell’indice di curtosi per ottenere una variabile di tipo
Capitolo IV 111
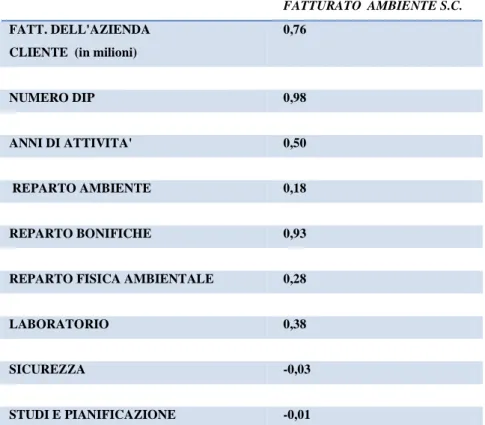
Sempre a fini esplorativi si è deciso di calcolare i vari indici di correlazione tra la variabile dipendente e le variabili esplicative di natura quantitativa, ottenendo i seguenti risultati:
FATTURATO AMBIENTE S.C.
FATT. DELL'AZIENDA CLIENTE (in milioni)
0,76 NUMERO DIP 0,98 ANNI DI ATTIVITA' 0,50 REPARTO AMBIENTE 0,18 REPARTO BONIFICHE 0,93
REPARTO FISICA AMBIENTALE 0,28
LABORATORIO 0,38
SICUREZZA -0,03
STUDI E PIANIFICAZIONE -0,01
Figura 2: Tabella delle correlazioni tra la variabile dipendente e le variabili esplicative.
Emerge in modo evidente come alcune variabili esplicative presentino una correlazione abbastanza forte con la variabile dipendente, ciò porta a considerare il modello di regressione lineare multipla come un valido strumento rispetto agli obiettivi di analisi proposti. L’indice di correlazione indica, infatti, la presenza e l’intensità di un rapporto lineare tra due variabili, tale relazione deve comunque essere ulteriormente approfondita. Per proseguire con l’analisi si è preferito trasformare le variabili qualitative in variabili dummy, così da poterle poi trattare come variabili quantitative. Tale codifica prevede che ogni variabile qualitativa con k modalità venga trasformata in k-1 variabili dummy corrispondenti a 1 modalità . Si preferisce non ricorrere a k modalità per evitare che la k-esima informazione sia ridondante e inutile, in quanto non aggiunge niente alle
Capitolo IV 112
informazioni precedenti. Ogni cariabile dummy presenta valore 1 quando l’unità è presente nella la modalità sottointesa, 0 altrimenti. Quando l’unità statistica presenta valore 0 per tutte le variabili dummy significa che è presente nella modalità eliminata, detta variabile base o base line.
La codifica è avvenuta nel seguente modo:
- La variabile “ragione sociale dell’azienda cliente” è stata codificata in 2 variabili dummy, “ragione sociale consorzi e cooperative”, “ragione sociale s.p.a. e s.r.l.”; quando entrambe presentano valore 0 siamo in presenza della modalità “corporation”.
- La variabile “fedeltà dell’azienda cliente” è stata codificata in 1 variabile dummy, “fedeltà”, che assume valore 1 quando l’azienda è fedele e valore 0 quando l’azienda non è fedele.
- La variabile “area geografica di attività dell’azienda cliente” è stata codificata in 3 variabili dummy, “area geografica nord ovest”, “area geografica nord est”, “area geografica centro”, quando tutte presentano valore 0 si è in presenza della modalità “area geografica sud e isole”.
- La variabile “settore di attività dell’azienda cliente” è stata codificata in 4 variabili dummy, “edilizia e costruzioni”, “ produzione industriale”, “settore chimico”, “consulenza e tecnologie ambientali”, quando tutte assumono valore 0 si è in presenza della variabile “servizi vari”.
Si sono così ottenute 20 variabili partendo da 14 variabili originarie.
4.2 LA METODOLOGIA PIU’ ADATTA ALL’ANALISI DEI DATI: LA
TEORIA DELLA REGRESSIONE LINERAE MULTIPLA
Lo scopo che ci si è preposti è quello di spiegare i valori della variabile dipendente, ovvero il fatturato che Ambiente S.C. ricava da ciascuna azienda cliente, partendo dai valori
Capitolo IV 113
assunti dalle 20 variabili dipendenti. Il modello che più sembra rispondere alle nostre esigenze di analisi è quello di regressione lineare multipla ².
La teoria della regressione lineare multipla risponde, infatti, all’obiettivo di studiare la dipendenza di una variabile quantitativa Y da un insieme di m variabili esplicative quantitative X1, …, Xm, dette regressori, mediante un modello lineare2:
Y = f (X1, …, Xm) + ε = β0 + β1 X1 + … + βm Xm + εi
il termine β0 + β1 X1 + … + βm Xm rappresenta la componente sistematica del modello, la
variabile casuale εi è la componente d’errore del modello.
La relazione che lega Y a (X1, …, Xm) non è quindi esprimibile mediante una funzione
matematica, all’equazione viene aggiunta una variabile aleatoria ε che riassume l’effetto su Y di tutti quei fattori non inclusi nella funzione f.
La funzione f dipende da parametri che determinano l’influenza di ogni singolo regressore sul valore di Y. Nella formulazione del modello di regressione multipla la linearità vale rispetto ai parametri.
I parametri (non noti) del modello sono: β0 (l’intercetta), e β1,…βm (i coefficienti di
regressione).
Devono necessariamente essere introdotte delle ipotesi su ε:
1. L’effetto su Y di tutti i fattori non rilevati e/o non rilevabili può essere positivo o negativo; εi non dipende dai valori dei regressori:
E(ε |X1, …, Xm) = E(ε) = 0 E(Y|X1, …, Xm) = β0 + β1 X1 + … + βmXm
βk rappresenta la variazione attesa di Y per una variazione unitaria positiva di Xk quando
gli altri regressori restano costanti (qualunque sia il loro valore).
2. La variabilità dell’effetto di tutti i fattori non rilevati e/o non rilevabili non dipende dai valori dei regressori;
2 Zani, S., Cerioli,A. (2007), “Analisi dei dati e data mining per le decisioni aziendali” ,
Capitolo IV 114
V(ε |X1, …, Xm) = V(ε) = → V(Y|X1, …, Xm) =
(ipotesi di omoschedasticità).
3. Gli effetti sulla spesa Y dei fattori non rilevati per la u.s. i non dipendono da quelli relativi alla u.s. j:
Cov (εi, εj) = 0 per ogni i≠ j
dove εi ed ε j sono il valore della variabile aleatoria per le due u.s.
(ipotesi di incorrelazione).
4. L’ultima ipotesi non è essenziale al modello lineare classico, ma necessaria per la stima dei parametri e il controllo di ipotesi sui parametri:
ε può essere considerato la somma algebrica degli effetti di molti fattori, alcuni positivi altri negativi
→ valori di ε piccoli (in valore assoluto) saranno più frequenti di valori grandi → la distribuzione di probabilità di ε è ipotizzata unimodale, con moda pari a 0.
5. Si assume inoltre che (X1, …, Xm) sono variabili deterministiche, ovvero misurate
senza errore;
Non c’è motivo di pensare che l’effetto dei fattori positivi incida sul valore di Y in misura superiore (o inferiore) a quello dei fattori negativi, ciascun valore di ε con segno positivo avrà la medesima frequenza del medesimo valore di ε con segno negativo; la distribuzione di probabilità di ε è ipotizzata simmetrica, le procedure inferenziali sul modello richiedono l’introduzione dell’assunzione di normalità della variabile casuale ε:
ε∼N(0, )
Il metodo dei minimi quadrati può essere utilizzato per stimare il vettore di parametri incogniti βi.
Posto il modello Y = β0 + β1 X1 + … + βm Xm + εi per la generica u.s vale la seguente
Capitolo IV 115
Yi = β0 + β1 Xi1 + … + βm Xim + εi
che, formulata per ciascuna delle n unità del campione, dà luogo al seguente sistema di n equazioni in m+1 incognite: Y1 =β0 + β1 X11 + … + βm X1m + ε1 … Yi = β0 + β1 Xi1 + … + βm Xim + εi … Yn = β0 + β1 Xn1 + … + βm Xnm + εn Indicando con:
Y il vettore n×1 dei valori della variabile dipendente per le n unità; X la matrice n×(m+1) dei valori degli m regressori per le n unità; β il vettore (m+1)×1 dei parametri del modello;
ε il vettore n×1 dei termini d’errore;
il sistema può essere riscritto in maniera compatta e semplificata nella forma di un’equazione matriciale:
Y = Xβ + ε
A partire dal vettore delle stime b calcolate rispetto a di n unità è possibile determinare il vettore y* dei valori teorici della variabile dipendente per le n unità nell’ipotesi di perfetta dipendenza lineare tra Y e gli m regressori:
y* = Xb
yi* = b0 + b1 xi1 + … + bm xim per i = 1, …, n.
La differenza tra gli n valori empirici ed i corrispondenti valori teorici di Y definisce il vettore dei residui campionari.
Capitolo IV 116
Come è noto il metodo dei minimi quadrati ricerca il vettore di coefficienti b in modo da rendere minima la somma dei quadrati degli scarti tra ordinate empiriche e ordinate teoriche, o equivalentemente, la somma dei residui al quadrato. Questo metodo garantisce la migliore stima lineare e corretta caratterizzata da varianza minima, proprietà desiderabili nei casi in cui si voglia trarre inferenza sui parametri della popolazione.
Il coefficiente di regressione multipla associato a una data variabile indipendente esprime il cambiamento nella variabile dipendente prodotto da un cambiamento di una unità nella variabile indipendente in questione, tenendo costanti gli effetti esercitati dalle altre variabili incluse nel modello.
4.3. TENTATIVO DI RIDUZIONE DELLA DIMENSIONALITA’
DELLA MATRICE DEI DATI: IL METODO DELLE COMPONENTI
PRINCIPALI
La dimensionalità della matrice dei dati risulta però piuttosto elevata, ciò porta ad alcuni svantaggi in termini di costi, perdita di tempo e maggiore complessità di analisi.
Una metodologia efficace per la riduzione della dimensione della matrice è quella delle componenti principali3. L’idea alla base del processo è di trasformare le variabili considerate in un numero minore di combinazioni lineari non correlate tra loro. Le componenti principali infatti si definiscono come combinazioni lineari tra loro indipendenti delle variabili originarie, la cui varianza complessiva uguaglia quella osservata. Le componenti principali di un insieme di dati si ricavano identificando in sequenza la combinazione lineare delle variabili osservate che estrae il massimo di variabilità, e per questo detto principale, dalla matrice di varianze-covarianze di volta in volta depurata della variabilità e della covariabilità delle componenti precedentemente estratte. I principi su cui poggia l’analisi esplorativa dei dati sono la parsimonia nella rappresentazione matematica e
3 Zani, S., Cerioli,A. (2007), “Analisi dei dati e data mining per le decisioni aziendali” ,
Capitolo IV 117
grafica dei dati, la robustezza essenziale dell’analisi in grado di far emergere le strutture latenti nei dati, l’immediata percettibilità delle rappresentazioni grafiche ottenibili con l’analisi4.
Avvalendosi del supporto informatico del programma STATA, sono state individuate le 20 componenti principali; ai fini di sintetizzare l’informazione contenuta nelle 20 variabili originarie è necessario considerare un numero inferiore di componenti principali. La regola che generalmente viene seguita prevede di estrapolare le componenti principali che spiegano congiuntamente circa l’80% della variabilità complessiva. Nel nostro caso sarebbe opportuno considerare almeno le prime 10 componenti principali che congiuntamente spiegano circa il 79% della variabilità complessiva.
La varianza di ogni componente principale corrisponde al suo autovalore, dall’analisi dei dati si è ottenuto quanto segue rispetto agli elementi degli autovettori:
variabile C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 X1 0,41 -0,18 0,06 0,22 0,04 -0,14 -0,15 -0,16 -0,02 0,08 X2 -0,14 0,10 0,28 0,35 -0,03 0,23 0,40 0,03 0,07 -0,05 X3 -0,06 -0,15 -0,28 -0,47 0,12 -0,10 -0,02 0,06 -0,15 0,01 X4 0,02 0,02 0,18 0,39 -0,08 -0,05 0,17 0,20 -0,44 0,18 X5 0,31 0,18 0,24 -0,11 0,29 0,15 0,09 -0,1293 -0,31 -0,06 X6 0,24 -0,25 -0,01 0,26 0,21 0,06 -0,11 -0,22 0,41 -0,14 X7 0,01 -0,23 -0,28 0,22 0,31 -0,15 0,11 0,07 -0,23 0,18 X8 0,16 0,29 -0,21 -0,03 -0,12 -0,33 0,16 -0,25 0,02 -0,30 X9 -0,20 0,02 0,40 -0,15 -0,07 0,29 -0,32 0,03 0,24 0,15 X10 -0,11 0,02 0,13 -0,11 0,56 0,02 0,19 0,01 0,15 -0,36 X11 0,11 0,14 0,23 -0,06 -0,22 -0,40 -0,04 -0,36 0,10 0,31 X12 0,03 -0,12 -0,08 0,16 -0,06 -0,22 -0,38 0,52 0,03 -0,36 X13 0,05 -0,23 -0,29 -0,14 -0,21 0,47 0,07 -0,14 -0,06 0,09 X14 0,41 0,02 0,15 -0,18 -0,11 -0,06 0,26 0,15 0,25 -0,14 X15 0,10 0,01 0,24 -0,10 0,34 0,06 -0,31 -0,23 -0,33 0,01 X16 0,37 -0,07 0,06 -0,28 -0,06 0,13 0,33 0,32 -0,01 0,09 X17 0,38 -0,25 0,07 -0,01 -0,05 0,08 -0,17 0,18 0,05 0,19 X18 0,08 -0,17 -0,19 0,25 -0,11 0,29 0,04 0,03 0,03 -0,19 X19 -0,11 -0,06 -0,09 0,04 0,35 -0,16 0,20 0,07 0,39 0,08
Capitolo IV 118
X20 0,17 0,49 -0,26 0,10 0,10 0,18 -0,17 0,12 0,08 0,12
Figura 3: Elementi degli autovettori calcolati da STATA
I valori dell’autovettore sono utilizzati come coefficienti di ponderazione per ottenere le componenti principali.
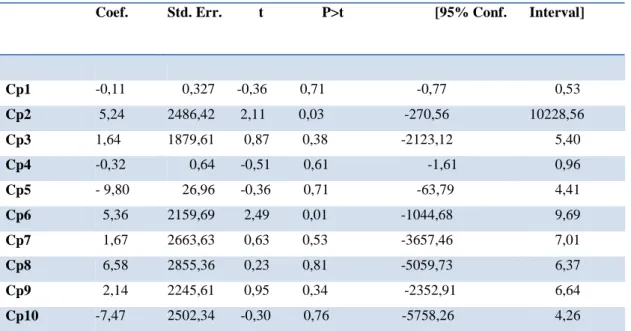
Si è quindi proceduto realizzando l’analisi di regressione lineare multipla applicata alle prime 10 componenti principali. Quanto emerso dai risultati finali ha però indotto ad abbandonare questa procedura: le componenti principali non determinano infatti in modo significativo il valore della variabile dipendente. Si è scelto un livello di significatività pari al 5% ma i coefficienti di regressione lineare non risultano significativamente diversi da 0. Infatti l’intervallo dei valori che possono assumere in corrispondenza delle unità statistiche considerate passa attraverso il valore 0.
Ciò emerge chiaramente anche grazie al test t, utilizzato proprio con lo scopo di mettere in luce questa problematica, infatti viene accettata l’ipotesi nulla in base alla quale i valori dei coefficienti di regressione non sono significativamente diversi da 0.
Vengono riportati di seguito i risultati conclusivi:
Coef. Std. Err. t P>t [95% Conf. Interval]
Cp1 -0,11 0,327 -0,36 0,71 -0,77 0,53 Cp2 5,24 2486,42 2,11 0,03 -270,56 10228,56 Cp3 1,64 1879,61 0,87 0,38 -2123,12 5,40 Cp4 -0,32 0,64 -0,51 0,61 -1,61 0,96 Cp5 - 9,80 26,96 -0,36 0,71 -63,79 4,41 Cp6 5,36 2159,69 2,49 0,01 -1044,68 9,69 Cp7 1,67 2663,63 0,63 0,53 -3657,46 7,01 Cp8 6,58 2855,36 0,23 0,81 -5059,73 6,37 Cp9 2,14 2245,61 0,95 0,34 -2352,91 6,64 Cp10 -7,47 2502,34 -0,30 0,76 -5758,26 4,26
Capitolo IV 119
Sarà pertanto necessario ricorrere ad un’altra tecnica per cercare di semplificare il data mart di riferimento. Il procedere per tentativi è proprio della metodologia di DM, che si propone di ricercare il modo migliore, sia in termini di parsimonia, sia di accuratezza, al fine di individuare nuove relazioni e nuovi schemi che spieghino i legami tra i dati in analisi.
4.4 IL METODO DELLA STEPWISE REGRESSION
Quando ci si trova ad operare con un elevato numero di variabili, individuare l’insieme ottimo da considerare è problematico sia dal punto di vista economico (tempo di calcolo), sia da quello della complessità dell’analisi, anche su un moderno calcolatore ad alta velocità e a grande capacità di memoria.
Per risolvere questo problema si può far riferimento al metodo della regressione stepwise o a gradini5.
Per ottenere una soluzione a gradini si rilevano, per ogni unità statistica una variabile dipendente Y e un insieme di p variabili predittive X sulle quali si vuole regredire Y. Il modello di analisi assume che ogni osservazione Yi sia esprimibile come una combinazione lineare delle X con coefficienti β e di una variabile non osservata ε, interpretabile come un errore residuale della regressione.
Y = f(X1, …, Xm) + ε = β0 + β1 X1 + … + βm Xm +εi
L’equazione conclusiva dell’analisi di regressione stepwise è come la precedente, ma alcuni coefficienti risultano nulli. E’ facile sapere quali variabili escludere se queste hanno correlazione nulle, in questo caso è sufficiente valutare la correlazione esistente tra i singoli predittori e la variabile criterio per determinare la selezione ottimale. Purtroppo questa situazione non si presenta quasi mai, molto spesso è necessario compiere alcune scelte. Dopo aver deciso quali sono i predittori tra i quali procedere alla selezione è necessario:
Capitolo IV 120
• Decidere quale criterio di selezione adottare: la scelta dipende dagli obiettivi di ricerca e dalle relazioni tra variabili emerse.
• Definire l’insieme di dati su cui svolgere l’analisi.
• Stabilire i parametri dell’analisi e delle eventuali ri-analisi: nell’analisi di regressione stepwise, la capacità esplicativa di un predittore è valutata in relazione alla riduzione di varianza di Y che consegue dall’inserimento del predittore nell’equazione di regressione e all’aumento di varianza che comporta l’eliminazione del predittore dall’equazione. Alla capacità esplicativa del predittore marginale, ovvero quello candidato ad entrare in una selezione progressiva, si rifanno vari criteri adatti per decidere il passo al quale conviene arrestare il processo di selezione delle variabili.
I criteri più noti per la selezione stepwise dei predittori sono vari6:
- La selezione progressiva, che consiste nell’inserire nell’equazione di regressione una variabile alla volta, partendo con un predittore, poi inserendo un secondo, e così di seguito. La selezione si basa sul contributo del predittore inserito alla spiegazione della variabilità di Y. Il processo di selezione continua finché non è soddisfatto un criterio di arresto della procedura, se i criteri di arresto sono poco restrittivi, il processo si conclude quando tutte le variabili sono inserite.
- Eliminazione a ritroso, che consiste nel rimuovere una variabile alla volta dall’equazione di regressione in ragione della minore perdita di capacità esplicativa della variabilità di Y conseguente dall’eliminazione della variabile. Il processo si arresta quando è soddisfatta una delle regole previste per troncare il processo di eliminazione.
- La regressione stepwise convenzionale, che è una combinazione delle due procedure precedenti, si realizza quando una variabile candidata è inclusa nell’equazione se, in una fase del processo, dà il contributo più significativo dell’interpretazione della variabilità di Y, ma può essere rimossa nelle fasi successive se la sua capacità esplicativa risulta surrogata da altre entrate nel
Capitolo IV 121
frattempo. Si tratta della procedura più conosciuta: è, infatti, a questa che si fa riferimento quando si parla di regressione stepwise senza specificazioni.
Nello specifico si è deciso di utilizzare quest’ultimo metodo.
L’equazione di partenza prevede che il predittore sia spiegato solo dal coefficiente dell’intercetta, pari al valore della media della Y stessa:
y=β0 = y
Il predittore candidato a entrare nel modello per primo è quello che porta alla massima riduzione di devianza della variabile risposta, analizzando il coefficiente di correlazione tra le due variabili. Una volta stabilito quale sia il predittore candidato a entrare nell’equazione si verifica, con il test F di Snedecor, se l’immissione riduce significativamente la variabilità di Y. Constatata la significatività della riduzione l’equazione è :
y=β0+β1 X1
ovvero nell’equazione è entrata una sola variabile esplicativa selezionata, e il coefficiente β1 è stato calcolato con il metodo dei minimi quadrati.
Per valutare l’opportunità di inserire altre variabili predittive, si simula l’inserimento nell’equazione una alla volta, di tutte le altre variabili finora escluse. La variabile che porta alla massima riduzione di varianza residua di Y entra nell’equazione, a condizione che tale riduzione risulti statisticamente significativa.
I coefficienti dell’equazione di regressione sono al netto delle altre variabili predittive presenti nell’equazione. Seguendo un criterio analogo a quanto illustrato per la prima variabile si inseriscono tutte le altre; a questo punto può darsi che l’immissione di una variabile renda insignificante l’effetto di una delle variabili entrate per prime nell’equazione di regressione. Se per esempio la prima variabile predittiva è molto correlata
Capitolo IV 122
con le altre due seguenti, tanto da poter essere espressa come loro funzione lineare, si può escludere dall’equazione senza che la devianza residua y subisca aumenti di rilievo.
Il processo di immissione progressiva delle variabili, e di eliminazione di quelle superflue, si ripete finché non è soddisfatta una delle condizioni stabilite per l’arresto della procedura, oppure tutte le variabili sono incluse nell’equazione. L’equazione finale, con q variabili (q≤m) variabili predittive incluse è:
Y = f(X1, …, Xm) = β0 + β1 X1 + … + βm Xm
dove m-q coefficienti di regressione relativi alle variabili escluse dal modello sono posti uguali a 0, ne gli altri q sono al netto delle variabili con coefficienti non nulli.
In un modello di regressione lineare la logica di fondo per valutare l’opportunità a comprendere nell’equazione una variabile predittiva è così composta7:
- L’omissione erronea di una variabile dal modello comporta distorsione in tutte le stime dei coefficienti di regressione, ma le stime ottenute sono più efficienti.
- Se la stima del coefficiente di regressione di un predittore ha valore inferiore al suo scarto quadratico medio, il predittore può essere eliminato dall’equazione e tutte le stime acquistano accuratezza.
- L’inclusione di variabili correlate con altre presenti nel modello non provoca distorsione nelle stime, ma ne aumenta la varianza.
Nelle decisioni per l’analisi di regressione a gradini, sui corretti criteri di specificazione del modello e sul contenimento dell’errore di stima, si fanno prevalere i fini euristici . La verifica statistica dei risultati dell’analisi passa dunque in secondo piano rispetto alla ricerca di strutture semplici e più facilmente percettibili all’analisi dei dati.
In genere un numero massimo di variabili da inserire nell’equazione di regressione viene fissato a priori per rendere agevole l’interpretazione dei risultati. Bisogna ricordare, però, che la relazione tra una variabile predittiva e la variabile dipendente, misurata dal coefficiente di regressione, è al netto dell’effetto di tutte le altre variabili e pertanto
Capitolo IV 123
l’interpretazione di questa relazione è concettualmente ardua se i predittori sono intercorrelati e il numero di variabili è alto. Si consideri inoltre che quanto più è elevato il numero di unità osservate in rapporto al numero di variabili selezionate, e tanto più numerosi saranno i gradi di liberà nella stima dei coefficienti e quindi tanto più attendibili saranno i risultati.
Il criterio di non includere altre variabili nell’equazione, se si è spiegata una data frazione di devianza, è comune nell’analisi statistica. Questo criterio è guidato dalla convinzione che non è necessario spiegare tutta la variabilità della variabile risposta, ma che si può essere soddisfatti quando la frazione spiegata è significativa, bilanciando la rinuncia alla completezza con la possibilità di comprendere meglio le relazioni tra le variabili, che in una relazione ridotta risultano più nitide8.
4.5.
APPLICAZIONE
DEL
METODO
DELLA
STEP
WISE
REGRESSION E CONTROLLO DEI RISULTATI
Avvalendosi ancora una volta del supporto informatico di STATA, si è stimato il modello di regressione lineare multipla per conseguire l’obiettivo preposto, chiedendo però al programma di ridare contemporaneamente il modello ridotto, ovvero comprensivo unicamente delle variabili significative, non considerando così quei predittori che in realtà non apportano contributi significativi per spiegare la variabilità della variabile risposta. Il modello è comprensivo delle seguenti variabili significative:
y Coef. Std. Err. T P>t [95% Conf. Interval]
x17 0,97 0,02 40,82 0,000 0,93 1,02 x2 3508,92 1655,67 2,12 0,038 205,06 6812,77 x11 5234,28 1808,49 2,89 0,005 1625,49 8843,06 x14 0,92 0,03 23,87 0,000 0,85 1,00 x16 1,04 0,03 33,93 0,000 0,98 1,10
Capitolo IV 124 x6 4607,75 1817,50 2,54 0,014 980,99 8234,52 x15 0,99 0,03 256,07 0,000 0,98 1,00 x19 0,94 0,07 13,09 0,000 0,80 1,09 x18 0,95 0,06 1 3,96 0,000 0,81 1,09 _cons -815,04 983,22 -0,83 0,284 -2777,05 1146,95
Figura 5: Step wise regression sulla matrice dei dati originaria.
Si ha quindi una situazione in cui le variabili significative sono le seguenti:
- Ragione sociale consorzi o cooperative: agisce in modo estremamente positivo la variabile risposta, il coefficiente di regressione è pari a 3508,92; ciò sta ad indicare che la presenza di questa variabile (quando assume quindi valore 1) comporta un incremento di 3508,92 della variabile dipendente.
- Fedeltà ad Ambiente S.C.: influenza in modo estremamente positivo la variabile risposta, il coefficiente di regressione è pari a 4607,75 ; la presenza di fedeltà nell’azienda-cliente comporta un incremento della variabile dipendente pari a 4607,75.
- Attività nel settore della produzione industriale: agisce in modo estremamente positivo la variabile risposta, il coefficiente di regressione è pari a 5234,28; l’aumento unitario della variabile indipendente comporta un aumento pari a 5234,28 nella variabile dipendente.
- Ammontare di fatturato realizzato nella sezione Ambiente S.C.: agisce in modo positivo sulla variabile risposta, il coefficiente di regressione è pari a 0,92; l’aumento unitario della variabile indipendente comporta un aumento pari a 0,92 nella variabile dipendente.
-Ammontare di fatturato realizzato nella sezione Bonifiche agisce in modo positivo sulla variabile risposta, il coefficiente di regressione è pari a 0,99; l’aumento unitario della variabile indipendente comporta un aumento pari a 0,99 nella variabile dipendente.
Capitolo IV 125
-Ammontare di fatturato realizzato nella sezione Fisica ambientale agisce in modo positivo sulla variabile risposta, il coefficiente di regressione è pari a 1,04 ; l’aumento unitario della variabile indipendente comporta un aumento pari a 1,04 nella variabile dipendente.
-Ammontare di fatturato realizzato nella sezione Laboratorio agisce in modo positivo sulla variabile risposta, il coefficiente di regressione è pari a 0,97: l’aumento unitario della variabile indipendente comporta un aumento pari a 0,97 nella variabile dipendente.
-Ammontare di fatturato realizzato nella sezione Sicurezza agisce in modo positivo sulla variabile risposta, il coefficiente di regressione è pari a 0,95; l’aumento unitario della variabile indipendente comporta un aumento pari a 0,95 nella variabile dipendente.
-Ammontare di fatturato realizzato nella sezione Studi e pianificazione agisce in modo positivo sulla variabile risposta, il coefficiente di regressione è pari a 0,94; l’aumento unitario della variabile indipendente comporta un aumento pari a 0,94nella variabile dipendente.
Il valore p value è strettamente minore del livello soglia α, pertanto in questo caso non si accetta l’ipotesi nulla secondo la quale il coefficiente di regressione non è significativamente diverso da 0. L’approccio p value è un’alternativa al test t di student. La tabella riassuntiva presenta, infatti, anche i valori della statistica t di Student. Una volta calcolati i coefficienti di regressione si deve verificare l’ipotesi di indipendenza di Y rispetto a una variabile esplicativa alla volta, tenendo fermi gli effetti degli altri predittori, ciò può essere realizzato avvalendosi del test t di Student, secondo la cui ipotesi nulla: H0: βk = 0
Poiché b ∼NMV(β,σ2(X’X)-1) si ha bk∼ N(βk, σ2ckk)
dove ckk è il k-esimo elemento della diagonale principale di (X’X)-1;
Supponendo che H0 sia vera e stimando la varianza incognita con la varianza di dispersione si ha:
Capitolo IV 126
Fissato un livello di significatività α, se t > +tα½ oppure t < -tα½ allora il test è significativo al livello α, e H0 va rifiutata; il contributo di Xk nel modello in cui vi sono gli altri regressori
è significativo.
Il programma STATA ridà anche la stima dell’intervallo di confidenza che con probabilità pari a 1-α conterrà il valore assunto dalla stima del coefficiente di regressione è pari a :
bk ± tα½√σ²e ckk
Il coefficiente di determinazione indica la proporzione della variazione totale di Y che è determinata dalla sua relazione lineare con le variabili esplicative, quando il suo valore è alto, le variabili indipendenti spiegano in modo adeguato la variabilità del fenomenoY, pertanto il modello è ritenuto buono. Questo indice riassume la bontà complessiva di adattamento del modello ai dati, nel caso multiplo si sommano le quote di covarianza tra ciascuna variabile indipendente e la variabile dipendente che rimangono dopo aver tenuto sotto controllo gli effetti esercitati congiuntamente con le altre variabili dipendenti.
Il coefficiente di determinazione può essere scomposto nel seguente modo:
R²= = 1-
in cui:
- SQT è la somma totale dei quadrati, cioè la variabilità totale del fenomeno
-SQR è la somma dei quadrati della regressione ovvero la variabilità spiegata dal modello di regressione lineare;
-SQE è la somma dei quadrati degli errori, cioè la parte di variabilità totale che non è spiegata dalla regressione
R² può assumere un valore compreso tra 0 (quando la varianza totale è SQT è uguale a SQE e quindi l’adattamento del modello ai dati è pessimo in quanto non riesce in alcun modo a
SQR SQT
SQE SQT
Capitolo IV 127
spiegarne la variabilità) e 1 (quando SQT=SQR e pertanto il modello lineare spiega perfettamente le relazioni tra le variabili).
In questo caso il modello si adatta perfettamente ai dati, raggiungendo un valore do 0,92 in un intervallo compreso.
La significatività dell’intera relazione di regressione viene verificata attraverso il test F che contempla la presenza di tutti i repressori insieme, non possiamo sottoporre a verifica questa ipotesi con test t separati perché si vuole sapere se i parametri sono congiuntamente significativi. L’ipotesi è quelle dell’indipendenza lineare di y dagli m repressori:
H0: β1 = β2 = … = βm = 0 Sreg SSR(Y)/m F= = ∼Fm, (n-m-1) Sreg SSE(Y)/(n m 1)
Fissato un livello di significatività α, se F > Fα allora il test è significativo al livello α, e H0 va rifiutata. Ciò significa che:
- la variabilità di Y spiegata dal modello è significativamente più elevata della variabilità residua;
- ad almeno uno degli m regressori corrisponde nel modello un coefficiente di regressione significativamente diverso da 0.
Se invece F ≤ Fα allora il test non è significativo al livello α, e H0 non viene rifiutata; in tal caso il modello non è adeguato, tra Y e gli m regressori non vi è alcuna relazione di dipendenza lineare.
In questo caso l’ipotesi nulla deve essere rifiutata, il modello è complessivamente significativo, il p value infatti si approssima quasi allo 0.
Per quanto riguarda invece le variabili escluse si è presentata la seguente situazione che ha portato alla loro eliminazione:
Capitolo IV 128
p = 0.9364 >= 0.1000 removing: “ settore di attività dell’azienda cliente: edilizia e costruzioni”
p = 0.7767 >= 0.1000 removing: “area geografica di attività dell’azienda cliente: nord ovest”
= 0.8208 >= 0.1000 removing: “ settore di attività dell’azienda cliente: consulenza e tecnologie ambientali”
p = 0.7676 >= 0.1000 removing: “fatturato dell’azienda cliente”
p = 0.5731 >= 0.1000 removing : anni di attività dell’azienda cliente”
p = 0.5940 >= 0.1000 removing : “area geografica di attività dell’azienda cliente: nord est”
p = 0.5028 >= 0.1000 removing : “numero dei dipendenti dell’azienda cliente”
p = 0.4458 >= 0.1000 removing: : “ settore di attività dell’azienda cliente: settore chimico”
p = 0.4838 >= 0.1000 removing: “ammontare di fatturato realizzato nel sezione Formazione”
p = 0.3653 >= 0.1000 removing: “ragione sociale dell’azienda cliente: spa o srl”
p = 0.3175 >= 0.1000 removing : “area geografica di attività dell’azienda cliente: centro”
Figura 6: Tabella riassuntiva delle variabili eliminate tramite la step wise regression.
Il valore p value è maggiore del livello soglia α, pertanto in questo caso si accetta l’ipotesi nulla secondo la quale il coefficiente di regressione non è significativamente diverso da 0.
Un ulteriore controllo da fare riguarda il legame che intercorre tra le variabili esplicative. Vi è multicollinearità nei dati quando si presentano relazioni lineari tra i regressori. Gli effetti della presenza di correlazione (e quindi di multicollinearità) tra i regressori riguardano soprattutto l’affidabilità delle procedure inferenziali, poiché V(b) = σ2 (X’X)-1 le varianze degli stimatori crescono al crescere della multicollinearità. Si possono verificare le seguenti situazioni:
- calo della precisione delle stime puntuali; - gli intervalli di confidenza si allargano;
- crescono le covarianze campionarie tra gli stimatori;
- i test t tendono a segnalare coefficienti non significativi anche con valori elevati di R².
Inoltre le stime b sono molto sensibili a variazioni anche molto piccole dei valori osservati di Y e/o dei regressori.
I sintomi che portano a presagire la presenza di una situazione di multicollinearità sono i seguenti:
Capitolo IV 129
- i coefficienti β hanno valore o segno non plausibile ,
- i coefficienti non sono significativi nonostante altri indici portino a ritenere il modello adeguato.
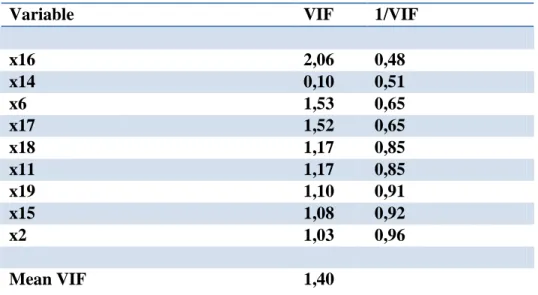
Un indice utilizzato per misurare il livello di multicollinearità della variabile Xi con le altre variabili esplicative è il Variance inflaction factor VIF:
In cui R²i è il coefficiente di determinazione multiplo del modello di regressione in cui le xi variabile dipendente dalle altre m-1 variabili indipendenti.
Il valore minimo del VIF è 1 quando xi è incorrelata con le altre, un valore maggiore di 2 indica la presenza di multicollinearità.
I risultati ottenuti grazie a STATA sono i seguenti:
Variable VIF 1/VIF
x16 2,06 0,48 x14 0,10 0,51 x6 1,53 0,65 x17 1,52 0,65 x18 1,17 0,85 x11 1,17 0,85 x19 1,10 0,91 x15 1,08 0,92 x2 1,03 0,96 Mean VIF 1,40
Figura 7: Tabella riassuntiva dei VIF calcolati sulle variabili significative.
Soltanto per la variabile “Ammontare di fatturato realizzato nella sezione Fisica ambientale” si raggiunge una valore del VIF maggiore di 2, ma poiché il VIF media ha un valore nettamente inferiore la situazione non sembra pericolosa per l’affidabilità dell’analisi.
Capitolo IV 130
Un metodo per esplorare i limiti della regressione lineare consiste nell’esaminare i residui. I residui ottenuti con il metodo dei minimi quadrati sono incorrelati con la funzione teorica e con la variabile esplicativa. L’analisi dei residui permette di:
• stabilire se le ipotesi formulate sul termine d’errore del modello di regressione sono valide rispetto al fenomeno analizzato: si procede esaminando il grafico realizzato con i residui in ordinata e in ascissa i corrispondenti valori teorici di Y .
Se i residui sono incorrelati con i valori teorici di Y e con le variabili esplicative, il grafico non mostrerà particolari relazioni, se il modello lineare è adatto bisognerà riscontrare incorrelazione degli errori e una situazione di omoschedasticità,
• identificare l’eventuale presenza di outlier, punti di leverage, osservazioni influenti. Per verificare in modo rigoroso la presenza di eventuale eteroschedaticità dei residui, è stato chiesto a STATA di procedere a un test statistico, in particolare si è ricorso al test di Breusch-Pagan / Cook-Weisberg, ottenendo i seguenti risultati:
Breusch-Pagan / Cook-Weisberg test for
heteroskedasticity Ho: Constant variance
Variables: fitted values of y chi2(1) = 2,01
Prob > chi2 = 0,1559
Figura 8: Test di omoschedasticità
Il test di Breusch-Pagan per la verifica di ipotesi di omoschedasticità dei residui della regressione lineare è valido per grandi campioni, assume che gli errori siano indipendenti e normalmente distribuiti, e che la loro varianza ( ) sia funzione lineare del tempo t secondo:
ciò implica che la varianza aumenti o diminuisca al variare di t, a seconda del segno di b. Se si ha l’omoschedasticità, si realizza l’ipotesi nulla:
Capitolo IV 131
H0:b = 0
Contro l’ipotesi alternativa bidirezionale:
Per la sua verifica, si calcola una regressione lineare, a partire da un diagramma di dispersione che:
• sull'asse delle ascisse riporta il tempi t
• sull'asse delle ordinate il valore dei residui corrispondente
Si ottiene una retta di regressione, la cui devianza totale (SQR) è in rapporto alla devianza d’errore precedente (SQE), calcolata con i dati originari secondo una relazione di tipo quadratico, che, se è vera l'ipotesi nulla, al crescere del numero delle osservazioni si distribuisce secondo una variabile casuale chi quadro con un grado di libertà.
Risulta evidente quindi che l’ipotesi nulla di varianza costante può essere accettata e siamo in presenza di una situazione di omoschedasticità.
Il grafico ottenuto ponendo i residui in ordinata e i valori teorici di Y in ascissa mostra la seguente situazione:
Capitolo IV 132
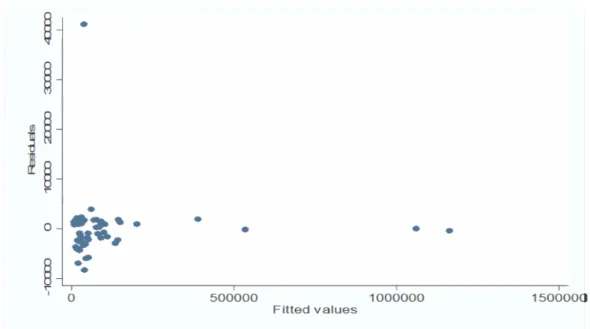
Figura 9: Grafico dei residui rispetto ai valori fittati.
Appare chiara la presenza di 4 leverage , che si discostano dalle altre osservazioni per un valore molto più grande riguardo al valore fittato della variabile dipendente, e un outlier, che presenta un residuo chiaramente maggiore rispetto alle altre unità; per capire se tali punti anomali sono anche punti influenti è necessario verificare come cambia il valore del coefficiente di determinazione eliminandoli dalla matrice dei dati.
Si è proceduto eliminando uno alla volta i punti anomali, e monitorando come si modica l’attendibilità dei risultati. Sostanzialmente è stato chiesto a STATA di realizzare il medesimo procedimento di stepwise regression e realizzare i test in questione, non considerando prima una riga della matrice dei dati, poi due, poi tre e così via, fino ad eliminarne cinque.
Come primo tentativo si è ignorato il leverage che più si discostava dagli altri, ottenendo un coefficiente di determinazione pari a 0,93, la situazione quindi è leggermente migliorata, l’ipotesi di omoschedasticità risulta verificata mentre il valore medio del VIF risulta, anche se lievemente, incrementato (da 1,4 a 1,52).
Procedendo con la medesima logica si sono confrontati i risultati ottenuti ad ogni tentativo, giungendo così alla conclusione che la soluzione migliore è quella che vede l’eliminazione
Capitolo IV 133
di tutti i punti anomali, i quali, anche se in modo lieve, conducevano a un peggioramento dei risultati.
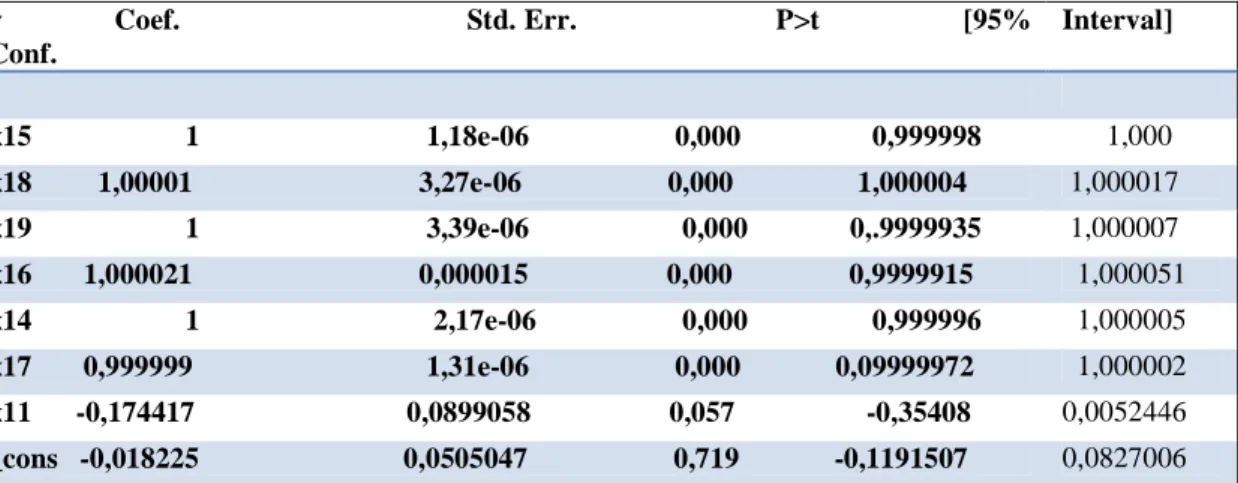
Il modello di regressione lineare conclusivo quindi prevede le seguenti variabili indipendenti significative: y Coef. Std. Err. P>t [95% Conf. Interval] x15 1 1,18e-06 0,000 0,999998 1,000 x18 1,00001 3,27e-06 0,000 1,000004 1,000017 x19 1 3,39e-06 0,000 0,.9999935 1,000007 x16 1,000021 0,000015 0,000 0,9999915 1,000051 x14 1 2,17e-06 0,000 0,999996 1,000005 x17 0,999999 1,31e-06 0,000 0,09999972 1,000002 x11 -0,174417 0,0899058 0,057 -0,35408 0,0052446 _cons -0,018225 0,0505047 0,719 -0,1191507 0,0827006
Figura 10: Step wise regression sulla matrice dei dati ridotta.
Le variabili dipendenti che risultano significative sono cambiate rispetto al caso precedente. In questo caso quelle che vanno a incidere sul livello di fatturato sono:
• “Settore di attività dell’azienda cliente produzione industriale”: incide negativamente in modo debole sulla variabile dipendente, il coefficiente di regressione è pari a -0,174417. Ciò significa che un aumento unitario della variabile indipendente porta ad una variazione pari a 0,174417 nella variabile dipendente.
• “Ammontare di fatturato realizzato nella sezione Ambiente”: incide positivamente sulla variabile dipendente in modo proporzionale, con un coefficiente di regressione unitario. Ciò significa che un aumento unitario della variabile indipendente porta ad una variazione pari a 1 nella variabile dipendente.
• “Ammontare di fatturato realizzato nella sezione Bonifiche”: incide positivamente sulla variabile dipendente in modo proporzionale, con un coefficiente di regressione unitario. Ciò significa che un aumento unitario della variabile indipendente porta ad una variazione pari a 1 nella variabile dipendente.
Capitolo IV 134
• “Ammontare di fatturato realizzato nella sezione Fisica ambientale”: incide in maniera praticamente proporzionale sulla variabile dipendente con un coefficiente di regressione pari a 1,000021. Ciò significa che un aumento unitario della variabile indipendente porta ad una variazione pari a 1,000021 nella variabile dipendente. • “Ammontare di fatturato realizzato nella sezione Laboratorio”: incide positivamente
in modo leggermente meno che proporzionale, il coefficiente di regressione è pari a 0,999999. Ciò significa che un aumento unitario della variabile indipendente porta ad una variazione pari a 0,999999 nella variabile dipendente.
• “Ammontare di fatturato realizzato nella sezione Sicurezza”: incide in maniera proporzionale sulla variabile dipendente con un coefficiente di regressione pari a 1,000001. Ciò significa che un aumento unitario della variabile indipendente porta ad una variazione pari a 1,000001 nella variabile dipendente.
• “Ammontare di fatturato realizzato nella sezione Studi e pianificazione”: incide in modo proporzionale sulla variabile dipendente con un coefficiente di regressione pari a 1. Ciò significa che un aumento unitario della variabile indipendente porta ad una variazione pari a 1 nella variabile dipendente.
Le variabili non incluse nel modello vengono ritenute non sufficentemente significative da giustificare una loro considerazione nel modello stesso:
p = 0.9613 >= 0.1000 removing :“ragione sociale dell’azienda cliente: spa o srl"
p = 0.9508 >= 0.1000 removing: “settore di attività dell’azienda cliente: consulenza e tecnologie ambientali”
p = 0.9447 >= 0.1000 removing : “ragione sociale dell’azienda cliente: consorzi e cooperative" p = 0.9100 >= 0.1000 removing: “fedeltà dell’azienda cliente ad Ambiente S.C.”
p = 0.8470 >= 0.1000 removing : “settore di attività dell’azienda cliente: edilizia e costruzione” p = 0.5988 >= 0.1000 removing : “fatturato dell’azienda cliente”
p = 0.5744 >= 0.1000 removing “settore di attività dell’azienda cliente: settore chimico” p = 0.4331 >= 0.1000 removing: “ammontare di fatturato realizzato nel sezione Formazione” p = 0.4573 >= 0.1000 removing : “ area geografica di attività dell’azienda cliente: nord ovest” p = 0.3042 >= 0.1000 removing: “area geografica di attività dell’azienda cliente: nord est” p = 0.2843 >= 0.1000 removing : “ area geografica di attività dell’azienda cliente: centro” p = 0.2055 >= 0.1000 removing : “numero di deipendenti dell’azienda cliente”
Capitolo IV 135
Figura 11: Tabella riassuntiva delle variabili eliminate tramite la step wise regression (dopo aver eliminato i punti anomali).
Il coefficiente di determinazione che misura la bontà di adattamento ai dati al modello complessivo è pari e 0,9. Il modello lineare può essere considerato ottimo ai fini dell'interpretazione dei dati.
Sono stati ripetuti anche gli altri test per verificare che l'esclusione dei valori anomali non abbia pregiudicato le ipotesi alla base del modello lineare.
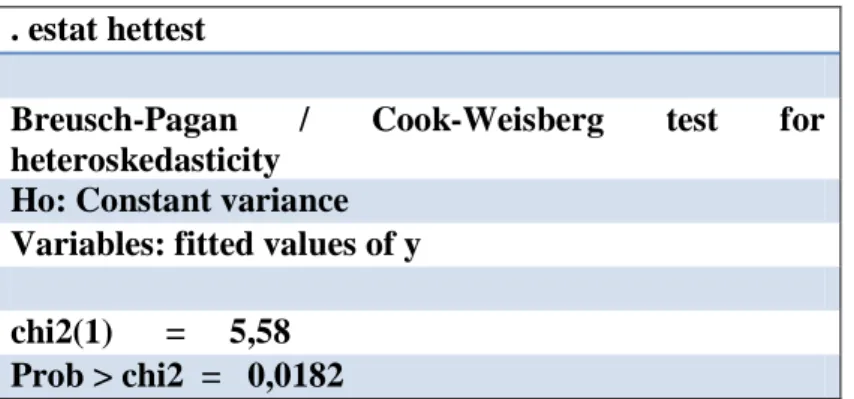
Il test volto alla verifica dell'ipotesi di omoschedasticità rivela che la situazione è addirittura migliorata, in quanto il valore ottenuto è maggiore rispetto a quanto ottenuto con il modello iniziale. L'ipotesi di omoschedasticità è quindi confermata.
. estat hettest
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity
Ho: Constant variance Variables: fitted values of y chi2(1) = 5,58
Prob > chi2 = 0,0182
Figura 12: Test di omoschedasticità (dopo aver eliminato i punti anomali).
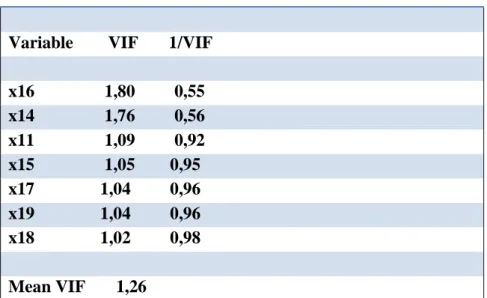
E' stato calcolato anche il vif per indagare circa l'esistenza di multicollinearità tra le variabili.
Nessun valore del vif supera la soglia di 2, non si ha quindi il pericolo di multicollinearità tra le variabili principali.
Capitolo IV 136
Variable VIF 1/VIF x16 1,80 0,55 x14 1,76 0,56 x11 1,09 0,92 x15 1,05 0,95 x17 1,04 0,96 x19 1,04 0,96 x18 1,02 0,98 Mean VIF 1,26
Figura 13: Tabella riassuntiva dei VIF calcolati sulle variabili significative (dopo aver eliminato i punti anomali).
Il grafico dei residui e dei valori fittati è il seguente. Non risultano esserci particolari valori anomali rispetto al valore dei residui (outliers) o dei valori fittati della y (leverage).
Capitolo IV 137 -1 -. 5 0 .5 1 R e s id u a ls 0 50000 100000 150000 200000 Fitted values
Figura 14: Grafico dei residui rispetto ai valori fittati (dopo aver eliminato i punti anomali).
Introducendo una variabile dipendente alla volta, e osservando come questo processo incida sulla variabile dipendente, si ottiene l’evoluzione che porta alla rappresentazione del modello contenente tutte le variabili giudicate significative.
Dopo vari tentativi si è dunque riusciti ad individuare una relazione tra i dati presi in esame, il modello di relazione lineare tra le variabili è quello che meglio spiega quali siano gli elementi che vanno ad influire sul fatturato che Ambiente S.C. ricava trattando con ciascun cliente. Ci sono 5 aziende che non sono state considerate perché le variabili rilevate su esse presentavano valori anomali , ciò poteva portare ad una distorsione dei risultati; tutte le ipotesi alla base del modello lineare sono state verificate, anche quelle che consentono di
Capitolo IV 138
fare inferenza e che quindi attribuiscono al modello anche valore predittivo oltre che esplicativo.