Capitolo 5
Risultati sperimentali e Conclusioni
Introduzione
In questo capitolo verranno esposti i risultati sperimentali ottenuti dal prototipo da noi realizzato e i possibili sviluppi futuri. Inizialmente verranno illustrate le caratteristiche dell’ambiente in cui sono stati condotti gli esperimenti in seguito saranno presentati alcuni microbenchmark svolti sul sottosistema di prenotazione e sul sottosistema di filtraggio. Successivamente si passerà ad illustrare i risultati ottenuti da test condotti sull’intero sistema in esecuzione. Tali test indagheranno il comportamento e i tempi di risposta del broker in varie situazioni di carico sia in funzione del numero di risorse gestite sia in funzione del numero di richieste di più istanze concorrenti di libreria. Ulteriori esperimenti sono stati condotti per illustrare il comportamento del sistema nel caso in cui sia composto da più broker, disposti in varie topologie.
Infine verranno presentate le conclusioni e saranno illustrati i possibili sviluppi che potrebbe avere tale progetto sia dal punto di vista delle ottimizzazioni dei meccanismi esistenti sia per quanto riguarda l’offerta di nuove funzionalità.
5.1 Descrizione dell'ambiente di esecuzione della sperimentazione
L'intera fase di sperimentazione del Broker system è stata condotta sul cluster pianosa.di.unipi.it situato presso il Dipartimento di Informatica dell'università di Pisa. La scelta di tale ambiente risulta molto restrittiva rispetto al normale contesto di esecuzione di uno strumento di questo tipo, che normalmente potrà essere eseguito in un ambiente che abbraccia diversi domini amministrativi interconnessi. Tuttavia l'utilizzo di un cluster ad accesso controllato ha permesso di condurre la fase di sperimentazione trascurando i numerosi problemi che normalmente si presentano in un ambiente reale. I rilevamenti effettuati pertanto sono esenti da alterazioni indotte dalla degradazione della banda di rete e da quelle causate dalla sovrapposizione di più processi utente. Tutto questo ha permesso di ottenere le valutazioni delle prestazioni dei vari componenti del tool nelle condizioni migliori possibili.
Il cluster pianosa è composto da 32 nodi di calcolo più un nodo master di controllo, suddiviso in due differenti chassis composti rispettivamente da 25 e 8 nodi. Ogni nodo di calcolo dispone della seguente configurazione:
• 1 processore Intel(R) Pentium(R) III Mobile 800 mhz • 32 Kbyte cahe L1
• 1 GByte di memoria Ram • 2 HD da 18 Gbyte
• 3 interfacce Ethernet Pro 100
I nodi sono interconnessi per mezzo di tre reti Ethernet con banda 100 Mbits/sec. Una di queste è utilizzata per il traffico di sistema in particolar
modo per PVFS40 e NFS41; le altre due sono dedicate al traffico utente. Gli indirizzi dei nodi sono relativi alle tre schede di rete: per il nodo i-esimo i tre indirizzi risultano ui, ti e vi.
5.2 Microbenchmark
La prima serie di test che andremo ad analizzare riguardano le prestazioni offerte dal sistema di filtraggio e dal sistema di prenotazione. Tali test sono stati effettuati decontestualizzando dal sistema generale gli algoritmi utilizzati nei sottosistemi, in modo da ottenere una valutazione delle prestazioni in un caso isolato. Questo tipo di test in letteratura prendono il nome di microbenchmark. L’esecuzione dei test è stata resa possibile grazie alla realizzazione di apposite applicazioni composte unicamente dalle implementazioni dei seguenti sotto-sistemi:
7) sistema di filtraggio 8) sistema di prenotazione
Al fine di stressare il sistema di filtraggio è stato implementato un generatore di filtri. Tale strumento simula le possibili richieste effettuabili da un tool di deployment generando in modo pseudo-casuale i vincoli che andranno a costituire i filtri. Gli attributi, i valori e gli operatori che compongono i vincoli sono scelti tra un insieme specificabile per mezzo di un apposito file di input. Il file può contenere una serie di attributi a cui associare i relativi valori e operatori relazionali per mezzo di intervalli di
40 Private Virtual File System.
numeri o di stringhe espressi con la seguente sintassi:
attributo1 : valore1 valore2 … valoreN : relOp1 relOp2 … relOpK
...
attributoM : valore1 valore2 … valoreN : relOp1 relOp2 … relOpK
5.2.1 Primo Test sul sistema di filtraggio
Il primo esperimento consiste nel cronometrare il tempo impiegato dall'algoritmo di filtraggio per effettuare un singolo confronto tra un filtro ed un descrittore di risorsa al variare di alcuni parametri. In questo caso indicheremo con tempo di servizio dell'algoritmo (TS) il tempo medio che intercorre tra l'inizio dell'elaborazione di due filtri consecutivi. Si vuole studiare l'andamento del tempo di servizio dell'algoritmo al variare del numero di vincoli specificati in un filtro. Il test è svolto su una delle macchine del cluster pianosa precedentemente descritto. Dato che il test prevede di effettuare un unico confronto, il file delle risorse utilizzato contiene la descrizione di un'unica risorsa computazionale che rappresenta una machine:
<resources> <machine>
<a name="hostname"> <d metric="address" type="string" value="u8" /> </a>
<a name="ostype"> <d metric="" type="string" value="Linux" /> </a> <a name="kernel"> <d metric="" type="string" value="2.6.4" /> </a> <a name="cpucount"> <d metric="units" type="int" value="1" /> </a>
<a name="license"> <d metric="" type="int" value="3" /> </a>
<a name="ip"> <d metric="address" type="string" value="10.0.10.8"> </a>
<processor>
<a name="clockSpeed"> <d metric="Mhz" type="int" value="800" /> </a>
<a name="cachesizeL1"> <d metric="Mhz" type="int" value="32" /> </a> <a name="vendor"> <d metric="" type="string" value="Intel" /> </a> <a name="model"> <d metric="" type="string" value="PentiumIII" /> </a>
</processor> <memory>
<a name="size"> <d metric="Mb" type="int" value="512" /> </a> <a name="speed"> <d metric="Mhz" type="int" value="133" /> </a> </memory>
<disk>
<a name="capacity"> <d metric="Gb" type="int" value="200" /> </a> <a name="transferRate"> <d metric="Mb/s" type="int" value="133" /> </a>
</disk> </machine> </resources>
Il generatore di filtri è impostato in modo da produrre solamente filtri contenenti vincoli soddisfacibili rispetto alla descrizione della risorsa data precedentemente, questo al fine di forzare l’algoritmo ad eseguire i confronti su tutti i vincoli. Durante il test vengono generati undici filtri contenenti un numero crescente di vincoli partendo da 0 e arrivando fino a 10. Ogni filtro generato è dato in input all'algoritmo per 1000 volte consecutive, quindi il tempo di servizio è calcolato come media aritmetica dei tempi ottenuti da tali esecuzioni.
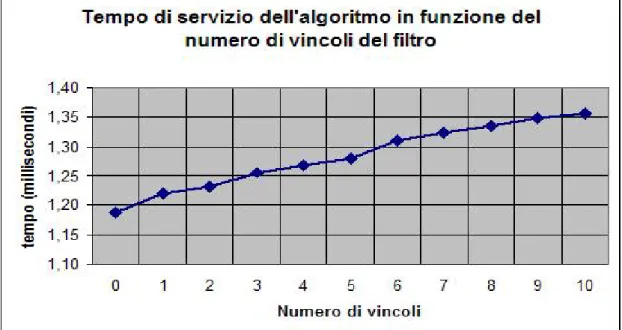
Dal grafico ottenuto, mostrato in figura 5.1, si deduce che, come era prevedibile, l'aumento del numero dei vincoli presenti in un filtro ha un impatto lineare sui costi di filtraggio. E’ importante notare come il coefficiente angolare della ipotetica retta ottenuta per mezzo dell’interpolazione dei punti ricavati dai valori campionati risulti molto basso. Infatti, il costo in termini temporali che si paga mediamente per
l’aggiunta di un nuovo vincolo al filtro è di 0.02 millisecondi.
Figura 5.1 Grafico rappresentante il tempo di servizio dell'algoritmo di filtraggio in funzione del numero di vincoli presenti nel filtro.
Il grafico mostra anche un costo fisso, il quale è stato misurato mediante un filtro non contenente vincoli. Il costo fisso misurato risulta preponderante rispetto al costo imputabile al numero dei vincoli, infatti incide su più della metà del tempo totale anche in filtri con oltre 50 vincoli. Tale costo è da imputare sia ai meccanismi per la gestione dello admission control, sia ai vincoli di vocabolario che anche se non specificati dall’utente assumono un valore di default. I vincoli di vocabolario richiedono un tempo di computazione differente dai vincoli generici in quanto servono per intraprendere azioni specifiche per i tipi di risorsa a cui si riferiscono e in genere possono scatenare anche algoritmi piuttosto complessi. Nel caso di risorsa computazionale sono attualmente presenti 4 attributi di vocabolario che quindi apportano un consistente peso sul costo totale di esecuzione
dell’algoritmo di filtraggio.
5.2.2 Secondo Test sul sistema di filtraggio
Il secondo esperimento consiste nel valutare il tempo di servizio dell'algoritmo di filtraggio in funzione sia del numero di risorse gestite, sia del numero di vincoli impostati nei filtri.
Tempo di servizio in funzione del numero di risorse
0 20 40 60 80 100 120 140 160 16 32 64 128 256 512 1024 2048 Numero di risorse Te m po ( m illis ec ondi )
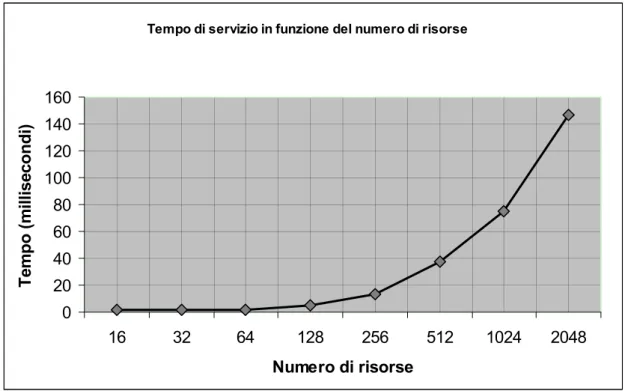
Figura 5.2 Questo grafico descrive l’andamento del tempo di esecuzione dell’algoritmo in funzione del numero di risorse da filtrare. Sull’asse x è riportato in scala logaritmica il numero di risorse filtrate; l’asse y è riportato il tempo.
In questo caso è stato utilizzato anche un generatore di risorse per creare, ogni volta, un file contenente il numero desiderato di descrizioni di risorse computazionali. Il generatore delle risorse e quello dei filtri usano in input il medesimo file delle risorse e lo stesso seme per il generatore pseudo-casuale, questa scelta è stata fatta in modo da garantire una percentuale
minima di successo del filtraggio che si attesta intorno al 30%.
Tempo di servizio in funzione del numero di risorse e del numero di vincoli 0 20 40 60 80 100 120 140 160 16 32 64 128 256 512 1024 2048 Numero di risorse T e m po (mil lisecon di)
1 vincolo 3 vincoli 5 vincoli 7 vincoli 9 vincoli
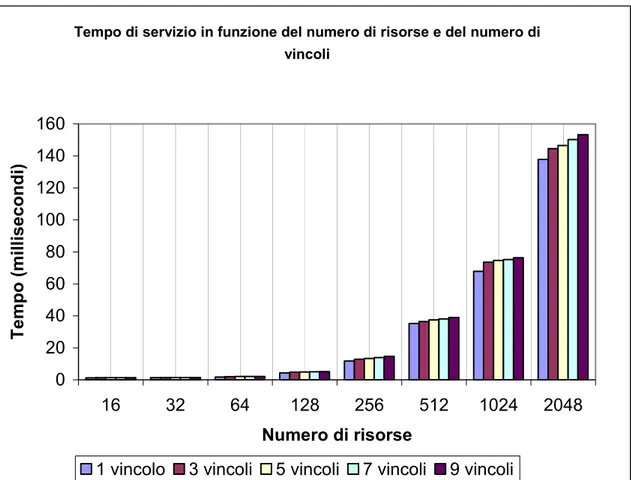
Figura 5.3 Questo grafico è un’espansione di quello presente in figura 5.2, in questo caso viene mostrato l’andamento della curva in funzione sia del numero del numero di risorse che del numero dei vincoli.
Il grafico della figura 5.2 è ricavato dai tempi medi necessari per richiedere un filtro contenente 5 vincoli su insiemi di risorse di cardinalità differente. Il grafico 5.3 rappresenta lo stesso test ma è stato effettuato variando anche il numero di vincoli per richiesta di filtraggio. I valori temporali riportati rappresentano la media di 1000 campionamenti. In entrambe i test non è stato richiesto ai broker di ordinare i risultati (filtro non ordinante). In tutti i casi si riscontra un incremento lineare del tempo di servizio rispetto al
numero di risorse trattate; inoltre si può notare che per ogni insieme di risorse al variare del numero dei vincoli si ottiene un risultato analogo a quello presentato in figura 5.1. In definitiva si deduce che il numero di risorse ha un impatto sul costo di esecuzione dell’algoritmo molto maggiore rispetto al numero dei vincoli. L’incremento medio del tempo di filtraggio rispetto al numero di risorse si attesta intorno ai 60 millisecondi per ogni 100 risorse.
5.2.3 Confronto con il matchmaker di RedLine System e Condor
I sistemi RedLine e Condor e i relativi Matchmaker sono stati descritti nel paragrafo riguardante lo stato dell’arte presente nel primo capitolo di questa tesi. A questo punto si vuole comparare l’efficienza del nostro algoritmo di matchmaker confrontando i nostri risultati con quelli forniti dai microbenchmark presenti in [LF03]. In tali microbenchmark è effettuato un semplice matching bilaterale nel quale viene effettuata un’unica richiesta la quale specifica unicamente l’identità del richiedente e un vincolo sulle dimensioni della memoria della risorsa computazionale. Nella tabella 5.1 è illustrata la sintassi per la richiesta e per la descrizione della risorsa sia per il linguaggio adottato da RedLine sia per quello di Condor (ClassAds). Questo test è stato svolto su un sistema Linux installato su una macchina con un processore AMD-K6 550 MHz e 128Mb di RAM, utilizzando un prototipo di RedLine e la libreria ClassAds di Condor versione 0.9.2. I risultati sono calcolati sulla media dei tempi ottenuti per mezzo di 10000 ripetizioni del test.
Tipo Descrizione della risorsa e della richiesta Temp o RedLine Resource = [ mem=200; user=ENUM[“chliu”,”lyang”]]
Request = [ mem > 100; user=”chliu” ]
1.4 ms ClassAd
s
Resource=[mem=200;requirements=other.user==”chliu”||other==”ly ang]
Request = [; user=”chliu” ; requirements=other.mem > 100]
3.7 ms
Tabella 5.1 Risultati del test sul matching bilaterale di Condor e RedLine
Per effettuare un confronto con il nostro prototipo si è cercato di replicare le condizioni del test per quanto riguarda la richiesta effettuata e la descrizione della risorsa; l’esecuzione è avvenuta su una macchina del cluster pianosa. Di seguito viene riportato la descrizione in formato XML di un’unica risorsa che e presenta caratteristiche simili a quelle specificate in tabella 5.1.
<resources> <machine>
<a name="user"><d metric="" type="string" value="pippo"/></a> <a name="ostype"><d metric="" type="string"
value="Linux"/></a> <memory>
<a name="size" ><d metric="MBytes" type="int" value="200" /></a>
</memory> </machine> </resources>
Allo stato attuale la sintassi utilizzata per la descrizione delle risorse, nel nostro prototipo, non consente la dichiarazione di liste multivalore, quindi abbiamo aggiunto un attributo (ostype) alla descrizione in modo da rendere il carico di lavoro eseguito dall’algoritmo simile a quello del test di riferimento.
seguente modo:
Filter filter = new Filter( new ComputationalResourceType() ); filter.set( new Constraint("size", "100",Value.MORE ) ); filter.set( new Constraint("ostype", "Linux", Value.EQUAL )); filter.set( new Constraint("user", "pippo",Value.EQUAL ) ); Come nel test di riferimento i risultati sono ottenuti mediando i tempi dell’esecuzione di 10000 richieste. Nel 96% dei casi non è stato possibile cronometrare l’esecuzione del test in quanto i tempi erano inferiori al millisecondo e l’orologio di sistema non fornisce una maggiore precisione. Quindi ci siamo posti nell’ipotesi peggiore assumendo, in tali casi, che il tempo di esecuzione fosse di un millisecondo. Sotto tale ipotesi la media dei tempi risulta di 1.02 millisecondi.
0,000 2,000 4,000 6,000 8,000 10,000 12,000 14,000 16,000 18,000 64 128 256 512 1024 numero di risorse Te m po di e se cuz ione ( se condi )
Broker System RedLine
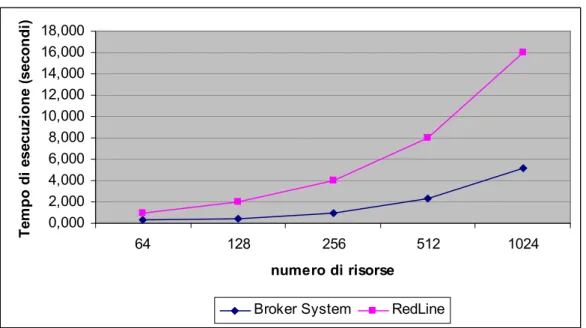
Figura 5.4 In questa figura è riportato il grafico comparativo tra il nostro prototipo di matchmaker e RedLine System. La scala dell’asse X è logaritmica.
In [LF03] è presente un altro microbenchmark che verifica la linearità dell’algoritmo di matching di RedLine System. In tale test sono costruiti
degli insiemi di risorse contenenti solo macchine aventi come attributo il tipo di sistema operativo il quantitativo di Ram installato un identificativo univoco e un tipo di licenza. Quest’ultimo attributo poteva assumere un valore intero compreso tra 0 e 3. Inoltre il test prevede che il tempo di esecuzione sia calcolato per 64 richieste consecutive. In figura 5.4 sono messi a confronto i risultati ottenuti con il nostro prototipo ottenuti simulando il solito contesto utilizzato con RedLine.
5.2.4 Test sul sistema di prenotazione
Con questo test vogliamo misurare il tempo medio necessario per effettuare l’operazione di admission control (metodo IsFree()) in funzione del numero di prenotazioni presenti nel sistema. Il test è stato condotto inserendo un certo numero di prenotazioni nella struttura dati e poi verificando il tempo necessario per effettuare 1000 operazioni di admission control su intervalli temporali casuali; il risultato riportato è la media dei rilevamenti effettuati. Il procedimento illustrato è poi stato ripetuto aumentando gradualmente il numero delle prenotazioni già presenti nel sistema. Le prenotazioni inserite sono state impostate con priorità minima e quindi obbligano la IsFree() a considerarne l’eventuale eliminazione in favore della prenotazione da allocare (di priorità massima).
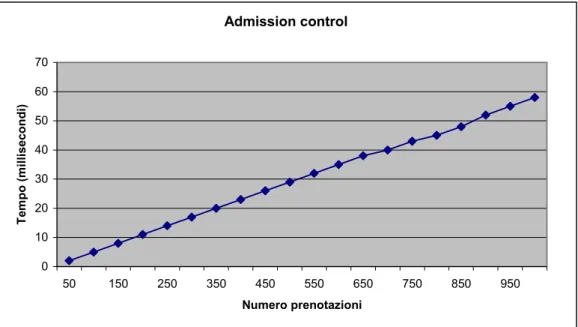
Admission control 0 10 20 30 40 50 60 70 50 150 250 350 450 550 650 750 850 950 Numero prenotazioni Te m p o ( m illis ec ond i)
Figura 5.5 Il grafico rappresenta il tempo necessario per effettuare l’operazione di admission control in funzione del numero di prenotazioni già presenti per la risorsa. L’andamento lineare è determinato dalla ricerca semplice operata dalla IsFree() all’interno della lista contenenti gli slot temporali. Il costo
dell’operazione di admission control aumenta di circa 6 millisecondi ogni 100 prenotazioni presenti del sistema. Nella tabella 5.2 è invece riportata l’occupazione di memoria delle principali strutture dati utilizzate nel sottosistema di reservation.
Struttura Dati Bytes
TimeSlotSchedule 1140
Booking 1100 Tabella 5.2 Occupazione di memoria delle strutture dati utilizzate per la funzionalità di reservation.
5.3 Valutazioni delle prestazioni del sistema
I test che seguono sono proposti allo scopo di dare una valutazione complessiva del Broker System. Nei grafici è riportato il tempo di servizio del cliente che utilizza la libreria BrokerLib. Ci interessa dare la valutazione delle prestazioni del cliente, per far questo ne descriviamo una possibile iterazione: repeat f(…, filter, …); iteratore = getResourceIterator(filter); if ( iteratore.hasNext() ) risorsa = iteratore.next(); g(…, risorsa, …);
risorsa.reserveAll();
forever
La funzione f() rappresenta una parte della computazione del cliente e comprende anche le operazioni necessarie per la composizione del filtro. Le successive tre istruzioni sono necessarie per interrogare i broker e per recuperare il primo elemento dell’insieme dei risultati. La funzione g( ) rappresenta un'altra parte di operazioni effettuate dal cliente che possono coinvolgere la risorsa precedentemente recuperata. Subito dopo viene effettuata la prenotazione della risorsa tramite il metodo reserveAll( ). All’interno del ciclo descritto sono presenti più interazioni cliente – servente; in generale in tale modello facendo tendere a zero il tempo medio di elaborazione della funzione del cliente si ottiene un aumento del tempo di risposta del servente, con conseguenti ripercussioni sul tempo di servizio del cliente. Nel nostro caso, allo scopo di congestionare il servente consideriamo nullo il tempo necessario per eseguire le due funzioni f( ) e g(
). I valori riportati nei grafici seguenti sono stati calcolati considerando
quindi solo i tempi di esecuzione delle funzioni che interagiscono con i broker.
Test 1
Il test seguente è stato condotto facendo variare il numero di filtri richiesti da cliente ad un broker; la famiglia di curve è stata prodotta ripetendo il test variando il numero di risorse gestito dal broker. Il test è stato eseguito con il meccanismo di caching dei filtri disabilitato.
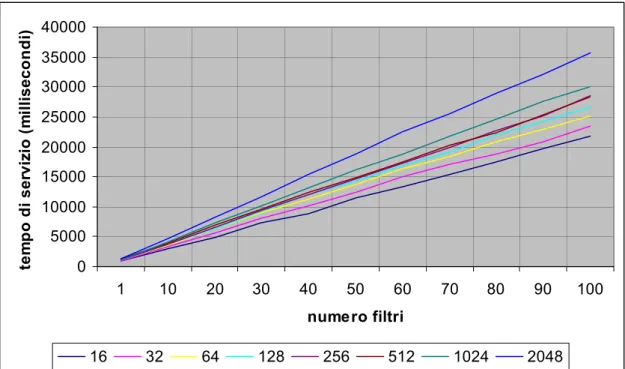
0 5000 10000 15000 20000 25000 30000 35000 40000 1 10 20 30 40 50 60 70 80 90 100 numero filtri te m p o d i ser viz io ( m illiseco n d i) 16 32 64 128 256 512 1024 2048
Figura 5.6 La figura mostra il tempo di servizio del cliente in funzione del numero dei filtri richiesti e della quantità di risorse gestite dal broker.
Il test evidenzia l’andamento lineare del tempo di servizio del cliente sia in funzione del numero di filtri richiesti sia in funzione del numero di risorse gestito dal broker. Si può notare che per selezionare e prenotare le risorse al fine di mettere in esecuzione una applicazione parallela composta da 25 processi saranno necessari mediamente fra i 5 e i 10 secondi, dipendentemente dal numero di risorse gestite dal broker.
Test 2
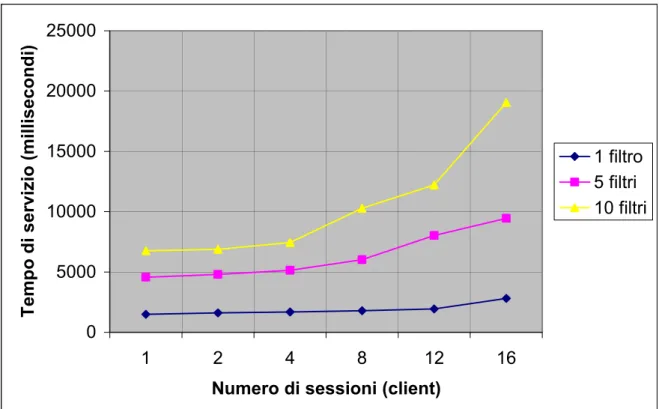
Questo test serve a valutare il tempo di servizio dei clienti che interagiscono con una sola istanza di broker, che gestisce 512 risorse, in funzione del numero dei clienti e del numero di filtri richiesti.
0 5000 10000 15000 20000 25000 1 2 4 8 12 16
Numero di sessioni (client)
Tem p o di ser vizi o (millisecondi) 1 filtro 5 filtri 10 filtri
Figura 5.7 Questo grafico mostra il tempo di risposta medio di una sessione nel caso in cui un unico broker venga stressato da un numero crescente di clienti in funzione del numero di filtri richiesti da ogni sessione.
Ogni cliente richiede al broker un certo numero di filtri contenenti ognuno tre vincoli; tutti i clienti sono in esecuzione su nodi distinti del cluster usato, così come il broker. I valori riportati sono la media dei dieci campionamenti effettuati per ogni tipo di richiesta. Dal grafico risulta che il tempo di servizio del cliente ha un andamento lineare all’aumentare del numero di sessioni contemporaneamente gestite dal broker. La famiglia di curve mostra come l’aumento del numero di filtri richiesto da ogni sessione impatti pesantemente sul tempo di servizio, tuttavia le curve mostrano un andamento lineare.
Test 3
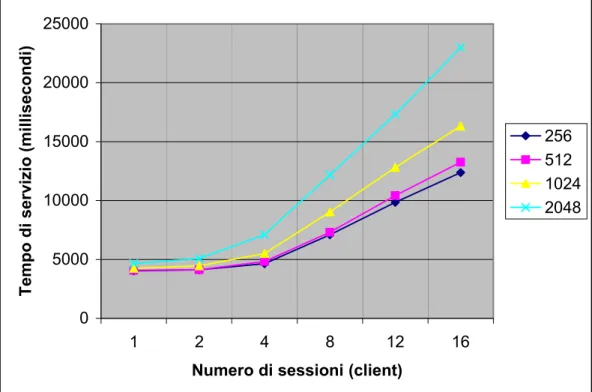
Il test seguente è stato condotto in modo analogo a quello precedente; la famiglia di curve descrive il tempo di servizio del cliente in funzione del numero di sessioni e della quantità di risorse gestite dal broker. Il numero di filtri richiesto da ogni cliente è 5.
0 5000 10000 15000 20000 25000 1 2 4 8 12 16
Numero di sessioni (client)
T em p o d i s erv izio (mil lis ec o n d i) 256 512 1024 2048
Figura 5.8 Grafico relativo al tempo di servizio del cliente in funzione del numero dei clienti e delle risorse gestite dal singolo broker.
Con questo esperimento si è voluto indagare l’andamento qualitativo del tempo di servizio in funzione sia del numero di sessioni, sia del numero di risorse gestite dal singolo broker. La famiglia di curve mostra un andamento lineare rispetto al numero di sessioni. L’andamento delle singole curve è influenzato dal numero di risorse su cui è eseguito l’algoritmo di filtraggio. Il numero di risorse infatti impatta sul tempo di servizio dell’algoritmo di filtraggio, come già mostrato in figura 5.2.
Test 4
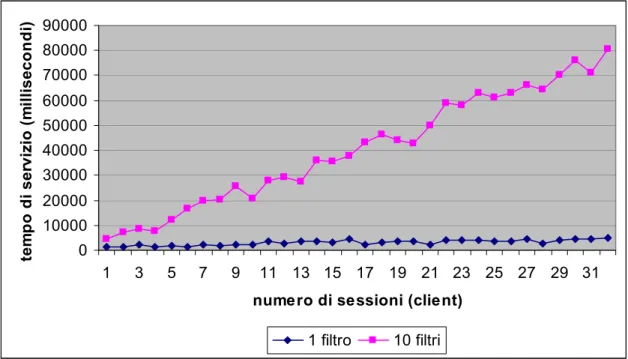
In questo test abbiamo voluto stressare pesantemente il broker assegnandogli 10000 risorse ed effettuando le richieste di filtraggio da 32 clienti dislocati su altrettante macchine distinte. Il grafico è stato ottenuto facendo variare il numero dei clienti e il numero di filtri richiesti. Per questo test è stata attivato il meccanismo di caching dei filtri.
0 10000 20000 30000 40000 50000 60000 70000 80000 90000 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
numero di sessioni (client)
te m p o d i ser viz io ( m illiseco n d i) 1 filtro 10 filtri
Figura 5.9 Nel grafico è visibile il tempo di servizio del cliente che interagisce con un broker singolo a cui è stato assegnato un alto numero di risorse da gestire (10000) e cache attivata. Il test viene ripetuto aumentando progressivamente il numero dei clienti.
L’andamento del tempo di servizio del cliente è rimasto lineare. Possiamo tuttavia notare delle fluttuazioni nei tempi, non presenti nei test precedenti, imputabili all’attivazione dei meccanismi di caching.
Test 5
Il test illustra il tempo di servizio del cliente al crescere delle sessioni ma le richieste sono effettuate su broker multipli e sullo stesso livello. Ogni curva è relativa ad un certo numero di broker, ognuno dei quali gestisce 1024 risorse. Il numero dei filtri richiesto dai clienti è 5 ed il numero dei vincoli per filtro è 3. 0 2000 4000 6000 8000 10000 12000 14000 16000 18000 20000 1 2 4 8 16 Numero sessioni(client) T em p o d i ser vi zi o ( m ill iseco n d i)
2 broker 4 broker 6 broker
Figura 5.10 Grafico relativo al tempo di servizio del cliente in funzione di un numero crescente di clienti e del numero di broker di primo livello. La situazione mostrata è tipica quando è presente un broker per dominio amministrativo.
Si può notare come al crescere del numero dei broker aumenti il tempo di servizio del cliente, specialmente con poche sessioni aperte, il divario si assottiglia al loro crescere. Considerando il grafico 5.8 si nota che un cliente in una situazione dove un singolo broker gestisce 1024 risorse e 8 sessioni contemporanee ha tempo di servizio di circa 9 sec., nel grafico di
questo test si può riscontrare che un cliente in analoga situazione ma con 4 broker ed un numero quadruplo di risorse gestite ha un tempo di servizio di circa 9.6 sec. Il meccanismo dei broker multipli permette quindi di gestire risorse di più domini amministrativi con poco overhead.
Test 6
Il grafico presentato è stato prodotto misurando il tempo di servizio di un cliente che richiede un numero sempre crescente di vincoli al broker. Le due serie raffigurano il comportamento con un broker solo che gestisce 50000 risorse e con due broker annidati con 25000 risorse ognuno. Il test è stato effettuato con il meccanismo di caching dei filtri attivo.
0 20000 40000 60000 80000 100000 120000 140000 1 10 20 30 40 50 60 70 80 90 100
numero filtri richiesti
te m p o d i ser viz io ( m illiseco n d i)
1 broker 2 broker annidati
Figura 5.11 La figura illustra il tempo di servizio del cliente in funzione del numero di filtri richiesti e rispetto a due configurazioni differenti del sistema di brokering.
Nella soluzione con due broker annidati ogni richiesta ha costo in media leggermente maggiore rispetto alla soluzione con broker singolo a parità di risorse totali gestite.
5.4 Possibili sviluppi
Il prototipo del broker e la relativa brokerLib sono stati realizzati utilizzando, nella maggior parte dei casi, strutture dati e algoritmi presenti nella libreria standard di Java fornita nel pacchetto SDK42 1.4.2.
Questo approccio ha consentito di ridurre notevolmente i tempi di sviluppo ma in molti casi ha costretto l’utilizzo di strutture dati e algoritmi generici non del tutto ottimizzate per alcuni dei nostri scopi. Un certo livello di ottimizzazione si potrebbe ottenere implementando nuove strutture dati specifiche, le quali dovranno essere realizzate ad hoc in funzione dell’algoritmo che le utilizzerà. Spesso, infatti, sono state utilizzate strutture dati aventi tempi di accesso, di inserimento e di modifica non sempre idonei agli algoritmi in cui sono state utilizzate. In certi algoritmi occorrerebbero strutture dati in grado di offrire per le operazioni più frequenti tempi di accesso sub-lineari, anche al costo di pagare tempi più elevati per le operazioni meno frequenti. Tali ottimizzazioni potranno essere realizzate agevolmente senza stravolgere l’implementazione del prototipo grazie al meccanismo delle interfacce e a quello dell’ereditarietà fornite dal linguaggio Java.
Notevoli sviluppi sarebbero possibili anche per quanto riguarda le
funzionalità messe a disposizione dalla libreria. Innanzi tutto potrebbe risultare utile arricchire la semantica del linguaggio di descrizione delle risorse e di conseguenza anche la semantica del filtro. Per esempio l’introduzione di liste multi-valore, associate agli attributi dei vincoli durante la costruzione dei filtri, offrirebbero la possibilità di specificare o le alternative desiderate dall’utente oppure un intervallo di valori per cui il vincolo potrà essere considerato soddisfatto.
Per alcuni contesti potrebbe risultare utile espandere la libreria aggiungendo la capacità di istanziare e gestire più filtri ed iteratori contemporaneamente. Questo potrebbe consentire la sovrapposizione dei tempi di filtraggio con i tempi che i tool, utilizzanti la libreria, spendono per le loro funzionalità interne. In questo caso una volta sottomessi ai broker tutti i filtri necessari, gli iteratori potranno essere richiesti ed utilizzati in un secondo momento. In tal modo gli insiemi filtrati saranno mantenuti dai broker nei descrittori di sessione e quindi potrebbero essere aggiornati in tempo reale sulle variazioni dello stato delle prenotazioni.
Al fine di fornire un'unica interfaccia in grado di espletare una completa gamma di funzionalità di prenotazione per tutte le tipologie di risorse sarebbe necessario fare in modo che il prototipo interagisse con un NRM43, come proposto in [ARWJS02] e in [BHKKL04]. Un NRM deve essere in grado di fornire funzionalità di prenotazione e controllo degli accessi oltre che per le risorse di rete del singolo dominio amministrativo, anche per le connessioni inter-dominio. Quindi un NRM concettualmente è un Bandwidth Broker e il suo compito sarà quello di pubblicare e monitorare lo stato della rete interagendo con i router del proprio dominio mediante
appositi protocolli: RSVP44 e/o SNMP45; la gestione delle connessioni inter-dominio, invece, dovrà essere effettuata per mezzo dell'interazione tra i vari NRM, rispettando le eventuali politiche di sicurezza.
Proprio a causa delle politiche di sicurezza adottate per controllare gli accessi alle risorse dei domini amministrativi occorrerà adottare tecnologie e meccanismi di comunicazione specificamente studiati per risolvere tale problema. Il primo passo per rendere il nostro prototipo uno strumento utilizzabile in un ambiente reale sarà quello di ristrutturare e stratificare i protocolli, utilizzati tra il borker e la brokerLib, sopra i protocolli adottati dalla tecnologia Web Service, in particolar modo SOAP, WSDL e UDDI.
5.5 Conclusioni
Il lavoro svolto in questa tesi è consistito nello studio, nella progettazione, nell'implementazione e nel testing di un sistema in grado di offrire le funzionalità di Information Gathering e Advance Reservation al fine di supportare i Deployment Tool per applicazioni parallele durante le fasi di Resource Discovery e Resource Selection. Il risultato ottenuto è un prototipo detto Resource Broker e una API per l'interfacciamento, implementata da una libreria denominata brokerLib. Una delle peculiarità che presenta il sistema è l'unificazione della funzionalità di raccolta delle informazioni sulle risorse con il meccanismo della prenotazione. Particolare cura è stata posta nello studio dell'astrazione dei meccanismi per la gestione della prenotazione delle risorse, la quale consente un alto grado di espandibilità del sistema, garantendo la possibilità di dotare nuove tipologie
44 Resource reSerVation Protocol.
di risorse dei meccanismi per gestirne le prenotazioni. La sezione dei test sperimentali si apre con una serie di microbenchmark effettuati sul sottosistema di filtraggio; questi esibiscono tempi generalmente contenuti, con andamento lineare sia rispetto al numero di vincoli per filtro sia rispetto al numero di risorse filtrate, caratteristica questa che permette al singolo broker di gestire anche numerose risorse (nell'ordine delle decine di migliaia). Il microbenchmark successivo evidenzia il comportamento del sottosistema di prenotazione, anche qui l'andamento dei tempi si rivela essere lineare rispetto al numero di prenotazioni presenti nel sistema. Infine I test completi dimostrano come la topologia che è possibile dare al Broker System allo scopo di superare le limitazioni imposte dalla presenza di più domini amministrativi non impatti significativamente sulle prestazioni. In certi casi, al contrario, l'utilizzo di più broker ha portato ad un incremento delle prestazioni a parità di risorse trattate rispetto al caso con broker singolo.