INDICE
INTRODUZIONE
...3
1.OPENFLOW
...5
1.1 Cos'è Openflow
...5
1.2 Flow table, Secure Channel, Controller
...5
1.2.1 Flow Table
...8
1.2.2 Counters
...9
1.2.3 Actions
...10
1.2.4 Processo di matching
…...12
1.2.5 Secure Channel e Controller
...15
1.3 Aggiunta Rimozione e Modifica dei flussi
...20
1.3.1 Rimozione di un flusso e Timeouts
…...27
1.4 Richiesta di statistiche
...27
2.IL CONTROLLER NOX
…...33
2.1 Event, Component ed Handler
...33
2.2 Il concetto di tempo
...36
3.IMPLEMENTAZIONE DEL BALANCER
…...38
3.1 Descrizione dell'algoritmo
...38
3.2 Strutture della STL C++
...42
3.2.1 Iterator
...43
3.2.3 Vector
...44
3.3 Scenario
...45
3.4 Implementazione dell'algoritmo
...48
3.5 Testing del balancer
...58
4. APPENDICI
...79
4.1 Moduli C++
...79
4.1.1 Balancer.hh
…...79
4.1.2 Balancer.cc
…...81
INTRODUZIONE
La tesi si propone di progettare, sviluppare e testare un load balancer su uno switch Openflow così che questo riceva pacchetti reali e li smisti equamente su più porte di uscita.
Per realizzare questo obbiettivo c'è la necessità di avere a
disposizione alcuni strumenti: un apparato che svolga la funzione di switch Openflow, un dispositivo che funzioni da controller e degli apparecchi che svolgano la funzione di host.
Per il primo ruolo verrà impegato un pc con installata la versione software di Openflow; come controller verrà utilizzato un pc collegato tramite cavo ethernet allo switch Openflow con installato il controller Nox; gli host saranno altri 4 pc collegati tramite schede Ethernet allo switch.
Il primo passo sarà quindi prendere conoscenza degli strumenti necessari per la realizzazione del sistema.
Per prima cosa si è dovuto studiare il funzionamento del protocollo Openflow, protocollo che permette la gestione di flussi di pacchetti. In parallelo, si è portato avanti lo studio del linguaggio di programmazione C++ necessario per l'implementazione pratica del software responsabile del balancer.
Gli step successivi riguardano la conoscenza del funzionamento del controller NOX e la scrittura vera e propria dell'algoritmo.
Questa tesi sarà articolata in maniera tale da rispecchiare il lavoro svolto: Il primo capitolo riguarderà il funzionamento di Openflow, il secondo sarà sul controller Nox mentre l'ultimo verterà sull'analisi dell'algoritmo implementato.
1.OPENFLOW
1.1 Cos'è Openflow
Openflow rappresenta un nuovo protocollo, capace di individuare più flussi di traffico distinti. Il programmatore ha la possibilità di raggruppare pacchetti con caratteristiche comuni in singoli flussi operando su ciascun flusso una o più operazioni. Tale raggruppamento si compie andando ad esaminare il valore di determinati campi, all'interno dei pacchetti in arrivo al dispositivo. Openflow nasce per rispondere ad una particolare esigenza di ricerca : è possibile compiere esperimenti nelle reti dei campus? Il proposito da raggiungere era quello di garantire l'equilibrio e la stabilità tra gli interessi degli amministratori di rete e quello dei ricercatori che necessitano di una porzione della rete reale per potere sperimentare le proprie idee senza ovviamente danneggiare gli altri utenti.
Lo sguardo si è quindi concentrato su quali funzionalità fosse necessario inserire in uno nuovo switch.
In un primo tempo si è tentato di convincere i venditori di switch e router commerciali a fornire una piattaforma open e programmabile sui loro apparecchi tale che i ricercatori possero sperimentare liberamente lasciando al contempo gli amministratori della rete tranquilli. Tale desiderio si è scontrato con la comprensibile riluttanza dei produttori ad “aprire” le interfacce interne dei loro prodotti: dopo
l'impegno speso nella ricerca e nello sviluppo di protocolli e algoritmi sempre più sofisticati, c'è la paura che nuovi esperimenti sui loro apparati possano provocare malfunzionamenti nelle reti già esistenti. In più, mostrare i propri segreti, abbasserebbe la “barriera di ingresso” per nuovi produttori concorrenti.
Dall'altro lato esistono le soluzioni derivate dalla ricerca che sono o troppo costose o poco performanti.
L'obiettivo di Openflow è dare una risposta a questi 4 requisiti: – Implementazioni a basso costo e alte prestazioni – Capacità di supportare un largo campo di ricerche – Dividere il traffico sperimentale da quello reale
– Compatibilità con il desiderio dei produttori di mantenere i propri segreti
Alcuni costruttori, come HP e IBM, hanno quindi deciso di mettere in produzione alcuni modelli che siano Openflow compiliant.
L'idea base è quella di raggruppare ed estendere tutte quelle funzionalità comuni a tutti gli switch considerando che al di là di come sono implementati, quasi tutti hanno al loro interno tabelle di flusso che vengono eseguite per implementare firewall, QoS e per la raccolta delle statistiche.
Openflow fornisce un protocollo in grado di programmare separatamente le tabelle di flusso dei vari switch e dei vari router. Questo permette ai ricercatori e ai loro amministratori di avere due flussi di traffico complemente distinti e processati in maniera diversa consentendo quindi lo sviluppo dei nuovi protocolli.
1.2 Flow table, Secure Channel, Controller
Gli switch Openflow sono composti da 3 parti fondamentali: Flow Table, Secure Channel ed un Controller.
La Flow Table è responsabile dell'esame dei pacchetti e del loro successivo inoltro, mentre il Secure Channel permette ad un controller esterno di gestire il comportamento dello switch tramite il protocollo Openflow.
Per ogni flusso di interesse sul quale si vuole che lo switch implementi una o più determinate azioni, viene inserita una voce all'interno della Flow Table nella quale sono specificati i valori
dell'header con i quali si vuole che i vari pacchetti vengano comparati. Infatti ogni pacchetto processato viene comparato con tutte le voci presenti in tabella e in caso di match, viene perfezionata l'azione/azioni associata a quel particolare flusso. In caso contrario, il pacchetto è inoltrato al controller al quale è demandata ogni decisione in merito (aggiungere un nuovo flusso, droppare il pacchetto etc.).
Sono inoltre presenti particolari porte virtuali che consentono azioni particolari quali il flooding o l'inoltro dei pacchetti direttamente dalla porte di ricezione dello stesso.
Le azioni permesse da uno switch Openflow sono molteplici e saranno illustrate più in seguito.
1.2.1 Flow Table
Concentriamoci adesso su come è organizzata la Flow table e su come viene effettuato il confronto dei pacchetti in arrivo con le voci presenti nella tabella.
Ciascuna voce della tabella di flusso (che da adesso chiameremo entry) è composta da i campi header, ovvero i campi del pacchetto su cui effettuare la comparazione; da un insieme di contatori che si aggiornano mano a mano che il matching prosegue e da una lista di azioni prevista per quel particolare flusso.
Headers
Field
Counters
Action
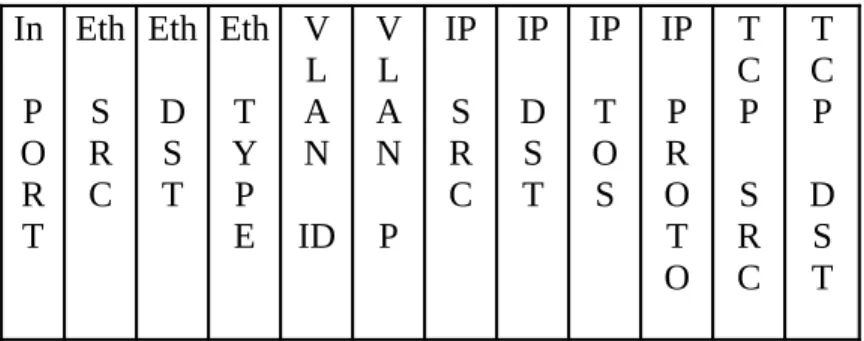
Concentriamoci sull'Header: abbiamo detto che del pacchetto vengono esaminati vari campi ed il valore di questi è confrontato con il valore presente nell'header fields dell'entry.
I campi dell'header con cui viene effettuato il matching sono rappresentati in figura 4 e possono assumere sia un particolare valore che un valore “ANY” che permette l'automatico match con qualsiasi valore.
In
P
O
R
T
Eth
S
R
C
Eth
D
S
T
Eth
T
Y
P
E
V
L
A
N
ID
V
L
A
N
P
IP
S
R
C
IP
D
S
T
IP
T
O
S
IP
P
R
O
T
O
T
C
P
S
R
C
T
C
P
D
S
T
Figura 4 – Campi presenti nell'Header Fields in un entry della Flow Table
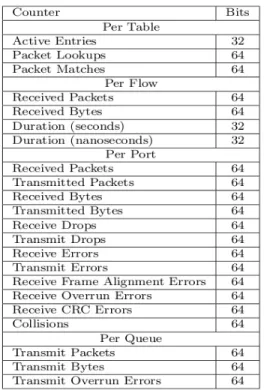
1.2.2 Counters
Il campo Counters racchiude quattro possibili tipologie: – per table
– per flow – per port – per queue
Ogni tipologia implementa una serie di contatori diversa che è illustrata in Figura 5.Nel nostro lavoro verranno utilizzati alcuni tipi di
questi contatori per verificare la bontà del lavoro effettuato.
1.2.3 Actions
Il campo Actions racchiude le azioni che l'utente vuole far compiere dallo switch su ogni specifico flusso. Nel caso che nessuna azione sia presente, ogni pacchetto appartenente a quel flusso viene scartato. Nel caso in cui siano invece presenti più azioni per il solito flusso queste sono eseguite nell'ordine specificato. Può succedere
che uno switch non sia in grado di eseguire le azioni nell'ordine specificato, in quel caso verrà generato un messaggio di errore verso il controller.
Uno switch Openflow non deve per forza essere in grado di eseguire tutti le tipologie di azione definite ma solo alcune che sono state dichiarate come “necessarie”: nella fase di set-up con il controller, lo switch comunica al controller se e quali azioni opzionali è in grado di supportare.
Le azioni base che devono essere implementate da uno switch denominato “Openflow-only“ sono:
FORWARDING: Ogni switch Openflow deve essere in grado di smistare i pacchetti sulle porte fisiche e sulle seguenti porte virtuali:
– ALL: Invio su tutte le porte ad eccezione di quella d'ingresso – CONTROLLER: Invio del pacchetto al Controller
– TABLE: Effettua l'azione prevista nella tabella di flusso (vale solo per i pacchetti in uscita)
– IN_PORT: Invio del pacchetto sulla porta dalla quale è arrivato.
– FLOOD: Inoltra il pacchetto lungo il minimo Spanning Tree ad eccezione della porta di ingresso
DROP: Eliminazione di un pacchetto (si effettua quando nessuna azione è presente).
Openflow-enable) :
– NORMAL: Processa il pacchetto secondo il tradizionale percorso di inoltro supportato dallo switch ( es. L2 tradizionale, VLAN, processing L3)
– ENQUEUE: Inoltra il pacchetto su una coda attaccata ad una porta.
– MODIFY-FIELD: Lo switch è in grado di modificare alcuni campi dell'header del pacchetto processato
1.2.4 Processo di matching
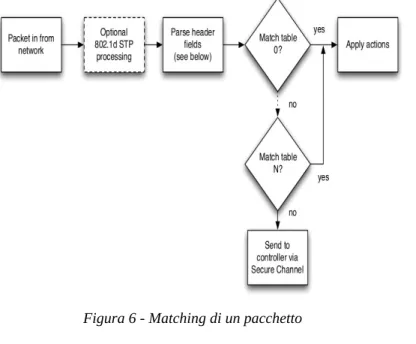
Il processo di matching è spiegato nelle figure seguenti:
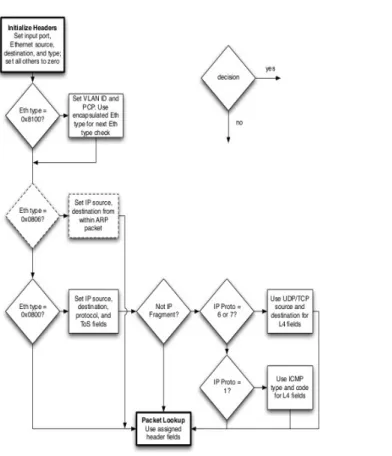
La figura 6 mostra il funzionamento complessivo di un sistema basato su Openflow mentre la figura 7 evidenzia passo per passo il comportamento tenuto per la verifica di una corrispondenza tra pacchetto in arrivo allo switch e i valori memorizzati nella Flow Table. Al ricevimento del pacchetto, lo switch Openflow esegue quanto mostrato in figura 6 e, a seconda del tipo di pacchetto che viene esaminato, vengono scelti i campi dell'Header con cui effettuare il confronto secondo le regole a cascata mostrate in figura 7:
L'analisi dell'input port e dei campi Ethernet type viene effettuato per i tutti i pacchetti in ingresso: se il pacchetto contiene un tag VLAN (Ethernet Type 0x8100) allora vengono confrontati anche i 2 campi successivi; se i pacchetti sono IP (E.T. 0x800) vengono esaminati anche i campi riguardanti IP; se il protocollo utilizzato su IP è TCP o UDP allora entrano nella comparazione anche le porte
sorgente/destinario. Una volta che c'è corrispondenza, si aggiornano i contatori e si esegue l'azione desiderata.
È importante precisare come nel caso che un pacchetto sia conforme a più entry (ciò è possibile visto che è possibile lasciare in alcuni campi il valore “ANY”). Questo conflitto è risolto con l'inserimento di una priorità per ogni campo lasciato senza un valore esatto. Una priorità più alta viene preferita, ovviamente, ad una più bassa. In caso di parità, lo switch è lasciato libero di scegliere casualmente. Nel caso che invece non ci sia alcuna entry in grado di assorbire il pacchetto, questo viene inviato al controller perchè decida cosa fare: scartarlo, inviarlo ad una porta specifica oppure inserire una nuova entry nella tabella.
1.2.5 Secure Channel e Controller
Il Secure channel è l'interfaccia che permette il collegamento tra lo switch ed il controller. Il controller gestisce il funzionamento dello switch ed attraverso il Secure Channel è in grado di ricevere ed inviare messaggi Openflow e pacchetti dati. L'interfaccia è “Implementation Specific” quindi è importante precisare che tutti i messaggi che viaggiano sul Secure Channel devono avere il formato stabilito dal protocollo Openflow. Ancora non è stato definito il supporto per Secure Channel multipli.
Di seguito si elencano alcuni dettagli importanti per quanto riguarda la connessione tra controller e switch.
Per adesso, un sistema per la scoperta dinamica del controller (dove l'indirizzo IP e la porta di comunicazione siano determinati a
run-time) non è previsto dallo standard ma è lo switch che deve essere in grado di stabilire una connessione con un indirizzo IP (fissato o configurato dall'utente) su una porta specificata dall'utente stesso. Il traffico che passa sul Secure Channel non è processato tramite l'analisi con la tabella di flusso.
Alla prima connessione col controller, la catena dei messaggi tra switch e controller è quella mostrata in figura 8.
I messaggi OFPT_HELLO sono inviati da entrambi i lati della comunicazione e contengono solo l'header openflow. Il campo Version contiene la versione di Openflow più evoluta supportata dal
dispositivo. Il ricevitore di questo messaggio calcola autonomamente la versione migliore per garantire una compatibilità alla conversazione. Nel caso una compatibilità sia impossibile, viene creato un messaggio di errore altrimenti la comunicazione va avanti. Successivamente il controller chiede tramite il messaggio FEATURES_REQUEST le caratteristiche dello switch. Lo switch nella risposta (FEATURES_REPLY) invierà il proprio identificativo (id_datapath), il numero di porte presenti e la loro struttura, quante tabelle e quali azioni sono supportate. Ciclicamente vengono inviati dei meassggi di echo per verificare che la connessione sia attiva. Nel caso lo switch perda il contatto con il controller, esiste una procedura di emergenza che prevede, dapprima, la ricerca di altri controller di riserva e, successivamente qualora questa ricerca fallisca, l'ingresso in una modalità che prevede una tabella di flusso particolare, detta appunto “emergency flow table”; in questo scenario tutte le entry sono eliminate ad eccezione di quelle marcate con il flag “emergency”. Alla prima connessione lo swtch è come se fosse in emergency mode.
La connessione che c'è tra switch e controller usa TLS e di default avviene sulla porta TCP 6633.
Facciamo una breve carrellata su quali sono i messaggi che possono intercorrere tra lo switch ed il controller. I messaggi di stretto interesse per il lavoro di tesi saranno approfonditi più avanti:
Symmetric message: messaggi inviati senza alcuna sollecitazione
Immutable Messages
OFPT_HELLO OFPT_ERROR OFPT_ECHO_REQUEST
OFPT_ECHO_REPLY
Figura 9 - Messaggi Immutabili
Asynchronous messages: sono inviati dallo switch senza che sia
stato il controller a richiederne l'invio. Lo switch segnala l'arrivo di un pacchetto, di un cambiamento nella configurazione o di un errore.
Asynchronous Messages
OFPT_PACKET_IN OFPT_FLOW_REMOVED
OFPT_PORT_STATUS ERROR
Figura 10 - Messaggi Asincroni
Controller to Switch Messages: sono inviati dal controller e possono
richiedere risposta dallo switch. Sono utilizzati dal controller per investigare lo stato e le statistiche dello switch o per il management dello stesso. Qua sono raccolti per funzione:
Controller to Switch Messages Controller command messages
OFPT_PACKET_OUT OFPT_FLOW_MOD OFPT_PORT_MOD Statistics messages OFPT_STATS_REQUEST OFPT_STATS_REPLY Barrier messages OFPT_BARRIER_REQUEST OFPT_BARRIER_REPLY
Queue Configuration messages
OFPT_QUEUE_GET_CONFIG_REQUEST OFPT_QUEUE_GET_CONFIG_REPLY
Switch configuration messages
OFPT_FEATURES_REQUEST OFPT_FEATURES_REPLY OFPT_GET_CONFIG_REQUEST
OFPT_GET_CONFIG_REPLY OFPT_SET_CONFIG
1.3 Aggiunta Rimozione e Modifica dei flussi
Per cambiare la flow table, si utilizzano i “flow modification messages”.
Quando si aggiunge un nuovo flusso (ADD message), si deve verificare che nessun pacchetto possa matchare due diverse entry con la stessa priorità.
struct ofp_match uint32_t wildcards; uint16_t in_port; uint8_t dl_src[OFP_ETH_ALEN]; uint8_t dl_dst[OFP_ETH_ALEN]; uint16_t dl_vlan; uint8_t dl_vlan_pcp; uint8_t nw_tos; uint8_t nw_proto; uint8_t pad[1]; uint8_t pad[2]; uint32_t nw_src; uint32_t nw_dst; uint16_t tp_src; uint16_t tp_dst Figura 12 - Match struct
Questo inconveniente si elimina con un particolare flag (check overlap) che, settato nel messaggio ADD, permette allo switch di scartare il flusso in arrivo e di generare un messaggio di errore. Per flussi validi, viene creata una nuova entry con i valori compresi nella struttura flow_match e le relative wildcard.
Come si può vedere dalla figura 12, questa struttura identifica tutti i campi su cui lo switch Openflow effettuerà il matching. Di particolare interesse è il membro wildcards di tipo uint32_t. Se vogliamo che uno dei campi su cui Openflow matcha i propri flussi venga ignorato, è necessario impostare correttamente il valore di questo membro di 32 bit. Infatti, ogni bit del campo wildcard ha una corrispondenza sui campi del matching. Lo switch considererà un matching valido su tutti quei campi, qualunque sia il valore presente nel pacchetto in arrivo, se il bit della wildcard associato a quel campo è settato con il valore 1, eliminando di fatto questo campo dal matching. Quindi i campi non di nostro interesse per il matching dei pacchetti in arrivo, dovranno avere il bit del campo wildcard settati ad uno.
Di seguito in figura 13, si forrnisce l'elenco completo delle wildcards, in modo da renderne comprensibile il funzionamento.
enum ofp_flow_wildcards OFPFW_IN_PORT = 1 << 0 OFPFW_DL_VLAN = 1 << 1 OFPFW_DL_SRC = 1 << 2 OFPFW_DL_TYPE = 1 << 4 OFPFW_NW_PROTO = 1 << 5 OFPFW_TP_SRC = 1 << 6 OFPFW_TP_DST = 1 << 7 OFPFW_NW_SRC_SHIFT = 8, OFPFW_NW_SRC_BITS = 6, OFPFW_NW_SRC_MASK=(( 1 << 6 ) - 1 ) << 8 OFPFW_NW_SRC_ALL= 32 << 8 OFPFW_NW_DST_SHIFT = 14, OFPFW_NW_DST_BITS = 6, OFPFW_NW_DST_MASK = (( 1 << 6 ) - 1) << 14 OFPFW_NW_DST_ALL = 32 << 14 OFPFW_DL_VLAN_PCP = 1 << 20 OFPFW_NW_TOS = 1 << 21 OFPFW_ALL = ((1 << 22) - 1)
Figura 13 - Wildcards Enum
Di default tutti i campi sono posti a zero e nessuna wild card è impostata. Per renderla attiva si utilizza l'operatore << ovvero l'operatore di shift bit a bit verso sinistra, impostando il valore 1 sul bit di interesse. Quindi la posizione del bit associato al campo è il
valore alla destra dell'operatore aumentato di uno. Ad esempio la wildcard per il campo input_port è rappresentata dal primo bit dal momento che io dovrei muovere il mio uno di zero posizioni.
Discorso a parte meriterebbero i campi ip_src e ip_dst che hanno più bit per permettere di considerare diverse netmask nel matching. Se tutti i bit sono a zero, un flusso matcha un pacchetto solo se l'indirizzo è esattamente lo stesso. Impostando uno o più bit dei 6 a disposizione è possibile creare delle netmask che allargano il numero di indirizzi che hanno un match positivo rendendo ininfluenti uno o più bit del campo ip_src/ip_dst .
Rendendo esplicita la dipendenza si ha che il valore 0 della wildcard significa che si desidera una corrispondenza esatta, il valore 1 rende ininfluente in bit meno significativo, il valore 2 rende influenti i 2 bit meno significativi e così via. Per 32 o valori superiori, l'intero indirizzo non è significativo cioè non è più un vincolo per la corrispondenza.
L'ultima wildcard è quella per impostare attive tutte le wildcard ovvero restitusce un match positivo qualunque pacchetto giunga allo switch.
La struttura match servirà non solo per il matching dei pacchetti ma ci consentirà anche di selezionare i flussi per i quali stiamo chiedendo le statistiche allo switch.
La struttura ofp_match è alla base del funzionamento dell'intero sistema. Infatti per aggiungere, modificare o cancellare una entry dalla tabella di flusso si utilizza la struttura ofp_flow_mod che al suo interno presenta una ofp_match.
In figura 14, si mostra la composizione della struttura ofp_flow_mod.
Struct ofp_flow_mod struct ofp_header header;
ofp_match match; uint64_t cookie; uint16_t command; uint16_t hard_timeout; uint16_t idle_timeout; uint16_t priority uint32_t buffer_id; uint16_t out_port; uint16_t flags;
struct ofp_action_header_ actions[0]; Figura 14 - Flow Modification Struct
Alcuni dettagli sui campi più particolari di questa classe. Il campo priority rende possibile impostare una priorità per ogni flusso ed è significativo solo per i campi con wildcard attive: infatti la gestione della priorità impedisce che un pacchetto possa matchare due distinte entry; tocca al progettista dello switch impostare i valori adeguati affichè lo switch stesso si comporti come si desidera. Il campo out_port, ha significato solo per il comando DELETE, per il quale rappresenta un ulteriore vincolo per l'eliminazione del flusso; il campo command indica che tipo di azione si sta facendo sulla tabella
(ADD,MODIFY,DELETE);
Il campo flag può attivare tre funzioni particolari quali:
– Inviare un pacchetto di conferma della rimozione del flusso – Check per Overlapping
– Rimarcare che il flusso va inserito nella tabella di emergenza
L'Overlapping è una opzione che se selezionata, obbliga lo switch a verificare se ci siano due o più entries distinte che possano matchare lo stesso pacchetto con la stessa priorità. In questo caso, l'entry non viene aggiunta e viene restituito al controller un messaggio di errore. La struttura ofp_action identifica quale azione tra le disponibili viene selezionata per quel flusso. L'azione che useremo nella creazione del balancer sarà OFP_ACTION_OUTPUT che semplicemente, inoltra il pacchetto verso una porta dello switch. Questa azione è così implementata: struct ofp_action_output uint16_t type; uint16_t len; uint16_t port; uint16_t max_len; Figura 15 – ofp_action struct
viene prima rimosso e poi nuovamente reinserito (per azzerare contatatori e timeouts).
In caso di errori (porta non valida, tabella piena etc.), lo switch risponde con il corrispondente messaggio di errore.
Nel caso si cerchi di inviare un pacchetto ad una porta inesistente, lo switch può sia eliminare silenziosamente i pacchetti che matchano quel flusso o inviare immediatamente un messaggio di errore al controller.
Per modificare l'azione corrispondente ad un flusso, si usano i messaggi MODIFY. Il loro funzionamento è equivalente ad un messaggio ADD se il flusso al quale va modificata l'azione non è presente in tabella.
Per cancellare un flusso si usano i mesaggi DELETE, che al contrario dei precedenti non danno luogo a nessun errore o comportamento diverso se il flusso da cancellare non è presente in tabella.
Per i comandi MODIFY e DELETE, è presente anche una versione _STRICT. In questa versione, anche le wildcard e la priorità sono dei vincoli che devono corrispondere perfettamente affinchè il flusso venga effettivamente modificato o cancellato. Per i messaggi MOD/DEL non strict che contengono wildcard, ci sarà una corrispondenza solo se tutte le wildcard corrispondono o se la entry è più specifica rispetto alla descrizione del messaggio MOD/DEL. Solo per i messaggi DELETE, si può inserire un ulteriore vincolo sul
matching che è quello sulla porta d'uscita, cioè l'azione che viene esuguita su quel flusso deve essere diretta verso quella porta d'uscita.
1.3.1 Rimozione di un flusso e Timeouts
Una entry viene rimossa non solo per la sollecitazione del controller che invia un DELETE message ma anche per la scadenza di uno dei 2 timeout implementati: IDLE timeout e HARD timeout.
Rappresentano rispettivamente il tempo di inattività (il tempo dall'ultima corrispondenza di un pacchetto con quel flusso) e il tempo da cui il flusso è stato creato in tabella. L'utente può impostare il valore di questi timout o disattivarli. Nel momento in cui uno dei due timeout scade, il flusso viene eliminato dalla tabella. Per i flussi della tabella di emergenza, i timeouts devono essere pari a zero.
1.4 Richiesta di statistiche
L'interpretazione del matching vista precedentemente vale anche per i messaggi con i quali si richiedono le varie statistiche viste nei capitoli precedenti ovvero i messaggi
– FLOW STATS
– AGGREGATE FLOW STATS – TABLE STATS
A seconda del messaggio inviato lo switch rispenderà un messaggio contenente le statistiche indicate in figura 5.
La struttura base del messaggio di richiesta e risposta delle statistiche è la seguente:
struct ofp_stats_request struct ofp_header header;
uint16_t type; uint16_t flag; uint8_t body[0];
Figure 16 - Ofp_stats Request struct
struct ofp_stats_reply struct ofp_header header
uint16_t type; uint16_t flags uint8_t body [0]; Figura 17 - Ofp_stats Reply struct
Il campo Type indica il tipo di statistiche richieste mentre il campo flag ancora non ha usi definiti. Il campo body dipende invece dal tipo di richiesta che viene effettuata. A determinata richiesta corrisponderà un tipo di risposta diversa di volta in volta.
Di seguito riportiamo le strutture AGGREGATE_STATS_REQUEST ed AGGREGATE_STATS_REPLY che sono quelle utilizzate nel lavoro di tesi:
struct ofp_state_request struct ofp_match match
uint8_t table_id uint_t pad; uint16_t out_port
Figura 18 - Ofp_Aggregate_stats_request struct
Questa richiesta del controller allo switch, ha l'obiettivo di avere statistiche su insiemi di più flussi con determinate caratteristiche. Per esempio, ci interesseranno le statistiche complessive di ogni porta per stabilirne il carico. Per fare ciò utilizzeremo il campo match, di cui abbiamo già parlato, mentre merita prestare la nostra attenzione sugli altri campi.Il campo table_id ed il campo out_port. Il campo table_id indica in quale tabella di flusso andiamo a leggere le sstatistiche. E' possibile richiedere le statistiche di flussi aggregati nella tabella dei flussi con wildcard, senza wildcard, flussi di emergenza o sulla totalità delle tabelle. Per le ultime due soluzioni ci sono dei particolari valori con cui impostare questo campo.
Il campo out_port indica ovviamente la porta sulla quale richiedere i dati dei flussi con una particolarità: è un campo opzionale, posso cioè impostare un valore per cui la porta non rappresenta un vincolo.
Avrò così le statistiche complessive su tutte le porte.
Il genere di informazioni che riceviamo in risposta da questa richiesta sono evidenziate nella seguente struttura.
Struct ofp_aggregate_stats_reply uint64_t packet_count;
uint64_t byte_count; uint32_t flow_count;
uint8_t pad[4]:
Figura 19 - Ofp_Aggregate_stats_reply struct
Riceviamo indietro le seguenti informazioni: il numero dei flussi attivi, il numero dei pacchetti che hanno ricevuto un matching positivo con i flussi attivi al momento della richiesta, il numero totale dei byte ricevuti per ogni flusso attivo. Come si vede non è però presente nella risposta un campo che ci indichi l'eventuale porta utilizzata come vincolo. Per realizzare l'accoppiamento corretto tra richiesta e risposta si utilizza un identificatore presente nell'header ofp_header presente in ogni pacchetto openflow. Riportiamo di seguito l'header del pacchetto Openflow:
struct ofp_header uint8_t version;
uint8_t type; uint16_t length;
uint32_t xid; Figura 20 - Ofp_header struct
Il campo xid facilita il pairing tra richiesta e risposta.
L'ultima struttura che esaminiamo nel dettaglio del Protocolllo Openflow, e d'interesse per la tesi, è la struttura Packet_in_message.
struct ofp_packet_in struct ofp_header header;
uint32_t buffer_id; uint16_t in_port;
uint8_t reason; uint8_t pad; uint8_t data[0]; Figura 21 - Ofp_packet_in struct
Un pacchetto può essere inviato al controller per due motivi: il pacchetto non matcha nessun flusso in nessuna tabella, oppure lo matcha e l'azione corrispondente per quel flusso è quella di inviare i pacchetti al controller.
Non sempre tutto il pacchetto viene inviato al controller; se siamo nel primo caso, viene inviato al controller solo una parte del pacchetto che di default è di 128 bytes. Nel secondo caso, viene inviato al massimo la quantità stabilità nel campo max_len della struttura Action_Output .
Per il nostro lavoro di tesi non ci distaccheremo mai dal primo caso ovvero tutti i “Packet in” inoltrati verso il controller, saranno inviati dallo switch perchè non avranno trovato un matching nella tabella di flusso.
2.IL CONTROLLER NOX
2.1 Event, Component ed Handler
Il controller utilizzato è il controller NOX versione 0.9.0 full-beta e di seguito verranno brevemente illustrati i concetti su cui questo controller basa il proprio funzionamento.
Intanto, il linguaggio di programmazione utilizzato è fondamentalmente il C++ anche se sono frequenti le iterazioni con il Python.
L'implementazione del Nox si basa su tre parti fondamentali ovvero la classe Event, la classe Component e gli Handler. Per poter sviluppare nuove funzionalità, è necessario familiarizzare bene con questi concetti. Un Event, come dice il nome stesso, rappresenta quanto può succedere all'interno della nostra rete a tutti i livelli; è una classe che permette di passare tutti gli eventi della rete in maniera conveniente al controller ma fondamentalmente rappresenta un'interfaccia visto che le informazioni davvero rilevanti sono nelle sue classi derivate.
Un Event fornisce solo informazioni perchè la maniera più comoda per processare un certo Event può differire da caso a caso e la loro gestione è demandata agli Handler.
Un Component invece è uno script che racchiude al suo interno specifiche funzionalità. Spesso un'applicazione in Nox è l'insieme di più Component che cooperano tra loro: per esempio il routing è implementato come un Component e quindi ogni funzione che
richieda il Routing deve dichiarare una dipendenza per averlo poi disponibile a run-time.
I Component risiedono nella directory /src/nox ma a seconda del tipo di funzionalità si dividono in altre 3 directory: Coreapps, Netapps, Webapps. In generale, ogni Component ha una propria cartella all'interno di questi tre raggruppamenti nonostante non sia strettamente necessario.
I Component, per svolgere la loro funzione, fanno ricorso agli Handler ovvero a delle funzioni che sono preposte alla gestione di un particolare evento. In un Component possono, quindi, essere presenti più Handlers, uno per ogni evento che si intende gestire. Per esempio nel balancer implementato in questa tesi, si farà ricorso a 2 distinti Handlers: uno per la gestione dei pacchetti in arrivo (Packet_in_Event), l'altro per la gestione delle statistiche aggregate in arrivo dallo switch (Aggregate_Stats_in_Event).
Nell'esempio, il nostro nuovo Component chiamato Hub deve derivare pubblicamente dalla classe Component, deve avere un costruttore e deve avere una chiamata a REGISTER_COMPONENT che agevola il caricamento del nuovo Component. In più deve avere due metodi Install() e Configure(), che chiamati a tempo di caricamento, permettono al Component di associare ogni Handler ad un preciso Event. In questo modo ogni qualvolta si presenta l'evento verrà chiamato quell'Handler con il quale è stato accoppiato. L'accoppiamento si ottiene con la chiamata alla funzione register_handler che ha questa signature:
Component::register_handler<Event>(boost::bind(&Hub::handler, this, _1));
dove al posto di Event va sostituito l'evento che si vuole gestire, ed in handler il nome della funzione che viene utilizzata per gestirlo. Gli Handlers restituiscono un particolare tipo chiamato Disposition che per definizione può avere due valori: CONTINUE o STOP. Il valore CONTINUE indica che l'evento processato dall'handler passerà all'eventuale successivo handler mentre con il valore STOP si vuole fermare la catena dell'evento.
Inoltre per poter utilizzare il nostro nuovo Component è necessario seguire questi passi:
– Creare una nuova directory in Coreapps, Netapps o Webapps (a seconda della natura del Component)
– Aggiungere gli appropriati header C e modificare i file meta.json e Makefile.am
– Aggiungere la directory in configure.in.ac – Eseguire ./boot.sh ed ./configure
I primi tre passi sono perfezionati da uno script Python presente nelle utilities del Nox, nox-new-c-app.py, mentre l'ultimo deve essere eseguito dall'utente. L'applicazione, fornendo ad essa il nome del nuovo Component, provvede a crearlo adeguatamente con la struttura vista in precedenza.
Il nuovo component sarà formato da due file aventi lo steso nome ma estensioni diverse: “Nome”.cc e “Nome.hh”.
Nell'header vanno le dichiarazioni dei membri che verranno utilizzati nel Component e va una breve descrizione di ciò che questi membri faranno operativamente.
Nel file .cc invece va il corpo del nuovo Component cioè va l'implementazione effettiva delle funzionalità che si desidera aggiungere al Nox.
2.2 Il concetto di tempo
Resta da capire come funziona operativamente il Nox. Il Controller in questione è Event-driven (non è totalmente vero ma per i nostri scopi è una assunzione più che ragionevole), cioè è guidato da ciò che succede nella rete e reagisce quindi agli Event che di volta in volta si presentano.
E' però possibile chiamare un Handler o una qualunque funzione dopo un certo periodo di tempo. Questo è possibile utilizzando la funzione post all'interno di install() o configure():
Timer post(const Timer_Callback&, const timeval& duration) const
in cui Timer_Callback è la funzione da chiamare mentre timeval è intervallo di tempo dopo il quale viene effettuata la chiamata.
E' possibile utilizzare questo meccanismo anche in maniera ricorsiva all'interno di una funzione, per permettere che una certa funzione venga ripetuta ogni intervallo di tempo prestabilito.
Questo meccanismo sarà molto utile, come vedremo nella descrizione del lavoro di tesi, nel momento in cui vorremmo chiedere al nostro switch Openflow le statistiche dei flussi e dei pacchetti in maniera continuativa ogni tot secondi. Questo sistema ci permetterà inoltre, di utilizzare il timer della richiesta delle statistiche come parametro variabile per valutare le prestazioni del load balancer. Il controller viene compilato dal compilatore c++ gcc 4.4.
3.IMPLEMENTAZIONE DEL BALANCER
3.1 Descrizione dell'algoritmo
Passiamo adesso in rassegna il funzionamento dell'algoritmo: prima lo faremo da un punto di vista logico e successivamente passeremo in rassegna l'implementazione pratica dello stesso.
Si è visto come il controller sia in realtà event-driven quindi alcuni passaggi dell'algoritmo saranno necessariamente legati al verificarsi di particolari eventi.
Altri invece potremo gestirli tramite l'utilizzo dei timer come descritto nel precedente capitolo.
Facciamo un excursus sul funzionamento dell'algoritmo dal punto di vista logico: per ogni pacchetto in arrivo vengono verificati i seguenti campi:
– IP source – IP destination – IP Protocol
– TCP/UDP Source Port – TCP/UDP Destination Port
Per ogni nuova combinazione della quintupla il controller crea una nuova entry nella tabella di flusso che rimane memorizzata fino al termine dell'idle_timeout.
bilanciamento così la strategia adottata è quella di smistare, a rotazione, ogni nuovo flusso verso una porta diversa (round-robin). A regime si sfrutta lo scadere di un altro timer, ciclico ed impostato dal progettista, per far richiedere dal controller le seguenti statistiche allo switch: pacchetti processati, byte processati e il numero di flussi attivi al momento della richiesta. Questa richiesta è ripetuta per ogni porta dello switch.
Terminata la ricezione delle informazioni si può effettuare la valutazione del bilanciamento sulle varie porte. La valutazione del bilanciamento dei carichi sulle varie porte viene effettuata ad ogni aggiornamento delle statistiche.
Quindi ogni volta che un pacchetto non appartentente ad un flusso in memoria si presenta allo switch, ci possiamo trovare nel caso di bilanciamento o di sbilanciamento del carico.
Nel primo caso, si procede come nel caso iniziale, a smistare a rotazione sulle porte i nuovi flussi; per cui se il flusso precedentemente creato è uscito dalla porta 1, quello appena generato uscirà dalla porta 2.
Nel secondo caso, il carico di ogni porta può essere sbilanciato in due modi: o è troppo elevato o è troppo scarso.
La combinazione degli stati delle varie porte può dare origine a 4 situazioni:
– tutte le porte hanno un carico bilanciato – una o più porte sono troppo cariche – una o più porte sono troppo scariche
– alcune porte sono troppo cariche altre troppo scariche
Nei primi due casi il comportamento tenuto è similare: lo switch continuerà nel suo round-robin con la differenza che nel secondo caso sarà portato ad escludere le porte troppo cariche dal round-robin.
I nuovi flussi andranno verso quelle porte che stanno sotto la soglia di bilanciamento (ad es. con 4 porte di uscita equivalenti sarà il 25%) Nel terzo e nel quarto caso il lo switch andrà a sanare la situazione più critica indirizzando tutti i nuovi flussi verso la porta più scarica senza curarsi che altre porte possano essere troppo cariche.
Il comportamento scelto è mantenuto dalla ricezione delle statistiche fino al loro successivo aggiornamento.
Si capisce quindi l'importanza della scelta di questo timer per il corretto funzionamento del sistema: intervalli troppo lunghi possono infatti impedire allo switch una pronta reazione nel caso di cambiamento di stato nel bilanciamento, d'altro canto tempi troppo stretti possono sobbarcare lo switch di un lavoro di processing inutile.
Si capisce quindi l'importanza della scelta di questo timer per il corretto funzionamento del sistema: intervalli troppo lunghi possono infatti impedire allo switch una pronta reazione nel caso di cambiamento di stato nel bilanciamento, d'altro canto tempi troppo stretti possono sobbarcare lo switch di un lavoro di processing inutile.
Vediamo adesso cosa succede all'arrivo dell'aggiornamento delle statistiche.
Questo è il momento in cui lo switch deve decidere quale caso tra quelli enunciati rappresenti la realtà in quel momento.
Per ogni porta presente, lo switch invia al controller un pacchetto con
all'interno alcune informazioni: numero di flussi attivi, numero di pacchetti processati, numero di byte processati.
Si ha quindi a disposizione sia il numero di pacchetti relativo ad ogni porta che, dopo la ricezione delle informazioni da tutte le porte, del numero totale di pacchetti processati.
E' possibile quindi vedere con una sempilce operazione quale sia il carico percentuale relativo ad ogni porta:
Numero pacchetti processati dalla porta
Numerototale di pacchetti processati dalle porte
∗100
(1) Scorrendo i valori di tutte le porte è possibile capire in quali condizioni versa lo switch e prendere così la giusta decisione sul comportamento da seguire.Per chiudere, non rimane che salvare i dati relativi ad ogni porta per vericare a posteriori il comportamento dello switch ed eventualmente operare qualche cambiamento.
Per ogni porta vengono salvati sul file relativo a quella porta il numero di flussi attivi, di paccchetti processati e il carico percentuale. Per ogni aggiornamento delle statistiche viene aggiunta nel file una riga con i nuovi valori dei parametri.
3.2
Strutture della STL C++
Prima di descrivere cosa è stato fatto operativamente, si opera un breve excursus su le strutture e gli algoritmi della libreria standard
del C++ utilizzati per realizzare il balancer.
3.2.1 Iterator
ITERATOR : Hanno la stessa semantica dei puntatatori e sono
oggetti che permettono di scorrere gli oggetti dei containers. Ogni tipo di container ha i suoi iteratori.
Map.begin(): iteratore che punta al primo elemento.
Map.end(): iteratore che punta all'elemento dopo l'ultimo (il container finisce all'elemento precedente quello puntato)
3.2.2 Map
MAP : Container associativo che memorizza elementi formati da una
chiave (key) e da un valore (value); la chiave deve essere univoca cioè non è possibile avere valori distinti con la stessa chiave mentre è possibile il viceversa. I tipi della chiave e del valore associato possono differire. La Map è un container ordinato per chiave, ciò è per essere visionato tramite le chiavi che sono ordinate in ordine crescente.
map.insert: inserisce un nuovo valore nella mappa. Restituisce una pair formata da un iteratore con la posizione in cui il nuovo elemento è stato inserito e da un booleano che indica se l'operazione è andata a buon fine (true) o se si è cercato di inserire un elemento con una chiave già presente (false).
posizione in cui la chiave risiede se questa viene trovata, altrimenti viene restituito l'iteratore che punta all'elemento dopo l'ultimo ovvero map.end().
Map.erase: elimina l'elemento desiderato dalla map.
Map.min_element: trova l'elemento con chiave più piccola nella mappa, è però possibile cambiare il criterio “di minimo” passando un callable object che implementi l'operatore minore (noi cercheremo l'elemento minore)
3.2.3 Vector
VECTOR: Sono un tipo di container che ordina i propri elementi
secondo una sequenza strettamente lineare.
Vector.erase : elimina l'elemento desiderato dal vector.
Figura 24 - Map KEY TYPE
VALUE TYPE
MAP.begin() MAP.end()
Vector.swap: Scambia gli elementi di due vector anche di dimensione diversa lasciando però validi tutti gli iteratori.
3.3 Scenario
Lo scenario ipotizzato è quello in figura 26 dove lo switch riceve i pacchetti da un'unica porta e li smista su quattro porte alle quali collegare quattro host specchio della macchina centrale.
L'idea è quella di suddividere il traffico in flussi distinti e ripartirli con equità secondo questi criteri:
– non interrompere le connessioni tcp del traffico processato – ottenere un bilanciamento del numero dei pacchetti su ogni
porta
Figura 25 - Funzione Swap Vector 1
Vector 2 SWAP
Vector 1
Questo ci porta a considerare di lavorare con dei flussi che siano composti da una quintupla di campi:
– Indirizzo IP sorgente – Indirizzo IP destinatario
– Tipo di protocollo IP (TCP/UDP) – Porta sorgente TCP/UDP – Porta destinario TCP/UDP
Ciò comporta che ogni pacchetto in arrivo che non abbia una
corrispondenza esatta in tutti questi campi con i flussi presenti in tabella dia luogo ad un nuovo flusso con una quintupla ricavata dai campi del pacchetto stesso.
Per evitare di distruggere le connessioni TCP si è scelto di settare i timeouts in questa maniera: l'hard timeout è imposto uguale a 0 e quindi disattivato; il motivo è ovvio visto che alla scadenza di questo timeout il flusso verrebbe eliminato, anche se sempre attivo, con la conseguenza che un eventuale pacchetto in arrivo appartentente al “vecchio” flusso (e alla connessione TCP) andrebbe a costituire un nuovo flusso indirizzato verso una porta d'uscita qualsiasi.
Il timeout idle è impostato con il valore di 120 secondi; in questo modo il tempo che deve trascorrere senza che un flusso abbia una corrispondenza con un pacchetto in arrivo prima di essere eliminato dalla tabella corrisponde al tempo di inattività di un flusso TCP. Per ogni pacchetto in ingresso al controller, e quindi non matchato da nessun flusso, dovrà essere creata una nuova entry nella tabella dello switch con i valori della quintupla relativi al pacchetto in arrivo. Sarà quindi necessario un handler NOX che permetta la gestione dei pacchetti in ingresso e che provveda ad inserire nella tabella di flusso i nuovi flussi che di volta in volta si vengono a creare. Questi flussi dovranno avere porta d'uscita variabile a seconda del carico sulle varie porte.
Servirà quindi un sistema per il quale si è in grado di variare la porta dei nuovi flussi in base al carico di pacchetti presente su ogni porta. A cascata, serve quindi avere a disposizione in intervalli di tempo regolari, le statistiche delle varie porte.
Quindi c'è la necessità di implementare un sistema che provveda a richiedere periodicamente le statistiche ed un sistema in grado di gestire le risposte ricevute.
Tutte queste parti devono essere poi essere in grado di coesistere fra loro ed integrarsi per garantire il comportamento desiderato. Deciso come orgnizzare il lavoro, si passa ad implementare il load balancer.
Una volta lanciata l'applicazione da nox-git/src/nox/netapps NOX-NEW-C-APP.PY con il nome balancer abbiamo a disposizione una cartella balancer in cui abbiamo i file .cc e .h da modificare come descritto nei precedenti capitoli.
Nel file header troveremo oltre a tutti gli include (che omettiamo di seguito), tutte le dichiarazioni delle funzioni e delle variabili utilizzate per realizzare il Component Balancer.
3.4 Implementazione dell'algoritmo
Alla accensione del controller vengono chiamate le funzioni di configurazione e di inizializzazione del sistema: install() e configure(). In install sono presenti due timer: uno riguarda il tempo da far passare per procedere alla creazione dei file che serviranno a raccogliere i dati ricevuti dalle varie porte; l'altro individua il tempo che deve passare affinchè il controller richieda allo switch le statistiche per la prima volta. Questo tempo è settabile dall'amministratore modificando nel file balancer.h l'oggetto const int FIRST_TIME_STATS.
Queste operazioni vengono effettuate attraverso due funzioni chiamate allo scadere di questi timer: new_file_stats() e ask_flows_stats().
post(boost::bind(&Prova::ask_flows_stats,this),FIRST_TIME_STATS )
Mentre new_file_stats() non verrà più usata, ask_flow_stats() sarà il primo scalino su cui ruoterà tutto l'algoritmo e verrà analizzata in seguito.
In questa fase vengono inizializzate tutte le variabili che serviranno nell'algoritmo.
Il primo step è il setup della connessione tra controller e switch nella quale la tabella di flusso viene resettata cancellando ogni flusso precedentemente attivo. Il NOX è event driven, quindi è necessario attendere l'arrivo del primo pacchetto, che sicuramente non avrà un match postivo nella tabella di flusso, per originare la catena di eventi che porterà il balancer a lavorare a regime.
Per ogni pacchetto non matchato ed inviato al controller, e quindi anche per il primo, viene chiamato l'handler “Packet_in”.
Questa funzione, semplicemente prende i valori dei campi del pacchetto appena arrivato e prepara un mesaggio Flow_mod da inviare allo switch per aggiungere la nuova entry in tabella.
L'azione corrispondente per ogni nuovo flusso sarà inviare tutti i pacchetti matchati verso una porta. Ma quale porta in particolare?
L'idea più semplice da considerare è quella di considerare un round-robin tra le varie porte cioè ruotare ciclicamente la porta di uscita in maniera brutale ogni volta che si vuole installare un nuovo flusso. Non avendo fatto alcuna assunzione sul traffico in arrivo, non ci è dato sapere se un dato flusso sarà composto da pochi o molti pacchetti ovvero non possiamo sapere quanto andrà ad incidere sul carico di ogni singola porta.
Questa strategia è quindi utilizzata all'avvio quando si cerca di ridistribuire un numero equo di flussi su ogni porta senza avere alcuna informazione su di essi.
In seguito, con a disposizione le statistiche di ogni porta, la stategia di selezione della porta portà essere più raffinata.
La scelta della porta è effettuata dalla funzione round() che viene chiamata ogni volta che l'handler deve scegliere la porta per il nuovo flusso.
Nel caso di round-robin, l'algoritmo è realizzato con una variabile static di tipo intero, r_robin_port, che viene incrementata di uno ad ogni chiamata della funzione round(); questa variabile fornisce la porta desiderata tramite la relazione :
r_robin_port mod Number_of_switch_port (2)
che fornisce il resto della divisione tra r_robin_port e Numero_porte_switch. Nel nostro caso, essendo le porte solo 4, può essere scritto come AND bit a bit tra r_robin_port e la maschera 11 (3 in binario):
(r_robin_port && 3) (3)
Questo sistema procede fino allo scadere del timer per la richiesta delle statistiche, al quel punto viene chiamata la funzione ask_flow_stats().
Questa funzione, prepara una serie di messaggi Aggregate_stats_request (uno per porta), nei quali vengono richieste allo switch le statistiche riguardanti il numero di flussi attivi, i pacchetti matchati inviati da quella porta e il numero di byte totali processati. Per ogni messaggio inviato, viene creato un numero che rappresenta un identificativo unico della richiesta. Le risposte a tale richiesta dovranno contenere al loro interno questo identificativo chiamato xid che permetterà la corretta associazione tra richiesta e risposta.
l'identificativo del messaggio inviato e come valore il numero della porta a cui la richiesta di statistiche è riferita. Questo consentirà poi di effettuare il giusto accoppiamento tra la risposta ricevuta e la porta a cui tale risposta è associata.
L'ultimo passo di questa funzione è il settaggio di un timer che allo scadere chiami nuovamente la funzione stessa. Questo timer è regolabile dall'utente ed è di particolare importanza perchè indica ogni quanto il sistema valuta il bilanciamento dei carichi sulle porte e di conseguenza la strategia da adottare.
Per modificare questo timer è necessario modificare nel file header la costante STATS_INTERVAL.
Le risposte generate dallo switch vengono raccolte da un handler chiamato handle_aggregate e specializzato per la gestione di un evento “ Aggegate_stats_in”.
All'arrivo dei messaggi, il controller scorre la mappa alla ricerca dello xid corrispondente: se non lo trova, c'è stato un errore e la mappa viene cancellata; altrimenti viene memorizzato il numero della porta con i dati ricevuti e infine cancellato l'entry nella mappa.
I dati in nostro possesso vengono quindi scritti nel file txt corrispondente alla porta e viene costruita un'altra mappa, chiamata packet_map, con queste caratteristiche: chiave uguale al numero della porta e valore numero di pacchetti inviati.
Se la scrittura va a buon fine, viene aggiornata la variabile sum ovvero la variabile che contiene il numero totale di pacchetti processati da tutte le porte. In caso di scrittura fallita, significa che una chiave uguale a quella che sto cercando di scrivere è già
presente nella mappa e quindi non faccio niente.
A questo punto l'handler controlla se la dimensione della mappa è minore, maggiore o uguale al numero delle porte:
– Maggiore: c'è un ovvio errore quindi considerando la mappa non attendibile questa viene cancellata e ripristinata la variabile sum a zero
– Minore: La mappa delle statistiche non è ancora completa, proseguo
– Uguale: La mappa è completa, si esegue la funzione balance_ok()
La funzione balance_ok () è preposta al controllo del bilanciamento dei pacchetti sulle varie porte e, a seconda dei risultati prodotti, determina la scelta del comportamento da seguire.
In questa funzione agiscono due pair C++ formate da un booleano e da un intero (balance_flag_up e balance_flag_down). Il booleano indica se il bilanciamento è corretto o meno, l'intero il numero della porta da considerare.
Il ragionamento è questo: nel caso ci sia un bilanciamento corretto, si continua con il round robin. Se c'è una porta che ha un carico troppo basso oltre una soglia impostata dall'amministratore (BALANCE_DOWN_BOUND_PERCENTAGE) tutti i nuovi flussi saranno inviati a quella porta. Altrimenti, nel caso che ci siano alcune porte cariche oltre ad una certa soglia percentuale rispetto alle altre, queste vengono escluse dal round-robin che prosegue solo sulle porte più scariche.
Il primo passo, è resettare tutte le flag sul bilanciamento che io pongo di default a true. Alla prima esecuzione avrò il vettore c++ port_vector che in seguito conterrà le porte in grado di accettare
nuovi flussi con un solo elemento contenente un numero di porta non valido (nel nostro caso tale valore è 5).
Se la packet_map è di dimensione pari al numero delle porte, scorro la mappa e guardo se per ogni porta c'è il bilanciamento. Su ogni porta eseguo la funzione packet_load_control() che calcola la percentuale di pacchetti presenti su ogni porta e la confronta con la soglia:
a=100*(packet_map.second/sum) (3)
Se a è < BALANCE_DOWN_BOUND_PERCENTAGE, allora il flag balance_down_flag è impostato a false.
Se DOWN_BOUND_PERCT < a < UP_BOUND_PERCT il numero della porta considerata viene aggiunto in cima al port_vector.
Se a > UP_BOUND_PERCT allora il flag balance_up_flag è impostato a false.
La funzione provvede a scrivere le statistiche (numero flussi attivi, numero pacchetti e carico in percentuale) dentro il file corrispondente a quella porta.
Al termine la funzione perfeziona, insieme alla funzione round(), a seconda dei vari casi la strategia da seguire:
se il balance_down_flag è false ovvero almeno una porta è sotto la soglia minima, viene cercata tramite la funzione template pairSecondCompare() la porta associata al minimo carico e tutti i nuovi flussi vengono indirizzati verso quella porta;
se il balance_down_flag è true cioè nessun flusso è così scarico e il balance_up_flag è false allora viene scorso il port_vector che
contiene tutte le porte sotto la soglia di bilanciamento.
Lo scorrimento del port-vector comporta una serie di operazioni aggiuntive per evitare errori a run-time.
Questo vettore è di dimensione variabile dal momento che il numero delle porte coinvolte può in teoria essere diverso di volta in volta. In più ogni volta che ricevo le statistiche aggiornate, questo vettore è riportato alla condizione iniziale di un solo elemento. L'elemento che resta ha come contenuto il numero di una porta non valida, e viene utilizzato come marca di fine array: ogni volta che scorriamo l'array e troviamo il valore fasullo da assegnare alla nostra porta significa che siamo arrivati alla fine dell'array stesso e che dobbiamo ripartire da capo.
Rimane un altro problema da risolvere, per scorrere il vettore si utilizzano degli iteratori che vengono poi deferenziati al valore da loro puntato. Questi iteratori non possono puntare ad aree di memoria vuote quindi nel momento in cui vengono cancellati gli elementi dall'array è necessario assicurarsi che tali iteratori non puntino agli elementi cancellati.
Per ovviare a questo inconveniente, si estende il port-vector ad un numero di elementi pari a quello del numero delle porte aumentato di uno. A questo punto si esegue lo swap con un vettore ausiliario che ha come ultimo elemento (ed anche unico, la prima volta) il valore della porta non valido. Adesso le informazioni sono sul vettore ausiliario che rimane sempre della stessa dimensione (Numero_porte_switch+1) ed è su quello che si faranno scorrere gli iteratori senza rischiare mai che puntino ad elementi non più
presenti. Il port-vector originario, privo di qualsiasi informazione utile viene quindi riportato alla condizione iniziale di singolo elemento. Nel caso invece di entrambi i flag posti a true, siamo nelle condizioni iniziali di buon bilanciamento e proseguo con il round-robin.
Le attività sono divise in due funzioni distinte con l'obbiettivo di far eseguire il minor numero di operazioni possibili:
in balance_ok() c'è la valutazione dei carichi e la preparazione delle strutture necessarie al funzionamento dell'algoritmo che viene effettuata una sola volta alla ricezione delle statistiche; in round() che invece viene chiamata ogni volta che arriva un pacchetto al controller (quindi molto più spesso), si utilizzano i risultati ottenuti da balance_ok() per determinare solamente la porta di uscita eseguendo il minimo numero di operazioni possibili.
A questo punto il processo è completo, infatti ogni volta che vengono richieste le statistiche, il controller è grado di calcolare il peso relativo a ciascuna porta e di indirizzare ogni nuovo pacchetto in arrivo verso la giusta destinazione.
3.5 Testing del balancer
Per provare la bontà dell'algoritmo è stato implementata la versione software dello switch Openflow 1.0.0 scaricata direttamente dal sito ufficiale www.Openflow.org e caricata su un pc con 4 schede di rete Ethernet. A questo switch è inoltre collegato tramite cavo Ethernet un altro pc sul quale è stato installato Nox e compilato con il compilatore gcc 4.4.
Ad una delle porte è stata quindi collegata un ulteriore macchina che forniva una traccia di traffico Internet con un packet rate di 100 pkt/sec. Di seguito vengono illustrati i grafici relativi al carico relativo di ogni porta e al numero di flussi corrispondenti per due simulazioni, la prima con tempo di richiesta tra una statistica e l'altra di 60 secondi mentre la seconda con tempo di reazione di 5 secondi. La scelta di mostrare contemporanemente sia il numero di flussi che il carico su ogni porta è finalizzato, a costo di complicare la visione del grafico, ed evidenziare come il numero di flussi si arresti o addirittura diminuisca nel momento in cui il carico su una determinata porta raggiunga la soglia limite.
Grafico 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120 125 130 135 140 145 150 155
Flow Number and Load on port 1
Stats interval 60 secLoad(%) Flows Time interval flo w n u m b e r a n d lo a d ( % )
Grafico 2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120 125 130 135 140 145 150 155
Number flows and load on port 2
Stats interval 60 secLoad(%) Flows Time interval N u m b e r flo w s a n d lo a d ( % )
Grafico 3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110
Number flows and Load on port 3
Stats interval 60 secLoad(%) Flows Time interval N u m b e r flo w s a n d lo a d ( % )
Grafico 4 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120 125 130 135 140 145
Flows number and load on port 4
Stats Interval 60 secLoad(%) Flows Time interval F lo w s n u m b e rs a n d lo a d (% )
Grafico 5 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85
Flows number and load on port 1 - Part 1
Stats interval 5 sec.Load(%) Flows Time interval F lo w n u m b e r a n d lo a d ( % )
Grafico 6 2526272829303132333435363738394041424344454647484950 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80
Flows number and load on port 1 - Part 2
Stats interval 5 sec.Load(%) Flows Time interval F lo w n u m b e r a n d lo a d ( % )
Grafico 7 1 2 3 4 5 6 7 8 9 101112131415161718192021222324 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120 125
Flow number and Load port 2 - Part 1
Stats interval 5 secLoad(%) Flows Time interval F lo w n u m b e r a n d L o a d ( % )
Grafico 8 2526272829303132333435363738394041424344454647484950 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120
Flow number and Load port 2 - Part 2
Stats interval 5 secLoad(%) Flows Time interval F lo w n u m b e r a n d L o a d ( % )
Grafico 9 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75
Flow number and Load port 3 - Part 1
Stats interval 5 secLoad(%) Flows Time interval F lo w n u m b e r a n d L o a d ( % )
Grafico 10 2526272829303132333435363738394041424344454647484950 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105
Flow number and Load port 3 - Part 2
Stats interval 5 secLoad(%) Flows Time interval F lo w n u m b e r a n d L o a d ( % )
Grafico 11 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115
Flow number and Load port 4 - Part 1
Stats interval 5 secLoad(%) Flows Time interval F lo w n u m b e r a n d L o a d ( % )
Grafico 12 2526272829303132333435363738394041424344454647484950 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120 125 130 135 140
Flow number and Load port 4 - Part 2
Stats interval 5 secLoad(%) Flows Time interval F lo w n u m b e r a n d L o a d ( % )