Capitolo 2
Architettura di sistema
2.1
Introduzione
La richiesta di alti data rate per sistemi radio mobili ´e grande E in costante aumento. Servizi multimediali di tipo broadband, come ad esempio audio, video ed internet, rappresenteranno in futuro la tipologia dominante di traf-fico per le comunicazioni mobili.
Per poter supportare tali tipologie di applicazioni, attualmente destinate ai sistemi 4G, sono necessari profondi cambiamenti della tecnologia di trasmis-sione radio e della architettura di sistema.
Gli attuali sistemi 3G e Wireless Lan sono incapaci di supportare alti data rate e di soddisfare richieste di QoS sempre maggiori.
I sistemi radio mobili 4G saranno in grado di supportare una grande variet´a di servizi, dal semplice accesso alla rete alle applicazioni di realt´a virtuale multimediale, oltre ad includere i tradizionali servizi di telecomunicazione di tipo telefonico in ambienti mobili. A causa di questa intrinseca eterogeneit´a tecnologica, IP ´e stato scelto come protocollo comune in modo da fornire un livello di interconnessione fra le varie applicazioni.
Nonostante l’ introduzione di un protocollo comune molti sono i problemi legati ai sistemi 4G, molti dei quali riguardano l’ architettura del livello fisico (PHY). Il progetto di ricerca PRIMO ha come obiettivo principale quello di risolvere tali tipologie di problemi.
Il progetto PRIMO (Piattaforme Riconfigurabili per Interoperabilit´a in mo-bilit´a), ´e un progetto di ricerca italiano che coordina l’ attivit´a di istituzioni accademiche, fra cui le Universit´a di Pisa, Padova, Torino, Palermo e Ro-ma, ed industriali verso lo sviluppo di una piattaforma comune per sistemi 4G. In particolare, PRIMO prende in esame la progettazione e lo sviluppo di base station(BS) ed user terminal(UT) per sistemi di comunicazionewire-less a banda larga in grado di fornire caratteristiche di riconfigurabilit´a ed interoperabilit´a richieste dai sistemi mobili di comunicazione di possima gen-erazione.
Il progetto PRIMO ´e suddiviso in 6 work package (WP), ognuna delle quali prende in esame uno specifico aspetto della fase di progettazione e sviluppo. In particolare, lo sviluppo di un algoritmo di allocazione dinamica delle risorse radio disponibili rappresenta un’ area di lavoro della WP3, work package che riguarda la progettazione del livello di collegamento e i relativi algoritmi.
2.2
Modello di un sistema 4G
2.2.1
Architettura Simulatore
Viene considerato[pa], sulla base delle osservazioni proposte in [14pa], un sistema multicellulare di tipo TD-OFDMA con un fattore di riutilizzo delle frequenze pari a uno. In questa particolare assunzione, le BS vengono po-sizionate su una griglia regolare, mentre le MS vengono uniformemente dis-tribuite all’ interno di ogni cella e collegate alla BS in funzione del miglior
canale medio.
Le componenti funzionali principali del sistema preso in esame nel progetto PRIMO sono rappresentate dallo scheduler e dall’ allocatore.
Lo scheduler ha il compito di gestire le richieste di trasmissione provenienti dai livelli pi´u alti, prendendo in considerazione specifiche di diverse QoS e di flussi di traffico, e trasla queste richieste sotto forma di parametri maneggia-bili dall’ allocatore.
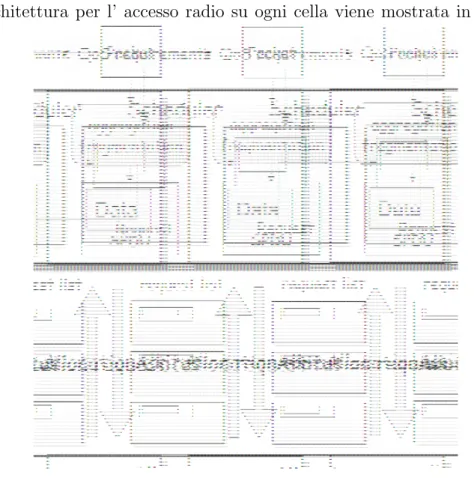
L’ architettura per l’ accesso radio su ogni cella viene mostrata in fig2.1 Il
Fig. 2.1: Architettura di sistema
blocco relativo allo scheduler accetta in ingresso il traffico utenti e le relative specifiche di QoS necessarie per la comunicazione fra BS e MS, mentre in uscita presenta le richieste per l’ allocazione delle risorse MAC.
Si assume che all’ inizio di ogni frame il trasmettitore possieda informazioni riguardo al canale e all’ interferenza percepita al ricevitore. Problematiche di segnalazione non vengono qui considerate dal momento che assumiamo che il controllo del trasferimento dell’ informazione venga eseguito da un separato canale di segnalazione esente da errore.
L’ allocatore lavora come un modulo di adattamento fra livello MAC e PHY, adattando i frame MAC su opportune PBU (Physical Base Unit). Il blocco relativo alla allocazione delle risorse (Resource Allocation RA) accetta in ingresso le richieste provenienti dallo scheduler e seleziona per ognuna di esse una PBU e i relativi valori di bitload e potenza, mappando tali richieste di livello MAC su livello PHY. L’ allocatore deve inoltre segnalare a livello MAC le allocazioni effettuate. A causa dell’ utilizzo di una tecnica di modulazione di tipo adattivo, il numero di PBU richieste per la trasmissione fisica di un frame MAC di una data lunghezza non viene fissato.
Ogni richiesta k proveniente dallo scheduler viene rappresentata tramite un rate massimo rk,max e un rate minimo rk,min che deve essere allocato.
Le risorse allocate possono essere usate dallo scheduler per trasmettere uno o pi´u pacchetti e una singola richiesta pu´o richiedere diversi frame successivi per essere completamente soddisfatta. Inoltre, assumiamo che il rate complessivo allocato in una cella sia vincolato ad essere pari a rtot. Il valore di rtot viene
stabilito in funzione di politiche di controllo di carico.
Ogni BS compie in maniera autonoma la procedura di allocazione senza che ci sia fra le celle una esplicita comunicazione.
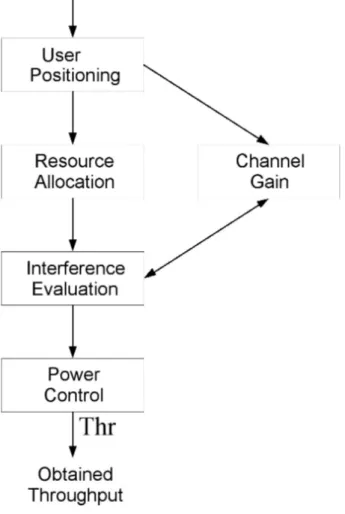
In fig2.2 viene mostrato il diagramma a blocchi utilizzato per il calcolo del throughput in corrispondenza di una specifica strategia di allocazione delle risorse. La metodologia adottata assume inizialmente un valore di ’aggregate throughput’ fisso per ogni cella. Sulla base di questo valore e dello scenario
Fig. 2.2: Algoritmo calcolo Throughput
selezionato viene generato uno ’snapshot’ del traffico utente per ogni cella. Tale ’snapshot’ viene ottenuto generando un determinato numero di utenti, ognuno dei quali pu´o trasmettere un certo numero di bit sia in downlink che in uplink. Una volta che gli utenti sono stati generati vengono distribuiti in modo uniforme all’ interno di ogni cella. Inoltre, viene utilizzata una strategia di allocazione opportuna per assegnare le risorse fisiche disponibili agli utenti, sulla base delle loro specifiche richieste. Una volta che gli utenti sono stati allocati, dobbiamo identificare per ogni collegamento tutte le fonti di interferenza e generare per ogni collegamento un canale di propagazione fra il trasmettitore interferente e il ricevitore preso in considerazione.
Il canale cos´ı generato prende in esame gli effetti di path loss, di fading e di shadowing. Questa operazione ha un grande impatto sulla complessit´a computazionale del simulatore del livello fisico.
modo da avere informazioni riguardo all’ ammontare della potenza richiesta per ogni trasmissione.
2.2.2
Architettura di sistema - livello MAC
La tecnica di accesso al mezzo viene organizzata in un modo ibrido FDMA-TDMA. Il frame MAC, riportato in fig2.3, ´e composto da Nt simboli OFDM
successivi di durata Tt, comprendente un prefisso di durata Tp e un simbolo
utile di durata Ts. Per questo motivo, il frame risulta avere una durata
complessiva pari a Tf = NtTt = Nt(Tp+ Ts).
La durata di una frame MAC proposta risulta essere uguale a TM AC=10ms,
per un numero totale di Nblock=625 simboli OFDM. La struttura proposta
prevede una fase di broadcast, una fase di trasmissione suddivisa in due parti, una relativa al downlink(DL) ed una all’ uplink(UL), ed infine una fase di accesso casuale.
La fase di broadcast, la cui lunghezza ´e stata fissata preliminarmente a 15 slot, viene utilizzata dalla base station(BS) per trasmettere in modalit´a broadcast le informazioni di cella, come ad esempio l’ identificativo della BS ed il livello di potenza di trasmissione. Inoltre, contiene informazioni riguardo la strut-tura del frame ed un preambolo utilizzato dai terminali mobili(MT) per la sincronizzazione del frame.
La fase di DL/UL ´e composta da 20 pacchetti di simbolo, con i primi 19 ded-icati alla trasmissione dell’ informazione e l’ ultimo dedicato all trasmissione di dati riguardanti lo stato del canale.
La fase di accesso random, infine, ´e stata ideata per fare in modo che MT non ancora schedulate possano comunque trasmettere.
Fig. 2.3: Struttura frame MAC
sul COST-259. Sulla base di tale modello consideriamo tre diverse tipologie di cella:
• ’urban/suburban’, denominata anche macro cella;
• ’street canyon’, denominata anche micro cella;
• ’indoor’, denominata anche pico cella;
In tabella 3 vengono riportati i principali parametri per questi tre diversi scenari. Per tutte le topologie proposte viene applicata la seguente legge di
Macro Cella Micro Cella Pico Cella Ambiente ’urban/suburban’ ’street canyon’ ’indoor’ delay spread σ 0.5 µs 0.75 µs 0.1 µs
attenuazione:
α(d) = α0d4 (2.1)
avendo indicato con α0 il termine che prende in considerazione il tipo di cella
e con d la distanza fra trasmettitore e ricevitore espressa in metri.
Gli effetti relativi al fenomeno di shadowing vengono modellati attraverso una attenuazione di tipo log-normale caratterizzata da una deviazione standard pari a 6dB.
L’ effetto del fading multipath viene modellato come una sommatoria di NR
funzioni delta pesate del tipo:
h(τ, t) = NR
X i=0
βi(t)δ(τ − τi(t)) (2.2)
avendo indicato con i il numero di percorso, con δ(·) l’ impulso di Dirac, con
βi(t) e τi(t) rispettivamente il guadagno tempo variante ed il ritardo dello
i-esimo percorso.
Il numero di percorsi NR varia in funzione del fattore di delay spread δ.
Il guadagno di canale βi(t) ´e un processo gaussiano stazionario mutuamente
indipendente a media nulla, la cui potenza Mβi = E |βi(t)|
2 risulta essere espressa da Mβi = F exp à −iT /Q σ ! = F exp à − i σnQ ! (2.3)
avendo indicato con Q il fattore di sovracampionamento, con T il periodo di campionamento, con σn= σ/T il valore normalizzato del delay spread e con
F un fattore di normalizzazione pari a: F = PN 1 R−1 i=0 exp ³ − i σnQ ´ (2.4)
Inoltre il processo βi(t) presenta un andamento spettrale di Jake con
frequen-za Doppler fd pari a :
fd = ν
cfcar (2.5)
avendo definito fcar=2GHz ed espresso ν in Km/h. Il modello preso in esame
considera valori di ν pari a 3, 50 e 120 Km/h, a cui corrispondono rispetti-vamente frequenze Doppler pari, approssimatirispetti-vamente, a 6, 100 e 240 Hz. Vengono inoltre definite tre diverse tipologie di traffico:
• ’real-time’;
• ’streaming’;
• ’data’.
In tabella 4 vengono riportate le principali caratteristiche dei modelli di traffico proposti.
Real-Time Streaming Data Transmission length exp., avg. 60s exp., avg.60s
Bit rate (kbit/s) 16,144, 384 144, 384, 2000
Packet size exp.,avg. 10 Mbit
Maximum delay (ms) 50 250
Direction ON/OFF 80%DL, 20%UL 70%DL, 30%UL Scenario 1 (% of aggr. throughput) 33% 33% 33% Scenario 2 (% of aggr. throughput) 20% 40% 40%
Il valore di ’aggregate throughput’ per cella risulta essere un parametro di ingresso del simulatore di sistema; tipicamente i valori sono contenuti nel range 10-50 Mbps.
Si assume inoltre che il tempo di arrivo di ogni tipo di traffico sia distribuito secondo Poisson. Inoltre, per semplificare ulteriormente il modello, assumi-amo che i traffici di tipo ’real-time’ o streaming’ possono utilizzare solamente un bit rate fra quelli riportati in tabella 4, ed in particolare, possono assumere solamente i valori di 144 e 384 Kbit/s rispettivamente.
2.2.3
Architettura di sistema - livello PHY
modalit´a di trasmissione
La modalit´a di trasmissione utilizzata ´e di tipo time division duplexing (TDD), dove lo stesso canale frequenziale viene utilizzato per la trasmissione la la ricezione dei segnali in modalit´a duplex, sia per la fase di downlink che di uplink. La durata della trasmissione viene fissata dal sistema.
Diversi fattori concorrono alla scelta di questa modalit´a di trasmissione per sistemi 4G, primo fra tutti il profilo asimmetrico dei rate trasmissivi per il traffico in fase di downlink e di uplink. Tale propriet´a rispecchia per-fettamente la necessit´a delle applicazioni di prossima generazione di poter usufruire di tecniche flessibili di assegnazione dei rate trasmissivi. Si deve inoltre considerare che le bande frequenziali su cui dovranno lavorare tali applicazioni sono di tipo ’unpaired’ e possibilmente non regolamentate da licenze.
Sulla base delle considerazioni sopra esposte TDD, che presenta anche una maggiore efficienza in termini di banda rispetto alla modalit´a di trasmis-sione frequency division duplexing (FDD), rappresenta la migliore modalit´a
trasmissiva utilizzabile.
Riguardo al formato di modulazione ´e stato scelta la tecnica Orthogonal Fre-quency Division Multiplexing (OFDM) in quanto risulta essere in grado di fornire ottime prestazioni per canali altamente dispersivi unita ad una buona efficienza spettrale. Per ogni tempo di simbolo , l’ intera banda viene divisa in Ns sottoportanti fra loro ortogonali, in modo da formare quindi una
ma-trice di risorse simbolo/portante di dimensione pari a Nt× Ns.
Per ridurre gli overhead in esame, le risorse radio vengono organizzate in gruppi di Ks sottoportanti disponibili per Kt tempi di simbolo consecutivi.
Questi gruppi vengono indicati con il termine PBU (Physical Base Unit). La dimensione della PBU, in termini di portanti e simboli, viene determinata sulla base delle informazioni sulla banda di coerenza e sul tempo di coerenza del canale. Questa scelta permette di usare lo stesso schema di modulazione e di trasmettere la stessa potenza su tutte le portanti e su tutti i simboli che riguardano una stessa PBU. Con le premesse fatte quindi, il numero di risorse utilizzabili si riduce ad una matrice di Ms× Mt PBU, dove abbiamo
assunto Mt= Nt/Kt e Ms= Ns/Ks.
Ad utenti appartenenti ad una stessa cella vengono assegnate risorse fra loro ’ortogonali’, ossia diverse PBU. Da ci´o, pu´o nascere solamente interferenza intracellulare.
Il sistema utilizza una tecnica di tipo OFDM adattiva, grazie alla quale ogni sottoportante pu´o essere caricata con un indipendente numero di bit e poten-za.
I parametri proposti nel progetto PRIMO riguardo al formato di modulazione OFDM possono essere riassunti nella tabella 1 sotto riportata. Per una anal-isi pi´u dettagliata riguardo a questa tecnica di modulazione rimandiamo alla lettura dell’ appendice A.
Parametri OFDM valori
Banda 20MHz
Periodo temporale elementare T=50ns Dimensione IDF T /DF T , Ncarrier 256
Durata prefisso ciclico 64xT=3.2 µs Durata di simbolo OFDM 320xT=16 µs Spaziatura fra sottoportanti 78.125 KHz
La lunghezza del prefisso ciclico ´e stato scelto in modo da ottenere buone prestazioni anche in canali molto dispersivi.
Assumendo che le sottoportanti OFDM siano modulate utilizzando una tec-nica di modulazione di tipo BPSK, QPSK, 16-QAM O 64-QAM e codificate con diversi code rate, in tabella 2 vengono riportatii vari bit rate che il sistema ´e in grado di offrire.
Modo Modulazione Code rate NIBR NIBOS
1 BPSK 1/2 8 128 2 BPSK 3/4 12 192 3 QPSK 1/2 16 256 4 QPSK 3/4 24 384 5 16-QAM 1/2 32 512 6 16-QAM 3/4 48 768 7 64-QAM 1/2 48 768 8 64-QAM 3/4 72 1152
Avendo indicato con NIBR il Nominal Information Bit Rate E CON
NIBOS il Number of Information Bit per OFDM Symbol. Si deve
tecnica di modulatione, dal momento che sfrutta un blocco di controllo della potenza che risulta essere indipendente dal concetto di modulazione. inoltre, nella versione finale del dimostratore proposto da WP3 viene utilizzato come ’codice madre’ un turbo codice con rate 1/3, mentre code rati pi´u alti vengono ottenuti tramite ’puncturing’.
Assumiamo che il canale sia modellabile come la sovrapposizione di P cammini distinti. In queste ipotesi, l’ inviluppo complesso della risposta impulsiva di canale, risulta essere espressa da:
c(t, τ ) = P X p=1
cp(t)δ(τ − τp) (2.6)
avendo indicato con cp(t) e τp(t) rispettivamente il guadagno complesso e il
ritardo del p-esimo percorso al tempo t.
Nella maggior parte degli scenari non ´e presente un cammino diretto tra trasmettitore e ricevitore quindi guadagni cp(t) sono modellati come variabili
aleatorie complesse gaussiane fra loro indipendenti, a media nulla e con var-ianza σ2
p. L’ effetto del multipath fading sul segnale trasmesso dipende dalla
durata del tempo di segnalazione Tse dal delay spread τrms. Nel caso in cui il
delay spread sia piccolo rispetto al tempo di simbolo, il canale risulta essere ’piatto’, quindi i cammini sono non distinguibili fra loro e si ha come risultato finale un unico percorso con un valore di potenza pari alla potenza totale del canale. In questo caso l’ unica forma di diversit´a che si pu´o sfruttare ´e quella di tipo temporale. La RA, in questo scenario, adatta potenza e formato di modulazione in trasmissione seguendo le variazioni temporali del canale. Nel caso in cui invece il delay spread sia confrontabile con il tempo di simbolo, oppure addirittura maggiore di esso, il canale risulta essere ’selettivo in fre-quenza’ e durante un singolo intervallo di segnalazione giungono al ricevitore i contributi di pi´u simboli che generano interferenza intersimbolica (Inter-Symbol Interference ISI).
Se non opportunamente mitigata, l’ ISI pu´o avere un impatto catastrofico sulle prestazioni. D’ altra parte la selettivit´a in frequenza rappresenta una risorsa di diversit´a per il ricevitore, il quale pu´o avvantaggiarsi della osser-vazione di repliche statisticamente indipendenti del segnale trasmesso. Si pu´o dimostrare che la tecnologia OFDM ´e quella che riesce a sfruttare meglio tale diversit´a frequenziale del canale multipath.
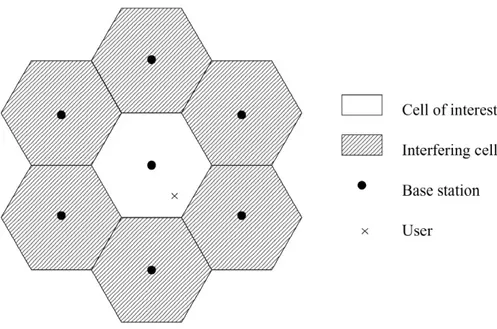
Per l’ esame della interferenza il sistema in esame presenta il layout riportato in fig.2.4 La cella di interesse, caratterizzata da un raggio di 500 m, viene
posizionata al centro della nostra struttura di riferimento. Questa risulta essere circondata da 6 celle disposte in modo tale da offrire una copertura completa dell’ intera area di interesse senza per´o presentare sovrapposizioni fra celle. Al centro di ogni cella viene posizionata una BS con antenna om-nidirezionale, mentre gli utenti possono essere distribuiti in modo uniforme all’ interno di ogni cella, con l’ unica limitazione rappresentata dal fatto che non possono ’uscire’ dalla cella su cui sono stati inizialmente schedulati. Per ridurre l’ interferenza inter-cella alcuni sistemi adottano un metodo basato sulle sequenza di scrambling.
le frequenze di trasmissione vengono riutilizzate attraverso ogni cella, e ai fini dei nostri studi il fattore di riutilizzo delle frequenze risulta essere uguale a uno.
Per ridurre la complessit´a del problema da simulare, consideriamo di avere in-izialmente un sistema perfettamente sincronizzato; in altre parole, non pren-diamo in considerazione eventuali offset di tempo o di frequenza, ne fra BS e MT, ne fra BS.
2.3
Algoritmo di Scheduling
Il MAC sviluppato nel simulatore risulta essere strutturato in due blocchi funzionali separati:
• Radio Resource Allocator (RRA), che compie l’ allocazione delle risorse radio;
• Packet Scheduler (PS), che ha come scopo quello di garantire la fairness o QoS richiesta.
Una alternativa a tale architettura MAC per una progettazione pi´u flessibile del PS si basa sull’ implementazione di un unico blocco funzionale in grado di
supportare sia la fase di allocazione che di scheduling in un unico integrato, definito Integrated Allocator and Scheduler (IAS). Rimandiamo al sottopara-grafo relativo per una analisi pi´u approfondita.
Gli obiettivi principali dello scheduler sono rappresentati da:
• garantire il QoS richiesto dal flusso dati, con particolare attenzione al flusso dati di tipo real-time
• garantire la fairness fra i flussi dati
• gestire il carico delle singole celle in accordo alle esigenze delle celle adiacenti.
I primi due punti sopra esposti riguardano la progettazione dei meccanismi di scheduling e la sua relazione con il meccanismo di allocazione, mentre il terzo punto riguarda la gestione delle celle , chiamando in esame anche una loro cooperazione. Il PS proposto nel modello del simulatore ´e organizzato in tre moduli:
• QoS Scheduler
• BE Scheduler - Best Effort
• Fase di controllo di carico
2.3.1
Operazioni generali dello scheduler
Il packet scheduler (PS) opera in modo asincrono, cio´e le sue decisioni non sono fornite periodicamente ma, al contrario, sono di tipo ’event-triggered’. Il PS ´e in grado di schedulare nuovi pacchetti in ogni frame in cui risulta esser disponibile una certa capacit´a trasmissiva. Per una gestione ottimale di tale tipologia di selezione viene prevista una coda per il flusso dati; ´e possibile
schedulare pi´u di un paccheto per flusso dati. In generale, la trasmissione di un singolo pacchetto deve durare pi´u di un frame. Perci´o, durante un dato frame, una porzione della capacit´a viene impiegata per la gestione della trasmissione dei pacchetti schedulati nel frame precedente ed allocati su un certo numero di frame contigui.
In generale viene fornito non un singolo valore ma un range di valori individ-uando il rate minimo rmin e il rate massimo rmax.
I pacchetti vengono quindi ordinati in una apposita lista e ad ognuno di essi viene associato ad un rate trasmissivo.
PS provvede all’ invio di tale lista a RRA, il quale, sulla base delle infor-mazioni contenute in essa, procede con l’ esecuzione di un appropriato algo-ritmo di allocazione.
Una volta terminata la selezione delle richieste trasmissibili RRA fornisce a PS la lista dei pacchetti attualmente allocati con i relativi rate, garantendo l’ eventuale eliminazione di quei pacchetti che non soddisfano le specifiche richieste.
Una caratteristica chiave di questo tipo di PS consiste nel fatto che, in gen-erale, vengono selezionati pi´u flussi da servire in parallelo. In particolare, anche se la trasmissione di un pacchetto schedulato non finisce nel frame cor-rente, essendo la sua durata dipendente dalla lunghezza del pacchetto e dal rate trasmissivo, pi´u di un paccheto viene programmati per la trasmissione.
2.3.2
Motivazioni per uno scheduler di tipo Best Effort
Lo scopo di un PS consiste nel fornire una tipologia di accesso al canale ’fair’ ai terminali in contesa, e di soddisfare le richieste di ’packet delay’.
Gli algoritmi di allocazione di tipo fair, sviluppati nel contesto di reti cab-late, risultano molto efficienti e in letteratura molto ´e stato scritto riguardo
a questo argomento [1].
Negli algoritmi di accodamento di tipo fair dei pacchetti, lo scheduler se-leziona fra tutti i flussi quello che deve trasmettere il pacchetto. Uno dei primi algoritmi di accodamento di questo tipo proposto ´e stato il GPS [2]. Questo opera su un rate di canale pari a C, mentre gli utenti sono caratter-izzati attraverso i loro pesi R1, R2, ... , RN.
Lo scheduler effettua le proprie scelte in una modalit´a di tipo ’round-robin’, servendo ad ogni turno un numero di bit per flusso proporzionale alla di-mensione del flusso stesso. In realt´a i pacchetti non vengono per´o schedulati un bit alla volta. Gli algoritmi realmente utilizzati di accodamento fair di pacchetti, come ad esempio il WFQ (Weighted Fair Queuing ), emulano il sistema GPS schedulando i pacchetti in base ai loro tempi di partenza su un ipotetico server, realizzato attraverso una funzione v(t) tempo-virtuale, che tiene traccia del numero di turni eseguiti. In questo modo si ha:
dv(t) dt = C P i∈B(t)Ri (2.7)
dove B(t) rappresenta l’ insieme degli utenti totali. Ad ogni pacchetto viene poi assegnato un ’timestamp’ Fk
i nel modo seguente:
Sik= max(v(aki), Fik−1) (2.8) Fk i = Sik+ Lk i Ri (2.9) Dove Sk
i, Fik, Lki e aki rappresentano rispettivamente il tempo virtuale
di inizio, il tempo virtuale di fine, la lunghezza del pacchetto in esame e il tempo di arrivo per il k-esimo pacchetto dell’ utente i-esimo.
L’ algoritmo WFQ serve poi i pacchetti in ordine crescente rispetto al proprio ’timestamp’, ossia in base al tempo di partenza.
Algoritmi basati sull’ idea del tempo-virtuale possono risultare di difficile implementazione, perci´o sono state proposte un gran numero di soluzioni al-ternative.
Un algoritmo di accodamento che non si basa sul tempo-virtuale ´e il Credit Base Fair Queuing(CBFQ). Tale algoritmo si basa sull’ utilizzo di contatori per tenere traccia dei ’crediti’ accumulati da ogni singolo flusso dati, e decide quale flusso deve essere trasmesso sulla base del valore dei suddetti contatori, sulla dimensione della banda associata ad ogni utente e sulla dimensione del head of line(HOL) del pacchetto.
In tale tipologia di algoritmo, il flusso dati che viene trasmesso non guadagna altri crediti, mentre i contatori degli altri flussi vengono incrementati in pro-porzione ai parametri sopra menzionati. Questo algoritmo risulta essere in grado di garantire una notevole fairness e di limitare i ritardi.
Un certo numero di problemi nasce nel momento in cui vogliamo adattare gli algoritmi di accodamento di tipo fair a reti wireless. Il punto principale consiste nel fatto che in ambienti di tipo wireless ci sono errori dipendenti dalla particolare locazione assegnata.
Alcune risorse allocabili possono risultare, per alcuni utenti, inadatte alla trasmissione a causa delle condizioni di canale per essi pessime, mentre per altri utenti le stesse condizioni possono essere ottimali.
In questo modo il canale risulta variabile nel tempo ma anche diverso da utente a utente. In questo caso si parla di ’diversit´a multiutente’.
Per le reti wireless viene definito l’ algoritmo Wireless Credit-based Fair Queueing (WCFQ), che risulta essere in grado di garantire la fairness sia a breve termine che a lungo termine, come mostrato in [ Yonghe Liu, Stefan Gruhl, Edward W. Knightly ’WCFQ: an Opportunistic Wireless Scheduler with Statistical Fairness Bounds’, IEEE 2003].
Tale algoritmo ´e di tipo ’credit-based’, basato cio´e sull’ algoritmo CBFQ. Per ogni utente viene considerato un costo di trasmissione, dipendente dalla qualit´a del canale percepita dall’ utente in esame; in questo modo, i crediti accumulati risultano bilanciati da tale costo. Per esempio, se la trasmis-sione corrente ´e caratterizzata da un alto costo, ossia le condizioni di canale risultano per l’ utente in esame non ottimali, lo scheduler pu´o posticipare la trasmissione dei pacchetti interessati malgrado i crediti accumulati fino a quel periodo.
Un limite statistico riguardo alla fairness pu´o esser calcolato per un algo-ritmo di tipo WCFQ in termini della distribuzione della funzione dei costi; tale funzione dipende dalla qualit´a del canale. Scegliendo una funzione dei costi adeguata ´e possibile raggiungere un buon compromesso fra fairness ed efficienza.
2.3.3
Specifiche dell’ algoritmo scheduler BE
Una peculiarit´a del sistema proposto nel progetto PRIMO consiste nel fatto che le decisioni dello scheduler possono essere ottenute e segnalate agli utenti al massimo ad ogni frame. Vengono generalmente schedulati pi´u utenti alla volta.
Viene inoltre assunto che PS lavori in modo da schedulare interi pacchetti. Per ogni flusso viene definito un contatore di ’crediti’ Ki che viene
incre-mentato nel momento in cui un flusso dati giunge a PS e non quando viene schedulato, un peso ´rφi, un costo Qi che risulta essere inversamente
pro-porzionale alla qualit´a del canale.
I crediti per un dato flusso vengono decrementati quando il flusso viene schedulato per la trasmissione. Nel momento in cui lo scheduler effettua la decisione solo una porzione dei pacchetti risulta essere allocata e trasmessa.
Di conseguenza, la diminuzione dei crediti, applicata ad un flusso schedulato prende in considerazione solamente il numero di bit effettivamente allocati nel frame corrente.
Lo scheduler associa un valore di priorit´a ad ogni flusso, basandosi sul numero di crediti che ha accumulato, sulla lunghezza del HOL del pacchetto, sul costo associato al flusso e sul suo ’peso’. Viene selezionato il flusso che presenta la pi´u alta priorit´a , e i crediti di tutti i flussi vengono aggiornati. L’ algoritmo di scheduling utilizzato nel progetto primo adotta la seguente notazione:
schedule [1] i = 1 to N i ∈ B(p) Ki(p) ← max(0, Ki(p) − c(i, t)) j = 1 to N
j ∈ B(p+1) and j 6= i Kj(p) ← Kj(p)+c(i,t)φi ×φj PN
i=1c(i, t)+cmax < Cmax i = 1
to N Lfirame(p) ← min(cmax, Li(p)) f(p+1) ← arg mini∈B(p)L
f rame i (p)−Ki(p)+Qi(t) φi t0=t to t + dLf p+1(p) cmax e − 2 c(fp+1, t 0 ) ← c(fp+1, t 0 ) + cmax c(fp+1, t + d Lfp+1(p) cmax e − 1) ← Lfp+1(p) − cmax× (d Lfp+1(p) cmax e − 1) i = 1 to N i ∈ B(p + 1) and i 6= fp+1 Ki(p + 1) ← Ki(p) max à Lf rame fi(p+1)(p)−Kfi(p+1)(p) φfp−1 , 0 ! × φi i /∈ B(p + 1)andi 6= fp+1 Ki(p + 1) ← 0 i ∈ fp+1 ∈ B(p + 1) Kfp+1(p + 1) ← max(0, Kfp+1(p) − L f rame fp+1 ) Kfp+1(p + 1) ← 0 return SchedList
Nello pseudo-codice seguente (schedule) viene descritta la procedura se-guita nel frame t-esimo. Per prima cosa, come possiamo vedere nelle linee 1-10, vengono aggiornati i codici dei flussi cumulati in accordo alla capacit´a gi´a schedulata per questo frame, cio´e i pacchetti gi´a schedulati e pi´u lunghi di un frame.
Nel ciclo ’while’, dalla linea 11 alla 32 viene riempita la capacit´a disponi-bile del frame, Cmax(t). Si deve notare che abbiamo preso in considerazione
i pacchetti la cui trasmissione risulta attualmente in corso. Nel ciclo ’for’, dalla linea 12 alla linea 14, viene calcolata l’ effettiva lunghezza del HOL del pacchetto per ogni flusso, cio´e la lunghezza del frammento che pu´o essere
p indice del numero di pacchetti in servizio
i indice di flusso
t indice di frame
N numero di flussi
φi peso del flusso i-esimo
fp flusso selezionato per il pacchetto p-esimo
B(p) insieme di flussi accumulati, dopo che il pacchetto p ´e stato ’schedato’
Ki(p) contatore dei crediti del flusso i-esimo su p
Li(p) lunghezza del HOL del pacchetto del flusso
i-esimo su p
Qi(p) costo stimato per l’ utente i-esimo
per trasmettere sul frame t-esimo
cmax capacit´a massima allocata al singolo
pacchetto in un frame
Cmax capacit´a massima totale allocata in un frame
c(i, t) capacit´a gi´a allocata al flusso i-esimo
nel frame t-esimo
Lf ramei (p) numero di bit del HOl del pacchetto per flusso i-esimo su p che pu´o essere trasmesso nel frame corrente
trasmesso in un dato frame. Viene poi selezionato il pacchetto da schedulare nella linea 15.
Nelle linee 16-18 vengono aggiornate le capacit´a allocate per i seguenti frame, nel caso in cui la trasmissione del pacchetto richieda pi´u di un frame. Nelle linee 27-31 vengono aggiornati i crediti per il flusso corrispondente al pac-chetto selezionato, mentre nel ciclo ’for’ che si trova alle linee 20-26 vengono
aggiornati i crediti di tutti gli altri flussi.
Possiamo definire il costo di trasmissione come
Qi = 1 Nf ree × X j∈P BUf ree Ii(j) gi(j) (2.10)
Usando un’ ulteriore notazione, definendo con
gi(j) Ii(j)
(2.11)
la qualit´a del canale per l’ utente mobile i-esimo nella j-esima PBU, il costo di trasmissione pu´o essere definito come
Qi = Nf ree× X j∈P BUf ree gi(j) Ii(j) −1 (2.12)
Nelle formule sopra riportate P BUf ree e Nf ree rappresentano rispettivamente
l’ insieme e il numero delle PBU libere in un frame, nel senso che tali PBU non riusultano essere allocate per la trasmissione in corso, mentre gi(j) e Ii(j) rappresentano rispettivamente il guadagno di percorso e il valore dell’
interferenza per l’ utente i-esimo nella j-esima PBU.
La capacit´a complessiva cmax che ogni cella pu´o utilizzare viene
determina-ta dal blocco di controllo del carico. Questo implemendetermina-ta un algoritmo che utilizza le informazioni provenienti dallo scheduler riguardo lo stato dell’ ac-codamento ed alcune informazioni trasmesse in modalit´a broadcast dalle celle vicine. Questo algoritmo, inoltre, genera le informazioni da inviare alle altre celle, per esempio il rate minimo o il massimo ritardo che sta sperimentando. L’ idea base consiste nel fatto che se una cella richiede una capacit´a maggiore, questa invia una segnalazione alle celle vicine, in modo da garantire un livello minimo di fairness fra celle contigue, o fra terminali associati ad esse.
2.3.4
Algoritmo per il controllo del carico
Due aspetti caratteristici del sistema radiomobile sviluppato nel progetto PRIMO sono:
• la capacit´a dell’ interfaccia radio non pu´o essere misurata a-priori dal momento che essa dipende dall’ attuale rate sostenibile in ogni PBU;
• in uno scenario multi-cella le risorse radio non sono partizionate a-priori.
Come conseguenza si ha che il progetto del livello MAC deve includere il blocco funzionale del controllo del carico che, in corrispondenza delle due caratteristiche di sistema sopra menzionate, presenta due processi tali da:
• controllare sulla quantit´a totale della capacit´a richiesta dal PS al RRA sulla base dell’ attuale ammontare delle risorse disponibili misurate;
• permettere, in uno scenario multi-cella, la coesistenza di celle limitrofe. Nella tabella seguente vengono riportate le notazioni usate per l’ algoritmo in esame:
schedule2 (Cmax) [1] i = 1 to N K∗
i ← Ki c(i) ← 0 PN
i=1c(i) < Cmax
f ← arg mini∈B 1−K
∗ i φi c (f ) ← c (f ) + 1 i = 1 to N i ∈ B and i 6= f K ∗ i ← K∗ i + max µ 1−K∗ f φf , 0 ¶ × φi i /∈ B Ki ← 0 f ∈ B K∗ f ← max ³ 0, K∗ f − 1 ´ K∗ f ← 0
SchedList.insert(pf) return SchedList
Schedule2 specifica l’ algoritmo di controllo del carico nel caso di singo-la celsingo-la. Nelle linee 1-5 vengono specificate le modalit´a di inizializzazione del sistema al frame t=0, settando il valore della capacit´a residua, allocata, richiesta ed utilizzata al tempo virtuale t=-1, in modo da rendere possibile l’ utilizzo di tale algoritmo al tempo t=0. Nelle linee 6-12 abbiamo l’ algo-ritmo di controllo del carico. La massima capacit´a che PS pu´o richiedere a
t indice di frame
Cbl(t) capacit´a totale cumulata al frame t-esimo
CT OT capacit´a massima totale dell’ interfaccia radio
Cres(t) porzione di capacit´a usata al frame t-esimo
da considerare allocate anche al frame (t+1)-esimo
Creq(t) capacit´a totale richiesta dal PS al RRA
nel frame t-esimo
Call(t) capacit´a allocata durante il t-esimo frame
in aggiunta alla capacit´a gi´a allocata al frame (t-1)-esimo
Cused(t) capacit´a totale usata durante il frame t-esimo
RRA viene limitata superiormente dal flusso totale cumulato e dalla massima capacit´a totale dell’ interfaccia radio. Perci´o, se ad un frame non risultano esserci pacchetti cumulati, non viene richiesta nessuna capacit´a aggiuntiva dal PS al RRA e per tale frame viene resa possibile la sola trasmissione di richieste residue. Uno sforzo per incrementare la capacit´a viene eseguito nelle linee 8-9, nel caso in cui RRA nel frame precedente sia stato in grado di allocare con successo l’ intera capacit´a richiesta. Al contrario, se nel frame precedente RRA ha allocato una capacit´a minore di quella richiesta dal PS, la capacit´a richiesta dal frame attuale viene settata in modo tale da uguagliare quella utilizzata nel frame precedente.
2.3.5
Allocatore e Scheduler Integrati - IAS
´
E possibile modificare il problema risolto dall’ allocatore rimovendo le indi-cazioni sul rate minimo e massimo di ogni utente ed assegnando un peso alla potenza di trasmissione di ogni utente.
l’ allocatore per ottenere una allocazione di tipo fair. Risulta evidente che questi pesi non possono essere costanti; in generale, se vogliamo ottenere una allocazione fair, quegli utenti che devono essere forzati ad usare una pi´u alta potenza di trasmissione risultano essere penalizzati in termini di risoluzione del problema di ottimizzazione della potenza utilizzata.
Nasce perci´o il bisogno di un blocco funzionale separato, che reagisca al cam-biamento di condizioni del canale modificando dinamicamente i pesi. In ques-ta configurazione lo scheduler deve aggiornare i pesi di controllo, con lo scopo di pilotare l’ allocatore in una allocazione fair delle risorse radio disponibili. Per fare questo deve conoscere la capacit´a allocata ad ogni utente. Tale in-formazione viene fornita dall’ allocatore attraverso una ’allocazione fitizia’, o ’di prova’.
In [9] viene sviluppato un metodo di ’scheduling opportunistico’ su canali multipli di tipo wireless. In tale struttura ogni sottoinsieme di utenti pu´o es-sere selezionato per una trasmissione dati in ogni tempo, sebbene con diversi valori di throughput e di richieste di risorse di sistema.
Seguendo tale approccio, possiamo quanto la porzione della capacit´a di trasmis-sione allocata ad ogni utente diverga dalla porzione rispetto alla quale ogni utenti aveva diritto sulla base dei pesi φi.
Si deve osservare che in questa soluzione l’ allocatore non dipende da una lista di pacchetti inviati dallo scheduler; una volta determinata la capacit´a che deve essere allocata per ogni utente nel frame corrente, accede diretta-mente alle code degli utenti.
In questo algoritmo, i parametri passati dall’ allocatore sono:
• i pesi φi(k), che sono gi´a stati discussi precedentemente e il cui scopo
consiste nel mantenere la fairness fra flussi;
interferenza totale generata da una cella e diretta verso le altre celle ad essa contigue.
2.3.6
Scheduler IAS
Gli algoritmi PS hanno lo scopo di fornire una allocazione della banda a dis-posizione di tipo fair. A causa della natura dei collegamenti wireless, non ´e realistico parlare di fairness in senso stretto. Una miglior soluzione con-siste nel permettere una minima parte di allocazione unfair, tenendo traccia di quanto ogni flussi risulta essere stato allocato per la trasmissione e com-pensando i flussi in accumulo. Lo scopo consiste quindi nell’ ottenere una allocazione di tipo fair su una lunga scala temporale.
Questa idea pu´o essere implementata in diversi modi. Algoritmi basati sui ’contatori di crediti’, come quelli sopra riportati, risultano efficienti in termi-ni di semplicit´a e di onere computazionale.
Lo stato di servizio di ogni flusso viene riassunto tramite un numero intero, il suo valore di ’credito’. Un flusso guadagna crediti quando non viene schedu-lato, mentre un utente guadagna crediti in caso contrario.
Lo scheduler IAS lavora insieme ad un algoritmo di Radio Resource Alloca-tion (RRA). Tale scheduler passa una lista di Cmax pacchetti all’ allocatore,
che sceglie fra essi un numero tale da raggiungere il valore della capacit´a richiesta Creq, avendo indicato con Cmax la capacit´a massima richiesta dall’
intera trasmissione in esame e con Cmin la capacit´a da allocare. Dobbiamo
ricordare che le richieste che da uno scheduler di questo tipo vengono inviate all’ allocatore sono caratterizzate da rmax = 1 e rmin = 0, quindi il valore
di Cmax ´e equivalente, dal punto di vista numerico, al numero di richieste
trasmesse, e Creq al numero di richieste da allocare.
assegnare pi´u risorse a collegamenti che meglio sperimentano le condizioni del canale, integrando le informazioni provenienti dal PHY con le richieste MAC provenienti dallo scheduler, in una implementazione di tipo cross-layer. Viene assunto che ogni PBU possa portare una quantit´a prefissata di bit informativi, anche se lo scheduler ´e in grado di operare con algoritmi di al-locazione di tipo multi-rate. La quanti´a di bit informativi viene presa pari a L, e i frame dei dati codificati vengono segmentati in blocchi lunghi L bit, denominati pacchetti.
Se tutti i frame mostrano lo stesso guadagno di percorso medio, e quindi la stessa potenza di trasmissione, possiamo minimizzare frame per frame la potenza trasmessa. In pratica, diversi flussi presentano diversi guadagni di percorso e per ottenere una allocazione di tipo fair anche i pi´u svantaggiati flussi devono essere abilitati alla trasmissione.
Una semplice politica consiste nel selezionare in ogni frame i flusso che sper-imentano le migliori condizioni di canale rellativamente al loro guadagno medio di percorso, come proposto in []. Questo obiettivo pu´o essere ottenuto definendo una opportuna funzione costo da minimizzare come la somma pe-sata delle potenze di trasmissione, dove i pesi sono rappresentati dai guadagni medi di canale.
Definendo con
Λ ⊆ {1, ..., K} (2.13)
l’ insieme dei flussi i cui pacchetti sono presenti nella lista delle richieste, per ogni k-esimo flusso in Λ RRA pu´o allocare al massimo M(k) PBU, avendo indicato con M(k) il numero di pacchetti relativi al k-esimo flusso presenti nella lista.
Per questo motivo, si ha
rmax = M(k)
Tf
(2.15)
Il fattore di carico della cella in esame, pari a
Creq = Tfrtot (2.16)
viene assunto costante. Nella funzione obiettivo utilizzata dall’ allocatore, la potenza pk,s,t richiesta dal k-esimo utente per trasmettere sulla PBU
individ-uata dalle coordinate (s,t) viene pesata con un coefficiente wk.
L’ algoritmo di allocazione delle risorse seleziona, in una prima fase, chia-mata fase di ’allocazione di prova’, i pacchetti da trasmettere in ogni frame assumendo wk = gk. Dopo aver selezionato i pacchetti idonei alla
trasmis-sione deve essere effettuata una assegnazione ottimale delle PBU, tramite una seconda fase di allocazione, in cui si assume wk = 1. In questa fase il valore
di M(k) viene dato dalle capacit´a assegnate ad ogni flusso secondo la tecnica adottata dall’ allocatore di risoluzione del problema di ottimizzazione. Per ogni flusso viene definito un peso fissato pari a φi ed un contatore di
crediti Ki. All’ inizio di ogni frame viene schedulata una lista di pacchetti
attraverso soluzioni di tentativo. Durante questa fase di scheduling assumi-amo temporaneamente i valori dei crediti pari a K∗
i. I valori dei crediti Ki
dovranno essere aggiornati solo dopo che l’ allocatore avr´a selezionato i pac-chetti che dovranno essere trasmessi nel frame in esame. Lo scopo principale delle simulazioni effettuate con lo scheduler IAS consiste nell’ allocare, in maniera fair, le risorse di trasmissione disponibili in base ai propri pesi. Una importante propriet’i. questo algoritmo di scheduling consiste nel fatto che l’ allocazione fair viene ottenuta indipendentemente dall’ algoritmo utilizzato dall’ allocatore. Di seguito viene assunto un limite di fairness, come proposto in [], che non prende in considerazione la politica di selezione dei creq su cmax
Assumendo t come indice del frame in esame, in modo che il tempo risulti quantizzato in frame, si ha la formulazione del seguente teorema.
Teorema dati due flussi i e j continuamente cumulati su un intervallo [t1, t2),
´e possibile ottenere la seguente relazione:
kRi(t1, t2) φ1 − Rj(t1, t2) φj | ≤ Cmax− Creq+ 1 t2, t1 × (1 φi + 1 φj ) (2.17)
avendo assunto con Ri(t1, t2) il rate di trasmissione medio, espresso in numero
di pacchetto al secondo, conseguito dal flusso i-esimo sull’ intervallo tempo-rale (t1, t2). In questo modo, la discrepanza ’pesata’ fra i rate di trasmissione
di ognuno dei due flussi pu´o risultare arbitrariamente piccolo scegliendo un intervallo temporale sufficientemente lungo.
´
E inoltre possibile mostrare che l’ indice di fairness di Jain, come proposto in [], calcolato per N flussi continuamente cumulati su un intervallo di m frame, risulta esser limitato come di seguito riportato:
F (m) ≥ 1 1 + 2N2 m2 × (CmaxCreq+1 − 1)2 (2.18) m ≥ 2 × (Cmax+ 1 Creq − 1) (2.19)