Capitolo 5
Costruzione di indici prestazionali
Introduzione:
Analizzare una rete per il traffico dati, significa principalmente fornire indicazioni sul suo stato di funzionamento, osservare e monitorare il suo comportamento istante per istante, ed inoltre osservare e riferire se le risorse siano sottoutilizzate.
Per poter dare un’indicazione sia qualitativa che quantitativa dello stato di una rete, come detto si possono osservare le informazioni contenute all’interno delle MIB, ma è facile capire che questo non basta per poterlo oggettivamente definire.
Quindi diventa necessario introdurre il concetto di indici prestazionali, ottenuti combinando insieme una o più informazioni contenute nel MIB, in modo da poter definire dei parametri di funzionamento in maniera semplice ed intuitiva.
In questo capitolo, vedremo come possono essere costruiti gli indici prestazionali relativi ad apparati di rete quali switch e router, riportando gli indicatori più comuni ottenuti tramite le MIB-2.
Inoltre, poichè lo scopo di questa tesi un’ analisi di una rete DiffServ, verranno illustrati gli indici prestazionali specifici per questo tipo di architettura di rete, che possono essere costruiti tramite le informazioni ricavate utilizzando il protocollo SNMP.
E’ importante notare, che un’accurata analisi di rete porta utili consigli riguardo possibili cambiamenti nella configurazione, in modo da prevenire eventualmente situazioni di congestione, oppure migliorare lo sfruttamento delle risorse utilizzate.
5.1 La pila OSI
Il modello di rete OSI (Open Systems Interconnection) è uno standard di comunicazione tra reti diverse. Le prime specifiche pubblicate nel 1978 dall’ISO (International Standards Organization), fanno riferimento ai sistemi aperti, sistemi cioè che permettono la comunicazione tra componenti hardware e software di fornitori diversi. La versione completa, pubblicata nel 1984, è diventata di fatto
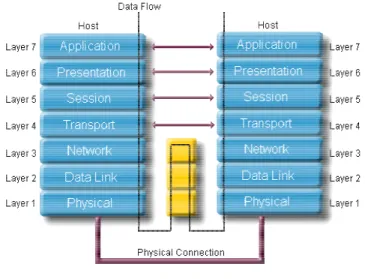
uno standard internazionale, nel senso che tutte le case produttrici progettano i loro prodotti in base alle specifiche del modello OSI. Il modello ha avuto successo grazie all'architettura modulare impostata su sette strati completamente indipendenti. Ogni strato infatti, poiché gestisce funzioni e servizi che svolgono attività simili, può essere modificato senza ripercussioni sugli altri strati; questo consente di suddividere operazioni molto complesse in elementi più semplici, di integrare i prodotti di venditori diversi, e quindi permette l’interoperabilità tra reti con caratteristiche differenti. Lo scambio delle informazioni tra i vari strati è invece delegata ad opportune interfacce di comunicazione. Il modello OSI si presenta strutturato in sette livelli, ciascuno dei quali implementa distinte funzioni di rete e fornisce servizi ai livelli adiacenti, in relazione ai protocolli che lo determinano. Ogni livello tuttavia si comporta come se la comunicazione avvenisse con il livello paritario dell’altra stazione di lavoro. Se prendiamo come riferimento le due serie dei 7 livelli, relative a due macchine che devono scambiarsi delle informazioni, allora possiamo affermare che il livello paritario è quello che svolge su ogni macchina la stessa funzione. Possiamo pertanto pensare che i due livelli paritari siano virtualmente connessi.La figura 5.1 illustra come avviene la comunicazione con i livelli adiacenti e con il livello paritario.
Figura 5.1: Modello OSI
Andiamo ad analizzare i vari Layer:
• (Layer 7) Application: occupa lo strato più alto della pila e per questo motivo non fornisce servizi agli altri livelli, ma
interagisce in modo diretto con le applicazioni usate dall’utente, fornendo i servizi di rete.
• (Layer 6) Presentation: si preoccupa di preparare le informazioni ricevute dal livello Application in un formato adatto alla
trasmissione. Lo stesso livello della stazione ricevente, coinvolta nella comunicazione, trasforma il formato in modo da renderlo compatibile con la stazione ricevente; in particolare effettua la codifica dei dati, la conversione del set di caratteri e l’espansione dei comandi grafici.
• (Layer 5) Session: si occupa di attivare la connessione tra due stazioni, di mantenerla per tutta la durata del trasferimento dei
dati e di abbatterla a fine trasmissione. L’intero processo è chiamato appunto sessione. Poiché i dati vengono trasmessi su una rete a commutazione di pacchetto, questo livello ha il compito fondamentale di definire la durata della trasmissione e il controllo del dialogo decidendo quale delle due stazioni deve trasmettere.
• (Layer 4) Transport: è il più basso dei 4 livelli superiori end-to-end, cioè in grado di stabilire una connessione logica con i
livelli paritari. Come gli altri livelli superiori, esso risulta completamente indipendente dal tipo di rete implementata a livello fisico. Questo livello incapsula i dati in segmenti in fase di trasmissione e li riassembla in fase di ricezione.
• (Layer 3) Network: si occupa della traduzione del nome logico dell’host destinatario in indirizzo fisico. Definisce
l’instradamento, determinando il percorso più breve, prima dell’invio dei messaggi, attraverso la consultazione di tabelle di instradamento statiche o dinamiche. Si occupa di gestire la comunicazione controllando il flusso dei dati al fine di evitare la congestione della rete. I dati ricevuti dal livello superiore sono organizzati in pacchetti o datagramma, che contengono il network header con l’indirizzo logico della sorgente e della destinazione.
• (Layer 2) Datalink: provvede che la trasmissione sul mezzo fisico sia affidabile. A questo livello diventa molto importante la
topologia della rete e il possibile accesso. Il Data Link si preoccupa inoltre dell’indirizzamento fisico, di ordinare e incapsulare i dati in una struttura logica detta trama o frame e di trasmetterla correttamente al sottostante livello Fisico.
• (Layer 1) Physical: è il livello più basso della pila OSI e lavora con i Bit, si occupa di inviare sul mezzo i segnali elettrici o
ottici.
Nei primi tre livelli (Application, Presentation, Session) i dati sono visti come un unico flusso mentre a mano a mano che scendiamo vengono organizzati in segmenti, pacchetti, frame e bit.
Il Network Manager, deve avere una visione molto chiara di questa struttura, perché ogni apparato di rete che deve amministrare lavora soltanto con alcuni livelli della pila. Quindi per ogni apparato il manager deve ricavare informazioni per ogni strato che esso implementa; ad esempio, di uno switch, che lavora a livello due non è possibile ricavare informazioni sui protocolli IP o TCP.
In linea di massima comunque per il Management di una rete vengono considerati sostanzialmente i primi quattro Layer del modello, in quanto sono questi che danno informazioni sul traffico.
5.2 I Case Diagram
L’utilizzo delle MIB non è semplice. Infatti, un indice da solo non dice molto sullo stato di un apparato di rete. Per capire se un nodo sta funzionando correttamente, dobbiamo osservare più grandezze contemporaneamente e confrontarle facendo anche riferimento allo standard OSI.
Per questo è necessario utilizzare i Case Diagram: diagrammi che per ogni livello della pila Osi definiscono il flusso delle grandezze dei MIB, cioè ci dicono se gli indici sono di ingresso o di uscita e verso quale livello (se il precedente o il successivo ) della pila OSI passano informazioni. La caratteristica principale di questi diagrammi è il fatto che sono di facile lettura. Infatti, dal verso delle frecce si può capire se la grandezza è additiva, sottrattiva o filtro.
Figura 5.2: esempio di Case Diagram
Nella figura 5.2 è rappresentato un esempio di case diagram che fa riferimento al gruppo Interfaces del MIB-2, La freccia ↑↑↑↑ rappresenta
il flusso di dati che dal livello1 vengono passati al livello3. Gli oggetti del MIB, rappresentati nel Case Diagram, possono avere associato tre tipi di frecce:
1) La freccia ←←←← significa che quegli oggetti sono “sottrattivi”, ovvero sono elementi che non saranno passati al livello superiore 2) La freccia →→→→ significa che quegli oggetti sono “additivi”, ovvero sono elementi che saranno passati al livello superiore. 3) la freccia senza punte identifica invece oggetti che fanno parte di un livello, cioè che non sono né additivi, né sottrattivi. Per il flusso dati in uscita ↓↓↓↓ valgono le stesse regole ma in modo invertito, ovvero gli oggetti che hanno la freccia →→ sono sottrattivi e →→ quelli con la freccia ←←←← sono additivi.
Con l’esempio in figura possiamo capire come questi diagrammi sono utili, infatti possiamo calcolarci con le regole dei case diagram il numero totale dei frame giunti all’interfaccia a cui il case diagram fa riferimento.
Dal diagramma se leggiamo la parte relativa all’ingresso vediamo che:
IfInUcastPkts + IfInNucastPkts = (frame giunte all’interfaccia) – ifInDiscards – IfUnknownProtos - IfInErrors.
• IfInUcastPkts : Numero di pacchetti trasmessi in modalità unicast in ingresso ad un’interfaccia • InInNucastPkts : Numero di pacchetti trasmessi non in modalità unicast in ingresso ad un’interfaccia
• IfInDiscards : Numero di pacchetti scartati in ingresso ad un’interfaccia, anche se non contenenti errori, che quindi non
possono raggiungere il livello successivo della pila Osi.
• IfUnknownProtos : Numero di pacchetti scartati poiché il tipo di protocollo non è supportato, che quindi non possono
raggiungere il livello successivo della pila Osi.
• IfInErrors : Numero di pacchetti contenenti errori, che quindi non possono raggiungere il livello successivo della pila Osi.
In base a questo possiamo calcolare semplicemente i frame giunti all’interfaccia.
Per ogni apparato di rete possiamo dunque costruire il case diagram partendo dal livello fisico in ingresso, salendo fino al livello più alto della pila OSI a cui il nodo lavora e scendendo poi dal lato “out” fino ancora al layer 1.
5.3 costruzione di grandezze significative dagli indici dei MIB
Come detto le informazioni che possiamo ottenere dai MIB sono tantissime e spesso sono di difficile interpretazione. Proprio per questo è importante, per ogni apparato di rete da monitorare, definire degli indici relativi ai livelli dello standard OSI implementato dal nodo stesso.Gli indici che costruiremo dovranno darci delle informazioni sul traffico, ma anche sullo stato di funzionamento del nodo. Queste grandezze saranno dunque utili per la parte di management che riguarda le Performance e il Fault.
Per quanto riguarda i MIB useremo sia lo standard MIB-2, sia la parte dei MIB privati (definite secondo diversi Standard delle principali case di apparati di telecomunicazioni).
Cercheremo dunque di costruire indici che diano informazioni più utili rispetto alle singole variabili dei MIB. Ad esempio, se prendiamo l’oggetto del MIB relativo al broadcast, vediamo che restituisce un valore assoluto delle trame broadcast spedite, se invece
la pesiamo con le trame totali spedite riusciamo ad ottenere la percentuale di broadcast spedito rispetto alle trame totali, che è un indice utile per capire se la rete stia funzionando in maniera corretta.
5.3.1 Switch
Iniziamo ad analizzare un componente di rete che lavora al livello 2 dello standard OSI: lo Switch.
Questo componente ha il compito di smistare su una rete LAN il traffico tra gli utenti. Il suo funzionamento è il seguente:
Quando riceve un frame di livello due in ingresso ad una sua porta, per prima cosa estrae l’indirizzo MAC sorgente e destinatario. Il sorgente viene utilizzato per costruire una tabella di tipo dinamico in cui scrivere a quale porta l’host, che ha quel determinato indirizzo, è collegato. L’indirizzo MAC destinatario serve invece per capire su quale porta mandare quel frame, analizzando gli indirizzi contenuti nella tabella che lo Switch si è costruito. Qualora non sia presente l’indirizzo MAC del destinatario, il messaggi viene inviato in modo broadcast.
Per questi apparati di rete possiamo ricavarci sia indici locali, che danno informazioni sulla macchina, che indici relativi ad ogni interfaccia.
Il case diagram per uno switch comprende il traffico che dal livello 1 della pila OSI “viaggia” verso il livello 3 (Fig 5.6)
• % Errori in ingresso all’interfaccia:
(IfInErrors/(IfInUcastPkts+IfInNucastPkts+IfInErrors+IfInDiscards+IfInUnknownprotos))% (1) Per questo indice si guarda la parte di ingresso del case diagram di una porta di uno switch, cioè:
Figura 5.3: Case Diagram della parte input di uno switch
Questo indice ci dice la percentuale di pacchetti Ethernet contenenti errori che arrivano su un’interfaccia. Rappresenta una grandezza da controllare perché se diverso da zero può indicare che in quel ramo della rete c’è qualcosa che non và e quindi bisogna intervenire e verificare che non ci siano difetti nel sistema di cablaggio.
Se nelle canaline dove passano i cavi di rete, sono presenti cavi di alimentazione, si possono generare interferenze che vanno a modificare il segnale che sta transitando all’interno del cavo di rete causando così errori nel CRC.
Questo fenomeno nasce dal fatto che in un cavo di alimentazione scorre una tensione variabile nel tempo con frequenza di 50Hz, questa tensione genera un campo elettromagnetico variabile che trasmette disturbi ai dispositivi vicini e quindi ai cavi di rete presenti nelle canaline.
Inoltre i cavi di rete fungono da antenne, e possono captare disturbi provenienti da motori elettrici, fotocopiatrici, ascensori, frigoriferi ecc…
Un proprietà dei cavi è l’impedenza caratteristica, che è il valore di impedenza che il cavo avrebbe se questo fosse infinitamente lungo.
L’impedenza caratteristica dipende dagli effetti capacitivi, resistivi e induttivi del cavo, questi valori sono stabiliti dai parametri fisici, come la dimensione dei conduttori, la distanza tra di loro e le caratteristiche del materiale isolante.
Il buon funzionamento di un sistema di cablaggio dipende da un’impedenza caratteristica costante per tutti i cavi e connettori della rete. Brusche variazioni dell’impedenza caratteristica provocano fenomeni di riflessione dei segnali, per cui i segnali trasmessi lungo i cavi vengono alterati, provocando errori nel CRC.
Di solito l’impedenza caratteristica viene alterata leggermente dai collegamenti e dalle terminazioni del cavo. Anche avvolgimenti troppo stretti e attorcigliamenti possono alterare l’impedenza caratteristica. Discontinuità di impedenza possono dunque interferire con la trasmissione dei dati in una rete LAN. Queste anomalie possono essere dovute a contatti elettrici incerti, terminazioni del cavo eseguite in modo errato, all’uso di un cavo e di un connettore non compatibili tra di loro, e all’intreccio sbagliato o irregolare delle coppie del cavo.
I cavi di rete sono costituiti da coppie di conduttori intrecciate tra di loro in modo che il campo elettromagnetico che un conduttore genera, sia di uguale intensità ma di verso opposto di quello generato dall’altro conduttore, per far si che si annullino. Nei punti nei quali i cavi non sono più intrecciati, i campi elettrici dei conduttori non si compensano più e si verifica il fenomeno della diafonia. Per diafonia si intende la propagazione indesiderata di un segnale da una coppia di conduttori ad una coppia vicina nello stesso cavo, ovvero il segnale di una coppia di conduttori viene propagato in altre coppie generando in questo modo interferenze e quindi errori.
Per ridurre i problemi che si possono creare in un sistema di cablaggio basta seguire i seguenti accorgimenti:
• Non abbinare mai cavi con impedenze caratteristiche diverse ( a meno che non vengano inseriti circuiti speciali di
conversione dell’impedenza ).
• Fare attenzione nell’eseguire le connessioni: le coppie intrecciate possono causare gravi problemi di diafonia.
Dunque, se si rilevano errori in ingresso ad un’interfaccia si deve andare alla ricerca di anomalie nel cablaggio, partendo dai punti di connessione (prese per telecomunicazioni, quadri di allacciamento, blocchetti terminali, connettori di transizione), in quanto i difetti sono, nella maggior parte dei casi, localizzati proprio in queste zone.
Sempre considerando la parte di ingresso del case diagram di uno switch ( Fig 5.3) possiamo ricavarci un indice di congestione:
• % pacchetti eliminati in ingresso, anche se privi di errore:
(IfInDiscard)/(IfInUnicastPkts+IfInNunicastPkts)% (2)
Questo è un indice di congestione, ovvero indica se la porta dello switch è molto utilizzata oppure no.
Lo switch esamina una per volta, le trame che giungono in ingresso su tutte le sue interfacce. Per non perdere frame in ingresso, esso ha un buffer per ogni porta, nei quali mette le trame in attesa; se le richieste su una porta giungono più velocemente rispetto al tempo che impiega lo switch ad esaminare le altre, parte del traffico viene scartato.
In questo caso, è necessario controllare la configurazione di rete, per vedere se è possibile smistare parte del traffico verso aree meno congestionate.
Prendendo in esame il case diagram della parte output di uno switch possiamo ricavare:
• % Errori in uscita ad un’interfaccia:
(IfOutErrors/(IfOutUcastPackets+IfOutNucastPackets+IfOutDiscards+IfOutErrors)% (3) Il cui case diagram è (Fig 5.4):
Figura 5.4: Case Diagram relativo alla parte output di uno switch
Questo indice dà invece un’informazione sullo stato di funzionamento dello switch, in quanto gli errori in uscita sono generati dall’apparato stesso, quindi se questo indice è diverso da zero si deve intervenire e controllare la scheda di rete dell’interfaccia. Un indice di congestione per il traffico di uscita da un’interfaccia è:
• % di pacchetti eliminati anche se non contenenti errori:
((IfOutDiscards)/(IfOutNunicastPkts+IfoutUcastPkts)% (4)
Se molte trame che giungono in ingresso allo switch, devono essere instradate sulla medesima porta, e la velocità è la stessa su tutte le porte, le trame, nell’attesa di essere spedite rimangono in un buffer in uscita, se però questo si riempie, le trame in eccesso vengono scartate.
Per evitare questo problema si possono utilizzare porte più veloci per alcuni collegamenti, infatti alcuni switch hanno alcune porte che lavorano a velocità più elevata rispetto alle altre.
Andiamo ora ad analizzare due indici orientati all’efficienza:
• Utilizzo dell’interfaccia:
(((ReceivedByteRate+TransmittedByteRate)*8)/InterfaceLinkSped) (5)
è importante principalmente per due motivi:
• Se osserviamo che l’utilizzazione risulta essere troppo elevata, (potremmo fissare una soglia al 60%), possiamo decidere che parte
del traffico sia instradato su un altro ramo della rete, mentre, nel caso in cui l’interfaccia sia scarsamente utilizzata (ad esempio sotto il 10%) potremmo pensare di utilizzarla per convogliarci parte del traffico che attraversa aree più congestionate della rete.
• Possiamo conoscere come è distribuito il traffico nella rete e quindi capire dove è meglio convogliare il traffico generato da
eventuali nuove applicazioni.
Un altro indice che descrive l’utilizzazione lo possiamo ricavare osservando gli ottetti che passano nell’interfaccia in esame per un tempo di osservazione stabilito, ovvero prendendo:
• DeltaIfInOctets = ottetti passati in ingresso nel tempo di osservazione. • DeltaIfOutOctets = Ottetti passati in uscita nel tempo di osservazione. • Deltatime = tempo di osservazione.
• % utilizzazione dell’interfaccia:
(((DeltaIfInOctets+DeltaIfOutOctets)*8*100)/(Deltatime*IfSpeed)% (6)
• Se vogliamo osservare l’utilizzazione percentuale dell’interfaccia in ingresso:
((DeltaIfInOctets*8*100)/(Deltatime*IfSpeed)% (7) • e in uscita: ((DeltaIfOutOctets*8*100)/(Deltatime*IfSpeed)% (8)
5.3.2 Router
Il Router è un apparato di rete che lavora a livello 3 dello Standard OSI, quindi, tutti gli indici ricavati per gli switch, possono essere utilizzati anche per questi apparati di rete.
La funzione dei Router è quella di collegare tra loro le varie LAN, utilizzando delle tabelle di instradamento e dei protocolli di Routing di tipo dinamico come RIP (Routing Information Protocol), IGRP (Interior Gateway Routine Protocol).
Quando un messaggio arriva ad un router questo estrae il pacchetto IP dalla trama Ethernet, elimina l’header e il trailer Ethernet, controlla l’indirizzo IP del destinatario del pacchetto e consulta la sua tabella di instradamento (per vedere su quale interfaccia mandare il pacchetto). Infine, rimpacchetta il messaggio in un Frame Ethernet con un nuovo Header e trailer contenenti l’indirizzo MAC del prossimo Hop, quindi, spedisce la trama.
Andiamo dunque a vedere quali indici di livello 3 (Network), possiamo utilizzare per amministrare il traffico IP di un router considerando il case diagram che descrive il traffico che transita dal livello Datalink al livello di trasporto (Fig 5.5):
Figura 5.5: Case Diagram di un router
Iniziamo a ricavare indici per il livello tre partendo dalla parte di input del case diagram (Fig 5.6):
Figura 5.6: Case Diagram relativo alla parte di input di un router
• % pacchetti ricevuti ma scartati a livello IP:
((IpInReceives-IpInDelivers)/IpInReceives)% (9) IpInReceives : numero di pacchetti IP ricevuti in ingresso all’interfaccia.
IpInDelivers : numero di pacchetti IP ricevuti senza errori, in ingresso all’interfaccia. Questa grandezza indica la percentuale di pacchetti scartati dal router a livello IP.
A questo livello i pacchetti vengono scartati perché contenenti errori, oppure perché il router non riesce ad instradare tutti i pacchetti che gli arrivano e quindi riempie il suo buffer.
Gli errori che vengono individuati, di solito, sono imputabili a problemi di routing: ad esempio se il pacchetto che arriva al router ha un indirizzo di una classe che il router non supporta, verrà scartato.
Quindi nel caso in cui vi siano molti errori presenti in uscita o in ingresso si deve andare a controllare la configurazione del router e verificare che i protocolli di routing siano funzionanti.
• % pacchetti IP scartati per errori nell’header IP:
(IpInHdrErrors/IpInReceives)% (10)
IpInHdrErrors : numero di pacchetti IP ricevuti con successo ma scartati perché contenenti errori nell’header IP
Questo errore viene generato quando viene riscontrato un errore nell’header IP, ovvero quando il Checksum non torna, quando la versione di IP è sbagliata, TTL è uguale a 0, oppure quando si riscontri un errore nel processare le opzioni, nel caso in cui venga utilizzato questo campo.
Per eliminare questo errore si deve controllare che i protocolli di routine stiano funzionando a dovere.
• % pacchetti scartati perché contenenti un protocollo non supportato:
(IpInUnknowProtos/IpInReceives)% (11)
IpInUnKnowProtos : Numero di pacchetti IP ricevuti con successo ma scartati poiché il tipo di protocollo non è supportato
Questo errore rientra tra quelli rilevati nell’header, indica che il protocollo di livello tre non è supportato dal router (questo caso si può verificare in una rete dove è presente sia traffico IP che traffico IPX; in questi ambienti infatti i router devono essere configurati per gestire entrambi i tipi di traffico). Nel caso in cui si verifichi questo errore, si deve andare a controllare la configurazione del router e settarla in modo che gestisca entrambi i protocolli di livello tre.
• % pacchetti scartati perché contenenti errori nell’indirizzo:
(IpInAddrErrors/IpInReceives)% (12)
IpInAddrErrors : numero di pacchetti IP ricevuti con successo ma scartati poiché contenenti errori nell’indirizzo IP.
Anche questo è un errore rilevato nell’header ed indica che l’indirizzo destinazione IP presente nel pacchetto non è supportato dal router oppure è un indirizzo invalido (ad esempio 0.0.0.0).
Su macchine che lavorano a livello 3 ma che non sono abilitate a instradare pacchetti IP comprende tutti i pacchetti che vengono scartati perché il destination address presente nel pacchetto non corrisponde al loro indirizzo IP. Anche in questo caso è necessario controllare la configurazione del router.
• % pacchetti scartati anche se non contenenti errori:
(IpInDiscards/IpInReceives)% (13)
Questa grandezza indica che il router è molto utilizzato e non riesce ad instradare tutti i pacchetti che gli arrivano in ingresso. Solitamente può verificarsi su un router, che in una configurazione di rete a stella, è posizionato proprio a centro stella, il quale deve soddisfare tutte le richieste di instradamento che gli giungono dalle reti periferiche. Se però questa grandezza è troppo elevata, le contromisure da apportare possono essere due:
• La sostituzione del router con un altro più potente.
• Il cambiamento della tipologia di rete, abbandonando quella a stella.
Passiamo ora alla parte output del case diagram che descrive il traffico che transita all’interno di un router (Fig 5.7):
Figura 5.7: Case Diagram relativo alla parte di output di un router
• % pacchetti scartati in uscita anche se non contenenti errori:
(IpOutDiscards/IpOutRequest)% (14)
IpOutRequest : Numero di pacchetti IP che hanno subito una richiesta di trasmissione verso un nodo della rete. IpOutDiscards : Numero di pacchetti IP che sono stati scartati anche se non contenenti errori.
Questo errore indica che i pacchetti (per i quali il router ha già calcolato l’interfaccia sulla quale devono uscire) rimangono nel buffer di uscita e qualora la memoria sia completamente riempita, vengono scartati i pacchetti in eccesso.
In questo caso il problema può essere ricercato nel sistema di cablaggio, quindi se si verifica questo errore è necessario andare a controllare gli indici relativi al gruppo dot3.
• % pacchetti scartati in uscita perché non si è trovato un instradamento:
(IpOutNoRoutes/IpOutRequest)% (15)
Questo errore indica la percentuale di pacchetti che non saranno instradati, perché controllando le tabelle di routing, non si è trovato un instradamento.
5.3.3 Server e Workstation
Server e Workstation sono apparati di rete che hanno tutti e sette i livelli della pila OSI. Per quello che riguarda il Network Management, i livelli da osservare sono solo i primi quattro (Physical, Datalink, Network, Transport). Quindi oltre agli indici già visti per Router e Switch, possiamo ricavare altri indici di layer 4 ottenuti dai livelli UDP (User Datagram Protocol) e TCP (Transmission Control Protocol) del MIB-2.
I case diagram che descrivono il traffico di livello 4 attraverso un router sono i seguenti (Fig 5.8, Fig 5.9):
Figura 5.8: Case Diagram per il protocollo TCP
Figura 5.9: Case Diagram per il protocollo UDP
TCP è un protocollo orientato alla connessione e quindi è importante vedere quante connessioni TCP sono attive sul Server. L’indice che ci dà questa informazione è: TCPcurrEstab.
TCP è inoltre un protocollo che fa controllo di flusso e si occupa di ritrasmettere le trame nel caso di errori sia a livello 2 che a livello 3, quindi è importante controllare quanti sono i segmenti TCP ritrasmessi
• % Segmenti TCP ritrasmessi:
(TcpRetranSegs/TcpOutSegs)% (16) TcpOutSegs: Numero di segmenti TCP inviati in uscita
TcpRetranSegs : Numero di segmenti TCP che sono stati ristrasmessi
Questa grandezza rappresenta i segmenti che vengono rispediti in quanto non sono arrivati gli ack prima dello scadere del timeout. I motivi di questa ritrasmissione possono essere molteplici e dipendere da uno o più apparati, quindi, se si vuole cercare la causa che la genera è consigliabile fare un’analisi approfondita di rete.
• % Segmenti TCP ricevuti con errori:
(TcpInErrors/TcpInSegs)% (17)
TcpInErrors : Numero di segmenti TCP ricevuti correttamente, ma contenti errori a livello TCP.
Questa grandezza indica gli errori che si sono verificati a livello 4 nel protocollo TCP, ad esempio nel CRC. Se questi errori risultano elevati è necessario controllare la configurazione TCP sul server.
Questi indici sono soltanto alcuni che possono aiutare nel controllo di una rete dati. In realtà, il network manager deve trovare indici specifici per ogni problema che deve risolvere, ricercandoli nel MIB privato o nella parte standard. Nel nostro caso per una rete DiffServ, risultano molto utili indicatori più specifici per l’architettura in analisi.
5.3.4 Indici Prestazionali per una rete DS
Analizzando i MIB che possiamo ottenere in seguito all’implementazione dell’architettura di monitoraggio della rete, descritta nei capitoli 3 e 4 di questa tesi, è possibile definire degli indicatori, che ci permettano di esprimere giudizi qualitativi e quantitativi sullo stato della rete DS.
La definizione delle MIB utilizzate per costruire questi indici, è stata riportata nell’ Appendice A di questa tesi.
In primo luogo, è importante specificare che andremo a costruire indicatori relativi ad ogni classe di servizio, in maniera tale da poter monitorare e capire il comportamento di ognuna de esse.
Un primo indicatore molto importante è relativo alla percentuale di pacchetti scartati (drops) ottenuta durante la trasmissione di traffico di una certa classe di servizio, in uscita da una determinata interfaccia.
• % Scarti in uscita dall’interfaccia 1 relativi alla classe EF:
(diffServCosIf1EFdrops/diffServCosIf1EFTkedPkts)% (18)
Questo particolare indice, osservato in questo caso per la classe di servizio Expedited Forwarding, può essere ricavato per ogni interfaccia e per ogni PHBs, cambiando semplicemente l’ifindex e l’identificativo della classe, come per esempio:
(diffServCosIf3AF1xdrops/diffServCosIf3AF1xTkedPkts)% (19)
Il valore ottenuto dal calcolo di questo indice, può essere confrontato con la percentuale di errori in uscita alla stessa interfaccia (3), per capire se si tratta di un problema legato alla scheda di rete dell’interfaccia, oppure se il problema è presente soltanto per quella determinata classe di servizio. In particolare, per meglio comprendere la natura del problema, potremmo servirci di un altro indicatore:
• % Scarti in uscita dall’interfaccia 3 relativi alla classe EF, rispetto a tutto il traffico in uscita dall’interfaccia:
(diffServCosIf1EFdrops / IfOutPkts) (20)
e confrontarlo con lo stesso indice calcolato per tutte le classi di servizio configurate su una certa interfaccia. In particolare, è importante osservare che il numero di pacchetti scartati è legato strettamente alla lunghezza della coda presente sull’interfaccia di uscita del router. Infatti, qualora la lunghezza della suddetta coda fosse infinita, non ci sarebbe alcun scarto dei pacchetti trasmessi, ma questo comporterebbe grossi ritardi di trasmissione, dovuti al tempo medio di attesa dei pacchetti all’interno della coda. Nel caso in cui siano richiesti per un particolare PHB, delay e jitter molto bassi, è necessario avere code possibilmente scariche per evitare tempi di attesa elevati. Quindi, tramite la lettura di questo indicatore, possiamo capire se il comportamento di un determinato PHB rispetti mediamente il Service Level Agreement concordato con l’utilizzatore del servizio. Fissando una certa soglia, possiamo quindi capire quando un determinato PHB stia svolgendo a pieno il proprio compito, oppure necessiti di una qualche modifica nella configurazione, cambiando, per esempio, la dimensione massima della coda in uscita, oppure la disciplina di coda configurata.
• La disciplina di coda FIFO
Si tratta della comune disciplina di coda “First In First Out”, nella quale nessun pacchetto riceve un trattamento particolare. La coda presenta un buffer di memorizzazione a lunghezza finita, che, non appena riempito, provoca lo scarto del traffico in eccesso che si presenta al suo ingresso.
• La disciplina di coda GRED
La disciplina di coda GRED (Generalized RED) rappresenta, un’estensione della RED (Random Early Detection). La RED prende il nome dall’omonimo algoritmo che fa parte della famiglia degli algoritmi di tipo “Active Queue Management”. Si tratta di un algoritmo che accoda, o scarta, un nuovo pacchetto con una probabilità che varia in funzione della dimensione della coda. (Fig 5.10).
Figura 5.10: Probabilità di scarto di una coda RED
A differenza della FIFO, dove occorre specificare unicamente la dimensione massima della coda, nel caso specifico della RED, occorrono anche altri parametri che sono: una soglia minima (min) oltre la quale la probabilità di scarto (Pb) non è più 0, una soglia massima (max), oltre la quale la Pb vale 1 e la probabilità di scarto massima (probability), che si ha quando la lunghezza media della coda è uguale a max. Inoltre, deve essere fornita una costante di tempo da utilizzarsi nel calcolo della lunghezza media
della coda. La disciplina di coda RED quindi, tende a scartare i pacchetti prima che la coda sia completamente piena, garantendo così dimensione medie delle code piccole.
In particolare la GRED, consente di avere più classi di priorità su cui poter mappare diversi livelli della probabilità di scarto. In pratica, si ha una singola coda fisica sulla quale vengono inviati i pacchetti, ma poi, all’interno della GRED, esistono tante code virtuali gestite con l’algoritmo RED alle quali corrispondono parametri diversi. Ne consegue che con la GRED si possono gestire differenti livelli di priorità all’interno di una stessa classe.
• La disciplina di coda HTB:
HTB (Hierarchical Token Bucket) rappresenta una disciplina di coda per la condivisione gerarchica del link (“Hierarchical Link Sharing) ed è di tipo classfull. Questo consente di definire al suo interno una serie di classi e sottoclassi alle quali assegnare una determinata percentuale di banda predefinita che vorremmo fosse disponibile anche in caso di congestione. La capacità principale dell’algoritmo è infatti quella di ripartire la banda di un certo link tra applicazioni, servizi, e utenti in maniera scalabile e flessibile. HTB assicura che la quantità di risorse destinate a ciascuna classe sia almeno la minima quantità richiesta, relativamente a quanto è stato assegnato. Quando le richieste da parte di una classe sono al di sotto di quanto gli è stato assegnato, la restante quantità di banda, è distribuita opportunamente a quelle classi che ne hanno fatto esplicita richiesta.
Ne consegue che un altro indicatore molto importante quindi, è legato alla lunghezza media della coda configurata su ogni interfaccia di uscita, durante la trasmissione di flusso di traffico appartenente una certa classe di servizio.
• ∆ = tempo di osservazione.
• Lunghezza media di una coda configurata per EF in uscita dall’interfaccia 1:
((diffServCosIf1EFBacklog)/(diffServCosIf1Efbps*∆∆∆∆)) (21)
Questo indicatore è molto importante perché, qualora la lunghezza media della coda sia di poco inferiore a quella massima, dovremmo decidere di aumentare la dimensione massima, per prevenire lo scarto di una percentuale di pacchetti piuttosto consistente (caso FIFO). Oppure nel caso in cui siano configurate altre discipline di coda (vedi GRED o HTB), consente di ottenere importanti informazioni che potrebbero permettere il cambiamento di alcuni parametri settati in fase di configurazione.
Per poter capire a che tipo di PHBs assegnare il traffico proveniente da un certo nodo della rete, è importante osservare l’utilizzazione media della banda assegnata ad ogni classe di servizio.
• ∆ = tempo di osservazione
• Utilizzazione percentuale della banda assegnata alla classe di servizio AF1x sull’interfaccia 1:
Costruendo tale indicatore per ogni classe AFyx configurata sull’interfaccia data, possiamo capire quale di queste risulti la più utilizzata. Fissando una soglia all’indicatore relativo all’utilizzazione della banda relativa ad una data classe di servizio, possiamo eventualmente decidere se assegnare o togliere parte del traffico, mantenendo comunque lo stesso Service Level Agreement.
Infine, è importante osservare che anche l’utilizzazione media di un interfaccia (5), risulta essere un indicatore fondamentale per poter decidere quale percorso assegnare ad un determinato flusso di traffico proveniente da un nodo della rete. Perciò è necessario calcolare più indici, che ci permettano così di poter prendere decisioni sulla scelta della migliore configurazione della rete DiffServ.