Capitolo 3: ALGORITMI USATI PER LA
GENERAZIONE AUTOMATICA DI AMBIENTI
VIRTUALI URBANI
Il sistema software realizzato in questa tesi prevede l’implementazione di una sequenza di algoritmi aventi come scopo la generazione automatica di un modello tridimensionale relativo ad una rete stradale, con particolare riferimento agli ambienti urbani, e di una serie di informazioni accessorie, quali ad esempio quelle relative agli isolati, che costituiranno l’input di ulteriori moduli software. I dati di input del modulo sono costituiti da mappe raster a colori, eventualmente integrabili con documenti di tipo DTM, per arricchire l’ambiente virtuale con informazioni relative all’altitudine del terreno e degli edifici.
Il sistema sviluppato fa parte di un un progetto più ampio, il CMPE (City Modelling
Procedural Engine), un framework per la generazione di città virtuali.
3.1. Framework di generazione di città virtuali (CMPE)
I passi necessari per la generazione automatica di una città virtuale il più possibile fedele a una città reale, prevedono l’analisi delle seguenti entità: [CARR]
• Zona urbana: Raggruppa sia le informazioni riguardanti le caratteristiche geografiche
del terreno (altezza, idrografia e vegetazione), sia le caratteristiche sociali e statistiche (densità demografica, rete stradale). Questi dati si trovano definiti solitamente nei GIS (sistemi d'informazione geografici), sia in formato raster che vettoriale.
• Rete stradale: Se il GIS non include dati sulla rete stradale, essa deve essere generata.
E’ possibile seguire diverse metodologie in proposito: la generazione procedurale a partire dai dati dei GIS (vengono generate reti plausibili ma non reali), la generazione automatica a partire da altri tipi di mappe digitali (mappe colorate, in bianco e nero, viste aeree), la generazione semiautomatica con l’assistenza manuale di un modellatore.
• Definizione degli isolati: Raramente queste informazioni sono presenti nei GIS
Generalmente (almeno per il contorno dell’isolato) possono essere dedotte da altri dati, quali ad esempio quelli riguardanti la rete stradale.
• Lotti: Gli isolati sono divisi in lotti, con metodi euristici o di pattern instantiation. • Edifici: Per determinare l'aspetto degli edifici, esistono parecchi metodi:
completamente procedurali (shape grammars), semi-procedurali (declarative modelling) o manuali (con l’uso di modelli geometrici).
Un framework completo per la generazione di un ambiente urbano dovrebbe quindi definire tali entità basandosi sul principio di sfruttare tutti i dati reali presenti, e di ricostruire i dati mancanti cercando di fare in modo che siano plausibili, o comunque compatibili con quelli esistenti. Questo significa che l’engine dovrebbe poter supportare una grande varietà di input come ad esempio mappe vettoriali, mappe raster, DTM, viste aeree, ecc, cercando di produrre un output coerente con i dati acquisiti. In mancanza di dati in input, il motore dovrebbe poter tentare di estrapolare le informazioni necessarie oppure dare la possibilità di intervenire manualmente per correggere eventuali errori del processo automatico, per ottimizzare il risultato o per introdurre alcuni dettagli.
Ulteriori moduli, come la “Procedural VRLib” (che implementa le funzioni relative alla generazione procedurale di semplici entità architettoniche) o l’interfaccia a programmi di modellazione manuale, potranno essere usati per rifinire il modello finale, al fine di consentire la modellazione di entità architettoniche complesse (ad esempio: chiese, templi, monumenti) non direttamente caratterizzabili da semplici parametri.
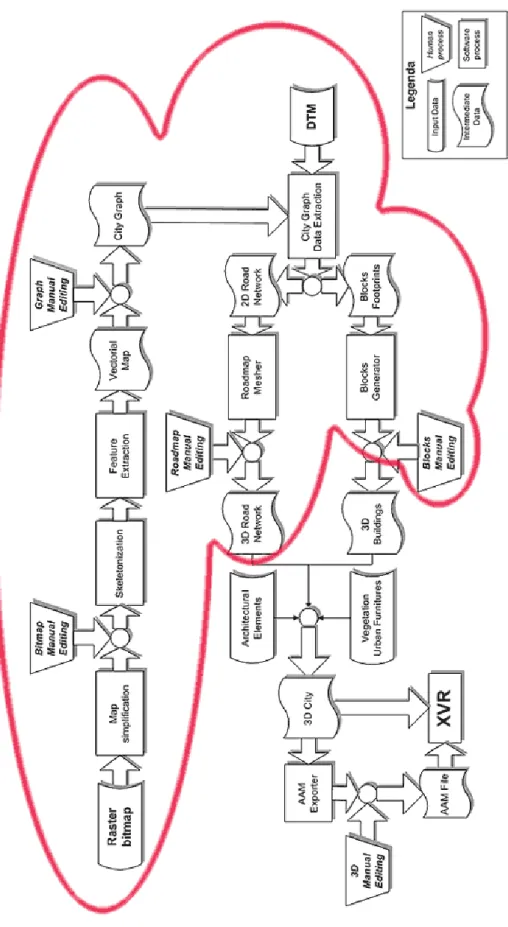
In sintesi, i passi che deve eseguire il CMPE per la costruzione di un ambiente urbano possono essere riassunti in: [figura 3.1]
1. Estrazione automatica da mappe raster di informazioni relative alla rete stradale o al contorno degli isolati (questo passo ovviamente non è necessario nel caso in cui i dati siano disponibili in un formato vettoriale)
2. Estrazione automatica di dati relativi al contorno degli isolati 3. Generazione di strutture dati per la gestione delle informazioni
4. Generazione del grafo rappresentante la rete stradale (eventualmente contenente anche informazioni relative a corsi d’acqua e strade ferrate)
5. Generazione delle mesh 3D relative alla rete stradale
6. Identificazione dei parametri utili ai passaggi successivi (palazzi e isolati) 7. Generazione di isolati, lotti ed edifici
8. Generazione in 3D del modello globale in un formato adatto per il rendering real-time e/o per poter introdurre rifiniture manuali con programmi di modellazione 3D (al momento si è scelto di generare dati compatibili con AAM, formato nativo di XVR, e di utilizzare 3D Studio Max come tool di modellazione)
9. Modellazione manuale dei dettagli (sia all’interno di 3D Studio Max, sia direttamente all’interno di XVR tramite la Procedural VRLib) ed esportazione del modello AAM
10. Rendering in XVR
3.1.1.
Requisiti dell’applicazione sviluppata in questa tesi
Rispetto al CMPE, l'applicazione implementata in questa tesi si occupa di sviluppare la porzione del framework che va (rispetto ai passi precedentemente descritti) dal punto 1 a parte del punto 6 (estrae informazioni relative ai soli isolati, escludendo i palazzi) del progetto globale. In particolare le mappe a cui fa riferimento il punto 1, si suppongono "mappe a colori", cioè che associano a ogni colore diverso, un diverso elemento della rete stradale (strade, edifici, corsi d'acqua ecc). Per i fini di questo lavoro di tesi, tale associazione si suppone nota, anche se il framework completo prevede l'uso di un editor integrato che consenta di poterla impostare esplicitamente. Laddove possibile, il programma può integrare l'input costituito dalle mappe raster con quello fornito da mappe di elevazione, opportunamente georeferenziate. L'applicazione è in grado di produrre un output intermedio, che rappresenta la struttura della rete viaria e degli altri elementi urbani sotto forma di grafo (costruito in modo da fornire una sorta di rappresentazione vettoriale della mappa cittadina) ed un output finale, consistente nei dettagli visuali (geometria e texture associate) del modello 3D relativo all'ambiente urbano, sia sotto forma di struttura dati direttamente gestibile da XVR, sia sotto forma di file contenente le informazioni 3D in formato compatibile con XVR. L’applicazione mette a disposizione dell’utente un semplice editor per manipolare l’output intermedio, permettendo quindi la correzione di eventuali errori dovuti al processo automatico. Il file prodotto dovrà essere di dimensioni sufficientemente ridotte (nell'ordine dei 100 KB) al fine di poter eventualmente essere agevolmente distribuito su rete, sia tramite collegamento internet PSTN o superiore, sia tramite LAN. L'output finale dovrà consistere in un modello geometrico di complessità tale da consentirne la navigazione in tempo reale. Evidentemente la complessità finale sarà dipendente dall'estensione e dalla ramificazione della mappa iniziale, per cui è difficile fissare un obiettivo preciso. Un possibile target può essere ragionevolmente fissato nel rapporto tra dimensioni in metri della porzione di ambiente descritta dalla mappa iniziale e numero di poligoni del modello 3D finale, con un valore indicativo compreso tra 102 e 103 (per il quale una mappa relativa ad un estensione di un kmq
dovrebbe generare un modello di complessità contenuta tra i 10.000 e i 100.000 poligoni). La [figura 3.2] illustra dettagliatamente il CMPE evidenziando il lavoro specifico della serie di algoritmi proposti. In aggiunta all'elaborazione automatica è previsto che venga fornito anche un editor minimale per modificare manualmente i dati estratti automaticamente dalla mappa,
al fine di caratterizzare in maniera più precisa alcuni parametri o di correggere eventuali errori macroscopici introdotti dal processo automatico.
L'applicazione deve essere in grado di funzionare su computer forniti di sistema operativo Microsoft Windows 2000 o superiore, provvisti di processori di fascia media (rispetto all'anno di pubblicazione di questa tesi), dotati di almeno 512 Mbyte di memoria RAM, con almeno 40Mbyte di spazio disponibile su disco fisso (soprattutto per l'archiviazione dei dati in input, raster e height map). Per la fruizione interattiva del modello 3D è invece necessaria una scheda grafica provvista di accelerazione hardware OpenGL e l’installazione del client XVR.
3.2. Fasi
preliminari
Le fasi preliminari di cleaning e thinning sono necessarie a rendere la mappa più facilmente interpretabile semplificandone la lettura. Queste due fasi sono molto importanti per una corretta interpretazione della mappa da parte degli algoritmi dei paragrafi successivi.
3.2.1.
Cleaning
Idealmente, le mappe raster utilizzate come input dovrebbero contenere solo gli elementi grafici relativi all’ambiente urbano, ma difficilmente tali mappe sono effettivamente disponibili in questo formato. Più spesso si tratta di mappe a risoluzione non elevatissima, contenenti elementi testuali e altro tipo di“rumore” non eliminabile, in quanto presente direttamente a livello di pixmap. Al fine di poter avere a disposizione un dato di input il più possibile utilizzabile per gli step successivi, è necessario procedere ad una fase di “pulizia” dell’immagine.
L’eliminazione di scritte e rumori dalla mappa, si sviluppa attraverso varie fasi che hanno lo scopo di semplificare l’immagine al fine di riconoscerne meglio gli elementi stradali presenti:
1. Viene ridotto il numero dei colori presenti nella mappa ad un numero costante (che può eventualmente essere specificato dall’utente)
2. Vengono eliminati i pixel “isolati”, ovvero pixel il cui colore non è presente nei pixel adiacenti. Questi pixel sono verosimilmente prodotti dalla compressione lossy dell’immagine, da un filtro antialiasing o da un’eventuale acquisizione tramite scanner. Il colore di questi pixel viene ricalcolato, assegnando loro il colore più frequente fra i pixel adiacenti.
3. Viene ridotto ulteriormente il numero dei colori: dapprima vengono calcolati gli n colori più frequenti. Successivamente ad ogni pixel viene assegnato un colore fra questi, scegliendo il più “vicino” a quello originale. La distanza fra colori viene calcolata come distanza euclidea fra 2 punti nelle tre dimensioni (in questo caso, corrispondenti ai canali R, G, B)
5. Vengono eliminati i pixel facenti parte di scritte, seguendo lo stesso algoritmo di eliminazione dei pixel isolati. In questo caso però vengono esclusi dal calcolo della “moda” i pixel col colore delle scritte.
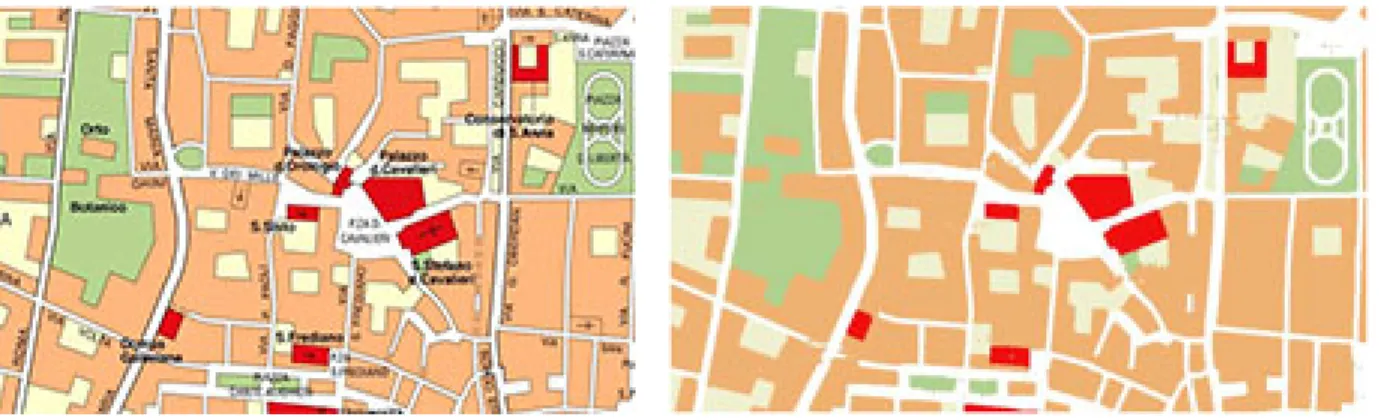
Questo passo produce una mappa relativamente pulita da imperfezioni. Più la mappa è pulita, maggiori sono le garanzie che nei passi successivi, gli elementi della rete stradale vengano riconosciuti correttamente. La fase di cleaning dà quindi la possibilità di acquisire informazioni (e, dunque utilizzare come dati di input) da documenti scaricabili gratuitamente dalla rete o acquisiti attraverso scannerizzazione da mappe cartacee.
figura 3.3 – mappa originale figura 3.4 – mappa dopo il “cleaning”
3.2.2.
Thinning
La skeletonization è una trasformazione di un'immagine digitale in un sottoinsieme dell’originale [KLETTE]. La trasformazione restituisce uno scheletro di spessore unitario (1
pixel) che mantiene invariata la struttura topologica dell’immagine originale, rendendone più semplice l’analisi. La nozione di skeleton fu introdotta nel 1967 da H.Blum, che lo definì come il risultato di una Medial Axis Transform (MAT) [figura 3.5] [BLUM1967]. Presi i punti
appartenenti al contorno della figura, vengono costruiti dei triangoli tali da avere questi punti come vertici (triangoli di Delaunay). Lo skeleton è quindi formato dai centri dei cerchi circoscritti a questi triangoli [figura 3.6].
figura 3.5 - skeleton ottenuto con MAT figura 3.6 – Skeletonizzazione tramite MAT
La skeletonization ha varie applicazioni [PALÁGYI]:
• Vettorializzazione di immagini raster [figura 3.9]
• Elaborazione e riconoscimento di circuiti stampati
• Riconoscimento di testi (OCR, optical carachter recognition) [figura 3.7]
• Riconoscimento di impronte digitali
• Riconoscimento di forme geometriche (ad esempio in robotica)
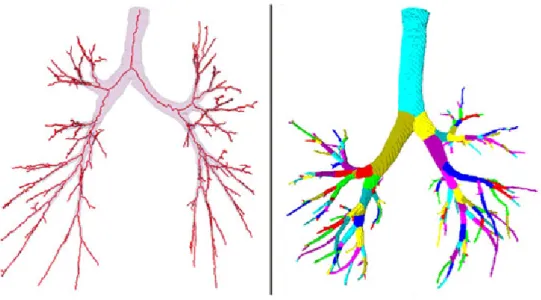
• Applicazioni mediche (analisi del colon, bronchi ecc) [figura 3.8]
• Analisi di mappe stradali, come suggerito anche in [ODDO], [WOJCIECH], [GAO] e [GOLD]
[figura 3.10]
figura 3.8 - partizionamento delle diramazioni bronchiali
figura 3.9 - vettorializzazione di un imm. raster figura 3.10 - skeleton di una mappa stradale
Il thinning è un metodo di skeletonization, definito tramite passi d'assottigliamento. Questo metodo sviluppa l’idea di un continuo restringimento del contorno dell’oggetto in analisi, fino ad ottenerne il solo scheletro. Non necessita quindi di conoscenze geometriche dell’immagine da skeletonizzare, ma solo della possibilità di distinguere i pixel appartenenti all’oggetto (foreground) da quelli che non gli appartengono (background).
Applicando il thinning alla rete stradale, è quindi possibile escludere informazioni inutili dalla mappa e riconoscere facilmente gli incroci fra strade, semplicemente percorrendone lo scheletro ed esaminandone i singoli pixel ,come spiegato nel paragrafo successivo.
Gli algoritmi di assottigliamento hanno un’elevata complessità in ordine di tempo, O(wN), dove w è lo spessore della linea da assottigliare e N è il numero di pixel dell’immagine. [CASE].
Altri tipi di algoritmi, come ad esempio il MAT o gli algoritmi di distance transform, hanno una complessità lineare, ma non danno garanzie sulla connettività dello skeleton in presenza di giunzioni sull’oggetto originale [figura 3.11]. Sono pertanto difficilmente utilizzabili nel riconoscimento di una mappa stradale. Anche gli algoritmi di thinning presentano problemi sul mantenimento della topologia dell’immagine originale. Infatti nel caso di oggetti che hanno larghezza e lunghezza simile, come ad esempio quadrati o cerchi, può accadere che lo
skeleton coincida perfettamente col solo centro [figura 3.12], oppure lo skeleton possa assumere forme imprevedibili nel caso la figura contenga una minima imperfezione come in [figura 3.13]. Fortunatamente questo problema risulta quasi ininfluente per la skeletonizzazione di mappe stradali in quanto è molto improbabile incorrere in forme simili.
figura 3.11 - (a) giunzione non rilevata; (b) confusione sulla giunzione
figura 3.12 figura 3.13
Quindi, nelle ipotesi di questa tesi (input contenuto in mappe raster a colori) il metodo di skeletonization più appropriato risulta il thinning, in quanto il foreground può essere facilmente distinto dal background (ogni colore della mappa, solitamente, corrisponde a
un’entità della stessa). Ma nell’ipotesi di mappe in bianco e nero, in cui sono indicati solo i contorni delle entità stradali (es.: mappe topografiche IGM), risulta invece necessario procedere con altri metodi, come ad esempio in [YAOYICHI], riconoscendo le strade attraverso i
contorni, imponendo alcune condizioni (il parallelismo fra rette) ed estraendone in seguito la linea mediana. Questo metodo di vettorializzazione, spiegato in [KLETTE], anche se applicabile
a un caso più generale, risulta meno efficace nel riconoscere le varie entità presenti in una mappa stradale e necessita di un ulteriore passo per correggere le discontinuità prodotte sullo skeleton.
L’idea di usare un algoritmo di thinning per il riconoscimento della mappa stradale è già stata applicata in sistemi simili con diverse varianti, come ad esempio in [CAO] o in [GAO] [figura 3.14], dove vengono create immagini binarie a partire da viste satellitari e applicando filtri all’immagine in modo da evidenziare le possibili strade, ricreando quindi più o meno le ipotesi di questa tesi.
figura 3.14 - (a) immagine binaria ottenuta da foto satellitari (b) risultato del thinning [gao]
L’algoritmo proposto in questa tesi prende spunto da quello proposto in [JAIN].
Si propongo alcune definizioni utili per la successiva esposizione:
• Pixel on: pixel acceso, ovvero inizialmente appartenente all’oggetto da skeletonizzare,
e alla fine dell’algoritmo appartenente allo skeleton
• Edge pixel: è un pixel on, di cui almeno un pixel fra quelli adiacenti è off
• Boundary: è il contorno di un oggetto O. Consiste di tutti gli edge pixel appartenenti
ad O.
Quindi si può affermare che:
Un pixel x appartiene allo skeleton di un oggetto O, se un qualunque cerchio D di centro x e raggio r, e contenuto interamente all’interno dell’oggetto è tangente al “boundary” dell’oggetto in due o più punti [NOBLE]:
} , 1 | )} ( ) ( { |, ) ( : { ) (O x O D x O D x BOUNDARY O r R skel = ∈ ⊆ I > ∈
Per applicare il filtro di thinning, è necessario rimuove i pixel dal bordo di un oggetto finché non ne rimane solo lo skeleton. L’algoritmo deve esaminare i pixel tenendo conto che un oggetto deve rimanere tale e non diventare due oggetti distinti, e lo skeleton deve essere formato da segmenti spessi non più di un pixel.
Altre definizioni:
• neighborhood di un pixel x: l’insieme dei pixel adiacenti ad x
• ZNZT(x): funzione che scorre i pixel adiacenti ad x in questa sequenza: PNW, PW, PSW, PS, PSE, PE, PNE, PN, PNW. Durante il percorso conta i passaggi da un pixel off ad uno on. Restituisce quindi, il numero di raggruppamenti di pixel on
• NZN(x): restituisce il numero dei vicini di x che sono settati su on
Un pixel x, appartenente all’oggetto da skeletonizzare, viene settato su off (escluso dallo scheletro) se rispetta una di queste 2 condizioni:
1. ZNZT(x)=1 2. 2<NZN(x)≤6
La prima condizione esclude la possibilità di cancellare un singolo pixel isolato o un pixel completamente circondato (casi corrispondenti a ZNZT(x)=0). Nel caso in cui ZNZT(x)=2, x non può essere eliminato in quanto potrebbe essere proprio il pixel che collega due altri pixel dello scheletro. Il caso ZNZT(x)=3 o ZNZT(x)=4 è molto simile al precedente in quanto il
pixel si troverebbe al centro di un possibile incrocio [figura 3.15]. La seconda condizione garantisce che un oggetto “assottigliato” non diventi anche troppo “corto”. Per NZN(x)=1 o
NZN(x)=2, se il pixel venisse impostato su off, verrebbe accorciato un “vicolo cieco”, oppure
verrebbe disconnesso lo scheletro. Nei casi NZN(x)=7 o NZN(x)=8, il pixel sarebbe completamente circondato (o quasi) dagli altri pixel. In pratica, tutte le condizioni possibili (a meno di rotazioni del quadrato di pixel 3x3) sono rappresentate in [figura 3.16]
figura 3.15 figura 3.16
L’algoritmo esamina tutti i pixel dell’immagine eseguendo varie passate. Termina quando alla fine una passata non ha settato neanche un pixel a off. I pixel on rimanenti rappresentano quindi lo skeleton dell’oggetto. Applicato ad una pixmap raffigurante una rete stradale, l’algoritmo ottiene il seguente risultato:
figura 3.17 figura 3.18
3.3. Creazione del CityGraph
In seguito alle fasi preliminari l’applicazione passa quindi alla vettorializzazione della mappa tramite il riconoscimento delle varie entità presenti, e la rappresenta con quello che viene
definito CityGraph. Il CityGraph è un grafo non orientato, comprendente varie informazioni topologiche composto da:
• Un insieme di nodi, caratterizzati da un tipo e dalle coordinate in pixel che ne identificano la posizione sulla mappa.
• Un insieme di link, caratterizzati da un tipo, dai rispettivi nodi che lo delimitano, da una lunghezza e da una larghezza. Ogni link rappresenta un segmento di strada che unisce due nodi. I link non sono orientati.
• Un insieme di piazze (aree definite da un insieme di nodi connessi)
• Un insieme di isolati (aree definite da un insieme di nodi e di link che ne delimitano il tracciato)
3.3.1.
Riconoscimento incroci e curve
Una volta effettuata la skeletonization, è necessario procedere al riconoscimento dei punti notevoli della mappa che saranno identificati come nodi nel CityGraph. Sarà quindi necessario riconoscere e marcare come nodi tutti i punti terminali e quelli in cui due o più rami dello skeleton si intersecano, ovvero:
• Incroci: nodi con tre o più link connessi
• Curve: nodi con due link connessi (i link formano un angolo diverso da 180°)
• Punti terminali dei vicoli ciechi: nodi con un solo link connesso.
Al fine di riconoscere gli incroci, l’algoritmo scorre tutta la mappa alla ricerca di un punto sullo skeleton non ancora visitato. Una volta trovato questo punto, segue il percorso sullo
skeleton (marcando i pixel già visitati, che non andranno rivisitati in seguito) fino a un pixel
circondato da almeno altri tre dello scheletro, dunque un incrocio. Ogni incrocio una volta individuato viene aggiunto alla struttura dati del CityGraph. Questa ricerca avviene fino al raggiungimento di un vicolo cieco. A questo punto è necessario ripetere il procedimento partendo dalla ricerca di un pixel dello scheletro non ancora visitato.
Questo algoritmo, sebbene non ottimo dal punto di vista dell’efficienza e dei tempi di calcolo, ha il pregio, rispetto ad altri forse più veloci e di facile implementazione (come ad esempio scorrere l’immagine alla ricerca dei soli pixel sullo skeleton candidati a essere incroci o vicoli ciechi), di permettere il riconoscimento anche di un circuito chiuso privo di incroci, come ad esempio una pista circolare. Questa è infatti facilmente riconoscibile quando, nel percorrere lo
skeleton, viene riconosciuto il nodo di partenza del percorso.
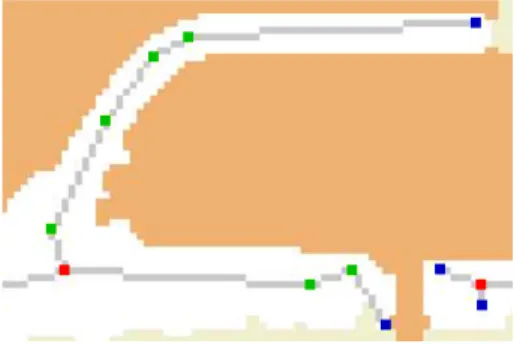
Per non ottenere un numero complessivo di nodi eccessivo, (nell’ottica di semplificare il modello 3D che verrà estratto dal CityGraph) non vengono memorizzati segmenti di lunghezza prefissata ma, di volta in volta, il programma procede all’individuazione di nodi curva lungo il tragitto fra un incrocio e l’altro. Durante il percorso, dopo un numero prefissato di passi (impostabile come parametro iniziale da parte dell’utente), viene controllato l’angolo di inclinazione del segmento percorso. Confrontando la pendenza di due segmenti successivi, è quindi possibile stabilire se fra questi due segmenti esiste una curva, (l’angolo fra i due segmenti deve essere vicino a 180° più o meno una certa soglia stabilita dall’utente) e aggiungerli, assieme al nodo, alla struttura dati del CityGraph. In questa fase vengono identificati anche i tipi di nodi (in base al numero di link connessi: 1 per i vicoli ciechi, 2 per le curve, 3 o più per gli incroci) e i tipi di link, in base al colore della mappa sottostante (un utente può indicare a quale colore corrisponde una qualsiasi entità, ad esempio: bianco per le strade, rosa per le ferrovie ecc). Nella [figura 3.19] sono stati evidenziati in rosso gli incroci, in verde le curve e in blu i vicoli ciechi.
Il passo successivo consiste in un’ottimizzazione del grafo ottenuto al fine di correggere eventuali errori dovuti ai passaggi precedenti (cleaning e thinning). In particolare, vengono collassati nodi molto vicini con particolare attenzione nel caso di incroci e vicoli ciechi.
3.3.2.
Calcolo della larghezza delle strade
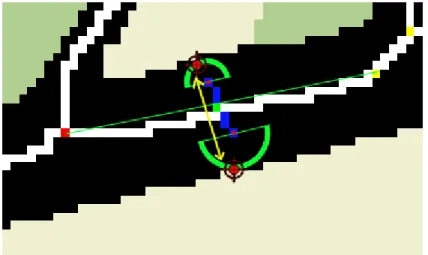
Durante la fase di ricerca delle curve avviene anche la determinazione della larghezza dei vari link. Al momento dell’aggiunta di un link al CityGraph, viene individuato il punto che si trova a metà del percorso effettuato sullo skeleton (ovvero un punto che sia preferibilmente lontano da eventuali incroci, che come spiegato in seguito complicano la determinazione della larghezza delle strade, e che sia preferibilmente equidistante dai bordi). Da questo punto viene seguita la direzione ortogonale al link in entrambi i versi. Se dopo n passi (parametro stabilito dall’utente) viene raggiunto il margine di una strada, viene presa come larghezza la distanza fra i due punti individuati. Altrimenti l’algoritmo procede cercando il margine della strada tracciando di volta in volta semicerchi concentrici (sia da un lato che dall’atro) fino a trovare il margine stesso della strada. I semicerchi vengono generati attraverso l’algoritmo di
Breshenam di scan-conversion del cerchio [ATT]. Il tutto, ovviamente avviene su entrambi i lati
della strada. Alla fine l’algoritmo termina con il calcolo della distanza fra i due margini trovati [figura 3.20].
figura 3.20 – Calcolo larghezza
Questo “doppio” modo di procedere è necessario nell’ottica di due considerazioni:
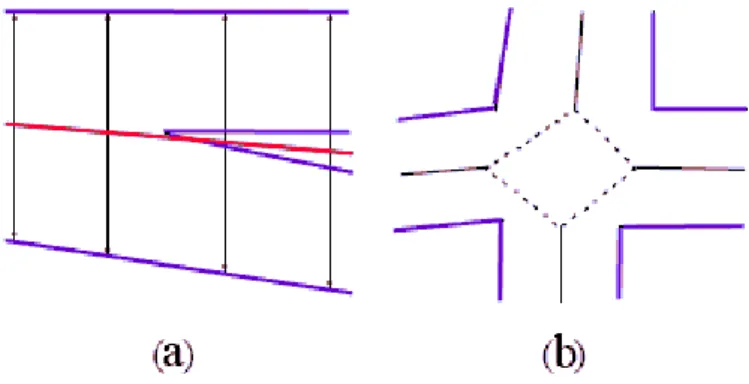
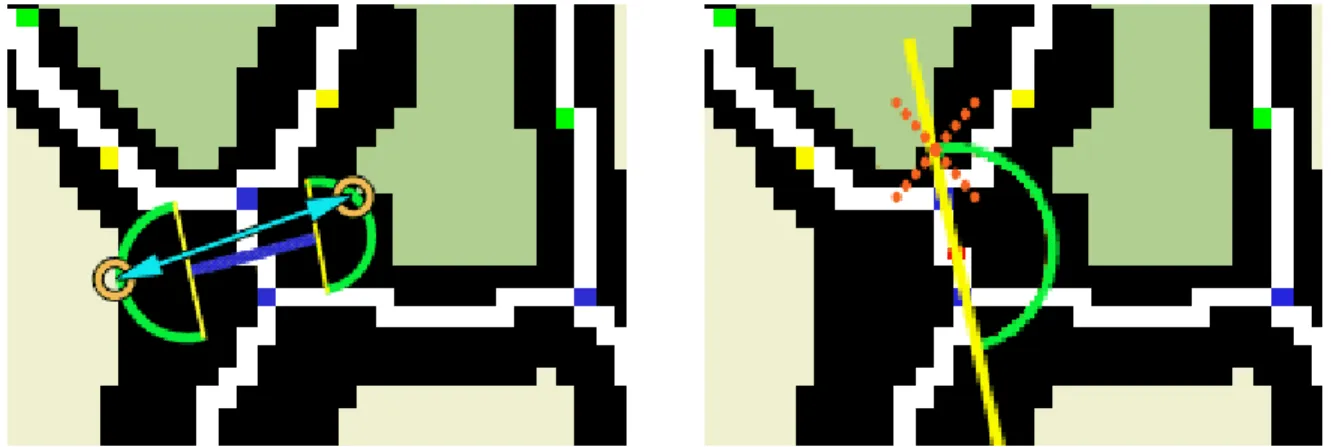
1. Applicando solo il primo algoritmo c’è il concreto rischio che in prossimità di un incrocio, l’algoritmo proceda lungo la lunghezza della strada incrociata, riportando quindi una misura errata, notevolmente maggiore di quella reale [figura 3.21].
2. Applicando solo il secondo algoritmo potrebbe avvenire sempre in prossimità di un incrocio, che la ricerca si fermi al ritrovamento di uno spigolo dell’incrocio, anziché al reale margine della strada [figura 3.22].
a: Algoritmo corretto b: applicazione del solo metodo della direzione ortogonale al link
figura 3.21 – Determinazione larghezza strade, caso particolare 1
Applicando prima l’algoritmo uno, la ricerca viene quindi già indirizzata e si riduce la probabilità di errore.
a: Algoritmo corretto b: applicazione del solo metodo dei semicerchi
3.3.3.
Riconoscimento piazze
Il compito di effettuare il riconoscimento delle piazze in modo automatico è abbastanza complicato, in quanto le stesse possono essere facilmente confuse con gli incroci [figura 3.23].
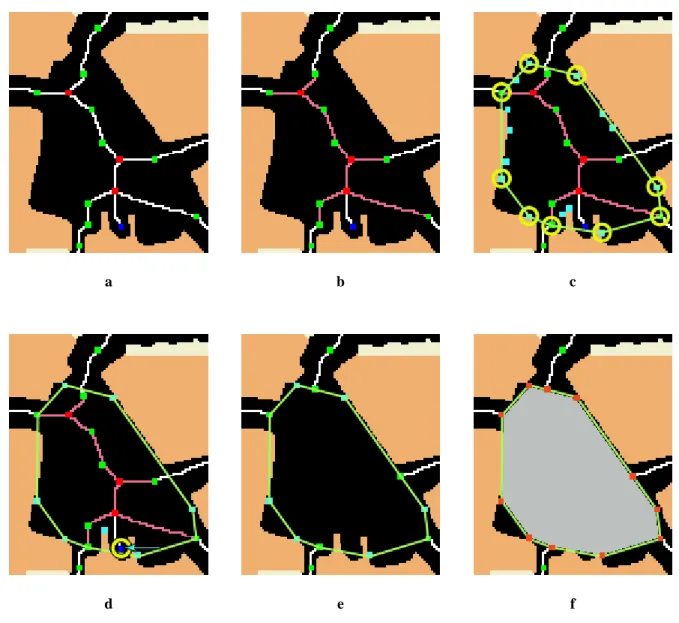
L’approccio scelto in questa tesi è stato quello di procedere comparando la lunghezza di un link con la sua larghezza. Quando in un link il rapporto fra larghezza e lunghezza è maggiore o uguale a 1 (oppure a un numero stabilito dall’utente), il link individua un possibile sottoinsieme di una piazza. Partendo quindi da questo link e muovendosi nel grafo attraversando i link adiacenti aventi le sue stesse caratteristiche, è possibile individuare una serie di nodi candidati a far parte della piazza in questione. [figura 3.23b].
Una volta ottenuto un insieme isolato di questi nodi (per ragioni di robustezza la ricerca si conclude comunque dopo l’attraversamento di un numero prefissato di link), è necessario calcolarne l’inviluppo convesso [PIGOLA] in modo da ottenere un contorno approssimato della
figura della piazza che, come positivo effetto collaterale, con sicurezza non è concavo (ciò facilita una serie di operazioni quali ad esempio il calcolo dell’area e la tessellazione). All’inviluppo convesso partecipano anche tutti quei punti a margine del contorno stradale ricavati durante il calcolo della larghezza di una strada [figura 3.23c]. Successivamente ne viene calcolata l’area (essendo la piazza un poligono convesso il calcolo dell’area è molto semplice e veloce). Le piazze con area minore di una certa soglia minima o maggiori di una certa soglia massima vengono così scartate.
Il passo successivo consiste in una scanline del poligono [ATT], in modo da riconoscere
eventuali nodi interni alla piazza sfuggiti ai passi precedenti [figura 3.23d]. Questo passo serve anche ad evitare la remota possibilità che due piazze si intersechino l’una con l’altra. Quando ciò si verifica, la seconda delle due viene automaticamente esclusa.
A questo punto è possibile rimuovere i nodi interni, oppure spostarli sul bordo, nel caso ad essi siano connessi dei nodi esterni al perimetro individuato [figura 3.23e].
I nodi che alla fine dell’algoritmo risultano appartenenti al bordo della piazza, vengono quindi contrassegnati come “nodi bordo” [figura 3.23f].
a b c
d e f
figura 3.23 – riconoscimento piazze
L’ultimo passo consiste in un’ulteriore ottimizzazione del grafo ottenuto. In particolare, vengono collassati nodi appartenenti al bordo che risultano molto vicini.
3.3.4.
Riconoscimento isolati
Si definisce isolato un edificio o un gruppo di edifici circondati da strade.
Nella teoria dei grafi un ciclo è un catena di link che parte da un nodo e termina sul nodo stesso. In un grafo fornito di informazioni topologiche sulla posizione spaziale dei nodi, un ciclo C è detto minimale se vale una delle seguenti condizioni: [EBERLY]
1. il poligono P i cui lati corrispondono ai link di C, non contiene altri cicli 2. P contiene solo cicli che condividono un solo vertice con C.
In pratica è possibile riconoscere gli isolati presenti sul CityGraph, individuandone i cicli minimali, che rispettino però la sola condizione 1. [figura 3.24]
a b c
figura 3.24 - a, b: cicli minimali assimilabili a isolati; c: ciclo minimale non assimilabile a un isolato
Intuitivamente, affinché possa essere riconosciuto un ciclo minimale a partire da un certo nodo, l’algoritmo dovrebbe calcolare il nodo successivo nel seguente modo: data la rosa di link uscenti dal nodo corrente viene scelto di percorrere il link il cui angolo con il link già percorso sia minimo (percorrendo la rosa in senso antiorario). La ricerca si arresta, al raggiungimento del nodo di partenza.
Il rischio è quello di percorrere un ciclo “esternamente” e di riconoscere come “minimale”, un ciclo che non lo è come in [figura 3.25]. E’ necessario quindi individuare un punto di partenza con caratteristiche precise, determinate condizioni iniziali e di arresto.
Per convenzione l’algoritmo quindi potrebbe partire da un punto “estremo” del ciclo, ad esempio da quello “più a sinistra”. Così facendo, sarebbe sufficiente scegliere come link iniziale da percorrere (rispetto a una coppia di link adiacenti) quello “più in basso” (volendo seguire in seguito i link in senso antiorario), ovvero quello con angolo minore rispetto all’asse y negativa con l’origine sul punto di partenza. Questo garantirebbe quindi di percorrere sempre il ciclo “internamente” [figura 3.26]. Pur non conoscendo a priori i punti più a sinistra di ogni ciclo, la condizione di partenza è facilmente controllabile in itinere, semplicemente verificando che il nodo corrente non sia “più a sinistra” del nodo di partenza.
figura 3.25 – ciclo percorso esternamente figura 3.26 – ciclo percorso internamente
Fissate quindi le condizioni iniziali e un possibile punto di partenza è necessario fissare anche le condizioni di arresto.
Come detto precedentemente, all’inizio di un ciclo assieme al link da percorrere, viene individuato anche il link adiacente posto immediatamente “più in alto”. Questo secondo link deve quindi necessariamente essere l’ultimo link visitato durante la ricerca del ciclo [figura 3.27 b].
Durante la ricerca inoltre può avvenire di passare più volte dal punto iniziale senza necessariamente percorrere il link marcato come “ultimo”, in questo caso si possono verificare due condizioni:
1. L’ultimo link visitato si trova “sotto” al link visitato in partenza. In questo caso il ciclo è stato sicuramente percorso “esternamente” ed è quindi da scartare. [figura 3.27 a]
2. L’ultimo link visitato si trova “sopra” al link di partenza. Ovvero c’è almeno un link posto fra i due (ad esempio quello marcato come “ultimo”). L’algoritmo prosegue nella sua visita, fino alle normali condizioni di arresto. [figura 3.27 c]
Un caso “limite” può essere rappresentato dai vicoli ciechi, i quali vengono percorsi due volte, una fino alla fine del vicolo, e l’altra per tornare indietro al punto in cui inizia il vicolo.[figura 3.27 d].
a – Link di partenza: AI; link di arrivo: BA. Il ciclo termina con LA, quindi: condizione di arresto non
valida, il ciclo A-I-L-A viene percorso esternamente.
b - Link di partenza: AL; link di arrivo: IA. Viene ricnosciuto il ciclo A-L-I-A.
c - Link di partenza: AH; link di arrivo: LA. Viene ricnosciuto il ciclo A-H-G-F-E-D-C-B-A-I-L-A. Il
nodo di partenza A viene attraversato 3 volte.
d – Caso particolare con la presenza di un “vicolo cieco” (AI). Link di partenza: AH; link di arrivo: IA. Viene ricnosciuto il ciclo A-H-G-F-E-D-C-B-A-I-A. Il nodo di partenza A viene attraversato 3
volte.
figura 3.27 – esempio di algoritmo di ricerca cicli applicato a un nodo dal quale partono più link.
Una volta riconosciuto un isolato è possibile effettuarne una scanline dei punti interni, e calcolando la moda dei pixel trovati è possibile stabilire con una buona approssimazione di che tipo di isolato si tratti (ES: giardino, edificio, specchio d’acqua ecc).
3.4. Passaggio alle tre dimensioni
Riconosciute le varie entità di una mappa è quindi necessario procedere al calcolo di una loro rappresentazione in tre dimensioni il più possibile rassomigliante alla realtà. Alcune informazioni verranno quindi dedotte dalla mappa stessa, da altri input aggiuntivi (file TFW e DTM), altre ancora ottenute proceduralmente.
3.4.1.
Uso di “World file” per la conversione da coord. in pixel a
coord. reali
Tramite DTM [par. 3.4.2], è possibile arricchire l’ambiente virtuale con informazioni relative all’altitudine del terreno e degli edifici. Per fare questo è però necessario georeferenziare gli oggetti del CityGraph, in modo da definire una corrispondenza punto-punto fra gli oggetti e i dati relativi alla loro altitudine.
Un metodo solitamente usato nei sistemi GIS per effettuare la georeferenziazione, consiste nell’uso dei “world file”, file ASCII contenenti le informazioni necessarie alla conversione delle coordinate di ciascun pixel della raster-map in coordinate reali [figura 3.29]. Lo standard è stato creato dalla ESRI Corporation (Environmental Systems Research Institute) [ESRI], per
essere usato all’interno del software ARCGIS.
Questi file contengono 6 numeri decimali, uno per ogni linea. I numeri descrivono la posizione, la scala e la rotazione della mappa. Se la mappa raster è originariamente di tipo
JPG, per convenzione il world file ha estensione “.jgw”, se è di tipo TIF, ha estensione “.tfw”. Le coordinate reali sono espresse secondo il sistema UTM (Universal Transverse
Mercator coordinate system). Questo sistema si basa sull'ellissoide di riferimento (datum) europeo del 1950. I "datum" sono dei modelli matematici della superficie terrestre, che periodicamente vengono aggiornati in seguito a campagne di rilevamenti geodetici.
Come risulta dalla [figura 3.28] il sistema UTM consiste in una proiezione su un piano della superficie terrestre (cioè della superficie esterna dell'ellissoide di riferimento) e nella successiva divisione in "zone". Ogni zona è delimitata da un meridiano occidentale e da un parallelo meridionale, e a partire da questi si estende per un certo numero di gradi. [DMA]
Per esempio l’Italia settentrionale è nella zona 32 T, l’Italia centrale è nella zona 33 T e l’Italia meridionale è nella zona 33 S.
All'interno di ciascuna di queste zone, la posizione di un punto è individuata da coordinate espresse in metri, a partire da un meridiano e da un parallelo di riferimento. Il meridiano di riferimento è quello che delimita la zona a occidente, mentre il parallelo di riferimento è sempre l'equatore.
figura 3.28 – sistema UTM, divisione in “zone”
In un world file, ad ogni linea corrispondono nell’ordine, i seguenti valori: [figura 3.29]
1. il rapporto sull’asse x fra metri e pixel (A) 2. rotazione attorno all’asse y, quasi sempre 0 (D) 3. rotazione attorno all’asse x, quasi sempre 0 (B) 4. il rapporto sull’asse y fra metri e pixel (E) 5. La coordinata x riferita al centro del pixel in alto a sinistra (C) 6. La coordinata y riferita al centro del pixel in alto a sinistra (F)
figura 3.29 – esempio di World file
Il parametro E (scalatura lungo l’asse y) risulta negativo in quanto l’origine di un immagine è diversa da quella delle coordinate geografiche. L’origine di un’immagine è situata nell’angolo in alto a sinistra, invece convenzionalmente nei sistemi geografici è posta in basso a sinistra. Le coordinate reali xr e yr, date le coordinate in pixel xp e yp, possono essere calcolate tramite la seguente trasformazione affine:
F Ey Dx y C By Ax x p p r p p r + + = + + =
Date le coordinate reali è quindi possibile ottenere le coordinate in pixel. Indicando: B D E A⋅ − ⋅ = ∆ Otteniamo: 1. ∆ = ′ E A 2. ∆ − = ′ D D 3. ∆ − = ′ B B 4. ∆ = ′ A E
5. ∆ ⋅ − ⋅ = ′ F B C E C 6. ∆ ⋅ − ⋅ = ′ D C F A F E quindi: F y E x D y C y B x A x r r p r r p ′ + ′ + ′ = ′ + ′ + ′ =
Va puntualizzato inoltre che le coordinate reali sono relative alla singola zona UTM, la quale nei world file non viene però indicata. Pertanto dovendo analizzare mappe a “cavallo”fra due o più zone, viene considerata una zona di riferimento (in genere quella in alto a sinistra). Le coordinate dei punti appartenenti alle zone successive vengono ottenute semplicemente sommando le coordinate relative alla zona di appartenenza con le dimensioni della zona di riferimento. E’ importante quindi che queste convenzioni vengano comunque rispettate nei vari file di input del programma (DTM, rastermap ecc).
3.4.2.
Calcolo delle altitudini tramite DTM
Un modello digitale di elevazione DEM (Digital Elevation Model) è la rappresentazione della distribuzione delle altitudini di una superficie, in formato digitale. Le altitudini possono essere relative sia al terreno ma anche agli oggetti presenti su di esso (vegetazione, edifici ecc). Nel caso particolare in cui le altitudini siano relative alla sola superficie terrestre, il modello viene chiamato DTM (Digital Terrain Model). Il modello digitale di elevazione viene spesso prodotto in formato raster associando a ciascun pixel l'attributo relativo all’altitudine assoluta eventualmente interpolando le singole altitudini.
Il DEM può essere prodotto con tecniche diverse. I modelli più raffinati sono in genere realizzati attraverso tecniche di telerilevamento che prevedono l'elaborazione di dati acquisiti attraverso un sensore montato su un satellite, un aeromobile o una stazione a terra. Ad esempio, una tecnica molto semplice per la produzione di DEM consiste nell'interpolazione delle isoipse che possono essere prodotte anche attraverso il rilevamento diretto sul terreno.
figura 3.30 – rappresentazioni 3D di DTM.
Le informazioni relative al DTM sono memorizzate in file ASCII. La rappresentazione ASCII più usata è quella proposta dalla ESRI, creata appositamente per essere utilizzata all’interno del pacchetto software ARCGIS. [ESRI].
Questi file sono composti da un header, contenente informazioni utili per leggere i dati veri e propri, seguito dall’elenco delle altitudini, che sono decimali separati da spazi e organizzati in un forma tabellare definita nello header. Le entrate della tabella corrispondono alle ascisse e alle ordinate UTM del terreno descritto
L’header è composto da 6 parametri [figura 3.31].:
• “ncols” indica il numero delle colonne della tabella
• “nrows” indica il numero delle righe
• “xllcorner”, ovvero la coordinata UTM lungo l’asse x corrispondente al centro del vertice in basso a sinistra del rettangolo di coordinate rappresentato dal DTM
• “yllcorner”, la coordinata UTM lungo l’asse y corrispondente al centro del vertice in basso a sinistra del rettangolo di coordinate rappresentato dal DTM
• “cellsize” indica la lunghezza in metri del lato di ogni singola cella della tabella (le celle si suppongono quindi quadrate)
• “NODATA_value”: significa che se un cella riporta questo valore, l’altitudine in quel punto non è stata rilevata (ad esempio nel caso di caserme o terreni militari)
figura 3.31 - header di un file DTM
Per completare le entità riconosciute sulla mappa con le informazioni relative all’altitudine (sia terreno che edifici), è sufficiente scorrere il file DTM, e salvarne i dati in una tabella a doppia entrata. Grazie al world file è possibile calcolare le coordinate UTM corrispondenti alle coordinate in pixel di ciascun nodo, in questo modo dalla tabella a doppia entrata (tramite opportuni arrotondamenti) è possibile estrarre il valore dell’altitudine.
3.4.3.
Tessellazione degli elementi stradali riconosciuti
I link sono provvisti di proprietà di lunghezza e di larghezza e questo fa si che possano essere facilmente assimilati a dei rettangoli [figura 3.32 a]. Questa soluzione può rappresentare una prima approssimazione di cosa diventerà la strada all’interno del modello tridimensionale. In questo modo però possono verificarsi i casi di porzioni di mappa non coperte da rettangoli o di sovrapposizioni tra rettangoli [figura 3.32 a]. In quest’ultimo caso sorge un problema di z-fighting, non accettabile in fase di renderizzazione. Lo z-fighting si verifica quando in fase di rendering non si riesce a stabilire a quale poligono appartenga un certo pixel (i piani a cui appartengono i poligoni sono infatti coincidenti). Questo non determinismo nella scelta provoca uno sfarfallio dell’immagine ogni qualvolta l’utente compie un movimento causando il refresh della scena [FLORIO]. Per ovviare a questo problema è opportuno quindi disegnare i
link come fossero dei quadrilateri generici e i nodi come dei poligoni, in modo che non si intersechino fra loro. Per ogni incrocio, è sufficiente trovare i punti di intersezione fra i due lati adiacenti di due link consecutivi, appartenenti alla rosa di link uscenti dall’incrocio. Questi punti saranno sia i vertici del poligono che rappresenta il nodo, sia anche i vertici che delimitano il quadrilatero descritto dai link [figura 3.32 b].
a b
figura 3.32
Un caso particolare piuttosto frequente si ha quando i due lati non si intersecano: in questo caso è necessario trovare il punto di intersezione delle due rette alle quali i segmenti appartengono [figura 3.33 a]. Nel caso in cui il nodo sia di tipo curva, il nodo viene quindi rappresentato come un poligono degenere corrispondente a un segmento (figura 3.33 b).
a b
La ricerca del punto di intersezione fra le due rette presenta un problema qualora l’angolo fra i due link sia prossimo a π. In questo caso le due rette risulterebbero parallele o quasi [figura 3.34 a]. Per ovviare a questo l’algoritmo sceglie come punto di intersezione il vertice di uno dei due lati adiacenti (per convenzione quello con larghezza maggiore). La strada con larghezza minore subisce quindi una leggera deformazione in quanto non ha più i due lati paralleli e la strada assume una forma ad “imbuto” [figura 3.34 b].
a b
figura 3.34
Nel caso di incroci fra strade e piazze l’algoritmo si comporta in maniera simile, anche se con alcune differenze. Analizziamo il caso in cui un nodo appartenente alla piazza abbia solo un link collegato [figura 3.35 a]. Vengono cercati i punti di intersezione fra le rette contenenti i lati del link e i lati della piazza che abbiano il nodo in esame come vertice comune. Questi punti di intersezione diventeranno i nuovi vertici del quadrilatero che rappresenta il link e due nuovi vertici del poligono convesso che rappresenta la piazza. Di fatto, al vertice rappresentato dal nodo, si sostituiscono questi due nuovi punti appena trovati. E il nodo è quindi rappresentato idealmente da un segmento che congiunge questi due punti [figura 3.35b].
a b
figura 3.35
Se le rette contenenti i lati del link non intersecano i lati della piazza collegati al nodo (figura 3.36a), similmente a quello che avviene negli incroci, i vertici del link si spostano fino a coincidere con gli estremi dei lati della piazza presi in considerazione [figura 3.36b].
a b
figura 3.36
Nel caso ci siano più link connessi a un nodo appartenente a una piazza, relativamente ai lati dei link non prossimi ai lati della piazza [figura 3.37a], l’algoritmo si comporta come per un normale incrocio e il nodo viene quindi rappresentato come un vero e proprio poligono [figura 3.37b].
a b
figura 3.37
3.4.4.
Calcolo della coordinate di texture dei vari elementi
Ai fini di un arricchimento del dettaglio visuale, il modello del manto stradale necessita di essere mappato con un’apposita texture che lo renda visivamente simile a quello reale. Per fare questo è stato deciso di usare texture “ripetute”, anziché “spalmate” sugli oggetti. [MASON]
Texture da applicare Texture “spalmata” Texture “ripetuta”
figura 3.38 - i due modi possibili di applicare una texture a una superficie
La scelta di usare texture ripetute fa si che i file delle texture occupino un ridotto spazio su disco e in memoria, ed evita che ci siano distorsioni antiestetiche sul manto stradale dovute alle diverse dimensioni degli oggetti. Per contro, in caso di texture di piccole dimensioni ripetute un gran numero di volte, è evidente un’artefatta simmetria dovuta alle numerose ripetizioni dello stesso frammento di immagine. All’utente viene quindi data la possibilità di indicare le dimensioni reali che corrispondono a ogni singolo frammento di manto stradale, cioè ogni singola texture. Poi la texture viene ripetuta varie volte a seconda delle dimensioni
della superficie da ricoprire. Particolare attenzione va posta alla scelta delle coordinate di texture. Soprattutto per quanto riguarda le strade è necessario che ogni texture sia orientata rispetto all’asse centrale di ogni link. Questo per evitare uno spiacevole senso di “irrealtà”, soprattutto in presenza di materiali come “sampietrini”, “mattonelle” e simili. Piazze e incroci non dispongono di un verso di orientazione vero e proprio e quindi questa esigenza passa in secondo piano. Per trovare le coordinate di texture è quindi necessario calcolare il bounding rectangle dell’oggetto, che nel caso dei link deve avere il lato più lungo corrispondente all’asse mediana del link. Per fare questo è sufficiente ruotare l’asse di riferimento rispetto al verso dell’asse mediana, calcolare il bounding rectangle e porre l’origine delle texture nell’angolo in basso a sinistra rispetto al nuovo sistema di riferimento.