Capitolo 3
Analisi dell’affidabilità della procedura di
identificazione mediante applicazione a dati simulati
Una volta messa a punto la tecnica di identificazione l’obiettivo è stato quello di convalidarla. L’attività di convalida è avvenuta applicando la tecnica di identificazione a dati simulati. I principali problemi che ci si aspettava potessero emergere e rispetto ai quali si voleva valutare l’affidabilità della tecnica sono: la presenza di rumore, la scelta di un ordine opportuno per il modello, la presenza di più variazioni di set-point consecutive.
Chiaramente la convalida della tecnica è avvenuta nel rispetto delle due principali ipotesi sulla quale questa si basa: assenza di disturbi e assenza di attrito.
Il problema della robustezza della tecnica in presenza di attrito o disturbi rimane comunque un problema fondamentale con cui ci si confronterà nei capitoli successivi.
Un altro aspetto importante, che però non riguarda la convalida della tecnica, quanto piuttosto la sua applicabilità, è quello riguardante la scelta della finestra sulla quale condurre l’identificazione. Anche questo aspetto verrà affrontato nei prossimi capitoli.
Di seguito si riporta quanto è stato fatto per convalidare la tecnica partendo da una tipologia piuttosto ampia di classi di processo e si riportano i risultati ottenuti.
3.1: Classi di processo
Le classi di processo per le quali sono stati simulati i dati su cui è stata poi condotta e valutata l’identificazione, sono le seguenti:
• Secondo ordine sovra-smorzato con zero e ritardo:
(
)
(
1) (
2)
1 1 1 s k s e s s ϑα
τ
τ
− + + ⋅ +• Secondo ordine sotto-smorzato con zero e ritardo:
(
)
e s s s s k ϑ τξ τ α − + + + 1 2 1 2• Sistemi di ordine elevato (4 e 5) con ritardo:
(
)
ne s s k ϑ τ − +1 • Sistemi integratori con ritardo: ke ss ϑ
−
Per ciascuna classe di processo sono state considerate delle combinazioni significative dei parametri caratteristici, per un totale di 54 processi differenti (Tabella 3.1).
PARAMETRI
ID Classe di processo
k ϑ τ1 τ2 τ3 ξ α n
1-3 Primo ordine con ritardo 1 0.1/1/10 1 - - - - -
4-9 Secondo ordine sovra-smorzato con ritardo 1 0.1/1/10 1 0.8/0.2 - - - -
10-15 Secondo ordine sotto-smorzato con ritardo 1 0.1/1/10 1 - - 0.5/0.25 - -
16-18 Terzo ordine sovra-smorzato con ritardo 1 0.1/1/10 1 0.9 0.8 - - -
19-27 Terzo ordine sotto-smorzato con ritardo 1 0.1/1/10 0.1/1 0.1/1 - 0.25 - -
28-31 Secondo ordine sovra-smorzato con zero e ritardo 1 0.1/1/10 0.1 0.8 - - +0.3/+3/ -0.8/-3 -
40-45 Secondo ordine sotto-smorzato con zero e ritardo 1 0.1/1/10 1 - - 0.5 3/-3 -
46-51 Sistemi di ordine elevato (4 e 5) con ritardo 1 0.1/1/10 1 - - - - 4/5 52-54 Sistemi integratori con ritardo 1 0.1/1/10 - - - -
Tabella 3.1: Valori dei parametri delle diverse classi di processo simulate
3.2: Indici di accuratezza dell’identificazione
La tecnica di identificazione, come è stato detto al capitolo precedente, minimizza l’errore quadratico medio VN(ϑ,ZN,L), ovvero massimizza l’indice EVARX così definito:
(
)
2 1 ( , , ) 1 1 N N ARX N i medio i V Z L EV y y Nϑ
= = − −∑
(3.1) Dove:VN (θ,ZN,L): errore quadratico medio (2.41).
i
y : i-esimo valore della variabile controllata nell’intervallo di dati su cui viene condotta l’identificazione.
L’indice EVARX confronta il valore reale della variabile controllata yi (Figura 3.1(a)) con quello
predetto dal modello impiegando i valori reali della variabile controllata e del segnale di controllo ai tempi di campionamento precedenti (y ) (Figura 3.1(b)). i
Si osserva che l’indice EVARX vale 1, nel caso in cui y = y e si allontana da 1 (tendendo a -∞)
all’aumentare delle differenze.
Figura 3.1: Origine dei dati su cui si basa il calcolo dell’indice EVARX.
Sebbene l’indice EVARX sia utile al fine di identificare il ritardo del modello che meglio approssima i
dati a disposizione, esso non è un indice significativo al fine di stabilire il successo o meno della tecnica di identificazione.
Un alto valore di tale indice, d’altra parte, non assicura che modello identificato e processo reale si somiglino né in anello chiuso, né in anello aperto.
Per questo motivo sono stati presi in considerazione altri indici su cui basare l’esito dell’identificazione. Nella scelta degli indici si è tenuto conto dello scopo dell’identificazione (ottenere un modello del processo “utile ai fini del controllo”) e della possibilità che una delle due ipotesi su cui si basa la tecnica (assenza di disturbi e attrito) possa venire meno.
L’indice che più di ogni altro è rappresentativo della somiglianza tra processo reale e modello identificato è certamente l’indice di confronto in anello aperto EVOEsr (3.2). Quest’ultimo rappresenta infatti la somiglianza tra il modello reale e il processo identificato quando questi
G C -
y
iu
ir
i [y
(i-1),..., y
(i-n)] [u
(i-m-L),..., u
(i-m-1)] Ĝ yi (a) (b)INDICE EVOEsr :
(
)
(
)
2 1 2 1 1 1 1 N sr sr i i sr i OE N sr sr i medio i y y N EV y y N = = − = − −∑
∑
(3.2) Dove: sr iy : i-esimo valore della variabile controllata ottenuta sottoponendo il modello identificato a gradino unitario.
sr i
y : i-esimo valore della variabile controllata ottenuta sottoponendo il processo reale a gradino unitario.
sr medio
y : valore medio della variabile controllata ottenuta sottoponendo il processo reale a gradino unitario.
Si osserva che l’indice EVOEsr vale 1, nel caso in cui modello identificato e processo reale sono identici (y =sr y ) e si allontana da 1 (tendendo a -∞) all’aumentare delle differenze. sr
Figura 3.2: Origine dei dati su cui si basa il calcolo dell’indice EVOEsr.
Sebbene l’indice EVOEsr non possa essere calcolato in campo industriale, possono essere calcolati altri due indici “più utili ai fini del controllo”. Ciò che interessa, infatti, è l’identificazione di un modello che in anello chiuso somigli al processo reale, piuttosto che l’identificazione di un modello identico al processo reale. Tali indici sono definiti di seguito:
G sr i y (a) Ĝ sr i y (b)
1. INDICE EVOE:
(
)
(
)
2 1 2 1 1 ( ) 1 1 N T i i i OE N i medio i y N EV y y Nϕ ϑ ϑ
= = − ⋅ = − −∑
∑
(3.3) Dove: ( ) iϕ ϑ
: vettore dei valori della variabile manipolata e di quelli della variabile controllata predetti dal modello (2.24).ϑ
: vettore dei parametri del modello identificati (aj e bj).medio
y : valore medio della variabile controllata nell’intervallo di dati su cui viene condotta l’identificazione.
i
y : i-esimo valore della variabile controllata nell’intervallo di dati su cui viene condotta l’identificazione.
L’indice EVOE si differenzia dall’indice EVARX (3.1) per come è calcolato l’errore quadratico
medio. Mentre nel primo caso, infatti, si considera il valore della variabile controllata predetto dal modello, noti i valori precedenti delle variabili controllata; nel secondo caso si considera quello predetto dal modello impiegando i valori della variabile controllata predetti dallo stesso ai tempi di campionamento precedenti.
In altre parole l’indice EVOE è la varianza spiegata che otterremmo nel caso identificassimo
un modello del tipo OE anziché un modello ARX (Figura 3.3).
Si ricorda che, sebbene l’indice EVOE sia più significativo dell’indice EVARX, si è scelto di
identificare un modello ARX in quanto è un modello a regressione lineare.
In definitiva l’indice EVOE è significativo di quanto modello reale e modello identificato si
somigliano a parità di ingressi. Il suo valore è pari a 1 se la somiglianza è perfetta e i due modelli sono identici, mentre tende a -∞ all’aumentare delle differenze.
G C -
y
iu
ir
i (a)2. INDICE EVOEcl :
(
)
(
)
2 1 2 1 1 1 1 N cl i i cl i OE N i medio i y y N EV y y N = = − = − −∑
∑
(3.4) Dove: cl iy : i-esimo valore della variabile controllata ottenuta sottoponendo il modello identificato alle stesse variazioni di set-point a cui è stato sottoposto il processo reale e impiegando un controllore con le stesse caratteristiche.
medio
y : valore medio della variabile controllata nell’intervallo di dati su cui viene condotta l’identificazione.
i
y : i-esimo valore della variabile controllata nell’intervallo di dati su cui viene condotta l’identificazione.
L’indice EVOEcl “misura” quanto l’andamento reale della PV e quello predetto dal modello
in anello chiuso, a parità di controllore e di andamento del set-point sono simili (Figura 3.4). Anche l’indice EVOEcl vale 1, nel caso in cui modello identificato e processo reale sono identici (y = cl
i
y ) e si allontana da 1 (tendendo a -∞) all’aumentare delle differenze.
Figura 3.4: Origine dei dati su cui si basa il calcolo dell’indice EVOEcl .
G C -
y
iu
ir
i (a) Ĝ C - cl i y ˆ ( ) i G ur
i (b)Per quanto riguarda le aspettative riguardo a quale dei due indici (EVOEcl o EVOE) sia più
significativo per i nostri scopi, è possibile fare le seguenti considerazioni:
1. EVOE, essendo un indice che valuta la somiglianza a parità di ingressi, dovrebbe essere
assimilabile ad un indice in anello aperto e come tale dovrebbe essere più sensibile di EVOEcl alle differenze tra modello identificato e processo reale. EVOE è per esempio capace di
mettere in evidenza differenze relative al guadagno, mentre EVOEcl non è in grado di farlo. 2. EVOEcl è il vero indice rappresentativo della somiglianza tra processo reale e modello
identificato in anello chiuso. Come si è già detto, il nostro scopo è quello di condurre un’identificazione che permetta di stabilire dei parametri opportuni per il regolatore. A tal proposito è importante ottenere un modello che abbia un comportamento simile a quello reale in anello chiuso, mentre non è fondamentale che il modello sia identico al processo reale. Sulla base di questo, EVOEcl dovrebbe essere l’indice più utile.
3. L’indice EVOE verrà comunque preso in considerazione anche in visione della possibile
presenza di attrito o della possibile sovrapposizione di disturbi. Se in presenza di una di queste due problematiche, si ottenesse un alto valore di EVOEcl , non ci si potrebbe ritenere
soddisfatti, dal momento che potremmo non aver modellato un processo che in anello chiuso si comporta come il processo reale, ma piuttosto un processo che si comporta come il processo reale in presenza di attrito o disturbi.
L’indice EVOE potrebbe risultare utile considerata la sua capacità di evidenziare le differenze
tra il guadagno del processo reale e quello del modello identificato. Il guadagno del processo è oltretutto un parametro fondamentale nella sintonizzazione del regolatore.
Quindi, riassumendo, si sono presi in considerazione quattro indici aventi le caratteristiche riportate di seguito:
• EVARX : è un indice utile ai fini dell’identificazione del ritardo, ma non è significativo della
somiglianza tra processo reale e modello identificato né in anello chiuso né in anello aperto. Questa sua forte limitazione ha spinto alla ricerca di indici alternativi capaci di decidere l’esito della tecnica di identificazione.
• EVOEsr : non è un indice candidato per stabilire l’esito dell’identificazione visto che può essere valutato solo in simulazione. Nella fase di convalida si è comunque ritenuto utile calcolare questo indice in modo da dare un giudizio sulla tecnica.
• EVOE: è il primo indice che si è pensato di impiegare per stabilire l’esito dell’identificazione.
• un alto valore degli indici EVARX, EVOE, EVOEcl potrebbe spesso essere accompagnato da un
basso valore dell’indice EVOEsr ;
• EVARX dovrebbe avere un valore sempre molto alto.
3.3: Considerazioni sull’ordine del modello
Anche se in seguito verrà analizzato l’effetto dell’ordine del modello sulla riuscita dell’identificazione, si può anticipare da subito che dal punto di vista pratico la coppia (n,m), che rappresenta il numero di istanti precedenti per i quali rispettivamente la PV e la OP agiscono sul valore attuale della PV, può essere fissata a valori ragionevolmente bassi.
È infatti importante notare che anche dinamiche complesse (cioè di ordine elevato) possono essere approssimate sufficientemente bene da modelli di ordine relativamente basso, purché venga utilizzato un opportuno valore del ritardo.
Oltretutto, proprio perché lo scopo dell’identificazione è la sintonizzazione adeguata del regolatore e la maggior parte delle tecniche di tuning prevedono una riduzione di ordine del modello, non avrebbe senso ricercare dinamiche complesse che comunque dovrebbero essere ridotte in seguito. Nelle simulazioni riportate di seguito, in cui non ci si occupa dell’effetto dell’ordine sulla riuscita dell’identificazione, la coppia (n,m) viene mantenuta costante e pari a (2,2).
3.4: Fasi operative dell’applicazione della procedura di
identificazione a dati simulati
Nelle prime simulazioni che sono state effettuate, si è tenuto costante l’ordine, si è inserito il rumore, si è scelto, sulla base di un certo criterio che verrà descritto più avanti, la finestra di dati utile all’identificazione, e si è eseguita la simulazione sia in caso di uno che in caso di più cambi di set-point.
Per ciascun processo, le fasi operative dell’applicazione della procedura di identificazione sono state le seguenti:
1. Scelta del tempo di campionamento, Ts. È stato valutato il tempo necessario alla variabile
misurata per raggiungere lo stazionario (3.5). Il tempo di campionamento è stato scelto pari ad 1/120 di tale tempo (3.6). * * : | sr sr( ) sr st end end t t ∀ > →t t 0.98 y⋅ < y t <1.02 y⋅ (3.5) st s T T 120 = (3.6) Dove: sr
y : vettore (di lunghezza opportuna) i cui termini rappresentano l’andamento della variabile controllata nel tempo quando il processo viene sottoposto ad un gradino unitario.
sr end
y : valore della variabile controllata a stazionario quando il processo viene sottoposto ad un gradino unitario.
2. Tuning del regolatore PI e sua implementazione digitale. La scelta dei parametri del regolatore è stata fatta mediante la tecnica SIMC (Skogestad, 2003) descritta al paragrafo 2.9.
Per quanto riguarda il tuning di un processo integratore la regola SIMC è applicabile. Un processo integratore può essere visto come un sistema del primo ordine con una costante di tempo (ed un guadagno) molto grandi. Pertanto, per un processo del tipo ( )
s ke G s s ϑ − = , i
parametri del regolatore PI proposti dalla regola SIMC sono:
c 1
k 0.5 k
ϑ
=
⋅ , τI =8ϑ (3.7)
Il regolatore è stato implementato in forma digitale:
0 k c s k c k i I i K T u K e e
τ
= = +∑
(3.8)dove ek =rk− yk è l’errore di inseguimento (tracking error) al tempo k-esimo della PV (y ) k rispetto al set-point (r ). k
3. Verifica della stabilità nominale in anello chiuso. Lo studio della stabilità non è stato fatto nel continuo ma nel discreto, impiegando una struttura in variabili di stato.
Come si è visto nel capitolo 2 la struttura di un processo chimico-fisico in variabili di stato è la seguente: 1 k k k k k x Ax Bu y Cx + = + ⎧ ⎫ ⎨ = ⎬ ⎩ ⎭ (3.9) Dove:
x: vettore degli stati del processo;
u: variabile manipolata (variabile in ingresso al processo); y: variabile controllata (variabile in uscita al processo)
-y: variabile in ingresso al controllore (la variabile in ingresso al controllore, se si suppone per comodità il set-point pari a 0, non è altro che la variabile controllata cambiata di segno);
u: variabile in uscita dal controllore (la variabile in uscita dal controllore è la variabile manipolata) , , , c c c c A B
C D : matrici caratteristiche del modello del controllore in variabili di stato. Facendo le opportune sostituzioni si ricava:
2 1 1 1 1 1 1 ... k c c k c c k c c c c k k k k c c c c x ABD C BC x ABD C BC x B C A B C A e e e x ABD C BC B C A e + − + − − − ⎛ ⎞ ⎛ ⎞ ⎛ ⎞ ⎛ ⎞ ⎛ ⎞ = ⋅ = ⋅ = ⎜ ⎟ ⎜ − ⎟ ⎜ ⎟ ⎜ − ⎟ ⎜ ⎟ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠ − ⎛ ⎞ ⎛ ⎞ = =⎜ ⎟ ⋅⎜ ⎟ − ⎝ ⎠ ⎝ ⎠ (3.11)
Secondo la definizione di stabilità asintotica un modello è stabile se per ogni valore di stati iniziale il limite per k che tende all’infinito degli stati tende a zero in assenza di disturbi ed è limitato in presenza di disturbi. Da questa definizione si deduce che, perché il processo possa essere stabile in anello chiuso il limite della matrice
k c c c c ABD C BC B C A − ⎛ ⎞ ⎜ − ⎟ ⎝ ⎠ deve tendere
a 0 quando k tende all’infinito. Tale limite tende a 0 se il raggio spettrale della matrice
c c c c ABD C BC B C A − ⎛ ⎞ ⎜ − ⎟
⎝ ⎠ è minore di 1. Quindi semplicemente valutando il raggio spettrale della
matrice sopra riportata si riesce a stabilire se il processo è stabile o meno in anello chiuso. 4. Eventuale modifica dei parametri di tuning fino al raggiungimento della stabilità in anello
chiuso. Per quei processi per cui il tuning effettuato secondo la tecnica SIMC dava origine ad un sistema instabile in anello chiuso (vedi limitazioni della tecnica SIMC al paragrafo 2.9) si è modificato il tuning moltiplicando τi per un fattore f jcon j=1,2,3… e dividendo Kc per lo stesso fattore, fintanto che il sistema non risultava stabile in anello chiuso.
Il parametro f è stato preso pari a 1.1.
5. Discretizzazione del processo. È stata ricavata la funzione di trasferimento nel discreto (utilizzando il comando “c2d.m”) ed è stato ricavato, quindi, il modello ARX corrispondente.
6. Simulazione dei dati in anello chiuso. Si sono simulati i valori della variabile controllata e di quella manipolata per una o più variazioni di set-point utilizzando le seguenti relazioni:
1 1 1 1 1 1 1 1 ( ) ... ... .... s k k k k k k k L k L L m k L m k n k n kc T u u kc e e e ti y b u b u b u a y a y − − − + − − + − − − − ⋅ ⎧ = + ⋅ − + ⋅ ⎫ ⎪ ⎪ ⎨ ⎬ ⎪ = + + + + − − − ⎪ ⎩ ⎭ (3.12)
La variazione di set-point non è stata imposta in corrispondenza di k=0 ma in corrispondenza di k=(n1+1) dove n1 è stato definito nell’espressione (2.44). Il valore di n1 è
stato fissato, dopo un certo numero di prove, pari a 90.
I dati sono stati simulati in assenza di rumore e poi “corrotti” con un segnale di rumore. Tale segnale è stato generato moltiplicando il comando MATLAB “randn.m” per una costante K. Così facendo si è generato una distribuzione normale di numeri casuali a media nulla e varianza K2. Dopo una serie di prove il valore della costante K è stato fissato a 0.02. Sebbene in questa prima fase il rumore sia stato fissato nel modo appena descritto, nel seguito verranno riportati i risultati dell’analisi condotta al variare delle caratteristiche del rumore.
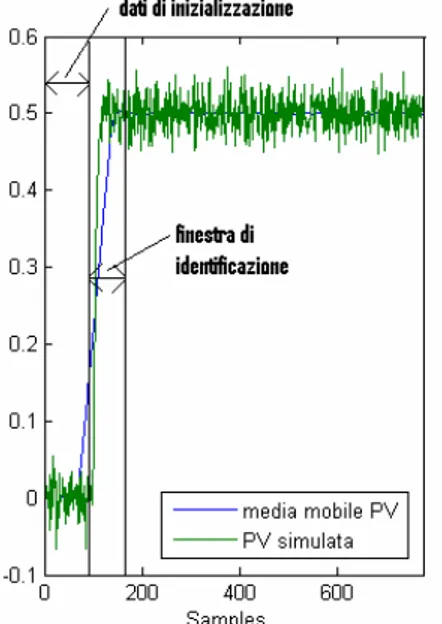
7. Scelta della finestra di dati su cui condurre l’identificazione. La finestra di dati su cui è stata condotta l’identificazione è quella compresa tra (n1+1) e (n1+N). N è definito
nell’espressione (3.13). * * 1 : ( ) | endmm kmm endmm N k +Ne n− ∀ >k k →0.95 y⋅ < y <1.05 y⋅ (3.13) Dove: mm k
y : k-esimo dato della media mobile (3.14) della variabile controllata.
mm end
y : ultimo valore della media mobile della variabile controllata.
2 1 Nu k j j Nu mm k y y Nu + + =− = +
∑
(3.14) Dove: k jy + : (k+j)-esimo dato della variabile controllata.
Nu: valore rappresentativo del numero di dati impiegati per il calcolo della media mobile.
Sebbene la scelta del parametro Nu dovrebbe dipendere dal tipo di processo, dopo svariate prove è stato fissato Nu pari a 35.
Figura 3.5: Dati simulati e scelta della finestra su cui condurre l’identificazione.
8. Identificazione del modello ARX e valutazione degli indici di accuratezza. I parametri del modello sono stati identificati secondo quanto descritto al capitolo 2. È opportuno sottolineare che ai dati predetti impiegando il modello, non si è sommato il vettore rumore che caratterizza invece i dati su cui è stata condotta l’identificazione. In questo modo si sono ottenuti degli indici che non sono rappresentativi della sola accuratezza dell’identificazione e di quanto il rumore possa compromettere la sua riuscita, ma anche del valore assoluto del rumore. La scelta di procedere in questo modo deriva dal fatto che nell’applicazione a dati industriali il vettore del rumore è chiaramente non noto.
3.5: Risultati
3.5.1: Risultati per un solo cambio di set-point
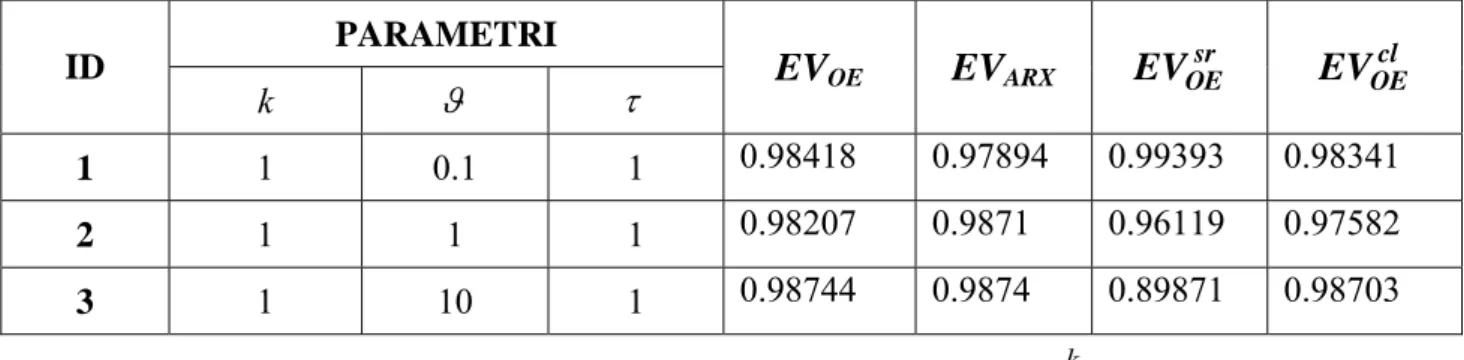
I risultati ottenuti in caso di una sola variazione di set-point sono riassunti nelle tabelle seguenti (Tabelle 3.2-3.12). PARAMETRI ID k ϑ τ EVOE EVARX sr OE EV EVOEcl 1 1 0.1 1 0.98418 0.97894 0.99393 0.98341 2 1 1 1 0.98207 0.9871 0.96119 0.97582 3 1 10 1 0.98744 0.9874 0.89871 0.98703
Tabella 3.2: Risultati per processi di primo ordine con ritardo: 1 s k e s ϑ τ − + PARAMETRI ID k ϑ τ 1 τ 2 EVOE EVARX sr OE EV EVOEcl 4 1 0.1 1 0.8 0.96498 0.98472 0.93279 0.97046 5 1 0.1 1 0.2 0.9692 0.98525 0.846 0.96348 6 1 1 1 0.8 0.98669 0.98806 0.98925 0.9835 7 1 1 1 0.2 0.98647 0.98738 0.98366 0.9832 8 1 10 1 0.8 0.98884 0.98884 0.92949 0.98864 9 1 10 1 0.2 0.98763 0.98757 0.91632 0.98727
Tabella 3.3: Risultati per processi di secondo ordine sovra-smorzati con ritardo:
(
1 1)(
2 1)
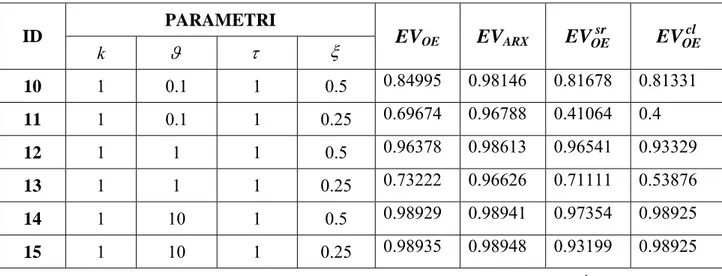
s k e s s ϑ τ τ − + +PARAMETRI ID k ϑ τ ξ EVOE EVARX sr OE EV EVOEcl 10 1 0.1 1 0.5 0.84995 0.98146 0.81678 0.81331 11 1 0.1 1 0.25 0.69674 0.96788 0.41064 0.4 12 1 1 1 0.5 0.96378 0.98613 0.96541 0.93329 13 1 1 1 0.25 0.73222 0.96626 0.71111 0.53876 14 1 10 1 0.5 0.98929 0.98941 0.97354 0.98925 15 1 10 1 0.25 0.98935 0.98948 0.93199 0.98925
Tabella 3.4: Risultati per processi di secondo ordine sotto-smorzati con ritardo: 2
2 1 s k e s s ϑ τ τξ − + + PARAMETRI ID k ϑ τ 1 τ 2 τ3 EVOE EVARX sr OE EV EVOEcl 16 1 0.1 1 0.9 0.8 0.96611 0.98094 0.98057 0.96653 17 1 1 1 0.9 0.8 0.98681 0.9878 0.99096 0.98464 18 1 10 1 0.9 0.8 0.98887 0.98888 0.92587 0.98873 Tabella 3.5: Risultati per processi di terzo ordine sovra-smorzati con ritardo:
( 1 1)( 2 1)( 3 1) s k e s s s ϑ τ τ τ − + + +
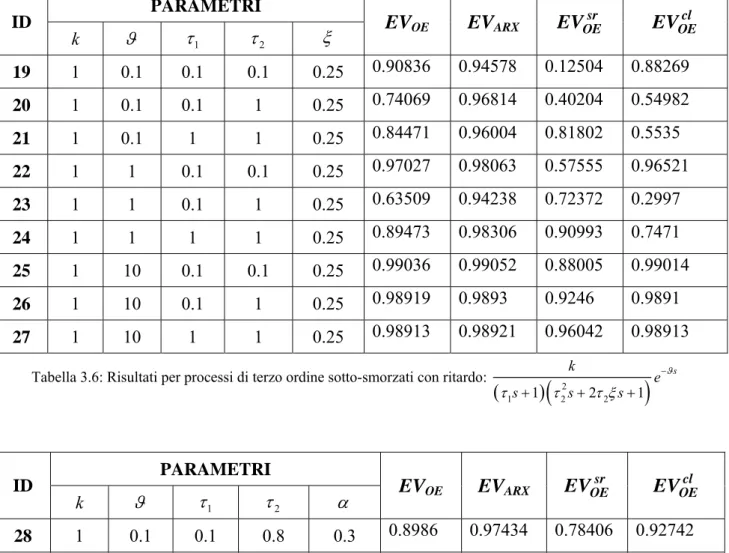
PARAMETRI ID k ϑ τ 1 τ 2 ξ EVOE EVARX EVOEsr cl OE EV 19 1 0.1 0.1 0.1 0.25 0.90836 0.94578 0.12504 0.88269 20 1 0.1 0.1 1 0.25 0.74069 0.96814 0.40204 0.54982 21 1 0.1 1 1 0.25 0.84471 0.96004 0.81802 0.5535 22 1 1 0.1 0.1 0.25 0.97027 0.98063 0.57555 0.96521 23 1 1 0.1 1 0.25 0.63509 0.94238 0.72372 0.2997 24 1 1 1 1 0.25 0.89473 0.98306 0.90993 0.7471 25 1 10 0.1 0.1 0.25 0.99036 0.99052 0.88005 0.99014 26 1 10 0.1 1 0.25 0.98919 0.9893 0.9246 0.9891 27 1 10 1 1 0.25 0.98913 0.98921 0.96042 0.98913
Tabella 3.6: Risultati per processi di terzo ordine sotto-smorzati con ritardo:
(
)
(
2)
1 1 2 2 2 1 s k e s s s ϑ τ τ τ ξ − + + + PARAMETRI ID k ϑ τ 1 τ 2 α EVOE EVARX sr OE EV EVOEcl 28 1 0.1 0.1 0.8 0.3 0.8986 0.97434 0.78406 0.92742 29 1 0.1 0.1 0.8 3 0.87093 0.97669 0.44862 0.71791 32 1 1 0.1 0.8 0.3 0.98336 0.98722 0.96388 0.97821 33 1 1 0.1 0.8 3 0.97823 0.98123 0.95446 0.93676 36 1 10 0.1 0.8 0.3 0.9872 0.987 0.53729 0.98713 37 1 10 0.1 0.8 3 0.98772 0.98751 -0.27836 0.98793 Tabella 3.7: Risultati per processi di secondo ordine sovra-smorzati con zero negativo e ritardo:(
)
(
)(
)
1 1 1 s k s e s s ϑ α τ τ − + + +PARAMETRI ID k ϑ τ 1 τ 2 α EVOE EVARX EVOEsr cl OE EV 30 1 0.1 0.1 0.8 -0.8 0.9086 0.99107 0.89899 0.85872 31 1 0.1 0.1 0.8 -3 0.78479 0.99631 0.74351 0.42753 34 1 1 0.1 0.8 -0.8 0.98448 0.98901 0.83889 0.98265 35 1 1 0.1 0.8 -3 0.89358 0.99241 0.72456 0.74509 38 1 10 0.1 0.8 -0.8 0.98584 0.98613 0.79068 0.98476 39 1 10 0.1 0.8 -3 0.98772 0.98905 0.88868 0.98468
Tabella 3.8: Risultati per processi di secondo ordine sovra-smorzati con zero positivo e ritardo:
(
)
(
1)(
2)
1 1 1 s k s e s s ϑ α τ τ − + + + PARAMETRI ID k ϑ τ ξ α EVOE EVARX sr OE EV EVOEcl 40 1 0.1 1 0.5 3 0.40722 0.95888 -0.88576 0.83673 42 1 1 1 0.5 3 0.76487 0.97237 0.52927 0.42419 44 1 10 1 0.5 3 0.98842 0.98843 -0.40754 0.98834Tabella 3.9: Risultati per processi di secondo ordine sotto-smorzati con zero negativo e ritardo: 2
(
1)
2 1 s k s e s s ϑ α τ τξ − + + + PARAMETRI ID k ϑ τ ξ α EVOE EVARX sr OE EV EVOEcl 41 1 0.1 1 0.5 -3 0.84667 0.98949 0.79322 0.58151 43 1 1 1 0.5 -3 0.9404 0.99283 0.78128 0.88512 45 1 10 1 0.5 -3 0.99068 0.99076 0.51368 0.99041 Tabella 3.10: Risultati per processi di secondo ordine sotto-smorzati con zero positivo e ritardo: 2
(
1)
2 1 s k s e s s ϑ α τ τξ − + + +
PARAMETRI ID k ϑ τ
n
EVOE EVARX sr OE EV EVOEcl 46 1 0.1 1 4 0.97119 0.98266 0.9895 0.95528 47 1 0.1 1 5 0.95918 0.98341 0.97176 0.91272 48 1 1 1 4 0.98253 0.98775 0.98302 0.97554 49 1 1 1 5 0.9852 0.98796 0.98773 0.97973 50 1 10 1 4 0.98917 0.98923 0.91908 0.98917 51 1 10 1 5 0.9889 0.98894 0.89336 0.98881Tabella 3.11: Risultati per processi di ordine elevato (4 e 5) con ritardo:
(
1)
s n k e s ϑ τ − + PARAMETRI ID k ϑ EVOE EVARX sr OE EV EVOEcl 52 1 0.1 0.98215 0.97523 0.99996 0.98156 53 1 1 0.98215 0.97523 0.99995 0.98156 54 1 10 0.98215 0.97523 0.99975 0.98156Tabella 3.12: Risultati per processi integratori: k s
e s
ϑ −
OSSERVAZIONI:
1. Per 43 dei 54 processi simulati la somiglianza tra il comportamento del processo reale e il comportamento del modello identificato in anello chiuso è ottima (valore dell’indice
cl OE
EV molto alto). I processi per i quali la tecnica di identificazione consente di ottenere un modello utile ai fini del controllo sono quelli che hanno una dinamica sovra-smorzata e che non hanno zeri. Questo tipo di processi è anche il più diffuso a livello industriale.
ricerca il processo che, fissati gli ingressi e i valori precedenti della variabile controllata, si comporta nello stesso modo del processo reale e pertanto può succedere che, sebbene il modello identificato sia piuttosto diverso dal processo reale, esso abbia per quegli stessi ingressi un comportamento simile.
Se già fino ad ora, in assenza di attrito o disturbi, la scelta di impiegare EVOEcl , come indice per definire il successo o meno dell’identificazione, risultava la più logica, adesso è rafforzata dal fatto che tale indice risulta, nella maggior parte dei casi, più cautelativo di EVOE
Poiché in presenza di attrito o disturbi, l’indice EVOEcl non può essere ritenuto rappresentativo della somiglianza tra processo reale e modello identificato in anello chiuso, di seguito si continuerà a calcolare il valore di EVOE, al fine di avere il maggior numero possibile di informazioni su cui
basare l’analisi.
3.5.2: Illustrazione dei risultati per un solo cambio di set-point
Si riportano ora, per alcune delle classi di processo analizzate, due grafici, in modo tale da acquisire sensibilità riguardo il significato dei numeri riportati al paragrafo precedente. Nel primo grafico si confronta l’andamento reale della variabile controllata con quello predetto mediante il modello a parità di ingressi. Nel secondo grafico si confronta l’andamento reale della variabile controllata con quello predetto mediante il modello a parità di cambio di set-point e di controllore. In altre parole quanto più le curve del primo grafico si somigliano tanto più EVOE è alto; quanto più le curve del
ESEMPI DI BUONA IDENTIFICAZIONE (43 dei 54 processi simulati)
Figura 3.6: Risultati per il processo N°1: ((a): EVOE =0.98418; (b): EVOEcl =0.98341)
ESEMPI DI NON BUONA IDENTIFICAZIONE (11 dei 54 processi simulati)
Figura 3.9: Risultati per il processo N°11: ((a): EVOE =0.69674; (b): EVOEcl =0.4)
Figura 3.10: Risultati per il processo N°31: ((a): EVOE =0.78479; (b): EVOEcl =0.42753)
Come si vede dagli esempi di buona identificazione che sono stati riportatati, per la maggior parte dei processi simulati il modello identificato ha, in anello chiuso, un comportamento effettivamente identico a quello del processo reale.
Dagli esempi di non buona identificazione che sono stati riportati è possibile ricavare una sensibilità sul significato del valore numerico degli indici. Si noti, che in ognuno dei tre esempi di non buona identificazione riportati, il valore dell’indice EVOEcl è sempre inferiore a quello dell’indice EVOE.
Si ricorda che gli esempi di non buona identificazione sono relativi ad una casistica di processi poco diffusa nella realtà industriale.
3.5.3: Risultati per N
scambi di set-point
Si riportano ora, per alcuni dei processi simulati, i risultati ottenuti imponendo Ns cambi consecutivi
di set-point.
È da sottolineare che per poter eseguire un confronto tra l’esito dell’identificazione in caso di un solo cambio di set-point e l’esito in caso di Ns cambi di set-point, occorre fare in modo che essa sia condotta sullo stesso numero di dati.
Ns è stato preso pari a 3.
I risultati sono riportati nelle seguenti tabelle (Tabelle 3.13-3.23):
PARAMETRI ID k ϑ τ EVOE EVARX sr OE EV EVOEcl 1 1 0.1 1 0.99121 0.98809 0.99689 0.99212 2 1 1 1 0.96084 0.96562 0.9657 0.96538 3 1 10 1 0.96341 0.96394 0.94876 0.96054
Tabella 3.13: Risultati per processi di primo ordine con ritardo: 1 s k e s ϑ τ − + PARAMETRI ID k ϑ τ 1 τ 2 EVOE EVARX sr OE EV EVOEcl 1 0.1 1 0.2 0.9788 0.98428 0.98495 0.98207
PARAMETRI ID k ϑ τ ξ EVOE EVARX sr OE EV EVOEcl 10 1 0.1 1 0.5 0.92479 0.99417 0.11866 0.94276 13 1 1 1 0.25 0.71293 0.983 0.27701 0.49141 14 1 10 1 0.5 0.96869 0.96899 0.9613 0.96856
Tabella 3.15: Risultati per processi di secondo ordine sotto-smorzati con ritardo:
2 2 1 s k e s s ϑ τ τξ − + + PARAMETRI ID k ϑ τ 1 τ 2 τ3 EVOE EVARX EVOEsr cl OE EV 16 1 0.1 1 0.9 0.8 0.91737 0.9908 0.06109 0.96241 17 1 1 1 0.9 0.8 0.97387 0.97766 0.98311 0.9743 18 1 10 1 0.9 0.8 0.96675 0.96712 0.93051 0.96531
Tabella 3.16: Risultati per processi di terzo ordine sovra-smorzati con ritardo:
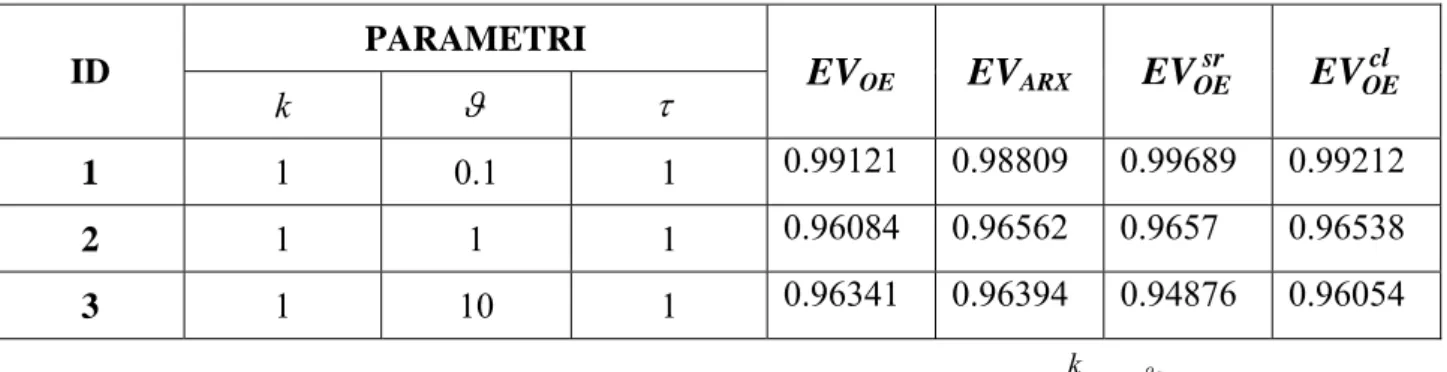
( 1 1)( 2 1)( 3 1) s k e s s s ϑ τ τ τ − + + + PARAMETRI ID k ϑ τ 1 τ 2 ξ EVOE EVARX sr OE EV EVOEcl 19 1 0.1 0.1 0.1 0.25 0.78388 0.9144 0.25601 0.74922 24 1 1 1 1 0.25 0.92352 0.99005 0.66914 0.87232 26 1 10 0.1 1 0.25 0.96918 0.96944 0.91862 0.96906
Tabella 3.17: Risultati per processi di terzo ordine sotto-smorzati con ritardo:
(
)
(
2)
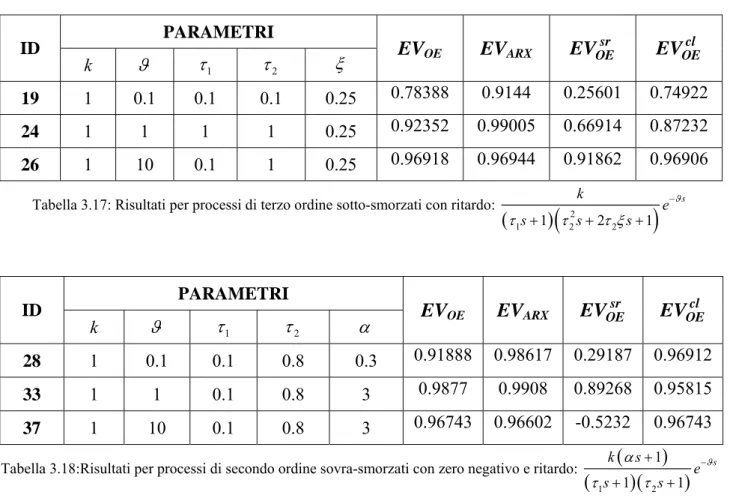
1 1 2 2 2 1 s k e s s s ϑ τ τ τ ξ − + + + PARAMETRI ID k ϑ τ 1 τ 2 α EVOE EVARX EVOEsr cl OE EV 28 1 0.1 0.1 0.8 0.3 0.91888 0.98617 0.29187 0.96912 33 1 1 0.1 0.8 3 0.9877 0.9908 0.89268 0.95815 37 1 10 0.1 0.8 3 0.96743 0.96602 -0.5232 0.96743Tabella 3.18:Risultati per processi di secondo ordine sovra-smorzati con zero negativo e ritardo:
(
)
(
1)(
2)
1 1 1 s k s e s s ϑ α τ τ − + + +PARAMETRI ID k ϑ τ 1 τ 2 α EVOE EVARX sr OE EV EVOEcl 31 1 0.1 0.1 0.8 -3 0.73787 0.9985 -3.1501 0.63751 34 1 1 0.1 0.8 -0.8 0.96637 0.98113 0.84642 0.9653 38 1 10 0.1 0.8 -0.8 0.96173 0.96329 0.91583 0.95679 Tabella 3.19:Risultati per processi di secondo ordine sovra-smorzati con zero positivo e ritardo:
(
)
(
1)(
2)
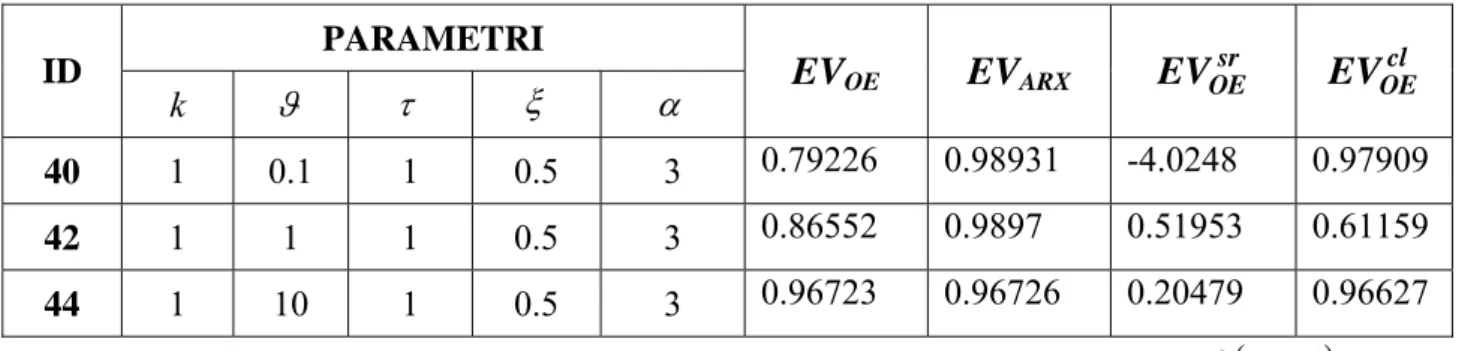
1 1 1 s k s e s s ϑ α τ τ − + + + PARAMETRI ID k ϑ τ ξ α EVOE EVARX sr OE EV EVOEcl 40 1 0.1 1 0.5 3 0.79226 0.98931 -4.0248 0.97909 42 1 1 1 0.5 3 0.86552 0.9897 0.51953 0.61159 44 1 10 1 0.5 3 0.96723 0.96726 0.20479 0.96627Tabella 3.20Risultati per processi di secondo ordine sotto-smorzato con zero negativo e ritardo: 2
(
1)
2 1 s k s e s s ϑ α τ τξ − + + + PARAMETRI ID k ϑ τ ξ α EVOE EVARX sr OE EV EVOEcl 41 1 0.1 1 0.5 -3 0.72136 0.99445 -1.1687 0.71241 43 1 1 1 0.5 -3 0.40534 0.99334 -6.712 0.66182 45 1 10 1 0.5 -3 0.97675 0.97929 0.63287 0.97536
Tabella 3.21Risultati per processi di secondo ordine sotto-smorzato con zero positivo e ritardo:
(
)
2 1 2 1 s k s e s s ϑ α τ τξ − + + +
PARAMETRI ID k ϑ EVOE EVARX sr OE EV EVOEcl 52 1 0.1 0.99508 0.99358 0.99999 0.99451
Tabella 3.23: Risultati per processi integratori: ke s s
ϑ
−
OSSERVAZIONI:
1. Dei 31 processi analizzati 21 hanno registrato un valore degli indici EVOEcl e EVOE
praticamente inalterato, 5 hanno registrato un miglioramento di entrambi gli indici, 3 hanno registrato un peggioramento, 2 hanno registrato un peggioramento di uno dei due indici e un miglioramento dell’altro.
2. I processi per i quali si è registrato un valore degli indici inalterato sono quelli con dinamica sovra-smorzata e senza zeri. Si ricorda che questi processi sono anche quelli per cui modello identificato e processo reale hanno un comportamento praticamente identico in anello chiuso.
3. Le tabelle sopra riportate evidenziano che non c’è alcuna corrispondenza tra i valori degli indici EVOEcl e EVOE e quello dell’indice EVOEsr . Sono molti, infatti, i processi per i
quali, passando da uno a tre cambi di set-point, il valore dell’indice EVOEsr diminuisce mentre quelli degli indici EVOEcl e EVOE aumentano.
4. I processi per i quali il risultato dell’identificazione è rimasto praticamente inalterato sono quelli ad alto rapporto ϑ /τ .
L’aumento degli indici EVOEcl e EVOE quando il set-point passa da una frequenza di variazione ω1
ad una frequenza più alta ω3, sta a significare che la somiglianza in anello chiuso, in corrispondenza della frequenza ω3, tra il processo reale e G3 è maggiore della somiglianza in anello chiuso, in corrispondenza della frequenza ω1, tra il processo reale e G1. G1 e G3 rappresentano i modelli identificati in corrispondenza di una frequenza di variazione del set-point rispettivamente pari a ω1 e ω3.
Certamente il fatto che l’indice EVOEsr diminuisca, fa nascere il sospetto che, in caso il set-point vari con una frequenza diversa da ω3, G3 possa non avere un comportamento simile a quello del processo reale e pertanto possa non risultare adeguato.
Quanto appena detto è stato verificato prendendo come esempio il processo N° 10, i risultati delle cui identificazione in caso di uno e tre cambi di set-point sono riassunti in tabella 3.24 e nella figura 3.12. Per comodità, nel seguito, ci riferiremo al modello identificato in caso di un solo cambio di set-point come al modello A e al modello identificato in caso di tre cambi di set-point come al modello B. PARAMETRI ID k ϑ τ ξ Ns EVOE EVARX sr OE EV EVOEcl 1 0.84995 0.98146 0.81678 0.81331 10 1 0.1 1 0.5 3 0.92479 0.99417 0.11866 0.94276
Figura 3.12: Risultati per il processo N°10: ((a): EVOEcl =0.8133; (b): EVOEcl =0.9428)
In figura 3.13 si confronta la risposta in anello chiuso del processo reale, del modello A e del modello B, in caso di un solo cambio di set-point.
Figura 3.13: Confronto tra il processo reale, il modello A e il modello B.
Come si vede dalla figura 3.13, il modello identificato in caso di tre cambi di set-point (modello B) se sottoposto in anello chiuso ad un solo cambio di set-point, non somiglia assolutamente al processo reale.
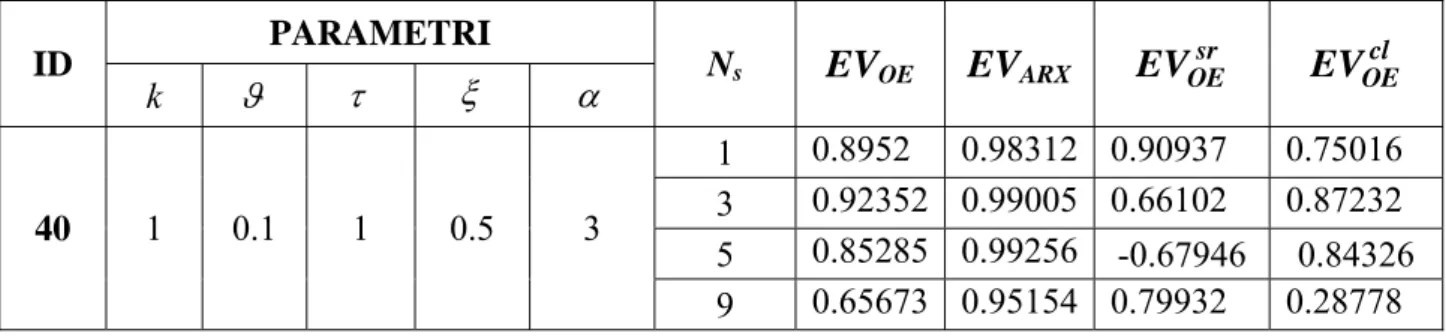
cambi di set-point nello stesso intervallo temporale. Le figure sono relative all’andamento del solo indice EVOEcl . PARAMETRI ID k ϑ τ ξ α Ns EVOE EVARX sr OE EV EVOEcl 1 0.8952 0.98312 0.90937 0.75016 3 0.92352 0.99005 0.66102 0.87232 5 0.85285 0.99256 -0.67946 0.84326 40 1 0.1 1 0.5 3 9 0.65673 0.95154 0.79932 0.28778
Tabella 3.25: Risultati per processi di secondo ordine sotto-smorzato con zero negativo e ritardo: 2
(
1)
2 1 s k s e s s ϑ α τ τξ − + + +
3.6: Conclusioni e approfondimenti
In conclusione, per 34 dei 54 processi simulati il modello identificato è identico al processo reale e inoltre ci sono altri 9 casi in cui, nonostante modello identificato e processo reale non coincidano, il loro comportamento in anello chiuso è molto simile. I 43 processi per i quali l’identificazione è ottima sono processi con dinamica sovra-smorzata e senza zeri. Questo risultato è molto incoraggiante se si considera che la maggior parte dei processi industriali ha proprio queste caratteristiche.
Gli 11 processi per i quali l’identificazione risulta più problematica o contengono zeri o hanno una dinamica sotto-smorzata.
Per i processi a ritardo dominante (alto rapporto ϑ /τ ) l’identificazione è più semplice. Dei quattro indici presi in considerazione solo due ( cl
OE
EV e EVOE) possono essere candidati per
stabilire la riuscita dell’identificazione: l’indice sr OE
EV è infatti un indice in anello aperto che non può essere calcolato in caso di applicazione della tecnica a dati industriali; l’indice EVARX non è
significativo della somiglianza tra il processo reale e il modello identificato né in anello chiuso né in anello aperto.
Poiché il nostro scopo è quello di identificare un modello che in anello chiuso abbia lo stesso comportamento del processo reale, non ci sono dubbi sul fatto che, in assenza di disturbi o di attrito l’indice che meglio consente il raggiungimento di tale scopo è cl
OE
EV .
L’indice EVOE consente, tuttavia, di mettere in risalto le differenze tra modello identificato e
processo reale riguardanti il guadagno e pertanto potrebbe essere un utile strumento di analisi in caso di sovrapposizione di disturbi o in presenza di attrito.
In definitiva, dalle simulazioni che sono state eseguite è risultato che l’indice che meglio consente di dare un giudizio ragionevole sull’esito della tecnica è cl
OE
EV , nonostante esso presenti due forti limitazioni:
• non risulta affidabile in presenza di attrito o disturbi;
• è significativo della somiglianza in anello chiuso tra processo reale e modello identificato, solo in corrispondenza delle frequenze per cui sono disponibili i dati.
Relativamente a questo secondo aspetto, è doveroso sottolineare che il tuning proposto sulla base di un modello identificato a cui è associato un alto valore di cl
OE
EV , potrebbe risultare inappropriato in caso di frequenze diverse da quelle su cui è stata condotta l’identificazione. In realtà per le classi di processo più semplici (le più comuni nella realtà industriale), questo problema non si pone, in
3.7: Approfondimenti
3.7.1: Effetto dell’ordine del modello
Per quei processi caratterizzati da zeri e da risposte sotto-smorzate c’è possibilità di migliorare l’accuratezza dell’identificazione impiegando un ordine del modello più elevato. Identificando un maggior numero di parametri si riesce certamente a definire un modello più simile al processo reale. Per stabilire l’opportunità o meno di ricorrere ad un ordine più elevato è necessario quantificare i miglioramenti che ne derivano e stabilire se essi giustificano il maggiore costo computazionale. Di seguito (Tabelle 3.26-3.31) si riportano i risultati ottenuti in caso di ordine (4,4), per quei processi per cui si erano ottenuti con un ordine (2,2)dei valori degli indici cl
OE
EV e EVOE bassi. Nelle
tabelle è stato omesso il valore di EVARX non essendo questo utile all’analisi.
PARAMETRI ID k ϑ τ ξ EVOE sr OE EV EVOEcl 10(4,4) 1 0.1 1 0.5 0.87109 0.83746 0.85924 10(2,2) 1 0.1 1 0.5 0.84995 0.81678 0.81331 11(4,4) 1 0.1 1 0.25 0.7934 0.59901 0.60984 11(2,2) 1 0.1 1 0.25 0.69674 0.41064 0.4 13(4,4) 1 1 1 0.25 0.89285 0.82068 0.66182 13(2,2) 1 1 1 0.25 0.73222 0.71111 0.53876
Tabella 3.26:. Risultati per processi di secondo ordine sotto-smorzati con ritardo:
2 2 1 s k e s s ϑ τ τξ − + + PARAMETRI ID k ϑ τ 1 τ 2 ξ EVOE sr OE EV EVOEcl 20(4,4) 1 0.1 0.1 1 0.25 0.83753 0.6263 0.72316 20(2,2) 1 0.1 0.1 1 0.25 0.74069 0.40204 0.54982 21(4,4) 1 0.1 1 1 0.25 0.8599 0.82918 0.57255 21(2,2) 1 0.1 1 1 0.25 0.84471 0.81802 0.5535 23(4,4) 1 1 0.1 1 0.25 0.85737 0.5727 0.32286 23(2,2) 1 1 0.1 1 0.25 0.63509 0.72372 0.2997 24(4,4) 1 1 1 1 0.25 0.92997 0.91592 0.80289 24(2,2) 1 1 1 1 0.25 0.89473 0.90993 0.7471 k
PARAMETRI ID k ϑ τ 1 τ 2 α EVOE sr OE EV EVOEcl 29(4,4) 1 0.1 0.1 0.8 3 0.97824 0.90645 0.93976 29(2,2) 1 0.1 0.1 0.8 3 0.87093 0.44862 0.71791
Tabella 3.28:Risultati per processi di secondo ordine sovra-smorzati con zero negativo e ritardo:
(
)
(
1)(
2)
1 1 1 s k s e s s ϑ α τ τ − + + + PARAMETRI ID k ϑ τ 1 τ 2 α EVOE EVOEsr cl OE EV 31(4,4) 1 0.1 0.1 0.8 -3 0.99237 0.98746 0.89591 31(2,2) 1 0.1 0.1 0.8 -3 0.78479 0.74351 0.42753 35(4,4) 1 1 0.1 0.8 -3 0.97733 0.91334 0.909 35(2,2) 1 1 0.1 0.8 -3 0.89358 0.72456 0.74509Tabella 3.29: Risultati per processi di secondo ordine sovra-smorzati con zero positivo e ritardo:
(
)
(
1)(
2)
1 1 1 s k s e s s ϑ α τ τ − + + + PARAMETRI ID k ϑ τ ξ α EVOE sr OE EV EVOEcl 40(4,4) 1 0.1 1 0.5 3 0.67447 -0.10415 0.93697 40(2,2) 1 0.1 1 0.5 3 0.40722 -0.88576 0.83673 42(4,4) 1 1 1 0.5 3 0.87895 0.66316 0.68078 42(2,2) 1 1 1 0.5 3 0.76487 0.52927 0.42419Tabella 3.30: Risultati per processi di secondo ordine sotto-smorzato con zero negativo e ritardo:
(
)
2 1 2 1 s k s e s s ϑ α τ τξ − + + +
OSSERVAZIONI:
1. Come si vede, in alcuni casi l’aumento dell’ordine porta a significativi miglioramenti, mentre in altri casi migliora solo leggermente le cose.
2. L’aumento degli indici cl OE
EV e EVOE è sempre accompagnato da un aumento dell’ indice
sr OE
EV . D’altra parte, essendo che il confronto è stato fatto a parità di andamento del set-point, questo risultato era facilmente prevedibile.
Nelle figure 3.15-3.18 si apprezzano i miglioramenti ottenibili a seguito di un incremento dell’ordine del modello (a sinistra n=m=2; a destra n=m=4).
Figura 3.15: Risultati per il processo N°29: ((a): EVOEcl =0.71791; (b): EVOEcl =0.93976)
Figura 3.17: Risultati per il processo N°31: ((a): EVOEcl =0.42753; (b): EVOEcl =0.89591)
Figura 3.18: Risultati per il processo N°31: ((a): EVOE= 0.78470; (b): EVOE=0.99237)
Per ognuna delle classi di processo “più difficili” si è valutato l’ordine a cui occorrerebbe ricorrere per ottenere valori accettabili degli indici cl
OE
EV e EVOE . Nelle seguenti figure si mostrano alcuni
Figura 3.20: Risultati per un processo del secondo ordine sovra-smorzato con zero positivo ritardo
Figura 3.21: Risultati per un processo del secondo ordine sovra-smorzato con zero negativo ritardo
Figura 3.22 Risultati per un processo del secondo ordine sotto-smorzato con zero negativo ritardo
OSSERVAZIONI:
1 Al fine di ottenere alti valori degli indici cl OE
EV e EVOE, è necessario ricorrere ad un ordine
più elevato per processi con dinamica sotto-smorzata, piuttosto che per processi contenenti zeri.
In particolare dalle simulazioni che sono state eseguite risulta che, per ottenere valori alti di entrambi gli indici in presenza di dinamiche sotto-smorzate, si deve ricorrere a valori di m ed n intorno a 5, mentre per processi con zeri negativi o positivi valori di m ed n intorno a 4 sono sufficienti.
Come valore di soglia oltre il quale si può dire di avere un alto valore degli indici si è preso 0.8.
2 Dal punto di vista applicativo pensare di impiegare un ordine (5,5) è impensabile oltre che superfluo sulla base di quanto detto al paragrafo 3.3.
3.7.2: Effetto del rumore
È interessante vedere come l’ampiezza del rumore influenza il risultato dell’identificazione. A tal proposito si sono fatte simulazioni con un solo cambio di set-point, per alcuni dei processi precedentemente riportati, al variare del rapporto tra l’ampiezza del rumore (ν) e l’ampiezza della variazione del set-point (r):
1. assenza di rumore;
2. presenza di rumore con rapporto ν /r ≤ 2%; 3. presenza di rumore con rapporto ν /r ≤ 5%; 4. presenza di rumore con rapporto ν /r ≤ 10%;
I risultati delle simulazioni sono riportati nelle seguenti tabelle (Tabelle 3.32-3.42). Dalle tabelle è stato omesso il valore di EVARX non essendo questo utile all’analisi.
PARAMETRI ID k ϑ τ EVOE sr OE EV EVOEcl 1 0.99968 1 0.99976 0.99976 0.9977 0.98217 0.99612 0.98599 1 1 0.1 1 0.95435 0.99825 0.94728
Tabella 3.32: Risultati per processi di primo ordine con ritardo: 1 s k e s ϑ τ − + PARAMETRI ID k ϑ τ 1 τ 2 EVOE sr OE EV EVOEcl 1 0.99983 1 0.9565 0.72619 0.95199 0.98275 0.79219 0.98634 4 1 0.1 1 0.8 0.91153 0.56741 0.91612 1 0.99978 1 0.99691 0.99545 0.99589 0.99183 0.99264 0.9893 7 1 1 1 0.2 0.96484 0.95704 0.94949 1 0.99966 1 0.9989 0.95979 0.99883 0.99329 0.8902 0.99291 9 1 10 1 0.2 0.97982 0.91587 0.97959
Tabella 3.33: Risultati per processi di secondo ordine sovra-smorzati con ritardo:
(
1 1)(
2 1)
s k e s s ϑ τ τ − + +PARAMETRI ID k ϑ τ ξ EVOE sr OE EV EVOEcl 1 0.99767 1 0.756 0.49565 0.49847 0.75702 0.4411 0.42284 11 1 0.1 1 0.25 0.80041 0.49395 0.33266 1 0.99948 0.99999 0.9618 0.95839 0.92204 0.96737 0.96446 0.93774 12 1 1 1 0.5 0.95164 0.95985 0.90888 1 0.99882 1 0.99851 0.90728 0.99845 0.99314 0.88803 0.99305 15 1 10 1 0.25 0.97836 0.91067 0.97828
Tabella 3.34: Risultati per processi di secondo ordine sotto-smorzati con ritardo:
2 2 1 s k e s s ϑ τ τξ − + + PARAMETRI ID k ϑ τ 1 τ 2 τ3 EVOE sr OE EV EVOEcl 0.99521 0.99824 0.99388 0.96654 0.9796 0.97409 0.972 0.98736 0.97675 16 1 0.1 1 0.9 0.8 0.92882 0.97009 0.90435 0.99962 0.99913 0.99941 0.99673 0.99564 0.99717 0.99323 0.99585 0.99241 17 1 1 1 0.9 0.8 0.93765 0.9266 0.86668 0.99999 0.99934 0.99999 0.99865 0.96088 0.99859 0.99361 0.92548 0.99345 18 1 10 1 0.9 0.8 0.97994 0.92687 0.9798
PARAMETRI ID k ϑ τ 1 τ 2 ξ EVOE EVOEsr cl OE EV 0.99215 0.98162 0.97402 0.86401 0.82894 0.6058 0.84333 0.82885 0.54003 21 1 0.1 1 1 0.25 0.82816 0.85779 0.53571 0.99992 0.98675 0.99993 0.98364 0.62412 0.98061 0.97122 0.58126 0.96463 22 1 1 0.1 0.1 0.25 0.95774 0.60318 0.95202 1 0.99876 1 0.99884 0.92402 0.99883 0.99445 0.92829 0.99438 26 1 10 0.1 1 0.25 0.97899 0.82781 0.97836
Tabella 3.36: Risultati per processi di terzo ordine sotto-smorzati con ritardo:
(
)
(
2)
1 1 2 2 2 1 s k e s s s ϑ τ τ τ ξ − + + + PARAMETRI ID k ϑ τ 1 τ 2 α EVOE sr OE EV EVOEcl 0.99382 0.96942 0.99487 0.95752 0.78761 0.97816 0.85671 0.27302 0.66127 29 1 0.1 0.1 0.8 3 0.87499 0.56153 0.67276 0.99963 0.99706 0.99949 0.99857 0.99485 0.99817 0.99075 0.96987 0.98823 32 1 1 0.1 0.8 0.3 0.96311 0.91144 0.95022 1 0.98917 1 0.9988 0.38781 0.99874 0.9939 -0.6948 0.99377 37 1 10 0.1 0.8 3 0.9765 -1.6542 0.97696Tabella 3.37:Risultati per processi di secondo ordine sovra-smorzati con zero negativo e ritardo:
(
)
(
1)(
2)
1 1 1 s k s e s s ϑ α τ τ − + + +PARAMETRI ID k ϑ τ 1 τ 2 α EVOE EVOEsr cl OE EV 0.99955 0.99481 0.991 0.96292 0.96236 0.67954 0.70921 0.75506 0.37729 31 1 0.1 0.1 0.8 -3 0.62071 0.66384 0.37955 0.99984 0.997 0.99965 0.98927 0.94227 0.9817 0.98781 0.80987 0.98737 34 1 1 0.1 0.8 -0.8 0.97555 0.82895 0.97288 1 0.99155 0.99999 0.99909 0.97367 0.99901 0.99285 0.82085 0.99231 38 1 10 0.1 0.8 -0.8 0.9777 0.59417 0.97689
Tabella 3.38:Risultati per processi di secondo ordine sovra-smorzati con zero positivo e ritardo:
(
)
(
1)(
2)
1 1 1 s k s e s s ϑ α τ τ − + + + PARAMETRI ID k ϑ τ ξ α EVOE sr OE EV EVOEcl 0.84209 0.58753 0.98026 0.58242 -0.26056 0.94263 0.30638 -0.80222 0.87046 40 1 0.1 1 0.5 3 0.33676 -0.97582 0.73972 0.98564 0.96134 0.92404 0.86599 0.69145 0.53282 0.781 0.57995 0.46919 42 1 1 1 0.5 3 0.64118 0.45846 0.40807 0.99992 0.97089 0.99991 0.99858 0.68997 0.99851 0.99239 0.086084 0.99223 44 1 10 1 0.5 3 0.97512 -1.452 0.97514PARAMETRI ID k ϑ τ ξ α EVOE sr OE EV EVOEcl 0.99959 0.99393 0.99794 0.75535 0.32947 0.75113 0.81249 0.66433 0.70215 41 1 0.1 1 0.5 -3 0.86978 0.78603 0.61084 0.99987 0.99335 0.99976 0.88186 0.45483 0.85279 0.95315 0.80114 0.89118 43 1 1 1 0.5 -3 0.9342 0.77484 0.8697 0.99999 0.98536 0.99998 0.99845 0.67583 0.99824 0.99473 0.61101 0.9944 45 1 10 1 0.5 -3 0.98144 0.55543 0.98119
Tabella 3.40: Risultati per processi di secondo ordine sotto-smorzato con zero positivo e ritardo:
(
)
2 1 2 1 s k s e s s ϑ α τ τξ − + + + PARAMETRI ID
k
θ
τ
n
EVOE sr OE EV EVOEcl 0.99543 0.99817 0.99182 0.97648 0.98682 0.96846 0.98226 0.99277 0.97693 46 1 0.1 1 4 0.68702 0.8408 0.74352 0.99815 0.99813 0.99592 0.99594 0.99479 0.99438 0.99169 0.99164 0.98945 49 1 1 1 5 0.95829 0.95071 0.92387 0.99997 0.9986 0.99996 0.9985 0.97231 0.99844 0.99378 0.94182 0.99357 50 1 10 1 4 0.97528 0.93532 0.97486Tabella 3.41: Risultati per processi di ordine elevato (4 e 5) con ritardo:
(
1)
s n k e s ϑ τ − +PARAMETRI ID k ϑ EVOE sr OE EV EVOEcl 1 1 1 0.99824 0.99964 0.99836 0.98918 0.99898 0.99016 52 1 0.1 0.64306 0.9144 0.82243
Tabella 3.42: Risultati per processi integratori: k s
e s
ϑ −
OSSERVAZIONI:
1 In assenza di rumore il valore degli indici tende a uno per tutti i processi ad eccezione di quelli del secondo ordine sotto-smorzati con zero negativo. Questo fatto può essere interpretato come la conferma che un ordine (2,2) può essere ritenuto sufficiente per tutte le classi di processo, ad eccezione di quella dei processi del secondo ordine sotto-smorzati con zero negativo.
2 Si distinguono tre tipologie di processi:
a) Processi praticamente insensibili al rumore in cui il valore di tutti gli indici risulta sempre molto alto, sia in assenza di rumore, sia in presenza di rumore di varie ampiezze (si tratta dei processi ad alto rapporto ϑ /τ , dei processi sovra-smorzati, dei processi integratori);
b) Processi in cui risulta determinante più che l’ampiezza del rumore la sua presenza. In questo tipo di processi, rumori anche piccoli rendono l’identificazione difficile, ma al crescere dell’ampiezza del rumore non si hanno significativi cambiamenti (si tratta di alcuni processi sotto-smorzati o contenenti zeri a basso rapporto ϑ /τ .);
c) Processi in cui all’aumentare dell’ampiezza del rumore l’identificazione risulta sempre più difficile (si tratta di alcuni processi sotto-smorzati o contenenti zeri a basso rapporto ϑ /τ .).
È quindi evidente che è proprio la presenza di rumore la causa di una cattiva identificazione. I processi per i quali l’identificazione da più problemi (presenza di zeri o di dinamica sotto-smorzata) sono anche quelli più sensibili alla presenza di rumore.
3.8: Conclusioni approfondimenti
Per quanto riguarda l’ordine del modello, si è notato che all’aumentare di questo l’accuratezza dell’identificazione aumenta, ovvero si ottengono valori più alti degli indici cl
OE
EV e EVOE. Quale
ordine debba essere raggiunto per ottenere valori degli indici superiori ad un certo valore di soglia dipende dalle caratteristiche del processo. Per classi di processo che non prevedono dinamiche sotto-smorzate o zeri sono sufficienti ordini bassi (2,2) per ottenere ottimi valori di entrambi gli indici (EVOEcl e EVOE superiori a 0.8), mentre per classi di processo che possiedono uno o entrambe
queste caratteristiche è necessario ricorrere ad ordini più alti (5,5).
Il problema dell’ordine è strettamente connesso al problema del rumore: quanto più il rumore è consistente tanto più è necessario ricorrere ad ordini elevati per ottenere una buona identificazione. In assenza di rumore l’identificazione è perfetta già con un ordine (2,2) per tutte le classi di processo, ad eccezione di quella con dinamica sotto-smorzata e zero negativo.
Ai fini pratici ricorrere ad ordini troppo elevati non è molto sensato per i seguenti motivi:
1 I processi industriali solitamente hanno dinamiche molto semplici per le quali risultano sufficienti bassi valori degli indici m ed n.
2 Come già detto al paragrafo 3.3 anche dinamiche complesse possono essere approssimate bene da modelli di ordine relativamente basso purché venga utilizzato un opportuno valore del ritardo.
3 L’identificazione di un modello di ordine elevato è inutile se il fine ultimo è la sintonizzazione del regolatore; praticamente tutte le tecniche di tuning prevedono una riduzione di ordine.