POLITECNICO DI MILANO
Master of Science in Computer Science and Engineering Dipartimento di Elettronica, Informazione e Bioingegneria
A Conceptual Modeling Approach for
the Rapid Development of Chatbots
for Conversational Data Exploration
Supervisor: Prof. Maristella Matera
Co-supervisors:
Prof. Florian Daniel,
Prof. Vittorio Zaccaria
M.Sc. Thesis by:
Nicola Castaldo - 875019
Abstract
A chatbot is a a conversational software agent able to interact with user through natural language, using voice or text channels and trying to emulate human-to-human communication. This Thesis presents a framework for the design of Chatbots for Data Exploration. With respect to conversational vir-tual assistants (such as Amazon Alexa or Apple Siri), this class of chatbots exploits structured input to retrieve data from known data sources. The ap-proach is based on a conceptual representation of the available data sources, and on a set of modeling abstractions that allow designers to characterize the role that key data elements play in the user requests to be handled. Starting from the resulting specifications, the framework then generates a conversa-tion for exploring the content exposed by the considered data sources. The contributes of this Thesis are:
• A characterization of Chatbots for Data Exploration, in terms of re-quirements and goals that must be satisfied when designing these agents; • A methodology to design chatbots which poses the attention on some
notable data elements, along with a technique to generate conversa-tional agents based on annotations made directly on the schema of the data source;
• An architecture for a framework supporting the design, generation and execution of these chatbots exploiting state-of-art technologies;
• A prototype of the framework integrating different technologies for chatbot deployment.
The Thesis also reports on some lessons learned that we derived from a user study that compared the user performance and satisfaction with a chatbot generated with our framework to the performance and satisfaction of the same users when interacting the basic SQL command line.
Sommario
Il chatbot `e un agente informatico capace di interagire con l’utente
attraver-so il linguaggio naturale, utilizzando canali vocali o testuali, nel tentativo di emulare la comunicazione tipica dell’uomo. Questa Tesi descrive un fra-mework per il design di Chatbot per l’Esplorazione di Dati. Rispetto agli as-sistenti virtuali (come per esempio Alexa di Amazon o Siri di Apple), questa classe di chatbot sfrutta richieste strutturate per estrarre dati da specifiche
sorgenti dati. L’approccio `e basato su un insieme di astrazioni concettuali che
permettono ai progettisti di specificare il ruolo che alcuni elementi della base di dati assumeranno nelle future richieste dell’utente. Sulla base di queste specifiche, il framework genera dunque una conversazione per l’esplorazione di tali dati. I contributi di questa Tesi sono:
• Una caratterizzazione dei Chatbot per l’Esplorazione di Dati, con par-ticolare attenzione ai requisiti e agli obiettivi da considerare durante la loro progettazione;
• Una metodologia per progettare tali chatbot che privilegia la tipologia e il ruolo degli elementi che i dati rappresentano, oltre a una tecnica per la generazione di agenti conversazionali basata su annotazioni effettuate direttamente sullo schema dell base di dati;
• L’architettura di un framework in grado di supportare la progettazione, la generazione e l’esecuzione di questi chatbot usando tecnologie allo stato dell’arte;
• Un prototipo di questo sistema che integra tecnologie innovative. La Tesi inoltre discute alcune implicazioni sul design di Chatbot per l’Esplo-razione dei Dati che derivano da quanto osservato in uno studio con gli utenti. Lo studio ha confrontato le prestazioni e la soddisfazione di un campione di utenti che ha interrogato un database di esempio usando un chatbot generato con il nostro framework e la linea di comando SQL.
Ringraziamenti
Ringrazio mia madre Cristina, mio padre Roberto e mia sorella Martina, per esserci sempre stati e non aver mai smesso di credere in me. Grazie per
aver-mi insegnato valori come l’onest`a e la cortesia e per avermi mostrato che con
l’impegno, la tenacia e la passione si possono raggiungere gli obiettivi pi`u
difficili. Ringrazio anche i miei zii, i miei cugini e le mie nonne, per l’affetto che mi avete sempre dimostrato.
Un ringraziamento speciale, poi, va a M´onica, per aver avuto cura di me
nei momenti felici e anche in quelli pi`u ardui, scegliendo sempre di viverli e
affrontarli assieme.
Vorrei inoltre ringraziare i miei amici, per i divertimenti e le difficolt`a che
abbiamo condiviso e per avermi sempre rispettato, apprezzato e voluto bene. Ringrazio inoltre i professori Florian Daniel e Vittorio Zaccaria per il sup-porto e i consigli che mi hanno dato durante tutta la stesura della Tesi. Un grazie sincero va anche ai ragazzi del “TIS Lab”, che hanno accettato di par-tecipare ai test di valutazione del sistema oggetto di questa Tesi.
Infine, un ringraziamento particolare va alla mia relatrice, la professoressa Maristella Matera, per il tempo, l’energia e la fiducia che ha scelto di dedicare a me e a questa Tesi.
Contents
Abstract I
Sommario III
Ringraziamenti V
1 Introduction 1
1.1 Scenario and Problem Statement . . . 2
1.2 Contributions . . . 3
1.3 Definitions . . . 4
1.4 Structure of Thesis . . . 5
2 State of the Art 7 2.1 The (R)evolution of Chatbots . . . 7
2.1.1 The Loebner Prize . . . 7
2.1.2 Virtual assistants . . . 8
2.1.3 A chatbot for everything . . . 8
2.2 Design Approach . . . 8
2.3 Development Choices . . . 9
2.3.1 Local or remote . . . 9
2.3.2 The chat interface . . . 10
2.4 Different Chatbot Frameworks . . . 11
2.5 Related Research Approaches . . . 13
3 Chatbots for Data Exploration 15 3.1 Concepts . . . 15
3.2 Main Requirements . . . 15
3.2.1 Connect to the database to obtain the schema . . . 17
3.2.2 Extract and learn database-specific vocabulary and
ac-tions from schema . . . 17
3.2.3 Automatic intent and entities generation and extraction 18 3.2.4 Proper communication and data visualization . . . 19
3.2.5 Allow the user to manipulate query results . . . 19
3.2.6 Support context and conversation history management 20 4 Approach 21 4.1 Design Process . . . 21 4.2 Schema Annotation . . . 22 4.2.1 Conversational Objects . . . 22 4.2.2 Display Attributes . . . 24 4.2.3 Conversational Qualifiers . . . 25
4.2.4 Conversational Types, Values and Operators . . . 26
4.2.5 Conversational Relationships . . . 28
4.3 Conversation Modeling . . . 28
4.3.1 Intents . . . 30
4.3.2 Entities . . . 31
4.4 From the Conversation Model to the Interaction . . . 34
4.4.1 Interaction paradigm . . . 34
4.4.2 Automatic query generation . . . 35
4.4.3 Chatbot responses . . . 42
4.4.4 History navigation . . . 45
5 System Architecture and Implementation 47 5.1 Technologies . . . 47 5.1.1 RASA . . . 47 5.1.2 Chatito . . . 51 5.1.3 Telegram . . . 52 5.2 Framework Architecture . . . 53 5.3 Chatbot Architecture . . . 55 5.4 Implementation Tools . . . 58 6 User Study 61 6.1 Comparative Study: General Setting and Research Questions . 61 6.2 Participants and Design . . . 63
6.4 Procedure . . . 65 6.5 Data Collection . . . 66 6.6 Usability Analysis . . . 67 6.6.1 Efficiency . . . 68 6.6.2 Effectiveness . . . 68 6.7 Satisfaction . . . 69 6.7.1 Usability . . . 70 6.7.2 Workload . . . 71
6.7.3 Easiness of exploring DB/retrieving data/using com-mands and quality of presentation . . . 72
6.7.4 User ranking of systems along completeness, easiness and usefulness . . . 73
6.8 Qualitative Data Analysis . . . 74
6.9 Lesson Learned . . . 75 7 Conclusions 79 7.1 Limitations . . . 80 7.2 Future Work . . . 81 7.3 Publications . . . 82 References 83 A Parsed Database Schema 87 B Database Schema Annotation 91 C User Study Questionnaires 103 C.1 Demographic Questionnaire . . . 103 C.2 System Questionnaire . . . 104 C.2.1 Ease of use . . . 104 C.2.2 Cognitive load . . . 106 C.2.3 General questions . . . 107 C.3 Final Questionnaire . . . 108 IX
List of Figures
3.1 A Conversation example between a user and the chatbot. . . . 16
4.1 The relational schema of the database. . . 23
4.2 The Conversational Objects annotation. . . 24
4.3 The Display Attributes annotation. . . 25
4.4 The Conversational Qualifiers annotation, focus on customer. . 27
4.5 The Conversational Relationships annotation. . . 29
4.6 An example of the entity extraction phase. . . 32
4.7 The typo resolution procedure. . . 42
4.8 The response of the chatbot to display a single result. . . 44
4.9 The response of the chatbot to display multiple results. . . 44
4.10 An example of conversation history visualization. . . 45
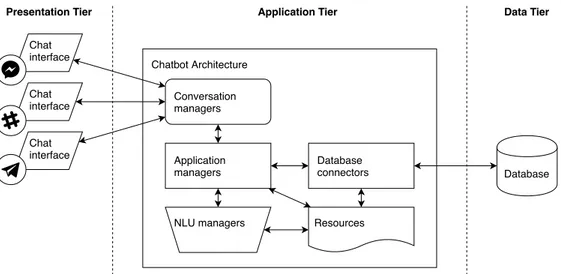
5.1 An overview of the Framework Architecture, based on the three-tier model. . . 53
5.2 The Chatbot Architecture in details. . . 55
6.1 The classicmodels database schema used in the evaluation tests. 62 6.2 Comparison for the two systems of the number of successes . . 71
6.3 NASA-TLX dimensions: means and standard deviation com-parison. . . 73
List of Tables
4.1 Phrase structure for find intents. . . 32
4.2 Phrase structure for filter intents. . . 33
4.3 Phrase structure for help intents. . . 33
6.1 Paired Sample t-test results related to the time the users spent
on each task. . . 69
6.2 Detail on the completion of each task: Failures, Partial
suc-cess, Success . . . 70
6.3 NASA-TLX dimensions values. . . 72
List of Algorithms
1 Find Query Builder . . . 36
2 Join Query Builder . . . 40
Listings
5.1 A json extract of the training data. . . 495.2 An example of input document for Chatito. . . 51
5.3 A json extract of the simplified database. . . 58
5.4 A json extract of the database Schema Annotation. . . 59
Chapter 1
Introduction
Chatbots are growing fast in number and pervade in a broad range of activ-ities. Their natural language paradigm simplifies the interaction with appli-cations to the point that experts consider chatbots one of the most promising technologies to transform instant messaging systems into software delivery platforms [15, 18]. The major messaging platforms have thus opened their APIs to third-party developers, to expose high-level services (e.g., messag-ing, payments, bot directory) and User Interface (UI) elements (e.g., buttons and icons), to facilitate and promote the development of innovative services based on conversational UIs [21].
Despite the huge emphasis on these new applications, it is still not clear what implications their rapid uptake will have on the design of interactive systems for data access and exploration. The applications proposed so far mainly support the retrieval of very specific data from online services. It is still unclear how this paradigm can be applied for the interaction with large bodies of information and machine agents. A critical challenge lies in understanding how to make the development of bots for data exploration scalable and sustainable, in terms of both software infrastructures and design models and methodologies [2, 27].
To fill this gap, in this Thesis we propose a methodology to support the design of chatbot interfaces for accessing extensive collections of data by means of a conversational interaction; in particular, we propose a data-driven paradigm that, starting from the annotation of a database schema, leads to the generation of a conversation that enables the exploration of the database content.
1.1
Scenario and Problem Statement
Let us consider the situation in which a person enters in a library and asks some information about a novel at the helping desk. Usually librarians are able to identify books quite well, but this time the task has some unexpected difficulties: the client does not know either the title or the author and just wants something to read. The employee cannot do very much without in-vestigating the client’s preferences or giving personal advices, because the searches on the online catalog of the library are possible only using keywords that are somehow related to a book, in terms of title, author or publishing house.
In this example the attitude of the client is not to simply find something in particular, based on some known properties of the object being researched, but is rather to explore the library resources without a fixed target and not knowing what will be the result of the inspection. What if the librarian could fulfill the customer’s needs with a tool able to support this kind of exploration? How could this device be designed?
The key point of this appliance would be the ease to use: its users should not need to learn how the system works, but they should understand its features and possibilities while using it. So, a possible approach is to cre-ate a tool able to emulcre-ate human-to-human interaction, by communicating through the natural language, using text or vocal channels. This technology is also known as chatbot and its implementation may fit the needs of our purpose. The chatbot, also known as conversational agent, should allow the user to navigate across the catalog, exploiting all the relations between the different entities in it. For example it could support the input phrase “find the books written by Dante” and execute the search against the catalog, by automatically understanding that “Dante” is the keyword for the name of the author. Then it could display the titles of the books in the forms of buttons and, upon clicking on “La Divina Commedia - Inferno”, it could present the details of the volume as well as its basic relations, i.e. author, publishing house, etc.
Up to now, it seems that our imaginary chatbot would be able to act as a special search engine, that understands and translates sentences into commands, but still distant from offering the above mentioned explorative feature. What if, then, the user could navigate from the “La Divina Comme-dia - Inferno” to the collections of volumes that include the masterpiece and
were borrowed by someone else? Then, after clicking on the details of one of these, the navigation could proceed towards its publishing house, then to its publishers, then maybe to one of these authors and then again to the books given to the library by someone that once borrowed a volume from this last writer. The chatbot could offer all of these features and more, by presenting to the user different relations and paths to be taken from the various entities under observation.
The term exploration can be finally applied to this type of navigation, since the user can navigate among entities and relations of the library catalog without really having a destination in mind.
There are many real world application where such a conversational agent could be used and each one of them might have different modalities, with respect to the users it is supposed to embrace, the quantity of relations among the data and the values to be displayed. For example, this feature could be supported by a data storage for investigative research, enabling detectives to easily and freely navigate across the data describing past cases. This system could be also applied to a medical database, allowing doctors to explore attributes and possible relations of clinical past situations. Moreover, this kind of chatbot may be used within a business company, in order to explore the data its database contains, with different levels of granularity, in terms of searches and relations among the various elements.
1.2
Contributions
In this Thesis we define a data-driven design paradigm that, starting from the structure of a typical data system, enables the generation of con-versation paths for its exploration.
In particular, we provide:
• An explanation of the concept of Chatbots for Data Exploration, with reference to the requirements and goals that must be satisfied when designing these type of systems;
• An architecture for a framework able to support the creation of these conversational agents, also exploiting state-of-art technologies;
• A methodology to design chatbots which poses the attention on the data characteristics, rather than the technologies involved;
• A technique to generate conversational agents based on annotations made directly on the schema of the data source;
• A prototype of this framework integrating different technologies to de-ploy it;
• Some design implications derived from a comparative study that we conducted to test the performance of the chatbot generated through our framework with respect to the basic SQL command line interaction. From the qualitative and quantitative analysis of the data gathered through the user study we can state that the resulting applications, as well as the framework for their development, can be considered as a first valid step towards the generation of Chatbots for Data Exploration.
1.3
Definitions
We provide below the definitions of the main concepts related to our work. • Chatbot: a conversational software agent able to interact with user
through natural language, using voice or text channels and trying to emulate human-to-human communication.
• Chatbot Framework: is a cloud based chatbot’s development platform that enable on line development and testing of chatbots; usually, it also provides Natural Language Processing (NLP), Artificial Intelligence and Machine Learning services with Platform as a Service paradigm (PaaS).
• Chat Interface: with this term, we refer to any system that supports text-based input from the users.
• Schema Annotation: abbreviation for Database Schema Annotation, it refers to the procedure (and its outcome) of characterizing tables, relations and attributes of a database conceptual model, in order to produce a mapping between the data source and the conversation in-teraction basis.
• NLU: it stands for Natural Language Understanding, and it is a branch of Artificial Intelligence that uses computer software to understand input made in the form of sentences in text or speech format [26].
• Intent: it represents the purpose of the user’s interaction with a chat-bot; for instance, from the phrase “What time is it? ” the intent, if defined, could be to know the current time.
• Intent-matching: it is the NLU process of understanding the intent from a given input phrase.
• Entity: it is a word or a set of words that represent a concept in a given utterance; for instance, in the phrase “I live in Milan” the word “Milan” may be an entity related to the concept of location.
• Entity-extraction: it is the NLU procedure of identifying entities inside input phrases provided to the chatbot.
• Context: it represents the current background of a user’s request;[12] in a chatbot, it is needed to correct handle subsequent inputs which may refer to previous outcomes; for instance, in the consecutive interactions [User: “What is the weather like in Milan? ”] → [Chatbot: “Sunny”] and [User: “And in Rome? ”] → [Chatbot: “Cloudy”], the second ques-tion would not make sense without the previous request, which creates the context (in this case, related to the weather) of the whole dialog.
1.4
Structure of Thesis
• Chapter 2 is an overview of the history of chatbots, the state of art and the most popular available frameworks that support the deploy-ment of such applications. In this Chapter we highlight the differences among the various technologies, highlighting pros and cons of each one, considering implementation and design choices.
• Chapter 3 provides a definition of Chatbots for Data Exploration and defines the main goals and requirements that must be treated to design them.
• In Chapter 4 we provide a conceptual modeling approach for the de-sign of these kinds of chatbots. We offer a solution to the requirements defined in the previous Chapter, splitting the design process in three parts: the Schema Annotation, the Conversation modeling and the In-teraction modeling.
• Chapter 5 describes the architectural and implementation choices that we made when developing the prototype of a Chatbot for Data Explo-ration.
• In Chapter 6 we provide an evaluation of our framework, by means of a comparative study between our conversational agent and the SQL command line, regarding the execution of some information retrieval tasks on the same data source. We discuss the details of our tests and the collected data, making quantitative and qualitative analysis. • In Chapter 7 we conclude the Thesis with a summary of the overall
study, considering limitations, future works and possible improvements of our framework.
• The Appendices report:
(i) a JSON-based specification of the database schema of the example database used throughout the Thesis (Appendix A),
(ii) the annotated database schema, which is the input of the process leading to the generation of a conversation for the exploration of the example database content (Appendix B),
(iii) the questionnaires administered during the user study (Appendix C).
Chapter 2
State of the Art
2.1
The (R)evolution of Chatbots
In this Section we will discuss how chatbots grew from past to present, in terms of technologies and capabilities, and how nowadays there are more and more domains in which they are applied.
2.1.1
The Loebner Prize
Nowadays, chatbots technologies are growing faster than ever [9], but their story started in in the second half of 1900s. The Turing Test, also known as the Imitation Game, was proposed by Alan Turing in 1950 as a replacement for the question “Can machines think? ” [1, 25]. It consists in a quiz to be held with a computer able to answer questions, requiring the judge to be uncapable to distinguish whether the interlocutor is a human or not.
This idea was taken by Hugh Loebner, which in 1991 decided to create an annual competition for evaluating computer programs ability to emulate a human, just like the original Turing Test required. The contest survived all of these years and different chatbots won the first place over time.
The first winning machine was ELIZA, a computer program created in 1966 whose conversation structure was then associated to the ones pursued by certain psychotherapists, known as Rogerians [32]; the program won three consequent Loebner prizes (’91, ’92, ’93).
Other examples of more recent winning chatbots are A.L.I.C.E (2000, 2001, 2004) and Mitsuku (2013, 2016, 2017, 2018) [1, 29]. Both programs were created using a AIML knowledge base, that is a derivative of XML, and
performed pattern matching on each input to elaborate a response.
2.1.2
Virtual assistants
The Loebner prize, as introduced in the Subsection 2.1.1, is assigned by evaluating ability of the chatbot to mock human behavior. However, in the last few years, another type of chatbot come up: the Virtual Assistant, a software agent that can interpret human speech and respond via synthesized voices. The most popular examples of such systems are Apple’s Siri, Ama-zon’s Alexa, Microsoft’s Cortana, and Google’s Assistant. According to [17], “these kinds of chatbots are always connected to the Internet and each in-teraction is sent back to a central computing system that analyzes the user’s voice commands and provides the assistant with the proper response.”
They offer generic one-size-fits-all services [11], by enabling their users to access different functionalities like setting reminders, performing inter-net searches, communicate with remote home automation systems and other simple tasks that would require longer interactions to be completed manually.
2.1.3
A chatbot for everything
Besides the systems described in the previous subsections, chatbots start to be created and used in an increasing number of specific domains, each with its own requirements. For example, a 19-year-old student designed a chatbot to help drivers that received parking tickets, in London and New York, to contest the fine; the results of 2016 show that the system had a success rate of 64%, in less than two years from its launch, by overturning 160,000 tickets [23]. In 2017, at the Manipal University, a conversational agent was designed to answer FAQs related to that educational institute [30]. Another more recent example, dated 2018, consists in the development of a chatbot for meal recommendation [13].
2.2
Design Approach
From a high perspective, chatbots can be distinguished in two different mod-els by the way they generate responses: Retrieval-based and Generative-based [31, 28].
The first approach allow to assemble the answer by selecting from a set of predefined responses according to the input, the context and some heuristic. The latter may be as simple as a rule-based expression match, or i could include Machine Learning classifiers trained to predict the matching score. Their main advantage is that the answers provided are always grammatically correct, but since they are picked from a finite set of choices, they may lack originality.
Chatbots designed following the second model, instead, build new re-sponses from scratch, treating generation of conversational dialogue as a statistical machine translation problem. In fact, depending on the current context of the conversation, they are able to autonomously create the answer word by word, based on a given vocabulary.
2.3
Development Choices
As we have seen in Section 2.1, there are multiple applications of the chatbot concept, each one with different purposes. It is important to highlight how, over the years and starting from the first conversational agent ELIZA, these systems increasingly exploited technologies belonging to the Web and, more specifically, those related to the APIs.
A common example is the case of the chatbot for weather forecasting, that is able to help getting information about present and future climate changes based on the location of the users. This is possible thanks to the availability of some external Web based APIs which the system can make request to, in order to transform their response into an utterance that includes the wanted data about weather.
Let us discuss now which development choices must be taken when start-ing to developstart-ing a chatbot like the one just described.
2.3.1
Local or remote
To begin with, we can distinguish three development choices related to the possibility of taking advantage of existing Web resources. Thus, let us pose our attention on where to place the internal modules of the chatbot, i.e. the Natural Language Understanding service and the application unit.
A first approach considers relying completely on existing development frameworks available online. These systems usually offer a user friendly
terface and tools to develop a fully functioning chatbot easily. Their main drawback is represented by their rigidity and lack of customization features, along with their strict dependence on the Web platform they stand upon.
Another option, instead, is to rely on a Web based system to develop the Natural Language Understanding unit, while deploying the application mod-ule independently. This gives both the opportunity to completely manage all the logic behind the conversation, while delegating the problem of intent matching and entity translation to the remote service. In this case, the latter acts as an on demand translator of input phrases, properly sent by means of a dedicated API. It is important to remind that this choice does not prevent the developer from instructing the Web service on how utterances should be managed: the necessity to define which intents the chatbot can recognize, as well as the entities, is still present and bound to the remote architecture specifications.
The last approach is related to the development of a standalone system, in which the developer has to create an ad-hoc model which includes both the utterance parsing and the dialogue management part. This development di-rection allows not to be dependent to Web services, on the Natural Language Understanding side, but it could still require a stable Internet connection in case information retrieval is related to some APIs. The main advantage of this development approach is the possibility to completely craft a system able to respond to the developers needs, both in terms of how the chatbot can interpret utterances and how the conversation must continue once this procedure is completed.
2.3.2
The chat interface
Another aspect that must be considered, during the development of a chat-bot, is the communication channel that will support the input of the users that will interact with the system.
A first solution may include the creation of a custom chat interface in-tegrated to the system and accessible through a dedicated application; it could be deployed locally or as a remote service, i.e. accessible by means of a Web page. In this situation an additional effort is required to the devel-oper, bearing in mind that the conversation quality may be enhanced by the introduction of dedicated buttons, for instance.
platforms that already offer a solution to these kind of problems. In fact, they allow the developer to create an account belonging to their system and provide an API to control the messages sent and received by this online profile. The main advantage derived by the usage of these online interfaces is that they are always available and already provide advanced user friendly communication features, e.g. buttons, images exchange, document sharing, etc. Moreover, the developer may use more than one of these systems at a time just enabling the system to understand and communicate with the APIs, without changing the logic of the application. The main drawback of such development choice is the dependence on an always available Internet
connection. Examples of these systems are Telegram1, Slack2, Messenger3,
Twitter4, Kik5, Line6, Viber7, etc.
2.4
Different Chatbot Frameworks
In the previous section we analyzed the choices that must be made when developing a chatbot, in terms of where the various modules could be allo-cated, if locally or remotely, and whether it is better to use an existing chat interface or to build a new one from scratch.
Now let us consider in details the most popular frameworks that allow to develop a chatbot, considering the services they offer with respect to the development decisions described so far. Thus, during this analysis we will concentrate both on NLU and dialogue management features, along with the ease of set up and interoperability with existing chat interfaces.
Dialogflow8, as first example, is an online framework that require a
manual configuration of intents, entities and contexts management and dec-laration capabilities. Besides the NLU feature, it integrates a dialogue man-agement system able to perform customizable API calls and to maintain in memory some parameters with settable lifespans. Moreover, it integrates well with the majority of chat interfaces available online, it offers SDKs for
multi-1https://telegram.org/ 2https://slack.com/ 3https://www.messenger.com/ 4https://twitter.com/ 5https://www.kik.com/ 6https://line.me 7https://www.viber.com/ 8https://dialogflow.com/ 11
ple programming language and integrates a Machine Learning procedure to increase the chatbot comprehension of the user’s input.
Wit.ai9 is a very similar online tool and provides almost the same
func-tionalities. The definition of custom actions is common to both, along with their ease of integration with external application programming and chat in-terfaces. Both the systems present an HTTP API to limit the interaction to create and use the chatbot; moreover, the two present an internal system for speech recognition.
PandoraBots10, instead, limits its features to the NLU tool, which is
accessible via its API. It is based on the AIML language, a derivation of XML, which allow the definition of input pattern and related templates for the answer. Its definition is not as intuitive as the other framework a analyzed so far, but it allows the total control of the bot’s knowledge based. In any case there is a limitation in terms of max number interactions with the free license.
Another online framework is FlowXO11, which allow the definition of the
chatbot conversation by means of an online graphical editor. While being highly integrated with various chat interfaces and existing APIs, it allows the connection with a custom Webhook as well. It also present an internal NLU system for message parsing.
Watson12 is another online tool that provides the development of
chat-bots. As DialogFlow and Wit.ai, it allows the definition of intents and entities and provides a dialogue management system, as well as a NLU interface. The developer can also connect a custom webhook and/or communicate with a dedicated API. The main disadvantages, besides requiring a continue Inter-net connection since it can only be hosted in cloud, include the necessity to define sequences of intents for context management.
Chatscript13, instead, is “a rule based engine, where rules are created by
human through a process called dialog flow scripting”. This chatbot tool can run locally and offer services like: a pattern matching algorithm aimed at detecting the phrase meanings, an extensive and extensible ontology of nouns, verbs, adjectives and adverbs, the ability of remembering user interactions
9https://wit.ai/
10https://www.pandorabots.com/ 11https://flowxo.com/
12https://www.ibm.com/watson
across conversations and the rules capabilities to dynamically alter engine and script behavior [12].
Another framework is represented by RASA14, which is “a set of open
source machine learning tools for developers to create contextual AI assis-tants and chatbots”. It offers two different technologies: RASA Core and RASA NLU.
The first one is a chatbot framework with Machine Learning-based dia-logue management, which allows the definition of the conversation structure, by means of a dedicated markup language. During the design phase, the developer may describe some wanted conversation paths, in terms of likely future sequences of intents. Then, after the dialogue engine is trained ac-cording to this model, the chatbot is able to match the received phrases against these intents while maintaining the context in a previously created target sequence. Moreover, the developer can specify custom actions which will be called when a specific intent is matched, as well as direct utterances to respond to user messages or custom variables to extract, persist and reuse during the conversation.
RASA NLU, instead, is a library for Natural Language Understanding which offers intent classification and entity extraction features. Its main advantages are that it can run locally and it is highly customizable, while being lightweight from a programming point of view. In fact, the developer does not have to learn and apply a new language, like in the case of AIML, since RASA NLU allows the definition of free-text training phrases; these examples, then, are used to train an Artificial Intelligence model that will be used during the conversation phase. Moreover, although it is an open-source solution, it easily competes with the other commercial products analyzed so far [5].
2.5
Related Research Approaches
As we said, in the last years we have assisted to the creation and spread of new frameworks for the development of chatbots, as well as the opening of the APIs conducted by the major messaging platforms towards third-party developers. However, what seems to be still missing is a common methodology that guide the creation of a conversational agent, i.e., a model
14https://rasa.com/
that define the design procedure in terms of requirements, objectives and dialogue characteristics.
Some commercial frameworks developed their own dialogue management system, exploiting the concepts coming from the NLU field and each defining a dedicated engine based on popular Knowledge Bases, Machine Learning
technologies or Artificial Intelligence concepts. However, besides offering
state-of-the-art technologies and a user-friendly interface for their integration, they are limited to the creation of specific chatbots; in other words, when using these systems, the design process is limited to the offered model and, above all, has to be conducted differently with respect to the requirements of each conversational agent.
The lack of a models for a design methodology can be traced back to the complexities that the development of a chatbot involves. A scientific investigation conducted in 2018 describes “the lack of research about how to effectively workout a Return-Of-Investment (ROI) plan” when dealing with the design of a chatbot [27]. In particular, it introduces a few important dimensions that need to be considered, like the interaction of the user with the agent, in terms of information retrieval and presentation, or the integration aspect with databases or external APIs. Moreover, the conversation quality assurance, maintainability and dialogue analysis are also fundamental aspects that need to be considered when designing these conversational agents.
A research approach similar to the one we discuss in this Thesis proposes a data-driven model for the design of a chatbot dedicated to educational sup-port [2]. Although the project aimed at the creation of a learning assistant, the first step for its development started from a definition of a paradigm to annotate the dataset involved. The introduction of a procedure that acts on the data system enabled the overall study not to be bound to the content of the data, rather to be extended to all the information systems built with the same technology.
This is also the aim of our research, i.e., the definition of a model that, starting from the characterization of the data, enables its exploration by means of a conversational support.
Chapter 3
Chatbots for Data Exploration
3.1
Concepts
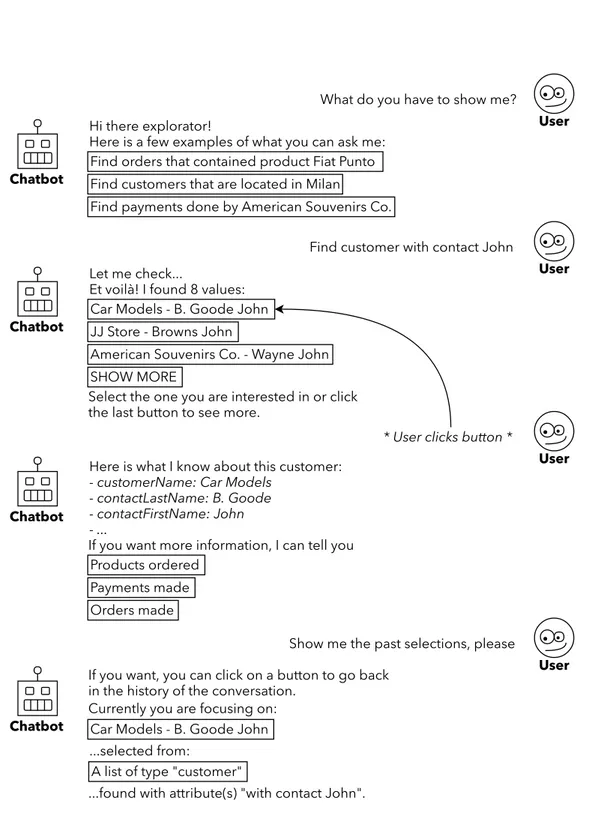
Let us introduce the idea of a Chatbot for Data Exploration with the help of a conversation example between an user and the chatbot itself, as shown in Figure 3.1.
At first, the user does not know how the system works, but after a few messages the capabilities of the chatbot are made clear. It is easy to see how all the interactions have a common thread, that is the dynamic visualization of some data. What is remarkable is that knowing the structure of data is not a precondition for their visualization, since the system helps the user by showing examples and buttons, which can be considered as hints for the continuation of the conversation. This mechanism of interplay between user requests and application responses, represents what can be defined as an exploration of a set of data, by means of a conversational approach.
These three keywords, indicated in bold above, are the concepts that will guide the definition of the objectives and the characterization of the field of action to develop our system.
3.2
Main Requirements
The goal of the system that is the object of this work is to offer a tool capable of navigating among some data. To achieve our objective, there are a number of requirements to be fulfilled by the environment for the chatbot generation and execution.
What do you have to show me? Hi there explorator!
Here is a few examples of what you can ask me: Find orders that contained product Fiat Punto Find customers that are located in Milan
Find payments done by American Souvenirs Co.
Find customer with contact John Let me check...
Et voilà! I found 8 values: Car Models - B. Goode John JJ Store - Browns John
American Souvenirs Co. - Wayne John Select the one you are interested in or click the last button to see more.
* User clicks button *
Here is what I know about this customer:
- customerName: Car Models - contactLastName: B. Goode - contactFirstName: John - ...
If you want more information, I can tell you Products ordered
Payments made Orders made
Show me the past selections, please If you want, you can click on a button to go back
in the history of the conversation. Car Models - B. Goode John Currently you are focusing on: ...selected from:
A list of type "customer"
...found with attribute(s) "with contact John". Chatbot Chatbot Chatbot Chatbot User User User User SHOW MORE
3.2.1
Connect to the database to obtain the schema
As a first requirement, the chatbot must be able to connect to with a database. In this Thesis we focus on relational databases, but in princi-ple this requirement is to be considered for any data model. However, in the following, we will make reference to the relational model, which is the one our prototype has been defined for. In any case, the information retrieval can take place only when both the right query language and the internal structure of the data system are known to the chatbot.
While the first problem can be solved with the help of the right connec-tor, which is capable of connecting to a database and performing queries, the second issue may be more difficult to solve: the system must be able to correctly identify the relations among the different tables and create an abstraction of the schema suitable for the type of navigation at the basis of the chatbot.
3.2.2
Extract and learn database-specific vocabulary
and actions from schema
Not only the conceptual model of a database is unique in terms of tables, attributes and relations, but also the information it stores varies depending on the elements its tables represent and the characteristics more valuable in the context of its usage. A system able to support this conceptual and logical heterogeneity is not likely to fit the need of a proper conversation by simply relying on the structure of the database, since there is no guarantee that the information it represents becomes relevant when visualized as it is. For example, if we consider a Cross-Reference Table in a relational database, we clearly see how its rows become human-readable only when analyzed with the tables it relates to. One possible approach to tackle this problem could be the automated limitation of the visualization of some tables based on their structure, but this might lead to the unintentional removal of possible valuable information.
A better perspective could be to consider the complexity of the database as a starting point towards the definition of a suitable abstraction in the con-text of a conversation. The result of such a procedure would be a data-driven model that represents the database as a network of connected elements that could fit the necessities of the final user. Specific vocabulary, for example,
might be used to refer to the different entities of the data system, as well as custom actions to take when focusing on each of them, by exploiting existing relations and defining new ones, in a user-oriented viewpoint.
This customization is more likely to be carried out manually, by a De-signer that knows how information is organized in the database and what could be the interests of visualization and navigation of the final users. This process can be considered as the design of the conversation and may allow the definition of multiple conversation models for the same data system, depend-ing on the most relevant interests of the ultimate consumers, as identified by the Designer.
3.2.3
Automatic intent and entities generation and
ex-traction
Since the key feature of a chatbot is the ability to interpret natural lan-guage input, one requirement that our system must meet is the capability to automatically train a natural language model which permits to understand phrases related to the context of the data it handles. In the previous Sub-section we discussed how the schema of the database may be abstracted in a conversation-oriented perspective, but we did not define how this resulting model might be used to guarantee the specifications just declared.
A possible approach, following along these design choices, could take ad-vantage of the concepts of intents and entities belonging to the Natural Lan-guage Processing (NLP) area. While intents, which can be considered as the intention of the user, could be mapped to specific actions to be performed on the database (e.g. filter, select, join, etc.), entities represent the elements that the chatbot can extract from an input phrase and that could be associated with the elements structuring the data system, i.e., its tables, relations and values.
Relying on these assumptions, when the chatbot receives a phrase, it could perform what is called intent matching: the process of understanding what the objective of the input utterance is and its consequent translation into a database query. Entity extraction, instead, could be used to correctly parametrize the request, in terms of table and attribute references.
It is important to consider the fact that the phrases the chatbot receives don’t have to be formulated in a metalanguage which only relax the syntax requirements of the SQL language; rather the system should rather accept
and correctly understand utterances belonging to the natural language. In order to reach this objective, the bot might train its NLP model using some sets of example phrases for each intent to recognize, labelled in accordance to the entities each pattern contains.
3.2.4
Proper communication and data visualization
Once the system interprets a user utterance and executes the correspond-ing command, the problem of presentcorrespond-ing the results arises. While the chat environment can be considered a user-oriented communication channel as it simplifies the way requests can be done by relying on the natural language format, it is also true that it may represent an issue from the system per-spective. In fact, the user experience must be designed on the basis of a conversation, thus with a number of limits that a graphic tool, for instance, would not have.
Since the object of the navigation are the data, the first issue to solve is how to present them in a readable way. Let us consider the Figure 3.1: after the user asks the bot to find some elements and the system performs the related search, the results are displayed as a list of buttons, identified with some words representing the elements they link to. This simple example already highlights how the chatbot should be able to:
• Respond to the user using natural language, in order to present its results;
• List the results in a readable way, taking into account their quantity and short messages to identify them;
• Take advantage of buttons, to simplify selections and the overall navi-gation.
Besides these requirements, the system may handle cases of typos, wrong insertions/selections, help requests and so on, which are conditions in which the communication flow skews from its expected path.
3.2.5
Allow the user to manipulate query results
A possible request by the user may involve the visualization of a high number of elements and, because of this, the chat environment might represent the
bottleneck of their readable visualization. Thus, the user may have the need not to view them all, but to filter them according to some attribute.
3.2.6
Support context and conversation history
man-agement
Other important aspects that may be part of the system refer to the man-agement of context memory. This represents the capability to interpret each user request not just as an independent single command, but as the out-come of an evolution of connected intentions over time. While from a human perspective this condition represents the basis of a conversation, in which every interaction is guided directly or indirectly by the progression of the past ones, this aspect has to be considered carefully in the computer systems dimension.
For what concerns the system we aim to define, we should consider the context management as a key functionality, since navigation is only possible when the steps that shape the chosen path among data are known to the chatbot. In other words, the the system must remember previous user’s requests to enable the refinement of the results by some filtering, or the exploration of elements related to the past ones displayed.
Besides this critical requirement, the chatbot could also offer the possibil-ity to go back in conversation, by restoring its context to a precise moment and allowing the navigation through a different dimension from the previ-ously chosen one. This is the case of the last interaction represented in Figure 3.1, where the chatbot displays the history of its conversation with some buttons linking to the elements they refer to.
Chapter 4
Approach
Now that the requirements and goals have been made explicit, it is important to define what are the steps that have to be taken when designing the chatbot according to our methodology. Since entities of various types are necessary and each of them play different roles in the system, we need to take particular care of their heterogeneity during the design phase and we must consider what is our purpose at each step. Therefore, our modeling choices are directed towards our objectives, while being feasible with respect to the architectures they rely upon.
4.1
Design Process
We can consider the creation of the chatbot for the exploration of a database as a semi-automatic procedure. In fact, the process of designing the system includes both automatic and manual phases. The manual phases have to be performed by a Designer, who knows the database, the goals and the requirements of the bot to be developed.
Parsing of the database schema. This is the first phase of the chatbot
design process and it is automatically executed by the system. In this step, the schema of the target database is parsed and interpreted, in order to obtain a simplified version which highlights its structure, in terms of table attributes and relations among entities, not considering additional details about data types, nullable or default values, etc. Moreover, this representation is needed to support the annotation activity described in the next paragraph.
Schema Annotation. This can be considered as the core part of the whole design process and must be performed manually by the Designer. In this phase the simplified database schema is annotated with special tags that will be used in next step to generate the conversation itself.
NLU model extraction This last phase is done automatically by the
system and consists in the training of the Natural Language Understanding (NLU) model. This process is carried out in two separate steps:
1) The generation of the training phrases, based on the annotation of the schema.
2) The training of the NLU model, starting from the utterances just cre-ated.
It is important to say that this phase is quite delicate even if it is completely performed by the system. In Section 4.3 we explain in details what are the key points to generate the NLU model, while in Chapter 5 we describe a possible solution that supports this procedure.
4.2
Schema Annotation
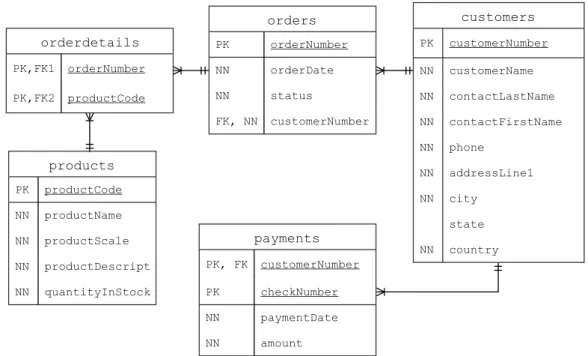
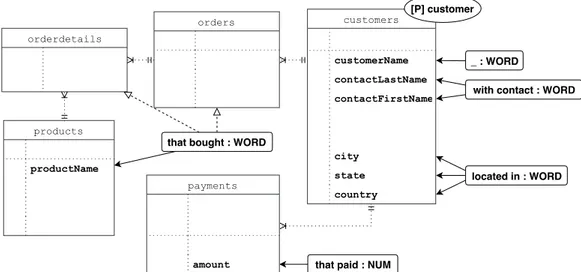
To translate an input phrase into a specific query on the database, we propose the definition of a mapping between what can be understood by the chatbot (intents and entities) and the elements of the database (tables, attributes, relations) by means of a Schema Annotation. This section is devoted to illustrate the main ingredients for this mapping procedure and the recipe of the approach; to make the description easier to follow, we will refer to an example database shown in Figure 4.1.
4.2.1
Conversational Objects
The first step is to characterize the database tables to express the role that the elements they represent play in the exploration of data:
1) Primary - tag [P] 2) Secondary - tag [S]
customers customerNumber PK customerName NN contactLastName NN contactFirstName NN phone NN addressLine1 NN city NN state country NN payments customerNumber PK, FK checkNumber PK paymentDate NN amount NN orderdetails orderNumber PK,FK1 productCode PK,FK2 orders orderNumber PK orderDate NN status NN customerNumber FK, NN products productCode PK productName NN productScale NN productDescript NN quantityInStock NN
Figure 4.1: The relational schema of the database.
The distinction between the first two types is that while values belonging to a Primary table may represent useful information without the need of a context, Secondary tables contain data strongly related to other entities, which become clear only when that specific relationship is considered. For example, tagging as Secondary the table payments means that the access to its values depends on another table, customers. In other words, with this characterization the Designer defines that instances of payments can be retrieved only by passing first through instances of customers, for example because payments data would not be meaningful otherwise. Labeling ta-bles as Primary, in contrast, relaxes this dependence constraint and enata-bles direct queries on tables. Finally, Crossable Relationship characterization is dedicated to bridge tables, i.e., the ones that represent many-to-many re-lationships between entities. Their rows may have a meaning only when a join operation across them is executed; thus no direct or deferred search is allowed on them.
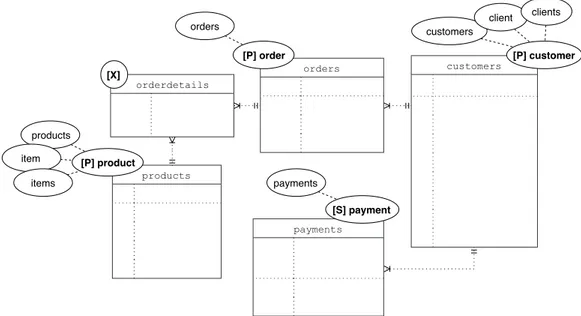
Some tables might have names not suitable in the context of a conver-sation. Thus, as reported in Figure 4.2, each Primary and Secondary table has to be labeled with a keyword, i.e., the name that will represent it during the conversation, that from now on we will call Conversational Object.
For example, in the request “find customer with contact John” in Figure 3.1, the chatbot understands that customer is the placeholder for the table customers. As represented in Figure 4.2, multiple words can be associated to a table, acting as aliases for the same element; this will allow the users to refer to them in multiple ways. As a result, the chatbot will be able to understand customer, client and both their plural form as keywords for the same, enabling the user to prefer different utterances, like “find client with contact John”. customers payments orderdetails orders products [X] [P] product [P] order [P] customer [S] payment customers client clients orders products item items payments
Figure 4.2: The Conversational Objects annotation.
4.2.2
Display Attributes
If we pay attention to Figure 3.1, we can see how the chatbot, after the first interaction, displays a list of customers. What is remarkable is that the values shown seems to be representative of the objects they refer to. In other words, the chatbot does not show all the information related to each element when displaying them in a list and it does not even limits the visualization to their primary key, which is unique but maybe not informative; it rather shows the name of the customer, as well as its contact.
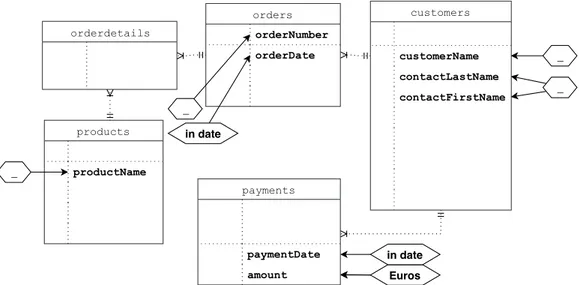
This is possible because the Designer, when dealing with the Schema An-notation, tagged the table attributes customerName and the pair
(contact-LastName, contactFirstName) as Display Attributes. In fact, this pro-cedure enables the chatbot to refer to the values there contained to display the results in lists as we described before and it can be applied to Primary and Secondary tables. In Subsection 4.4.3 the problem of results visualiza-tion is described in details. In Figure 4.3 there is a graphic representavisualiza-tion of the Display Attributes annotation performed on the example database.
By looking at the Figure, we can appreciate how some of these columns may be aggregated into a single list, like in the case of (contactLastName, contactFirstName), as we already considered in the example just described. Some others, instead, present a word or a short phrase linked to them. This annotation, visible in correspondence to the table payments in which the label for amount is Euros and the one for paymentDate is in date, will allow the chatbot to display lists of payments with this example format: “[Euros: 12345 - in date: 16-04-2019]” customers customerName contactLastName contactFirstName payments paymentDate amount orderdetails orders orderNumber orderDate products productName _ _ Euros in date _ _ in date
Figure 4.3: The Display Attributes annotation.
4.2.3
Conversational Qualifiers
Defining the role of tables and their related placeholders enables the system to translate phrases like “find customers”, which aim to select all the in-stances of the corresponding table. Other elements are needed to interpret conditions for filtering subsets of instances, for example queries like “find customers that are located in Milan”. In order to support this granularity in
the results, the Designer can define a set of Conversational Qualifiers for each data element, as shown in Figure 4.4 where the treated entity refers to the customers.
This annotation procedure considers what are the attributes that will be used to filter the results and how the final user will refer to them, i.e., through which expressions. For example, in Figure 4.4, the attributes city, state and country are labeled with the expression located in: this gives the chat-bot the capability to understand input phrases like “find customer located in Milan”, and process it as a query that selects the customers having city = Milan, or state = Milan, or country = Milan. These Conversational Qualifiers may belong to other tables, rather than the one directly addressed by the user request. This is for example the case of the Conversational Qual-ifier that bought, that, even if it was defined for the field productName of table products, can be used also in queries like “find customer that bought Fiat Punto”. The table customers is indeed reachable through the tables orders and orderdetails. This is graphically represented in Figure 4.4 by means of dotted arrows.
In some cases the user may also ask: “find customer Car Models”, without including in the utterance any Conversational Qualifier, i.e., without speci-fying what the Car Models value stands for. The system, then, will search for related instances in the table customers by the attribute customerName; for this attribute, indeed, there is not any specific expression specified as Conversational Qualifiers (graphically denoted by “ ”).
4.2.4
Conversational Types, Values and Operators
In order to help the chatbot process and interpret correctly the utterance, for each Conversational Qualifier it is important to specify its Conversational Type:
• WORD: any information without a particular structure or syntax; • NUM: numerical values;
• DATE: datetime/date values;
• Custom ENUM: entities that can assume enumerable values.
The last one may be useful when an attribute can assume only a fixed set of values. An example, not present in our database, could be the attribute
customers customerName contactLastName contactFirstName city state country payments amount orderdetails orders products productName [P] customer
with contact : WORD _ : WORD
located in : WORD
that paid : NUM that bought : WORD
Figure 4.4: The Conversational Qualifiers annotation, focus on customer.
businessName for the table customers and with enumerable values Public Administration and Private Company.
It is important to clarify how the Conversational Type format is used by the Designer during the Schema Annotation phase and it will be recovered by the framework during the Conversation Modeling phase, as we will describe in Section 4.3. However, from now on when dealing with example phrases, we will use the term Conversational Value to refer to the real value, always remembering that its identity is strictly related to the concept of Conversa-tional Type, as already described. Thus, according to this notation, in the phrase “find customer Car Models” the bold words will be identified as the Conversational Value.
The utterances received may include some more complexity, apart from the examples analyzed so far. For instance, the user may type a phrase like “find the customer that paid more than 42000 Euros”, and the system should identify the correct references for what concerns the Conversational Object “customer ”, Conversational Qualifier “that paid ” and Conversational Type NUM, with Conversational Value “42000 ”. The problem here is that the chatbot may not consider the expression “more than”, leading to a malformed search with likely wrong results.
This issue can be solved by introducing the concepts of Conversational Operators and enabling their usage with respect to the defined Conversa-tional Types.
A possible trace could be the following:
• WORD → “like”, “different from”; • NUM → “more than”, “less than”; • DATE → “before”, “after”;
4.2.5
Conversational Relationships
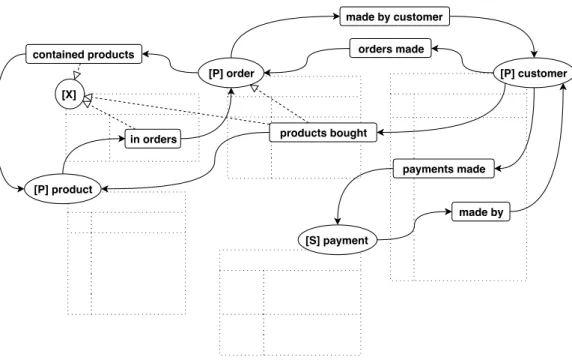
Always referring at the the conversation example in Figure 3.1, after the user has successfully selected a customer, its data and a few buttons are dis-played. These last represent the relationships that can be navigated starting from the instance being examined; we will refer to them as Conversational Relationships. These relationships have to be specified in the annotated database schema (see labeled arcs in Figure 4.5) so that user utterances can also imply navigation in the database through join operations. The arcs in Figure 4.5 are not bidirectional, since during conversation the user may refer differently to relationships depending on the direction in which they are traversed. Note that the relation between product and order needs to be supported by a Crossable Relationship table, being it a many-to-many relationship.
This kind of support is needed also in the relation named as products bought, that links the customer entity to product. Here we can appreciate how enabling the definition of this kind of connection relaxes the constraints imposed by the structure of the database. In fact, the Conversational Rela-tionship just analyzed is oriented to what the final user may be interested in, rather than on how data is physically organized: customers and products, in this case, are connected with a direct link, while the underlying relational model needs multiple subsequent relations to obtain the same functionality.
4.3
Conversation Modeling
In the previous section we analyzed how Schema Annotation opens the design process. In this section, instead, we will consider how that procedure can be used to obtain a chatbot able to understand phrases related to the considered data system, by taking advantage of the concepts already defined in the previous Section.
[X] [P] product [P] order [P] customer [S] payment contained products in orders made by customer orders made payments made made by products bought
Figure 4.5: The Conversational Relationships annotation.
Designing a Natural Language Understanding model means to define the intents and the entities that the chatbot will be able to match and extract, respectively. However, we are in the situation in which the target database of the system is not fixed, so it is not possible to define an end-to-end con-nectivity between these NLU concepts and the query they refer to when they appear in a utterance.
This limit becomes evident if we consider that the chatbot may be in-terfaced with a very large database, with dozens of complex tables and even more relations: defining, for example, an intent for each possible query struc-ture and an entity related to each value of the tables could lead to a NLU model exponentially bigger than the data system.
In order to avoid this situation, we came up with a solution that auto-matically generates intents and entities starting from the database Schema Annotation. However, we also needed a procedure to generate the example phrases to train the chatbot, each with labelled entities and related to an intent.
4.3.1
Intents
With respect to the tools our chatbot should provide, we decided to define four types of intents related to the following concepts: find, filter, naviga-tion and help. A descripnaviga-tion of each one of them follows.
• Find intents. They are related to the action of searching into the data source specific elements that will represent the starting point for the consequent conversational exploration.
• Filter intents. They are associated to methods that allow to further filter a list of elements already presented in the chat.
• History intents. They allow the user to access the history of the conversation or undoing operations.
• Help intents. They provide general or specific advice and hints during the navigation.
In order to enable the correct match of these concepts, the NLU model must be trained with phrases featuring a structure similar to the one of possible user utterances. In particular, we decided to take advantage of some words that were more likely to be found in phrases related to some intents with respect to the others. This way, we could automatize the whole phrase generation process.
For example, all the training utterances for the find intents start with a word that can be either “find ”, “are there” or “show me”, followed by a sequence of other words related to the particular elements they refer to. We will discuss about this pattern composition in the next Subsection, when talking about the entities, since the majority of phrases cannot be generated without them.
The only intent category that does not depend on the target database for which the chatbot is generated refers to the history intents, whose training phrases are fixed since no entity is used. We provide here an extract of their possible definition:
• show history → “show me the history”, “the history, please”, “where are we? ”, etc.
4.3.2
Entities
They are related to the database that the chatbot is going to interface and, because of this, they depend on the specific outcome of the Schema Anno-tation phase, as well as on the real values that compose the data system. While intents are used to understand what is the general purpose of the received utterance, entities become arguments of the methods that will be called. Therefore, they cannot be extracted without a previous successful intent-matching step.
In this context, we used and applied all the modeling primitives con-cepts described in Section 4.2, in order to define the type of entities that the chatbot should be able to support. The only exception refers to the Con-versational relationships introduced in Subsection 4.2.5, which do not have a corresponding entity to be identified in the utterance, since their usage is limited to the interaction via buttons and thus they do not pass through the NLU unit. We will discuss this aspect in the following section, when treating the issues related to the chat environment.
Let us now describe in details the structure of the training phrases related to the intents with dynamic content.
Entities for find intents. The intents of this type must contain the
Con-versational Object for which the search is intended and at least one Conver-sational Value that will be used to filter the results. By looking at Table 4.1 we clearly see that there is a pattern to define and generate these phrases, whose structure depends on the types and number of the utterance compo-nents to include. Even if the table only shows generated utterances related to the customer, we see how the Conversational Qualifiers are coherent with the related Type:
• “located in” is followed by a WORD whose Value is “Milan” • “that paid” is linked to a NUM, with Value “20000 ”
What is remarkable is that the phrases have a meaning because the Con-versational Values are consistent with the rest of the utterance. In fact, while Conversational Objects and Qualifiers are defined by the Designer, the values are extracted automatically by the system. This can be made possible by defining an ad-hoc procedure that connects to the database and executes a
Keyword Entities Example
Find * Obj Val Find - customer - Car Models
Find * Obj Qual Val Are there - customers - located in - Milan
Find * Obj Qual Op Val Search - customers - that paid - more than - 20000
Find * Val* Obj Find - Private Company - customers
Find * → Find, Are there, Search
Val* → Values related to ENUM Conversational Types
Table 4.1: Phrase structure for find intents.
series of short queries to extract example Values for each referenced Con-versational Type. These values will be used in the training phrases, thus enabling the definition of utterances very similar to the one the chatbot will receive.
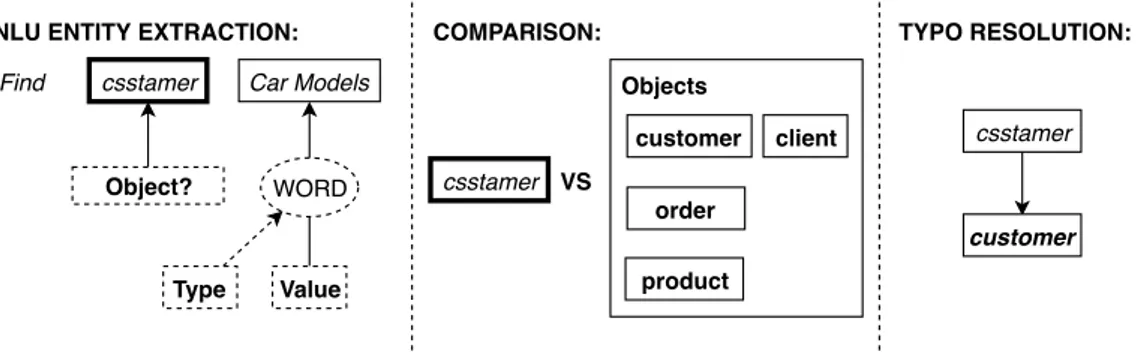
The entity extraction phase, during the conversation, will be able to per-form the extraction based on the NLU model trained according to these training phrases. A simple graphical example of how this procedure works can be seen in Figure 4.6. We can see how in the received utterance the word “Euros” is present, but this does not limit at all the capabilities of the system to correctly understand the overall meaning, thanks to an accurate definition of the training phrases. In fact, since “Euros” is not present in the examples, it will not be extracted as an entity, but this will not prevent the correct mapping of the other utterance components.
Find customer that paid more than 20,000 Find customer that paid more than 20,000 Euros
Euros
Object Qualifier
Operator Value
> NUM
PHRASE RECEIVED:
NLU ENTITY EXTRACTION:
Type