1 Introduzione ai Sistemi Informativi 2
1.1 Processi e dati . . . 2
1.2 DBMS . . . 4
1.3 Il modello Entit´a Relazione . . . 4
1.4 I Data Flow Diagram . . . 6
1.5 I DBMS relazionali . . . 6
1.6 Linguaggi per la manipolazione dei dati . . . 8
1.7 Gli utenti . . . 8
1.8 Architettura client-server . . . 9
1.9 Cenni sull’organizzazione delle reti di computer . . . 9
1.10 Cenni su XML . . . 10
1.11 Cenni su HTML . . . 11
2 I Sistemi Informativi Sanitari 13 2.1 La cartella clinica . . . 13
2.2 Hospital Information System (HIS) . . . 20
2.3 Diagnosis Related Group (DRG) . . . 21
2.3.1 Indici di efficienza . . . 24
2.4 Scheda di Dimissione Ospedaliera (SDO) . . . 24
2.5 Centro Unificato di Prenotazione (CUP) . . . 25
2.6 Radiology Information System (RIS) . . . 25
2.6.1 DICOM . . . 26
2.7 HL7 . . . 27
Introduzione ai Sistemi Informativi
Un sistema informativo (SI) pu´o essere definito come l’insieme dei flussi di informazione gestiti all’interno di una organizzazione.
Pertanto si tratta di un componente (sotto-sistema) di una organizzazione che gestisce (acquisisce, elabora, conserva, produce) le informazioni di interesse (cio´e utilizzate per il perseguimento degli scopi dell’organizzazione).
Ogni organizzazione ha un sistema informativo, eventualmente non esplicitato nella struttura; quasi sempre, il sistema informativo ´e di supporto ad altri sotto-sistemi, e va quindi studiato nel contesto in cui ´e inserito; il sistema informativo, ´e di solito suddiviso in sotto-sistemi (in modo gerarchico o decentrato), pi´u o meno fortemente integrati.
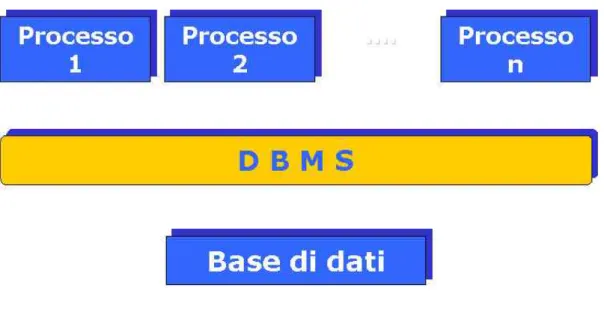
Un sistema informativo pu´o essere automatizzato in parte o del tutto con le moderne tecnologie dell’informazione. I componenti di un sistema informativo automatizzato sono essenzialmente i processi, la base dati ed il DBMS (fig. 1.1).
1.1
Processi e dati
Un processo ´e un insieme di attivit´a (sequenze di decisioni e azioni) che l’organiz-zazione svolge per realizzare un risultato definito e misurabile (prodotto o servizio), che trasferisce valore al fruitore del prodotto o servizio, che contribuisce al raggiungimento della missione dellorganizzazione.
Da un punto di vista informatico, un processo ´e un programma, scritto in un op-portuno linguaggio, che accede alla base di dati per consultarla e aggiornarla (vedi fig. 1.1).
I processi possono essere classificati in:
Processi direzionali concorrono alla definizione degli obiettivi strategici.
Processi gestionali traducono gli obiettivi strategici in obiettivi economici e ne con-trollano il raggiungimento.
Figura 1.1: I componenti di un Sistema Informativo.
La base di dati rappresenta una raccolta di informazioni sulle entit´a del mondo reale (ad es. paziente, personale medico, terapie, esami di laboratorio etc. . . . ) che devono essere gestite.
I dati possono essere classificati in:
Dati anagrafici descrivono attributi costanti delle entit´a (nome, cognome, codice fiscale etc. . . . )
Dati di stato descrivono le condizioni in cui si trovano le entit´a (diagnosi, terapia corrente, etc. . . . )
Dati sugli eventi descrivono le operazioni compiute sulle entit´a (esame diagnostici, cambiamento di terapia, interventi chirurgici, etc. . . . )
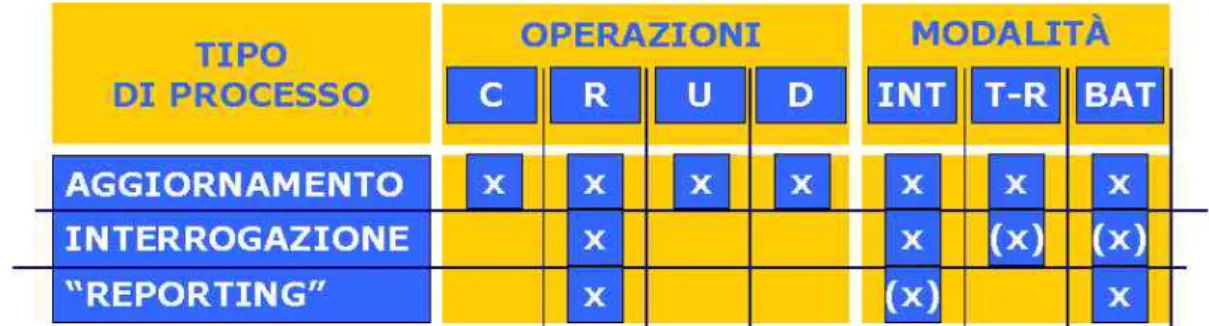
Le operazioni che ´e possibile eseguire sui dati sono le seguenti:
• Creazione di un nuovo dato (Create) • Lettura di un dato esistente (Read) • Modifica di un dato esistente (Update) • Cancellazione di un dato (Delete)
Le modalit´a di effettuazione di tali operazioni pu´o essere:
Interattiva prevede il dialogo diretto tra utente e sistema (ad es. accettazione, dimis-sione)
In tempo reale (Real-time) l’elaborazione conseguente ad una operazione deve com-pletarsi prima dell’operazione successiva (ad es. prenotazione esami)
Batch (A lotti) l’elaborazione ´e tipicamente asincrona rispetto alla richiesta (ad es. rendiconto annuale)
Figura 1.2: Classificazione dei processi secondo la modalit´a di accesso ai dati.
1.2
DBMS
Il Data Base Management System ´e un sistema software che standardizza l’accesso dei processi alla base di dati offrendo delle interfacce generalizzate che permettono:
• la condivisione dei dati da parte dei processi (i dati possono essere utilizzati da
pi´u processi e da pi´u utenti);
• l’indipendenza dei dati rispetto ai processi (se i processi vengono cambiati non ´e
necessario modificare anche la struttura dei dati e viceversa). Come ogni prodotto informatico, un DBMS deve essere:
efficiente utilizzando al meglio le risorse di spazio e tempo del sistema; l’efficienza dipende sia dalle tecniche utilizzate per l’implementazione del DBMS che dalla bont´a della realizzazione della base in fase di progettazione;
efficace rendendo produttive le attivit´a dei suoi utilizzatori.
L’architettura di un DBMS ´e definita da vari schemi che rappresentano la base dati a differenti livelli di astrazione:
schema logico descrizione dell’intera base di dati.
schema esterno descrizione di una parte della base di dati (‘viste’ parziali), ad es. un certo utente (personale dell’accettazione) non ha bisogno di ‘vedere’ l’intera base dati ma solo una parte di essa.
schema fisico rappresentazione dello schema logico per mezzo di strutture fisiche di memorizzazione.
1.3
Il modello Entit´
a Relazione
Nel progetto di una base dati si procede per livelli di raffinamento successivi. In questo contesto ´e rilevante il modello entit´a-relazione (E-R) che consente di trarre una de-scrizione a livello logico della base dati. Tale dede-scrizione pu´o essere poi efficacemente
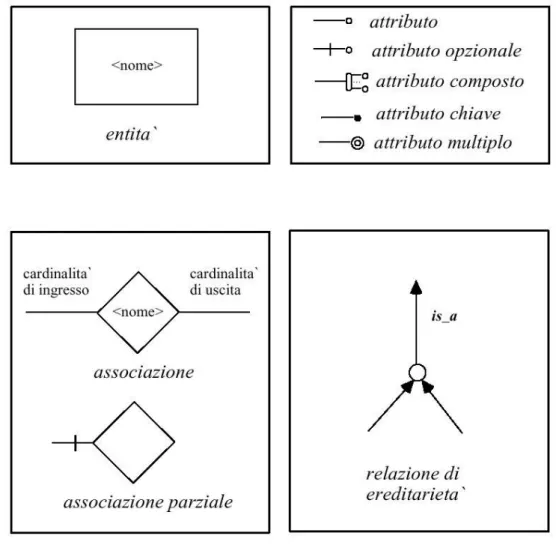
Figura 1.3: Simboli usati per la costruzione dei diagrammi E-R. I componenti del modello E-R sono (fig. 1.3, 1.4):
Entit´a oggetti sui quali si memorizza informazione; hanno associati degli attributi (ad es. ‘Nome’ e ‘Cognome’ sono attributi dell’entit´a ‘Persona’).
Relazioni definiscono rapporti tra le entit´a (ad es. ‘Impiegato’ ´e dipendente di ‘Azien-da’); possono avere anch’esse degli attributi.
In questo modello la struttura del Database ´e composta da:
• Un insieme di diagrammi ER che rappresentano i dati operativi che devono essere
strutturati nel SI;
• Un insieme di dizionari dei dati associati ai diagrammi E-R che descrivono
verbal-mente i diagrammi per mezzo di tabelle riassuntive;
• Un insieme di vincoli di integrit´a sui dati che specificano condizioni particolari
che non possono essere desunte dai diagrammi (ad es. l’et´a di una persona ´e un numero che non pu´o essere negativo).
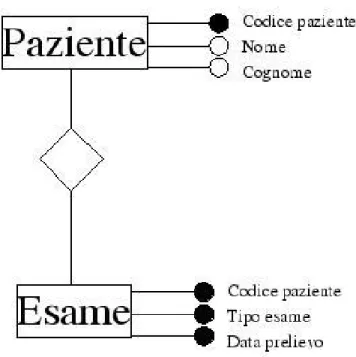
Figura 1.4: Esempio di diagramma E-R.
1.4
I Data Flow Diagram
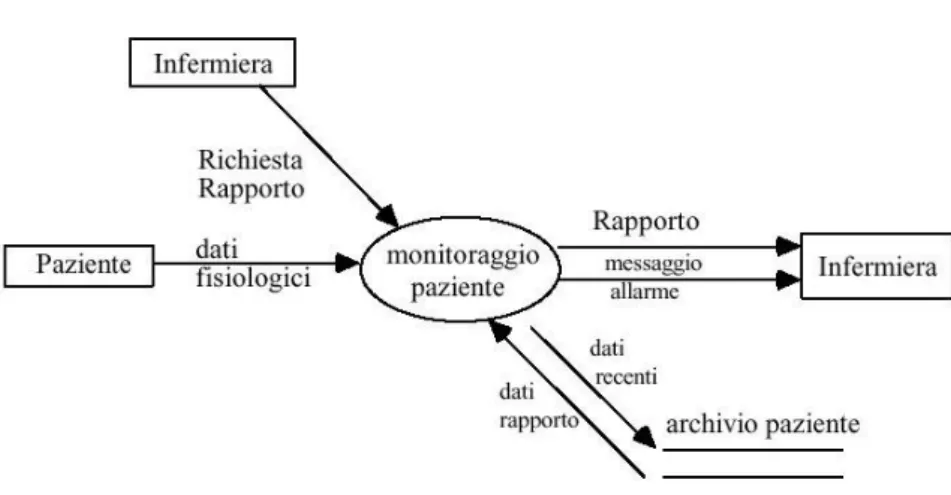
I Data Flow Diagrams (Diagrammi di Flusso dei Dati, DFD) sono complementari al formalismo E-R: infatti non si concentrano sulla struttura e sul significato dei dati, bens´ı sulle operazioni, o funzioni, applicate ad essi: mostrano come i dati vengono elaborati nel sistema (fig. 1.5).
I DFD descrivono le operazioni effettuate sui dati e le dipendenze funzionali che si creano in virt´u dei flussi di informazione esistenti tra i diversi processi.
Utilizzano una notazione grafica che si concentra sull’elaborazione funzionale, la memorizzazione dei dati e il passaggio di dati tra funzioni.
Nella figura 1.6 ´e rappresentato un esempio di processo di monitoraggio paziente modellato con la metodologia DFD.
1.5
I DBMS relazionali
Il modello relazionale dei dati ´e il modello che si ´e affermato sin dagli anni ’70 per i DBMS.
In questo modello le entit´a e le relazioni (derivate dal diagramma E-R) sono rapp-resentate mediante tabelle. In ogni riga (denominata anche record) di tali tabelle sono scritti gli attributi della entit´a o della relazione in esame. Ad esempio la tabella seguente rappresenta gli attributi dell’entit´a ‘persona’.
Figura 1.5: Simboli usati per la costruzione dei diagrammi DFD.
Tabella ‘persona’
Codice Fiscale Nome Cognome Et´a
RSSMRA Mario Rossi 32
MNDLCA Lucia Mondella 27
Ogni tabella ´e caratterizzata da uno schema, cio´e da una struttura che indica il tipo di valore inserito in una data colonna della tabella ad es.:
(Codice Fiscale, Nome, Cognome, Et´a)
Nello schema precedente il campo sottolineato indica una chiave cio´e un tipo di valore che pu´o essere utilizzato per identificare univocamente la riga della tabella.
1.6
Linguaggi per la manipolazione dei dati
Per effettuare delle interrogazioni su una base di dati ´e opportuno disporre di opportuni linguaggi.
Lo standard in questo senso ´e il linguaggio SQL (Structured Query Language, Lin-guaggio per interrogazioni strutturate). Senza entrare nel dettaglio di tale linLin-guaggio diamo un esempio di come sia possibile effettuare una interrogazione su una base dati:
SELECT Nome, Et´a FROM Persona WHERE Cognome=’Rossi’;
Questa interrogazione preleva il Nome e l’Et´a (SELECT Nome, Et´a) dalla tabel-la ’Persona’ (FROM Persona) di tutte le persone che si chiamano Rossi di cognome (WHERE Cognome=’Rossi’).
Il SQL ´e composto di due sottoinsiemi di linguaggi:
DATA DESCRIPTION LANGUAGE (DDL) serve per descrivere lo schema del-la base di dati. Consente di separare il progetto deldel-la base di dati dal progetto dei processi.
DATA MANIPULATION LANGUAGE (DML) Linguaggio che fornisce una sin-tassi standard per accedere alla base di dati.
1.7
Gli utenti
Gli utenti di una base dati possono essere distinti in:
Database Administrator Persona o gruppo di persone responsabile del controllo centralizzato e della gestione del sistema, delle prestazioni, dell’affidabilit´a, delle autorizzazioni. Le funzioni del DBA includono quelle di progettazione, anche se in progetti complessi ci possono essere distinzioni.
Utenti finali Sono gli utenti quotidiani del sistema. Di norma essi hanno diritti di accesso ai dati limitati; vengono identificati medianteusername e password.
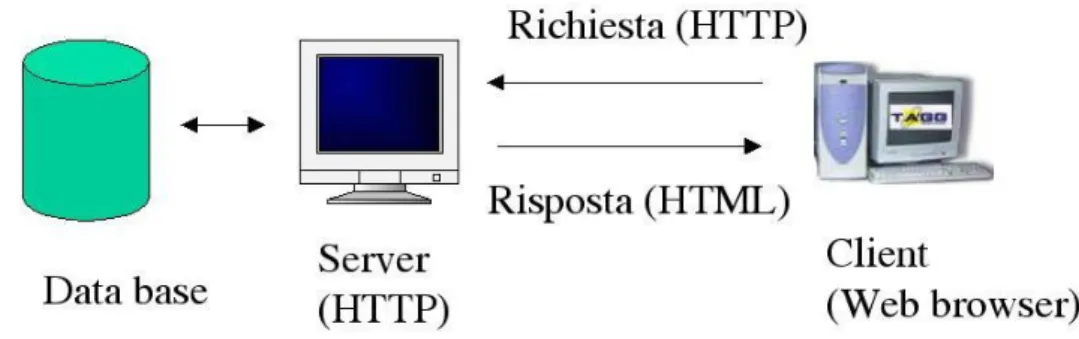
Figura 1.7: Modello Client-Server.
1.8
Architettura client-server
In questa architettura (fig. 1.7) un computer client invia una richiesta di dati ad un computer server il quale a sua volta inoltra la richiesta nel linguaggio idoneo per il
DBMS che gestisce la base dati. La risposta del DBMS viene interpretata e riformattata
opportunamente dal server ed inviata da questi al client. Pertanto il server intermedio ha il compito di interrogare la base dati e formattare adeguatamente le risposte per il client (architettura three-tier).
Allo stato attuale quasi tutti i DBMS disponibili in commercio utilizzano l’architet-tura client-server. Tra i pi´u noti citiamo:
• Oracle (Oracle)
• SQLServer (Microsoft) • MySQL (free)
• PostgreSQL (free)
1.9
Cenni sull’organizzazione delle reti di computer
Le reti locali (Local Area Networks, LAN) connettono calcolatori situati nello stesso edificio o in edifici diversi e situati nell’arco di pochi Km. Le WAN (Wide Area Networks) inter-connettono varie LAN.
La pi´u comune topologia di rete ´e quella a BUS (fig. 1.8). Con queste topologie di solito si utilizza un controllo casuale di trasmissione: un calcolatore invia un pacchetto in rete che viene ricevuto da tutti gli altri; gli altri elaboratori elaborano il contenu-to ricevucontenu-to solo nel caso in cui quescontenu-to contenga il proprio indirizzo; diversamente lo ignorano.
La rete Ethernet ´e un particolare tipo di rete a BUS con metodo di accesso CS-MA/CD (Accesso multiplo con rilevamento di portante e con rilevazione della collisione). In questo tipo di rete una stazione che deve trasmettere un pacchetto si accerta che sul mezzo di trasmissione non ne stia viaggiando gi´a un altro. Se si genera una collisione viene rinviato il pacchetto.
Nelle reti di computer vengono trasmessi pacchetti di dati. Ogni singolo pacchetto di dati subisce una complessa trasformazione (incapsulamento) prima di essere inviato
Figura 1.8: Rete a BUS.
sulla rete. Il meccanismo di incapsulamento dei dati ´e simile al modo in cui potrem-mo trasmettere un libro usando il sistema postale: il libro viene scomposto in pagine, ciascuna pagina (i dati) viene numerata (protocollo TCP) ed inserita in una busta con l’indirizzo del mittente e destinatario (indirizzo IP) infine viene imbucata (bus Ethernet). All’interno di una stessa rete locale i singoli computer vengono individuati da un numero (indirizzo IP).
Quando si vuole colloquiare con un computer che non si trova sulla stessa rete locale bisogna trasferire i pacchetti alle altre reti in maniera simile a quanto succederebbe se una persona di Napoli volesse comunicare con una persona di Milano tramite posta: la lettera spedita verrebbe intercettata dall’ufficio postale principale Napoletano che lo spedirebbe a quello Milanese ed a quel punto tramite dei sottouffici e infine tramite il postino la lettera giuge a destinazione.
In internet questo meccanismo viene chiamato routing (instradamento) dei pacchetti. Esistono dei computer (denominati router) che hanno il ruolo degli uffici postali di smistamento.
Infine poich´e i numeri sono difficili da ricordare per gli esseri umani esiste un sistema di codifica degli indirizzi IP che associa ad ogni indirizzo un nome. Esistono pertanto dei computer (denominati DNS) che possiedono l’elenco degli indirizzi con i nomi associati (ad es. www.miodominio.it → 192.10.10.5).
1.10
Cenni su XML
XML (eXtended Markup Language, Linguaggio a Marcatori Esteso ) ´e un linguaggio per la rappresentazione dei dati in maniera testuale utilizzando dei marcatori appunto. Chiariamo subito con un esempio. Supponiamo di avere la tabella dei dati anagrafici dei pazienti:
Tabella ‘Pazienti’
Codice Fiscale Nome Cognome Et´a
RSSMRA Mario Rossi 32
MNDLCA Lucia Mondella 27
< T abP azienti >
< P aziente >
< CF > RSSMRA < /CF > < Nome > Mario < /Nome > < Cognome > Rossi < /Cognome > < Eta > 32 < /Eta >
< /P aziente > < P aziente >
< CF > MN DLCA < /CF > < Nome > Lucia < /Nome >
< Cognome > Mondella < /Cognome > < Eta > 27 < /Eta >
< /P aziente > < /T abP azienti >
Le informazioni sono racchiuse da un tag o marcatore di apertura (ad es. < CF >) ed uno di chiusura (ad es. < /CF >) i quali differiscono solo per la presenza di uno
slash. ´E importante che ogni tag aperto sia poi chiuso. Come si vede i tag possono essere innestati l’uno dentro l’altro (ad es. < CF > ´e contenuto in < P aziente >). Si vede che un record della tabella Pazienti corrisponde al contenuto di un tag < P aziente >.
Questa rappresentazione non ´e una semplice manipolazione della tabella perch´e ´e suscettibile di una serie di varianti che la rendono estremamente flessibile e potente.
Una delle carattersitiche pi´u importanti ´e che la sequenza dei tag pu´o essere dichiara-ta opzionale, cio´e un campo pu´o essere assente (ad es. potrei non volere le Et´a). Questo rende il linguaggio XML in grado di mettere in comunicazione due strutture dati che abbiano un sottoinsieme comune (ad es. in una prima struttura uso tutti i campi mentre nella seconda uso solo il CF Nome e Cognome, in questo caso per comunicare dati dalla prima verso la seconda potr´o indicare che il campo Et´a ´e opzionale)
La modalit´a in cui i vari tag si possono innestare tra di loro, i dati opzionali, i dati ripetuti (ad es. ci pu´o essere pi´u di una diagnosi) ed altre caratterstiche devono essere dichiarate all’interno di un documento chimato DTD (Documet Type Definition, Definizione dei tipi di dati, oppure XML-Schema nelle ultime versioni di XML), in questo modo ´e possibile verificare se un documento XML ´e ben formato.
1.11
Cenni su HTML
HTML ´e un linguaggio a marcatori per la rappersentazione di documenti sul web. In ef-fetti pu´o essere considerato un derivato dell’XML anche se cronologicamente lo sviluppo ´e stato inverso (cio´e prima html e poi XML).
In effetti la differenza tra XML e HTML (Hyper Text Markup Language, linguaggio per ipertesti a marcatori) consiste nel fatto che in XML i tag sono decisi dall’utente che prepara il testo e possono essere qualsiasi a patto che vengano specificati nel DTD (o XML-Schema); nell’HTML invece i tag sono predefiniti e sono riconosciuti da tutti i Browser commercali (ad es. MS Explorer, Netscape, Opera etc.. . . ).
Facciamo un esempio di pagina HTML: <html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"> <meta name="GENERATOR" content="Microsoft FrontPage 3.0">
<title>Pagina di HTML</title> </head>
<body>
<h1>Salve</h1>, <h2>sono una pagina HTML!</h2> <a href="atrapagina.htm">Questo \’e un link</a> </body>
</html>
Il tag < hmtl > deve essere sempre presente e racchiude l’intero documento che ´e costituito da un header < head > e da un body < body >. Nell’header sono contenute informazioni di controllo (metadati) che servono poter interpretare corretamente il doc-umento: nell’esempio troviamo il set di caratteri ed il software che ´e stato usato per generare la pagina. Nel body invece troviamo il documento vero e proprio che verr´a interpretato dal browser e visualizzato all’utente.
Ogni tag ha un significato preciso ad es. < h1 > significa che il testo va visualizzato in grasseto con un carattere grande; < h2 > significa che il testo ´e un p´o pi´u piccolo: questa organizzazione serve a rendere il documento pi´u leggibile e renderlo visualizzabile su qualunque dispositivo.
Un altro aspetto importante di HTML ´e il tag < a > (link ipertestuale) che consente di ‘puntare’ ad un altra pagina o a un altro documento generico.
I Sistemi Informativi Sanitari
La finalit´a di un sistema informativo in sanit´a ´e la gestione di informazioni utili alla misura ed alla valutazione dei processi gestionali e clinici al fine di ottimizzare le risorse impiegate nel conseguimento degli obbiettivi istituzionali e ottimizzare le modalit´a di comunicazione.
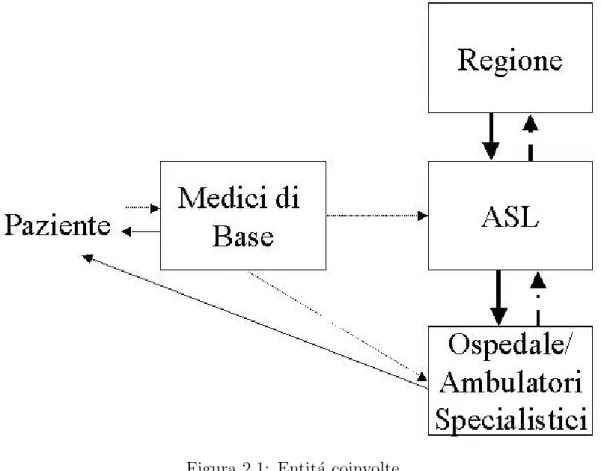
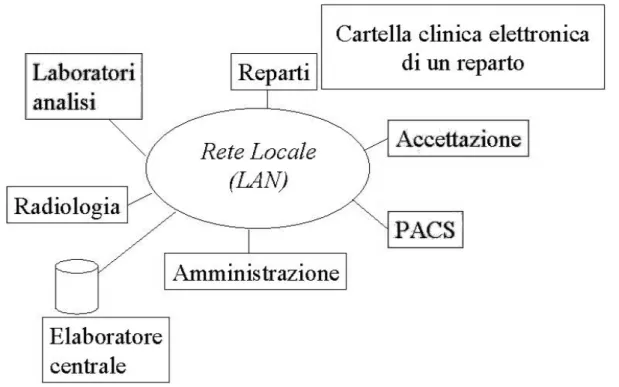
Le entit´a coinvolte sono rappresentate nella figura 2.1 in cui sono rappresentati anche i flussi informativi e le richieste di servizi.
L’architettura proposta dallo standard Europeo CEN/TC 251 per i sistemi informa-tivi sanitari, prevede al centro del sistema il soggetto di cura. Senza entrare nel dettaglio dello standard su citato, si pu´o comunque comprendere il concetto osservando la figura 2.2.
In effetti dal momento dell’accettazione, in cui il paziente accede alla struttura san-itaria, fino al momento della dimissione, il sistema informativo deve tenere traccia di ogni accadimento, per motivi medico/legali/amministrativi.
In questo contesto il fattore centrale di tutto il sistema informativo ´e la cartella clinica, sia essa cartacea o elettronica.
2.1
La cartella clinica
La finalit´a della cartella clinica ´e di facilitare la cura del paziente, avere a dispo-sizione una raccolta cronologica del processo di cura, semplificare la comunicazione fra il personale, la raccolta dati a fini medico/legali, le operazioni di rimborso, le ricerche retrospettive e prospettiche.
Una storia semplificata della cartella clinica pu´o essere cos´ı riassunta: 1910 Raccolta dati orientata al paziente
1940 Ospedali Americani con accreditamento 1969 Riflessione sui modelli di cartella clinica
Figura 2.1: Entit´a coinvolte.
1960-70 Sistemi informativi ospedalieri ‘elettronici’ per accettazione, dimissione, ren-diconto economico
1980 Prime cartelle cliniche ‘di reparto’ 1990 Esempi di cartelle cliniche condivise
2000 Possibile trasformazione del concetto per favorire la continuit´a della cura I tipi di cartella clinica proposti intorno agli anni ’70:
• Orientati temporalmente: collezione di dati sequenziali, in questo modello i dati
vengono raccolti ed organizzati solo in base alla sequenza temporale degli eventi. ad es.
21/02/01 Mancanza di respiro, tosse, febbre. Temp:39.3 C
Diagnosi: bronchite acuta Hb: 7.8 mg/dl
Trattamento: 100mg Ascal/d
• Orientati alla ‘sorgente’ informativa: organizzazione temporale in una
classifi-cazione per sorgente dei dati. In questo modello i dati vengono organizzati anche in base al tipo di sorgente informativa (cio´e se i dati vengono da una visita, da un esame diagnostico etc. . . . ) ad es.
Visite
21/02/01 Mancanza di respiro, tosse, febbre. Temp:39.3 C
Diagnosi: bronchite acuta Trattamento: 100mg Ascal/d Esami
21/02/01 Hb: 7.8 mg/dl
• Orientati al problema: organizzazione temporale in una classificazione per
proble-mi. In questo modello il nucleo centrale ´e il problema ed i dati vengono classificati in soggettivi ed oggettivi. ad es.
Problema Bronchite acuta
21/02/01 Soggettivi: Mancanza di respiro, tosse, febbre. Oggettivi: Temp:39.3 C, Hb: 7.8 mg/dl
Diagnosi: bronchite acuta Trattamento: 100mg Ascal/d
Una interessanteclassificazione delle cartelle cliniche si fonda sull’individuazione di categorie di pazienti rispetto ai quali esistono differenti trattamenti clinici: a causa di questi differenti trattamenti e del tempo, nel corso del quale tali trattamenti sono effet-tuati, differenti tipologie di informazioni devono essere gestite. Si distinguono cartelle cliniche per:
pazienti in terapia intensiva la cartella clinica ´e rivolta a pazienti in condizioni se-vere, in cui il controllo del quadro clinico ´e effettauto di continuo da una opportuna strumentazione. ´E il caso tipico della sala di rianimazione o unit´a coronarica. ´E presente una sofisticata strumentazione in grado di monitorare di continuo alcuni parametri vitali e di generare allarmial personale in presenza di anomalie. Tale strumentazione acquisisce una grande mole di dati che pu´o essere memorizzata ed inclusa nella cartella clinica computerizzata. Dunque il sistema informatico di gestione dovr´a interfacciarsi anche con la strumentazione oltre che gestire le informazioni inputate da tastiera.
pazienti ospedalizzati in questo caso la cartella clinica raccoglie oltre alle infor-mazioni identificative, anche dati significativi acquisist durante la degenza (terapie, esami effettuati).
pazienti ambulatoriali in follow-up in questo caso le informazioni sono controllate ad intervalli di tempo variabili. Qeuste cartelle si possono dividere in cartelle a termine e a tempo indefinito. Le prime sono relative a patologie che si suppone vengano risolte in breve tempo, Le seconde sono relative a patologie che restanp croniche.
In una cartella clinica orientata temporalmente vengono gestiti dati raccolti durante visite periodiche. Un esempio di tabella orientata temporalmente ´e riportata di seguito:
data visita freq. card. press. max press. min
02-03-90 110 180 110
04-05-90 90 145 90
06-07-90 105 140 100
Il riferimento temporale cionsente di ricostruire l’andamento del quadro, la valu-tazione clinica pu´o essere migliorata. Tipiche categorie di pazienti sono gli ipertesi, i pazienti affetti da scompenso cariaco, oncologici, post-infartuati, etc.. . . .
I dati presenti in una cartella clinica possono esser di vario tipo:
• Numerici: misure di parametri vitali del paziente;
• Alfanumerici: parametri che non possono essere quantificati ad es. l’ombra
car-diaca ‘aumentata’ su una lradiografia;
• Date: istante di accadimento di un evento; • Testo libero: refertazioni etc.. . . ;
• Segnali: ECG, EMG, etc.. . . ;
• Immagini: CT, MRI, ecografia, etc.. . . ; • Suoni fonocardiografia etc.. . . ;
I vantaggi della cartella clinica elettronica rispetto ad una cartella clinica cartacea possono essere cos´ı riassunti:
• riduzione dello spazio fisico necessario per archiviare le cartelle: con i moderni
• possibilit´a di effettuare ricerche in tempi rapidissimi; • possibilit´a di condividere le cartelle tra i vari reparti;
• possibilit´a di consultare i dati attraverso le reti informatiche e quindi in linea di
principio da qualunque postazione all’interno della struttura ospedaliera o della rete sanitaria nazionale o addirittura mondiale.
Questi vantaggi si pagano per´o con alcuni svantaggi:
• i dati devono essere altamente strutturati per poter essere trattati con i mezzi
informatici;
• i dati devono venire digitati dall’operatore e questo pu´o essere un aspetto
rile-vante soprattutto se vengono commessi errori; tuttavia in questo campo sono stati compiuti grossi sforzi allo scopo di semplificare la inputazione dei dati (vedi ad esempio i sistemi di dettatura vocale) e nella correzione automatica di certi tipi di errore;
• disomogeneit´a dei dati tra i diversi reparti. In effetti ´e praticamente impossibile
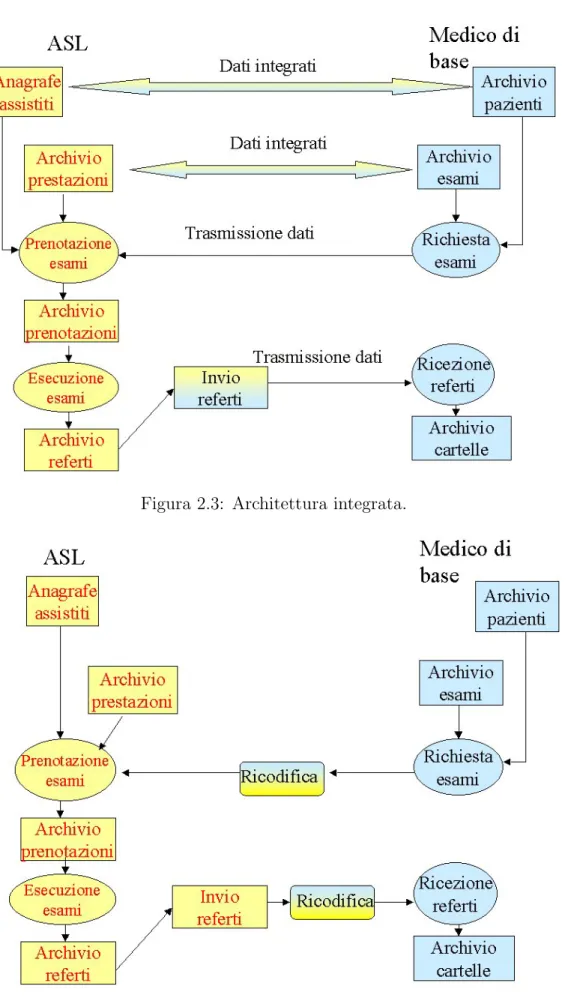
organizzare un sistema informativo che sia efficace ed efficiente per tutti i sotto-sistemi presenti all’interno di una struttura sanitaria: la tendenza attuale ´e quella di rassegnarsi ad avere sistemi informativi diversi per ciascun reparto, ma lavo-rare nella direzione della integrazione dei vari sottosistemi mediante lo sviluppo di metodi di interfacciamento che consentano di transcodificare le informazioni da un sistema all’altro (vedi fig. 2.3 e 2.4);
• la sicurezza del dato in formato elettronico presenta forse degli aspetti pi´u delicati
rispetto al dato cartaceo; tuttavia sono stati compiuti grossi sforzi nel campo della sicurezza elettronica (firma digitale, crittografia dei dati, etc.. . . ).
Le informazioni contenute nella cartella clinica comprendono sicuramente i dati ana-grafici del paziente. Tra i dati anaana-grafici ve ne sono alcuni che oltre ad identificare le generalit´a del paziente costituiscono la chiave per l’individuazione univoca dell’in-dividuo all’interno dell’archivio e rappresentano l’anello di collegamento con tutte le altre informazioni che vengono progressivamente immagazzinate nel corso della degen-za e del trattamento anche in occasione di ricoveri ripetuti e contribuiscono a rendere pi´u rapido e sicuro lo scambio di dati tra diverse realt´a che vengono a contatto con lo stesso individuo. Questo, oltre a rappresentare un vantaggio per le varie strutture coinvolte nello scambio dei dati, contribuisce a rendere pi´u complete le informazioni relative all’individuo consentendo un pi´u completo e rapido trattamento delle patologie concomitanti.
Tra i dati anagrafici il minimo set di informazioni, indispensabili per identificare univocamente un individuo, ´e rappresentato da:
COGNOME NOME
DATA DI NASCITA SESSO
Mediante queste informazioni ´e possibile identificare univocamente la quasi totalit´a delle persone ad eccezione di qualche raro caso in Italia, per il quale occorre considerare
qualche altro dato. A tale riguardo una circolare del ministero della funzione pubblica, gi´a nel 1990, aveva individuato il codice fiscale quale sistema unitario di individuazione e di accesso dei cittadini. Per questi motivi un buon sistema di gestione della cartella clinica dovrebbe prevedere l’utilizzo del codice fiscale come identificatore univoco dell’in-dividuo all’interno del sistema. Quando questo non ´e immediatamente disponibile viene parzialmente costruito in modo automatico utilizzando il cognome, il nome, il sesso e la data di nascita (campi obbligatori) per i primi 12 caratteri, aggiungendo un numero progressivo di 4 cifre per distinguere eventuali individui con lo stesso codice parziale. Il codice cos´ı costruito dovr´a essere sostituito al pi´u presto con il codice fiscale completo.
´
E auspicabile la possibilit´a di collegamento con un archivio anagrafico standard messo a disposizione da altre strutture quali l’ospedale, il comune, la regione ecc.. . . , per prelevare i dati anagrafici garantendo la correttezza dei dati.
Sui dati anagrafici dovr´a essere possibile effettuare rapide ricerche, anche con chiave parziale, per consentire il ritrovamento immediato di pazienti precedentemente registrati ed evitare inserimenti errati, come nel caso di soggetti il cui nominativo potrebbe essere scritto in modo non univoco (es. Depaoli, De Paoli, de Paoli).
A questi dati potranno essere aggiunte ulteriori informazioni ritenute di utilit´a nel-la gestione specifica di ogni singonel-la realt´a (indirizzo, recapito telefonico, stato civile, cittadinanza, titolo di studio) che potranno anche essere aggiornate con procedure auto-matiche basate sui dati trasmessi dalle anagrafi dell’ospedale o comunali (nascite, morti, cambi d’indirizzo).
Un dato deve sempre essere legato ad una data. Quale data? Nel caso dei dati sanitari risultano essere di importanza il ‘Tempo di transazione’ (cio´e il momento in cui si effettua l’inserimento del dato), ed il ‘Tempo di validit´a’ (validit´a del dato). Questa distinzione ´e cruciale per gli esami di laboratorio (che risultano significativi solo per un certo periodo di tempo) ed anche per per giudicare l’attivit´a del reparto e gli esiti del processo clinico.
Una parola chiave nel contesto della disomogeneit´a delle informazioni ´e
interoper-abilit´a: il modello non integrato ´e possibile a patto di avere uno strato software di
in-termezzo (detto ‘middleware’) che deve assicurare l’interoperabilit´a dei sistemi informa-tivi. L’interoperabilit´a ´e la possibilit´a di scambiare informazioni e utilizzare procedure mediante stazioni di lavoro con caratteristiche hardware e software diverse.
In effetti allo stato attuale molti sono i software proprietari (cio´e con caratteristiche non standard), ed esiste una non uniformit´a dei dati raccolti ed una difficolt´a nello scambiare i dati con altri centri, tuttavia ´e pressoch´e impossibile pensare a sistemi informativi completamente integrati.
Tale considerazione risulta ancora pi´u critica nell’area clinica della terapia intensiva, in cui la struttura organizzativa e la dinamica dei flussi informativi risultano spesso fortemente dipendenti dalle realt´a locali, cos´ı da rendere difficilmente trasportabili soft-ware preconfezionati che avrebbero costretto l’utente di tali prodotti ad adeguare il proprio modo di lavorare a degli standard non perch´e considerati superiori, ma solo perch´e imposti dal sistema. Quindi nonostante l’impegno di numerose case di software nella progettazione di cartelle cliniche sofisticate, in grado di contenere infinite quantit´a di informazioni, la maggior parte delle esperienze si sono rivelate fallimentari.
´
E necessario pertanto l’adeguamento del prodotto al modo di operare della singola realt´a in modo da incidere minimamente sui metodi e sulle abitudini di lavoro consideran-do assolutamente indispensabile l’adeguamento del software alla struttura piuttosto che viceversa. Questo naturalmente comporta una notevole personalizzazione del ‘prodotto’ cartella clinica rendendo difficilmente trasportabile un software, anche se ottimo, da una realt´a operativa ad un’altra, con la richiesta di una elevata disponibilit´a di risorse e competenze specifiche, non solo tecniche ma anche organizzative, non sempre facilmente reperibili.
La vera possibilit´a di standardizzazione non sta quindi nell’adozione di cartelle cliniche uguali per tutti e che gestiscono le stesse informazioni, quanto piuttosto nello stabilire un numero minimo di informazioni che ciascun sistema deve contenere lascian-do all’iniziativa del singolo l’integrazione con dati che si adeguano alle necessit´a imposte dal sistema di lavoro e dal flusso di informazioni che la singola realt´a decide di trattare. La standardizzazione e l’adeguamento al minimo set di informazioni non sar´a quindi un obiettivo ma una necessit´a qualora si richieda al sistema di colloquiare con un altro. Tuttavia poich´e ´e auspicabile che una cartella clinica di reparto sia in grado di scambiare dati con cartelle cliniche di altri reparti, con l’intero sistema informativo ospedaliero e con reparti di altri ospedali, tale standardizzazione risulta pressoch´e indispensabile. Questo ´e in linea con quanto ribadito da una buona parte della letteratura che ritiene prioritario lo studio dei flussi informativi, indipendentemente dagli strumenti utilizzati per la gestione delle informazioni.
2.2
Hospital Information System (HIS)
Si potrebbe definire un HIS (in italiano Sistema Informativo Ospedaliero - SIO) come il risultato dell’integrazione ed interazione di alcuni sottosistemi informativi principali (vedi fig. 2.5).
Sottosistema amministrativo-finanziario vengono in esso identificate sia le fun-zioni tradizionalmente pertinenti alla gestione economico-finanziaria dell’Ente (con-tabilit´a analitica, generale, fatturazione, ordini, rilevazione presenze e gestione personale), sia quelle pi´u generalmente volte a garantire l’erogazione di servizi di rilevante importanza logistica (gestione mensa, turni, personale infermieristico, . . . ).
Sottosistema di gestione del paziente racchiude l’insieme di protocolli e modulis-tiche relative alla gestione del paziente degente ed ambulatoriale: tradizionalmente le informazioni processate sono quelle relative alla cartella clinica (generalit´a, dati anamnestici, obiettivit´a, terapie, . . . ) ed al monitoraggio strumentale di parametri clinici rilevanti.
Sottosistema servizi e laboratori in tale ambito vengono incluse sia le esigenze in-formative che caratterizzano la gestione interna dei servizi ospedalieri (radiologia, laboratori chimico-clinici e microbiologici, centro emotrasfusionale, . . . ), sia i flus-si informativi inerenti all’interazione con il sottoflus-sistema di gestione del paziente
Figura 2.5: Hospital Information system.
Sottosistema di prenotazione rappresenta il sistema di gestione degli accessi del paziente alla struttura ospedaliera (prenotazione esami, visite ambulatoriali, ri-coveri). Risulta, pertanto, fortemente integrato con i sottosistemi di gestione dei paziente e dei servizi.
2.3
Diagnosis Related Group (DRG)
Il DRG/ROD (Raggruppamenti Omogenei di Diagnosi) ´e un metodo per la classifi-cazione dei pazienti dimessi dagli ospedali 2.6. Il sistema DRG ´e un sistema di classi-ficazione che si basa su raggruppamenti omogenei di diagnosi, traduzione italiana del sistema statunitense noto con la sigla DRG (Diagnosis Related Groups). ´E un sistema di classificazione dei pazienti dimessi dagli ospedali per acuti che attualmente viene uti-lizzato anche in Italia come base per il finanziamento delle Aziende Ospedaliere. Tale sistema si basa su alcune informazioni contenute nella scheda di dimissione ospedaliera (SDO) ed individua circa 500 classi di casistiche, tendenzialmente omogenee per quanto riguarda il consumo di risorse, la durata della degenza e, in parte, il profilo clinico. Con l’applicazione di tale sistema viene introdotto nel SSN una nuova modalit´a di finanzia-mento delle attivit´a ospedaliere basato sulla remunerazione delle prestazioni mediante tariffe predeterminate.
Le informazioni necessarie all’attribuzione dei pazienti alle singole categorie sono facilmente ottenibili dal sistema informativo disponibile negli ospedali. Le informazioni necessarie all’attribuzione dei pazienti alle singole categorie sono facilmente ottenibili dal sistema informativo disponibile negli ospedali. Ragione principale della scelta operata dal Ministero della Sanit´a ´e stata la considerazione della ‘robustezza’ del sistema DRG
Figura 2.6: DRG.
rispetto alla qualit´a ed alla completezza delle informazioni attualmente ottenibili dalla Scheda di Dimissione Ospedaliera (SDO) in uso presso gli ospedali dal 1991. I campi relativi ai dati contenuti nella SDO sono stati in seguito in parte modificati sia dal Ministero (dati minimi essenziali) che da alcune regioni per adeguarli a nuove normative. La transcodifica ´e il procedimento mediante il quale i codici diagnostici del sistema ICD-9 dell’OMS vengono convertiti a quelli dell’ICD-9-CM. Questo ´e necessario perch´e il software Grouper, che attribuisce i DRG, ´e stato predisposto per utilizzare la classifi-cazione delle malattie ICD-9-CM che ´e quella utilizzata negli USA. La transcodifica pu´o causare alcune difficolt´a pratiche nella definizione del DRG1.
I gruppi diagnostici principali (MDC, Major Diagnostic Category) sono i gruppi di diagnosi che formano la struttura del sistema di classificazione DRG. Sono 25 (vedi tab. 2.1)
Le MDC sono costruite per fornire ai DRG una struttura che dia significativit´a e coerenza clinica, e rispondono a criteri anatomici, eziologici e di specialit´a clinica simili a quelli che caratterizzano i settori diagnostici della classificazione internazionale ICD-9. L’assegnazione di un caso ad una specifica MDC avviene in base alla diagnosi principale di dimissione e rappresenta la prima fase del processo di attribuzione del DRG.
Ciascun caso dimesso viene attribuito ad uno specifico DRG da un software (Grouper) che, fra le informazioni contenute nella scheda di dimissione, utilizza sempre quelle rela-tive alla diagnosi principale e agli eventuali interventi chirurgici o procedure, e le infor-mazioni relative a sesso, et´a, stato alla dimissione e diagnosi secondarie, se presenti. Nel caso le diagnosi vengano ancora codificate secondo la 9a revisione della classificazione
internazionale delle malattie (ICD-9), mentre il Grouper ´e stato costruito per utilizzare i codici della sua modificazione clinica (ICD-9-CM) utilizzata negli USA, ´e indispensabile una transcodifica per riconoscere la maggioranza dei codici di diagnosi. La logica del funzionamento del sistema di ´e la seguente: il software individua la diagnosi principale dalla scheda nosologica ed in base a questa sceglie la MDC appropriata. Valuta poi la
1Dal Gennaio 2000 alcune Regioni hanno adottato ufficialmente la classificazione ICD9-CM per la
compilazione della SDO, come da indicazione ministeriale. A tutt’oggi alcune Regioni non si sono ancora adeguate. ´E necessario inoltre far notare come l’OMS abbia nel frattempo aggiornato pi´u volte la classificazione ICD e lo stesso avviene, con frequenza annuale, per l’ICD9-CM, aggiornata con la
1 Malattie e disturbi del sistema nervoso 2 Malattie e disturbi dell’occhio
3 Malattie e disturbi dell’orecchio, del naso e della gola 4 Malattie e disturbi dell’apparato respiratorio
5 Malattie e disturbi dell’apparato cardiocircolatorio 6 Malattie e disturbi dell’apparato digerente
7 Malattie e disturbi epatobiliari e del pancreas
8 Malattie e disturbi dell’apparato muscoloscheletrico e connettivo 9 Malattie e disturbi della pelle, del sottocutaneo e della mammella 10 Malattie e disturbi endocrini, metabolici e nutrizionali
11 Malattie e disturbi del rene e delle vie urinarie
12 Malattie e disturbi dell’apparato riproduttivo maschile 13 Malattie e disturbi dell’apparato riproduttivo femminile 14 Gravidanza, parto e puerperio
15 Malattie e disturbi del periodo neonatale
16 Malattie e disturbi del sangue e degli organi ematopoietici e del sistema immunitari
17 Malattie e disturbi mieloproliferativi e tumori poco differenziati 18 Malattie infettive e parassitarie (sistematiche)
19 Malattie e disturbi mentali
20 Uso di alcool o farmaci e disturbi mentali organici indotti da alcool o farmaci 21 Traumatismi, avvelenamenti ed effetti tossici dei farmaci
22 Ustioni
23 Fattori influenzanti lo stato di salute ed il ricorso ai servizi sanitari 24 Traumi multipli significativi
25 Infezioni da HIV.
presenza o meno di interventi chirurgici e, successivamente, dopo aver preso in consid-erazione le altre informazioni presenti attribuisce il DRG. Infine, l’attribuzione al DRG dipende anche da:
• et´a del paziente (in particolare, alcuni DRG sono relativi a pazienti: > 17 anni, < 18 anni, > 35 anni, < 36 anni);
• presenza o meno di patologie secondarie ossia di complicanze (la complicanza viene
individuata in relazione alla diagnosi principale)
• stato alla dimissione: vivo, deceduto, dimesso contro il parere dei sanitari,
trasfer-ito ad altro reparto
• peso alla nascita
Il processo di cura viene quindi esaminato mediante alcune delle variabili presenti all’interno della scheda di dimissione.
2.3.1
Indici di efficienza
Detti:
Dj la degenza media del DRGj nello standard,
Pj la proporzione dei ricoveri per il DRGj nello standard
Dst la degenza media nello standard, data da
P
jDj· Pj
dij la degenza media del DRGj nel reparto i-esimo
pij la proporzione dei ricoveri per il DRGj nel reparto i-esimo
L’indice di Case-Mix (ICM), o grado di complessit´a dei casi trattati, del reparto i-esimo ´e definito come: ICM =Pj Dj·pij
Dst
Se ICM > 1 la casistica del reparto i-esimo ´e pi´u complessa dello standard, se
ICM < 1 la casistica ´e meno complessa dello standard.
L’indice comparativo di performance (ICP), che valuta l’efficienza della struttura rispetto alla media, del reparto i-esimo ´e definito come: ICP =Pj Pj·dij
Dst
Un ICP < 1 indica buona efficienza del reparto i-esimo, mentre un ICP > 1 indica una cattiva efficienza.
2.4
Scheda di Dimissione Ospedaliera (SDO)
´
E uno strumento informativo per la raccolta dei dati relativi ai singoli dimessi dagli istituti di ricovero ospedaliero; costituisce la sintesi delle informazioni contenute nella cartella clinica. La identificazione delle informazioni da rilevare attraverso la scheda di dimissione e le relative modalit´a di compilazione e codifica sono disciplinate dal D.M. 28.12.91 e dal D.M. 26.07.93. A far data dal 1 gennaio 2001, la nuova disciplina della SDO ´e stabilita dal decreto ministeriale 27 ottobre 2000, n. 380.
La tabella seguente riporta i codici presenti nella SDO per identificare il tipo di stato alla dimissione, nella tabella successiva sono riportati i dati presenti nella SDO (la lunghezza di un campo ´e espressa in caratteri ).
Codici stato alla dimissione 01 dimesso a domicilio
02 trasferito ad altro ospedale per acuti 03-06 trasferito ad altro ospedale per acuti 07 dimesso contro il parere dei sanitari
20 deceduto
Nome del campo Lunghezza Descrizione INPUT
Et 3 0-124
Sex 1 1:Maschio,2:Femmina
DSP 2 Stato alla dimissione
DX1 5 Diagn. principale(ICD-9-CM)
DX2 5 Diagn. Secondaria(ICD-9-CM)
DX3 5 Diagn. Secondaria(ICD-9-CM)
DX4 5 Diagn. Secondaria(ICD-9-CM)
Proc1 4 Procedura/Interv. (ICD-9-CM)
Proc2 4 Procedura/Interv. (ICD-9-CM)
Proc3 4 Procedura/Interv. (ICD-9-CM)
Proc4 4 Procedura/Interv. (ICD-9-CM)
2.5
Centro Unificato di Prenotazione (CUP)
Il CUP consente di ottimizzare le risorse, riducendo contemporanemente le liste di attesa all’interno di una singola struttura ospedaliera.
A livello regionale un sistema CUP pu´o gestire l’accessibilit´a alle prestazioni erogate da tutto il SSR (Servizio Sanitario Regionale), in maniera semplice per il cittadino che ha a disposizione una variet´a di opzioni di accesso (sportelli CUP, farmacie, telefono, web), con la possibilit´a di ottimizzazione una serie di parametri: ad es. scegliendo la prestazione pi´u conveniente in termini geografici, temporali, tecnologici, professionali.
2.6
Radiology Information System (RIS)
Il RIS (Sistema Informativo di Radiologia) fornisce supporto alla attivit´a di preno-tazione esami, referpreno-tazione, archiviazione e interrogazione della base dati delle immagini radiologiche.
Nei sistemi RIS un componente importante ´e il sistema PACS2 (Picture Archiving
2Per la sua vocazione prevalente alla gestione delle immagini pu´o essere considerato un sistema
and Communicatiosn System) cio´e il sistema di gestione delle immagini (trasferimento dalle apparecchiature radiologiche ai sistemi di archiviazione, stampa etc. . . . ).
Il Sistema Informativo Radiologico costituisce in pratica un piccolo Sistema Infor-mativo Sanitario a s´e stante. La forza di un sistema del genere ´e basato sulla possibilit´a di scambiare immagini diagnostiche, corredate di numerosi dati, quali ovviamente quelli anagrafici (ma volendo, anche clinici), grazie all’utilizzo di un protocollo comune (ad esempio, DICOM).
La possibilit´a di disporre le immagini diagnostiche ´e un notevole punto di forza in un sistema ospedaliero. Il vantaggio indiscusso ´e quello di spostare le informazioni senza spostare in pratica gli operatori: si aprono scenari di lavoro cooperativo, refertazioni guidate a distanza, ma anche semplice invio di dati al fine di stampa o consultazione. Ma i vantaggi non sono finiti qui: il radiologo ha la possibilit´a infatti di intervenire sull’immagine variandone le caratteristiche (ad esempio di contrasto e luminosit´a) anche molto tempo dopo l’esame, mettendo in evidenza i particolari che pi´u gli interessano.
Si intuisce come l’integrazione del RIS all’interno di un pi´u ampio Sistema Informa-tivo Ospedaliero costituisca una scelta obbligata da un lato ed un vantaggio indiscusso dall’altro.
2.6.1
DICOM
La possibilit´a di scambiare immagini mediche corredate da varie informazioni attraverso reti telematiche, fa sorgere l’esigenza di uno standard di comunicazione globale. Ci´o offrirebbe al radiologo la possibilit´a di consultare tutti gli esami dello stesso paziente contemporaneamente ed in un solo posto, ed al medico di reparto di accedere immedi-atamente alle immagini, attraverso un collegamento in rete locale.
Uno standard, infatti, consiste in un insieme di norme fissate allo scopo di ottenere l’unificazione delle caratteristiche di una determinata prestazione o processo tecnologico, da chiunque o comunque prodotto.
DICOM (Digital Imaging and Communication in Medicine) rappresenta un mod-ello di tale standardizzazione, la cui nascita ´e stata per´o inizialmente ostacolata dalla pluralit´a di produttori di hardware in campo medico, i quali, proponendo standard pro-prietari avevano creato una situazione di completa incomunicabilit´a tra apparecchi di case costruttrici differenti. Tale fatto, non favorendo il decollo commerciale, ha portato l’organismo che rappresenta i costruttori Americani, la NEMA, ad affrontare il problema della standardizzazione. DICOM rappresenta il risultato di tale impegno.
DICOM pu´o essere considerato una evoluzione del PACS, in quanto prevede l’in-terconnessione sia meccanica che elettrica delle apparecchiature con costi e difficolt´a minori ed una manutenzione semplificata. Come possiamo vedere nella figura 2.7, in cui ´e rappresentato uno schema di un dipartimento di immagini completamente infor-matizzato, DICOM offre molteplici vantaggi. Infatti consente sia l’utilizzo di un unico sistema di documentazione (stampante laser) e di memorizzazione, sia il collegamento diretto bidirezionale ai sistemi informativi di reparto (RIS) ed ospedaleri (HIS), oltre che la comunicazione all’esterno con altri ospedali o con Internet.
Figura 2.7: Architettura di rete DICOM.
L’introduzione di DICOM si ´e resa necessaria per superare i problemi nel campo delle immagini radiologiche, adesso anche altre branche mediche specialistiche tipo Odontoia-tria e Dermatologia producono immagini, risulta quindi opportuno andare a verificare se anche in questi campi DICOM pu´o produrre dei vantaggi. A tal proposito sono nati dei gruppi di lavoro in collaborazione con la ACR-NEMA.
In Europa DICOM ´e in sperimentazione presso l’Universit´a di Ginevra nell’ambito del progetto PAPYRUS. La stessa Comunit´a Europea nell’ambito di CEN/TC 251 (http://miginfo.rug.ac.ac.be:8001/index.htm) sta studiando le funzionalit´a dello stan-dard DICOM a confronto con lo stanstan-dard SPI (Stanstan-dard Product interconnect) proposto da Philips (http://www.philips.com/ms/) e Siemens (http://www.siemens.de/med).
2.7
HL7
L’esigenza di condividere i dati clinici dei pazienti all’interno della struttura ospedaliera e in modo pi´u ampio fra centri di cura remoti e sul territorio (medici di base, unit´a sanitarie, farmacie, abitazione dei pazienti) ´e sentita da sempre.
Le motivazioni che spingono in questa direzione sono principalmente la possibilit´a di pervenire a:
• miglioramento dell’assistenza al paziente attraverso un’analisi completa della sua
• miglioramento dell’organizzazione dell’assistenza sanitaria attraverso la riduzione
delle consulenze esterne e dei tempi di attesa;
• efficace e tempestiva assistenza diagnostica e terapeutica per i centri periferici, con
disponibilit´a immediata di consulenze specialistiche;
• riduzione dei disagi per il paziente, che pu´o evitare spostamenti, e di costi per la
struttura e per la comunit´a;
• miglioramento delle possibilit´a di analisi e ricerca a partire da database clinici
omogenei e completi.
Fino ad oggi la difficolt´a di pervenire ad una condivisione di informazione clinica attraverso basi di dati eterogenee ´e stata grande, a causa della diversit´a di piattaforme software, di struttura dei database e di connessione fra i vari luoghi di deposito dei dati. Gli approcci a questo problema sono sostanzialmente due: il primo, portato avanti fin dagli esordi dell’informatica clinica, tende a perseguire la codifica e la traduzione dei documenti clinici in un vocabolario controllato. Ma la difficolt´a di ottenere una codifica realmente universale ´e enorme, ed il sistema di codifica decurta il documento clinico della ricchezza informativa del linguaggio naturale. Inoltre sono sempre necessarie soluzioni locali di condivisione fra piattaforme e software differenti
L’altro approccio ´e quello cosiddetto document-centered, che renda il documento indipendente da software e da piattaforma e consenta uno scambio di informazione completo, semplice ed immediato.
Lo sforzo di standardizzazione dello scambio di documenti ha portato alla creazione di insiemi di specifiche, fino all’approvazione dello HL7 (Health Level 7) come standard ANSI nel 1997.
HL7 (Health Level 7) ´e una specifica per lo scambio di dati elettronici fra istituzioni di cura e fra differenti sistemi informativi.
La HL7 PRA (Patient Record Architecture - Architettura del Record Paziente, o anche la CDA Clinical Document Architecture) definisce la semantica ed i vincoli strut-turali necessari per lo scambio di documenti clinici, cio´e definisce la struttura minima della cartella clinica.
L’architettura ´e indipendente dalla piattaforma e da software proprietario ed ´e specificata in XML.
Ogni documento PRA consiste di uno header e di un body. Lo header fornisce dei metadati che identificano e classificano il documento, mentre il body supporta la visualizzazione dei dati.
Le finalit´a di un PRA HL7 sono:
• utilizzo di uno standard open;
• supporto allo scambio di documenti fra utenti remoti; • supporto alla loro elaborazione successiva;
• preparazione veloce dei progetti di documenti clinici.
tec-La PRA ´e un’architettura multilivello. Il concetto di livello si riferisce a diversi gradi di granularit´a dei markup richiesti, di pari passo con la profondit´a dell’informazione clinica.
LIVELLO 1 (Coded Header) ´E la specificazione della struttura del documento. Non e’ richiesta semantica.
LIVELLO 2 (Coded Structure) ´E possibile condividere anche la semantica dei doc-umenti, identificando sezioni e sottosezioni con titolo codificato (ad esempio: una sezione Anamnesi con sottosezione Storia della patologia attuale). Il Livello 2 specifica dei markup per queste sottostrutture. Grazie al Livello 2 e’ possibile l’ estrazione e compilazione dalla scheda di dimissione, creata anche per dettatura, o di liste di consigli di terapia. Il Livello 2 dovra’ avere un DTD di specifica che determini la tipologia del documento clinico e un catalogo di possibili sezioni e sottosezioni.
LIVELLO 3 (Coded Content) Il Livello 3 richiede un’articolazione semantica com-pleta. Un documento di Livello 3 pu´o essere elaborato dai riceventi con algoritmi di analisi di qualsivoglia complessit´a che riconoscano i suoi markup.
Oltre alla struttura della cartella clinica, HL7 definisce anche i cosiddetti eventi
Trigger cio´e eventi che scatenano un flusso di informazioni all’interno della struttura
sanitaria (ad es. la accettazione di un paziente implica l’aggiornamento della anagrafica pazienti ma anche del sistema di gestione dei posti letto). A tali eventi corrispondono pertanto dei messaggi che i vari sottosistemi informativi si scambiano per tenersi aggior-nati l’uno con l’altro (ad es. il sistema di prenotazione esami e quello amministrativo devono essere sempre sincronizzati tra loro per consentire di calcolare efficientemente il DRG all’atto della dimissione).
Lo sviluppo dello standard HL7 e la sua economicit´a e semplicit´a fanno prevedere una rapida diffusione di questa tecnologia.
Molte case di software sanitario negli Stati Uniti stanno incorporando PRA nei loro sistemi di sviluppo, perch´e si tratta di una soluzione realmente percorribile al problema di codifica, scambio e conservazione dei documenti clinici
2.8
Sicurezza
I requisiti per un sistema sicuro di scambio di documenti elettronici sono: Consenso il mittente deve esprimere consenso sul contenuto.
Paternit´a la paternit di un documento digitale deve essere garantita.
Integrit´a il messaggio non deve essere contraffatto dagli altri utenti incluso il desti-natario.
Segretezza gli interlocutori siano in grado di scambiare documenti senza che nessuno all’infuori di loro due sia in grado di leggerli.
Questi requisiti possono essere ottenuti con sistemi di crittografia.
Gli algoritmi di crittografia possono essere di due tipi: a chiave simmetrica e chiave
asimmetrica.
Negli algoritmi a chiave simmetrica il messaggio scambiato tra i due interlocutori viene codificato mediante un codice (chiave) che ´e noto ad entrambi e solo ad essi.
Negli algoritmi a chiave asimmetrica vengono usate due chiavi: una chiave pubblica ed una privata. La chiave pubblica ´e nota a tutti mentre la chiave privata ´e nota solo al suo possessore. Un messaggio codificato con la chiave pubblica pu´o esere decodificato solo con la chiave privata. Pertanto per scrivere un messaggio ad Alice si user´a la chiave pubblica di Alice: in questo modo saremo sicuri che solo Alice con la sua chiave privata potr´a decodificare il messaggio (Segretezza).
Analogamente se ci arriva un messaggio codificato con la chiave privata di Alice, saremo in grado di decodificarlo solo con la chiave pubblica di Alice. In questo modo sapremo che solo Alice pu´o aver inviato un certo messaggio (Paternit´a e autenticit´a)
Grazie al meccanismo della chiave pubblica e privata ´e possibile realizzare anche la firma digitale dei documenti.
Dato un documento elettronico ´e possibile calcolare mediante una funzione hash (cio´e una funzione che associa ad un documento un valore numerico unico) una impronta
digitale del documento. Il creatore del documento pu´o codificare l’impronta digitale con
la sua chiave privata (l’impronta codificata viene detta firma digitale). Quindi invia il documento non codificato assieme alla firma digitale.
Colui che riceve il documento pu´o ricalcolare l’impronta digitale e verificare se cor-risponde alla impronta che ottiene decodificando la firma digitale con la chiave pubblica di colui che ha inviato il documento.
Una qualunque alterazione del documento o della firma digitale da parte di un terzo interlocutore farebbe s´ı che impronta digitale decodificata e impronta digitale ricalco-lata non coincidano. Con questo meccanismo ´e possibile essere sicuri dell’integrit´a del documento e dell’identit´a di colui che lo ha inviato 2.8.
Per le transazioni sicure su World Wide Web si utilizza attualmente il protocollo HTTPS che ´e una variante del protocollo HTTP cui si aggiunge il Secure Socket Layer (SSL, Strato per la sicurezza).
Questo protocollo utilizza i certificati ed entrambi i tipi di crittografia.
Si basa sull’identificazione del server (colui che fornisce un servizio su Internet). Il protocolllo si svolge nelle fasi seguenti. il client fa una richiesta al server web HTTPS ricevendo una risposta con un certificato che attesta l’identit´a del server. Quindi client e server insieme stabiliscono (con un sofisticato algoritmo) una chiave simmetrica da usare negli scambi per quella sessione di comunicazione.