Corso di Laurea Magistrale in Ingegneria Informatica
per la Gestione d’Azienda
Tesi di Laurea:
Progettazione e realizzazione di una web application
per il miglioramento dell’assistenza clienti online
Relatore:
Ing. Mario G. CIMINO
Relatore:
Prof.ssa Gigliola VAGLINI
Indice Generale
Introduzione1 Requisiti dell’applicazione ... 9
1.1 Specifiche ... 9
1.1.1 Architettura ... 10
1.1.2 Scambio dei messaggi ... 11
1.2 Parametri di Valutazione ... 12
1.2.1 Accuratezza ... 12
1.2.2 Word Error Rate ... 12
1.2.3 Tempo di risposta del sistema ... 13
2 Tecnologie e strumenti di sviluppo ... 14
2.1 Ajax….. ... 14
2.2 HTML 5, CSS3… ... 15
2.3 Javascript, Jquery, Java EE ... 16
2.4 Spring Framework ... 18
2.5 Mongo Database NoSql ... 18
3 Elaborazione del linguaggio naturale ... 20
3.1 Obiettivi principali ... 21 3.2 Problemi ... 21 3.3 Apache OpenNLP ... 22 3.3.1 Part-Of-Speech (POS) ... 22 3.3.2 Sentence Detector ... 23 3.4 Apache Lucene ... 23 3.4.1 Tokenizer ... 23 3.4.2 Stemmer ... 24
4 Similarità tra testi brevi ... 25
4.1 Obiettivi principali ... 25 4.2 Stato dell’arte ... 25 4.3 Problemi ... 27 4.4 Funzioni di somiglianza ... 28 5 Progettazione ... 32 5.1 Passi fondamentali ... 33
5.1.1 Analisi della richiesta ... 33
5.1.2 Analisi del matching ... 34
5.2 Scelte Progettuali ... 36
5.2.1 Scelta della configurazione NLP ... 36
5.2.2 Scelta dell’algoritmo ... 38 5.2.3 Descrizione dell’algoritmo ... 39 5.3 Interfaccia ... 41 5.3.1 Modalità Azienda ... 41 5.3.2 Modalità Utente ... 45 5.4 Visualizzazione Risultati ... 48
5.5 Definizione delle Classi ... 49
5.6 Modalità di interazione ... 51
5.6.1 Modalità Azienda di inserimento ... 51
5.6.2 Modalità Azienda di eliminazione ... 52
5.6.3 Modalità Azienda di aggiornamento ... 53
5.6.4 Modalità Utente di ricerca della domanda ... 54
6 Sviluppo ……. ... 57 6.1 Descrizione Generale ... 57 6.2 Descrizione Dettagliata ... 59 6.2.1 Index.jsp ... 59 6.2.2 Function.js ... 61 6.2.2.1 Function: request() ... 61 6.2.2.2 Function: showMessage() ... 62 6.2.2.3 Function: plus(index) ... 63 6.2.2.4 Function: minus(index) ... 63 6.2.2.5 Function: addQuestion() ... 64 6.2.2.6 Function: showDB() ... 64 6.2.2.7 Function: delQuestion(indexQ) ... 65 6.2.2.8 Function: updateQuestion(indexQ) ... 65
6.2.2.9 Funzioni per effetti grafici ... 66
6.2.3 Answer.java ... 66 6.2.4 Question.java ... 67 6.2.5 MessageController.java ... 68 6.2.6 QuestionController.java ... 73 6.2.7 POSTagger.java ... 75 6.2.8 SentenceDetector.java ... 76 6.2.9 Stemmer.java ... 77 6.2.10 Tokenizer.java ... 77 6.2.11 Matching.java ... 78 6.2.12 AsnwerRepository.java ... 79 6.2.13 AnswerRepositoryImpl.java ... 80 6.2.14 QuestionRepository.java ... 81 6.2.15 QuestionRepositoryImpl.java ... 82
6.2.16 POM.xml ... 84
6.2.17 dispatcher-servlet.xml ... 85
6.2.18 web.xml ... 85
7 Testing………. ... 87
7.1 Casi di studio ... 87
7.2 Creazione del Test-set ... 89
7.3 Analisi dei testi effettuati ... 89
8 Risultati.……. ... 92
9 Manualistica…. ... 94
10 Conclusioni e sviluppi futuri ... 95
Bibliografia ... 97
Sitografia ... 98
Indice Figure e Tabelle
1.1 Pattern Design MVC ... 10
1.2 Architettura Three-Tier ... 11
1.3 Modello Request - Response ... 11
2.1 Confronto tra modello classico e Ajax ... 14
2.2 Interazione Ajax ... 15
5.1 Schema di analisi del linguaggio naturale ... 37
5.2 Interfaccia inserimento per le aziende ... 42
5.3 Interfaccia per visualizzare contenuto del DB ... 43
5.4 Interfaccia per visualizzare storia domande degli utenti ... 44
5.5 Interfaccia utente con pulsante “INVIA” disabilitato ... 46
5.6 Interazione con il sistema ... 46
5.7 Situazione di errore riconosciuta ... 47
5.8 Feedback positivo ... 48
5.9 Feedback negativo ... 48
5.10 Diagramma delle classi ... 50
5.11 Diagramma di sequenza: inserimento domanda ... 52
5.12 Diagramma di sequenza: eliminazione domanda ... 52
5.13 Diagramma di sequenza: aggiornamento parole chiave ... 53
5.14 Diagramma di sequenza: ricerca domanda ... 56
6.1 Struttura della directory di progetto ... 58
6.2 Header di index.jsp ... 59
6.3 Assistente in index.jsp ... 60
6.4 Interfaccia aziende ... 61
6.5 Annotazione classe Answer.java ... 67
7.1 Criticità frase con singola parola ... 90
7.2 Situazione di errore nel test YourMusicOnline.it ... 91
Tabella 1 - Risultati dei test ... 92
Introduzione
L’utilizzo del World Wide Web come canale di commercio e, più in generale, di comunicazione da parte delle aziende verso i clienti ha introdotto delle problematiche che si vanno ad affiancare a quelle già presenti presso i tradizionali punti vendita. Nella creazione di un portale web, bisogna affrontare problematiche concernenti la sicurezza dei dati sensibili, del sistema di pagamento e lo sviluppo di un’adeguata accoglienza che consenta all’utente la percezione dell’affidabilità dell’azienda. A oggi sono state sviluppate delle soluzioni affidabili che permettono una risoluzione dei problemi sopra citati in maniera agevole. Una problematica che non ha ancora trovato una soluzione definitiva riguarda l’assistenza online rivolta ai clienti. Analizzando la situazione attuale si nota come le aziende, in base al numero dei clienti, vertono su sistemi complessi con un alto utilizzo di risorse umane oppure sull’uso di canali tradizionali quali telefono ed email per fornire assistenza. In particolare le grandi società forniscono assistenza mediante call center, proprietari o in outsourcing, con un elevato costo di gestione e manutenzione del servizio che, tuttavia, non fornisce un efficiente livello di assistenza, salvo alcune eccezioni. Al contrario le piccole e medie imprese, non avendo una disponibilità economica tale da poter demandare il servizio ai call center, preferiscono gestire autonomamente il rapporto con i clienti non riuscendo spesso a soddisfare tempestivamente le esigenze degli utenti. Da qualche anno sono state create delle piattaforme di interazione online con i clienti, gestibili in maniera autonoma e agevole. Queste soluzioni se da un lato permettono di ridurre i costi per le piccole e medie imprese (PMI), dall’altro non permettono di offrire un servizio di qualità percepito dal cliente poiché
comportano un incremento dei costi riguardanti il personale. Inoltre la bassa qualità del servizio è percepita nelle fasce serali, poiché l’80% degli acquisti online è fatto dalle ore 20:00 alle ore 02:00. In questa fascia oraria vi è una bassa disponibilità del servizio di assistenza che induce l’utente ad abbandonare il processo di acquisto al primo problema o dubbio riscontrato. Infatti, il 60% degli utenti abbandona l’acquisto per mancanza di un supporto di assistenza immediato. Ciò si traduce in un tasso di conversione da utenti che approdano sul sito in clienti che acquistano pari al 2,9%, a fronte di un investimento pari a circa il 44% del budget per acquisire clienti.
Il presente lavoro di tesi ha l’obiettivo di creare un’applicazione web che permette alle aziende di fornire un sistema di assistenza online automatizzata consentendo di superare le problematiche sopra descritte ed incrementare il tasso di conversione.
La piattaforma è costituita da un client realizzato in HTML, CSS e
Javascript facilmente integrabile sui portali aziendali e da un server
basato su tecnologia Java integrato con un Database Management
System (DBMS) di tipo NoSql.
Il client fornisce un’interfaccia utente per interagire con il sistema, raccoglie le richieste e le inoltra al Server che, dopo una fase di analisi ed elaborazione della richiesta restituisce al Client la risposta migliore. Il lavoro svolto consiste nella creazione della piattaforma client – server e in una fase di studio, progettazione e realizzazione della logica di analisi delle richieste dell’utente. Sono stati trattati, infatti, aspetti di Natural
Language Processing (NLP) per migliorare l’accuratezza del matching e,
infine, è stata fatta una fase di studio, implementazione e test sugli algoritmi di accoppiamento per frasi brevi al fine di scegliere il migliore in
termini di accuratezza, tasso di errore. Tutti gli aspetti saranno trattati in maniera esaustiva nei successivi capitoli.
Parole chiave: Applicazione web, assistenza clienti online, natural
language processing, somiglianza testi brevi.
Abstract
This work aims at creating a web application that allows companies to provide a system for automated online support, allowing to resolve the unsatisfactory customer care for users.
The platform consists of a client built in HTML, CSS and Java Script that can easily be integrated on corporate websites, and of a server based on Java technology integrated with a NoSql Database Management System.
The client provides a user interface to interact with the system, collects the requests and forwards them to the server that, after a phase of analysis and processing of the request, returns the response to the client with the best match.
The work creates the client-server platform, and a phase of study, design and implementation of the logical analysis of the user’s requests. Aspects of Natural Language Processing (NLP) were, in fact, dealt with to improve the accuracy of matching and, at last, a study phase, implementation and testing of algorithms was conducted for matching short phrases in order to choose the best terms of accuracy and error rate.
Keywords: Web application, Natural language processing, short text
Capitolo 1
Requisiti dell’applicazione
In questo capitolo analizziamo i requisiti che la web application deve avere per essere performante rispetto ai parametri di valutazione. Inoltre è presa in esame la metodologia di sviluppo affinché il sistema sia stabile, tollerante ai guasti, scalabile ed usabile.
1.1 Specifiche
Un’applicazione web è ben fatta (well-formed), se rispetta gli standard di programmazione. Lato web il codice deve essere sviluppato secondo gli standard proposti dal consorzio W3C. Per far ciò occorre utilizzare validatori di standard HTML5, CSS3, così da garantire una compatibilità con tutti i browser ad oggi più utilizzati.
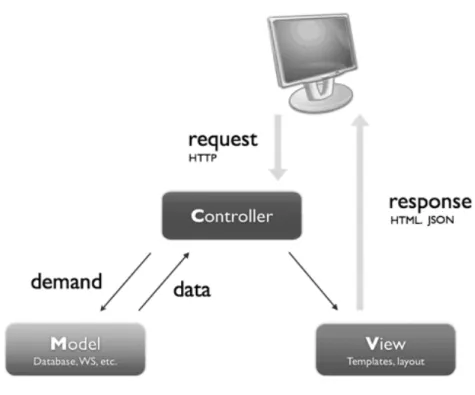
Un buon sistema è sviluppato implementando un pattern design
Model-View-Controller (MVC) in cui sono presenti:
• Model, l'insieme dei componenti che mantengono lo stato, i dati e i metodi per accedervi. Costituisce la logica applicativa.
• View, deputato alla visualizzazione vera e propria dell'interfaccia utente per la presentazione dei dati.
• Controller, gestisce le interazioni dell'utente con l'applicazione (tipicamente intercettando e gestendo gli eventi e gli input dell'utente) mediante accesso al Model e definendo la View corrispondente da presentare.
Figura 1.1 - Pattern Design MVC
1.1.1
Architettura
Dal punto di vista architetturale la scalabilità del sistema è garantita progettando l’applicazione con un’architettura Three-tier in cui abbiamo:
• Livello di presentazione, per interagire con il sistema e ricevere le risposte.
• Livello applicazione (Business Logic, Middleware), che si incarica di ricevere le richieste dall’interfaccia, effettuare le elaborazioni, ed implementa l’interfaccia di collegamento con il Database.
Figura 1.2 - Architettura Three-tier
Con questo tipo di approccio è possibile dislocare i vari livelli su macchine distinte conferendo maggiore flessibilità, scalabilità e manutenibilità.
1.1.2
Scambio dei messaggi
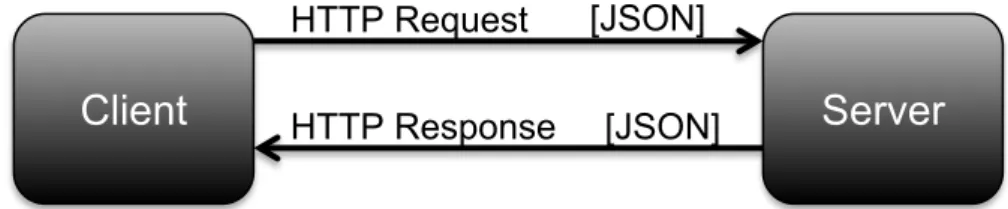
L’applicazione prevede un modello di scambio dei messaggi Request –
Response asincrono sfruttando la tecnologia Ajax. All’interno dei
messaggi i dati sono strutturati secondo il formato Javascript Object
Notation (JSON), che, mediante l’utilizzo di strutture universali quali
coppie nomi/valore o elenco ordinato di valori, conferisce una notevole flessibilità, rendendo possibile l’utilizzo di tutti i linguaggi di programmazione, per integrazioni e modifiche del codice sorgente.
Client
Server
HTTP Request [JSON]
[JSON] HTTP Response
1.2 Parametri di Valutazione
Trattiamo ora alcuni indici di valutazione che hanno permesso di misurare le prestazioni del sistema calcolando delle misure che specificano la qualità della risposta presentata all’utente.
1.2.1
Accuratezza
L'accuratezza delle informazioni statistiche è il grado di corrispondenza tra la stima ottenuta dall'indagine e il vero (ma ignoto) valore della caratteristica in oggetto nella popolazione obiettivo. Può anche essere descritta in termini di maggiori fonti di errore che potenzialmente causano inaccuratezza; invece, una misura dell'accuratezza viene fornita dall'errore totale.
In riferimento al sistema sviluppato, l’accuratezza è il valore di ritorno della funzione di similarità implementata. Questa è ottenuta confrontando le parole chiave estratte dalla domanda dell’utente e le parole chiave estratte dalla domanda immessa nel sistema dall’azienda.
1.2.2
Word Error Rate
Word Error Rate (WER) è una metrica comune delle prestazioni di un
riconoscimento vocale o traduzione automatica di sistema.
La generale difficoltà di misurare le prestazioni sta nel fatto che la sequenza parola riconosciuta può avere lunghezza diversa dalla sequenza parola di riferimento (presumibilmente quella corretta). Il WER deriva dalla distanza di Levenshtein, che lavora a livello di parola invece a livello di fonema. Il WER è uno strumento utile per comparare diversi sistemi e per valutare i miglioramenti all'interno di un sistema. Questo
tipo di misura, tuttavia, non fornisce dettagli sulla natura degli errori di traduzione e un ulteriore lavoro deve essere fatto per identificare la fonte principale di errori.
L'esame di questo problema è visto attraverso una teoria chiamata la legge di potenza che indica la correlazione tra perplessità e WER.
Il tasso di errore Word può essere calcolato come:
𝑊𝐸𝑅 =
𝑆 + 𝐷 + 𝐼
𝑁
dove: • S è il numero di sostituzioni, • D è il numero di eliminazioni, • I è il numero di inserimenti,• N è il numero di parole del riferimento.
1.2.3
Tempo di risposta del sistema
Per garantire una buona usabilità del sistema è necessario che il sistema abbia un tempo di risposta rapido. Per avere una stima del tempo trascorso tra una richiesta e una risposta è preso in considerazione il tempo di elaborazione 𝑇!"#$ che il sistema impiega a processare la
richiesta espresso in numero di richieste elaborate al secondo.
Grazie all’affidabilità del DBMS MongoDB, possiamo considerare trascurabile il tempo di ricerca all’interno del Database. Infine non è incluso nel calcolo il tempo di attraversamento del canale, poiché esso è un parametro dipendente da fattori esterni all’applicazione stessa.
Capitolo 2
Tecnologie e strumenti di sviluppo
Per avere una visione complessiva e chiara della tesi è bene comprendere le tecniche utilizzate per lo sviluppo. In questo capitolo daremo una breve spiegazione degli strumenti e tecnologie impiegate.
2.1 Ajax
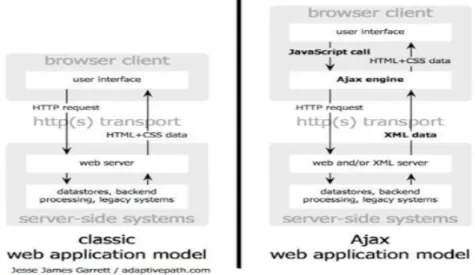
Acronimo di Asynchronous JavaScript and XML, AJAX è una tecnica di sviluppo che consente di ottenere pagine web che rispondono agli eventi in maniera più rapida quando gli eventi hanno bisogno di ulteriori informazioni che il client non riesce a fornire. Grazie ad uno strato software intermedio tra browser e web-server, chiamato AJAX-Engine, permette di fare l'aggiornamento dinamico di una pagina web senza che questa venga ricaricata dall’utente. La figura seguente mostra il meccanismo di comunicazione client – server in un’applicazione web, sia nella modalità classica che con Ajax.
Figura 2.2 - Interazione Ajax
2.2 HTML 5 e CSS3
L’ Hyper Text Markup Language (HTML) è un linguaggio di marcatori la cui funzione è descrivere come devono essere presentati i contenuti dei documenti. Esso permette per esempio di:
• Recuperare informazioni tramite collegamenti ipertestuali.
• Progettare moduli per effettuare transazioni con servizi remoti per effettuare la ricerca di informazioni, fare prenotazioni.
• Includere fogli elettronici, video, brani.
Le pagine web sono scritte in HTML. Il codice HTML è interpretato dal browser con ampia tolleranza sintattica. Per una corretta interpretazione è bene seguire gli standard sintattici definiti dal W3C. HTML si esprime in forma testuale, e questo lo rende intelligibile e aperto. Un particolare
tag, detto àncora, consente di rappresentare un documento in moduli
collegati e sparsi su vari nodi della rete: tutto ciò ha consentito una rapida diffusione del web a livello globale e una organizzazione distribuita della informazione.
HTML è un linguaggio di pubblico dominio la cui sintassi è stabilita dal
World Wide Web Consortium (W3C). La versione ultima, ampiamente
supportata dai browser è la 5. È importante riuscire a separare la struttura di un documento dai suoi aspetti di presentazione. Questo riduce i costi necessari per servire un’ampia gamma di piattaforme e facilita la manutenzione dei documenti. Per realizzare tale separazione e definire la formattazione è utilizzato il linguaggio CSS (Cascading Style
Sheets), disponibile alla versione 3.
2.3 Javascript e programmazione ad
oggetti
JavaScript è un linguaggio di scripting indipendente dalla piattaforma e orientato agli oggetti. Questo per cercare di disaccoppiare il più possibile
le diverse funzionalità del software e renderlo così più facilmente estendibile e manutenibile. La caratteristica principale di JavaScript è di essere un linguaggio interpretato, dove il codice non è compilato ma appunto interpretato. L’”interprete” si trova all’interno del browser utilizzato. Javascript non implementa il concetto di classe, però permette di definire il tipo di oggetto.
Un oggetto è una struttura dati che può contenere variabili e metodi. Negli oggetti JavaScript non è possibile dichiarare metodi pubblici o privati oppure ereditare i metodi di un altro oggetto. Mostriamo un esempio di classe JavaScript contenente variabili e metodi:
function className (value1, value2, …) { this.property1=value1; this.property2=value2; … this.method1=function; ... }
Una volta dichiarato un tipo di oggetto, è possibile istanziare variabili di quel tipo, con le proprietà specificate nella dichiarazione. Per accedere alle proprietà dell'oggetto verrà applicata la notazione punto:
objectName.propertyName
Per accedere ai metodi si utilizza la stessa notazione: objectName.function(...)
Le interfacce che consentono a JavaScript di rapportarsi con un browser prendono il nome di DOM (Document Object Model in italiano Modello a Oggetti del Documento). Molti siti web usano la tecnologia JavaScript lato client per creare applicazioni web dinamiche. Questo linguaggio è, per molti aspetti, simile al linguaggio di programmazione Java. Quest’ultimo, nella versione Enterprise Edition, permette di sviluppare applicazioni web facilitando l’utente nella gestione delle richieste e risorse http.
2.4 Spring Framework MVC Pattern
Spring è un framework open source per lo sviluppo di applicazioni in linguaggio Java.
Spring è stato largamente riconosciuto all'interno della comunità Java come valida alternativa al modello basato su Enterprise JavaBeans (EJB). Rispetto a quest'ultimo, il framework Spring lascia una maggiore libertà al programmatore fornendo allo stesso tempo un'ampia e ben documentata gamma di soluzioni semplici adatte alle problematiche più comuni. Sebbene le peculiarità basilari di Spring possano essere adottate in qualsiasi applicazione Java, esistono numerose estensioni per la costruzione di applicazioni web-based (applicazioni Web) costruite sul modello della piattaforma Java EE.
2.5
Mongo Database NoSql
MongoDB (da "humongous", enorme) è un database non relazionale, orientato ai documenti. Classificato come un database di tipo NoSQL, MongoDB si allontana dalla struttura tradizionale basata su tabelle dei database relazionali in favore di documenti in stile JSON con schema
dinamico (MongoDB chiama il formato BSON), rendendo l'integrazione di dati di alcuni tipi di applicazioni più facile e veloce. MongoDB è stato adottato come backend da un alto numero di grandi siti web e società di servizi per garantire velocità in fase di accesso ai dati memorizzati.
Capitolo 3
Elaborazione del linguaggio naturale
L’elaborazione del linguaggio naturale, detta anche NLP (Natural
Language Processing), è il processo di trattamento automatico mediante
strumenti informatici delle informazioni scritte o parlate nel linguaggio umano o naturale.
Questo processo è particolarmente difficile e complesso a causa delle caratteristiche intrinseche di ambiguità del linguaggio umano. L’elaborazione è solitamente suddivisa in fasi:
1. Analisi lessicale: consiste nella scomposizione di un’espressione linguistica in parole (token).
2. Analisi grammaticale: in cui è associata ad ogni parola del testo una parte del discorso.
3. Analisi sintattica: consiste nella creazione di una struttura sintattica, solitamente ad albero, contenente i token.
4. Analisi semantica: in cui è assegnato un significato (semantica) alla struttura sintattica e, di conseguenza, all’espressione linguistica analizzata.
In questo capitolo tratteremo gli aspetti rilevanti del NLP e le problematiche da affrontare per garantire una corretta comprensione del testo digitato dall’utente.
3.1
Obiettivi principali
L’obiettivo prefisso è la comprensione della frase presentata in ingresso dall’utente in modo tale da estrarre le parole rilevanti (keyword). L’attività di analisi permette di semplificare notevolmente la complessità, poiché il risultato dell’elaborazione consente di riassumere l’espressione linguistica in una lista di parole chiave, senza alterare il significato della frase stessa.
L’obiettivo è raggiunto mediante l’utilizzo di librerie Java atte al trattamento dei testi in linguaggio naturale. In particolare, mediante
Apache OpenNLP[B] è possibile realizzare il processo di Part-of-Speech
Tagging (POS Tag), attività che assegna ai token estratti la parte del
discorso associata (es. soggetto, predicato, verbo, avverbio).
Mediante il Sentence Detector, anch’esso facente parte della libreria OpenNLP, è possibile estrarre dal discorso le diverse frasi in modo da poter essere analizzate singolarmente.
Un’altra libreria utile all’analisi del testo è Apache Lucene[C], che mediante i moduli Tokenizer e Stemmer, consente l’estrazione delle parole (token) dalle frasi, in modo da poter essere analizzate singolarmente e la riduzione della parola stessa alla sua forma radice.
3.2
Problemi
L’attività di NLP è stata oggetto di studi e test approfonditi volti a trovare la configurazione dei moduli migliore. Sebbene le librerie sopra citate siano state ampiamente testate e documentate nell’analisi della lingua inglese, è stata riscontrata una documentazione e un supporto limitato relativo alla lingua italiana. La complessità della lingua italiana ha creato altre complicanze; il modulo POS Tag, infatti, pur avendo una fase di
addestramento, in alcuni casi non ha associato correttamente la parte del discorso al token analizzato, riconoscendo, per esempio, alcuni verbi ausiliari come principali. Una ridondanza nell’estrazione delle keyword permette di non snaturare il senso della frase ricavata.
Andiamo ora ad approfondire i moduli descritti.
3.3 Apache OpenNLP
La libreria Apache OpenNLP è un insieme di moduli per il machine
learning che supporta le attività più comuni come la suddivisione in token, la segmentazione del testo in più frasi (sentence), la codifica di
una parte del discorso, l’analisi e la risoluzione di coreference. Include inoltre un apprendimento basato su una classificazione supervisionata quali la massima entropia e il perceptron. La composizione dei moduli permette di costruire una pipeline per l’analisi completa del linguaggio naturale.
3.3.1
Part-of-Speech (POS) Tagger
Questo modulo permette di associare la parte del discorso alla parola analizzata, sia essa un verbo, un complemento o un avverbio. Utilizza un modello basato su probabilità per predire il tag corretto da assegnare al
token, preso da un tag-set prestabilito. Per aumentare la correttezza
della predizione vi è una fase di addestramento che serve ad istruire il modulo per il riconoscimento della lingua trattata.
3.3.2
Sentence Detection
Questo modulo permette di individuare i caratteri di punteggiatura alla fine di una frase o meno. In questo modo una frase è definita come la più lunga sequenza di caratteri, intervallati da spazi bianchi, tra due segni di punteggiatura. La prima e l’ultima frase di un discorso rappresentano un’eccezione. Questo processo è utile per spezzare il discorso in più frasi in modo tale da poter essere analizzate separatamente e delineare meglio il contesto della frase. Anche questo modulo è inizialmente addestrato per apprendere meglio la struttura della lingua trattata.
3.4 Apache Lucene
La libreria Apache Lucene è principalmente utilizzata per l’indicizzazione e la ricerca full text. A oggi ha raggiunto un’ottima stabilità e le sue funzionalità sono utilizzate da molti portali web. All’interno del core troviamo numerosi moduli che permettono l’analisi sui dati. In particolare il modulo analyzers permette la creazione di funzioni per effettuare l’analisi lessicale della frase e successivamente riportare le parole estratte nella forma radice.
3.4.1
Tokenizer
La classe ItalianAnalyzer, contiene al suo interno un metodo che consente di eseguire un’analisi lessicale sulla frase data in ingresso, restituendo una lista di parole.
3.4.2
Stemmer
Sempre all’interno della classe ItalianAnalyzer troviamo dei metodi che consentono di estrarre la radice da ogni parola presa in esame. Questa funzione cerca di comprimere il testo dato in ingresso ad un set di parole più piccolo, andando per esempio a trasformare i verbi coniugati nel loro corrispettivo infinito presente.
Capitolo 4
Similarità tra testi brevi
In questo capitolo analizziamo le problematiche e i sistemi utilizzati per calcolare la similarità tra la richiesta posta dall’utente e la risposta che il server fornisce. Questa parte costituisce l’elemento di maggiore criticità del sistema complessivo, poiché determina la bontà del sistema stesso.
4.1 Obiettivi principali
L’obiettivo della funzione di similarità è trovare il valore migliore di accuratezza tra la domanda posta dall’utente e la risposta presente nel sistema.
In particolare il sistema deve ricavare il valore migliore di accuratezza andando a confrontare le parole chiave della domanda e della risposta estratte dal processo di NLP descritto nel capitolo 2.
4.2 Stato dell’arte
Da uno studio condotto sugli algoritmi esistenti, è stata rilevata la possibilità di sviluppo dell’algoritmo basandosi su diversi approcci per la realizzazione del contesto. In particolare:
1. Sistemi Corpus-Based [1][4]
I Sistemi basati su Corpora prendono in considerazione un dominio di informazioni che sono specifiche di un contesto ben definito. Mediante la definizione dei campioni che costituiscono il dominio, i sistemi sono in grado di disambiguare i termini analizzati semanticamente. Maggiore è il dominio definito, più alta sarà la
percentuale di similarità tra le domande, che dovranno essere formate in prevalenza da parole appartenenti al Corpora.
2. Sistemi Knowledge-Based [1][2][5]
Un sistema basato sulla conoscenza (KBS) è un tentativo di rappresentare la conoscenza in modo esplicito attraverso strumenti quali ontologie e regole. Esso ha almeno uno e di solito due tipi di sottosistemi: una base di conoscenza e un motore di inferenza. La base di conoscenza rappresenta fatti del mondo, spesso sotto forma di sillogismi dell'ontologia. Il motore d’inferenza rappresenta affermazioni logiche e le condizioni sul mondo, di solito rappresentate con regole IF - THEN.
Il sistema basato sulla conoscenza si riferisce all'architettura del sistema, che rappresenta la conoscenza esplicitamente anziché come codice procedurale.
3. Sistemi Wiki-Based [3]
I più recenti KBS adottano le tecnologie Internet per comporre la conoscenza. Internet ha sempre più dati complessi e non strutturati, che non possono essere utilizzati per adattarsi a un modello di dati specifico. I moderni motori di inferenza hanno la capacità di classificare gli oggetti su richiesta e ciò li rende ideali per i dati presi da internet. I sistemi basati su Wiki, sono una specializzazione dei
KBS che utilizzano i dati strutturati presi dai Wiki, in altre parole delle
applicazioni web che permettono alle persone di aggiungere, modificare o eliminare il contenuto in collaborazione con altri. In un wiki tipico, il testo è scritto usando un linguaggio di markup semplificato o un editor di testo RTF. In questo modo i dati hanno una
struttura associata che fornisce ai sistemi KBS una maggiore capacità di classificazione. Un esempio di Wiki è il progetto di enciclopedia Wikipedia[A], il wiki più popolare al mondo.
4. Sistemi senza base di apprendimento
Questi sistemi non si avvalgono dell’utilizzo di nessun Corpora o base di conoscenza ma si affidano esclusivamente alla bontà della funzione di similarità. Sono utilizzati principalmente in applicazioni il cui contesto non è ben identificabile, risultando eterogeneo e atto a contenere informazioni provenienti da diversi ambiti.
4.3 Problemi
Nello sviluppo dell’applicazione le principali difficoltà riguardano la possibilità di recuperare un set di training sufficientemente grande e completo per addestrare il sistema. Ciò inficia, di fatto, le scelte progettuali 1 e 2. Sono stati fatti dei test con un dataset costruito ad-hoc con i dati in possesso, con risultati mediocri, dovuti soprattutto alla mancata individuazione di un contesto specifico di riferimento. Questa problematica, in generale, affligge gli algoritmi di similarità per frasi brevi e si ripercuote sulla scelta progettuale Wiki-based, in quanto, la presenza nella lingua italiana di numerosi sinonimi, non permette di avere un livello di accuratezza che sia funzionale come discriminante per la scelta migliore della risposta del sistema.
4.4 Funzioni di somiglianza
Studiando la letteratura in materia e dopo aver condotto dei test su un dataset di 50 coppie domanda/risposta, sono stati presi in considerazione 4 misure di distanza:
1. Distanza Coseno
Il coseno di similitudine, o cosine similarity, è una tecnica euristica per la misurazione della similitudine tra due vettori effettuata calcolando il coseno tra di loro, usata generalmente per il confronto di testi e nell'analisi del testo.
Formalmente, dati due vettori di attributi numerici, A e B, il livello di similarità tra di loro è espresso utilizzando la formula:
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 = cos 𝜃 =
𝐴 ∙ 𝐵
∥ 𝐴 ∥∥ 𝐵 ∥
dove la funzione cos(𝜃) non va confusa con il coseno tra vettori, perché in questo caso si applica una normalizzazione grazie alla magnitudine. Un altro modo di indicare la formula, del tutto equivalente, è:
𝐴 𝑘 𝐵(𝑘)
! !!!𝐴(𝑘)
! ! !!!!!!!
𝐵(𝑘)
!Nel caso tipico del confronto fra testi, il contenuto dei due vettori è la frequenza dei termini, ossia il numero di volte in cui una certa parola ricorre all'interno del testo. Il k-simo elemento di ogni vettore conterrà dunque il numero di volte in cui la parola numerata con k ricorre nel testo, oppure 0 se non ricorre mai. Applicando la formula nel caso
dell'analisi dei testi, poiché le frequenze dei termini sono sempre valori positivi, si otterranno valori che vanno da 0 a 1, dove 1 indica che le parole contenute nei due testi sono le stesse (ma non necessariamente nello stesso ordine) e 0 indica che non c'è nessuna parola che appare in entrambi. Per rendere più efficace il confronto, in genere, si eliminano le parole più corte e molto frequenti che servono a costruire le frasi, come ad esempio congiunzioni e preposizioni, che possono essere identificate velocemente con un'euristica appropriata. In genere, questa euristica è usata per confrontare degli elementi che sono indicati da dei parametri il cui numero e significato non è noto a priori.
2. Distanza di Levenshtein
La distanza di Levenshtein tra due stringhe A e B è il numero minimo di modifiche elementari quali sostituzioni, cancellazioni e inserimento, che consentono di trasformare la A nella B. Questa misura sarà analizzata nel dettaglio in seguito.
3. Distanza di Jaccard
L'indice di Jaccard, noto anche come coefficiente di similarità di Jaccard, è un indice statistico utilizzato per confrontare la similarità e la diversità di insiemi campionari. Esso misura la similarità tra insiemi campionari, ed è definito come la dimensione dell'intersezione divisa per la dimensione dell'unione degli insiemi campionari:
𝐽 𝐴, 𝐵 =
| 𝐴 ∩ 𝐵 |
| 𝐴 ∪ 𝐵 |
La distanza di Jaccard, che misura la dissimilarità tra insiemi campionari, è complementare al coefficiente di Jaccard e si ottiene sottraendo il coefficiente di Jaccard da 1, o, in modo equivalente, dividendo la
differenza delle dimensioni dell'unione e dell'intersezione di due insiemi per la dimensione dell'unione:
𝐽
! !,! ! !!! !,! !𝐴 ∪ 𝐵 − | 𝐴 ∪ 𝐵|
|𝐴 ∪ 𝐵|
4. Coefficiente di Dice
L'indice o coefficiente di Dice, è una statistica utilizzata per confrontare la somiglianza di due campioni. Formalmente, dati due campioni A e B, il quoziente di somiglianza è definito come:
𝑄𝑆 =
2𝐶
𝐴 + 𝐵
=
2 | 𝐴 ∩ 𝐵 |
𝐴 + |𝐵|
dove A e B sono il numero di elementi nei campioni A e B, rispettivamente e C è il numero di elementi comuni ai due campioni; QS varia da 0 a 1. Può essere visto come una misura di similarità rispetto agli insiemi:
𝑠 =
2 | 𝑋 ∩ 𝑌 |
𝑋 + | 𝑌 |
Analogamente a Jaccard, il set di operazioni possono essere espresse in termini di operazioni vettoriali su vettori binari A e B :
𝑠
𝑣= 2 |𝐴 ∙ 𝐵|
che dà lo stesso risultato su vettori binari e dà anche una somiglianza più generale metrica su vettori in termini generali.
Per insiemi X e Y di parole chiave utilizzate nell’Information Retrieval, il coefficiente può essere definito come il doppio delle informazioni condivise (intersezioni) oltre la somma di cardinalità. Se il coefficiente è assunto come misura di somiglianza tra stringhe, può essere calcolato come segue:
𝑠 = 2𝑛
𝑛
𝑡 𝑥+ 𝑛
𝑦dove nt è il numero di caratteri bigramma (coppie di lettere all’interno
della parola) presenti in entrambe le stringhe, nx è il numero di bigrammi
Capitolo 5
Progettazione
Questo capitolo è dedicato alla descrizione della fase di progettazione. Dopo aver individuato le caratteristiche che l’applicazione web deve avere per raggiungere gli obiettivi prefissati, è possibile definire l’architettura del sistema in maniera naturale e continua dalla fase di analisi precedente. Nella fase di progettazione, l’intento è stabilire una struttura software, in accordo con quanto definito nelle specifiche, in grado di realizzare le specifiche elaborate nel modulo di analisi. Si vuole costruire un modello implementabile nella maniera più lineare e modulare possibile, quindi caratterizzata da elementi slegati e indipendenti tra loro. Comporre il sistema in maniera modulare ci fornisce delle caratteristiche molto importanti quali una maggiore manutenibilità ed estendibilità, flessibilità ed adattabilità ai continui cambiamenti che possono verificarsi nel tempo.
Lo stile di programmazione è quello della programmazione ad oggetti, appunto per rendere il codice estendibile e manutenibile.
A livello logico possiamo immaginare la struttura del sistema suddivisa in quattro parti:
1. La prima parte è caratterizzata da operazioni che permettono l’analisi della richiesta effettuata dall’utente verso il sistema, che include le operazioni di prelievo dei dati dall’interfaccia e la creazione delle strutture dati necessarie per le successive operazioni di elaborazione.
2. La seconda parte comprende la fase di analisi del matching, che si concretizza nelle operazioni di prelievo dei dati dal database e il
confronto tra il risultato della fase precedente e i dati estratti dal database. In questa fase si vanno a calcolare gli indici di valutazione che sono utilizzati per l'identificazione della risposta migliore da fornire all’utente.
3. La terza parte è legata alla presentazione della risposta del sistema all’utente, alla gestione degli errori, alla gestione del rilascio del feedback degli utenti e infine al salvataggio delle informazioni relative all’interazione avvenuta tra sistema e utente. 4. Vi è poi l’ultima parte che riguarda strettamente la gestione
dell’interazione del sistema con le aziende. In questa fase vi è la gestione delle domande e delle risposte immesse nel sistema e la creazione delle parole chiave; questi dati saranno memorizzati nel sistema in maniera persistente.
5.1 Passi fondamentali
Di seguito andiamo a dettagliare i quattro passi fondamentali sopra descritti.
5.1.1
Analisi della richiesta
In questa fase l’interfaccia web riceve in ingresso il testo della domanda immessa dall’utente e, mediante una funzione, confeziona la richiesta asincrona che invia alla Business Logic Unit. Quest’ultima, mediante il
Controller associato, si occupa di definire le strutture dati per la
memorizzazione persistente su Database, istanzia i moduli necessari all’elaborazione della richiesta ricevuta quali POS Tagger, Sentence
Il risultato dell’elaborazione crea una lista di parole chiave associate alla richiesta.
5.1.2
Analisi del matching
La lista di parole chiave, risultato dell’elaborazione al passo precedente, è utilizzata per compiere una ricerca all’interno del Database, ritornando come risultato tutte le tuple che contengono almeno una delle parole chiave presenti nella lista. La lista di tuple, risultato della query all’interno del database, contiene delle informazioni ridondanti poiché all’interno compaiono delle frasi che non appartengono strettamente al contesto della richiesta. Questa scelta progettuale è stata fatta per introdurre una tolleranza ai sinonimi. Una query il cui risultato fosse stato la lista di tuple contenenti tutte le parole chiave presenti nel criterio di selezione, avrebbe portato ad una selezione esclusiva delle tuple, impedendo così la gestione dei sinonimi.
In seguito è effettuato un confronto tra le parole chiave ricavate dalla richiesta dall’utente e le parole chiave di ogni tupla ricavate dalla query sul database. Da notare che la lista di tuple è ordinata secondo un ordine lessicografico; ciò ha consentito un incremento della prestazioni dell’algoritmo di matching. La valutazione degli indici della funzione di corrispondenza identifica la tupla che ha il più alto grado di corrispondenza con la richiesta presentata al sistema e, quindi, la risposta migliore che il sistema fornisce alla richiesta fatta dall’utente.
5.1.3
Analisi della risposta
Una volta che il sistema ha ricavato la risposta migliore da fornire all’utente predispone tutti i dati nelle apposite strutture create, andando a salvare il tutto sul database. Questo passo è da ritenersi fondamentale
per tenere traccia delle interazioni tra sistema e utente poiché è possibile fare delle analisi e ricavare delle statistiche utili al miglioramento del sistema stesso. Sono memorizzati infatti: la domanda dell’utente con le parole chiave estratte, la risposta del sistema con le parole chiave associate, l’accuratezza, ovvero il risultato dell’algoritmo di somiglianza, e viene istanziato un contatore che verrà aggiornato con il feedback rilasciato dall’utente. Quest’ultimo serve ad aggiornare la corrispondenza tra domanda e risposta, creando, di fatto, un apprendimento del sistema basato sulle interazioni. Infine il sistema confeziona la risposta da restituire all’interfaccia che si occuperà della corretta visualizzazione. Da notare che il sistema mediante l’uso del modulo di Sentence Detector elabora ogni domanda singolarmente. Infatti, anche se l’utente immette un testo contenente più domande, il sistema fornirà una risposta ad ogni singola domanda aumentando così la qualità della risposta generale. Se il sistema non riesce trovare una risposta alla richiesta presentata è attivata la gestione dell’errore. Ciò comporta una risposta all’utente in cui viene invitato a riformulare la domanda con altri termini. Infine il sistema chiede un’interazione con l’utente per il rilascio del feedback sulla risposta.
5.1.4
Gestione dell’interazione con le aziende
A livello logico, una parte a se stante è dedicata a come l’azienda interagisce con il sistema. È prevista, infatti, un’interfaccia in cui l’azienda può inserire le domande e le risposte associate. Il sistema si occuperà di fare un’analisi della domanda come al punto 5.1.1 e gli assocerà le parole chiave ricavate. Il tutto sarà memorizzato in maniera persistente sul database.
Mediante l’interfaccia è possibile aggiornare le parole chiave associate alla domanda, andando ad aggiungere per esempio dei sinonimi, in modo da aumentare la percentuale di corrispondenza con il contesto del quesito. E’ possibile inoltre eliminare la tupla qualora non fosse più necessaria.
Infine, è possibile visualizzare le domande poste dagli utenti, la risposta fornita dal sistema, i parametri di valutazione ricavati e le situazioni di errore.
5.2 Scelte progettuali
Di seguito vengono descritte le scelte di progetto per la realizzazione del sistema, ricavate da test condotti con la combinazione dei vari sistemi di elaborazione del linguaggio naturale e degli algoritmi di similarità tra testi brevi descritti in precedenza.
5.2.1
Scelta della configurazione NLP
L’utilizzo dei moduli relativi all’elaborazione del linguaggio naturale e i test fatti con varie configurazioni hanno permesso di delineare la struttura migliore per l’analisi del testo al fine di ricavare dalla frase immessa dall’utente una lista di parole chiave nella loro forma radice che diventa, nella fase successiva, oggetto di confronto per l’algoritmo di similarità discusso nel capitolo 3.
Testo utente
Sentence Detector
Tokenizer
Stemmer
POS Tagging
TAG
Rilevanti
NO
SI
Pulizia del Tag
Ordinamento Lessicale
Per ricavare i tag rilevanti da estrarre, è stato fatto uno studio condotto sulle principali forme di domanda poste dagli utenti ai call center, ai sistemi di assistenza computerizzata, Frequently Asked Question (FAQ) e risponditori automatici.
L’analisi di oltre 200 domande ha permesso di ricavare il seguente schema che riassume la struttura sintattica più frequentemente utilizzata:
Avverbio, Soggetto, Verbo, Complemento Oggetto
Dopo la fase di POS Tagging il sistema va ad analizzare i tag applicati ai
token, scartando tutto ciò che non rientra nella struttura sopra esposta.
La fase di ordinamento lessicale è importante per ottimizzare in termini di velocità ed efficienza la funzione di similarità.
Al fine di valutare la bontà della scelta progettuale è stata sviluppata un’implementazione parallela formata dal modulo Sentence Detector e
Tokenizer cui in seguito era affiancato un confronto con una lista di stop-words. La lista comprendeva le parole che non aggiungevano significato
al testo come ad esempio, congiunzioni, aggettivi, preposizioni. Questa scelta si è rilevata fallimentare in quando non era possibile rimuovere alcuni verbi che in alcuni contesti erano verbi ausiliari e in altri no. Inoltre la complessità della lingua italiana faceva crescere esponenzialmente la lista, rendendola di fatto inutilizzabile.
5.2.2
Scelta dell’algoritmo
Per quanto riguarda la metodologia di similarità, dopo una fase di studio è stato deciso di adottare come scelta progettuale la creazione di un sistema senza base di apprendimento. Per ognuna delle distanze descritte in precedenza sono stati condotti dei test con una dataset di
oltre 100 coppie di domanda/risposta, alcune delle quali sono riformulazioni con sinonimi dello stesso concetto, aventi quindi significato semantico uguale. Da notare che le domande sono riferite a contesti differenti.
I risultati dei test hanno individuato come misura migliore la distanza di Levenshtein poiché riesce a raggiungere un’accuratezza dell’81%, un tasso di errore pari a 7,88.
Infine sono state apportate dei miglioramenti al codice sorgente che hanno consentito un miglioramento dell’accuratezza fino all’85,5%.
5.2.3
Descrizione dell’algoritmo
La distanza di Levenshtein è una metrica che misura la distanza tra due stringhe. La misura è calcolata come il numero minimo di modifiche elementari che consentono di trasformare la stringa A nella stringa B. Formalmente, la distanza di Levenshtein può essere espressa nel seguente modo:
Date due stringhe a e b in un alfabeto Σ, la distanza di Levenshtein d(a,b) è la serie di pesi minimi di operazioni di modifica che trasformano
a in b. Le operazioni definite sono:
• Inserimento di un singolo simbolo • Sostituzione di un singolo simbolo • Cancellazione di un singolo simbolo
A ogni modifica è associato un costo unitario e la somma dei pesi dà come risultante la similarità tra le stringhe.
Applicando l’algoritmo nel caso specifico dell’applicazione web, la stringa A è formata dalle parole chiave ricavate dall’analisi NLP (discussa nel
capitolo 3) fatta sulla domanda immessa dall’utente mediante l’interfaccia apposita, la stringa B è formata dalle parole chiave ricavate dall’analisi NLP della domanda immessa nel sistema dall’azienda. Conducendo dei test con questa funzione di somiglianza, è stato costatato che il sistema riesce a rispondere correttamente nell’81% dei casi, su un campione di 107 coppie di domande.
La problematica riscontrata in questo caso è legata al valore di similarità che la funzione restituisce poiché non permette una netta distinzione tra le soluzioni candidate. La distanza di Levenshtein, infatti, ha il limite superiore pari alla differenza fra le due stringhe, e, nel caso peggiore, è pari alla lunghezza della stringa più lunga. Viceversa, nel caso migliore, il limite inferiore è uguale a 0 ed indica l’identità delle due stringhe. I risultati dei test hanno evidenziato che, non avendo un limite superiore definito con un valore massimo, la funzione di somiglianza, nel caso peggiore di stringhe completamente diverse, ritorna un valore alto che è difficilmente confrontabile.
L’obiettivo prefisso dalla tesi è la creazione di un indice di somiglianza che abbia come limite inferiore e superiore rispettivamente 0, per indicare la completa uguaglianza tra le stringhe, e 1, per indicare la differenza totale. Per far ciò è stata condotta una serie di prove andando a modificare per ogni test i pesi delle modifiche elementari sopra descritte.
Considerando l’alta complessità del linguaggio italiano e la grande presenza di sinonimi associata a ogni parola, i risultati dei test non hanno prodotto rilevanti miglioramenti.
Si è proceduto quindi con la modifica della distanza di Levenshtein assegnando un peso pari a 1 per ogni modifica elementare, e andando a normalizzare il risultato con la dimensione della stringa più lunga.
In questo modo il valore di ritorno della funzione di somiglianza rientra nei limiti prefissi come obiettivo. Inoltre questa modifica ha portato un incremento della distinzione tra le soluzioni candidate, andando, inoltre, ad incrementare il livello di accuratezza fino all’87%.
Sono stati condotti dei test per validare la bontà della modifica fatta ed i risultati sono dettagliati nel capitolo 8.
Per una descrizione dettagliata si rimanda al capitolo 6.
5.3 Interfaccia
Di seguito presentiamo le interfacce realizzate per l’interazione con il sistema. L’interfaccia implementa i requisiti di usabilità del web, in particolare, ha degli elementi facilmente riconoscibili e utilizzabili, che non richiedono lo studio di manualistica associata; ha un’interazione intuitiva, in quanto ogni operazione possibile è resa spontanea, con una buona gestione dell’errore e del feedback associato agli eventi.
5.3.1
Modalità Azienda
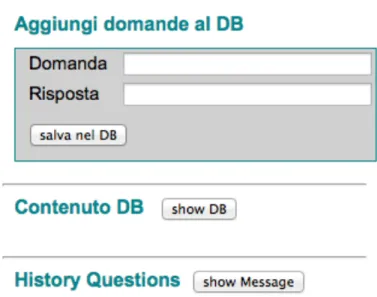
L’interazione dell’azienda con l’applicazione sviluppata interessa, in particolar modo, il meccanismo di immissione delle domande a cui la stessa vuole rispondere, predisponendo una lista che il sistema elaborerà al fine di consentire la facile individuazione da parte dell’utente. Quindi l’operazione di inserimento è affidato ad un form di immissione ben identificabile in cui l’operatore aziendale inserirà la domanda e la relativa risposta.
Figura 5.2 - Interfaccia di inserimento per le aziende.
In seguito, alla pressione del pulsante “salva nel DB”, il sistema eseguirà l’elaborazione del testo inserito, facendo un controllo sulla domanda inserita per accettarsi che sia composta da una sola frase, e, in caso di esito positivo, salvando il risultato prodotto sul Database in maniera del tutto trasparente all’utente. Infine, sarà presentata all’utente, in forma tabellare, la lista delle domande immesse, con le caratteristiche associate alle domande.
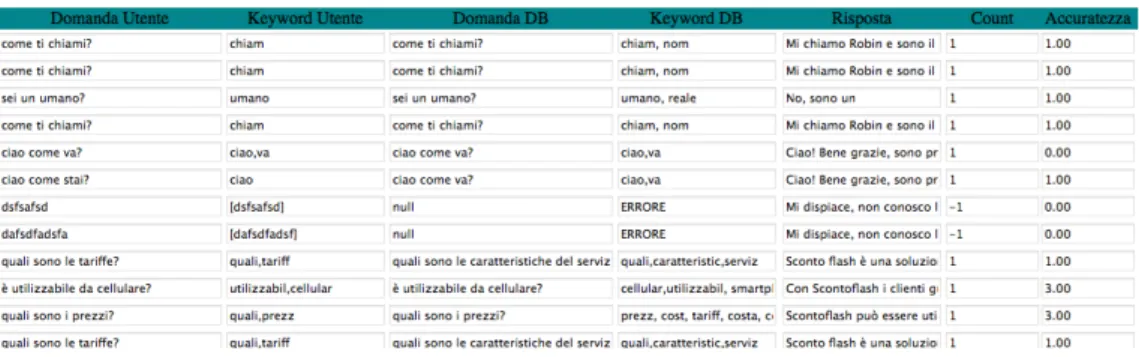
Figura 5.3 - interfaccia per visualizzare il contenuto del Database.
È possibile consultare la lista delle domande immesse anche mediante la pressione del pulsante “show DB”.
Analizzando nel dettaglio la struttura della tabella presentata all’utente aziendale, possiamo trovare le caratteristiche delle domande immesse quali:
• L’ID della domanda che la identifica univocamente all’interno del database
• La domanda immessa nel sistema
• Le keywords estratte in maniera automatica dal sistema che saranno utilizzate dalla funzione di similarità
• La risposta immessa nel sistema dall’operatore.
Ad ogni domanda sono associati due pulsanti “Elimina” e “Update Keyword”, che servono rispettivamente all’eliminazione della domanda immessa e all’aggiornamento delle parole chiave che il sistema estrae in maniera automatica. È lasciata, infatti, all’azienda la possibilità di completare la lista di parole rilevanti al fine di aumentare la tolleranza ai sinonimi e migliorare la contestualizzazione della domanda stessa.
Per limitare gli errori di modifica accidentali, tutti i campi, ad eccezione del campo “keyword”, sono presentati in modalità “solo lettura”.
L’azienda, infine, ha un modulo per la visualizzazione delle statistiche associate all’interazione con l’utente finale.
Infatti, mediante la pressione del pulsante “show Message” è possibile leggere tutte le interazioni che l’utente ha avuto, mediante l’apposita interfaccia, con il sistema. Nel dettaglio la struttura in forma tabellare prevede:
• La domanda immessa dall’utente.
• Le parole chiave che il sistema ha estratto dalla domanda digitata dall’utente.
• La domanda, memorizzata sul database, che ha avuto il miglior valore di similarità con quella immessa dall’utente, risultato delle elaborazioni del sistema.
• Le keywords associate alla domanda presente sul database. • La risposta che il sistema ha fornito all’utente.
• Il valore cumulativo dei feedback rilasciati dagli utenti. • Il livello di accuratezza fornita dalla funzione di matching.
Un‘analisi approfondita dei dati presenti in questa tabella fornisce informazioni rilevanti al fine di migliorare il livello di interazione tra utente finale e sistema, perfezionando la risposta da fornire, specializzando le parole chiave presenti nel sistema per aumentare l’accuratezza del matching e, in generale, il livello di soddisfazione dell’utente finale.
5.3.2
Modalità Utente
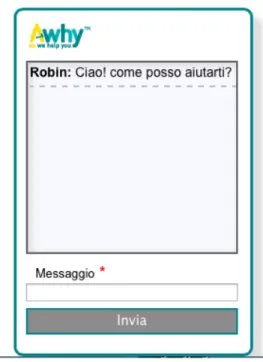
Per l’utente finale è stata progetta un’interfaccia intuitiva e familiare, con cui è possibile interagire facilmente con il sistema.
Infatti, la realizzazione di una chat-box consente all’utente di avere subito dimestichezza con l’interfaccia senza la necessità di una fase di tutorial. L’utente è da subito invitato ad interagire con il sistema grazie ad una frase di benvenuto e la predisposizione del cursore sul campo di testo utilizzato per l’inserimento. Per evitare errori di battitura accidentali, l’interfaccia fa un controllo sul numero di lettere immesse nell’apposita area di testo. Se il testo immesso ha meno di tre caratteri il sistema non abilità il pulsante “Invia” per l’inoltro della richiesta.
Alla pressione del suddetto pulsante si avvia lo scambio dei messaggi, con le modalità descritte nel capitolo 4, inoltrando la richiesta al server.
Figura 5.5 - Interfaccia Utente con pulsante “Invia” disabilitato
Alla ricezione della risposta prodotta dal sistema, l’utente visualizzerà la domanda inviata in precedenza e la risposta associata.
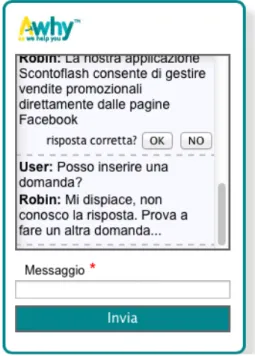
Se il sistema non riesce a individuare una risposta che soddisfa i criteri di valutazione, invia un messaggio di errore all’utente invitandolo a riformulare la domanda con altri termini.
Figura 5.7 - situazione errore riconoscimento
Durante la fase di elaborazione, se il sistema ha individuato la risposta opportuna secondo i criteri stabiliti, associa un messaggio in cui viene richiesto il feedback relativo alla risposta data. Il feedback può essere espresso mediante i pulsanti “OK” e “NO” che indicano se la risposta ottenuta dal sistema è soddisfacente o meno. A seconda del feedback il sistema risponderà con un messaggio di avvenuta ricezione.
5.4 Visualizzazione Risultati
Per non appesantire l’interfaccia con informazioni poco utili sia per l’utente che per l’azienda e garantire la migliore usabilità possibile, si è scelto di non visualizzare mediante l’interfaccia web alcuni indici di valutazione come il tempo di risposta del sistema e il Word Error Rate. Infatti, la comprensione di questi indici presume una conoscenza avanzata del trattamento del linguaggio naturale mediante strumenti informatici che un utente di norma non possiede.
Per il personale specializzato è possibile comunque consultare questi indici mediante console del Content Servlet Tomcat o mediante i file di log del server stesso.
5.5 Definizione delle Classi
Di seguito è presentato il diagramma delle classi che costituiscono l’applicazione web. Il progetto è costituito da package ben definiti, in particolare troviamo:
• Package Controller, contiene le classi di implementazione dei controller per la gestione degli eventi che si verificano sull’interfaccia web. Al suo interno troviamo la classe MessageController, atta alla gestione degli eventi che accadono sull’interfaccia riguardante gli utenti finali, e la classe
QuestionController, utile per la gestione degli eventi derivati
dall’interfaccia creata per gli utenti aziendali.
• Package NLP, che contiene i moduli di analisi di elaborazione del linguaggio naturale. In particolare sono presenti le classi
POSTagger per l’analisi semantica, SentenceDetector per il
rilevamento delle frasi distinte di un discorso, Tokenizer per la
tokenizzazione delle parole di una frase e Stemmer per la
l’estrazione della radice di una parola.
• Package Bean, racchiude le classi che costituiscono i modelli di oggetti utilizzati dall’applicazione. In particolare troviamo la classe
Answer, per la gestione del modello di dati utilizzato
dall’interfaccia utente, e la classe Question, utilizzata dall’interfaccia aziendale.
• Package Matching, contiene la classe stringSimilarity, al cui interno troviamo l’implementazione della funzione di similarità tra testi brevi e il calcolo dell’indice di valutazione WER.
• Package Repository, che contiene le classi e le interfacce per il collegamento e le operazioni necessarie alla gestione del Database.
5.6 Modalità di interazione
Analizziamo ora i diagrammi di sequenza per le principali interazioni tra l’utente, sia esso aziendale o finale, e il sistema.
5.6.1
Modalità Azienda di inserimento
In questa modalità, all’attivazione della richiesta da parte dell’azienda, viene invocata la funzione addQuestion() sull’interfaccia, che si occuperà di passare al Controller associato i dati contenenti il testo da inserire. A sua volta il controller inizializzerà la fase di analisi del testo, effettuando una chiamata alla classe SentenceDetector che si occuperà di controllare se la frase immessa è singola. Successivamente il
QuestionController effettuerà la chiamata alla classe Stemmer, che
mediante una invocazione della classe Tokenizer ed elaborazioni di
stemming, restituirà i token da inviare alla classe POSTagger.
Quest’ultima completerà l’analisi associando la parte del discorso ad ogni token ricevuto, restituendo l’analisi semantica al Controller. Dai
token taggati saranno estratte le parole rilevanti del discorso, che una
volta puliti dal tag, formeranno le parole chiave estratte. Infine quest’ultime mediante un’invocazione all’interfaccia questionRepository saranno salvate sul Database.
Figura 5.11 - Diagramma di sequenza - inserimento domanda
5.6.2
Modalità Azienda di eliminazione
Nella seguente modalità, l’azienda, mediante la chiamata alla funzione
deleteQuestion() sull’interfaccia, attiva il Controller associato passando
come parametro l’identificatore della domanda da eliminare. I parametri sono inoltrati all’interfaccia questionRepository() che effettuerà una ricerca all’interno del Database eliminando la tupla identificata. L’esito dell’evento viene comunicato come valore di ritorno al Controller che si occuperà di invocare la funzione showDB() per far visualizzare all’utente, mediante l’interfaccia, lo stato del Database aggiornato.
5.6.3
Modalità Azienda di aggiornamento
Un discorso analogo al precedente è fatto nella modalità di aggiornamento delle parole chiave associate alle domande. Mediante l’invocazione della funzione updateQuestion() l’utente aziendale invia al Controller associato la lista di parole chiave e l’identificatore della domanda contenente le keyword da aggiornare. Sarà compito della classe questionController invocare la funzione dell’interfaccia
questionRepository che, mediante la sua implementazione, si occuperà
di ricercare nel Database l’ID ricevuto come parametro ed aggiornare il campo keyword con la lista di parole ricevute come parametro. L’esito positivo dell’evento è comunicato come valore di ritorno al Controller che si occuperà di invocare la funzione showDB() per far visualizzare all’utente, mediante l’interfaccia, lo stato del Database aggiornato.
5.6.4
Modalità Utente di ricerca della domanda
La modalità di interazione relativa all’utente finale permette di effettuare una domanda al sistema. Essa richiede un carico computazionale maggiore rispetto alle altre modalità poiché, al suo interno, sono presenti dei cicli operativi ripetuti per ogni frase immessa. Infatti, l’utente finale ha la possibilità di immettere, mediante l’interfaccia dedicata, un intero discorso, costituito da più frasi. Quest’ultimo mediante l’invocazione del metodo request() lo inoltrerà alla classe MessageController. Successivamente, il Controller di occuperà di inizializzare le classi per l’elaborazione del linguaggio naturale. L’invocazione del metodo
SentenceDetector() consentirà di dividere il discorso ricevuto come
parametro in singole frasi da analizzare separatamente. Ogni frase estratta sarà presentata come parametro di ingresso nell’invocazione del metodo PhraseStemmer() della classe Tokenizer che a sua volta chiamerà il metodo tokenStream() della classe Stemmer(). Il risultato delle due invocazioni restituirà la lista di token al Controller che, mediante il metodo POSTag(), li invierà alla classe POSTagger. Essa si occuperà di elaborare la frase semanticamente e restituirà al Controller le parole con l’aggiunta di un tag che identifica la parte del discorso associata. Le successive elaborazioni della classe MessageController consentiranno di estrarre le parti del discorso significative. Dopo un’operazione di pulizia del tag, la lista di parole estratte sarà passata come parametro all’interfaccia questionRepository, che mediante la sua implementazione associata, si occuperà di effettuare una ricerca all’interno del Database. Il risultato dell’operazione di ricerca è ritornato al Controller. Per ogni tupla trovata all’interno del Database, sarà estratta la lista di parole chiave associate. Questa sarà confrontata, mediante l’invocazione della funzione stringSimilarity() della classe Matching, con
le keyword estratte dalla frase immessa dall’utente. Questa operazione restituirà per ogni confronto un valore di accuratezza. Sarà compito della classe MessageController scegliere il valore migliore. Una volta individuato, il Controller effettua una chiamata all’interfaccia
MessageRepository che, mediante la sua implementazione, si occuperà
di salvare il risultato delle elaborazioni all’interno del Database.
Tutto il processo è effettuato per ogni frase estratta dalla classe
SentenceDetector. Infine, il Controller si preoccupa di confezionare i
messaggi di risposta, associando ad ogni domanda fatta dall’utente la risposta associata, risultante dal processo descritto. Sarà compito dell’interfaccia visualizzare la coppia domanda-risposta in maniera opportuna.