School of Industrial and Information Engineering
Master of Science in Management Engineering
Academic year 2019/2020
The bright side of transparency: how to foster trust and data
disclosure in a world that seeks for privacy.
Prof. Daniel Trabucchi
Supervisor
Lorenzo Romor 913086 Fabio Wang 918793
Ringraziamenti - Lorenzo
Ringrazio il Professor Daniel Trabucchi per il supporto prezioso datoci durante tutto il percorso di tesi e per essere sempre stato al nostro fianco nelle scelte fatte, dandoci possibilità di dialogare ed esporre sempre le nostre idee trasmettendoci passione ed etica nel lavoro.
Grazie infinitamente a Fabio, il mio compagno di avventura, il mio amico, per il suo modo di lavorare incredibile e per essere fonte di ispirazione per me ogni giorno.
Un sincero ringraziamento va a tutta la mia famiglia, ai miei genitori, a mia sorella e ai Nonni. Mi siete stati a fianco lungo tutto il tragitto, mi avete sempre affettuosamente supportato, ascoltato e suggerito la strada migliore per me, credendoci sempre, facendomi capire che con volontà, determinazione e duro lavoro si arriva dove si vuole.
Ringrazio Fabio, Davide, Matteo e Giulio, per avere condiviso tanto in questi cinque anni di università. Per essere cresciuti assieme a suon di esami, di successi e fallimenti, senza mai risparmiarci. Grazie per l’amicizia senza tempo nata quei primi giorni di triennale al Poli e per quello che verrà.
Grazie a tutti i miei Amici, per essere stati parte a loro modo del mio percorso di studi e per averlo vissuto di persona con racconti e decisioni condivise. Capaci di essere il porto sicuro dopo le giornate tempestose e la spalla di mille nuove esperienze, passate e future.
E per il futuro… Tout azimut!
Ringraziamenti - Fabio
Parto anche io ringraziando il Professor Daniel Trabucchi, per averci supportato e guidato lungo questo percorso, per l’immensa disponibilità ed i costanti feedback, per essere un esempio di passione e di trasparenza.
Ringrazio Lorenzo, con cui ho avuto la fortuna di condividere il percorso universitario, sin dai primi giorni, per aver portato entusiasmo e positività, e per avermi spinto a dare sempre di più, anche nelle situazioni difficili, per aver condiviso successi e fallimenti, ambizioni e paure. Grazie ai miei genitori, per aver supportato le mie ambizioni, anche da lontano, per avermi dato la possibilità di seguire la mia strada, nonostante tutto e tutti. Senza i vostri enormi sacrifici e difficoltà che solamente ora inizio a capire, non sarei dove sono e la persona che sono oggi. Grazie a mio fratello Xiang, per essere sempre stato la mia guida ed ispirazione, per il supporto, i consigli, i pareri, le risate, per esser stato il primo a percorrere sentieri inesplorati ed inimmaginabili.
Grazie a Matteo, Davide e Giulio, già menzionati da Lorenzo, per questi anni di Politecnico, per la compagnia, lo studio e le risate, che le nostre strade possano sempre incrociarsi.
Agli amici d’infanzia, ormai quasi fratelli, come Hamza e Amir, con cui sono cresciuto e con cui ho condiviso avventure incredibili. A chi si è aggiunto nel viaggio, per brevità, “I
Fulminati”, perché ogni volta mi ricordo che persone magnifiche siate. A Stefano, per essermi
stato vicino in uno dei miei momenti più difficili. A Elena, per avermi sempre sopportato, e, soprattutto, per la scelta della combinazione perfetta per il titolo di questa tesi.
Agli ASPers e al Team DAPO, per essere le persone più in gamba che abbia mai incontrato, per avermi spinto a migliorare sempre, ma anche per essere stati una seconda famiglia.
A Lisa, Gianlorenzo, Matteo, Nicola, Alessia e tanti altri, persone che sono entrate nella mia vita in questo anno in giro per il mondo, arricchendo la mia memoria di dolci ricordi.
Ma ogni viaggio inizia con un passo, e questo non è che il primo di molti altri a venire.
Table of Contents
Abstract ... 9
Executive summary ... 11
1. Introduction ... 19
Current trends on digital platforms concerning privacy and transparency ... 21
2. Theoretical background ... 27
The rise of big data ... 27
2.1.1. What do we mean for “Big Data”? ... 27
2.1.2. Big Data Analytics and Value creation ... 28
2.1.3. Data as the main product ... 30
2.1.4. Platforms as data-intensive businesses ... 32
2.1.5. Strategies to capture value from User-generated data in Two-sided Platforms. ... 37
2.1.6. Roadblock to data exploitation: ... 38
Privacy in the age of information ... 39
2.1.7. The consumer information privacy definition ... 41
2.1.8. The privacy analysis framework ... 41
2.1.9. Privacy concerns ... 42
2.1.10. Privacy, a matter of trade-offs ... 44
2.1.11. Privacy calculus and its limits ... 45
2.1.12. Privacy, a behavioural perspective ... 46
2.1.13. Privacy paradox ... 47
2.1.14. What does privacy concern lead to? ... 48
2.1.15. Privacy nowadays ... 51
2.1.16. Privacy in the digital platforms ... 52
Transparency ... 54
3. Theoretical model and hypotheses development ... 57
3.1. Literature Gap ... 57
3.2. Research question ... 58
3.3. Hypotheses definition ... 60
3.3.1. Value of data and issues in privacy ... 60
3.3.2. From Willingness-to-Use to Willingness-to-Disclose ... 60
3.3.3. Hyp1a: Transparency ... 61
3.3.4. Hyp1b: Trust ... 62
3.3.5. Hyp1c: Time as a behavioural proxy ... 62
3.3.6. Hyp2a/Hyp2b: Personality traits ... 63
3.3.7. Hyp3: Industry domain as a contextual factor ... 65
3.3.8. Summing up hypotheses ... 66
4. Research design ... 66
4.1. Experiment model design ... 66
4.1.1. Control Variables ... 67
4.1.2. Perceived transparency ... 68
4.1.3. Measurement of willingness to disclose ... 68
4.1.4. Trust ... 69
4.1.6. Summing up the experiment setting and literature baseline ... 73
4.1.7. Manipulation check ... 74
4.2. Mock-ups ... 75
4.2.1. Transparency by design ... 76
4.2.2. The actual mock-ups ... 79
4.2.3. The retail (e-commerce) app ... 79
4.2.4. The Financial services – Payment/investment app ... 86
4.2.5. The Healthcare app ... 88
4.3. Survey design and operationalization of constructs ... 91
4.3.1. Testing and Data gathering ... 91
4.3.2. Bias Control ... 93
4.3.3. Manipulation checks ... 94
4.3.4. Statistical approaches for model testing ... 95
5. Results ... 98
5.1. Descriptive analysis ... 98
5.2. Confirmatory Factor Analysis (CFA) ... 108
5.3. Model testing ... 112
5.3.1. ANOVA - Multi-industry preliminary analysis ... 113
5.3.2. Within the model ... 114
5.3.3. The industry ... 116
5.3.4. Multi industry observations – Layer 1 ... 119
5.4. Order effect analysis - One-way ANOVA ... 120
5.5. Hypotheses verification ... 126
5.5.1. Hyp1a and Hyp1b ... 127
5.5.2. Hyp1c ... 128
5.5.3. Hyp2a and Hyp2b ... 129
5.6. Summary ... 130 6. Discussion ... 131 6.1. Transparency ... 131 6.2. Personality traits ... 133 6.3. Industry ... 135 6.4. Behavioural intentions ... 136
6.5. Methodology and previous researches ... 138
7. Implications, further developments, and conclusion ... 139
7.1. The implications of our study ... 139
7.1.1. Theoretical implications ... 139
7.1.2. Implications for practitioners ... 142
7.2. Limitations and Future gaps ... 145
8. Bibliography ... 148
9. Annexes ... 167
Tables and figures index
Tables
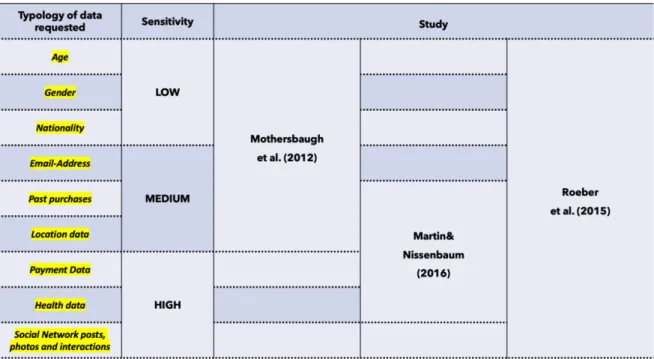
Table 1: Levels of sensitivity of specific categories of information in the literature ... 50
Table 2: The hypotheses of our research ... 66
Table 3: Experiment settings and literature baseline ... 74
Table 4: Design principles for privacy Transparent mobile apps (Betzing et al., 2019) ... 77
Table 5: How to maximize transparent communication (Rossi and Lenzini, 2020) ... 78
Table 6: types of data requested (Retail mock-up) ... 83
Table 7: Survey flow ... 93
Table 8: Manipulation check, t-test descriptive statistics ... 94
Table 9: Statistical result analysis framework ... 98
Table 10: Descriptive statistics of our sample ... 99
Table 11: Privacy Concern and Value concern across ages ... 100
Table 12: Distribution of privacy traits among age groups ... 101
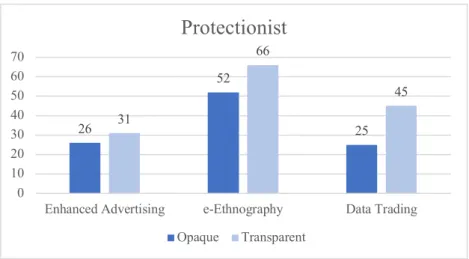
Table 13: Disclosure typology per personality traits, Privacy apathist ... 102
Table 14: Disclosure typology per personality traits, Privacy Protectionist ... 102
Table 15: Disclosure typology per personality traits, Privacy Capitalist ... 103
Table 16: Disclosure typology per personality traits, Privacy Pragmatist ... 103
Table 17: Enhance advertising acceptance across personality traits ... 104
Table 18: E-etnography acceptance across personality traits ... 105
Table 19: Data trading acceptance across personality traits ... 105
Table 20: Enhanced advertising acceptance across industries ... 106
Table 21: Data trading acceptance across industries ... 107
Table 22: Matrix of covariances ... 108
Table 23: Variance explained per Component (PCA) ... 109
Chart 24: Scree plot ... 109
Table 25: Matrix of rotated components (Varimax rotation) ... 110
Table 26: Matrix of covariances of components ... 110
Table 27: AVE, CR, CA for the latent variables of our model ... 111
Table 29: ANOVA between WTD and Trust across industries ... 113
Table 30: Model Fit of the whole sample – Pre CFA ... 115
Table 31: Model fit of the whole sample – Post CFA ... 115
Table 32: Model fit for the 3 industries – Multigroup analysis - Post CFA ... 116
Table 33: Model fit post CFA per industries FS and HC ... 117
Table 34: Model fit post CFA per industries FS and R ... 118
Table 35: Model fit post CFA per industries R and HC ... 119
Table 36: Order effect analysis for financial services ... 121
Table 37: ANOVA for financial services ... 121
Table 38: ANOVA in WTD and Trust per financial services industry ... 123
Table 39: ANOVA on single WTD and Trust items ... 123
Table 40: ANOVA on perceived transparency per healthcare industry ... 124
Table 41: ANOVA in WTD and Trust per retail industry ... 124
Table 42 ANOVA on single WTD and Trust per retail industry ... 124
Table 43: ANOVA on perceived transparency per healthcare industry ... 125
Table 44: ANOVA in WTD and Trust per healthcare industry ... 125
Table 45: ANOVA on single WTD and Trust per healthcare industry ... 125
Table 46: Differences in the order cluster, Opaque-Transparent and Transparent-Opaque ... 126
Table 47: Focus on hypotheses 1 and 2 ... 127
Table 48: Hypotheses testing, Hyp1a ... 127
Table 49: Hypotheses testing, Hyp1b ... 128
Table 50: Hypotheses testing, Hyp2a ... 129
Table 51: Hypotheses testing, Hyp2b ... 130
Figures
Figure 1: The model ... 14
Figure 2: Experiment paths and layers ... 15
Figure 3: The privacy analysis framework ... 42
Figure 4: Our experiment model ... 67
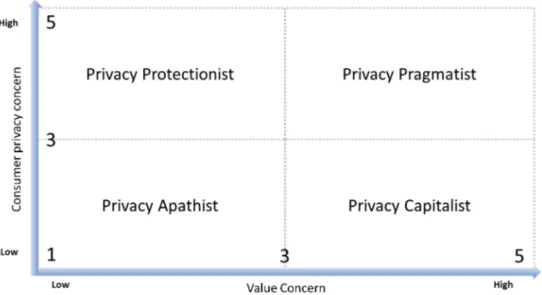
Figure 5: The privacy archetypes matrix ... 71
Figure 6: Sample of the 3 mock-ups ... 79
Figure 7: Page 1-2 opaque retail mock-up ... 80
Figure 8: Page 3-4 opaque retail mock-up ... 81
Figure 9: Page 1 transparent retail mock-up ... 82
Figure 10: Page 2-3 transparent retail mock-up ... 83
Figure 11: Page 4-5 transparent retail mock-up ... 84
Figure 12: Page 6 transparent retail mock-up ... 85
Figure 13: Opaque financial services mock-up ... 86
Figure 14: Page 1-2-3 transparent financial services mock-up ... 87
Figure 15: Page 4-5-6 transparent financial service mock-up ... 88
Figure 16: Page 1-4 opaque healthcare mock-up ... 89
Figure 17: Page 1-2-3 transparent healthcare mock-up ... 89
Figure 18: Page 4-5-6 transparent healthcare mock-up ... 90
Figure 19: Our research model ... 96
Figure 20: Our statistical model – Pre confirmatory factor analysis (Pre CFA) ... 114 Figure 21: Our statistical model – AMOS – Post confirmatory factor analysis (Post CFA) . 115
Abstract
We live in the age of big data. Nowadays, companies are exploiting more and more the potential embedded in the huge amount of information that we generate online every day. These new ways to capture value, as the trading of users’ data, allowed innovative digital services and platforms to be economically sustainable in a landscape characterized by users with a low willingness to pay. However, users are realizing more and more about the danger of online privacy violations. Hence, privacy concerns regarding data activities by companies are rising, making users unwilling to disclose their information online, affecting data-driven companies. To lower these resistances, firms started to invest in transparency, reassuring customers, and defining boundaries for data activities.
The effectiveness of these practices has been limitedly covered in literature; thus, the objective of this study is assessing whether transparency affects the propensity to disclose and trust from users, also analysing industry and personal characteristics as contextual and personal factors. Within a field experiment, transparency is embedded into the design of a privacy disclaimer for a digital service, and the reactions to two mock-ups – one transparent and one opaque – are collected through a survey. Answers from 312 respondents were analysed through a Covariance-Based Structural Equation Modelling (CB-SEM) method. Results show that transparency has a statistically significant positive effect on disclosure intentions. Plus, this behaviour changes depending on the industry and the personality of the respondent. These results, novel in the privacy literature, open a wide set of possibilities for practitioners, which might find in transparency a competitive advantage to overcome diffidence, build long-term relationships with users, and foster data disclosure, obtaining in turn a relevant source of value.
Abstract versione in Italiano
Viviamo nell'era dei Big Data. Oggi le imprese sfruttano sempre di più il potenziale insito nell'enorme quantità di informazioni che generiamo ogni giorno online. Questi nuovi modi di generare valore, come la vendita dei dati degli utenti, hanno permesso a servizi e piattaforme innovative di essere economicamente sostenibili in un panorama caratterizzato da utenti con poco propensi a pagare per i servizi digitali. Tuttavia, gli utenti si stanno rendendo conto sempre più dei pericoli derivanti dalle violazioni della privacy online. Di conseguenza, la preoccupazione degli utenti per la loro privacy ed il trattamento dei dati è in crescita, rendendoli meno disposti a rivelare informazioni online, con ripercussioni sulle imprese e servizi basati sui dati degli utenti. Per ridurre queste resistenze, le imprese hanno iniziato a investire sulla trasparenza rassicurando gli utenti e definendo dei limiti per le attività riguardanti i dati personali.
L'efficacia di queste pratiche è stata studiata in letteratura in modo limitato. L’obiettivo di questo studio è valutare se la trasparenza influisce sulla propensione a condividere dati personali e sulla fiducia verso il servizio. La relazione tra la trasparenza, condivisione dei dati e fiducia viene analizzata rispetto a variabili di contesto, come fattori personali ed il settore del servizio. Nell’ambito di un esperimento, è stata progettata una privacy policy trasparente per un servizio digitale, e le reazioni a due mock-up - uno trasparente e uno opaco - sono state raccolte attraverso un questionario. Le risposte di 312 intervistati sono state analizzate tramite un modello di Covariance-Based Structural Equation Modelling (CB-SEM). I risultati mostrano che la trasparenza ha un effetto positivo significativo sull’intenzioni di condivisione di dati personali da parte degli utenti. Il comportamento cambia a seconda del settore e della personalità dell'intervistato. Questi risultati contribuiscono all’arricchimento della letteratura sulla privacy, portando ampie possibilità per i managers del settore, che potrebbero trovare nella trasparenza un vantaggio competitivo per superare la diffidenza, costruendo relazioni a lungo termine e favorendo la divulgazione dei dati, ottenendo una rilevante fonte di valore aggiunto ai loro business.
Executive summary
The diffusion of smartphones, digital services, and platforms drastically changed our lives. Nowadays, users generate millions of online interactions every day, leaving a remarkable digital footprint of who they are, what they have bought, or what they like or dislike. This huge amount of data could become a valuable opportunity for digital Content and Service Providers (CSP), completely disrupting traditional business models.
The generated data are often described as the new oil, and digital companies have started to invest in them (e.g., Ostrom et al., 2015). The product and services that are born under this new standard of doing business in the digital world are data-driven. They often offer time and money savings to users, or even better health and well-being, in turn of data. However, besides the value still given back to consumers by CSP, something is rapidly changing in the current attention of people toward privacy, especially in digital services (Del Vecchio et al., 2018). Attention towards privacy is dramatically rising. For instance, a large majority of Americans believe that they would not benefit from large data gathering campaigns from CSPs, and the risk of data disclosure outweighs the benefit they receive back (Pew Research, 2019). Around 75% of people are concerned about their data and how they could be used, and 32% of users are changing their behaviour based on these concerns.
Privacy scandals of the last decade are a multiplier factor of privacy concerns, influencing, and changing disclosure behaviours in users, who became afraid of possible misbehaving by digital companies. Hence, data breaches seem to influence the importance given to privacy and the value of transparency (Martin K.D. et al. 2017). The Cambridge Analytica scandal is an excellent example to dig into these concerns - with Mark Zuckerberg first apologizing and then revising the Facebook privacy policy (Confessore, 2018).
Looking at the strategies implemented by big tech companies, transparent disclosures of data practices seem to be a possible relief to the rising concerns on privacy topics, defining new business routes for practitioners. The objective of this thesis is to develop this conjecture, building on previous privacy studies, and trying to assess the actual impact of transparency on the user.
A first review of the existing literature has been performed to understand the reason why companies are constantly seeking data. Indeed, firms can benefit in several ways from data exploitation, both in terms of (i) processes efficiency, improving activities based on a deep knowledge of the reality, and (ii) strategic value, acquiring advanced comprehension of users’ needs and helping in delivering the value proposition effectively. These alternative sources of value are particularly relevant for two-sided platforms and other digital services, which often compete in a market with a low willingness to pay and, thus, they must find additional sources of revenues to be economically sustainable. Hence, overcoming these resistances is becoming a crucial point for CSPs.
Given the crucial role of privacy, we reviewed the literature, and we identified the main perspectives through which the phenomenon has been analysed. A general framework to describe privacy is the Antecedents - Privacy Concerns - Outcome Model (Smith et al., 2011), which describes how the behavioural outcome is linked to the privacy concerns, which in turn are shaped by a set of Antecedents (both personal and contextual). Within this model, willingness to disclose is the less explored outcome variable, especially considering the recent evolutions of users’ preferences and the available alternatives. Instead, the less explored
antecedents are represented by personal traits, especially in terms of the contrasting effect of
value-seeking versus attention to privacy. On top of the model, privacy is heavily influenced also by the approach adopted, of the rational approach versus heuristics, depending on the effort from the user (Barth et al., 2017). Finally, we observe that privacy is heavily context-dependent, thus a valuable direction is understanding the role of the industry and the associated sensitivity. Parallelly, literature leaves the role of transparency within the previous models almost unexplored. Transparency had been investigated only in the terms of personalization (Karwatzki et al., 2017) and impact on adoption (Trabucchi et al., 2019). This highlights how it is a widely explorable research route for the next decade.
This direction is valuable also from a practical point of view, indeed, transparency somehow could be a win-win feature. On the side of the CSP, it could generate trust and increase the willingness to disclose from users. On the side of the users, it could deliver a pain reliever about privacy and data handling practices adopted by the companies.
Following suggestions from both literature and companies, this study has the objective to clarify the relationship between transparency and users’ data disclosure in digital services, in terms of (i) amount and (ii) categories of data disclosed by users. In this sense, we develop the following research question:
RQ. How does transparency influence the disclosure of data and personal
information toward the content and service provider by the users, across different contexts and personal characteristics?
This question has been studied through a field experiment, based on a digital survey, structured following the literature adaptable to our aim.
As already mentioned, in our study we decided to analyse the willingness to disclose instead of other forms of intentions. In this way, it is possible to increase the degree of detail compared to adoption, since opting out is a costly – and too drastic – alternative that often is not chosen by users. Thus, we want to analyse customers’ decisions on data sharing throughout utilization and observe the relationship with the business model transparency.
Considering the less explored elements from the theoretical background of our research, we derived a set of variables we wanted to take into account and we describe the relationship through the following hypotheses:
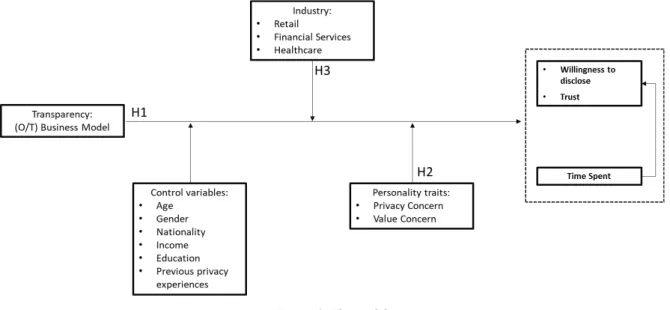
• Hyp1a: A transparent business model generates a higher willingness to disclose personal information in terms of data disclosed and purpose allowed, compared to an opaque one. • Hyp1b: A transparent business model results in a higher level of trust from the user,
compared to an opaque one.
• Hyp1c: A transparent business model leads to a higher amount of time spent on reading and interacting with the choices, compared to an opaque one.
• Hyp2a: A privacy trait with a low concern for privacy would result in a higher willingness to disclose and trust with a low time spent.
• Hyp2b: A privacy trait with a high focus on benefits and value would result in a higher willingness to disclose and trust with a low time spent.
• Hyp3: The level of sensitiveness of the industry has a moderating effect on the structure of preferences regarding willingness to disclose and trust.
As it is possible to see in the following figure (fig.1), we represent the model on which our hypotheses are based:
Figure 1: The model
Once we defined the model, we tested it empirically through an artefactual field experiment (Podsakoff and Podsakoff, 2018; Carpentel et al., 2004). In our experiment, respondents adopt the point of view of a hypothetical digital service user, being exposed to the privacy policies of two mock-ups. Afterwards, the disclosure intentions in both willingness and consent are collected through a survey.
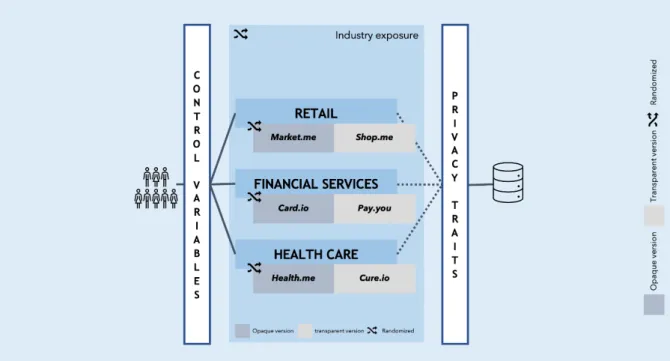
The experimental procedure follows the process described in the figure below (fig.2). Our sample has been tested randomly on two layers: the first considered the industry to which the user was exposed; the second distributed respondents between who see the transparent mock-up as first and the opaque one as second, and vice versa (within the assigned industry).
Figure 2: Experiment paths and layers
We gathered a total of 497 responses, that after a data cleaning phase, become 312 usable and complete responses.
Statistical analyses of our experiment have been carried out through the definition of a model able to test and describe the scenarios analysed. In AMOS and SPSS (Vers.26.0), software provided by IBM, we designed a covariance-based structured equation modelling (CB-SEM), which is a common method for testing models like ours and usually is employed in this type of research (Hair et al., 2017).
The model had the following configuration:
• 5 latent (independent) variables: Previous Privacy Experience - Question 1; Previous Privacy Experience - Question 2; Perceived Transparency; Privacy and Value Concerns variables.
• 2 dependent variables: Willingness to Disclose personal data to the digital service, and the sense of trust of the users toward the CSP.
Our statistical analysis followed a standard path of statistical analysis for researches of this typology (Trabucchi et al., 2019). After a brief data snooping analysis of our samples, we perform a Confirmatory Factor Analysis (CFA), reducing the dimensions of our model. Then,
we act sequentially on two different layers of analysis: (i) the first consists of an analysis of the industry and main differences across them, testing hypothesis 3; (ii) in the second layer, we split the samples and we investigate the intra-industry point of view, where we (a) analysed differences between opaque and transparent exposures, and (b) verified our hypotheses through the significance of regression paths and structural weights.
Regarding the first layer, an ANOVA did not support the evidence for Hyp3 in terms of differences in the level of WTD and Trust across different industries. Instead, a multi-group analysis, demonstrates that paths and, thus, the configuration of preferences, are significantly different across the two extremes in terms of industry sensitivity (retail, with the lower level of attention in the literature (Roeber et al., 2015), and healthcare, with the highest one).
Before testing the hypotheses, we identified the dimension of analysis in which we should perform the verification. Since there were significant differences between retail and healthcare, we kept these two clusters separated. In addition, since model fit had good indexes for every industry, we kept also financial services separated, to investigate possible variations in single paths. Finally, we identified two clusters defined by the exposure order (Transparent or opaque as first mock-up). An ANOVA and a multi-group analysis verified that there was no overall significant difference across them. Thus, it was not necessary to further cluster every single industry based on the order.
Hence, we verified the hypotheses for each industry. As result: (i) hypotheses Hyp1a and Hyp1b, are both verified across all the industries considered in the experiment. Therefore, perceived transparency influences both the willingness to disclose of users and their sense of trust toward the CSP. Looking at the estimates and the correlations indexes among variables, the industry that appreciates more transparency is healthcare, the one with the highest level of sensitivity toward personal data (Roeber et al., 2015); (ii) The hypotheses regarding the impact of transparency on time spent in decision making was discarded due to bias in the variable. This bias affected only the time variable, due to the familiarity to the typology of the service during the second exposure; (iii) hypotheses Hyp2a and Hyp2b regarding personality traits are confirmed: privacy concerns are significant in decreasing the intention to disclose and trust, while value concerns increase them.
Our study provides interesting insight while compared the results with the actual status of the literature. In particular, we build on previous literature and we add novel results regarding the following aspects: (i) methodology of the study: we demonstrate the validity of mock-up design and consequential exposure as an experimental setting to study the effect of attention to privacy from CSPs; (ii) transparency: opposed to precedent literature, which found no impact on willingness to share (Karwatzki et al., 2017) nor on other behavioural variables as adoption (Trabucchi et al., 2019), we find that transparency is not only appreciated by users, it generates trust and it has a positive effect on willingness to disclose. In addition, we find that being transparent on the operating boundaries fosters the acceptance of Data Trading activities; (iii)
personal traits: we confirm that personal characteristics have a significant impact on trust and
willingness to disclose. We add that the attention to value has a stronger positive effect, compared to the negative effect of concerns, and that transparency has a different effect depending on personal predispositions; (iv) industry: we confirm the difference of the configuration of preferences across different industries characterized by different sensitivity of data. We add that the industry with the highest level of sensitivity benefits the most from transparency in terms of disclosure and trust; (v) behavioural intentions: we add that transparency affects more trust than the actual disclosure. The perceived transparency of the opaque mock-up, if displayed after the transparent one, is generally lower. This would remark how there might be the endowment effect (Kahneman, 2011) and, within the Kano model (Berger, 1993), transparency can have a different role depending on what users are used to.
From the previous theoretical contributions, we also derive implications for practitioners and companies. We suggest that transparency can become a competitive lever to build trust and long-term relationships with the CSP (Amit and Zott, 2001), and, at the same time, to foster data disclosure; this is particularly relevant especially in a world that is moving towards higher and higher attention to privacy. In addition, since transparency increases disclosure, but it does not affect adoption, this shifts the attention on the quality of the users, instead of quantity: the objective is engaging the available users in the creation of valuable data, allowing the generation of alternative revenue streams for the company. Moreover, based on the different perception and effects of transparency across different personality traits, companies might start investigating which typology of customers they have, to tailor privacy actions accordingly.
Finally, we outline the limitation of our study. The first limitation is related to the data we collected: we have participants mainly from restricted demographics, income, and education level. About the setting, we considered both a limited set of possible scenarios of disclosure and variables. Finally, we have a behavioural limitation and contrast with reality, indeed, users tend not to read privacy statements, especially given the wide variety of services utilized, while our results are based on, at least, the reading of disclaimer pages.
Thus, valuable further directions might be: (i) extending the scenarios and the variables included in the model, in order the observe willingness to disclose and transparency in a wide set of contexts; (ii) shift towards the observation of data and behavioural patterns from real services, especially in terms of actual interactions, disclosure, and value generated from data; (iii) mapping the current privacy initiatives from companies, identifying the directions and building a framework of analysis to determine the possible competitive levers/dimensions in the privacy field.
1. Introduction
Smartphones and digital platforms have become routine aspects of our life. They support us in a wide range of activities and, year after year, they have widened the fields of application into industries where it seemed impossible just some years ago. Nowadays it is possible to have a digital tool that follows you and guides you in your grocery shopping, gives you advice in your financial activities and investments, keeps you in shape providing tips and suggestions on your health status. The millions of interactions generated become a profitable asset that can be leveraged in several ways, completely twisting traditional business models. Interactions between the mentioned counterparties generate data, often described as the new oil.
The Pew research centre in 2019 finds evidence that more than six out of ten Americans believe it is impossible to carry out a day of our life completely offline, without having any of their data collected. Hence, most Americans believe their online and offline activities are being tracked and monitored by companies and the government with some regularity.
Data-driven products and services are often traded with the potential to save users’ time and money or lead to better health and well-being. For example, data-driven businesses could be free, permitting money savings to their users, provide a service, and still be profitable, by analysing and trading the data they collected.
Besides the value given back to consumers by Content and Service Providers (Fast, 2019), the Pew research of 2019 points out that large shares of U.S. adults are not convinced they could benefit from this system of widespread data gathering. The risks respondents face because of data collection by companies outweigh the benefits for 81% of them, and 66% say the same about government data collection. At the same time, most of the Americans report being concerned about the way their data is being used by companies (79%) or the government (64%). Most also feel they have little or no control over how these entities use their personal data: worldwide, 40% of people feel they lack control over their personal data (McAfee, 2019). Hence, for example, 79% of Americans say they are not too or not at all confident that companies will admit mistakes and take responsibility if they misuse or compromise personal information, and 69% report having this same lack of confidence that firms will use their personal information in ways they will be comfortable with (Pew Research, 2019). This generates concerns on data security, considered more elusive today than in the past.
As the evidence shows, concerns about privacy are increasing among the public but until now this has not been always translated into higher diligence and attention on actions and decisions concerning privacy and data from users. Privacy scandals such as the one involving Facebook and Cambridge Analytica could be a suitable example of big privacy concerns which led to not a big deal on actions and pragmatic reactions to it. Just after the scandal, the impact on the users’ perception was massive, generating a big media wave plenty of social movements such as #boycotfacebook and #deletefacebook. As a result, privacy concerns increased in the mind of the users. In addition, in a poll made by Harris Poll just after the CA scandal which involves Facebook 78 percent of U.S. consumers believe a company's ability to protect user data is “extremely important” and only 20 percent “completely trust” that organizations protect their data. However, only a minority of users choose to stop utilizing Facebook every day.
Even though the concerns increase strongly, actions undertaken by consumers to protect their own privacy did not change significantly in the medium term. This is valid also for content and service providers (CSPs) involved in the scandal, which did not implement significant changes. Facebook for example after the Cambridge Analytica scandal made some moves towards higher transparency and made a call for higher regulation in the field, but it did not focus deeply on the matter.
Right now, digital content and service providers must be compliant with regulation concerning privacy, disclosing their data management activities in their privacy policies. However, this seems not to be enough. The privacy policy doesn’t generally guarantee thoroughness. Only a minority (22%) of Americans read it carefully and, in addition, more than half of Americans say they understand very little or nothing at all about the laws and regulations that are currently in place to protect their data privacy (Pew research, 2019). These evidences suggest that the law and regulation are not enough; being compliant with the law is not sufficient to defend users’ privacy effectively. Laws and regulations are useful in proving a boundary to what is possible and what is not, limiting bad habits. Laws in digital privacy can increase the safety of your personal information but can never guarantee protection from malicious attacks. The prevention of data misuse and privacy scandal start from the users, in its actions and understanding of the matter.
The actual rising attention toward privacy could be the driver of some changes, as Andrew Hawn, founder of MetaForesight points out: “We’re seeing a social shift in the long-term effects of privacy, people are starting to more deeply question their growing lack of data privacy and control while in the meantime more ventures invest on data-driven businesses where our personal data are traded in a multitude of ways.”. Indeed, in the United States, 74% of consumers have limited their online activities due to privacy concerns, where the 45% are more worried about their privacy than in the previous year (TRUSTe, 2016).
A possible solution that could help in addressing the problem of rising concerns about privacy among users and the increasing hype around data-driven business models, could be investing in business model transparency. Data-driven companies could overcome increasing users’ concerns about privacy by delivering precise privacy policies that explain their data practices, avoiding dissatisfaction, generating trust in their brand and practices, and, in the long-term, affiliate more users.
Nowadays, transparency is a trendy word but is not just as simple as being honest. In the business dictionary, transparency is defined as “A lack of hidden agendas and conditions. Sharing of all information required for collaboration, cooperation, and collective decision-making” (Strauss, 2020). Or more simply, accurate and timely disclosure of all information. Hence being transparent is something that requires big emphasis, is something that must be developed and become cultural.
Current trends on digital platforms concerning privacy and transparency
All the big techs are investing in privacy during these years, with different approaches and attention towards it. They started already considering it as a strategic advantage or a strategic differentiator in their business models (Gal-Or et al. 2018; Martin and Murphy 2017). To investigate the different positions and trends emerging in the field we have decided to analyse the behaviour toward privacy of some of the big techs and platforms. We have selected to analyse Google, Apple, and Microsoft.
Google in the last years has made a lot of statements concerning privacy, providing the idea of their efforts in addressing the problem concerning data practices and privacy, increasing the overall transparency on the topic. Google increase the amount of control and volume of information delivered to their users concerning data management and privacy setting. Google is moving towards transparency providing a lot of information about their data practices to users and simple menus where privacy could be set and controlled by the users. From an overview of these new menus and privacy settings, Google seems to talk about data privacy as something that must be present but should not obstacle the benefit coming from the usages of the Google ecosystem, where value is delivered to users thanks to a huge amount of data collected and analysed. Compared to other big tech companies (e.g. Apple), Google focuses on the value delivered through data analysis maintaining an acceptable level of privacy more than designing data-intensive services in a non-invasive way. Google in all its privacy menus and highlights the importance of a huge collection of data. Hence Google makes clear that its business has data as a baseline and that its services are built on a huge integrated data ecosystem. Summing up, for Google the effort is made into the direction of “More data means better services”, defining for privacy the role of monitoring the safeness of data collection and analysis procedures, without impacting on the value delivered to the clients.
Apple
During the last years, Apple is pitching itself as a privacy provider (The Verge, 2019). It puts big efforts into how data are treated and how digital companies use its devices and operative system (iOS), collect information, and conduct opaque behaviours concerning data, mining trust on a well-designed ecosystem. The first targeted attempt made by apple to solve this problem is the introduction of the “Sign-in with Apple” feature. This feature permits users to log into digital services using an Apple ID that changes every time you make a new access to a digital service, and it is completely anonymous. This could permit at the same time great user experiences and great privacy. Furthermore, users should be able to enjoy the convenience and security of one-tap sign-in without compromising their privacy. With that principle in mind, Sign-in with Apple has been built to limit the amount of information that users are required to share, reassuring them that Apple will not track them as they interact with the apps. In addition, the native apps of the Apple ecosystem will provide different perks to avoid privacy intrusion
by third parties, protecting users. To give an example, Safari will use a built-in anti-tracking to avoid 3rd parties’ intrusions on user’s data, and, in general, overall generated data will be associated to a random variable, avoiding the link with the Apple id of the person involved, keeping personal information secure.
Apple pivots on 4 main pillars concerning privacy: device processing, data minimization, security protections, and transparency control.
During the WWDC 2020, event that took place in Cupertino (US) on the 22nd of June 2020,
Apple put a big emphasis on privacy (The Verge, 2020). They underline the efforts that they are doing on the topic and their next moves, highlighting the fact that on privacy they are walking the talk. With the upcoming iOS14 and macOS they will introduce 3 main features: • Approximate location: advertisers will have no more precise location. A user could choose
to share an approximate location (few kilometres) defining an intermediate level of disclosure of your data that permits all the apps to work properly (weather and news) without revealing too much to “big brother” advertiser and trackers.
• Smile, you are on camera: with iOS 14, users get a camera and microphone indicator shown up alongside the location indicator icon, similar to the red light that lights up on top of most laptops when the camera is in use. In case this indicator turns on unexpectedly, it’s time to control the apps and related camera and mic access.
• App nutrition labels: Apple took the familiar solution of nutrition labels we see on food items at the supermarket to explain the sort of self-reporting developers will have to do about the permissions their apps ask for, upfront, on the App Store. Users could review the app privacy policies displayed out in an easy-to-consume way and control whether the app requires data such as contacts, browsing history, location, and other identifying details with the app before downloading the app.
Apple is investing in privacy following its recognized increasing importance for the consumers in recent times, believing in the relationship between trust and transparency. Its efforts are more and more routed towards the definition of new standards concerning privacy and how data are treated.
Microsoft
Microsoft in the last years put a big emphasis on the privacy theme, addressing the topic by giving all the decision power to its users. It considers privacy as something that users must consider and care about. Hence, they are committed to providing products, information, and controls that let users choose how your data is collected and used. Its effort is towards the creation of simple and ready-to-use privacy settings that would help users in understanding the value of data and how reasonable data sharing could be beneficial. Microsoft supports GDPR and privacy policy that go in the direction of a higher standard of data transparency in the market. It has also an active role in the definition of best practices concerning data protection on its servers. A big point underlined by Microsoft is the idea that data generates value for both the company and the clients, providing update services and products, always able to answer to their needs. Some further moves are expected in the direction of higher transparency and deeper privacy settings tools, but right now this effort is not in the top list of the company.
As you can appreciate, concerns toward privacy are different and strategies to address privacy problems either. Apple built in the years a kind of competitive advantage in selling high-end devices characterized by strong security and privacy protection perks. Apple seems to consider privacy transparency and control towards fair practices in its ecosystem as a possible field on which to build a new set of competitive features. The other two groups are more concentrated on assuring privacy protection but neither one of the two seems that has done a big step toward 100% transparency, thinking about it as a possible competitive lever. As we observed, Google places a big emphasis on the value data generate through data analysis and tries to convey to the users and the public audience that as much as possible of that value is given back to the final users. Microsoft seems to be more focused on providing a deep and spread set of tools to control each aspect of privacy, delegating full control of data to users.
Contact tracing app, an Italian case: “Immuni”
Under the 2020 Covid-19 pandemic, privacy concerns and privacy issues regarding data and information practices implemented by digital services have become a trending topic more than ever. The pandemic could be in part solved and the diffusion of the virus slowed by the definition of contact tracing app that, by tracking its users, could define a map of interactions of different subjects. Then, once an individual is tested positive for the virus, it gives an alert
to its contacts, defining backwards a map of the people (probably) involved, that could have been infected.
Immuni is the Italian contact tracing app that the government, in partnership with a private Italian company (Bending Spoons), has launched on the market. Immuni from the beginning had to fight against big privacy concerns. Citizens were frightened by possible privacy intrusions and extensive monitoring that governments could do with data that people imagined would be collected by the app. The adoption was good just in the first few weeks after the rollout with 500/700.000 download per week. However, afterwards adoption slowed down. In September, after more than 3 months from the rollout, Immuni has been installed on the 14% of the smartphone present in the Italian territory (it also must be mentioned that the download rate does not take into consideration the amount of uninstalled app), with a low increasing trend in download (+ 80/100k users a week), resulting in an average failure in addressing almost all the Italian population as the initial target demanded.
It is important to also mention that uploading a positive result to the Covid19 test on the Immuni app is difficult and characterized by a long procedure and only a minority of the infected people managed to upload their status on the app, reducing the perceived benefit for the users.
The case of the Italian contact tracing app “Immuni”, highlights the fact that privacy concerns arise when the value delivered to the users is not sufficient, generating concerns and low willingness in the download, providing additional practical evidence on the existence of a trade-off between attention to privacy and value delivered to users. Hence it is peculiar to analyse and understand how a super transparent app as Immuni has problems of adoption.
Considerations about the real cases of transparency
Looking at the above-mentioned cases, transparency seems to be nowadays a hot trending topic for practitioners. The missed presence of shared best practices and strong univocal understanding of what transparency is and how to achieve strong it in data practices and privacy policy presentation to the end-users, determine de facto the following problems:
• There is no standard for transparency nowadays across industries. For privacy, CSPs (Content and service providers) must follow some schemes defined by the legislative authorities (e.g., GDPR or CCPA), while this is not the same for transparency.
• The legislation is more about protecting users from the possible misbehaving of the CSPs than generating rules and define a strong action toward a deeply comprehensive informative campaign for users, teaching users how to control their data and to be protected online. Comprehensibility of data practices and understandability of the privacy policies would become key points for legislator since big techs (e.g., Microsoft) are increasing the number of privacy control menus in the hands of the user and these new functions would be useless if the users are not able to play with them, but most importantly to understand them.
• Being transparent is not the same for everyone and the actual easy-going strategic alternative to “Be transparent” is to “Look transparent”. In the cases analysed previously, we could highlight how those transparency procedures and, thus, how the CSP communicates privacy policies and procedures (Beke et al., 2015), are linked to the business model of the CSP. Apple starts its campaign toward becoming a privacy provider (The Verge, 2019) also because it has a business model based less on data, being less data-hungry compared to other big tech firms, having fertile soil to lever against competitors that are more linked to data gatherings procedures and that fear a world of perfect information between counterparts concerning data. The counterattack placed in action by data-intensive companies is often linked to the value they give back to the user thanks to data provided to them (e.g Google). Data-hungry companies try to shift the focus of the discussion more on what they deliver thanks to data, speaking about the value given back instead of talking about data usage minimization.
In conclusion, big tech companies are following the trends of rising concerns about privacy and data management of their users. They have understood the fundamental role that could be given to transparency to generate possible competitive advantage in the future and they are designing their own solutions regarding it, defining a possible future competitive field.
In this scenario, it is important to test the actual role of transparency for practitioners (CSPs) and users, defining the relationships and estimating its impacts on both the actors considered. Indeed, in this way, we would have a comprehensive vision of what privacy leads to in users’ behaviours and, thus, which might be the most effective strategies for companies. Indeed, if transparency is the key to reach higher trust and disclosure by the users, this would impact the
business model configuration from practitioners. Thus, due to the high potential implications, we must empirically test this phenomenon with its cause-effect relationships.
Now we will investigate and understand more rigorously what has been studied by researchers and the academic landscape, in the field of potentials of Big Data, data management activities, and the rising issues of privacy. Hence, the next section will review the literature and outline the theoretical background.
2. Theoretical background
The rise of big data
We are living in the age of Big Data. The pervasiveness of digital technologies allows an unprecedented generation of data from a variety of different sources. Indeed, every year, 16.1 trillion gigabytes of data are recorded, and forecasts are that this will grow to 163 trillion gigabytes by 2025 (Reinsel et al., 2017). This availability of data changed dramatically the competitive landscape in which businesses operate, how they generate value, and, therefore, the perception and attention that users pay to their “digital footprint”. At the same time, due to recent data scandals and the elevated amount of information we disclose (voluntarily or not) every day about ourselves through our smartphone and several other devices, we are feeling more and more vulnerable and we are starting to care about our privacy.
Therefore, in our discussion, first, we will define what the phenomenon of Big Data is. Second, we will review the business landscape that shaped users’ privacy attention in time, understanding the evolution of practices adopted by digital services to capture value from data. Digital platforms will be discussed as an example of services that heavily rely on user-generated data (Trabucchi et al., 2017) and that raised some concerns on privacy in recent years (i.e., Cambridge Analytica). This will lead to the second section, which will review the literature related to privacy issues and the discording reactions from users.
2.1.1. What do we mean for “Big Data”?
Before diving into what companies do, we must define what it is intended for “Big Data”, which is a phenomenon that shaped its definition only throughout time (Gandomi and Heider, 2015). Indeed, it moved from a blurred “large collection of data” from the mid-1990s (as reported from Diebold, 2012) towards a more defined definition based on 3Vs: “Volume”, “Variety” and
“Velocity” (Laney, 2001; Gartner, 2012), extended more recently with “Veracity” (Chen et al., 2017) and “Value” (Forrester, 2012; Elia et al., 2020).
In detail, according to a review from Wiener and colleagues (2020), the definition contains the following aspects: (i) “Volume” refers to the elevated quantity of data collected and that must be processed. (ii) “Variety” refers to the heterogeneity and range of sources and types of data. (iii) “Velocity” refers to the speed at which data are generated, which must be matched with the elaborating capability. (iv) “Veracity” refers to the quality and accuracy of data collected, in terms of trustworthiness. (v) “Value”, in terms of the exploitability of what is collected and the capability of generating strategic insights and relevant benefits. Due to the managerial approach of this thesis, we will review in detail this last characteristic in the next chapter. 2.1.2. Big Data Analytics and Value creation
During the last decade, scholars and practitioners started realizing systematically the potential embedded in Big Data. Indeed, data assumed the status of resources that, if exploited correctly through analytics techniques, would enable the generation of meaningful insights, which, in turn, can lead to innovative products, services (Davenport et al., 2012) and processes (Brown et al., 2011). Besides, awareness increased due to successful examples of companies that outperformed traditional companies in terms of productivity and profitability (McAfee and Brynjolfsson, 2012).
Over the years, several implementation and typologies of value creation from Big Data were identified. From literature, and we depict the landscape of Big Data applications, with a focus on the value generated and the approach from the firm. To do so, we adopt the framework proposed by Elia and colleagues (2020), which identifies 5 directions of value creation from Big Data:
(i) Strategic value: finding meaningful insights about the market, customers, and which
value proposition to offer. Indeed, Through Big Data it is possible to obtain a deeper understanding and a more comprehensive knowledge of the customer and his decision making (Van Auken, 2015; Miklosik et al., 2020). In this way, integrating information about different products, channels, time, and location (Hossain et al., 2017) it is possible to: (i) identify the most suitable product (or need to satisfy) for a certain market, (ii) target customers with personalized promotion and pricing, (iii) choose the most
effective way to communicate (Amado et al., 2018; Elia et al., 2020) and (iv) create a stronger and deeper customer relationship (Xie et al., 2016).
Some examples from companies are the anticipatory shipping from Amazon (Banker, 2014), the dynamic ticket pricing on digital marketplaces (Laker, 2014) or the product and process innovation of Ford, which are based on data collected from sensors on the vehicles on the road (King, 2012).
(ii) Transactional value: exploiting the availability of data about internal processes to
enhance efficiency in operations (Bradley et al., 2017), communication, asset exploitation, supply chain (Moretto, Ronchi, and Patrucco, 2017), and its sustainability (Liu et al., 2020). These practices would lead, on the one hand, to an increase in productivity, and, on the other hand, to a reduction of cost in both terms of energy efficiency and direct materials, boosting the overall profitability and economic value generation of the firm.
As an example, Big Data are exploited by companies to enhance logistic in terms of delivery planning, aggregating orders, and optimizing routes based on the final user behaviour, or to optimize production, including a broader pool of parameters – as, for instance, internal punctual location and flows of materials - and indirect source of costs (McKinsey, 2016).
(iii) Transformational value: in terms of organizational benefits that have as an outcome the
reinforcement of innovating capability, within products, services, customer segments, and markets in which the firm operates (Elia et al., 2020). This perspective focuses on results that go beyond the current observable benefit and shift towards a broader evolutionary dimension (Gregor et al., 2006)
(iv) Informational value: in terms of supporting decision making and discovering hidden
knowledge within the firm. In this case, Big Data and analytics are exploited to have a systematic method to access information in a faster and easier way (Elia et al., 2020). The insights generated in this way are in a processed format, with already a focus on their utilization. Therefore, an example of outcomes might be the facilitation of strategic planning (Constantiou and Kallinikos, 2015) and a solid decision-making process, based on knowledge of what is happening within the firm (Sharma et al., 2014).
(v) Infrastructural value: in terms of technology and innovation lead by Big Data. Indeed,
existing ones in terms of efficiency and performance (Wamba et al., 2015). This also leads to the preparation of processes, organizations, and systems for future technological evolutions as a collateral consequence. In addition, BD initiatives, as observed in a case study on an Italian bank (Elia et al., 2020), indirectly unveil otherwise precluded possibilities as (i) more accurate risk management (due to a renovated IT infrastructure, originally oriented to improve computational performances for BD), (ii) closer customer relationship due to integrated data, and (iii) cost reduction due to visibility on system failures and malfunctions.
So far, we discussed in detail one approach: the application of analytics on already available and collected Big Data. This way of dealing is related to the fact that digital technologies by themselves generate and capture data from a variety of sources never exploited before, such as RFID tags, web information, consumer preferences (Davenport, 2014), wearable devices, sensors, and IoT (Ehret and Wirtz, 2017). In addition, “Businesses are collecting more data than they know what to do with” (McAfee, Brynjolfsson et al., 2012) and, hence, the focus is on competencies, management, and organization to generate knowledge and capture their value (Raguseo, 2018).
Parallelly, due to the value embedded into data, we can observe how more and more digital services seek actively for data collection (though this direction is still not deeply explored in literature, as stated in a recent review from Wiener and colleagues in 2020), shaping their business model to capture and storage a specific set of information and leverage on it as a source of recognized value. This led to innovative business models, such as the free-to-consumer ones (Trabucchi et al., 2017) which provide, for instance, digital services and apps without a direct cost for the user.
2.1.3. Data as the main product
“If you're not paying for it, you become the product.”.
With a citation from Scott Goodson (2012), we introduce the next section in which we will explore the concept of “Data as a product” (Trabucchi and Buganza, 2018). Indeed, in recent years, we have several examples of services that have set as the main goal the collection of valuable data.
In particular, the authors identify three relevant cases that faced (in their case, from an innovation process perspective) the necessity to obtain a certain typologies of information and, therefore, designed a service that can specifically provide them:
(i) UpCoffee: it was a service offered from Jawbone in 2014, a producer of smart
wristbands, which realized that within the data they already gathered from previous features and devices, patterns about caffeine consumption were missing. To solve this criticality and enhance the service provided by its main service, this ad-hoc service (UpCoffee) has been designed. It exploited the interest of existing users in understanding the impact of coffee on their health and allowed to expand the spectrum of behaviour tracked by the company.
Despite the negative evolution of the company, which was liquidated in 2017 due to more structural difficulties in remaining competitive against other players, this case is relevant to observe how the focus could be not just on providing a complementary service but, instead, targeting a specific customer base that can generate the required data.
(ii) Duolinguo: it is a free educational service that offers a different approach to learning a
new foreign language. Its uniqueness is related to the exploitation of technology to create a gamified and adaptive experience even without direct human supervision. The peculiarity, in this case, is related to the reason why the whole platform (which later evolved towards a B2C direction, with a “premium” version and proficiency certifications) was originally designed. Indeed, the founder Luis von Ahn aimed to exploit the knowledge generated from millions of users (300 million in 2020, source: Duolinguo.com) to create a translating service for other companies. This points out how, even in this case, data (and rules that might be extracted from them) were the objective and not a collateral outcome.
(iii) mPower: it was a service that aimed to collect information about the symptoms and the
evolution of Parkinson’s degenerative disease. In this case, the data gathering objective was clear and it is relevant to observe how platforms unveiled the possibility to implement it on a large scale, allowing the design of a digital service that can capture with its features a large pool of extremely valuable and previously inaccessible information.
Finally, we report a case study from Pesce and colleagues (2019), to describe a case that contains both elements of subsequent elaboration of data collected for an initially different purpose and, instead, an active seeking:
(i) Google Arts&Culture: it is a no-profit side branch started by Google in 2011 which
collaborates with cultural heritage institutions to recreate, thanks to Google’s proprietary Street View technologies in imaging and indexing, a high-definition digital version of museums and exhibitions. Besides, this platform accomplished the objective of Google of obtaining high-quality images from more and more different sources to apply their machine learning (image recognition and classification) and artificial intelligence algorithms.
Thus, parallelly to a precise identity and to the objective of positioning the company in the cultural heritage sector, Google Arts&Culture pursued an additional strategy of gathering data for a third party, in this case, other divisions of Google itself. It exploited network externalities generated by the number of visitors to onboard institutions into the platform. At the same time, in this way, it could collect the data necessary to accomplish the other company objectives.
Finally, another example of data collection from Google Arts&Culture was its feature, released in 2018, of “face matching” between selfies taken from users and characters from all artworks characters within the database, through “visual similarity” indexes given from an artificial intelligence algorithm. In the first days, people took more than 30 million pictures (Luo, 2018).
Beyond the pure collection of data, this case shows the double underlying nature of, providing an engaging and valuable experience for the final users to overcome their resistance in giving up their data.
2.1.4. Platforms as data-intensive businesses
From the previous discussion, we can see that services that target the acquisition of data from a variety of users often configure themselves as digital platforms. In this section, we will deepen the concept of platforms, their historical evolution, possible classifications, and the reason why they tend to be businesses with a high level of data exploitation. Indeed, besides the disruptive role of platform-based business in recent years (with famous examples such as Uber, Airbnb, and Facebook), the concept of “platform” has a long story and different definitions.
Throughout time, platforms have been analysed from several points of view. For instance, Thomas and colleagues (2014) identify 4 possible dimensions:
(i) Organizational platforms, as containers of resources and capabilities developed by an
organization, which allows the firm to adapt to new contexts and evolve efficiently (Pralahad and Hamel, 1990; Garud et al., 2006). In this case, the focus is on the common basis and pool of competencies that be re-adapted to face changes with a minimum effort.
(ii) Product family platforms, as – from a technological and innovation perspective – a “set
of assets organized in a common structure from which a company can efficiently develop and produce a stream of derivative products” (Gawer and Cusumano, 2014, pp. 418). This common basis reduces the costs of every single new product due to the utilization of an already existing starting point, instead of developing from scratch. An example is the MQB Platform from Volkswagen which granted to producers a high level of flexibility and adaptability of existing and standardized modules (Lampon et al., 2017).
(iii) Market intermediary platforms, as two-sided markets, that facilitate the contact and
reduce matchmaking frictions between two (or more) groups of participants. They rely on network externalities to increase the number of users. Indeed, the offer available depends on the members, and the members are incentivized by the presence of a broad offer.
(iv) Platform ecosystems – or external platforms, within the definition from Gawer and
Cusumano (2014) – which represent a broader concept, with elements from the product family definition and the market intermediary one. From the former, it inherits the role of the common assets that work as a basis, in this case, not only for the product line itself but also for complementary products. From the latter, it takes the focus on network externalities and the value given by the number of adopters on-top of the industrial efficiency improvements. An example is operative systems as iOS, Android or Windows, which works as a basis for the development of new versions and functionalities (e.g., Android for tablets/cars/TVs/specialized devices or new applications) but also benefit from externalities since the more they can onboard developers and services the more they become appealing to the final user.