Descrizione del sistema
In questo capitolo esponiamo le idee seguite nella progettazione e realizzazione di un sistema per la ricerca di risorse in ambiente Grid. Il sistema è composto da un insieme di servizi che consentono ai partecipanti di una Griglia di mettere a disposizione informazioni sulle risorse su cui in seguito effettuare ricerche. Abbiamo scelto volutamente il termine generico “informazioni” in quanto il nostro sistema, per come è stato progettato ed implementato, permette di ricercare ed indicizzare praticamente ogni tipo di informazione.
L’obiettivo del nostro lavoro è principalmente rivolto all’analisi, allo sviluppo e all’integrazione all’interno del GT3 di Globus di un insieme di servizi per collezionare ed indicizzare informazioni sulle risorse presenti nella Griglia. Il sistema da noi sviluppato, infatti, è OGSA-compliant poiché rispetta le convenzioni OGSA e si basa su strumenti e librerie messe a disposizione dal Globus Toolkit. Inoltre, sfruttando e migliorando i meccanismi attualmente implementati dal Monitoring and Discovery Service (MDS) di Globus, consentire un’efficiente ed efficace ricerca di tali informazioni.
Tu non lo udisti e il tempo passava con le stagioni al passo di java ed arrivasti a varcar la frontiera in un bel giorno di primavera.
Capitolo 4 4.1 Strumenti utilizzati
Dopo la descrizione degli strumenti usati per lo sviluppo del progetto, descriveremo le principali caratteristiche dello MDS evidenziandone alcuni limiti dovuti soprattutto alla sua struttura gerarchica e mostrando come il modello Peer-to-Peer (P2P) sia probabilmente più adatto a questo tipo di applicazioni.
4.1 Strumenti utilizzati
In questa sezione daremo una breve descrizione degli strumenti utilizzati.
• Il sistema operativo Linux (distribuzioni Redhat e Mandrake) come
piattaforma software: si tratta di un sistema operativo molto potente e versatile, soprattutto per lo sviluppo di applicazioni server. Inoltre, siccome è un sistema open source, è liberamente disponibile in rete.
• Globus toolkit (versione 3.0.2): comprende una serie di componenti per
sviluppare infrastrutture e applicazioni Grid. Si sta imponendo come standard de facto per ambienti Grid.
• Java (versione 1.4.1) come linguaggio di programmazione: Java è un
linguaggio di programmazione multi-threaded, completamente orientato agli oggetti e, caratteristica molto importante, indipendente dalla piattaforma. Inoltre, il core di Globus Toolkit 3.0.2 è stato sviluppato quasi interamente in java.
• Jakarta ant (versione 1.5.3): è un progetto di Apache Software Foundation.
Simile al classico comando make, permette di ottenere in un unico passo la compilazione ed il deploy del servizio a partire dai file sorgenti.
• Le API di Axis (Axis.jar) per la codifica dei messaggi SOAP. SOAP è un
protocollo middleware che permette di fare chiamate RPC attraverso messaggi in formato XML trasportati su internet via HTTP riuscendo in questo modo a passare senza problemi attraverso i firewall.
• XML come linguaggio per la comunicazione dei dati: questa scelta si
per il quale esistono un gran numero di strumenti per il trattamento dei documenti xml. Utilizzare XML per la comunicazione dei dati, consente inoltre di poter in futuro pubblicare delle DTD, o altri formalismi, per l’interazione di altri sistemi e/o applicazioni con quello del progetto.
• Le API DOM (Document Object Model) del W3C (xml-apis-1.1.jar) per il
trattamento dei file XML: semplici e versatili, consentono di fare il parsing di oggetti XML ottenendo i relativi DOM. Benché occupano più memoria rispetto alle SAX (Simple Api for Xml parsing) e quindi risultano più lente, sono meno complesse, facili da usare e mantenibili di quest’ultime.
4.2 I limiti dello MDS
MDS è il servizio di informazione di Globus; esso fornisce un framework per gestire informazioni statiche e dinamiche sui componenti delle Griglie costruite usando GT3. La principale caratteristica introdotta in GT3 è rappresentata dal fatto che ogni entità viene rappresentata come un Grid Service. Quest’ultimo rappresenta un’estensione di un Web Service(1) che rispetta un insieme di convenzioni (interfacce e comportamenti).
I Grid Service esprimono il loro stato in un modo standardizzato che è quello dei Service Data (SD). Questi ultimi non sono altro che una collezione strutturata di informazioni associate ad un Grid Service. Tali informazioni sono facilmente interrogabili cosicché i Grid Service possono essere classificati e indicizzati in accordo alle loro caratteristiche. MDS deve, quindi, fornire le funzionalità per indicizzare, ricercare e interrogare gli SD. Queste funzionalità all’interno dello MDS sono svolte dallo Index Service. Prima di analizzare la struttura dello Index Service, cerchiamo di capirne il funzionamento con l’aiuto della seguente figura.
Capitolo 4 4.2 I limiti dello MDS
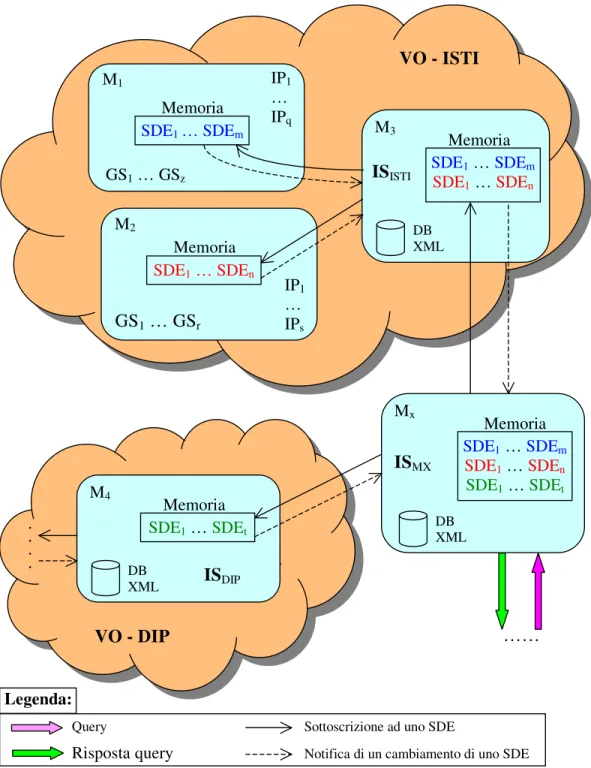
Figura 4.1: gerarchia di Index Service.
Su ognuna delle macchine M1 e M2, appartenenti alla VO (Virtual Organization)
ISTI, vi sono un insieme di Grid Service che generano dei Service Data Element (SDE). Lo Index Service della VO ISTI (ISISTI), installato sulla macchina M3, per
Memoria M3 SDE1 … SDEm SDE1 … SDEn ISISTI DB XML Memoria M4 ISDIP DB XML SDE1 … SDEt Memoria Mx SDE1 … SDEm SDE1 … SDEn SDE1 … SDEt DB XML ISMX M2 Memoria IP1 … IPs SDE1 … SDEn GS1 … GSr M1 Memoria IP1 … IPq GS1 … GSz SDE1 … SDEm …… . . . . VO - ISTI VO - DIP
Query Sottoscrizione ad uno SDE
Risposta query Notifica di un cambiamento di uno SDE
collezionare ed indicizzare tutti i Service Data Element di M1 e M2, deve
sottoscriversi ad ognuno di essi. Le frecce ‘singole e continue’ che, in figura 4.1 collegano M3 con M1 e M2, rappresentano le operazioni di sottoscrizione. A
questo punto, ogni modifica del valore di uno qualsiasi degli SDE di M1 o di M2,
comporta la notifica del cambiamento di valore, di quello SDE, allo ISISTI.
Quest’ultimo, tutte le volte che riceverà una notifica di cambiamento di uno SDE al quale è sottoscritto, effettuerà una copia dello SDE. Inoltre, al fine di rendere gli SDE persistenti vengono anche memorizzati in un database XML. Lo IS della VO DIP (ISDIP), al fine di collezionare ed indicizzare tutti gli SDE della propria
VO, avrà un comportamento analogo a quello appena descritto, sottoscrivendosi a tutti gli SDE presenti sulle macchine (non rappresentate in figura) della propria VO. Infine lo Index Service della macchina Mx (ISMX), per aggregare gli SDE di
entrambe le VO, ISTI e DIP, si sottoscrive a tutti gli SDE dello ISISTI e dello
ISDIP, creando una struttura gerarchica di Index Service. Le notifiche di
cambiamento di uno SDE effettuate allo ISMX sono una diretta conseguenza delle
notifiche effettuate sia allo ISISTI che allo ISDIP. Ad esempio, se il valore di uno
SDE presente sulla macchina M1 viene modificato, verrà inviato un messaggio di
notifica allo ISISTI che a sua volta invierà un messaggio di notifica allo ISMX.
Gli Index Service ISISTI, ISDIP ed ISMX, come è rappresentato anche in figura 4.1,
sono sottoscritti ad un insieme di Service Data Element. In che modo, però, uno Index Service viene a conoscenza dei Service Data Element ai quali sottoscriversi? Ovvero, in che modo viene effettuata la pubblicazione di un nuovo SDE? Attraverso il proprio file di configurazione oppure tramite l’operazione addSubscription appartenente all’interfaccia del servizio. Consideriamo i due casi separatamente.
Nel primo caso le informazioni sul Service Data dovranno essere inserite manualmente nel file di configurazione dello Index Service. Quindi, in fase di
Capitolo 4 4.2 I limiti dello MDS
attivazione lo Index Service recupererà, dal file di configurazione, la lista dei Service Data, sottoscrivendosi ad ognuno di essi.
Nel secondo caso, invece, è l’utente che segnala a runtime a quali SDE lo Index Service deve sottoscriversi. Ciò viene fatto invocando il metodo addSubscription appartenente all’interfaccia dello Index Service stesso. Questa metodo però non ha l’effetto di rendere permanente una sottoscrizione poiché non va a modificare il file di configurazione del servizio.
Consideriamo adesso la struttura dello Index Service che è formato da:
• un meccanismo Provider per la generazione di nuovi SD attraverso
programmi esterni. Questi programmi sono implementati in java o tramite degli script. Alcuni di tali programmi sono forniti come parte dello MDS mentre altri possono essere creati dall’utente per generare ulteriori informazioni. Quelli forniti di default dallo MDS generano informazioni su processore, memoria, sistema operativo e file system.
• un meccanismo Aggregator per l’aggregazione e l’indicizzazione degli SD
provenienti da altri Grid Service.
I principali limiti dello MDS, a nostra avviso, nascono proprio dalla sua struttura gerarchica:
1) la pubblicazione di un nuovo SD, nelle due modalità viste precedentemente, non ha l’effetto di propagarsi ai livelli superiori della gerarchia. Si manifesta, quindi, l’impossibilità dello Index Service a scoprire in modo dinamico nuove risorse, caratteristica molto importante per i servizi di informazione.
2) Al crescere della dimensione delle VO, il numero di Service Data che gli Index Service ai livelli alti della gerarchia devono contenere potrebbe
essere molto grande. Questo meccanismo può far sì che tali Index Service possono diventare potenziali colli di bottiglia, degradando le prestazioni generali del sistema.
I modelli gerarchici e centralizzati, quindi, sono inadatti a supportare applicazioni che vivono in ambienti fortemente distribuiti. Tali ambienti, caratterizzati soprattutto da una grande eterogeneità dei nodi e dalla dinamicità con cui i nodi si collegano o escono dal sistema, hanno favorito la crescita di un nuovo modello di progettazione: le reti Peer-to-Peer (P2P) [Min].
4.3 Verso una sinergia tra P2P e Griglie
Nonostante il grande interesse verso le tecnologie P2P e Grid pochi sono stati gli sforzi dei ricercatori per cercare una sinergia tra queste tecnologie. Eppure sia le reti P2P che le Griglie sono modelli di calcolo distribuito che abilitano la collaborazione decentralizzata integrando computer in reti nelle quali ognuno può usare o offrire dei servizi.
Entrambe le tecnologie risultano poter essere sfruttate per sviluppare sistemi distribuiti e applicazioni efficienti. Diversamente dai classici modelli client-server, nei quali i ruoli sono ben separati, le reti P2P e Grid possono assegnare ad ogni nodo il ruolo client o server in accordo alle operazioni che loro stanno eseguendo.
Analizzando entrambi i modelli, si intuisce che le Griglie sono, in essenza, sistemi P2P [Syn]. Sebbene molti aspetti delle Griglie attuali sono basati su servizi gerarchici, questi sono aspetti implementativi che potrebbero essere rimossi nel prossimo futuro. Quando le Griglie usate per applicazioni complesse cresceranno da decine a centinaia di nodi, per evitare colli di bottiglia, alcune
Capitolo 4 4.3 Verso una sinergia tra P2P e Griglie
comunità e quindi lo sfruttamento continuato delle due tecnologie dovrebbe portare a soluzioni efficienti per gli ambienti Grid.
Un primo passo verso questa direzione è stata fatta da Geoffrey Fox e alcuni suoi colleghi introducendo una architettura P2P [web1] per connettere risorse di Griglia, tuttavia molto rimane da fare dalle due comunità.
In [Syn], due ricercatori dell’Università della Calabria sottolineano l’importanza del ruolo che potrebbe avere OGSA in tutto ciò. Così come OGSA definisce il concetto di Grid Service usando i principi e le tecnologie di entrambe le comunità Grid e Web Service, così potrebbe fornire una opportunità per integrare P2P e Grid. A loro avviso un middleware “P2P-Grid” potrebbe essere di aiuto agli sviluppatori per costruire applicazioni Grid basate sul modello P2P.
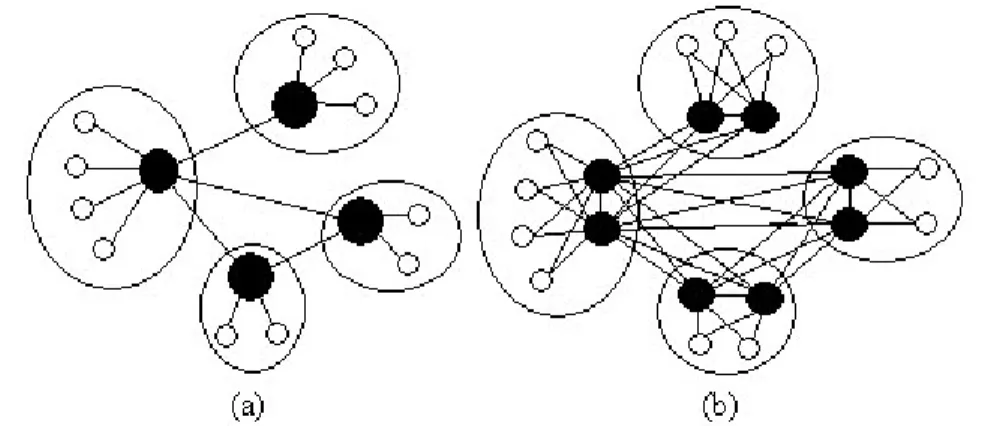
Nella loro visione almeno due componenti del nucleo del Globus Toolkit: MDS e Replica Management Service, potrebbero essere progettate usando un approccio P2P. Secondo gli autori, considerando che le Griglie attuali potrebbero essere viste come federazioni di tante piccole Griglie (figura 4.2) ognuna gestita da una organizzazione (VO) diversa, si potrebbe pensare di adottare per MDS Globus un modello di rete detto super-peer. In questo modello alcuni nodi detti super-peer si comportano, anche temporaneamente, da server. In effetti alcuni studi [Rip, Rit] hanno dimostrato che ambienti decentralizzati sprecano gran parte della banda utile in funzioni che potrebbero essere centralizzate in server di cache. Questa topologia fornisce un utile bilanciamento tra efficienza e autonomia della ricerca centralizzata e bilanciamento del carico e robustezza della ricerca decentralizzata. Nel progettare la nostra architettura prendiamo spunto dal modello dei super peer. Inoltre, per diminuire alcuni svantaggi intrinseci delle reti P2P abbiamo usato tecniche di Routing Indices (RI) [CM] e ridondanza dei super peer [YM].
Gli RI permettono di inoltrare le query ai nodi “vicini” che più probabilmente avranno la possibilità di rispondere evitando così problemi di flooding della rete. Mentre replicando i super peer si evitano i problemi dovuti al singolo “point of failure” e al potenziale “collo di bottiglia”.
4.4 Architettura del sistema realizzato
Una rete super peer opera esattamente come una rete P2P pura, eccetto che alcuni nodi fungono da server centrale e sono connessi ad un sottoinsieme di client. I client a loro volta sono connessi esattamente ad un singolo super peer nella rete senza ridondanza e a due super peer nella rete con ridondanza due. Della ridondanza parleremo nel paragrafo 4.4.2.5. La figura 4.2 illustra la topologia di una rete super peer. L’insieme dei super peer e dei suoi client viene chiamato cluster, precedentemente denominato organizzazione.
Figura 4.2: illustrazione di una rete super peer senza ridondanza (a), con ridondanza 2 (b). I nodi in nero rappresentano i super peer mentre i nodi bianchi rappresentano i client. I cluster sono delineati dalle linee circolari.
Quando un utente decide di sottomettere una query, questa viene sottomessa solo al super peer (nodi in nero) del suo cluster. Tale super peer oltre a valutare localmente la query la sottomette ai propri vicini, e inoltre la processa per conto dei suoi client piuttosto che inoltrarla a essi. A tale scopo, un super peer mantiene sia i dati pubblicati dai client che un indice su tali dati per effettuare la ricerca in
Capitolo 4 4.4 Architettura del sistema realizzato
modo più efficiente. I dati sono nella forma di Service Data e vengono indicizzati attraverso alcune parole chiave che danno un’indicazione delle informazioni contenute. Le query sono formulate usando tali parole chiave.
Affinché i super peer mantengono l’indice sui dati, i client che si collegano al sistema all’atto della pubblicazione di un dato forniscono una lista di parole chiave sulle quali indicizzare tale dato. Inoltre, viene fatta una distinzione tra quando un client cancella un dato e quando lascia il sistema. Nel primo caso, i dati pubblicati da un client vengono cancellati come richiesto. Nel secondo caso, invece, in mancanza di una richiesta esplicita di cancellazione, i dati vengono conservati. Questo perché la Griglia è nata come infrastruttura di calcolo e molti dei dati pubblicati sono inerenti a risorse fisiche. Quindi, in base a ciò, la scelta è stata quella di continuare a rendere disponibili tali dati, lasciando il compito di controllare a chi intende usare tali risorse se esse sono disponibili, ossia se fanno ancora parte della Griglia.
Il nostro sistema può anche essere visto, secondo una visione web, come un motore di ricerca ibrido; in tali sistemi i dati vengono inseriti sia manualmente dall’utente, fornendone una breve descrizione, sia da programmi, detti crawler, che esplorano il web. I super peer analogamente ai motori di ricerca indicizzano i documenti, mentre i client analogamente ai crawler dopo una descrizione iniziale delle risorse da parte dell’utente hanno il compito di mantenere i dati aggiornati interrogandoli periodicamente. Inoltre, anche il mantenimento e la cancellazione dei dati, nel nostro sistema sono realizzati in modo analogo a quanto accade nei motori di ricerca. Nei motori di ricerca è il proprietario dei documenti che decide se e quando pubblicarli o cancellarli. Infatti, in quelli basati su directory le due operazioni sono eseguite in modo diretto dal proprietario, mentre in quelli basati su crawler, il proprietario specifica attraverso speciali metatag se possono essere indicizzate.
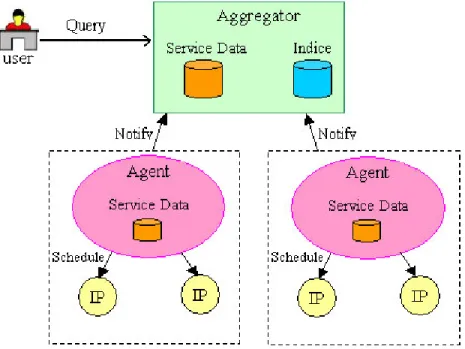
L’architettura da noi proposta è composta da due entità, esse sono:
• Agent: è la parte client del sistema. Tale programma è eseguito su ogni
macchina della Griglia occupandosi di generare le informazioni sulle risorse, sotto forma di Service Data (SD). Tali informazioni verranno gestite dallo Aggregator,
• Aggregator: è la parte server del sistema, detto anche super peer. Questo
modulo opera come server centrale all’interno della Griglia mantenendo le informazioni pubblicate dai propri client. Inoltre, contiene un indice delle risorse contenute negli altri super peer che viene usato per instradare le query verso i nodi che più probabilmente avranno la possibilità di rispondere alle query.
Capitolo 4 4.4 Architettura del sistema realizzato
4.4.1 Il servizio Agent
Lo Agent è un Grid Service locale ad ogni macchina della Griglia. È inoltre la parte client del sistema e si occupa di generare le informazioni che verranno mantenute dagli Aggregator. Tali informazioni sono generate con l’ausilio di speciali programmi java detti Information Provider (IP) che interrogano la risorsa generando le informazioni e memorizzandole in uno stile coerente con le convenzioni OGSA: i Service Data.
4.4.1.1 Gli Information Provider
Un IP è un programma java che interroga periodicamente una risorsa e memorizza, sotto forma di Service Data per conto dello Agent, le informazioni recuperate. Per risorse intendiamo sia risorse fisiche, ossia risorse computazionali, ma anche applicazioni, ossia in generale componenti software e infine documenti di testo, multimediali e così via. Lo scopo degli IP è di generare informazioni che descrivono le risorse in modo da poter essere indicizzate in accordo alle loro caratteristiche.
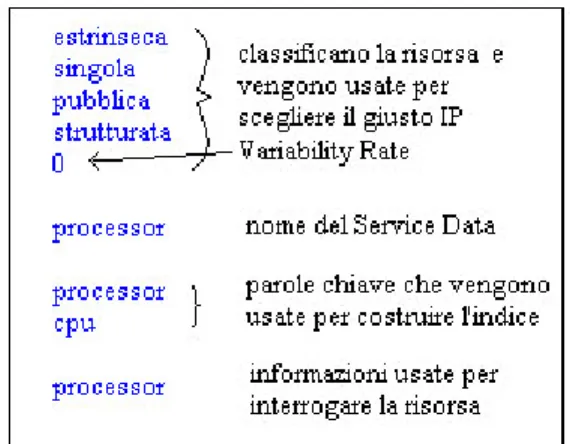
Le caratteristiche di una risorsa sono date in base alla tassonomia sviluppata nel capitolo precedente; dunque non esiste un unico IP ma uno per ogni possibile tipo di risorsa. La scelta dello IP giusto, che più si adatta ad interrogare una particolare risorsa, viene perciò fatta in base alla sua classificazione. All’atto della pubblicazione di un dato l’utente fornisce al sistema un file di testo chiamato descrittore di risorsa che contiene appunto la descrizione della risorsa fatta usando gli attributi della tassonomia. Il Variability Rate indica ogni quanto tempo, espresso in secondi, aggiornare le informazioni. Se il suo valore è zero significa che la risorsa, così come indicato da un attributo della tassonomia, è statica cioè le informazioni che la descrivono non cambiano con il tempo. Un esempio di descrittore di risorsa è rappresentato in figura 4.4.
Figura 4.4: esempio di descrittore della risorsa processore.
L’interrogazione di una risorsa da parte dello IP avviene attraverso le informazioni contenute nell’ultima sezione del descrittore, per esempio per una risorsa strutturata potrebbe contenere una lista di coppie <nome, valore>. Il nome rappresenta una caratteristica della risorsa, ad esempio la frequenza, e il valore il metodo usato per ottenerla. Oppure, può essere usato un ulteriore programma o come in questo caso uno script linux che schedulato dallo IP restituisce le informazioni sulla risorsa.
Figura 4.5: esempio di rappresentazione della risorsa processore.
Una volta recuperate queste informazioni, lo IP le memorizza come SD in Agent. Inoltre, quest’ultima soluzione è molto utile quando un utente vuole fornire un IP alternativo, ad esempio quando vuole pubblicare informazioni frutto di speciali ricerche in un database.
Capitolo 4 4.4 Architettura del sistema realizzato
Nello Service Data vengono memorizzate, inoltre, ulteriori informazioni utili a chi sottomette una query. Tali informazioni sono lo “Originator”, ossia lo Agent che lo ha generato, la data di creazione e la data di scadenza. Quest’ultima data non sta ad intendere che al suo raggiungimento lo SD verrà cancellato ma bensì aggiornato.
Figura 4.6: i Service Data delle risorse processore e memoria visualizzate tramite il Service Data Browser di Globus.
Il descrittore della risorsa contiene ulteriori informazioni tra cui il nome del service data da associare alla risorsa e una serie di parole chiave. Quest’ultime, analogamente ai METATAG dei documenti ipertestuali, danno una indicazione delle informazioni contenute dal Service Data e vengono usate dallo Aggregator per costruire l’indice locale su cui vengono valutate le query.
4.4.1.2 Pubblicazione e rimozione di una risorsa
Durante la fase di pubblicazione della risorsa lo Agent invia a tutti gli Aggregator del proprio cluster il nome del Service Data, cosicché gli Aggregator potranno sottoscriversi ad esso e, quindi, ricevere le notifiche di cambiamento. Per evitare che gli Aggregator interroghino periodicamente gli Agent sui cambiamenti avvenuti, abbiamo scelto l’approccio push [OGSA]. In tale approccio è lo Agent
che avvisa gli Aggregator dell’avvenuta modifica, fornendo inoltre il service data modificato.
Dopo la sua pubblicazione, il dato potrà essere eventualmente eliminato. L’operazione di cancellazione consiste nella eliminazione del Service Data corrispondente, ciò avviene informando gli Aggregator che provvederanno, inoltre, alla sua rimozione dall’indice.
Sia l’operazione di pubblicazione che di eliminazione di un dato può essere svolta, a runtime, dall’utente con l’ausilio di due programmi java: Publish_IP e Remove_IP.
Per evitare che tutte le volte che il sistema venga riavviato occorra l’intervento umano per pubblicare le risorse il sistema scrive nel file (agent-service-config.xml) tutte le risorse pubblicate . Un esempio è raffigurato nella figura 4.7.
Figura 4.7: esempio di file di configurazione.
In questo file di configurazione sono registrate tutte le informazioni necessarie allo Agent per generare i Service Data evitando di dover rileggere i descrittori delle risorse. Di default tale file si trova nella directory “etc” contenuta nella directory di installazione di Globus; tuttavia tale file può essere spostato modificando il parametro “serviceConfig” del descrittore del servizio:
Capitolo 4 4.4 Architettura del sistema realizzato
<parameter name="serviceConfig" value="etc/agent-service-config.xml"/>. 4.4.2 Il servizio Aggregator
Lo Aggregator è un Grid Service che gestisce i Service Data (SD) della propria organizzazione. Viene detto super peer poiché ha funzionalità tipiche di un server, infatti funge da server centrale all’interno della propria organizzazione e mantiene un indice sugli SD presenti negli Aggregator “vicini”(2). Tali indici,
detti Routing Indices, permettono di inoltrare una query ai nodi vicini che hanno maggiori probabilità di soddisfare la query stessa. Vedremo successivamente come selezionare questi nodi.
4.4.2.1 I Routing Indices
L’obiettivo del Routing Indices (RI) è quello di selezionare il “miglior” vicino al quale inoltrare una query. Uno RI è una struttura dati che permette di calcolare la “probabilità” con la quale un determinato vicino può soddisfare una certa query. Nel calcolare questa “probabilità” si considera il numero dei documenti nei nodi vicini. Lo Hop Count Routing Indices (HRI) è un particolare Routing Indices nel quale la scelta del vicino a cui inoltrare la query viene presa considerando, oltre al numero dei documenti nei nodi vicini, anche il “numero dei salti” (hop count) necessari per raggiungere tali documenti. Dato un cammino tra due nodi A e B, il numero dei salti tra A e B è definito come il numero di archi lungo tale cammino. Quindi se A e B sono separati da un salto, cioè è necessario un messaggio da A per accedere i documenti di B e viceversa, allora A e B sono vicini. Nello HRI vengono memorizzati il numero di documenti raggiungibili ad ogni salto, fino ad un massimo numero di salti, chiamato orizzonte dello RI. I documenti ad ogni nodo sono suddivisi logicamente in classi rispetto al tipo di informazioni fornite; queste classi sono poi rappresentate con una parola chiave.
Lo HRI può essere visto, intuitivamente, come una tabella formata da M righe e N colonne, dove M è il numero dei vicini e N coincide con l’orizzonte dello HRI. Quindi un vicino viene identificato con un numero di riga. Nel seguito, con il termine tabella di routing si indicherà lo HRI presente ad un nodo. Si consideri la k-esima riga (k < M) della tabella di routing. L’i-esima colonna di questa riga, con i N, contiene una particolare tabella con una sola riga. Questa tabella (riferita nel seguito con il termine “indice di routing”) contiene nella prima colonna il numero totale di documenti raggiungibili, tramite il vicino ‘k’, con ‘i’ salti e nelle colonne successive, per ogni classe individuata da ‘k’, il numero dei documenti appartenenti a quella classe. Per chiarire meglio la struttura dello HRI si consideri la seguente figura.
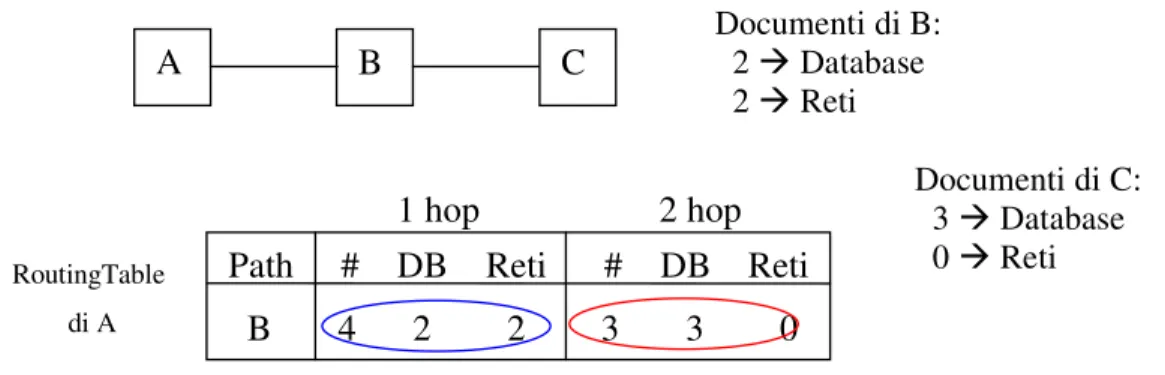
Figura 4.8: esempio di Hop Count Routing Indices con orizzonte uguale a 2.
Si supponga di avere una configurazione simile a quella della figura 4.8, con i nodi B e C che hanno due classi di documenti: database e reti. Il nodo B ha 4 documenti (2 contenenti informazioni su database e 2 contenenti informazioni sulle reti) e il nodo C ha 3 documenti (3 contenenti informazioni su database e 0 contenenti informazioni sulle reti). Si supponga, inoltre, che l’orizzonte sia 2. Secondo quanto detto in precedenza, la tabella di routing di A è formata da una sola riga, poiché A ha un solo vicino, e da due colonne(3) poiché l’orizzonte è
Documenti di B: 2 Database 2 Reti Documenti di C: 3 Database 0 Reti B C A RoutingTable di A 1 hop 2 hop Path # DB Reti # DB Reti B 4 2 2 3 3 0
Capitolo 4 4.4 Architettura del sistema realizzato
uguale a due (in base alla supposizione effettuata). Si consideri il contenuto dell’unica riga della tabella di routing:
la prima colonna contiene l’indice di routing contenente informazioni sui documenti posseduti da B e raggiungibili, da A, mediante un salto. L’indice di routing relativo ad un salto (vedi cerchio blu in figura 4.8) contiene, in sequenza, il numero totale dei documenti di B, ossia quattro, e per ogni classe il numero dei documenti relativi, ovvero due documenti su database e due documenti sulle reti.
la seconda colonna contiene l’indice di routing (vedi cerchio rosso in figura 4.8) contenente informazioni sui documenti posseduti da C e raggiungibili, da A, mediante due salti. La sua struttura è simile a quella dell’indice di routing, relativo ad un salto, descritto al punto precedente. Per decidere quale sia il miglior vicino al quale inoltrare la query è necessario un modello dei costi per calcolare la “bontà” di ogni vicino. Ad esempio, se al nodo B (in figura 4.9) viene fatta una query sui documenti inerenti i “database”, sembrerebbe, considerando solo i documenti raggiungibili con un salto, che il miglior vicino fosse D, mentre proseguendo per A si raggiungerebbero più documenti.
Quindi, se si definisce il costo in termini del numero di messaggi, allora la bontà del vicino sarà data dal rapporto tra il numero di documenti disponibili attraverso quel vicino e il numero di messaggi richiesti per accedere i documenti stessi. Un semplice modello [GMT, GMT+] che permette di calcolare questo rapporto si basa su due assunzioni: la prima è che i documenti risultano uniformemente distribuiti sulla rete, e la seconda che la rete è rappresentabile come un albero regolare con ramificazione F. Sotto queste assunzioni e considerando che la
radice di un albero è al livello zero e che un salto corrisponde ad un livello dell’albero, è necessario un messaggio per accedere i documenti presenti alla radice dell’albero (livello 0), 1+F messaggi per accedere i documenti presenti nei primi due livelli, 1+F+F2 messaggi per accedere i documenti presenti nei primi tre livelli e così via.
Sia h l’orizzonte; si definisce la bontà dello HRI (goodnesshc) di un vicino i
(Neighbori) rispetto ad una query Q come:
dove
In quest’ultima formula, ‘NumeroDocumenti’ rappresenta il numero totale dei documenti disponibili localmente al vicino ‘i’.
Prima di chiarire il significato di Ni[j][k], è necessario premettere che una query
Q è formata dalla congiunzione di un insieme di parole ‘chiave’. Nell’esempio di figura 4.8 si era supposto l’esistenza di due classi di documenti (database e reti). Tipi di query relative a quell’esempio potrebbero essere le seguenti:
q1 = database q2 = reti q3 = database reti
Il significato del termine Ni[j][k] è il seguente:
goodness(Ni[j], Q) F j-1 j = 1 h goodnesshc (Neighbori , Q) = goodness (Ni[j], Q) = NumeroDocumenti x Ni[j][k] NumeroDocumenti k Q
Capitolo 4 4.4 Architettura del sistema realizzato
Ni è l’i-esima riga della tabella di routing; il nome del vicino è identificato
con l’indice ‘i’,
Ni[j] è l’indice di routing in corrispondenza della j-esima colonna della
riga Ni; l’indice di routing, come detto in precedenza, è una tabella
formata da una sola riga,
k rappresenta una parola chiave appartenente alla query Q,
Ni[j][k], quindi, è il valore in corrispondenza della colonna relativa a k
dell’indice di routing Ni[j].
Segue un esempio che illustra il modo in cui è calcolata la bontà di un vicino. La figura 4.9 mostra un insieme di nodi (A, B, C, D) e la tabella di routing di B. Si supponga che venga sottomessa a B la query ‘Q = DB’ (vedi figura 4.9) e si calcoli la bontà dei vicini A e D rispetto a tale query assumendo F = 2. Nel fare ciò deve essere considerata la tabella di routing di B mostrata nella seguente figura.
Figura 4.9: esempio di tabella di routing. In figura sono anche evidenziati i valori dei termini descritti precedentemente per spiegare come ottenere Ni[j][k]. In particolare, per i = j = 1 e per k=’DB’ si ha N1 rappresentato dal cerchio rosso, N1[1] rappresentato dal cerchio blu e N1[1][DB] rappresentato dal cerchio verde.
La bontà del nodo A è
Tabella di routing di B
1 hop 2 hop Path # DB Reti # DB Reti A 5 1 4 8 6 2 D 3 3 0 0 0 0
A C
B
goodnesshc (A, Q) = ( 5 x 15 ) + ( 8 x
8
6 ) / 2 = 4 mentre la bontà del nodo D è
goodnesshc (D, Q) = ( 3 x 33 ) = 3.
Quindi, il “miglior” vicino del nodo B, relativamente alla query Q, è rappresentato dal nodo A.
4.4.2.2 Aggiornare un Hop Count Routing Indices
Poniamo adesso la nostra attenzione su come venga aggiornato uno HRI. Supponiamo, quindi, che lo stato iniziale del sistema sia quello mostrato in figura 4.10(a) e che il nodo C, come rappresentato dalla freccia tratteggiata in figura, non faccia ancora parte del sistema. Analizziamo cosa succede quando il nodo C entra a far parte del sistema dopo aver deciso che B è il suo vicino. Non avendo altri vicini, il nodo C invia a B il proprio indice sui documenti locali, mentre, il nodo B calcola l’indice aggregato(4) ed invia quest’ultimo a C. Questo indice è ottenuto nel seguente modo: innanzi tutto si sommano i valori sulle colonne della tabella di routing senza considerare la riga relativa al vicino al quale deve essere inviato l’indice aggregato; successivamente, le colonne della riga risultante dalla somma si spostano a destra di un salto, cosicché la prima colonna della riga diventa la seconda, la seconda diventa la terza e così via, fino ad eliminare l’ultima colonna. In questo modo la prima colonna della riga è vuota e inserendo l’indice locale dei documenti in questa colonna si ottiene l’indice aggregato. Il nodo B, come raffigurato in figura 4.10(b), una volta ricevuto l’indice di C, modifica la sua tabella di routing, andando ad inserire (o sostituire se già presente) la riga relativa al vicino C. Successivamente, per ogni vicino diverso da
Capitolo 4 4.4 Architettura del sistema realizzato
C, ovvero quello dal quale ha ricevuto l’indice aggregato, calcola il nuovo indice aggregato e invia quest’ultimo a quel vicino.
Figura 4.10: esempio di aggiornamento di uno Hop Count Routing Indices.
Il comportamento appena descritto può provocare degli effetti indesiderati in presenza di cicli. Supponiamo, infatti, considerando la figura 4.10(b), che esista un arco che colleghi A con C. L’aggiunta di un nuovo documento in A, in B o in C, darebbe il via ad un continuo invio di indici aggregati tra i nodi che formano il ciclo rendendo inconsistenti i valori delle tabelle di routing. Sebbene vi siano molte soluzioni sia per evitare che per individuare i cicli una volta formati, la soluzione usata, descritta in [CM], consiste nell’accettare l’esistenza dei cicli stessi limitando però gli effetti che possono produrre. Gli effetti negativi dei cicli vengono limitati stabilendo la seguente condizione: il numero di propagazioni di un indice aggregato non può essere maggiore dell’orizzonte. In questo modo, un ciclo la cui lunghezza è superiore all’orizzonte non ha effetti negativi sui valori delle tabelle di routing. In caso contrario (ovvero la lunghezza del ciclo è inferiore all’orizzonte), gli effetti negativi che il ciclo ha sui valori delle tabelle di routing possono essere definiti “accettabili” rispetto al caso precedente dove non vi era una limitazione sul numero di propagazioni dell’indice aggregato.
I sistemi P2P hanno avuto un grande crescita negli ultimi anni. Un nodo appartenente ad un sistema P2P può direttamente scambiarsi informazioni con un qualsiasi altro nodo del sistema. Questi sistemi rappresentano una enorme ricchezza di informazione permettendo agli utenti di scambiarsi liberamente documenti (Freenet [web2]), file musicali (Napster [web3], Gnutella [web4]) e cicli di calcolo (Seti-at-Home [S@H], FightAIDS-at-Home [FA@H]). Una parte chiave del sistema P2P è la scoperta dei documenti.
Esistono molti meccanismi di ricerca di informazioni per sistemi P2P, ognuno con i propri vantaggi e svantaggi. Tali soluzioni possono essere classificate in tre ampie categorie: soluzioni senza indici, soluzioni con indici centralizzati e soluzioni con indici distribuiti.
• Gnutella usa un meccanismo dove i nodi non hanno un indice e le query sono propagate da un nodo ad un altro finché i documenti desiderati non sono stati trovati. Sebbene questo approccio sia semplice e robusto ha lo svantaggio di causare il flooding della rete (o di un suo sottoinsieme) per ogni query generata.
• Un sistema di ricerca centralizzato usa dei nodi specializzati che mantengono un indice dei documenti disponibili nel sistema P2P. Per cercare un documento gli utenti interrogano un nodo indice per identificare i nodi che contengono il documento desiderato. Questi indici centrali possono essere costruiti con la cooperazione degli altri nodi (ad esempio i nodi di Napster forniscono una lista dei documenti disponibili in un certo momento) o attraverso il crawling della rete P2P (come nei motori di ricerca). Il vantaggio dei meccanismi di ricerca centralizzati è sicuramente l’efficienza, basta un messaggio per rispondere ad una query, mentre lo svantaggio è la vulnerabilità, per esempio dovuta ad attacchi da parte di
Capitolo 4 4.4 Architettura del sistema realizzato
hacker.
• Un meccanismo con indici distribuiti mantiene un indice ad ogni nodo. Poiché l’indice ad ogni nodo può essere soggetto a frequenti modifiche, è necessario che questo abbia dimensioni ridotte; quindi invece di usare un indice tradizionale che contenga la locazione dei documenti desiderati, viene usato un Routing Indices tramite il quale viene selezionato il “miglior” vicino al quale inoltrare una query, fornendo, in un certo senso, una direzione verso il documento piuttosto che la sua attuale locazione.
4.4.2.4 Il processo di query
Un sistema P2P è formato da un ampio numero di nodi. Ciascun nodo può unirsi al sistema, o lasciarlo, in qualsiasi momento. Ogni nodo è connesso ad un certo numero di vicini che a loro volta sono connessi ad altri nodi.
Figura 4.11: esempio di query.
In figura 4.11, i vicini del nodo A sono i nodi B, C e D. Ci possono essere cicli nel sistema come quello causato dall’arco tra E e G. Ogni nodo ha un database locale che può essere acceduto tramite un indice locale. L’indice locale riceve una query e restituisce il nome degli SD che soddisfano la condizione espressa nella query; infine tramite un accesso per nome vengono prelevati e restituiti gli
In un sistema di ricerca distribuito, gli utenti sottomettono le query ad ogni nodo con una condizione di stop, ad esempio il numero dei risultati desiderati. Nel nostro caso ad ogni query viene associato un tempo dopo il quale non viene più considerata valida. Un nodo che riceve una query, prima controlla se quest’ultima è ancora valida; in tal caso, cerca il miglior vicino a cui inoltrarla. Poi controlla se esistono gli SD che potrebbero soddisfare la query. In questo modo si sovrappone il tempo di ricerca locale con il tempo di comunicazione necessario ad inoltrare la query.
Durante il processo di valutazione di una query un nodo trasforma sotto forma di elementi XML e invia all’applicazione utente gli SD che trova. L’applicazione utente da parte sua rimane in attesa finché non riceve un messaggio vuoto che testimonia la scadenza della query.
Come illustrato in figura 4.8, inizialmente il nodo A riceve una query. Quindi, assumendo, che la condizione di stop non sia stata raggiunta seleziona il nodo D come il migliore dei propri vicini a cui inoltrarla (freccia tratteggiata). A sua volta D processa la query scegliendo il nodo I come il migliore che possa continuare a gestirla. A questo punto, non avendo il nodo I vicini a cui inoltrare la query la restituisce al nodo D che la inoltra al prossimo migliore vicino (J in questo caso).
Un approccio alternativo a quello da noi usato è quello di inoltrate le query in modo parallelo, ossia a più nodi simultaneamente. Nell’esempio precedente, D ha inviato la query ad I, ha atteso i risultati e poi ha inviato la query a J; oppure avrebbe potuto inviare la query ad I e J contemporaneamente. Un approccio parallelo produce un tempo di risposta migliore ma genera un alto traffico e può
Capitolo 4 4.4 Architettura del sistema realizzato
sprecare risorse (ad esempio, se I avesse raggiunto la condizione di stop non sarebbe stato necessario inviare la query a J).
4.4.2.5 K-redundancy
Sebbene i cluster possono essere efficienti un super peer diviene un potenziale singolo punto di fallimento per il suo cluster e un potenziale “collo di bottiglia”. Quando un super peer fallisce o semplicemente lascia il sistema, tutti i client divengono temporaneamente disconnessi fino a quando non riescono a connettersi ad un nuovo super peer. Per fornire affidabilità al cluster e diminuire il carico sui super peer, introduciamo la ridondanza nella progettazione del super peer. Diciamo che un super peer è K-ridondante [YM] se ci sono K nodi che condividono il carico dei super peer, formando un singolo super peer “virtuale”. La figura 4.2(b) illustra una topologia di rete super peer con ridondanza 2. Ogni nodo nel super peer virtuale è un partner con uguali responsabilità: ogni partner è connesso ad ogni client ed ha l’indice completo dei dati dei client. I client inviano le query a ogni partner, ad esempio, in stile round-robin; analogamente, le query provenenti dai vicini sono ugualmente distribuite attraverso i partner. Un super peer k-ridondante è più affidabile rispetto ad un singolo super peer poiché anche quando un partner fallisce gli altri possono continuare ad assistere i client ed i vicini, ad esempio, rispondendo alle query. La probabilità che tutti i partner falliscano, prima che un partner fallito possa essere sostituito, è molto più bassa della probabilità che un singolo super peer fallisca.
Tuttavia, la ridondanza dei super peer comporta un costo. Affinché ogni partner abbia un indice completo con cui rispondere alle query, un client, quando si unisce al sistema, deve inviare dei metadati a ogni partner. Dunque, il costo
più grande rispetto a quando si unisce ad un singolo super peer. Inoltre, i vicini devono essere connessi a ognuno dei partner, cosicché ogni partner possa ricevere i messaggi da ogni vicino. Assumendo che ogni super peer nella rete sia K-ridondante, il numero di connessioni aperte fra i super peer aumenta di un fattore k2.
In base a quanto detto sembrerebbe che la ridondanza dei super peer controbilanci affidabilità e costi. Al crescere di k aumenta l’affidabilità e diminuisce il carico individuale dei super peer per le query ma diminuisce la banda dovuta al crescente numero di connessioni aperte. Tuttavia non c’è un’euristica che ci aiuti a scegliere il numero k ottimale. Quest’ultimo potrebbe essere scelto in seguito a delle prove effettuate con valori arbitrari di K.
Una politica alternativa che ci permetterebbe di diminuire i costi a scapito, però, dell’affidabilità consiste nel suddividere un cluster con k ridondanza in k cluster senza ridondanza. Cosicché, analogamente al caso della k ridondanza, si riduce di un fattore k sia il numero di client per cluster sia il carico individuale dei super peer per le query.
4.5 La scoperta dei super peer
I sistemi distribuiti prevedono una sola tipologia di nodi che, svolgendo sia mansioni da server che da client, vengono chiamati servent. Sistemi di questo tipo dovrebbero saper risolvere diversi problemi, il primo fra tutti è appunto il problema della prima connessione. Sebbene nella architettura da noi proposta c’è una distinzione tra client (Agent) e server (Aggregator) questo problema coinvolge entrambi. Gli Agent, da parte loro, hanno il problema di conoscere gli Aggregator del proprio cluster su cui pubblicare i dati. Mentre, gli Aggregator hanno il triplice problema di trovare i loro simili sia nel proprio cluster sia nei
Capitolo 4 4.6 Prove effettuate
cluster vicini e persino gli Agent precedentemente attivi per ottenere i dati pubblicati.
La nostra soluzione prevede una gerarchia di server, dove al livello più basso abbiamo un server per cluster. Questo nodo mantiene tre liste: la lista degli Aggregator locali al cluster, la lista degli Aggregator vicini e la lista dei dati pubblicati da ogni Agent a cui sottoscriversi.
Ogni qualvolta un nuovo Aggregator viene attivato comunica la sua attivazione e scarica le tre liste, cosicché può sottoscriversi ai dati dei propri Agent, condividere il carico delle query con gli Aggregator nel proprio cluster e inoltrare le query ai vicini. I vicini vengono scelti da una lista mantenuta da un server di livello superiore. Si selezionano gli n nodi più “vicini” in base al tempo di risposta a messaggi di tipo Ping.
4.6 Prove effettuate
In questa sezione sono descritte una serie di prove condotte per la valutazione del sistema proposto. Le prove sono state fatte usando una Grid costituita da pochi PC appartenenti al Dipartimento di Informatica dell’Università di Pisa e all’ISTI (vedi figura 4.12)
Considerando che entrambe le reti sono protette da firewall, per poter effettuare le prove sono state aperte alcune porte su Orione e Rubentino. Quindi, le comunicazioni tra le due organizzazioni dovevano passare attraverso queste due macchine. In tabella 4.1, per ognuna della macchine utilizzate, vengono mostrate le principale caratteristiche hardware/software.
Hostname Sistema Operativo Processore Memoria
orione.di.unipi.it Linux Red Hat 3.2 Kernel 2.4.24
Pentium Celeron
701 MH 512 MB rubentino.isti.cnr.it Linux Mandrake 9.2
Kernel 2.4.22
AMD Athlon
2088 MHz 1 GB barolo.isti.cnr.it Linux Mandrake 9.1
Kernel 2.4.21
2* AMD Athlon
1533 MHz 512 MB novello.isti.cnr.it Linux Mandrake 9.1
Kernel 2.4.21 AMD Athlon 2000 MHz 1 GB tocai.isti.cnr.it Windows 2000 Professional AMD Athlon 900 MHz 512 MB Tabella 4.1: descrizione delle caratteristiche hardware e software dei computer usati per le prove.
Su ogni elaboratore è stato installato il Globus Toolkit (versione 3.0.2) e Java (versione 1.4.1). Nonostante il sistema sia stato scritto e testato in ambiente Linux, si noti come su Tocai, a testimonianza della portabilità del sistema, a differenza degli altri computer è usato Windows. Le uniche difficoltà incontrate nell’uso della piattaforma Windows sono nate da due situazioni:
• nello schieramento dei servizi poiché gli script erano stati scritti per
ambienti Linux,
• nella generazione delle informazioni descriventi le risorse, anche qui
Capitolo 4 4.6 Prove effettuate
Entrambe le difficoltà sono state superate riscrivendo le utility.
Una ulteriore difficoltà, nata durante le prove effettuate, è stata la mancanza di sincronizzazione degli orologi di sistema dei computer usati. Poiché le query hanno associate un tempo, trascorso il quale la query viene considerata scaduta, capitava che un nodo non elaborasse una query anche se questa in realtà non era scaduta.
4.6.1 Esempio 4.1
La prima prova effettuata ha lo scopo di verificare il funzionamento del sistema nell’elaborazione di una query. Una volta configurato, il sistema appare come mostrato in figura 4.13.
Figura 4.13: configurazione macchine nel primo esempio.
I nodi rappresentati in figura 4.13 sono tutti super-peer. Il sistema contiene complessivamente 3 Service Data Element (SDE) contenenti informazioni sulla risorsa memoria, di cui 2 sono presenti su Barolo e 1 su Orione. Tutti i restanti nodi non contengono informazioni rilevanti per la query trattata. La query è stata generata dall’applicazione utente presente su Novello e ad esso sottomessa. Novello, avendo un solo vicino, inoltra la query a Rubentino. A sua volta Rubentino inoltra la query a Barolo che è il suo miglior vicino, infatti contiene più documenti del tipo ricercato, rispetto a Tocai ed Orione. Ricevuta la query e non avendo vicini, Barolo prima la restituisce a Rubentino e poi la valuta nel
proprio database restituendo i risultati trovati direttamente all’applicazione utente. Nel frattempo Rubentino ha inoltrato la query ad Orione che la valuta nel proprio database.
Di seguito vengono mostrati i tempi presi nei passi principali descritti in precedenza. Per questo test gli orologi dei tre sistemi sono stati opportunamente sincronizzati. Si suppone che la query venga generata al tempo T=0.
• T0 = 0: generazione della query e sottomissione a Novello,
• T1 = 437 ms: Rubentino riceve la query da Novello,
• T2 = 811 ms: Barolo riceve la query da Novello,
• T3 = 1,208 s: Rubentino riceve il messaggio “nessun vicino” da Barolo e
invia la query ad Orione,
• T4 = 1,371 s e T5 = 1.578 s: l’applicazione utente riceve i prime risultati da
Barolo,
• T6 = 1,588 s: Orione riceve la query da Rubentino,
• T7 = 2,259 s: l’applicazione utente riceve l’ultimo risultato da Orione. 4.6.2 Esempio 4.2
Lo scopo di questa prova è quello di confrontare in termini di prestazioni il nostro sistema con lo Index Service di Globus. Quest’ultimo si basa su un modello gerarchico. Tale Index Service non usa alcun tipo di memoria cache, risultando come server centrale per tutte le informazioni memorizzate nei nodi dei livelli inferiori. Per tale motivo i nodi ai livelli superiori della gerarchia possono diventare dei potenziali colli di bottiglia. Inoltre, lo Index Service fornisce due modi per sottomettere una query: attraverso il Service Data Browser di Globus (GUI scritta in java) o il comando ogsi-find-service-data (script linux). È stato usato quest’ultimo poiché permette, in modo più facile, il recupero dei tempi di risposta alla query. Successivamente è stata calcolata una media su questi tempi.
Capitolo 4 4.6 Prove effettuate
Sono state fatte tre serie di test, ognuna costituita da 10 run. Come mostrato in figura 4.14 le tre serie differiscono per il numero di salti eseguiti per rispondere alla query. Nella prima serie i dati sono memorizzati su Rubentino, al quale viene sottomessa anche la query. Nella seconda, i dati sono memorizzati su Novello e la query viene sottomessa a Rubentino. Infine, nella terza ed ultima serie i dati sono memorizzati su Tocai e la query è ancora sottomessa a Rubentino.
Figura 4.14: configurazione macchine nel secondo esempio.
Poiché lo Index Service di Globus è gerarchico ma non implementa alcun meccanismo di caching, il livello più alto della gerarchia contiene tutti i dati dei livelli sottostanti. In questo modo tutte le query vengono valutate localmente. Infatti, tutte le prove effettuate oscillavano tra 3,70 e 4 secondi, rimanendo pressoché costanti.
La figura seguente mostra le medie dei tempi (espressi in secondi) rilevati usando il nostro sistema nelle tre serie.
Figura 4.15: tempi di risposta del nostro sistema.
Come mostrato in figura 4.14, il nostro sistema risulta essere più performante di quello del GT3. Chiaramente ulteriori e più complessi test andranno fatti per verificare completamente la bontà e i limiti del sistema da noi sviluppato.
4.7 Conclusioni
Dopo una breve descrizione degli strumenti utilizzati, sono stati descritti i limiti del Monitoring and Discovery Service (MDS) di Globus che, a nostra avviso, nascono dalla sua struttura gerarchica. I modelli gerarchici e centralizzati, infatti, sono inadatti a supportare applicazioni che “vivono” in ambienti fortemente distribuiti. Tali ambienti, eterogenei e dinamici, hanno favorito la crescita di un nuovo modello di progettazione: le reti Peer-to-Peer (P2P). In questo capitolo, inoltre, è stata messa in evidenza una possibile sinergia tra le tecnologie Grid e Peer-to-Peer (P2P).
Successivamente, è stata descritta l’architettura del sistema realizzato. Quest’ultimo è costituito da due entità principali: Agent e Aggregator. Lo Agent, eseguito su ogni macchina della Griglia, genera le informazioni sulle risorse sotto forma di Service Data (SD). Lo Aggregator, invece, detto anche super peer,
Capitolo 4 4.7 Conclusioni
gestisce le informazioni pubblicate dai propri client e contiene un indice delle risorse possedute dagli altri super peer. Questo indice, detto Hop Count Routing Indices (HRI), permette di scegliere il vicino al quale inoltrare la query. La scelta viene presa considerando, oltre al numero dei documenti nei nodi vicini, anche il “numero dei salti” (hop count) necessari per raggiungere tali documenti. Inoltre, sono stati descritti il K-redundancy e il processo di scoperta dei super peer. Il primo è stato usato per fini di affidabilità e tolleranza ai guasti, mentre il secondo permette di risolvere il problema della prima connessione.
Infine sono stati svolti alcuni test atti a dimostrare la funzionalità del sistema ed un confronto, seppur non molto accurato, con lo Index Service del GT3.

![Figura 4.9: esempio di tabella di routing. In figura sono anche evidenziati i valori dei termini descritti precedentemente per spiegare come ottenere Ni[j][k]](https://thumb-eu.123doks.com/thumbv2/123dokorg/5660050.71011/20.918.251.670.638.863/figura-esempio-tabella-evidenziati-descritti-precedentemente-spiegare-ottenere.webp)



