Capitolo 2 SOA, Web Service e BPEL
2.1.
Introduzione
Le architetture orientate ai servizi (SOA) costituiscono il paradigma emergente per la progettazione ed implementazione di applicazioni di rete. I servizi sono strumenti indipendenti dalla piattaforma, che possono essere descritti, pubblicati e composti ottenendo reti di applicazioni distribuite.
La SOA è un’architettura concettuale che non fa riferimento a nessuna particolare implementazione. Essa pone delle specifiche condizioni che i componenti del sistema devono rispettare e delle caratteristiche che tale sistema deve necessariamente avere. I Web Service sono invece una nuova tecnologia, che si basa su standard, quali XML, SOAP, WSDL e UDDI, la quale fornisce un facile metodo di interfacciamento tra le applicazioni e si propone quindi come implementazione della SOA, sfruttando i protocolli standard di Internet per essere language e platform neutral.
Il Business Execution Language (BPEL) è il linguaggio proposto come standard per la composizione di servizi. L’importanza di un linguaggio per comporre servizi risiede nel fatto che, sia in ambienti EAI (Enterprise Application Integration) che B2B (Business to Business), la composizione di più servizi permette di effettuare delle operazioni di integrazione per offrirne di nuovi e più complessi, portando valore aggiunto all’azienda. Questo capitolo si propone di analizzare gli aspetti tecnologici e le motivazioni che hanno portato al successo dell’architettura orientata ai servizi presso le aziende.
2.2.
Dal Client/Server a SOA
Il crescente sviluppo delle reti di telecomunicazioni e delle applicazioni informatiche di rete ha portato l’industria IT a confrontarsi con nuove possibilità e nuove sfide. Da un lato la grande diffusione della rete ha permesso lo sviluppo di applicazioni distribuite basate su protocolli aperti per fornire servizi a valore aggiunto agli utenti, dall’altra è aumentata la complessità delle applicazioni e la necessità di integrare sistemi informativi e piattaforme eterogenee. In particolare, le aziende in un mercato globalizzato sentono sempre più spesso la necessità di rendere i servizi globalmente accessibili. Ciò richiede che si vada oltre il semplice front-end (il portale web ad esempio) e che ci sia integrazione tra i sistemi e le applicazioni dell’azienda con quelle dei suoi partner, fornitori e clienti.
La SOA è stata introdotta proprio per affrontare le sfide appena delineate. Prima di descriverne le caratteristiche è bene sintetizzare in breve l’escursus storico che ha consentito la transizione dalle architetture client/server alle attuali architetture orientate ai servizi.
Fino a qualche decennio fa, infatti, le aziende richiedevano soluzioni IT attraverso un approccio diretto alla copertura: dato un requisito funzionale dell’azienda si contattava un vendor capace di soddisfare “nel miglior modo possibile” l’esigenza. In questo modo le aziende ben presto si ritrovarono con un insieme confuso di isole di automazione, indipendenti e non comunicanti. Le funzionalità informatiche erano spesso replicate e ridondanti, creando con notevole frequenza situazioni di inconsistenza tra le applicazioni. Velocemente queste applicazioni inizialmente autonome ebbero il bisogno di diventare interdipendenti per poter assolvere a un completo e più complesso processo di business. Ovviamente la complicazione nel fare ciò risiedeva nel fatto che queste applicazioni non erano nate per comunicare e quindi erano il più delle volte sviluppate da vendor diversi attraverso tecnologie eterogenee (in termini di piattaforma, di linguaggi di programmazione, ecc…).
Quest’esigenza d’integrazione inizialmente fu sopperita utilizzando delle particolari interfacce SW proprietarie che permettessero alle applicazioni di interoperare. I costi per la realizzazione e manutenzione di queste interfacce erano ovviamente elevati.
L’interfaccia quindi non è altro che un’entità intermedia che si interpone tra i due interlocutori, in modo che possa intercettare i messaggi inviati da uno di essi, tradurli e inoltrarli al destinatario, che può così comprenderne il contenuto.
Ad esempio in uno scenario di request-response tra un’applicazione cliente residente su un mini-computer e una servente residente su un mainframe si ha il seguente flusso di eventi (Figura 1):
L’applicazione client invia una request;
La request viene intercettata dall’interfaccia;
L’interfaccia traduce la request in modo da formattarla secondo le modalità comprensibili dal server;
Il server riceve la request e elabora la response;
La response viene intercettata dall’interfaccia;
L’interfaccia traduce la request in modo da renderla comprensibile al client;
Il client riceve la response.
Figura 1 - Scenario di request/response con interfaccia
Il problema è che l’interfaccia è un componente svilupato ad-hoc e per questo la sua realizzazione è costosa e poco flessibile ai cambiamenti. Inoltre se l’interfaccia è basata su tecnologie proprietarie l’azienda sarà legata strettamente al relativo vendor, con perdite non quantificabili nel caso di fallimento di quest’ultimo.
La soluzione sta nell’eliminare le interfacce proprietarie e quindi rendere i sistemi SW eterogenei interoperabili attraverso standard aperti. Dal 1990 tali standard vennero da
Internet e sono: HTTP1 ed XML.
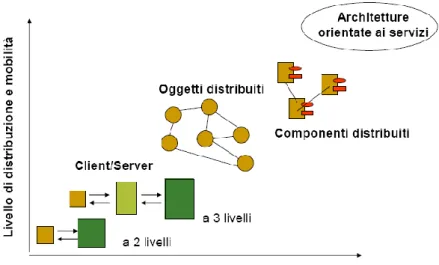
Prima di arrivare a ciò in realtà ci sono stati altri passi che occorre citare (Figura 2).
Il primo è l’avvento dell’object-orientation, che propone una nuova filosofia per scrivere SW. Tale filosofia soppianta la programmazione procedurale e permette di avere avanzati costrutti di programmazione come: ereditarietà, polimorfismo, information-hiding, riuso, ecc…
Alcuni di questi come l’information-hiding e il riuso sono stati fatti propri da molte delle architetture di middleware che sono poi sorte per far fronte alle prime esigenze d’interoperabilità tra le applicazioni. Anche SOA sfrutta tali principi.
Il secondo evento importante è la diffusione del paradigma client-server e quindi di request/response, che può essere considerato come il pattern di programmazione di maggior successo per l’implementazione di SW distribuito.
Il mix di object-orientation e di paradigma client-server ha portato alla nascita del modello ad oggetti distribuiti, che è stato uno dei più esaltanti e pioneristici tentativi di realizzazione di un middleware per la cooperazione distribuita tra componenti SW. Il prodotto di maggior successo di tale filosofia è CORBA, standardizzato dalla OMG. Tale modello si è poi evoluto nel modello a componenti distribuiti, che offre il vantaggio di distribuire in rete non singoli oggetti ma intere applicazioni, indipendenti e quindi riusabili.
Il problema di quest’approccio stava comunque nel fatto che la comunicazione non avveniva attraverso protocolli standard e questo rendeva difficoltosa la comunicazione tra applicazioni che utilizzavano middleware diversi2.
1
Uno dei vantaggi più significativi di HTTP è il fatto che è forse l’unico protocollo non bloccato dalla stragrande maggioranza dei firewall di Internet. Ciò non vale per altri protocolli di livello applicazione.
2
Tale necessità si ha sicuramente se si vuole far comunicare il sistema informativo dell’azienda con un sistema informativo di un suo fornitore per stabilire un rapporto di tipo B2B
Figura 2 - Evoluzione dei sistemi distribuiti in termini di distribuzione e complessità
Ecco che allora sono nati i Web-Service, che implementano la SOA, utilizzando solo ed unicamente HTTP come veicolo di trasporto di messaggi tra applicazioni diverse ed XML. In particolare i Web-Service utilizzano un’interfaccia comunemente accettata che è SOAP (Simple Object Access Protocol) e in genere, ma non necessariamente, il paradigma request/response del Web.
2.3.
SOA e Business
In passato l’integrazione di applicazioni avveniva tra software che risiedevano sulla stessa piattaforma o middleware e tipicamente all’interno della stessa organizzazione. Volendo invece interconnettere middleware diversi le cose si complicano, data la necessità di standardizzare le interfacce di applicazioni appartenenti a sistemi differenti per permettere loro di interagire.
Figura 3 - Applicazioni Etereogenee all'interno della stessa organizzazione
Nacque quindi da subito l’esigenza di superare tale approccio per passare da un mondo eterogeneo, dove le varie architetture si sommano in un agglomerato caotico, ad un insieme più ordinato di risorse le quali gravitano intorno ad un nucleo detto “infrastruttura di integrazione”, che si preoccupa di collegare tutto l’insieme impresa (Figura 3).
Come abbiamo visto nel precedente paragrafo i primi tentativi di integrazione si rivolsero alla creazione di interfacce di interazione proprietarie tra applicazioni eterogenee. Quest’approccio risultava però spesso impraticabile oltre che estremamente dispendioso, specie quando si doveva far comunicare applicazioni di aziende diverse che puntavano all’integrazione della propria catena del valore.
La SOA si evolve in uno scenario dove sempre più aziende sviluppano rapporti di partnership e quindi in tale contesto diventa indispensabile che i rispettivi sistemi informativi riescano a raggiungere un certo livello di integrazione, tenendo comunque presente che il più delle volte le piattaforme di partenza sono tra loro eterogenee. Quindi la nascita della SOA deve essere vista come un’evoluzione dei sistemi middleware, che, dall’integrazione delle applicazioni della singola azienda, vengono estesi all’integrazione delle applicazioni di più imprese.
2.4.
Vantaggi e benefici di una SOA
A fronte della globalizzazione sia dei mercati sia della risorse della catena del valore di un’impresa, occorre rispondere con un nuovo modello di competitività, basato sulle tre A (vedi [Error! Bookmark not defined.]):
Agility;
Adaptability;
Alignment.
La più importante delle tre è senza dubbio Adaptability, che è traducibile con “flessibilità”.
Da ciò nasce l’idea della RTE (Real-Time Enterprise). La RTE è infatti quella organizzazione dove i fattori di mutamento vengono immediatamente percepiti e individuati per attivare una serie di reazioni che si applicano a tutta la catena del valore e che si esplicano nel modificare i processi di business o nell’introdurne di nuovi. Il costante monitoraggio delle attività di business e la tempestiva valutazione dell’effetto che queste vengono ad avere sulle prestazioni aziendali costituiscono l’input di un ciclo virtuoso che tende a ridurre sempre più il ritardo nell’adeguare processi e attività al mutare delle situazioni. In altre parole: permettono di rendere l’impresa sempre più flessibile.
L’ostacolo più importante offerto dall’IT allo sviluppo di una RTE sta nel fatto che le applicazioni sono molto cresciute sul fronte delle funzionalità, ma la loro flessibilità nei confronti delle esigenze del business è rimasta limitata, se non ridotta proprio dalla ricchezza e complessità delle loro funzioni.
Una qualsiasi modifica del processo, anche quella che agli occhi degli uomini del business può sembrare la più banale, come l’inclusione di sconti in fattura a fronte di date condizioni di vendita, comporta per l’IT un intervento sull’applicazione che può essere, specie se si tratta di software di vecchia generazione, oneroso in termini di risorse umane e di tempo.
Questa rigidità non solo è un freno allo sviluppo della RTE, ma è anche responsabile di un problema ancora più grave. Si tratta dello “scollamento” tra la funzione IT e le funzioni di
business che affligge il management di molte imprese.
La SOA risolve buona parte di questi problemi, poiché oltre a ridurre il costo e la complessità dei servizi IT può contribuire a migliorare significativamente il rapporto tra le funzioni di business e tra queste e l’IT, cambiando il modo stesso di operare dell’impresa verso una maggiore collaborazione e una maggiore flessibilità.
Un servizio di business è l’incapsulamento logico di una o più funzioni di business. Esso va considerato come un singolo componente applicativo, che si relaziona con gli altri componenti attraverso un’interfaccia formalizzata secondo specifici standard. Di conseguenza, l’architettura orientata ai servizi è un approccio alla progettazione software che scompone le applicazioni di business in blocchi funzionali separati (i “servizi di business”) che possono essere realizzati in modo indipendente dalle applicazioni stesse e dalle piattaforme sulle quali queste vengono utilizzate. Inoltre risulta molto semplice poter sostituire un servizio con uno diverso (loose coupling). Tant’è che una metafora molto diffusa a proposito della SOA è quella dei mattoncini “Lego”, ma forse rende di più l’idea del loose coupling il modello “Scarabeo”, dove a differenza dei mattoncini, che una volta sistemati non si possono più cambiare senza disfare il lavoro fatto, le tessere con le lettere si possono combinare e ricombinare fino a formare un’infinità di parole.
Questa intercambiabilità nasce dal fatto che nei servizi di una SOA le logiche di business, quelle che dicono cosa deve fare il servizio, sono disaccoppiate dalle logiche applicative, quelle che si occupano di come erogare il servizio in base alle risorse dell’infrastruttura. Nei confronti dell’applicazione che ne fa uso, il servizio è una black box il cui contenuto può essere tranquillamente ignorato. Quello che conta è che faccia quello che gli viene chiesto di fare.
Una SOA funziona nella misura in cui i servizi di business comunicano con modalità standard; e se oggi esiste un ambiente davvero universale, questo è quello della Rete. I protocolli, i linguaggi e gli standard nati o adottati dal Web e dai servizi da esso veicolati, forniscono un framework che permette di scrivere un servizio di business (che a questo punto possiamo chiamare servizio Web) in grado, potenzialmente, di parlare con qualsiasi
altro servizio Web reso visibile e disponibile sulla rete. Attualmente la rete utilizzata è Internet e questo semplifica l’adozione della SOA in tutte quelle aziende che hanno già un portafoglio applicativo di tipo web-based.
Ovviamente non basta tradurre in servizi Web tutte le funzioni del parco applicativo per avere un’architettura orientata ai servizi. Infatti una SOA esiste in quanto i servizi su cui si basa separano nettamente le funzioni di business dalla tecnologia che le realizza. Occorre quindi prima scomporre la logica dell’applicazione in una serie di logiche di business e poi tradurre queste in servizi Web gestibili e riutilizzabili in ottica SOA. Tale processo è di tipo top-down. Si parte cioè dall’analisi dei processi di business complessi presenti in azienda (es. processi svolti dalle applicazioni di ERP, CRM, SCM, ecc…), per identificare quelle operazioni più semplici, ma comunque riferibili ad un’attività di business, che una volta incapsulate in forma di servizio Web, possano essere pubblicate, distribuite e riutilizzate in più applicazioni.
Un punto importante su cui occorre riflettere è quale è il livello di frammentazione da adottare. Si potrebbe pensare che decomponendo le applicazioni in servizi per quanto possibile elementari, o, come si dice molto spesso, granulari, si dovrebbe raggiungere la massima riusabilità dei servizi stessi, ottenendo quindi dalla SOA il migliore valore per il business. In realtà non è così, perché l’assemblaggio dei servizi in un’applicazione composita ha comunque un costo d’integrazione, che ovviamente cresce con l’aumentare del numero dei componenti da assemblare. D’altra parte, è vero che disporre di pochi componenti di grandi dimensioni, quindi con logiche di business più complesse, ne riduce la possibilità di riutilizzo. Si tratta quindi di raggiungere un compromesso tra costi e flessibilità individuando il punto in cui questo rapporto ha il maggior valore per il business. Ancora una volta, non ci sono regole che determinano la granularità ottimale, che va trovata per ogni applicazione.
Altro aspetto da considerare riguarda i requisiti di qualità e affidabilità delle tecnologie a supporto delle imprese, che rendono essenziale stabilire degli SLA (Service Level Agreement) e saperli controllare e rispettare. Garantire queste condizioni in un sistema tradizionale è principalmente compito dell’infrastruttura ICT. In un’architettura SOA si
introduce un ulteriore livello di complessità, poiché il servizio offerto al business è costituito a sua volta da una serie di servizi, ognuno dei quali deve garantire uno SLA almeno pari (meglio superiore) a quello richiesto per l’applicazione risultante. Premesso che in una SOA la robustezza richiesta all’infrastruttura non è certamente inferiore che in un’architettura tradizionale, ma anzi alquanto più elevata, il compito di garantire i livelli di servizio concordati con il business spetta ad una serie di strumenti software che si identificano con la sigla BPM (Business Process Management). Essi collaborano tra loro attraverso un bus SW (Enterprise Service Bus), che assicura le funzioni base di connettività tra i servizi Web componenti il servizio di business erogato.
2.5.
Caratteristiche della SOA
Una SOA è un modello architetturale per la creazione di sistemi residenti su una rete che focalizza l’attenzione sul concetto di servizio. Un servizio è un componente computazionale autonomo, platform indipendent, che può essere composto con altri servizi, realizzando in questo modo applicazioni di maggiore complessità.
L’astrazione delle SOA non è legata ad alcuna specifica tecnologia, ma semplicemente definisce alcune proprietà, orientate al riutilizzo e all’integrazione in un ambiente eterogeneo, che devono essere rispettate dai servizi che compongono il sistema. In particolare un servizio dovrà:
essere ricercabile e recuperabile dinamicamente – un servizio deve poter essere ricercato in base alla sua interfaccia e richiamato a tempo di esecuzione;
essere autocontenuto e modulare – ogni servizio deve essere ben definito, completo ed indipendente dal contesto o dallo stato di altri servizi;
essere definito da un’interfaccia ed indipendente dall’implementazione – un servizio
deve essere definito in termini di ciò che fa, astraendo dai metodi e dalle tecnologie utilizzate per implementarlo. Questo determina l’indipendenza del servizio non solo dal linguaggio di programmazione utilizzato per realizzare il componente che lo implementa, ma anche dalla piattaforma e dal sistema operativo su cui è in esecuzione: non è necessario conoscere come un servizio è realizzato ma solo quali
funzionalità rende disponibili;
essere debolmente accoppiato con altri servizi (loosely coupled) – un’architettura è debolmente accoppiata se le dipendenze fra le sue componenti sono in numero limitato. Questo rende il sistema flessibile e facilmente modificabile;
essere reso disponibile sulla rete attraverso la pubblicazione della sua interfaccia (in un Service Directory o Service Registry) ed accessibile in modo trasparente rispetto alla sua locazione – essere disponibile sulla rete rende il servizio accessibile da quei componenti che ne richiedono l’utilizzo. L’accesso deve avvenire in maniera indipendente rispetto alla locazione in cui esso è in esecuzione, mentre la pubblicazione dell’interfaccia deve rendere note anche le modalità di accesso al servizio;
fornire un’interfaccia possibilmente a “grana grossa” (coarse-grained) – il servizio
deve mettere a disposizione un basso numero di operazioni, cioè poche funzionalità, in modo tale da non dover avere un programma di controllo complesso. Deve essere invece orientato ad un elevato livello di interazione con gli altri servizi attraverso lo scambio di messaggi. Per questo motivo e per il fatto che i servizi possono trovarsi su sistemi operativi e piattaforme diverse è necessario che i messaggi siano composti utilizzando un formato standard largamente riconosciuto (Platform Neutral). I dati che vengono trasmessi attraverso i messaggi possono essere costituiti sia dal risultato dell’elaborazione di un certo servizio sia da informazioni che più servizi si scambiano per coordinarsi fra loro;
essere realizzato in modo tale da permetterne la composizione con altri – nell’architettura SOA le applicazioni sono il risultato della composizione di più servizi. E’ per questo motivo che ogni servizio deve essere indipendente da qualsiasi altro, in modo tale da ottenere il massimo della riusabilità. La creazione di applicazioni o di servizi più complessi attraverso la composizione dei servizi di base viene definita Service Orchestration e sarà descritta nel prosieguo del presente capitolo.
2.6.
Come funziona una SOA
SOA è un’architettura per sviluppare sistemi informatici, che ha come obiettivo fondamentale la flessibilità rispetto ai cambiamenti e il riuso.
SOA è costituita da un insieme di componenti che interagiscono e per i quali l’architettura si limita a definire quali sono i componenti e come interagiscono tra loro.
Figura 4 - Funzionamento della SOA
I componenti in SOA sono (Figura 4):
Service consumer, o Service requestor – è la parte che implementa il front-end verso l’utente;
Service (o service provider) – è la parte che si occupa della implementazione delle funzionalità e incapsula in sé gli aspetti connessi alla business logic dell’applicazione. Un servizio è caratterizzato da un “contratto” che dettaglia una descrizione di quelle che sono le funzionalità, i vincoli e le modalità d’uso del servizio;
Service repository (o service registry) – fornisce delle primitive che consentono di reperire il servizio in modo semplice e immediato. Esso fornisce alcune informazioni importanti tra cui:
o Le funzionalità offerte in termini di operazioni e il modo in cui poterle poi richiamare (viene usato WSDL per questa funzionalità – vedi paragrafo 2.7.1 );
o Access rigths (meccanismi di sicurezza);
Enterprise Service BUS – connette tutti i partecipanti di una applicazione SOA-based. Il ruolo del Service Bus è simile al ruolo dell’ORB nell’architettura di CORBA (vedi Error! Reference source not found.).
Ci sono due diversi approcci allo sviluppo di applicazioni con SOA:
Binding Statico – il service requestor conosce tutte le informazioni per il reperimento del servizio (firma delle operazioni e localizzazione del servizio). Questo è l’approccio più semplice, ma anche meno flessibile;
Binding Dinamico – il binding del servizio è fatto a runtime. Il service requestor effettua quindi una lookup del servizio nel registry, utilizzando il nome del servizio o alcune sue caratteristiche.
Il meccanismo di binding dinamico può prevedere due scenari differenti:
o Il service requestor conosce già l’interfaccia del servizio e conosce già come richiederlo (in tal caso riceve dal registry solo le informazioni di localizzazione del servizio);
o Il service requestor non conosce l’interfaccia del servizio e in tal caso dovrà provvedere a trovare a run-time le firme delle operazioni richieste, in modo da richiamare correttamente il servizio reperito.
2.7.
Da SOA ai Web Service
I Web Service (WS) sono un nuovo tipo di applicazioni web che cooperano fra loro, indipendentemente dalla piattaforma sulla quale si trovano, attraverso lo scambio di messaggi. Essi rappresentano il miglior modo per implementare una architettura orientata ai servizi.
Indipendenza dalla piattaforma – i Web Service possono comunicare fra loro anche se si trovano su piattaforme differenti;
Indipendenza dall’implementazione del servizio – l’interfaccia che un Web Service
presenta sulla rete è indipendente dal software che implementa tale servizio. In futuro tale implementazione potrà essere sostituita o migliorata senza che l’interfaccia subisca modifiche e quindi senza che tali modifiche impattino sull’esterno (verso altri utenti o servizi sulla rete);
Riuso dell’infrastruttura – per lo scambio di messaggi si utilizza il protocollo applicativo SOAP, a sua volta incapsulato nel protocollo applicativo del Web (HTTP), grazie al quale si ottiene anche il vantaggio di permettere ai messaggi di passare attraverso sistemi di filtraggio del traffico sulla rete;
Riuso del software – è possibile riutilizzare software implementato precedentemente e renderlo disponibile attraverso la rete. Il concetto di Web Service implica quindi un modello di architettura ad oggetti distribuiti (oggetti intesi come applicazioni), che si trovano localizzati in punti diversi della rete e su piattaforme di tipo differente. Il legame con l’architettura SOA sta nel fatto che, sfruttando al meglio tutte le caratteristiche della tecnologia dei Web Service, il sistema che si ottiene implementa proprio un’architettura orientata ai servizi.
Le tecnologie su cui si basano i Web Service sono:
XML, eXtensible Markup Language;
SOAP, Simple Object Access Protocol;
WSDL, Web Services Description Language;
UDDI, Universal Description, Discovery and Integration.
Attraverso l’utilizzo di questi ed altri standard i Web Service rendono possibile la comunicazione e la cooperazione attraverso il web di più applicazioni (servizi), le quali mettono a disposizione alcune funzionalità e, allo stesso tempo, utilizzano quelle rese disponibili da altri Web Service. Si può cioè ricercare ed invocare servizi che possono essere composti per formare un’applicazione che sia utilizzabile da un utente finale, che
abiliti transazioni di business o che implementi un nuovo Web Service.
Si ottiene così quella che oggigiorno è da molti considerata la migliore soluzione per l’implementazione di un sistema con architettura Service-Oriented.
2.7.1
WSDL
3WSDL, ovvero Web Services Description Language, è un linguaggio, basato su XML, usato per descrivere in modo completo un Web Service. Più precisamente un documento WSDL fornisce informazioni riguardanti l’interfaccia del Web Service in termini di:
servizi offerti dal Web Service,
URL ad esso associato,
modi per l’invocazione,
argomenti accettati in ingresso e modalità con cui debbono essere passati,
formato dei risultati restituiti,
formato dei messaggi.
In altri parole si può dire che un file WSDL fornisce la descrizione relativa ad un Web Service in termini di:
cosa fa,
come comunica,
dove si trova.
Attraverso tale file si possono quindi conoscere tutti i dettagli per poter invocare correttamente un servizio.
3 Maggiori dettagli sulla struttura di un documento WSDL sono disponibili su Error! Reference
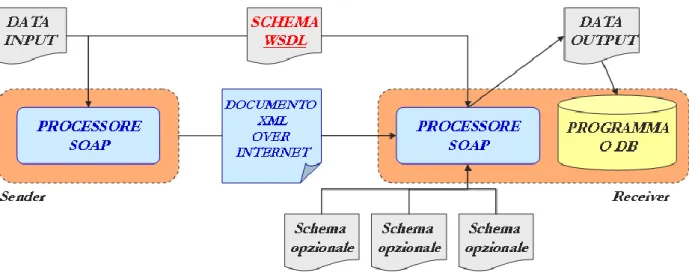
Figura 5 - Utilizzo di WSDL in una comunicazione sender/receiver
La Figura 5 mostra come il WSDL consenta la comunicazione tra un sender e un receiver. Sia il sender che il receiver devono conoscere il documento WSDL per poter poi riferirsi alle stesse regole di comunicazione. Il sender può ad esempio conoscere dal documento WSDL come invocare dei servizi esposti dal receiver, nell’ipotesi che il sender sia il service requestor e il receiver il service provider.
Le comunicazioni vengono poi formattate sottoforma di messaggi SOAP (vedi paragrafo 2.7.2 ) dal Processore SOAP residente sul sender e poi ricevute dal Processore SOAP residente sul receiver.
Esistono generatori automatici di codice in grado di creare l’implementazione del client per accedere al servizio a partire dal documento WSDL ad esso associato.
Più semplicemente si può vedere il vantaggio apportato dall’uso dei documenti WSDL nel disaccoppiamento del servizio Web dal protocollo di trasporto e dai percorsi fisici, come gli endpoint. Si ottiene così un livello di trasparenza grazie al quale non è necessario conoscere su quale macchina è fisicamente localizzato il Web Service (trasparenza alla localizzazione). Inoltre in questo modo se vi saranno molti client che utilizzano il servizio, nel momento in cui esso cambia indirizzo, non si dovrà riconfigurarli tutti, ma semplicemente aggiornare tale informazione nel documento WSDL, poichè è da questo che i client otterranno l’endpoint (trasparenza alla migrazione).
2.7.2
SOAP
4SOAP, Simple Object Access Protocol, è un protocollo di trasmissione di messaggi in formato XML. SOAP mette a disposizione un meccanismo semplice, ma allo stesso tempo solido, che permette ad una applicazione di mandare un messaggio XML ad un’altra applicazione. Un messaggio è costituito da una trasmissione in un senso, dal mittente al ricevente, ma si possono avere uno o più messaggi, che definiscono così il tipo di comunicazione che stiamo stabilendo: One-way, Request-response, Solicit-response, Notification.
Un messaggio SOAP viene mandato da un mittente ad un destinatario. Ad essi ci si riferisce facendo uso del termine Nodo. Un nodo, oltre che mittente e destinatario, può essere anche intermediario. Un messaggio SOAP può attraversare anche molti intermediari prima di raggiungere il destinatario ed ogni intermediario può elaborare le intestazioni del messaggio. Affinchè tali intestazioni vengano elaborate correttamente esistono degli attributi specifici che determinano ruolo e comportamento degli intemediari.
Uno degli obiettivi di SOAP, oltre al trasferimento di dati, è l’incapsulamento all’interno dei messaggi delle chiamate a procedure remote (Remote Procedure Calls). Le informazioni necessarie ad invocare una SOAP RPC sono le seguenti:
Indirizzo del nodo SOAP a cui è indirizzata la chiamata;
Nome della procedura o metodo da invocare;
Parametri con relativi valori da passare al metodo e parametri di output;
Trasmissione (opzionale) della signature del metodo;
Dati (opzionali) che possono essere stati trasportati come parte dei blocchi header.
2.7.3
UDDI
La presenza del Service Registry è ciò che rende il sistema dei Web Service visto precedentemente un’architettura Service-Oriented.
Per implementare il Service Registry i Web Service fanno uso di UDDI, Universal
4 Maggiori dettagli sulla struttura del Messaggio SOAP sono disponibili su Error! Reference
Description, Discovery and Integration.
UDDI è un servizio di registro pubblico in cui le aziende possono registrare (pubblicare) e ricercare Web Service. Esso mantiene informazioni relative ai servizi come l’URL e le modalità di accesso. Quindi anche UDDI è un Web Service, che mette a disposizione due operazioni:
Publish, per la registrazione;
Inquiry (o lookup), per la ricerca.
UDDI usa una comunicazione basata su XML ed utilizza SOAP per le comunicazioni da e verso l’esterno. Inoltre esso definisce un meccanismo comune per pubblicare e trovare informazioni sui Web Service, in base alle loro descrizioni WSDL. Ciò che UDDI mette a disposizione è un registro nel quale si possa accedere, attraverso specifiche funzioni, per:
pubblicare servizi che un’azienda rende disponibili;
cercare aziende che mettono a disposizione un certo tipo di servizio;
avere informazioni “Human Readable”, cioè comprensibili all’utente, circa indirizzi, contatti o altro relativi ad una azienda;
avere informazioni tecniche “Machine Readable”, cioè interpretabili ed utilizzabili dalla macchina, relative ad un servizio in modo tale da potervisi connettere.
Un registro UDDI è costituito in realtà da un database distribuito, cioè da molti registri distribuiti sulla rete, ognuno dei quali si trova sul server di una azienda che contribuisce allo sviluppo di questo archivio pubblico, e connessi fra loro. Il sistema mantiene una centralizzazione virtuale, cioè l’informazione che viene registrata su uno dei nodi (registri) del sistema viene propagata e resa disponibile su tutti gli altri tramite una loro sincronizzazione. Questo, oltre che ad alleggerire il carico di lavoro che un singolo nodo deve sopportare, contribuisce alla protezione del sistema contro possibili situazioni di failure del database, grazie alla ridondanza dei dati. Per semplificità consideriamo UDDI come un unico grande registro. Esso può essere visto come le pagine gialle, nelle quali cerchiamo informazioni sulle aziende che attraverso esse ottengono maggiore visibilità e di conseguenza la possibilità di avere un più alto numero di clienti.
In particolare, la registrazione di un servizio all’interno di un registro UDDI è costituita da tre parti:
Yellow Pages;
White Pages;
Green Pages.
Con le Yellow Pages (pagine gialle) le aziende ed i loro servizi vengono catalogati sotto differenti categorie e classificazioni.
Nelle White Pages (pagine bianche) possiamo trovare informazioni come gli indirizzi di una azienda o contatti ad essa relativi.
Infine vi sono le Green Pages (pagine verdi), dove sono contenute informazioni tecniche relative ai servizi, grazie alle quali questi ultimi possono essere invocati.
2.8.
La composizione dei servizi
Abbiamo visto nel dettaglio come ogni Web Service metta a disposizione alcune funzionalità che, in relazione alla complessità del compito che svolgono, risultano però essere di basso livello. Queste tecnologie non forniscono quindi la possibilità di portarsi ad un livello superiore a quello del singolo servizio e di costruire ed utilizzare un processo più grande e complesso ottenuto dalla composizione di più servizi web. Una tale composizione prende il nome di business process.
Il processo di composizione di servizi rappresenta quindi la naturale estensione dei Web Service ed è trasparente al fruitore del servizio. Dal punto di visto del fruitore deve essere infatti trasparente la tipologia del servizio richiesto (semplice o composito).
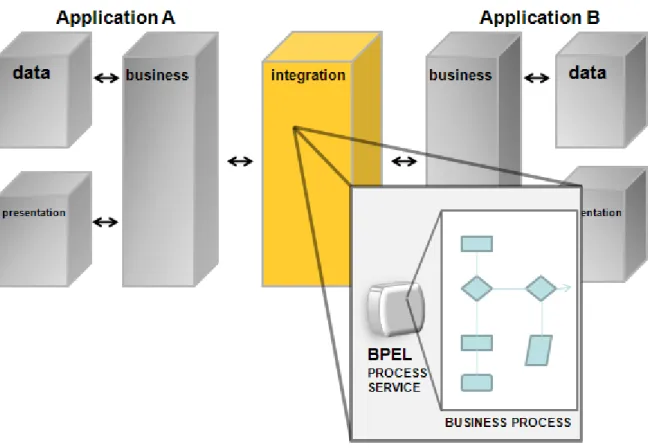
Figura 6 - Esempio composizione di servizi
Come si può vedere in Figura 6 il business process espone al fruitore un servizio complesso ottenuto mediante composizione dei servizi esposti dalle Applicazioni A e B. La schematizzazione del business process come diagramma di flusso non è casuale, tant’è che esistono diversi formalismi che utilizzano diagrammi di flusso e/o attività per descrivere un business process.
La composizione di business process può avvenire secondo due possibili modalità (Figura 7):
Orchestration – descrive il processo di business ed in particolare la sua logica in termini del flusso di esecuzione controllato da una singola parte. Definisce le interazioni, costituite da scambi di messaggi, che vi possono essere fra i servizi web e stabilisce il loro ordine di esecuzione;
Choreography – definisce la sequenza dei messaggi che può coinvolgere i vari web service. In tale sequenza viene identificato il ruolo che ogni parte svolge all’interno del processo. Il processo è quindi descritto a livello collaborativo, rappresentando la cooperazione fra i servizi che ne fanno parte.
Figura 7 - Schematizzazione di orchestration e choreography
La differenza importante fra queste due modalità risiede nel punto di vista da cui si osserva il processo. Per “Orchestration” il punto di vista è quello relativo ad una delle parti che costituiscono il processo, in particolare quella che ne detiene il controllo, mentre per la modalità di “Choreography” il punto di vista è quello generale, cioè di una visione della cooperazione fra i vari servizi dall’interno.
I due principali vantaggi che si ottengono dal processo di composizione sono il:
Riuso – attraverso la composizione è possibile sviluppare i servizi in modo modulare così da favorire la riusabilità degli stessi. Il concetto è analogo alla modularizzazione utilizzata nei linguaggi di programmazione;
Governo della complessità – è possibile progettare e sviluppare i servizi in moduli e, in questo modo, avere un elevato controllo della complessità architetturale. I servizi vengono considerati come delle componenti atomiche e semplici che, composte, .formano un servizio composito e complesso che porta valore aggiunto all’azienda.
Quando si progettano e sviluppano business process che coinvolgono molti Web Service e la cui esecuzione può avere un tempo di durata elevato bisogna tenere presenti alcuni requisiti tecnici molto importanti. Per prima cosa è necessario che i servizi possano essere invocati in modo asincrono; in questo modo un business process può invocare concorrentemente più Web Service per migliorare le prestazioni. Devono poi essere gestite le eccezioni e l’integrità delle transazioni, definendo il comportamento del sistema in caso di errore o di mancata risposta di un servizio invocato entro un certo limite di tempo.
Infine caratteristiche importanti nell’attività di coordinamento dei Web Service sono dinamicità, flessibilità, adattabilità e riutilizzabilità; tenendo separata la logica del processo dai Web Service che lo realizzano si ottiene un alto livello di flessibilità che permette al business process di essere dinamicamente adattato per vari scopi, semplicemente richiamando i servizi necessari.
Tutto ciò è garantito dalla presenza di modelli per la composizione dei Web Service.
2.9.
Il modello di composizione dei WS
I modelli di composizione di WS sono solitamente piuttosto complessi, di seguito verranno presentate le differenti dimensioni (componenti logiche) che li formano.
In un modello di composizione sono presenti sei principali dimensioni:
Component model – definisce il tipo di elementi che compongono il modello e che tipo di assunzioni possono essere fatte su tali componenti;
Orchestration model – definisce le astrazioni e i linguaggi che sono utilizzati per definire in che ordine i servizi devono essere invocati;
Data access model – definisce come i dati sono definiti e in che modo tali dati sono scambiati tra i vari componenti del modello;
Service selection model – definisce in che modo i servizi sono selezionati (ad esempio in modo statico o dinamico);
Transactions – definisce come viene gestito l’aspetto transazionale dei servizi;
Exception handling – definisce in che modo vengono catturate e gestite le eccezioni che possono occorrere durante l’esecuzione del servizio composito.
2.9.1
Component Model
I principali elementi che caratterizzano un modello di composizione sono i tipi di componenti che lo costituiscono. Ad esempio un modello potrebbe assumere che i componenti siano un insieme specifico di standard relativi ai Web Service come HTTP, SOAP, WSDL, etc… Ovviamente un’assunzione di questo tipo comporta un’implementazione molto semplice ma è, allo stesso tempo, piuttosto limitante,
soprattutto in ambienti fortemente eterogenei. Una soluzione radicalmente opposta potrebbe considerare i componenti come degli oggetti che sono in grado di comunicare in modo sincrono o asincrono attraverso messaggi di tipo XML. Ovviamente, una soluzione di questo tipo lascia molta libertà e rende il modello molto generale ma, allo stesso tempo, rende il processo di composizione molto complesso e laborioso.
Una soluzione intermedia potrebbe essere quella di supportare diversi tipi di componenti e avere la possibilità di definire delle soluzioni personalizzate per quei componenti che non ricadono in nessuna delle categorie definite.
2.9.2
Orchestration Model
Con orchestration model si intende il modello utilizzato per definire quali servizi devono essere invocati, il relativo ordine e sotto quali condizioni. Esistono numerosi strumenti che permettono di definire il modo di interagire dei vari servizi; alcuni derivano dalla metodologia UML (come ad esempio l’Activity Diagram), mentre altri sono dei veri e propri linguaggi che sono stati definiti per molteplici scopi ma che possono essere ugualmente utili in questo contesto (ad esempio lo stesso BPEL).
2.9.3
Data transfer model
Analogamente a quanto avviene nei linguaggi di programmazione, anche nel caso dei modelli di composizione è necessario definire come sono rappresentati i dati e come questi sono trasferiti tra i vari servizi.
I dati possono essere distinti in:
dati applicativi – sono i parametri dei servizi che vengono scambiati attraverso i messaggi;
dati di controllo – sono quei dati necessari per valutare le espressioni condizionali che determinano l’esecuzione di un servizio o di un altro, quindi servono per eseguire il corretto flusso definito dalla logica applicativa.
Generalmente i dati applicativi sono sempre in quantità maggiori rispetto a quelli di controllo, inoltre i dati applicativi coinvolgono tipi di dati arbitrariamente complessi,
mentre i dati di controllo sono formati da tipi di dato semplice (interi, booleani, stringhe, etc…). In base a queste considerazioni, i dati applicativi sono quelli che determinano il modello di gestione dei dati.
Esistono due approcci per la gestione dei dati applicativi. Il primo approccio considera i dati come una black-box e si preoccupa solamente di inviare i puntatori a queste black box da un servizio ad un altro. In questo modello i Web Service si scambiano URL o puntatori ai dati (documenti, immagini, …) anziché messaggi testuali.
L’approccio basato sulle black-box comporta diversi vantaggi, il principale è che il modello di composizione può ignorare completamente lo scambio di dati tra le attività. D’altro canto questo approccio obbliga gli sviluppatori a scrivere dei wrapper per tutte quelle applicazioni che si aspettano di ricevere dei dati e non dei puntatori.
Il secondo approccio cerca di rendere tutti i dati applicativi espliciti, includendo, all’interno dello schema di composizione, le adeguate definizioni per ogni tipo di dato. Una soluzione intermedia che viene attualmente utilizzata nei Web Service è lo scambio di messaggi XML con la possibilità di avere dei file allegati di qualsiasi tipo.
La rappresentazione dei dati è importante, ma ancora più importante è come questi vengono trasferiti tra le varie attività (servizi). Esistono due approcci: quello basato su
blackboard e quello chiamato explicit data flow.
L’approccio basato su blackboard segue la logica utilizzata dai linguaggi di programmazione. Il principio su cui si basa è che durante l’esecuzione del servizio composito tutte le variabili hanno un nome e sono elencate. La blackboard è una collezione di variabili dove le attività possono memorizzare le proprie variabili in output e prendere i valori delle variabili in input. Sia in fase di invio che di ricezione, le attività accedono alla propria blackboard per leggere o scrivere i valori delle variabili di interesse. Ogni attività ha la propria blackboard e le attività possono avere differenti diritti di accesso per una stessa variabile (ad esempio read-write, read-only, etc. . . ).
L’approccio chiamato explicit data flow consiste nel rendere il flusso di dati tra le attività parte del processo di composizione. Attraverso l’utilizzo di particolari connettori tra le attività, il progettista può specificare che l’input di una particolare attività è l’output di
un’altra attività eseguita precedentemente. Questo approccio permette una maggiore flessibilità, introduce una maggiore complessità sia in termini di implementazione del modello sia in termini di progettazione, mentre invece l’approccio basato su blackboard è più naturale per gli sviluppatori in quanto rispecchia pienamente il modello utilizzato negli attuali linguaggi di programmazione.
2.9.4
Service selection
Tipicamente in uno schema di composizione non vengono specificati gli indirizzi fisici dei servizi che compongono il servizio composito, l’operazione di assegnazione di un indirizzo ad un servizio è detta binding.
Esistono quattro metodi per effettuare il binding di un servizio:
binding statico – consiste nella soluzione banale di scrivere l’indirizzo del servizio all’interno dello schema di composizione. Questo metodo è il più semplice ma è anche il meno flessibile, infatti se un servizio cambia indirizzo allora bisogna cambiare lo schema di composizione;
binding dinamico per riferimento – il modo più semplice per ovviare alle limitazioni del modello basato su binding statico è quello di seguire l’approccio basato sul riferimento. L’indirizzo del servizio è identificato da un nome e non viene fatta nessuna assunzione sulla politica di assegnazione dell’indirizzo fisico alla variabile che ne rappresenta il valore. Questo approccio è una naturale estensione del modello statico con l’aggiunta di poter scegliere dinamicamente l’indirizzo di un servizio; proprio per la sua semplicità e flessibilità è il modello maggiormente utilizzato dai principali modelli e linguaggi di composizione;
binding dinamico per lookup – in questa soluzione è possibile definire, per ogni attività, una query il cui risultato è utilizzato per determinare l’indirizzo del servizio. Ad esempio, la query associata ad ogni attività potrebbe essere l’interrogazione ad un registro UDDI;
binding per selezione dinamica dell’operazione – in alcuni casi esiste la possibilità
eseguire, questo approccio è chiamato dynamic operation selection.
2.9.5
Transaction
L’approccio utilizzato per fornire le proprietà transazionali ad un servizio composito consiste nel definire delle regioni atomiche all’interno dello schema di composizione. Solitamente le attività che fanno parte di una regione atomica o devono essere eseguite tutte o non ne deve essere eseguita nessuna. L’atomicità può essere ottenuta facilmente attraverso l’esecuzione di protocolli di tipo 2PC (Two Phase Commit). In ambienti distribuiti la soluzione di effettuare un lock sulle risorse non è praticabile, soprattutto per i servizi di lunga durata. La soluzione adottata in molti casi si basa sulla compensazione, se una delle attività appartenenti alla regione atomica fallisce, allora sono eseguite delle operazioni di compensazione che annullano le operazioni eseguite precedentemente. Un interessante modello per la gestione delle transazioni di lunga durata è detto saga. Questo modello permette di suddividere una transazione in sotto-transazioni eseguite in un particolare ordine, rispettando le tradizionali proprietà ACID (Atomicity, Consistency, Isolation and Durability). Ogni sotto-transazione ha associata una transazione di compensazione che ha il compito di annullare l’effetto della sotto-transazione. Un’operazione di compensazione comporta l’esecuzione delle sotto-transazioni di compensazione, ovviamente in ordine inverso rispetto all’esecuzione della transazione.
2.9.6
Exception handling
Un’altra problematica importante riguarda la gestione delle eccezioni. Una soluzione piuttosto ovvia è quella di ricorrere alle transazioni per gestire le eccezioni, ma in molti casi non è la soluzione più adeguata, in quanto l’operazione di compensazione comporta l’annullamento di tutte le operazioni svolte in precedenza e, molte volte, questa non è la soluzione più adeguata.
Si possono utilizzare diversi approcci per gestire le eccezioni: basati sul flusso, try-catch-throw e basati su regole:
quando non è stato previsto un modello specifico per la gestione delle eccezioni. Questa tecnica è analoga a quella adottata nei linguaggi di programmazione sprovvisti di sistemi per la gestione delle eccezioni: alla fine dell’esecuzione di un’operazione vengono controllati determinati valori e nel caso di una situazione di errore vengono eseguite ulteriori operazioni. Bisogna notare che in ambito distribuito si possono verificare delle situazioni particolari, ad esempio una situazione di errore potrebbe essere quella di ricevere un risultato incompleto. Gestire una situazione di questo tipo a livello applicativo risulta piuttosto complesso;
Try-Catch-Throw – questa tipo di approccio non è altro che la gestione delle eccezioni in Java adattata alla composizione di servizi. L’idea fondamentale consiste nell’associare ad ogni attività un handler che si occupi di catturare le eccezioni. Questo approccio comporta notevoli vantaggi. Primo fra tutti è la netta separazione tra la logica applicativa normale e quella legata alle eccezioni, questo comporta una notevole strutturazione in termini di composizione e rende la progettazione, lo sviluppo e la manutenzione molto più semplice e veloce. Inoltre, utilizzando questo approccio, si può adottare una strategia di continuazione, infatti attraverso una gestione di questo tipo un’eccezione non comporta necessariamente la terminazione del programma;
Approcci basati su regole – in questo tipo di approcci la gestione delle eccezioni è basata su un insieme di regole, in modo analogo a quanto avviene nei sistemi reattivi. Ad ogni evento è associata un’espressione booleana che esprime la presenza di una condizione di errore o meno. Se l’espressione viene soddisfatta, allora è presente un’eccezione che viene gestita in base alla particolare logica applicativa. Esiste un linguaggio specifico per l’espressione delle regole, tale linguaggio può essere più o meno espressivo e più o meno complesso. Utilizzando un approccio basato su regole si ottiene una chiara separazione tra le proprietà classiche e quelle eccezionali di un processo. Esistono comunque degli svantaggi, infatti il sistema deve gestire un ulteriore linguaggio e, allo stesso tempo, gli
sviluppatori devono conoscere un linguaggio aggiuntivo. Un ulteriore svantaggio consiste nel fatto che, in sistemi particolarmente complessi, l’insieme delle regole può diventare piuttosto grande, di conseguenza il sistema è difficile da gestire e, necessariamente, poco scalabile.
2.9.7
Il linguaggio BPEL
Il linguaggio più diffuso che permette di effettuare la composizione di servizi attraverso la definizione di processi di business è il linguaggio BPEL. Si tratta di un linguaggio che permette di definire le specifiche degli schemi di composizione dei protocolli di coordinazione di servizi.
Gli schemi di composizione di BPEL sono dei processi eseguibili, cioè le specifiche che definiscono la logica implementativa per un servizio composito. I protocolli di coordinazione di BPEL adottano una logica service-centric e non sono altro che le specifiche di un processo astratto.
Attraverso questo linguaggio è possibile definire sia le caratteristiche esterne, attraverso i processi astratti, sia la logica implementativa interna, attraverso i processi eseguibili. Questo aspetto duale del linguaggio è molto utile, in quanto consente di utilizzare lo stesso formalismo per esprimere i processi astratti e quelli eseguibili e rendere lo sviluppo del sistema di composizione molto più semplice e veloce.
Una caratteristica fondamentale è che BPEL è sostanzialmente un linguaggio XML-based. Questa peculiarità gli permette di integrarsi e collaborare con altre applicazioni basate su XML.
Il linguaggio BPEL utilizza pertanto documenti XML per definire le caratteristiche dei processi:
i ruoli che partecipano al servizio composito;
i port type che devono essere supportati dai differenti ruoli che partecipano al servizio composito;
la specifica dell’orchestration, quindi l’ordine in cui devono essere scambiati i messaggi e tutte gli aspetti relativi;
le informazioni utili per la determinazione del routing dei messaggi (correlation information).
2.9.7.1
Component Model
Il component model di BPEL permette la definizione di attività che possono essere di due tipi: semplici (basic) o complesse (structured). Le structured activities sono utilizzate per definire l’orchestration, quindi una structured activity non è altro che un servizio composito. Le basic activities sono i “componenti” del servizio composito, quindi rappresentano l’invocazione di un’operazione di un Web Service semplice.
Il linguaggio offre diverse tipologie di attività semplici predefinite:
invoke – rappresenta l’invocazione di una richiesta/risposta o di una operazione a senso unico offerta da un determinato servizio;
receive – rappresenta la ricezione di un messaggio da un client;
reply – rappresenta la risposta ad un messaggio in relazione alla richiesta effettuata da un client;
assign – è utilizzata per l’assegnazione delle variabili;
wait – è utilizzata per bloccare una determinata attività per un certo periodo di tempo;
terminate – è utilizzata per terminare l’intero processo;
throw – è utilizzata per generare un’eccezione;
empty – è un’operazione nulla (no-op);
compensate – viene eseguita al termine di un gruppo di attività, può essere utilizzata per eseguire un rollback (nel caso transazionale), oppure per eseguire un’attività post-completation.
In modo analogo sono presenti un insieme di attività complesse (structured activity) predefinite. Queste attività saranno descritte nel prossimo paragrafo in quanto attraverso di esse viene definita l’orchestration.
siano definite attraverso dei documenti WSDL e quindi assume che sia presente un insieme di port type e che l’interazione tra i servizi avvenga attraverso l’invocazione delle operation definite nei documenti WSDL.
2.9.7.2
Orchestration Model
BPEL utilizza un particolare orchestration model che combina due differenti approcci: activity diagram e activity hierarchy.
Questa combinazione è stata presentata implicitamente nella sezione precedente, ora verrà esplicitata. Come abbiamo detto in precedenza, BPEL permette di definire attività semplice e strutturate. La definizione di attività strutturate è equivalente a definire una gerarchia di attività, queste attività possono essere connesse, di conseguenza il modello utilizzato è una combinazione tra activity diagram e activity hierarchy.
Le attività complesse predefinite possono essere di diversi tipi:
while – include solamente un’attività (semplice o complessa) e la esegue fino a quando una determinata condizione è verificata;
switch – è equivalente al costrutto switch utilizzato nei linguaggi di programmazione, ad ogni attività è associata una condizione, la prima attività che soddisfa la condizione viene eseguita. Essa consente inoltre la definizione di un’attività di default;
pick – è possibile definire un insieme di eventi ognuno associato ad una attività, quando si verifica un particolare evento l’attività associata viene eseguita e l’attività complessa (pick) viene considerata conclusa;
sequence – contiene un insieme di attività che sono eseguite in sequenza;
flow – raggruppa un insieme di attività che devono essere eseguite in parallelo; questa attività è considerata terminata quando sono terminate tutte le sotto-attività che la compongono;
scope – raggruppa un insieme di attività e definisce uno scope; questo tipo di attività verrà descritta in seguito in quanto è utile per la gestione delle transazioni e delle eccezioni.
Un’attività che necessita di un maggior approfondimento è l’attività di tipo flow. Attraverso questo tipo di attività è possibile definire il grafo del servizio composito. Ogni nodo del grafo rappresenta un’attività e le attività sono unite tra di loro attraverso dei link. In questo modo, è possibile specificare l’ordine di esecuzione delle attività, l’esecuzione parallela e la sincronizzazione delle varie attività.
2.9.7.3
Data type e data transfer
BPEL utilizza variabili per tenere traccia dello stato del processo e per gestire i dati di controllo (control data). In BPEL le varabili sono molto simili a quelle comunemente utilizzate nei linguaggi di programmazione. Una variabile è identificata da un nome e da un tipo specificato come un riferimento ad un message type WSDL o ad uno schema XML. Una volta definite, le varabili possono essere utilizzate come valori di input o di output di un’operazione.
Le variabili utilizzate come input o come output devono essere dei message type WSDL. Parallelamente a quanto avviene nei linguaggi di programmazione, quando un servizio viene invocato e una nuova istanza viene creata, le proprie variabili non sono inizializzate. Attraverso l’attività semplice assign è possibile inizializzare esplicitamente le variabili di una particolare attività.
Il linguaggio BPEL permette inoltre l’utilizzo di linguaggi di interrogazione XML per l’assegnazione delle variabili, il linguaggio predefinito di BPEL è XPath 2.05. Come è stato descritto precedentemente, esistono due approcci per la gestione dei dati: blackboard e explicit data flow. BPEL adotta il modello basato su blackboard.
2.9.7.4
Service selection
BPEL gestisce la selezione dei servizi attraverso le nozioni di partner link type, partner link e endpoint reference.
Un partner link type descrive il tipo di messaggi che due servizi (descritti da un documento WSDL) intendono scambiarsi. Un partner link type caratterizza lo scambio di
5
messaggi, definendo il ruolo di ogni servizio e specificando il port type specifico del servizio. In sostanza, i partner link type descrivono i ruoli degli attori che partecipano al processo. Ad esempio, un partner link type di tipo orderPT può specificare che il processo genera delle interazioni tra due ruoli supplier e customer e questi due ruoli devono supportare due port type: supplierPT e customerPT.
Dopo aver definito i partner link type, occorre specificare i partner link.
Attraverso i partner link è possibile identificare i servizi invocati durante l’esecuzione di un processo, di conseguenza devono essere legati in qualche modo a degli specifici endpoint.
Il riferimento ad uno specifico endpoint può essere associato ad un partner link, identificando uno specifico attore. Questa associazione può essere fatta a tempo di deploy con una metodologia che dipende dalla particolare implementazione di BPEL. In alternativa, i riferimenti ai partner link possono essere assegnati dinamicamente in modo analogo a quanto avviene per l’assegnazione delle variabili. L’assegnazione può essere eseguita più volte durante l’esecuzione di un processo, quindi in base alla particolare logica applicativa un endpoint può cambiare durante l’esecuzione.
La definizione delle attività può far riferimento ai partner link, in questo modo il motore di composizione è a conoscenza dello specifico servizio a cui i messaggi devono essere inviati.
2.9.7.5
Eccezioni e Transazioni
BPEL segue un approccio basato sul modello try-catch-throw; questo è possibile in quanto l’orchestration model del linguaggio permette la definizione di attività annidate (activity diagram e activity hierarchy).
Un’attività definisce in modo implicito uno scope, inoltre, come presentato in precedenza, è possibile definire esplicitamente uno scope attraverso l’attività complessa scope.
È possibile associare ad ogni scope uno o più fault handler, specificando come deve essere gestita ogni particolare eccezione. Un fault handler è caratterizzato da un elemento di tipo catch che definisce l’eccezione che gestisce e l’attività (semplice o complessa) che deve
essere eseguita in caso di eccezione. Un’eccezione può occorrere a run-time (WSDL fault o invocata dal motore di composizione), ma può anche essere sollevata esplicitamente attraverso l’attività throw descritta precedentemente.
Un altro costrutto importante per la gestione delle eccezioni è l’event handler. Questo costrutto permette di eseguire un’attività quando accade un particolare evento. Un event handler è sempre attivo è può essere invocato anche più di una volta.
BPEL utilizza un approccio particolare che combina l’approccio per la gestione delle eccezioni con le tecniche transazionali. Esso permette, per ogni scope, la definizione di un compensation hanlder che si occupa di eseguire l’undo delle operazioni svolte fino a quel punto. La logica di compensazione è eseguita da una singola attività (semplice o complessa).
Ad ogni scope, è associato un compensation handler e la sua invocazione può essere esplicita, attraverso un attività di tipo compensate, o può avvenire in modo automatico come parte del fault handler di default. È importante precisare che un’attività di tipo compensate può essere definita solamente all’interno di un fault handler o all’interno di un compensate handler. BPEL permette anche di definire un compensation handler che può essere invocato dopo che il processo è terminato per effettuare l’undo di tutto il processo.
2.9.8
La differenza tra BPMN e BPEL
Parlando di SOA molto spesso oltre all’acronimo BPEL si incontra l’acronimo BPMN (Business Process Modeling Notation) in riferimento ai linguaggi usati in questo contesto. Si cerca di seguito di capire le differenze sostanziali tra i due linguaggi.
Tra i principali linguaggi di orchestrazione dei Web Service, fino ad oggi è certamente il BPMN ad aver fatto registrare la maggiore diffusione. Tale linguaggio è di tipo visuale (Figura 11) ed è disponibile in quasi tutte le tecnologie SOA presenti sul mercato. Esso consente l’integrazione dei servizi disponibili nell’architettura con operazioni di disegno di tipo “drag and drop”.
In alternativa un processo di orchestrazione può essere scritto con la tradizionale modalità di sviluppo di codice, facendo ricorso al linguaggio BPEL diffusamente descritto in precedenza.
I principali vendor di tecnologie SOA rendono disponibili strumenti di modellazione dei processi tramite BPMN e convertitori automatici verso la loro rappresentazione BPEL. È il processo BPEL che una volta installato in un BPEL engine ad essere eseguito automaticamente dalle macchine.