7. Metodo della differenza post classification.
7.1. Applicazione delle diverse tecniche di
classificazione.
Un analista che cerca di classificare delle somiglianze in un’immagine usa elementi di interpretazione visuale (quali tono, struttura, grandezza, tessitura, ecc.) per identificare gruppi omogenei di pixels che rappresentino classi di coperture del suolo di interesse.
La classificazione di immagini digitali usa le informazioni spettrali rappresentate dai numeri digitali in una o più bande, e tenta di classificare ogni singolo pixel sulla base di queste informazioni.
Questo tipo di classificazione è detta spectral pattern recognition ed è proprio il tipo di classificazione che è stata adottata per la nostra ricerca.
In definitiva, l’obiettivo è quello di assegnare tutti i pixels di un’immagine a particolari classi o argomenti (per esempio acqua, bosco, terreno secco, terreno umido, ecc.). La risultante immagine così classificata è composta da un mosaico di pixels, ognuno dei quali appartiene ad una particolare classe, ed è essenzialmente una mappa tematica dell’originale immagine.
Quando parliamo di classi, dobbiamo distinguere tra classi di informazione e classi spettrali.
Le prime sono quelle categorie di interesse che il ricercatore cerca di identificare nell’immagine, come differenti tipi di terre coltivate, differenti tipi di foreste, differenti unità geologiche o tipi di roccia, etc.
Le seconde invece sono gruppi di pixels che sono uniformi (o molto simili) rispetto ai loro valori di brillantezza nelle differenti bande spettrali.
L’obiettivo è di accoppiare le classi spettrali con le classi di informazione di interesse. Raramente c’è un accoppiamento uno a uno tra queste due tipologie di classi. Piuttosto, accade spesso che una classe spettrale possa presentarsi non necessariamente in corrispondenza con nessuna classe di informazione utile o di particolare interesse per l’analista.
Alternativamente, una vasta classe di informazione (per esempio foresta) può contenere un certo numero di sottoclassi spettrali. Usando l’esempio della foresta, le sottoclassi possono essere dovute a variazioni di età, specie, e densità, o forse come il risultato di un’ombreggiatura o variazione di illuminazione.
E’ compito del ricercatore decidere sull’utilità di differenti classi spettrali e della loro eventuale corrispondenza con classi di informazione.
Le comuni procedure di classificazione possono essere scisse in due ampie suddivisioni in base al metodo usato :
• Supervised classification; • Unsupervised classification.
Nella classificazione supervised, l’analista identifica nell’immagine campioni omogenei rappresentativi di differenti tipi di coperture superficiali (classi di informazione) di interesse. Questi campioni sono chiamati comunemente ROI (Regions Of Interest).
La selezione delle appropriate regioni di interesse è basata sulla familiarità dell’analista con l’area geografica oppure sul riconoscimento all’interno dell’immagine di coperture superficiali note. In tal modo, l’operatore è il supervisore della classificazione di un set di classi specifiche.
Le informazioni numeriche in tutte le bande spettrali per i pixels compresi in tali aree vengono usate per orientare il computer al riconoscimento di aree con risposta spettrale simile per ogni classe considerata.
Il computer usa un programma speciale o algoritmo (del quale esistono diverse modificazioni), per determinare la “firma” numerica per ogni ROI.
Una volta che il computer ha determinato le firme per ogni classe, ogni pixel nell’immagine è comparato a queste firme e marchiato in modo tale da essere ricampionato digitalmente all’interno della classe di appartenenza. Così, in una classificazione supervised vengono per prima cosa identificate le classi di informazione che sono poi usate per determinare le classi spettrali che le rappresentano (Richards et al.,1994).
La classificazione unsupervised in essenza rovescia il processo seguito per la classificazione supervised. Le classi spettrali sono raccolte in un primo momento, esclusivamente sulla base delle informazioni numeriche dei dati, e successivamente vengono accoppiate dall’operatore in classi di informazione (se possibile!).
I programmi, chiamati algoritmi di clustering, sono usati per determinare i raggruppamenti naturali (statistici) o le strutture dei dati. Solitamente, l’operatore specifica quanti gruppi o clusters vuole che vengano trovati nell’immagine. In aggiunta a questo, l’operatore può anche specificare i parametri correlati alla distanza di separazione tra i clusters e la variazione all’interno di ogni clusters.
Il risultato finale di questo processo di clustering iterativo può portare ad alcuni clusters che l’analista può combinare, o ad alcuni clusters che può disunire.
Così, la classificazione unsupervised non è completamente disgiunta dall’intervento umano. Tuttavia, non inizia con un predeterminato set di classi come nella classificazione supervised (Tou et al.,1974).
In questo paragrafo verranno confrontate le differenti tipologie di classificazione supervised con applicazioni dirette sulle due immagini, mentre verranno tralasciate le applicazioni delle tecniche unsupervised in quanto non utilizzabili per gli scopi successivi di questa tesi. Le classificazioni sono state effettuate sopra i due ritagli numero 1 perché molto più grandi in superficie e quindi più rappresentativi degli altri due.
Supervised classification
Le tecniche di classificazione supervised prese in esame includono :
1. Parallelepiped. 2. Minimum distance. 3. Mahalanobis distance. 4. Maximum likelihood.
Questo tipo di classificazione viene usato per raggruppare i pixels dell’immagine in classi corrispondenti alle regioni di riferimento definite dall’utente.
Le regioni di riferimento sono gruppi di pixels (ROI) o spettri individuali. Le ROI vengono selezionate come aree rappresentative che vogliamo individuare. La cosa migliore è cercare di scegliere ROI più omogenee possibile.
In questa parte del lavoro, proprio perché ci interessava solamente confrontare le varie tecniche, le ROI utilizzate sono state solamente sei:
1. Rosso = area urbana o roccia. 2. Verde = prato.
3. Blu = acqua. 4. Giallo = bosco.
5. Ciano = terreno non vegetato. 6. Verde pallido = fuori schermo.
Le zone di colore nero, che compaiono in tutte le immagini classificate, sono aree non classificabili con le ROI a nostra disposizione.
Nelle figure successive mostriamo come sono state scelte le cinque ROI di riferimento.
Figura 7.1. Scelta della ROI rossa per le zone urbane e le zone spoglie di vegetazione.
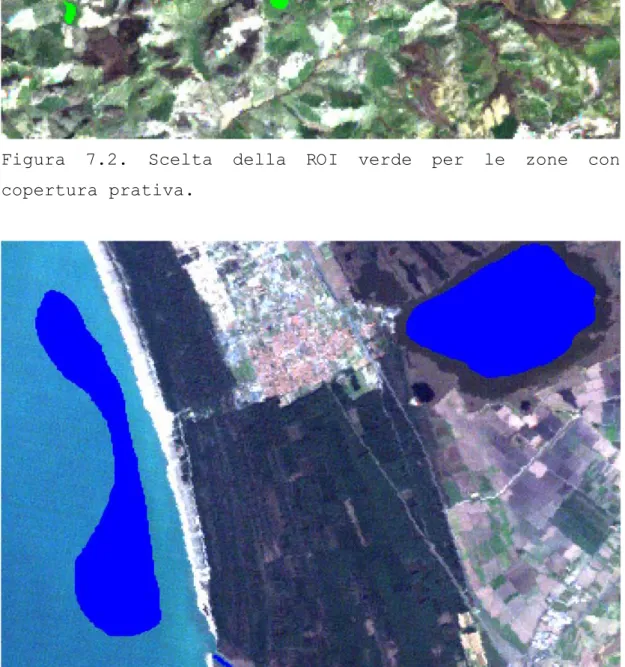
Figura 7.2. Scelta della ROI verde per le zone con copertura prativa.
Figura 7.4. Scelta della ROI gialla per le zone con copertura di tipo boschivo.
Figura 7.5. Scelta della ROI ciano per le zone con copertura non vegetata.
7.1.1. Parallelepiped classification.
Parallelepiped classification usa una semplice regola decisionale per classificare dati multispettrali. I limiti imposti formano un parallelepipedo n-dimensionale nello spazio dell’immagine.
Le dimensioni del parallelepipedo sono definite basandosi sulla variazione di standard deviation dal valore della media di ogni classe. Se il valore di un pixel resta sotto il limite inferiore e sopra il limite superiore per tutte le n- bande viene classificato. Se il valore del pixel cade in più classi, ENVI assegna il pixel all’ultima classe incontrata. Aree che non ricadono in nessun parallelepipedo vengono designate come non classificate (Richards et al.,1994).
I parametri da fornire al calcolatore prima di poter eseguire la classificazione secondo questo metodo sono :
• le classi prese dalle ROI;
• il massimo valore di standard deviation dalla media.
Parametri Valori
Classi prese dalle ROI Tutte e 6
Massima standard deviation dalla media 2.00
Tabella 7.1. Parametri per la parallelepiped classification.
Vediamo come risultano le immagini pre e post del ritaglio 1 dopo questo tipo di classificazione.
Figura 7.6. Ritaglio 1 dell’immagine pre con il metodo parallelepiped classification.
Figura 7.7. Ritaglio 1 dell’immagine post con il metodo Parallelepiped classification.
Le due distribuzioni statistiche per la parallelepiped classification sono quelle mostrate negli istogrammi 7.1 e 7.2 di seguito riportati :
Istogramma 7.1. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.6.
Istogramma 7.2. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.7.
7.1.2. Minimum distance classification.
La tecnica minimum distance calcola la distanza Euclidea di ogni pixel sconosciuto dal vettore rappresentante il valore medio per ogni classe.
Tutti i pixels sono classificati nella classe più vicina a meno che non siano specificati una standard deviation o una distanza soglia. In quel caso alcuni pixels possono essere non classificati se non rientrano nei criteri selezionati (Richards et al.,1994).
I parametri da fornire al calcolatore prima di poter eseguire la classificazione secondo questo metodo sono :
• le classi prese dalle ROI;
• il massimo valore di standard deviation dalla media;
• il massimo errore in distanza (non è obbligatorio inserire dei valori).
Parametri Valori
Classi prese dalle ROI Tutte e 6
Massima standard deviation dalla media Nessun valore imposto
Massimo errore in distanza Nessun valore imposto
Tabella 7.2. Parametri per la minimum distance classification.
Vediamo come risultano le immagini pre e post del ritaglio 1 dopo questo tipo di classificazione.
Figura 7.8. Ritaglio 1 dell’immagine pre con il metodo minimum distance classification.
Figura 7.9. Ritaglio 1 dell’immagine post con il metodo minimum distance classification.
Le statistiche dell’immagine pre e post con una classificazione minimum distance sono :
Istogramma 7.3. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.8.
Istogramma 7.4. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.9.
7.1.3. Mahalanobis distance classification.
Mahalanobis distance è un classificatore rispetto alla distanza che usa le statistiche per ogni classe. E’ simile al maximum likelihood ma assume che le covarianze di tutte classi siano uguali e oltretutto è un metodo più veloce.
Tutti i pixels sono classificati nella più chiusa classe di ROI a meno che non venga specificata una distanza limite, in quel caso alcuni pixels possono essere non classificati se non rientrano nei limiti (Richards et al.,1994).
I parametri da fornire al calcolatore prima di poter eseguire la classificazione secondo questo metodo sono :
• le classi prese dalle ROI; • il massimo errore in distanza.
Parametri Valori
Classi prese dalle ROI Tutte e 6
Massimo errore in distanza Nessun limite imposto
Tabella 7.3. Parametri per la mahalanobis distance classification.
Vediamo come risultano le immagini pre e post del ritaglio 1 dopo questo tipo di classificazione.
Figura 7.10. Ritaglio 1 dell’immagine pre con il metodo mahalanobis distance classification.
Figura 7.11. Ritaglio 1 dell’immagine post con il metodo mahalanobis distance classification.
Le due distribuzioni statistiche per la mahalanobis distance classification sono quelle mostrate negli istogrammi 7.5 e 7.6 di seguito riportati :
Istogramma 7.5. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.10.
Istogramma 7.6. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.11.
7.1.4. Maximum likelihood classification.
Maximum likelihood assume che le statistiche per ogni classe in ogni banda siano normalmente distribuite e calcola la probabilità che un dato pixel appartenga ad una classe specifica.
A meno che non venga selezionata una probabilità limite, tutti i pixels sono classificati. Ogni pixels è assegnato alla classe che ha la più alta probabilità (Mazer et al., 1998).
I parametri da fornire al calcolatore prima di poter eseguire la classificazione secondo questo metodo sono :
• le classi prese dalle ROI;
• la probabilità limite (non è obbligatorio inserire dei valori).
Parametri Valori
Classi prese dalle ROI Le prime 5
Massimo errore in distanza Nessun limite imposto
Tabella 7.4. Parametri per la maximum likelihood classification.
La ROI relativa ai pixels fuori immagine in questo metodo non è stata presa in considerazione perché comportava problemi nella riuscita della classificazione.
Vediamo come risultano le immagini pre e post del ritaglio 1 dopo questo tipo di classificazione.
Figura 7.12. Ritaglio 1 dell’immagine pre con il metodo maximum likelihood classification.
Figura 7.13. Ritaglio 1 dell’immagine post con il metodo maximum likelihood classification.
Istogramma 7.7. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.12.
Istogramma 7.8. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.13.
7.1.5. Spectral Angle Mapper (SAM).
Spectral angle mapper è una classificazione spettrale che usa un angolo n-dimensionale per paragonare i pixels a un spettro di riferimento. L’algoritmo determina la similarità spettrale tra due spettri mediante il calcolo di un angolo tra gli spettri, trattando essi come vettori in uno spazio con dimensioni pari al numero delle bande (Kruse et al., 1993).
I parametri da fornire al calcolatore prima di poter eseguire la classificazione secondo questo metodo sono :
• gli spettri calcolati sulle ROI;
• l’angolo massimo (in radianti) scelto.
Parametri Valori
spettri calcolati sulle ROI Le prime 5
l’angolo massimo (in radianti) 0.10
Tabella 7.5. Parametri per la spectral angle mapper classification.
Anche in questo caso la ROI relativa ai pixels fuori immagine non è stata presa in considerazione perché comportava problemi nella riuscita della classificazione.
Vediamo come risultano le immagini pre e post del ritaglio 1 dopo questo tipo di classificazione.
Figura 7.14. Ritaglio 1 dell’immagine pre con il metodo spectral angle mapper classification.
Figura 7.15. Ritaglio 1 dell’immagine post con il metodo spectral angle mapper classification.
Le due distribuzioni statistiche per la spectral angle mapper classification sono quelle mostrate negli istogrammi 7.9 e 7.10 di seguito riportati:
Istogramma 7.9. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.14.
Istogramma 7.10. Distribuzione in frequenza dei pixels per ogni classe di riferimento dell’immagine di figura 7.15.
7.2. Confronto metodi di classificazione.
La parte dedicata da ENVI alla post classification è molto vasta ed articolata ma noi prenderemo in esame solo quella relativa alle matrici di confusione, perché proprio attraverso lo studio di tali matrici si può valutare la capacità classificativa di ogni metodo. I metodi analizzati sono i cinque della supervised classification: parallelepiped, minimum distance, mahalanobis distance, maximum likelihood e spectral angle mapper.
ENVI può calcolare la matrice di confusione usando sia ground truth image sia ground truth regions of interest, ed è proprio questa ultima via che verrà seguita avendo a disposizione delle ROI.
Il risultato di tale operazione ci fa vedere tutta una serie di parametri che analizzeremo nel dettaglio (J.R. Jensen,1986).
Overall accuracy
L’accuratezza totale è calcolata sommando il numero di pixels classificati correttamente e dividendo per il numero totale di pixels. Le regioni di interesse di superficie vera definiscono le vere classi dei pixels.
I pixels classificati correttamente si trovano lungo la diagonale della matrice di confusione che registra il numero di pixels che sono stati classificati nella corretta classe. Il numero totale di pixels è la somma di tutti i pixels in tutte le classi (ENVI User’s Guide edizione, 2001).
Kappa coefficient
Il coefficiente kappa (k) è un’altra misura dell’accuratezza della classificazione. Esso viene calcolato moltiplicando il numero totale di pixels in tutte le classi (N) per la somma delle diagonali della matrice di confusione (xkk), sottraendo la somma di tutti i pixels appartenenti alla classe moltiplicati per i pixels associati alla classe considerata (commission) (x k ∑x∑ k), e dividendo per il numero totale di pixels al quadrato meno lo stesso termine di prima. Nel caso di classificazione perfetta (ogni pixel associato ad una classe
è stato propriamente assegnato) il coefficiente kappa vale 1 ( ENVI User’s Guide edizione, 2001).
κ = ( N ∑ xkk - ∑ x k ∑x∑ k )/ ( N2 - ∑ x k ∑x∑ k )
Matrice di confusione
La matrice di confusione è calcolata comparando la posizione e la classe di ogni pixels di superficie vera con la corrispondente posizione e classe nell’immagine di classificazione.
Ogni colonna della matrice rappresenta una classe di superficie vera e i valori nelle colonne corrispondono al numero di pixels attribuiti a ciascuna classe rispetto a quelli originariamente scelti nella classe stessa. Per esempio, osserviamo la colonna di superficie vera per la classe bosco nella tabella 7.6. La superficie vera mostra 2921 pixels nella classe. La classificazione è stata in grado di registrare 2337 di questi pixels in modo corretto ma 445 pixels risultano non classificabili e 139 classificati come area urbana o priva di vegetazione. Il livello di classificazione può essere anche espresso come percentuale. Per esempio, nella classe bosco la percentuale di pixels classificati correttamente è 2337/2921= 0.80006 o 80.006 % (ENVI User’s Guide edizione, 2001).
Commission
Errori di commissione rappresentano i pixels che provenendo da un’altra classe sono stati classificati come provenienti dalla classe d’interesse. Gli errori di commissione sono mostrati nelle righe della matrice di confusione.
Nell’esempio della tabella 7.6, la classe prato ha un totale di 1069 pixels dove 889 sono classificati correttamente e 3 altri pixels sono registrati in modo sbagliato come appartenenti alla classe prato.
Il rapporto fra il numero di pixels classificati non correttamente e il numero totale di pixels nella ground truth class determina un errore di
commissione. Per il prato l’errore di commissione è 3/1069 = 0,0028 oppure 0,28 % (ENVI User’s Guide edizione, 2001).
Ommission
Errori di omissione rappresentano pixels che provengono da classe di superficie vera ma che la tecnica di classificazione ha sbagliato a classificare nella propria classe. Gli errori di omissione sono mostrati nelle colonne della matrice di confusione.
Usando sempre l’esempio di prima, la classe prato ha un totale di 1069 pixels di superficie vera dove 889 sono classificati correttamente e 180 pixels prato di superficie vera sono registrati in modo non corretto.
Il rapporto fra il numero di pixels classificati non correttamente e il numero totale di pixels nella ground truth class determina un errore di omissione. Per il prato l’errore di omissione è 180/1069= 0,168 o 16,8 % (ENVI User’s Guide edizione, 2001).
Producer accuracy
L’accuratezza del produttore è una misura indicante la probabilità che il classificatore abbia registrato un pixel all’interno della classe A dato che la superficie vera è la classe A. Nella tabella 7.6, la classe prato ha 1069 pixels di superficie vera dove 889 sono classificati correttamente.
La accuratezza del produttore è il rapporto 889/1069= 0,83165 o 83,165 % (ENVI User’s Guide edizione, 2001).
User accuracy
L’accuratezza dell’utente è una misura indicante la probabilità che un pixel sia di classe A dato che il classificatore lo ha registrato nella classe A. Nell’esempio di tabella 7.6, il classificatore ha ripartito 1069 pixels come appartenenti alla classe prato e un totale di 889 pixels sono stati ordinati correttamente.
L’accuratezza dell’utente è il rapporto 889/892= 0,9966 o 99,66 % (ENVI User’s Guide edizione, 2001).
Di seguito vengono riportate tutta una serie di tabelle con le matrici di confusione di tutte le tecniche di classificazione supervised utilizzate per ogni data di rilevazione (pre e post).
Tabella 7.6. Matrice di confusione per la parallelepiped classification dell’immagine pre.
Tabella 7.7. Matrice di confusione per la minimum distance classification dell’immagine pre.
Tabella 7.8. Matrice di confusione per la mahalanobis distance classification dell’immagine pre.
Tabella 7.9. Matrice di confusione per la maximum likelihood classification dell’immagine pre.
Tabella 7.10. Matrice di confusione per la spectral angle mapper classification dell’immagine pre.
Tabella 7.11. Matrice di confusione per la parallelepiped classification dell’immagine post.
Tabella 7.12. Matrice di confusione per la minimum distance classification dell’immagine post.
Tabella 7.13. Matrice di confusione per la mahalanobis distance classification dell’immagine post.
Tabella 7.14. Matrice di confusione per la maximum likelihood classification dell’immagine post.
Tabella 7.15. Matrice di confusione per la spectral angle mapper classification dell’immagine post.
Analizzando bene queste matrici di confusione, confrontando soprattutto le percentuali della producer e della user accuracy, si può notare come la tecnica della maximum likelihood sia quella che mostra i più alti valori di questi parametri; pertanto, in seguito sarà usato questo sistema di classificazione.
7.3 Classificazione delle immagini.
Partendo dal presupposto che la miglior tecnica di classificazione sia la maximum likelihood verrà fatta una classificazione molto più rigorosa delle immagini pre e post inserendo le seguenti 10 regioni di interesse: urbano, urbano industriale, bosco, vegetazione in ombra, prato, agricolo, acqua, suolo e roccia, litorali e, infine, suolo in ombra.
L’immagine su cui sono state scelte queste ROI è l’immagine pre a falsi colori creata combinando in RGB la banda TM 7, 4 e 3 (un esempio è mostrato in figura 7.16). Questa combinazione ha la particolarità di mettere bene in evidenza la presenza di copertura vegetale e la sua distribuzione.
Le ROI sono state abbinate ai seguenti colori: 1. urbano = rosso,
2. urbano industriale = arancione, 3. bosco = verde,
4. prato = verde mare, 5. agricolo = giallo, 6. acqua = blu,
7. suolo e roccia = celeste,
8. vegetazione in ombra = marrone, 9. suolo in ombra = viola,
10. litorali = magenta.
Figura 7.16. Esempio di selezione ROI urbano e ROI urbano industriale prese sulla città di Firenze.
Figura 7.17. Classificazione maximum likelihood dell’immagine pre.
Figura 7.18. Classificazione maximum likelihood dell’immagine post.