A mamma e papà, che mi hanno permesso di arrivare a questo giorno.
Indice
Introduzione ... 1
Organizzazione della tesi ... 4
Capitolo 1... 5
Knowledge Discovery in Databases: Data Warehouse e data Mining... 5
1.1 Introduzione al KDD – Knowledge Discovery in Data Base ... 5
1.1 Il processo di KDD... 8
1.1.1 Consolidamento dei Dati e Data Warehouse ... 9
1.1.1.1 Modello multidimensionale ... 13 1.1.2 Selezione e Preprocessing... 14 1.1.3 Data Mining ... 15 1.1.3.1 Regole di associazione ... 17 1.1.3.2 Clustering ... 23 1.1.3.3 Alberi di classificazione... 25 1.1.4 Interpretazione e valutazione ... 28 1.2 CRISP D.M. Model... 29
1.3 Ambienti e strumenti del processo KDD utilizzati ... 31
1.3.1 SQL Server... 32 1.3.2 Weka ... 34 1.3.3 KDDML ... 35 1.3.4 Clementine 6.5 ... 36 1.3.5 Knowledge Studio... 38 Capitolo 2... 40
Il contesto applicativo: metodologie ... 40
2.1 Il MISA-2... 41
2.1.1 Tecniche statistiche e risultati ... 42
2.2 Studi epidemiologici e ambientali nell’area di Pisa... 44
2.2.1 Linee di indirizzo sulla base della letteratura... 45
2.2.2 Strumenti e metodi ... 45
2.2.2.1 Indagine sullo stato di salute della popoalzione... 46
2.2.2.2 Analisi della interazione inceneritore-salute attraverso studi epidemiologici esistenti... 48
2.2.2.3 Indagine ambientale su suolo, aria e acqua... 48
2.2.3 Analisi dei risultati ... 49
2.3 Data Mining e Statistica ... 50
Capitolo 3... 52
Il contesto applicativo: i dati ... 52
3.1 Il punto di partenza: le SDO... 52
3.2 I Dati Anagrafici ... 55
3.3 I dati del Censimento ... 56
3.4 I Dati Meteo e di rilevazione atmosferica ... 57
3.5 Una prima fase di consolidamento dei dati ed il Data Set completo ... 59
Capitolo 4... 67
4.1 Un processo KDD completo: Data Warehousing e il modello CRISP-DM .
... 67
4.2 Data Warehousing e analisi OLAP ... 68
4.2.1 Creazione del data warehouse “Ricoveri Pisa” ... 69
4.2.2 Data Mart “Censimento”, analisi e risultati ... 71
4.2.3 Data Mart “Inquinamento”, analisi e risultati ... 75
4.3 Preprocessing e Data Mining ... 78
4.3.1 Analisi iniziale dei dati... 79
4.3.2 L’albero di decisione... 84 4.3.3 Clustering ... 86 4.3.4 Regole di associazione ... 88 Capitolo 5 ... 91 Analisi particolari... 91 5.1 Un ulteriore studio... 91
5.2 La analisi delle distribuzioni ... 92
5.2 Regole associative ... 94
5.2.1 Apriori per le malattie dell’apparato circolatorio... 94
5.2.2 Apriori per la malattie dell’apparato digerente ... 96
5.3 Clementine ... 97 Conclusioni... 101 APPENDICE A ... 103 APPENDICE B ... 129 Ringraziamenti ... 139 Bibliografia... 141
Introduzione
Nella realtà odierna, l’utilizzo di sistemi automatici per l’elaborazione dell’informazione è diventato un aspetto strategico per l’organizzazione delle aziende e delle strutture pubbliche. In genere, le informazioni memorizzate ed elaborate da tali sistemi hanno un duplice utilizzo nell’ambito di una azienda od organizzazione: sono infatti usate per scopi operativi e come base per il supporto alle decisioni (DSS - Decision Support System).
Al momento attuale, in genere un DSS raccoglie milioni o anche centinaia di milioni di dati. Si consideri per esempio un’agenzia di carte di credito che deve memorizzare i dati relativi agli acquisti effettuati dai suoi clienti. Supponiamo che ognuno di loro effettui mediamente 10 transazioni in un mese, 120 per anno. Con 3 milioni di clienti e 5 anni di dati, è facile prevedere come la velocità di crescita di tali dati vada ben aldilà della capacità di controllo umana.
In definitiva, i dati possono essere considerati la spina dorsale per il funzionamento di qualsiasi organizzazione, di qualunque tipo e dimensione.
Nasce quindi l’esigenza di strumenti ad hoc, quali i Data Base Management System (DBMS), in grado di raccogliere, memorizzare ed elaborare in modo automatico questi dati. Questa necessità è andata di pari passo con il drastico abbassamento del rapporto prezzo/capacità dei supporti di memorizzazione cui si è aggiunto il potenziamento delle capacità di calcolo dei moderni elaboratori che hanno offerto sinora, e continueranno ad offrire in futuro, un robusto strumento per raccogliere ed organizzare tali dati.
Ma raccogliere ed organizzare i dati non è sufficiente; questi devono anche essere analizzati, compresi e trasformati in informazione utile, obiettivi difficili da raggiungere con la tecnologia dei moderni DBMS.
Spesso, infatti, le informazioni che cerchiamo sono “nascoste” in grossi volumi di dati che sono di per se poco significativi. Per ottenere questa informazione è quindi necessaria una chiave di lettura ad hoc.
Per questo motivo, la ricerca si è spinta negli ultimi anni verso un settore dell’informatica ed in particolare dei sistemi per la gestione dei dati conosciuto con l’acronimo di KDD (Knowledge Discovery in Databases).
Il processo di KDD è finalizzato ad ottenere conoscenza “utile” a partire da dati “grezzi”; come vedremo, questo processo consta di diverse fasi incrementali durante le quali i dati vengono sottoposti ad operazioni di preparazione per le analisi finali, che costituiscono proprio la parte fondamentale del KDD. La fase di analisi può avvenire sia con tecniche di analisi multidimensionale (strumenti OLAP), che con l’applicazione di algoritmi di Data Mining utilizzando software dedicati. Tali algoritmi giocano un ruolo molto importante nel processo KDD perché sono quelli che ci permettono di estrarre dei modelli attraverso i quali è possibile trasformare l’informazione in conoscenza.
Come detto sopra, le tecniche di KDD si sono diffuse inizialmente presso quelle organizzazioni che possiedono/raccolgono una grande quantità di dati transattivi e di dettaglio, quali l’ambiente bancario, le reti di supermercati. Successivamente le potenzialità delle tecniche KDD hanno catturatro l’attenzione di altre strutture organizzative diffondendosi così molto velocemente.
In particolare il contesto applicativo considerato da questa tesi è quello degli studi epidemiologici realizzato dal laboratorio di Epidemiologia e Biostatistica dell’Istituto di Fisiologia Clinica del C.N.R. di Pisa.
Il metodo di lavoro perseguito negli studi epidemiologici ha come obiattivo l’osservazione di molti fenomeni di un determinato contesto ambientale per cercare di capire le correlazioni con alcune patologie di una data popolazione. Gli strumenti a disposizione dell’epidemiologo sono essenzialmente di natura statistica e l’osservazione dei dati mira a verificare ipotesi che lo studioso di volta in volta si pone.
Le metodologie ed i risultati ottenuti da questi studi sono stati raccolti nel in diverse pubblicazioni, e fanno parte di una serie di iniziative della Regione Toscana all’interno del più vasto progetto nazionale del Misa-2.
Il primo obiettivo della tesi, iniziato durante l’esperienza di tirocinio, è stato quello di mettere al servizio degli studi epidemiologici le tecniche di Data Warehousing e di conseguenza mostrare i vantaggi che le analisi OLAP possono portare ai suddetti studi.
A partire da sorgenti dati eterogenee è stato creato un ambiente di analisi omogeneo, contenente i dati dei ricoveri avvenuti in Pisa dal 1998 al 2000, uniti ai dati anagrafici, di inquinamento atmosferico e ai dati del censimento del 1991.
Tramite SQL Server si è proceduti alla creazione di un Data Warehouse che ci ha consentito di ottenere un archivio unico contenente tutti i dati sopra elencati, organizzati per ricoveri. Successivamente, a partire dal Data Warehouse è stato possibile effettuare analisi OLAP sui dati, le quali hanno portato alla creazione di indici ad hoc per rendere più precisi ed interessanti i risultati delle funzioni di aggregazione dell’analisi multidimensionale.
Tali analisi hanno messo in rilievo la possibilità di relazioni sia tra i ricoveri avvenuti nel comune di Pisa e le condizioni abitative dei residenti nel comune, che tra i ricoveri e i livelli di inquinamento dell’aria rilevati nei giorni precedenti il ricovero.
In una seconda fase della Tesi si sono effettuati studi di Mining sugli stessi dati. Questi studi hanno avuto un duplice obiettivo: per primo sono stati messi a confronto diversi ambienti di Data Mining (Weka, Clementine 6.5, e KDDML) e successivamente sono stati analizzati i dati utilizzando soprattutto Clementine 6.5, rivelatosi il più adatto alle caratteristiche dei dati a disposizione.
I risultato ottenuti da questo lavoro di tesi possono essere divisi in due categorie.
In prima analisi possiamo affermare di aver creato una sorgente dati omogenea, contenente la totalità dei dati a disposizione per le analisi epidemiologiche nella zone di Pisa che sarà messo a disposizione dell’Istituto di Fisiologia Clinica del C.N.R. Il Data Warehouse implementato è inoltre di facile aggiornamento; nel momento in cui si vorranno inserire nuove informazioni, lo si potrà fare in maniera semplice e senza grande dispendio di tempo.
Anche i risultati del Data Mining sono stati rilevanti: non solo ci è stato possibile osservare il comportamento di vari tools di Data Mining utilizzati su un data Set molto ampio, ma tramite Clementine, si sono ottenuti modelli e cluster che descrivono perfettamente come le sostanza inquinanti presenti
nell’aria e le condizioni abitative dei residenti di Pisa influiscono sullo stato di salute della popolazione.
Organizzazione della tesi
La presente tesi è strutturata nel seguente modo:
Capitolo 1
• Come nasce e si sviluppa il processo di KDD • Le fasi del processo di KDD
• Descrizione della fase di Datawarehousing • Descrizione dalla fase di Data Mining • Algoritmi di Data Mining più diffusi • Il modello CRISP-DM
• Ambienti e strumenti utlizzati
Capitolo 2
• Il contesto applicativo • Il progetto Misa-2
• Studi epidemiologici in Pisa
• Confronto tra la Statistica e il Data Mining
Capitolo 3
• Descrizione dei dati
• Le schede di dimissione ospedaliera (SDO) • Descrizione dei dati anagrafici
• Descrizione dei dati del censimento • Descrizione dei dati di inquinamento
Capitolo 4
• Realizzazione del Data Warehouse e analisi OLAP • Analisi preliminari per il Data Mining
• Descrizione dell’utilizzo degli algoritmi di Mining • Rappresentazione dei risultati
Capitolo 5
• Analisi per patologie specifiche
• Descrizione dell’utilizzo dell’algoritmo Apriori per analisi specifiche • Uno stream di Clementine
Capitolo 1
Knowledge Discovery in Databases: Data
Warehouse e data Mining
1.1 Introduzione al KDD – Knowledge Discovery in Data
Base
Nella realtà contemporanea ogni individuo ha a disposizione una vasta quantità di dati relativi al proprio contesto di riferimento, sia esso personale, professionale o aziendale.
Tale abbondanza di dati costituisce un notevole potenziale informativo che, se compreso e valorizzato, consente di intraprendere migliori azioni e decisioni.
Si è assistito infatti nell’ambito delle basi di dati ad una abnorme crescita delle dimensioni dovuta a vari motivi, quali il minor costo dei supporti di memorizzazione e alla crescente esigenza di riuscire ad automatizzare tutti quei processi dell’attività
umana in cui l’elaborazione automatica riusciva ad apportare un considerevole vantaggio in termini economici, temporali e di sicurezza.
La spropositata dimensione di questi “giacimenti magnetici” di dati li ha resi pressoché inutilizzabili per operazioni che esulano dal semplice inserimento e cancellazione, quali possono essere l’ottenimento di risultati statistici o la determinazione di relazioni tra i dati stessi ovvero, in generale, operazioni che sintetizzano le “caratteristiche” dei dati contenuti.
Per fronteggiare queste esigenze furono ideati alcuni strumenti (Data Warehouse, DBMS) e, verso la fine degli anni ‘80, ricercatori ed aziende hanno iniziato a sviluppare nuovi modelli per riuscire meglio nell’intento; quello che si è ottenuto è una serie di strumenti e metodologie polivalenti, provenienti e utilizzabili in diverse branche della ricerca quali l’intelligenza artificiale, le reti neurali, genetica, la statistica ed altre.
Tale campo è noto in letteratura con il nome di Knowledge Discovery in Databases (KDD).
Il processo KDD ha motivo d'esistere proprio in condizioni di disponibilità di una quantità considerevole di dati ai fini dell'estrazione di nuove informazioni potenzialmente utilizzabili e comprensibili.
In tale contesto il KDD si pone come processo di selezione, esplorazione e modellazione di grandi masse di dati, al fine di scoprire regolarità o relazioni non note a priori, ed allo scopo di ottenere informazione utile da trasformare in conoscenza per supportare le decisioni.
Da questa definizione data possiamo evidenziare i tratti caratteristici del KDD: in primo luogo è un processo, non una analisi statica di dati; la sua valenza multidisciplinare, ed infine l’importanza degli obiettivi dell’analisi, riconducibili a decisioni d’azione di breve o medio periodo.
Le discipline che intervengono nel processo di KDD, sono: la scienza dell’informazione per quanto riguarda il trattamento e l’organizzazione dei dati; la statistica metodologica per scoprire relazioni di regolarità non predeterminate; e le discipline economico-aziendali, alle quali il KDD fornisce un supporto alle decisioni.
Negli ultimi anni, la ricerca si è concentrata su una specifica parte del processo di KDD, quella più “operativa”, relativa all’estrazione di conoscenza, nota appunto con il nome di Data Mining (DM).
Le prime applicazioni realizzate sono state nel campo delle vendite al dettaglio, quali ad esempio la segmentazione della clientela (Database Marketing) in cui si cerca di individuare gruppi omogenei in termini di comportamento d'acquisto e di caratteristiche socio-demografiche.
L'individuazione delle diverse tipologie di clienti permette di effettuare campagne di marketing diretto (Direct Marketing e CRM) e di valutarne gli effetti, nonché di ottenere indicazioni su come modificare la propria offerta, e rende possibile monitorare nel tempo l'evoluzione della propria clientela e l'emergere di nuove tipologie oppure l’analisi delle associazioni (Basket Analysis), in cui si ha l’applicazione di tecniche per individuare associazioni tra i dati di vendita al fine di conoscere quali prodotti sono acquistati congiuntamente.
In seguito queste tipologie di applicazioni hanno cominciato ad essere trasferite verso tutti gli altri settori che sono in grado di disporre dei dati transattivi di dettaglio (dalle carte di credito ai servizi di telecomunicazioni, agli utenti di siti web).
Settori particolarmente interessanti sono quelli del risk management e della fraud detection, in particolare nei campi bancario, assicurativo e delle telecomunicazioni, ma anche in quello della sanità e del recupero dell’evasione fiscale o ancora l’analisi testuale (Text Mining) in cui si individuano gruppi omogenei di documenti in termini di argomento trattato, consentendo di accedere più velocemente all'argomento di interesse e di individuarne i legami con altri argomenti; Technology Watch (Competitive Intelligence) in cui la ricerca si applica a banche dati di tipo tecnico-scientifico ed è volto a determinare i gruppi tematici principali (nel caso di banche dati di brevetti, un gruppo tematico indica una particolare tecnologia), le loro relazioni, l'evoluzione temporale, le persone o le aziende coinvolte.
Il KDD è pertanto applicabile a qualsiasi ambito di indagine in cui siamo di fronte a grandi quantità di dati e abbiamo l'esigenza di conoscerne il contenuto.
Consolidamento dei dati Selezione e preprocessing Data Mining Interpretazione e valutazione Sorgenti Dati Dati consolidati Dati preparati Patterns warehouse Conoscenza
1.2 Il processo di KDD
Il processo di estrazione della conoscenza può essere scomposto in quattro fasi, come illustrato in figura1. Le quattro fasi sono: il consolidamento, la selezione e il preprocessing, il Data Mining e l’interpretazione e valutazione de modelli. Per ora non ci si preoccupi di cosa sia un modello, il suo significati verrà spiegato successivamente, per il momento basti sapere che esso rappresenta una descrizione astratta di un sottoinsieme di dati.
Figura 1
Il KDD è senza dubbio un processo iterativo, in quanto richiede l’intervento umano in tutte le sue fasi, ma con particolare riguardo durante le ultime due fasi, il
Data Mining e l’interpretazione dei risultati, per esempio per le scelte del modello, degli algoritmi e l’analisi dei risultati, valutandoli interessanti o meno.
1.2.1 Consolidamento dei Dati e Data Warehouse
L’obiettivo di questa fase è quello di creare una sorgente dati omogenea, prelevando i dati da sorgenti eterogenee (DB relazionali, DB deduttive, files di testo, ecc). Il più delle volte l’output di questo passo è la creazione di un data warehouse, utilizzato per il supporto alle decisioni e mantenuto separato dal data base operazionale dell’azienda, sul quale vengono effettuate le consuete operazioni di inserzione e cancellazione ed altre di transaction processing.
Secondo Bill Inmon, uno dei proponenti di questo tipo di applicazione, un data warehouse è una raccolta di dati storici integrati, non volatile, organizzata per soggetti, o temi, e finalizzata al recupero di informazione di supporto ai processi decisionali [Inm96, Kim96, eSR02]. Da questa definizione emergono quelle che sono le caratteristi che principali di un data warehouse:
Deve contenere dati storici con un ampio orizzonte temporale, e indicazione di almeno un elemento di tempo.
Non deve essere volatile: i dati devono essere usati per operazioni ricerca e non di modifica.
Deve essere orientato al soggetto: ossia alle aree di maggior interesse dell’organizzazione.
Deve essere integrato, le inconsistenze introdotte nella codifica e rappresentazione da sorgenti diverse devono essere eliminate nel data warehouse.
Di seguito viene dato uno schema esplicativo dell’architettura di un Data Warehouse:
Figura 2
Di solito, in una azienda una base di dati utilizzata per le attività gestionali non coincide con la base di dati usata per l’analisi dei dati, ovvero il data warehouse; questo perché le due basi di dati contengono informazioni diverse; per esempio mentre la base di dati è orientata verso la rappresentazione dello stato attuale del dominio del discorso, il data warehouse contiene in genere informazioni storiche che riguardano tutte le transazioni eseguite in un certo intervallo di tempo; più in generale non conviene appesantire lo schema della base di dati inserendovi informazioni che sono di interesse solo al supporto alle decisioni e non per le attività gestionali ed operative, ne conviene inserire nel data warehouse informazioni che non si è interessati ad analizzare.
Per comprendere meglio l’utilizzo di un data warehouse rispetto ad una normale base di dati si propone le seguente tabella (tab.1) esplicativa nella quale vengono analizzate le principali differenze fra le classiche applicazioni transazionali interattive che usano basi di dati (On Line Transaction Processing, OLTP) e le applicazioni per il supporto alle decisioni che usano data warehouse (On Line Analytical Processing, OLAP).
Il progetto del data warehouse è una operazione complessa, centrata sull’analisi delle specifiche applicazioni di supporto alle decisioni che si desidera eseguire sul sistema.
Durante questo progetto occorre stabilire in particolare:
Quali informazioni mantenere nel data warehouse: ad esempio scegliere il livello di granularità. Mantenere tutti i dati di ogni scontrino potrebbe far aumentare oltremodo le dimensioni del sistema, ma nello stesso tempo memorizzare solo i dati complessivi delle vendite di giornata
renderebbe impossibile analizzare le correlazioni tra acquisti di prodotti diversi in un’unica spesa.
Come popolare il data warehouse, risolvendo i problemi dovuti all’eterogeneità delle sorgenti dei dati.
Quali applicazioni sviluppare sul data warehouse
OLTP OLAP
Utenti
Impiegati o tecnici DirigentiScopi
Operazioni giornaliere Supporto alle decisioniOrganizzazioni
Per settori Per soggettiUsi
90% predefiniti 90% estemporaneiDati
Attuali,dettagliati, relazionaliStorici, multidimensionali,
integrati
Tipi di accesso
Brevi transazioni con letturee scritture
Letture con ricerche complesse
Quantità di dati
100 Mb – 1 Gb 1 Gb – 1 TbTabella 1
In generale un Data Warehouse è composto da una tabella dei fatti e da diverse tabelle delle dimensioni.
Figura 3
La figura di sopra ci viene in soccorso per mostrare un formalismo grafico di rappresentazione di un Data Warehouse: questo formalismo viene chiamato schema a stella. La tabella dei fatti è quella centrale, rappresentata con l’intestazione gialla.
Le misure in questo caso sono store_sales, store_cost e unit_sales, mentre le dimensioni sono product_id, time_id, customer_id, promotion_id e store_id.
Le tabelle aventi l’intestazione azzurra sono le tabelle delle dimensioni, una per ogni dimensione, dove troviamo esplicitati gli attributi di ogni dimensione della tabella dei fatti. La presenza degli attributi dimensionali, e di gerarchie tra questi attributi aumentano le possibilità di analisi dei dati da prospettive diverse (analisi multidimensionale). Ad esempio, una volta analizzate le vendite dei prodotti in certi supermercati relativamente ad un certo periodo di tempo, si può passare ad un livello di dettaglio diverso per analizzare le vendite dei prodotti costosi per trimestre.
1.2.1.1 Modello multidimensionale
Un modo intuitivo per capire le finalità dei Data Warehouse si basa sul concetto di modello multidimensionale dei dati (data cube), con il quale i fatti da analizzare sono rappresentati da punti in uno spazio n-dimensionale. Un punto (fatto) è individuato dai valori di un insieme di dimensioni ed ha associato un insieme di misure. Alcuni sistemi specializzati implementano direttamente il modello multidimensionale, usando un’opportuna struttura dati permanente tipo matrice. Sono i cosiddetti sistemi MOLAP (multidimensional OLAP).
Le operazioni OLAP ci consentono di calcolare il valore di più funzioni di aggregazione (count, sum, avg…) applicate alle misure dei dati raggruppati secondo certe dimensioni di analisi. Gli operatori di più frequente utilizzo sono:
• Slice: usato per ristringere i dati ad un sottoinsieme con condizioni sul valore di una dimensione.
• Dice: usato per restringere i dati ad un sottoinsieme con condizioni sui valori di una dimensione in certi intervalli.
• roll-up: adoperato per raggruppare i dati su alcune dimensioni a calcola il valore di un funzione di aggregazione applicata ad una misura, diminuendo il livello di dettaglio dell’analisi.
• Drill-down: si usa per aumentare il livello di dettaglio dell’analisi, considerando più dimensioni.
Di seguito viene rappresentato uno schema a stella di un Data Warehouse contenente dati sulle vendite di un prodotto (fig. 4).
Figura 4
1.1.2 Selezione e Preprocessing
Per poter applicare gli algoritmi di Data Mining, i dati devono essere corretti e devono avere un formato ben preciso. Per esempio molti algoritmi di clustering richiedono che i dati siano completi e privi di eccezioni o errori. Però il fatto che i dati derivino da fonti eterogenee può aver portato alla presenza di ridondanze, errori o inconsistenze.
Ed è proprio in questa fase che i dati vengono ripuliti (Data Cleaning) da ogni imperfezione per prepararli al processo di Data Mining, infatti questa fase viene anche chiamata di Preprocessing.
In genere questa è la fase che richiede un maggiore sforzo e maggior tempo, ed è di particolare importanza in quanto una buona preparazione influisce positivamente sui risultati ottenuti dagli algoritmi di Data Mining.
In generale i problemi più ricorrenti che il Data Cleaning si propone di risolvere sono i seguenti:
• Valori mancanti: le tecniche per la gestione dei valori mancanti sono diverse, a seconda del livello di perfezione che si vuole raggiungere. Ad esempio possiamo marcare con NULL o UNKNOWN un campo di cui non abbiamo o non si conosce il valore, oppure possiamo riempire questi campi con la
media ricavata dagli altri valori, oppure con valori ottenuti con calcoli statistici e probabilistici.
• Errori ed eccezioni: questi possono essere considerati quei valori che troppo si discostano dalla media, dovuti a evidenti errori di calcolo o di battitura. Per gestire questi errori ci sono tecniche baste sul clustering, su metodi statistici o di regressione.
Un altro task della fase di preprocessing è di rimuovere tutte le inconsistenze e le ridondanze prodotte durante l’integrazione precedente (Data Integration). Ad esempio, quando un attributo che rappresenta lo stesso oggetto viene riferito con due nomi differenti (sinonimia), oppure valori che in realtà sono equivalenti si presentano diversi perché memorizzati con formalismi non omogenei. I dati ridondanti possono essere individuati con tecniche di correlazione.
In questa fase vengono anche stabiliti quali sono i dati da utilizzare durante il processo e quali non sono necessari, eliminando attributi non significativi ai fini del processo o campionando un insieme di tuple (Data Reduction). Ad esempio, nel caso in cui si studi la gravidanza è inutile conservare il sesso dei pazienti.
Ancora, in questo fase si può scegliere di effettuare un lavoro di
discretizzazione degli attributi. Questo avviene soprattutto per quegli attributi che
assumono molti valori diversi e sui quali molte operazioni aritmetiche non hanno molto senso.
Anche durante la fase di preprocessing, può essere utile ricorrere a tecniche di visualizzazione dei dati, che mettono a disposizione un modello concettuale del data warehouse già decritto in precedenza. I tools OLAP (On Line Analytic
Processing), ad esempio, si basano su strutture multidimensionali, dette Data Cube,
che offrono la possibilità di aggregare i dati in base ad ogni dimensione, visualizzare grafici o eseguire calcoli statistici.
1.1.3 Data Mining
I dati trasformati sono adesso esplorati usando una o più tecniche a disposizione in modo da poter estrarre il tipo d'informazione desiderata. Tale informazione non è
semplicemente l'insieme dei dati memorizzati, ma più in generale è l'informazione che si può inferire dalla base di dati.
Da un punto di vista logico esistono essenzialmente due principali tecniche di inferenza:
• la deduzione; • l’induzione;
La deduzione permette di inferire informazione che sia conseguenza logica della informazione contenuta nella base di dati. Molti sistemi di gestione di basi di dati (DBMS), quali i sistemi relazionali, mettono a disposizione dei semplici operatori di deduzione dell'informazione, quale ad esempio l'operatore di join. In questo campo, comunque, vi è stato un notevole sviluppo per la realizzazione di basi di dati deduttive che arricchiscono un DBMS con capacità di deduzione logica (KBMS, Knowledge Base Managment Systems).
L'induzione permette di inferire informazione che è una generalizzazione dell'informazione contenuta nella base di dati. Questo tipo di informazione costituisce conoscenza, cioè delle affermazioni generali su proprietà degli oggetti. Quindi il processo induttivo cerca delle regolarità nella base di dati, cioè combinazioni di valori di certi attributi che siano condivisi da tutti i fatti della base di dati. Queste regolarità possono essere formulate in termini di regole in modo che il valore di un attributo possa essere previsto in termini di altri attributi.
La differenza sostanziale tra deduzione e induzione è che mentre la deduzione inferisce sempre dati che possono essere dimostrati validi all'interno della base di dati, purché ovviamente la base di dati sia corretta, l'induzione inferisce asserzioni che sono solo supportate dalla base di dati ma che potrebbero non essere valide in generale. Pertanto uno dei compiti principali dell'induzione consiste nel selezionare le regole più plausibili che riducano al minimo gli errori nel caso siano sperimentate su fatti precedentemente sconosciuti. Sebbene molti DBMS supportino capacità di inferenza deduttiva (KBMS), ancora pochi supportano capacità di inferenza induttiva.
Esiste quindi un crescente interesse nell’estendere i DBMS con capacità di inferenza induttiva, ovvero con capacità di estrazione di conoscenza utile contenuta
implicitamente nella base di dati che è appunto l'obiettivo principale del Data Mining .
Il processo di Data Mining può quindi essere visto come un processo di apprendimento induttivo quando l'ambiente circostante è una base di dati.
Cerchiamo ora di concretizzare il concetto di modello andando a descrivere le principali tecniche utilizzate nell’ambito del DM che sono classificate in base al tipo di risultato che riescono a ricavare. Ci concentreremo in modo particolare su quei modelli che sono stati utilizzati durante questo lavoro di tesi: regole di associazione, clusters e alberi di decisione.
1.1.3.1 Regole di associazione
Le regole di associazione, proposte in [AIS93], costituiscono un modello per rilevare regolarità fra dati. L’esempio di applicazione più noto riguarda l’analisi sui prodotti venduti all’interno di un supermercato, detta Market Basket Analysis
(MBA) [BL97], utilizzata per individuare le correlazioni tra i vari prodotti (e le
categorie di prodotti) che un cliente acquista attraverso l’analisi dei dati contenuti negli scontrini di cassa (figura 1.4). Le informazioni trovate possono aiutare il settore marketing a progettare sconti o promozioni particolari, oppure a disporre i prodotti nelle posizioni più strategiche, in base ai gusti dei clienti.
L’analisi MBA non è relegata al solo contesto di un supermercato, ma trova applicazioni anche nelle telecomunicazioni (per correlare le chiamate telefoniche dei clienti), nell’analisi di fenomeni atmosferici o nelle analisi mediche (per studiare le relazioni tra le patologie).
Cliente1 Cliente2 Cliente3
Informalmente, una regola di associazione è un legame di causalità valido tra gli attributi dei record di un database, ossia una espressione del tipo X ¼Y dove X e Y sono insiemi di attributi. Considerando per esempio le transazioni di un supermercato, una possibile regola di associazione è la seguente: "il 70% dei clienti che comprano pane e burro comprano anche il latte". Il numero 70 indica il fattore di confidenza della regola che dà una misura della validità del legame.
Solitamente, non si è interessati ad ottenere una singola regola bensì un insieme di regole che soddisfano qualche condizione introdotta dall’utente.
Diamo ora una definizione formale del problema di trovare regole di associazione così come viene definita in [AIS93]:
“ Dato I un insieme di letterali chiamati items. Dato un insieme di transazioni D, dove ogni transazione T è un insieme di items tali che T⊆ I. Dato un insieme di items X, diciamo che la transazione T contiene l’itemset X se T contiene X.
Una regola di associazione (RdA) è un’implicazione della forma XÆY, dove X ⊆ I, Y ⊆ I, X ∩ Y = ∅; la regola di associazione ha una confidenza c se il c% delle transazioni di D che contengono X contengono anche Y; la regola ha inoltre un supporto s su D se l’s% delle transazioni in D contengono X ∪ Y.”
Dunque la confidenza di una regola misura la forza dell’implicazione mentre il supporto indica la frequenza con cui gli items ella regola sono presenti nelle tuple del database.
Il problema di mining di RdA è comunque rivolto a generare tutte le regole di associazione che siano anche “valide”, ovvero che abbiano il supporto e la confidenza maggiore di due quantità specificate dall’utente, che sono rispettivamente il supporto minimo e la confidenza minima; infatti in genere il problema del mining di RdA viene spezzato in due passi:
• Estrazione dell’insieme di itemsets che hanno il supporto maggiore di quello minimo specificato
• Generazione dall’insieme precedente delle regole di associazione valide, controllando quindi che la confidenza sia maggiore della minima specificata.
La maggior parte degli algoritmi per le RdA implementano questi due passi: Apriori [AMSS94], DHP [PCY 95], AIS [AIS 94] ecc…
Una cosa da notare sul Mining di RdA è che il suo interesse è rivolto all’estrazione di tutt le regole valide dal dataset più che a verificare se una certa regola vale; questo perché l’obiettivo principale è di estrarre anche regole inaspettate e sorprendenti che risultano essere più interessanti di quelle gia conosciute.
Sono già stati proposti de lavori su come quantificare l’utilità e l’interesse delle regole di associazione [PSD 91] [PSM 94], che dimostrano che questo è fortemente dipendente dall’applicazione.
Di seguito viene fornito un esempio di come si possono individuare delle regole associative.
Esempio:
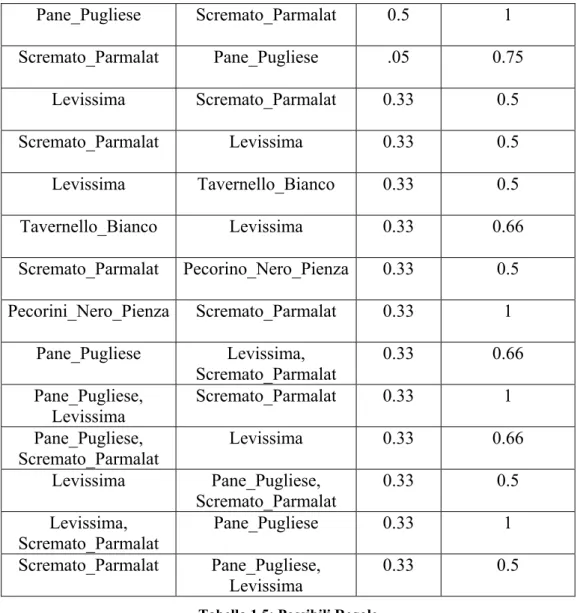
Supponiamo di avere il sottoinsieme degli scontrini di Tab.1.2 da cui si vogliono estrarre RdA con min_sup = 0.3 e min_conf = 0.6
L’insieme di item I da prendere in considerazione in questo caso è:
I={Pane_Pugliese, Levissima, Scremato_Parmalat, Pecorino_Nero_Pienza, Tavernello_Bianco}
Molti algoritmi per l’estrazione di RdA operano rispetto all’insieme di item che ha un supporto maggiore o uguale al minimo supporto (insieme frequente); in questo caso con min_sup = 0.3, gli item dovranno essere presenti in almeno 2 scontrini sulle 6 transazioni di esempio. Per calcolare l’insieme frequente, presentato in Tab.1.4, si può procedere per passi (Algoritmo Apriori):
Tabella 1.2: Il sottoinsieme degli scontrini di un supermercato
nel primo passo si determina l’insieme frequente composto da un solo item (Tab.1.3) che è detto frequent 1-itemset. I passi successivi sono composti da due fasi: considerando ad esempio il passo k, nella prima fase si prendono tutti gli item dell’insieme frequente calcolato al passo precedente e si combinano quelli che hanno k-2 item uguali. Sia, ad esempio:
Lk-1 = L3 = {{1,2,3}, {1,2,4},{1,3,4},{1,3,5},{2,3,4}} allora Lk = L4 ={{1,2,3,4},{1,3,4,5}}.
Nella seconda fase vengono cancellati tutti quegli itemset che hanno almeno un sottoinsieme di cardinalità k-1 che non è nel frequent (k-1)-itemset . Nell’esempio precedente il sottoinsieme {3,4,5} non è presente in Lk-1 quindi l’elemento {1,3,4,5} va cancellato da Lk. Cancellando, poi, da Lk gli insiemi di item che non hanno un supporto pari almeno a min_sup, si ottiene il frequent k-itemset.
Itemset Supporto {Pane_Pugliese} 0.5 {Levissima} 0.66 {Scremato_Parmalat} 0.66 {Pecorino_Nero_Pienza} 0.33 {Tavernello_Bianco} 0.5
Tabella 1.3: Frequent 1-itemset
Scontrino Items 1 Pane_Pugliese,Levissima, Scremato_Parmalat 2 Pane_Pugliese,Levissima, Scremato_Parmalat 3 Pane_Pugliese,Scremato_Parmalat, Pecorino_Nero_Pienza 4 Levissima, Tavernello_Bianco 5 Levissima, Tavernello_Bianco 6 Scremato_Parmalat,Pecorino_Nero_Pienza, Tavernello_Bianco
Dall’insieme frequente di Tab.1.4 si possono estrarre le RdA. Dagli item {Pane_Pugliese, Levissima} si possono avere le regole Pane_Pugliese → Levissima e Levissima Æ Pane_Pugliese; queste verranno restituite come regole solo se verificano il vincolo della confidenza che, come detto, deve essere maggiore o uguale alla minima confidenza.
Le regole che si possono estrarre dall’insieme frequente di esempio, ricordando che min_sup = 0.3 e min_conf = 0.6, sono riportate in Tab.1.5, mentre quelle che effettivamente si ottengono sono in Tab.1.6.
Items Supporto {Pane_Pugliese} 0.5 {Levissima} 0.66 {Scremato_Parmalat} 0.66 {Pecorino_Nero_Pienza} 0.33 {Tavernello_Bianco} 0.5 {Pane_Pugliese, Levissima} 0.33 {Pane_Pugliese, Scremato_Parmalat} 0.5 {Levissima, Scremato_Parmalat} 0.33 {Scremato_Parmalat, Pecorino_Nero_Pienza} 0.33 {Pane_Pugliese, Levissima,Scremato_Parmalat} 0.33
Tabella 1.4: Insieme frequente rispetto agli acquisti in Tab.1.2
Body Head Supporto Confidenza
Pane_Pugliese Levissima 0.33 0.66
Pane_Pugliese Scremato_Parmalat 0.5 1 Scremato_Parmalat Pane_Pugliese .05 0.75 Levissima Scremato_Parmalat 0.33 0.5 Scremato_Parmalat Levissima 0.33 0.5 Levissima Tavernello_Bianco 0.33 0.5 Tavernello_Bianco Levissima 0.33 0.66 Scremato_Parmalat Pecorino_Nero_Pienza 0.33 0.5 Pecorini_Nero_Pienza Scremato_Parmalat 0.33 1 Pane_Pugliese Levissima, Scremato_Parmalat 0.33 0.66 Pane_Pugliese, Levissima Scremato_Parmalat 0.33 1 Pane_Pugliese, Scremato_Parmalat Levissima 0.33 0.66 Levissima Pane_Pugliese, Scremato_Parmalat 0.33 0.5 Levissima, Scremato_Parmalat Pane_Pugliese 0.33 1 Scremato_Parmalat Pane_Pugliese, Levissima 0.33 0.5
Tabella 1.5: Possibili Regole
Body Head Supporto Confidenza
Pane_Pugliese Levissima 0.33 0.66 Pane_Pugliese Scremato_Parmalat 0.5 1 Scremato_Parmalat Pane_Pugliese 0.5 0.75 Tavernello_Bianco Levissima 0.33 0.66 Pecorino_Nero_Pienza Scremato_Parmalat 0.33 1 Pane_Pugliese Levissima, Scremato_Parmalat 0.33 0.66 Pane_Pugliese, Levissima Scremato_Parmalat 0.33 1 Pane_Pugliese, Scremato_Parmalat Levissima 0.33 0.66 Levissima, Scremato_Parmalat Pane_Pugliese 0.33 1
1.1.3.2 Clustering
Il processo di raggruppamento di oggetti fisici o astratti in classi di oggetti simili prende il nome di Clustering, e ogni classe estratta prende il nome di cluster.
Dal punto di vista del Data Mining il Clustering ha come compito fondamentale quello di identificare un certo numero di clusters, cioè di regioni densamente popolate, da grandi databases multidimensionali; infatti in tali database, di solito i dati non sono distribuiti in modo uniforme, e quindi è possibile estrarre un modello che descriva zone maggiormente popolate.
Un esempio di applicazione in campo commerciale è quello in cui si vogliono trovare gruppi di clienti con comportamenti di acquisto simili o clienti con comportamenti non usuali, sulla base di un insieme di dati sui clienti contenenti le loro caratteristiche e i prodotti da loro acquistati.
La qualità di un clustering si misura sempre in base a due parametri:
• Alta similarità tra oggetti appartenenti allo stesso cluster • Bassa similarità tra oggetti appartenenti a clusters diversi
Un possibile modo per esprimere la similarità tra oggetti è di utilizzare una funzione distanza d(i,j) la cui definizione differisce dal tipo delle variabili trattate.
Generalmente, un database contiene vari tipi di variabili, ad esempio booleane, a valori nominali o continui, variabili intervallo. E’ quindi necessario utilizzare la misura di distanza più opportuna per ogni tipo di variabile e combinare i loro effetti attraverso una formula pesata.
La ricerca ha prodotto un gran numero di algoritmi ad hoc per il calcolo di clusters. In generale, i metodi di clustering si distinguono in 5 categorie principali [HK00]:
1. Metodi di partizionamento: costruiscono k partizioni dei dati che andranno inserite in altrettanti clusters ed eseguono iterazioni successive per rilocare ad ogni passo gli oggetti nel gruppo opportuno.
2. Metodi gerarchici: costruiscono una decomposizione gerarchica (alberi) dei dati utilizzando qualche criterio di valutazione.
3. Metodi basati sulla densità: il concetto su cui si basano è quello di densità (ossia il numero di oggetti all’interno di un dato raggio); in questo caso vengono aggiunti oggetti ai clusters finché la densità non supera una soglia minima prefissata.
4. Metodi basati su griglia: codificano lo spazio degli oggetti da analizzare utilizzando un numero finito di celle che formano una struttura a griglia. Il maggiore vantaggio che offrono è il tempo di esecuzione, indipendente dalla cardinalità del dataset, ma collegato al numero di dimensioni degli elementi. 5. Metodi basati su modello: cercano di rappresentare i dati secondo un
modello di tipo matematico, basandosi sulla assunzione che i dati sono generati secondo distribuzioni probabilistiche ben precise.
Esaminiamo più approfonditamente i metodi basati sul partizionamento, che sono i più diffusi.
I metodi di partizionamento sono basati sul concetto di distanza, precedentemente visto, che fornisce una misura della “vicinanza” tra oggetti. Il più importante algoritmo di questa classe è il k-means [MacQ67] che è basato su metodi euristici. Dato in ingresso il numero di clusters da estrarre k, l’algoritmo procede con i passi seguenti:
1. Si partizionano gli oggetti del database in k clusters non vuoti
2. Si calcolano i k centroidi associati ai clusters della partizione corrente. Il centroide è il centro, ossia il punto di media, del cluster.
3. Viene riassegnato ogni oggetto al cluster il cui centroide calcolato in 2 è più vicino.
4. Si ripete il passo 2 finché non ci sono più assegnamenti o fino ad una condizione di terminazione stabilita a priori.
Tipicamente, il criterio di terminazione è lo squared error, che rappresenta la somma degli errori al quadrato di tutti gli oggetti del database. La figura 6 riporta un esempio di iterazione dell’algoritmo delle k-medie.
Figura 6
1.1.3.3 Alberi di classificazione
La classificazione consiste nell’esaminare il comportamento di un nuovo oggetto di interesse e di assegnarlo in una classe predefinita, precedentemente determinata rispetto ad un insieme di elementi.
Secondo [WF99] un approccio “dividi e conquista” al problema di estrarre conoscenza da un insieme di istanze indipendenti conduce in modo naturale ad uno stile di rappresentazione chiamato albero di classificazione. I nodi in un albero delle decisioni coinvolge un test su un particolare attributo. Di solito, il test su un nodo confronta il valore di un attributo con una costante. Tuttavia, alcuni alberi confrontano l’uno con l’altro due attributi, o utilizzano qualche funzione di uno o più attributi. I nodi foglia forniscono una classificazione che si applica a tutte le istanze che raggiungono la foglia, o un insieme di classificazioni, o una distribuzione di probabilità su tutte le possibili classificazioni.
Per classificare un’istanza sconosciuta viene intrapreso nell’albero un percorso a seconda dei valori degli attributi che vengono testati nei nodi ad ogni passo successivo e quando viene raggiunta una foglia l’istanza viene classificata secondo la classe assegnata a quella foglia.
Se l’attributo testato è di tipo nominale allora il numero dei nodi figli è di solito pari al numero dei possibili valori dell’attributo. In questo caso, poiché vi è un unico
ramo per ogni possibile valore, lo stesso attributo non verrà ulteriormente testato nella parte sottostante dell’albero. Qualche volta i valori degli attributi sono divisi in due sottoinsiemi e l’albero si dirama quindi in due vie che dipendono da quale sottoinsieme il valore si trova. In questo caso, l’attributo potrebbe essere testato più di una volta in un cammino.
Se l’attributo è numerico, il test in un nodo in genere determina se il suo valore è più grande o meno rispetto ad una predeterminata costante, producendo una scissione a due vie. Alternativamente potrebbe essere usata una scissione a tre vie, nel qual caso ci sono diverse possibilità. Una alternativa per un attributo a valori interi potrebbe essere una diramazione a tre vie: una per il caso “minore di”, una per il caso “uguale a” e una per il caso “più grande di”.
Una alternativa per un attributo a valori reali, per il quale l’opzione “uguale a” non è molto significativa, potrebbe essere testato su un intervallo piuttosto che su una singola costante, ancora producendo una diramazione a tre vie: “sotto”, “entro” e “sopra”.
Un attributo numerico viene spesso testato diverse volte in un qualsiasi dato cammino dalla radice alla foglia dove ogni test coinvolge una costante diversa.
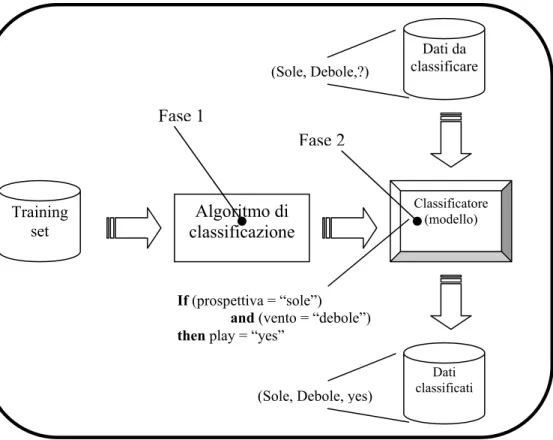
Dopo aver individuato i possibili scenari che si creano a seconda del tipo di attributi utilizzati, torniamo alla classificazione: essa si articola sempre attraverso un processo a due fasi:
1. Costruzione del modello. Per costruire il modello è necessario prima di tutto scegliere l’attributo dei dati che si desidera classificare il cui valore deve essere stimato; questo attributo è detto attributo di classificazione (o attributo target). Successivamente, occorre disporre di un database campione, detto training set, costituito da esempi pre-classificati, nel quale ogni tupla è già stata osservata e classificata e quindi contiene un valore ben preciso per l’attributo di classificazione. Il modello costruito può assumere varie forme, ad esempio regole di classificazione, alberi decisionali, reti neurali oppure formule matematiche.
2. Utilizzo del modello. Una volta costruito, tale modello può essere utilizzato per classificare nuove tuple di cui ignoriamo l’attributo di classificazione.
In figura 7 troviamo un chiarimento sulle due fasi sopra descritte:
Figura 7 : Le due fasi della classificazione
Di seguito forniamo un esempio, per comprendere meglio come si creano e che aspetto hanno gli alberi di decisione.
Tabella 1.7
Età Reddito Studente Stimadelcredito Compra_computer
<=30 Alto No Discreto No
<=30 Alto No Eccellente No
31..40 Alto No Discreto Yes
>40 Medio No Discreto Yes
>40 Basso Yes Discreto Yes
>40 Basso Yes Eccellente No
31.40 Basso Yes Eccellente Yes
<=30 Medio No Discreto No
<=30 Basso Yes Discreto Yes
>40 Medio Yes Discreto Yes
<=30 Medio Yes Eccellente Yes
31..40 Medio No Eccellente Yes
31..40 Alto Yes Discreto Yes
>40 Medio No Eccellente No Training set Dati classificati Algoritmo di classificazione Dati da classificare Classificatore (modello) Fase 1 Fase 2 (Sole, Debole,?)
(Sole, Debole, yes)
If (prospettiva = “sole”) and (vento = “debole”) then play = “yes”
Si consideri il training set riportato nella tabella da cui interessa estrarre un
albero di decisione che permetta di classificare nuove tuple relative ai potenziali clienti che acquisteranno un computer. L’attributo di classificazione in questo caso è Compra_computer che può assumere soltanto due valori possibili. Il classificatore ottenuto è mostrato nella figura sotto (figura 8).
L’albero consente di stabilire se un cliente sarà un potenziale acquirente di computer. Come si può notare, le foglie contengono solo uno dei possibili valori dell’attributo di classificazione (yes, no).
Per classificare una nuova istanza è sufficiente partire dalla radice e procedere verso le foglie, selezionando, ad ogni livello, l’attributo specificato dal nodo corrente e procedendo lungo l’arco etichettato con il valore assegnato all’istanza. Il valore di classificazione da assegnare sarà quello della foglia raggiunta.
Figura 8
1.1.4 Interpretazione e valutazione
I patterns identificati ed estratti dal sistema sono interpretati in conoscenza utile che può essere usata come supporto alle decisioni dall’analista o dal manager. Lo scopo del risultato dell’interpretazione, tuttavia, non è solamente quello di visualizzare (graficamente o logicamente) l’output del data mining, ma anche di filtrare l’informazione che sarà presentata.
Età ?
Studente ? Stima del credito ?
31..40 > 40 <= 30
E’ necessario quindi definire uno schema automatico usando misure di interestingness (ad esempio di tipo statistico) per filtrare la conoscenza estratta dall’output. I parametri che sono utilizzati per valutare la bontà di una soluzione possono essere sia di tipo oggettivo (basati su statistiche) che soggettive (ossia basati sull’utente, ad esempio attraverso stime riguardanti il grado di novità della soluzione).
La ricerca attuale ha prodotto tecniche di visualizzazione, quali istogrammi o animazioni, comodi per aiutare l’analista a fissare l’utilità della conoscenza estratta e a stabilire le decisioni finali (figura 9).
Se i risultati ottenuti non sono soddisfacenti, allora si dovranno ripetere una o più fasi precedenti e questo rende quindi il processo KDD iterativo.
Figura 9 – Raffinata tecnica per la visualizzazione di regole di associazione
1.3 CRISP
D.M.
Model
Il raffinamento delle tecniche e delle tecnologie utilizzate durante il processo di KDD, oltre all’aumento del volume dei dati a nostra disposizione nelle più diverse realtà aziendali e amministrative, ha reso necessario uno studio che portasse alla definizione di una linea guida contenente il ciclo di vita di un progetto di Data Mining.
CRISP-DM (Cross Industry Standard Process for Data Mining) è un progetto finanziato dalla Commissione Europea, con il fine di definire un approccio standard
25/11/1997 26/11/1997 27/11/1997 28/11/1997 29/11/1997 30/11/1997 01/12/1997 02/12/1997 03/12/1997 04/12/1997 05/12/1997 0 5 10 15 20 25 30 35
Support Pasta => Fresh Cheese 14
Bread Subsidiaries => Fresh Cheese 28 Biscuits => Fresh Cheese 14
Fresh Fruit => Fresh Cheese 14 Frozen Food => Fresh Cheese 14
ai progetti di data mining. Il CRISP-DM affronta le necessità di tutti gli utenti coinvolti nella diffusione di tecnologie di data mining per la soluzione di problemi aziendali.
Scopo del progetto è definire e convalidare uno schema di approccio indipendente dalla tipologia di business. Questo tipo di approccio renderà l'implementazione di grandi progetti di data mining più veloce, più efficiente, più sicura e meno costosa. I problemi affrontati includono:
• passaggio da problemi di business a problemi di data mining • acquisizione e comprensione dei dati
• identificazione e soluzione dei problemi inerenti i dati • applicazione di tecniche di data mining
• interpretazione dei risultati del data mining nel contesto aziendale • diffusione e manutenzione dei risultati raggiunti
• acquisizione e trasferimento del know-how acquisito per estendere il beneficio dell'esperienza ai progetti futuri
Oltre a fornire un modello di processo per affrontare i problemi di data mining, il progetto fornirà anche linee guida per la soluzione dei potenziali problemi che possono insorgere nella definizione di un progetto di data mining.
Figura 10- Le fasi del Crisp model
Come si nota dalla figura qui sopra, le fasi del CRISP-DM sono le seguenti:
• Business Understanding: in questa fase vengono determinati gli obiettivi del Business, i criteri di successo, viene fatta “L’Inventory of Resources”, l’analisi dei rischi e valutazione dei costi e degli eventuali benefici. Inoltre si fissano gli obiettivi del Data Mining, viene steso il piano del progetto, e la valutazione dei tools e delle tecniche.
• Data Understanding: questa è la fase in cui i dati vanno “capiti” e descritti, per poter fare una prima esplorazione, e creare i primi report. • Data Preparetion: questa fase corrisponde alla fase di preprocessing
descritta nel paragrafo 1.1.2. (Data Cleaning, Data Integration, ecc…). • Modelling: in questa fase viene costruito il modello, si seleziona la
tecnica e si scelgono i parametri di settaggio.
• Evaluation: i risultati forniti dall’esecuzione degli algoritmi, in questa fase vengono valutati ed utilizzati per determinare una lista di decisioni possibili da prendere.
• Deployment: è la fase conclusiva del CRISP, qui vengono creati i report finali e le varie presentazioni. In molti casi viene creata una documentazione sull’esperienza fatta.
1.4 Ambienti e strumenti del processo KDD utilizzati
Come già detto, in questi ultimi anni, il numero di dati a nostra disposizione è cresciuto a dismisura, e di conseguenza anche lo sviluppo dei software dedicati all’analisi dei dati per l’estrazione di conoscenza ha incrementato il suo ritmo.
Così oggi abbiamo una ampia scelta sugli strumenti da utilizzare sia per le analisi OLAP che per il Data Mining.
Le motivazioni nell’utilizzare un prodotto piuttosto che un altro si devono cercare nella valutazione di diversi fattori:
• Costo: il costo dei prodotti per l’analisi dei dati, sia per quanto riguarda l’analisi OLAP ma soprattutto per il Data Mining, è in genere molto elevato. Nonostante il prezzo sia spesso sinonimo di qualità e garanzia dei risultati, esistono dei tools free per il Data Mining molto validi, essendo questi il risultato di un lavoro di ricerca a livello universitario. • Tipologia algoritmi: in questo caso stiamo valutando solo i software per
Data Mining, la cui prerogativa fondamentale è quella di mettere a disposizione una suite completa di algoritmi, sia per la fase di preprocessing che per la fase di creazione dei modelli.
• Interfaccia grafica: la presenza di una interfaccia grafica intuitiva e curata facilita il compito per un utente inesperto, ma non altera la qualità dei risultati finali. Ovviamente i software proprietari sono più curati sotto questo aspetto, per essere resi più appetibili al pubblico.
L’insieme di queste e di altre caratteristiche ci permette di fare delle valutazioni di convenienza circa il prodotto da utilizzare nelle analisi.
Per l’implementazione del Data Warehouse e le relative analisi OLAP la nostra scelta è stata quella di utilizzare SQL Server 2000 della Microsoft.
Mentre per l’analisi di Mining sono stati utilizzati due tools open source, Weka e KDDML e due software proprietari: Clementine 6.5 e Knowledge Studio..
1.4.1 SQL Server
SQL Server è un pacchetto completo per la gestione e creazione di Data Base relazionali, ma non solo; infatti Analysis Services, uno dei tools facenti parte di SQL Server ci ha consentito di popolare e di creare Data Warehouse e Data Mart. Consente la creazione di misure e membri calcolati aggiuntivi, potendo così raffinare la nostra analisi con lo studio di indici calcolati ad-hoc.
Inoltre mette a disposizione un semplice ed intuitivo editor di cubi, in cui è possibile sia creare il cubo di analisi (tabella dei fatti e dimensioni), sia navigare i dati creando nuovi indici di analisi e membri calcolati.
Nella immagine qui sotto è rappresentato l’interfaccia di Analysis Services che consente la creazione del cubo.
Figura 11
Nello spazio sulla destra possiamo notare lo schema a stella di rappresentazione del cubo. Qui è possibile aggiungere nuove dimensioni, cancellare quelle presenti ed inserire le connessioni di join tra la tabella dei fatti e quelle delle dimensioni.
Nei riquadri di sinistra invece abbiamo quelle dimensioni selezionate per le analisi, vengono inoltre indicate le misure presenti nel cubo e i membri calcolati dall’utente per rendere più precise le analisi.
Nella figura 12 invece abbiamo l’interfaccia per effettuare le analisi OLAP. Questa volta il riquadro di destra è diviso in due parti. Nella parte superiore abbiamo le dimensioni di analisi prescelte e le misure.
Lo spazio in basso, contenente la tabella di analisi ci consente di navigare i dati, selezionando le dimensioni nel riquadro superiore e potendo effettuare le classiche operazioni di drill-down o drill-up sui dati per aumentare o diminuire il dettaglio di analisi.
Figura 12
1.4.2 Weka
Weka è un completo toolbench per il machine learning e per il Data Mining; è stato realizzato dalla Università di Waikado in Nuova Zelanda, scritto in Java e mette a disposizione una ampia gamma di algoritmi: per il preprocessing, per la classificazione, clustering, visualizzazione dei dati, regole associative. L’interfaccia grafica è discreta, non curata nei particolari, ma gradevole. Presenta ancora dei difetti ma è sicuramente il software free più completo.
Nella figura qui sotto si riporta un esempio dell’interfaccia grafica di Weka Explorer.
Si è ritenuto di suddividere l’area dell’interfaccia grafica in quattro sottoaree. Nella zona “1” abbiamo tutti i pulsanti che implementano l’insieme di algoritmi messi a disposizione da Weka, sia per la fase di preprocessing che per la creazione dei modelli di analisi.
Nella zona “2” vengono indicati tutti gli attributi appartenenti al data set; in questa zona è possibile selezionare gli attributi o eliminarli se non si intende portarli avanti nella fase di analisi.
Nell’area “3” si trovano alcuni dati statistici e analisi preliminari degli attributi (media, varianza, massimo, minimo)
Nell’area “4” invece abbiamo i grafici di distribuzione degli attributi selezionabili con un menù a tendina.
Figura 13
1.4.3 KDDML
Il KDDML (KDD Markup Language) è una creazione del laboratorio di KDD dell’Università di Pisa, ancora in fase di realizzazione, infatti la versione attualmente disposizione è una versione alfa. Ma nonostante questo ci è stato possibile testarlo per capire le sue potenzialità, la sua efficienza e completezza dal punto di vista degli algoritmi disponibili. La particolarità di KDDML consiste nel fatto che è basato sul linguaggio XML sia per la preparazione dei dati che per la rappresentazione dei risultati e dei modelli. Una query KDDML è un documento XML dove i tags XML corrispondono alle operazioni da effettuare sui dati o sui modelli, e gli attributi dei tags corrispondono ai parametri degli operatori, e i sotto elementi definiscono gli argomenti da passare agli operatori. La struttura di KDDML consente di renderlo facilmente estendibile, sia per quanto riguarda le sorgenti dati, che per gli algoritmi di preprocessing e i mining.
Figura 14
La figura sopra riportata rappresenta l’interfaccia di KDDML.
La zona “1” è dove viene scritta la query XML; nella zona “2” troviamo tutte la operazioni possibili che si possono fare sui dati, sia operazioni di preprocessing, sia algoritmi di Mining, che operazioni di caricamento dati.
Nell’area “3” il software ci indica lo stato di avanzamento del processo di Mining o di caricamento dei dati, e l’esito delle compilazioni delle query.
1.4.4 Clementine 6.5
Clementine costituisce sicuramente la soluzione ideale per il Data Mining. Propone una suite completa di algoritmi, sia per il preprocessing che per l’analisi dei dati, anche se non a livello di Weka, ma lavora ottimamente anche con grandi quantità di record ed attributi. L’interfaccia grafica è molto curata e le soluzioni a disposizione per la visualizzazione dei dati sono molteplici. Per la nostra analisi si è rivelato il più efficiente, riuscendo a fornirci risultati migliori rispetto ai due
software descritti in precedenza. Il punto a suo sfavore è il costo, in genere molto elevato, soprattutto se acquistato da un privato.
Figura 15
La figura 15 sopra rappresenta l’interfaccia di Clementine come si mostra all’apertura del programma.
Come mostrato in figura, l’interfaccia può essere divisa in quattro sottoaree. L’area denominata con il numero “1”, è quella i cui vengono indicati i modelli generati. Ciccando sui modelli presenti in questa area è possibile effettuare operazioni di salvataggio, caricamento, o di browser.
L’area “2”, è la zona dell’interfaccia dedicata alla rappresentazione del flusso dei dati. Ogni nodo del grafico rappresenta una operazione che si intende fare sui dati.
Il nodo radice è il nodo di input, tramite il quale si importano i dati. I nodi foglia sono sempre nodi output, ovvero sono quei nodi che generano i modelli o i grafici di rappresentazione dei dati. I nodi intermedi servono per implementare le varie operazioni di preprocessing.
Nelle aree “3” e “4” troviamo tutti gli algoritmi che Clementine mette a disposizione per le analisi. Nella zona “3” troviamo i tipi di input accettati dal software, le operazioni di preprocessing possibili, sia sui record che sui campi.
Nell’area “4” invece abbiamo tutti gli algoritmi di mining disponibili per la creazione di modelli (K-means, C5.0, Apriori Regressione Lineare, Reti Neurali eccc…), e tutte le rappresentazioni grafiche dei dati (Plot, grafici di distribuzione, istogrammi, ecc…). Per ultimo, abbiamo anche i nodi di output, che ci consentono di esportare i dati in altri formati o di effettuare delle analisi statistiche preliminari.
1.4.5 Knowledge Studio
Knowledge studio è un software completo e di facile utilizzo. Durante le nostre analisi si è rivelato utile in quanto dispone di molte soluzioni per la visualizzazione dei dati. Mette a disposizione una grande varietà di grafici, con la possibilità di un alto livello di personalizzazione degli stessi.
La figura 16 mostra l’interfaccia grafica di Knowledge Studio divisa in due sezioni. Nella sezione di sinistra vengono memorizzate tutte le operazioni effettuate sui dati, o i grafici creati. Mentre Clementine 6.5, per rappresentare le operazioni effettuate sui dati, utilizza un diagramma a flussi (fig. 15), possiamo dire che Knowledge Studio implementa una metodologia a cascata, in cui in sequenza cronologica vengono riportati modelli o i grafici creati.
Nella sezione di destra invece si riportano i risultati delle analisi, siano essi grafici o i report dei dati. In figura 16 ad esempio abbiamo un grafico, mentre in figura 17 abbiamo i risultati delle analisi preliminari, in cui sono indicati il tipo dei dati, i nomi dei campi, la cardinalità, la percentuale dei valori mancanti, il minimo e il massimo ed altri calcoli statistici come la media e la varianza (ovviamente queste solo per gli attributi continui).
Capitolo 2
Il contesto applicativo: metodologie
La medicina moderna genera una grande quantità di dati, ma allo stesso tempo notiamo anche un largo e profondo gap tra lo storage dei dati e la loro comprensione.
Di conseguenza c’è una crescente pressione non solo per individuare migliori metodi di analisi, ma anche per creare dei processi automatici di creazione di conoscenza che a sua volta può essere usata per il “clinical decision-making”.
Per cercare di riempire questo vuoto metodologico molte organizzazioni si stanno avvalendo delle nuove tecniche che il Data Warehousing e il Data Mining mettono a disposizione per l’analisi dei dati e la rappresentazione dei risultati.
Fino a poco tempo fa gli studi in materia, sia sui dati riguardanti la mortalità sia sui dati epidemiologici, hanno utilizzato metodologie e tecniche statistiche. Obiettivo di questo lavoro di tesi è di mostrare come si possa arrivare ad ottenere risultati concreti ed interessanti attraverso un’analisi effettuata con il supporto di tecnologie avanzate, atte all’individuazione di relazioni tra i dati. Al contrario del metodo statistico, in una analisi OLAP e di Mining non vengono fatte ipotesi sui
dati, questi vengono esplorati ed analizzati nella loro totalità, liberi di mostrarci l’informazione nascosta nei loro contenuti.
2.1 Il
MISA-2
Questo lavoro di tesi è entrato a far parte di un progetto più vasto ed ambizioso, denominato MISA-2. Questo è un grande studio pianificato di metanalisi sugli effetti a breve termine degli agenti inquinanti atmosferici ( CO, NO2, SO2, PM10, e Ozono), rilevati nel periodo 1996-2002 in 15 città italiane.
Un pool di esperti distribuito in quindici città italiane ha stimato il numero di decessi (per tutte le cause naturali, cardiovascolari e respiratorie) e di ricoveri ospedalieri (per cause cardiovascolari e respiratorie) attribuibili all’inquinamento.
I loro studi sono stati effettuati con analisi statistiche ed hanno notato che nel periodo di studio il PM10 (la componente dell’inquinamento atmosferico costituita di particelle con diametro inferiore a 10 micron) ha provocato circa 900 decessi in più l’anno.
Anche gli inquinanti gassosi (biossido di zolfo, NO2, e monossido di carbonio, CO) provocano un gran numero di vittime: si sono contati ogni anno circa 2000 morti in più attribuibili a NO” a 1900 morti attribuibili al CO.
Rispetto all’anidride solforosa (SO2), rispetto agli novanta è stato registrato un dato positivo. La riduzione dell’uso del gasolio negli impianti di riscaldamento, infatti ha contribuito a far diminuire la concentrazione di questo inquinante.
Inoltre i risultati di questo studio smentiscono che l’effetto negativo dell’inquinamento atmosferico si limiti all’anticipazione di pochi giorni del decesso di soggetti gia fortemente compromessi. MISA-2 mostra un eccesso di morti statisticamente significativo che va ben al di la della semplice anticipazione di decessi che si sarebbero verificati in ogni caso. L’aumento della mortalità cardiovascolare si manifesta entro i 4 giorni successivi al picco di inquinamento e, come prevedibile, l’impatto più forte riguarda la mortalità per cure respiratorie.
Per la prima volta in Italia sono stati studiati anche gli effetti dell’aria di città sulle fasce estreme di età (neonati e ultracinquantenni). La relazione tra concentrazioni degli inquinanti e mortalità e ricoveri ospedalieri è risultata
tendenzialmente maggiore tra gli anziani, in particolare tra soggetto con più di 85 anni, e per NO2 e CO,per neonati fino a 24 mesi. Ciò non significa che gli effetti deleteri dell’inquinamento riguardino un sottoinsieme della popolazione, perché il MISA-2 ha osservato rischi anche in quelle fasce giovani-adulte che si ritenevano meno suscettibili. Con una differenza: mentre negli anziani l’inquinamento può uccidere, perché peggiora le condizioni di un fisico già debilitato, nei più piccoli gli effetti si manifestano appieno solo col passare del tempo, con la comparsa di ulteriori malattie.
MISA-2 mostra anche che l’impatto sanitario dell’inquinamento varia da città a città. Il carico di morti e ricoveri è maggiore nelle sedi in cui il traffico veicolare (specialmente da veicoli diesel) rappresenta la sorgente principale di particelle sospese. Inoltre in estate gli inquinanti risultano più dannosi. Il motivo va cercato nel fatto che la temperatura elevata rende i singoli composti chimici più pericolosi e che d’estate nelle città rimangono le persone più deboli: anziani e malati. Infine non va trascurato che tenendo le finestra e aperte ci si espone più a lungo agli inquinanti atmosferici esterni.
Come già detto, i risultati del MISA-2 sono stati ottenuti con l’applicazioni di tecniche statistiche.
2.1.1 Tecniche statistiche e risultati
Per ogni città è stato adattato un modello lineare generalizzato sulla frequenza giornaliere degli eventi sanitari in studio. L’effetto degli inquinanti è stato specificato come lineare e come modelli bi-pollutant sono stati considerati PM10+NO2 e PM10+O3 .
La temperatura è stata modellata in modo parametrico con punto di svolta a ventuno gradi e con effetti ritardati. Umidità, giorno della settimana, festività nazionali ed epidemie influenzali (definite usando i dati del sistema nazionale di sorveglianza dal 1999 in poi) sono gli altri confondenti nel modello.
Una spline cubica naturale specifica per classe di età è stata introdotta sulla stagionalità con mediamente 5 gradi di libertà per anno per la mortalità e 7 per i ricoveri. Il modello base è stratificato per classi di età (0-64, 65-74, 75+ anni). Sono stati adattati modelli specifici per genere, età, stagione. Cinque analisi di sensibilità