Facolt`
a di Scienze Matematiche Fisiche e Naturali
Corso di laurea specialistica in Informatica
Tesi di laurea
Active learning per
estrazione dell’informazione
Laureando:
Diego Marcheggiani
Relatori:
Dott. Andrea Esuli
Dott. Fabrizio Sebastiani
Controrelatore:
Dott. Vincenzo Gervasi
L’active learning si occupa di definire una funzione di ranking che, dato un classificatore derivato da relativamente pochi esempi di training, ordina un insieme di esempi non etichettati in termini di quanta informazione ciascuno apporterebbe, a una fase di re-training che cerchi di ottenere un classificatore migliore. In questa tesi proponiamo e testiamo alcune strategie realistiche di active learning per information extraction, e in particolare per il subtask della named entity recognition. Ogni strategia consiste in una regola che prende gli output del classificatore per ogni singola occorrenza di parola (“token”), li combina creando un valore per la frase a cui i token appartengono, e ordina le frasi non etichettate in base al valore che esse hanno ricevuto. Presentiamo i risultati di alcuni esperimenti sul corpus CoNLL 2003, uno dei corpora standard per la sperimentazione sulla named entity recognition.
Questa tesi `e stato un nostro grande traguardo, considerando che la nostra carriera universitaria `e iniziata quasi per prova, senza nessuna pretesa, ab-biamo pensato:“chiss`a che succede?”. E’ successo che siamo andati avanti, a volte lentamente, altre volte pi`u spediti, e siamo arrivati qui, a Pisa, e dall’arrivo alla tesi il passo `e stato breve, o no? In questo periodo passato da studente fuori sede le persone da ringraziare sono diverse, ringraziamo Fabrizio e Andrea che ci hanno accompagnato praticamente per mano nella storia raccontata nel volume che state leggendo, ringraziamo pap`a e mamma che hanno sempre creduto in noi, ringraziamo Fabio e Monica che sperano ancora che mettiamo la testa sulle spalle, ringraziamo la postina, la prima a dire:“ma vai a studiare fuori no?!”, ringraziamo Laura per il suo inestimabile aiuto, ringraziamo tutti gli amici di Todi, e infine ringraziamo casapiddu, la ringraziamo di quasi 3 anni di vita insieme, la ringraziamo perch´e senza casapiddu, probabilmente, non saremmo arrivati fin qui.
1 Introduzione 6 1.1 Estrazione dell’informazione . . . 7 1.2 Active Learning . . . 8 1.3 Obiettivi . . . 9 1.4 Panoramica . . . 9 2 IE e AL 10 2.1 Estrazione dell’informazione . . . 10
2.1.1 Breve storia dell’estrazione dell’informazione . . . 12
2.1.2 Named entity recognition . . . 14
2.1.3 Coreference . . . 15
2.1.4 Relationship extraction . . . 16
2.2 Active Learning . . . 17
2.2.1 Dati di training limitati . . . 18
2.2.2 Active learning . . . 18
2.2.3 Algoritmo canonico di active learning . . . 21
2.2.4 Valutazione . . . 25
3 Tools 28 3.1 YamCha e SVM . . . 28
3.1.1 Support vector machine . . . 28
3.1.2 YamCha . . . 29
3.2 CoNLL 2003 e Preprocessing . . . 30
3.2.1 CoNLL . . . 31 3.2.2 Corpus CoNLL 2003 . . . 31 3.2.3 Preprocessing . . . 34 4 Strategie di AI per IE 36 4.1 Dimensioni . . . 37 4.1.1 La dimensione Evidence . . . 37 4.1.2 La dimensione Class . . . 38 4.1.3 Round Robin . . . 40 4.2 Esperimenti . . . 41 4.2.1 Protocollo utilizzato . . . 41 4.2.2 Baseline . . . 43 4.3 Metodi di valutazione . . . 43 4.3.1 Misure annotation-based . . . 44 4.3.2 Misure token-based . . . 46 4.4 Altre politiche . . . 48
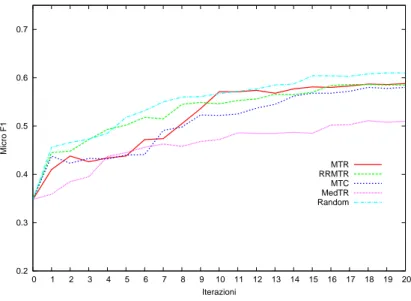
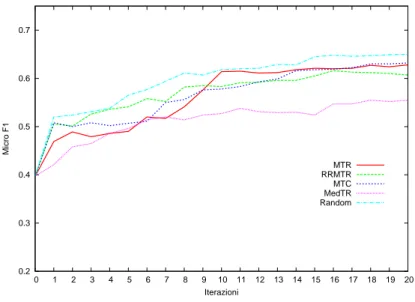
4.4.1 Max Tag Ratio . . . 48
4.4.2 Round Robin Max Tag Ratio . . . 49
4.4.3 Max Tag Count . . . 49
4.4.4 Medium Tag Ratio . . . 50
4.5 Risultati . . . 50
5 Conclusioni 70
Introduzione
Molti problemi di classificazione automatica sono tipicamente affrontati usan-do un modello di apprendimento supervisionato. L’apprendimento supervi-sionato consiste nel fornire a un algoritmo di apprendimento un insieme di esempi detto training set, ciascuno rappresentato da un vettore di input che rappresenta “il significato” dell’esempio in modo compatto e un output che rappresenta la classe o le classi di appartenenza. Questi verranno utilizza-ti dall’algoritmo per generare un classificatore; l’algoritmo apprende dagli esempi classificati (o “etichettati”) le caratteristiche che un esempio deve avere per poter appartenere alla classe.
Il risultato dell’apprendimento `e un classificatore che prende in input un insieme di esempi di test, dello stesso tipo di quelli di training; detto test set, che devono essere classificati, e li restituisce classificati, cio`e con associato un valore di output predetto dal classificatore.
Un problema tipico di molte applicazioni di apprendimento supervisiona-to `e la scarsit`a di esempi di training. Per risolvere quessupervisiona-to problema `e utile utilizzare un algoritmo che prende in input un insieme di esempi non eti-chettati, quindi facilmente reperibili, li ordina, e successivamente chiede a un annotatore umano di etichettarne alcuni, iniziando da quelli in cima alla li-sta. Il compito di questo algoritmo `e quindi quello di ordinare gli esempi non etichettati in termini di quanto possono essere utili, una volta etichettati, al
“ri-allenamento” del classificatore. Questa tecnica `e chiamata comunemente active learning. In questa tesi studiamo il problema dell’active learning per l’estrazione dell’informazione.
1.1
Estrazione dell’informazione
L’estrazione dell’informazione pu`o essere considerata una branca dell’information retrieval. Il suo obiettivo `e di estrarre informazioni strutturate da documen-ti non strutturadocumen-ti, come ad esempio estrarre nomi di persone o di endocumen-tit`a geografiche da articoli scritti in linguaggio naturale.
La maggior parte dei sistemi di estrazione dell’informazione ricadono in due grandi categorie: i sistemi basati su regole scritte a mano e quelli basati su apprendimento supervisionato. I sistemi basati su regole scritte a mano, come dice il nome stesso, sono sistemi le cui regole di estrazione sono state scritte da un esperto del dominio applicativo. Solitamente i sistemi basati su regole scritte a mano vengono sviluppati per domini molto specifici, quindi la loro portabilit`a `e altamente limitata dalle regole stesse. Ci si trova dunque di fronte a un serio problema, detto knowledge acquisition bottleneck. Infatti per domini diversi da quello per quale il sistema `e stato progettato `e necessario scrivere manualmente un nuovo insieme di regole.
Una soluzione a questo tipo di problema viene offerto dalle tecniche di apprendimento automatico, attraverso l’apprendimento supervisionato. Un sistema di estrazione dell’informazione pu`o essere prodotto a partire da un set di training di esempi etichettati. In questo modo l’apprendimento su-pervisionato abbassa notevolmente il costo di costruzione di un sistema di estrazione dell’informazione, dato che non si ha pi`u la necessit`a di regole ad hoc, ci`o permette risparmi considerevoli e aumenta la produttivit`a del personale coinvolto.
Anche l’apprendimento supervisionato ovviamente ha delle limitazioni. Infatti il suo funzionamento richiede una notevole disponibilit`a di dati di training etichettati. In molte applicazioni dell’estrazione dell’informazione
c’`e abbondanza di dati non etichettati ma non di dati etichettati, visto il costo insito nell’etichettarli manualmente. Il fenomeno della scarsit`a di dati etichettati prende il nome di label acquisition bottleneck. Ad esempio, ottene-re una insieme di pagine web `e poco costoso, e possono esserne collezionate migliaia in poche ore, ma etichettare tutte queste pagine richiede un grande impiego di tempo e risorse.
Applicare quindi l’apprendimento supervisionato su questi tipi di dominio `e a volte difficile. Una possibile soluzione al label acquisition bottleneck `e proprio la tecnologia che si affronta in questa tesi, e cio`e l’active learning.
1.2
Active Learning
Le tecniche di apprendimento supervisionato danno per scontata la dispo-nibilit`a di un alto numero di dati etichettati. I dati di training forniti al-l’algoritmo di apprendimento supervisionato sono costruiti etichettando ma-nualmente un vasto numero di esempi non etichettati. Nella realt`a il costo di generare un corpus di materiale di training utilizzabile dagli algoritmi di apprendimento supervisionato `e alto. Gli esempi non etichettati sono invece poco costosi e facilmente reperibili.
Gli alti costi di etichettatura restringono i domini di applicazione dell’ap-prendimento automatico ai domini in cui i dati etichettati sono abbondanti. L’active learning `e una tecnica di apprendimento automatico usata per pro-durre un sistema di classificazione accurato partendo da un relativamente piccolo insieme di esempi etichettati.
L’algoritmo di active learning costruisce sequenzialmente, in collabora-zione con un annotatore umano, l’insieme di dati di training etichettati, or-dinando un insieme di dati non etichettati in termini di quanto informativi essi sarebbero, una volta etichettati, se aggiunti al training set. L’algoritmo, secondo le strategie che vengono utilizzate, esegue un ranking degli esem-pi esem-pi`u informativi; successivamente viene richiesto all’annotatore umano di etichettarne alcuni (il pi`u possibile) partendo dalla cima del ranking. Una
volta finito il processo di apprendimento, si ha un training set composto da tutti esempi molto informativi, che riesce a generare un classificatore usando relativamente pochi esempi etichettati, e quindi con un dispendio di risorse limitato rispetto al processo tradizionale di apprendimento supervisionato.
1.3
Obiettivi
In questa tesi affrontiamo il problema di migliorare (rendere pi`u efficiente) il processo di generazione di corpora annotati per estrazione dell’informazione tramite l’uso di tecniche di active learning, ispirandoci principalmente alla metodologia introdotta da Esuli e Sebastiani [3] per un’altra applicazione di apprendimento supervisionato, cio`e la classificazione di testi multietichetta.
Proponiamo e testiamo alcune strategie realistiche di active learning per information extraction, e in particolare per il subtask della named entity recognition.
Ogni strategia consiste in una regola che prende gli output del classifica-tore per ogni singola occorrenza di parola (“token”), li combina creando un valore per la frase a cui i token appartengono, e ordina le frasi non etichettate in base al valore che esse hanno ricevuto.
1.4
Panoramica
Nei prossimi capitoli descriviamo come abbiamo sviluppato l’intero sistema. Nel Capitolo 2 presenteremo una panoramica su cosa sono l’estrazione del-l’informazione e l’active learning. Nel Capitolo 3 illustreremo gli strumenti e il corpus utilizzati per la sperimentazione, mentre nel Capitolo 4 descri-veremo in dettaglio le politiche di active learning che abbiamo sviluppato e testato e i metodi di valutazione che abbiamo adottato. Nell’ultimo capitolo trarremo alcune conclusioni.
Estrazione dell’informazione e
active learning
2.1
Estrazione dell’informazione
L’estrazione dell’informazione `e composta da diversi subtask che vanno a indagare sui diversi tipi di informazione contenuti in un testo. In questa sezione sono descritti i vari subtask di estrazione dell’informazione e si chia-rificano la relazione tra estrazione dell’informazione e i task di elaborazione del linguaggio naturale. In generale l’output di un processo di estrazione dell’informazione pu`o essere o un annotazione inserita nel documento origi-nale, oppure dei collegamenti tra annotazioni, che indicano se esiste qualche legame tra due entit`a (per esempio collegamenti tra il soggetto e il verbo in una frase).
L’estrazione dell’informazione si muove in un ampio spettro di documenti con diversi tipi di strutture, che possono essere categorizzati partendo da quelli rigidamente strutturati come i documenti HTML, a testi di linguaggio naturale senza nessuna struttura. Iniziando dai pi`u strutturati, incontriamo i testi strettamente formattati come l’HTML, in casi come questo, l’estrazione dell’informazione pu`o essere effettuata tramite una tecnica di apprendimento automatico detta wrapper induction [5] (WI). La WI `e spesso utilizzata su
documenti altamente strutturati come cataloghi, liste di risultati di motori di ricerca, etc. In molti casi di applicazione di WI, le strutture da estrarre sono definite facilmente; infatti essa `e spesso applicata su testi di tipo HTML o XML, e i risultati che si ottengono sono spesso molto accurati.
Subito dopo i documenti pi`u strutturati troviamo i testi di linguaggio naturale strutturati, come per esempio gli annunci per offerte di lavoro, dove solitamente `e impiegato un linguaggio con un ristretto vocabolario e sintassi telegrafica, che semplifica notevolmente il processo di estrazione. All’estremo opposto dei documenti altamente strutturati troviamo i testi di linguaggio naturale, poco o per niente strutturati, come gli articoli di giornale. Questi documenti sono caratterizzati da una notevole complessit`a semantica e sin-tattica che complica il processo di estrazione. Dall’altro lato per`o possono essere applicate tecniche di elaborazione del linguaggio naturale, viste le pro-priet`a grammaticali che un testo in linguaggio naturale possiede. Per esempio il POS tagging `e una di quelle informazioni che possono essere aggiunte ai token di un testo appartenente a questa categoria. Aggiungendo informa-zioni come il POS o il chunk si riesce a migliorare il processo di estrazione. Un task che ha a che fare con questo tipo di documenti `e l’Opinion Mining, e pi`u precisamente l’Opinion Extraction (OE), che cerca di identificare nel testo ogni espressione di soggettivit`a, come per esempio un parere, il soggetto che esprime questo parere, e l’oggetto a cui il parere `e riferito. L’OE appare essere un task pi`u difficile di uno qualsiasi di estrazione dell’informazione, questo perch´e le opinioni, e in generale la soggettivit`a, possono essere espres-se in moltissimi modi. Infatti `e cosa non ovvia dare una forma strutturata alle espressioni di opinione, visti i molteplici modi con cui la soggettivit`a `e espressa. Per esempio ognuna delle seguenti frasi esprime un’opinione simile, ma ognuna differisce dall’altra nel modo in cui l’opinione `e espressa:
1. X is good.
2. Y scares me.
4. I believe X is faster than Y.
La frase 1 assegna esplicitamente una valutazione positiva all’oggetto X, usando l’aggettivo good. La frase 2 non assegna nessuna propriet`a a Y ma riporta un’emozione (negativa) di Y. Le frasi 3 e 4 fanno un confronto tra X e Y, ma come si pu`o ben vedere la soggettivit`a `e espressa in maniera dif-ferente. Nella frase 3 la soggettivit`a `e espressa dall’aggettivo comparativo better mentre nella frase 4 la soggettivit`a non `e data da faster ma dal verbo believe che indica non una comparazione oggettiva, ma un opinione di chi ha scritto la frase.
2.1.1
Breve storia dell’estrazione dell’informazione
Il primo importante passo nell’estrazione dell’informazione `e stato il Message Understanding Conference (MUC), dove oltre a venir definita una metodolo-gia di valutazione dei sistemi di estrazione dell’informazione, si sono dati altri importanti contributi a questa disciplina: la disponibilit`a di un grande quan-tit`a di dati annotati, l’enfasi sull’indipendenza dal dominio e la portabilit`a, e l’identificazione di un numero differente di task che possono essere valutati separatamente. In particolare il MUC rese disponibili corpora annotati per training e testing, insieme a un software di valutazione. Al MUC-7 sono stati definiti e valutati i seguenti task:
• Named Entity consiste nell’identificare persone (PERSON), luoghi (LO-CATION), e nomi di organizzazione (ORG), ma anche espressioni tem-porali, date e quantit`a monetarie.
• Coreference consiste nel trovare espressioni che si riferiscono a entit`a equivalenti nel testo, include name coreference (Microsoft
Corporation e Microsoft), definite reference (the Seattle-based company) e pronominal reference (it, she, he).
• Template Element consiste nell’identificare le entit`a principali (persone, organizzazioni, luoghi), con un template per ogni entit`a che include: il
nome dell’entit`a, alias o forme abbreviate del nome e una corta frase descrittiva utile a caratterizzarlo. I template costituiscono la base per costruire relazioni che vengono estratte dai task successivi: Template Relation e Scenario Template.
• Template Relation consiste nell’identificare le propriet`a dei Templa-te Elements o relazioni tra questi (ad esempio empolyeeOf metTempla-te in relazione un persona con un organizzazione, locatioOf connette orga-nizzazioni e luoghi).
• Scenario Template consiste nell’estrazione di eventi predefiniti e il col-legamento di questi con una particolare organizzazione, persona, o artefatti coinvolti nell’evento.
Recentemente, il National Institute of Standard and Technology (NIST) ha indetto un nuovo programma, Automatic Content Extraction (ACE), l’o-biettivo del programma ACE `e lo sviluppo di una tecnologia di estrazione dei contenuti per supportare l’elaborazione automatica del linguaggio uma-no in forma di testo. I corpora utilizzati nel programma includouma-no uma-notizie, conversazioni, blog, forum di discussione, newsgroup e conversazioni telefo-niche. Gli obiettivi dell’ACE sono la scoperta e la caratterizzazione di entit`a (Entity Detection and Recognition, EDR), relazioni (Relation Detection and Recognition, RDR), e eventi (Event Detection and Recognition, VDR). In ognuno di questi task, dopo aver determinato tipi di entit`a, relazioni o even-ti, che sono menzionati nei dati sorgente, questi devono essere riconosciueven-ti, e insieme a informazioni collegate a essi devono esser raggruppati in un unica rappresentazione.
• Entity Detection and Recognition (EDR) `e il task principale su cui si basano tutti i successivi. L’obiettivo di questo task `e identificare set-te tipi di entit`a: Persone, Organizzazioni, Luoghi, Attrezzature, Armi, Veicoli e Entit`a Geopolitiche. Ogni tipo pu`o essere suddiviso in sotto-categorie, per esempio Organizzazione ha come sottocategorie Governo, Commerciale, Educazione.
• Relation Detection and Recognition (RDR) si occupa di identificare le relazioni tra entit`a. Questo task si occupa di relazioni fisiche, personali o sociali, di impiego e di appartenenza, etc. Per ogni relazione gli annotatori identificano due argomenti primari, solitamente due entit`a, e gli attributi temporali della relazione.
• Event Detection and Recognition (VDR) si tratta del task ACE pi`u spe-rimentale, ed `e stato proposto la prima volta nel ACE 2005, e si occupa della scoperta di eventi che associano entit`a e espressioni temporali.
Nelle prossime sezioni saranno presentati task principali dell’estrazione dell’informazione.
2.1.2
Named entity recognition
Il named entity recognition (NER) si occupa di trovare nel testo espressio-ni che compongono una named entity o entit`a e assegnare a quella entit`a la giusta classe. Le named entity sono definite in maniera diversa secondo il contesto di ricerca, secondo cio`e i documenti che vengono sottoposti come input al NER. I pi`u classici tipi di entit`a da ricercare sono le persone, organiz-zazioni e luoghi, ma in conferenze recenti come l’ACE, il task si `e complicato inserendo altre entit`a come armi, veicoli, espressioni temporali (date, orari). I domini in cui `e stato utilizzato il NER sono diversi, si parte dagli articoli di notizie, passando per i dispacci militari, fino ad arrivare a domini pi`u scienti-fici come la biologia molecolare, la bioinformatica e l’e-healt, in questi ultimi il maggior interesse si ha per le entit`a che identificano i geni e la produzione di geni.
In letteratura sono stati affrontati molti modi per risolvere il problema del NER, sono state toccate la maggior parte delle metodologie usate in ambito di estrazione dell’informazione, si sono infatti sviluppati sistemi con regole scritte a mano, sistemi di apprendimento non supervisionato che usano come approccio tipico il clustering, sistemi di apprendimento semi supervisionato
dove la principale tecnica utilizzata `e quella del bootstrapping, sistemi di ac-tive learning di cui parleremo esaustivamente nella Sezione 2.2, e sistemi di apprendimento supervisionato come Hidden Markov Models (HMM), Sup-port Vector Machine (SVM), Conditional Random Fields (CRF), che finora risultano i pi`u utilizzati.
La ricerca di entit`a `e necessari per capire quali sono le unit`a che si ritengono pi`u informative in un qualsiasi testo, per esempio nella frase:
Peter studies at Massachusetts Institute of Technology conside-rando le categorie pi`u comuni utilizzate nel NER (persone, luoghi, organiz-zazioni), ci sono 2 entit`a, la prima di tipo persona `e Peter, la seconda di tipo organizzazione `e Massachusetts Institute of Technology. La ricerca di entit`a in un testo, `e uno dei primi processi che si effettuano nell’estrazione dell’informazione, infatti come si vede nelle sezioni successive, i processi di coreference e estrazione delle relazioni hanno come unit`a di riferimento le named entity trovate con il processo di NER.
2.1.3
Coreference
La risoluzione di coreference `e il processo per determinare se due o pi`u espressioni nel linguaggio naturale, si riferiscono alla stesso oggetto nella realt`a.
Algoritmi per il problema della risoluzione dei pronomi sono stati svi-luppati dagli anni sessanta, e mentre i primi approcci incorporavano molti domini e conoscenze linguistiche, gli algoritmi pi`u recenti hanno mostrato un inclinazione verso metodi knowledge-lean (guidati dalle informazioni). Que-sto tipo di algoritmi sono stati aiutati dalla comparsa di parser e tagger molto potenti. Le espressioni da relazionare nella maggior parte dei casi so-no determinate dal subtask del NER in un passo precedente di estrazione dell’informazione. Gli approcci adottati per risolvere il problema del corefe-rence sono molteplici data la longevit`a del problema stesso, si possono per`o racchiudere in due ampie categorie:
• Linguistic-based, basati pesantemente sulla linguistica e la conoscenza del dominio.
• Machine learning-based, basati principalmente sull’apprendimento au-tomatico.
Un tipico esempio di coreference `e: John arrived. He looked tired.. Si nota facilmente che le parole sottolineate si riferiscono sempre alla stesso oggetto nella realt`a, cio`e a qualcuno chiamato John. Le relazioni di corefe-rence possono comparire nella stessa frase ma anche in frasi molto distanti da loro nel testo, si pensi per esempio al numero di volte che il protagonista di un romanzo viene nominato con appellativi diversi, per esempio Sherlock Holmes, Mr. Holmes, Detective Holmes, sono espressioni che si riferiscono alla stessa persona.
Il task della risoluzione di coreference `e stato introdotto come subta-sk di estrazione dell’informazione nel MUC-6 vista la criticit`a che assume-va nei sistemi costruiti per risolvere i task presentati nel DARPA Message Understanding Conference.
2.1.4
Relationship extraction
L’estrazione delle relazioni tra entit`a di un testo `e un’altro importante subta-sk dell’estrazione dell’informazione, che permette di scoprire se due elementi nel testo hanno una qualche tipo di relazione. A volte infatti `e molto uti-le sapere non solo uti-le entit`a coinvolte nel testo, ma anche quali relazioni ci sono tra queste entit`a. Per esempio se vogliamo conoscere dove lavora una persona, dovremo ricercare nel testo la relazione “is employee of ”.
Come nel NER la maggior parte dell’impeto della ricerca sul relationship extraction `e stato dato dalle varie competizioni tipo MUC e ACE che si foca-lizzano sull’elaborazione del linguaggio naturale. L’estrazione delle relazioni `e importante anche in ambito di linguaggio non-naturale, per esempio pu`o essere informativo estrarre la relazione “is price of ” tra un prodotto e molti prezzi concorrenti in una pagina web.
Tipicamente le relazioni vengono considerate essere binarie cio`e tra 2 sole entit`a. Dato un numero fissato di tipi di relazione che coinvolgono una coppia di tipi o classi di entit`a, l’obiettivo dell’estrazione delle relazioni `e di identificare tutte le occorrenze di diverse relazioni in un documento dove tutte le entit`a sono state gi`a riconosciute.
Le entit`a coinvolte sono quelle che vengono estratte con il processo di NER, dove le classi nei task classici sono persone, luoghi e organizzazioni.
Esempi di relazione possono essere persona-associazione, o organizzazione-luogo. Per esempio le frasi:
• John Smith is the chief scientist of the Hardcom Corporation
• The Hardcom Corporation is based in Canada
contengono al loro interno le 3 entit`a John Smith (persona), Hardcom Corporation (organizzazione) e Canada (luogo). Le 3 entit`a sono legate tra loro da 2 rela-zioni, la relazione persona-associazione (John Smith, Hardcom Corporation) e organizzazione-luogo (Hardcom Corporation, Canada).
2.2
Active Learning
L’active learning `e una tecnica di apprendimento automatico che si va ad af-fiancare a quelle pi`u conosciute come quelle di apprendimento supervisionato e apprendimento non supervisionato. A differenza di questi l’active learning accelera il processo di apprendimento, permettendo un controllo sulla scelta dei dati che costituiscono il training set e riducendo notevolmente i costi di etichettatura dei dati di training. Invece che selezionare esempi di training casualmente, l’active learning seleziona e etichetta accuratamente solo gli esempi pi`u significativi. L’active learning porta beneficio in tutti quei domi-ni dove il costo di etichettatura `e alto ma anche in quelli in cui c’`e bisogno di una veloce fase di apprendimento.
2.2.1
Dati di training limitati
Nei problemi del mondo reale i dati sono abbondanti e facili da ottenere, mentre per etichettare un esempio si va incontro a costi. In alcuni domini i costi sono eccessivamente alti questo porta ad avere una quantit`a esigua di dati etichettati di training. Una quantit`a limitata di dati di training pone un problema per le tecniche di apprendimento supervisionato, che dipendono dalla disponibilit`a di un elevato numero di dati di training etichettati per produrre un classificatore di ottima qualit`a. Il problema che ci troviamo ad affrontare `e che tecniche di apprendimento supervisionato non possono essere applicate su determinati domini.
Anche in domini dove l’acquisizione di un gran numero di dati etichettati `e comune, spesso si sorvola sul costo per ottenere questi dati. Come esempio andiamo a vedere l’etichettatura del corpus RCV1, questo comprende oltre 800,000 articoli Reuters prodotti nei 12 mesi tra Agosto 1996 e Agosto 1997, categorizzati manualmente per task come text classification. E’ stato riporta-to che una sessione Reuters impiega uno staff di 90 persone per categorizzare 5.5 milioni articoli prodotti in un anno. La stima per il lavoro di etichet-tatura del corpus RCV1 `e di 12 anni persona. Perdipi`u nonostante severi controlli di qualit`a il corpus risultante contiene molti errori di etichettatura. Siccome l’etichettatura `e un lavoro molto dispendioso, un sistema di classificazione dovrebbe essere derivato dal minimo numero di esempi, ne-cessari alla creazione di un classificatore accurato. Perdipi`u ridurre il nu-mero di esempi etichettati diminuisce la probabilit`a di errori, dato che la classificazione manuale non `e infallibile.
2.2.2
Active learning
Solitamente gli algoritmi di apprendimento supervisionato sono affiancati a un ampio insieme di dati di training etichettati per assicurare la produzione di un classificatore accurato. La Figura 2.1 mostra il processo attraverso il
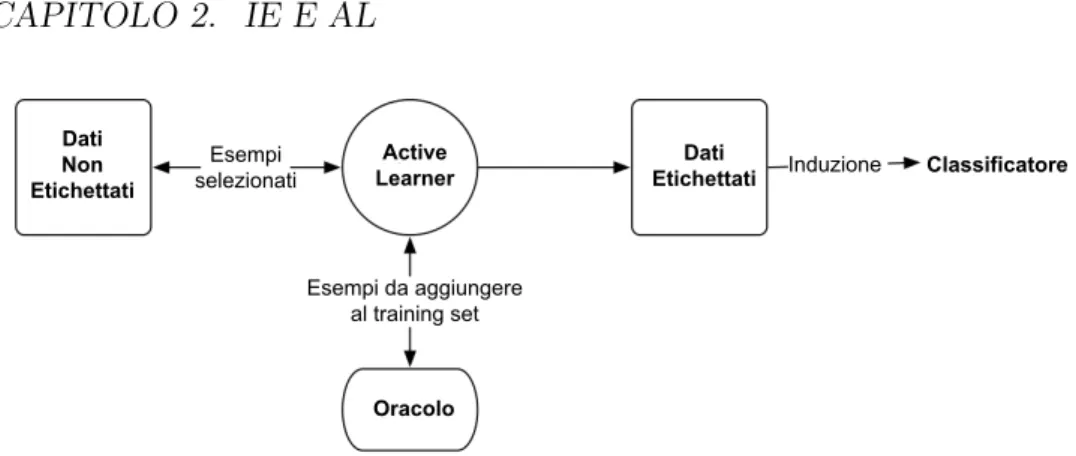
quale i dati di training sono forniti al learner. Il learner ha come output un classificatore derivato dai dati di training.
Figura 2.1: L’apprendimento supervisionato passivo non ha nessun tipo di controllo sui dati di training, che sono forniti all’algoritmo di apprendimento del classificatore. Il classificatore `e derivato da tutti i dati di training.
In questo modo il learner non ha un controllo sulla costruzione dei dati di training. Esistono molti domini dove la costruzione di una grande quan-tit`a di dati di training etichettati `e impraticabile a causa del costo eccessivo dell’etichettatura. La cosa migliore in questo caso sarebbe quella di crea-re un training set composto da un modesto numero di esempi altamente informativi.
L’active learning `e una tecnica di apprendimento automatico che da’ al learner il controllo sui dati di training. Un annotatore umano interagisce con il sistema di active learning per etichettare esempi scelti dal learner da un insieme di esempi non etichettati. La figura 2.2 mostra una active learner dove il processo passivo di apprendimento visto nell’apprendimento supervisionato, `e sostituito con un processo interattivo.
L’insieme di dati di training scelti dall’active learning non dovrebbero con-tenere esempi ridondanti o non informativi, permettendo cos`ı una riduzione delle risorse impiegate nell’etichettatura. Teoricamente quindi, dovrebbero essere etichettati soltanto il minimo numero di esempi per ottenere un classi-ficatore accurato. Una volta che il processo di active learning `e completato, l’output che si ottiene `e un classificatore accurato quanto un classificatore prodotto da un processo di apprendimento passivo, derivato da tutti i dati di training.
Figura 2.2: L’active learning dispone del controllo sui dati di training. Co-struisce dati di training interagendo con un entit`a esterna (l’oracolo) pri-ma di applicare l’algoritmo di apprendimento supervisionato per costruire il classificatore.
Ad un active learner viene fornita una piccola quantit`a di dati di training etichettati, e l’accesso a una grande quantit`a di dati non etichettati. I dati di training sono accumulati iterativamente, e attraverso ogni iterazione, l’active learner sceglie accuratamente esempi non etichettati e acquisisce la loro eti-chetta attraverso l’interazione con un’entit`a esterna (l’oracolo). Il processo `e iterato finch´e il criterio di arresto `e stato raggiunto. I dati di training pro-dotti attraverso le iterazioni dell’algoritmo di active learning, sono popolati soltanto con esempi molto informativi selezionati dal learner. In questo modo viene accelerato il processo di learning e si riducono i costi di etichettatura, dato che gli esempi da etichettare sono numericamente inferiori a quelli di un processo di apprendimento supervisionato.
Il learner seleziona gli esempi pi`u informativi dai dati non etichettati tramite le strategie, o politiche, di selezione. Per esempi informativi, possia-mo intendere per esempio quelli difficili da classificare, dato che spesso con-tengono pi`u informazioni di classificazione rispetto a un esempio facilmente classificabile.
Nel caso ideale l’active learning pu`o ridurre esponenzialmente il numero di esempi etichettati di training richiesto. Ci potrebbero per`o essere
alcu-ni domialcu-ni dove per creare un classificatore molto accurato, dati m esempi di training, sono necessari praticamente tutti gli m esempi. In questo caso limite, l’active learning non genera comunque per l’utente un costo superio-re rispetto all’utilizzo di una politica di selezione casuale degli esempi da etichettare.
2.2.3
Algoritmo canonico di active learning
L’algoritmo di active learning prende come input una modesta quantit`a di dati etichettati di training e una grande quantit`a di dati non etichettati. Nuovi esempi significativi sono scelti in accordo con la strategia, o politica di selezione, e presentati a un oracolo dal quale si ottengono le etichette degli esempi. I nuovi esempi etichettati vengono poi aggiunti ai dati di training etichettati.
La quantit`a di dati etichettati cresce a ogni iterazione dell’algoritmo di active learning. In questo modo esempi scelti dall’iterazione precedente aiu-tano a scegliere esempi pi`u significativi nelle iterazioni successive. Il passo di scegliere esempi significativi e aggiungerli al training set viene iterato finch´e un criterio di arresto viene raggiunto. Un volta fermato, da tutti i dati di training etichettati conosciuti viene derivato il classificatore finale.
Questo algoritmo canonico di active learning va formare la base per i prin-cipali metodi di active learning che si possono trovare in letteratura. L’active learning `e applicato in numerosi domini dando spazio a un’ampia variet`a di settaggi. Il componente pi`u critico dell’active learning come vedremo, sono le politiche di selezione dei nuovi esempi che saranno aggiunti al training set. Ad ogni iterazione un classificatore `e derivato da tutti i dati di training etichettati conosciuti, aggiunti fino all’iterazione corrente al training set.
Dati non etichettati In letteratura troviamo diversi metodi per fornire all’algoritmo di active learning dati non etichettati, questi metodi possono essere racchiusi in due categorie:
Active learning basato su stream Tutti gli esempi non etichettati sono se-lezionati da uno stream infinito fornito al learner. A ogni iterazione il learner deve decidere se selezionare l’esempio non etichettato come in-formativo oppure no, e muoversi sull’esempio non etichettato successivo nello stream. Questo tipo di decisione `e detta on-line, dove il learner ha accesso al solo esempio corrente, non al precedente ne’ al successivo, e non pu`o quindi considerare altre alternative.
Active learning basato su poolTutti gli esempi non etichettati sono conte-nuti in un insieme, dal quale il learner sceglie gli esempi pi`u informativi. Differisce dall’active learning basato su stream dato che ogni possibile esempio non etichettato pu`o essere valutato prima della scelta dell’e-sempio pi`u informativo. L’active learning basato su pool `e visto come un problema off-line.
Figura 2.3: Rappresentazione grafica di active learning basato su stream e su pool. L’active learning basato su stream indica che il learner ha un infinito stream di esempi non etichettati. L’active learning basato su pool ha un insieme di tutti esempi non etichettati.
L’active learning basato su stream `e stato applicato ad alcuni problemi come in Dagan e Engelson 1995[2]. Invece quello basato su pool `e il pi`u popolare nei settaggi di active learning, viene utilizzato in Hoi et al. 2006[4], Lewis e Gale 1994[6],Shohon e Cohn 2000[8] e Tong e Koller 2001[10].
Granularit`a Per comprendere a pieno come funziona un algoritmo di ac-tive learning dobbiamo introdurre un nuovo importante concetto, la granu-larit`a. In un algoritmo di active learning si intende granularit`a il numero di esempi scelti a ogni iterazione per essere inseriti nel training set. Una politica di selezione effettua il ranking degli esempi non etichettati, tali che gli esempi pi`u in alto nel ranking sono quelli scelti per fare parte del training set. Scegliendo pi`u o meno esempi da aggiungere al training set, si posso-no ottenere vari livelli di granularit`a. La granularit`a pi`u fine in assoluto, `e quando uno solo degli esempi etichettati, il pi`u alto nel ranking, `e aggiunto al training set. Granularit`a meno fine `e ottenuta aggiungendo al training set i primi N esempi del ranking. Avere una granularit`a molto fine significa che per ogni iterazione sono selezionati i soli esempi che aggiunti al training set danno come risultato l’apprendimento massimo, in questo modo per`o i costi computazionali aumentano in quanto per raggiungere un training set della stessa dimensione di uno creato da un algoritmo con granularit`a me-no fine, saranme-no necessarie pi`u iterazioni. Di contro, avere una granularit`a meno fine da la possibilit`a di selezionare degli esempi che sono sub-ottimi e quindi ottenere un classificatore meno accurato. In letteratura sono stati descritti e sperimentati molti modi di prendere i primi N esempi informativi, per esempio [4] seleziona quegli esempi tali che la ridondanza tra gli esempi non etichettati `e minimizzata. Un altro metodo utilizzato per selezionare gruppi di esempi significativi `e il clustering dove i metoidi dei cluster sono gli elementi in cima al ranking effettuato dalla politica di selezione.
Criteri di arresto Un altro aspetto molto importante in un algoritmo di active learning sono i criteri di arresto dell’algoritmo. Solitamente un algo-ritmo di active learning ha un parametro che determina quando il processo iterativo deve essere fermato. Decidere quando fermare un processo di ac-tive learning `e un problema sorprendentemente difficile e rimane tuttora un problema aperto. I criteri di arresto possono essere classificati in due ampie categorie, quelli fissi o fixed, e quelli adattivi o adaptive.
• Fixed I criteri di arresto fissi terminano il processo di active learning una volta che una risorsa `e stata esaurita. Il pi`u usato criterio di arresto `e il limite sul numero delle etichette che un oracolo assegna. Quando l’oracolo esaurisce le sue risorse rifiuta ogni altro esempio da etichettare, cos`ı l’active learner deve ottenere l’accuratezza massima in un numero limitato di iterazioni. Un’altra risorsa che potrebbe esaurirsi potrebbe essere l’insieme di esempi non etichettati. Una volta che questi sono stati tutti inseriti nel training set, l’active learning si ferma dato che non ci sono pi`u esempi da poter etichettare.
• Adaptive Questo tipo di criterio ferma il processo di active learning appena il livello di performance desiderato `e stato raggiunto. Questo necessita di un meccanismo di controllo delle performance dell’accura-tezza dei classificatori creati ad ogni iterazione. Solitamente in casi di apprendimento supervisionato le performance vengono valutate su un test set, questo soluzione `e a volte impraticabile nei casi di active lear-ning, data la scarsit`a di dati etichettati. Un’altra possibile soluzione `e quella di calcolare le performance facendo una cross validation sui dati etichettati.
In letteratura sono stati suggeriti diversi criteri, ma non si `e ancora a arrivati a un soluzione definitiva. Per esempio Vlachos 2008[11] utilizza il campionamento incerto (uncertainty sampling), dove a ogni iterazio-ne la confidenza del classificatore corrente `e calcolata usando un dataset non etichettato, separato da quello utilizzato per fare il learning. In-tuitivamente dato che i dati di training sono maggiori e l’active learner apprende, la confidenza dovrebbe aumentare. Uncertainty sampling `e una strategia che seleziona quegli esempi che sono pi`u difficili da clas-sificare e sono pi`u differenti da quelli gi`a presenti nel training set. Con questo metodo viene raggiunto un limite quando gli esempi non etichet-tati rimanenti hanno un alta confidenza. Esempi aggiunti al training set da questo punto non daranno nessuna informazione in pi`u all’ac-tive learner dato che sono simili a quelli gi`a presenti nel training set.
Gli autori hanno dimostrato empiricamente che il processo di active learning si pu`o fermare 3 iterazioni dopo che il limite `e stato raggiunto ottenenendo buoni risultati, non hanno per`o dato una misura definitiva per arrestare il processo.
Oracolo Un elemento fondamentale per il processo di active learning `e sen-z’altro l’oracolo. Tipicamente un algoritmo di active learning deve assegnare delle etichette agli esempi scelti dalle politiche di decisione. Un oracolo `e un entit`a esterna il cui ruolo `e quello di assegnare un’etichetta agli esem-pi non etichettati che gli vengono presentati. Nel passive learning i dati di training vengono etichettati dall’oracolo prima del loro utilizzo nel learner. Contrariamente nell’active learning i dati sono accumulati passo dopo passo interagendo con l’oracolo a ogni iterazione.
Si assume generalmente che l’oracolo sia umano, ma non `e detto che sia sempre cos`ı. Un ulteriore assunzione `e che l’oracolo sia infallibile, e nessun tipo di disturbo (noise) sia introdotto dall’oracolo nel processo di active lear-ning. Questa assunzione non `e generalmente valida, infatti l’algoritmo A2 di
Balcan et al. 2006[1] `e un active learner agnostico che lavora in presenza di forme di disturbo arbitrarie, quindi in questo caso l’assunzione che l’oraco-lo sia infallibile pu`o essere rilassata. Nei nostri esperimenti l’oracol’oraco-lo non `e umano, ma assumiamo che sia infallibile.
2.2.4
Valutazione
L’obiettivo dell’active learning `e di produrre un classificatore accurato usando il numero minimo di esempi di training etichettati. E’ quindi desiderabile misurare le performance di pi`u active learner per permettere di comparare strategie di selezione diverse. Le performance di un classificatore dipendono dal training set da cui `e derivato. Diverse politiche di selezione degli esempi daranno luogo alla costruzione di diversi training set, queste politiche possono essere comparate esaminando le performance dei classificatori ottenuti dai training set costruiti dalle varie politiche.
Intervalli fissati Le performance di politiche di active learning diverse tra loro, possono essere viste comparando i valori delle performance ottenuti dal-le varie politiche di sedal-lezione dopo un determinato numero di iterazioni. Il classificatore ottenuto alla iesima iterazione `e valutato su un test set ester-no usando un appropriata misura di valutazione (Sezione 4.3). Nei casi pi`u estremi le performance sono valutate una sola volta. Questa forma di valuta-zione `e computazionalmente conveniente dato che non `e effettuata per ogni iterazione dell’algoritmo di active learning.
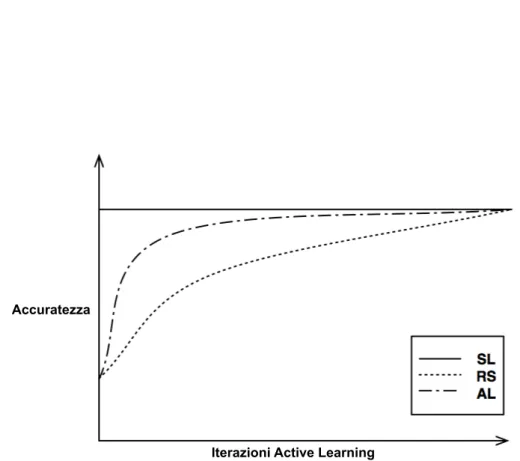
Curve di apprendimento Un modo diretto per mostrare le performance dell’algoritmo di active learning attraverso il suo ciclo vitale, `e di valutare le performance del classificatore ottenuto a ogni iterazione. Un classificatore `e ottenuto da tutti i dati etichettati conosciuti e valutato su un test set esterno, a ogni iterazione. Si ottengono una serie di valori di performance, uno per ogni iterazione dell’active learner. Facendo i grafici di questi valori si ottiene la curva di apprendimento della particolare politica di selezione. Diverse politiche di selezione, selezionando esempi differenti, creano diversi training set, e conseguentemente curve di apprendimento diverse (vedi Figura 2.4). La performance top-line dell’active learning `e ottenere gli stessi risultati dell’apprendimento supervisionato. La baseline `e la politica random (vedi Sezione 4.2.2). L’active learning dovrebbe avvicinarsi alla top-line usando il minimo numero di esempi etichettati, allo stesso tempo deve superare la baseline.
Le curve di apprendimento sono un modo facile per mostrare le perfor-mance di varie politiche di active learning. I risultati dei nostri esperimenti saranno mostrati tramite curve di apprendimento.
Figura 2.4: Curve di apprendimento. Il grafico mostra la performance top-line ottenuta con il supervised learning (SL) cos`ı come la basetop-line `e ottenuta con la politica random (RS). L’active learner dovrebbe migliorare rispetto alla baseline e avvicinarsi alla top line usando il numero minimo di esempi etichettati.
Tools
In questo capitolo illustriamo gli strumenti utilizzati per creare il sistema di estrazione dell’informazione e l’infrastruttura di active learning. Nella sezione 2.1 parliamo di YamCha, un annotatore basato su support vector machine, e nella sezione 2.2, descriviamo il corpus utilizzato nella sperimentazione. Nell’ultima sezione illustriamo il preprocessing applicato al corpus.
3.1
YamCha e SVM
3.1.1
Support vector machine
Con il nome Support vector machine (SVM) si identifica un insieme di me-todi utilizzati nel apprendimento supervisionato per task di classificazione e regressione. Nel processo di apprendimento binario per una classe X, i dati di training sono visti come punti in uno spazio a n dimensioni (dove n `e il numero di caratteristiche (feature) di ogni elemento di input) ossia rappre-sentati da un vettore di dimensione n. Ogni punto `e associato all’insieme X (dei dati di training appartenenti alla classe X) oppure all’insieme ¯X (dei dati di training non appartenenti alla classe X). SVM costruisce un iperpia-no che separa nello spazio i punti ∈ X da quelli ∈ ¯X. Nello specifico questo iperpiano dovr`a essere quello che massimizza il margine tra i due insiemi.
Il margine viene calcolato a partire dagli elementi di X e ∈ ¯X pi`u vicini all’iperpiano separatore, chiamati support vector. Una volta creato il classi-ficatore, per ogni nuovo elemento che chiediamo di classificare, ci restituir`a la distanza dall’iperpiano che indicher`a l’appartenenza a una delle due classi, pi`u formalmente Φ(d) : Rn → {X, ¯X} dove Φ `e un classificatore e d un nuovo
elemento da classificare.
Quando si hanno pi`u di due classi tra cui discriminare, viene utilizzato un metodo detto multiclass SVM : dove il problema di classificazione multipla, viene scomposto in pi`u problemi di classificazione binaria. Due metodi tipici utilizzati per ottenere ci`o sono:
• One Versus All - Viene creato un classificatore per ogni classe Xi,
ognuno dei quali assegna al nuovo elemento da classificare la classe Xi
o ¯Xi. La classificazione di un nuovo elemento `e data dalla strategia
winner-takes-all, dove il classificatore con il risultato pi`u alto assegna la classe.
• One Versus One - Date n classi vengono creati (n-1)*(n/2) classifica-tori, ognuno dei quali assegner`a al nuovo elemento una classe, la classe assegnata pi`u volte sar`a il risultato del classificatore multiclass.
3.1.2
YamCha
Come classificatore utilizzato per implementare il sistema di estrazione del-l’informazione abbiamo utilizzato YamCha1. Come dice il nome stesso2
Yam-Cha `e un sistema general purpose per svolgere task di text chunking. Come algoritmo di apprendimento utilizza SVM, e pi`u precisamente il package Ti-nySVM3. YamCha ha ottenuto il miglior risultato nel CoNLL 2000 Shared
Task.
1
http://www.chasen.org/~taku/software/YamCha/
2
L’acronimo YamCha sta per Yet Another Multipurpose CHunk Annotator.
3
I dati di input utilizzati nella fase di training sono composti da una se-quenza di token, {t1,...,tk}, dove ogni token ti `e rappresentato da un insieme
di feature Fi = {fi1,...,fin} e un’etichetta di classificazione ci.
YamCha offre un utile strumento per arricchire le caratteristiche di un token con altre informazioni provenienti da una finestra (window) di token vi-cini. Ad esempio, specificando una finestra di [-2,+2], la rappresentazione del token ti, sar`a composta anche dalle caratteristiche dei due token precedenti
e dei due token successivi, cio`e Fi = {fi − 21,...,fi − 2n,...,fi1,...,fin,...,fi +
21,...,f
i − 2n}. Questo permette di ottenere informazioni dal contesto che
circonda il token osservato.
Oltre a queste feature statiche, cio`e che sono note anche prima della classificazione, `e possibile aggiungere alla rappresentazione dei token una fi-nestra di feature dinamiche, cio`e etichette assegnate ai token vicini dopo la classificazione, cos`ı da utilizzare questa informazione aggiuntiva per la classi-ficazione del token corrente. Ovviamente la finestra di feature dinamiche pu`o essere composta soltanto da token che precedono il token corrente. Durante la creazione del classificatore i valori delle caratteristiche dinamiche vengono estratti dai dati di training, mentre durante la classificazione, sono calcolati sui dati di test.
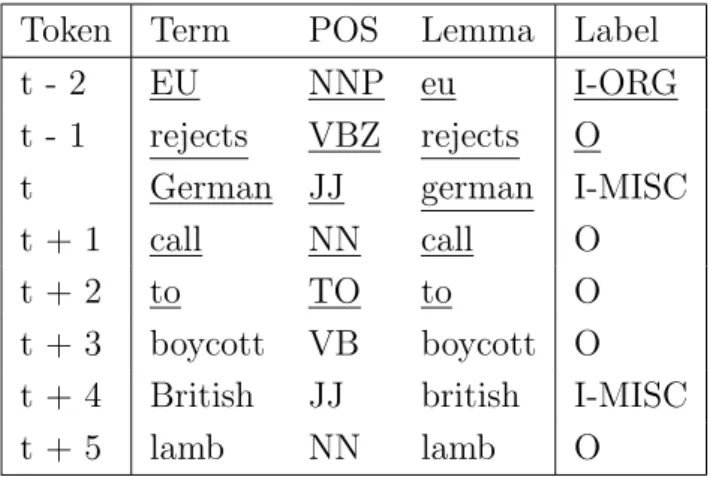
La Tabella 3.1 mostra un esempio di rappresentazione dei token evi-denziando l’insieme di feature usato per rappresentare il token t dove sono specificate una finestra statica [-2,+2] e una finestra dinamica [-2,-1].
YamCha, nel caso in cui il classificatore non sia binario ma abbia pi`u di due classi da assegnare, permettere di scegliere la modalit`a multiclass che si desidera: pairwise o one vs rest, che ricalcano rispettivamente i metodi di multiclass svm one vs one e one vs all (vedi Sezione 3.3.1).
3.2
CoNLL 2003 e Preprocessing
Questo sezione descrive il CoNLL corpus utilizzato allo shared task CoNLL 2003, ovvero il corpus utilizzato per i nostri esperimenti.
3.2.1
CoNLL
Il CoNLL4 `e un convegno annuale organizzato dal SIGNLL5 un sottogruppo
del ACL6. Dal 1999, ogni anno CoNLL ha incluso uno shared task in cui
vengono offerti dagli organizzatori dati di training e di test per poter con-correre a una competizione su uno dei task dell’elaborazione del linguaggio naturale, in queste competizioni viene permesso ai sistemi che partecipano di essere valutati e comparati in modo sistematico, e quindi di capire in maniera abbastanza oggettiva quali sono le migliori tecniche per gli specifici task.
3.2.2
Corpus CoNLL 2003
Nel 2003 la competizione organizzata dal CoNLL ha avuto come interes-se il Language Independent Named entity Recognition. Le entit`a su cui si concentra la competizione sono quattro:
• persone(PER)
4
L’acronimo per CoNLL sta per Conference on Natural Language Learning
5
Special Interest Group on Natural Language Learning
6
Association for Computational Linguistics
Token Term POS Lemma Label t - 2 EU NNP eu I-ORG t - 1 rejects VBZ rejects O t German JJ german I-MISC t + 1 call NN call O
t + 2 to TO to O
t + 3 boycott VB boycott O t + 4 British JJ british I-MISC t + 5 lamb NN lamb O
Tabella 3.1: Esempio di rappresentazione dei token con incluse le feature della finestra statica e dinamica del token t sottolineate
• organizzazioni(ORG)
• luoghi(LOC)
• nomi di entit`a miste(MISC) (entit`a che non appartengono a nessuno dei primi tre tipi)
Ai partecipanti sono stati dati corpus training e test, in lingua inglese e tedesca, con l’obiettivo di sviluppare un sistema di named entity recognition con una parte di apprendimento automatico. Per ogni linguaggio sono stati forniti 4 file, uno di training, uno di sviluppo, uno di test e uno non annotato, il corpus in lingua inglese `e stato preso dal corpus di notizie Reuters7 che
comprende gli articoli tra l’Agosto 1996 e Agosto 1997. I corpora di training e di sviluppo sono composti da articoli datati Agosto 1996, invece il corpus di test `e composto da articoli del Dicembre 1996.
Articoli Frasi Token Training set 946 14,987 203,621 Development set 216 3,466 51,362 Test set 231 3,684 46,435
Tabella 3.2: Numero di articoli frasi e token per ogni file
LOC MISC ORG PER Training set 7140 3438 6321 6600 Development set 1837 922 1341 1842 Test set 1668 702 1661 1617
Tabella 3.3: Numero di named entity per ogni file
7
I set annotati sono stati preprocessati con un tokenizer, un part of speech tagger e un chunker, sono stati quindi suddivisi in token e sono state aggiunte le informazioni su part of spech e chunk. I tag delle entit`a sono stati annotati a mano dagli esperti dell’Universit`a di Anversa. Come gi`a detto oltre ai tre classici tipi di entit`a, ne `e stata aggiunta un’altra MISC, che sta a indicare tutti le espressioni che non appartengono ai tipi ORG PER o LOC, per esempio aggettivi come Italians o eventi come 1000 Lake Rally.
Ogni file del corpus contiene una parola per linea, una riga vuota rappre-senta la fine di una frase, alla fine di ogni riga c’`e un tag che indica se la parola fa parte di una entit`a oppure no, il tag indica anche il tipo di entit`a. Un esempio di struttura della frase del corpus originale `e mostrato nell’esempio 3.4.
U.N. NNP I-NP I-ORG official NN I-NP O Ekeus NNP I-NP I-PER heads VBZ I-VP O for IN I-PP O Baghdad NNP I-NP I-LOC
. . O O
Tabella 3.4: Esempio frase nel corpus originale
Ogni riga contiene 4 campi: il token, il tag part of speech, il tag chunk, il tag named entity. I tag named entity sono etichettati seguendo lo schema detto IOB. Lo schema IOB, `e uno standard per la rappresentazione dei dati in questo tipo di task. Nell’ IOB le parole etichettate con O sono al di fuori di qualsiasi named entity, quelle etichettate con I-XXX(Inside) sono parole all’interno di un named entity di tipo XXX. Ogni volta che due named entity dello stesso tipo XXX sono immediatamente successive, la prima parola della seconda entit`a avr`a come tag B-XXX(Begin), per mostrare che da quella
parola comincia un’altra entit`a. Si assume anche che i named entity non siano ricorsivi o sovrapposti, e quando un’entit`a `e all’interno di un’altra soltanto l’entit`a esterna `e annotata.
CDU NNP B-NP I-ORG / SYM nil I-ORG CSU NNP B-NP I-ORG SPD NNP I-NP B-ORG FDP NNP I-NP B-ORG Greens NNP I-NP B-ORG PDS NNP I-NP B-ORG
Tabella 3.5: Esempio di modello IOB
Nell’esempio 3.5 si nota che l’entit`a CDU /CSU `e la prima entit`a leggendo dall’alto verso il basso, di tipo ORG che si trova nella frase. Le entit`a suc-cessive sono tutte di tipo ORG ma tutte distinte, hanno quindi come prefisso di etichetta B, che appunto sta a indicare che ogni token, in questo caso, `e un’entit`a a se stante.
3.2.3
Preprocessing
I data set utilizzati nello shared task CoNLL 2003, sono stati ulteriormente processati con TagPro per aggiungere altre informazioni a ogni parola. Tag-Pro `e un sistema per il POS-tagging basato su SVM, fa parte di TextTag-Pro una suite completa per l’elaborazione del linguaggio naturale[7]. TagPro estende le informazioni con altri campi: la parola normalizzata in minuscolo, prefis-si, suffissi e caratteristiche ortografiche come capitalization e hyphenation. Queste offrono maggiori feature all’algoritmo SVM, rendendolo pi`u efficace. Dopo il preprocessing di TagPro la struttura del corpus sar`a come quella in 3.6
CDU cdu c cd cdu nil u du cdu nil U N NNP B-NP I-ORG
/ / / nil nil nil / nil nil nil N W SYM nil I-ORG
CSU csu c cs csu nil u su csu nil U N NNP B-NP I-ORG
SPD spd s sp spd nil d pd spd nil U N NNP I-NP B-ORG
FDP fdp f fd fdp nil p dp fdp nil U N NNP I-NP B-ORG
Greens greens g gr gre gree s ns ens eens C N NNP I-NP B-ORG
PDS pds p pd pds nil s ds pds nil U N NNP I-NP B-ORG
Strategie di active learning per
estrazione dell’informazione
In questo lavoro abbiamo considerato come unit`a di scelta le frasi, le pi`u piccole unit`a che anche decontestualizzate non perdono valore informativo, a differenza dei token, che presi uno per volta non hanno nessun particolare significato. In un task come il NER infatti non si pu`o prendere come unit`a solamente il token privo di ogni contesto. Una named entity pu`o essere costituita da pi`u token; prendiamo per esempio il token States che, da solo non appartiene a nessuna classe; se per`o viene inserita in un contesto pu`o essere un token che fa parte di una named entity di tipo LOC: United States of America. Da questo fatto non possiamo di sicuro scegliere come unit`a informativa il token dato che andrebbero perse tutte quelle named entity composte da pi`u token. Oltretutto il fatto di avere un contesto ampio diversi token ci permette di associare una finestra di feature a ogni singolo token (vedi Sezione 3.1.2). Un’unit`a di scelta pi`u ampia di una frase creerebbe dei contesti inconsistenti, dato che potrebbero esserci unit`a composte da pi`u frasi, che porterebbero a degli errori di classificazione.
Si dovranno adottare quindi delle funzioni che partendo dai punteggi asse-gnati dal classificatore a ogni token, restituiscano punteggi relativi alle frasi. Abbiamo definito una funzione σ(s) → R che data una frase s, restituisce un
valore reale di rilevanza di s rispetto al processo di active learning. Queste frasi saranno poi ordinate dalle nostre politiche. Negli esperimenti effettuati abbiamo comparato diverse strategie σ per fare il ranking delle frasi.
4.1
Dimensioni
Le strategie sono state definite basandosi su varie dimensioni, ispirandoci in tal modo al lavoro di Esuli Sebastiani sull’active learning nella multi-label text classification [3].
Per rendere chiaro il concetto di dimensioni dobbiamo introdurre due insiemi:
T = {LOC, P ER, ORG, MISC} (4.1) e
L = T + {O} (4.2)
. Gli elementi dell’insieme T sono le etichette che devono essere assegnate alle named entity secondo gli obiettivi del task CoNLL 2003 [9]. L’insieme L contiene tutti gli elementi di T con in pi`u l’etichetta O (che significa nessun tag), che sar`a assegnata dal classificatore a tutti quei token che non sono classificati con gli elementi dell’insieme T .
4.1.1
La dimensione Evidence
La prima dimensione su cui abbiamo basato la definizione delle politiche di active learning `e la dimensione evidence. La dimensione evidence `e stret-tamente legata alla confidenza che ha il classificatore nell’etichettare un token.
Una potenziale scelta `e quella di usare come evidence, il valore di confi-denza con il quale i token vengono classificati. L’intuizione che sta dietro a questa scelta `e che, avendo un basso valore di confidenza su di un token, il classificatore ha un’alta incertezza riguardo alla sua classe di appartenenza.
Aggiungendo il token con bassa confidenza al training set si aiuta il classifica-tore a risolvere un caso “difficile”. Chiameremo questa scelta Min Confidence (in simboli MC). La confidenza di un token `e definita dalla funzione:
tokenScore(t) = maxx∈L(x(t)) (4.3)
dove t rappresenta i token che compongono il testo su cui fare il ranking, e x(t) rappresenta la funzione che, dato un token, restituisce un punteggio associato alla label x; per esempio; LOC(′′
UK′′
) = 0, 83879.
Una scelta alternativa `e usare come evidence il valore di score con il quale i token vengono classificati, qui l’intuizione `e che pi`u alto `e lo score e con maggiore sicurezza il token sar`a un esempio positivo (pi`u il valore assoluto dello score `e alto, pi`u il classificatore ha un’alta confidenza rispetto al token, e quindi `e un esempio positivo, pi`u il valore assoluto dello score si avvicina a zero, pi`u il classificatore ha una bassa confidenza rispetto al token, e quindi `e un esempio negativo), che nei task di apprendimento supervisionato `e molto pi`u utile di un esempio negativo. Chiameremo questa scelta Max Score (MS). Lo score di un token `e definito dalla funzione:
tagScore(t) = maxx∈T(x(t)) (4.4)
dove t rappresenta i token, e x(t) rappresenta la funzione che, dato un token, restituisce un punteggio associato al tag x.
Come gi`a detto, il nostro obiettivo `e di effettuare il ranking delle frasi. In una frase non esiste soltanto un valore, sia questo confidenza o score, ma m singoli valori, uno per ogni token. Come utilizzare questi m valori `e lo scopo della dimensione class (discussa nel Capitolo 4.1.2) la quale ci dice qual `e “il” valore rappresentativo di una frase.
4.1.2
La dimensione Class
La dimension “class” ha a che fare con il fatto che qualsiasi valore si scelga di usare come dimensione “evidence”, sia questo confidenza o score, ci sono
m diversi valori per ogni frase s. La dimensione class rappresenta le politi-che su come scegliere un valore combinando i m valori politi-che otteniamo dalla dimensione evidence.
Se la nostra scelta `e MC, possiamo scegliere di prendere il minimo valore di confidenza dei token per assegnarlo alla frase come valore rappresentativo, e poi ordinare le frasi in maniera crescente, in accordo con la dimensione “evidence”. Questo significa avere:
σ = min(mintj∈Si(tokenScore(tj)) (4.5)
(dove Si sono le frasi che compongono l’unlabelled set appena classificato),
questa politica `e chiamata Min Min Confidence (MMC).
Se invece scegliamo MS, possiamo scegliere di prendere il massimo valore di score dei token per assegnarlo alla frase, e poi ordinare le frasi in ma-niera decrescente, in accordo con la dimensione “evidence”, la strategia che otteniamo `e
σ = max(maxtj∈Si(tagScore(tj)) (4.6)
cio`e la politica Max Max Score (MMS). Lo scopo di queste due politiche `e quello di far concentrare l’annotatore manuale su frasi che hanno dei token che vengono considerati casi estremi. Queste due scelte vengono chiamate MIN/MAX(M).
Un’altra scelta alternativa `e fare la media tra i valori di confidenza o di score, ottenendo due strategie distinte, la prima
σ = min(averagetj∈Si(tokenScore(tj)) (4.7)
detta Min Average Confidence (MAC), e la seconda
σ = max(averagetj∈Si(tagScore(tj)) (4.8)
chiamata Max Average Score, (MAS). Questa politica `e intesa a forzare l’annotatore a etichettare i token di quelle frasi che hanno una buona media di casi interessanti. Chiamiamo questa scelta Average (A).
4.1.3
Round Robin
Le strategie esposte finora effettuano una scelta abbastanza ineguale sui tag che si hanno a disposizione. In pratica `e possibile che le strategie prendano delle frasi che migliorano il classificatore sul riconoscimento di alcuni tag, lasciando invariato o peggiorando il riconoscimento sul resto dei tag. La strategia che andiamo a illustrare considerando le politiche gi`a esposte, crea un ranking per ogni tag, quindi 4 rank, che saranno poi uniti per creare un rank globale. Questo `e ottenuto:
1. prendendo per ogni o ∈ T i token “migliori”, in accordo con la scelta MS della dimensione evidence.
2. facendo per ogni o ∈ T il ranking delle frasi secondo il criterio della dimensione class.
3. inserendo nel ranking globale le k migliori frasi di ogni o ∈ T .
Come si pu`o vedere la dimensione class viene utilizzata diversamente dalle politiche round robin, prendendo MS come dimensione “evidence” (l’unica possibile). Per ogni frase si hanno 4 valori di score, uno per ogni oj ∈ T . Al
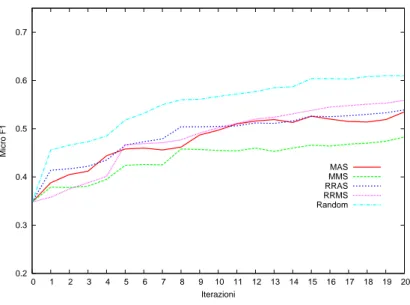
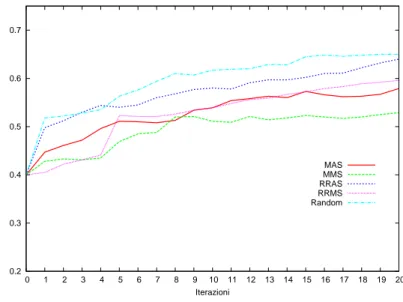
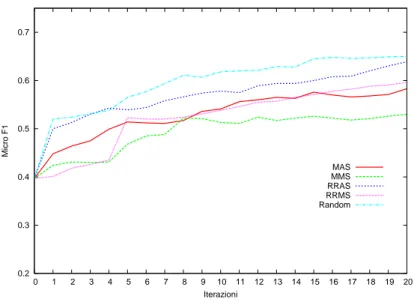
solito, ogni valore sar`a assegnato in accordo alla scelta fatta sulla dimensione “class”: Average o Max. Round Robin Max Average Score (RRMAS) `e dato da:
σo = max(averagetj∈Si(tokenScoreo(tj))∀o ∈ T (4.9)
dove tokenScoreo(tj) `e il valore dello score del tag o del token tj.
Round Robin Max Max Score (RRMMS) `e dato da:
σo= max(maxtj∈Si(tokenScoreo(tj))∀o ∈ T (4.10)
La dimensione “round robin” `e compatibile soltanto con le politiche MMS e MAS in quanto lo score `e una misura globale, cio`e per affermare che un token ha uno score basso tutti gli score devono essere bassi, mentre uno score alto per un singolo tag `e comunque rilevante indipendentemente dal valore
degli altri. Non ha senso parlare di “round robin” sulle strategie MMC e MAC dato che l’insieme che sta alla base delle due strategie contiene anche O che non `e un tag.
Nella Tabella 4.1 sono riassunte le strategie sperimentate.
MMC Min Min Confidence MAC Min Average Confidence MMS Min Min Score
MAS Min Average Score
RRMMS Round Robin Min Min Score RRMAS Round Robin Min Average Score
Tabella 4.1: Riassunto politiche basate su dimensioni
4.2
Esperimenti
4.2.1
Protocollo utilizzato
In questo lavoro abbiamo utilizzato il seguente protocollo sperimentale, ba-sato su tre parametri interi α, β e γ. α rappresenta il numero di esempi di training da cui l’algoritmo parte, β sta a indicare il numero di iterazioni che il learner deve compiere, e γ sta a indicare il numero di token che vanno in-seriti nel training set. Ovviamente questi token sono tradotti in frasi, questo `e stato fatto per avere training set della stessa dimensione, e non favorire politiche banali che prediligono frasi molto lunghe. Sia Ω il nostro corpus, diviso in un training set T r e un test set T e e sia σ una strategia di active learning.
2. impostare un training set corrente T rt con l’insieme delle prime α frasi
di T r; impostare l’unlabelled set corrente Ut ← T r/T rt;
3. For t = 1,...,β ripetere i seguenti passi:
(a) Generare un classificatore ˆΦt dal training set corrente T r t
(b) Valutare l’efficacia di ˆΦt su T e
(c) Classificare Ut con ˆΦt
(d) Fare il ranking delle frasi in Ut in accordo con la strategia σ
(e) Sia r(Ut, γ) l’insieme dei γ elementi di Ut top-ranked; impostare
T rt+1 ← T rt∪r(Ut, γ); impostare Ut+1 ← Ut/r(Ut, γ)
E’ importante notare che lo Step 3.b ha il solo scopo di collezionare risultati per fini sperimentali (ad esempio per i grafici e le tabelle della Sezione 4.5), dato che viene utilizzato il test set questi risultati non sono accessibili in nessun modo all’algoritmo. Il protocollo sopra simula l’attivit`a di un anno-tatore umano che all’inizio del processo ha disponibile un training set T r0
che consiste in α esempi (frasi) e un “unlabelled set” U0 che consiste in |T r|
− α esempi non etichettati. L’annotatore genera un classificatore ˆΦ0 da T r
0,
lo usa per classificare le parole in U0 e chiede all’agente di active learning
il ranking delle frasi di U0, poi manualmente l’annotatore umano (oracolo)
etichetta le prime γ, viene generato un classificatore ˆΦ1 con il training set
in-grandito che comprende T r0 e γ nuovi esempi etichettati, viene cos`ı ripetuto
il processo β volte. Si pu`o notare che il criterio di arresto utilizzato e quello fixed sul limite di esempi che l’annotatore pu`o etichettare. Infatti dopo che aver etichettato per β volte γ token, l’oracolo si ferma e non ne etichetta altri.
Negli esperimenti che abbiamo condotto abbiamo impostato i valori in questo modo: α = 110 corrispondente a circa 2000 token, β = 20 e γ = 200. Abbiamo assunto che questi parametri siano realistici, dato che simulano la situazione in cui:
• inizialmente ci sono soltanto 110 frasi di training (questo `e ragionevole dato che in molte applicazioni in cui sono disponibili pi`u esempi di trai-ning, gli annotatori umani possono pensare che valga la pena annotarne di pi`u)
• ogni volta che un annotatore umano etichetta le frasi che corrispondono a 200 token, l’annotatore vuole aggiornare il sistema (`e ragionevole dato che l’annotatore vuole vedere se gli ultimi esempi aggiunti al training set hanno migliorato l’accuratezza del classificatore (questo pu`o essere fatto tramite lo Step 3.b)).
4.2.2
Baseline
Come strategia baseline per la valutazione dei risultati `e stata utilizzata la politica random, che consiste nello scegliere frasi non etichettate in maniera casuale, e aggiungerle una volta etichettate al training set. In pratica questa politica simula il comportamento di un annotatore umano che prende esempi non etichettati, e li etichetta senza avere un preciso ordine.
4.3
Metodi di valutazione
Per valutare i nostri esperimenti usiamo 3 diversi modelli di valutazione (exact match, token model, token & blank model) che appartengono a due classi di metodi di valutazione:
• La prima (annotation-based ), `e basata considerando una testo annotato come un singolo elemento. Per annotazione si intende l’associazione di una certa etichetta a pi`u parole che appartengono a una determinata classe, per esempio ORG potrebbe essere un’annotazione per Governo Italiano. La valutazione `e basta sulla comparazione dei match tra due insiemi di annotazioni, quelle ottenute dal classificatore e quelle effettive del corpus utilizzato per la valutazione.
• La seconda (token-based ), `e basata sul considerare ogni token come un singolo elemento. La valutazione `e effettuata misurando l’accuratezza della classificazione usando misure standard di information retrieval, come precision, recall e F1.
4.3.1
Misure annotation-based
Le misure di valutazione annotation-based considerano un testo annotato come un unico elemento. La valutazione `e eseguita comparando i match tra due insiemi, uno con le classificazioni corrette GX = {g1, ..., gn}, l’altro con
la classificazione eseguita dal nostro sistema, PX = {g1, ..., gn}, per ogni tipo
di etichetta X1. Si pu`o notare che P pu`o contenere un numero arbitrario
di elementi, che non `e detto sia uguale al numero di elementi inclusi in G. Inoltre, le annotazioni in P possono riferirsi a qualsiasi porzione di testo nel documento annotato, senza nessuna relazione con G. Una conseguenza di questo fatto `e che `e impossibile stabilire una relazione uno a uno tra elementi di G e P .
Nell’estrazione dell’informazione un approccio tipico `e quello di definire un predicato del tipo match(g, p) → {true, f alse}, che determina se due elementi, p ∈ P e g ∈ G, hanno un match, e usare questo predicato per calcolare una versione approssimata delle misure di precision (π), recall (ρ), e F1. π(G, P ) = |{p|p ∈ P ∧ ∃g ∈ G : match(g, p)}| |P | (4.11) ρ(G, P ) = |{g|g ∈ G ∧ ∃p ∈ P : match(g, p)}| |G| (4.12) F1(G, P ) = 2π(G, P )ρ(G, P ) π(G, P ) + ρ(G, P ) (4.13) Il predicato match `e definito in vari metodi:
overlap: matchoverlap(g, p) = T rue se e solo se due annotazioni si sovrappongono;
1
head: matchhead(g, p) = T rue se e solo se due annotazioni iniziano dalla stessa
posizione nel testo;
exact: matchexact(g, p) = T rue se e solo se due annotazioni iniziano e finiscono
nella stessa posizione nel testo;
Ad esempio, dati un annotazione ottimale e i tre predicati visti sopra: g = “from the [LOCNational Rifle Association]LOC gun lobby”2
p1 = “from the National Rifle [LOCAssociation]LOC gun lobby”
p2 = “from the [LOCNational Rifle]LOC Association gun lobby”
p3 = “from the [LOCNational Rifle Association]LOC gun lobby”
il predicato matchoverlap(g, pi) `e vero per ogni frase pi, il predicato
matchhead(g, pi) `e vero per le frasi p2 e p3, mentre matchexact(g, pi) `e vero
solo per la frase p3.
Sfortunatamente questo tipo di predicati hanno qualche inconveniente. Il predicato overlap tende a sovrastimare le performance di un sistema che ten-de a produrre frasi etichettate molto lunghe. Dall’altro lato i predicati head e exact sono troppo severi nella loro valutazione, dato che trattano i match approssimati come completamente errati. Ad esempio rispetto alla frase an-notata g, “from [LOCthe National Rifle Association]LOC gun lobby”,
viene considerata da entrambi i predicati come un errore nonostante abbia una piccola differenza.
Questi due predicati non prendono in considerazione il grado di overlap tra due frasi annotate, per esempio, due frasi annotate lunghe entrambe 10 parole e che hanno un overlap di una sola parola, avranno lo stesso significato di due frasi annotate di 10 parole che hanno un overlap di 9 parole.
Infine con usando delle misure annotation-based, non `e possibile calcolare una tabella di contingenza vista la mancanza del concetto di veri negativi. Infatti `e possibile separare le annotazioni in tre categorie:
2