Subroutines
La subroutine è una parte di codice condiviso e rappresenta la traduzione nel bytecode del blocco finally.
Per implementare il blocco finally il compilatore della Sun utilizza un meccanismo simile a quello dei gestori delle eccezioni: attraverso l’uso di due istruzioni particolari, jsr (jump to subroutine) e ret (return from subroutine), il codice della subroutine diventa “condivisibile” perché la chiamata a quel codice è parametrizzata; la jsr salva su stack l’indirizzo di ritorno e salta alla prima istruzione del codice condiviso; il returnAddres è un tipo particolare che può essere utilizzato solo dall’istruzione ret.
L’istruzione jsr b inserisce l’indirizzo di ritorno (il returnAddress) nello stack e passa il controllo al ramo b. A questo punto si è all’interno del codice condiviso, l’istruzione ret x permetterà di ritornare all’istruzione successiva alla jsr associata, prelevando il valore del returnAddress dal registro specificato, in questo caso x.
L’utilizzo della subroutine complica notevolmente la verifica del bytecode a causa della difficoltà di gestire correttamente i frame all’entry point della subroutine stessa e a causa delle difficoltà di individuare durante la verifica quali sono i successori dell’istruzione ret, in più si aggiunge una scarsa documentazione offerta dalla Sun [vmspecv2] che non aiuta a comprendere effettivamente dove termini il codice di una subroutine.
4.1 Eccezioni in Java
In Java quando un metodo può potenzialmente sollevare eccezioni (ad esempio la Integer.readLine(), legge un intero dallo stdin e può lanciare una NumberFormatException) deve essere presente all’interno di un blocco try in modo da avere un meccanismo per cui vada in esecuzione un handler (gestore di eccezioni) che gestisca correttamente le situazioni di errore.
Ogni handler viene definito all’interno di un blocco catch ed è associato al tipo di eccezione specificato dal catch. Capitano situazioni in cui è necessario compiere determinate operazioni a prescindere che l’eccezione sia sollevata o meno, queste operazioni vengono definite all’interno del blocco finally, il compilatore garantisce quindi che le istruzioni contenute all’interno del blocco finally siano eseguite dopo il try o il try-catch, quindi i modi con cui si può arrivare al codice di una subroutine sono: dopo l’ultima istruzione del blocco try se non vengono lanciate eccezioni, dopo l’ultima istruzione di un blocco catch, o in seguito ad una eccezione lanciata proprio dal gestore di una eccezione.
Un handler specifica all’interno del bytecode il proprio range di istruzioni e il metodo per cui l’handler è attivo. Un handler inoltre descrive il tipo di eccezione che è in grado di gestire e quali parti di codice dovrà proteggere. Ad una eccezione verrà quindi associato un handler se l’offset dell’istruzione che ha sollevato l’eccezione è contenuta nel range di codice che l’handler protegge e se il tipo dell’eccezione appartiene alla stessa classe dell’eccezione gestibile dall’handler.
Quando si lancia un‘eccezione, la JVM cerca il giusto handler nel metodo corrente, una volta trovato, il sistema trasferirà l’esecuzione alla prima istruzione dell’handler.
Se non viene trovato alcun gestore nel metodo corrente, l’invocazione di tale metodo terminerà improvvisamente (completes abruptly). L’eccezione sarà quindi “passata” ( rethrow) nel contesto del chiamante e così via.
Il bytecode generato dal compilatore della Sun rispetta sempre i seguenti vincoli:
− Entrambi i range di istruzioni protette da due differenti handlers sono sempre disgiunti, o uno è il subrange dell’altro.
− L’handler per un’eccezione non deve essere all’interno del codice che protegge.
− L’unico modo per eseguire il codice di un handler è quello di sollevare un’eccezione, è impossibile accedere a tale codice attraverso un salto.
Questi vincoli non vengono controllati dal verificatore.
Per capire meglio la struttura di un costrutto try-catch-finally si prenda in considerazione un esempio dato dalla stessa Sun [vmspecv2 7.13]:
void tryCatchFinally() { try { tryItOut(); } catch (TestExc e) { handleExc(e); } finally { wrapItUp(); } }
Method void tryCatchFinally()
0 aload_0 // Beginning of try block
1 invokevirtual #4 // Method Example.tryItOut()V
4 goto 16 // Jump to finally block
7 astore_3 // Beginning of handler for
// TestExc;
// Store thrown value in local
// variable 3
8 aload_0 // Push this
9 aload_3 // Push thrown value
10 invokevirtual #6 // Invoke handler method:
// Example.handleExc(LTestExc;)
13 goto 16 // Huh???
16 jsr 26 // Call finally block
19 return // Return after handling TestExc
20 astore_1 // Beginning of handler for
// exceptions
// other than TestExc, or
// exceptions
// thrown while handling TestExc
21 jsr 26 // Call finally block
24 aload_1 // Push thrown value...
25 athrow // ...and rethrow the value to
// the invoker
26 astore_2 // Beginning of finally block
27 aload_0 // Push this
28 invokevirtual #5 // Method Example.wrapItUp()V
31 ret 2 // Return from finally block
Exception table:
From To Target Type
0 4 7 Class TestExc
Se il blocco try termina normalmente, l’istruzione goto al punto 4 salta al punto della chiamata della subroutine ( index 16). La subroutine viene eseguita, il controllo passa all’istruzione al punto 19 ( l’istruzione successiva alla jsr) e tryCatchFinally termina normalmente.
Se tryItOut solleva un eccezione del tipo TestExc, l’handler è selezionato attraverso l’utilizzo di una tabella. Il codice di tale gestore inizia al punto 7, passa il valore dell’eccezione a handleExc e prima di terminare chiama la subroutine. Se l’eccezione è stata gestita correttamente e non sono state lanciate altre eccezioni TryCatchFinally termina normalmente.
Se tryOutFinally solleva un tipo di eccezione che non è TestExc o se lo stesso handleExc solleva un eccezione la gestione passa alla seconda entry della exception table, che gestice ogni tipo di eccezione sollevato dal codice compreso tra 0 e 16. Tale gestore trasferisce il controllo al punto 20, dove il throw value ( il valore che identifica il tipo di eccezione) è memorizzato nel registro 1. Il controllo passa alla subroutine. Una volta terminata l’esecuzione della subroutine, il throw value viene risollevato esplicitamente attraverso l’istruzione athrow. Se durante l’esecuzione della subroutine si fosse sollevata una nuova eccezione, l’esecuzione abortiva, il metodo terminava bruscamente trasferendo il controllo al chiamante.
4.2 Il problema delle subroutines
Fino a questo momento il verificatore ipd era visto come un verificatore monovariante, per verifica monovariante si intende una verifica che a ogni punto del flusso tiene in considerazione un solo stato; la verifica polivariante invece consente dove è necessario di avere più stati associati ad un certo punto del bytecode ( per esempio la prima istruzione della subroutine). L’analisi polivariante permette di verificare il corpo della subroutine in diversi momenti partendo con un determinato stato iniziale. La verifica polivariante è equivalente ad estendere in linea il corpo della subroutine ogni qualvolta questa viene invocata ma l’estensione in linea vera e propria non sarebbe possibile perché:
− Non è possibile staticamente individuare il corpo della subroutine
− È complesso al run-time; le istruzioni vengono prelevate in modo casuale, senza un preciso ordine.
Come accennato l’utilizzo delle subroutines complica notevolmente la verifica del bytecode, le difficoltà relative alla verifica si possono elencare come segue:
− Successore della ret. Durante la verifica è necessario identificare quali sono i successori delle istruzioni in modo da propagare correttamente il frame contenente il tipo. Il successore di un‘istruzione ret non si può determinare staticamente , dato che il valore dell’indirizzo di ritorno (il returnAddress) non è specificato come operando ma è un valore memorizzato all’interno di un registro. Si prenda in considerazione l’esempio che utilizza Xavier Leroy [Leroy] per comprendere meglio il problema:
0 .. // Il registro 1 non è inizializzato 3 jsr 50 // Chiamata alla subroutine 6 ..
20 iconst_1
21 istore_1 // In questo punto il registro ha // tipo “int”
22 jsr 50 // Chiamata alla subroutine 25 iload_1 // Si legge l’intero dal registro 1 26 ireturn // .. e si ritorna al chiamante 50 astore_2 // Subroutine!
51 ... // Memorizza il return Address nel // registro 2
58 ret 2 // Ritorna al successore
// fisico della jsr che // ha invocato la subroutine
In questo caso il valore del returnAddress è memorizzato nel registro 2 , e i successori della ret saranno differenti a seconda del punto di chiamata della subroutine; in un caso il successore è l’istruzione al punto 6 , nell’altro l’istruzione al punto 25.
− Polimorfismo dei registri. Come detto le subroutines possono avere differenti punti di chiamata con differenti tipi per alcuni registri. Ci aspetteremmo che tali registri al ritorno della subroutine conservino comunque lo stesso tipo che avevano prima della chiamata.
Nell’esempio visto le due istruzioni jsr hanno il medesimo successore : l’istruzione al punto 50. Al punto 3 il registro 1 non è inizializzato ; al punto 22 contiene un intero. Di conseguenza al punto 50 il registro conterrà un tipo indefinito (il least upper bound tra tipo indefinito ed int). La subroutine non modifica il registro 1 . La ret al punto 58 ha come successori le istruzioni ai punti 6 e 25. Al punto 25 il registro contiene il tipo indefinito e non può essere usato come un intero dall’istruzione 25 e 26. Quindi nonostante ci si aspetti il contrario questo codice verrà rigettato.
− Limiti della subroutine. Come si approfondirà successivamente in alcuni casi potrebbe essere non chiaro quando termini la subroutine, si presenta la necessità di capire quali istruzioni appartengano alla subroutine (fig. 4.1).
0: jsr 5 3: nop 4: return 5: astore_2 6: iconst_0 7: iload_1 8: if_icmpeq -> 3 10: ret 2
fig. 4.1: Il bytecode non è strutturato: quali sono le istruzioni della subroutine? La nop fa parte della subroutine?
− Annidamento tra subroutines. All’interno del codice di una subroutine potrebbe essere presente una istruzione jsr che a sua volta invoca una chiamata ad un'altra subroutine e cosi via. Questo contribuisce a rendere ancora più difficile determinare staticamente il returnAddress corretto relativo ad ogni istruzione ret.
− Bytecode modificato: Il bytecode può esser scritto e modificato “a mano”, esiste quindi del bytecode valido che però non può essere generato da nessun codice sorgente compilato da compilatore standard (fig 4.2).
0: jsr 4 3: return 4: dup 5: astore_2 6: pop 7: ret 2
fig. 4.2: Bytecode corretto che nessun compilatore “standard” produce a partire da un sorgente java. Questo codice supera la verifica effettuata dal verificatore della Sun, è invece rigettato dal JustIce.
4.3 Vincoli strutturali sulle subroutines specificati dalla Sun
Si riportano i vincoli strutturali [vmspecv2 4.8.2] per le subroutines:
−
Non deve essere possibile caricare un returnAddress ( l’indirizzo di ritorno da una subroutine) da una variabile locale con una aload.(
No return address (a value of type returnAddress) may be loaded from a local variable).− Le istruzioni che seguono ogni jsr o jsr_w devono essere ritornate solo da una singola istruzione ret. (The instruction following each jsr or jsr_w instruction
may be returned to only by a single ret instruction).
−
Nessuna istruzione jsr o jsr_w deve essere utilizzata per chiamate ricorsive, ma possono essere presenti subroutine annidate.
(No jsr or jsr_w instruction may be used to recursively call a subroutine if that subroutine is already present in the subroutine call chain. (Subroutines can be nested when usingtry-finally constructs from within a try-finally clause).
− Ogni istanza del tipo returnAddress può essere utilizzata al massimo una volta. Se una istruzione ret ritorna in un punto nella subroutine prima della ret stessa la stessa istanza del returnAddress non può essere utilizzata.
(Each instance of type returnAddress can be returned to at most once. If a ret instruction returns to a point in the subroutine call chain above the ret instruction corresponding to a given instance of type returnAddress, then that instance can never be used as a return address).
Questi vincoli servono probabilmente ad evitare “errori di programmazione” involontari, in particolare nei cicli infiniti nel grafo.
Il primo vincolo impedisce che sia possibile leggere con una qualunque istruzione load il valore di tipo returnAddress da una variabile locale, il returnAddress è un tipo utilizzato esclusivamente dall’istruzione ret che quindi deve essere l’unica in grado di accedere al valore di tipo returnAddress memorizzato in un registro. Nel caso in cui fosse possibile leggere e modificare un’istanza del returnAddress, si potrebbe facilmente creare del codice malizioso variando il successore della ret e quindi il punto di ritorno della subroutine che in ogni caso deve essere l’istruzione successiva all’istruzione jsr.
Dal secondo vincolo risulta chiaro che all’interno di una subroutine deve essere presente al massimo un’istruzione ret, questo lo si è provato anche modificando “a mano” vari bytecode compilati dal compilatore Sun aggiungendo più istruzioni ret all’interno di un unica subroutine e in tutti casi il codice veniva rigettato, per cui ad una subroutine viene associato un’istanza di returnAddress e a questo viene associata una sola istruzione ret.
Il terzo vincolo impedisce le chiamate ricorsive di subroutines, permettendo però l’annidamento tra subroutines, dato che la subroutine è la traduzione del blocco finally ciò significa che all’interno di un blocco finally sarà presente un altro blocco di tipo finally.
Il quarto vincolo afferma che l’istanza di un returnAddress deve essere utilizzata dall’istruzione ret una sola volta, questo per avere la certezza di ottenere un corretto annidamento delle subroutine, ad ogni successore della jsr, quindi ad ogni jsr va associata al massimo un’istruzione ret, di conseguenza non avrebbe senso utilizzare più di una volta un istanza del returnAddress.
Nel paragrafo 4.9.6 delle vmspecv2 della Sun (Exceptions and finally) viene descritta a grandi linee come avviene la verifica in presenza di subroutines (che si descriverà nel paragrafo seguente) in più la Sun aggiunge un ulteriore vincolo:
− Quando si esegue una ret, che implementa il ritorno da una subroutine, deve essere presente una sola subroutine da cui ritornare. Due differenti subroutine non possono convergere la loro esecuzione in una singola istruzione ret. ( When executing the ret instruction, which implements a return from a subroutine, there must be only one possible subroutine from which the instruction can be returning. Two different subroutines cannot "merge" their execution to a single ret instruction).
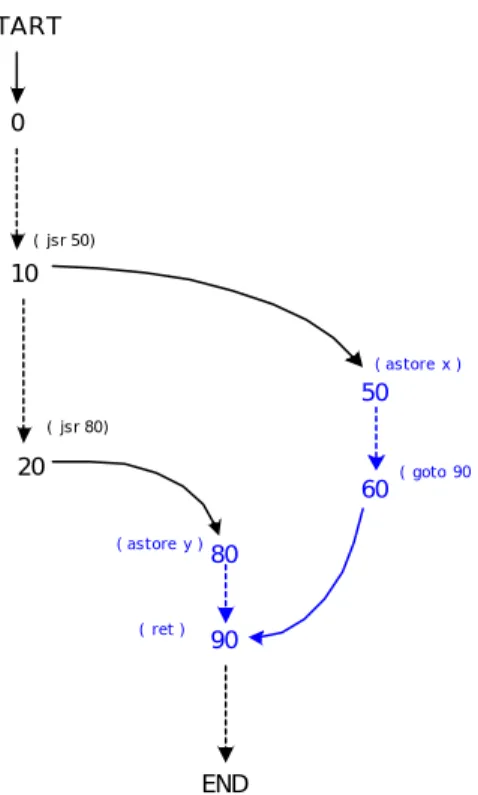
Consideriamo una subroutine che in un certo punto ha un’istruzione goto all’interno del corpo di un altra subroutine e che il target del goto sia proprio l’istruzione ret (fig. 4.3). Si avrebbe un “merge” delle due subroutine su un unica ret , tale codice sarà rigettato in quanto non rispetta le specifiche (le due subroutine tentano un “merge” su un'unica istruzione ret). Questo vincolo si impone per avere un corretto annidamento delle subroutines (un unica coppia returnAddress-ret) ma non è chiaro se con ciò si voglia anche eliminare il codice condiviso o meno, perla regola, il codice condiviso tra subroutines è lecito dato che una subroutine dopo il goto nel corpo della seconda subroutine può ritornare con un nuova istruzione goto all’interno del corpo della prima subroutine terminando correttamente con la “propria” istruzione ret. Il JustIce come vedremo invece non permette la condivisione di codice tra subroutines.
START 0 10 20 80 50 90 60 ( jsr 50) ( jsr 80) ( astore x ) ( astore y ) ( ret ) ( goto 90 ) END
fig. 4.3: Grafo di codice non valido, due subroutines tentano il “merge” su unica istruzione di ret
4.4
Verifica
delle
subroutines secondo la Sun
La Sun propone delle idee per effettuare la verifica [vmspecv2 4.9.6]:
• ogni istruzione deve tener traccia della lista di targets della jsr per raggiungere una determinata istruzione; spesso questa lista contiene una sola istruzione perché avere più jsr annidate vuol dire avere più blocchi finally annidati, e questa è una cosa statisticamente poco probabile nei codici sorgenti.
• per ogni istruzione eseguita dopo la jsr viene tenuta traccia, con un vettore di bit, quali sono le variabili modificate dalla subroutine; in questo modo è possibile in seguito al raggiungimento dell’istruzione ret propagare solo i tipi di variabili modificate.
• Quando si esegue l’istruzione ret, che implementa un ritorno da una subroutine, deve esserci un unica subroutine dalla quale l’istruzione deve ritornare. Due differenti subroutines non possono fare il merge su un unica ret.
• Nell’analisi del flusso dei dati quando si ha una ret si avrà che:
o Per ogni variabile locale modificata dalla subroutine a tale variabile si assocerà il nuovo tipo dopo il
ritorno dalla ret.
o Per le altre variabili ( quelle non modificate dalla
subroutine ) verrà associato il tipo che avevano prima della chiamata alla subroutine.
La Sun utilizza un vettore di bit che indica quali dei registri sono stati modificati all’interno della subroutine, quando si ritorna dalla subroutine il merge sarà parziale:il merge coinvolgerà solo le variabili locali modificate all’interno della subroutine per le restanti variabili si conserverà il tipo che avevano prima dell’entry point della subroutine stessa.
4.5 Verifica delle subroutines secondo il JustIce
Il JustIce aggiunge ulteriori vincoli per le subroutine in modo da rendere la definizione di subroutine più chiara e comprensibile, di seguito vengono riportate tali regole con alcuni commenti per evidenziare le ragioni di alcune scelte e approfondimenti per le regole che verranno adottate anche nello sviluppo del verificatore ipd.
• Deve essere presente esattamente una istruzione ret per subroutine.Tale istruzione deve lavorare sulla variabile locale N.
Questa regola rende più forte ciò che specifica la Sun. Nelle vmspecv2 si afferma che deve essere presente al massimo una ret per subroutine (ma non specifica se è corretto che la subroutine termini con un istruzione return) per il Justice la subroutine può solo terminare con una istruzione ret.
• Ogni Istruzione è parte di una sola subroutine (o appartiene al top-level).
Questo vincolo è conseguente alla regola precedente; dato che la subroutine deve terminare con un’istruzione ret e dato che due o più subroutine non possono convergere su un'unica ret di conseguenza non é possibile la condivisione del codice delle subroutine.
• La prima istruzione di una subroutine è una astore N che memorizza il valore del returnAddress nella variabile locale N.
Questo è senza dubbio il vincolo più importante che impone il Justice; ll codice compilato ha sempre come prima istruzione una astore N , la quale preleva il valore del returnAddress dallo stack e lo memorizza nel registro N dove la ret al termine della subroutine lo preleverà per tornare esattamente all’istruzione immediatamente successiva all’istruzione jsr. Se il codice venisse modificato in modo tale che come prima istruzione ci fosse una dup (che duplica il valore memorizzato in cima allo stack) il valore del returnAddress verrebbe copiato e utilizzato in modo sicuramente non utile all’ esecuzione della subroutine , per cui potrebbe essere codice malizioso. Imponendo che la prima istruzione sia una astore ci si assicura che il valore del returnAddress è subito memorizzato nel registro N , dove (date le specifiche della Sun) nessuna istruzione può prelevarne il contenuto se non l’istruzione ret.
Inoltre con l’aggiunta di questo vincolo ci si assicura un corretto annidamento tra le subroutines.
• Ogni Istruzione è parte di una sola subroutine ( o appartiene al top-level ).
Come accennato nel paragrafo sulla descrizione delle regole della Sun a riguardo delle subroutines nel Justice non è permesso la condivisione del codice tra subroutines, ancora una volta il Justice rende più forte il vincolo dato dalle specifiche della Sun , dato che in Justice non è permesso ( almeno in teoria ) che una subroutine termini con una return allora effettivamente può avere poco senso la condivisione del codice tra subroutines.
• Le subroutines non sono protette da gestori di eccezioni
Questo punto richiede alcune precisazioni.
La subroutine può essere invocata da vari punti del bytecode. Prendendo in considerazione il caso in cui è presente un blocco try-catch-finally, si ricorda che la subroutine viene invocata:
o Al termine del blocco try.Se non si è sollevata nessuna eccezione viene invocata la subroutine e al termine di questa il metodo termina con l’istruzione return.
o Se si solleva un eccezione gestibile dal blocco catch. Terminato il codice del gestore viene invocata la subroutine al termine della quale il metodo termina con l’istruzione return.
o Nel caso in cui si solleva un eccezione che non è un istanza gestibile dal gestore interno al blocco catch o se il codice dello stesso gestore solleva un eccezione, viene invocato un secondo gestore il quale ha il solo compito di invocare la subroutine e al
termine di questa eseguire l’istruzione atrow in modo da passare la gestione dell’eccezione al chiamante.
Quindi effettivamente la subroutine non è protetta da gestori di eccezione.
Prendendo però in considerazione la situazione in cui si ha un blocco try annidato (un blocco try all’interno di un altro blocco try ) in cui si hanno rispettivamente due blocchi finally, la subroutine esterna anche in questo caso non sarà protetta da gestori di eccezioni al contrario la subroutine interna sarà protetta poiché il blocco finally interno è inglobato dal blocco try esterno, il quale chiaramente è protetto da gestore di eccezioni.
Quindi nei casi comuni in cui non è presente un annidamento dei blocchi try effettivamente la subroutine non è protetta da eccezioni in casi di annidamento la subroutine può essere protetta da gestori di eccezioni.
D’altronde la descrizione della compilazione del blocco finally delle vmspecv2 dice:
“[…] If a new value is thrown during execution of the finally clause, the finally clause aborts, and tryCatchFinally returns abruptly, throwing the new value to its invoker”. (7.13 Compiling finally )
Un eccezione all’interno della subroutine quindi provocherebbe l’interruzione del metodo con il conseguente passaggio della gestione della eccezione sollevata al chiamante.
4.6 Vincoli strutturali sulle subroutines nel verificatore ipd
Dopo aver preso in considerazione le regole sulle subroutines specificate dalla Sun si è cercato nella scelta dei vincoli per il verificatore ipd di restare quanto più fedeli a tali specifiche basandoci solo in parte sulle scelte del Justice e eliminando quei vincoli ridondanti o troppo restrittivi. I vincoli del verificatore ipd sono i seguenti:
1. La prima istruzione di una subroutine è una astore N che memorizza il valore del returnAddress nella variabile locale N.
2. Ogni istruzione è parte di una sola subroutine ( o appartiene al top-level ). 3. Nessuna istruzione che è parte di una subroutine può essere il target di un
gestore di eccezioni.
4. Le subroutines non sono protette da gestori di eccezioni.
5. Non è permesso l’annidamento tra subroutines, ciò significa che nel corpo della subroutine non devono essere presenti istruzioni jsr.
Nella nostra soluzione si è permesso che una subroutine termini con la istruzione return (che termina l’intero metodo) questo perchè potrebbero esserci casi in cui all’interno di un costrutto condizionato di una subroutine, uno dei rami termini con una istruzione return e con diverse prove si è constatato che questi sono codici validi per il verificatore della Sun, anche se non viene specificato nelle vmspec è possibile che una subroutine termini con un’istruzione return.
Nel verificatore ipd come nel justIce non saranno permessi parti di codice condiviso di subroutines, questa possibilità avrebbe richiesto un numero di controlli elevato e che quindi avrebbe reso la verifica piuttosto onerosa.
Al contrario del verificatore della Sun e del JustIce nel verificatore ipd non è permesso l’annidamento tra subroutines il motivo principale di tale scelta è che la nostra soluzione è destinata alle Java card e la scelta di permettere annidamento tra subroutines avrebbe reso più complesso il codice e aumentato il numero di campi del frame del verificatore ,quindi data la rarità dei casi in cui le subroutines annidate si incontrano si è optato per una soluzione più “leggera”, d’altronde nelle specifiche Sun si legge:
Tali regole sono relative alle scelte per l’implementazione delle subroutines nel verificatore ipd, chiaramente a queste si aggiungono quelle specificate dalla Sun che si elencano di seguito:
1. il codice della subroutine può avere al massimo una ret.
2. un particolare indirizzo di ritorno può essere utilizzato al massimo una volta.
3. Quando si esegue l’istruzione ret, che implementa un ritorno da una subroutine, deve esserci un unica subroutine dalla quale l’istruzione deve ritornare. Due differenti subroutine non possono fare il merge su un unica ret.
4.7 Problemi nel verificatore ipd per i salti condizionati
interni ed esterni alle subroutines
L’algoritmo del verificatore ipd è basato sull’idea di una gestione dinamica del dizionario, le entries del dizionario vengono cioè allocate/deallocate non tutte all’inizio ma durante il processo di verifica, e su una politica di scelta della sequenza delle istruzioni da verificare in modo da rendere “ottimo” tale processo.
Come si già è visto l’algoritmo salva il frame dei targets delle istruzioni di salto condizionato, di conseguenza dato che l’istruzione jsr è un’istruzione di salto incondizionato non è necessario salvarne il frame (a meno che l’istruzione jsr non sia ipd di un salto condizionato), in definitiva tale istruzione sarà considerata nella data-flow-analysis come un’istruzione goto, per cui l’ipd di un’istruzione jsr sarà il suo target cioè la prima istruzione della subroutine.
Nel calcolo dell’ipd l’istruzione ret richiede un calcolo più complesso; sappiamo che la chiamata alla subroutine è parametrica e che l’indirizzo di ritorno è del tipo returnAddress e viene inserito nello stack dalla jsr, per cui durante il calcolo dell’ipd che precede la data-flow analysis non si ha ancora traccia di tale indirizzo, risulta quindi difficile determinare qual è il reale successore dell’istruzione, la scelta adottata è quella di settare come successori dell’istruzione ret tutti i possibili
successori, cioè ogni istruzione che nel bytecode segue l’ istruzione jsr che invoca
tale subroutine (successore fisico della jsr). I successori di una istruzione ret saranno più di uno solo per quel che riguarda il calcolo dell’ipd, nella data-flow analysis la verifica sarà polivariante e ogni ret avrà il suo corretto successore dato che in questa fase si è in grado di determinarlo esattamente.
Consideriamo un semplice esempio di bytecode contenente una subroutine:
0: aconst_null ... 5: istore_3 6: iload_3 7: bipush 10 9: if_icmpge 18 12: iinc 1 15: goto 6 ....
29: jsr 75 // Chiamata alla subroutine 32: goto 119
35: astore_3 // Inizio gestore d’eccezioni ...
61: jsr 75 // Chiamata alla subroutine 64: goto 119
67: astore 4 // Inizio gestore d’eccezioni generale 69: jsr 75 // Chiamata alla subroutine
72: aload 4 74: athrow 75: astore 5 // Subroutine! ... 98: invokevirtual 12 101: getstatic 5 104: ldc 13 106: invokevirtual 12 109: getstatic 5 112: ldc 13 114: invokevirtual 12
117: ret 5 // Fine della subroutine 119: aload_1
120: invokevirtual 14 123: return
0 18 6 75 69 104 101 29 61 64 98 67 END 32 119 END START ( jsr ) ( jsr ) ( ret) ( if ) ( goto ) ( goto ) ( return ) ( astore ) 5 9 7 12 15 35 ( goto ) 117 120 123 72 ( jsr )
( Prima istr handler )
( Prima istr handler )
appartenenti alla subroutine
appartenenti al gestore d'eccezioni
fig. 4.4: Grafo di una parte di codice in cui è presente una subroutine, nel calcolo dell’ipd i successori della ret sono tutti i possibili successori
Nel grafo si nota che due delle chiamate alla subroutine vengono effettuate dai gestori d’eccezioni, il primo è relativo al tipo di eccezione che è in grado di gestire il
blocco catch il secondo è quello che gestisce tutte le eccezioni passando il controllo al chiamante ( dopo aver eseguito la subroutine).
Nel grafo il primo nodo dei gestori non ha archi entranti, questa parte non è ancora stata implementata ma intuitivamente ogni istruzione protetta dall’handler dovrebbe avere un arco uscente che va alla prima istruzione del gestore, quindi tutte le istruzioni protette dall’handler hanno più archi uscenti, uno verso i suoi successori reali e l’altro verso la prima istruzione del gestore, per maggiore chiarezza nel grafo non si visualizzano gli archi entranti ma si specifica che i nodi 35 e 67 sono le prime istruzioni dei gestori d’eccezioni.
In questo caso l’ipd della jsr è il nodo 75, la ret ha tre successori dato che la subroutine viene invocata tre volte, uno dei successori è un’istruzione athrow di conseguenza l’ipd della ret è il nodo END, questo esempio rappresenta il caso in cui tali ipd non vengono presi in considerazione in quanto non ci sono salti condizionati che in qualche modo includono o appartengono alla subroutine. L’unico salto condizionato di cui si salverà il frame è il nodo 9, il suo ipd è il nodo 18, all’entry point della subroutine il dizionario sarà già deallocato.
0: aconst_null .... 5: iconst_4 6: if_icmpge 19 9: new 2 ... 18: athrow 19: new 5 22: dup ....
30: jsr 76 // Chiamata alla subroutine 33: goto 105
34 astore 3 // Inizio del gestore d’eccezione …..
62: jsr 76 // Chiamata alla subroutine del gestore 65: goto 105
68: astore 4 // Inizio del gestore d’eccezione
70: jsr 76 // Chiamata alla subroutine del gestore 73: aload 4 75: athrow 76: astore 5 // Subroutine! ... 86: aload_1 87: ifnull 103 90: iconst_0 91: istore 6 93: iload 6 95: iconst_4 96: if_icmpne 103 99: aload_1 100: invokevirtual 16
103: ret 5 // Fine della subroutine 105: return
18 0 19 9 6 76 73 END 75 100 90 96 99 34 30 62 65 87 103 70 END 33 105 END START ( jsr ) ( jsr ) ( jsr ) ( ret) ( if ) ( if ) ( athrow ) ( if ) ( goto ) ( goto ) ( return ) ( astore ) 68 appartenenti alla subroutine appartenenti al gestore d'eccezioni
( Prima istr handler )
( Prima istr handler )
fig. 4.5: Grafo di una parte di codice in cui è presente una subroutine, all’interno della subroutine sono ci sono dei salti condizionati con ipd pari al nodo ret.
In questo esempio la subroutine contiene due salti condizionati, i nodi 87 e 96 l’ipd di entrambi i salti risulta essere proprio l’istruzione ret, quindi in questa tipologia di codice l’ipd di salti interni alla subroutine non può essere che un’istruzione appartenente alla subroutine (in questo caso l’istruzione ret). Anche questo è un caso in cui l’aggiunta della gestione delle subroutine non incide sull’ottimizzazione dell’algoritmo ipd, le entries dei salti saranno deallocate prima del termine della subroutine stessa.
Si può quindi affermare che se sono presenti dei salti condizionati nel corpo di una subroutine l’ipd di questi sarà un’istruzione appartenete alla subroutine stessa ( o sarà il nodo END nella tipologia di subroutine che vedremo con il prossimo esempio).
0: aconst_null .... 5: iconst_4 6: if_icmpge 19 9: new 2 ... 18: athrow 19: new 5 22: dup ....
30: jsr 76 // Chiamata alla subroutine 33: goto 105
34 astore 3 // Inizio del gestore d’eccezione …..
62: jsr 76 // Chiamata alla subroutine del gestore 65: goto 105
68: astore 4 // Inizio del gestore d’eccezione
70: jsr 76 // Chiamata alla subroutine del gestore 73: aload 4 75: athrow 76: astore 5 // Subroutine! ... 86: aload_1 87: ifnull 103 90: iconst_0 91: istore 6 93: iload 6 95: iconst_4 96: if_icmpne 105 99: aload_1 100: invokevirtual 16
103: ret 5 // Fine della subroutine 105: return // Fine della subroutine 106: return
18 0 19 9 6 76 73 END 75 100 90 96 99 34 30 62 65 87 103 70 END 33 106 END START ( jsr ) ( jsr ) ( jsr ) ( ret) ( if ) ( if ) ( athrow ) ( if ) ( goto ) ( goto ) ( return ) ( astore ) 68 subroutine gestore d'eccezioni
( Prima istr handler )
( Prima istr handler )
105 END ( return ) IPD = END IPD = END IPD = END
fig. 4.6: Grafo di una parte di codice in cui è presente una subroutine, all’interno della subroutine sono ci sono dei salti condizionati con ipd pari al nodo END
Rispetto alla situazione precedente in quest’esempio all’interno di uno dei due rami del salto condizionato (nodo 96) appartenenti alla subroutine è presente un’istruzione di return (nodo 105), di conseguenza l’ipd dei due salti ai nodi 87 e 96 diverrà END (essendo i salti annidati tra loro). Vediamo cosa comporta questo in termini di ottimizzazione del verificatore; la subroutine viene invocata diverse volte in diversi punti e ad ogni chiamata per i due salti dovremo allocare il dizionario, i salti si “chiuderanno” solo al nodo END per cui si dovranno conservare nel dizionario le entries dei salti aperti e il dizionario potrà essere deallocato solo al nodo END, si intuisce facilmente che in una situazione simile a questa richiede una discreta quantità di spazio necessaria per memorizzare tutte le informazioni, la soluzione a questa problematica sarà esposta nel prossimo paragrafo.
Si è visto le difficoltà nel calcolo dell’ipd relative ai salti condizionati che appartengono al corpo di una subroutine, ora si prenderanno in considerazione i salti che presentano in uno o più rami delle chiamate alle subroutine, anche questo caso necessita una modifica all’algoritmo, per capire meglio cosa avviene nella verifica prendiamo diversi esempi:
( if ) 9 IPD = 70 0 START 7 22 30 12 20 50 60 END ( jsr ) ( jsr ) ( astore ) ( ret ) 31 41 70 ( goto )
fig. 4.7: Grafo di una parte di codice in cui è presente una subroutine la cui chiamata è interna ad un salto condizionato, l’ipd del salto è il nodo 70
In questo primo esempio (fig 4.7) si ha un salto condizionato in cui in due rami c’è una chiamata alla stessa subroutine nel terzo ramo non sono presenti jsr ma un istruzione di goto al punto 70.
Quando nella verifica si raggiunge il nodo 9 si applica la regola (il salto viene incontrato per la prima volta), come da regola si crea l’entry point nel dizionario relativo ai targets 22, 31 e all’ipd 70 in più si salva nel contesto la coppia [9,2]. Si va a verificare il successore naturale del salto (il nodo 12) e si procede fino alla chiamata alla subroutine (nodo 20), si salta all’interno del codice della subroutine e si giunge all’istruzione ret, il successore sarà il nodo 22, si continua
con la verifica fino al nodo 50, l’ipd del salto, si rileva che esistono altri rami da verificare, si applica la regola ipd≠0 e si procede verificando gli altri rami fino a
quando si giungerà dopo aver verificato il terzo ramo all’ipd e si potrà applicare la regola ipd=0 e quindi eseguire simbolicamente l’istruzione e deallocare le relative
entries nel dizionario.
L’esempio non crea problemi sia nel calcolo dell’ipd sia nella verifica grazie alla polivarianza del nostro verificatore.
( if ) 9 IPD = 20 0 START 7 12 50 60 END ( jsr ) ( astore ) ( ret ) 18 16 21
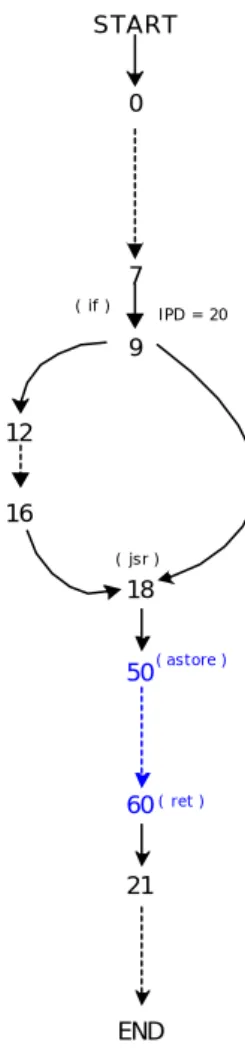
fig. 4.8: Grafo di una parte di codice in cui è presente una subroutine, l’ipd del salto è l’istruzione jsr alla posizione 18
Anche il secondo caso (fig 4.8) non crea difficoltà nel calcolo dell’ipd, al punto 9 è presente un salto in cui l’ipd è l’istruzione jsr, per tale istruzione sarà salvata un entry e una volta terminata la verifica di entrambi i rami sarà applicata la regola ipd=0, quindi la jsr sarà eseguita simbolicamente e il dizionario relativo al salto
aperto sarà deallocato prima di entrare nel corpo della subroutine. Il grafo mostrato si chiamerà di seguito Extended Control-flow graph (ECFG) per differenziarlo dal Control-flow Graph tradizionale in cui non è possibile evidenziare la polivarianza della verifica. ( if ) 9 IPD = 50 0 START 7 22 30 12 20 50 60 ( jsr ) ( jsr ) ( astore ) ( ret ) 50 60 END ( astore ) ( ret ) 23 33
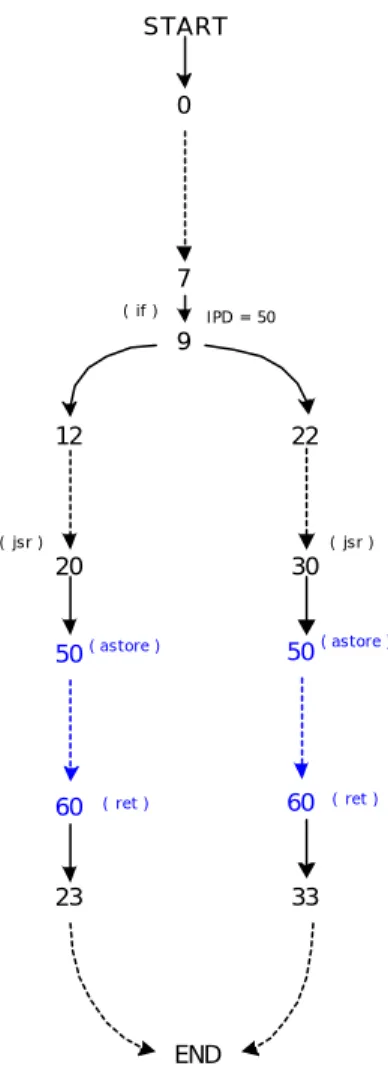
Nella figura 4.9 si riporta un ultimo esempio. Questa situazione è quella che richiede una modifica dell’implementazione della nostra verifica, intuitivamente nel grafo già si può notare il problema: l’algoritmo calcola come ipd del salto condizionato l’istruzione che è la prima istruzione della subroutine.
Nei due rami del grafo abbiamo due istruzioni jsr1 che invocano la chiamata alla
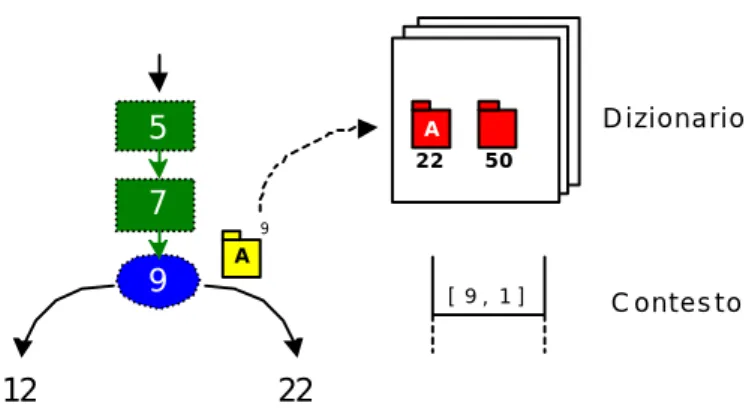
stessa subroutine, l’ipd di tale salto è proprio la prima istruzione della subroutine. Vediamo in dettaglio cosa avviene con il verificatore ipd. Quando nella verifica si raggiunge il nodo 9 essendo un salto condizionato, si applica la regola branch∉ (fig. 4.10): si esegue simbolicamente l’istruzione, si salva nel dizionario un frame per il target (nodo 22) e un null-frame per il “presunto” ipd (nodo 50).
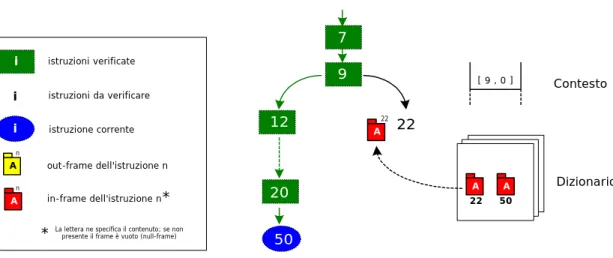
7 5 9 12 22 A Dizionario A 22 [ 9 , 1 ] C ontes to 50 9 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
* La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n
n
i
i
i
fig. 4.10: Regola branch∉
Si prosegue la verifica con il successore naturale del salto (12) fino a raggiungere il nodo 50 (fig. 4.11), dato che 50 è l’ipd del salto e che resta un ramo da verificare l’esecuzione simbolica dell’ipd viene rimandata: viene quindi aggiornato l’in-frame
1 Le due istruzioni jsr sono in diverse posizioni del bytecode altrimenti l’ipd del salto sarebbe proprio
del dizionario relativo all’ipd facendo il merge con il frame attuale, viene caricato nel frame corrente l’entry del dizionario relativa alla prima istruzione del prossimo ramo da verificare (22), in modo da poter ricominciare l’esecuzione simbolica (fig. 4.12) e viene decrementato il contatore k della coppia [salto_condizionato_j, k] che si trova in testa al contesto.
7 9 50 22 Dizionario A 22 [ 9 , 0 ] Contesto 50 A n n istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n i i i A 12 50 20
fig. 4.11: Regola ipd≠0 , si fa il merge del frame con il frame nel dizionario e si rimanda l’esecuzione, con questa operazione si perderà la polivarianza.
7 9 22 A Dizionario A 22 [ 9 , 0 ] Contesto 50 A n n 22 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n i i i 12 50 50 20
fig. 4.12: Si carica il nuovo frame nel frame corrente per il target del salto
Si raggiunge l’ipd, questa volta non restano rami da verificare di conseguenza si applica la regola ipd=0 e il nodo 50 viene eseguito simbolicamente, quindi se ne
ricava il successore e si procede con la verifica, si procede fino a raggiungere l’istruzione ret, a questo punto il successore della ret sarà il nodo 33, cioè il successore fisico dell’ultima jsr incontrata, si è quindi persa l’informazione relativa al successore della ret relativa alla chiamata della subroutine nel primo ramo (nodo 20), tale codice non verrà più eseguito (fig. 4.13).
7 9 22 Dizionario Contesto n n istruzioni verificate istruzioni da verificare istruzione corrente i i i 12 50 12 50 60 33 50 5050 50 50 23 istruzioni che non verranno
più verificate
i
50
20 3050
fig. 4.13: Si raggiunge nella verifica il nodo 33, perdendo le informazioni relative al nodo 23 e ai suoi successori
In situazioni in cui la prima istruzione di una subroutine è ipd2 di un salto
condizionato la regola ipd≠0 che rimanda l’esecuzione rende la verifica non più
polivariante, per cui si “perde” il successore della ret relativa alla jsr alle chiamate invocate nei rami precedentemente verificati, bisogna quindi implementare un verificatore che esegua sempre il codice del corpo di una subroutine senza rimandarne l’esecuzione ad un secondo tempo, in modo da ottenere sempre una verifica polivariante, quindi la regola ipd≠0 non potrà essere applicata se l’ipd è la
prima istruzione di una subroutine.
2
Tra le istruzioni appartenenti alle subroutine solo la prima può essere ipd di un salto
4.8 Soluzione proposta per i salti condizionati interni alle
subroutines
Nei salti condizionati interni alle subroutines la presenza del return tra le istruzioni di uno o più rami fa si che l’ipd di tale salto sia il nodo END. Questo porta l’algoritmo a mantenere nel dizionario i frame relativi a tali salti fino alla fine del metodo, anche se potrebbero essere eliminati dal dizionario al termine della subroutine.
Se i salti condizionati interni alla subroutine non hanno come ipd il nodo END, allora l’ipd di questi può essere solo un’istruzione appartenente alla stessa subroutine, questo perché la subroutine può terminare con una sola istruzione ret, i salti dovranno quindi richiudersi prima che la subroutine termini (sempre considerando che non ci siano istruzioni di return).
La soluzione scelta per ottimizzare i casi nei salti interni alle subroutines è la seguente: associare ai salti condizionati che appartengono alla subroutine e che hanno l’ipd uguale ad END un ipd uguale al successore della ret, ovvero l’algoritmo dovrà calcolare gli ipd dei salti con l’algoritmo tradizionale e durante l’analisi polivariante del codice rilevare se i salti con ipd uguale ad END appartengono ad una subroutine e modificarne l’ipd, il nuovo ipd è il successore reale dell’istruzione ret, tale successore siamo in grado di ricavarlo perché compiamo questa operazione di modifica durante la data-flow-analysis. La decisione di utilizzare come nuovo ipd del salto il successore della ret si ricollega alla certezza che terminato il corpo della subroutne le entries dei salti aperti non possono più servire di conseguenza, alla prima istruzione successiva alla subroutine si può deallocare il dizionario.
Questa aggiunta richiede una modifica piuttosto semplice che consiste in un controllo all’interno della funzione che rappresenta il cuore della verifica. Nel caso di un salto condizionato appartenente ad una subroutine e con ipd uguale ad END, tale ipd viene modificato e sostituito con il successore della ret.
Riprendiamo l’esempio visto precedentemente, nella figura 4.14 viene riportato il grafo mostra la polivarianza dell’algoritmo infatti la subroutine viene trattata come se fosse stata espansa in linea.
18 0 19 9 6 76 73 END 75 100 90 96 99 34 30 62 65 87 103 70 END 33 106 END START ( jsr ) ( jsr ) ( jsr ) ( ret) ( if ) ( if ) ( athrow ) ( if ) ( goto ) ( goto ) ( return ) ( astore ) 68 subroutine gestore d'eccezioni
( Prima istr handler )
( Prima istr handler )
105 END ( return ) IPD = 73 IPD = 73 IPD = END 76 100 90 96 99 87 103( ret) ( if ) ( if ) ( astore ) 105 END ( return ) IPD = 33 IPD = 33 76 100 90 96 99 87 103 ( ret) ( if ) ( if ) ( astore ) 105 END IPD = 65 ( ret) 106 ( return ) IPD = 65 END
fig. 4.14: ECFG dell’esempio 4.6 in cui vengono modificati gli ipd dei salti appartenenti alla subroutine
Nell’esempio, questa volta, a seconda dal punto in cui la subroutine viene invocata cambia l’ipd dei due salti alle posizioni 87 e 96, i nuovi ipd saranno:
• Il nodo 33 se la subroutine è stata invocata dalla jsr alla posizione 30
• Il nodo 73 se la subroutine è stata invocata dalla jsr alla posizione 70
• Il nodo 65 se la subroutine è stata invocata dalla jsr alla posizione 62
L’ipd del salto al punto 6 rimarrà END a causa dell’istruzione athrow alla posizione 18.
4.9 Soluzione proposta per i salti condizionati esterni alle
subroutines
Nei salti condizionati esterni alla subroutine quando l’ipd del salto è la prima istruzione della subroutine la regola ipd≠0 rimanda l’esecuzione simbolica dell’ipd e
in questo caso particolare ciò comporta la perdita della polivarianza.
Questa eventualità anche se rara richiede una modifica dell’algoritmo, in modo che la regola ipd≠0 non sia applicabile se l’ipd del salto condizionato è la prima
istruzione della subroutine.
L’idea per risolvere il problema è la seguente: all’ipd di un salto condizionato si controlla se è la prima istruzione della subroutine, in caso affermativo dal contesto si preleva l’informazione relativa al salto condizionato aperto relativo e se ne modifica l’ipd con due possibilità:
− Se il salto condizionato in questione appartiene ad un ramo di un altro salto condizionato aperto gli viene assegnato come ipd proprio l’ipd del salto che lo include.
− Se il salto condizionato non è incluso in altri salti allora gli viene associato come ipd il nodo END.
A questo punto l’istruzione corrente (la prima istruzione della subroutine) non è più ipd del salto e viene quindi eseguita.
( if ) 9 IPD = 50 0 START 7 22 30 12 20 50 60 ( jsr ) ( jsr ) ( astore ) ( ret ) 50 60 END ( astore ) ( ret ) 23 33 IPD = END
7 5 9 12 22 A Dizionario A 22 [ 9 , 1 ] C ontes to 50 9 istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
* La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n
n
i
i
i
fig. 4.16: Regola branch∉
Riprendiamo l’esempio precedente (fig. 4.15), giunti nella verifica per la prima volta al nodo 9 l’ipd attuale è l’istruzione alla posizione 50 e si applica la regola branch∉
(fig. 4.16) : si esegue simbolicamente l’istruzione, si salva nel dizionario un frame per il target (22) e un null-frame per l’ipd attuale.
Si verifica il successore naturale (nodo 12) e si va avanti fino ad incontrare il nodo 50 (l’ipd attuale). A questo punto si controlla e si ricava che l’ipd è la prima istruzione di una subroutine quindi non si applica la regola ipd≠0 ma si va a
modificare l’ipd stesso del nodo 9, dato che non sono presenti altri salti a livello superiore gli associa come nuovo ipd il nodo END (fig. 4.17).
Il contesto non cambia e nel dizionario il null frame relativo al nodo 50 si assocerà al nodo END (questo in teoria in realtà non serve salvare il frame se l’ipd è END perché questa è un’istruzione simbolica che non andremo ad eseguire).
7 9 50 22 Dizionario A 22 [ 9 , 1 ] Contesto 50 A n n istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n i i i 12 END 50 20
fig. 4.17 Nella verifica del nodo 50 si va a modificare l’ipd del salto aperto associandogli il nodo END
Si riprende la verifica andando ad eseguire il vecchio ipd (il nodo 50) e si procede raggiungendo l’istruzione ret (nodo 60) e il suo successore (il nodo 23) e quindi raggiungere il nodo END ,si applica la regola ipd≠0 e si carica nel frame corrente il
7 9 50 22 Dizionario A 22 [ 9 , 0 ] Contesto A n n istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n i i i 12 END 50 50 60 50 23 END A 22 50 20
fig. 4.18: Si carica nel frame corrente il frame relativo al target
Dal target si riprende la verifica e si raggiunge il nodo 50, che viene eseguito normalmente, si procede fino a raggiungere l’istruzione ret il nodo 60, questa volta la polivarianza del nostro algoritmo ci restituirà come successore il nodo 33 e si procederà fino all’ipd (fig. 4.19), si applica la regola ipd=0 e si libera il dizionario.
Con questa strategia la gestione della problematica dell’ipd prima istruzione della subroutine è risolta senza perdere la polivarianza e con l’unico svantaggio di aver mantenuto le entries per più tempo (nel peggiore dei casi fino al nodo END).
7 9 50 Dizionario A 22 [ 9 , 0 ] Contesto A n n istruzioni verificate istruzioni da verificare istruzione corrente A out-frame dell'istruzione n A in-frame dell'istruzione n*
*La lettera ne specifica il contenuto; se non presente il frame è vuoto (null-frame) n n i i i 12 END 50 50 60 50 23 END 50 20 50 22 50 50 60 50 33 END 50 30 33
fig. 4.19: Si procede nella verifica, questa volta non “dimenticando” parti di codice
Il nuovo ipd viene spostato dalla prima istruzione della subroutine ad un'altra che è al di fuori della subroutine; i nodi interni alla subroutine non possono essere che ipd di salti interni alla stessa subroutine, in quanto come da specifiche non si può saltare nel mezzo del corpo del subroutine e da questo se ne deduce che solo la prima istruzione della subroutine può essere ipd di un salto esterno.
Nel caso fossero presenti altri salti condizionati tra la posizione del vecchio e del nuovo ipd del salto, questi si chiuderanno prima del nuovo ipd (o al limite proprio sul nuovo ipd se i salti sono esterni alla subroutine) se l’ipd dei salti interni è END allora sarà END anche il nuovo ipd del salto in questione.
Una situazione sfavorevole per l’efficienza di questo verificatore sarebbe quella mostrata nella figura 4.20.
20 IPD = 130 60 70 80 IPD = 120 120 130 10 VECCHIO IPD = 60 NUOVO IPD = 130 START END ( if ) ( tableswitch ) ( astore ) ( ret ) ( tableswitch )
fig. 4.20: Grafo di un esempio di bytecode in cui l’ipd del salto viene spostato dal nodo 60 al nodo 130
In questo esempio inizialmente il nodo 60 è ipd del salto condizionato alla posizione 20, con il nuovo algoritmo l’ipd del salto viene modificato e diventa il nodo 130 ( cioè l’ipd del salto superiore). Ciò significa mantenere le informazioni relative ai due switch fino al nodo 130 ma considerando che il verificatore non salva frame duplicati (in questo caso quelli relativi ai targets dello switch), la situazione non è gravosa dal punto di vista di occupazione della memoria.
4.10 Regole del verificatore ipd per le subroutines
Le regole del verificatore ipd relative alle subroutines possono essere formalizzate e scritte in forma compatta utilizzando la seguente notazione:
- Ipd(i) è l’ipd del salto condizionato i;
- c=[i,m]·c’ è la struttura del contesto e sta ad indicare che in testa al contesto c c’è la coppia [i,m], ovvero ‘·’ è l’operatore di concatenazione (il contesto è una struttura dati organizzata a stack);
- <h, c, S, D> è la struttura che caratterizza uno stato dell’interprete astratto: h è l’istruzione da eseguire simbolicamente, c è il contesto, S è il suo stato (ovvero il suo in-frame) e D è il dizionario. Ogni regola è caratterizzata da una transizione di stato dell’interprete astratto;
- {M,St} è la struttura di un frame: variabili locali (M) e stack (St); - i+1 è il successore naturale di una istruzione di salto condizionato i; - retaddr rappresenta il returnAddress da inserire nello stack; - type(i) restituisce l’istruzione alla posizione i;
- lastjsr(i) restituisce l’ultima jsr nel control-flow graph (null se si è al top level);
- succ(lastjsr(i)) restituisce il successore fisico dell’ultima jsr incontrata; - target(lastjsr(i)) restituisce il target dell’ultima jsr incontrata ovvero la
- ∃ r=branchsup? idp(j)=ipd(r); idp(j)=END; sta ad indicare che se esiste r
branch di ordine superiore a j allora l’ipd di j sarà l’ipd di r, altrimenti l’ipd di j diverrà END;
− D↑i [DL:=S] è l’operazione di creazione o eventuale aggiornamento delle
entries relative ai targets dell’insieme L={L1,..,Lm} e all’ipd del salto
condizionato j );
Vengono di seguito riportate le regole:
jsr L
<i,c,S,D>→< L, c, (M, retaddr▪St), D >
if ( type(i)= jsr AND lastjsr(i)=null )
Se i è un istruzione jsr L con target L, nello stack si salva il returnAddress (retaddr▪St), e il controllo passerà al punto L del bytecode, la jsr non deve appartenere al corpo di una subroutine (lastjsr(i)=null).
ret x
<i,c,S,D>→< succ(lastjsr(i)), c, {M,St}, D >
Se i è un’istruzione ret x il suo successore sarà il successore fisico dell’ultima jsr del control-flow graph (succ(lastjsr(i))), l’istruzione ret deve appartenere ad una subroutine (lastjsr(i)≠ null).
branch∈ sr
<i,c,S,D>→< i+1, [i,m]▪c, {M,St}, D↑i [DL:=(ipd(i)=succ(lastjsr(i)))] >
if (type(i) ∈ {if, tableswitch,..} AND lastjsr(i)≠ null AND ipd(i)=END)
Se i è un’istruzione di salto condizionato appartenente ad una subroutine (lastjsr(i)≠ null) e l’ipd di tale salto è END (ipd(i)=END) allora l’idp del salto diverrà il successore fisico dell’ultima jsr incontrata nel control-flow graph, ovvero il punto di ritorno dalla subroutine (ipd(i)=succ(lastjsr(i))).
ipd∈ sr
<i,c,S,D>→<i+1, c, {M,St}, D↑i [DL:=(∃ r=branchsup? idp(j)=ipd(r); idp(j)=END;)] >
if ( i= idp(j) AND i=target(lastjsr(i)) AND type(j)
∈
{if, tableswitch,..}))Se l’istruzione i è ipd di un salto condizionato
(i= idp(j)) AND type(j)