Capitolo 3
I Reversible Sketch
3. 1 Gli Sketch
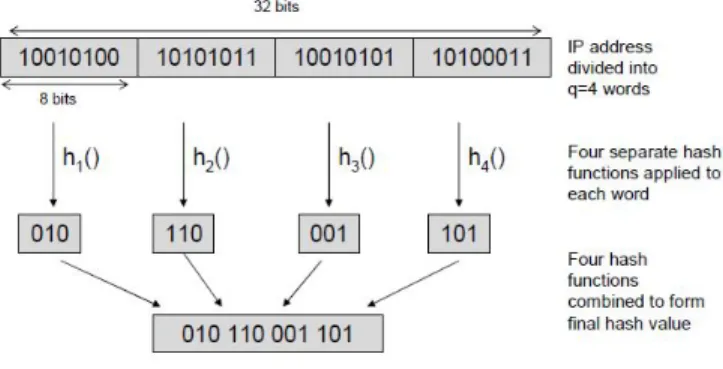
Uno sketch è una matrice bidimensionale S[d][w] (d
D,w
W ) in cui ogni riga d è associata ad una funzione hash hd, che fornisce un’uscita nell’intervallo(1,…,W), associata alle colonne della matrice. In questo modo, ogni riga dello sketch corrisponde ad una hash table di dimensione W, indicizzata da una funzione hash scelta in modo indipendente e casuale. Per esempio, l'elemento S[d][w] è associato al valore w in uscita dalla funzione hash hd.
Figura 6. Meccanismo di aggiornamento dei count-min sketch.
W D
Supponiamo che I=α1, α2,… sia un flusso in ingresso che
arriva in modo sequenziale, cioè elemento per elemento. Gli sketch sono utilizzati per memorizzare in modo sintetico tali tipi di dati.
Gli sketch differiscono tra loro per come aggiornano i bucket delle hash table e come usano i dati memorizzati per ottenerne delle stime, ma in generale uno sketch è impiegato allo scopo di indicare se una chiave mostra dei grandi cambiamenti.
Tra i diversi sketch, quello con le prestazioni migliori in termini di spazio e tempo è il cosiddetto “count-min sketch”, di cui spieghiamo il funzionamento.
Ogni elemento αi in ingresso è costituito da una chiave
hash it
1,...,N
e da un peso ct. Quando arriva un nuovodato, lo sketch è aggiornato in questo modo:
d
hd
it
S
d
hd
it
+ctS .
La procedura di aggiornamento è realizzata per tutte le diverse funzioni hash come mostrato in figura 6.
Le funzioni hash hi sono scelte in modo da rispettare
queste proprietà: hi
x hj
x per i≠j, e sehi
x =hi
y allora
x h
ysufficientemente alto, questo permette di minimizzare la probabilità di falsi positivi.
Una funzione hash è una funzione che prende in ingresso le chiavi, di n bit, e restituisce in uscita i risultati di m bit, con
m<<n: essa permette quindi di rappresentare un’enorme
quantità di dati in un dominio più piccolo. Tuttavia, se da un lato le funzioni hash permettono di memorizzare un'enorme quantità di dati (cioè aggregare), dall'altro introducono la possibilità di avere un gran numero di collisioni (dove per “collisione” si intende che più di una chiave individui la stessa cella dello sketch). È quindi necessario trovare un modo per risalire all'aggregato di partenza; a questo scopo, gli autori di [3] hanno modificato la procedura di aggiornamento dello sketch introducendo gli algoritmi del modular hashing e dell’IP mangling.
Figura 7. Il modular hashing.
Lo schema del modular hashing prevede, invece di applicare la funzione hash all’intera chiave x (lunga n bit, per ottenere valori compresi tra 0 e W), di dividerla in q parole, ognuna di
n
q bit. Per esempio, se come chiave si impiega
l’indirizzo IP di destinazione - su 32 bit - e al parametro q si associa il valore 4, la chiave viene ripartita in quattro parole, ognuna di 8 bit. Alle diverse parole sono applicate q funzioni hash hd,j (j=0,…,q-1), indipendenti tra di loro, che mappano
dallo spazio [ q n 2 ] in quello [ q log 2 2W
]- quindi l’uscita della singola funzione hash hd,j è su
q log2W
=
s bit. I risultati di tali funzioni hash sono poi concatenati tra loro per creare il valore hash finale,
x =h
x1 |h 2
x2 |h 3
x3 |h 4
x4δd d,1 d, d, d, (8)
che richiederà q bit. L’uscita della formula (8) selezionerà s
una colonna dello sketch, infatti i numeri che essa può rappresentare vanno da 0 a W=2qs . Questo procedimento è illustrato in figura 7.
Per quanto riguarda le prestazioni, se per ottenere un valore da una funzione hash è richiesto un tempo costante, il modular hashing aumenta il numero delle operazioni di aggiornamento da O
D a O
qD
; dall’altra parte non è necessario alcun accesso aggiuntivo alla memoria rispetto all’hashing tradizionale.In generale l’utilizzo di funzioni hash k-universal1 garantisce un mappaggio omogeneo delle chiavi in ingresso su tutti i bucket dello sketch.
Tuttavia, se come chiavi si utilizzano gli indirizzi IP, questa tecnica di hashing presenta un problema. Poiché _________________
1Una classe di funzioni H:
1,...N
1,...,W
è una hash k-universal se per ogni distinto x0,...,xk1
1,...,N
e ogni possibile ν0,...,νk1
1,...,W
: i i k H h W = k , i ; ν = x h = 1,... 1 Pr
esistono forti somiglianze tra gli indirizzi IP, cioè molti flussi simultanei variano soltanto in alcuni degli ultimi bit dei loro indirizzi di sorgente o di destinazione, la probabilità di collisione di tali chiavi è significativamente alta.
Per esempio, poiché l’insieme di indirizzi IP 129.105.56.* condivide i primi 3 ottetti, il modular hashing mapperà sempre questi tre byte negli stessi valori hash. Così, anche se si utilizzano delle funzioni hash hd,j completamente
casuali, tutti gli indirizzi IP distinti, ma che iniziano con questi stessi ottetti, sarebbero mappati uniformemente in 23 bucket. Questo andrebbe a causare molte collisioni, poiché la maggior parte degli indirizzi IP cadrebbe in poche celle dello sketch. Di conseguenza, applicando il solo modular hashing alle tracce di rete, si ottiene che la distribuzione relativa al numero di chiavi per bucket è molto anomala. Questo quindi diminuisce notevolmente l’efficacia nelle performance dei Reversibile Sketch: per superare il problema, è stato necessario implementare anche la tecnica dell’IP mangling.
Lo scopo dell’utilizzo dell'IP mangling è rendere artificialmente casuali i dati in ingresso, in modo da cercare di distruggere qualsiasi correlazione gerarchica o somiglianza spaziale tra le chiavi; questo processo deve essere ancora reversibile.
Il procedimento consiste nell'applicare ad ogni chiave in ingresso xi una funzione biiettiva (uno a uno) che trasforma uno
spazio di chiavi di dimensione n in un altro spazio della stessa dimensione. Si mappa ogni xi attraverso una funzione di
mangling f(xi), e si applicano poi le funzioni hash all’insieme
degli {f(xi)}. In questo modo, si ottiene un mangling, cioè un
“rimescolamento”, psuedo casuale.
Esistono diversi modi per realizzare l’IP mangling; ad esempio, uno schema di mangling valido utilizza una semplice aritmetica sui campi di Galois (GF) per ottenere una tecnica di rilevazione degli attacchi che può lavorare su uno spazio qualsiasi delle chiavi. I campi di Galois di ordine 2l (GF(2l), dove l è un intero positivo) sono definiti come l'insieme di interi {0,…,2l-1} associati alle operazioni aritmetiche modulo 2l-1; poiché ogni elemento è relativamente primo con 2l, esso ammette un inverso moltiplicativo.
In particolare, in questo lavoro ci si riferisce alla trasformazione definita nel GF f
x =ax⊕b, dove a e b corrispondo a numeri interi scelti in modo uniforme e casuale dal campo, ‘’ è l'operazione di moltiplicazione definita suGF(2l) e ‘ ’ è l'operazione di XOR bit a bit. Precalcolando l’inverso a-1 su GF(2l), possiamo facilmente risalire alla chiave di partenza da quella “rimescolata” y utilizzando la formula inversa f1
y =a1
yb
; questa caratteristica garantisce la reversibilità dell’algoritmo di IP mangling.Tuttavia, il calcolo diretto dell’operazione a può x
essere molto costoso, poiché, secondo le regole dell’aritmetica dei campi, richiederebbe la moltiplicazione di due polinomi di grado l-1 modulo un polinomio irriducibile di grado l: in [3], per velocizzare il calcolo di a si è preferito realizzare x
allora la tecnica della tabulazione. L'idea di base infatti è dividere la chiave in ingresso x in parole di dimensioni minori; poi, memorizzando in una tabella il prodotto tra a e ogni altro possibile carattere possiamo ottenere il calcolo completo di
x
a attraverso un numero piccolo di ricerche in questa
tabella. Per esempio, una chiave x di 32 bit, può essere divisa in quattro caratteri di 8 bit, x x3x2x1x0. Secondo l'aritmetica
x i
a x x x x a x a 3 2 1 0 i30 i 8 , dove ‘<<’ èl'operazione di shift a sinistra. Allora, riempiendo quattro tabelle ti[0..255], in modo che
y =a
y<<8i
i=0..3, y=0..255
ti (9)
è possibile calcolare in modo efficiente la quantità a x
accedendo soltanto quattro volte alla tabella:
x3 t2
x2 t1
x1 t0
x0t = x
a 3 . (10)
Per calcolare f—1, si può ancora utilizzare lo stesso approccio tabellare, ma utilizzando la tabella opportuna. In base alle risorse disponibili, è possibile anche usare parole di lunghezze diverse.
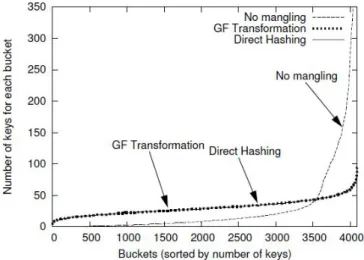
In conclusione, questo schema di mangling offre una soluzione ottimale al problema delle distribuzioni molto anomale del numero di chiavi per bucket, che sorge, come visto in precedenza, dall'uso del modular hashing. Ipotizzando di scegliere come chiave l'indirizzo IP di sorgente di ogni flusso, confrontiamo la distribuzione del numero di chiavi per bucket all’uscita da tre metodi diversi di hashing: hashing diretto (una funzione hash completamente casuale), modular hashing senza IP mangling e modular hashing con la trasformazione GF per l'IP mangling. La figura 8 mostra il comportamento che si
distribuzione delle chiavi del modular hashing che realizza la trasformazione GF appena descritta somiglia molto a quello dell'hashing diretto; mentre in quella senza IP mangling la probabilità che tante chiavi cadano negli stessi pochi bucket è molto alta. Questa tecnica di mangling è quindi molto efficiente nel rendere casuali, in modo reversibile, le chiavi in ingresso e rimuovere la correlazione tra le chiavi.
Figura 8. Distribuzione del numero di chiavi per bucket per tre diversi metodi di hashing.
Inoltre, lo schema presenta delle buone proprietà statistiche: è infatti molto resistente ad attacchi in cui gli hacker tentano di sovvertire il sistema di rilevazione creando collisioni nei bucket del Reversible Sketch per rendere alta la probabilità
di falsi positivi; infatti in tutte le hash table ogni possibile coppia di chiavi sarà mappata in modo completamente casuale nei bucket, anche se condivide alcuni byte.
3.4 I Reversible Sketch
Il maggiore ostacolo alla costruzione degli Intrusion Detection System sugli sketch è la non reversibilità di questi ultimi; uno sketch infatti non può segnalare in modo efficace l’insieme di tutte le chiavi che collidono in un certo bucket, poiché è una struttura dati sintetica che non memorizza alcuna informazione sugli ingressi.
Per superare questa limitazione, sono stati proposti i Reversibile Sketch, che mantengono anche informazioni sulle chiavi che collidono nelle varie celle, e lo fanno in modo efficiente, perché memorizzano le chiavi utilizzando una quantità molto limitata di memoria.
Per quanto riguarda la memorizzazione delle chiavi, è necessario introdurre alcune definizioni: si indica come
wσf (11)
Si indicherà con D il numero di hash table utilizzato e con W il numero di bucket.
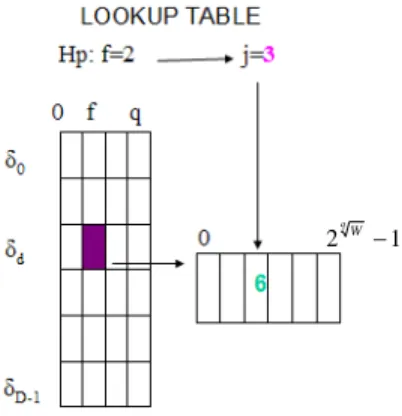
Si introduce poi una struttura dati tridimensionale che corrisponde ad una tabella di lookup, in cui nella cella indicizzata da [d][f][j] vengono memorizzate le parole f-esime delle chiavi che nello sketch cadono nel bucket w dell'hash table d, tale che σf
w = j.Il procedimento è visualizzato in figura 9: ipotizziamo di avere come chiave, in ingresso alla funzione hash δd
‘24.6.96.0’, e che il valore w – che corrisponde a un indice di bucket- restituito in questo caso dalla funzione sia ‘5.3.0.2’. Questa quantità, espressa in notazione decimale, è un valore compreso tra 1 e W.
Supponiamo di voler memorizzare la seconda (f=2) parte di chiave ‘6’; di conseguenza, j σ2
w 3. Allora, nella lookup table la parola ‘6’ sarà immagazzinata nella cella[d][f][j]=[d][2][3].
Per quanto detto finora, le dimensioni della nuova tabella saranno Dq2qW , dove la terza dimensione assume questo
Figura 9. Funzionamento della memorizzazione delle chiavi nelle lookup table.
È questa tabella di lookup che permette di memorizzare in modo efficiente le informazioni sulle chiavi. Infatti, l’approccio più intuitivo potrebbe essere quello di memorizzare direttamente ogni indirizzo IP (su 32 bit) in una struttura che abbia le stesse dimensioni D W dello sketch, e memorizzare in ogni bucket l’indirizzo IP che vi cade (ipotizziamo per semplicità che in un qualsiasi bucket possa cadere esattamente una chiave). Tuttavia, usando questo tipo di struttura di memorizzazione, la quantità complessiva di memoria occupata sarebbe W 32D bit (ad esempio, con W=4096 e D=16
1 2qW
al contrario, sarà necessario impiegare solamente q D q q W 32
2 bit (con le scelte di D e W precedenti e
q=4, avremmo in totale 131072 bit), quantità molto inferiore
rispetto alla precedente.
Immaginando di essere a conoscenza della lista dei bucket anomali, definiamo poi come If l’insieme di tutte le
parole f-esime delle chiavi che cadono in un qualsiasi bucket anomalo in almeno D-r delle D hash table, con
2 D < r .
Questo permetterà di escludere le parole che per caso sono cadute nei bucket anomali di r hash table diverse, ma non sono anomale.
I set If sono chiamati “potenziali modulari intersecati”.
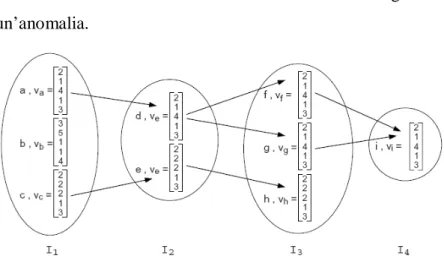
Per ogni elemento z di If è creato il relativo nodo Bf(z)(o
vz), chiamato “matrice degli indici di bucket” per z, che
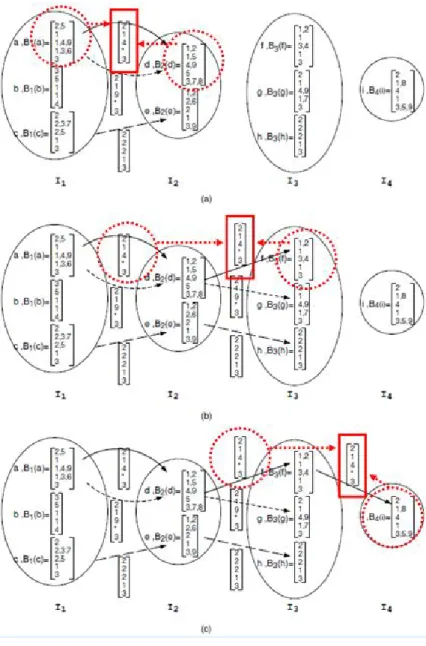
contiene per ogni hash table d una lista degli indici dei bucket anomali in cui la chiave è caduta. Ad esempio in figura 10 il fatto che il primo elemento di va valga 2 significa che una
chiave che aveva come prima parola “a” è caduta nel bucket 2 (che era risultato anomalo) dell’hash table 0.
Si sottolinea che, per creare le matrici degli indici di bucket, si ricorre alle informazioni memorizzate in precedenza
nella tabella di lookup: infatti, per ogni bucket anomalo è possibile determinare la corrispondente cella della lookup table e risalire a tutte le parti di chiave sospette.
In questo modo si ottiene il grafo, costituito dal complesso delle parole sospette, che permetterà di conoscere le
chiavi che hanno generato
un’anomalia.
Figura 10. Gli insiemi If di un grafo i cui percorsi di lunghezza q
corrispondono a una chiave sospetta.
Ad esempio, in figura 10 si ottiene complessivamente che I1={a,b,c} sia l’insieme, di tre elementi, delle prime parti delle
chiavi che risultano sospette, I2={d,e} l’insieme delle seconde
parti di chiavi, I3={f,g,h} delle terze e I4={i} delle quarte.
esempio, la matrice B3
f =
1,2,1, 3,4 ,1, 3 è in realtà l’insieme di quattro vettori, ognuno chiamato “vettore degli indici di bucket per z”:
1,1, 3 ,1, 3 ,
2 ,1, 3,1, 3 ,
1,1, 4 ,1, 3 ,
2 ,1, 4 ,1, 3 .Descriviamo adesso la fase di identificazione, il cui scopo è ottenere una lista delle chiavi malevole, assicurando nel contempo di ottenere la soluzione corretta in un tempo polinomiale con q e D con probabilità molto elevata.
L’algoritmo di identificazione considera inizialmente gli insiemi I1 e I2: per ogni nodo di I1 verifica con ogni nodo di I2
se nelle hash table corrispondenti ci sono dei valori gli indici di bucket a comune (realizzando in questo modo un’operazione di intersezione tra insiemi). Se questo avviene in almeno D-r hash table, l’algoritmo memorizza questi indici di bucket, che corrispondono a un link del grafo: ad esempio in figura 11.a, l’r-intersezione B1
a B2
d =
2,1, 4 , *, 3r
è un link e
la sequenza a.d può essere parte di una chiave anomala(il carattere * indica che per quella hash table non ci sono intersezioni); al contrario non ci sono link tra i nodi B1(a) e
Sebbene la dimensione degli insiemi dei vettori degli indici di bucket cresca esponenzialmente con D, quella delle matrici lo fa in modo polinomiale e permette quindi di eseguire l’operazione di intersezione in un tempo polinomiale.
Figura 11. Esempio di funzionamento del’algoritmo di identificazione delle chiavi per i Reversible Sketch.
Questo stesso procedimento viene poi ripetuto in maniera iterativa, cercando le intersezioni tra i link appena ottenuti e le liste di indici di bucket anomali dei nodi di I3 (in figura 11.b,
l’intersezione tra a,d,f, vale ancora [2 1 4 * 3]) ed infine tra i nuovi link e i nodi di I4 (figura 11.c).
Se anche il vettore finale contiene almeno r valori diversi da *, allora si sono individuati i quattro pezzi che compongono una chiave anomala (nell’esempio di figura 11.c, a.d.f.i), altrimenti la chiave è scartata. Vale a dire, in termini matematici, che una chiave x è sospetta se e solo se le sue parole xf rispettano la relazione
f 0 f r =1...q f B x
. (12)Infine, è possibile definire l’insieme Af come il set
costituito da tutte le sequenze di dimensione f e i relativi link; ogni elemento di Af è chiamato “percorso”. In questo modo A1
coincide con I1, l’insieme A2 contiene i percorsi
a,d , 2,1,4,*,3
,
a,d , 2,1,9,*,3
e
c,e , 2,2,2,1,3
come mostrato in figura 11.a; da questo si determina A3, che
contiene gli elementi
a,d,f , 2,1,4,*,3
,figura 11.b. Alla fine si calcola A4 =