Processing coordinated structures: Incrementality and connectedness
Patrick Sturt
∗and Vincenzo Lombardo
†∗
University of Glasgow
†
Universit`a di Torino
Running title: Processing Coordinated structures Corresponding author:
Patrick Sturt
Department of Psychology University of Glasgow 58 Hillhead Street Glasgow
G12 8QB
Tel: +44 141 330 3606 Fax: +44 141 330 4606
email:patrick@psy.gla.ac.uk
Abstract
We recorded participants’ eye-movements while they read sentences containing verb-phrase coordination. Results showed evidence of immediate processing disruption when a reflexive pronoun embedded in the conjoined verb phrase mismatched the sentence subject. We argue that this result is incompatible with models of human parsing that employ only bottom-up parsing procedures, even when flexible constituency is employed.
Models need to incorporate a mechanism similar to the adjoining operation in Tree Adjoining Grammar, in which one structure is inserted into another.
It is a widely held assumption that human language processing occurs at a fast pace; partial interpretations can be built on a more or less word–by–word basis (Marslen-Wilson, 1973).
This assumption is generally known as incremental interpretation. In the psycholinguistic literature a number of proposals have been made for the syntactic processing strategies that support incremental interpretation.
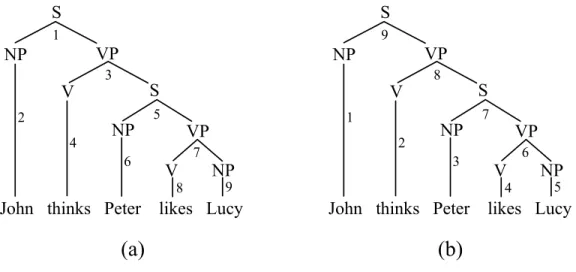
One major issue that distinguishes the strategies is the eagerness with which the sentence words are incorporated into the developing structure as they are read in the input from left to right. The most eager strategy is to insert each word directly into the current partial phrase marker. According to this strategy, during parsing the syntactic structure is always fully connected, and cannot be fragmented into several parts. One way for achieving this strategy is to incorporate a top-down, or predictive, component into the parsing algorithm. For example, Figure 1a shows the sequence of rule application yielded by a top–down parser with a
context–free grammar (the order is represented by the numbers). In the top-down strategy, the structure corresponding to a context-free rule is recognized immediately.
(a) (b)
S
VP
John thinks Peter likes Lucy NP
S VP V
NP
V NP
1
2
3
4
5
6 7
8 9
S
VP
John thinks Peter likes Lucy NP
S VP V
NP
V NP
9
1
8
2
7
3 6
4 5
Figure 1: Order of parsing steps in top–down (a) and bottom–up (b) approaches, respectively.
This eagerness can be moderated by introducing delay strategies that use buffers to hold disconnected portions of phrase structure. The various approaches differ in the conditions under which such disconnected portions are merged together. For example, Figure 1b shows the order of rule applications of a pure bottom–up parser over a context–free grammar, which combines structures only when the whole right hand side of a rule is recognized.
This purely bottom–up method represents the least eager strategy in the incrementality framework. A more eager strategy is represented by the left-corner method, in which a node is built immediately after its leftmost daughter (Abney & Johnson, 1991). Other approaches rely on some linguistic principle to decide the eagerness. For example, Pritchett (1991) argued for a head-driven approach, in which a node is constructed as soon as its head daughter has been recognised. Although cast in a very different computational framework, the hybrid
competition–based models of Stevenson (1994), Tabor and Hutchins (2004) and Vosse and
Kempen (2000) can also be seen as analogous to the head-driven approach, with respect to the degree of eagerness.
Bottom–up and head–driven proposals predict delays in structure building and
interpretation. Purely bottom-up approaches predict that right-branching structures cannot be built until the rightmost input word is recognised (unless extra machinery is employed to inspect the internal state of the parser, e.g. an LR parser state (Shieber & Johnson, 1993)).
Head–driven approaches allow greater eagerness in the processing of right-branching structures, but do not allow the eager processing of head-final constructions. This means that these
approaches often predict considerable delays in the processing of head–final languages, which is at odds with a growing body of experimental evidence, for example, in Japanese (Kamide &
Mitchell, 1999; Kamide, Altmann, & Haywood, 2003; Aoshima, Phillips, & Weinberg, 2003).
The considerations above are based on the assumption of a traditional phrase–structure grammar. However, the conclusions differ radically depending on the syntactic framework adopted. In fact Steedman (2000) shows that even purely bottom-up algorithms are compatible with a high degree of eagerness when paired with Combinatory Categorial Grammar (CCG), which allows flexible constituency. Steedman argues that bottom-up approaches are thus preferable on grounds of simplicity.
In CCG, as in other categorial approaches, the categories of lexical items are either atomic category labels (e.g. NP, or S), or otherwise functions that take (possibly complex) categories as arguments, and yield (possibly complex) categories as the result. These functions are specified for the direction in which the argument is expected to be found, usually using a slash: X/Y means that a Y category is required on the right in order to yield an X, while X\Y means that a
John thinks Peter likes Lucy NP
NP
10
1
VP/S
2
S/VP
3
S/S
4
NP
5
S/VP
6
S/VP
7
VP/NP
8
S/NP
9
S
11
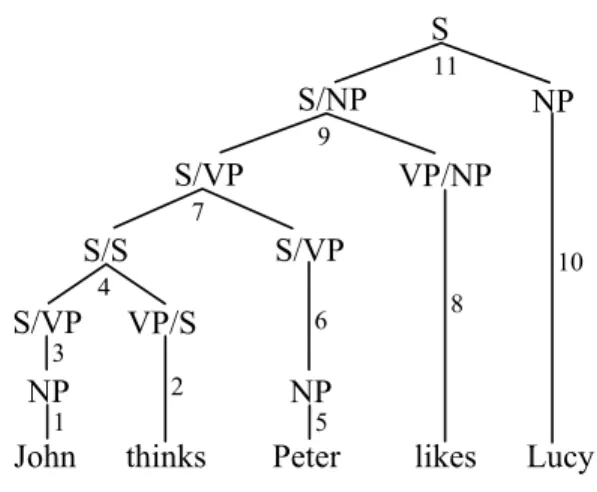
Figure 2: CCG derivation in phrase structure terms.
Y category is required on the left to yield an X. In figure 2 we can see a CCG derivation cast in phrase–structure terms1.
A CCG derivation combines functional categories through a sequence of combinatorial operations, the simplest of which is functional application (FA), which simply applies the functional category to an argument category to yield the result category. An example is the application of the functional category S/NP (meaning a sentence missing an NP on the right, and spanning “John thinks Peter likes”) to an argument NP (“Lucy”) on its right in order to become a sentence S.
A high degree of eagerness is made possible by creating more complex categories through the operation of type raising and combining two functions through function composition. In figure 2, the category of John, which is NP, has been type raised to S/VP (in other words, a
1Notice that this derivation is depicted differently from the usual proof–style adopted in the categorial framework.
This phrase–structure representation helps in the comparison between the various approaches to incrementality. Note also that the “VP” label is a shorthand for the complex category “S\NP”.
category which requires a verb phrase on the right, in order to become a sentence). Notice that this effectively reverses the head-dependent relation between the subject and the verb phrase.
This category can then combine with the sentence complement verb thinks, through function composition. The derivation proceeds incrementally through function compositions and applications until the whole sentence has been processed.
It is important to notice that in Figure 2 derivation, each new word completes an interpretable constituent, resulting in a left–branching structure, which allows the highest degree of eagerness for the purely bottom-up strategy. This contrasts with Figure 1, where traditional phrase structure grammars assign a purely right-branching structure to the same sentence. This left branching analysis is only possible because of the flexible constituency allowed by CCG, as evidenced by the existence of some constituents (e.g. the S/VP “John thinks Peter”) that are not traditionally considered as constituents.
The combination of CCG and bottom–up parsing can yield a high degree of eagerness in many syntactic constructions. However, there exist cases where the CCG/bottom-up approach predicts attachment delays. These are cases where only right-branching analyses are available (Phillips, 1996). One of these cases, which has been discussed by Schneider (1999) is
coordination, where the bottom–up parser waits for the second conjunct to be complete before combining the two conjuncts together into the coordination structure (see Schneider, 1999, pp.
19–21, for discussion). For this reason, coordination provides a useful test case to evaluate the level of eagerness in human sentence processing and to adjudicate between alternative theories of the time-course of structure building. This is of particular interest since CCG currently offers the most complete account of the syntax and semantics of coordination within a
computationally well-understood formalism. It is therefore desirable to test whether the theory accounts for performance facts as well.
In the next section we introduce the coordination construction, its syntactic treatment and the consequences for the time course of processing. Then, we introduce the experiment we have designed to evaluate the degree of eagerness required in the processing of coordination
structures.
1 The syntactic treatment of coordination
Coordinate constructions occur in over 50% of sentences in written text2. It is therefore surprising that very little is known about how conjoined phrases are processed, especially in relation to the time-course with which coordinate structures are built3.
Most theories of syntax treat constituent coordination using a schema in which a
conjunction like and takes a constituent of typeXon either side, to form a new constituent of typeX. This can be represented, for example, by a context-free rule schema like
X → X and X. One of the questions of the present paper is how such a schema could be used
in on-line processing. As an example, consider a case of verb-phrase coordination (1):
(1) The pilot embarrassed Mary and put himself in a very awkward situation.
In the following paragraphs, we explain why purely bottom-up strategies, including those that employ flexible constituency, predict a delay in the processing of VP coordination.
2This figure is based on a search of the British National Corpus. Similar figures can be found in other corpora, such as the Turin Treebank (Italian), the Penn Treebank (English) and the Negra corpus (German).
3Though see for example Frazier, Munn, and Clifton (2000) for experiments on a related issue.
The pilot embarassed Mary and put herself in a very awkward situation S/VP
4
VP VP/PP
VP
PP NP
NP
VP CONJ
VP/PP/NP S
1
2 3
5
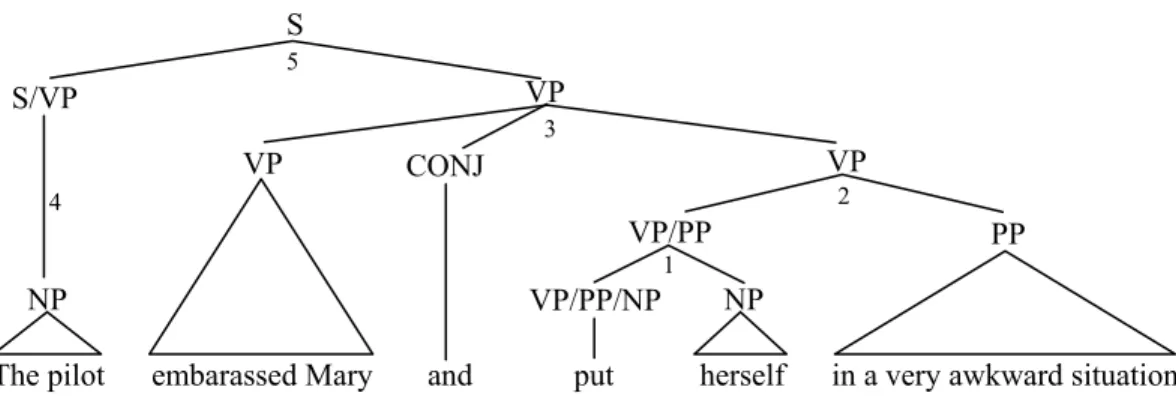
Figure 3: CCG derivation of VP coordination in phrase structure terms.
Figure 3 schematically illustrates a CCG analysis for sentence (1), assuming a bottom-up processing strategy, with the numbers representing the derivation order for the final constituents in the derivation. As in most other theories, CCG assumes a coordination schema of the type described above. Therefore, in order to process a verb-phrase coordination structure, a predominantly right-branching analysis of the sentence needs to be made—for example, the pilot cannot immediately combine with embarrassed, since this will prevent the construction of
the VP node required by the coordination schema. Similarly, the use of a bottom-up procedure implies a delay in the attachment of the two Verb-phrase conjuncts, since the input to the schema needs to be two complete VP’s. This means that it is necessary to wait to the end of the second VP before combining the two conjuncts. It can be seen that the final two steps of the derivation consist of the application of the coordination schema to combine the two verb
phrases, followed finally by the combination of the subject NP with the conjoined verb phrase.4 One possible way to gain more flexibility is to use chart parsing techniques (Kay, 1980)
4To facilitate comparison with figure 2, we have included a type-raising operation on the subject NP before combining it with the VP. However, identical conclusions apply whether or not this step is included.
which can represent multiple parse hypotheses. In the case of (1), this effectively allows for the simultaneous availability of a connected and a disconnected structure as shown in (2):
(2) a. [S[NPThe pilot] [VPembarrassed Mary]]... (connected) b. [NPThe pilot] [VPembarrassed Mary]... (disconnected)
A chart-based bottom-up CCG parser would be able to continue the (b) analysis by building the second VP, after which point, the (a) analysis would play no further part in the grammatical derivation. However, because of the bottom-up architecture, the conjoined verb phrase could still not be combined with the pilot until the completion of the second VP.5
These comments do not apply to top-down approaches, which predict a strongly eager processing of VP coordination. However, here other difficulties arise, such as the well-known problem of dealing with left recursion, as well as the fact that the top-down strategy necessitates either predicting the coordination schema in advance, or revising the structure when and is reached.
It seems, then, that a strongly eager strategy requires a mechanism which is able to insert material directly into a structure that is already completed. One such mechanism is the
adjoining operation provided by Tree Adjoining Grammar (Joshi, Levy, & Takahashi, 1975),
which will be discussed in the Discussion section.
However, we first need to establish the degree of eagerness with which humans process Verb-phrase coordination, which is the motivation for the experiment reported below. The
5Similar conclusions apply to related proposals by Niv (1994), Pareschi and Steedman (1987), which introduce extra machinery into CCG derivations to allow a completed derivation to be partially revised in the case of post- modification (see Schneider, 1999).
experiment exploits the fact that, as pointed out by Schneider (1999) using a similar example, strategies with a low degree of eagerness predict that binding cannot immediately take place between the reflexive himself and its antecedent the pilot in (1), because the structural relations on which binding relies (e.g. c-command and structural locality) will not be available until the end of the second verb phrase. In contrast, strongly eager models require these structural relations to be available immediately.
2 Experiment
2.1 Dsign and stimuli
The experiment used eye-movement recording during reading to gain a picture of the time-course of processing. The design involved a manipulation of stereotypical gender (Carreiras, Garnham, Oakhill, & Cain, 1996; Osterhout, Bersick, & McLaughlin, 1997).
Consider (10), for example:
(10) The pilot embarrassed Mary and put herself in a very awkward situation.
Here, the morphological gender of herself does not match the stereotypical gender of pilot, which is usually interpreted as masculine. This means that processing disruption should be found when people read (10) compared with a condition in which the reflexive matches the stereotypical gender (i.e. himself) (see also Sturt, 2003). Note that the use of stereotypical gender allows us to avoid the use of ungrammatical sentences.
According to standard assumptions, the detection of such processing difficulty should imply that the relevant structural relation between the reflexive and the antecedent has been established. However, it is important to control for other explanations of this potential effect.
For example, processing difficulty at herself in (10) could occur if the reflexive is simply
associated with the first mentioned character (Gernsbacher, Hargreaves, & Beeman, 1989). It is possible that this could occur during the early stages of processing, and at a superficial level of analysis, in which case, processing difficulty associated with the initial reading of herself in (10) could occur even in the absence of a structural relation between the anaphor and (the pilot). For this reason, the experiment included control conditions using simple pronouns (him and her), which also either matched or mismatched the stereotypical gender of the subject. If the
influence of gender match occurs regardless of structural relations, then it should occur equally with the simple pronoun and with the reflexive. In contrast, if the difficulty of (10) is due to structural configurations, then there should be no difficulty when a simple pronoun mismatches in gender with the pilot, because this is not a possible antecedent for a pronoun according to binding theory.
The full design is illustrated below:
(3) a. Reflexive/Subject-match
The pilot embarrassed John and put himself in a very awkward situation.
b. Reflexive/Subject-mismatch
The pilot embarrassed Mary and put herself in a very awkward situation.
c. Pronoun/Subject-match
The pilot embarrassed John and put him in a very awkward situation.
d. Pronoun/Subject-mismatch
The pilot embarrassed Mary and put her in a very awkward situation.
All conditions included a second character (John or Mary), which always matched with the gender of the anaphor. This was always a grammatical antecedent in the pronoun conditions, both in terms of gender matching and in terms of binding theory. Thus, all conditions allowed a grammatical antecedent for the reflexive/pronoun. The gender manipulation of the second character (John vs. Mary) was mirrored in the reflexive conditions to maintain balance in the design (Sturt (2003) showed that the gender of ungrammatical antecedents has little effect on the early stages of the resolution of reflexive binding in reading).
Twenty-four stimuli were constructed on the model of (3). Half of the stimuli used stereotypically male nouns (like pilot) and half used stereotypically female nouns (like nurse).
These nouns were the same as those used by Sturt (2003).
All materials were constructed so that the sentence could not grammatically end at the reflexive/pronoun, as judged by an off-line pretest (see below). For example, in (3), the use of the ditransitive verb put places a very strong requirement for extra words following the anaphor.
Material evaluation To evaluate the grammatical status of the initial fragment ending in the pronoun/reflexive, 18 members of the Glasgow university community participated in a
continuation task. Each experimental material, from the first word to the reflexive (inclusive), was embedded in a preposed subordinate clause, forming a sentence fragment, as in (4):
(4) After the pilot put himself . . .
The subordinate clause was used in order to force participants to continue the sentence. The dependent variable was the proportion of responses in which the subordinate clause was
continued before the participant continued the main clause (e.g. “After the pilot put himself in a difficult situation, he was admired by the passengers”). To control for any overall bias in the
frequency of continuations of the subordinate clause, each experimental fragment was paired with a control sentence fragment, where according to our own judgements, the subordinate clause clearly could grammatically end at the reflexive, as in (5), which uses a mono-transitive verb:
(5) After the pilot embarrassed himself . . .
The experimental and control sentence fragments were printed in booklets, in an
pseudo-random order, such that no experimental fragment appeared in the same half of the experiment as its corresponding control fragment. The participants were asked to write the first continuation that occurred to them.
Analysis of responses showed that experimental subordinate clauses were continued in 96% of the trials, while the control subordinate clauses were continued only 13% of the trials.
This difference was found for each individual item pair (N = 24) and for each individual participant’s responses (N = 18), (sign test: p’s< .001). This supports the conclusion that the experimental sentences could not terminate at the reflexive pronoun, or were at least very strongly biased against this.
7
8
9
5 4
3 2
1 6
10 11
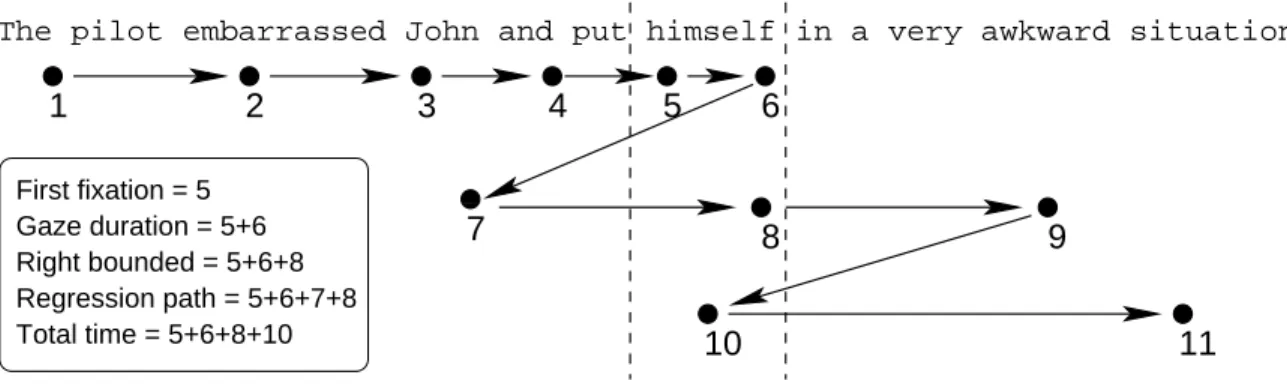
First fixation = 5 Gaze duration = 5+6 Right bounded = 5+6+8 Regression path = 5+6+7+8 Total time = 5+6+8+10
The pilot embarrassed John and put himself in a very awkward situation.
Figure 4: Example sequence of fixations illustrating eye-movement measures for the critical region (vertical axis is added only for clarity)
2.2 Eye-movement measures
All psycholinguistic theories predict that processing difficulty should be found in (3b) relative to (3a) after the reflexive is read, and that such a difference should not be found between the two pronoun conditions (3c) and (3d). This should lead to a statistical interaction between the two factors of subject-match and anaphor type. The important consideration is when this effect manifests itself in the eye-movement record. A number of different eye-movement measures are available, which allow different inferences to be made about the timing of cognitive processes.
Figure 4 illustrates the five different eye-movement measures that we employ in this paper, in terms of the analysis region corresponding to the word himself.
The first fixation measure is the time of the first fixation on the region of interest. Since fixations in reading are generally only around 250 milliseconds a difference between conditions in first-fixation duration indicates a very early effect. The gaze duration measure is simply the sum of the duration of all initial fixations, before the gaze moves on to another word, either to left or right. Right bounded reading times are the sum of all fixations on the word before the eye
gaze first moves to the right of the word (including those made on the word after a regressive eye-movement to previous words). Regression path times are the sum of all fixations that are made (including to the left of the word) before the eye gaze first moves to the right of the word.
All of these measures are crucial for the present experiment because they are informative about the processing that occurs before the gaze moves beyond the anaphor (i.e. at a point where bottom-up approaches predict a disconnected structure). In contrast, total time is the sum of all fixations on a word, including those made after subsequent words have been fixated.
The analyses were conducted on the pronoun/reflexive. Short function words like pronouns receive very few initial fixations, so we extended the region of analysis to include not only the space before the pronoun/reflexive, but also the space after it. In cases where no initial fixation was made on the anaphor plus preceding and following space, we iteratively extended the word’s left boundary by one character space at a time, until a fixation was found.6 If no fixation was still found after the left boundary had been shifted by four character spaces, the relevant data point was excluded from analysis. This procedure resulted in a first-pass fixation rate of 98% for the reflexives and 87% for the pronouns. The analysis did not include short fixations (less than 100 milliseconds).
2.3 Participants
28 members of the Glasgow University community participated in the experiment. All were native speakers of English and had normal uncorrected vision.
6Similar procedures were used by Sturt (2003) for first-fixation and gaze duration.
2.4 Procedure
Four stimulus lists were constructed, rotating the four experimental conditions in a Latin Square design. Each stimulus list consisted of the 24 experimental stimuli combined with 48 stimuli from an unrelated experiment on word recognition. Presentation order was random.
The participants were tested individually in a darkened room, using a Fourward
technologies Generation 5 Dual Purkinkje eyetracker. The participant’s head was immobilized using a bite bar with dental impression compound, and a brief calibration procedure was conducted at the start of the experiment. The whole experiment was usually completed in around 40 minutes.
2.5 Results
Analyses of variance were computed on the data for the critical anaphor, on both participant (F1) and item (F2) means. Anaphor type and Subject-match were treated as within-participant and within-item factors.
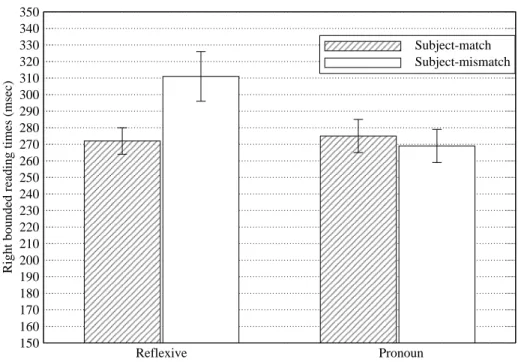
Table 1 shows the means and standard errors for the participant analysis, along with the F-ratio for the critical interaction of anaphor-type×match, for both participant and item analyses. The basic pattern of results is illustrated in Figure 5, which shows the results for the right bounded reading time measure.
It can be seen that the critical interaction was fully significant withα =.05, for all measures in the participants analysis, and was significant in the items analysis for all measures except first fixation and gaze duration (though the latter approached significance). The pattern
First fixation Gaze duration Right bounded Regression path Total Time
Reflexive/Subj-match 241 (7) 260 (8) 272 (8) 30 (15) 342 (14)
Reflexive/Subj-mismatch 260 (10) 288 (16) 313 (16) 358 (22) 438 (31)
Pronoun/Subj-match 260 (9) 272 (9) 276 (10) 310 (23) 295 (12)
Pronoun/Subj-mismatch 261 (10) 270 (10) 270 (10) 284 (10) 306 (14)
Ana×match: F1(1,27) 4.52∗ 4.72∗ 8.54∗∗ 6.36∗ 6.33∗
Ana×match: F2(1,23) 1.29ns 3.07+ 5.48∗ 6.89∗ 13.64∗∗
Table 1: Means (and standard errors) for the four first-pass measures and total time (based on the analysis by participants) and F-ratios for the anaphor ×match interaction, for analysis by participants (F1) and items (F2) [+p < .1;∗p < .05;∗∗p < .01].
was as predicted: reading times were longer in the reflexive/subject-mismatch condition than the reflexive/subject-match condition, but there was no reliable difference between the two pronoun conditions. This claim is backed up byt-tests, which were computed separately on the data for the reflexives and pronouns respectively. For the reflexives, subject-mismatch was slower than subject-match, in all measures (first fixation:p1 < .05,p2 < .05, gaze duration:
p1 < .06,p2 < .05; right bounded:p1 < .01,p2 < .05; regression-path:p1 < .05,p2 < .07; total time: p1 < .01,p2 < .001), while the respective pronoun conditions never differed significantly in any measure (allp’s> .1).
3 Discussion
The experiment shows that the computation of structural relations in the case of anaphor binding requires full connectivity, even in coordinate structures. In fact, the difference between the two reflexive conditions was found in measures informative of the earliest stages of
processing, such as the duration of the first fixation. This demonstrates that the relevant structural relations are available as soon as the reflexive is lexically accessed. A similar first
Reflexive Pronoun 150
160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350
Right bounded reading times (msec)
Subject-match Subject-mismatch
Figure 5: Right-bounded reading times for the critical region, including standard errors (partici- pants analysis)
fixation effect is reported for reflexive binding in Sturt (2003), and the numerical difference between the match and mismatch conditions was of a similar magnitude to that reported for the reflexive conditions here. As that paper did not use coordinated structures, the presence of a similar first fixation effect in the two experiments implies that the relevant structural relations are available equally early whether or not coordination is used. This result is compatible with an eager approach to incremental processing, and rules out incremental models where the
mismatch effect in sentences involving VP coordination is predicted to be delayed because of bottom-up structure building. Therefore, in order to model the time-course of the processing of binding relations, we must turn our attention to those processing models that include a parsing component that keeps a fully connected structure in cases like the coordination examples used
in the experiment. There are various options for this, including adopting an approach to coordination based on processing states (Milward, 1994), introducing some top-down processing operations into CCG, or adopting a different formalism.
Our account is based on the Adjunction operation, introduced first in the Tree Adjoining Grammar (TAG) formalism family (Joshi et al., 1975) to deal with recursive structures. TAG shares some desirable computational properties with CCG (Joshi, Vijay-Shanker, & Weir, 1991), which make it a suitable candidate for modelling human performance. In linguistic terms, adjunction provides a treatment of modification and optional constructions in a syntactic structure. The TAG lexicon consists of elementary trees, initial trees, that represent
predicate–argument structures, and auxiliary trees, that represent modifiers. Initial trees replace argument nodes in the syntactic structure through the Substitution operation, auxiliary trees are inserted to modify predicate–argument structures through the Adjunction operation. In
particular, the Adjunction operation can expand a structure by disrupting existing immediate dominance relations by inserting modifiers in the middle of the predicate–argument structure.
Notice that this account not only results in a fully connected structure, but also derives the coordination structure through a single incremental derivation, avoiding the need to maintain the connected and disconnected partial analyses in a chart, as discussed above for the CCG analysis.
Lombardo and Sturt (2002) have introduced a TAG–related formalism, called Dynamic Version of TAG (DV–TAG), which incorporates an eagerly incremental derivation process in the formalism definition (it is a so–called dynamic grammar), so that it is the combinatory rules that force input to be combined word-by-word in a left-to-right order (Milward, 1994; Phillips, 1996).
The eager incremental processing of VP coordination is sketched in Figure 6.7
The elementary tree for the conjunction and is a VP auxiliary tree, that is a tree that can be inserted into the left–context structure spanning the left fragment The pilot embarassed Mary at the VP node (Figure 6a). The resulting structure has a Substitution VP node (the one with a down arrow) where the initial tree for put can be inserted via a Substitution operation (Figure 6b). Finally, the other arguments will be substituted: in particular, himself will be inserted in the connected structure in a position that is c-commanded by the pilot, and is available for the computation of the binding relation at a very early stage of processing.
VP coordination is not the only case that can benefit from an incremental treatment based on Adjunction. The attachment of post–modifiers, discussed in the CCG literature by Pareschi and Steedman (1987) and Niv (1994), involves a processing time-course that is similar to the VP coordination discussed here. Consider the following:
(6) John loves Mary madly.
An incremental parse is possible for the first three words, yielding a result category S (sentence). However, if we assume that the adverb madly is a verb phrase modifier it should have the type: VP\VP. With a bottom-up strategy, this syntactic type cannot be combined with the completed sentence which is the result of incrementally parsing John loves Mary. In fact, the adverb can only be combined with the verb phrase loves Mary, which implies that the initial noun phrase John has to be stored in a disconnected state before being combined with the
7Although the figure shows a flat structure for the coordination, the account is equally compatible with a right- branching structure (Munn, 1999). Moreover, the solution illustrated here is not presented in full detail. In fact, the elementary tree anchored by ”put” extends its projection up to a root S node and a Substitution subject NP node.
A full treatment of Adjoining the latter tree involves a form of tree unification (as illustrated by Sarkar and Joshi (1996) and Lombardo and Sturt (2002)) which is beyond the scope of this paper.
(a)
(b)
(c)
VP*
VP and VP NP
Mary NP
The pilot S
VP V embarassed
NP Mary NP
The pilot S
VP V embarassed
VP
and VP
VP V put
NP PP
NP Mary NP
The pilot S
VP V embarassed
VP
and VP V put
NP PP
NP himself
PP in a very awkward
situation Figure 6: Eager account of VP coordination in DV–TAG.
overall analysis. Both Pareschi and Steedman (1987) and Niv (1994) propose an extra operation which allows part of the derivation of the S category to be “undone” so that the VP modifier can be applied, clearly going beyond a simple bottom-up approach. Alternatively, we can think again of a chart–based representation of two readings, one that considers John loves Mary totally connected and one that considers John and loves Mary disconnected. Only the second reading is compatible with the post–attachment modifier madly. The solution based on the Adjunction operation can deal uniformly also with the cases of post–attachment modifiers, without extra machinery or the chart–based method.
Author Note
This research was supported by a Royal Society joint project grant, awarded to the authors under the European science exchange programme. We gratefully acknowledge the assistance of Jacqueline Craig and Jeremy Pacht for running experimental participants. We thank Simon Garrod, Leonardo Lesmo, Alessandro Mazzei, Paola Merlo and Mark Steedman for comments on previous versions of the manuscript.
References
Abney, S. P., & Johnson, M. (1991). Memory requirements and local ambiguities of parsing strategies. Journal of Psycholinguistic Research, 20(3), 233–250.
Aoshima, S., Phillips, C., & Weinberg, A. (2003, March). On-line computation of two types of
structural relations in Japanese. Paper presented at the 16th annual CUNY Sentence
Processing Conference. Cambridge, MA.
Carreiras, M., Garnham, A., Oakhill, J., & Cain, K. (1996). The use of stereotypical gender information in constructing a mental model: Evidence from english and spanish.
Quarterly Journal of Experimental Psychology, 49, 639–663.
Frazier, L., Munn, A., & Clifton, C. (2000). Processing coordinate structure. Journal of Psycholinguistic Research, 29, 343–368.
Gernsbacher, M. A., Hargreaves, D., & Beeman, M. (1989). Building and accessing clausal representations: The advantage of first mention versus the advantage of clause recency.
Journal of Memory and Language, 28, 735–755.
Joshi, A. K., Levy, L. S., & Takahashi, M. (1975). Tree adjunct grammars. Journal of Computer and System Sciences, 10, 136–163.
Joshi, A. K., Vijay-Shanker, K., & Weir, D. (1991). The convergence of mildly context-sensitive grammar formalisms. In P. Sells, S. M. Shieber, & T. Wasow (Eds.), Foundational issues in natural language processing (pp. 31–81). Cambridge, MA: MIT Press.
Kamide, Y., Altmann, G. T. M., & Haywood, S. L. (2003). The time-course of prediction in incremental sentence processing: Evidence from anticipatory eye movements. Journal of Memory and Language, 49, 133–156.
Kamide, Y., & Mitchell, D. C. (1999). Incremental pre-head attachment in Japanese parsing.
Language and Cognitive Processes, 14, 631–632.
Kay, M. (1980). Algorithm schemata and data structures (Tech. Rep.). Palo Alto, CA: Xerox Parc. (CSL-80-12)
Lombardo, V., & Sturt, P. (2002). Towards a dynamic version of TAG. In Proceedings of the sixth international workshop on tree adjoining grammar and related formalisms (pp.
101–110). Universit`a di Venezia.
Marslen-Wilson, W. (1973). Linguistic structure and speech shadowing at very short latencies.
Nature, 244, 522–533.
Milward, D. (1994). Dynamic dependency grammar. Linguistics and Philosophy, 17, 561–605.
Munn, A. (1999). First conjunct agreement: against a clausal analysis. Linguistic Inquiry, 30, 643–668.
Niv, M. (1994). A psycholinguistically motivated parser for CCG. In Proceedings of the 32nd annual meeting of the Association for Computational Linguistics (ACL-94) (pp.
125–132). Las Cruces, NM.
Osterhout, L., Bersick, M., & McLaughlin, J. (1997). Brain potentials reflect violations of gender stereotypes. Memory and Cognition, 25, 273–285.
Pareschi, R., & Steedman, M. J. (1987). A lazy way to chart-parse with categorial grammars.
In Proceedings of the 25th annual meeting of the Association for Computational Linguistics (ACL-87) (pp. 81–88). Stanford, CA.
Phillips, C. (1996). Order and structure. Unpublished doctoral dissertation, Department of Linguistics and Philosophy, MIT, Cambridge, MA.
Pritchett, B. L. (1991). Head position and parsing ambiguity. Journal of Psycholinguistic Research, 20(3), 251–270.
Sarkar, A., & Joshi, A. (1996). Coordination in tree adjoining grammars: Formalization and implementation. In Proceedings of COLING (pp. 610–615). Copenhagen.
Schneider, D. (1999). Parsing and incrementality. Unpublished doctoral dissertation, University of Delaware.
Shieber, S., & Johnson, M. (1993). Variations on incremental interpretation. Journal of Psycholinguistic Research, 22(2), 287–318.
Steedman, M. (2000). The syntactic process. Cambridge, MA: MIT press.
Stevenson, S. (1994). Competition and recency in a hybrid network model of syntactic disambiguation. Journal of Psycholinguistic Research, 23(4), 295–321.
Sturt, P. (2003). The time-course of the application of binding constraints in reference resolution. Journal of Memory and Language, 48(3), 542–562.
Tabor, W., & Hutchins, S. (2004). Evidence for self-organized sentence processing: Digging in effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30(2), 431–450.
Vosse, T., & Kempen, G. (2000). Syntactic structure assembly in human parsing: a computational model based on competitive inhibition and a lexicalist grammar.
Cognition, 75, 105–143.