Scuola di Ingegneria Industriale e dell’Informazione
Corso di Laurea Magistrale in Ingegneria Informatica
Dipartimento di Elettronica, Informazione e Bioingegneria
A predicated grammar for X509 certificates
and its parser: systematically checking
for syntactic soundness of digital certificates
Relatore: Prof. Gerardo PELOSI
Correlatore: Ing. Alessandro BARENGHI
Tesi di Laurea di:
Questo lavoro di tesi non sarebbe stato realizzabile senza il costante sup-porto di Alessandro Barenghi e Gerardo Pelosi, che ringrazio moltissimo per la disponibilità che hanno sempre avuto e dimostrato, fornendo esperien-za e capacità analitiche che mi hanno permesso di uscire da situazioni com-plesse e che rischiavano di essere delle sabbie mobili in cui rimanere bloccato.
Un ringraziamento va anche ai miei genitori e alla mia ragazza che mi hanno sopportato soprattutto in questo ultimo mese di estremo nervosismo, sem-pre comsem-prendendo la situazione e senza mai provare risentimento per una risposta brusca, o la poca attenzione verso questioni extra universitarie.
Un’altra parte fondamentale di questa tesi è stato il mio caro laptop, che quasi tutti scommettevano si sarebbe rotto prima della fine del lavoro, vista la sua età ormai notevole. Io lo ho messo decisamente sotto pressione, tanto che alcune volte si è spento da solo, con la zona processore bollente. In questi casi, il dubbio che fosse arrivato al capolinea è venuto, ma dopo un po’ di riposo si è sempre ripreso. Probabilmente questa è stata la sua ultima sfi-da, però apprezzo davvero molto che sia riuscito a portarla a termine con me.
Infine, questa tesi è il passo finale di un percorso durato più di 5 anni, che ho condiviso con persone fantastiche e con cui si sono instaurati rappor-ti che saranno sicuramente duraturi. Quindi un ringraziamento va anche a tutti loro per questi 5 anni di divertimento, duro lavoro e incessanti battute sempre più nerd per cui sentirsi delle brutte persone tutti insieme.
Transport Security Layer (TLS) è un protocollo largamente usato nelle telecomunicazioni per garantire una comunicazione sicura anche su reti che sono pubblicamente accessibili a chiunque, come Internet. Il più famoso con-testo applicativo di TLS è sicuramente HTTPS. Questo protocollo è in realtà l’unione di HTTP con TLS. In particolare, i messaggi HTTP sono incapsu-lati in messaggi TLS, quindi quest’ultimo lavora con messaggi HTTP come input. TLS è sostanzialmente diviso in due fasi. Nella prima, il cosiddetto handshake, il canale sicuro viene instaurato; nella seconda, questo canale viene effettivamente utilizzato per comunicare i dati. L’obiettivo della prima fase è ottenere una chiave segreta, specifica per ogni sessione instaurata, da utlizzare per cifrare i dati nella successiva fase di comunicazione, e accordarsi su quale algoritmo di cifratura usare. Questa chiave è generata a partire da altre informazioni, che solo le parti possono conoscere, unite ad alcuni byte generati casualmente per ogni sessione.
TLS garantisce 3 fondamentali proprietà di un sistema sicuro, che sono con-fidenzialità, autenticazione e integrità. La confidenzialità è garantita dalla cifratura dei dati che avviene nella fase di comunicazione, mentre l’integri-tà è realizzata tramite un apposito controllo per ogni messaggio scambiato. L’autenticazione va invece garantita durante l’handshake, dato che quando si vuole instaurare un canale sicuro con un altro nodo della rete, si vuole accertare l’identità dello stesso. TLS ha diverse alternative per garantire questa proprietà. Quella più comune è la Public Key Infrastructure (PKI). Questa infrastruttura utlizza dei certificati digitali, che in sostanza certifi-cano la validità di un’associazione tra un’identità, tipicamente un indirizzo web, e una chiave pubblica, entrambe contenute nel certificato stesso. Un certificato è dunque un file contenente questa associazione, e il cui contenuto è firmato digitalmente da una autorità di certificazione, indicata dalla sigla CA. Le CA sono fondamentali nella PKI. Infatti, sono enti di cui gli utiliz-zatori della PKI si fidano, cioè se un certificato è firmato da loro, allora le informazioni in esso contenute vengono considerate valide. Ogni implemen-tazione che verifica certificati, ha una lista di CA che sono considerate fidate. Tuttavia, non si può assumere che ogni certificato presente in rete possa esse-re firmato diesse-rettamente da queste CA, perché o queste CA sono troppo poche e quindi avrebbero troppe richieste da soddisfare, o queste sono moltissime,
motivo, PKI prevede una struttura gerarchica, in cui le CA possono delegare le loro funzioni ad altre entità che agiscono come CA, ma non sono conside-rate fidate dalle implementazioni. La delegazione avviene sempre tramite un certificato, rilasciato da un’altra CA, che associa l’entità certificata ad una chiave pubblica, che però può essere utilizzata per verificare le firme digitali sui certificati emessi da quella CA, utlizzando ovviamente la corrispettiva chiave privata. Questo processo può essere reiterato dalle nuove CA, se han-no il permesso dalle CA certificatrici naturalmente, dando origine a diversi livelli di delegazione. Per ogni entità certificata, si ha quindi un insieme di certificati, costituito dal certificato relativo all’entità stessa, e tutti i certifi-cati che delegano le diverse CA coinvolte nella certificazione, fino a che non si arriva a un certificato di una CA fidata.
Questo insieme di certificati è chiamato catena. Durante la verifica di un certificato, viene sostanzialmente controllata la validità di ogni certificato della catena, comprese le firme digitali, e che alla sommità della gerarchia di CA utilizzate ci sia una CA considerata fidata dall’implementazione stessa. Di solito, la catena di certificati viene fornita dal nodo che deve identificarsi durante la fase di handshake di TLS, anche se ci sono altre informazioni contenute nel certificato che possono aiutare nella costruzione di questa ca-tena da parte del verificatore. Se l’associazione tra identità e chiave pubblica nel certificato è validata, e il canale di comunicazione viene stabilito, allora l’autenticazione è garantita, in quanto per derivare la chiave segreta da usa-re nella cifratura, l’altro nodo necessita della chiave privata associata alla chiave pubblica del certificato, e quindi l’handshake può essere terminato con successo solo se l’altro nodo possiede la chiave privata, dimostrando di essere l’entità dichiarata nel certificato.
La verifica di un certificato è dunque fondamentale per la sicurezza di TLS. Si tratta tuttavia di un processo complesso, e perciò incline ad errori implemen-tativi. Infatti, diversi bug continuano ad emergere, nonostante il protocollo sia abbastanza datato (la prima versione, quando ancora si chiamava SSL, risale al 1995). Mentre gli errori sono abbastanza comuni nelle prime imple-mentazioni di un protocollo, generalmente dopo qualche versione la libreria raggiunge un livello di maturità tale per cui molti problemi sono mitigati, e la frequenza si riduce drasticamente. Nei casi di TLS, diversi errori sono stati trovati recentemente [22] [33]. Questo è un chiaro indizio della complessità della verifica di un certificato.
Questi sono genericamente considerati errori implementativi, per cui, nella letteratura scientifica a riguardo, vengono solo condotti dei test sistematici per individuare gli errori presenti nelle implementazioni correnti. Tuttavia, almeno una parte della verifica può essere migliorata. Infatti, questo proces-so può essere diviproces-so in due parti: nella prima viene analizzata la struttura dei certificati di una catena, o, in altre parole, questi vengono parsati; nella
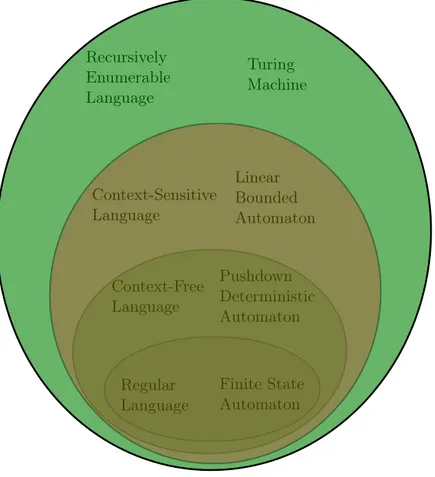
di una CA fidata, e altri vincoli opzionali. Le tradizionali librerie di TLS mischiano queste due fasi, realizzando quello che viene definito shotgun par-sing, che dovrebbero tuttavia rimanere ben separate e avvenire in maniera sequenziale [43]. Questo è un design piuttosto naturale se si pensa che que-sti parser sono programmati direttamente dagli sviluppatori, e non realizzati con strumenti più consoni a questo compito. Infatti, un parser è essenzial-mente un riconoscitore di un linguaggio. Nella teoria dei linguaggi formali, questi sono suddivisi in classi a seconda dell’automa a potenza minima che può riconoscerli. Considerando la classe dei linguaggi context-free, esistono algoritmi ben noti che possono generare automaticamente un parser per rico-noscere un linguaggio, specificato con una grammatica context-free. Questo generalmente è il modo in cui si dovrebbero sviluppare i parser, ove possibi-le. Infatti, questo approccio si può utilizzare solo se linguaggio che si deve riconoscere è generabile da una grammatica context-free. Nel caso dei cer-tificati, il linguaggio definito dalla struttura dei certificati opportunamente codificata in binario è context-sensitive, il che è una valida ragione del per-ché non esistono, per quanto ne sappiamo, parser automaticamente generati per riconoscere certificati. Tuttavia, questo approccio è sicuramente valido, perché scrivere manualemente un parser usando un linguaggio di program-mazione è un processo ad alto rischio di errori, specie per un linguaggio così complicato come quello che esprime i certificati. Al contrario, generando un parser automaticamente, molti dettagli implementativi sono delegati all’al-goritmo di generazione, e lo sviluppatore può concentrarsi sulla definizione della struttura più ad alto livello. L’ambizioso obiettivo di questo progetto è quindi quello di eliminare le strutture linguistiche che introducono context-sensitiveness, ottenendo un nuovo linguaggio che includa ovviamente anche i certificati correnti. In seguito, ottenere una corrispondente grammatica context-free da cui poter generare automaticamente un parser che riconosca correttamente i certificati, identificando quelli che sono malformati. La logi-ca conseguenza che ci aspettiamo è che questo parser dovrebbe essere molto più accurato delle implementazioni correnti delle più diffuse librerie TLS. Il primo passo del progetto è quello di individuare le strutture context-sensitive nei certificati. A questo proposito, è bene sottolineare come i certifi-cati siano definiti utilizzando ASN1, che è un meta-linguaggio per descriverne altri. Questa descrizione di alto livello ha una corrispondente codifica bina-ria, di cui ci sono due versioni, DER (Distinguished Encoding Rules) e BER (Basic Encoding Rules). Il punto chiave di queste codifiche è l’utilizzo di un campo lunghezza per delimitare gli elementi. In pratica, se nel campo lunghezza di un elemento c’è il byte N , i seguenti N bytes rappresentano il contenuto di quell’elemento. Questa codifica diventa context-sensitive nel momento in cui non c’è un limite superiore al numero N che può essere rappresentato in un campo lunghezza. Infatti, in questo caso bisognerebbe
linear bounded automaton. Questo è proprio il caso della specifica dei certi-ficati, che prevede questi campi lugnhezza senza limite superiore.
Di conseguenza, c’è una soluzione piuttosto semplice a questo problema, os-sia fissare dei limiti superiori per i certificati. Se questi ultimi vengono scelti in maniera tale da accettare comunque tutti i certificati correnti, allora il nuovo linguaggio definito, che è persino regolare, soddisfa anche il requisito di includere anche i certificati correnti. Il passo successivo è la progettazione della corrispettiva grammatica context-free. Tuttavia, una stima sul numero minimo di regole richieste da questo tipo di grammatica per riconoscere que-sto linguaggio dimostra che una grammatica per queque-sto genere di linguaggio è decisamente irrealizzabile. Infatti, c’è una dipendenza esponenziale rispet-to al limite massimo scelrispet-to per un campo lunghezza. Già una scelta piutrispet-tosrispet-to conservativa per questo limite, ossia 1024 byte, richiede 2257− 2 regole della grammatica.
Chiaramente, le dimensioni della grammatica sono troppo elevate. Per que-sto motivo, una grammatica context-free non è realizzabile per queque-sto lin-guaggio. Tuttavia, un parser può essere ancora automaticamente generato utilizzando una grammatica a predicati. Questo tipo di grammatiche è stato recentemente introdotto dagli autori di ANTLR [47], il generatore di parser utilizzato per l’implementazione. Le grammatiche a predicati sono sostan-zialmente delle grammatiche abituali con l’aggiunta di predicati semantici e di modificatori di stato. I predicati semantici sono delle espressioni boo-leane, scritte nel linguaggio di programmazione usato per il parser generato, che attivano o disattivano regole in base al loro valore di verità. Queste espressioni sono basate sul valore di variabili che sono impostate dai modifi-catori, ossia azioni semantiche che cambiano il valore di una o più variabili usate in un predicato semantico. Le grammatiche a predicati permettono di generare parser che riconoscono anche linguaggi context-sensitive, o ad-dirittura ricorsivamente enumerabili. Il lato negativo è che delle istruzioni in un linguaggio di programmazione generalmente Turing completo vengono aggiunte, e questo può far diventare il parser equivalente a una macchina di Turing, con tutti i problemi annessi (ad esempio l’indecidibilità). Utilizzando questo tipo di grammatica, è possibile contare un numero arbitrario di byte utlizzando i predicati semantici e dei semplici modificatori, che impostano un contatore con il valore trovato nel campo lunghezza, e questo contatore viene decrementato ogni volta che viene letto un byte. I byte vengono riconosciuti come contenuto dell’elemento considerato fino a che il contatore è maggiore di 0, condizione che viene verificata usando un predicato semantico.
Altri predicati semantici sono stati utlizzati per altre parti della grammatica per semplificare la stessa, ma non portano a un incremento della potenza riconoscitiva del parser. Inoltre, alcuni vincoli sulla struttura del certificato non sono verificati dalla grammatica, ma utilizzando delle azioni semantiche.
influenza, cambiando lo stato su cui si basa la valutazione delle espressioni contenute nei predicati semantici, sulle decisioni del parser stesso. Questi vincoli dunque non sono considerati nel linguaggio riconosciuto dal parser generato automaticamente, ma solo se consideriamo anche le azioni seman-tiche aggiunte alla grammatica. Per una lista delle principali dipendenze, e di come sono state risolte (grammatica, predicati semantici o azioni seman-tiche), si consulti la tabella 4.1. Ancora una volta, evidenziamo che questi vincoli sarebbero potuti essere inclusi nella grammatica senza portare a un incremento della potenza computazionale del parser generato, in quanto ri-conoscibili persino da un automa a stati finiti (eccetto un paio di casi che richiedono una macchina di Turing). Tuttavia, sono stati implementati se-manticamente ciascuno a causa di almeno una di queste due ragioni. La prima è che alcuni vincoli richiedono un elevato numero di regole per essere riconosciuti. Oppure, questi vincoli si riferiscono a parti della grammatica già molto complicate a causa di altre dipendenze già riconosciute sintattica-mente, in contrasto con la relativa semplicità di una verifica semantica. Il parser generato da ANLTR è di tipo LL(*). Il meccanismo di funziona-mento è lo stesso del più noto LL(k), l’unica differenza è che questo parser è in grado di utilizzare un lookahead arbitrariamente grande. Tuttavia, un generico parser LL(*) non ha garanzia di decidibilità, a causa dei possibili modificatori Turing completi, e potrebbe impiegare la tecnica del backtrac-king per utilizzare un lookahead arbitrariamente lungo. Il backtracbacktrac-king è necessario quando il parser non riesce a decidere tra due o più produzioni utilizzando il lookahead corrente. Questa tecnica, seppur potente, ha tutta-via delle controindicazioni dal punto di vista dell’efficienza computazionale. Infatti, quando avviene backtracking, il parser sceglie una delle produzioni tra cui è indeciso e prosegue a parsare secondo quella alternativa. Se suc-cessivamente viene rilevato un errore di parsing, anzichè andare avanti con un comportamento impredicibile o interrompersi, il parser torna indietro al punto di backtracking e prova a parsare con un’altra produzione. Questo meccanismo consente di scrivere grammatiche più potenti, ma può aumenta-re notevolemente la complessità temporale del parsing, a seconda di quante volte viene fatto backtracking. Un’attenta analisi rivela che il nostro parser ha un linguaggio di lookahead regolare, eliminando una delle possibili ra-gioni per cui il backtracking è necessario, ossia un linguaggio di lookahead context-free. Tuttavia, questa analisi non basta ad affermare che il back-tracking non può avvenire. Siamo comunque piuttosto convinti, considerato il tipo di regole utilizzate, che il nostro parser utilizzi sempre un lookahead finito, come farebbe un normale LL(k). Tuttavia, non abbiamo ancora effet-tuato un’analisi o delle prove per verificare questo dato.
Infine, un’ulteriore analisi sui predicati semantici e i modificatori utilizza-ti mostra che il nostro parser termina sempre, garantendo la decidibilità, a
azioni semantiche, e il Ls linguaggio definito nei seguenti standard [16] [12] [54] [35] per il formato dei certificati, valgono le seguenti condizioni:
Ls\ Lp 6= ∅ (1)
Lp\ Ls 6= ∅ (2)
La prima indica che ci sono certificati che sono validi secondo lo standard, ma non riconosciuti dal nostro parser automaticamente generato. Questo è dovuto a delle restrizioni che abbiamo imposto su alcuni campi. In particola-re, il nostro parser non accetta certificati con dimensioni superiori a 231+ 4, cioè file di circa 4 GB. Questo è stato scelto per evitare problemi legati al dover allocare più di questa quantità di memoria per il parsing di un solo certificato, con gli annessi problemi di scalabilità sul parsing parallelo di più certificati. In secondo luogo, solo gli algoritmi indicati nello standard come algoritmi di chiave pubblica o di firma digitale sono accettati. Lo standard invece accetta un generico algoritmo. Tuttavia, consideriamo questo un fon-damentale requisito di sicurezza, dato che TLS si basa pesantemente sulla robustezza delle primitive crittografiche utilizzate nelle diverse fasi. Infine, non è consentito l’utilizzo di alcuni identificatori (OID) in campi diversi da quelli in cui hanno un significato. Per esempio, non si può utilizzare un OID di un algoritmo di firma digitale come identificatore di un’estensione di un certificato. Questo uso non è esplicitamente proibito dallo standard, ma non ha chiaramente un significato concreto. Perciò, siccome questo utilizzo inappropriato complica notevolmente la progettazione di alcune parti della grammatica, e può introdurre anche problematiche legate alle diverse inter-pretazioni delle informazioni contenute in un certificato, abbiamo deciso di non consentirlo.
La seconda condizione indica che ci sono certificati che non sono validi secon-do lo standard, ma riconosciuti come tali dal nostro parser. Questi corrispon-dono ai certificati che sono invalidi perché violano vincoli che sono verificati semanticamente, che non sono inclusi nelle capacità riconoscitive del parser automaticamente generato. Di conseguenza, considerando il linguaggio effet-tivamente riconosciuto dal nostro parser, con l’aggiunta dei vincoli semantici, la seconda condizione non è più valida, e quindi questo diventa un subset di Ls. Ovviamente, si tratta di un subset che è ancora context-sensitive,
da-to che vengono riconosciute dalla grammatica dei campi lunghezza che non hanno limiti superiori.
Per testare la bontà del nostro approccio, abbiamo considerato 7 diverse librerie tra le più comuni implementazioni di TLS:
• OpenSSL, forse la più nota implementazione di TLS;
• BoringSSL, un progetto derivato dalla stessa base di codice di OpenSSL modificata da Google, attualmente utilizzato in Chrome e Android;
• NSS, l’implementazione usata da Mozilla Firefox;
• Bouncy Castle, la libreria di crittografia generalmente utilizzata per applicazioni Java
• CryptoAPI, implementazione di primitive e protocolli crittografici da parte di Microsoft
• Secure Transport, implementazione di TLS usata da Apple in iOS e OS X
Si noti che un comportamento da shotgun parser è ipotizzato per queste implementazioni. Di conseguenza, siccome parsing e validazione sono mi-schiati, il testing è svolto considerando l’esito della validazione dell’inte-ra catena che contiene il certificato che deve essere confrontato. Per de-rivare l’esito di un singolo certificato da quello di una catena, un’analisi differenziale sulle sotto-catene è applicata. In sostanza, per ogni catena C = (C0, C1, .., CN), dove CN è il certificato della CA fidata, si considera
sotto-catena C0 = (C1, C2, ..., CN). Si confrontano gli esiti dati dalla
libre-ria considerata sia per C che per C0. Se l’esito di C non corrisponde a un errore, allora C0 è considerato valido. Altrimenti, vengono confrontati gli
esiti di C e C0: se sono uguali, allora l’errore non è dovuto a C0, che viene riconosciuto come valido, se sono diversi allora l’errore è dovuto a C0, che riceve quindi lo stesso esito di C. Questa analisi consente di assegnare a ogni certificato un esito che può essere confrontato con quello emesso dal nostro parser. Ovviamente, siccome queste librerie sono considerate shotgun parser, ci aspettiamo che ci siano sia errori sintattici, quindi relativi a dipendenze interne a un singolo certificato, e non relazionate alla posizione ricoperta dal certificato in una catena (ci sono alcuni vincoli sui certificati se si trovano in una posizione nella catena > 0), che legati alla validazione della catena. Per questo motivo, abbiamo diviso, per ogni libreria, gli errori emersi dal testing in 3 categorie: sintassi, validazione e generici. Quest’ultima categoria rac-chiude gli errori la cui descrizione è troppo ampia per poterli classificare in una delle due categorie precedenti. La classificazione è riportata in tabella 5.6
Inoltre, per avere un chiaro indizio su quali errori nei certificati sono ricono-sciuti dal nostro parser, ma non dalle altre librerie, oltre che per farsi un’idea degli errori più comuni nel dataset considerato, abbiamo aggiunto al nostro parser una funzione che li classifica. Senza questa funzione infatti, ogni volta che c’è un errore di parsing verrebbe sollevato un errore generico che non dà indizi sull’effettivo problema del certificato. La funzione da noi aggiunta, utilizza principalmente 3 informazioni:
• La regola corrente e i non terminali già parsati nella regola corrente
• Il token atteso dal parser, la cui mancanza ha causato l’errore di parsing che si sta cercando di classificare
Usando un dataset costituito da circa 600 mila certificati, abbiamo analizza-to queste 3 informazioni ogni volta che un certificaanalizza-to viene riconosciuanalizza-to come errato. La combinazione di queste 3 informazioni identifica l’errore, che verrà dunque riconosciuto nei successivi certificati parsati. Una lista degli errori riconosciuti con questo metodo, uniti a quelli che rappresentano violazioni dei vincoli semantici, che non usano questo meccanismo, dato che sono ba-nalmente emessi se la verifica del vincolo fallisce, è riportata in Figura 5.2. Il testing è stato effettuato su un dataset con circa 10 Milioni di certificati. Il nostro parser riconosce come corretti 85.64% di questi certificati. La di-stribuzione degli altri errori è riportata in Figura 5.2. I risultati ottenuti nel confronto con le implementazioni correnti confermano le nostre aspettative. Infatti, considerando, per ogni libreria, l’insieme di certificati riconosicuti come validi dalla stessa, osserviamo che ci sono certificati riconosciuti come errati dal nostro parser. La percentuale di certificati errati è intorno al 13%, simile per tutte e 7 le librerie, dato che gli insiemi dei certificati identificati come corretti da queste ultime sono probabilmente molto simili. Alcuni di questi errori, introducono delle vulnerabilità legate alla diversa interpretazio-ne di alcuni campi in diverse implementazioni, che possono condurre anche ad attacchi di impersonificazione. In Figura 5.5, vengono mostrati i diversi errori non riconosciuti dalle diverse librerie. I codici riportati sulle ordinate corrispondono a quelli definiti in Figura 5.2. Un’analisi dettagliata di questi errori e delle possibili vulnerabilità associate è svolta nella stessa sezione. Per quanto riguarda il confronto opposto, cioè considerare l’insieme di cer-tificati corretti secondo il nostro parser e osservare l’esito di ognuna delle 7 implementazioni valutate, nessun errore non riconosciuto dal nostro parser sembra emergere. Infatti, la maggior parte dei certificati errati secondo le librerie, lo sono per ragioni di validazione. In alcuni casi, ci sono errori clas-sificati come sintattici, ma un’analisi manuale di questi certificati mostra che sono validi secondo lo standard e respinti dalle librerie a causa di restrizioni che non implementano alcune parti dello standard stesso. Ad esempio, un er-rore sintattico comune è quello di un algoritmo non valido trovato. Tuttavia questi algoritmi non sono considerati validi dall’implementazione, mentre lo sono per lo standard, o per mancanza di supporto (GOST), o perché consi-derati obsoleti (MD2,MD5). Una simile analisi manuale ha consentito, sui certificati che mostrano un errore generico, di individuare la causa più speci-fica dell’errore, e in tutti i casi, il problema individuato è legato all’algoritmo di validazione, e non a un vincolo che sarebbe dovuto essere controllato dal nostro parser. Tuttavia, è rimasta una non trascurabile percentuale di
cer-In conclusione, purtroppo non siamo riusciti ad ottenere una grammatica context-free per il parsing dei certificati. Tuttavia, passando a grammatica a predicati, siamo comunque riusciti a ottenere un parser automaticamente generato, con tutti i potenziali benefici annessi. Inoltre, abbiamo evitato le potenziali problematiche introdotte dalle grammatiche a predicati, ossia l’indecidibilità e, molto probabilmente, il backtracking. C’è tuttavia qual-cosa a cui dobbiamo rinunciare rispetto ad una grammatica context-free, ed è la decidibilità del problema di equivalenza tra due grammatiche. Questa proprietà non ha valenza solo teorica, in quanto diversi attachi a PKI si basano su linguaggi riconosciuti da due distinte implementazioni che hanno delle piccole ma significative differenze. La decidibilità del problema di equi-valenza, avrebbe significato poter dimostrare che due diverse grammatiche generano parser che riconoscono lo stesso linguaggio.
I risultati ottenuti confermano indubbiamente le migliori performance in ter-mini di riconoscimento di errori sintattici nei certificati da parte del nostro parser automaticamente generato. La nostra speranza è che miglioramenti così netti delle capacità riconoscitive siano una prova valida per gli sviluppa-tori delle librerie TLS, per convincerli che questo è l’approccio corretto per il parsing, con rilevanti riduzioni dela superficie d’attacco di TLS. Inoltre, il nostro approccio consente anche una separazione tra parsing e validazio-ne, evitando tutti i tipici problemi di shotgun parsing. Riteniamo poi che dall’adozione del nostro approccio possa beneficiare anche la validazione dei certificati. Infatti, il codice che si occupa della validazione non ha biso-gno di svolgere funzioni di parsing, e quindi può diventare più semplice e lineare, riducendo il rischio di introdurre bug ed errori di implementazione. Auspichiamo che tutti questi vantaggi possano convincere gli sviluppatori delle librerie correnti a prevedere una reingegnerizzazione delle loro imple-mentazioni per utilizzare il nostro approccio. Siamo consapevoli che questo non può essere un processo immediato, data la notevole quantità di cam-biamenti probabilmente richiesta per le implementazioni, ma ritenitamo che questa migrazione dovrebbe essere pianificata il prima possibile, per elimi-nare potenziali problemi derivanti dal parsing. La correzione dei bug emersi non è una soluzione permanente, perché la probabilità che ne compaiano altri non è trascurabile, ed ha delle solide motivazioni teoriche, delineate nel nostro lavoro. Inoltre, riteniamo che il nostro parser, dopo le opportune reingegnerizzazioni delle librerie, possa essere incluso in queste ultime sen-za grosse modifiche. Infatti, c’è già una struttura dati che contiene tutte le informazioni trovate in un certificato che è popolata durante il parsing. Infine, consideriamo il nostro lavoro un’ottima dimostrazione della validità dei concetti espressi in LANGSEC [53], un nuovo settore di ricerca che cerca di applicare i concetti e gli strumenti della teoria dei linguaggi formali alla sicurezza informatica, nella convinzione che un appropriato riconoscimento
nostro parser, che può aiutare a individuare errori non ancora riconosciuti, è costituita dal testing sui Frankencerts [15], che costituiscono un brillante metodo per generare un dataset con esempi di certificati malformati difficil-mente riscontrabili in insiemi con certificati reali. La grande varietà di errori che si possono trovare in un dataset costituito da questi Frankencerts può essere utile anche per migliorare e raffinare la classificazione degli errori di parsing. Siccome questa è basata sugli errori che sono stati incontrati nei certificati, è piuttosto evidente che una tale varietà di errori sintattici può introdurre molti più casi noti per la funzione classificatrice.
Una dettagliata analisi sul lookahead massimo utilizzato dal nostro parser non è ancora stata fatta, ma è sicuramente interessante in quanto permet-terebbe di confermare la nostra ipotesi sul fatto che un lookahead finito sia sempre sufficiente per ogni decisione di parsing, senza quindi ricorrere al backtracking. In questa maniera, potremmo sicuramente affermare che il nostro parser ha una complessità temporale lineare.
Infine, anche un test sulle performance sarebbe interessante. Un veloce con-fronto del nostro parser con OpenSSL ha mostrato che il nostro approccio non è solo più accurato, ma anche più efficiente. Tuttavia, questo risultato non è supportato da un testing sistematico con una solida base statistica, e quindi al momento questo dato non può essere confermato.
TLS is a widely used protocol to guarantee secure communication over an untrusted network. TLS ensures 3 different properties: confidentiality, authentication and integrity. Authentication is commonly provided using Public Key Infrastructure, which is based on digital certificates. Neverthe-less, certificate parsing is still an open problem, as suggested by bugs which continuously emerge in current implementations. In this work, we analyze this problem from a language theoretical point of view, and we try a new approach to achieve properly parsing goal, which is a milestone in order to guarantee PKI security. Proposed approach tries to avoid current parsing issues by designing a grammar which can be used to automatically gener-ate a parser. The main problem with this approach is that the language to express certificate structure is context-sensitive, while algorithms to gener-ate parsers generally required context-free grammars. We tackle this issue by analyzing if it is possible to obtain a new context-free language, which obviously includes all current certificates, and a corresponding context-free grammar to generate a parser. While we succeed in language definition, context-free grammar turns out to require too many rules to recognize this new language. Therefore, we employ predicated grammars, which allows to automatically generate a parser even for context-sensitive languages, but with the drawback of introducing semantic predicates, and thus potentially Turing complete statements, in the parser. Nevertheless, our analysis sug-gests that generated parser is equivalent to a linear bounded automaton, and recognize a context-sensitive language which is a subset of the one defined in X509 standard. We also perform a comparison between our parser and main TLS libraries in order to spot advantages and pitfalls of our approach against current implementations. Results show our parser outperforms these ones, recognizing actually invalid certificates which other libraries consider valid, while basically no issues in our parser recognizing capabilities have been found. These results prove the goodness of our approach and suggest its usage in current implementations.
1 Introduction 1
2 State of the Art 7
2.1 TLS protocol for secure communication . . . 7
2.1.1 Establishing TLS Session . . . 8
2.1.2 TLS-PKI and X509 Certificates . . . 13
2.1.3 TLS-PSK . . . 18
2.2 Attacks against TLS . . . 20
2.2.1 BEAST Attack . . . 20
2.2.2 Padding Oracle Attacks . . . 22
2.2.3 Issues with Key Material . . . 23
2.2.4 Logjam . . . 26
2.2.5 DROWN . . . 27
2.2.6 Other Attacks Against TLS . . . 29
2.3 X509 Parsing Issues and Related Work . . . 32
2.3.1 LANGSEC . . . 37
2.3.2 X509 context-sensitiveness and our aim . . . 42
3 A Detailed Analysis of X509 Standard 45 3.1 Depth Analysis of X509 Certificate and its Constraints . . . . 45
3.1.1 Brief Introduction on ASN1 Textual Representation . 45 3.1.2 Analysis of X509 Certificate Structure . . . 49
3.1.3 X509 Standard Extensions . . . 54
4 Proposed Grammar for X509 Parsing 73 4.1 Grammar Design . . . 73
4.1.1 How to deal with context-sensitiveness? . . . 73
4.1.2 Predicated Grammar Analysis . . . 79
4.1.3 Lexing Grammar Highlights . . . 82
4.1.4 Parser Grammar Analysis . . . 94
4.1.5 Semantic Part and Verified Constraints . . . 107
4.2 Implementation Using ANTLR . . . 118
4.2.2 Generated Parser and Recognized Language . . . 121
5 Experimental Validation and Comparison 129 5.1 Testing Principles . . . 129
5.2 Dataset and Database Description . . . 132
5.3 Classifying Parsing Errors . . . 136
5.4 TLS Libraries Comparison . . . 142
5.4.1 Testing Infrastructure . . . 143
5.5 TLS Libraries Implementation Details . . . 147
5.6 Result Analysis . . . 152
5.6.1 Parsing Outcomes Analysis . . . 152
5.6.2 Subchain Testing . . . 158
6 Conclusion 179 6.1 X509 Parsing Improvements . . . 179
6.2 Future Developments . . . 185
A Appendix Title 187 A.1 Lexer Grammar . . . 187
A.2 Parser Grammar . . . 203
2.1 TLS Protocol Handshake and Record Phases . . . 11 2.2 CRL file structure . . . 16 2.3 CSR file structure . . . 18 2.4 Chomsky hierachy of formal languages and corresponding least
powerful automaton which can recognize that class of languages 38
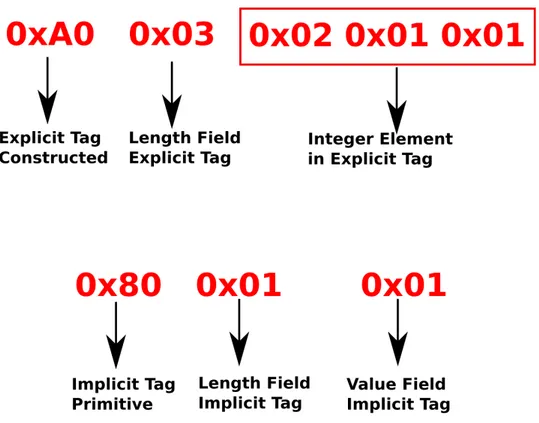
3.1 ASN1 Explicit (above) and Implicit (below) Tagging Encoding of ASN1 INTEGER 1 . . . 48
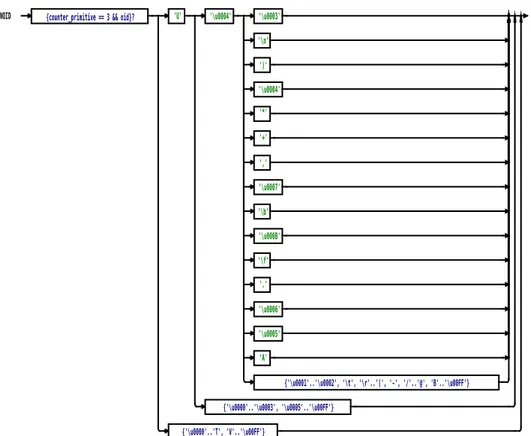
4.1 SHA1OID rule structure. Note that characters are present instead of bytes when the byte is a valid ASCII encoding . . . 86 4.2 DNOID rule structure. Note that characters are present
in-stead of bytes when the byte is a valid ASCII encoding . . . . 88
5.1 Logical Schema of DB. Primary Keys are indicated by red columns. The black circle is close to the column which is referenced by another one in a foreign key constraint . . . 134 5.2 Our parser error split according to different order of
magni-tudes. Starting from the top left corner bar, the subsequent bar is the expansion of the indicated label of the previous bar. Rare Errors are displayed in next page . . . 153 5.3 Rare Errors recognized by our parser. Total size of dataset is
9798426 . . . 154 5.4 Warnings found by our parser. Y-axis contains warning code,
X-axis percentage over total size of the dataset which have this warning . . . 157 5.5 Error Classification of considered TLS libraries. . . 164 5.6 Error not recognized by TLS libraries. Each horizontal bar
is split among 7 libraries. If there is coloured sub-bar for a library, then the error is not recognized by the library . . . . 173
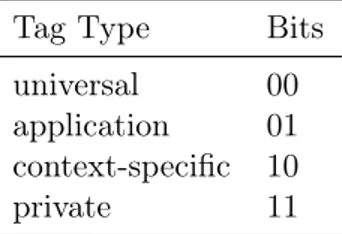
3.1 ASN1 default primitive types . . . 46 3.2 ASN1 default constructed types and their EBNF meaning . . 46 3.3 Most significant bytes values for different tag types . . . 49 3.4 Consistency between EKU and KeyUsage. Integers used in
third column represents the enumeration of usages found in KeyUsage extension . . . 66 3.5 Summary of X509 constraints and issues. Computational Power
column indicates the weakest computational model which can check for the constraint. . . 71
4.1 Summary of X509 constraints and issues. Computational Power column indicates the weakest computational model which can check for the constraint. Solution indicates how this con-straint or issue has been solved in our parser . . . 124
5.1 Testing Machine Technical Details . . . 129 5.2 OpenSSL Parsing Outcomes . . . 155 5.3 BoringSSL Parsing Outcomes . . . 155 5.4 GNUTLS Parsing Outcomes . . . 156 5.5 CryptoAPI Parsing Outcomes . . . 156 5.6 List of error found by each TLS library. Second comlumns
is the number of certificates which exhibit the error. Third one is a description of the error taken from reference of the libraries. Last column shows classification of the error, where V is validation, S syntactic, G generic. . . 162 5.7 Classification of outcomes for certificates accepted by our parser.
Values in round brackets are the actual number of certificates with a syntactic error, which have been however discarded by (A, RS) set after manual analysis of these certificates. Same
notation is used for (A, RG). . . 165
3.1 To Be Signed Certificate . . . 51 3.2 Key Usage Extension . . . 56 4.1 Parser rules to distinguish between Value fields which can have
a null character or not . . . 84 4.2 Part of the grammar to recognize extension dependencies . . . 96 4.3 Part of the grammar to match signature algorithm OIDs . . . 102 4.4 Management of counters stack for constructed types length
fileds . . . 104 4.5 Key Usage checkings function . . . 114 5.1 Code to update parsing state information . . . 138 5.2 List of errors recognized by our parser, with their
correspond-ing numeric codes. . . 141 A.1 Lexer Grammar with semantic predicates and mutators . . . 187 A.2 Terminal Symbols Parser Grammar. . . 203 A.3 Non-Terminal Symbols Parser Grammar . . . 204 A.4 Parser Grammar with semantic predicates and mutators . . . 206
Introduction
SSL (Secure Socket Layer), and its recent version, TLS (Transport Layer Security), is probably the most widely known cryptographic protocol, used especially in Internet context to provide and guarantee secure communica-tion between parties. The most famous applicative context is HTTPS, which is the well known HTTP protocol with the addition of an encryption layer provided by TLS. HTTPS is nowadays used by basically each website which stores sensitive information or needs a login form, therefore TLS is a tech-nology which quite everyone employs in his everyday life. Other relevant applicative contexts of TLS are Virtual Private Networks (VPN). VPNs are used to build a secure communication channel between two groups of hosts which are connected through the wild, unsecure Internet, as if they were in the same private network unaccessible from the outside. In order to guaran-tee confidentiality, authentication and integrity to VPNs, TLS is a common choice.
Note that TLS is not a particular cypher, but a cryptographic protocol. In-deed, a cypher is basically a pair of algorithms to perform encryption and decryption. Encryption algorithm, given a plaintext m, computes an output message C(m), using a number k, which is called key, and this encrypted message appears completely random to an eavesdropper. The original plain-text is recovered through decryption algorithm, which uses either the same k, or another one which is related to k but known only to the receiver. Instead, TLS defines format and sequence of messages to be exchanged be-tween two parties in order to establish a secure channel, which is secure because of content encryption. This one is performed using a cypher and a key which is negotiated by the parties during the establishment of con-nection. In conclusion, TLS relies on cryptographic primitives to guarantee secure communication. TLS role is providing a mechanism in order to let the parties agree on the cypher and the key which have to be used.
During secure channel negotiation, also authentication is generally needed. Indeed, when you connect to a website to communicate sensitive information,
you have to be sure that you are establishing a secure communication with that website, and not with a generic host which claims to be the target web-site. TLS provides authentication too, at least to one of the parties, generally the server, but also mutual authentication is possible. Different mechanism are defined in TLS to guarantee authentication. The most widely used is Public Key Infrastructure (PKI), which is also the focus of presented work.
PKI relies on asymmetric key primitives, which are characterized by usage of two keys, one for encryption and the other one for decryption. The first one, called public key, is known to everybody, while the second one, called private key, it is known only to the entity which owns the key pair. Encryption is performed using public key, and the cyphertext C(m) can be decrypted only using the private key, thus only by the receiver. Hence, if two parties (famous Alice and Bob) want to communicate using asymmetric key encryption, both of them owns a key pair, and they provide each other their public keys. If Alice wants to send a message to Bob, she encrypts it using Bob’s public key. In this way, confidentiality is ensured, since only Bob can decrypt it with his private key. Note that authentication is not guaranteed by this scheme, because everyone could send to Alice a public key claiming it is Bob’s one. PKI adds authentication to this scheme using digital certificates, that is files or a stream of bytes which have the same purpose of certificates released by countries public authorities in everyday life. Digital certificates are issued by apposite authorities, which are called Certificate Authorities (CA), which digitally sign these certificates as a proof that the content of the certifi-cate is guaranteed by them. Basically, the content of the certificertifi-cate provides a verified binding between an identity and a public key stated in that certificate. Such binding is ensured to be valid by the CA which issues the certificate, in the same way a country ensures identity of its citizens through ID documents. Note that this binding is considered valid only if it is issued by an entity which is recognized as a CA. Thus, PKI authentication relies on a set of entities which are considered trusted CA, which are called trust anchors.
For scalability reasons, PKI has a hierarchical structure. On the top there are trust anchors, which can delegate to other entities the task of issuing certificates. These entities are authorized again through a digital certificate which provides a binding between their identity and the public key needed to verify signatures on certificates which claim to be signed by these author-ities. Of course, in the certificate it is explicitly stated if the entity can issue other certificates or not, and thus if the public key can be used to verify signatures on other certificates. These entities, if the anchor allows them to do it, which is again stated in their authorization certificate, can issues certificates to other CA, building up the PKI hierarchy. The end points of this hierarchy are so called leaf certificates, which certify an entity which is not a CA. Therefore, a path is associated to every leaf certificate, which
each element of this path to prove identities and provide public keys of CAs involved, in order to verify digital signatures of each certificate in the path. TLS protocol using PKI as authentication method requires that a certifi-cation path, or a single certificate, of at least one part (the server) of the communication is sent to the other one (the client). The key which is agreed during negotiation depends on the private key associated to public one stated in the certificate. If server does not own this public key, a successful estab-lishment of secure communication can not happen. Hence, if a secure com-munication is successfully established, the client can be sure that the host it shares connection with is the server, since it owns the private key related to public one stated in the server certificate, which is a binding guaranteed by a legitimate CA.
Nevertheless, this scheme relies on the correct verification of information contained in the certificate. This process is however quite complex. Indeed, a verifier must process all information contained in all the certificates of the path and check if it is valid, which basically means all certificates signatures are correct and the path ends with a trust anchor issued certificate. As an expected consequence of the complexity of this process, several errors in main TLS implementations have been continuously emerged since its birth. Issues are obviously quite common in first releases of new implementations, but they should gradually disappear. However, history of SSL/TLS is quite long from a development point of view (more than 20 years), but still bugs and verification errors have been recently found [15].
This is generally considered an evidence of the intrinsic complexity of PKI verification algorithm. However, these issues are generally considered as expected but unavoidable implementation errors, which cannot be overcome by another theoretical approach or different strategies, unless the verification process is simplified. The basic idea which drives the presented work is that verification process can, and actually should, be split in two different parts, and the previous statement may be true only for one of these two parts. Ver-ification process can indeed be split in parsing and validation phases. During the first one, the certificates in the path must be correctly parsed to collect all information stated in them, while subsequently, in second phase, these information must be used to validate the path, thus verifying signatures and issuers identities. Note that parsing input may not be a trivial task, espe-cially in case of certificates, which have a quite complex structure. Indeed, there are some dependencies which have to be fulfilled among certificates fields, which can increase parsing complexity. Also the binary encoding used by certificates is not that trivially recognizable, and this can lead to even serious issues [27].
Issues raised by a unproper parsing are not occasional. Indeed, an insight-ful analysis of most common security issues, carried on in [53], shows that
quite all vulnerability types, like Buffer Overflow or SQL injection, are quite always related to bad input handling offered by the parser of a vulnerable implementation. Therefore, properly parsing can improve security of these implementations. A possible approach to achieve, or at least get closer to properly parsing input can be derived by the claim that input handling is basically a formal language recognition problem. That is, building a parser means actually designing an automaton which recognizes a specific input language. The key point is that there exists algorithms which can automat-ically generate this automaton, providing them a grammar specification of the input language. Unfortunately, there algorithms generally work only if input grammar is deterministic context free. Moreover there are other two desirable properties ensured by these parsers which can increase security. First, they always terminate with a positive or negative outcome, for each possible input string. Secondly, it is always possible to algorithmically prove that two deterministic context free grammars generate the same language, and thus corresponding generated parsers recognize the same language. As a consequence of this analysis, a clear design principle is derived: keep the input language as weak as possible. That is, a language should be de-signed to require the minimum recognizing capabilities needed for operations which have to be achieved.
In the light of this important design principle, this work tries to slightly modify certificate structure in order to build a parser generated by a gram-mar specification, which, to the best of our knowledge, has never been done before. Indeed, certificate structure can be expressed by an equivalent rec-ognized language L, which is unfortunately context-sensitive, which is likely the motivation why no certificate parser has been automatically generated. Therefore, in order to use parsing generation algorithm, the language must become context-free. Obviously, the modified language should still include current valid certificates. In such a way, with little changes to certificate structure definition, an automatically generated parser could be employed to parse certificates, which should probably lead to a sensible performance improvement, in terms of recognizing capabilities, against currently hand-written parsers.
Contributions of presented work are:
• A detailed analysis on certificate structure defined language, and rea-sons behind its context-sensitiveness
• Proposals to modify this structure in order to get a language which can be described by a context-free grammar, but still including current certificates
• An analysis on the number of rules needed by a context-free grammar to generate this modified language, with corresponding feasibility issues
context-free one requires too many rules)
• A comparison between recognizing capabilities of generated parser and current TLS implementations, to show achieved improvements towards properly parsing goal, and to spot certificate issues which current li-braries are not able to detect
This work, even if it does not achieve one of its aims, that is defining a context-free grammar to generate certificates, provides an automatically gen-erated parser which outperforms current ones, proving the validity of pre-sented approach. Generated parser could be easily attached directly in TLS implementations, or could provide a strong proof fo effectiveness of employed approach to TLS implementers, convincing them that parser errors are avoid-able even without decreasing certificate structure complexity. It is just a matter of using the right technique. Unfortunately, such an approach is not applicable to validation phase, which can only be improved by code reviews, testing, and consequently bug fixing, but we claim that if our approach is employed in current implementations, validation code becomes much simpler and smaller, and so less errors should appear.
In the next chapters, all details about this work are deeply explained. In chapter 2, a more detailed overview of TLS and analysis of the issues which motivates this work are presented, together with a discussion on context-sensitiveness of certificate format. In chapter 3, standard certificate struc-ture is deeply described. In chapter 4, all the grammar design issues and key parts are discussed. In addition, a formal analysis on predicated grammars, the obtained parser and the recognized language is performed. In chapter 5, all details about the comparison of generated parser with other TLS im-plementations are discussed, and results of this comparison are presented. In chapter 6, final considerations on the presented work, in the light of ob-tained results, are expressed, together with some future developments and integrations which could be done. Last, an appendix is provided where there can be found the entire designed grammar.
State of the Art
The aim of this chapter is providing to the reader a basic knowledge of the context in which this work can be placed. We decide to start from a user perspective, explaining the applicative context and gradually descending into deeper technical details. Hence, this chapter is divided into 3 main sections:
1. Introduction about TLS and PKI infrastructure
2. Issues related to PKI-based TLS
3. State of the art about X.509 parsing and validation
2.1
TLS protocol for secure communication
The most used communication stack worldwide is TCP/IP. However, this stack does not take into account security properties, since it was designed not for an open community like Internet, but to exchange data among scholars. Nevertheless, security properties have become absolutely required in a lot of applicative contexts, leading to the birth of Secure Socket Layer (SSL) , a protocol to guarantee secure communication over TCP/IP stack. SSL was designed in 1995, by Netscape. The first published version was 2.0. In 1999, Transport Layer Security (TLS) was standardized by IETF. TLS is basically an SSL evolution, which patches some security issues and increases security margins. By now, the most recent version of TLS is 1.2, whose novelty is support for Elliptic Curve cryptography.
TLS provides an encryption layer to a whatever insecure application proto-col. For instance, TLS is used under HTTP communications to send and receive encrypted data, a combination which is commonly known as HTTPS. Whenever you browse a site with HTTPS instead of HTTP, TLS is used to encrypt and decrypt HTTP messages. In this way, an eavesdropper sees only a meaningless cyphertext. TLS is also commonly used with quite all email protocols (SMTP,IMAP,POP3), to provide an encryption layer in
the same way it does with HTTP.
Virtual Private Networks (VPN) are another common scenario where TLS is used. Indeed, VPN is a network which is composed of hosts which are not in the same physical network, but could be connected even through Internet. Nevertheless, logically they should behave as if they were in the same physical private network. If information has to travel across public networks, encryption is the key to provide confidentiality. TLS is specifically designed to supply an encryption layer on top of TCP/IP stack, and thus perfectly fits VPNs requirements.
Last, Stunnel is a tool which relies on TLS to provide secure communi-cation to services which does not include TLS server functionality without edit and redeploy this services. Basically, it acts as a port mapper. Stunnel opens a port on which it operates like a TLS server and it maps to the port where target service is listening. Hence, clients which would like to securely communicate with target service, can connect to Stunnel port using TLS. Stunnel provides all TLS functionalities and forward plain input/output to and from the service port.
Moreover, confidentiality is not the only security property guaranteed by TLS. Indeed, this protocol ensures also integrity and authentication, us-ing Public Key Infrastructure (PKI) mechanism, which will be deeply ana-lyzed later, or a Pre-Shared Key (PSK) one. Moreover, there is another secu-rity property, which is ensured depending on the algorithm used to perform key agreement: forward secrecy. If a protocol provides forward secrecy, it means that an attacker cannot recover past collected encrypted messages or decrypt a current session, even if the long term secret is disclosed (unless the attacker find long term secret before key agreement for the current session is performed, of course).
After this brief analysis about TLS properties, it’s time to deeply analyze how this protocol actually works.
2.1.1 Establishing TLS Session
Before getting into detailed explanations of the TLS handshake and ex-changed messages, some technical concepts have to be briefly introduced. First of all, a scalable approach should consider asymmetric encryption to provide authentication. Indeed, authentication with symmetric encryption is guaranteed by knowing the common secret key. Nevertheless, if the scheme requires also confidentiality, symmetric encryption is not scalable. Indeed, there should be a key for every pair of entities who want to talk each other, and this key should be exchanged by out of band means. Suppose you have to perform this exchange for every web server you want to securely connect with, and you will immediately realize why this solution is absolutely not feasible. Instead, asymmetric encryption does not suffer this issue. Indeed, in asymmetric encryption, authentication relies on a proof that the host we
are connecting with, actually knows the private key corresponding to the public key stated to be associated with that host. Clearly, a trusted source is needed to state the binding between a public key and a host (for example a web server), otherwise impersonation attacks are possible, which are com-monly known as Man In The Middle attacks. In fact, without this trusted source, an attacker could generate a pair of private/public keys, and claim to the victim that the public key he has just sent is the public key of the host to which victim wants to communicate. Hence, the victim would encrypt his messages with attacker’s public key, allowing the attacker to decrypt the messages, as in a normal asymmetric scheme. Providing this trusted source is fulfilled by Public Key Infrastructure in TLS, by means of digital certifi-cates. These certificates have to be trusted during TLS handshake, a process which is quite complex, and which will be deeply explained later in PKI sub-section 2.1.2. In order to understand TLS protocol, it’s sufficient to assume that the provided certificate guarantees a valid binding between a host and his public key, if this certificate succeeds the trusting process.
Coming back to scalability issues we have discussed, it’s quite straightfor-ward that this scheme is scalable, since there is only one key pair and a corresponding certificate for every host who wants to securely communicate. Nevertheless, asymmetric encryption scheme are quite slower with respect to symmetric ones. TLS approach tries to get the best from both classes of cryptographic primitives. Hence, asymmetric encryption is used in the start-up phase of the protocol, to start an authenticated encrypted commu-nication. This secure established channel is used to exchange an ephemeral session key (that is a key which is used only in that session, so an ephemeral one because it does not last), which is used as a shared secret key to perform symmetric encryption of the actual information parties want to send each other.
Another important concept necessary to understand TLS is cypher suite. A cypher suite is basically a set of all the algorithms supported by an entity, classified according to 5 different functionalities.
1. Authentication Primitives. These algorithms can be used to perform the initial asymmetric encryption phase and to authenticate hosts using certificates. Classical examples are RSA,DSA, ECDSA.
2. Key Exchange Primitives. These algorithms can be used to generate the ephemeral shared session key. Classical examples are RSA, DH, ECDH.
3. Encryption Primitive. These algorithms can be used to perform sym-metric encryption during the communication phase of the protocol, when the actual content messages are exchanged. Classical examples are AES, Camellia or GOST.
4. Cryptographic Hash Function. These algorithms can be used whenever a hash function is required (for instance digital signatures or integrity checks) and as Pseudo-Random Function to generate nonces or the shared session key. Classical examples are SHA1, 256, SHA-2-512.
5. Integrity Primitives. Usually these are MAC algorithms, which com-putes an integrity check using also the shared session key used to en-crypt the message. Classical examples are SHA1 or HMAC-SHA-2-256.
Of course, for every class there could be more than one algorithm, that is all the ones supported by entity which is sending the cypher suite.
After these explanations, TLS handshake can be fully understood. First of all, every TLS message is called a record. Each record has a byte to state the content type of the record, and other fields like TLS version used and the length of the record. After this header, there are actual content bytes of the message, optionally trailed by the output of a Message Authentication Code (MAC), which is a cryptographic primitive to provide integrity, and padding bytes, if necessary.
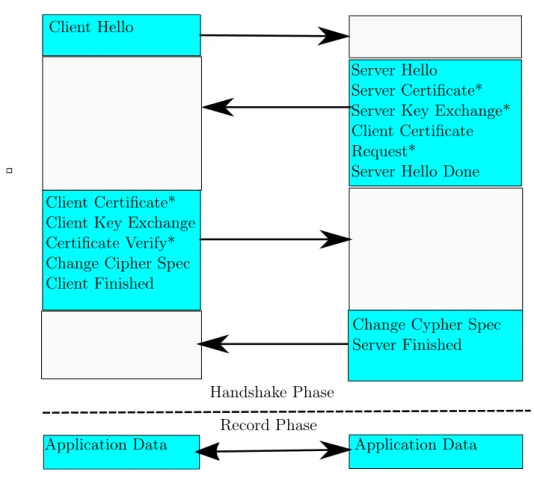
TLS Protocol phases are depicted in Figure 2.1. Handshake is the first one, where the session setup happens. The latter is simply when the actual communication takes place, that is information are sent among the parties. During both these phases, every message sent is still a record, but there is different content type byte value, distinguishing these two parts of the protocol. The most relevant part of TLS is in handshake phase, since record one is basically a usage of symmetric encryption algorithm to communicate. Handshake steps are listed below. Note that some steps can vary depending on the cryptographic algorithms or authentication method (PKI vs PSK).
1. TLS handshake starts with a client sending to server a record called ClientHello. The purpose of this message is communicating to the server the following information about the client:
• Highest TLS version supported; • Client’s cypher suite;
• Suggested compression methods;
• A random nonce which will be used later in session key computa-tion;
Obviously, this message is sent in clear because no authentication has been performed yet.
2. Server responds with a ServerHello message. This message commu-nicates choice of the server among the parameters client has previous
Client Hello
Server Hello Server Certificate* Server Key Exchange* Client Certificate Request*
Server Hello Done Client Certificate*
Client Key Exchange Certificate Verify* Change Cipher Spec Client Finished
Change Cypher Spec Server Finished
Application Data Application Data Handshake Phase
Record Phase
Figure 2.1: TLS Protocol Handshake and Record Phases
sent. In particular, the version must be chosen as the highest which is supported by both client and server. Obviously, also choices about compression method and cryptographic algorithms should be the ones which provides the higher, respectively, efficiency and security margin. Another random number is sent by the server in addition to aforemen-tioned choices.
3. If Public Key Authentication has been chosen, server also sends its cer-tificate and all other cercer-tificates necessary to trust and validate server certificate.
4. Server could also sends a Server Key Exchange message, again de-pending on the algorithm used. This record contains information to compute the so called master secret, from which the session key is derived.
5. Server could also sends a request for a client certificate, if mutual au-thentication is required.
by the client have been transmitted.
7. If a server certificate is sent, Client runs verify algorithm to evaluate if the certificate is trusted or not.
8. If a certificate request is sent, Client sends its certificate and all other certificates necessary to correctly validate it. Moreover, Client sends also a CertificateVerify message, which contains a copy of the hand-shake records sent so far signed with Client’s private key. Verifying the signature with public key stated in Client certificate, server can actually verify its identity, since in this way Client prove to be the owner of the private key and thus the legitimate subject of provided certificate. Note that this check is necessary in mutual authentica-tion because during normal handshake, Client Key Exchange message is encrypted with the server public key. Hence, if some attacker is trying to use a valid certificate to impersonate server, handshake will not work, because the attacker will not be able to decrypt informa-tion contained in Client Key Exchange message and thus to compute the master common secret. Instead, no encryption with public key of the Client usually happens (at least for some cipher choices), and so, without this check, an impersonation attack would be really easy to perform.
9. Client sends a Client Key Exchange with all the information nec-essary to the server to compute the session key. Again, content of this message can change depending on the algorithms used. This is the first message sent encrypted with server’s public key. From now on, both Client and Server have all the information needed to compute the master common secret, that is nonces and an eventual pre-master key.
10. When the Client finishes to compute secret session key, it sends a ChangeCypherSpec record, basically saying that everything from now on will be encrypted using the secret session key, providing both authentication and confidentiality (also integrity if a MAC algorithm was negotiated in the handshake). Note that ChangeCypherSpec is a record with a specific content type byte, different from handshake ones.
11. Client sends a Finished record. It contains a MAC of all the messages exchanged during handshake.
12. Server decrypts Finished record (secret session key is needed to perform this decryption, hence server should have already computed it) and verify MAC of the handshake messages. Then, it performs the same step as the client, that is sending ChangeCypherSpec record and its Finished message.
13. Client performs same verification procedure.
14. If none of the above steps fail, now the protocol can enter into Record Phase, where application data could actually be sent by symmetric encryption using computed secret session key.
As an example of Server Key Exchange message, consider Diffie-Hellman Ephemeral as a choice for the key agreement algorithm. In this case, server sends his public token obtained as gamod p where a is the secret random number chosen by the server. Client will send its public exponent in Client Key Exchange record, which is encrypted, hence only the server can compute the key using Diffie-Hellman scheme.
Since asymmetric encryption operations are quite slow, performing a com-plete handshake quite often can be inefficient. Hence, there is also a fast-resume version of TLS handshake. During standard handshake, server includes a Session ID in his ServerHello message. When the master secret is computed, Server keeps a mapping between the Session ID sent and the secret. Client associated received Session ID with master secret and an iden-tity of the server (URL, socket etc).
When Client wants to resume a TLS session, it sends a ClientHello including Session ID, plus the usual content of this record in basic handshake. If server receives Session ID, it checks existence of a mapping for this ID. If such map-ping is found, server communicates it to Client by sending the same Session ID in its ServerHello message. Otherwise, a newly generated Session ID is sent to indicate that a basic handshake have to be performed by Client. In case of a fast-resume handshake, at this time both Client and Server should manage to recover the master secret and compute the session key. Hence, handshake can be resumed starting from Client sending ChangeCypherSpec record, and it goes on exactly in the same way as standard one until Finished messages are sent and protocol can enter again in Record phase.
2.1.2 TLS-PKI and X509 Certificates
As stated in the previous section, Public Key Infrastructure (PKI) is probably the most common method used by TLS to guarantee authenti-cation. The identity of a host is stated by a Digital Certificate, that is a file which has the same role that paper certificates have in everyday life: an official trusted document which declares something entities can rely on. Before going on with details about PKI, it’s necessary to have a look to the structure of a digital certificate file. In this section there is only a brief introduction necessary to understand how PKI works, but the structure is deeply analyzed in section 3 since it’s the core of the presented work. X509 Standard defines structure of certificates.
• Version. X509 standard defines 3 different versions of certificates, which provides additional content and extensions;
• Serial Number. Unique positive number to identify a certificate;
• Issuer. The entity who issued the certificate and signed it with its public key;
• Validity Period. Two dates which represent the period in which the certificate can be considered valid;
• Subject. The entity whose identity is certified by the certificate;
• Subject Public Key. This is the public key bound to the subject of the certificate;
• Extensions. These appears only in version 3 certificates, and contain additional information about the subject, certificate and public key. In particular, two information are more relevant: if subject is a CA or not, and what usages are legitimate for the public key;
• Signature Algorithm. The algorithm used to sign the certificate;
• Signature. The digital signature of the certificate, computed using issuer’s public key and the algorithm specified in Signature Algorithm.
A straightforward question could arise: Who is the issuer of a digital certifi-cate? The answer depends on the system used to trust digital certificates. Indeed, a certificate by itself adds no security because the information con-tained are not guaranteed by anyone, and thus cannot be trusted. PKI is one of the possible solution in order to ensure the validity of information contained in a digital certificate, in particular it uses a centralized approach. It mimics working principles of bureaucracies in quite every country of the world. A simple example should help understanding this infrastructure. Consider a degree from a university. A degree is just a piece of paper which states that the subject reported on it successfully completed a university course and acquired some competences. Why is this paper legally valid? Why can’t everyone self-write a paper like this and declare it legally valid? What makes that piece of paper legal is the issuer, that is the university where the student graduates. So, next question should be why can’t someone declare himself a university and starting issues degrees to whoever required him to do it? And, again a university is considered legal when it receives an authorization from the education ministry. This authorization can have different forms (a law, a grant etc) but all of them can logically be consid-ered a certificate, where it’s stated that the subject, that is the university, can issues legally valid degrees to its students. The country, "impersonated" by education ministry in this case, issues this certificate. Now, country is