C
C
a
a
p
p
i
i
t
t
o
o
l
l
o
o
V
V
I
I
Applicazione del SEM
ai dati sperimentali
VI.1 Introduzione
Il fine ultimo di questo lavoro di tesi è quello di tentare uno studio di connettività effettiva sulle aree cerebrali coinvolte nello svolgimento dell’attività olfattiva. Nel corso dei capitoli precedenti abbiamo cercato di affrontare tutte le problematiche inerenti a questo tipo di studio, a partire dall’individuazione della probabile struttura di connettività cerebrale, la scelta del metodo di analisi di connettività effettiva più adatto al nostro scopo (il SEM), fino allo studio e l’analisi di tale metodo per capirne le potenzialità ed i limiti.
Finalmente in questo capitolo affrontiamo la cosiddettà analisi dei dati reali ovvero applichiamo il SEM a sets di dati sperimentali acquisiti sull’uomo, attraverso tecnica fMRI, durante una particolare stimolazione olfattiva.
interessate all’attività olfattoria che ci aiuteranno ulteriormente a capire le difficoltà che si incontrano in questo tipo di ricerca.
VI.2 Descrizione dell’Esperimento
L’idea fondamentale su cui ci siamo basati per la creazione dell’esperimento è quella di eseguire una scansione fMRI durante la quale il soggetto viene sollecitato con una serie di stimoli olfattivi, in alternanza a periodi di riposo, scanditi secondo una sequenza temporale ben definita.
Questa impostazione, che prevede l’alternarsi di due momenti distinti (stimolo/non-stimolo) durante la sequenza di acquisizione, è quasi una scelta obbligata nel campo degli studi di neuroimaging con Risonanza Magnetica funzionale, infatti l’ampiezza del segnale BOLD rappresenta una misura pesata e indiretta della concentrazione di desossiemoglobina nel sangue, per di più influenzata da numerosi fattori variabili quali il particolare voxel in esame, il tipo di scansione e le caratteristiche fisiologiche del soggetto under-test, e non può essere legata direttamente al grado di attività presente in quel punto in quel particolare momento. Quindi per l’individuazione delle attivazioni indotte dallo stimolo sensoriale è necessario procedere ad una misura differenziale che metta a confronto l’ampiezza del segnale tra due condizioni diverse all’interno di una stessa acquisizione: una condizione è appunto quella in cui è presente lo stimolo e l’altra è quella in cui lo stimolo è assente.
In particolare il modello di stimolazione che abbiamo implementato nel nostro esperimento è del tipo Block Design che prevede la successione di veri e propri periodi di stimolazione, alternati a intervalli in cui sono ristabilite le condizioni “normali”, cioè l’assenza di quella particolare sollecitazione, durante i quali la stimolazione viene prolungata per tutto l’intervallo generalmente in modo continuo
ma talvolta anche in modo frazionato (i singoli stimoli all’interno di uno stesso blocco prendono il nome di trial).
Nella figura 6.1 è riportato lo schema di massima di un paradigma del tipo Block Design in cui si mette in evidenza l’alternarsi delle fasi di stimolo (indicate comunemente con ON o experimental) con quelle di non-stimolo (OFF o rest).
E’ da sottolineare il fatto che le due fasi devono essere distinte tra loro esclusivamente per la presenza o meno dello stimolo così che i relativi livelli della risposta BOLD rilevata possano essere associati, durante la fase OFF, all’attività legata esclusivamente ai vari processi cognitivi evocati dall’ambiente circostante e, nella fase ON, alla somma di questi e dei processi evocati dalla vera e propria stimolazione. In questo modo, supponendo che la differenza tra le attività cerebrali
Figura 6.1 : schema di paradigma Bolcked Design; il livello A+X rappresenta la fase di stimolazione (ON) mentre il livello X rappresenta la condizione normale di assenza di stimolo (OFF). Con TON e TOFF sono indicate le durate temporali
durante la fase di experimental, è possibile individuare la risposta legata a quella particolare stimolazione come se fosse una sorta di metodo sottrattivo tra i due stati. In alternativa allo schema sperimentale tipo Block Design avremmo potuto scegliere quello Event-Related Design che prevede la ripetizione di fasi ON di durata tale da fornire al soggetto un singolo evento di stimolazione (un singolo trial) e indurre quindi una singola risposta emodinamica assimilabile alla risposta impulsiva del sistema biologico (h-IRF). Tuttavia la scelta è ricaduta sul primo modello pechè ci offre il vantaggio di generare risposte emodinamiche complessive molto più consistenti, grazie alla sovrapposizione di più HRF consecutive durante l’intero periodo di stimolazione, permettendoci così di migliorare il rapporto segnale-rumore delle sequenze temporali estratte. Infatti l’alta rumorosità dei dati è uno degli aspetti più delicati dell’intero esperimento, a causa delle dimensioni ridotte di alcune delle aree olfattive, della loro collocazione piuttosto centrale all’interno del cervello (specialmente l’Amygdala e la Corteccia Piriforme) e soprattutto della presenza di numerose interfaccie aria-osso e osso-tessuto cerebrale, ed è quindi stato necessario prendere tutti gli accorgimenti possibili, tra cui questo, per cercare di migliorare la qualità dei segnali acquisiti.
VI.2.1 L’Olfattometro
Nel nostro caso specifico la fase di stimolazione è costituita da una sollecitazione odorosa portata alle narici del soggetto attraverso un flusso d’aria continuo, mentre quella di non-stimolo è costituita da un flusso d’aria pulita cioè inodore. Per realizzare questo tipo di sollecitazione è stato impiegato un apparato, indicato con il nome di Olfattometro, progettato ad hoc per soddisfare le particolari esigenze imposte dal tipo di acquisizione.
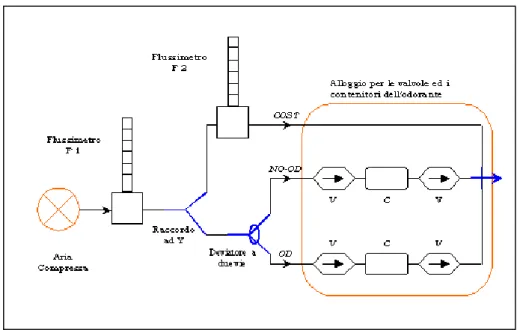
Nella figura 6.2 è riportato lo schema di massima dell’olfattometro che ci permetterà di dare una descrizione concisa della sua architettura e del principio di funzionamento.
Il funzionamento è basato su un flusso d’aria continuo e costante che arriva al naso del paziente attraverso una mascherina da anestesia che rappresenta l’interfaccia tra l’apparecchio ed il soggetto. Alla maschera arrivano tre tubature di piccolo diametro due delle quali (canale OD e NO-OD) lavorano in modo alternativo grazie ad un deviatore a due vie posto a monte; su ciascuna di esse sono montate due valvole unidirezionali (v), allo scopo di non far diffondere l’odorante a ritroso nelle tubature, e un contenitore (c) che, sul canale OD, costituisce l’alloggio dell’essenza odorosa mentre sull’altro canale ha solamente il compito di equilibrare i carichi fluidodinamici. Quando il flusso d’aria viene direzionato nel canale OD esso attraversa il contenitore con l’odorante determinando in uscita la fase di stimolo, quando invece il flusso d’aria è deviato nell’altro canale (NO-OD) allora si
Figura 6.2 : schema di massima dell’Olfattometro. Le sigle V indicano le valvole unidirezionali e la C indica i contenitori dell’odorante. Solamente il contenitore sul canale OD è predisposto per contenere l’essenza odorosa mentre quello sul canale NO-OD è vuoto e ha solamente la funzione di rendere simmetrici i due canali così che offrano la solita resistenza al passaggio dell’aria.
interrompe lo stimolo e si torna nella fase di non-stimolo (l’interruzione è netta grazie all’utilizzo delle valvole di ritegno).
Il terzo canale (COST) ha una doppia funzione: la prima è quella di permettere insieme al flussimetro F2 la regolazione della frazione di flusso odoroso rispetto al flusso totale (da 1
3 a 1), la seconda è quella di attenuare e compensare le variazioni
del flusso totale dovute alla commutazione del deviatore, mantenendo in uscita dalla mascherina un flusso totale costante e continuo.
Con il flussimetro (F1) posto a monte di tutto l’apparato, che riceve aria dall’impianto di aria compressa presente nella stanza di risonaza (aria clinica), è possibile regolare il flusso d’aria totale in ingresso al sistema (e quindi anche in uscita) in modo da avere tempi di risposta sufficientemente brevi e contemporaneamente nessun fastidio per il soggetto. Il flusso d’aria ottimale è di 3 l/min; esso garantisce tempi di risposta inferiori a 500ms quindi assolutamente compatibili con un’acquisizione fMRI. Questo dato è stato stimato attraverso test effettuati su più soggetti basandosi sulle loro risposte cognitive e quindi è comprensivo anche dei loro tempi di reazione; inoltre il controllo della commutazione odore/non-odore avviene in modo manuale e perciò il dato risente anche dei tempi di reazione dell’operatore, tuttavia grazie ad un adeguato addestramento siamo riusciti a rendere la procedura assolutamente affidabile, con tempi di risposta largamente compresi in quel range.
I materiali con cui è realizzato il sistema sono completamente amagnetici e garantiscono la sua completa compatibilità con l’ambiente della sala di risonanza, inoltre nei condotti terminali è utilizzato il teflon che assicura una buona resistenza alla contaminazione da parte degli odori, permettendo di utilizzare l’olfattometro con essenze odorose differenti senza rischio di miscelamenti di odore.
In conclusione questo apparato permette di generare stimoli olfattivi replicabili, di durata e concentrazione note, con una precisione nella realizzazione del paradigma inferiore al mezzo secondo ed è estremamente semplice e veloce cambiare gli odoranti dando la possibilità di eseguire scansioni consecutive con odoranti differenti senza spostare il soggetto e senza attese troppo lunghe tra un run e l’altro.
Nel suo impiego questo apparato si è dimostrato varamente pratico e funzionale, permettendoci di effettuare numerose acquisizioni con diversi task di stimolazione con lo scopo di individuare le condizioni migliori per l’individuazione delle principali aree cerebrali coinvolte nell’attività olfativa.
VI.2.2 Individuazione dei parametri dell’esperimento e
acquisizione dei dati
Un aspetto particolarmente importante, che è stato affrontato nella messa a punto dell’esperimento, è stato la scelta dei due parametri caratteristici della sequenza di stimolazione (paradigma):
Durata dello Stimolo (SD o
T
ON)Intervallo Inter-Stimolo (ISI o
T
OFF)Il primo indica la durata del singolo blocco di stimolo, cioè il lasso di tempo che intercorre tra l’inizio e la fine della fase ON mentre il secondo indica indica la durata della fase OFF (figura 6.1).
L’importanza di settare nel modo giusto questi due parametri risiede nel fatto che l’olfatto è un senso chimico, cioè basato sul legame delle molecole odorose con le sedi recettive poste nel naso, e quindi facilmente sottoposto a fenomeni di saturazione o desensibilizzazione se il soggetto è esposto ad una stimolazione eccessivamente lunga; inoltre affinchè i recettori si sleghino dalle molecole odorose è necessario un tempo di rilassamente opportununamente lungo.
Oltre a queste due necessità è evidente che occorre anche cercare di ottimizzare il rapporto
(
O N)
O F F
T
T in modo tale da massimizzare la sensibilità statistica del
Tutto questo tenendo in considerazione che la lunghezza dell’intero task ed il periodo di ripetizione (
T
ON+
T
OFF) devono essere tali da permettere un numero distimolazioni sufficiente a ricostruire abbastanza immagini potenzialmente attivate. In particolare, avendo fissato TR=2, per garantire all’interno di un periodo ON l’acquisizione di almeno quattro volumi interi è necessario che il tempo SD sia maggiore o uguale a 8 sec.
In conclusione sono state selezionate e testate tre possibili combinazioni: SD=10 s, ISI=20 s
SD=15 s, ISI=25 s SD=20 s, ISI= 20 s
Di cui successivamente sono stati scartati i numeri 2 e 3 in base ai risultati ottenuti nel primo esperimento che abbiamo svolto, il quale aveva proprio l’obiettivo di evidenziare le differenze tra i risultati ottenuti con i diversi task. Nelle sedute di acquisizione successive è stato adottato il paradigma 10/20 sec che ha dimostrato di essere in grado di fornire attivazioni abbastanza intense e congruenti con quelle attese (le cosiddette core regions dell’olfatto), coerenti sia per odoranti diversi che tra soggetti distinti, riducendo più degli altri i problemi di assuefazione del soggetto all’odorante.
Entrando più nel dettaglio, gli esperimenti si sono articolati in due sedute:
1. Seduta n° 1 composta da tre acquisizioni assiali (chiamate anche run), tutte sullo stesso soggetto e con lo stesso odorante (olio essenziale di citronella), con l’obiettivo di provare i tre tipi di task suddetti, con diverse lunghezze totali, in particolare (figura 6.2):
1a) 30 s iniziali di NON ODORE +10 cicli ognuno con due blocchi 10/20 s
2a) 30 s iniziali di NON ODORE +8 cicli ognuno con due blocchi 15/25 s
ON/OFF (durata complessiva 350 s);
3a) 30 s iniziali di NON ODORE +8 cicli ognuno con due blocchi 20/20 s
ON/OFF (durata complessiva 350 s).
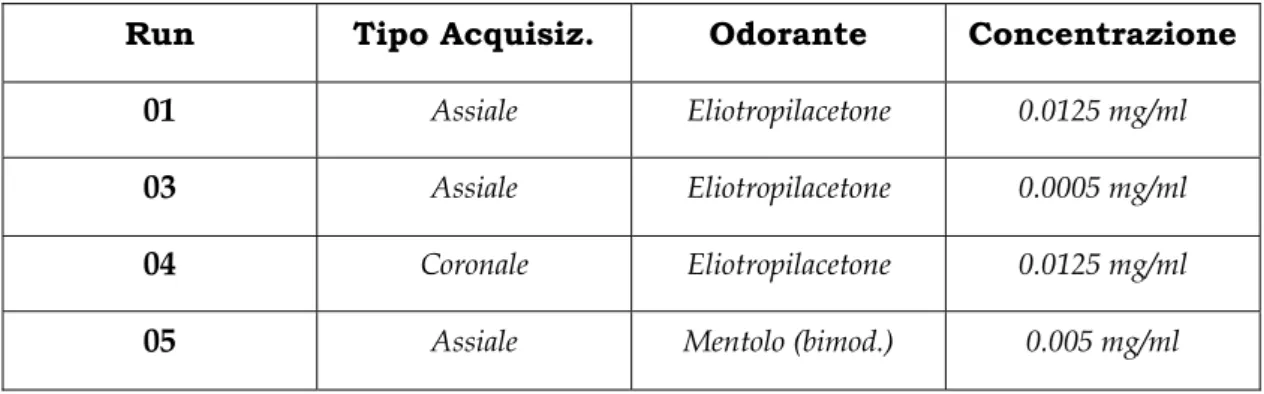
2. Seduta n° 2 composta da quattro acquisizioni (tre assiali ed una coronale), tutte su uno stesso soggetto, ma con odoranti e concentrazioni diverse (vedi tabella 6.1), con l’obiettivo primario di aumentare il numero di regioni visualizzate e la loro coerenza nei diversi run e quindi per i diversi odoranti ed alle diverse concentrazioni. Tutti i quattro run impiegavano il task a (10/20 s). a) c) b) Tempo (sec) Figura 5.2 : forme d’onda dei tre paradigmi utilizzati nell’esperimento n°1
Run Tipo Acquisiz. Odorante Concentrazione 01 Assiale Eliotropilacetone 0.0125 mg/ml
03 Assiale Eliotropilacetone 0.0005 mg/ml
04 Coronale Eliotropilacetone 0.0125 mg/ml
05 Assiale Mentolo (bimod.) 0.005 mg/ml
Durante ogni run l’olfattometro è stato calibrato in modo che il flusso d’aria odorosa fosse di 1,5 l/min su un flusso totale di 3 l/min, così da avere un rapporto del 50 % che è risultato essere quello ideale per le diluizioni degli odoranti che abbiamo utilizzato.
Occorre precisare che prima di ogni esperimento (qualche giorno) sono state effettuate delle prove sui soggetti con lo scopo di verificare eventuali anosmie specifiche per gli odoranti utilizzati, confrontare i giudizi sull’intensità e la qualità forniti da soggetti distinti per uno stesso odorante a parità di concentrazione, calibrare la concentrazione e la quantità di odorante da inserire nel contenitore e l’ammontare del flusso aereo nel canale COST dell’olfattometro tali da evitare l’assuefazione del soggetto nel corso dell’esperimento.
Un latro aspetto interessante da sottolineare riguarda il fatto che si sono riscontrate ampie variabilità di giudizio sulla percezione dello stesso odorante a pari concentrazione da parte di individui diversi, sia preliminarmente all’acquisizione che in risposta a domande successive; ed in ogni caso il mentolo è risultato il più nettamente riconosciuto ed anche quello per il quale l’assuefazione denunciata è stata inferiore. Va detto che tutte le prove mirate a stabilire la giusta concentrazione per un certo odorante nella stimolazione di un determinato soggetto si sono basate su giudizi che quest’ultimo forniva in seguito ad una certa sollecitazione del proprio olfatto, senza la possibilità di avere riscontri oggettivi circa l’effettiva “quantità” di odorante legato ai recettori e percepito, né sull’inizio effettivo della stimolazione, né
sulla sua persistenza o sull’entità della assuefazione indotta e su quando esattamente questa cominciasse a pesare significativamente sulla misura.
In definitiva le acquisizioni maggiormente interessanti nell’ottica dell’applicazione del modello di connettività effettiva sono state quelle effettuate nella seconda sessione sperimentale utilizzando il paradigma 10/20 sec con l’unica eccezione del run_04 ; infatti essendo quest’ultima un’acquisizione coronale ed avendo la macchina di risonanza dei vincoli che impongono un numero limitato di “fette” non siamo riusciti a caturare le regioni cerebrali più arretrate come l’Amygdala e la Corteccia Piriforme.
Tutte le acquisizioni sono state svolte mediante uno scanner RM General Electric Signa Cvi Horizon 1.5 T, con i seguenti parametri per le immagini funzionali, che sono Gradient Echo, Echo Planar:
- TR=2000 ms - TE=40 ms - FA=90° - Banda=62.5 KHz - Spessore fette=5 mm - FOV=24 cm - Risoluzione piana=64x64
Entrambe le sedute sono iniziate con l’acquisizione MRI di una mappa strutturale, cui sovrapporre le successive mappe funzionali, al fine di ottenere la localizzazione delle regioni attivate.
La supervisione degli esperimenti, svolti presso il laboratorio di RM dell’Istituto di Fisiologia Clinica del CNR con sede nell’Area della Ricerca S.Cataldo (Pisa), è stata condotta dal Dr. Domenico Montanaro, neuroradiologo presso l’IFC.
Mentre l’olio essenziale di citronella è stato acquistato in un laboratorio farmaceutico, gli altri odoranti sono stati preparati e messi a disposizione da Istituto di Chimica Cosmetica dell’Università degli Studi di Siena.
VI.3 Analisi GLM per l’individuazione delle aree
olfattive
I dati provenienti dallo scanner di RM sono costituiti, per una singola acquisizione, da numerosi volumi, cioè collezioni di fette tridimensionali (slice), ciascuna formata da un certo numero di punti 3D chiamati voxel. Ogni slice ha uno spessore di qualche millimetro e ogni volume corrisponde alla rappresentazione dell’intero cervello del soggetto.
Il tempo di acquisizione di un volume varia di norma fra 2 e 4 s (il TR) ed ogni slice può essere vista come una matrice di voxel; la tecnica di fast imaging più comunemente utilizzata con un contrasto BOLD
T
2*−
weighted
è quella EPI (Echo Planar Imaging), nella quale si acquisisce una slice per volta.I dataset così raccolti sono anche detti 3D+time perché ciascun voxel, che rappresenta un punto nello spazio 3D, ha associata una serie temporale costituita dai campioni misurati ogni TR del segnale fMRI.
Su questi dataset devono essere applicate tutta una serie di procedure che possiamo suddividere in due parti: la prima, chiamata pre-processing, comprende tutte le azioni necessarie per la preparazione dei dati all’analisi statistica mentre la soconda, quella di processing, riguarda la vera e propria analisi statistica dei dati fMRI. Di seguito riportiamo brevemente i processi fondamentali che caratterizzano la fase di pre-processing:
1. Traslazione temporale delle fette : l’analisi statistica dei dati presuppone
che un intero volume, e quindi ogni sua fetta ed ogni suo voxel, sia
acquisito istantaneamente, cioè rappresenti in ogni suo elemento uno
st
esso istante nel tempo. Ciò non è certamente realistico, infatti la tecnica EPI acquisisce il volume di fetta in fetta e quindi ogni slice si riferisce ad un punto nel tempo sfasato rispetto a quello di acquisizione delle altre slice appartenenti al medesimo volume. Il risultato è che una stessa variazione nella HRFapparirebbe anticipata in fette acquisite in istanti successivi a quello assunto come unico nella analisi statistica. La tecnica utilizzata per il riallineamento temporale delle fette è una interpolazione, la quale fa in modo che tutti i voxel di uno stesso volume assumano all’incirca il valore che avrebbero avuto se fossero stati acquisiti nello stesso istante della fetta di riferimento: in questo modo uno stesso cambiamento nella HRF ha un’origine temporale comune per tutti i voxel di tutte le fette di un dato volume.
2. Riallineamento nello spazio e Despike : l’analisi statistica dei dati fMRI prevede anche che un determinato voxel rappresenti la stessa posizione nel cervello del soggetto durante tutta la scansione cioè per ciascun volume acquisito ad intervalli TR; poichè i volumi acquisiti in una sessione sono centinaia e fra di loro possono essere occorsi movimenti della testa del paziente che hanno cambiato l’elemento della struttura cerebrale rappresentato da un certo voxel, quella condizione potrebbe non essere verificata. Gli artefatti di movimento potrebbero causare l’aumento della rumorosità dei dati (diminuzione SNR) o addirittura la rilevazione di false attivazioni quindi è necessario eliminarli. La procedura di rimozione è chiamata di riallineamento spaziale o registrazione; essa si basa sull’assunzione come riferimento di uno dei volumi acquisiti, e cerca una trasformazione geometrica (traslazioni e rotazioni) che riposizioni tutti gli altri volumi della scansione in modo da riallinearli al volume-base. La trasformazione è diversa per ciascuno dei volumi e viene calcolata con un algoritmo che minimizza la differenza quadratica (pesata) tra il volume da riposizionare e quello di base. Tuttavia il riallineamento non è in grado di correggere movimenti molto grandi della testa del soggetto ed è quindi necessario un ulteriore passo di pre-processing (in verità realmente necessario solo per le acquisizioni molto movimentate), conosciuto come Despike, con cui vengono rimossi quei campioni della serie temporale di un voxel che contengono grossi picchi nel segnale osservato.
3. Filtraggio spaziale o Smoothing : questa procedura viene sempre applicata ai dati fMRI prima dell’analisi statistica, nonostante provochi chiaramente una certa perdita di risoluzione spaziale nelle immagini. L’operazione consiste nella convoluzione di ciascun voxel di ogni volume con una Gaussiana 3D (Gaussian Kernel), che è qualificata in base al suo FWHM (Full Width Half at Maximum) ossia la larghezza in mm che essa presenta quando assume una ampiezza pari alla metà del suo valore massimo. Il risultato principale di tale trasformazione è un filtraggio spaziale che aumenta l’SNR in quanto elimina il rumore che ha frequenze spaziali elevate e lascia passare il segnale utile, il quale ha frequenze spaziali più basse perché deriva da variazioni del flusso sanguigno, che hanno un raggio d’azione di pochi mm. La FWHM è solitamente scelta pari a 2-3 volte le dimensioni di un voxel (es. 8 mm per voxel di 3x3x3 mm) così che cluster attivati di quelle dimensioni possano essere rivelati con la massima sensibilità.
Per quanto riguarda la fase di processing vero e proprio, la metodica di analisi più largamente utilizzata per uno studio di specializzazione funzionale su dati fMRI è il GLM (General Linear Model). Di seguito presentiamo una breve panoramica dei concetti fondamentali che stanno alla base di questo metodo.
Esso ci consente di costruire un modello di regressione multipla per il segnale fMRI misurato in ciascun voxel e quindi di applicare un test per verificare se il singolo voxel è attivato dalla stimolazione somministrata durante l’esperimento, separando l’effetto utile dal rumore. Ciò è attuato analizzando separatamente la serie temporale di ogni voxel (ossia con un approccio univariato), che è composta dall’andamento temporale della HRF in quell’elemento del cervello più del rumore, e confrontandola con il suddetto modello.
Gli elementi essenziali di cui è composto il modello sono tre: la forma della HRF che rappresenta il segnale utile (l’attivazione), la baseline ed il rumore; questi termini sono tutti additivi, così che la serie fMRI misurata in un singolo voxel
)
(t
rumore
HRF
baseline
t
z
(
)
=
+
+
Il rumore nasce da numerose sorgenti che interferiscono con l’osservazione della HRF e rappresenta perciò la deviazione delle osservazioni dai valori predetti dalla parte del modello HRF+baseline; esso è generalmente additivo ed aleatorio, distribuito con legge
N
(
0
,
σ
2)
e quindi rappresentato, nei vari istanti di acquisizione, da una successione di variabili aleatorie identicamente distribuite e supposte fra loro indipendenti (⇒
i.i.d.).Il concetto di baseline deriva invece dalla considerazione che ciò che cerchiamo come HRF, cioè il nostro segnale, non è un valore assoluto, bensì una variazione rispetto ad una attività “di riposo” nella quale il processo cognitivo di interesse (ma solo questo) non è presente: allora vi sarà un livello di “attività” neuronale di fondo che potrà essere costante, oppure avere andamenti più complessi (ad esempio lineare o parabolico), ma che dovrà comunque essere inclusa nel modello ideale in forma additiva rispetto alla variazione HRF.
Infine per quanto concerne la componente del modello che rappresenta la variazione della HRF, ossia il segnale BOLD vero e proprio, essa può essere vista come l’uscita di un sistema lineare e stazionario che trasforma lo stimolo presentato al soggetto durante l’esperimento (onda quadra paradigma) in HRF (la risposta BOLD); perciò questa è ottenibile tramite la convoluzione della funzione di stimolo con la funzione di risposta impulsiva (IRF) di tale sistema.
In generale la IRF dovrà allora essere stimata e sarà diversa per ciascun distinto voxel: si parla quindi di analisi di deconvoluzione ad indicare la stima della IRF ottenuta deconvolvendo la componente di segnale ipotizzata nel modello con la funzione di stimolo che è nota.
Più precisamente l’espressione che descrive il modello di regressione previsto dal GLM assume la forma:
i p i p i i i i
X
X
X
X
Y
=
0⋅
β
0+
β
1⋅
1+
β
2⋅
2+
...
+
β
−1⋅
−1+
ε
dove:1
0=
iX
iε
~N
(
0
,
σ
2)
i.i.d. 1 0,...,
β
p−β
, p parametri di regressione da stimare1 1
,...,
ip−i
X
X
, p-1 costanti notei=1,…,n l’indice delle osservazioni
Solitamente la stima dei parametri del modello viene effettuata attraverso il metodo dei minimi quadrati andando a cercare i valori da attribuire ai
β
i che minimizzano lafunzione:
∑
= −−
−
−
−
=
n i ip p i iX
X
Y
Q
1 2 1 1 1 0...
)
(
β
β
β
In sostanza l’analisi di regressione multipla GLM consiste nell’ipotizzare un modello teorico per le relazioni esistenti fra un campione di osservazioni e delle variabili deterministiche note (i predittori) e nello stimarne i parametri, costruendo così un modello stimato (di quello teorico) che si basi sui dati osservati. Il valore stimato per una osservazione da questo modello di fit dovrà poi essere confrontato con l’osservazione stessa per stabilirne la rispondenza e quindi valutare la significatività del modello di regressione stimato. Generalmente lo strumento impiegato per questo scopo è il cosiddetto F-test, che per una maggiore comprensione dei risultati viene affiancato anche dal coeficiente di determinazione multipla R2, che quantifica l’effetto dei predittori nella variazione della risposta,
ovvero indica la porzione della variazione dei dati che è spiegata dal modello, e da un altro test statistico, il t-test, che valuta la significatività dei singoli parametri. Senza entrare troppo nel dettaglio, occorre precisare che in realtà l’analisi di regressione lineare che si effettua solitamente sui dati fMRI è leggermente diversa da quella appena presentata. La differenza consiste nell’ipotizzare a priori la forma d’onda della risposta IRF e quindi, convolvendo questo segnale con il paradigma, ricavare la HRF da inserire come regressore nel modello GLM.
Esistono due modi di procedere: esprimere la IRF come precisa relazione funzionale nel tempo, solitamente una funzione tipo GAMMA (vedi figura 5.2), da cui si ricava un’ipotetica risposta BOLD da fornire al modello come unico regressore, oppure esprimere la IRF come espansione in serie di una base di funzioni (solitamente impulsi
δ
o impulsi triangolari, denominate funzioni tent, di durata e ampiezza opportuni) da cui si ottiene non più un solo regressore ma un numero di regressori pari alla dimensione della base.I dati che abbiamo acquisito nelle varie sedute sperimentali sono stati elaborati seguendo le tappe di pre-processing che abbiamo presentato e successivamente sono stati analizzati attraverso il modello di regressione GLM, sia utilizzando come un unico regressore il segnale BOLD sia sfruttando il metodo delle “tent”. Infine i risultati ottenuti sono stati interpretati attraverso i vari test statistici preposti a questo scopo ottenendo così delle mappe di attivazione in cui sono evidenziate, ammettendo valida la nostra modellizzazione, le aree maggiormente coinvolte nell’attività olfattiva.
I risultati più convincenti, sia dal punto di vista della qualità del fitting del modello sui segnali reali sia dal punto di vista del numero di attivazioni individuate nelle aree di nostro interesse, sono stati ottenuti con il modello di regressione con le funzioni tent; in particolar modo nei run acquisiti nella seconda seduta, in cui erano stati messi a punto i vari parametri sperimentali, siamo riusciti a individuare delle buone attivazioni relative alle aree olfattive principali: Corteccia Piriforme, Amygdala, Corteccia Orbitofrontale e Insula.
Tali attivazioni sono state individuate ponendo una soglia minima una soglia sullo F-Test tale da garantire un valore del p-value pari 0.01 il che significa che sono caratterizzate da un grado di affidabilità maggiore del 99%. Naturalmente un riscontro certo dell’effettivo coinvolgimento di queste aree nello svolgimento della funzione olfattiva ci è stato fornito dal dott. Montanaro (neuroradiologo) che ci ha confermato la bontà delle zone selezionate.
Nella figura 6.3 sono riportate, a titolo esemplificativo, le mappe delle attivazioni ricavate dal run 03 della prima seduta sperimentale attraverso la regressione con le funzioni tent; tali mappe sono state sovrapposte ad una immagine anatomica del soggetto, acquisita nella stessa sessione sperimentale, così da poter individuare la posizione precisa dei vari voxel attivati all’interno del volume cerebrale.
Figura 6.3 : mappe delle attivazioni ricavate nel run 03 della prima seduta. Da sinistra verso destra sono riportate le sezioni coronali e assiali delle regioni: Corteccia Orbito Frontale destra, Corteccia Piriforme sinistra, Insula sinistra e Amygdala sinistra.
In figura 6.4 si può osservare un tipico segnale fMRI, in cui sono evidenti i contributi dovuti al livello basale dell’attività cerebrale, la baseline, alla risposta emodinamica vera e propria e alla componente di rumore che si somma su tutto il segnale distorcendolo notevolmente.
VI.4 Analisi di Connettività
I dati su cui ci accingiamo ad applicare il modello di connettività SEM sono quelli ricavati dai run 1, 3 e 5 della seconda seduta di acquisizione, i cui dettagli tecnici sono stati decsritti nel paragrafo VI.2.1.
Le sequenze che utiliziamo per creare il set di dati da fornire al LISREL sono quelle relative ai voxel massimamente attivati selezionati tra quelli delle regioni implicate nell’attività olfattiva.
L’individuazione dei voxel appartenenti a tali aree, indicate genericamente come Figura 6.4 : in nero il segnale fMRI relativo al voxel massimamente attivato nella regione dell’Amygdala sinistra nel run 03 della seduta uno. In blu la ricostruzione del segnale bold stimata dal modello di regressione e in rosso la risposta ideale attesa.
che ha presieduto ai vari test, costruendo sulle immagini anatomiche a nostra disposizione delle mashere selettive per quelle particolari zone.
Andando a sovrapporre le mappe funzionali a quelle anatomiche e utilizzando le maschere delle ROI, sono stati isolati i gruppi di voxel appartenenti a tali regioni e successivamente tra questi sono stati scelti, per ogni area, quelli che presentavano le attivazione più significative secondo la soglia da noi stabilita. Come accennato nel paragrafo precedente il criterio di scelta si è basato sul valore dell’ F-stat del singolo voxel, selezionando solo quelli che superavano la soglia minima (soglia per la F-stat = 3.92) tale da imporre un p-value di 0.01.
Infine abbiamo individuato in ogni ROI, ad eccezione del Bulbo Olfattivo e dell’Amygdala sinistra dei run 1 e 3 che non presentavano alcuna attivazione significativa, il voxel massimamente attivato rispetto a tutti gli altri appartenenti alla stessa regione e di questo abbiamo estratto la sequenza temporale.
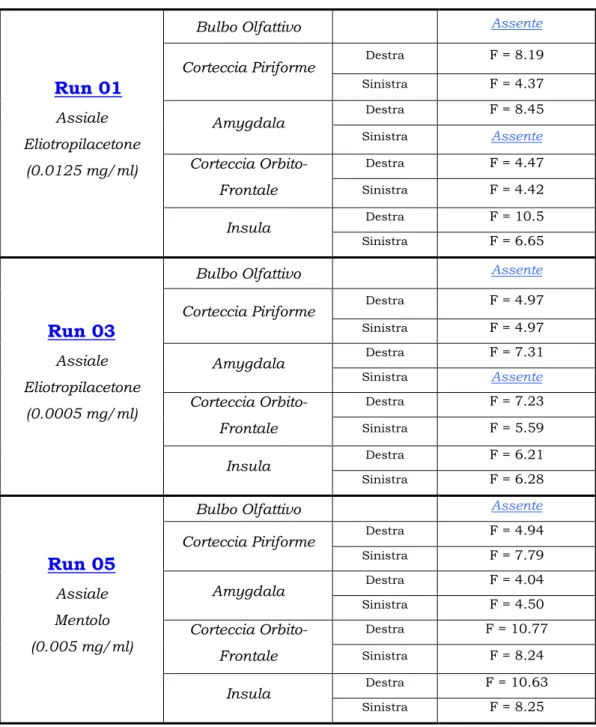
Escludendo il Bulbo Olfattivo, le quattro ROI di nostro interesse (vedi Capitolo II) sono la il Corteccia Piriforme, l’Amygdala, la Cortaccia Orbito-Frontale e l’Insula ognuna delle quali è costituita da due parti che si sviluppano simmetricamente nei due emisferi cerebrali; quindi per ogni run, eccezioni a parte, avremmo due set di quattro segnali ciascuno, relativi rispettivamente all’emisfero destro e a quello sinistro. Nella tabella 6.2 sono indicati i voxel selezionati, suddivisi per emisfero, con i relativi valori del test-F.
Anche se i dati a nostra disposizione non ci permettono di costruire tutti i 6 sets previsti, infatti solamente per il run 5 abbiamo a disposizione due set di dati completi mentre per i run 1 e 3 abbiamo un solo set (in entranbi i casi relativo all’emisfero destro), possiamo comunque impostare l’analisi di connettività in modo da mettere a confronto i risultati ottenuti dai segnali dell’emisfero destro nei tre run, cercando di capire se il peso delle connessioni possa dipendere in qualche modo dalla concentrazione o dalla qualità dell’odorante. Inoltre, nel caso del run 5 possiamo mettere a confronto i risultati ottenuti nei due emisferi cerebrali cercando di capire quali differenze possano esserci nei due casi.
Bulbo Olfattivo Assente Destra F = 8.19 Corteccia Piriforme Sinistra F = 4.37 Destra F = 8.45 Amygdala Sinistra Assente Destra F = 4.47 Corteccia Orbito-Frontale Sinistra F = 4.42 Destra F = 10.5
Run 01
Assiale Eliotropilacetone (0.0125 mg/ml) Insula Sinistra F = 6.65 Bulbo Olfattivo AssenteDestra F = 4.97 Corteccia Piriforme Sinistra F = 4.97 Destra F = 7.31 Amygdala Sinistra Assente Destra F = 7.23 Corteccia Orbito-Frontale Sinistra F = 5.59 Destra F = 6.21
Run 03
Assiale Eliotropilacetone (0.0005 mg/ml) Insula Sinistra F = 6.28 Bulbo Olfattivo AssenteDestra F = 4.94 Corteccia Piriforme Sinistra F = 7.79 Destra F = 4.04 Amygdala Sinistra F = 4.50 Destra F = 10.77 Corteccia Orbito-Frontale Sinistra F = 8.24 Destra F = 10.63
Run 05
Assiale Mentolo (0.005 mg/ml) Insula Sinistra F = 8.25Come già spiegato nel paragrafo precedente le sequenze temporali associate ai singoli voxel sono costituite da tre componenti: la baseline, che rappresenta il livello
dell’attività cerebrale estranea allo stimolo, la risposta HRF suscitata dalla specifica stimolazione (nel nostro caso olfattiva) e la componente di rumore gaussiano.
Prima di procedere è necessario ricordare ancora una volta che questa descrizione deriva pur sempre da una modellizzazione ipotetica che non è detto rispecchi la realtà delle cose; tuttavia essa è tanto più valida quanto più è elevato il valore del test-F del singolo voxel analizzato. Per i voxel selezionati nei vari run il grado di affidabilità del modello è superiore al 99% e quindi possiamo assumere quella modellizzazione come vera; da qui in avanti procederemo con questa ipotesi senza più ritornare sulla questione.
Immaginaniamo per un attimo di escludere il rumore, che non porta alcun tipo di informazione utile; quello che effettivamente rivela la presenza o meno di un’attività cerebrale causata dallo stimolo olfattivo è l’entità della variazione della HRF rispetto alla baseline; in altre parole il valore e l’andamento della baseline non danno alcuna informazione riguardo la risposta neurale alla stimolazione ma semplicemente indicano come si svilupperebbe l’attività cerebrale in quel punto se non fosse mai presente lo stimolo. Per questo motivo talvolta le sequenze temporali vengono rielaborate andando a sottrarre in ognuna la baseline stimata, così da ottenere dei segnali composti esclusivamente dalla risposta BOLD “ricostruita”, cioè quella stimata dalla regressione, e dalla componente di rumore gaussiano.
Oltretutto siamo giustificati dal fatto che il “segnale ” baseline non è coinvolto nel modello di connettività, cioè non si propaga attraverso le connessioni tra le varie regioni olfattive, e quindi se lo lasciassimo all’interno dei segnali andrebbe a ricadere interamente nel termine
ζ
ˆ
come quella parte di informazione contenuta nei segnali ma estranea al modello connettività.Alla luce di questo i segnali sono stati ricostruiti andando a sommare la componente di segnale utile e la componente di rumore stimate con il GLM, escludendo il contributo portato dalla baseline. Analiticamente tale operazione può essere
espressa dall’equazione:
y
i=
β
ˆ
3i⋅
x
Bold( )
t
+
ε
i ; in cui è stata tagliata laparte:
y
i=
β
ˆ
0i+
β
ˆ
1i⋅ +
t
β
ˆ
2i⋅
t
2 relativa alle componenti della baseline.Per quanto riguarda il modello di connettività che prendiamo a riferimento per settare il modello di stima più opportuno, esso è lo stesso già presentato nei capitoli precedenti (capitolo II ) ed è quello su cui abbiamo lavorato anche in fase di simulazione (capitolo V). Ricordiamo brevemente che tale modello è stato costruito sulla base delle conoscenze anatomo-fisiologiche delle regioni olfattive e dei risultati ottenuti nei più recenti studi di connettività svolti sul sistema olfattivo. In particolare esso presenta due connessioni certe che collegano rispettivametne la Corteccia Piriforme alla Corteccia Orbitofrontale e all’Amygdala (indicate con
b
21 eb
31nello shema di figura 6.5) più altre probabili connessioni (non certe) tra queste ultime due e la quarta regione coinvolta (l’Insula).
A questo dobbiamo aggiungere che in fase di simulazione abbiamo riscontrato che il SEM non è adatto ad un utilizzo esplorativo (paragrafo V.5), poichè non è in grado di valutare la veridicità o meno di una connessione, perciò non avrebbe senso lasciare nel modello di stima quei legami di cui non abbiamo informazioni certe sulla loro esistenza.
Un altro elemento cruciale di cui dobbiamo tenere conto nell’impostazione del modello di stima con cui affrontare l’analisi di connettività è l’assenza di attivazioni significative nella regione del Bulbo Olfattivo. Rifacendoci ancora una volta ai risultati ottenuti dalle simulazioni (vedi paragrafi V.4.2 e V.4.3), le possibilità che si prospettano sono due: il modello di stima senza variabile essogena oppure quello con variabile esogena ideale. Sostanzialmente le due strade sono del tutto equivalenti ai fini della valutazione dei parametri di connettività, la seconda offre il vantaggio di fornire una stima della varianza del rumore sulla prima variabile endogena che potrebbe rivelarsi utile nell’interpretazione dei risultati.
In conclusione il modello di stima che andiamo ad implementare è composto da quattro variabili esogene, corrispondenti alla Corteccia Piriforme, la Corteccia
Orbitofrontale ed all’Amygdala, connesse come descritto sopra, cui associamo i relativi segnali di massima attivazione ricavati dall’analisi GLM, e da una variabile esogena cui associamo un segnale BOLD ideale costruito come convoluzione del paradigma di stimolazio e della risposta IRF (funzione gamma).
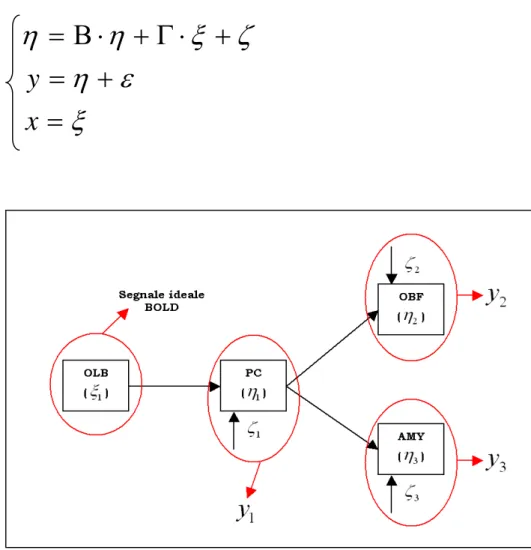
In figura 6.5 è schemattizzato il modello di stima con i parametri associati alle varie connessioni; per ogni regione sono evidenziati i segnali osservati (
y
i) appartenentiad esse e la scomposizione che ne fa il SEM in componente del modello (
η
i) ecomponente di rumore (
ζ
i); di seguito le equazioni descrittive del modello.y
x
η
η
ξ ζ
η ε
ξ
= Β ⋅ + Γ ⋅ +
= +
=
Figura 6.5 : schema del modello di stima con cui viene effettuata l’analisi di connettività sui dati sperimentali
Per ogni set di dati è stato calcolato il rapporto segnale-rumore dei tre segnali che lo compongono così da avere a disposizione un indicatore sintetico della loro qualità. I sets sono stati analizzati con il LISREL che ha fornito la stima dei parametri di connettività e degli elementi della matrice di covarianza del rumore (
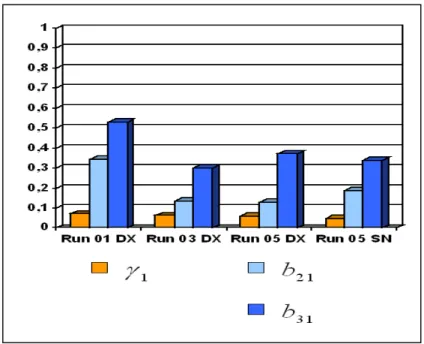
Ψ
). Nella tabella 6.3 ed in figura 6.6 sono riassunti i risultati ottenuti.RUN 01 Emisfero DX Assiale Eliotropilacetone (0.0125 mg/ml) RUN 03 Emisfero DX Assiale Eliotropilacetone (0.0005 mg/ml) RUN 05 Emisfero DX Assiale Mentolo (0.005 mg/ml) RUN 05 Emisfero SN Assiale Mentolo (0.005 mg/ml) SNR(dB) (y1,y2,y3) -20.2 dB (-18.3 -24.3 -17.9) -20.7 dB (-23.3 -19.4 –19.5) -21.4 dB (-23.3 -15.4 -25.4) -26.1 dB (-35.9 -18.0 -24.3) 1
ˆ
γ
0.0070 0.0062 0.0060 0.0031 21 ˆ b 0.3427 0.1326 0.1304 0.1858 31 ˆ b 0.5310 0.2993 0.3718 0.3382 9.0947 9.3370 13.4298 21.0821 7.6928 7.8134 7.2875 7.3062ˆ
Ψ
19.0911 9.8009 4.6320 9.5263 Tabella 6.3 : risultati dell’analisi di connettivitàLa prima questione che dobbiamo chiarire è quella del rumore che affligge i dati a nostra disposizione. Dall’osservazione dei risultati riportati nella tabella 6.3 appare subito chiaro che la qualità dei segnali acquisiti è pessima, infatti il rapporto segnale-rumore medio, calcolato mediando gli SNR delle tre sequenze che compongono ogni set, è molto basso e si attesta addirittura su valori inferiori ai –20 dB. Questo significa che la potenza della risposta emodinamica legata allo stimolo olfattivo è circa un centesimo della potenza della componente di rumore presente sui dati. D’altra parte le motivazioni di questa situazione sono note: le regioni che siamo andati a “cercare” sono molto profonde e per raggiungerle si incontrano numerose interfacce (aria-osso osso-cervello) che creano una notevole interferenza nei segnali fMRI.
Questo ci impone molta cautela nell’interpretazione della stima dei parametri di connettività prodotta da LISREL. Infatti, come abbiamo avuto modo di verificare in fase di simulazione (paragrafo V.4.1), la bontà dei risultati della stima dipende
Figura 6.6 : Coefficienti stimati dei legami di connettività per i set di dati ottenuti dai run 01 DX, run 03 DX, run 05 DX e run 05 SN.
moltissimo dal valore del rapporto segnale-rumore che caratterizza i set di segnali. Cercando di quantificare l’errore commesso dallo stimatore quando si trova a lavorare in queste condizioni, cioè su segnali con un SNR di circa –20 dB, in base alla tendenza che abbiamo riscontrato sui dati raccolti nel capitolo precedente e in base ad alcune brevi simulazioni (non riportate) che abbiamo effettuato sul momento, possiamo affermare che l’errore relativo sulla stima dei parametri di connettività si dovrebbe aggirare intorno all’ 80%. Ciò significa che qualsiasi interpretazione dei coefficienti di connettività daremo, non potrà essere ritenuta affidabile ma dovrà essere confermata in futuro attraverso altri studi che dispongano di dati più significativi.
La prima osservazione che possiamo fare riguarda il coefficiente di connettività
γ
1;per come abbiamo strutturato il modello di stima, assegnando alla variabile esogena un segnale BOLD ideale costruito artificialmente, questo parametro non rappresenta una vera e propria connessione fisica ma semplicemente in quale rapporto stanno il segnale associato a
ξ
1 (BOLD ideale) e il segnale reale, estratto dalla regione della corteccia piriforme, associato alla variabiley
1.Si osserva che questo parametro è abbastanza simile nei modelli relativi a run02 DX e run03 DX attestandosi intorno 3
6 10
⋅
− . Nel run01 DX si discosta di poco da quel valore mentre nel run05 SN è praticamente dimezzato ( 33.1 10
⋅
− ). Quindi, tenuto conto anche del rumore che affligge i segnaliy
1 nei quattro modelli(rispettivamente SNR = -18.3 dB, -23.3 dB, -23.3 dB e –35.9 dB), si può dedurre che l’intensità dell’attivazione che si rileva nella corteccia piriforme ha più o meno la stessa intensità indipendentemente dall’odorante o dalla sua concentrazione.
Per quanto riguarda invece i pesi delle vere e proprie connessioni cerebrali, si nota una certa coerenza di comportamento in tutti e quattro i run, sia per quanto riguarda il singolo valore stimato ma soprattutto nel rapporto tra
b
21 eb
31, nel sensoche il secondo coefficiente è sempre più grande del primo a testimonianza di un legame di causalità presumibilmente più forte tra la Corteccia Piriforme e l’Amygdala
Come accennato anche tra i singoli valori numerici (stimati) assunti da
b
21 eb
31 neidiversi run, escludendo il run 01 che presenta valori molto discordanti per entrambi i coefficienti, si osserva una certa consistenza, soprattutto per il primo coefficiente. Infatti il
b
21 assume i valori (0.13, 0.13 e 0.18) che tutto sommato non sono troppolontani tra loro; per il
b
31 anche se in questo caso i valori assunti sono leggermentepiù variabili si riscontra una certa somiglianza (0.30, 0.37 e 0.34).
In conclusione, anche se per i motivi sopra citati non possiamo assolutamente attribuire al peso delle connessioni i valori stimati dal LISREL sui set di dati a nostra disposizione, possiamo affermare che si osserva un comportamento abbastanza coerente nei tre set di dati, sebbene acquisiti in run successivi e con condizioni di stimolo differenti per quanto riguarda il tipo di odorante o la sua concentrazione, soprattutto per quanto riguarda la diversa “importanza” dei due legami causali in gioco. Questo ci lascia ben sperare per eventuali sviluppi futuri di questo tipo di ricerca che sicuramente dovranno essere indirizzati ad un miglioramento della qualità dei segnali dal punto di vista del rapporto segnale-rumore e ad un allargamento del campione di persone studiato che potrà certamente dare validità ai risultati che si otterranno.