I
SOMMARIO
In questa tesi è proposto un sistema non supervisionato per l’estrazione di relazioni semantiche da testi. L’estrazione automatica di relazioni semantiche costituisce un aspetto cruciale sia nell’ambito dell’apprendimento automatico di ontologie da testi che per l’annotazione semantica e rappresenta una soluzione al “knowledge acquisition bottleneck” nel contesto del Semantic Web.
Il sistema sviluppato, valutato sulla lingua italiana e sull’inglese ma applicabile a qualsiasi altra lingua, prende in input coppie di termini e determina se tra tali coppie esiste una relazione semantica. Le coppie di termini iniziali sono estratte dal “Target Corpus” mediante un sistema statistico non supervisionato in grado di determinare se due termini possono essere considerati “distribuzionalmente simili”, sulla base dell’ipotesi della Semantica Distribuzionale secondo la quale “Il significato di una parola è fortemente correlato ai contesti nei quali essa appare”.
Per verificare che una relazione semantica sia effettivamente presente tra due termini e determinarne la natura, il sistema cerca le parole su un “Support Corpus” (il Web) nel contesto di pattern lessico-sintattici “affidabili” (a bassa “recall” ma ad alta “precision”), dove tali parole compariranno nella stessa frase (come, per esempio, le parole “sterzo” ed “auto” nella frase “lo sterzo è parte dell’auto”).
In questa tesi è descritto il processo complessivo che ha condotto allo sviluppo del sistema RelEx, a partire dalla definizione e dalla applicazione dei pattern lessico-sintattici e includendo le misure utilizzate per valutare l’affidabilità delle specifiche relazioni semantiche che il sistema suggerisce. Il lavoro si è focalizzato sulle relazioni semantiche di iponimia (“is_a”), meronimia (“part_of”) e co-iponimia (i.e. due termini sono iponimi dello stesso termine, come “leone” e “tigre” rispetto a “felino”). L’approccio può tuttavia essere esteso per l’estrazione di altre relazioni cambiando la batteria di pattern affidabili utilizzati.
La precisione del sistema è stata valutata all’83.3% per l’iponimia, il 75% per la meronimia e il 72.2% per la co-iponimia, dimostrando la validità dell’approccio proposto.
In questo lavoro, oltre ai concetti inediti di “Closed Pattern” e “Open Pattern”, sono descritte due nuove metodologie. La prima tecnologia proposta, chiamata “trans-language boosting”, è dedicata all’applicazione dei pattern affidabili ed è studiata per aumentare le performance del sistema utilizzando pattern e coppie di termini espressi in altre lingue. La seconda metodica, definita come “cross-reference near-synonymy extraction” si basa sull’applicazione di particolari tipi di pattern “aperti” per il riconoscimento di relationi di quasi-sinonimia tra termini.
ABSTRACT
In this thesis we propose an unsupervised system for semantic relation extraction from texts. The automatic extraction of semantic relationships is crucial both in ontology learning from text and for semantic annotation and represents a solution to the "knowledge acquisition bottleneck" in the context of the Semantic Web.
The developed system, assessed on English and Italian language but applicable to any other languages, takes as input pairs of words and determines whether there is a semantic relationship between these words. The initial pairs of terms are extracted from a "Target Corpus" by an unsupervised statistical system in charge of determining if two terms can be considered "distributionally similar", on the assumption of distributional semantics that "the meaning of a word is strongly related to the contexts in which it appears."
To verify that there is actually a semantic relation between two terms and determine its nature, the system searches for words on a "Support Corpus" (the Web) in the context of lexico-syntactic “reliable” (low "recall" but "high precision") patterns, where these words appear in the same sentence (as, for example, the words "steer" and "car" in the phrase "the steer is part of the car”).
This thesis describes the overall process that led to the development of the RelEx system, starting from the definition and application of the lexico-syntactic patterns, and including the measures used to assess the reliability of specific semantic relations that the system suggests. The work focuses on the semantic relations of hyponymy (“is_a”), meronymy ("part_of") and co-hyponymy (i.e. two terms are hyponyms of the same term, as “lion” and “tiger” with respect to “feline”). The approach may however be extended to extract other relationships changing the battery of reliable patterns used.
The precision of the system was evaluated as 83.3% for hyponymy, 75% for meronymy and 72.2% for co-hyponymy, demonstrating the validity of the proposed approach.
In this work, in addition to the novel concepts of "Closed Pattern" and "Open Pattern", two new technologies are described. The first methodology, called “trans-language boosting” is devoted to the application of reliable patterns and pairs of terms expressed in different languages with the aim of increasing the performance of the system. The second technique, defined as “cross-reference near-synonymy extraction”, is based on the application of “open” patterns for the recognition of near-synonymy relations.
III
INDEX
1. INTRODUCTION ... 1
1.1. State of the art ... 2
1.1.1 Ontologies ...2
1.1.2 Ontology Learning from text ...4
1.1.3 Relation extraction using statistical approaches...5
Synonyms ...5
Concept hierarchies and ontology population...6
Non-taxonomic relationships...6
1.1.4 Relation extraction using pattern-based approaches...7
Synonyms ...7
Concept hierarchies and ontology population...7
Non-taxonomic relationships...8
Automatic definition of patterns ...9
1.1.5 Hybrid approaches ...9
Concept hierarchies and ontology population...9
Non-taxonomic relationships... 10
2. THE APPROACH ... 12
2.1 Basic notions ... 12
2.2 The overall approach... 13
2.3 The core process ... 13
2.4 Obtaining the candidate term pairs ... 14
2.4.1 Using the distributional system ...14
2.4.2 Using Generic Patterns...15
2.5 The choice of the support corpus ... 15
3. DEFINITION AND USE OF RELIABLE PATTERNS ... 17
3.1 The syntax of Reliable Patterns... 17
3.2 Querying the web for patterns ... 19
3.2.1 Looking for hyponymy patterns ...19
3.2.2 Looking for meronymy patterns...27
3.3 Typologies of Reliable Patterns... 34
3.3.1 Closed Patterns ...34
3.3.2 Open Patterns...35
4. THE RELEX SYSTEM ... 38
4.1 Input resources... 38
4.2 System parameters... 39
4.3 The algorithm... 40
4.4 The Closed Patterns Module... 40
4.4.2 CPM parameters ...42
4.4.2.1 CPM parameters: variants ... 42
4.4.2.2 CPM parameters: inversion ... 43
4.4.2.3 CPM parameters: features in patterns ... 44
4.5 The Open Patterns Module ... 45
4.5.1 The OPM algorithm...45
4.5.2 OPM parameters...46
4.5.2.1 OPM parameters: adjective... 46
4.5.2.2 OPM parameters: lemma ... 46
4.6 The Ranking Module... 47
4.6.1 Scores for hyponymy and meronymy...47
4.6.2 Scores for co-hyponymy...48
4.7 A working example ... 50
4.7.1 Definition of the battery of RPs ...50
4.7.2 Setting of the system parameters ...50
4.7.3 Application of the Closed Pattern Module ...51
4.7.4 Application of the Open Pattern Module...53
4.7.5 Application of the Ranking Module ...55
5. EVALUATION OF THE SYSTEM... 56
5.1 Definition of the evaluation measures ... 56
5.2 Definition of the test set ... 57
5.2.1 Agreement among raters ...58
5.2.2 Direct/indirect relations ...59
5.3 Results ... 59
5.4 Using the RelEx system to extend lexical ontologies ... 60
5.5 Comparing the WWW to Wikipedia... 60
6 FURTHER DIRECTIONS OF RESEARCH: TRANS-LANGUAGE BOOSTING ... 62
6.1 Available resources for translating terms... 62
6.1.1 Online dictionaries ...62
6.1.2 Wikipedia ...63
6.1.3 Online translation tools...64
6.1.4 Comparing the three resources...65
6.2 Trans-language boosting experiments for hyponymy ... 65
7. CONCLUSIONS ... 70
REFERENCES ... 71
1
1. INTRODUCTION
Ontology is a philosophical discipline, dealing with the nature and the organization of reality. In the last twenty years, ontology engineering has emerged as an important research area in Computer Science.
In the modern era of Internet and the Semantic Web [1], the role of ontologies has become crucial to share and reuse knowledge across domains and tasks.
Currently, “formal” ontologies are widely used in many fields of computer science, such as in knowledge engineering, soft computing, knowledge management, natural language processing, e-commerce, information retrieval, database design and integration, bio-informatics, education, and so on.
Natural Language Processing (NLP) systems, for example, need ontologies to interpret the meaning of texts, in the same way people do using the world’s knowledge stored in their brain.
The acquisition of ontologies as machine-readable semantic resources is very expensive in terms of human effort: for this reason, it is necessary to develop methods and techniques that allow reducing the effort necessary for the knowledge acquisition process, being this the goal of Ontology Learning.
This thesis aims at exploring ways to improve the quality of ontology learning systems, focusing on the acquisition of semantic relations between relevant terms.
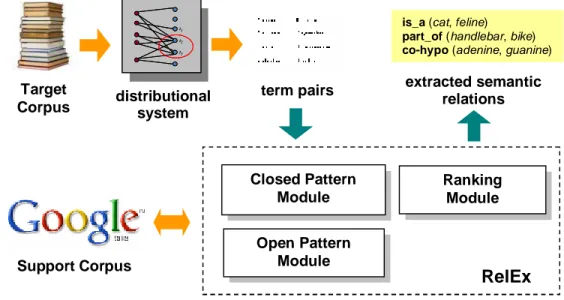
We propose an unsupervised approach for semantic relation extraction from texts. The implemented system, called RelEx, takes as input pairs of words and determines whether there is a semantic relationship between these words. The initial pairs of terms are extracted from a "Target Corpus" by an unsupervised statistical system in charge of determining if two terms can be considered "distributionally similar", on the assumption of distributional semantics that "the meaning of a word is strongly related to the contexts in which it appears."
To verify that there is actually a semantic relation between two terms and determine its nature, the system searches for words on a "Support Corpus" (the World Wide Web) in the context of lexico-syntactic “reliable” (low "recall" but "high precision") patterns, where these words appear in the same sentence (as, for example, the words "steer" and "car" in the phrase "the steer is part of the car”).
This thesis describes the overall process that led to the development of the RelEx system, starting from the definition and application of the lexico-syntactic patterns, and including the measures used to assess the reliability of specific semantic relations that the system suggests. The work focused on the semantic relations of hyponymy (”is_a”), meronymy ("part_of") and co-hyponymy (i.e. two terms are hyponyms of the same term, as “lion” and “tiger” with respect to “feline”). The approach may however be extended to extract other relationships changing the battery of reliable patterns used.
The precision of the system, assessed on English and Italian language but applicable to any other language, was evaluated as 83.3% for hyponymy, 75% for meronymy and 72.2% for co-hyponymy, demonstrating the validity of the proposed approach.
In this work, in addition to the novel concepts of "Closed Pattern" and "Open Pattern", two new technologies are described. The first methodology, called “trans-language boosting” is devoted to the application of reliable patterns and pairs of terms expressed in different languages with the aim of increasing the performance of the system. The second technique, defined as “cross-reference near-synonymy
extraction”, is based on the application of “open” patterns for the recognition of near-synonymy relations..
1.1. State of the art
1.1.1 Ontologies
An ontology can be defined as a formal, explicit specification of a shared conceptualization [2]. Conceptualization refers to an abstract model of the world expressed by concepts. Explicit means that the type of concepts used, and the constraints of their use, are explicitly defined. Shared to be intended that an ontology captures consensual knowledge and it is accepted by a group. Other definitions of ontology can be found in [3].
The basic building blocks of ontologies are concepts. Concepts are typically organized in a concept hierarchy and they can be related to each other with non-taxonomic relations. Though different knowledge representation formalisms exist for the definition of ontologies, they all share the following two components:
• Concepts: they represent the entities of the domain being modelled. They are designated by one or more natural language terms and are normally referenced inside the ontology by a unique identifier.
• Relations: represent a type of association between concepts. There are taxonomic relationships between concepts (defining the concept hierarchy), and non-taxonomic relationships.
Some ontologies contain axioms, usually formalized into some logic language, that specify additional constraints on the ontology and can be used in ontology consistency checking and for inferring new knowledge from the ontology through some inference mechanism.
On the basis of some definitions, ontologies can also contain “instances” of concepts and relations, though some prefer to use the term “Knowledge Base” to refer to the semantic resource composed of an ontology and the relative instances. An interesting classification of ontologies was proposed by Guarino [4], who classified types of ontologies according to their degree of generality (see Fig. 1).
• Top-level ontologies: sometimes called “foundation”, or “upper” ontologies, they describe very general concepts like space, time, event, that are common to all domains. They are designed as ontologies to be shared in large communities of users. Among the most widespread top-level ontologies there are Cyc [5], BFO [6] and DOLCE [7].
• Domain ontologies: sometimes, called “reference” ontologies, describe the entities and relations related to a generic domain by specializing the concepts introduced in the top-level ontology. There are many domain-specific ontologies in the area of e-commerce (UNSPSC1, NAICS2, SCTG3, e-cl@ass4, RosettaNet5), medicine (GALEN6, UMLS7, ON98), engineering 1 http://www.unspsc.org 2 http://www.naics.com 3 http://www.bts.gov/programs/cfs/sctg/welcome.htm 4 http://www.eclass.de
3 (EngMath [8], PhysSys [9]), enterprise (Enterprise Ontology [10], TOVE [11]), and knowledge management (KA [12]).
• Task ontologies: describe the vocabulary related to a generic task or activity (e.g. selling or diagnosing) by specializing the top-level ontologies. (see, for example, [13], [14] and [15])
• Application ontologies: the most specific kind of ontologies, close to databases’ conceptual schemata, where concepts often correspond to roles played by domain entities. Application ontologies have a very narrow context and limited reusability as they depend on the particular scope and requirements of a specific application. These ontologies are typically developed ad hoc by the application designers. (see [16], [17], [18]).
Methods and methodologies for building ontologies pertain to the field of Ontology engineering [19]. Ontology engineering is a set of tasks related to the development of ontologies for a particular domain.
The manual construction of ontologies is an expensive and time-consuming task, requiring the support of highly specialized domain experts and knowledge engineers. This problem is known as the ”knowledge acquisition bottleneck”: a possible solution is to provide an automatic or semi-automatic support for ontology construction. This field of research is usually referred to as “ontology learning”.
When the source of knowledge is constituted by textual corpora the process is called “ontology learning from text”. Other ontology learning approaches depending on different inputs are: ontology learning from dictionary, from knowledge base, from semi-structured schemata and from relational schemata [20]. In this dissertation we will focus on ontology learning from text.
5 http://www.rosettanet.org 6 http://opengalen.org 7 http://nih.gov/research/umls 8 http://saussure.irmkant.rm.cnr.it/ON9/index.html top-level ontology
domain ontology task ontology
application ontology
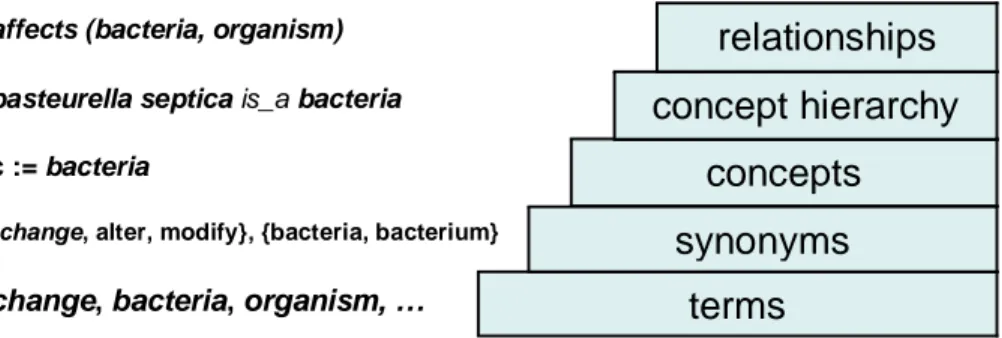
Independently from the source of knowledge, the ontology learning process can be divided in a series of steps. Although there is no standard regarding this development process, Buitelaar et. al in [21] organizes the aspects and tasks involved in ontology development into a set of layers, as depicted in Fig 2.
In order to identify the set of concepts of a domain it is necessary to identify the natural language terms that refer to them. Synonym identification helps to avoid redundant concepts, since two or more terms can represent the same concept. The next step is to identify the taxonomic relationships (generalization and specialization) between the concepts. The product of this task is a concept hierarchy. It is also necessary to extract non taxonomic relations, i.e. all those “not hierarchical” relations between the concepts (such as the “affects” relation holding between the concepts of “bacteria” and “organism” in the example of Fig. 2). . Some authors (see for example [21]) also consider rule acquisition for deriving facts that are not explicitly expressed in the ontology.
1.1.2 Ontology Learning from text
Ontology learning from text (also known as “ontology learning from unstructured data”) consists in the construction of ontologies on the basis of the knowledge extracted from texts.
Concerning the relation extraction steps (including both taxonomical and non-taxonomical relations) the process usually involves the application of statistical or pattern-based approaches, both of which are based on natural language processing techniques.
One commonly accepted assumption in statistical approaches is the Harris distributional hypothesis [22], stating that similar words tend to occur in similar contexts, resulting in the extraction of paradigmatic relations [23], called ‘associations’ by Saussure [24].
On the other hand, pattern-based approaches search the texts for certain patterns indicating some kind of relation. One commonly cited approach is the Hearst patterns [25] [26], where lexico-syntactic patterns indicate hyponymy/hypernymy or meronymy/holonymy relationships in the text. Marti Hearst, considered the pioneer of the pattern-based methodology, extracted
Fig. 2 - Layers of the Ontology Learning Process
change, bacteria, organism, …
terms
{change, alter, modify}, {bacteria, bacterium}
synonyms
c := bacteria
concepts
pasteurella septica is_a bacteria
concept hierarchy
affects (bacteria, organism)relationships
5 relationships from the text of Grolier’s Encyclopaedia. The method can be illustrated with an example. Given the following sentence:
At night, keep pets inside in a secure, covered kennel; roaming pets are easy prey for cougars and other predators
it is possible to extract a specific semantic relation between the words “cougars” and “predators” by applying a pattern like this:
“X and other Y”
indicating that the word X can be considered an hyponym of Y.
The two following sections summarize the methodologies and systems described in literature and relative to the two main approaches described above for relation extraction from texts. In the context of ontology learning the task of relation extraction can help in the discovery of synonyms, in the definition of concept hierarchies through hyponymy and hypernymy detection, for ontology population and for non-taxonomic relationships extraction. In this perspective, each one of the following sections describes approaches focusing on one or more of these fields.
1.1.3 Relation extraction using statistical approaches
Statistical systems based on distributional properties of words consist in studying co-occurrence distributions of words in order to calculate a semantic distance between the concepts represented by those words.
Synonyms
Automatic or semi-automatic synonyms discovery has been widely investigated in the context of distributional approaches.
Pointwise Mutual Information and Information Retrieval techniques are used by Peter Turney in [27] to measure the similarity of pairs of words. The algorithm exploits statistical data acquired by querying a Web search engine, it has been evaluated using the Test of English as a Foreign Language and compared with Latent Semantic Analysis.
In [28] a distributional method for the extraction of synonyms is proposed. It makes use of different resources including a monolingual dictionary, a English-Chinese bilingual corpus, and a large monolingual corpus. The method uses a weighted ensemble to combine the results of the individual extractors using. The authors say that experimental results prove that the three resources are complementary to each other on the synonym extraction task.
Concerning synonyms, a clear distinction between attributional similarity and relational similarity is illustrated in [29] by Turney, where a method called Latent Relational Analysis (LRA), extending the Vector Space Model framework, is presented for measuring relational similarity between words.
An extensive use of the Web is proposed by Nakov in the context of automatic acquisition of synonyms [30]. The algorithm measures the semantic similarity between pairs of words by comparing their local contexts extracted from the Web using the Google search engine. Cosine between the frequency vectors in the Euclidean space is calculated, then TF-IDF measure is introduced to exclude
“parasite” words. In [31] Shimizu et al. face the problem of synonym acquisition using the machine learning techniques of metric learning. In particular, metric learning is applied to improve the results obtained with the application of standard distributional methods.
Concept hierarchies and ontology population
Widdows [32] combines syntactic and statistical information to build taxonomies starting from a set of unknown words. They apply Latent Semantic Analysis and part-of-speech information to find semantic neighbours then they place the unknown words in the part of the taxonomy where the neighbours are most concentrated. The approach is evaluated trying to classify nouns already present in the WordNet taxonomy [71].
Cimiano and Staab build the concept hierarchy via Formal Concept Analysis using syntactic dependencies as attributes [33]. The approach is evaluated by comparing the produced concept hierarchies against two handcrafted taxonomies belonging to tourism and finance domains.
In the context of “ontology refinement”9, in the work of Alfonseca and Manandhar the WordNet taxonomy is extended with domain terminology [34]. The chosen domains are the “Lord of the Rings” novel and Darwin’s “the Voyage of the Beagle”, from which concepts concerning locations, rivers, seas, animals, races and people are extracted. A Distributional Semantic model is applied to locate the right places in the WordNet taxonomy where to put the obtained synsets. The proposed methodology has been extended to include the use of patterns as described in a paper that followed [35] (see 1.1.4).
A similar unsupervised approach, applied to thesauri enrichment, is described by Pekar and Staab [36]. The system classifies words in a taxonomy on the basis of the distributional hypothesis: the classification decision is a function of both the distributional similarity of the new word to the target class and the strength of the semantic relatedness of the target class to other likely candidates.
Concerning the task of ontology population (i.e. the assignment of instances to concepts) Wang et al. ([37]) introduced a semi-supervised approach: they applied a boot-strapping technique based on a “positive-only learning” algorithm to extract semantic relations from Wikipedia. Having to work with few positive training examples they used seed instances and approaches such as strong negative identification and transductive inference.
Non-taxonomic relationships
Concerning statistical approaches for non-taxonomic relationships extraction, Faure and N'edellec describes an approach for learning subcategorization frames of verbs and ontologies from syntactic parsing of technical texts in natural language using clustering techniques [38].
A similar approach involving the use of parsed text is described by Maedche and Staab in [39]. They use generalized association rules to detect non-taxonomic relations between concepts and to determine the appropriate level of abstraction at
9
Maedche and Staab define Ontology Refinement as the adaptation of an ontology to a specific domain or to some user’s requirements, without altering its overall structure [20].
7 which to define relations. The authors propose an empirical evaluation of the approach with regard to a manually engineered ontology.
A more recent work is aimed at the definition of the appropriate generalization level for binary ontological relations [40]. In particular, they extract verb frames from texts and then tuples Noun-Verb-Noun and Noun-Verb-Preposition-Noun. They construct binary relations from the tuples then they look for the correct level of generalization for the verb’s arguments with respect to a given taxonomy, using three different measures: the conditional probability of a concept given a verbslot, the pointwise mutual information between a concept and a verb slot, and the chi-square-based measure.
1.1.4 Relation extraction using pattern-based approaches
Apart from the already cited, pioneristic works by Marti Hearst [25, 26], a lot of research has been devoted to pattern-based relation extraction from text.
Synonyms
Patterns have been used for the automatic discovery of synonyms. In [58], an extension of the system introduced in [41] and [42] (see below) is described. To overcome the limits of WordNet and similar resources regarding technical terms synonyms coverage, Sánchez and Moreno propose a system for the automatic extraction of synonyms from the Web. In particular, complex terms are stripped of their lexical head and looked for in the Web, then the obtained heads are compared and taken as synonyms: for example, the term “hormone ablation resistant metastatic prostate“ (stripped of the head “cancer”) can provide the synonym “tumor” or the lexicalitation “carcinoma”.
Concept hierarchies and ontology population
Among the more recent works inspired by Hearst research, it is worth citing [09_43], where Cimiano and Staab present a methodology for hyponymy discovery and ontology population. The described system, called PANKOW, looks for instances of lexico-syntactic patterns indicating certain semantic relations and counts their occurrences in the World Wide Web. They make use o a pre-existing ontology to evaluate the accuracy of the system.
The use of the WWW as a corpus is gaining more and more interest inside the ontology learning community. Another approach using the Web is described by Sánchez and Moreno in [41] and [42], where a taxonomy is constructed starting from a keyword and analysing with NLP tools web pages containing that keyword. In the approach, patterns are exploited for hyponymy extraction from complex terms on the basis of lexical inclusion. An extension of this work, involving synonyms extraction, is presented in [44] and described in the next paragraph.
One of the latest research conducted on concept hierarchies construction for ontology learning is introduced by Velardi et al. in [45] and [46] and implemented in the OntoLearn system. In the approach all domain terminology is extracted from the corpus using contrastive techniques10, then hypernyms of the terms are searched for on the Web using patterns applied to the syntactically analyzed
10
Only terms found in domain related documents, and not found in other domains used for contrast, are selected as candidates for the domain terminology.
sentences representing the definitions. Terms are then arranged in forests of concept trees, according to the hypernymy information extracted in the previous steps. For each of the steps the algorithm is articulated in an evaluation procedure is proposed.
Non-taxonomic relationships
In the context of pattern-based techniques for non-taxonomic relations extraction, we can distinguish between research focused specifically on meronymy and works tackling non-taxonomic relations identification in general.
The very first approach described in literature for meronymic relations extraction belongs to Berland and Charniak [47]. The authors apply their lexico-syntactic patterns to a very large corpus (NANC corpus composed of 100 million words) obtaining an accuracy of 55 percent. The described algorithm consists of three phases: the first identifies all occurrences of patterns in the corpus, the second filters out all words ending with suffixes such as "ing', "ness', or "ity' (for they typically occur in words that denote a quality rather than a physical object), then in the last step the possible parts are ordered by the likelihood that they are true parts according to a particular metric.
A similar approach to meronymic relations discovery is proposed by Girju et al. in [48]. The paper provides a supervised method for the automatic detection of part–whole relations in English texts. The system is supervised: it first identifies lexico-syntactic patterns encoding part-whole relations, then, on the basis of a set of positive (encoding meronymy) and negative (not encoding meronymy) training examples it creates a decision tree and a set of rules that classify new data. The classification rules are learned automatically through an iterative semantic specialization (ISS) procedure applied on the noun constituents’ semantic classes provided by WordNet.
Concerning non-taxonomic relations extraction in general, several approaches make use of lexico-syntactic patterns. In [49] and [50], Casado et al. describe a methodology for the automatic extraction of semantic relations aimed at the enrichment of the WordNet resource. They first find general patterns for the hypernymy, hyponymy, holonymy and meronymy relations from Wikipedia and, using them, they extract more than 1200 new relationships that did not appear in WordNet originally.
The domain of biology is the field where the system of Ciaramita et al. and described in [51] is applied. The declared objective is to enrich existing biomedical ontological resources with non-taxonomic relations. The described unsupervised system applies a series of NLP tools to a corpus of molecular biology literature (the GENIA corpus), and generate a list of labelled binary relations between pairs of GENIA ontology concepts. Evaluation on precision is conducted manually by a biologist and an ontologist, both familiar with the corpus.
The use of Web as a corpus is used in several recent works with very promising results. An extension of the research already cited in [41] and concerning non-taxonomic relation discovery from the Web is introduced in [52]. Starting from an initial keyword, in the first step they extract patterns (expressed by verb phrases) relative to the semantic relations they focus on using weakly supervised techniques. In the next step, they use the patterns to discover concepts that are non-taxonomically (verb-labelled) related with the initial keyword and incorporate them to the ontology of reference.
9 Another approach sharing some similarities with the one introduced here is implemented in the Espresso system by Pantel and Pennacchiotti [53]. In this work the concepts of “generic” and “reliable” lexico-syntactic patterns have been introduced for the first time. The idea is to apply generic (high recall but low precision) patterns to a corpus looking for semantic relations and then to filter incorrect instances using reliable (low recall but high precision) patterns to the Web. The algorithm is minimally supervised: it begins with seed instances of a particular semantic relation and then iterates through the phases of pattern induction, pattern ranking/selection and instance extraction. The author demonstrate that by exploiting generic patterns, system recall substantially increases with little effect on precision.
A similar minimally supervised approach for semantic relation extraction is introduced in [54] by Bunescu et al. Starting from a small set of relations holding between Named Entities the Web is crawled for sentences containing the two words and applying patterns to the parsed text. The described system automatically learns how to extract instances of a specific relation in the framework of Multiple Instance Learning (MIL).
Automatic definition of patterns
Regarding pattern-based approaches, several techniques aim at providing support for the automatic (or semi-automatic) definition of the patterns. Many of the cited works on pattern-based relation extraction ([26, 45, 48, 49, 50, 55]) include a step for pattern definition, .
In [56] Mititelu presents an approach for the automatic extraction of patterns for hyponymy and hypernymy extraction using WordNet as a support resource. The aim of the work is to extract from a corpus those sentences in which at least one hyponym is co-occurrent with one of its direct or indirect hypernyms.
More recently, Peter Turney describes an approach [57] sharing some similarities with the one introduced in this dissertation, though aimed at the identification of patterns. Starting from a pair of words with some unspecified semantic relation, a large corpus, extracted from the Web, is mined for lexico-syntactic patterns expressing the implicit relations between the two words. The paper introduces the notion of relational similarity between two pairs of words, defined as the degree to which their semantic relations are analogous. An advance of this work is introduced in [58], where synonyms antonyms and associations between words are studied.
1.1.5 Hybrid approaches
Hybrid approaches combining statistical and pattern-based techniques have been recently proposed and represent a very promising area of research for semantic relation extraction from text. While the two approaches (pattern-based and distributional) are largely complementary, there have been just few attempts to combine them for semantic relation extraction.
Concept hierarchies and ontology population
One of the first hybrid approaches proposed in literature is illustrated by Caraballo, where bottom-up clustering methods are applied to conjunctions and appositives appearing in the Wall Street Journal [59]. An unlabeled noun hierarchy is constructed, the internal nodes of which are then labelled using hypernyms
extracted through patterns applied to the parsed corpus. Validation of the hierarchy is done by human judges.
One of the works already cited ([32]), aimed at the extraction of hyponymy relations, has been extended to use lexico-syntactic patterns [60]. In particular, Latent Semantic Analysis (LSA) is applied to filter hyponymy relations extracted with patterns, thus reducing the rate of error of the initial pattern-based hyponymy extraction by 30%.
A hybrid approach, sharing some similarities with the one described in this thesis, is introduced in [61] by Cimiano and Staab as an extension of the work described in [33] and aimed at the learning of concept hierarchies. Semantically related pairs of words are extracted from a corpus using a clustering algorithm: the process is supported by hypernyms derived from WordNet and by the matching of lexico-syntactic patterns indicating a hypernym relationship on documents extracted from the Web.
More recently, dependency structure based patterns have been applied to the Wikipedia online resource for the automatic acquisition of IS-A relations [62]. Candidates relations are ranked using domain knowledge (based on distributional association) and interactive pattern reliability and instance reliability mechanism.
Hybrid approaches have also been applied for ontology population and ontology enrichment. In [35], for example, the distributional approach described in [34] has been extended to include patterns. The ontology refinement algorithm the authors propose is improved by finding hypernymy patterns in domain-specific texts.
Non-taxonomic relationships
Hybrid approaches considering the extraction of non-taxonomic relations are still quite scarce in literature.
In [55] Finkelstein-Landau and Morin apply and compare two distinct approaches for the extraction of semantic relations from text. On the one hand, an unsupervised system is used for term identification and term relationship extraction aimed at finding interesting relationships between terms and to label these relationships. From the other hand, a supervised relation classification system, requiring predefinition of lexico-syntactic patterns, is applied to find pairs that belong to predefined relations. The major conclusion of this study is that the two methods are complementary and they can be exploited to design an integrated system able to overcome the disadvantages of each method and thus providing better results.
In a more recent work by Mirkin et al. pattern-based and distributional similarity methods have been combined for lexical entailment acquisition [57_63]. Conclusions of the study are similar to the ones drawn in the previously cited paper, highlighting the complementarity of the two approaches. In particular, the authors note how it is possible to extract pattern-based information that complements the weaker evidence of distributional similarity.
This evidence of complementarity has led to the definition of the approach described in this thesis and to the implementation of the RelEx system. As it emerged from the experiments we have conducted, the single approach (distributional or pattern-based) alone is able to detect and extract a limited set of semantic relation instances. We can say that the distributional approach recognizes that two words are semantically related on the basis of distributional
11 similarity of the different contexts in which the two words occur. The distributional method identifies a somewhat loose notion of semantic similarity (sometimes addressed to as semantic relatedness [64]), as holding between “company” and “government”, denoting the presence of a “paradigmatic” relation of some kind between the two words. On the other hand, the pattern-based approach is based on identifying joint occurrences of the two words within particular lexico-syntactic patterns, which typically indicate a syntagmatic relationship. The pattern-based approach tends to yield more accurate hyponymy and meronymy relations, but is less suited to acquire, for example, co-hyponyms, which only rarely co-occur within short patterns in texts.
From a semiotic point of view, the distinction between syntagmatic and paradigmatic semantic relations between words was introduced by Saussure [24]: he claims that meaning arises from these two types of relations between words. These two dimensions of meaning are often presented as two orthogonal “axes”: syntagmatic relations involve associations between linguistic expressions that exist “in presentia”, whereas paradigmatic relations involve associations that exist “in absentia”. In a sentence like “the cat eats”, for instance, the association between “cat” and “eats” is realised through their co-occurrence within the same sentence; the semantic association between “eats” and “sleeps”, on the other hand, exists even if it does not show up explicitly in the sentence. To put it in other words, syntagmatic relations hold intratextually within co-occurring words, whilst paradigmatic relations refer intertextually to words which do not co-occur together in the text but which can be substituted one for another.
In the following chapters of the thesis the approach and the system will be described in details.
In particular, the overall approach will be introduced in chapter 2, including experimental versions of the methodology, the choice of the Support Corpus (where lexico-syntactic patterns will be applied) and a brief description of the distributional system and the Natural Language Processing tools used to extract the candidate pairs of terms.
Definition and use of Reliable Patterns will be described in chapter 3, starting from a description of the methodology used to detect and isolate good lexico-syntactic patterns and introducing the distinction between Closed and Open Patterns.
The RelEx system and its parameters will be described in chapter 4. The three main sub-components, the Closed Pattern Module, the Open Pattern Module and the Ranking Module will be introduced in sections 4.4, 4.5 and 4.6.
The evaluation of the system, on Italian and English language, will be described in details in chapter 5 while chapter 6 will be devoted to the presentation of two novel techniques, the “trans-language boosting” and the “cross-reference near-synonymy extraction”.
2. THE APPROACH
In this chapter we describe the proposed methodology for the extraction of semantic relations from texts. The idea is to combine the distributional and the pattern-based approaches (introduced in chapter 1) to develop a hybrid system capable of exploiting the better characteristics of both methodologies.
2.1 Basic notions
Before introducing the approach we here describe the main entities involved:
− Reliable Patterns (RPs): patterns representing specific syntactic constructions involving two terms and representing semantic relations (as, for example, <T1 and other T2> representing an IS_A (hyponymy) relation
between words T1 and T2). They are called “reliable” (as defined by Pantel
and Pennacchiotti [53]) since once they match with a very high probability a semantic relation holds between the two terms. In other words, RPs can be defined as “high precision but low recall” patterns, since usually just a very few occurrences can be found in small- and medium-sized corpora. On the contrary, so called Generic Patterns (GPs) are “high recall but low precision” patterns, such as <T1 is a T2> for the IS_A relation (e.g. “lion is
a feline”): patterns of this kind are very frequent in all corpora but most of the time they don’t denote the expected semantic relation.
− Instantiated Patterns (IPs): patterns that have been instantiated with terms. Given, for example, the Reliable Pattern <T1 is composed of T2>
and the term pair “nucleus, protons”, the relative IP would be <nucleus is composed of protons>.
− Target Corpus (TC): the textual corpus from which we want to extract semantic relations instances. It is usually a domain-specific corpus, and it must be linguistically annotated in order to extract related pairs of words from it. The pairs of words extracted from the TC (for example through the application of a distributional system) are candidate to be semantically related: to verify if a semantic relation actually holds between them (and to determine the nature of the relation), the two terms must be applied inside Reliable Patterns and looked for in the Support Corpus.
− Support Corpus (SC): the corpus where the pairs of words extracted from the TC are searched in the context of Reliable Patterns. The SC must be of very large dimension so that RPs can match a significant number of times. Since we will use the Web as the SC, it cannot be linguistically analyzed, and syntax of RPs must be defined accordingly.
− Term pair: a pair of terms (T1, T2). With “term” we indicate a word or
group of words denoting an entity in a particular context.
− Hyponymy (is_a): semantic relation in which one word is a hyponym of another (e.g. “lion” is an hyponym of “feline”). Hypernymy is the inverse relation (e.g. “feline” is a hypernym of “lion”).
− Meronymy (part_of): semantic relation in which one word is a meronym of another (e.g. “paw” is a meronym of “cat”). Holonymy is the inverse relation (e.g. “cat” is a holonym of “paw”).
13
− Co-hyponymy: semantic relation holding between two words that share a common hypernym (e.g. “lion” and “tiger” are co-hyponym of “feline”).
2.2 The overall approach
The overall approach involves a Target Corpus, a methodology to extract candidate related pairs of terms from the Target Corpus, the sets of Reliable Patterns (each set representing a specific semantic relation) and a Support Corpus where instantiated RPs must be applied. The approach can be summarized in the following sequence of steps:
Inputs: i) a specific (unannotated) Target Corpus (TC), from which we want to extract semantic relations between terms;
ii) the sets of RPs (each one relative to a specific semantic relation); Step 1: the set of candidate semantically related term pairs is obtained;
Step 2: each set of RPs is applied to the term pairs by instantiating each pattern with the two terms obtaining the relative sets of Instantiated Patterns (IPs);
Step 3: each IP belonging to every set is looked for inside the Support Corpus (SC);
Step 4: all the results relative to each pair are gathered and compared: a scoring function is used to determine the most probable (if any) semantic relation holding between the two terms;
Output: a set of labelled term pairs representing semantic relation instances.
The system that has been implemented (described in chapter 4) deals with steps 2. 3 and 4 and works independently from the way the candidate term pairs are obtained.
2.3 The core process
In this paragraph the core process of the approach (represented by the aforementioned steps 2, 3, and 4) is described.
The idea is to take a set of term pairs (extracted from a Target Corpus) and verify if the given terms are involved in specific semantic relations. Independently from the way the pairs have been obtained, the basic principle is to apply them to particular “low recall but high precision” lexical patterns (the Reliable Patterns) and look for matches inside a predefined Support Corpus: if for a specific class of RPs representing a certain semantic relation a relevant number of matches is obtained, we can say that the two terms are involved in that semantic relation. For details about the definition of the RPs see chapter 3.
The core process can be summarized in the following sequence of steps:
Inputs: i) a set of n term pairs (tp1, tp2, … , tpn)
ii) a set of m semantic relations, each one represented by a set of RPs (rps1, rps2, … , rpsm)
iii) a support corpus (SC)
Step 1: each term pair tpi is applied to every set of RPs rpsj obtaining the
Step 2: each IP belonging to every set ipsij is looked for inside the Support
Corpus;
Step 3: all the results relative to each term pair are gathered and compared: a scoring function is used to determine the most probable (if any) semantic relation holding between the two terms;
Output: a set of s ≤ n labelled term pairs ltpi representing semantic relation
instances.
Anyway, that is a simplified version of the core process: as it will be shown later on (see chapter 4), the algorithm is more complex and, among the other things, it involves two different kinds of Reliable Patterns (see section 3.3).
2.4 Obtaining the candidate term pairs
There can be several ways of obtaining the initial set of term pairs. In general, we want to detect and extract semantically related term pairs (i.e. semantic relation instances) from the TC. Since the final objective is to provide a contribution in the ontology learning from text field, the TC will be constituted of documents related to a specific domain, for which a few structured and assessed ontological information is available.
As introduced in chapter 1, this research has been mainly devoted to the application and combination of two distinct approaches (distributional and pattern-based), and for this reason most of the experiments have taken into account initial term pairs generated with the help of a distributional system.
As a matter of fact, the proposed approach has been developed through a series of modifications and adjustments. First experiments, for example, have been conducted including the use of generic “high recall but low precision” lexico-syntactic patterns (as illustrated in section 2.4.2). The Support Corpora where Reliable Patterns have been applied on have been subject to changes as well. 2.4.1 Using the distributional system
As discussed previously, to obtain the initial set of term pairs a distributional system has been applied to the TC. Identification of the pairs was carried out by CLASS [65], a distributionally-based algorithm for building classes of semantically-related terms. According to CLASS (and to distributional systems in general), two words are considered as semantically related if they can be used interchangeably in a statistically significant number of syntactic contexts. CLASS grounds its semantic generalizations on controlled distributional evidence, where not all contexts are equally relevant to an assessment of the semantic similarity between words (e.g. contexts with so-called light verbs, such as “to take” in “to take a shower” or “to have” in “to have a drink”, play quite a marginal role in the assessment of semantic similarity).
CLASS has been used with success for the extraction of Related Terms (RTs) in the context of T2K (Text-to-Knowledge), a system for the extraction of knowledge from texts available at ILC-CNR [66]. T2K has been applied to corpora belonging to a number of different domains. For experiments performed to evaluate the RelEx system (see chapter 5) T2K has been used to extract Related Terms from a corpus belonging to the History of Art domain.
15 2.4.2 Using Generic Patterns
An alternative way to obtain candidate term pairs is through the application of so called Generic Patterns (GPs, in the following), as they have been defined and used by Pantel and Pennacchiotti [53].
The general idea, adopted in the first set of experiments we have conducted, was to identify candidate relationships by applying a set of GPs to the chosen TC, then filtering and classifying the results using RPs applied to the SC. In more details, generic “high recall but low precision” lexico-syntactic patterns have been applied to the linguistically analyzed TC to detect a set of pairs of co-occurring words. These words, appearing close to each other inside a sentence, can be involved in “syntagmatic” relations, such as the words “cougar” and “mammal” in the sentence “the cougar is a mammal”. The TC we chose in the experiments involving GPs was a portion of the Italian Wikipedia.
Two GPs have been used, one for hyponymy defined as <T1 is a T2> and the
other for meronymy defined as <T1 of T2>. The application of GPs to the
syntactically analyzed TC provided, as expected, a lot of noisy results. Concerning the application of the GP for meronymy, the greatest part of the obtained term pairs were not involved in a meronymic relation. On the other hand, much better results were obtained for hyponymy.
Once the set of term pairs have been extracted, the sets of RPs have been instantiated with the words and applied to the SC, thus filtering the candidate relations obtained through GPs.
Just to provide some numbers, 66% of the term pairs extracted with the hyponymy GP were involved in a (direct) hyponymic relation, while just in the 0.64% of the term pairs obtained with the meronymy GP a (direct) meronymic relation was holding.
2.5 The choice of the support corpus
Several experiments have been done concerning the choice of the most appropriate support corpus where RPs should have been applied on. As a basic assumption, we decided to use raw (not linguistically annotated) support corpora. We have taken this choice because, except for a few domains (such as the biomedical one), large annotated domain-specific corpora are not available and the greatest part of the them cannot be found for languages other than English. Since the objective of this work is to provide support in the process of ontology learning, domain-specific corpora are needed.
Since the initial design of the approach, it was evident that the most appropriate corpus would be the Web (see also section 5.5). However, some experiments have been conducted using large unannotated texts, also to provide an objective comparison with the WWW.
As expected, the application of RPs on raw locally stored texts provided very poor results. Apart from the very few matches obtained, the computational load required to search strings inside large texts is excessive, especially when using regular expressions. To overcome this problem, some experiments have been done by indexing the texts using the Google Desktop™ freeware application: search time was cut to zero, but the application didn’t allow the use of wildcards inside the query, thus strongly limiting the application of the RPs.
Apart from being, unfortunately, linguistically unannotated, the Web as the support corpus provided a lot of advantages:
−
size. The (indexed) Web is several orders of magnitude larger than any other available collection of documents. The number of web sites indexed (by the most popular search engines) in the beginning of 2010 is estimated in more than 50 billions11, each one containing a variable quantity of text.−
languages. Though most of web contents is in English (56.4% on the basis of a survey conducted in 200212) it is possible to have access to millions of documents written in hundreds of different languages.−
content. The Web is composed of documents belonging to all existent domains of knowledge, incorporating an enormous variety of domain-specific (and very domain-specific) corpora.−
high redundancy. The amount of repetition of information can represent a measure of its relevance [67, 68, 69, 70]: we cannot trust the information contained in an individual website, but we can give more confidence to a fact that is enounced by a considerable amount of possibly independent sources.−
evolution. The Web is not a static corpus: it evolves over time thanks to the daily contribution of millions of “text producing” users, in every domain of interest. For this reason, the Web is also the most up-to-date corpus, including, for example, neologisms as they are being produced.To access to the Web using RPs two distinct popular search engines have been tested: Google™ and Yahoo!™. Experimental evidence proved that better results in the application of the approach were obtained using the Google™ search engine, which thus has been used for the evaluation of the system.
Experiments have been conducted also to evaluate the potential of the whole Web compared to Wikipedia. Results are shown in section 5.5.
11
http://www.worldwidewebsize.com/
12
17
3. DEFINITION AND USE OF RELIABLE PATTERNS
Reliable Patterns (RPs) constitute a key element of the described approach. The choice of the RPs represent a crucial part, since they have to meet two opposite requirements:
- they must be sufficiently specific to match (hopefully) just phrases representing a semantic relation between the two involved terms;
- they must not be too specific to provide a significant number of matches.
In other words, a too specific pattern can be very reliable (not providing “false positive” results) but not providing any matches (or just a few of them). On the contrary, a “loose” pattern can match many times but resulting in a lot of “false positives”.
Reliable Patterns have been defined on the basis of specific experiments. The algorithm we have used was inspired by Marti Hearst [26]:
i) decide on a semantic relation of interest,
ii) decide a list of word pairs in which this relation is known to hold,
iii) extract sentences from the Web in which these words both occur, and record the lexical and syntactic context;
iv) find the communalities among these contexts and hypothesize that the common ones yield patterns that indicate the relation of interest.
For step ii) we used (as Hearst did) the WordNet resource [71], a lexical database for English where words are grouped into sets of synonyms (called synsets) and that includes various semantic relations between synsets. The equivalent resource for Italian is ItalWordNet [72].
Experiments have shown that to isolate useful reliable lexico-syntactic patterns it is better to use non polysemic and domain-specific words, or “domain terms”, as it will be shown in sections 3.2 and 3.3.
3.1 The syntax of Reliable Patterns
To generalize the particular patterns that can be found in step iii), RPs have to be described using particular syntactical “placeholders”. For example, given the two patterns:
- “T1 is a critical part of T2” (e.g.: “Bathroom is a critical part of houses”)
- “T1 is a fundamental part of T2” (e.g.: “Dermatopathology is a fundamental
part of pathology”)
it is necessary to represent both patterns with a single RP, where the adjectives “critical” and “fundamental” can be substituted with a syntactical placeholder “A”, standing for the Part-Of-Speech (POS) tag “Adjective”. The resulting RP would be:
The possible POS tags that can appear inside RPs are13:
- A: adjective (“T1 is an important part of T2”)
- B: adverb (“T1 is the most important part of T2”)
- C: conjunction (“T2 is also composed of T1”)
- D: determiner (“T1 is that part of T2”)
- E: preposition (“T1 is a type of T2”)
- N: cardinal number (“T1 are the two most important families of T2”)
- NO: ordinal number (“T1 is the second most used part of T2”)
- PA: possessive adjective (“T1 is our most frequent kind of T2”)
- PI: indefinite pronoun (“T1 is one of the biggest T2”)
- R: article (“T1 is a part of T2”)
It is convenient to consider placeholders as “optional”: for example we want to find both patterns like “stalk is a crucial part of flowers” and “stalk is a part of flowers”.
Further generalizations can be made. RP1, for example, contains the
indeterminative article “a”: it can be substituted with the placeholder “R” standing for the determiner POS tag, thus including determinative articles too:
- “T1 is [R] [A] part of T2” (RP2)
RP2 would match, for example, patterns like “RNA is a part of ribosomes”, “RNA is
the part of ribosomes” and “RNA is an important part of ribosomes. In a more concise way, we can describe pattern RP2 as:
- “T1 is [R|A|R-A] part of T2” (RP3)
stating that the matching contexts can include, between the words “is” and “part”: nothing, just an article, just an adjective, an article followed by an adjective.
In some cases, it can be useful to aggregate distinct RPs into a single one by specifying an “OR” operator between words appearing inside the pattern14. For example, given the two following RPs:
- “T1 is composed by T2”
- “T1 is formed by T2”
it is possible to merge them into a single pattern:
- “T1 is (composed OR formed) by T2”
13
the chosen Part-Of-Speech tags come from the Tanl tagset (url: http://medialab.di.unipi.it/wiki/Tanl_POS_Tagset)
14
Every web search engine accepts boolean operators, thus allowing queries containing such kinds of patterns.
19 In the following examples, word pairs extracted from WordNet, among which specific semantic relations are known to hold (hyponymy and meronymy), are looked for on the Web. Common words are compared with domain terms.
3.2 Querying the web for patterns
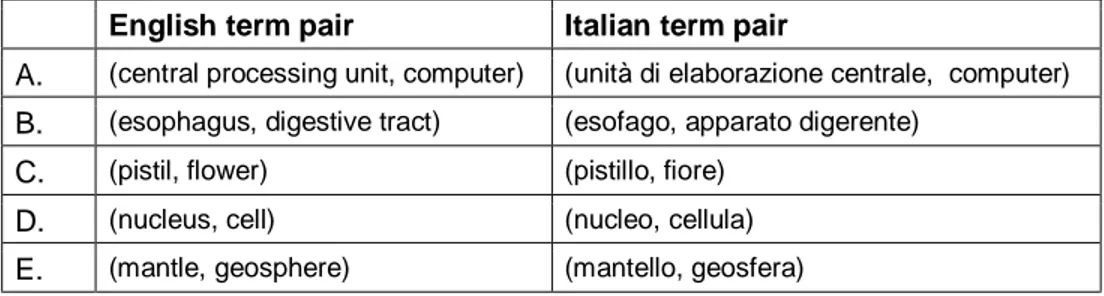
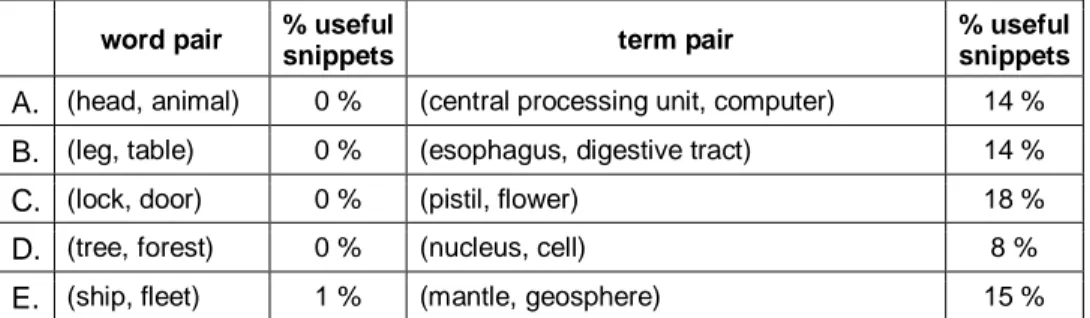
Several word pairs extracted from WordNet and involved in direct hyponymic and meronymic relations have been taken into account. Just to provide some examples, we have selected five common word pairs and five term pairs for hyponymy and for meronymy, both in English and Italian.
3.2.1 Looking for hyponymy patterns
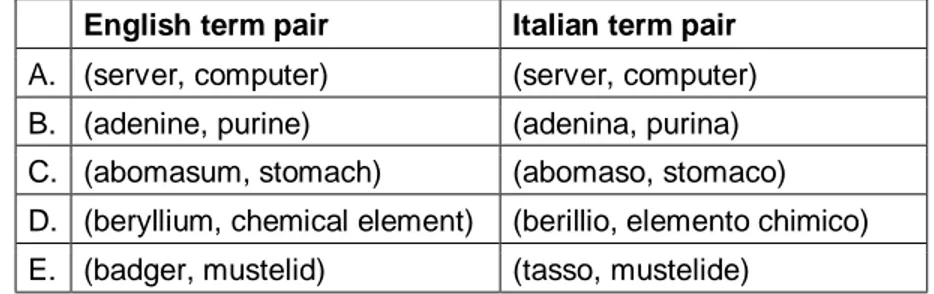
Concerning hyponymy relation, five word pairs and five term pairs involved in a direct hyponymic relation have been extracted from WordNet (Table 1 and Table 2).
English word pair Italian word pair A. (predator, animal) (predatore, animale) B. (desk, table) (scrivania, tavolo) C. (car door, door) (portiera, porta) D. (jungle, forest) (giungla, foresta) E. (flotilla, fleet) (flottiglia, flotta)
Table 1 - The word pairs used for the discovery of hyponymy Reliable Patterns
English term pair Italian term pair A. (server, computer) (server, computer) B. (adenine, purine) (adenina, purina) C. (abomasum, stomach) (abomaso, stomaco) D. (beryllium, chemical element) (berillio, elemento chimico) E. (badger, mustelid) (tasso, mustelide)
Table 2 - The term pairs used for the discovery of hyponymy Reliable Patterns
The Web has been queried using Google™, one of the most popular search engines available. For each word pair (w1, w2) two different queries have been
- English: <w1 w2 -“ w1 w2” -“ w1 w2s” -“ w2 w1” -“ w2 w1s”> 15
(e.g.: <predator animal -“predator animal” -“predator animals” -“animal predator” “animal predators”>)
- Italian: <w1 w2>
(e.g.: <predatore animale>)
In the case of English, the “w2 w1” and “w2 w1s” sequences have been removed
(using the minus special character) to avoid the match of noun compounds that would be of no use for lexical pattern discovery.
Considering the first 100 snippets obtained, the following tables show how many of them contained useful patterns indicating a relation of hyponymy. Table 3 refers words in English and Table 4 to words in Italian.
word pair % useful
snippets term pair
% useful snippets
A. (predator, animal) 4 % (server, computer) 4 %
B. (desk, table) 0 % (adenine, purine) 4 %
C. (car door, door) 0 % (abomasum, stomach) 27 % D. (jungle, forest) 0 % (beryllium, chemical element) 30 % E. (flotilla, fleet) 1 % (badger, mustelid) 15 %
Table 3 - Percentage of useful snippets for the definition of hyponymy patterns using common words and domain terms (English)
word pair % useful
snippets term pair
% useful snippets
A. (predatore, animale) 1 % (server, computer) 4 % B. (scrivania, tavolo) 0 % (adenina, purina) 24 % C. (portiera, porta) 1 % (abomaso, stomaco) 25 % D. (giungla, foresta) 0 % (berillio, elemento chimico) 15 % E. (flottiglia, flotta) 0 % (tasso, mustelide) 32 %
Table 4 - Percentage of useful snippets for the definition of hyponymy patterns using common words and domain terms (Italian)
A small but relevant number of useful snippets (four) have been retrieved for the word pair (predator, animal) in English:
15
21 - …A Predator is an animal that catches and kills others, known as its
prey…
- …Which animal is the most dangerous predator? As stated already, the human.
- ... When an animal is referred to as a predator, it means that the animal either hunts or catches other animals...
- ... A predator is any animal that feeds on other creatures. Prey, of course, are the animals used as food....
One snippet has been found for the (jungle, forest) pair:
- ...From what I've read, jungle is only a term to describe some dense
forest...
Just one snippet, coming from a dictionary, was found for the pair (flotilla, fleet):
- ...Flotilla a small fleet...
For Italian, one snippet has been found:
- La portiera o portellone in ambito stradale e non solo è la porta che serve per entrare nell'abitacolo di un determinato mezzo (Wikipedia)
It is interesting to note that the only useful snippet for meronymy, relative to the Italian pair (albero, foresta), was found in the context of computer science, where “tree” and “forest” have specific meanings as data structures. This suggests that domain terms offer a greater chance of appearing in the context of lexico-syntactic patterns. The reason is quite obvious: it makes no sense of explicitly stating, for instance, that “the head is a part of an animal” or that “the desk is a kind of table”, expect inside dictionary entries (as for the snippet coming from Wikipedia relative to the “portiera, porta” word pair). In other words, it will be uncommon to find sentences implicitly known as true on the basis of common sense. On the contrary, the more specific and domain-related is a term, the more important is to clearly define it.
The difference of results obtained using domain terms is relevant. Below we report, for each of the tested term pairs, a synthesis of the snippets (both for English and Italian) containing potential reliable lexico-syntactic patterns for hyponymy. After each set, we list some of the most interesting patterns that can be derived from the snippets. The patterns have been selected by keeping in mind that we want to construct RPs that can be easily instantiated and found on the Web, so they have to be short and compact.
Here are some snippets excerpts taken from the ones in English containing useful lexico-syntactic patterns:
term pair: (server, computer)
A1 ... In information technology, a server is a computer program that provides