5 MC8051 IP Core.
5.1 Descrizione del microcontrollore.
Come spesso accade nella tecnologia “System On a Chip” occorre integrare un microcontrollore all’interno di un ASIC. In questi casi non è necessario sviluppare il codice VHDL dell’intero microcontrollore ma si possono utilizzare delle IP (Intellectual Property) che comprendono dei building block ad alto livello descritti tramite VHDL o Verilog. Tipici esempi di microcontrollori di cui è fornito il modello VHDL sono l’8051 e il 68HC11 [5]. In genere ogni microcontrollore comprende le seguenti unità:
• Timer, Counter, PWM, ecc. • Serial (A)Synchronous Interface. • Interfaccie parallele e porte I/O.
• Memoria On-Chip (RAM, (EEP)ROM).
Il core del microcontrollore, che è la CPU privata delle sue periferiche, può essere vista come parte autonoma dell’intero microcontrollore che interagisce con le periferiche tramite dei Special Function Register (SFR).
L’8051 costituisce la famiglia di microcontrollori CISC ad 8 bit più venduta in tutto il mondo. Si tratta di un microcontrollore ottimizzato per applicazioni di controllo [6]. Le operazioni numeriche sui dati e il byte-processing sono facilitati da varie modalità di indirizzamento veloce per accedere alla RAM interna. Il set di istruzioni prevede delle istruzioni aritmetiche ad 8 bit, incluso le istruzioni di moltiplicazione e divisione. Inoltre un estensivo supporto su chip prevede un tipo dati separato per le variabili ad un solo bit: ciò è particolarmente utile nei sistemi logici e di controllo che richiedono delle operazioni booleane di test e manipolazione su singoli bit.
In [7], l’8051 è usato per applicazioni spaziali: esso deve processare dei dati provenienti da una sonda all’interno della superficie di Marte e che riguardano temperatura, pressione, presenza di acqua. Il modulo totale comprende un 8051 che lavora a 3.3 V, 128 Kbyte di RAM, 128 Kbyte di EEPROM, circuiteria del clock, 32 canali ADC, 8 DACS, 32 canali digitali di I/O per eventuali interfacce, sei porte seriali. In questo caso per ridurre la potenza, sono state ridotte le capacità delle interconnessioni tra i vari chip che compongono il modulo, e inoltre l’EEPROM è stata spenta dopo che è stato eseguito il programma di boot. Il modulo totale consuma meno di 50mW @ 5 MHz.
Un altro metodo per ridurre la potenza in sistemi che usano l’8051 è descritto in [8]: tipicamente un 8051 esegue sempre lo stesso programma durante il suo tempo di vita; un esempio è il programma eseguito da un microcontrollore all’interno di una digital-camera. All’interno di questo programma, spesso si possono individuare dei loop software critici; se si fa in modo che un subset di questi loop vengono eseguiti dalla logica configurabile (CSL) disponibile su chip, mentre il microcontrollore aspetta in un low -power state, allora si riesce a risparmiare il 71% di potenza. Alternativamente si può giovare dell’aumentata velocità di esecuzione del programma: si porta l’intero sistema a lavorare con un’alimentazione più bassa in modo che la velocità di esecuzione del programma ritorni uguale a quella di partenza. In questo modo si risparmia fino all’89% di potenza.
In [9], l’8051 è invece usato per sistemi di navigazione e di guida nello spazio di nuova generazione: viene proposto un innova tivo Star Tracker (strumento usato da molti veicoli spaziali per determinare la loro posizione in 3-D), ultra low-power (70 mW @ 1 MHz @ 3.3V) e costituito da soli 2 chip: un Active Pixel Sensor che è un image detector di tipo CMOS e un ASIC che comprende 1500 bytes di ROM, 1000 bytes di RAM, un interfaccia I2C (per fornire in uscita dei dati di tipo pixel), un microcontrollore 8051, un oscillatore del clock e altra logica.
L’ MC8051 è un IP Core dell’Oregano Systems: in particolare si tratta di un microcontrollore VHDL ad 8 bit [10]. Le sue caratteristiche principali sono:
• E’ un progetto completamente sincrono: tutti i flip flop sono sensibili al fronte in salita e sono clockati dallo stesso segnale di clock.
• Il set delle istruzioni è compatibile con quello standard dell’originale Intel 8051.
• Possiede un’architettura ottimizzata in modo da eseguire velocemente ogni operazione in un numero di cicli di clock variabile da 1 a 4 in base al tipo di operazione.
• E’ 10 volte più veloce rispetto agli 8051 tradizionali a causa della sua architettura innovativa.
• Possiede un numero N di timer/counter e serial interface unit selezionabile dall’utente.
• Per selezionare una delle N unità timer/counter o serial inteface sono stati aggiunti due registri (Extended-Special-Function-Registers) ognuno ad 8 bit, chiamati TSEL e SSEL.
• Implementazione dei comandi MUL (Multiply), DIV (Divide), DA (Decimal Adjustement) tramite l’utilizzo di un moltiplicatore parallelo, di un divisore parallelo e di un’unità per il calcolo della rappresentazione decimale (BCD) di un bus dati.
• Le porte di I/O non sono multiplexate.
• 128 bytes di Internal RAM, 64Kbytes di External RAM, 64 Kbytes di ROM.
• Codice sorgente VHDL disponibile free (GNU LGPL).
• Codice sorgente VHDL indipendente dalla tecnologia, strutturato in modo chiaro e ben commentato.
• Facilmente espandibile adattando o modificando il codice sorgente VHDL.
• Parametrizzabile tramite delle costanti VHDL.
5.1.1 Struttura a blocchi del microcontrollore.
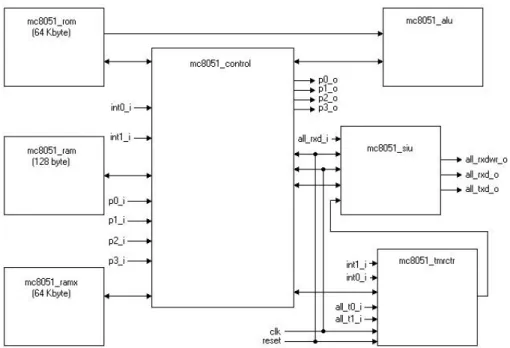
Il numero di serial interface e timer/counter unit è selezionabile dall’utente.
Figura 5-1 Struttura a blocchi del microcontrollore MC8051 IP-Core.
Le porte di I/O sono:
• clk: clock.
• reset: reset asincrono.
• all_t0_i: ingressi per gli N timer/counter 0. • all_t1_i: ingressi per gli N timer/counter 1.
• all_rxd_i: ingressi seriali per le N serial interface unit. • int0_i: N sorgenti di interruzione 0.
• int1_i: N sorgenti di interruzione 1.
• p0_i, p1_i, p2_i, p3_i: porte di ingresso parallele ognuna ad 8 bit. • p0_o, p1_o, p2_o, p3_o: porte di uscita parallele ognuna ad 8 bit. • all_rxdwr_o: il bit n di questo segnale indica la direzione di
all_rxd(n) (high = output, low = input).
• all_rxd_o: uscite seriali delle N serial interface unit in modalità 0.
5.1.2 Progetto gerarchico.
In Figura 5-2 è illustrata la gerarchia e i corrispondenti file VHDL del progetto:
Figura 5-2 Design hierarchy del microcontrollore 8051 IP-Core.
Come si può notare i file delle entity sono chiamati: entity_name_.vhd, i file delle architecture sono chiamati: entity_name_rtl.vhd per moduli contenenti della logica oppure entity_name_struc.vhd per moduli che connettono semplicemente altri sottomoduli.
5.1.3 Un accenno all’ architettura.
Poiché il progetto è pienamente sincrono, tutti i registri sono clockati dallo stesso segnale clk, inoltre il clock gating non è utilizzato. Poichè i segnali int0_i e int1_i possono essere generati da una circuiteria esterna che opera ad una frequenza di clock diversa, per sincronizzare questi segnali è stato adottato uno stadio di sincronizzazione a due livelli:
if clk'event and clk = '1' then
for i in 0 to C_IMPL_N_EXT-1 loop
s_int0_h1(i) <= int0_i(i); -- external INT0 s_int0_h2(i) <= s_int0_h1(i);
s_int0_h3(i) <= s_int0_h2(i);
s_int1_h1(i) <= int1_i(i); -- external INT1 s_int1_h2(i) <= s_int1_h1(i);
s_int1_h3(i) <= s_int1_h2(i); end loop;
Un altro aspetto importante riguarda l’interfacciamento con le memorie: per ottimizzare l’architettura, i segnali che provengono/vanno dai/ai blocchi di memoria non sono stati registrati e per questo motivo possono essere utilizzate solo memorie sincrone.
Si è già parlato della parametrizzazione: variando una semplice costante che si trova all’interno del file mc8051_p.vhd si può variare il parametro N e quindi il numero di timer/counter unit, il numero di serial interface unit e il numero di bit di int0_i e int1_i:
--- -- Select how many timer/counter units should be implemented -- Default: 1
constant C_IMPL_N_TMR : integer := 1;
--- -- Select how many seria l interface units should be implemented -- Default: C_IMPL_N_TMR ---(DO NOT CHANGE!)--- constant C_IMPL_N_SIU : integer := C_IMPL_N_TMR;
---
--- -- Select how many external interrupt-inputs should be implemented -- Default: C_IMPL_N_TMR ---(DO NOT CHANGE!)---
constant C_IMPL_N_EXT : integer := C_IMPL_N_TMR; ---
Si vede che le costanti C_IMPL_N_TMR, C_IMPL_N_SIU, C_IMPL_N_EXT non possono essere cambiate indipendentemente; quindi aumentare di uno la costante C_IMPL_N_TMR significa generare due addizionali timer/counter (infatti in ogni blocco i_mc8051_tmrctr ci sono due timer/counter), un’addizionale serial interface e due addizionali sorgenti di interruzioni esterne (infatti si aggiunge un bit ad int0_i e un bit a int1_i).
La configurazione del MC8051 che si è usata in questo lavoro di tesi è quella con:
C_IMPL_N_TMR = 1
Per scrivere sui registri di queste unità generate, sono stati introdotti 2 registri ad 8 bit: TSEL (Timer-unit SELect) e SSEL (Siu-unit SELect): se questi registri puntano ad un dispositivo non esistente, viene scelta per default l’unità 0:
s_tsel <= conv_integer(tsel) when tsel < C_IMPL_N_TMR
else conv_integer(0); -- selected timer unit is (not) implemented s_ssel <= conv_integer(ssel) when ssel < C_IMPL_N_SIU
In questo modo, ad esempio, per scrivere su uno degli N registri TCON (Timer CONtrol), si usa il segnale s_tsel:
if Rising_Edge(clk) then case s_regs_wr_en is when "100" | "101" =>
case conv_integer(s_adr) is -- write one byte of a SFR when 16#88# => tcon(s_tsel) <= std_logic_vector(s_data); ……
Una conseguenza importante dell’esistenza di questi registri è che se un dispositivo non selezionato, ad esempio da TSEL, presenta una richiesta di interruzione, questa interruzione non viene eseguita immediatamente bensì appena il dispositivo verrà selezionato (il corrispondente flag di interruzione resta settato finchè l’inter ruzione non è eseguita). Ne segue che più richieste di interruzione provenienti da un dispositivo non selezionato verranno interpretate come un’unica richiesta di interruzione.
Molto spesso, le unità multiplier, divider, o decimal adjust non sono necessarie e perciò, per risparmiare in termini di area del chip, c’è la possibilità di eliminare questi blocchi: basta resettare delle opportune costanti presenti nel file mc8051_p.vhd:
--- -- Select whether to implement (1) or skip (0) the multiplier -- Default: 1
constant C_IMPL_MUL : integer := 1;
---
--- -- Select whether to implement (1) or skip (0) the divider -- Default: 1
constant C_IMPL_DIV : integer := 1;
---
---
-- Select whether to implement (1) or skip (0) the decimal adjustment command
-- Default: 1
constant C_IMPL_DA : integer := 1;
---
La configurazione del MC8051 che si è usata in questo lavoro di tesi è quella con:
C_IMPL_MUL = C_IMPL_DIV = C_IMPL_DA = 1
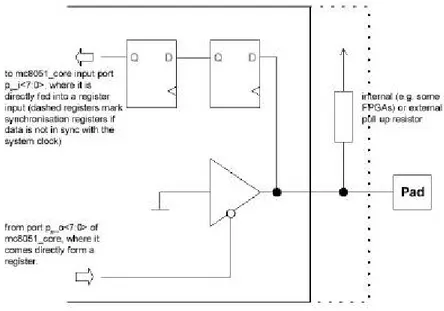
Per quanto riguarda le porte parallele di I/O, la loro struttura è la seguente:
Figura 5 -3 Porte parallele di I/O.
-- Model the 8 bit I/O ports.
-- NOTE: The two stage synchronization flip flops, have not been modeled here.
gen_portmodel : for i in 0 to 7 generate s_p0_i(i) <= s_p0(i);
s_p1_i(i) <= s_p1(i); s_p2_i(i) <= s_p2(i); s_p3_i(i) <= s_p3(i);
s_p0(i) <= '0' when s_p0_o(i) = '0' else FUNC_PULLUP(s_p0_ext(i)); s_p1(i) <= '0' when s_p1_o(i) = '0' else FUNC_PULLUP(s_p1_ext(i)); s_p2(i) <= '0' when s_p2_o(i) = '0' else FUNC_PULLUP(s_p2_ext(i)); s_p3(i) <= '0' when s_p3_o(i) = '0' else FUNC_PULLUP(s_p3_ext(i)); end generate;
5.2 Scelta di un programma di riferimento.
Un programma di riferimento da far girare sulla CPU per l’analisi della potenza potrebbe essere un Dhrystone 1.1 (scritto in codice C). E’ stato scelto il Dhrystone perché esso è un benchmark-test per la misura delle performance generali di una CPU. Inoltre è stato usato anche per l’analisi in potenza perché esso è quanto di più vicino ci possa essere ad un’applicazione generica. Infatti non esegue nessuna elaborazione significativa, semplicemente cerca di sollecitare un po’ tutta la CPU in maniera bilanciata (ovvero le fa eseguire una certa percentuale di assegnamenti, di statement di controllo, di chiamate a funzioni e procedure).
• Assegnamenti: 53%.
• Statement di controllo: 32 %.
Sviluppato da Reinhold Weicker nel 1984, questo benchmark viene usato principalmente per misurare e comparare le performance di diverse CPU oppure l’efficienza del codice generato per la stessa CPU ma da differenti compilatori. In questo modo, in seguito alle modifiche architetturali apportate al codice VHDL della CPU, si può vedere lanciando questo programma, se e quanto le prestazioni si siano modificate (in generale non c’è da meravigliarsi se, ottimizzando in potenza, le prestazioni diminuiscono).
Il test fornisce le performance in Dhrystones/second.
Questo programma consiste di operazioni standard e soprattutto di operazioni sulle stringhe. Esso è pesantemente influenzato dal progetto hardware e software, dalle opzioni del compilatore e del linker, dall’ottimizzazione del codice, dalla prese nza o meno di una memoria cache, dagli stati di wait, ecc.
In [11] vengono fornite le prestazioni di un microprocessore RISC 32 bit di tipo StrongARM usando il Dhrystone 2.1. Inoltre anche la sua potenza dissipata viene misurata durante l’esecuzione del Dhrystone 2.1. A 160 MHz e 1.65 Volts, esso esegue 185 (Dhrystone 2.1) MIPS e consuma 450 mW.
In [12] il Dhrystone non è usato per la misura delle prestazioni, ma è usato per confermare la validità di una instruction-level cycle -accurate simulation del consumo di energia in un processore StrongARM 1100: si è visto che i risultati della simulazione differiscono da quelli effettivi (questi ultimi ottenuti tramite delle misure hardware) meno del 5%.
Per maggiori dettagli sulle operazioni eseguite dal Dhrystone 1.1, utilizzato in questa tesi, si veda il suo codice C riportato nei programmi di esempio di uVision2 che è un tool della Keil Software [13].
5.2.1 Breve descrizione del Dhrystone 1.1.
Il programma main dapprima chiama la funzione initserial( ) che inizializza l’interfaccia seriale assegnando dei valori opportuni ad alcuni registri SFR (Special Function Register). In generale in ogni 8051, i registri SFR consistono di 128 byte di memoria usati per controllare timer, contatori, intefaccie
seriali di I/O, porte di I/O, e periferiche. Questi registri hanno un indirizzo compreso tra 0x80 e 0xFF e possono essere acceduti come byte, word e bit [14]. Essi sono dichiarati allo stesso modo delle altre variabili C, la sola differenza è che il tipo di queste variabili è “sfr”. Un esempio di dichiarazione è la seguente:
sfr P0 = 0x80; /* Port 0, address 80h */
Tra gli assegnamenti fatti nella funzione initserial( ) ricordiamo:
• TMOD = 0x20: inizializza il registro TMOD (Timer MODe) al valore “00100000”. Ciò fa lavorare da timer in modalità 0 il timer/counter0 e da timer in modalità 2 il timer/counter1.
• TH1 = 254: inizializza la parte alta di s_count1 (Timer High 1) al valore 0xFE.
• TCON = 0x40: inizializza il registro TCON (Timer CONtrol) al valore “01000000”; poiché TCON(4) = ’0’ e TCON(6) = ’1’ allora viene disabilitato timer/counter0 e abilitato timer/counter1.
• SCON = 0x50: inizializza il registro SCON (Serial CONtroller) al valore “01010000”; poiché SCON(7 downto 6) = ”01” allora la serial interface unit lavora in modalità 1, poiché SCON(4) = ’1’ allora la serial interface unit è abilitata anche a ricevere.
• SBUF = 0x0D: inizializza il registro SBUF (Serial data BUFfer) al valore “00001101”; in questo modo il primo carattere trasmesso dalla serial interface unit è un ritorno carrello.
• TI = 1: setta il flag di interruzione in trasmissione. In genere TI viene settato all’inizio del bit di stop di ogni carattere trasmesso.
Quindi durante la trasmissione di dati dall’interfaccia seriale al mondo esterno, si nota che la serial interface unit lavora in modalità 1; inoltre, essendo il registro s_smodreg (all’interno di control_mem_rtl.vhd) al valore logico basso, l’inverso del baud rate vale 32 volte il periodo del segnale timer/counter overflow flag 1. Si sa anche che il segnale s_count1 partendo dal valore 0xFE00 arriva al
valore 0xFEFF, e poi oscilla tra il valore 0xFEFE e 0xFEFF con periodo pari a 2 ) 16 ( ×Tclk × . Quindi, scegliendo fclk =10MHz: ns s T T RATE BAUD clk clk 102400 10 10 1024 1024 ] 2 ) 16 [( 32 _ 1 6 = × = × = × × × = −
Una volta fatto ciò, viene chiamata la funzione Proc0( ): essa esegue per LOOPS volte (si è scelto LOOPS = 200 che è il valore di default, ma per migliorare l’accuratezza della misura delle performance questo valore si può aumentare a proprio piacimento) un gruppo di operazioni equivalenti ad un Dhrystone (principalmente operazioni su interi e stringhe) e alla fine fornisce in uscita, utilizzando il comando printf, il tempo impiegato per eseguire l’intero programma e fornisce anche il numero di Dhrystones/sec. E’ importante soffermarsi sul modo in cui viene calcolato il tempo. A questo scopo è stata implementata la seguente funzione:
timerint ( ) interrupt 1 { timeval++;
}
In questo modo, ogni volta che timer/counter0 genera un’interruzione, viene incrementata la variabile timeval. Per sapere il valore della variabile timeval in un certo istante, viene chiamata la funzione TIME. Quindi tutto ciò serve per contare il numero delle interruzioni avvenute in un certo intervallo di tempo. Cerchiamo ora di calcolare ogni quanto tempo ∆t viene generata un’interruzione. Si è visto che timer/counter0 lavora in modalità 0, e inoltre s_count0 viene incrementato ogni 16×Tclk. Questo segnale genera un’interruzione ogni volta che arriva al valore 0x1FFF; quindi:
ms T t 2 (16 clk) 13.1072 13× × = = ∆
Questo valore determina la granularità con cui viene contato il tempo. Per sapere quanto tempo è passato per svolgere 200 volte il Dhrystone, alla fine viene moltiplicato il numero delle interruzioni avvenute per la granularità degli interrupt (∆t). Introducendo la variabile benchtime (numero delle interruzioni avvenute), e
Hz t
HZ =∆ −1≈76
, alla fine dell’esecuzione di LOOPS volte il Dhrystone verranno lanciati i seguenti comandi:
printf("Dhrystone time for %ld passes = %ld\n", (long) LOOPS, benchtime);
printf("This machine benchmarks at %ld dhrystones/second\n", ((long) LOOPS) * HZ / benchtime);
5.2.2 Compilazione del programma.
Per compilare il programma Dhrystone, si è usato l’ambiente di sviluppo uVision2 for Windows™ che è un tool della Keil Software per la famiglia dei microprocessori 8051. I passi da seguire sono i seguenti [15]:
• In Project→"Options for target Oregano"→"Device" bisogna selezionare: 8051 IP Core dell’Oregano Systems.
• In Project→"Options for target Oregano"→"Target" bisogna scrivere la frequenza di clock: Xtal(MHz) = 10.
• In Project→"Options for target Oregano"→"Output" bisogna abilitare l’opzione: Create Hex file.
• In Project→"Options for target Oregano"→"BL51 Locate"→”Code” bisogna scrivere la configurazione: ?C_C51STARTUP(0x0810). Così la prima istruzione (indirizzo 0 della ROM) sarà un salto all’indirizzo 0x0810 in cui verrà scritta la routine di startup del programma. L'indirizzo 0x0810 è stato scelto per essere compatibile con la versione Keil di prova, che come
limitazione inseriva a forza un salto da 0 a 0x0810; in generale si può scegliere un indirizzo di salto qualsiasi.
• Se si è pronti per compilare e linkare il progetto, si usa il comando Build Target. Lo stato di questo build process è mostrato nell’Output Window in cui, se tutte le operazioni sono corrette, si dovrebbe leggere:
creating hex file from "Dhrystone"...
"DHRYSTONE" - 0 Error(s), 0 Warning(s).
In questo modo viene prodotto in uscita un file di tipo esadecimale che contiene tutte le informazioni sul codice macchina da caricare in ROM. La struttura di questo file è la seguente:
:03000000020810E3
:0C081000787FE4F6D8FD758121020857BE ….
….
:00000001FF
Le prime due righe bastano per capire come poter risalire da questo file .hex al file binario che può essere caricato direttamente in ROM. Infatti ogni riga rappresenta un’istruzione e può essere interpretata come un vettore di caratteri che chiamiamo line, allora:
• line[1], line[2] rappresentano il numero di byte consecutivi necessari per quella istruzione.
• line[3], line[4], line[5], line[6] rappresentano l’indirizzo iniziale in cui scrivere l’istruzione.
• line[9], line[10] rappresentano il primo byte dell’istruzione. • line[11], line[12] rappresentano il secondo byte dell’istruzione. • line[13], line[14] rappresentano il terzo byt e dell’istruzione.
• ecc.
Bisogna quindi scrivere un programma che ricevendo in ingresso questo file .hex produca in uscita un file .bin che inizia in questo modo:
00000010 00001000 00010000 ….
Si potrebbe usare un programma in C, che chiameremo hex2dual. c di cui riportiamo solo la struttura di base:
…
while (fgets (line, sizeof(line), fpr) != NULL && strncmp(line,":00000001FF",11) != 0) { n = 1; nmbr = hex2int(line[n]); n++; nmbr = nmbr*16 + hex2int(line[n]);
row = hex2int(line[3])*16*16*16 + hex2int(line[4])*16*16 + hex2int(line[5])*16 + hex2int(line[6]); for ( n = 5; n < nmbr+5; n++) { (void)strcpy(nline,hex2bin(line[2*n -1])); (void)strcpy(nline + 4,hex2bin(line[2*n])); (void)strcpy(nline + 8 ,"\n"); nline[9]='\0'; (void)strcpy(mat[row+n-5],nline); } }
for(i=0;i<65536;i++) /* 64K bytes di ROM */ fputs(mat[i],fpw);
…
dove:
• fpr e fpw sono rispettivamente i puntatori al file di ingresso e al file d’usc ita;
• hex2int è una funzione che converte in intero il carattere esadecimale che riceve in ingresso.
• hex2bin è una funzione che riceve in ingresso un carattere esadecimale e restituisce in uscita un puntatore a carattere (più precisamente converte un carattere esadecimale in una stringa formata da quattro caratteri binari più il carattere di fine stringa \0). • line e nline sono vettori di caratteri (la dimensione di nline è 4
volte più grande della dimensione di line). • mat è una matrice di caratteri.
• n, nmbr, e row sono interi.
5.2.3 Lettura delle prestazioni.
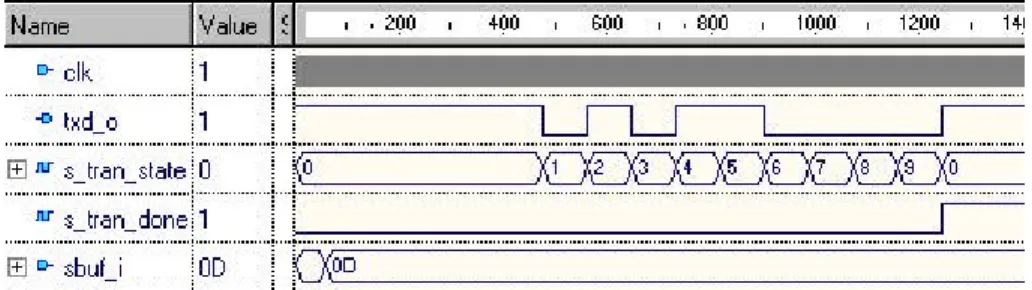
Come si è visto il comando printf implica una trasmissione seriale tramite il piedino di uscita txd_o. L’invio di un carattere al mondo esterno si traduce nella trasmissione di:
• 1 bit di start (al livello logico basso).
• 8 bit corrispondenti alla codifica ASCII del carattere. • 1 bit di stop (al livello logico alto).
Figura 5-4 Trasmissione di un ritorno carrello.
Per riuscire a decodificare ogni carattere e a stamparlo sullo schermo durante la simulazione, si potrebbe usare un blocco VHDL che chiameremo watcher.vhd che riceve in ingresso il segnale txd_o, il clock e il reset.
L’idea di base di questo blocco è quella di dichiarare una costante che chiameremo “ASCII” (array di caratteri) e che contiene in ordine (in base alla codifica ASCII) tutti i 128 caratteri. All’interno di un process si potrebbe inserire un loop, in cui per ogni carattere trasmesso si iterano i seguenti costrutti sequenziali:
• Attesa di un fronte in discesa sull’ingresso txd_o.
• Verifica di una corretta trasmissione dell’intero bit di start. • Attesa di
2 _ _BAUD RATE INV
per campionare correttamente (esattamente nel punto medio) il primo bit trasmesso.
• Attesa di INV _BAUD _RATE per campionare correttamente (esattamente nel punto medio) il secondo bit trasmesso. Questo punto si ripete per i rimanenti sei bit trasmessi. Alla fine avrò nella variabile data_in gli 8 bit trasmessi.
• Verifica della trasmissione del bit di stop.
• Memorizzazione del carattere letto all’interno di un array di caratteri chiamato “message”: message ( msg_index ) <= ASCII ( conv_integer ( unsigned ( data_in ) ) ).
• Se questo carattere è un ritorno carrello allora viene stampato su file e sullo schermo il valore del segnale message, inoltre la
variabile msg_index viene riportata ad 1, altrimenti viene solo incrementata la variabile msg_index.
5.3 Analisi della CPU originale.
Il programma Dhrystone ha dato esito al seguente risultato:
Dhrystone time for 200 passes = 14;
This machine benchmarks at 1085 dhrystones/second;
La sintesi di tipo bottom-up per la tecnologia standard cells CMOS a 0.18 µm ha prodotto il seguente report:
Combinational area: 97468.414062 2 m µ Noncombinational area: 37060.605469 2 m µ
Total cell area: 134529.015625 2
m µ
Ciascuna cella che compone il progetto è caratterizzata dalle seguenti aree:
Cell Reference Area Gate eq.
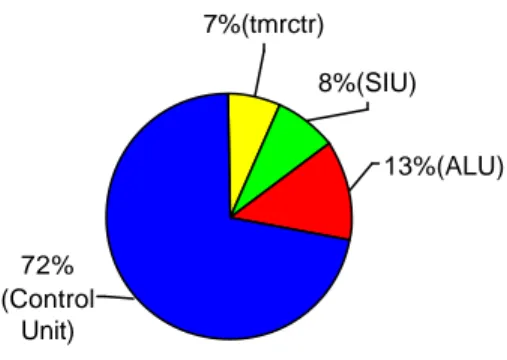
i_mc8051_alu mc8051_alu_DWIDTH8 17289.22 2 m µ 1406.77 i_mc8051_control mc8051_control 97480.70 2 m µ 7931.71 i_mc8051_siu_0 mc8051_siu 10604.54 2 m µ 862.86 i_mc8051_tmrctr_0 mc8051_tmrctr 9154.56 2 m µ 744.88 Total 4 cells 134529.03 2 m µ 10946.22
13%(ALU) 8%(SIU) 72% (Control Unit) 7%(tmrctr)
Figura 5-5 Complessità circuitale di ciascun blocco.
Il critical path è per definizione il percorso combinatorio tra 2 registri che presenta il massimo ritardo e che quindi limita la massima frequenza di clock. Nel caso della CPU originale si ha:
Data required time 99.90 ns
Data arrival time -21.30 ns
Slack (MET) 78.60 ns
Infatti il tempo di setup vale 0.10 ns e il periodo di clock vale 100 ns. Da cui si ricava che il tempo richiesto per i dati vale 99.90 ns. Inoltre il tempo di arrivo dei dati è calcolato sommando tutti i ritardi delle reti combinatorie poste tra lo start point e l’end point del critical path. Da questi dati si può affermare che la CPU originale è caratterizzata da:
MHz ns f ns Tclk clk 46.73 40 . 21 1 40 . 21 (max) (min)= ⇒ = ≈
Una simulazione gate-level lunga quanto tutta la durata del programma (circa 200 ms, che equivalgono a 2e+06 cicli di clock) sarebbe troppo lunga in termini di tempo, quindi si è deciso di realizzare diverse simulazioni di durata più breve e nello stesso tempo si è visto che i risulati ottenuti variano di poco al variare del tempo di simulazione. Ma analizziamo più in dettaglio la struttura del programma:
• 0<t<0.57335ms: fase di inizializzazione.
• 0.57335ms<t<5.06295ms: sul piedino d’uscita dell’interfaccia seriale viene trasmesso il carattere “S” (S = Start).
• 5.06295ms<t<186.05175ms: esecuzione di 200 Dhrystone.
• t>186.05175ms: sul piedino d’uscita dell’interfaccia seriale vengono trasmessi i caratteri che indicano le prestazioni della CPU.
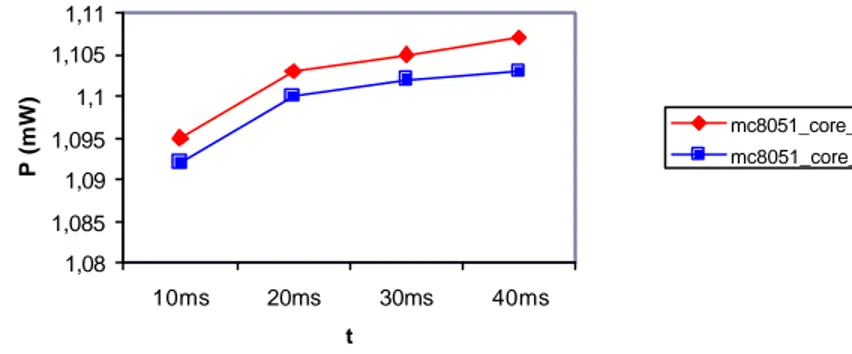
Si è già detto che i risultati ottenuti variano di poco al variare del tempo di simulazione: ciò è dovuto al fatto che per 5.06295ms<t<186.05175ms viene eseguita 200 volte la stessa serie di operazioni, quindi in questo intervallo di tempo la potenza istantanea risulta pressocchè periodica e la potenza media (calcolata sul tempo di simulazione) è una funzione quasi costante al variare del tempo di simulazione (sarebbe praticamente costante se si scegliesse il tempo di simulazione come multiplo intero del tempo impiegato per eseguire un solo Dhrystone). Lanciando contemporaneamente quattro simulazioni (ognuna da 10 ms, da 20 ms, da 30 ms e da 40 ms) il tempo richiesto dal simulatore, con le macchine a nostra disposizione, è di circa 3 giorni. Con un periodo di clock di 100 ns, queste quattro simulazioni corrispondono rispettivamente a 1e+05, 2e+05, 3e+05 e 4e+05 cicli di clock. In questo caso, l’analisi in potenza ha prodotto il seguente report: Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.502 0.591 1.43e+06 1.095
i_mc8051_tmrctr0 3.47e-03 4.34e-02 1.00e+05 4.70e-02
i_mc8051_siu_0 6.63e-04 5.39e-02 1.17e+05 5.47e-02
i_mc8051_alu 8.29e-03 4.06e-03 1.68e+05 1.25e-02
i_mc8051_control 0.200 0.490 1.04e+06 0.691
Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.509 0.592 1.43e+06 1.103
i_mc8051_tmrctr0 3.48e-03 4.34e-02 1.00e+05 4.69e-02
i_mc8051_siu_0 6.43e-04 5.36e-02 1.17e+05 5.44e-02
i_mc8051_alu 8.95e-03 4.44e-03 1.68e+05 1.36e-02
i_mc8051_control 0.207 0.491 1.04e+06 0.699 Tempo di simulazione = 20 ms Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.512 0.592 1.43e+06 1.105
i_mc8051_tmrctr0 3.49e-03 4.33e-02 1.00e+05 4.69e-02
i_mc8051_siu_0 6.37e-04 5.35e-02 1.17e+05 5.43e-02
i_mc8051_alu 9.17e-03 4.56e-03 1.68e+05 1.39e-02
i_mc8051_control 0.209 0.491 1.04e+06 0.701 Tempo di simulazione = 30 ms Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.513 0.593 1.43e+06 1.107
i_mc8051_tmrctr0 3.49e-03 4.33e-02 1.00e+05 4.69e-02
i_mc8051_siu_0 6.33e-04 5.35e-02 1.17e+05 5.42e-02
i_mc8051_alu 9.28e-03 4.63e-03 1.68e+05 1.41e-02
i_mc8051_control 0.210 0.491 1.04e+06 0.703
Tempo di simulazione = 40 ms
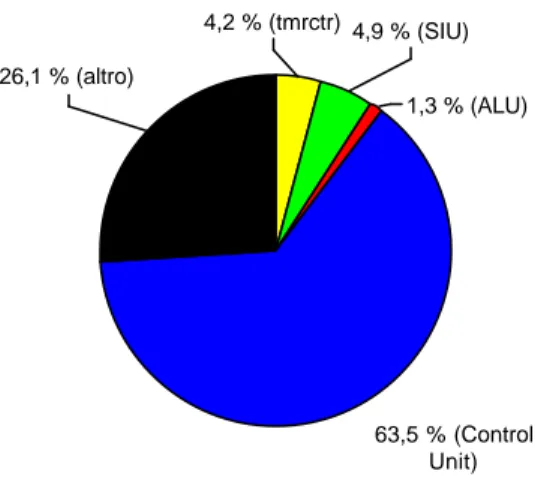
Usando i dati dell’ultima simulazione (40 ms) che sono più precisi, si ottiene che nel nostro caso il core consuma una switching power di 0.0513 mW/MHz. A causa della libreria CMOS utilizzata (di tipo low-leakage), il contributo della componente statica è di pochi Wµ (circa 0.13 % della potenza totale). Inoltre la percentuale di potenza consumata da ognuno dei quattro blocchi i_mc8051_tmrctr_0, i_mc8051_siu_0, i_mc8051_alu, i_mc8051_control è riportata in figura seguente:
1,3 % (ALU) 4,9 % (SIU) 63,5 % (Control Unit) 4,2 % (tmrctr) 26,1 % (altro)
Figura 5-6 Percentuale di consumo in potenza all’interno di mc8051_core.
5.3.1 Individuazione del blocco che consuma più potenza.
Dalla figura di sopra si può notare che tra i quattro blocchi che compongono l’mc8051_core, quello che ha un maggiore contributo in potenza è il blocco i_mc8051_control. Perciò bisognerà concentrarsi e proporre qualche soluzione su questo blocco per avere un maggiore risparmio in potenza a parità di percentuale di potenza risparmiata.
5.4 Tecniche di ottimizzazione in potenza utilizzate per il
blocco i_mc8051_control.
In questo lavoro di tesi, si è cercato di ridurre la potenza totale del blocco i_mc8051_control concentrandoci sulla riduzione della switching power. Si è cercato cioè di ridurre il numero di commutazioni dei nodi all’interno di tale blocco. In questo modo ci aspettiamo anche una riduzione dell’internal power: infatti si sa che durante una commutazione di un pin di uscita di una cella si crea
un percorso di cortocircuito tra alimentazione e massa causato dai tempi di salita e discesa diversi da zero degli ingressi della cella. Non si è fatto nulla per diminuire la potenza di leakage perché essa è trascurabile rispetto alle altre componenti (solo quando la CPU è in standby e non compie nessuna elaborazione significativa, la potenza di leakage non è più trascurabile, ma que sto non è il nostro caso). Inoltre la potenza di leakage è stata mantenuta bassa dalla scelta di una tecnologia CMOS di tipo low -leakage.
Allo scopo di minimizzare la componente di switching sono state adottate delle teniche di ottimizzazione a livello logico:
• State encoding. • Clock gating. • Operand Isolation.
Quindi sono state evitate tecniche di tipo technology-dependent (come ad esempio voltage scaling, uso di DC-DC converter, uso di opportune tecnologie low -power ecc.). Inotre le tecniche proposte possono essere combinate con tutte le altre tecniche low -power esistenti in letteratura.
5.5 Prima soluzione: state encoding.
5.5.1 Descrizione della tecnica utilizzata.
L’idea principale nel progetto di una macchina a stati low-power è di minimizzare la distanza di Hamming tra gli stati caratterizzati dalla più alta probabilità di transizione. Questa soluzione potrebbe anche aumentare la logica richiesta e quindi bisogna trovare un compromesso tra riduzione della switching activity e minimizzazione delle capacità.
Ogni macchina a stati è caratterizzata da un insieme di sei elementi: ) , , , , , ( σ Q q0 δ λ
l’insieme dei simboli in uscita, Q≠∅ è l’insieme degli stati, q0∈Q è lo stato di reset, δ :Q×Σ→Q è la funzione che dati gli ingressi e lo stato calcola il nuovo stato, λ:Q×Σ→σ è la funzione che dati gli ingressi e lo stato calcola le uscite. La sestupla M può essere descritta tramite un grafico delle transizioni di stato (STG) in cui dei nodi corrispondono agli stati e degli archi orientati, etichettati con i simboli in ingresso, descrivono le transizioni tra gli stati. In un implementazione hardware di una macchina a stati, ciascuno stato corrisponde ad un vettore binario che viene memorizzato in un apposito banco di registri. Poi con delle logiche combinatorie vengono implementate le funzioni δ e λ. Mentre la relazione tra gli ingressi, lo stato e le uscite è fissata dalla particolare applicazione, la codifica degli stati può essere definita in fase di progetto.
I metodi tradizionali per la codifica degli stati consistono nel minimizzare il numero di flip -flop: que sta soluzione minimizza l’area per implementare i registri di stato ma dall’altro può richiedere della logica combinatoria complessa. Quindi si cerca contemporaneamente di minimizzare l’area e il ritardo.
Invece, per la progettazione low-power di macchine a stati si deve tener conto della switching activity e delle probabilità di transizione. Si potrebbe ad esempio usare una descrizione probabilistica della macchina a stati e cercare di minimizzare il numero di commutazioni tra stati con alta probabilità di transizione. In questo modo il problema è risolto utilizzando un numero di bit per la codifica degli stati, compreso tra
log2 n
e n dove n è il numero degli stati.Queste tecniche di codifica vengono spesso usate in strutture tipo gate-array o stantard-cells. Mentre per gli FPGA in genere si sceglie una codifica di tipo One-Hot (per ogni stato c’è un solo bit al livello alto): questa soluzione usa un numero elevato di flip-flop (uno per ogni stato) ma permette l’uso di reti combinatorie piuttosto semplici e inoltre la distanza di Hamming tra 2 qualsiasi stati è sempre di 2 bit. La soluzione One-Hot quindi potrebbe andar bene al crescere del numero degli stati (poiché in questo caso, una distanza di Hamming costante e sempre di 2 rappresenta un ottimo risultato); invece per macchine a stati piccole potrebbe non andar più bene: in tal caso si potrebbe usare una codifica di tipo binario. Un’altra possibile codifica è chiamata “out-oriented”: consiste nel codificare gli sta ti in
base alla soluzione che minimizza la logica d’uscita. Da alcuni risultati sperimentali [16], si è verificato che:
• In genere, per macchine a stati con un numero di stati minore di 8 conviene una codifica binaria; per un numero di stati compreso tra 8 e 16 non c’è una chiara relazione ma a seconda dei casi conviene di più la One-Hot oppure la “Out-Oriented”; se si supera il valore di 16 stati, la codifica One-Hot diventa via via sempre più conveniente rispetto alle altre.
• Le variabili potenza dissipata e numero di stati sono linearmente correlate con un coefficiente di correlazione molto prossimo a 1 (circa 0.85).
• Le variabili: area e numero di stati sono anch’esse linearmente correlate (coefficiente di correlazione pari a 0.80).
• Le variabili: area e potenza dissipata sono linermente correlate (coefficiente di correlazione pari a 0.91). Quindi in genere i circuiti più piccoli in area consumano meno potenza.
• Un coefficiente di correlazione più piccolo (circa 0.6) esiste tra le variabili: potenza dissipata e ritardi.
5.5.2 Introduzione dello state encoding all’interno del blocco che
consuma di più.
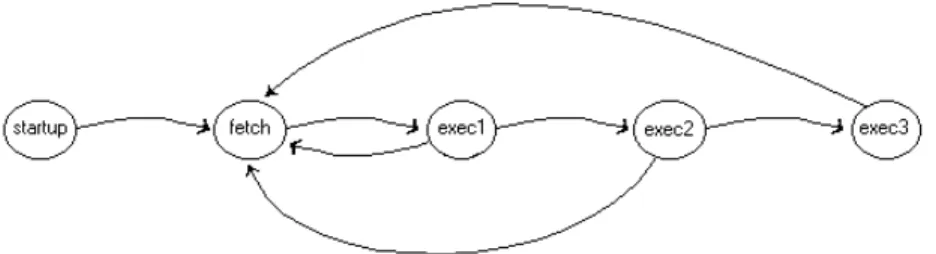
Analizzando il blocco control_fsm_rtl.vhd, si può notare che la successione degli stati è la seguente:
Figura 5 -7 STG del MC8051.
Come si può vedere, se ad esempio lo stato corrente è exec1, il prossimo stato può essere fetch oppure exec2. Ciò dipende dal tipo di istruzione che viene eseguita. Un discorso analogo si può fare anche se lo stato corrente è exec2.
Se si guarda all’interno del file mc8051_p.vhd si nota la seguente definizione di tipo:
type t_state is (STARTUP, FETCH, EXEC1, EXEC2, EXEC3);
I tipi enumeration sono codificati per default nel seguente modo: al primo elemento è assegnato il valore 0, al secondo elemento il valore 1, ecc.
Quindi per default la codifica degli stati del MC8051 è la seguente:
• STARTUP = “000” • FETCH = “001” • EXEC1 = “010” • EXEC2 = “011” • EXEC3 = “100”
In questo caso, a seconda delle istruzioni, si hanno le seguenti commutazioni:
STARTUP
→
FETCH: commutazione di 1 bit;FETCH→EXEC1→FETCH: commutazione di 4 bit;
FETCH→EXEC1→EXEC2→FETCH: commutazione di 4 bit;
FETCH→EXEC1→EXEC2→EXEC3→FETCH: commutazione di 8 bit;
Supponiamo ora di codificare gli stati nel seguente modo:
• STARTUP = “000” • FETCH = “001” • EXEC1 = “011” • EXEC2 = “111” • EXEC3 = “101”
Si ottengono ora le seguenti commutazioni:
STARTUP→FETCH: commutazione di 1 bit;
FETCH→EXEC1→FETCH: commutazione di 2 bit;
FETCH→EXEC1→EXEC2→FETCH: commutazione di 4 bit;
FETCH→EXEC1→EXEC2→EXEC3→FETCH: commutazione di 4 bit;
Quindi la seconda soluzione presenta una minore switching activity. Il VHDL prevede degli attributi predefiniti per la sintesi. Di essi fa parte l’attributo ENUM ENCODING, che permette di specificare i valori del codic e numerico per l’implementazione dei tipi enumeration.
Ad esempio per ottenere una codifica come quella vista prima, si è modificato il codice VHDL di sopra nel modo seguente:
type t_state is (STARTUP, FETCH, EXEC1, EXEC2, EXEC3);
attribute ENUM_ENCODING of t_state: type is “000 001 011 111 101”;
5.5.3 Analisi della CPU modificata.
Il programma Dhrystone ha dato esito al seguente risultato:
Dhrystone time for 200 passes = 14;
This machine benchmarks at 1085 dhrystones/second;
Si nota che il numero di dhrystones/sec non cambia: ciò è dovuto al fatto che la nuova CPU è rimasta sostanzialmente inalterata (è cambiata solo la logica combinatoria che riceve in ingresso lo stato attuale e produce il nuovo stato e quella che dato lo stato attuale produce l’uscita).
La sintesi di tipo bottom-up per la tecnologia standard cells CMOS a 0.18 µm ha prodotto il seguente report (in parentesi è indicata la variazione percentuale rispetto alla CPU originale):
Combinational area: 97603.578125 2 m µ (+0.14 %) Noncombinational area: 37060.609375 2 m µ (0 %)
Total cell area: 134664.187500 2
m µ (+0.1 %)
Cell Reference Area Gate eq. I_mc8051_alu mc8051_alu_DWIDTH8 17289.22 2 m µ (0 %) 1406.77 I_mc8051_control mc8051_control 97615.86 2 m µ (+0.14 %) 7942.71 I_mc8051_siu_0 mc8051_siu 10604.55 2 m µ (0 %) 862.86 i_mc8051_tmrctr_0 mc8051_tmrctr 9154.56µm2 (0 %) 744.88 Total 4 cells 134664.19µm2 (+0.1 %) 10957.22
Il critical path è dato da:
D ata required time 99.89 ns
Data arrival time -20.81 ns
Slack (MET) 79.08 ns
Infatti il tempo di setup vale 0.11 ns e il periodo di clock vale 100 ns. Da cui si ricava che il tempo richiesto per i dati vale 99.89 ns. Inoltre il tempo di arrivo dei dati è calcolato sommando tutti i ritardi delle reti combinatorie poste tra lo start point e l’end point del critical path. Da questi dati si può affermare che la CPU originale è caratterizzata da: (in parentesi è indicata la variazione percentuale rispetto alla CPU originale)
MHz ns f ns Tclk clk 47.80 92 . 20 1 92 . 20 (max) (min)= ⇒ = ≈ (+2.3 %)
Le simulazioni gate-level da 10 ms, 20 ms, 30 ms e 40 ms hanno prodotto il seguente report (in parentesi è riportata la variazione percentuale della potenza rispetto alla CPU originale):
Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.500 (-0.4 %) 0.591 (0 %) 1.43e+06 (0 %) 1.092 (-0.3 %) i_mc8051_tmrctr0 3.47e-03 (0 %) 4.34e-02 (0 %) 1.00e+05 (0 %) 4.70e-02 (0 %) i_mc8051_siu_0 6.63e-04 (0 %) 5.39e-02 (0 %) 1.17e+05 (0 %) 5.47e-02 (0 %) i_mc8051_alu 8.29e-03 (0 %) 4.04e-03 (-0.5 %) 1.68e+05 (0 %) 1.25e-02 (0 %) i_mc8051_control 0.198 (-1 %) 0.489 (-0.2 %) 1.04e+06 (0 %) 0.688 (-0.4 %) Tempo di simulazione = 10 ms Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.506 (-0.6 %) 0.592 (0 %) 1.43e+06 (0 %) 1.100 (-0.3 %) i_mc8051_tmrctr0 3.48e-03 (0 %) 4.34e-02 (0 %) 1.00e+05 (0 %) 4.69e-02 (0 %) i_mc8051_siu_0 6.43e-04 (0 %) 5.36e-02 (0 %) 1.17e+05 (0 %) 5.44e-02 (0 %) i_mc8051_alu 8.96e-03 (+0.1 %) 4.42e-03 (-0.5 %) 1.68e+05 (0 %) 1.35e-02 (-0.1 %) i_mc8051_control 0.204 (-1.4 %) 0.490 (-0.2 %) 1.04e+06 (0 %) 0.696 (-0.4 %) Tempo di simulazione = 20 ms Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.509 (-0.6 %) 0.592 (0 %) 1.43e+06 (0 %) 1.102 (-0.3 %) i_mc8051_tmrctr0 3.49e-03 (0 %) 4.33e-02 (0 %) 1.00e+05 (0 %) 4.69e-02 (0 %) i_mc8051_siu_0 6.37e-04 (0 %) 5.35e-02 (0 %) 1.17e+05 (0 %) 5.43e-02 (0 %) i_mc8051_alu 9.18e-03 (+0.1 %) 4.55e-03 (-0.2 %) 1.68e+05 (0 %) 1.39e-02 (0 %) i_mc8051_control 0.206 (-1.4 %) 0.491 (0 %) 1.04e+06 (0 %) 0.698 (-0.4 %) Tempo di simulazione = 30 ms
Switch Power (mW) Internal Power (mW) Leak Power (pW) Total Power (mW) mc8051_core 0.510 (-0.6 %) 0.592 (-0.2 %) 1.43e+06 (0 %) 1.103 (-0.4 %) i_mc8051_tmrctr0 3.49e-03 (0 %) 4.33e-02 (0 %) 1.00e+05 (0 %) 4.69e-02 (0 %) i_mc8051_siu_0 6.33e-04 (0 %) 5.35e-02 (0 %) 1.17e+05 (0 %) 5.42e-02 (0 %) i_mc8051_alu 9.29e-03 (+0.1 %) 4.61e-03 (-0.4 %) 1.68e+05 (0 %) 1.41e-02 (0 %) i_mc8051_control 0.207 (-1.4 %) 0.491 (0 %) 1.04e+06 (0 %) 0.699 (-0.6 %) Tempo di simulazione = 40 ms
Si nota che non è da escludere una variazione di potenza anche nei tre blocchi (i_mc8051_tmrctr_0, i_mc8051_siu_0, i_mc8051_alu) che non sono stati modificati. Ciò è dovuto al fatto che essi si interfacc iano con il blocco modificato (i_mc8051_control) e quindi, anche se la loro struttura gate-level non cambia, essi vedono delle capacità di carico diverse e ciò può provocare delle variazioni, anche se piccole, della potenza dissipata.
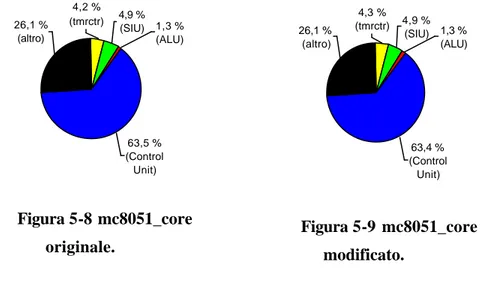
Usando i dati dell’ultima simulazione (40 ms) che sono più precisi, si ottiene (nel grafico a destra) la percentuale di potenza consumata da ognuno dei quattro blocchi i_mc8051_tmrctr_0, i_mc8051_siu_0, i_mc8051_alu, i_mc8051_control:
26,1 % (altro) 4,2 % (tmrctr) 63,5 % (Control Unit) 4,9 % (SIU) 1,3 % (ALU) Figura 5-8 mc8051_core originale. 26,1 % (altro) 4,3 % (tmrctr) 63,4 % (Control Unit) 4,9 % (SIU) 1,3 % (ALU) Figura 5-9 mc8051_core modificato.
Si può notare che la percentuale di i_mc8051_control è diminuita da 63.5% a 63.4%.
Analizziamo ora più da vicino come variano, al variare del tempo di simulazione, le varie componenti della potenza nel top level mc8051_core rispetto alla CPU originale:
0,49 0,495 0,5 0,505 0,51 0,515 10ms 20ms 30ms 40ms t P (mW) mc8051_core_orig mc8051_core_mod
0,59 0,5905 0,591 0,5915 0,592 0,5925 0,593 0,5935 10ms 20ms 30ms 40ms t P (mW) mc8051_core_orig mc8051_core_mod
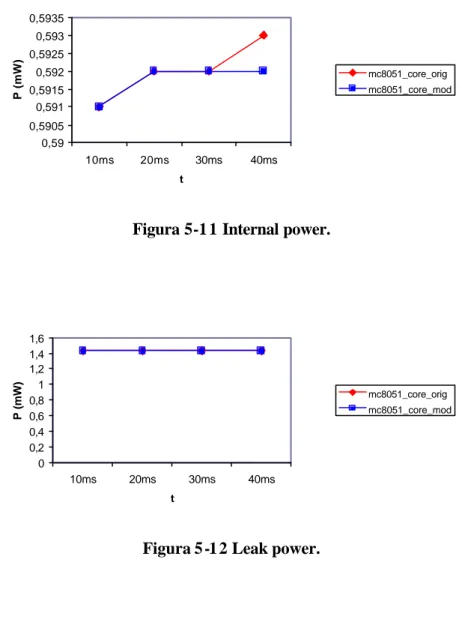
Figura 5-1 1 Internal power.
0 0,2 0,4 0,6 0,8 1 1,2 1,4 1,6 10ms 20ms 30ms 40ms t P (mW) mc8051_core_orig mc8051_core_mod
1,08 1,085 1,09 1,095 1,1 1,105 1,11 10ms 20ms 30ms 40ms t P (mW) mc8051_core_orig mc8051_core_mod
Figura 5 -13 Total power.
5.5.4 Considerazioni.
Dall’analisi in potenza della CPU modificata, si osservano i seguenti risultati:
• La leakage power rimane inalterata rispetto all CPU originale.
• L’internal power rimane pressocchè inalterata sia in i_mc8051_control che in mc8051_core.
• La switching power diminuisce sia in i_mc8051_control (-1.4 %) sia in mc8051_core (-0.6 %).
Si sa che la leakage power aumenta all’aumentare del numero di celle che compongono il progetto. Ma come si vede dal report, l’area non cambia sostanzialmente (+0.1 %) e ciò spiega perché la leakage power rimane inalterata.
Il motivo per cui l’internal power rimane pressocchè inalterata non è ben chiaro: probabilmente il risparmio sul numero di commutazioni dei registri di stato non è sufficiente a risparmiare meno potenza interna a causa della sua dipendenza da altri fattori (ad esempio dai tempi di salita e di discesa degli ingressi di ciascuna cella).
La switching power invece diminuisce, anche se si tratta di una diminuzione percentuale abbastanza piccola (-1.4 % nel blocco modificato). Questo risultato è dovuto alla diminuzione della switching activity nei registri di stato. Ad esempio, dai comandi di set_switching_activity (ottenuti dalla simulazione gate-level di 40 ms) sui pin di uscita dei registri di stato, si osservano i seguenti risultati:
Pin -period -toggle_rate -static_prob
state_regx0x/Q 40 ms 318456 0.601925
state_regx1x/Q 40 ms 261815 0.541556
state_regx2x/Q 40 ms 56640 0.070800
CPU originale.
Pin -period -toggle_rate -static_prob
state_regx0x/Q 40 ms 1 0.999994
state_regx1x/Q 40 ms 261815 0.541556
state_regx2x/Q 40 ms 171430 0.285087
CPU modificata.
Facendo il totale delle commutazioni nella CPU originale e quella modificata, in 40 ms si risparmiano 203665 commutazioni.
5.6 Seconda soluzione: clock gating.
5.6.1 Descrizione della tecnica utilizzata.
Nei circuiti sincroni, il segnale del clock commuta ad ogni ciclo di clock e inoltre pilota capacità molto elevate: quindi il segnale del clock è la maggiore sorgente di consumo della potenza dinamica all’interno del chip. Il clock gating è una tecnica che disabilita il clock alle parti del circuito che sono inattive durante certi periodi di tempo [17]. In questo modo si hanno due vantaggi:
• Riduzione del fattore di switching activity del segnale di clock in ingresso alle parti inattive.
• Riduzione della capacità pilotata dal clock.
Quindi il clock gating riduce la dissipazione della potenza dinamica di un circuito.
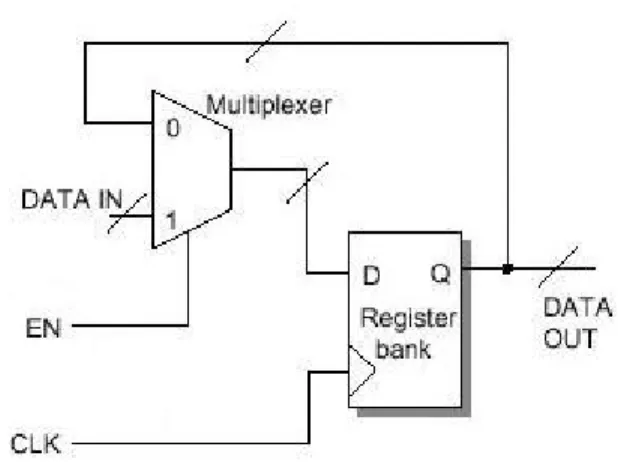
Senza il clock gating, ogni banco di registri è implementato con un loop di feedback e un multiplexer:
Figura 5-1 4 Registro con load-enable sincrono.
In questo modo, quando il banco di registri mantiene lo stesso valore per più cicli di clock allora il banco di registri, la rete del clock e il multiplexer consumano una potenza non trascurabile.
L’inserzione del clock gating presuppone una struttura come in figura seguente (dove CL sta per Combinational Logic ed F è la circuiteria di controllo del clock):
Figura 5 -1 5 Latch-based clock gating.
Si sa che nei progetti sincroni si tende ad evitare l’uso di latch trasparenti a causa del loro comportamento asincrono, ma si vedrà che essi sono necessari per evitare che i glitch presenti sul segnale O quando clk è allo stato logico alto si propaghino fino ad arrivare al segnale gclk.
In letteratura sono presenti anche delle tecniche di clock gating che non utilizzano dei latch. Un esempio è il caso in Figura 5-16:
Figura 5-16 Latch-free clock gating.
In questo caso, quando il segnale EN è alto allora il registro è clockato normalmente, altrimenti se EN è basso allora il segnale ENCLK è permanentemente a livello alto e il registro non è clockato. L’eliminazione del latch può ulteriormente ridurre la dissipazione in potenza e anche l’area. Il problema pricipale di questa soluzione è che il segnale EN deve stabilizzarsi al suo nuovo valore prima del prossimo fronte in discesa del clock altrimenti dei glitch su EN potrebbero provocare dei glitch anche sul segnale ENCLK. A seconda dei casi si può trovare una rete “Control logic” più veloce o meno veloce.
Per essere sicuri che in ogni caso non ci siano rischi di malfunzionamento, quest’ultima soluzione è stata accantonata.
Ritorniamo perciò al caso di Figura 5-15. Sotto le normali condizioni in cui il banc o di registri deve essere clockato, l’uscita O della logica di controllo è alta; questo segnale passa attraverso il latch trasparente e arriva a CLK_CNTL quando CLK è basso. Poiché CLK_CNTL è alto, il segnale GCLK coincide con CLK a meno del ritardo della porta AND.
Durante i periodi di inattività in cui il banco di registri non deve essere clockato, il segnale O è basso: ciò porta ad avere CLK_CNTL basso e quindi anche GCLK basso. In questo modo viene eliminata la switching activity non necessaria associata al ricaricamento dello stesso valore per più cicli di clock.
Facciamo un analisi di timing e indichiamo con:
• ∆F: massimo ritardo della rete F. • ∆CL: massimo ritardo della rete CL. • δCL: minimo ritardo della rete CL.
• ∆L: ritardo dall’ingresso LG all’uscita LQ del latch.
• ∆REG: massimo ritardo dall’ingresso clock all’uscita Q dei registri.
• δREG: minimo ritardo dall’ingresso clock all’uscita Q dei registri. • ∆AND: ritardo della porta AND.
Bisogna assicurarsi che quando CLK è alto, CLK_CNTL non sia affetto da glitch. Per far ciò bisogna che sia rispettata la seguente condizione:
• CLK_CNTL deve cambiare solo dopo il fronte in discesa del clock e deve raggiungere un valore stabile prima del prossimo fronte in salita del clock.
Figura 5 -1 7 Timing diagram.
La presenza del latch con enable attivo basso assicura che CKL_CNTL cambi dopo un tempo ∆L dal fronte in discesa del clock. Ora bisogna assicurarsi che CLK_CNTL si stabilizzi prima del prossimo fronte in salita del clock, cioè deve essere:
1. t1+∆REG+∆CL+∆F+∆L<t3
Inoltre per permettere un corretto campionamento del segnale A da parte del banco di registri bisogna rispettare il tempo di setup e di hold, quindi deve essere anche:
2. t1+∆REG+∆CL+tsetup<t3+∆AND
3. t1+δREG+δCL>t1+∆AND+thold
Quindi da queste 3 condizioni si ricava:
• Tclk >∆REG+∆CL+max(∆F +∆L,tsetup −∆AND) • δREG +δCL>∆AND+thold
Bisogna ora determinare le condizioni durante le quali può essere disabilitato il clock ad un banco di registri. In genere ogni circuito deve eseguire parecchie operazioni sui dati in ingresso e per far ciò esso viene implementato come un blocco datapath che contiene diversi operatori (ad esempio adder, moltiplicatori ecc.): in questo modo le uscite intermedie di un’operazione saranno
registrate e usate come ingressi per una nuova operazione al prossimo ciclo di clock. Un possibile algoritmo potrebbe analizzare la descrizione di tipo behavioral di un tale circuito e determinare le condizioni per cui ciascuna operazione non necessita di essere eseguita. Fatto ciò, si potrebbe disabilitare il clock dei registri che memorizzano gli ingressi dell’operazione: in questo modo oltre alla potenza risparmiata sulla rete del clock, si risparmia potenza anche perché gli ingressi dell’operatore si mantengono costanti e quindi non c’è dissipazione di potenza all’interno della rete combinatoria in questione.
Consideriamo una descrizione hardware (H) di un circuito pronta per essere sintetizzata: il nostro algoritmo consiste nel creare una nuova descrizione (H’) che una volta sintetizzata, darà origine ad una struttura di tipo clock gating del circuito di partenza. I passi da seguire potrebbero essere i seguenti:
1. Ricerca, all’interno di H, di costrutti sintattici di tipo condizionale. 2. Identificazione dei segnali e variabili (Vi) che non cambiano il loro
valore sotto certe condizioni (Gi).
3. Stima del risparmio di potenza e dei ritardi introdotti. 4. Introduzione del clock gating.
Analizziamo ora, passo dopo passo, il nostro algoritmo, riferendoci ad una descrizione di tipo VHDL.
I costrutti condizionali in una descrizione VHDL sono:
• if {condition} then {statements} else {statements}.
• case {case selector} is when {choises}=>{statements}.
• with {case selector} select {variable/signal} when {condition}.
• {signal assignment} if {condition} else {signal}.
Ogni volta che troviamo dei rami condizionali diversi tra di loro (ad esempio esiste almeno un segnale o una variabile (Vi) a cui è assegnato un valore in un ramo ma non in un altro ramo), è possibile identificare una coppia (Vi, Gi).
Ora bisogna trovare un elemento clockato (component clockato o process clockato) associato a Vi che potrà essere pilotato da un gated clock (anziché dal clock) nel circuito sintetizzato.
Per fare una stima del risparmio di potenza basta sapere che:
• 2 V C f P= clk × clk × • P f C V2 f (C C C ) V2 add gated clk clk gated clk Gi gated =α × × × + × − + × Dove:
P : potenza dissipata nel circuito originale. gated
P : potenza dissipata nel circuito modificato con clock gating. clk
C : capacità di carico della rete del clock nel circuito originale.
gated
C : capacità di carico pilotata dal nodo GCLK. add
C : capacità di ingresso della porta AND e del LATCH.
Gi
α : fattore di switching activity del nodo GCLK dipendente dalla
condizione Gi. clk
f : frequenza di clock.
V: tensione di alimentazione.
Quindi il risparmio di potenza sarà:
] ) 1 ( [ 2 add Gi gated clk gated net P P f V C C P = − = × × × −α −
Per stimare la perdita in performance bisogna vedere come si modifica il critical path nel circuito con clock gating. Infatti la logica che si è aggiunta introduce dei ritardi che possono essere stimati. Consideriamo il caso in cui la rete F è realizzabile sotto forma di somma di prodotti e sia x il numero di bit che F riceve in ingresso: supponendo di poter disporre di porte AND e OR a due ingressi, allora ogni prodotto tra x termini si può realizzare con log2x livelli di
logica e la somma di 2x termini si può realizzare con x x = ) 2 ( log2 livelli di logica; quindi: ) log (x 2x T F = gate × + ∆ L F CL REG AND t L F CL REG Tclk setup ∆ + ∆ + ∆ + ∆ ≈ ≈ ∆ − ∆ + ∆ + ∆ + ∆ > max( , )
dove Tgate è il ritardo di una porta AND o OR a 2 ingressi.
Ne segue che: L x x T CL REG
Tclk min ≈∆ +∆ + gate ×( +log2 )+∆
A questo punto, per introdurre la logica di gating basta modificare il codice VHDL per:
• isolare il comportamento condizionale. • rimpiazzare il segnale clk col segnale gclk. • includere un nuovo process che generi gclk.
Vediamo un semplice esempio. Supponiamo di avere il seguente codice VHDL: process(clk) begin if Rising_Edge(clk) then X<=B; Y<=C&D; if(not Gi) then
Vi<=A; end if;
end process;
Questo process si potrebbe splittare in due process (p1 e p2):
p1: process(clk) begin if Rising_Edge(clk) then X<=B; Y<=C&D; end if; end process p1; p2: process(gclk) begin if Rising_Edge(gclk) then if(not Gi) then
Vi<=A; end if;
end if; end process p2;
Inoltre gclk può essere generato in questo modo:
p3: process(clk,Gi) begin if(clk='0') then if (Gi) then clk_cntl<='0'; else clk_cntl<='1'; end if; end if;
end process p3;
gclk<=clk_cntl and clk;
Si nota che per generare clk_cntl, durante la sintesi verrà usato un latch trasparente sul livello basso di clk. Infatti ogni volta che clk è a livello logico alto, il segnale clk_cntl deve conser vare il suo valore. Il segnale gclk si ottiene poi con un AND logico fra clk e clk_cntl.
Testando questo semplice esempio, e facendo qualche simulazione pre-sintesi si è scoperto che la nuova rete non è funzionalmente identica a quella di partenza. Infatti la sequenza dei process nella nuova rete è:
• t = t1: commuta clk;
• t = t1 + (1 delta delay) : parte il processo p1 insieme con tutti gli altri process(clk) e commuta gclk ;
• t = t1 + (2 delta delay): parte il processo p2 ;
Quindi il processo p2 e il processo p1 non vengono eseguiti contemporaneamente come succedeva prima. Ne segue che se in t = t1 vengono modificati dei segnali (ad esempio il segnale A), il nuovo valore di questi segnali potrebbe andare a modificare il comportamento del successivo process p2 provocando un assegnamento scorretto del segnale Vi. Questa situazione è illustrata in figura:
Figura 5 -1 8 Simulazione non corretta.
Quindi per risolvere questo problema, si è pensato di introdurre un piccolo ritardo sui segnali all’interno del process p2. Così nel nostro esempio, in t = t1 + (1 delta delay) il segnale Vi si aggiorna in base al valore corretto di A:
p2: process(gclk) begin
if Rising_Edge(gclk) then if(not Gi_old) then
Vi<=A_old; end if; end if; end process p2; A_old<=A; Gi_old<=Gi;
Ora la sequenza dei process è questa:
• t = t1: commuta clk;
• t = t1 + (1 delta delay): parte il processo p1 insieme con tutti gli altri process(clk) e commuta gclk;
• t = t1 + (2 delta delay): parte il processo p2 e commutano A_old e Gi_old;
E il process p2 si comporta esattamente come se fosse eseguito contemporaneamente a p1.
La nuova situazione è illustrata in figura:
Figura 5 -1 9 Simulazione corretta.
L’importanza dei segnali di tipo “_old” non va sottovalutata in quanto senza di essi quasi tutti i registri con clock gating inseriti all’interno del blocco i_mc8051_control avrebbero prodotto delle simulazioni non corrette. Basti vedere il seguente esempio in cui non vengono utilizzati i segnali “_old”:
process (reset,gclk) begin
if reset='1' then
s_help <= conv_unsigned(0,8); elsif Rising_Edge(gclk) then case s_help_en is
when "0000" => NULL;
when "0001" => s_help <= unsigned(rom_data_i); when ……
when others => NULL; end case;
end if; end process;
Ha dato esito alla seguente simulazione non corretta dove in t = 450 ns, s_help si aggiorna in base al nuovo e non al vecchio valore di rom_data_i:
Figura 5 -20 Esempio di simulazione non corretta
Ciò è dovuto al fatto che rom_data_i commuta in t = 450 ns + (1 delta delay) mentre s_help commuta in t = 450 ns + (2 delta delay).
5.6.2 Introduzione del clock gating all’interno del blocco che
consuma di più.
Dopo il fronte in salita di clk, i seguenti segnali conservano oppure no il loro valore dipendentemente da una certa condizione di enable (Gi):
• All’interno del process p_write_ram: sp (8 bit), acc (8 bit), p0 (8 bit), dpl (8 bit), dph (8 bit), pcon + s_smodreg (5 bit), tmod (8 bit), s_reload + s_wt (10 bit), t_sel (8 bit), p1 (8 bit), sbuf (8 bit), ssel (8 bit), p2 (8 bit), ie (8 bit), p3 (8 bit), ip (8 bit), b (8 bit), gprbit (16x8 bit), s_ri_bj (8x8 bit).
• All’interno del process p_wr_internal_reg: s_ir (8 bit), s_help (8 bit), s_help16 (16 bit), s_helpb (1 bit), s_intpre2 (1 bit), s_intlow (1 bit), s_inthigh (1 bit).
Concentriamoci inizialmente sul primo process. Ad esso appartengono prevalenteme nte tutti registri ad 8 bit. Confrontiamo le due soluzioni in figura:
Soluzione A. Soluzione B.
Nella soluzione A si fa un clock gating globale: cioè tutti i registri ad 8 bit sono clockati da un unico segnale gclk.
• Vantaggi: viene utilizzata un’unica porta AND e quindi il segnale clk pilota una capacità molto piccola.
• Svantaggi: il segnale gclk ha una switching activity molto elevata (deve avere un fronte in salita ogni volta che almeno un registro ad 8 bit deve essere aggiornato) e inoltre pilota una capacità molto elevata.
Nella soluzione B si fa un clock gating locale: cioè ogni registro ad 8 bit è clockato da un proprio segnale gclk.
• Vantaggi: ogni segnale gclk ha una switching activity più bassa rispetto alla soluzione A e inoltre commuta su una capacià più piccola rispetto alla soluzione A.
• Svantaggi: vengono utilizzate molte porte AND e quindi il segnale clk pilota una capacità più elevata rispetto alla soluzione A.
Quindi bisognerà trovare una soluzione di compromesso tra A e B. Supponendo di avere un numero M di segnali gclk (gclk1, gclk2, …, gclkM) e che ogni segnale gclk piloti sempre lo stesso carico capacitivo (Cgated) si avrà la situazione in figura:
Figura 5-21 Una possibile soluzione per il clock gating.
Vogliamo calcolare il numero K di registri (ognuno ad 8 bit) clockati dallo stesso segnale gclk che consente di avere un risparmio di potenza massimo.
In base alla formula sul risparmio di potenza, si avrà:
∑
= − − × × × = M i add i gated clk net f V C C P 1 2 ] ) 1 ( [ αDove αi è la switching activity del nodo gclki.
Si è verificato dopo aver fatto una sintesi di questa struttura, che:
add
gated K C
Ciò si spiega perchè la capacità d’ingresso di una porta AND è circa uguale alla capacità vista dall’ingresso clock di un registro ad un solo bit. Quindi:
∑
= = − − × × × × × = M i i add clk net f V C K P 1 2 ] 1 ) 1 ( 8 [ α ] ) ( 8 [ 1 2 M M K C V f M i i add clk× × × × × − − =∑
= αGuardando il process p_write_ram, si nota che viene fatto un case sul segnale s_regs_wr_en: in genere, fra tutti i registri elencati sopra viene aggiornato un solo registro ogni ciclo di clock (fanno eccezione: il registro sp che può essere aggiornato insieme a qualsiasi altro registro nel caso in cui s_regs_wr_en = “101” ed i registri acc e b che vengono aggiornati contemporaneamente nel caso in cui s_regs_wr_en = “111” e si devono memorizzare i risultati di un operazione di divisione o moltilplicazione). Quindi con qualche approssimazione, si può supporre che al variare di M rimanga costante il valore: c
M i i =
∑
=1 α . Si sa inoltre che: N M K× = × 8Dove N è il numero totale di flip flop.
Quindi bisognerà massimizzare, al variare di K, la funzione:
K N c K N k f × − × × − = 8 8 ) ( si ottiene: c N Kopt = × 8 1
Dove nel nostro caso N = 327, mentre per calcolare il valore della costante c si può considerare ad esempio il caso in cui si fa un clock gating globale (soluzione A) ho M = 1: gclk1 deve avere un fronte in salita ogni volta che almeno un registro (fra tutti quelli elencati sopra) deve essere aggiornato. Ciò avviene ogni volta che il segnale s_regs_wr_en è diverso da “000”. Quindi la costante c dipende dal programma che è caricato in memoria: intuitivamente la formula torna perché se ad esempio viene eseguito un programma con c<<1 allora ottengo Kopt più grande possibile, cioè mi conviene fare il clock gating globale (soluzione A). Nel caso del Dhrystone, facendo una simulazione lunga quanto tutta la durata del programma, si può contare il numero di periodi di clock in cui s_regs_wr_en è diverso da zero in questo modo:
process(clk,reset) begin
if reset='1' then num<=0;
elsif Rising_Edge(clk) then
if s_regs_wr_en /= "000" then num<=num+1; end if;
end if; end process;
Dove num è un segnale di tipo intero. Ovviamente in fase di sintesi, questo process è stato eliminato. Si divide il valore finale di num per il numero di cicli di clock dell’intero programma e si ottiene:
48 , 0 ≈ c 26 , 3 ≈ ⇒Kopt
Bisogna necessariamente scegliere un K intero, per far ciò valutiamo il grafico: 280 285 290 295 300 305 0 2 4 6 8 10 12 K f(K)
Figura 5-22 Rappresentazione della funzione f(K).
In particolare si nota che:
86 . 301 ) 3 (k = ≈ f 42 . 301 ) 4 (k = ≈ f
Quindi si sceglierà K = 3; cioè si farà in modo che ogni segnale gclk piloti sempre la stessa capacità che è quella di 3×8=24 volte la capa cità dell’ingresso clk di un flip flop. Inoltre va detto che per tutte le applicazioni in cui 0.42<c<0.82 allora risulta 2.5<K<3.5, quindi la soluzione con K = 3 offre ancora ottimi risultati. Fra i tanti possibili, si è scelto il seguente raggruppamento: