ALMA MATER STUDIORUM
UNIVERSITÀ DI BOLOGNA
CAMPUS DI CESENA
SCUOLA DI SCIENZE
Corso di Laurea in Ingegneria e Scienze Informatiche
Deep Learning per la Sentiment Analysis
Cross-Domain: Studio e Sperimentazione con
Dynamic Memory Networks
Relatore: Chiar.mo Prof. Gianluca Moro
Correlatori:
Ing. Andrea Pagliarani Ing. Roberto Pasolini
Presentata da: Nicola Piscaglia
Sessione II
Dedico questa mia tesi ed il percorso triennale, tanto impegnativo quanto edificante, che si conclude, alle persone che mi supportano sempre e da cui ho più imparato, Antonio, Daniela e Linda
Indice
Introduzione xiii
1 Deep Learning e Transfer Learning 1
1.1 Machine Learning . . . 1 1.2 Discipline correlate . . . 1 1.3 Deep Learning . . . 2 1.3.1 Definizione . . . 2 1.3.2 Motivazioni . . . 3 1.4 Modalità di apprendimento . . . 4 1.5 Transfer Learning . . . 5 1.5.1 Introduzione . . . 5 1.5.2 Motivazioni . . . 5 1.5.3 Definizione . . . 6 1.5.4 Scenari . . . 7 1.6 Applicazioni . . . 8
2 Reti neurali artificiali 9 2.1 Definizione . . . 9 2.2 Analogia biologica . . . 9 2.3 Storia . . . 11 2.4 Applicazioni . . . 12 2.5 Esempi . . . 12 2.6 Caratteristiche . . . 13 2.6.1 Insieme di apprendimento . . . 13 2.6.2 Algoritmo di apprendimento . . . 13 2.6.3 Architettura . . . 13 2.7 Modello generale . . . 13 2.7.1 Unità elaborative . . . 14 2.7.2 Stato di attivazione . . . 14 2.7.3 Funzione di output . . . 15
2.7.4 Connessioni fra unità . . . 15 2.7.5 Regola di propagazione . . . 15 2.7.6 Funzione di attivazione . . . 16 2.7.7 Regola di apprendimento . . . 16 2.8 Funzionamento in sintesi . . . 17 2.9 Reti feedforward . . . 17 2.10 Reti ricorrenti . . . 19 2.10.1 Breve storia . . . 19 2.11 Principali architetture . . . 20 2.11.1 Fully Recurrent . . . 20 2.11.2 Recursive . . . 21
2.11.3 Long short-term memory . . . 21
2.11.4 Gated recurrent unit . . . 24
2.11.5 Bi-directional . . . 25
2.11.6 Convolutional Neural Networks . . . 26
2.11.7 Neural Turing machines . . . 31
2.11.8 Memory Networks . . . 31
2.11.9 End-To-End Memory Networks . . . 33
2.11.10 Differentiable Neural Computers . . . 33
2.12 Addestramento . . . 34
2.12.1 L’algoritmo di Backpropagation . . . 34
2.12.2 Descrizione del processo di training . . . 35
2.12.3 Complessità dell’algoritmo . . . 40
3 Dynamic Memory Networks 43 3.1 Introduzione . . . 43
3.1.1 Definizione . . . 43
3.1.2 Motivazioni delle DMNs . . . 43
3.2 Architettura . . . 44
3.3 Specifiche dei moduli . . . 45
3.3.1 Modulo di input . . . 45
3.3.2 Modulo di domanda . . . 46
3.3.3 Modulo di memoria episodica . . . 46
3.3.4 Modulo di risposta . . . 47
3.4 Addestramento . . . 48
3.5 DMN Plus . . . 49
3.5.1 Motivazioni e differenze . . . 49
INDICE iii
4 Natural Language Processing 55
4.1 Definizione . . . 55 4.2 NLP e ML . . . 56 4.3 Breve storia . . . 57 4.4 Word embedding . . . 57 4.5 Modelli per il ML . . . 58 4.5.1 One-hot encoding . . . 58 4.5.2 Modello N-gram . . . 58 4.5.3 Bag of words . . . 59 4.5.4 Word2vec . . . 59 4.5.5 GloVe . . . 60 4.5.6 Position Encoding . . . 62 5 La libreria TensorFlow 63 5.1 Definizione . . . 63 5.2 Breve storia . . . 63 5.2.1 DistBelief . . . 63 5.2.2 Tensorflow . . . 64
5.2.3 Tensor processing unit (TPU) . . . 64
5.2.4 Tensorflow Lite . . . 64 5.3 Requisiti . . . 65 5.4 Importare la libreria . . . 65 5.5 Principi di base . . . 65 5.5.1 I Tensori . . . 65 5.5.2 Il grafo computazionale . . . 66 5.5.3 Sessione . . . 66 5.5.4 TensorBoard . . . 67 5.5.5 Placeholders . . . 67 5.5.6 Variabili . . . 69 5.5.7 Training . . . 70 5.5.8 tf.contrib.learn . . . 73
6 Specifiche del progetto 77 6.1 Introduzione . . . 77
6.2 Prerequisiti . . . 78
6.3 Analisi del problema . . . 78
6.4 Design degli esperimenti . . . 79
6.4.2 Configurazione iperparametri . . . 82
6.4.3 Creazione della rete . . . 83
6.4.4 Compilazione del modello . . . 83
6.4.5 Addestramento della rete . . . 84
6.4.6 Salvataggio e Testing della rete . . . 84
6.5 Implementazione . . . 84
6.5.1 Funzionalità sviluppate . . . 84
6.5.2 Librerie utilizzate . . . 85
6.5.3 Struttura del progetto . . . 86
7 Esperimenti 89 7.1 Introduzione . . . 89
7.2 Amazon Reviews . . . 90
7.2.1 Risultati In-Domain . . . 90
7.2.2 Risultati Cross-Domain . . . 92
7.3 Stanford Sentiment Treebank . . . 95
7.4 DMN+ vs. LSTM . . . 97
7.4.1 In-Domain . . . 97
7.4.2 Cross-Domain . . . 97
7.5 Analisi dei tempi . . . 99
7.5.1 Tempi In-Domain . . . 100
7.5.2 DMN+ vs. LSTM . . . 100
7.5.3 CPU vs. GPU . . . 102
8 Conclusioni e sviluppi futuri 103 8.1 Sintesi dei risultati . . . 103
8.2 Sviluppi futuri . . . 104
Bibliografia 107 Ringraziamenti 109 Guida agli esperimenti 111 .1 Training DMN+ . . . 111
.1.1 Lanciare un nuovo addestramento . . . 111
.1.2 Variare il numero di esempi utilizzati . . . 111
.1.3 Effettuare Fine-Tuning su un modello salvato . . . 112
.1.4 Variare dimensione del Fine-Tuning . . . 112
.1.5 Riprendere un addestramento interrotto . . . 112 .1.6 Eliminare i file di training/validation/testing al termine del processo . 112
INDICE v
.1.7 Specificare il numero di esecuzioni dell’addestramento . . . 113
.1.8 Specificare il valore di perdita L2 . . . 113
.1.9 Abilitare la supervisione . . . 113
.2 Training CNN . . . 113
.3 Testing DMN+ . . . 114
.3.1 In-Domain . . . 114
.3.2 Cross-Domain . . . 114
.3.3 Variare numero di esempi nei test Cross-Domain . . . 115
.3.4 Eliminare i file di training/validation/testing set al termine del pro-cesso . . . 115
Elenco delle figure
1.1 Evoluzione temporale dell’AI . . . 4
1.2 Modello base del Transfer Learning . . . 5
1.3 Fonti del successo industriale del Machine Learning secondo Andrew Ng, chief scientist at Baidu e professore di Stanford, fonte: conferenza NIPS 2016 (Neural Information Processing Systems) - top two conference in Machine Learning (insieme a ICML) . . . 6
2.1 Modello di un neurone biologico . . . 10
2.2 Modello computazionale di una rete neurale artificiale . . . 16
2.3 Modello di base di una rete neurale feedforward . . . 19
2.4 Modello di una Recurrent Neural Network . . . 20
2.5 Recursive Neural Network . . . 22
2.6 Modello tradizionale LSTM . . . 24
2.7 Modello con equazioni di una Gated Recurrent Unit . . . 24
2.8 Un-directional vs. Bi-directional Neural Network . . . 25
2.9 Una semplice Convolutional Neural Network . . . 26
2.10 L’operatore di convoluzione. La matrice di output è chiamata Convolved Feature o Feature Map . . . 27
2.11 L’operatore ReLU . . . 29
2.12 Max Pooling . . . 30
2.13 Livello Fully Connected - ogni nodo è connesso ad ogni altro nodo nel livello adiacente . . . 30
2.14 Convolutional Neural Network per la Sentiment Classification . . . 31
2.15 Neural Turing Machine . . . 32
2.16 Architettura di una Memory Network End-To-End . . . 33
2.17 Architettura di un DNC . . . 35
2.18 Composizione di un neurone artificiale . . . 36
2.19 Rete neurale di riferimento per la spiegazione dell’addestramento . . . 36
2.21 Propagazione dei segnali attraverso lo strato nascosto . . . 37
2.22 Propagazione dei segnali attraverso lo strato di output . . . 38
2.23 Il segnale di output y della rete è confrontato con il valore in output desiderato 38 2.24 Retropropagazione dell’errore δ del segnale . . . 39
2.25 Gli errori propagati e provenienti da più neuroni vengono sommati . . . 39
2.26 Aggiornamento dei pesi . . . 40
2.27 Passo finale di aggiornamento pesi e dell’algoritmo di Backpropagation . . . 41
3.1 Architettura ad alto livello di una DMN . . . 45
3.2 Architettura dettagliata di una DMN . . . 48
3.3 Architettura dettagliata del modulo Input ed Episode di una DMN Plus . . . . 53
4.1 Rappresentazione del testo GloVe . . . 61
5.1 Operazione di somma in un grafo TensorFlow . . . 67
5.2 Nodo dell’operazione di somma tra due placeholders in un grafo TensorFlow 68 5.3 Nodo somma tra due placeholders e moltiplicazione del risultato parziale in un grafo TensorFlow . . . 69
5.4 Grafo TensorFlow della regressione lineare . . . 73
7.1 Risultati classificazione binaria In-Domain Dataset Amazon applicando DMNs+ . . . 91
7.2 Risultati classificazione fine-grained In-Domain Dataset Amazon applican-do DMNs+ . . . 91
7.3 Media dei risultati ottenuti nella classificazione fine-grained In-Domain di recensioni Amazon applicando CNNs . . . 93
7.4 Media dei risultati ottenuti nella classificazione binaria Cross-Domain di recensioni Amazon con Fine-Tuning di 200 esempi applicando reti DMNs+ . 94 7.5 Media dei risultati ottenuti nella classificazione Fine-Grained Cross-Domain di recensioni Amazon con Fine-Tuning di 200 esempi applicando reti DMNs+ 94 7.6 Confronto dei risultati ottenuti nella Sentiment Classification sullo Stanford Sentiment Treebank utilizzando DMN+ inizializzate con vettori GloVe e Google News . . . 96
7.7 Confronto dei risultati ottenuti nella Sentiment Classification sullo Stanford Sentiment Treebank utilizzando DMN e DMN+ inizializzate entrambe con vettori GloVe . . . 97
7.8 DMN+ vs. LSTM In-Domain . . . 98
7.9 DMN+ vs. LSTM Cross-Domain . . . 98
ELENCO DELLE FIGURE ix
7.11 Tempi di addestramento DMN+ vs. LSTM . . . 101 7.12 Tempi di addestramento CPU Quad Core vs. GPU Nvidia Titan X . . . 102
Elenco delle tabelle
7.1 Risultati relativi alla classificazione In-Domain eseguita sul dataset di re-censioni Amazon applicando reti DMN+. Le precisioni riportate negli espe-rimenti con 2k, 20k, 100k esempi sono state ottenute eseguendo
rispettiva-mente 3, 2, 1 run. . . 90 7.2 Risultati relativi alla classificazione In-Domain eseguita sul dataset di
re-censioni Amazon applicando reti CNN. Le precisioni riportate negli esperi-menti sono state ottenute eseguendo un singolo run. . . 92 7.3 Risultati relativi alla classificazione Cross-Domain eseguita sul dataset
di recensioni Amazon applicando la tecnica del Transfer Learning e re-ti DMNs+. Le precisioni riportate negli esperimenre-ti sono state ottenute
eseguendo un singolo run. . . 95 7.4 Risultati relativi alla classificazione binaria e fine-grained eseguita sul
data-set Stanford Sentiment Treebank. Le precisioni riportate negli esperimenti
sono state ottenute eseguendo un singolo run. . . 96 7.5 Risultati relativi alla classificazione In-Domain eseguita sul dataset di
re-censioni Amazon applicando reti DMN+ e LSTM . . . 99 7.6 Risultati relativi alla classificazione Cross-Domain eseguita sul dataset di
recensioni Amazon applicando reti DMN+ e LSTM . . . 99 7.7 Tempo utilizzato (in ore) nei processi d’addestramento delle reti neurali. I
valori sono classificati in relazione al tipo di reti neurali (Long-Short-Term-Memory o Dynamic (Long-Short-Term-Memory Network Plus), all’architettura hardware
Introduzione
L’argomento principale della tesi è la progettazione di un classificatore di recensioni re-lative a prodotti commerciali, caratterizzate da linguaggi e contesti differenti, utilizzando lo stato dell’arte in ambito Deep Learning, rappresentato dalle reti neurali artificiali Dy-namic Memory Networks Plus, e tecniche di Transfer Learning in compiti di in-domain e cross-domain sentiment classification.
Quest’ultima tecnica consiste nel valutare pareri positivi o negativi di un certo dominio, detto target, utilizzando la conoscenza estratta da un dominio sorgente eterogeneo nel lin-guaggio. La motivazione delle tecniche cross-domain è il superamento della costosa pre-classificazione di numerosi esempi altrimenti operata da un esperto umano.
Soluzioni altamente scalabili sono state largamente applicate solamente in compiti di clas-sificazione in-domain, utilizzando documenti appartenenti allo stesso dominio, nonostante l’area di ricerca del Transfer Learning sia di grande interesse in termini economici da parte di numerose aziende.
Questa tesi mira ad analizzare l’efficacia di applicazione di tecniche di Deep Learning pre-valentemente tramite Dynamic Memory Networks Plus modellando i problemi di classifica-zione come compiti di Question Answering, e negli esperimenti In-Domain anche attraverso l’uso di Convolutional Neural Networks per la Sentiment Classification.
I risultati ottenuti verranno confrontati con esperimenti di classificazione analoghi ese-guiti attraverso l’utilizzo di reti Dynamic Memory Network originali e Long-Short-Term-Memory per dimostrare come l’applicazione delle architetture CNN e DMN+ migliori effettivamente i risultati precedentemente ottenuti in questo ambito.
Capitolo 1
Deep Learning e Transfer Learning
1.1
Machine Learning
Il Machine Learning è la branca della scienza informatica che fornisce ai computer la capa-cità di imparare senza essere esplicitamente programmati. Si evolve dallo studio del pattern recognition e della teoria dell’apprendimento computazionale nel campo dell’intelligenza artificiale.
Il Machine Learning esplora lo studio e la costruzione di algoritmi che possono imparare e fare previsioni sui dati - tali algoritmi superano le istruzioni di programma strettamente statiche, predisponendo invece predizioni o decisioni, attraverso la costruzione di modello di conoscenza dal campionamento dell’input.
L’apprendimento delle macchine viene impiegato in una serie di compiti di calcolo in cui la progettazione e la programmazione di algoritmi espliciti con buone prestazioni è diffi-cile o impraticabile; Le applicazioni di esempio includono il filtraggio tramite posta elet-tronica, la rilevazione di intrusi di rete o gli insider maliziosi intenzionati a violare i dati, riconoscimento ottico dei caratteri (OCR), classificazione e computer vision.
1.2
Discipline correlate
Il Machine Learning è strettamente legato alle seguenti discipline:
• Statistica computazionale: si concentra anche sulla previsione attraverso l’utilizzo di computer;
• Ottimizzazione matematica: fornisce metodi, teorie e domini applicativi al settore; • Data Mining: si concentra maggiormente sull’analisi dei dati esplorativi e si profila
L’apprendimento automatico può anche essere non supervisionato, può imparare e stabi-lire i profili comportamentali di base di varie entità e poi utilizzarli per trovare anomalie significative.
Nell’ambito dell’analisi dei dati, il machine learning è un metodo utilizzato per ideare com-plessi modelli e algoritmi che si prestano alla previsione; In ambito commerciale, questo è noto come analisi predittiva. Questi modelli analitici permettono ai ricercatori, agli scien-ziati di dati, agli ingegneri e agli analisti di produrre decisioni e risultati affidabili e ripeti-bili e scoprire informazioni nascoste all’occhio attraverso l’apprendimento delle relazioni e delle tendenze dei dati.
1.3
Deep Learning
1.3.1 Definizione
Il Deep Learning è un’area del Machine Learning che si basa sull’apprendimento dei dati "in profondità" su più livelli. È caratterizzato dalla creazione di un modello di apprendi-mento automatico a più strati, nel quale i livelli più profondi prendono in input le uscite dei livelli precedenti, trasformandoli e astraendoli sempre di più. Questa intuizione sui livelli di apprendimento dà il nome all’intero ambito (apprendimento in profondità) e si ispira al modo in cui il cervello dei mammiferi processa le informazioni ed impara, rispondendo agli stimoli esterni.
Ogni livello di apprendimento corrisponde, in questo ipotetico parallelo, ad una delle diver-se aree che compongono la corteccia cerebrale. Ad ediver-sempio, la corteccia visiva, che è pre-posta al riconoscimento delle immagini, mostra una sequenza di settori, posti in gerarchia. Ciascuno di questi settori riceve una rappresentazione in ingresso, per mezzo dei segnali di flusso che lo collegano agli altri settori. Ogni livello di questa gerarchia rappresenta un di-verso livello di astrazione, con le caratteristiche più astratte definite in termini di quelle del livello inferiore.
Nel momento in cui il cervello riceve in ingresso delle immagini, le elabora tramite diver-se fasi, ad ediver-sempio il rilevamento dei bordi, la percezione delle forme (da quelle primitive a quelle gradualmente sempre più complesse). Si parla per questo di rappresentazione ge-rarchica dell’immagine a livello di astrazione crescente. Così come il cervello apprende per tentativi e attiva nuovi neuroni apprendendo dall’esperienza, anche nelle architetture prepo-ste al Deep Learning, gli stadi di estrazione si modificano in base alle informazioni ricevute in ingresso.
Lo sviluppo del Deep Learning è avvenuto conseguentemente e contestualmente allo studio delle intelligenze artificiali, ed in particolar modo delle reti neurali. Dopo gli inizi negli an-ni ’50, ‘e soprattutto negli anan-ni ’80 che questo ambito si sviluppa, per mano di Geoff
Hin-1.3. DEEP LEARNING 3
ton e dei suoi collaboratori di Machine Learning. In quegli anni però, la tecnologia infor-matica non era sufficientemente sviluppata per consentire un reale miglioramento in questa direzione, per questo abbiamo dovuto aspettare fino ai nostri giorni per vedere, grazie alla disponibilità di dati ed alla potenza di calcolo, progressi ancora più significativi.
1.3.2 Motivazioni
Fortemente legato al Machine Learning è il tema del pattern recognition, ovvero della ri-cerca di schemi e regolarità nei dati che permettono ad un sistema, dopo una fase di adde-stramento, di classificare ogni input che gli viene presentato, solitamente sotto forma di un vettore di features, in una particolare classe di un insieme di classi possibili.
Nell’ ambito del pattern recognition, uno dei principali ostacoli riguarda l’elevata dimensio-nalità dei dati. Ciò significa che, al crescere del numero delle features disponibili in input, il numero degli esempi di training necessari al sistema per l’ addestramento cresce esponen-zialmente. Ovvero, fissato il numero di esempi disponibili, la capacità predittiva del sistema diminuisce al crescere del numero di features, con un conseguente peggioramento delle prestazioni.
Questo problema, detto "curse of dimensionality", ha fatto si che l’approccio tipicamente usato per sistemi di pattern recognition consista nella divisione del sistema in due modu-li : un modulo di feature extraction , che pre-elabora i dati in input in al fine di ridurne la dimensionalità , seguito da un classificatore , che prende in input i dati di dimensionalità ridotta dalla feature extraction e su di essi viene addestrato.
Il principale problema di un tale approccio risiede nel fatto che l’ accuratezza e la precisio-ne delle predizioni sono fortemente influenzate dall’ abilità di colui che realizza il modu-lo di feature extraction, che richiede inoltre un forte sforzo ingegneristico ed una notevole conoscenza del dominio di applicazione del sistema.
Il Deep Learning è uno degli approcci di Machine Learning che permette principalmen-te il superamento di questo problema, attraverso metodi e algoritmi di rappresentazione dei dati in maniera gerarchica, su vari livelli di astrazione. L’aspetto chiave del Deep Lear-ning sta nel fatto che questi livelli di rappresentazione delle features, ad un grado di astra-zione sempre crescente, non sono progettati e realizzati direttamente dall’uomo, ma sono appresi automaticamente dai dati utilizzando particolari algoritmi di apprendimento : i con-cetti ai livelli più alti sono definiti a partire da quelli ai livelli più bassi tramite una serie di trasformazioni non lineari.
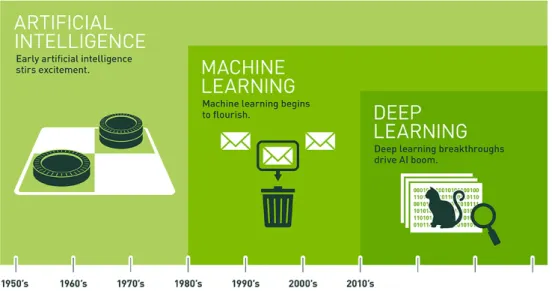
Figura 1.1: Evoluzione temporale dell’AI
1.4
Modalità di apprendimento
Le attività di apprendimento automatico sono tipicamente classificate in tre categorie:
• Apprendimento supervisionato: vengono presentati degli esempi in input e l’output desiderato. L’obiettivo è quello di insegnare alla rete una regola generale su un certo dominio di dati in modo che successivamente riesca a generalizzare
• Apprendimento non supervisionato: non vengono fornite etichette all’algoritmo di apprendimento, lasciando che trovi da solo la struttura nel suo input. L’apprendimen-to non supervisionaL’apprendimen-to può costituire un obiettivo in sè (scoprire modelli nascosti nei dati) o un mezzo per una precisa finalità (apprendimento delle funzionalità).
• Renforcement learning: un applicativo interagisce con un ambiente dinamico in cui deve svolgere un determinato compito (ad esempio guidare un veicolo o giocare una partita contro un avversario). Al programma è fornito un feedback in termini di ricompense e punizioni mentre si naviga sul suo spazio problema.
Tra l’apprendimento supervisionato e non sorvegliato si trova l’apprendimento
semi-supervisionato, in cui il "trainer" fornisce un insieme di informazioni incomplete i.e. un dataset con alcuni (spesso molti) risultati mancanti.
1.5. TRANSFER LEARNING 5
1.5
Transfer Learning
1.5.1 Introduzione
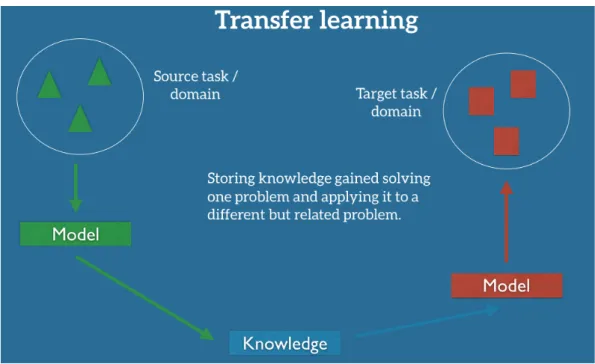
Il Transfer Learning è una tecnica di Machine Learning, dove il modello di conoscenza co-struito durante l’addestramento in un tipo di problema viene adattato e applicato al fine di effettuare previsioni su un altro problema di dominio simile.
Nel Deep Learning, i primi strati sono addestrati per identificare le caratteristiche del pro-blema. In questo modo, durante l’applicazione del Transfer Learning, è possibile rimuovere gli ultimi strati della rete addestrata e riqualificarla con livelli nuovi adatti al dominio di destinazione.
Il Transfer Learning si rileva davvero utile quando non si possiedono sufficienti dati etichet-tati nello scenario da analizzare con cui addestrare il modello di conoscenza, in questo caso infatti il tradizionale paradigma di apprendimento supervisionato perde di efficacia.
Figura 1.2: Modello base del Transfer Learning
1.5.2 Motivazioni
Nel contesto attuale, l’applicazione di tecniche di machine learning è caratterizzata da due fattori:
• Da una parte, la capacità di addestrare modelli sempre più accurati e precisi, con la conseguente diffusione di tali tecnologie su larga scala a milioni di utenti;
• Guardando l’altra faccia della medaglia, tali modelli si sono dimostrati poco efficienti se non supportati da una gran quantità di dati utili all’addestramento.
Sicuramen-te bisogna considerare che i grandi datasets sono spesso proprietari o estremamenSicuramen-te costosi.
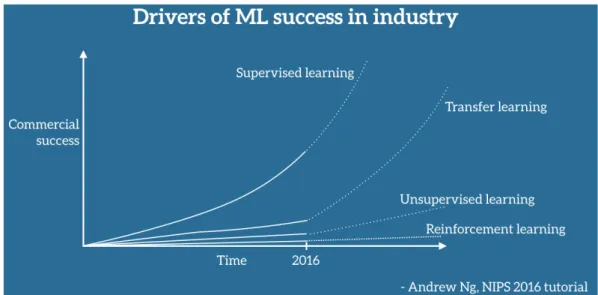
Ciò implica che utilizzare in un particolare scenario un modello addestrato su un contesto differente, porta inevitabilmente a significativi cali di performance, se non persino all’inef-ficacia totale del sistema. Questo perchè, applicando il modello addestrato al mondo reale, è normale imbattersi in condizioni e combinazioni differenti che non si erano mai visti. Il Transfer Learning diventerà un elemento chiave per il successo di tali tecnologie nel setto-re industriale, grazie alla sua capacità di estendesetto-re l’utilizzo del Machine Learning oltsetto-re ai compiti ed ai domini di cui si è colmi di informazioni.
Figura 1.3: Fonti del successo industriale del Machine Learning secondo Andrew Ng, chief scientist at Baidu e professore di Stanford, fonte: conferenza NIPS 2016 (Neural Information Processing Systems) - top two conference in Machine Learning (insieme a ICML)
1.5.3 Definizione
Per la seguente definizione seguiamo lo studio condotto da Pan e Yang (2010), [28]: Il Transfer Learning coinvolge i concetti di dominio e di compito. Un dominio D è definito da due parti, uno spazio funzionale X e una distribuzione marginale di probabilità P (X), dove X = x1, · · · , xn∈ X .
Successivamente analizziamo un esempio in cui l’applicazione del Machine Learning ha il compito di identificare moduli difettosi di un software.
Ogni metrica del software è considerata una feature dove xiè l’i-esimo vettore delle
featu-res corrispondente all’i-esimo modulo software, in cui n è il numero di vettori featufeatu-res in X, X è invece lo spazio di tutti possibili vettori features di cui X è un particolare esempio.
1.5. TRANSFER LEARNING 7
Dato un dominio D, un task T è definito da due parti: uno spazio delle etichette Y ed una funzione di predizione f (.), distribuzione di probabilità condizionale P (Y |X), la quale è appresa dalle coppie di esempi provienti dagli spazi feature ed etichetta {xi, yi} dove
xi∈ X e yi ∈ Y. Riferendoci all’esempio precedente, Y è l’insieme di tutte le etichette,
il quale conterrà i valori true e false mentre f (xi) è la funzione che predice l’etichetta yidi
un dato modulo xida classificare.
Dalle spiegazioni precedenti deriva che D = {X , P (X)} e T = {Y, f (.)}. Dato un domi-nio di origine DS = {(xS1, yS1), ..., (xSn, ySn)}, dove xSi∈ XSè l’i-esimo esempio in DS
e ySiè l’i-esima etichetta relativa all’esempio xSi.
Analogamento DT = {(xT 1, yT 1), ..., (xT n, yT n)} è il dominio su cui verrà effettuato il
trasferimento dell’apprendimento, dove xT i ∈ XT è l’i-esimo esempio in DT e yT iè
l’i-esima etichetta relativa all’esempio xT i. Oltre a ciò, TSdenota il task svolto sul dominio
sorgente dalla funzione di predizione fS(.) mentre TT denota il task svolto sul dominio di
trasferimento dalla funzione di predizione fT(.).
Si ottiene così la definizione formale di Transfer Learning:
Dato un dominio sorgente DSed un corrispondente task TSed un dominio target DT con
un corrispondente task TT, con Transfer Learning si intende la tecnica di
miglioramen-to della funzione di predizione fT(.) usando le informazioni e gli esempi appartenenti al
dominio DSed al compito TS, dove DS 6= DT o TS 6= TT.
Tale definizione di Transfer Learning su un unico dominio sorgente appena descritto può essere esteso anche all’utilizzo di molteplici domini sorgente.
Poichè sia il dominio D che l’attività T sono definiti come tuple, queste disuguaglianze danno luogo a quattro scenari di Transfer Learning, discussi in seguito.
1.5.4 Scenari
Seguendo la definizione precedente, dati:
• Domini sorgente e destinazione, DSe DT dove D = {X , P (X)}
• Task sorgente e destinazione, TS e TT dove T = {Y, P (Y |X)}
le condizioni di sorgente e target possono variare in quattro principali condizioni, che illu-streremo tramite un esempio che concerne la classificazione dei documenti:
• XS 6= XT. Lo spazio del dominio sorgente e destinazione sono differenti, e.g. i
do-cumenti sono scritti in due linguaggi differenti. Nel contesto della NLP ci si riferisce solitamente ad adattamento del linguaggio;
• P (XS) 6= P (XT). La probabilità di massa marginale del dominio sorgente e
destina-zione è differente, e.g. i documenti discutono di argomenti differenti. Questo scenario è conosciuto come adattamento del dominio;
• YS 6= YT. I task devono svolgere classificazioni differenti, e.g. i documenti vengono
applicati a funzioni differenti. In pratica, questo scenario si verifica generalmente insieme allo scenario seguente, poichè è raro che due compiti differenti, con funzioni differenti, abbiano la stessa probabilità di distribuzione condizionale;
• P (YS|XS) 6= P (YT|XT). La probabilità di distribuzione condizionale del task
sor-gente e destinazione sono diversi, e.g. i documenti sono sbilanciati riguardo le lo-ro classi. Questo è uno scenario molto comune nella pratica, poichè i dati non sono creati ad-hoc ma provengono da contesti reali.
1.6
Applicazioni
Per quanto riguarda gli ambiti di applicazione, il Deep Learning trova ampio spazio nello sviluppo di sistemi di riconoscimento vocale e del parlato, nella ricerca di pattern e soprat-tutto nel text processing e nel riconoscimento di immagini, grazie alle sue caratteristiche di apprendimento per livelli, che gli consentono di concentrarsi, passo dopo passo, sulle varie aree di un’immagine da processare e classificare.
Capitolo 2
Reti neurali artificiali
2.1
Definizione
La risoluzione dei problemi cognitivi all’interno del cervello umano è affidata a reti (o cir-cuiti) neurali, composte solitamente da svariate centinaia di cellule neuronali. Queste reti, la cui estensione e grandezza varia a seconda del compito richiesto, possono coinvolgere an-che diverse aree cerebrali e il loro sviluppo e formazione è stato fondamentale nel processo di evoluzione della specie umana.
Quando ci si riferisce alle reti neurali artificiali, si intendono sistemi di elaborazione dell’in-formazione il cui scopo è di simulare il funzionamento delle reti biologiche all’interno di un sistema informatico.
Le reti neurali artificiali possono essere considerate come un’ampia rete informatica com-posta da diverse decine di entità di elaborazione che svolgono lo stesso ruolo che i neuroni svolgono all’interno delle reti biologiche. Ognuno di questi nodi artificiali è collegato agli altri nodi della rete attraverso una fitta rete di interconnessioni, le quali permettono anche alla rete stessa di comunicare con il mondo esterno. Lo scopo finale di una rete così artico-lata è quello di acquisire informazioni dal mondo esterno, elaborarle e restituire un risultato sotto forma di impulso.
Le reti neurali artificiali sono quindi spesso utilizzate nel campo della programmazione del-le intelligenze artificiali per affrontare e tentare di risolvere determinate categorie di probdel-le- proble-mi. Nonostante la loro utilità, ovviamente non si può dire che questi reti siano intelligenti: l’elemento di intelligenza nell’intero processo è inserito dallo sviluppatore che deve analiz-zare il problema e costruire un’applicazione che utilizzi le reti neurali con la configurazione appropriata.
2.2
Analogia biologica
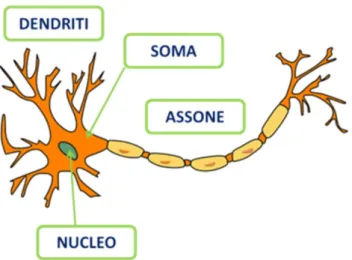
Il neurone è una cellula come qualsiasi altra, con una membrana ed un nucleo centrale, ma si differenzia notevolmente sia anatomicamente sia fisiologicamente. Il neurone "tipico"
(garden-variety neuron) presenta da un lato una protuberanza piuttosto lunga simile ad un filo chiamata assone e dall’altro lato una serie di fili ramificati più corti, spinosi e aguzzi chiamati dendriti.
Figura 2.1: Modello di un neurone biologico
Ciascun neurone riceve segnali attraverso i suoi dendriti, li elabora nel corpo cellulare o soma e poi lancia un segnale tramite l’assone al neurone successivo. Il neurone si eccita mandando un impulso elettrico lungo l’assone. L’assone di un neurone non è direttamente collegato ai dendriti di altri neuroni: il punto in cui il segnale viene trasmesso da una cellula ad un’altra è un piccolo spazio denominato fessura sinaptica.
Una sinapsi è formata da una protuberanza sull’assone chiamata "bottone" o "nodo sinap-tico" che sporge a forma di fungo e che si incastra con una prominenza a forma di spina dorsale sulla superficie del dendrite.
L’area tra il bottone e la superficie dendritica postsinaptica è chiamata fessura sinaptica ed è attraverso di essa che il neurone eccitato trasmette il segnale. Il segnale viene tra-smesso non da una connessione elettrica diretta tra il bottone e la superficie dendritica, ma dall’emissione di una piccola quantità di fluidi chiamati neurotrasmettitori.
Quando il segnale elettrico si muove dal corpo cellulare lungo l’assone fino alla fine del bottone, questi provoca l’emissione di fluidi neurotrasmettitori nella fessura sinaptica. Que-sti ultimi entrano in contatto con dei recettori poQue-sti sul lato dendritico post-sinaptico. Ciò causa l’apertura dei canali e gli ioni - atomi e gruppi di atomi carichi elettricamente - entrano ed escono dal lato dendritico, alterando così la carica elettrica del dendrite. Lo schema è dunque il seguente: vi è un segnale elettrico sul lato dell’assone seguito da una
2.3. STORIA 11
trasmissione chimica nella fessura sinaptica, seguito da un segnale elettrico sul lato del dendrite.
La cellula riceve un’intera serie di segnali di suoi dendriti, li somma all’interno del suo cor-po cellulare e, sulla base della somma, aggiusta la frequenza delle scariche da inviare alla cellula successiva.
I neuroni ricevono sia segnali eccitatori - ovvero segnali che tendono ad aumentare la lo-ro frequenza di scarica - che segnali inibitori - quelli cioè che tendono a diminuire la lolo-ro frequenza di scarica.
Anche se ogni neurone riceve sia segnali eccitatori che inibitori, esso emette poi un solo tipo di segnale.
Per quanto si sa, salvo poche eccezioni un neurone è di tipo sia eccitatorio che in inibitorio. La struttura e il funzionamento dei neuroni costituiscono l’intero fondamento causale della nostra vita cosciente.
2.3
Storia
L’ampia varietà di modelli non può prescindere dal costituente di base, il neurone artificiale proposto da W.S.McCulloch e W.Pitts in un famoso lavoro del 1943, il quale schematizza un combinatore lineare a soglia, con dati binari multipli in entrata e un singolo dato binario in uscita: un numero opportuno di tali elementi, connessi in modo da formare una rete, è in grado di calcolare semplici funzioni booleane.
Nel 1958, F.Rosenblatt introduce il primo schema di rete neurale, detto "perceptron" (per-cettrone), precursore delle attuali reti neurali, per il riconoscimento e la classificazione di forme, allo scopo di fornire un’interpretazione dell’organizzazione generale dei sistemi bio-logici [1]. Il modello probabilistico di Rosenblatt è quindi mirato all’analisi, in forma mate-matica, di funzioni quali l’immagazzinamento delle informazioni, e della loro influenza sul riconoscimento dei patterns; esso costituisce un progresso decisivo rispetto al modello bina-rio di McCulloch e Pitts, perchè i suoi pesi sinaptici sono variabili e quindi il percettrone è in grado di apprendere.
L’opera di Rosenblatt stimola una quantità di studi e ricerche, e suscita un vivo interesse e notevoli aspettative nella comunità scientifica, destinate tuttavia ad essere notevolmente ridimensionate allorchè nel 1969 Marvin Minsky e Seymour A.Papert mostrano i limiti ope-rativi delle semplici reti a due strati basate sui percettroni, e dimostrano l’impossibilità di risolvere per questa via molte classi di problemi, ossia tutti quelli non caratterizzati da sepa-rabilità lineare delle soluzioni: questo tipo di rete neurale non è abbastanza potente, infatti non è in grado di calcolare neanche la funzione or esclusivo (XOR). [3] Di conseguenza, a causa di queste limitazioni, ad un periodo di euforia per i primi risultati della "cibernetica" (come veniva chiamata negli anni ’60), segue un periodo di diffidenza durante il quale tutte
le ricerche in questo campo non ricevono più alcun finanziamento dal governo degli Stati Uniti d’America e le ricerche sulle reti tendono, di fatto, a ristagnare per oltre un decennio, e l’entusiasmo iniziale risulta fortemente ridimensionato.
Il contesto matematico per addestrare le reti MLP (Multi-Layers Perceptron, ossia percet-trone multistrato) fu stabilito dal matematico americano Paul Werbos nella sua tesi di dot-torato del 1974. Uno dei metodi più noti ed efficaci per l’addestramento di tale classe di reti neurali è il cosiddetto "algoritmo di retropropagazione dell’errore" (error backpropa-gation), proposto nel 1986 da David E.Rumelhart, G. Hinton e R. J. Williams, il quale mo-difica sistematicamente i pesi delle connessioni tra i nodi, così che la risposta della rete si avvicini sempre di più a quella desiderata [4]. L’algoritmo di backpropagation (BP) è una tecnica d’apprendimento tramite esempi, costituente una generalizzazione dell’algoritmo d’apprendimento per il percettrone sviluppato da Rosenblatt [2] nei primi anni ’60.
2.4
Applicazioni
Le ANN vengono utilizzati in molte discipline scientifiche, in cui modelli analitico-matematici non sono disponibili oppure presentano una complessità eccessiva che li rende inutilizzabili. In questi casi, le ANN possono estrarre un modello empirico a partire dai dati sperimentali. In un certo senso possono essere considerati degli interpolatori: sulla base di una serie di informazioni sul comportamento di un certo sistema (informazioni spesso incomplete e/o in parte scorrette in quanto affette da errori sperimentali), una rete neurale artificiale può essere "allenata" su questi dati al fine di poter prevedere il risultato di nuovi esperimenti.
2.5
Esempi
Esempi classici di utilizzo degli ANN comprendono il pattern recognition / classification: questo compito consiste nell’assegnare un pattern in entrata (ad esempio un segnale acusti-co o un’immagine) ad una o più classi predefinite. Le applicazioni pratiche sono innumere-voli: classificazione dei segnali bioelettrici, riconoscimento della voce, riconoscimento di un volto in un’immagine, ecc. L’applicazione classica è il Data Mining, cioè l’analisi mi-nuziosa di banche dati enormi (es. dati sui clienti di una compagnia di assicurazioni) per trovare relazioni nascoste e correlazioni interessanti. Altri due esempi significativi sono la forecasting market prediction e le previsioni metereologiche: in questi due casi è neces-sario poter prevedere il comportamento futuro di un sistema conoscendo le osservazioni compiute nel passato.
2.6. CARATTERISTICHE 13
2.6
Caratteristiche
2.6.1 Insieme di apprendimento
L’insieme di apprendimento contiene l’informazione su ciò che la rete neurale dovrebbe fa-re. La rete neurale, infatti, dovrebbe acquisire esperienza dagli esempi facenti parte dell’in-sieme di apprendimento. A questo proposito, quindi, la rete neurale può essere considerala come un meccanismo di generazione di un modello di conoscenza basato sull’imitazione della struttura del cervello umano. Questo processo va rapportato all’ambito dell’intelligen-za artificiale, dove l’imitazione del cervello umano avviene a livello di macrostruttura. II problema di valutare se l’insieme di apprendimento contenga tutta l’informazione necessa-ria al compilo che deve essere realizzato non è stato ancora interamente risolto ed è inoltre collegato a quello della riduzione della ridondanza dei dati.
2.6.2 Algoritmo di apprendimento
L’algoritmo di apprendimento serve a elaborare ed inserire l’informazione contenuta nel-l’insieme di apprendimento nell’architettura della rete neurale, fissandone i parametri. In particolare l’apprendimento si articola in una sequenza di operazioni iterative, che nel gene-rico passo prevedono l’azione dell’ambiente esterno e la modifica convergente dei parame-tri della rete mediante un algoritmo opportuno. Anche in questo caso non è completamen-te risolto il problema di valutare l’efficienza dell’algoritmo circa la capacità di estrarre la suddetta informazione. Sono disponibili soltanto risultati parziali.
2.6.3 Architettura
La struttura della rete neurale con i parametri che mette a disposizione è per sua natura adatta a realizzare compiti specifici. Quindi, assegnato un certo compito, occorre utilizza-re un’architettura che ben si putilizza-resti al tipo di problema per risolverlo. Uno dei problemi posti dal tipo di architettura è l’eccessiva dimensionalità e ridondanza dei dati. Sono stati svilup-pati diversi tipi di architetture di reti neurali e nelle sezioni successive verranno trattati di modelli di maggior successo.
2.7
Modello generale
Tra i componenti principali del Modello generale di rete neurale troviamo: • un insieme di unità elaborative;
• uno stato di attivazione;
• le connessioni fra le unità;
• una regola di propagazione per propagare i valori; di output attraverso la rete di con-nessioni;
• una funzione di attivazione per combinare gli input con il valore di attivazione corren-te e produrre un nuovo livello di attivazione;
• una regola di apprendimento per modificare le connessioni.
2.7.1 Unità elaborative
Le unità elaborative sono semplici e uniformi e l’attività di una unità consiste nel ricevere un input da un insieme di unità connesse e calcolare un valore di output da inviare ad un altro insieme di unità connesse in output. Il sistema è intrisecamente parallelo poichè mol-te unità possono effettuare la loro computazione in modo concomitanmol-te generalmenmol-te si distinguono tre tipi di unità:
• unità di input; • unità di output; • unità interne (Hidden).
2.7.2 Stato di attivazione
Ogni unità è caratterizzata da un valore di attivazione al tempo t : ai(t) Modelli diversi
fanno assunzioni diverse circa i valori di attivazione che le unità possono assumere alterna-tivamente valori:
• discreti;
• binari (attivo/inattivo) es.: 0,1, +1,-1; • in un insieme ristretto es.: -1,0,+1, 1,2, ... 9; • continui;
• limitati es.: [0,1]; • illimitati [−∞, +∞].
2.7. MODELLO GENERALE 15
2.7.3 Funzione di output
Le unità interagiscono trasmettendo segnali ai loro vicini (unita connesse). La forza dei loro segnali, e quindi il grado di influenza esercitata sul vicini dipende dal loro grado di attiva-zione. Ogni unità ui ha associata una funzione di output fi(ai(t)) che trasforma il valore
corrente di attivazione ai(t) nel segnale in output
oi(t) : oi(t) = fi(ai(t)) (2.1)
In alcuni modelli il valore di output è uguale a quello di attivazione: f (x) = x. In altri mo-delli f è una funzione a soglia, cioè un’unità non influenza le altre se la sua attivazione non supera un certo valore, in altri ancora f è una funzione stocastica del valore di attivazione.
2.7.4 Connessioni fra unità
Le unità sono connesse in una struttura a rete (digrafo). È definita una matrice di connessio-ni W in cui ogconnessio-ni connessione wji è caratterizzata da:
• unità di partenza (j) • unità di arrivo (i)
• forza della connessione (numero reale): – wji> 0 connessione eccitatoria
– wji< 0 connessione inibitoria
– wji= 0 nessuna connessione
L’insieme delle connessioni costituisce la conoscenza della rete neurale e determina la sua risposta agli input. La memoria risiede nelle connessioni, le quali non sono programma-te ma apprese automaticamenprogramma-te. Vi possono essere diversi tipi di connessione (a, b, ...), ognuno dei quali rappresentato da una matrice di connessione (wa, wb, ...).
2.7.5 Regola di propagazione
È la modalità con cui gli output delle unità o(t) sono propagati attraverso le connessioni della rete per produrre i nuovi input. Se vi sono più tipi di connessioni diverse (es.: eccitato-rie, inibitoeccitato-rie, ...) la propagazione avviene indipendentemente per ogni tipo di connessione. Denominiamo netai(t) l’input di tipo a dell’unità -iesima.
2.7.6 Funzione di attivazione
È una funzione, F , che prende il valore corrente di attivazione a(t) e il vettore netkdi input
all’unità (k = tipo di connessione) e produce un nuovo valore di attivazione.
a(t + 1) = F (a(t), net1(t), net2(t), ...) (2.2)
In genere F è:
• una funzione a soglia;
• una funzione quasi-lineare (es: sigmoide); • una funzione stocastica.
2.7.7 Regola di apprendimento
Le reti neurali non sono programmate da un esperto umano ma si autodefiniscono median-te apprendimento automatico. L’apprendimento in una RN consismedian-te nella modifica delle connessioni effettuata mediante una regola di apprendimento. Vi possono essere tre tipi di modifiche:
1. la creazione di nuove connessioni; 2. la perdita di connessioni esistenti;
3. la modifica della forza di connessioni esistenti.
I casi 1 e 2 possono essere visti come casi particolari del caso 3.
La regola di apprendimento verrà approfondita in maniera esauriente durante la trattazione dell’algoritmo di Backpropagation.
2.8. FUNZIONAMENTO IN SINTESI 17
2.8
Funzionamento in sintesi
I nodi che compongono una rete neurale artificiale sono suddivisi in tre macro-categorie. Abbiamo i nodi appartenenti alla categoria delle unità di ingresso (Input); i nodi appar-tenenti alle unità di uscita (Output); infine i nodi delle unità nascoste (Hidden). Ognuna di queste unità svolge un compito molto semplice: attivarsi nel caso in cui la quantità to-tale di segnale che riceve (sia da un’altra unità sia dal mondo esterno) supera una certa soglia di attivazione. In questo caso emette a sua volta un segnale attraverso dei canali di comunicazione fino a raggiungere le altre unità cui è connessa.
La funzione di trasferimento del segnale nella rete non è programmata ma è ottenuta attra-verso un processo di apprendimento basato su dati empirici. Questo processo può essere supervisionato, non supervisionato o per rinforzo. Nel primo caso la rete utilizza un insie-me di dati di addestrainsie-mento grazie ai quali riesce a inferire i legami che legano questi dati e sviluppare un modello "generale". Questo modello verrà successivamente utilizzato per risolvere problemi dello stesso tipo.
Nel caso del processo di apprendimento non supervisionato, il sistema fa riferimento ad algoritmi che tentano di raggruppare i dati di ingresso per tipologia, individuando cluster rappresentativi dei dati stessi facendo uso tipicamente di metodi topologici o probabilistici. Nel processo per rinforzo un algoritmo si prefigge di individuare un modus operandi a par-tire da un processo di osservazione dell’ambiente esterno. In questo processo è l’ambiente stesso a guidare l’algoritmo nel processo di apprendimento.
2.9
Reti feedforward
Le reti neurali si basano principalmente sulla simulazione di neuroni artificiali opportuna-mente collegati.
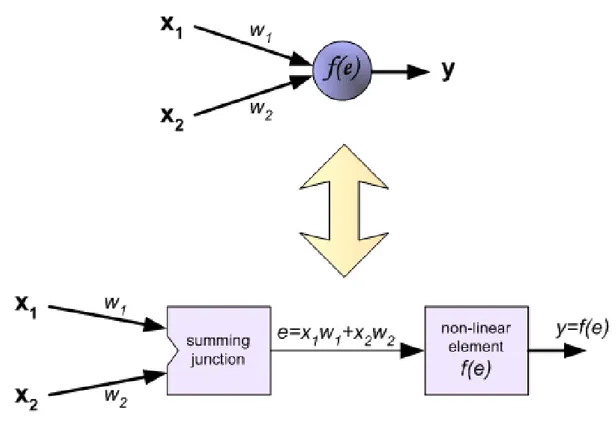
I suddetti neuroni ricevono in ingresso degli stimoli e li elaborano. L’elaborazione può es-sere anche molto sofisticata ma in un caso semplice si può pensare che i singoli ingressi vengano moltiplicati per un opportuno valore detto peso, il risultato delle moltiplicazioni viene sommato e se la somma supera una certa soglia il neurone si attiva attivando la sua uscita.
Il peso indica l’efficacia sinaptica della linea di ingresso e serve a quantificarne l’importan-za, un ingresso molto importante avrà un peso elevato, mentre un ingresso poco utile all’e-laborazione avrà un peso inferiore. Si può pensare che se due neuroni comunicano fra loro utilizzando maggiormente alcune connessioni allora tali connessioni avranno un peso mag-giore, fino a che non si creeranno delle connessioni tra l’ingresso e l’uscita della rete che sfruttano "percorsi preferenziali". Tuttavia è sbagliato pensare che la rete finisca col
produr-re un unico percorso di connessione: tutte le combinazioni infatti avranno un certo peso, e quindi contribuiscono al collegamento ingresso/uscita.
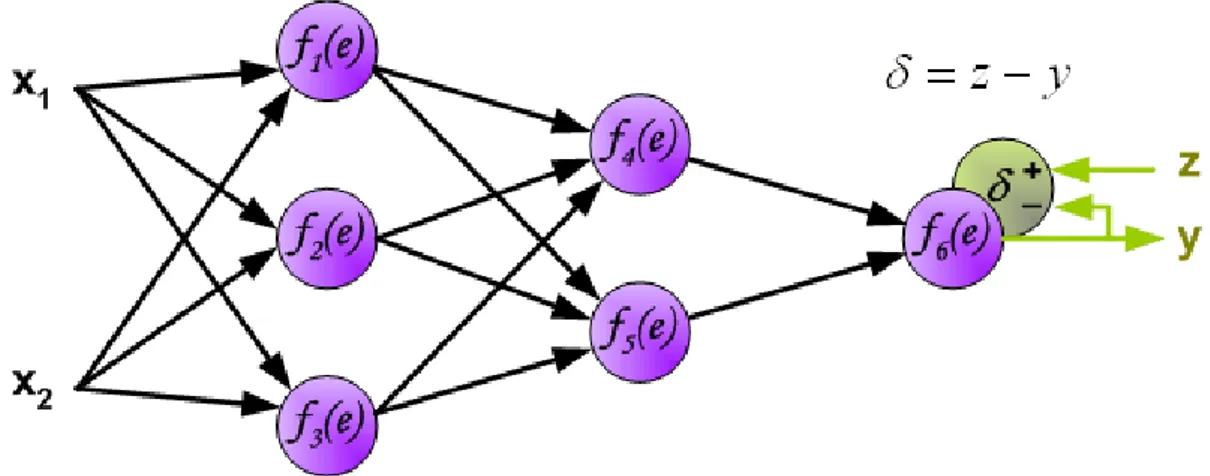
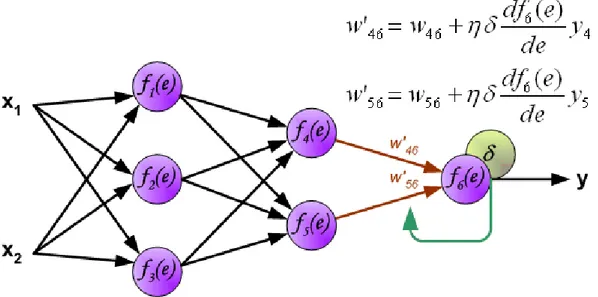
Le equazioni 2.3 e 2.4 rappresentano la formulazione matematica formale di quanto descrit-to precedentemente. Ogni livello avrà una propria variabile di indice: k per i nodi di uscita, j (e h) per i nodi nascosti e i per i nodi di input.
In una rete di avanzamento, il vettore di input x, viene propagato attraverso un layer di pesi V . θ è detto bias e può essere pensato come un settaggio della funzione di attivazione (per es. quando f (x) = x), o come un livello base di attivazione per l’output del neurone (per es. quando f (x) = sign(y) o f (x) = yΘ(y) dove Θ è la funzione di Heaviside).
In quest’ultima situazione, il valore −b rappresenta un valore di soglia che la somma pesata degli input deve superare affinché il dispositivo sia attivo (cioè che l’output sia positivo).
yj(t) = f (netj(t)) (2.3) netj(t) = n X i xi(t)vji+ θj (2.4)
n è il numero di ingressi, θjè un bias, e f è una funzione di output (di qualsiasi
differenzia-bile tipo).
L’uscita della rete è determinata dallo stato e da un insieme di pesi di output W :
yk(t) = g(netk(t)) (2.5) netk(t) = m X j yj(t)wkj+ θk (2.6)
dove g è una funzione di output (possibilmente uguale a f ).
I singoli neuroni vengono collegati alla schiera di neuroni successivi, in modo da formare una rete di neuroni. Normalmente una rete è formata da tre strati.
Nel primo abbiamo gli ingressi (I), questo strato si preoccupa di trattare gli ingressi in modo da adeguarli alle richieste dei neuroni. Se i segnali in ingresso sono già trattati può anche non esserci.
Il secondo strato è quello nascosto (H, hidden), si preoccupa dell’elaborazione vera e pro-pria e può essere composto anche da più colonne di neuroni.
Il terzo strato è quello di uscita (O) e si preoccupa di raccogliere i risultati ed adattarli alle richieste del blocco successivo della rete neurale. Queste reti possono essere anche molto complesse e coinvolgere migliaia di neuroni e decine di migliaia di connessioni.
Per costruire la struttura di una rete neurale multistrato si possono inserire N strati hidden; vi sono però alcune dimostrazioni che mostrano che con 1 o 2 strati di hidden si ottiene una
2.10. RETI RICORRENTI 19
stessa efficace generalizzazione da una rete rispetto a quella con più strati hidden. L’effica-cia di generalizzare di una rete neurale multistrato dipende ovviamente dall’addestramento che ha ricevuto e dal fatto di essere riuscita o meno ad entrare in un minimo locale buono.
Figura 2.3: Modello di base di una rete neurale feedforward
2.10
Reti ricorrenti
Una rete neurale ricorrente[8] (RNN) è una classe di rete neurale artificiale in cui i colle-gamenti tra unità formano un ciclo diretto. Questa architettura consente alla RN di avere comportamenti temporali dinamici. A differenza delle reti neurali senza stato, le RNN pos-sono utilizzare la propria memoria interna per elaborare sequenze arbitrarie di input. Ciò li rende applicabili a attività come il riconoscimento della scrittura a mano o il riconoscimen-to vocale non segmentariconoscimen-to. In una semplice rete ricorrente, il vetriconoscimen-tore di input è similmente propagato attraverso un layer di pesi, ma anche combinato con la precedente attivazione di stato attraverso un ulteriore layer di pesi ricorrente U :
yj(t) = f (netj(t)) (2.7) netj(t) = m X i xi(t)vji+ m X h yh(t − 1)ujh) + θj (2.8)
dove m è il numero dei nodi "di stato".
L’uscita della rete è determinata dallo stato e da un insieme di pesi di output W in modo equivalente a quanto descritto nella sezione precedente sulle reti neurali feedforward.
2.10.1 Breve storia
Le reti neurali ricorrenti sono state sviluppate negli anni ’80. Tra le prime architetture ricor-renti sono state sviluppate le reti Hopfield, inventate da John Hopfield nel 1982, e nel 1993 un sistema neurale compressore ha risolto un compito "molto profondo" che richiedeva più di 1000 livelli successivi in una RNN distribuita nel tempo.
Figura 2.4: Modello di una Recurrent Neural Network
Nel 1997, Hochreiter e Schmidhuber inventano le Long-Short-Term-Memory[11] che rag-giungono il record di precisione in più domini di applicazioni.
Intorno al 2007, le LSTM hanno iniziato a rivoluzionare il riconoscimento vocale, superan-do i modelli tradizionali in alcune applicazioni vocali. Nel 2009, le LSTM addestrate dalla CTC sono state il primo modello di RNN a vincere i concorsi di pattern-recognition, nel ri-conoscimento della scrittura a mano collegata. Nel 2014, il gigante cinese di ricerca Baidu ha utilizzato i RNN addestrati da CTC per superare il benchmark di riconoscimento vocale Switchboard Hub5’00, senza utilizzare metodi tradizionali di elaborazione vocale.
Le reti LSTM hanno inoltre migliorato il riconoscimento vocale, la sintesi text-to-speech, anche per Google Android. Nel 2015, le prestazioni del riconoscimento vocale di Google sono aumentate del 49% tramite le LSTM addestrato da CTC, utilizzato dalla ricerca vocale di Google.
Le LSTM hanno superato i record nella traduzione automatica, la modellazione linguistica e l’elaborazione della lingua multilingue.
Inoltre le LSTM combinate con reti neurali convolutive (CNNs) hanno migliorato la dida-scalia automatica delle immagini.
2.11
Principali architetture
2.11.1 Fully Recurrent
Le RNN di base sono una rete di nodi simili al neurone, ognuno con una connessione di-retta (unidirezionale) ad ogni altro nodo. Ogni nodo (neurone) ha un valore di attivazione reale dipendente dal tempo. Ogni connessione (sinapsi) ha un peso valorizzato da un nume-ro reale. I nodi sono: in ingresso (che ricevono dati dall’esterno della rete), nodi di output (forniscono i risultati) o nodi nascosti (che modificano i dati in elaborazione dall’ingresso all’uscita).
2.11. PRINCIPALI ARCHITETTURE 21
Nell’apprendimento supervisionato con configurazioni temporali discrete, sequenze di vet-tori di input validi in valore arrivano ai nodi di ingresso, un vettore alla volta. In un determi-nato periodo di tempo, ogni unità di non-input calcola la sua attivazione corrente (risultato) come funzione non lineare della somma ponderata delle attivazioni di tutte le unità che si collegano ad essa. Le attivazioni di target specificate dal supervisore possono essere fornite per alcune unità di output in determinati passaggi temporali. Ad esempio, se la sequenza di input è un segnale vocale corrispondente a una cifra vocale, l’output finale di destinazione alla fine della sequenza può essere un’etichetta che classifica la cifra.
Nelle configurazioni di apprendimento per rinforzo, una funzione "ricompensa" è occasio-nalmente utilizzata per valutare le prestazioni del RNN, che influenza il suo flusso di in-gresso attraverso unità di uscita collegate ad attuatori che influenzano l’ambiente. Questa configurazione potrebbe essere usata ad esempio per giocare una partita in cui il progresso viene misurato con il numero di punti vinti.
Ogni sequenza produce un errore come somma delle deviazioni di tutti i segnali delle attiva-zioni corrispondenti calcolate dalla rete. Per un training set di numerose sequenze, l’errore totale è la somma degli errori di tutte le sequenze individuali.
2.11.2 Recursive
Una rete neurale ricorsiva è una sorta di rete neurale creata applicando lo stesso insieme di pesi ricorsivamente su una data struttura, per produrre una predizione sulle strutture di input a grandezza variabile o scalare su di esso, visitando il percorso in ordine topologico. Le reti ricorsive hanno avuto successo, ad esempio, nell’apprendimento di sequenze e strutture ad albero nel Natural Language Processing, principalmente su rappresentazioni continue e frasi basate sull’integrazione di parole.
Le RNN ricorsive sono state introdotte per imparare rappresentazioni distribuite di struttura, come termini logici.
Modelli e quadri generali sono stati sviluppati in ulteriori opere[14] fin dagli anni ’90 tra cui le Recursive Neural Tensor Networks[13] (Richard Socher, Alex Perelygin, Jean Y. Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng & Christopher Potts, 2013) applicate al dataset Stanford Sentiment Treebank.
2.11.3 Long short-term memory
La Long Short-Term Memory (Hochreiter & Schmidhuber, 1997)[11] è un’architettura di rete neurale artificiale ricorrente (RNN), che consente ai dati di fluire sia in avanti che indie-tro all’interno della rete. La LSTM è universale nel senso che, date delle unità di rete suffi-cienti, permette calcolare tutti i risultati alla portata di un computer convenzionale, a condi-zione che abbia configurata una corretta matrice di pesi, che può essere considerata come il
Figura 2.5: Recursive Neural Network
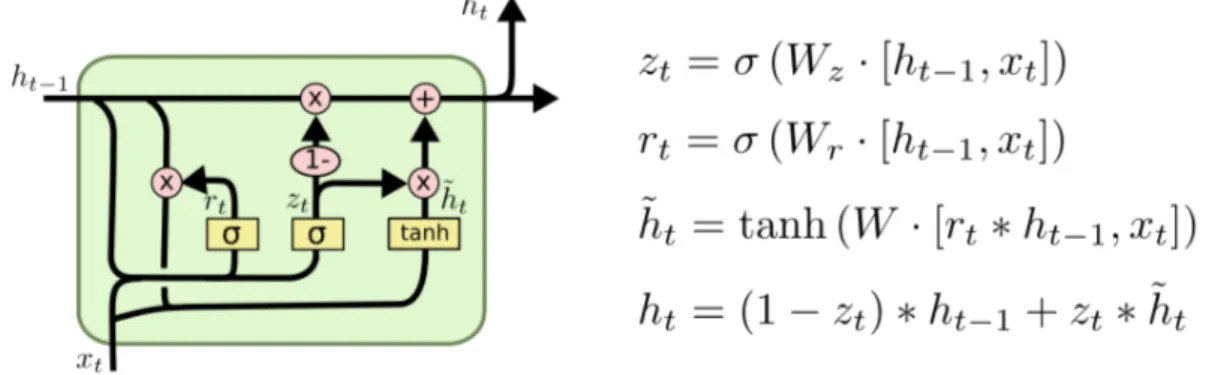
suo programma. Una LSTM è adatta ad imparare a classificare, elaborare e predire la serie temporale dati dei ritardi di tempo variabili compresi tra più eventi. L’insensibilità relativa alla lunghezza delle fessure offre un vantaggio alle LSTM sugli altri tipi di RNN, sui mo-delli di Markov e altri metodi di apprendimento sequenziale in numerose applicazioni[10]. Una rete LSTM contiene unità LSTM in aggiunta o in sostituzione ad altre unità elaborative convenzionali. Un’unità LSTM eccelle a ricordare i valori sia per periodi di tempo lunghi sia per periodi brevi. Il motivo principale di questo punto di forza delle LSTM è che non utilizzano alcuna funzione di attivazione all’interno dei suoi componenti ricorrenti. Pertan-to, il valore memorizzato non viene periodicamente trascinato verso lo 0 e il gradiente non tende a svanire nel tempo, quando viene addestrato con l’algoritmo di backpropagation. Le unità LSTM vengono spesso implementate in "blocchi" contenenti diverse unità. Questo design è tipico delle reti neurali e facilita le implementazioni con hardware parallelo. Nelle equazioni sottostanti, ogni variabile in corsivo minuscolo rappresenta un vettore con una lunghezza pari al numero di unità LSTM nel blocco.
Valori iniziali: c0= 0 e h0= 0. L’operatore ◦ rappresenta il prodotto di Hadamard.
ft= σg(Wfxt+ Ufht−1+ bf) (2.9)
it= σg(Wixt+ Uiht−1+ bi) (2.10)
2.11. PRINCIPALI ARCHITETTURE 23 ct= ft◦ ct−1+ it◦ σc(Wcxt+ Ucht−1+ bc) (2.12) ht= ot◦ oh(ct) (2.13) Variabili: • xt: vettore di input; • hT: vettore di output;
• ct: vettore di stato della cella;
• W, U e b: matrici dei pesi e vettore dei bias; • ft, ite ot: vettori dei gate
– ft: vettore del gate Forget;
– it: vettore del gate Input;
– ot: vettore del gate di output.
Funzioni di attivazione tradizionali • σg: funzione sigmoidea;
• σc: tangente iperbolica;
• σh: tangente iperbolica.
I blocchi LSTM contengono 3 o 4 gate che controllano il flusso di informazioni. Queste porte vengono implementate usando la funzione logistica per calcolare un valore compre-so tra 0 e 1. La moltiplicazione viene applicata con questo valore per consentire o negare parzialmente le informazioni che entrano o escono dalla memoria. Ad esempio, una porta "input" controlla la misura in cui un nuovo valore scorre nella memoria. Una porta "for-get" controlla la misura in cui un valore rimane in memoria. Una porta "output" controlla la misura in cui viene utilizzato il valore nella memoria per calcolare l’attivazione di uscita del blocco. (In alcune implementazioni, le porte di ingresso e di "forget" vengono fuse in un unico gate. La motivazione per combinare i due tipi di gate è che il momento in cui di-menticare un valore coincide al momento in cui viene reso disponibile un valore nuovo da memorizzare.)
I pesi in un blocco LSTM (W e U ) vengono utilizzati per dirigere il funzionamento delle porte. Questi pesi sono utilizzati quando i valori che entrano nel blocco (compreso il vettore di input xte l’output precedente al passo ht−1) e in ciascuna delle porte. In questo modo,
il blocco LSTM determina come mantenere la propria memoria in funzione di tali valori e l’addestramento dei suoi pesi insegna al blocco la funzione che minimizza l’errore tra input e output desiderato.
Figura 2.6: Modello tradizionale LSTM
2.11.4 Gated recurrent unit
Le Gated recurrent unit (GRUs) sono un meccanismo di gating in reti neurali ricorrenti, introdotte nel 2014. La loro performance sulla modellazione polifonica e la modellazione del segnale vocale è stata simile a quella delle LSTM. Hanno meno parametri rispetto a LSTM, poichè mancano di una porta di uscita. Combina i gate Forget e Input in una singolo "Update Gate". Inoltre unisce lo stato della cella e lo stato nascosto e apporta alcune altre modifiche. Il modello risultante è più semplice dei modelli standard LSTM e sta diventando sempre più popolare.
2.11. PRINCIPALI ARCHITETTURE 25
2.11.5 Bi-directional
Le RNN bidirezionali utilizzano una sequenza finita per predire o etichettare ogni elemento della sequenza in base ai contesti passati e futuri dell’elemento. Ciò avviene concatenando le uscite di due RNN, una che tratta la sequenza da sinistra a destra, l’altra da destra a sini-stra. Le uscite combinate sono le previsioni dei segnali target forniti dal supervisore. Questa tecnica è risultata particolarmente utile quando è combinata con le LSTM.
2.11.6 Convolutional Neural Networks
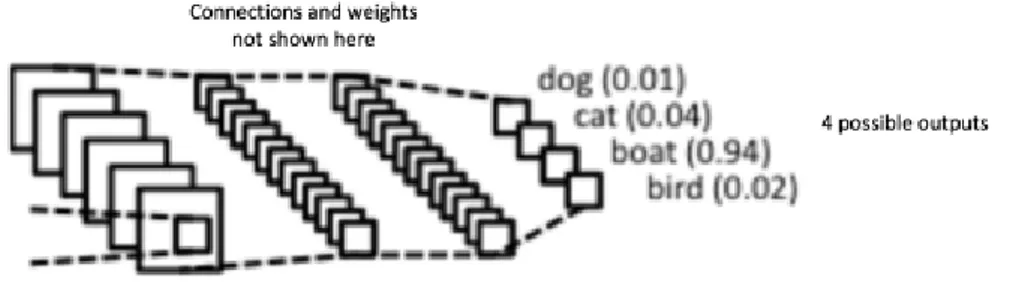
Le reti neurali convoluzionali (ConvNets o CNN) sono una categoria di reti neurali che si sono dimostrate molto efficaci in settori quali il riconoscimento e la classificazione delle immagini. I ConvNets sono riusciti a identificare facce, oggetti e segni di traffico, oltre a supportare la visione in robot e autovetture. Ultimamente, i ConvNets sono stati efficaci in diverse attività di elaborazione del linguaggio naturale[12] (come la classificazione di frasi[15] in Figura 2.14). ConvNets, quindi, sono uno strumento importante per la maggior parte dei praticanti del Machine Learning oggi.
LeNet è stata una delle prime reti neuronali convoluzionali che hanno contribuito all’evolu-zione del campo del Deep Learning. L’architettura LeNet è stata utilizzata principalmente per attività di riconoscimento dei caratteri come la lettura di codici postali, cifre, ecc. La rete neurale convoluzionale in Figura 2.9 è simile in architettura al LeNet originale e classifica un’immagine di input in quattro categorie: cane, gatto, barca o uccello (il LeNet originale è stato utilizzato principalmente per attività di riconoscimento dei caratteri). Come evidente dalla figura precedente, quando riceve un’immagine barca come input, la rete as-segna correttamente la più alta probabilità per la barca (0.94) tra tutte e quattro le categorie. La somma di tutte le probabilità nel livello di output deve essere 1.
Le ConvNet si basano su 4 principali operazioni mostrate in Figura 2.9: 1. Convoluzione
2. Funzione di attivazione non lineare (ReLU) 3. Pooling o Sub Sampling
4. Classificazione (Fully Connected Layer)
Queste operazioni sono i blocchi fondamentali di ogni CNN, per questo ne forniremo una spiegazione in modo intuitivo al fine di comprendere il funzionamento di questo tipo di reti neurali.
2.11. PRINCIPALI ARCHITETTURE 27
Convolution Step Le ConvNets devono il loro nome all’operatore "convolution". Lo sco-po principale di Convolution in caso di una ConvNet è quello di estrarre le features dal-l’immagine di input. La convoluzione conserva la relazione spaziale tra i pixel imparando le funzioni dell’immagine usando piccoli quadrati di dati di input. Non ci addentreremo nei dettagli matematici della Convoluzione, ma cercheremo di capire come funziona sulle immagini.
Ogni immagine può essere considerata come una matrice di valori di pixel: per esempio si consideri un’immagine 5 x 5 i cui valori di pixel sono solo 0 e 1 (si noti che per un’imma-gine in scala di grigi, i valori dei pixel vanno da 0 a 255, la matrice verde sotto è un caso speciale dove i valori dei pixel sono solo 0 e 1):
Inoltre, si consideri anche la matrice 3 x 3 seguente:
Dunque, la convoluzione dell’immagine 5 x 5 e della matrice 3 x 3 può essere calcolata come mostrato dal primo passo dell’operazione nella Figura 2.10:
Figura 2.10: L’operatore di convoluzione. La matrice di output è chiamata Convolved Feature o Feature Map
La matrice arancione viene traslata sull’immagine originale (verde) di un pixel (chiamato anche "stride") e per ogni posizione, viene calcolata la moltiplicazione per elemento (tra
le due matrici) ed i prodotti vengono sommati per ottenere un l’intero finale che forma un singolo elemento della matrice di output (rosa). Si noti che la matrice 3 x 3 viene applica-ta solo ad un parte dell’input ad ogni "stride". Nella terminologia delle CNN, la matrice 3 x 3 è chiamata "filtro" o "nucleo" o "feature detector" e la matrice costruita applicando in successione il filtro sull’immagine e calcolando il prodotto scalare è chiamata "Convolved Feature" o "Activation Map" o "Feature Map". È importante notare che i filtri fungono da feature detectors dell’immagine in input originale.
È evidente che valori diversi della matrice di filtro produrranno diverse Feature Maps per la stessa immagine di input. È importante notare che l’operatore di convoluzione cattura le di-pendenze locali nell’immagine originali: in pratica, una CNN impara i valori di questi filtri da sé durante il processo di training (sebbene sia necessario specificare parametri come il numero di filtri, la dimensione dei filtri e l’architettura della rete prima dell’addestramento). Più filtri abbiamo, più caratteristiche dell’immagine vengono estratte e meglio la nostra rete riconosce immagini mai viste prima.
La dimensione della mappa delle funzionalità (Feature Map) è controllata da tre parametri che dobbiamo decidere prima della fase di convoluzione:
• Profondità: corrisponde al numero di filtri utilizzati per l’operazione di convoluzione. • Stride: è il numero di pixel con cui scorriamo la nostra matrice di filtro sulla matrice
di input. Quando il passo è 1, spostiamo i filtri un pixel alla volta. Quando il passo è 2, i filtri salgono due pixel alla volta mentre li scorriamo. Avere un passo più grande produrrà mappe di funzionalità più piccole.
• Zero-padding: a volte è conveniente applicare la matrice di input con zeri intorno al bordo, in modo da poter applicare il filtro a elementi ai bordi della nostra matrice di immagini di input. Una caratteristica utile del zero padding è che ci permette di controllare la dimensione delle mappe delle funzioni. L’aggiunta del zero-padding è anche chiamata wide convolution, e non utilizzando lo zero-padding può essere pensata come una convoluzione ridotta.
Introducing Non Linearity (ReLU) Una operazione aggiuntiva denominata ReLU è stata utilizzata dopo ogni operazione di Convoluzione nella Figura 2.9. ReLU rappresenta l’unità lineare rettificata ed è un’operazione non lineare. Il suo output è dato da:
ReLU è un’operazione applicata elemento per elemento (pixel per pixel in questo caso) e sostituisce tutti i valori dei pixel negativi nella mappa delle funzioni con il valore zero. Lo scopo di ReLU è quello di introdurre la non linearità nel nostro ConvNet poiché la maggior parte dei dati del mondo reale che vorremmo che la nostra ConvNet imparasse sarebbe non
2.11. PRINCIPALI ARCHITETTURE 29
Figura 2.11: L’operatore ReLU
lineare (la Convoluzione è un’operazione lineare così come la moltiplicazione e somma di matrici, quindi si introduce una funzione non lineare come ReLU).
Anche altre funzioni non lineari come la tangente iperbolica o la sigmoide possono essere utilizzate anziché ReLU, ma ReLU si è dimostrata più efficace nella maggior parte delle situazioni.
Pooling Step Lo Spatial Pooling (anche chiamato subsampling or downsampling) ri-duce la dimensionalità di ogni mappa delle funzionalità ma mantiene le informazioni più importanti. Il pooling nello spazio può essere di diversi tipi: Max, Media, Somma, ecc. Nel caso di Max Pooling, si definisce un intorno nello spazio (ad esempio una finestra 2x2) e si prende l’elemento più grande dalla mappa funzionale rettificata all’interno di quella finestra. Invece di prendere l’elemento più grande possiamo anche prendere la media (Ave-rage Pooling) o la somma di tutti gli elementi in quella finestra. Nella pratica, Max Pooling ha dimostrato di funzionare meglio.
La Figura 2.12 mostra un esempio di operazione Max Pooling su una Rectified Feature map (ottenuta applicando la convoluzione + l’operazione ReLU) usando una finestra 2x2. La funzione di Pooling consiste nel ridurre progressivamente la dimensione della rappresen-tazione dell’ input rendendola più piccola e gestibile. Questa operazione riduce il numero di parametri e calcoli della rete, controllando quindi l’overfitting. Rende la rete invariante a piccole trasformazioni e distorsioni nell’immagine di input (una piccola distorsione dell’in-gresso non cambierà l’output di Pooling - poiché prendiamo il valore massimo/medio in una finestra locale). Il Pooling quindi ci aiuta ad arrivare ad una rappresentazione quasi inva-riante della nostra immagine: in questo modo possiamo rilevare gli oggetti in un’immagine indipendentemente da dove si trovano.
Fully Connected Layer Il livello Fully Connected è un tradizionale Percettrone Multi Layer che utilizza una funzione di attivazione softmax nel livello di output (altri classifica-tori come SVM possono essere usati, ma useremo Softmax). Il termine "Fully Connected"
Figura 2.12: Max Pooling
implica che ogni neurone nello strato precedente sia collegato ad ogni neurone sul livello successivo.
L’output dei livelli convoluzionali e di pooling rappresentano le caratteristiche di alto li-vello dell’immagine di input. Lo scopo del lili-vello Fully Connected è di utilizzare queste funzionalità per classificare l’immagine di input in varie classi in base al set di dati di adde-stramento. Ad esempio, l’attività di classificazione dell’immagine che abbiamo impostato dispone di quattro possibili uscite come mostrato nella Figura 2.13 (si noti che la Figura 2.13 non mostra le connessioni tra i nodi del livello Fully Connected).
Figura 2.13: Livello Fully Connected - ogni nodo è connesso ad ogni altro nodo nel livello adiacente
Oltre alla classificazione, aggiungere un livello completamente collegato è anche un modo (di solito) economico per imparare combinazioni non lineari di queste funzionalità.
2.11. PRINCIPALI ARCHITETTURE 31
La maggior parte delle funzionalità degli strati convoluzionali e di pooling può essere utile per l’attività di classificazione, ma le combinazioni di queste funzionalità potrebbero essere ancora migliori.
La somma delle probabilità di uscita dal livello Fully Connected è 1. Ciò è garantito uti-lizzando Softmax come funzione di attivazione nel livello di uscita. La funzione Softmax prende un vettore di punteggi arbitrari di valori reali e lo trasforma in un vettore di valori tra zero e uno la cui somma è uno.
Figura 2.14: Convolutional Neural Network per la Sentiment Classification
2.11.7 Neural Turing machines
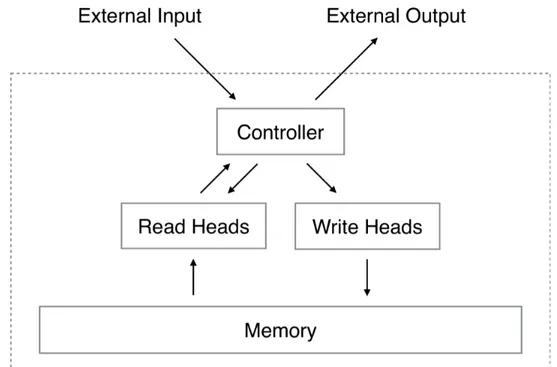
Le Neural Turing Machines (Alex Graves, Greg Wayne & Ivo Danihelka, 2014)[23] com-binano le capacità di matching dei modelli delle reti neurali con la potenza algoritmica dei computer programmabili. Una NTM ha un controller della rete neurale accoppiato a risorse di memoria esterne, che interagisce con i meccanismi di focus dell’attenzione. I meccani-smi di interazione con la memoria sono differenziabili, permettendo di ottimizzare il siste-ma usando la discesa di gradiente. Una NTM con un controller di rete LSTM può inferire semplici algoritmi quali la copia, l’ordinamento dagli esempi di input e di output.
I Differential Neural Computers rappresentano un’evoluzione delle Neural Turing Machi-nes. Sono dotati meccanismi di attenzione che controllano dove la memoria è attiva ed in generale raggiungono prestazioni migliori.
2.11.8 Memory Networks
L’architettura delle Memory Networks (Jason Weston, Sumit Chopra & Antoine Bordes, 2015)[24] combina componenti inferenziali a componenti di memoria a lungo termine.