Alma Mater Studiorum · Universit`
a di Bologna
FACOLT `A DI SCIENZE MATEMATICHE, FISICHE E NATURALI Corso di Laurea Triennale in Informatica
Algoritmo “Session correlation management
with Radix Tree”:
Sviluppo di un’implementazione apposita
per il linguaggio JOLIE
Tesi di Laurea in Paradigmi di Programmazione
Relatore:
Chiar.mo Prof.
Maurizio Gabbrielli
Presentata da:
Davide Lerose
Sessione II
Anno Accademico 2009/2010
Introduzione
Il Service-Oriented Computing (SOC) `e un paradigma di programmazione utile alla creazione di applicazioni, basate su un’architettura Service-Oriented (SOA), nella quale le applicazioni sono costituite da servizi. Uno degli aspetti principali del SOC `e la composizione. Ciascun servizio, infatti, ne consente la composizione di altri, complessi, combinando tra loro varie funzionalit`a. La modellazione di queste composizioni di servizi pu`o avvenire seguendo un approccio basato sull’orchestrazione o un approccio di tipo coreografico: il primo offre un punto di vista locale, mentre il secondo offre una visione glob-ale della situazione del SOA. La tecnologia basata sui SOC pi`u utilizzata ai giorni nostri `e il Web Service, un sistema software basato sull’interoperabilit`a tra diversi elaboratori in rete. Ci`o `e ottenuto tramite lo scambio di appositi “messaggi” (tipicamente SOAP) formattati utilizzando XML e trasportati tramite HTTP.
A differenza di un approccio di tipo Object Oriented, in un SOA non esiste un meccanismo che garantisca l’identificazione di una nuova sessione creata. Una soluzione a questo problema, pubblicata da WS-BPEL, consiste nel-l’utilizzo dei Correlation Set. I Correlation Set sono un sottoinsieme delle variabili di una sessione, definito a priori, i cui valori vengono utilizzati per identificare la sessione stessa. Un’implementazione di questo meccanismo di correlazione `e fornita dal linguaggio Service-Oriented JOLIE. In questo lin-guaggio, sviluppato in Java, sia il messaggio che la sessione contengono un insieme di variabili utilizzate come Correlation Set. All’arrivo di un mes-saggio ne vengono letti i valori delle variabili; in seguito lo si indirizza alla
ii INTRODUZIONE
sessione avente le medesime variabili ed il medesimo valore.
La complessit`a attuale dell’algoritmo utilizzato da JOLIE per gestire la cor-relazione `e lineare rispetto al numero di sessioni presenti. Con l’algorit-mo descritto in questa tesi si vuole fornire un’alternativa avente complessit`a molto inferiore e dunque avente prestazioni migliori nella ricerca delle ses-sioni. “Tale algoritmo `e stato proposto in [15]”.
L’implementazione dell’algoritmo presentata, ribattezzata “Session Correla-tion management with Radix Tree”, ha complessit`a esponenziale sul numero delle variabili del Correlation set, ma `e indipendente dal numero di sessioni presenti. Questo comporta un considerevole miglioramento, poich´e in un sis-tema Service-Oriented l’aspetto prestazionale `e influenzato soprattutto dal numero di sessioni presenti ed il numero di variabili nel Correlation set si pu`o considerare costante. Questo `e un risultato ottenibile, poich´e la ricer-ca in una struttura a Radix Tree `e indipendente dal numero di foglie, ma rimane dipendente dalla lunghezza della stringa utilizzata come chiave di ricerca. Come vedremo in dettaglio in seguito, la chiave utilizzata per mem-orizzare le sessioni e per ricercarle `e il risultato della composizione dei valori delle variabili che formano il Correlation set.
Lo sviluppo di questo algoritmo `e stato improntato per poter consentire una futura integrazione con il linguaggio JOLIE, allo scopo di migliorarne le prestazioni nell’ambito della correlazione di sessioni. Come vedremo, a questo si `e voluta aggiungere la possibilit`a di integrare il suddetto algoritmo con un qualunque linguaggio Service-Oriented implementato in Java. A tal scopo sono state fornite delle funzioni apposite che consentono di integrare l’algoritmo senza modificare nient’altro all’interno del codice sorgente.
Indice
Introduzione i
1 Il Service-Oriented Computing 1
1.1 Service-Oriented Computing. . . 1
1.2 Web Service . . . 3
1.2.1 Web Services Description Language (WSDL) . . . 3
1.2.2 Web Services - Choreography Description Language (WS-CDL) . . . 4
1.2.3 Web Services - Business Process Execution Language (WS-BPEL) . . . 5
1.3 Correlation Set . . . 6
2 JOLIE 9 2.1 Il linguaggio . . . 9
2.2 Gestione attuale delle sessioni in JOLIE . . . 10
2.3 Limiti prestazionali . . . 12
3 Algoritmo “Session correlation management with Radix Tree” 15 3.1 Introduzione all’algoritmo . . . 15
3.2 Struttura dell’algoritmo . . . 17
3.2.1 Radix Tree . . . 17
3.2.2 Cluster . . . 19
3.2.3 Generazione delle chiavi . . . 19
3.2.4 Generazione dei radix tree . . . 22
iv INDICE
3.2.5 Algoritmo RTG (Radix Trees Generator ) . . . 23
3.3 Utilizzazione dell’algoritmo . . . 27
4 Algoritmo “Session correlation management with Radix Tree”: un’implementazione 31 4.1 Cluster Manager . . . 32 4.1.1 ClustersManager.java . . . 32 4.1.2 ClustersManagerLinear.java . . . 35 4.1.3 ClustersManagerImpl.java . . . 35 4.2 Cluster . . . 42 4.2.1 Cluster.java . . . 42 4.2.2 ClusterEmpty.java . . . 43 4.2.3 ClusterImpl.java . . . 45 4.3 Radix Tree . . . 58 Bibliografia 65
Capitolo 1
Il Service-Oriented Computing
1.1
Service-Oriented Computing.
Il Service-Oriented Computing (SOC) fa riferimento all’insieme di con-cetti, principi e metodi che rappresentano un paradigma di programmazione utile alla creazione di applicazioni basate su un’architettura Service-Oriented (Service-Oriented Architecture o SOA) [1]. In una SOA le applicazioni sono costituite da servizi semplici e indipendenti ma componibili a formare servizi pi`u complessi. L’idea su cui si basano SOC e SOA `e separare nettamente l’ingegnerizzazione del software dalla programmazione vera e propria, cos`ı da enfatizzare la prima rispetto alla seconda. A questo scopo, il SOC separa lo sviluppo delle applicazioni in tre componenti distinte e ben definite:
• Creatori di servizi: usano linguaggi di programmazione tradizionali quali Java, C e C# per implementare componenti di programmi. Questi componenti vengono quindi incapsulati, fornendo interfacce grazie che ne consentano l’utilizzo. Questi servizi possono essere paragonanti ad una fabbrica di mattoncini Lego.
• Fornitori di servizi: Consentono il pubblico accesso ai servizi creati, oltre ad agevolare i creatori di applicazioni nella ricerca dei servizi di cui necessitano. Possiamo paragonarli ad un negozio specializzato di mattoncini Lego.
2 1. Il Service-Oriented Computing
• Creatori di applicazioni: Sono programmatori che, anzich´e creare applicazioni basandosi sui componenti di base di un linguaggio di pro-grammazione, utilizzano i servizi come componenti di un linguaggio ad alto livello. Riprendendo l’esempio dei mattoncini, possiamo parag-onare i creatori di applicazioni ai bambini, che usano i mattoncini (servizi) per creare oggetti complessi (applicazioni).
Da quanto detto finora si deduce che uno degli aspetti principali del SOC `e la composizione. L’interfaccia pubblica fornita da ciascun servizio, infatti, consente la composizione di complessi servizi, riutilizzando funzionalit`a gi`a fornite dagli stessi. La modellazione di queste composizioni di servizi pu`o avvenire seguendo due approcci:
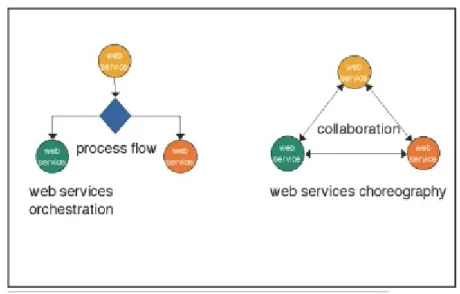
• Orchestrazione (Orchestration): descrive come i servizi interagis-cano tra loro a livello di messaggi scambiati. Il risultato consiste nella specifica di un processo “long-running” di alto livello, la quale descrive un’applicazione eseguibile da un proprietario. Secondo questo approc-cio, il processo implementa il punto di vista di uno dei partner, e il flusso `e sempre controllato da esso. Il processo risultante pu`o essere a sua volta esposto come servizio.
• Coreografia (Coreography): tramite questo approccio viene tenu-ta traccia della sequenza di messaggi che pu`o coinvolgere pi`u appli-cazioni attraverso una visione globale del processo. Si punta a fornire una rappresentazione pi`u collaborativa delle interazioni (ogni attore de-scrive la sua parte e tutti gli attori si trovano allo stesso livello). Nella coreografia non `e presente un punto di controllo centralizzato.
Riassumendo, possiamo dire che l’orchestrazione offre un punto di vista locale, mentre la coreografia uno globale.
1.2 Web Service 3
Figura 1.1: Orchestrazione e Coreografia
1.2
Web Service
La tecnologia basata sui SOC pi`u utilizzata ai giorni nostri `e il Web Ser-vice [2]. Un Web SerSer-vice (servizio web) `e un sistema software progettato per supportare l’interoperabilit`a tra diversi elaboratori su di una medesima rete. La caratteristica fondamentale di un Web Service `e di offrire un’interfaccia software (ad esempio WSDL [3]) grazie alla quale altri sistemi possano inter-agire con lo stesso. A tal fine, gli altri sistemi attivano le operazioni descritte nell’interfaccia tramite appositi “messaggi” (tipicamente SOAP [4]) format-tati secondo lo standard XML [5] e trasporformat-tati tramite il protocollo HTTP [6].
Come accennato in precedenza, l’interfaccia dei Web Services viene general-mente descritta utilizzando il linguaggio WSDL:
1.2.1
Web Services Description Language (WSDL)
`
e un linguaggio formale, in formato XML, utilizzato per la creazione di descrizioni di Web Service. Mediante WSDL pu`o essere infatti descritta l’in-terfaccia pubblica di un Web Service, cio`e un elenco di informazioni (XML)
4 1. Il Service-Oriented Computing
riguardanti le modalit`a di interazione con un determinato servizio. Un “doc-umento” WSDL contiene, infatti, relativamente al Web Service descritto, informazioni riguardanti:
• cosa pu`o essere utilizzato (le “operazioni” messe a disposizione dal servizio);
• come utilizzarlo (il protocollo di comunicazione da utilizzare per ac-cedere al servizio, il formato dei messaggi accettati in input e restituiti in output dal servizio ed i dati correlati), ovvero i “vincoli” (bindings, in inglese) del servizio;
• dove utilizzare il servizio (cosiddetto end-point del servizio che solita-mente corrisponde all’indirizzo - in formato URI - che rende disponibile il Web Service).
Le operazioni supportate dal Web Service ed i messaggi scambiabili con lo stesso sono descritti in maniera astratta, quindi collegati ad uno specifico protocollo di rete e ad uno specifico formato. Grazie all’utilizzo di standard basati su XML ed alle interfacce pubbliche, applicazioni software implemen-tate in diversi linguaggi di programmazione e su diverse piattaforme hard-ware possono quindi essere utilizzate, sia per lo scambio di informazioni sia per effettuare operazioni complesse, su reti aziendali come su Internet. L’in-teroperabilit`a fra diversi software e diversi sistemi operativi `e resa possibile dall’uso di standard aperti e accessibili a tutti.
Facendo riferimento alla Coreografia ed all’Orchestrazione nell’ambito dei Web Services, ad oggi i linguaggi di rifermento per la gestione di questi ultimi sono, rispettivamente, WS-CDL [7] e WS-BPEL [8].
1.2.2
Web Services - Choreography Description
Lan-guage (WS-CDL)
`
e un linguaggio basato su XML che descrive una collaborazione tra pari definendo, da un punto di vista globale, i loro comportamenti osservabili
1.2 Web Service 5
comuni e complementari. Con lo scambio di messaggi tra pari si cerca di ottenere il raggiungimento di un comune scopo (come da definizione di coreografia).
1.2.3
Web Services - Business Process Execution
Lan-guage (WS-BPEL)
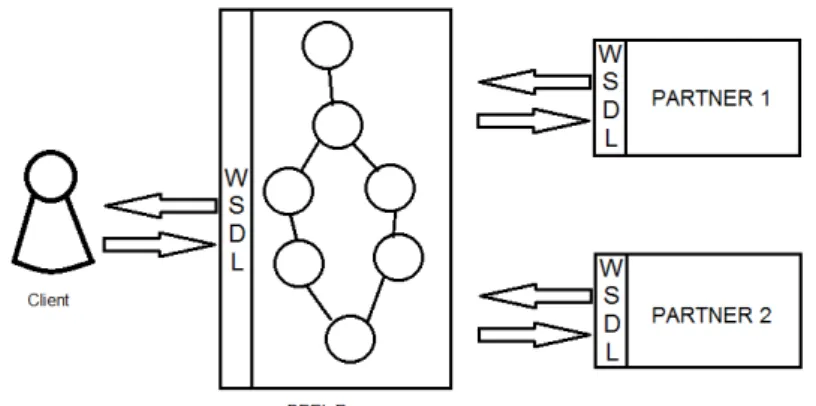
Nasce nel 2002, definendo un standard di settore per l’Orchestrazione e l’esecuzione dei processi di business. `e un linguaggio che permette la model-lazione del comportamento dei partecipanti nelle interazioni basate sui Web Services. Un processo BPEL pu`o rappresentare un Web Service, che pu`o essere utilizzato a sua volta da altri Web Service esterni chiamati partner, oppure essere esso stesso il richiedente di Web Services offerti da altri partner. Riguardo la sua implementazione, BPEL esprime la logica di funzionamento di un processo attraverso una grammatica basata su XML, la quale `e inter-pretabile mediante un motore di orchestrazione opportunamente progettato. Il compito di questo motore di orchestrazione `e di coordinare i vari servizi che compongono il processo. Una delle particolarit`a di BPEL consiste nel fatto che i Web Service possono avere una composizione ricorsiva. Infatti, un processo definito da un insieme di Web Service collaboranti pu`o essere esso stesso un Web Service. Questo nuovo servizio sar`a quindi visibile all’ester-no come un servizio semplice, di cui `e definita un’interfaccia Web Services Description Language (WSDL) e nascondendo di conseguenza la sua compo-sizione interna.
Comunque sia, entrambi i linguaggi non offrono definizioni formali del loro comportamento. Una conseguenza di ci`o `e che, per un medesimo programma, ambienti di esecuzione diversi possono portare a risultati diversi.
6 1. Il Service-Oriented Computing
Figura 1.2: BPEL Interface
1.3
Correlation Set
Come si `e potuto notare, i Web Services sono basati su un intenso utilizzo di comunicazione tramite messaggi, garantito dallo sfruttamento di primitive implementate da ogni linguaggio operante in quest’ambito. Queste primitive sono chiamate operation (operazioni), e vengono suddivise in due categorie: “operazioni in entrata” (input operation) e “operazioni in uscita” (output operations). Per fornire una classificazione pi`u dettagliata, si hanno quattro tipi di operations (due per ciascuna categoria):
• One-Way operations (Input): sono operazioni che hanno il compito di rimanere in attesa di un messaggio in arrivo.
• Request-Response operations (Input): simili alle One-Way oper-ations, all’arrivo di un messaggio spediscono al mittente una risposta.
• Notification operations (Output): complementari rispetto alle One-Way operations, sono utilizzate per inviare messaggi.
• Solicit-Response operations (Output): complementari rispetto alle Request-Response operations, hanno lo scopo di inviare un mes-saggio e ricevere una risposta.
1.3 Correlation Set 7
Nella loro applicazione pratica, i Web Sevices possono avere pi`u istanze di ese-cuzione di un medesimo modello comportamentale. Queste istanze sono chia-mate Sessioni, e vengono definite formalmente come istanze di esecuzione del comportamento di un servizio, associato al suo stato locale (i.e. Sono un associazione comportamento-stato). Di conseguenza, uno dei problemi principali legati al paradigma orientato ai servizi (SOC) consiste nell’iden-tificazione delle sessioni a cui un determinato servizio vuol fare riferimento. Dato che due sessioni aventi lo stesso comportamento potrebbero essere dis-tinte solo tramite il loro stato, una soluzione a questo problema `e stata data da WS-BPEL tramite i Correlation Set [9].
Possiamo cos`ı descrivere il meccanismo dei Correlation Set: una sessione X `e composta dalla coppia (C, S), dove C rappresenta il comportamento della sessione e S il suo stato locale; lo stato S della sessione `e dato dall’associ-azione tra tutte le variabili locali V e tutti i loro rispettivi valori v (V − > v). Di conseguenza, due sessioni X = (C, S1)eY = (C, S2) risulterebbero non
distinguibili se e solo se S1 = S2, cio`e se e solo se lo stato locale risultasse
identico. Per distinguere due sessioni, quindi, `e possibile definire un sotto insieme delle variabili che compongono lo stato della sessione stessa. Sta-bilendo, poi, che questo sotto insieme rappresenta una sorta di identificativo della sessione, si impone che questo sia sempre diverso da quello delle altre sessioni. I Correlation Set operano esattamente in base a questo principio: infatti, essi sono un sotto insieme predefinito di V, che possiamo definire come VC. Formalmente, si ha che V = V C + V R, dove VR rappresenta l’insieme delle variabili di V non comprese nel Correlation Set. Quindi, indicando con vc l’insieme dei valori delle variabili di VC, si ha che due sessioni X e Y aventi, V Cx = V Cy, risultano non distinguibili per correlazione se e solo se
Capitolo 2
JOLIE
2.1
Il linguaggio
JOLIE (acronimo di Java Orchestration Language Interpreter Engine) [10] `e un linguaggio di programmazione basato sul Service-Oriented Com-puting. Il linguaggio `e, di conseguenza, fortemente basato sui servizi. In JOLIE, non si fa distinzione tra servizi remoti e locali. Questo comporta la possibilit`a di spostare fisicamente questi ultimi senza che vi sia la necessit`a di modificare la struttura interna del sistema: `e sufficiente modificare la nuova locazione a cui fa riferimento il servizio spostato. Come spiegato nel capitolo 1, nell’ambito dei SOC la possibilit`a di combinare servizi `e molto ampia, al punto che questi possono essere a loro volta composti da ulteriori servizi, reiterando il pattern all’infinito. Questa possibilit`a `e disponibile anche in JOLIE, dove ne `e fornito un meccanismo che la implementa nativamente, semplificando la composizione di servizi.
JOLIE `e sviluppato tramite Java, ed ha quindi un forte legame con esso. Di-fatti, `e possibile creare servizi Java per poi utilizzarli all’interno di un appli-cazione JOLIE sfruttandone le API. Data la capacit`a di JOLIE di processare le richieste HTTP, si ha inoltre la possibilit`a di interagire direttamente con i Browser o con i Web Server.
Le Service-Oriented Architecture sono composte tipicamente da un
10 2. JOLIE
to numero di servizi, molti dei quali forniscono funzionalit`a ausiliare ad un singolo servizio. Questa struttura `e implementata in JOLIE, garantendo la possibilit`a di incapsulare vari servizi in un servizio unico, ed `e eseguita dalla medesima JVM (Java Virtual Machine).
Data questa struttura composta dei SOA, `e utile avere un unico punto di convergenza a cui fare riferimento come destinazione. Questo endpoint avr`a come scopo quello di inoltrare i messaggi ai servizi richiesti. `e possibile imple-mentare in JOLIE questo meccanismo in modo semplice. Nel caso in cui un servizio interno venga rimpiazzato o spostato, gli utenti accederanno sempre e comunque al servizio principale, lasciando a quest’ultimo la responsabilit`a di inoltrare le richieste.
2.2
Gestione attuale delle sessioni in JOLIE
Essendo JOLIE un linguaggio basato sul Service-Oriented Computing, `e molto importante, ai fini prestazionali, il modo in cui `e implementata la ges-tione delle sessioni. Infatti, in una SOA `e fondamentale il meccanismo che consente una corretta identificazione delle sessioni a cui fare riferimento e, dato che tipicamente il numero di sessioni attive `e molto elevato, `e di fonda-mentale importanza anche la velocit`a con cui queste possano essere reperite. In JOLIE, l’identificazione delle sessioni `e effettuata fornendo nativamente il meccanismo dei Correlation Set. Siccome vengono utilizzati dei protocolli stateless (i.e. privi di stato, quali SOAP e HTTP), ci si affida al contenuto dei messaggi per poter identificare la sessione destinataria.
Questo meccanismo pu`o essere spiegato approssimativamente nel seguente modo: sia il messaggio che la sessione contengono entrambi un insieme di variabili utilizzate come Correlation Set. Possiamo indicare le variabili di questo insieme come variabili di correlazione, le quali avranno associato un determinato valore a tempo di esecuzione. All’arrivo di un messaggio si leg-gono le sue variabili di correlazione e lo si indirizza alla sessione avente le medesime variabili col medesimo valore.
2.2 Gestione attuale delle sessioni in JOLIE 11
In realt`a, in JOLIE, la questione `e pi`u complesse, dato che esiste la possibilit`a (presente in pochissimi altri linguaggi) di avere pi`u di una variabile di corre-lazione, oltre al fatto che alcune variabili sono non definite. Ipotizziamo, ad esempio, che si voglia creare un servizio S che consenta la comunicazione tra due client, specificando che la comunicazione venga gestita da una sessione. Ipotizziamo inoltre che ogni client possa essere identificato univocamente tramite il suo nome (X e Y), e che ciascun client possa comunicare con un solo altro nello stesso momento. Prendendo in esame una sola variabile di correlazione che identifichi il primo richiedente di inizio conversazione, il mit-tente sarebbe costretto a fornire il proprio ID X. Questo potrebbe causare un problema di sicurezza (il destinatario Y potrebbe usare l’ID della controparte per fingere di essere X in una futura conversazione), oppure potrebbe sem-plicemente non essere realizzabile (un firewall potrebbe bloccare determinati messaggi in arrivo). `E quindi auspicabile l’utilizzo di due variabili di cor-relazione, una per X ed una per Y. Per attuare questa variante si potrebbe utilizzare un servizio centrale (SC) che gestisca le richieste di conversazione (come ad esempio un server di Instant Messaging). Alla ricezione di un mes-saggio di tipo attendo conversazione(id1) (con id1 = X), indicante che X
`e disponibile per iniziare una conversazione, SC inizializzer`a una sessione S avente come prima variabile di correlazione id1 = X, e come seconda variabile
id2 non definita. Quando Y volesse iniziare una conversazione con un altro
utente, potrebbe inviare un messaggio m di tipo conversazione casuale(id2)
(con id2 = Y ). Dato che id2 non `e definita, allora m correla con S (o,
nel-l’eventualit`a, con una qualunque sessione avente id2 non definito). A questo
punto, SC memorizza id2 come Y: di conseguenza, entrambi i client
potran-no, d’ora in avanti, fare riferimento alla sessione S tramite il loro ID.
L’esempio sopra citato `e utile a dimostrare l’utilit`a e le potenzialit`a di questo meccanismo basato sui Correlation Set. Il costo di questo metodo in termini prestazionali risulta dalla forte dipendenza con il numero di sessioni presenti, poich´e si tratta di effettuare una ricerca in un insieme di dimensioni tipica-mente elevate. Una stima precisa delle prestazioni dei differenti algoritmi che
12 2. JOLIE
gestiscono la correlazione non `e semplice da effettuare, dato che la documen-tazione presente a riguardo `e molto scarna ed in alcuni casi l’implementazione degli stessi non `e coerente con con le specifiche.
2.3
Limiti prestazionali
In realt`a, sulla base dell’osservazione del codice sorgente, risulta come la maggioranza delle implementazioni della gestione delle correlazioni seguano due approcci differenti e ben definiti: il primo si basa sull’utilizzo di un array associativo (ad esempio una Hash Table), dove le variabili del Correlation set vengono utilizzate come chiavi di ricerca (PHP e JavaEE, ad esempio, utilizzano questo approccio). Il secondo metodo consiste, invece, nel memo-rizzare le associazioni Correlation set - sessioni in una struttura a lista, dove la ricerca di una correlazione si riduce alla scansione della lista.
Nell’implementazione corrente di JOLIE si `e scelto il secondo approccio, poich´e questo `e l’unico utilizzabile in presenza di una sola variabile di corre-lazione. Tecnicamente, la prima soluzione ha prestazioni migliori dato che la complessit`a non dipende dal numero di sessioni presenti. Il secondo approc-cio, al contrario, `e fortemente dipendente dal numero di sessioni presenti e all’aumentare di quest’ultimo perde efficienza con complessit`a lineare. Come si `e visto, in un sistema Service-Oriented `e di fondamentale impor-tanza la complessit`a con cui viene gestita la correlazione, dato che `e una delle operazioni pi`u eseguite e che una carenza in questo senso comporta una riduzione considerevole nelle prestazioni. Per questo motivo si `e voluto creare un nuovo algoritmo che consentisse l’utilizzo di pi`u di una variabile di correlazione, oltre a non avere complessit`a lineare nel numero di sessioni, e anzi, di complessit`a tendenzialmente indipendente dal loro numero.
Nel capitolo seguente verr`a fornita una visione di insieme dell’algoritmo che si `e voluto implementare. Questo algoritmo si basa sui Radix Trees, `e in-dipendente dal numero di sessioni ed ha complessit`a esponenziale sul numero di variabili di correlazione presenti. Dato che tipicamente il numero di tali
2.3 Limiti prestazionali 13
variabili non supera le tre unit`a, si pu`o dire che l’algoritmo ha complessit`a costante pari a tale numero.
Capitolo 3
Algoritmo “Session correlation
management with Radix Tree”
3.1
Introduzione all’algoritmo
Come accennato alla fine del capitolo precedente, la complessit`a attuale dell’implementazione dell’algoritmo che gestisce la correlazione `e lineare nel numero di sessioni presenti. Con l’algoritmo presentato dal Dr. Maurizio Gabbrielli, Claudio Guidi, Jacopo Mauro e Fabrizio Montesi [15] (che in queste pagine `e stato modificato in minima parte) si vuole fornire un’alter-nativa di complessit`a molto inferiore, dunque avente prestazioni migliori. L’idea su cui si basa l’algoritmo per migliorare le prestazioni `e quella di uti-lizzare i Radix Tree per memorizzare la correlazione delle sessioni, in modo da trovare pi`u efficientemente le sessioni che correlano con il messaggio. Per poter approfondire il meccanismo in questione `e necessario prima for-malizzare alcuni concetti descritti in precedenza:
• Correlation Set: il correlation set (c-set) di un servizio `e rappresen-tato da un insieme finito di variabili V C = v1, v2, ...., vn (dove v1...vn
possono essere variabili nominate ad esempio come nome, cognome ecc.)
• Istanza (di c-set): identifica l’associazione tra il valore posseduto
16 3. Algoritmo “Session correlation management with Radix Tree”
da una data variabile di correlazione e la variabile stessa. L’istanza pu`o essere rappresentata da una funzione di questo tipo: F(nome) = “Giovanni”. Questo si pu`o interpretare come “l’istanza della variabile nome possiede il valore “Giovanni””.
• Definire una variabile: un messaggio in arrivo potrebbe contenere valori associati a variabili facenti parte del correlation set, quindi, in questo caso, si dice che un messaggio definisce una variabile di cor-relazione v quando contiene un valore associato ad essa, cio`e quando possiede un istanza di v. Dato un messaggio m definiamo con Fm(v)
l’istanza della variabile v nel messaggio m; quando, viceversa, non `e presente l’istanza di una variabile v0, si dice che essa non `e defini-ta. Analogamente, una sessione s definisce una variabile v quando ne possiede un’istanza che denoteremo con Fs(v).
• Correlazione (Correlation): ipotizziamo di avere un servizio S com-prendente un Correlation set VC. In questo caso, si avrebbe una ses-sione s correlata con un messaggio m se e solo se ∀v ∈ V C se Fm(v) e
Fs(v) sono definiti allora si ha che Fm(v) = Fs(v).
Di conseguenza, esiste la possibilit`a che un messaggio correli con pi`u di una sessione, dato che `e possibile che esistano variabili non definite. In-fatti, la definizione di correlazione non esclude che un messaggio possa correlare tramite le sole variabili che definisce. Si consideri, ad esempio, una situazione in cui due sessioni aventi le variabili del correlation set siano definite nel seguente modo:
s : nome = “Mario” e cognome = “Rossi” s’ : nome = “Mario” ma cognome non definito
Alla ricezione di un messaggio m( “Mario” , “Rossi” ), questo potrebbe correlare con entrambe le sessioni, dato che per s’ la variabile definita `e nome e si ha che Fm(nome) = Fs0(nome), come da definizione. In
re-alt`a, per poter correlare con la sessione pi`u ragionevole (s nell’esempio) si sfrutta un concetto pi`u restrittivo che definiamo qui di seguito.
3.2 Struttura dell’algoritmo 17
• Massima copertura (Maximal coverability): riprendiamo in esame il servizio S avente il solito set di variabili di correlazione VC e un insieme di sessioni s1, ..., sn che correlano con il messaggio m. Una
ses-sione si ha massima copertura con il messaggio m se e solo se non esiste
nessun altra sessione sj tale che:
∀v ∈ V C se Fsi(v) `e definita allora Fsj(v) `e definita
∃v ∈ V C tale che Fsi(v) non `e definita mentre Fsj(v) e Fm(v) sono
definite.
Data questa definizione, potremmo dire che si creano degli insiemi di sessioni basati sulle caratteristiche delle variabili. Di questi “insiemi” di sessioni, abbiamo la certezza che solo una possa correlare con il messaggio. Questo `e garantito dalla definizione stessa delle sessioni, le quali per loro natura possiedono istanze diverse delle variabili del correlation set. In caso contrario si avrebbero sessioni non distinguibili la cui gestione `e definita nell’implementazione del linguaggio. Come vedremo, nell’implementazione del nuovo algoritmo di cui andremo a discutere, sono ammesse sessioni col medesimo correlation set a patto che esse siano interscambiabili (cio`e non faccia differenza quale delle due si scelga).
3.2
Struttura dell’algoritmo
3.2.1
Radix Tree
I Radix Tree (o Patricia Tree) [11] sono delle strutture dati ad albero or-dinate, utilizzate per memorizzare stringhe di caratteri. In questa struttura ad albero vi `e un nodo per ogni prefisso comune, e gli archi dell’albero ven-gono etichettati per una pi`u veloce identificazione; i dati (in questo caso le sessioni) vengono salvati nelle foglie. I Radix Tree, a differenza dei normali alberi, consentono la memorizzazione nei nodi di serie di caratteri anzich´e di caratteri singoli. Questa modifica strutturale d`a la possibilit`a di ridurre ulteriormente la ricerca a prefissi comuni, e non solo a caratteri comuni.
18 3. Algoritmo “Session correlation management with Radix Tree”
Intuitivamente, appare chiaro che la ricerca in una data struttura `e indipen-dente dal numero di foglie, ma dipenindipen-dente al pi`u dalla lunghezza della stringa cercata, dato che si hanno miglioramenti prestazionali nel caso in cui la stringa sia leggermente scomposta all’interno dell’albero.
A riprova di ci`o, potremmo fare il seguente esempio: data una lista di invitati ad una festa, utilizzando l’algoritmo lineare saremmo costretti a scorrere la lista ogni volta alla presenza un nuovo invitato e, nel caso pi`u sfortunato, quest’ultimo potrebbe essere in coda alla suddetta lista. Se la lista fosse organizzata tramite Radix Tree, all’arrivo dell’invitato “Mario Rossi” scor-remmo nel caso pi`u sfortunato ogni singola lettera. Questo `e esemplificativo di come l’algoritmo lineare sia dipendente dal numero di invitati mentre quel-lo basato sui Radix Tree non ne sia influenzato, e di come quest’ultimo sia molto pi`u efficiente nel memorizzare dati con stringhe (chiavi) che abbiano lunghi prefissi in comune.
Le operazioni di aggiunta di una stringa al Radix Tree, quella di rimozione di una stringa e quella di ricerca hanno un costo computazionale di O(n), nel peggiore dei casi, dove n rappresenta la stringa di lunghezza massima presente nel radix tree.
L’idea su cui si basa l’algoritmo presentato in questa tesi `e consiste nello sfruttare questa potenzialit`a dei radix tree per poter correlare le sessioni con i messaggi in arrivo: si utilizza il valore delle variabili del correlation set come chiave di ricerca. Riassumendo, data una sessione avente variabili del correlation set nome e cognome, si compongono i valori di tali variabili in modo da ottenere una stringa che verr`a utilizzata per memorizzare la sessione all’interno del radix tree.
Nella fattispecie, il tutto `e organizzato in cluster (gruppi) di radix tree, uno per ogni sottoinsieme di variabili presenti nel correlation set specificato dal comportamento del servizio.
3.2 Struttura dell’algoritmo 19
3.2.2
Cluster
Come accennato, all’inizializzazione di un servizio viene creato un cluster per ciascun sottoinsieme di variabili che compongono il correlation set (la de-scrizione dettagliata del funzionamento dell’algoritmo in questo ambito sar`a fornita nella sezione 3.3). Ipotizziamo, ad esempio, di avere tre variabili di correlazione a, b, c: per poter coprire tutti i sottoinsiemi di variabili ([a]; [b]; [c]; [a,b]; [a,c]; [b,c]; [vuoto] ), come risultato otterremmo 2n cluster, ed in questo caso 23 = 8.
Di seguito indicheremo con C(v,...,v’) il cluster che “copre” le variabili v,....,v’. La “copertura” serve ad indicare che nel suddetto cluster verranno memo-rizzate le sole sessioni che definiscono tali variabili. Riprendendo l’esempio precedente, i cluster risultanti dalla considerazione di tre variabili (a, b, c) sono: C(a); C(b); C(c); C(a,b); C(a,c); C(b,c); C(a,b,c), e per ultimo il caso vuoto C(empty). Di conseguenza, nel cluster C(c) avremo le sole sessioni che definiscono la sola variabile di correlazione c, in C(a,b) le sessioni che definiscono solo le variabili a e b e via dicendo.
Alla ricezione di un messaggio, si verificheranno quali variabili del correlation set questo definisce. Grazie a queste informazioni, verr`a costruita una “lista di ricerca” nei cluster, a cominciare da quello con massima copertura (vedi 3.1), e seguendo con tutti gli altri, fino a trovare una sessione che correli e che dovr`a ricevere il messaggio. Nel caso in cui non venga trovata alcuna sessione, l’algoritmo non generer`a un errore: si limiter`a invece a notificare il fatto che nessuna sessione `e stata trovata.
3.2.3
Generazione delle chiavi
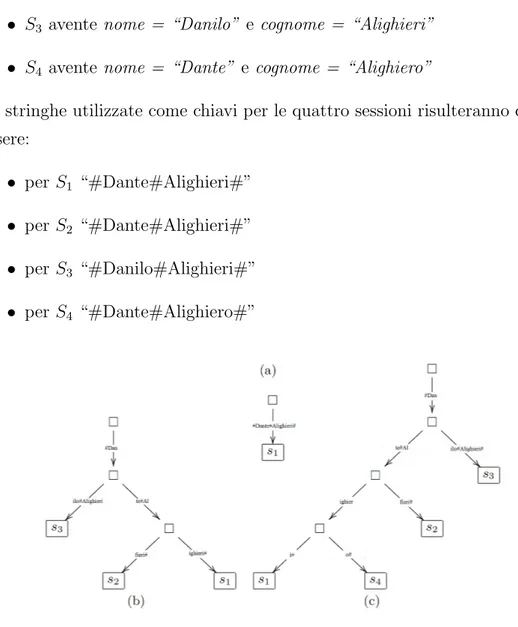
Per creare una chiave che sia utile alla ricerca all’interno dei radix tree, sono state concatenate le stringhe dei valori delle variabili coperte dal cluster, intervallate dal carattere # (il cui utilizzo `e vietato altrove). Poniamo, ad esempio, un radix tree che memorizza le sessioni specificanti nome, cognome.
20 3. Algoritmo “Session correlation management with Radix Tree”
Si vogliono inserire ora quattro nuove sessioni all’interno di tale radix tree:
• S1 avente nome = “Dante” e cognome = “Alighieri”
• S2 avente nome = “Dante” e cognome = “Alfieri”
• S3 avente nome = “Danilo” e cognome = “Alighieri”
• S4 avente nome = “Dante” e cognome = “Alighiero”
Le stringhe utilizzate come chiavi per le quattro sessioni risulteranno quindi essere:
• per S1 “#Dante#Alighieri#”
• per S2 “#Dante#Alighieri#”
• per S3 “#Danilo#Alighieri#”
• per S4 “#Dante#Alighiero#”
Figura 3.1: Esempio composizione di un Radix Tree
In seguito ad una attenta analisi, risulta evidente come questo meccanis-mo di concatenazione di stringhe abbia un punto debole nel meccanis-momento in cui le variabili della sessione sono pi`u di una. Infatti, come vedremo pi`u avanti,
3.2 Struttura dell’algoritmo 21
i cluster necessitano di pi`u radix tree per poter correlare, nel caso in cui essi “coprano” pi`u variabili.
Ipotizzando la presenza di una sola variabile all’interno del correlation set (ad esempio nome), si ha 21 = 2 cluster, cio`e C(nome) e C(empty). Inizialmente,
all’interno del cluster C(nome) `e presente un radix tree vuoto, composto dal solo nodo radice. Sono create in seguito due sessioni S e S’, aventi la vari-abile nome memorizzata rispettivamente come “#Dante#” e “#Danilo#”. Si pu`o notare come, negli angoli dell’albero, siano presenti i prefissi comuni di maggiore lunghezza: all’arrivo di un messaggio m che definisca il valore “#Danilo#” per la variabile nome, risulta evidente dalla figura che, per effet-tuare la ricerca della sessione che correli con m, `e sufficiente scorrere l’albero del cluster C(nome) nei suoi nodi. Nell’ipotetico caso in cui non fosse possi-bile trovare una sessione correlante all’interno del cluster C(nome), avremmo in risposta una qualunque delle sessioni presenti in C(empty). Le sessioni presenti in quest’ultimo cluster, infatti, hanno la medesima copertura: l’una o l’altra, dunque, `e indifferente.
Come accennato, la presenza di pi`u di una variabile di correlazione genera problemi nella ricerca delle sessioni correlanti. Riprendiamo l’esempio in cui sono presenti due variabili nel correlation set (nome e cognome) e le quattro sessioni definite in precedenza (S1, ..., S4): i cluster risultanti dalla presenza di
due variabili sono 22 = 4, nella fattispecie C(empty), C(nome), C(cognome) e C(nome, cognome). Le quattro sessioni (S1, ..., S4), definendo entrambe le
variabili, sono memorizzate tutte all’interno di C(nome, cognome), mentre gli altri cluster rimangono vuoti. Alla ricezione di un messaggio specificante, ad esempio, solo il valore “alfieri” per la variabile del correlation set cognome, viene effettuata una prima ricerca all’interno del cluster C(cognome), la quale non avr`a, per`o, esito positivo. Si prosegue, dunque, con il cluster successivo avente la massima copertura in questo caso C(nome, cognome). Se per tale cluster (che comprende pi`u di una variabile) si considera la presenza di un so-lo radix tree (il quale possiederebbe un struttura rappresentabile nel seguente modo: #nome#cognome#), risulter`a evidente come esso non possegga un
22 3. Algoritmo “Session correlation management with Radix Tree”
prefisso composto dal cognome specificato nel messaggio. In realt`a, nessun cognome potr`a essere utilizzato come prefisso in una siffatta struttura. Dalla definizione di correlazione (vedi 3.1), per`o, la sessione S2 correlerebbe con
il messaggio, dimostrando cos`ı la necessit`a di avere pi`u di un radix tree per tale cluster. Per risolvere questo problema, dunque, sarebbe necessario avere un radix tree per ogni sottoinsieme delle variabili definite in tale cluster: in realt`a, come vedremo in seguito, `e sufficiente un sottoinsieme di tale numero di radix tree per coprire tutte le variabili specificate nel cluster.
3.2.4
Generazione dei radix tree
Tendenzialmente, il numero dei radix tree di un cluster sarebbe esponen-ziale secondo il numero di variabili definite: se un cluster memorizza sessioni che definiscono n variabili, si dovrebbero avere, teoricamente, 2n radix tree. L’algoritmo di generazione dei radix tree RTG (Radix Trees Generator ) che andremo a presentare ha lo scopo di ridurre al minimo il numero di radix tree che `e necessario creare per ciascun cluster. Prendendo come esempio il cluster C(nome, cognome), si pu`o notare come il radix tree con strut-tura #nome#cognome# copra contemporaneamente il caso di un messaggio specificante nome e cognome, un messaggio specificante il solo nome, dato che quest’ultimo pu`o essere comunque utilizzato come prefisso, e per finire anche un messaggio che non definisce alcuna variabile.
Di seguito si fornisce una formalizzazione del concetto: dato un cluster avente un numero di variabili n, si definisce SEQi una sequenza v1, ..., vn di
vari-abili, dove ogni SEQi `e composto da un prefisso della sequenza (SEQi+1) successiva.
Si consideri, ad esempio, un cluster C(nome, cognome, et`a). Alcune delle sequenze risultanti potrebbero essere:
• SEQ1 : nome
• SEQ2 : nome, cognome
3.2 Struttura dell’algoritmo 23
Per rappresentare la struttura di un radix tree, si utilizzer`a dunque la no-tazione RT (SEQ1, ..., SEQm) con SEQm = v1, ..., vh (con h ≤ n), stante ad
indicare un radix tree della forma #v1#...#vh#. Con la dicitura RT (SEQ1, ..., SEQm),
invece, si vogliono invece indicare, oltre alla struttura del radix tree, le vari-abili di correlazione che esso d`a la possibilit`a di controllare. Un radix cos`ı descritto d`a la possibilit`a di controllare l’esistenza di una sessione che definis-ca ciascuna delle combinazioni di variabili descritte dalle sequenze SEQi. Si
prenda, ad esempio, il cluster descritto in precedenza. Uno dei radix tree contenuto al suo interno potrebbe essere rappresentato come:
• RT(empty, [nome], [nome, cognome], [nome, cognome, et`a])
Usando questa notazione, si pu`o affermare il bisogno di un numero minimo di schemi di radix tre RT, numero tale per cui per ogni sottoinsieme I di variabili definite nel cluster esista una sequenza SEQj che contenga tutte e
le sole variabili in I.
3.2.5
Algoritmo RTG (Radix Trees Generator )
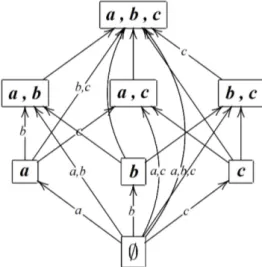
per risolvere questo problema, `e utile una rappresentazione tramite grafo. Dato un insieme di variabili V, si crea un grafo G(V); si denota poi con S(V) l’insieme composto da tutti i sottoinsiemi di variabili di V. Si ha inoltre che:
• i nodi sono etichettati con gli elementi di S(V)
• vi `e un arco da u a v se le variabili contenute in u sono presenti anche in v (u, v ∈ S(V ))
• l’arco (u,v ) `e etichettato con le variabili con cui differiscono u e v (usando notazione insiemistica possiamo indicare con u / v )
Nella figura seguente, `e rappresentato un esempio di come risulterebbe un grafo costruito partendo dalle variabili a, b e c. Per problemi legati alla disponibilit`a di spazio, non sono state inserite tutte le etichette degli archi.
24 3. Algoritmo “Session correlation management with Radix Tree”
Figura 3.2: Esempio di grafo G(V)
Ogni cammino del grafo rappresenta un possibile schema di radix tree RT. Data questa rappresentazione, possiamo ridurre il problema alla ricerca del numero minimo di cammini necessari alla copertura di tutti i nodi. L’algoritmo RTG (del quale `e stata data un’implementazione descritta in 3.3) opera nel seguente modo:
Il grafo G(V) viene suddiviso in livelli. Ciascun livello `e costituito dal nu-mero di variabili che ogni nodo contiene, cosicch´e il livello i `e formato dai nodi aventi i variabili (Il livello con il nodo vuoto `e il livello 0). Si considerino i livelli a coppia partendo da quelli pi`u in basso (i.e. Livelli 0 e 1). Le coppie di livelli i e i + 1 sono considerati come un grafo bipartito diviso in base ai nodi dei due livelli. Secondo la teoria dei grafi, un grafo bipartito `e un grafo non orientato tale per cui l’insieme dei suoi vertici si pu`o partizionare in due sottoinsiemi; questi insiemi, a loro volta, sono tali per cui ogni vertice di ognuna di queste due parti `e collegato solo ai vertici dell’altra. Da questo grafo cos`ı creato sono eliminati gli archi seguendo l’algoritmo di massima avvicinabilit`a (maximum bipartite matching). Si ha un maximum matching quando i nodi di un grafo sono collegati tramite un arco o, al pi`u, con un altro nodo, e contemporaneamente il numero di nodi collegati tra loro `e il pi`u
3.2 Struttura dell’algoritmo 25
alto possibile. Il maximum bipartite matching `e, invece, il maximum match-ing applicato ad un grafo bipartito. Questa scelta degli archi `e ripetuta nei livelli successivi i + 1 con i + 2, i + 2 con i + 3 ed a seguire, fino alla fine del grafo, cio`e al livello n. Il grafo G0(V ) cos`ı ottenuto conterr`a il numero minimo di cammini che coprono tutti gli insiemi di variabili in S(V ).
Prima di fornire l’algoritmo in pseudocodice, verr`a esposta la notazione uti-lizzata. Si indicher`a con S l’insieme delle variabili del cluster (ad esempio a, b, c): la funzione level(x) restituir`a l’elenco di nodi al livello x nel grafo, cio`e l’insieme di nodi con cardinalit`a x ; con bipartite(A, A0) si indicher`a il grafo bipartito creato partendo dai due insiemi di variabili A e A0: la funzione maximum matching(B) restituir`a uno dei maximum matching del grafo bipartito B; M rappresenter`a il grafo in costruzione.
Radix_Trees_Generator(S){ i = 0; M = empty; while (i < n){ L = level(i); L’ = level(i+1); G = bipartite( L, L’ ); M’ = maximum_matching(G); M = M U M’; i++; } return (M); }
Una volta ottenuto il grafo dall’algoritmo RTG, sar`apossibile creare gli sche-mi dei radix tree seguendo i camsche-mini di tale grafo. Si ricordi, a questo proposito, che uno schema di radix tree `e della forma RT (SEQ1, ..., SEQm)
con ogni sequenza i di lunghezza minore rispetto alla successiva i + 1, e che ogni nodo del grafo `e rappresentabile come una sequenza di variabili.
figu-26 3. Algoritmo “Session correlation management with Radix Tree”
ra precedente. Nella figura successiva si mostrer`a una possibile esecuzione dell’algoritmo in questione: si utilizzer`a la notazione → per indicare gli archi considerati dall’algoritmo di maximum matching (i.e. gli archi in G), mentre con ⇒ quelli che verranno scelti.(i.e. gli archi in M0). Inoltre, solo i nodi racchiusi in linee continue saranno presi in considerazione (i.e. i nodi in L e L0). Infine, i nodi processati saranno indicati con una linea tratteggiata.
Figura 3.3: Esempio di esecuzione dell’algoritmo RTG
Dopo aver fornito questo formalismo, si pu`o fornire un esempio di es-ecuzione dell’algoritmo. Ipotizziamo di avere tre variabili a, b e c: uno dei risultati ottenibili `e una situazione che presenta i seguenti cluster con corrispettivi radix tree, dove gli elementi tra parentesi quadre (i.e. “[a] ”) rappresentano le sequenze (SEQi) descritte in precedenza:
• C(empty) : RT ([empty])
3.3 Utilizzazione dell’algoritmo 27
• C(b) : RT ([empty, [b])
• C(c) : RT ([empty, [c])
• C(a, b) : RT ([empty, [a], [a, b]); RT ([b])
• C(a, c) : RT ([empty, [a], [a, c]); RT ([c])
• C(b, c) : RT ([empty, [b], [b, c]); RT ([c])
• C(a, b, c) : RT ([empty], [a], [a, b], [a, b, c]); RT ([b], [b, c]); RT ([c], [c, a])
Si noti come le variabili nella seconda sequenza del terzo radix tree del cluster C(a, b, c) siano in ordine invertito, cosicch`e la prima sequenza ([c]) sia un prefisso della seconda ([c, a]).
3.3
Utilizzazione dell’algoritmo
Ottenuta la struttura dell’algoritmo presentato in questa tesi mediante i procedimenti esposti al punto 3.3, si vuole ora fornire un quadro del suo utilizzo.
Gestione delle sessioni L’algoritmo RTG presentato in precedenza `e uti-lizzato in ciascun cluster. L’esempio di esecuzione raffigurato nell’immagine precedente, infatti, `e uno dei possibili risultati dati dall’utilizzo di suddetto algoritmo all’interno del cluster C(a, b, c).
Per gestire una tale struttura, sono necessarie funzioni che consentano di aggiungere, rimuovere e trovare sessioni all’interno dei vari cluster e dei vari radix tree. Il concetto su cui ci si basa `e quello di propagazione delle infor-mazioni dei cluster ai radix tree che essi contengono.
Le funzioni di base per la manipolazione dei cluster sono:
• CLS.add(S): `e l’operazione che si occupa della memorizzazione di una sessione S all’interno del cluster CLS. Ci`o `e effettuato acquisendo le variabili V del correlation set di S e creandone delle stringhe (come
28 3. Algoritmo “Session correlation management with Radix Tree”
descritto in 3.2.3 [Generazione delle chiavi] ), seguendo le strutture dei radix tree presenti all’interno del cluster. Per ciascuno di questi radix tree, si utilizza l’operazione RT.add(S), la quale memorizza all’interno di RT la sessione utilizzando come chiave le stringhe ottenute al passag-gio precedente. Si supponga, ad esempio, di avere un cluster C(SEQh)
con SEQh = V1, ..., Vh, e che si voglia inserire una sessione S0: si
in-izier`a utilizzando la funzione C(SEQh).add(S0) la quale propagher`a la
richiesta ad ogni radix tree presente all’interno del cluster utilizzan-do come chiave il valore delle variabili composte, seconutilizzan-do lo schema del radix tree. Prendiamo in considerazione uno di questi radix tree RT avente come struttura RT (SEQ1, ..., SEQh). Quando `e utilizzata
la RT.add(S0), si crea la stringa seguendo la struttura #v1#...#vh#,
dove v1, ..., vhsono i valori delle variabili V1, ..., Vh = SEQh(la sequenza
di lunghezza maggiore di RT ).
• CLS.del(S): quest’operazione sfrutta lo stesso procedimento illustrato per la CLS.add(S) per rimuovere una sessione S anzich´e aggiungerla.
• CLS.find(M): restituisce la sessione che correla con il messaggio M . Se non sono state trovate sessioni che correlino con M , `e restituito “nulla00. Come noto, in realt`a, un messaggio m definisce un insieme di variabili di correlazione Vm, i quali possono non comprendere tutte le
variabili definite all’interno del cluster Vc. La funzione CLS.f ind(M )
sceglie il radix tree su cui propagare la richiesta scegliendo RT avente SEQi = Vm∩ Vc (cio`e il radix tree che possiede la sequenza di variabili
risultante dall’intersezione tra le variabili di correlazione del messag-gio e quelle del cluster). La RT.f ind(m) risultante, inoltre, pu`o es-sere applicata se e solo se la sequenza di variabili prese dal messaggio SEQm = x1, ..., xm `e in un ordine tale da rappresentare un prefisso
per il radix tree RT . In questo caso, la chiave di ricerca risultante risieder`a nella forma #x1#...#xm#, e la RT.f ind(m) restituir`a una
3.3 Utilizzazione dell’algoritmo 29
prefisso, infatti, si potrebbe trovare pi`u di una sessione correlante ma, come si `e visto, tali sessioni sono indifferenti l’una dall’altra per quanto concerne la correlazione.
Si possiedono ora elementi sufficienti per fornire una formalizzazione esplicita del funzionamento dell’algoritmo discusso in questa dissertazione. Sono for-niti, di seguito, gli algoritmi in pseudocodice delle funzioni f ind session(m) e add session(S) (non sar`a fornito lo pseudo codice delle delete session(S) dato che `e intuibile da quest’ultima). Successivamente, verranno chiarite le funzioni utilizzate.
• allCluster() : restituisce l’elenco dei cluster presenti nel servizio
• getBestM atchingCluster(m, C) : cercando all’interno dell’elenco di cluster C questa funzione restituisce il cluster C0 avente il numero mag-giore possibile di variabili in comune con il messaggio (ad esempio se si ha un messaggio m(a, b) la funzione restituir`a il cluster C0(a, b) oppure, nel caso quest’ultimo non sia presente in C, ver`a restituito il cluster C00(a, b, c) e cos`ı via).
• getBestM atchingRT (m, C0) : ha lo scopo di restituire il radix tree RT
che possegga la sequenza di variabili SEQm specificate dal messaggio.
find_session(m){ C = allCluster(); S = null;
while (S == null or C != null){ C’ = getBestMatchingCluster(m, C); RT = getBestMatchingRT(m, C’); S = RT.find(m) if( S == null){ C = C - C’; } }
30 3. Algoritmo “Session correlation management with Radix Tree”
Return S; }
Una volta controllato un cluster, esso sar`a eliminato dalla lista ( C = C − C0 ), in modo da non dover essere pi`u controllato.
La funzione add session(s) risulta essere molto simile alla precedente, in quanto necessita anch’essa del cluster avente il numero massimo possibile di variabili in comune con la sessione passata come parametro. Di seguito `e presentata la stessa notazione dell’operazione precedente.
add_session(s){ C = allCluster(); C’ = getBestMatchingCluster(s, C); forall RT in C’ { RT.add(s); } }
Intuitivamente, per ottenere lo pseudocodice della funzione delete session(s) `e sufficiente sostituire l’operazione RT.add(s) con una RT.del(s).
Capitolo 4
Algoritmo “Session correlation
management with Radix Tree”:
un’implementazione
In questo capitolo `e fornita un’implementazione dell’algoritmo discusso nel capitolo precedente. Questa tesi `e stata sviluppata utilizzando il linguag-gio di programmazione JAVA [12]. L’algoritmo qui presentato `e stato creato in JAVA ai fini di migliorare le prestazioni del linguaggio JOLIE, integrando l’algoritmo stesso a questo nuovo linguaggio. Come discusso nel capitolo 2, infatti, tale linguaggio di programmazione Service-Oriented `e stato svilup-pato in JAVA; inoltre, l’algoritmo di cui dispone attualmente per la gestione della correlazione ha complessit`a lineare, ed `e quindi meno efficiente dell’al-goritmo qui presentato.
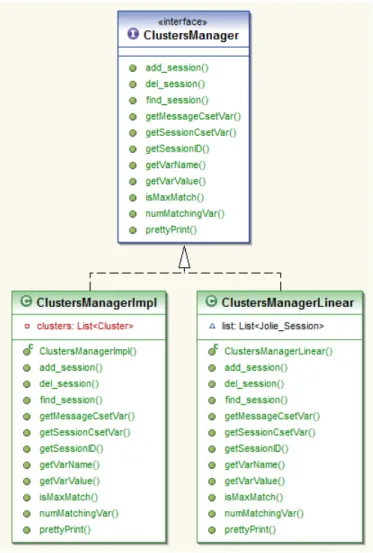
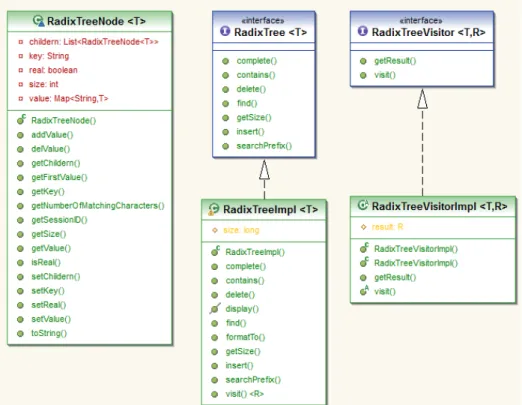
I concetti e la struttura esposti nel capitolo precedente sono stati rappre-sentati mediante tre insiemi di classi: l’inseme denominato Cluster Manager racchiude il gestore generale delle componenti dell’algoritmo; l’inseme Clus-ter contiene l’implementazione del concetto di ClusClus-ter (vedi 3.2); l’insieme radix tree comprende l’elenco dei radix tree.
Si indicher`a con “[...]” l’interruzione/proseguimento dell’esposizione del codice (per dare modo di commentarlo in sezioni), mentre si indicher`a con “[###]”
32
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
l’omissione di codice (perch´e non utile ai fini esplicativi).
4.1
Cluster Manager
Ecco implementate le funzioni add session(s), delete session(s) e f ind session(m) descritte al punto 3.3.
4.1.1
ClustersManager.java
Di seguito si fornisce l’interfaccia descritta nella classe ClustersManag-er.java
public interface ClustersManager { /**
* Store a session s *
* @param s the session to be stored */
public void add_session(Jolie_Session s);
/**
* Remove a session s *
* @param s the session to be removed */
public void del_session(Jolie_Session s);
/**
* Returns the session which correlate with a message m. If no sessions * correlates with m then null is returned.
4.1 Cluster Manager 33
* @param m the message to correlate with
* @return the session that correlates with the massage * returns null if nothing found
*/
public Jolie_Session find_session(Jolie_Message m);
/**
* For printing purpose */
public void prettyPrint();
/**
* Checks if two list have the same variables */
public boolean isMaxMatch(List<Jolie_Var> lv1, List<Jolie_Var> lv2);
/**
* Returns number of common variables between two list */
public int numMatchingVar(List<Jolie_Var> lv1, List<Jolie_Var> lv2);
/**
* JOLIE INTEGRATION SECTION */
public List<Jolie_Var> getSessionCsetVar(Jolie_Session s);
public List<Jolie_Var> getMessageCsetVar(Jolie_Message m);
34
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
public String getVarValue(Jolie_Var v);
public String getSessionID(Jolie_Session s); }
L’interfaccia definisce il comportamento generale su cui si basa l’algoritmo. Come da specifiche Java, infatti, uno degli scopi delle interfacce `e definire le linee guida da seguire per implementare un algoritmo. Le funzioni descritte andranno poi implementate in sotto-classi, le quali definiranno effettivamente il loro comportamento. Come si pu`o notare, nalla sezione commentata come JOLIE INTEGRATION SECTION `e stato fornito un formalismo per imple-mentare in modo immediato una futura integrazione con il linguaggio JOLIE (o con un qualunque altro linguaggio sviluppato in Java e strutturalmente simile a JOLIE). Attualmente, infatti, l’implementazione fornita gestisce clas-si create ad hoc che imitano la struttura e il comportamento delle rispettive classi JOLIE. Tali strutture e comportamenti sono limitati allo stretto indis-pensabile, cos`ı da rendere possibile un’integrazione.
Le classi in questione sono:
• Jolie Message.java: possiede un elenco di variabili che rappresen-tano, a loro volta, le variabili del correlation set. `e presente, inoltre, un meccanismo utile ad ottenere tali variabili. `e utilizzata come parametro nella f ind session(m).
• Jolie Var.java: Implementa il concetto di variabile e, pi`u specificata-mente, `e utilizzata per indicare le variabili di correlazione. Possiede un nome ed un valore reperibili mediante apposite funzioni.
• Jolie Session.java: rappresenta una sessione e, come le variabili, `e caratterizzata da un nome. Lo stato della sessione `e indicato in una lista di variabili di cui `e stato fornito un getter (i.e. Funzione specifi-catamente creata per restituire una data variabile)
4.1 Cluster Manager 35
4.1.2
ClustersManagerLinear.java
Per motivi di test sono state sviluppate due implementazioni dell’inter-faccia ClustersManager. Nella classe ClustersManagerLinear.java, `e stato sviluppato l’algoritmo con complessit`a lineare, cos`ı da poterlo confrontare con l’algoritmo presentato in questa tesi.
Di seguito vediamo una porzione del codice:
public class ClustersManagerLinear implements ClustersManager { List<Jolie_Session> list;
public ClustersManagerLinear() {
this.list = new ArrayList<Jolie_Session>(); }
public void add_session(Jolie_Session s) { this.list.add(s);
}
public void del_session(Jolie_Session s) { this.list.remove(s);
}
[...]
Appare chiaro, dal codice, che le sessioni sono memorizzate in una lista: di conseguenza, un accesso per la ricerca di una sessione specifica necessita, nel peggiore dei casi, della scansione della lista intera.
4.1.3
ClustersManagerImpl.java
La classe che implementa l’interfaccia seguendo il comportamento dell’al-goritmo presentato in questa tesi `e descritta in ClustersManagerImpl.java.
36
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
Per questioni di lunghezza, il codice sar`a discusso in sezioni e non nella sua interezza:
public class ClustersManagerImpl implements ClustersManager { private List<Cluster> clusters;
/**
* @param list
* list of all correlation set variables in the Jolie program */
public ClustersManagerImpl(List<Jolie_Var> list) { this.clusters = new ArrayList<Cluster>();
init(list, new ArrayList<Jolie_Var>(), 0, list.size()); }
[...]
Il costruttore della classe ha il compito di inizializzare la struttura dati in base alle variabili presenti nel correlation set. Tali variabili, infatti, sono alla base della creazione dei Cluster, effettuata dalla funzione init(). Questa funzione ha lo scopo di creare la lista dei cluster in base ad ogni singolo sottoinsieme di variabili (vedi 3.2.2 [Cluster]). Qui di seguito si presenta il codice di tale funzione.
[...] /**
* Creates a list of Cluster from all subsets of a list of variables * (i.e.: init(<x,y>) => C(empty), C(x), C(y), C(x,y) )
*/
private void init(List<Jolie_Var> l, List<Jolie_Var> acc, int i, int n) { if (i == n) {
Cluster c;
if(acc.size() == 0)
4.1 Cluster Manager 37
else
c = new ClusterImpl(acc, this);
this.clusters.add(c); }
else {
init(l, acc, i + 1, n);
List<Jolie_Var> tmp = new ArrayList<Jolie_Var>(); tmp.addAll(acc); tmp.add(l.get(i)); init(l, tmp, i + 1, n); } } [...]
Essendo questa la classe su cui `e necessario interfacciarsi per sfruttare le potenzialit`a dell’algoritmo, questa implementa le tre funzioni principali atte alla gestione delle sessioni. Come si nota dal codice seguente, lo scopo di questa classe `e di reperire il cluster che copre la maggior parte delle variabili, per poi propagarvi la richiesta.
[...]
public void add_session(Jolie_Session s) { List<Jolie_Var> l = getSessionCsetVar(s); findMaxCoveringCluster(l).addSession(s); }
public void del_session(Jolie_Session s) { List<Jolie_Var> l = getSessionCsetVar(s); findMaxCoveringCluster(l).delSession(s); }
38
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
public Jolie_Session find_session(Jolie_Message m) { List<Jolie_Var> l = getMessageCsetVar(m);
Cluster c = findMaxCoveringCluster(l); Jolie_Session s = c.findSession(m);
if(s == null){
List<Cluster> toCheck = new ArrayList<Cluster>(); toCheck.addAll(this.clusters);
toCheck.remove(c);
s = findMaxCoveringSession(l, toCheck, m, l.size()); }
return s; }
[...]
Il compito di reperire il cluster pi`u adatto a soddisfare la richiesta `e imple-mentato nel metodo seguente:
[...] /**
* finds the maximal matching Cluster for given variables * (i.e: findCluster(<x,y>) => C(x,y) )
*/
private Cluster findMaxCoveringCluster(List<Jolie_Var> messageVar) { Cluster emptyCluster = null;
for (Cluster c : this.clusters) {
if (c.getClusterVariables().size() == 0) { emptyCluster = c; } if(isMaxMatch(c.getClusterVariables(), messageVar)){ return c; } }
4.1 Cluster Manager 39
return emptyCluster; }
[...]
Data la lista di variabili, la funzione scansiona tutti i cluster in cerca di quello che ha lo stesso set di variabili fornite; in caso contrario, restituisce di de-fault il cluster C(empty). L’implementazione della funzione isM axM atch() utilizzata precedentemente `e la seguente:
[...] /**
* Checks if two list have the same variables */
public boolean isMaxMatch(List<Jolie_Var> lv1, List<Jolie_Var> lv2){ if(lv1.size() == lv2.size()){ if(lv1.size() == 0) return true; if(numMatchingVar(lv1, lv2) == lv1.size()) return true; } return false; } /**
* Returns number of common variables between two list */
public int numMatchingVar(List<Jolie_Var> lv1, List<Jolie_Var> lv2){ int numMatch = 0;
for (Jolie_Var v1 : lv1) { for (Jolie_Var v2 : lv2) {
if (getVarName(v1) == getVarName(v2)) numMatch++;
40
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione } } return numMatch; } [...]
Come si nota dal codice finora esposto, si fa un utilizzo massiccio di funzioni per il reperimento di informazioni riguardanti le sessioni e le variabili. Queste funzioni sono implementate nella sezione dedicata all’integrazione con il lin-guaggio di programmazione (JOLIE).
Di seguito `e fornita l’implementazione utilizzata in questo progetto, la quale sar`a sostituita con una specifica, a seconda del linguaggio in cui questo algoritmo voglia essere integrato.
[...] /**
* JOLIE INTEGRATION SECTION */
public List<Jolie_Var> getSessionCsetVar(Jolie_Session s) { return s.getVar();
}
public List<Jolie_Var> getMessageCsetVar(Jolie_Message m) { return m.getVar();
}
public String getVarName(Jolie_Var v) { return v.getName();
}
public String getVarValue(Jolie_Var v) { return v.getValue();
4.1 Cluster Manager 41
}
public String getSessionID(Jolie_Session s){ return s.getName();
} [###]
Un quadro generale della sezione discussa finora `e visibile in modo chiaro e diretto grazie all’utilizzo del seguente diagramma UML [13].
42
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
4.2
Cluster
Il compito di un cluster `e di memorizzare le sessioni che definiscono un set specifico di variabili indicate nella struttura del cluster stesso. Inoltre, `e indispensabile, per un cluster, fornire funzioni che consentano di manipolare tale elenco di funzioni.
4.2.1
Cluster.java
Nell’interfaccia fornita di seguito (presente nel file Cluster.java) si definis-cono le funzioni su cui il clustersManager propaga le richieste.
public interface Cluster { /**
* Stores a session into the cluster *
* @param s the session to be stored */
public void addSession(Jolie_Session s);
/**
* Removes a session from the cluster *
* @param s the session to be removed */
public void delSession(Jolie_Session s);
/**
* Finds the session that correlates with provided message *
* @param m the message to correlate with
* @return the session that correlates with provided massage * returns null if nothing found
4.2 Cluster 43
*/
public Jolie_Session findSession(Jolie_Message m);
/**
* For printing purpose *
* @return the string to be printed */
public String prettyPrint();
/**
* Gets the cluster’s variable structure *
* @return list of cluster’s variable * (i.e. for cluster C(x,y) returns <x,y> */
public List<Jolie_Var> getClusterVariables(); }
4.2.2
ClusterEmpty.java
La semplicit`a concettuale del cluster C(empty) contenente sessioni non specificanti variabili di correlazione ha portato alla creazione di un imple-mentazione separata rispetto a quella degli altri cluster. In questo cluster, data l’assenza di variabili su cui basarsi, l’implementazione mediante radix tree non era fattibile. Le sessioni memorizzate in tale cluster, inoltre, han-no lo stesso livello di correlazione. Si `e scelto, dunque, di implementare, in questo caso, mediante la memorizzazione delle sessioni in una struttura a lista gestita tramite hash table.
public class ClusterEmpty implements Cluster { /**
44
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
*/
private Map<String, Jolie_Session> sessions; /**
* The cluster’s structure (i.e. C(<empty>)) */
private List<Jolie_Var> clusterVariables; /**
* Cluster’s manager */
private ClustersManager manager;
public ClusterEmpty(List<Jolie_Var> list, ClustersManager cm) { this.clusterVariables = list;
this.manager = cm;
this.sessions = new HashMap<String, Jolie_Session>(); }
public void addSession(Jolie_Session s) {
this.sessions.put(manager.getSessionID(s), s); }
public void delSession(Jolie_Session s) {
this.sessions.remove(manager.getSessionID(s)); }
public Jolie_Session findSession(Jolie_Message m) { if(this.sessions.isEmpty())
return null; else{
/* returns the first session stored */ return this.sessions.get(
4.2 Cluster 45
this.sessions.keySet().iterator().next() );
} }
public List<Jolie_Var> getClusterVariables() { return this.clusterVariables;
}
public String prettyPrint() { return "empty";
} }
Dal codice, appare chiaro che, nel caso di un cluster C(empty), la memo-rizzazione (tramite addSession(s)) e la rimozione (tramite delSession(s)) di una sessione sono effettuate rispettivamente tramite una put e una remove su una hash table. La ricerca di una sessione ha un costo computazionale O(1) dato che viene restituita la prima sessione in lista (in quanto ogni sessione `e indifferente dall’altra per quanto riguarda la correlazione).
4.2.3
ClusterImpl.java
Per quanto risulti immediata e semplice la gestione di un cluster C(empty), risulta allo stesso modo complessa negli altri casi. Tutti gli altri cluster, in-fatti, implementano il meccanismo di gestione delle sessioni tramite radix tree.
Per gestire la struttura a grafo su cui si basa l’algoritmo di generazione dei radix tree (vedi 3.2.5 [algoritmo RTG ]), sono state create due classi ad hoc GraphBuilder e GraphNode.
46
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
GraphNode
Di seguito, una porzione del codice (quella pi`u significativa) della classe GraphNode. class GraphNode { List<Jolie_Var> key; List<GraphNode> children; boolean chosen; public GraphNode(List<Jolie_Var> k) { this.key = k; this.chosen = false;
this.children = new ArrayList<GraphNode>(); }
public void addChild(GraphNode n) { this.children.add(n);
}
public boolean wasChosen() { return this.chosen;
}
public boolean choose() { if (this.chosen) { return false; } else { this.chosen = true; return true; } }
4.2 Cluster 47
public List<Jolie_Var> getKey() { return this.key;
}
public void fixList(List<Jolie_Var> l){
List<Jolie_Var> tmp = new ArrayList<Jolie_Var>();
for(Jolie_Var v : l){
for(int i = 0; i < this.key.size(); i++){ Jolie_Var k = this.key.get(i); if(getVarName(v) == getVarName(k)){ tmp.add(k); this.key.remove(i); break; } } } tmp.addAll(this.key); this.key.clear(); this.key.addAll(tmp); } [###] /**
* JOLIE INTEGRATION SECTION */
public String getVarName(Jolie_Var v) { return v.getName();
48
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
}
La struttura di un nodo del grafo `e delineata dalle variabili del correlation set che esso specifica, e queste sono memorizzate all’interno della variabile List < J olie V ar > key. Per gestire la scelta di un nodo da parte dell’algo-ritmo RTG, `e stato fornito il metodo choose(), in modo da poter specificare se il nodo in questione `e stato scelto o meno.
Come noto, risulta indispensabile che una sequenza di variabili nella strut-tura di un radix tree sia un prefisso della sequenza successiva nella stessa struttura. A questo scopo, `e stata implementata la funzione f ixList(List < J olie V ar > l), per gestire i casi in cui si necessiti un cambiamento nell’or-dine delle variabili.
Si vuole porre l’accento sulle ultime righe di codice della classe precedente. Si noti, infatti, come in tale classe `e necessaria un’implementazione del mecca-nismo di integrazione con il linguaggio JOLIE, per quanto concerne il reper-imento del nome delle variabili.
GraphBuilder
Di seguito, una porzione del codice (quella pi`u rilevante) della classe GraphBuilder.
class GraphBuilder {
List<List<GraphNode>> level; // each level of the graph List<GraphNode> roots;
public GraphBuilder(List<Jolie_Var> list) { this.level = new ArrayList<List<GraphNode>>(); for (int i = 0; i < list.size() + 1; i++) {
this.level.add(new ArrayList<GraphNode>()); }
4.2 Cluster 49
GraphNode last = new GraphNode(list); build(last, list);
}
[###]
/**
* Generates a list of root-Node which represents a hierarchy * for building a Radix tree.
*
* @return a list of root-node */
public List<GraphNode> radix_trees() { GraphNode found;
for (List<GraphNode> l : this.level) { for (GraphNode n : l) {
// -- for each node in graph found = null;
for (GraphNode c : n.children) { if (c.choose()) { found = c; break; } } n.children.clear(); if (found != null){ found.fixList(n.getKey());
50
4. Algoritmo “Session correlation management with Radix Tree”: un’implementazione
n.addChild(found); }
/*
* if wasn’t chosen in lower level than is a root */ if (!n.wasChosen()) { roots.add(n); } // --} } return roots; } /**
* Build a graph of all possible subset of given variable *
* @param next The node with biggest number of variables * @param a list of variables
*/
private void build(GraphNode next, List<Jolie_Var> l) { // adds a node into a level, based on number of variables this.level.get(l.size()).add(next);
for (int i = 0; i < l.size(); i++) { // subset of l.size()-1 elements
List<Jolie_Var> tmp = new ArrayList<Jolie_Var>(); for (int j = 0; j < l.size(); j++) {
if (j != i) {