Indice
Introduzione 5
Motivazioni . . . 6
Contributo della tesi . . . 7
Organizzazione della tesi . . . 10
1 Background e stato dell’arte 13 1.1 Web Mining . . . 13
1.2 Web usage mining e Knowledge discovery in database . . . 15
1.2.1 Raccolta dei dati . . . 16
1.2.2 Preprocessing . . . 18 1.2.3 Pattern discovery . . . 20 Regole associative . . . 20 Clustering . . . 21 Classificazione . . . 21 Pattern sequenziali . . . 22 Analisi statistiche . . . 22 1.2.4 Pattern analysis . . . 23
1.3 Sistemi di web usage mining: stato dell’arte . . . 23
1.4 Persistenza dei dati . . . 24
1.4.1 DBMS relazionali . . . 25
1.4.2 DBMS a oggetti . . . 26
1.4.3 Database misti (object-relational) . . . 28
1.5 Gigabase . . . 29
2 Web Object Store 35 2.1 Introduzione . . . 35
2 Indice
2.2 Formati dati input . . . 38
2.2.1 Common Log Format (CLF) e Combined Log Format 38 2.2.2 Squid Log Format . . . 40
2.3 Modellazione degli oggetti web . . . 42
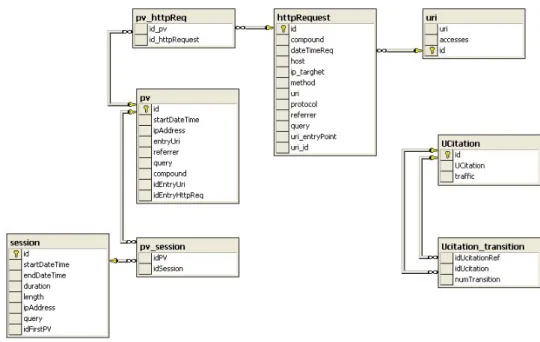
2.3.1 Uri . . . 42
2.3.2 Http request . . . 42
2.3.3 Page view . . . 44
2.3.4 Session . . . 44
2.3.5 UCitation . . . 45
2.3.6 Repository e web object . . . 46
2.4 Modello di un framework . . . 50
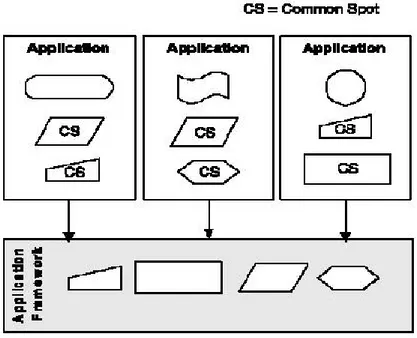
2.4.1 Common spot . . . 51
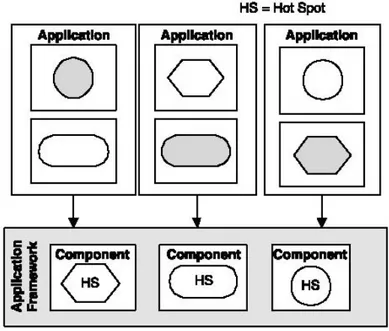
2.4.2 Hot spot . . . 51
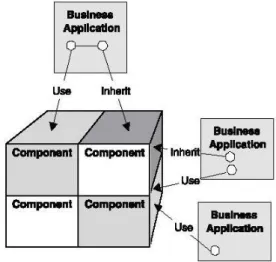
2.4.3 White-box, Black-box o Gray-box Frameworks . . . 55
2.5 Algoritmi di preprocessing . . . 57
2.5.1 Parser . . . 58
2.5.2 Ricostruzione PageView . . . 61
2.5.3 Identificazione sessioni . . . 62
2.5.4 Costruzione insieme UCitation . . . 62
2.6 Pivot-based clustering . . . 65
2.7 Utilizzo ed estensione del framework . . . 68
3 Euristiche di preprocessing 71 3.1 Introduzione . . . 71
3.1.1 Identificazione PageView . . . 72
3.1.2 Identificazione Utenti . . . 72
3.1.3 Identificazione Sessioni . . . 73
3.2 Euristiche implementate nel Wos . . . 75
3.2.1 PageView . . . 76
3.2.2 Sessioni . . . 78
Time window heuristic . . . 78
Path session heuristic . . . 80
Path completion heuristic . . . 82
Indice 3
Q-session heuristic . . . 86
4 Analisi delle prestazioni 89 4.1 Implementazione su database relazionale . . . 89
4.1.1 Popolamento database . . . 92
4.1.2 Ricostruzione delle PageView . . . 92
4.1.3 Identificazione delle Sessioni . . . 93
4.1.4 Costruzione dell’insieme di UCitation . . . 94
4.2 Analisi comparativa delle prestazioni . . . 94
5 Casi d’uso 101 5.1 Clustering su query session . . . 101
5.1.1 Istanziazione dell’algoritmo . . . 105
Estrazione delle query . . . 106
Esecuzione delle query – Google API . . . 107
Memorizzazione dei risultati . . . 109
Esecuzione del clustering . . . 110
5.2 Analisi del traffico di un sito web commerciale . . . 111
5.2.1 Definizione e costruzione del grafo del traffico . . . 112
Conclusioni 119
Introduzione
Lo sviluppo che ha avuto il web negli ultimi anni e che sembra non arre-starsi, ha portato ad una vera e propria rivoluzione nel campo dell’informazio-ne. Sebbene infatti grandissime quantit`a di informazioni fossero gi`a presenti e fruibili, prima dell’avvento di Internet il web ha estremamente semplificato la loro diffusione. Il numero di persone che, quotidianamente, utilizza il web `e cresciuto in modo esponenziale e il traffico sulla rete genera un nuovo tipo di informazione, legata non tanto ai documenti recuperati, quanto alle modalit`a con cui gli utenti interagiscono con le risorse presenti su internet.
Le informazioni legate all’uso dei documenti disponibili si sono presto rivelate una fonte di conoscenza estremamente preziosa per i fornitori dei servizi web e si `e cos`ı iniziato a memorizzare sistematicamente i dati relativi al traffico degli utenti. In particolare `e sempre pi`u diffusa la volont`a di ana-lizzare tali dati, per cercare di scoprire significativi schemi comportamentali, che possono essere sfruttati per molteplici scopi, quali il marketing, la perso-nalizzazione dei contenuti, il miglioramento della struttura di un sito e cos`ı via.
In questo contesto si sono sviluppate, accanto alle pi`u diffuse tecniche di analisi dei contenuti reperibili sul web, anche metodologie pi`u complesse che sfruttano le potenzialit`a dei dati di uso, da soli o combinati con i dati di contenuto. Avendo a disposizione enormi quantit`a di informazioni di questo tipo si `e arrivati in modo naturale all’utilizzo di metodi e strumenti di Data Mining che, adattati al contesto di internet, hanno portato allo sviluppo di uno specifico settore denominato Web Mining.
All’interno di quest’ultimo, in particolare, ritroviamo la branca del Web Usage Mining, specificatamente dedicata al trattamento dei dati di uso de-scritti sopra.
6 Introduzione
Motivazioni
Nel corso degli ultimi anni si sono sviluppati alcuni sistemi indirizzati verso il Web Usage Mining, che per`o si rivelano insufficienti da diversi punti di vista: spesso questi sistemi si limitano ad analisi statistiche sul traffico del sito senza fornire meccanismi ed astrazioni per analisi pi`u sofisticate, non offrono un ambiente sufficientemente efficiente per l’elaborazione di grandi quantit`a di dati, non forniscono degli ambienti sufficientemente flessibili e modulari, utilizzabili nei diversi contesti che si possono individuare nell’ambito del web, in quanto mettono a disposizione un insieme predefinito di funzionalit`a non modificabili dall’utente finale.
Il contesto di internet `e estremamente vasto e al suo interno possiamo trovare numerose situazioni, molto eterogenee, in cui possono rivelarsi utili analisi di usage mining.
Possiamo pensare ai numerosi siti di e-commerce in cui diventa fondamen-tale una segmentazione degli utenti in base agli accessi effettuati per perso-nalizzare i contenuti del sito, oppure per inserire opportunamente contenuti pubblicitari all’interno delle pagine pi`u visitate.
A livello di proxy server, possono essere utilizzati strumenti di analisi del traffico per implementare delle cache pi`u sofisticate effettuando un prefet-ching delle pagine web sulla base di gruppi di pagine frequentemente visitate l’una di seguito all’altra.
Sistemi di web usage mining ben si adattano anche allo sviluppo di siste-mi di raccomandazione per motori di ricerca, sulla base di sisiste-milarit`a tra le interrogazioni svolte dagli utenti in momenti precedenti. Questi sono solo al-cuni dei molteplici ambiti in cui possono rivelarsi utili tecniche di web usage mining.
Sebbene in ognuno di questi ambienti si possano riconoscere differenti fon-ti di dafon-ti e differenfon-ti analisi che devono essere sviluppate, `e possibile tuttavia individuare diverse caratteristiche comuni nell’ambito della preparazione dei dati e, spesso, anche nell’ambito delle operazioni di analisi.
In primo luogo, infatti, i dati relativi al traffico di un server web o di un proxy server, di qualsiasi genere essi siano, vengono memorizzati secondo modalit`a molto simili tra loro. Ogni server pu`o autonomamente scegliere il
Introduzione 7
formato in cui memorizzazione queste informazioni, ma in pratica sono seguiti i formati pi`u diffusi e riconosciuti come standard de facto, quali il Common Log Format utilizzato da quasi tutti i web server e lo Squid native format gestito dai proxy server.
Inoltre, proprio per la natura delle informazioni registrate, in ogni con-testo devono essere applicate delle tecniche di preparazione dei dati che si occupano della loro trasformazione e della loro pulizia in modo da limitare le analisi solo a dati significativi eliminando, per esempio, le richieste perve-nute da robot oppure le richieste che hanno generato degli errori e non sono state servite. Nella maggior parte delle applicazioni di web usage mining, inoltre, si utilizzano delle tecniche per ovviare all’incompletezza dei dati do-vuta, a seconda del livello a cui sono stati raccolti, alla presenza di cache o a meccanismi di protezione della privacy utilizzati dal client e altro ancora.
Oltre a operazioni comuni svolte durante la fase di preprocessing, possia-mo individuare anche delle operazioni di analisi che vengono svolte frequen-temente. Analisi tipiche sono il clustering degli utenti, per individuare gruppi di persone con comportamenti simili, oppure la ricerca di pattern frequenti, molto adatta al contesto del web, in cui `e importante delineare i pattern di navigazione degli utenti.
In questo vasto ed eterogeneo contesto si pu`o rivelare di grande utilit`a un framework per applicazioni di web mining che, fornendo un’implementazione per i principali metodi di data preparation e analisi, funga da base per sistemi pi`u complessi.
Contributo della tesi
Nell’ambito di questa tesi `e stato sviluppato un framework flessibile ed efficiente, denominato Web Object Store (WOS), un sistema di Web Usage Mining, flessibile ed efficiente, che pu`o essere utilizzato come infrastruttura per lo sviluppo di applicazioni di web mining.
Questo lavoro completa quello gi`a iniziato in una precedente tesi di laurea [2], di cui si riprendono essenzialmente la modellazione dei dati e l’imposta-zione generale, opportunamente rivisitati.
8 Introduzione
le astrazioni di oggetti web d’uso pi`u comune nell’ambito del Web mining, in modo da poter sviluppare analisi a diversi livelli. Tali astrazioni modellano non solo i tipi di dato pi`u elementari, come le richieste HTTP o le URI delle pagine web, ma rappresentano delle entit`a pi`u complesse, che permettono analisi pi`u approfondite, ottenute a partire dagli oggetti pi`u semplici.
Le astrazioni modellate all’interno del sistema sono le seguenti: Uri : l’identificativo di ogni risorsa presente nel web
HttpRequest : una richiesta HTTP effettuata dal client al server
PageView : l’insieme di componenti necessari per la corretta visualizzazione di una pagina web (documenti html, immagini, elementi multimediali, ecc) rappresentati sotto forma di aggregati di HttpRequest
Session : un insieme di PageView visitate da un utente in un certo periodo di tempo o selezionate a partire da specifiche caratteristiche
UCitation : rappresenta la transizione tra due pagine visitate l’una successi-vamente all’altra da un utente durante una sua sessione di navigazione. A partire da queste entit`a sono state implementate sia delle opportune classi che modellano tali astrazioni sia delle interfacce per la loro memorizza-zione e il successivo recupero. Attraverso l’uso di queste interfacce il sistema risulta indipendente dal meccanismo scelto per la gestione della persistenza. Oltre alle classi che implementano gli oggetti web, sono stati implementati gli algoritmi di preprocessing per la loro ricostruzione. Per ovviare all’incom-pletezza dei dati di input tutti questi metodi si basano necessariamente su delle euristiche.
All’interno del WOS `e stato implementato un insieme completo di euristi-che, contenente le pi`u diffuse presenti in letteratura, sia per la ricostruzione delle Page View, che per l’identificazione delle sessioni utente. In particolare, nell’ambito della individuazione delle sessioni utente, a seconda del forma-to dei dati di uso, `e possibile ricostruire l’insieme delle pagine visitate da uno stesso utente in un certo periodo di tempo, quelle visitate seguendo la struttura degli hyperlink presenti sulla rete, includendo, eventualmente, an-che le pagine an-che non sono state esplicitamente richieste al server perch´e gi`a presenti in cache.
Introduzione 9
Per fornire, oltre alle funzionalit`a di preprocessing, anche la possibilit`a di eseguire operazioni di mining, `e stato aggiunto al sistema un semplice algo-ritmo di clustering applicabile su un qualsiasi insieme di oggetti. L’algoalgo-ritmo `
e stato introdotto, per mostrare la possibilit`a di integrare molto velocemente funzionalit`a di data mining, senza modificare la struttura del sistema sotto-stante.
Il sistema `e stato sviluppato secondo il paradigma ad oggetti che si `e ri-velato ideale in quanto ha permesso di rappresentare naturalmente le entit`a di web usage e la loro gerarchia di aggregazione come collegamenti tra gli oggetti stessi. Le molte relazioni presenti tra gli oggetti modellati nel sistema rendono frequente la necessit`a di navigare all’interno della rete formata da essi e quindi `e preferibile un modello a oggetti piuttosto che uno relaziona-le in cui la ricostruzione delrelaziona-le astrazioni `e basata sull’esecuzione di costose operazioni di join.
E’ stata quindi data un’implementazione in un linguaggio a oggetti (C++) delle funzionalit`a descritte in precedenza utilizzando un DBMS object-relational (Gigabase) per la gestione della persistenza. La scelta si `e rivelata ottimale e il sistema risulta efficiente e scalabile.
Per valutare la performance del sistema sono stati effettuati dei test sulla scalabilit`a utilizzando dati provenienti da sorgenti eterogenee, quali i dati d’uso di un motore di ricerca e quelli di un sito web commerciale che presen-tano caratteristiche molto diverse. Oltre ad una valutazione della scalabilit`a `
e stata fornita un’implementazione di alcuni degli algoritmi di preprocessing utilizzando un DBMS puramente relazionale, ovvero SQL Server 2000. Nono-stante il sistema utilizzato nel WOS per la persistenza sia un software open source, i risultati ottenuti dal confronto con SQL-Server 2000, in termini di efficienza, sono comparabili e, a seconda delle operazioni e della struttura dei dati disponibili, migliori.
Infine, per verificare l’effettiva usabilit`a del WOS, sono stati delineati e implementati due casi d’uso su dati reali.
Il primo `e un classico studio del traffico web all’interno di un sito com-merciale, in cui viene mostrato come il sistema possa essere utilizzato senza
10 Introduzione
la necessit`a di una conoscenza approfondita della sua struttura e sfruttando semplicemente le funzionalit`a gi`a disponibili.
Il secondo ha portato all’implementazione di un’applicazione pi`u comples-sa con l’obiettivo di effettuare un clustering su sessioni di query ad un motore di ricerca. Per questo `e stato agevolmente esteso il WOS, introducendo nuove strutture dati e implementando algoritmi adatti alla preparazione dei dati su cui applicare l’algoritmo di clustering, gi`a disponibile nel framework.
Il software sviluppato durante il lavoro di tesi `e disponibile con licenza GPL, all’indirizzo www-ecd.isti.nr.it, dove `e possibile scaricare la libreria dei metodi forniti dal WOS, la documentazione completa, generata con Doxy-gen, e alcuni semplici esempi per il loro utilizzo, nonch´e il codice utilizzato per implementare i casi d’uso, che fornisce ulteriori esempi per aggiungere funzionalit`a al sistema.
Organizzazione della tesi
I capitoli della tesi sono strutturati nel modo seguente:
Capitolo 1: Background e stato dell’arte
In questo capitolo verranno descritte le principali caratteristiche del Web Mining, con particolare attenzione al Web Usage Mining e a come le tecniche di data mining vengono adattate a questo contesto.
Verr`a proposta poi una panoramica dello stato dell’arte di applicazioni di web mining e di sistemi di memorizzazione dei dati d’uso web. Infine ver-ranno confrontati i DBMS relazionali e quelli a oggetti, cercando di spiegare pregi e difetti di entrambi e mostrando infine le caratteristiche principali del sistema scelto per la gestione della persistenza.
Capitolo 2: Web Object Store
Questo capitolo rappresenta il nucleo principale della tesi, poich´e contiene la descrizione della struttura del sistema realizzato.
In particolare, nella prima parte verranno indicate le idee base, delineate in un precedente lavoro di tesi, su cui si `e sviluppato il Web Object Store. Di
Introduzione 11
tale prototipo `e stata mantenuta la modellazione degli oggetti web e le loro relazioni.
Successivamente mostreremo le caratteristiche principali di un applica-tion framework e come il sistema sviluppato possieda tali caratteristiche. In particolare viene proposta la descrizione degli algoritmi di preprocessing implementati e di come forniscono un insieme di funzionalit`a completo e per-sonalizzabile attraverso l’uso di euristiche di preprocessing.
Capitolo 3 : WOS - Euristiche di preprocessing
In questo capitolo sono descritte le euristiche di preprocessing pi`u diffuse in letteratura e quelle implementate nel WOS, dettagliando, per quest’ul-time, attraverso la presentazione di pseudocodice, gli algoritmi seguiti per l’aggregazione a pi`u livelli dei vari oggetti.
Capitolo 4: Analisi delle prestazioni
Per valutare l’efficienza e la scalabilit`a del sistema `e stato eseguito un insieme di test di cui riportiamo i risultati. Per non limitare la valutazione alla scalabilit`a, `e stata confrontata la performance con quella di un sistema analogo sviluppato su un DBMS puramente relazionale (SQL-server)
Capitolo 5: Casi d’uso
In questo capitolo vengono presentati due casi d’uso.
Il primo consiste nel clustering di sessioni utente di un motore di ricerca effettuato sulla base della similarit`a delle query eseguite. Il secondo caso d’u-so mostra come il sistema possa essere utilizzato per analizzare il traffico di un sito web, effettuando in modo estremamente facile delle analisi statistiche e arrivando alla costruzione del grafo del traffico, che mostra come le pagine web sono visitate.
Conclusioni
Capitolo 1
Background e stato dell’arte
In questo capitolo illustreremo come le principali tecniche di data mining possono essere utilizzate per eseguire analisi su dati provenienti dal web e come si sviluppa il processo del web mining, dalla raccolta dei dati all’inter-pretazione delle regole individuate. Inoltre verra proposta una panoramica sui principali sistemi di web mining, con una particolare attenzione verso quelli che si occupano anche di proporre un’efficace metodo di memorizza-zione dei dati astratti.
1.1
Web Mining
Il data mining si inserisce all’interno del pi`u vasto processo di Knowledge Discovery in Databases (KDD) e, molto spesso viene utilizzato come sinoni-mo di esso, mentre in realt`a `e solo un suo sotto-task fondamentale [20]. Il data mining `e il processo di estrazione di conoscenza da banche dati di grandi dimensioni tramite l’applicazione di algoritmi che individuano le informazio-ni pi`u significative. I dati possono essere memorizzati in qualsiasi tipo di repository: database relazionali, data warehouse, database transazionali, file testuali e anche il World Wide Web.
Con il diffondersi dell’uso del Web `e venuto naturale adattare ed inte-grare le tecniche classiche di data mining, information retrieval e intelligenza artificiale per gestire ed analizzare l’enorme quantit`a di informazioni, a volte complesse, che il web stesso fornisce. Ci sono diversi punti di vista da cui
14 Background e stato dell’arte
queste informazioni possono essere studiate e con diversi obiettivi: l’utente vuole avere dei buoni motori di ricerca che gli permettano di trovare ci`o che si cerca in modo veloce e preciso, un provider di servizi Web cerca il modo di capire le esigenze dei diversi gruppi di utenza per adattare l’ambiente e personalizzare le informazioni fornite, gli analisti vogliono conoscere le neces-sit`a dei consumatori. Tutti si aspettano di avere gli strumenti per soddisfare le proprie necessit`a e il web mining si occupa proprio di fornire tali strumenti.
Il web mining, introdotto in [16], si pu`o definire come “l’uso delle tecniche di data mining per scoprire ed estrarre informazioni da documenti e da servizi Web in modo automatico”, al fine di aiutare le persone a cercare, trovare e visualizzare i contenuti del Web. All’interno del complesso processo del web mining vengono subito riconosciuti alcuni sotto-task fondamentali: la ricerca delle risorse da cui far partire il processo, la selezione di tali risorse, la loro elaborazione attraverso una fase di preprocessing, che ha come obiettivo la pulizia dei dati in input, e la loro rappresentazione in una forma pi`u strut-turata, la generalizzazione e la scoperta dei pattern interessanti, usando le principali tecniche di data mining e l’analisi finale che consente la scelta, la validazione e l’interpretazione dei risultati precedentemente individuati. Co-me proposto in [23, 6] possiamo suddividere il Web mining in tre categorie principali: web content mining, web structure mining, web usage mining.
Il web content mining [23] si occupa principalmente dell’estrazione di in-formazioni dalle molteplici risorse che si possono trovare sul web, siano esse documenti di testo o risorse multimediali come immagini, file au-dio, video...
Da questo punto di vista possiamo includere in questa categoria anche il text mining effettuato su documenti semi-strutturati rappresentati dalle pagine html.
Il web structure mining [23] associa all’analisi dei contenuti anche un’a-nalisi dei collegamenti tra le varie pagine web all’interno di un singolo documento, di un sito oppure tra siti diversi. In generale, infatti, se due pagine sono collegate da un link oppure sono vicine, `e interessante capire quali relazioni le legano: possono avere contenuti simili, oppure
1.1.2 Web usage mining e Knowledge discovery in database 15
possono essere collegate da sinonimi o ancora possono risiedere sullo stesso server o possono essere state create dalla stessa persona.
Un altro obiettivo del web structure mining pu`o essere quello di scopri-re la gerarchia dei link di uno o pi`u siti web, per cercare di generalizzare la struttura di un sito che appartiene a un particolare dominio.
Il web content mining e il web structure mining si basano entrambi sull’analisi dei “dati primari” del web, come i documenti e le pagine, e spesso vengono utilizzati in modo combinato nelle applicazioni di data mining.
Il web usage mining [40], infine, ha come obiettivo quello di estrarre co-noscenza dai “dati secondari”, cio`e dai log di utilizzo, ottenuti a livello server, a livello client, da un proxy o da un database. Se gli altri due metodi di mining cercano di studiare i documenti presenti sul web, que-sto valuta l’uso che gli utenti fanno di tali documenti, cercando, tra le altre cose di predire il comportamento che avr`a un utente durante la navigazione di un sito in modo da poter ottimizzare la struttura delle pagine e dei link del sito stesso.
Un esempio di campo in cui pu`o trovare applicazione il web usage mi-ning `e quello dell’e-commerce, in cui il profiling degli utenti diventa fondamentale per la personalizzazione delle offerte e pu`o venir fatto attraverso l’analisi delle modalit`a di navigazione all’interno di un sito o nell’intera rete, basandosi sulla sequenza dei “click”.
Nella prossima sezione daremo una descrizione pi`u precisa di quest’ultima branca del web mining, poich´e il sistema sviluppato durante la tesi fornisce proprio metodi e infrastrutture per lo sviluppo di applicazioni di questo tipo.
1.2
Web usage mining e Knowledge discovery
in database
L’analisi sviluppata con il web mining si inserisce, cos`ı come il data mi-ning, all’interno del processo KDD in cui, come nel caso pi`u generale, possono
16 Background e stato dell’arte
Figura 1.1: Tassonomia del Web Mining
essere individuate delle fasi distinte che coprono l’intero processo.
Come possiamo osservare nella figura 1.2 abbiamo come primo passo quello di raccolta e consolidamento dei dati grezzi, su cui possono essere applicati dei task di preprocessing che permettono di ottenere delle astrazioni dei dati web su cui eseguire gli algoritmi di data mining. Tutto questo pu`o essere fatto in modo automatico e per la maggior parte senza un intervento dall’esterno, che invece diventa indispensabile nella fase di interpretazione dei risultati in cui `e necessaria una buona conoscenza del dominio per selezionare i risultati “interessanti” e scartare gli altri.
1.2.1
Raccolta dei dati
I dati di partenza per questo processo possono essere raccolti a vari livelli. Generalmente si possono avere dei dati a livello server, altri a livello client, altri ancora a livello proxy ed ognuna di queste fonti fornisce un segmento dei pattern di navigazione che possiamo ottenere. In particolare, dai dati a livello server possiamo avere un’idea di come molti utenti navigano all’interno di un sito web, da quelli raccolti a livello utente possiamo recuperare informazioni sull’accesso al web di una singola persona, mentre i dati recuperati da un
1.1.2.1 Raccolta dei dati 17
Figura 1.2: Fasi del processo di Web Usage Mining
proxy forniscono dati multi-utente e multi-sito.
Un file di log di un web server `e la fonte dati pi`u diffusa per analisi di web usage mining e contiene la registrazione di tutte le richieste HTTP effettuate per la visualizzazione del sito.
Tali file spesso forniscono delle informazioni incomplete sulla navigazione degli utenti a causa della presenza di cache a vari livelli, utilizzate per mi-gliorare la velocit`a di accesso ai contenuti, non effettuando nuove richieste per pagine visitate recentemente che vengono memorizzate dal browser del client.
Talvolta `e possibile quindi utilizzare altri metodi per il recupero dei da-ti, tra cui il packet sniffing che consiste nel monitorare il traffico attraverso la rete ed estrarre i dati direttamente dai pacchetti tcp/ip; in questo mo-do `e possibile recuperare le informazioni relative ai parametri passati con un metodo POST, ma anche avere visione dei cookies, marcatori usati per riconoscere automaticamente uno stesso visitatore del sito.
La possibile disabilitazione dei cookies e la gi`a menzionata presenza di ca-che tuttavia rendono incompleta oltre all’informazione recuperabile dai log di un web server,anche quella ottenuta tramite packet sniffing e quindi si pu`o ricorrere alla raccolta dei dati direttamente al livello del cliente. Chiara-mente in questo modo avremo dati riguardanti un solo utente e un solo sito web. Questi dati possono essere ottenuti con un agente remoto (per esempio
18 Background e stato dell’arte
un’applet java o del codice javascript) oppure modificando il codice di brow-ser come Mosaic o Mozzilla che lo permettono. Tutti questi meccanismi per`o richiedono la collaborazione esplicita dell’utente che pu`o disabilitarli in ogni momento ed `e proprio la possibilit`a di convincere l’utente a “collaborare” che rende difficile il loro utilizzo.
Un’altra fonte di dati web sono i log file di un proxy server. Un proxy server funge da intermediario tra un insieme di utenti e i web server. I dati memorizzati a livello proxy possono essere utili perch´e memorizzano richie-ste HTTP di molti utenti a molti server web e quindi possono servire per caratterizzare i comportamenti di utenti diversi su tutta la rete e non su un singolo sito web.
Per cercare di colmare le, se pur diverse, lacune presenti nei dati raccolti ad ogni livello si rende necessaria una fase di preprocessing precedente all’ applicazione degli algoritmi di mining.
1.2.2
Preprocessing
Il preprocessing `e il primo passaggio, indispensabile, per ripulire, comple-tare e rendere omogenei i dati, che provenendo da diverse fonti presentano anche caratteristiche diverse. I dati devono essere resi uniformi, devono essere selezionate le informazioni necessarie e scartate quelle superflue. Inoltre pu`o essere necessario integrare dati di un file di log, dati relativi alla struttura topologica di un sito, dati che descrivono un documento web, altri relativi agli utenti registrati in un sito...
Oltre a questa prima fase di pulizia, il preprocessing consiste anche nel-l’identificazione delle astrazioni dei dati che vogliamo considerare. I dati va-riamente raccolti, infatti, vengono classificati in astrazioni degli oggetti web tra cui le principali sono state definite dal WCA(W3C Web Characterization Activity) [42] :
User : il singolo utente che, attraverso un browser, accede ai file contenuti in uno o pi`u web server
PageView : consiste di tutti i file e le risorse (frames, immagini, file au-dio, scripts...) che contribuiscono alla visualizzazione completa di una pagina web in un preciso momento
1.1.2.2 Preprocessing 19
Click-stream : una sequenza di page view richieste e visualizzate
User session : un insieme di click-stream generati da un singolo utente attraverso tutta la rete web; l’insieme delle page view di una user session all’interno di un singolo web server `e anche chiamata server session
L’obiettivo della fase di preprocessing `e quello di ottenere, a partire dai web server log, un insieme di sessioni, una identificazione della topologia del sito (che in alcuni casi pu`o essere un dato di input anzich´e di output), una classificazione delle pagine web (in pagine di contenuto o in pagine di transizione)[12].
Questa fase `e probabilmente la pi`u difficile nell’ambito del web usage mi-ning a causa dell’incompletezza dei dati a disposizione, soprattutto per quan-to riguarda l’identificazione degli utenti a causa della necessit`a di garantire la privacy degli utenti stessi, e della presenza di cache e proxy server. Molti web browser infatti per migliorare la performance e minimizzare il traffico sulla rete implementano delle cache locali in modo che se l’utente richiede una pagina gi`a visitata poco tempo prima (tipicamente usando il tasto “back”), questa viene visualizzata senza inoltrare la richiesta al server web. Ancor pi`u problemi creano i proxy server, in quanto tutte le richieste provenienti da un proxy hanno lo stesso identificatore (in genere l’indirizzo ip) e quindi, dal lato server, sembrano provenire tutte dallo stesso utente, sebbene spesso siano molti utenti diversi. Possiamo anche incorrere nel problema opposto, ip differenti che in realt`a corrispondono allo stesso utente poich´e alcuni tool per la privacy assegnano ad ogni richiesta un indirizzo ip completamente ran-dom che porta ad avere una singola sessione con diversi indirizzi. O ancora possiamo avere problemi nel riconoscere due sessioni di una stessa persona se questa si collega da macchine diverse in momenti diversi oppure dalla stessa macchina, ma usando browser diversi anche durante la stessa sessione.
Come accennato precedentemente si potrebbe ovviare a questi problemi grazie a meccanismi che raccolgono informazioni a livello client, che per`o si rivelano poco affidabili in quanto possono essere disabilitati in qualsiasi momento.
Supponendo quindi di avere dati incompleti e di non avere la possibilit`a di integrarli con la collaborazione degli utenti, si ricorrere all’uso di euristiche
20 Background e stato dell’arte
e statistiche (per esempio delle euristiche di path completion per ovviare alla mancanza di richieste al server per pagine presenti nella cache locale del browser di un client, oppure euristiche per diversificare gli utenti che utilizzano un proxy).
Per una analisi pi`u approfondita delle classiche euristiche presenti in let-teratura si rimanda al capitolo 3, in cui vengono descritte tali tecniche e mostrate quelle introdotte nel WOS.
1.2.3
Pattern discovery
Successivamente alla fase di preprocessing abbiamo quella di pattern di-scovery in cui si utilizzano le tecniche pi`u classiche di data mining, machine learning, statistica per estrarre delle informazioni utili dai dati a disposizione. Chiaramente gli algoritmi devono essere adattati al contesto del web mining. Per esempio se nella ricerca di regole associative, il concetto di transazione non considera l’ordine in cui sono selezionati gli elementi, una sessione pu`o essere vista sia come un insieme di pagine, sia come una sequenza di richieste temporalmente ordinate.
Vediamo come possono essere adattate al web mining le principali tecniche di estrazione della conoscenza tipiche del data mining.
Regole associative
L’analisi associativa [20] consiste nell’individuare delle regole associative che rappresentino delle relazioni sui dati analizzati che ricorrano con una certa frequenza. Una regola associativa X ⇒ Y definisce il fatto che “gli ele-menti del database che soddisfano la condizione X, allora soddisfano anche Y”, oppure, se X e Y sono due attributi dei dati analizzati, la regola indica come la presenza dell’attributo X sia legata a quella dell’attributo Y.
Nel web mining le regole associative sono utilizzate per individuare degli insiemi di pagine che spesso vengono visitate insieme in una stessa sessione, non necessariamente sempre con lo stesso ordine [12]. Tali pagine non devo-no essere necessariamente collegate l’una all’altra tramite link. Possiamo, per esempio, scoprire che gli utenti che visitano pagine che si occupano di prodotti
1.1.2.3 Pattern discovery 21
tecnologici, visitano spesso anche siti di attrezzatura sportiva. L’individua-zione di regole associative pu`o rivelarsi utile anche per la ristrutturazione di un sito web, oppure per ridurre la latenza delle richieste ad un web server, su cui potr`a essere implementata una sorta di prefetching sulle possibili pagine che possono venir richieste successivamente ad un’altra pagina.
Clustering
Il clustering `e una tecnica che consiste nel raggruppare insieme elementi (in questo caso pagine) che presentano delle caratteristiche simili. Gli oggetti sono raggruppati, o suddivisi, con l’obiettivo di “massimizzare la similarit`a tra elementi dello stesso cluster e minimizzare quella inter-cluster” [20] . In questo modo `e possibile ottenere dei sottoinsiemi del dataset iniziale, in mo-do che gli oggetti all’interno di uno di essi abbia un alto gramo-do di somiglianza con gli altri elementi contenuti, quantomeno se confrontato con quello di og-getti di altri cluster. La relazione di similitudine `e definita di volta in volta, in base al contesto in cui si inserisce l’analisi.
Nel web mining possiamo isolare due categorie interessanti di clustering: quello sugli utenti e quello sulle pagine.
Il clustering sugli utenti tende a creare gruppi di utenti con pattern di navigazione simili e pu`o essere molto utile per sviluppare opportune strategie di marketing nel campo dell’E-commerce o per personalizzare al meglio i contenuti per singoli individui o gruppi omogenei.
Il clustering sulle pagine, invece, pu`o servire per ottimizzare i motori di ricerca, individuando gruppi di pagine con contenuti simili.
Classificazione
La classificazione [20] consiste nel cercare un insieme di modelli (o funzio-ni) che descrivono e distinguono delle classi di dati, in modo da poter predire la classe a cui apparterr`a un nuovo item in base alle sue caratteristiche. La bont`a del modello `e testata con l’utilizzo di un training set, cio`e un insieme di elementi di cui si conosce la classe di appartenenza, che deve risultare uguale
22 Background e stato dell’arte
a quella che viene assegnata dalla classificazione.
Nel contesto web questo sistema viene sfruttato per avere un buon profi-ling degli utenti cercando di identificare ognuno con una categoria predefini-ta. Ci`o richiede il riconoscimento e la selezione delle caratteristiche che ben descrivono una certa classe o categoria. La classificazione, anche in questo settore, pu`o venire fatta tramite i classici algoritmi induttivi, che possono essere i decision tree, i classificatori Bayesiani...
Pattern sequenziali
I pattern sequenziali hanno come obiettivo l’estrazione di sottosequenze interessanti e frequenti da una sequenza temporalmente ordinata di transa-zioni.
Se consideriamo le sessioni di navigazione di un utente come transazioni, questa tecnica permette di trovare dei pattern frequenti inter-session, come, per esempio, la presenza di un insieme di elementi che ne segue un altro in un insieme ordinato di sessioni. Usando questo approccio si possono posizionare meglio dei messaggi pubblicitari oppure possono essere fatte analisi temporali sulle modalit`a di navigazione all’interno di un sito [40].
Analisi statistiche
Anche se non rientrano nell’ambito del data mining, possiamo includere nelle tecniche di web mining anche le analisi statistiche, che risultano essere il metodo pi`u semplice e pi`u diffuso per estrarre informazioni sugli accessi a un sito web. Analizzando le sessioni `e possibile ottenere buoni risultati statistici (come la frequenza, la media...) usando come variabili le PageView, il tempo di permanenza su una pagina o in un sito, la lunghezza di una sessione o di un pattern. Senza scendere troppo nei dettagli, possiamo dire che questo tipo di conoscenza pu`o servire a migliorare le performance di un web server e migliorarne la sicurezza, facilitare le modifiche a un sito e fornire un primo supporto per delle decisioni di marketing.
1.1.2.4 Pattern analysis 23
1.2.4
Pattern analysis
Questa `e la fase finale del processo di usage mining ed ha come fine ultimo l’eliminazione delle regole o dei pattern poco interessanti, basandosi di volta in volta sull’obiettivo dell’applicazione realizzata, e la presentazione dei risul-tati in una forma umanamente comprensibile. Molto spesso infatti l’output dei processi precedenti produce dei risultati in una forma poco consultabile ed `e necessario trasformarli in un qualcosa di pi`u intuitivo e facilmente gesti-bile. Questo pu`o essere fatto con meccanismi di analisi che possono portare, per esempio, al caricamento dei dati in cubi su cui poi eseguire operazioni Olap oppure, utilizzando strumenti di visualizzazione, per proporre i risultati sotto forma di grafici, particolarmente adatti, per esempio, per i pattern di navigazione.
1.3
Sistemi di web usage mining: stato
del-l’arte
Negli ultimi anni sono stati sviluppati diversi progetti nell’ambito del Web Usage Mining. Di seguito riportiamo una breve descrizione dei pi`u rap-presentativi, presenti in letteratura.
WebSift [14] `e un sistema che combina le informazioni di contenuto con quelle d’uso. Partendo dai log file che registrano le richieste degli utenti e combinandoli con informazioni di contenuto, fornisce dei metodi per svolgere una prima fase di preprocessing che permette la ricostruzione delle sessioni utente. Sulla base delle sessioni ricostruite, il sistema permette di estratte informazioni utili attraverso tre task di data mining: pattern sequenziali, re-gole associative e clustering.
Un sistema analogo al precendente `e WebMiner [27] che suddivide il pro-cesso di Web Usage Mining in una prima fase di preprocessing, una seconda di pattern discovery e una fase finale di pattern analysis. Anche in questo caso lo scopo del preprocessing `e l’identificazione degli utenti e delle sessioni, usate come input per le fasi successive. I task di data mining integrati
permet-24 Background e stato dell’arte
tono di estrarre pattern sequenziali, cluster di sessioni e regole associative. Il riconoscimento di quest’ultime prevede un’ulteriore passo di identificazione delle transazioni che permette di identificare semanticamente gruppi di pa-gine riferite, suddividendo una sessione in transazioni pi`u piccole.
Tra i migliori progetti accademici troviamo inoltre Weblog Utilization Miner (WUM) [38], un ambiente integrato per analisi di weblog. Il punto di forza del sistema `e la presenza di un query language (MINT) usato per l’estrazione di pattern usando un linguaggio SQL-like.
All’interno dei sistemi commerciali troviamo infine SpeedTracer [43], pro-posto dall’IBM. La caratteristica principale del sistema `e il riconoscimento delle sessioni attraverso la ricostruzione dei cammini degli utenti, senza uti-lizzare informazioni aggiuntive sui visitatori. A partire da queste sessioni vengono applicati gli algoritmi di data mining, con lo scopo di raggruppare le pagine che pi`u frequentemente vengono visitate insieme.
Dal punto di vista della gestione efficiente di dati web, invece, `e da ri-cordare Web fountain [19] , anch’esso sviluppato dall’IBM. Pur occupandosi soprattutto di dati di contenuto, fornisce dei meccanismi per la gestione di grandi quantit`a di informazioni con lo scopo di effettuare analisi, completa-mente automatiche, sulla semantica dei documenti disponibili in rete.
1.4
Persistenza dei dati
In ogni applicazione di data mining svolge un ruolo fondamentale il siste-ma usato per la gestione della persistenza dei dati. La persistenza permette di avere dei dati che esistono anche dopo la terminazione del programma che li ha creati e che possono essere reperiti in seguito, anche da un programma diverso da quello di partenza. La persistenza `e il servizio fondamentale offerto da un database.
Un database `e una collezione di dati a cui si pu`o accedere da diverse applicazioni. Un database `e persistente se lo sono i dati in esso contenuto.
1.1.4.1 DBMS relazionali 25
Un DBMS `e invece il programma che interfaccia un database con le ap-plicazioni che lo usano fornendo anche dei meccanismi per la protezione e la gestione del database stesso.
Se non si `e interessati alle funzionalit`a che fornisce un DBMS, ma solo all’implementazione della persistenza dei dati, questa si pu`o facilmente otte-nere con dei meccanismi del linguaggio in cui viene sviluppata l’applicazione finale. E’ possibile infatti derivare tutte le classi che vogliamo memorizzare da una classe comune, ed implementare un metodo che permette di scrivere il contenuto dell’oggetto sul supporto della persistenza, che in genere `e uno stream di byte. Attraverso il successivo uso di un costruttore `e possibile ri-costruire l’oggetto a partire dallo stream.
Con un meccanismo di questo tipo il massimo che si pu`o ottenere `e la persi-stenza dati, e una rudimentale gestione del locking per gli accessi concorrenti, mentre se si vogliono utilizzare le caratteristiche pi`u tipiche di un database come le interrogazioni o la gestione concorrente degli accessi `e necessario ri-correre a sistemi pi`u complessi.
Volendo scegliere quale sia il sistema migliore per gestire la persistenza dei dati di un sistema di data mining, `e possibile orientarci verso DBMS relazionali, DBMS a oggetti oppure un DBMS object-relational, che cerca di integrare le caratteristiche degli altri due.
1.4.1
DBMS relazionali
Nei classici database relazionali i dati sono rappresentati tramite tabelle, caratterizzate dalle colonne di cui sono composte e contenenti le ennuple dello stesso tipo contenute nel database. Le colonne rappresentano gli attributi dei dati rappresentati dalla tabella, mentre ogni riga corrisponde a un record. Le colonne possono contenere solo dati di tipi elementari (stringhe, interi, date...), non possono contenere puntatori, n´e valori multipli, n´e sottotabelle. Un grande vantaggio dei DBMS relazionali `e quello di avere un linguaggio comune, chiamato SQL (Structured Query Language), che permette ad una stessa applicazione di interagire con diversi DBMS e di trasferire facilmente i dati da uno all’altro.
organizza-26 Background e stato dell’arte
zione logica dei dati e organizzazione fisica. La vista logica `e quella a tabelle, ma questo non implica che la realizzazione fisica del database sia strutturata per tabelle. Questa differenza preclude l’ottimizzazione del database da parte del programmatore che lo utilizzer`a, ma implica che nella realizzazione del DBMS siano utilizzati sofisticati algoritmi per l’ottimizzazione degli accessi.
Se in alcuni casi i DBMS relazionali rappresentano la miglior soluzione auspicabile, soprattutto per le ottime prestazioni di sistemi collaudati e estre-mamente ottimizzati, quando si cerca di integrarli con una programmazione ad oggetti sorgono non pochi problemi. Infatti l’impossibilit`a di avere in una colonna valori multipli o sottotabelle o puntatori ad altri oggetti porta ad una dispersione dei vari oggetti in molte tabelle. Per ricostruire un’entit`a del dominio saranno allora necessarie molte operazioni di join, che sono tra le operazioni pi`u lente da eseguire per un qualsiasi DBMS. Anche le relazioni tra gli oggetti possono causare difficolt`a in quanto per rappresentare una re-lazione m:n in un database relazionale `e necessario aggiungere una tabella extra, mentre in un database a oggetti `e sufficiente usare due attributi mul-tivalore ai due capi della relazione.
I DBMS relazionali sono talmente diffusi e conosciuti che `e inutile dilun-garci sui dettagli pi`u specifici. Se vogliamo citare alcuni, tra i pi`u diffusi, possiamo ricordare i sistemi commerciali Oracle o SQL-server, o il database open-source My-sql, anche se l’elenco potrebbe continuare a lungo.
1.4.2
DBMS a oggetti
Nel modello a oggetti le entit`a del dominio sono modellate con oggetti e relazioni tra oggetti.
In questo modello, a differenza di quello relazionale, gli attributi di un oggetto possono essere di qualunque tipo, in particolare un oggetto pu`o con-tenere altri oggetti. Inoltre un DBMS a oggetti pu`o essere organizzato per privilegiare gli accessi a gruppi di oggetti eterogenei, piuttosto che a gruppi di entit`a dello stesso tipo, in modo che il caricamento di un oggetto con tutte le sue componenti si svolga con un unico accesso al disco, invece che con una
1.1.4.2 DBMS a oggetti 27
serie di costose join.
Una limitazione dei DBMS a oggetti rispetto a quelli relazionali `e la man-canza di interoperabilit`a, infatti ogni programma viene scritto per interfac-ciarsi con un particolare DBMS, in quanto non esiste uno standard ufficiale per questi sistemi. Per porre rimedio a questa mancanza `e nato ODGM (Ob-ject Database management group) [8], un consorzio di costruttori do ODBMS che ha proposto quello che `e ormai diventato uno standard de facto. In questo modo `e stato definito un linguaggio astratto per la definizione dello schema del database (ODL: Object Definition Language), un linguaggio standard per le interrogazioni sul database (OQL: Object Query Language) e il mapping di questi linguaggi astratti sui linguaggi di programmazione reali.
L’ultimo aspetto `e particolarmente importante poich´e una caratteristica che si cerca se si sceglie un database a oggetti `e la facilit`a di integrazione con il linguaggio di programmazione. Un programmatore vuole poter usare il proprio linguaggio di programmazione senza l’obbligo di passare per un altro linguaggio come Sql e soprattutto non vorrebbe avere differenze tra i dati persistenti e quelli “transienti”, i normali dati del suo programma.
Non distinguere i dati persistenti da quelli non persistenti vuol dire che “la persistenza `e ortogonale al tipo”, cio`e che la persistenza non dipende dal tipo di dato.
In un linguaggio di programmazione infatti non esistono dati persistenti, ma i seguenti tipi di dato:
dati automatici : parametri e variabili locali di una funzione che esistono solo per la durata della funzione a cui appartengono
dati statici : esistono per tutta la durata del programma a cui appartengono dati allocati dinamicamente : la cui vita `e determinata esplicitamente tramite operazioni di allocazione e deallocazione, ma comunque non pu`o estendersi oltre la durata del programma a cui appartengono I dati persistenti invece hanno una vita che `e determinata esplicitamen-te da allocazione `e cancellazione, ma si pu`o estendere oltre la durata del programma a cui appartengono.
28 Background e stato dell’arte
I database relazionali usano dei tipi di dato distinti per i dati persistenti e quelli non persistenti, mentre i database a oggetti usano gli stessi dati per entrambi, secondo l’approccio della persistenza ortogonale al tipo. Questo ap-proccio implica la possibilit`a di avere un’istanza transiente di un tipo che ha anche istanze persistenti. Quella che sembra una conseguenza innocua, anzi utile, crea notevoli problemi in alcuni casi. Per esempio sorge un problema quando `e necessario salvare oggetti persistenti che contengono riferimenti ad oggetti temporanei; una possibile soluzione `e impedire di inserire riferimenti ad oggetti transienti in oggetti permanenti, rinunciando in parte all’ortogo-nalit`a, oppure permettere tali riferimenti, ma non considerarli al momento del salvataggio oppure rendere persistente ogni oggetto referenziato da un altro persistente. Altri inconvenienti sorgono riguardo alla vita di un ogget-to nel database e all’integrit`a delle referenze, oppure quando `e necessario ripristinare il database in conseguenza dell’aborto di una transazione.
1.4.3
Database misti (object-relational)
Accanto ai DBMS relazionali e a quelli puramente ad oggetti trovano spa-zio anche i cosiddetti database misti (o object-relational) [], estensioni a og-getti dei database relazionali che mantengono un linguaggio di interrogazione SQL-like.
L’obiettivo di questi sistemi `e quello di assicurare le funzionalit`a dei data-base relazionali per quanto riguarda i dati pi`u semplici, estendendo il modello relazionale per la gestione di strutture dati pi`u complesse, tipiche della pro-grammazione a oggetti. Dal punto di vista del modello dei dati, questi DBMS cercano di aggiungere delle funzionalit`a object-oriented alle classiche tabelle. I dati persistenti stanno ancora nelle tabelle, ma le entry possono avere una struttura pi`u ricca.
Anche le modalit`a di accessori dati sono miste, in quanto `e possibile utilizzare sia la navigazione con puntatori, tipica dei linguaggi a oggetti, sia le interrogazioni del sistema relazionale. In genere infatti `e presente un linguaggio simile a quello SQL che fornisce dei costrutti per eseguire delle query.
Come per i DMBS a oggetti, non esiste uno standard e di conseguenza si perde completamente il vantaggio della portabilit`a dei clienti, poich´e ogni
1.1.5 Gigabase 29
interfaccia `e diversa dall’altra, mentre l’efficienza `e intermedia tra quella di un database relazionale e quella di un database a oggetti puro.
La scelta fatta per gestire la persistenza nel sistema realizzato `e stata quella di un database di questo tipo: Gigabase
1.5
Gigabase
Gigabase `e un DBMS object-relational [33], che `e stato scelto in quanto propone un’efficiente e facilmente usabile interfaccia C++ ed `e completamen-te open-source, requisito fondamentale poich´e doveva essere parte integrante di un sistema anch’esso open-source.
Gigabase integra ad un’interfaccia che permette di gestire la persistenza degli oggetti direttamente usando le classi C++, come i database object-oriented e fornisce un semplice linguaggio per eseguire delle interrogazioni. Il linguaggio fornito non `e completo come Sql, in quanto non `e possibile eseguire delle join e le query restituiscono sempre insiemi di elementi provenienti da una sola tabella, non `e possibile gestire il valore NULL e il linguaggio,essendo integrato con il C++, `e case sensitive. Queste limitazioni tuttavia dipendono proprio dalla natura a oggetti del linguaggio. Le join diventano superflue dal momento in cui `e possibile accedere agli oggetti tramite riferimenti e puntatori in modo decisamente pi`u efficiente.
Da un classico DBMS relazionale Gigabase eredita anche la suddivisione degli oggetti memorizzati in tabelle e database. Ogni tabella contiene oggetti dello stesso tipo e ogni database pu`o contenere pi`u tabelle. Venendo meno la possibilit`a di eseguire join tra tabelle non sussiste pi`u l’obbligo di mantenere tutte le tabelle in uno stesso database.
Gli elementi fondamentali su cui basarsi per sviluppare un’applicazione utilizzando Gigabase sono: Tabelle, Query, Cursori e Database
30 Background e stato dell’arte
I dati sono memorizzati in tabelle che trovano una diretta corrispondenza con le classi C++, cos`ı come le istanze di una classe rappresentano i record memorizzati all’interno della tabella. Per ottimizzare il sistema di memo-rizzazione, semplificando le query e riducendo le dimensioni dei file per lo storage, soltanto i tipi pi`u elementari sono accettati come componenti di un oggetto che deve essere persistente. I vincoli sugli elementi non sono tuttavia cos`ı restrittivi come per i database relazionali ed `e possibile usare all’interno dei record anche delle strutture annidate.
Poich´e il C++ non fornisce dei meccanismi semplici per ottenere meta-informazioni sulle classi a runtime `e necessario dichiarare esplicitamente i campi di ogni oggetto che deve essere incluse nel database (questo rende anche pi`u flessibile il mapping tra tabelle e classi) e Gigabase fornisce una serie di macro e classi per semplificare questa enumerazione. Ogni classe o struttura, le cui istanze diventeranno record di un database, deve con-tenere nell’header uno speciale metodo che descrive i suoi campi. Questo metodo viene generato attraverso due macro, TYPE DESCRIPTOR(field list )
e CLASS DESCRIPTOR(name, field list ), con al loro interno altre possibili macro, di cui elenchiamo le principali:
FIELD(name)
campo non indicizzato di cui si deve specificare solo il nome KEY(name, index type)
campo su cui `e possibile specificare delle opzioni aggiuntive. Se indicato il flag indexed significa che il campo deve essere indicizzato, e questo avviene attraverso la creazione di un B-Tree.
E’ possibile inoltre dare delle indicazioni che risultano utili al momento delle query. Per esempio il campo pu`o essere indicato come unique, in modo da ottimizzare le query sulla base del fatto che all’interno della tabella non ci saranno valori duplicati per questo attributo. E’ impor-tante osservare per`o che non `e un vincolo, ma solo un’informazione fornita al sistema e l’unicit`a non viene forzata.
E’ possibile anche fornire un’indicazione opposta a questa con il flag optimize duplicate, che permette di ottimizzare, la gestione di un indice
1.1.5 Gigabase 31
che contiene molti valori duplicati. Un’ultima opzione che vale la pe-na menziope-nare (autoincrement ) `e quella che permette di assegnare un valore automatico, auto-incrementato, all’attributo.
Sebbene soltanto i campi con tipo primitivo possano essere indicizzati, `e possibile creare degli indici anche sulle strutture; un indice su una struttu-ra viene creato costruendo indici sui suoi elementi, ma solo se tale indice `e gi`a stato specificato nella maschera di dichiarazione della struttura stessa. Poich´e una struttura `e in genere utilizzata in pi`u oggetti, questo permette ai programmatori di abilitare o disabilitare gli indici sulle strutture a se-conda del ruolo che giocano all’interno dei record da inserire nel database. Oltre all’esplicita definizione dei descrittori degli oggetti, `e anche necessa-rio eseguire un mapping tra una classe C++ e una tabella; questo viene fatto con la macro REGISTER(name ) che deve essere usata
nell’implementa-zione della classe anzich´e nell’header e che costruisce un descrittore per la tabella associata alla classe. Utilizzando questa macro ogni tabella (e la cor-rispondente classe) pu`o essere usata con solo un database per volta. Se si vuole condividere una tabella tra pi`u database `e necessario usare la macro
REGISTER UNASSIGNED(name ).
Cursor
I cursori sono oggetti fondamentali per l’utilizzo del sistema in quan-to vengono usati per accedere agli elementi e modificarli. Sono disponibili due tipi di cursore, quelli in sola lettura (dbCursorViewOnly) e quelli che permettono anche di modificare gli oggetti puntati (dbCursorForUpdate).
I cursori sono tipizzati e sono implementati in C++ con una classe tem-plate dbCursor<T> dove T rappresenta la classe associata alla tabella i cui
elementi dovranno essere gestiti con il cursore.
L’accesso agli elementi di un database pu`o avvenire con una scansione sequenziale oppure eseguendo una query e iterando solo sugli oggetti che soddisfano una certa condizione oppure secondo un certo ordine. Attraverso i metodi select() o select(dbQuery q ) si sceglie un sottoinsieme degli ele-menti, che verranno poi acceduti con il metodo get(), che restituisce quello puntato dal cursore al momento della chiamata. Per spostare il cursore su-gli altri elementi della collezione sono disponibili i metodi next(), prev(),
32 Background e stato dell’arte
first() elast(), che eseguono le omonime operazioni. Attraverso l’overload dell’operatore -¿ `e possibile accedere ai vari campi dell’oggetto recuperato e, a seconda del cursore utilizzato, modificarne i valori. Le modifiche sono rese persistenti solo con la successiva chiamata del metodoupdate(T const& record ) e ovviamente del commit sul database.
L’unica operazione di modifica dei database che non `e eseguita con i curso-ri `e l’inserzione di un nuovo elemento, effettuabile con il metododbDatabase: :insert(T const& record ). L’elemento viene inserito sempre alla fine della
collezione.
Database
Un’altra classe fondamentale `e dbDatabase che gestisce l’interazione del-l’applicazione con il database. In modo simile ai cursori, anche i database pos-sono essere aperti (con il metodo dbDatabase::open(char const* filename = NULL )) in sola lettura, oppure nel modo standard che permette anche
modi-fiche specificando, nel costruttore rispettivamente il parametro dbDatabase: :dbReadOnly odbDatabase::dbAllAccess. Se il file, indicato al momento
del-l’apertura, non esiste viene creato, altrimenti viene aperto e reso disponibile per l’utilizzo.
Nel costruttore `e possibile specificare anche un altro parametro che indica la dimensione del pagePool, cio`e il numero di pagine da usare per ottimizzare l’I/O. Se il parametro non `e specificato Gigabase calcoler`a il valore pi`u adatto usando informazioni sulla memoria fisica di cui pu`o disporre. La dimensione del pool non dovrebbe comunque superare quella della memoria fisica del computer, che tra l’altro dovrebbe essere riservata in parte per l’esecuzione del sistema operativo
Query
Accenniamo infine alla classe Query che permette di eseguire delle inter-rogazioni al database.
Anche la costruzione delle query avviene utilizzando gli operatori propri del C++: i parametri possono essere specificati al momento dell’utilizzo, eli-minando la necessit`a di eseguire un mapping tra quest’ultimi e le variabili del C++. Possiamo vedere un esempio in cui abbiamo due variabili memorizzate
1.1.5 Gigabase 33
nella query, che di volta in volta verr`a eseguita con differenti valori di tali parametri.
dbQuery q;
int price, quantity;
q = "price >=", price, "or quantity >=", quantity;
L’overloaded delle funzioni elimina anche la necessit`a di addurre ulteriori specifiche sui tipi.
Per ottimizzarne l’esecuzione, la compilazione di ogni query `e eseguita solo la prima volta e poi salvata in modo che le volte successive possa essere usato direttamente l’albero con il piano d’accesso precedentemente generato.
Capitolo 2
Web Object Store
In questo capitolo mostreremo quali sono le caratteristiche principali del Wos visto soprattutto come repository di astrazioni di oggetti web. Saranno presentate le classi che modellano tali oggetti e come questi sono organizzati in repository che permettono di gestire comodamente la persistenza e l’inter-faccia con Gigabase.
2.1
Introduzione
Il WOS `e stato ideato per fornire un supporto alle applicazioni di web mining cercando prima di tutto di fornire un’utile astrazione per i concetti relativi ai componenti web, implementando in secondo luogo un repertorio di modelli per estrarre delle informazioni dai dati (pattern frequenti, regole, classificatori, algoritmi di clustering) e interfacce per crearne di personalizzati e infine fornendo delle strutture dati efficienti sia in termini di memoria che di tempo.
L’idea iniziale era stata sviluppata in un precedente lavoro di tesi in cui si delineavano gli aspetti principali di un ambiente di web usage mining, delineandone le componenti essenziali e i molteplici risultati che possono essere raggiunti attraverso l’uso di un sistema di questo tipo [2].
L’approccio seguito era per`o fortemente condizionato dagli specifici risul-tati che si voleva dimostrare potessero essere facilmente raggiunti, nonch´e dai dati disponibili e aveva portato alla realizzazione di quello che possiamo
36 Web Object Store
Figura 2.1: Web object
considerare un prototipo del Wos, in cui era stata proposta una prima im-plementazione composta da alcune classi che modellavano i principali oggetti web e da semplici metodi di preprocessing per costruire tali oggetti.
Sulla base delle idee presentate nel precedente lavoro `e stato rivista l’in-tera struttura dell’applicazione e sono stati implementate una serie di funzio-nalit`a di preprocessing e di analisi dei dati in modo da coprire le tecniche pi`u tipiche nell’ambito del web mining, cercando di rendere facilmente estensibile il sistema nel caso si vogliano funzionalit`a non presenti.
Ci`o che `e stato mantenuto pressoch´e inalterato del prototipo precedente-mente sviluppato `e il modello dei dati di uso web, con cui sono stati modellati le principali astrazioni degli oggetti web: le Uri, le HttpRequest, le PageView, le Session. Queste entit`a sono strettamente correlate l’una all’altra e possono venir ricostruite attraverso una serie di meccanismi che aggregano insiemi di oggetti per costruire un oggetto di altro tipo.
Oltre al modello dei dati era stato individuato un insieme di metodi per realizzare i vari task di preprocessing premettendo di ricostruire le astrazioni
2.2.1 Introduzione 37
degli oggetti attraverso l’aggregazione di oggetti precedentemente individua-ti. In particolare erano stati isolati i seguenti passi della fase di preprocessing:
• Parser del file contenente i dati di uso
• Estrazione e memorizzazione delle HttpRequest e delle Uri
• Ricostruzione delle PageView a partire da un insieme di HttpRequest • Identificazione delle Sessioni utente, aggregando insiemi di PageView Questa suddivisione in task delle fasi di preprocessing `e stata mantenuta anche con la ristrutturazione del sistema, mentre sono stati modificati tutti i singoli algoritmi in modo da rendere gli stessi pi`u efficienti, e prevedendo opportuni meccanismi per adattarli ai vari campi di applicazione. Si pu`o per esempio pensare al pi`u semplice metodo per la creazione delle sessioni utente: una finestra temporale in cui richieste HTTP provenienti dallo stesso client sono considerate appartenenti alla stessa sessione. E’ chiaramente opportuno che l’intervallo di tempo massimo che deve intercorrere affinch´e due pagine web siano associate alla stessa sessione sia modificabile a seconda del conte-sto in cui viene fatta l’analisi. Per esempio `e difficile pensare che nel caso di un motore di ricerca una sessione utente duri pi`u di qualche minuto, mentre se i dati riguardano un sito web ricco di contenuti `e probabile che un utente si trattenga anche mezz’ora prima di uscire dal sito.
Sempre per quanto riguarda la fase di preprocessing `e stato esteso il si-stema con metodi di parser per gestire i formati pi`u diffusi con cui sono memorizzate le richieste HTTP in un log file di un server web. Un grosso limite dell’applicazione iniziale, che per quanto ben organizzata a livello teo-rico, la rendeva solo un prototipo non utilizzabile, era, infatti, il formato dei dati che potevano essere analizzati. I dati grezzi erano stati ottenuti grazie alla collaborazione con il centro Serra, che ha permesso la raccolta dei dati di Usage attraverso una tecnica di packet sniffing. A partire dai pacchetti tcp/ip venivano estratte alcune delle molte informazioni a disposizione e copiate su un file di testo. Sebbene i file costruiti con questo procedimento siano molto pi`u completi dal punto di vista delle informazioni raccolte, sia perch´e la fonte `
38 Web Object Store
siti, sia perch´e nel file di log non vengono memorizzate tutte le informazioni presenti nel pacchetto tcp della richiesta (basta pensare ai parametri passati con il metodo POST), tuttavia la gestione di questo unico formato di input rendeva il sistema molto poco utilizzabile da terzi.
2.2
Formati dati input
Nonostante siano molti i formati in cui un server web pu`o memorizzare i suoi log file, i pi`u diffusi sono il “Common Log File Format” e lo “Squid native log file format”. Il primo `e utilizzato dai web server Apache, ma `e anche preso come riferimento da molti altri server che utilizzano dei file log, formalmente diversi, ma in realt`a con una struttura molto simile. Il secondo `
e invece lo standard pi`u conosciuto e pi`u diffuso tra i web proxy server.
Tra le informazioni estraibili da questi file ce ne sono alcune comuni a tutti, altre disponibili a seconda del formato scelto. A seconda dei dati di-sponibili sar`a pertanto possibile ottenere differenti risultati. Per esempio, in mancanza di un campo che indichi con esattezza la pagina da cui proviene la richiesta per una pagina successiva (il campo Referrer), sar`a difficile otte-nere delle sessioni utente basate su un’idea di path sequenziale di navigazione.
2.2.1
Common Log Format (CLF) e Combined Log
Format
Il common log format `e, come detto, il formato utilizzato da web server Apache. Le seguenti sono possibili entry di un file in questo formato [45].
bacuslab.pr.mcs.net - - [01/Jan/1997:12:57:50 -0600] “GET /∼bacuslab/HomeCount.xbm HTTP/1.0” 200 890
151.99.190.27 - - [01/Jan/1997:13:06:51 -0600] “GET /∼bacuslab HTTP/1.0” 301 -4
2.2.2.1 Common Log Format (CLF) e Combined Log Format 39
151.99.190.27 - - [01/Jan/1997:13:06:54 -0600] “GET /∼bacuslab/BLI Logo.jpg HTTP/1.0” 200 8210
In ognuna di queste righe troviamo i seguenti campi, separati da righe: remotehost (151.99.190.27 o bacuslab.pr.mcs.net)
Hostname , o IP address del client che effettua la richiesta rfc931 (-)
L’identificatore usato per riconoscere il client. (Se tale valore non `e disponibile il server inserisce il carattere -)
authuser (-)
Lo username inserito dall’utente nel caso venga richiesto, perch´e neces-sario per accedere ad un documento. E’ disponibile quando si gestiscono pagine protette da password. (Anche in questo caso se non disponibile viene inserito il segno -)
date (01/Jan/1997:13:07:21 -0600)
Data e ora della richiesta. Il formato `e: day/month/year:hour:minute:second zone
“request” (“GET / bacuslab/celsheet.html HTTP/1.0”)
La richiesta HTTP vera e propria. In particolare troviamo informazioni su:
metodo (GET)
il metodo HTTP utilizzato per effettuare la richiesta url (/∼bacuslab/celsheet.html)
l’indirizzo della risorsa richiesta protocol ((HTTP/1.0))
il protocollo utilizzato dal client status (200)
Il codice HTTP di risposta, che indica se il file `e stato recuperato con successo o se ci sono stati degli errori, nel qual caso il codice rappresenta l’errore che `e stato rilevato
40 Web Object Store
bytes (13276)
Il numero di bytes trasferiti
Una variante di questo formato `e il Combined Log format (o Extended Common Log File format), in cui, oltre ai campi precedenti, ne possiamo trovare altri due e abbiamo delle entry di questo tipo:
bacuslab.pr.mcs.net - jvb [01/Jan/1997:12:57:45 -0600]
“GET /∼bacuslab/ HTTP/1.0” 304 0 “http://www.mcs.net/” “Mozilla/2.0GoldB1 (Win95; I)”
I campi aggiuntivi sono gli ultimi due e contengono le seguenti informa-zioni:
“referrer” (“http://www.mcs.net/”)
La pagina in cui il client si trova prima di effettuare la richiesta (Se non pu`o essere determinata, per esempio perch´e la richiesta non `e ef-fettuata tramite un link, ma digitando la url direttamente nel browser, troveremo il segno -)
“user agent” (“Mozilla/2.0GoldB1 (Win95; I)”)
Il software, browser e sistema operativo, utilizzato dal client (Anche in questo caso se l’informazione non `e disponibile troveremo un -)
Poich´e un web server pu`o gestire in modo automatico lo switch tra questi due formati `e possibile che all’interno di un log file si trovino entry di entrambi i tipi. Per questo motivo, `e stato implementato un parser che riesce a gestire contemporaneamente entrambi i tipi di file, in maniera trasparente all’utente, che dovr`a semplicemente indicare se il log file da analizzare `e in uno di questi due formati, senza ulteriori specificazioni.
2.2.2
Squid Log Format
Un file di log contenente entry memorizzate secondo il formato nativo di Squid registra informazioni diverse rispetto al Common log format. Una possibile entry in questo formato `e la seguente:
2.2.2.2 Squid Log Format 41
1049790275.517 880 192.168.5.12 TCP MISS 20012689 GET ftp://it.samba.org/pub/samba - DIRECT/ 217.56.103.6 text/html
In ogni riga di un file di questo tipo sono registrati i seguenti campi: timeStamp (1049790275.517)
il momento in cui la richiesta diretta verso il sistema di cache `e stata processata, in formato “UNIX Time” con la risoluzione in millise-R
condi
elapsed time (880)
il tempo necessario per processare la richiesta, espresso in millisecondi client address (192.168.5.12)
l’indirizzo IP sorgente della richiesta result code (TCP MISS)
la codifica del risultato della transazione. Il codice presente nella prima parte indica la presenza o l’assenza in cache della richiesta, se essa `e stata soddisfatta o la causa del fallimento
bytes (20012689)
la quantit`a di byte inviati al client request method (GET)
il metodo HTTP che viene utilizzato per ottenere un oggetto URL (ftp://it.samba.org/pub/samba)
la Url richiesta rfc931 (-)
l’eventuale identificativo del client che ha richiesto il servizio hierarchy code (DIRECT/ 217.56.103.6)
identificatore di come e dove la richiesta `e stata processata type (text/html)
il content type dell’oggetto come presente nell’header della richiesta HTTP.
42 Web Object Store
Per ulteriori dettagli rimandiamo alla descrizione dettagliata del formato presente in [46].
2.3
Modellazione degli oggetti web
Dal punto di vista dell’implementazione troviamo cinque classi fondamen-tali che rappresentano i corrispondenti dati web: Uri, HttpRequest, PageView, Session, UCitation
2.3.1
Uri
Il termine URI `e usato per identificare un Uniform Resource Identifier [18], che permette di rappresentare in modo uniforme una qualsiasi risorsa disponibile nella rete: un documento, un’immagine, ma anche un servizio o addirittura oggetti e persone che sono collegate a ci`o a cui si pu`o accedere via rete e identificabile in qualche modo. All’interno del WOS, in realt`a una URI viene vista come un Uniform Resource Locator (URL), in quanto ci`o che viene memorizzato `e la stringa utilizzata per localizzare la URI stessa, cio`e l’indirizzo HTTP a cui pu`o essere recuperata, e che troviamo registrato, per esempio, in ogni richiesta di un file log di un server web.
Una URI viene modellata con l’omonimo oggetto in cui vengono memo-rizzati, oltre all’indirizzo web, che funge anche da chiave, il numero di accessi alla pagina, che si riveler`a utile nei casi di analisi statistiche sul traffico. Ogni oggetto di tipo Uri si trova in relazione con una o pi`u HttpRequest che cor-rispondono alle richieste effettuate al server in cui l’utente voleva ottenere la risorsa identificata con quella URI.
2.3.2
Http request
Quando un utente visita una pagina web, il browser invia un certo nu-mero di richieste al server web. La prima richiesta `e per il file Html, tutte le altre, generate automaticamente dal browser usato dal client, servono per recuperare gli altri elementi che compongono la pagina. Definiamo una Htt-pRequest come la generica richiesta al web server di inviare all’utente una