RDF e SPARQL
Questo capitolo espone dei concetti base per poter comprendere il lavo-ro svolto. Verranno esposte le caratteristiche del linguaggio RDF oltre che il linguaggio di interrogazione SPARQL. Di quest’ultimo verrà approfondita la versione standard 1.0 mentre verranno presentate in linea di massima le principali proposte della versione 1.1.
1.1
Resource Description Framework
Il Web è uno strumento che permette lo scambio di informazioni tra esseri umani. Si vuole però estendere il web in modo da favorire questo scambio anche tra applicazioni, tramite una rappresentazione comprensi-bile per la macchina. Nasce così il web semantico che fornisce una struttura in grado di far condividere dati fra applicazioni, aziende e comunità. Per permettere questo, i dati pubblicati devono essere associati a dei meta-dati che contengono informazioni su di essi e sono leggibili in maniera automatica da tutte le macchine.
Uno dei primi linguaggi definiti per il web semantico è l’RDF, una particolare applicazione XML che descrive le risorse del Web mediante URI. In RDF tutto viene rappresentato mediante risorse. Per risorsa del Web si intende qualsiasi informazione che può essere identificata nel Web. Le informazioni rappresentabili con l’RDF sono molteplici: è possi-bile descrivere prodotti acquistabili on-line, informazioni di pagine web,
immagini, motori di ricerca, librerie elettroniche.
Le informazioni RDF vengono principalmente elaborate da applicazio-ni, non sono strutturate dunque con lo scopo di essere comprensibili dalle persone.
1.1.1
Risorse, proprietà, valori
L’idea base dell’RDF è quella di identificare una risorsa tramite gli URI1 e descrivere le risorse tramite semplici proprietà e valori.
Il modello RDF è costituito da due componenti fondamentali: 1. Sintassi e modello RDF
2. RDF Schema
Il secondo punto verrà approfondito nella sottosezione omonima.
Come accennato l’informazione elementare RDF è una asserzione co-stituita da una tripla
< soggetto predicato oggetto > chiamato statement o tripla RDF.
Tutte e tre le componenti sono delle URI anche se l’oggetto può alter-nativamente essere una semplice stringa.
Il soggetto è ciò che si vuole descrivere. Il predicato è una proprietà che si vuole definire per il soggetto. L’oggetto è il valore del predicato.
Figura 1.1: Statement RDF
1Uno Uniform Resource Identifier (URI) è una stringa che identifica univocamente
una risorsa generica nel web. Può essere un indirizzo web, un documento, un immagine, un file, un indirizzo email ecc. L’URI può essere classificato come URL, una URI che descrive la location della risorsa, e URN che identifica la risorsa mediante il nome in un particolare dominio.
Graficamente possiamo rappresentare uno statement come un semplice grafo come mostra la Figura 1.1. Soggetto e oggetto sono dei nodi mentre la proprietà è un arco orientato verso l’oggetto.
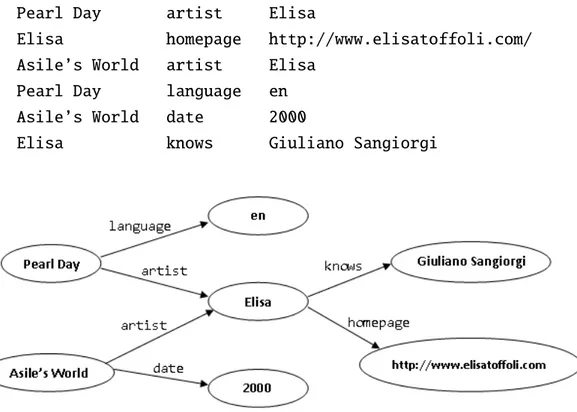
Di seguito viene mostrato un esempio di triple RDF e la loro rapppre-sentazione grafica.
Pearl Day artist Elisa
Elisa homepage http://www.elisatoffoli.com/ Asile’s World artist Elisa
Pearl Day language en Asile’s World date 2000
Elisa knows Giuliano Sangiorgi
Figura 1.2: Esempio di grafo RDF Per ogni risorsa è possibile avere infinite proprietà.
1.1.2
Grafo RDF
L’unione delle triple RDF compone un insieme di informazioni che prende il nome di grafo RDF. Il grafo RDF è un grafo orientato diretto in cui i nodi sono soggetti o oggetti e gli archi sono proprietà.
Come indicato in [10], il vocabolario di un grafo è l’insieme di tutti i termini che compaiono come soggetti, proprietà o oggetti nelle sue triple. I tipi dei termini possono essere:
1. URI 2. Literal 3. Blank Node
Come detto in precedenza le URI identificano le risorse nel web. Alcuni esempi sono presenti nella Tabella 1.1.
URIs
<http://www.w3schools.com/rdf> <http://www.mp3.it/cd/Pearl Day>
Tabella 1.1: Alcuni esempi di URI
I literal sono delle semplici stringhe che possono essere usate nell’og-getto. Si classificano in plain Literal e typed Literal. I plain literal indicano una semplice porzione di testo, opzionalmente può avere abbinato un lan-guage tag che indica la lingua in cui la stringa è scritta. In particolare un plain literal senza il tag di linguaggio è chiamato simple literal. I typed literal invece sono stringhe abbinate ad un datatype indicato da una URI, danno quindi l’informazione aggiuntiva sul tipo del dato contenuto nella stringa. La Tabella 1.2 mostra alcuni esempi.
Plain Typed
“Alice” “27”^^xsd:integer “cat”@en “1999-08-16”^^xsd:date
Tabella 1.2: Alcuni esempi di literal
I blank nodes modellano risorse che non si è interessati ad identificare, oggetti o soggetti che non sono nè URI nè literal.
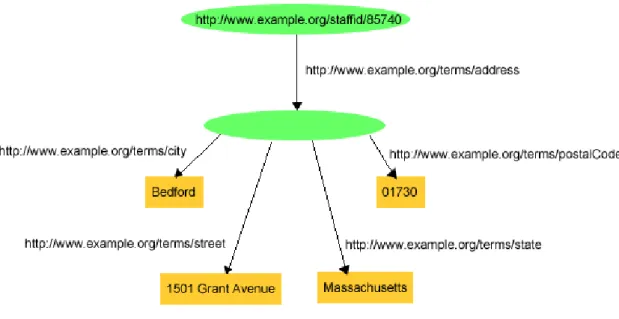
Un esempio dell’utilizzo dei blank nodes sono attributi multivalore nel modello relazionale. Pensiamo all’esempio classico di un indirizzo civico di una persona composto da: città, via, stato, cap. In RDF, per modellare il valore della proprietà address, usiamo il blank node.
La Figura 1.3 mostra il nodo blank che si trova nella posizione di oggetto della proprietà address dell’impiegato 85740 che a sua volta è soggetto per le proprietà city, street, state e Code.
Figura 1.3: Esempio di nodo blank
I blank node sono generalmente indicati dall’etichetta “_:” seguita da un nome. Nomi blank differenti identificano nodi blank differenti. I nodi blank, in quanto nodi possono trovarsi all’interno di una tripla RDF solo nella posizione del soggetto e dell’oggetto, non del predicato.
1.1.3
Container, Collection
Spesso può essere necessario modellare degli insiemi di risorse. Pen-siamo per esempio ad un insieme di server ftp che possiedono un software. Vogliamo poter dire che esso è scaricabile da uno di questi server, e voglia-mo anche ordinare i server secondo una certa priorità. Questo problema non può essere risolto utilizzando semplicemente dei nodi blank in quanto non ci permettono di esprimere le proprietà di ordine o esclusività degli elementi dell’insieme.
In RDF modelliamo gli insiemi con delle risorse chiamate Container. Gli elementi dell’insieme sono risorse o literal e sono chiamati membri. I container possono avere tre tipi:
1. Bag 2. Sequence
3. Alternative
Bag è l’insieme più generico. Può contenere dei membri duplicati e il loro ordine non è importante.
Sequence è un insieme in cui i membri seguono un preciso ordine alfabetico, numerico o temporale.
Alternative è un insieme i cui membri sono esclusivi tra loro.
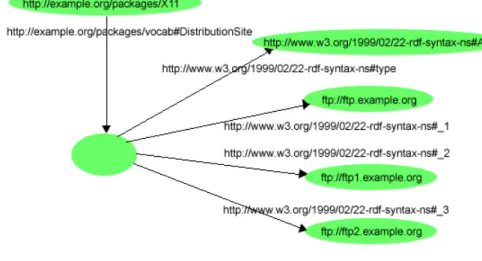
La Figura 1.4 mostra l’esempio dei server ftp modellato utilizzando un container di tipo Alternative.
Figura 1.4: Esempio di nodo Alt
I membri dell’insieme possono essere dichiarati in qualsiasi parte del documento RDF che contiene il grafo. Un’applicazione può correttamente aggiungere i membri di uno stesso insieme in momenti diversi. Possiamo quindi vedere il container come un insieme aperto. Da un certo punto di vista questo potrebbe essere un problema, perchè in certi casi si vuole “chiudere” un insieme e indicare una volta per tutte i soli e unici membri di esso.
Per fare questo l’RDF mette a disposizione un particolare container chiamato Collection. La sua struttura è una lista per cui tramite le proprie-tà rdf:first, rdf:rest e rdf:nil indichiamo rispettivamente il primo membro, il successivo e la fine della lista. La Figura 1.5 mostra un insieme di quattro studenti per il corso 6.001.
Figura 1.5: Esempio di collection Alt
1.1.4
RDF Schema
Lo Schema RDF (RDFS) è un’estensione dell’RDF. Non pone dei vincoli al grafo RDF ma fornisce informazioni aggiuntive sulla semantica di esso. È esso stesso scritto in RDF e non è molto espressivo in quanto gli strumenti che fornisce sono pochi. Lo schema RDF è alla base di altre ontologie che risultano essere molto più espressive come OWL.
È un type system per l’RDF. Permette di definire delle classi e delle proprietà con dominio e codominio.
Tutto ciò che viene definito nello schema deriva dalla classe rdfs:Resource, classi e proprietà sono risorse. Vediamo nel dettaglio la descrizione degli oggetti che possiamo trovare nello schema.
Classi. Le classi sono categorie di cose che si vogliono descrivere. Questo concetto è abbastanza simile a quello di classe nel modello object-oriented.
Una classe è una risorsa che ha tipo rdfs:Class. Per esempio:
significa che ex:MotorVehicle è una classe. Tutte le risorse che avranno come tipo ex:MotorVehicle saranno istanze della classe. ex:MotorVehicle a sua vola è un’istanza della classe rdfs:Class. ex è il prefisso che sta per http://www.example.org/schemas/vehicles e indica la URI dello sche-ma. rdf:type è la proprietà che indica che una risorsa (soggetto) è istanza di una classe (oggetto).
È possibile definire una sottoclasse nel seguente modo:
ex:Van rdf:type rdfs:Class
ex:Van rdfs:subClassOf ex:MotorVehicle
ex:Van sottoclasse di ex:MotorVehicle significa che un’istanza del-la cdel-lasse ex:Van è anche un’istanza deldel-la cdel-lasse ex:MotorVehicle. La proprietà rdfs:subClassOf è transitiva.
Proprietà. Una proprietà è una caratteristica di una classe. Qual-siasi risorsa che si vuole definire tale deve essere istanza della classe rdf:Property. Come le classi anche le proprietà possono avere sotto-proprietà. Per esempio:
ex:driver rdf:type rdf:Property .
ex:oldDriver rdf:type rdf:Property . ex:oldDriver rdf:subPropertyOf ex:driver
definisce le proprietà ex:driver e ex:oldDriver e dice che ex:oldDriver è una sottoproprietà di ex:driver.
Per le proprietà è possibile definire un dominio e un codominio rispet-tivamente con le proprietà rdfs:domain e rdfs:range.
Per esempio con le seguenti triple
ex:driver rdfs:domain ex:MotorVehicle . ex:driver rdfs:range ex:Person
specifichiamo che ex:driver è una proprietà della classe ex:MotorVehicle e avrà come valore istanze della classe ex:Person. Il range può anche riferirsi direttamente a un tipo XML Schema.
Non è obbligatorio specificare dominio e range delle proprietà, può esserne specificata solo una o nessuna, o ancora possono esserne specificate più di una come nelle seguenti triple:
ex:driver rdfs:domain ex:MotorVehicle . ex:driver rdfs:domain ex:Vehicle
In questo caso ogni elemento del dominio della proprietà ex:driver è sia un’istanza della classe ex:MotorVehicle che della classe ex:Vehicle.
Altre descrizioni. È possibile aggiungere un commento ad una risor-sa con la proprietà rdfs:comment. Oppure riferire un’altra risorrisor-sa che potrebbe avere informazioni riguardati essa tramite rdfs:seeAlso.
Nel web si hanno a disposizione degli schemi RDF che possono essere utilizzati per grafi senza doversi creare uno schema RDF da sé.
Quelli utilizzati negli esempi che verranno mostrati sono il Dublin Core [7] della Dublin Core Metadata Initiative che fornisce delle proprietà per descrivere qualsiasi materiale web tra cui articoli, software, archivi ecc, il Friend of a Friend Project (FOAF) [4] per descrivere persone, relazioni tra persone e attività e il vCard della W3C [9] per descrivere biglietti da visita elettronici.
1.1.5
Serializzazione
La serializzazione è quel processo informatico che permette al dato RDF di essere esportato. Consente lo scambio di informazioni RDF.
Fino ad ora abbiamo visto le informazioni RDF espresse come triple. Il nome preciso di questo formalismo è N-Triples. Esiste anche la sintassi N3 però quella più utilizzata è quella XML.
Il documento [3] mostra in che modo ogni elemento RDF viene tradotto in XML. La Figura 1.6 mostra il frammento XML per la Figura 1.5.
1.2
SPARQL
1.2.1
Il linguaggio
SPARQL è un linguaggio di interrogazione per i grafi RDF. È diventato standard nel gennaio 2008 con una prima versione minimale. Nel gennaio
Figura 1.6: Frammento XML di un Alternative
2010 sono stati pubblicati i working draft per la versione 1.1 che aggiungo-no caratteristiche tipiche di un linguaggio di interrogazione aggiungo-non presenti nella versione iniziale.
Dovendo interrogare dati organizzati come triple, le query SPARQL hanno a loro volta una parte composta da triple con la differenza che queste possono contenere delle variabili al posto del soggetto, predicato o oggetto. Per esempio:
?doc cd:autore ?autore
è una tripla che contiene le variabili ?doc e ?autore. Tale tripla prende il nome di triple pattern.
SPARQL si basa sul graph matching per eseguire le query, ossia la corrispondenza di un graph pattern con il grafo RDF.
Definiamo con il termine embedding il matching tra una tripla del graph pattern tp e una tripla del grafo tg. Viene cioè fatto corrispondere soggetto, predicato e oggetto di tp al soggetto, predicato e oggetto di tg.
Ad ogni embedding corrisponde un assegnamento
[variabile1= valore1, . . . , variabilen= valoren]
chiamato binding in cui le variabili appartengono alla tripla del pattern e i valori alla tripla del grafo. Per esempio consideriamo la tripla del pattern
?doc cd:year ?anno e la tripla del grafo
_:a cd:year “2004-02-10” il binding corrispondente è
[?doc = _:a, ?anno = “2004-02-10”]
Il matching tra la tripla del pattern e un grafo RDF genera una tabella chiamata tabella di binding che avrà come schema le variabili definite nel pattern e come righe i valori che esse assumono in corrispondenza di ogni tripla del grafo per cui è definito l’embedding. Questa è la struttura candidata come risultato della query. Facciamo un esempio.
PREFIX dc: <http://purl.org/dc/elements/1.1/> _:a dc:creator “Eric Miller”
_:a dc:year “2004-02-10” _:b dc:title “RDF Semantics” _:c dc:creator “Luca Cardelli” _:c dc:year “2004-02-25”
Tabella 1.3: Un grafo RDF (1)
Considerando il grafo RDF in Tabella 1.3 e il basic graph pattern:
?doc dc:creator ?autore Le triple per cui è definito l’embedding sono:
_:a dc:creator “Eric Miller” _:c dc:creator “Luca Cardelli”
La tabella di binding è:
?doc ?autore
_:a “Eric Miller” _:c “Luca Cardelli”
Questa è la tabella di un solo triple pattern. Successivamente verrà indicato il modo di ottenere le tabelle di binding di più triple pattern.
La sintassi di una semplice query SPARQL che esegue l’interrogazione dell’esempio precedente è la Query 1.1.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?doc ?autore
FROM <http://example.org/esempio/defGraph> WHERE { ?doc dc:creator ?autore }
Query 1.1: Singolo triple pattern
Con il PREFIX vengono indicati dei namespaces, proprio come in un documento XML, che poi verranno utilizzati all’interno della query. La componente SELECT identifica una proiezione delle variabili indicate sulla tabella dei binding. La clausola FROM indica il grafo RDF su cui viene eseguita la query e nel WHERE specifichiamo il graph pattern composto in questo caso da un singolo triple pattern.
Nelle sottosezioni successive verranno approfondite queste componen-ti e ne verranno introdotte delle altre.
1.2.2
Graph pattern
Come introdotto nella sezione precedente, il graph pattern è la compo-nente della query con la quale viene selezionato il sottografo RDF.
È la componente di base di una query SPARQL ed è ottenuta dalla composizione di più strumenti complessi ed è delimitato dalle parentesi graffe2.
Nella sezione precedente è stato introdotto il concetto di triple pattern. Il basic graph pattern (BGP) è un insieme di triple pattern separate dal simbolo “.” ed è il componente di base del graph pattern.
Il BGP crea una tabella di binding finale avente come schema l’insieme di tutte le variabili definite e considera tutti i binding definiti non nulli.
2Nelle specifiche viene indicato con group graph pattern ma per semplicità da questo
Se un record della tabella avesse un valore nullo in almeno una variabile definita allora verrebbe scartato.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?doc ?autore
FROM <http://example.org/esempio/defGraph> WHERE { ?doc dc:creator ?autore .
?doc dc:year “2004-02-10” } Query 1.2: Basic graph pattern
Per esempio la Query 1.2 ha un graph pattern composto da un BGP in cui si vogliono selezionare autore e documento del 10 febbraio 2004. Pensando di eseguire la query nel grafo in Tabella 1.3 le tabelle di binding rispettivamente del primo e del secondo triple pattern sono:
?doc ?autore _:a “Eric Miller” _:b “Patrick Hayes”
?doc _:a
L’and sui valori della variabile in comune ?book ci darà:
?doc ?autore
_:a “Eric Miller”
Si noti che il documento _:b, sebbene abbia un autore, non possiede un anno di edizione infatti compare nella tabella di binding del primo triple pattern. Ma non avendo un anno di edizione, non compare nella seconda tabella, per cui viene scartata dall’and.
È possibile abbreviare due triple pattern che hanno in comune il sog-getto usando il simbolo “;” anzichè “.”:
?doc dc:creator ?autore ; dc:subject ?oggetto
Optional pattern. Il pattern opzionale, a differenza del BGP, non elimina i binding nulli per un preciso insieme di variabili.
L’optional pattern non è altro che un graph pattern preceduto dalla parola chiave OPTIONAL e generalmente è contenuto a sua volta in un graph pattern più esterno.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?doc ?autore ?anno
FROM <http://example.org/esempio/defGraph> WHERE { ?doc dc:creator ?autore .
OPTIONAL { ?doc dc:year ?anno } }
Query 1.3: Optional pattern
La Query 1.3 ha una graph pattern composto da un triple pattern e un optional pattern. Selezionerà i libri e ne stamperà un autore e, se tali libri hanno associata anche l’informazione dell’anno in cui sono stati pubblicati, allora verrà stampata anche quella. Il risultato della query eseguita sul grafo in Tabella 1.3 sarà:
?doc ?autore ?anno
_:a “Eric Miller” “2004-02-10”
_:b “Patrick Hayes”
I binding esterni al pattern opzionale sono le colonne ?doc e ?autore. Si può notare che esse sono complete. Mentre la colonna ?anno proviene dal pattern opzionale. Il book2 non avendo un anno di pubblicazione, avrà valore nullo per quella colonna.
La parola chiave OPTIONAL è associativa da sinistra, quindi i seguenti pattern sono equivalenti:
pattern OPTIONAL pattern OPTIONAL pattern {pattern OPTIONAL pattern } OPTIONAL pattern
Alternative pattern. Il pattern alternativo combina due o più graph pattern unendo i diversi binding.
Il pattern alternativo viene specificato con parola chiave UNION. La Query 1.4 mostra un esempio.
PREFIX dc10: <http://purl.org/dc/elements/1.0/> PREFIX dc11: <http://purl.org/dc/elements/1.1/> SELECT ?title
WHERE { { ?doc dc10:title ?title } UNION
{ ?doc dc11:title ?title } } Query 1.4: Alternative pattern
I prefissi dc10 e dc11 stanno rispettivamente per versione 1.0 e 1.1 dello schema Dublin Core. Questa query vuole selezionare i titoli dei libri memorizzati, indipendentemente dalla versione del Dublin Core usata.
PREFIX dc10: <http://purl.org/dc/elements/1.0/> PREFIX dc11: <http://purl.org/dc/elements/1.1/> _:a dc10:title “RDF Primer”
_:a dc10:creator “Eric Miller” _:a dc10:year “2004-02-10” _:b dc11:creator “Patrick Hayes” _:b dc11:title “RDF Semantics”
_:c dc11:title “Semantics of SPARQL” Tabella 1.4: Un grafo RDF (2)
Considerando il grafo RDF in Tabella 1.4 la soluzione sarebbe:
?title “RDF Primer” “RDF Semantics” “Semantics of SPARQL”
Se invece si volesse tener traccia della versione, si potrebbero utilizzare due variabili diverse al posto della sola ?title come mostra la query 1.5.
PREFIX dc10: <http://purl.org/dc/elements/1.0> PREFIX dc11: <http://purl.org/dc/elements/1.1> SELECT ?x ?y
WHERE { { ?doc dc10:title ?x } UNION
Query 1.5: Alternative pattern con variabili diverse Il risultato sarebbe: ?x ?y “RDF Primer” “RDF Semantics” “Semantics of SPARQL”
Altri pattern non mostrati sono il pattern sui named graph e la restri-zione sulle triple del grafo. Occorrono delle premesse per introdurli per cui verranno esposti nelle sotto sezioni successive.
Tutti questi pattern possono essere combinati tra loro ed annidati per-mettendo così la creazione di query complesse.
1.2.3
Selezione
SPARQL fornisce lo strumento FILTER per selezionare le triple che soddisfano una condizione. Precisamente elimina ogni soluzione in cui il risultato della condizione su di essa restituisce il valore booleano false oppure un errore.
Si implementa usando la parola chiave FILTER seguita da un predicato logico semplice o complesso applicato a variabili definite nel graph pattern in cui è inserito. La Query 1.6 mostra il titolo degli articoli di “Eric Miller”.
PREFIX dc: <http://purl.org/dc/elements/1.0/> SELECT ?title
WHERE { ?doc dc:title ?title . ?doc dc:creator ?autore . FILTER (?autore = “Eric Miller”) } Query 1.6: Graph pattern con restrizione
SPARQL applica ai termini RDF e alle variabili una serie di funzioni e operatori. Alcuni sono propri del linguaggio mentre altri vengono im-plementati invocando delle funzioni o usando operatori XQuery e XPath.
Tali funzioni/operatori usano come argomenti dati aventi un tipo XML Schema, pertanto è necessario un mapping tra questi tipi e i termini RDF.
Un plain literal corrisponde ad un tipo string mentre un typed lite-ral corrisponde esattamente al tipo espresso, quindi ai valori numerici o xsd:date, xsd:dateTime. Nella sezione 11.3 di [17] vi è una tabella in cui ogni riga è composta da un operatore, i tipi degli argomenti attesi, la funzione invocata e il tipo del risultato.
Nella Tabella 1.5 sono riportate alcune righe della tabella citata in cui ci sono le funzioni definite da SPARQL per i test si rimanda alla citazione per tutti gli operatori classici e le altre funzioni.
Operatore Tipo (A/B) Funzione Risultato
BOUND(A) variabile bound(A) xsd:boolean
isIRI(A) isURI(A) termine RDF isIRI(A) xsd:boolean isBLANK(A) termine RDF isBlank(A) xsd:boolean isLITERAL(A) termine RDF isLiteral(A) xsd:boolean sameTERM(A,B) termine RDF sameTerm(A,B) xsd:boolean langMATCHES(A,B) simple literal langMatches(A,B) xsd:boolean REGEX(S,P) simple literal fn:matches(S,P) xsd:boolean
Tabella 1.5: Operatori SPARQL
La funzione bound rende true se la variabile passata come argomento ha un valore non vuoto, isIri3 se il termine è un IRI, isLiteral se è un
literal e idBlank se è un blank node. sameTerm rende true se i parametri sono lo stesso termine, langMatches se il tag di linguaggio A è presente nell’insieme dei tag di linguaggi B. REGEX è un operatore che, invoca la funzione XPath matches che rende true se la stringa S soddisfa il pattern P.
La Tabella 1.6 elenca alcune funzioni usate da SPARQL. str rende la stringa corrispondente al valore di un literal oppure di una IRI, lang rende il solo tag di linguaggio di un literal (se non è definito rende una stringa vuota), datatype rende la IRI relativa al tipo del literal se questo è typed, altrimenti rende xsd:string se è plain.
3Sia isIRI che isURI invocano questa funzione. Questo perchè SPARQL usa gli IRI
Operatore Tipo (A) Funzione Risultato
STR(A) literal str(A) simple literal
STR(A) IRI str(A) simple literal
LANG(A) literal lang(A) simple literal DATATYPE(A) typed literal datatype(A) IRI
DATATYPE(A) simple literal datatype(A) IRI Tabella 1.6: Funzioni accessorie SPARQL
Alcuni esempi [17] dell’utilizzo del FILTER sono mostrati nelle Query 1.7 e 1.8.
PREFIX dc: <http://purl.org/dc/elements/1.1/> PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name
WHERE { ?x foaf:givenName ?name .
OPTIONAL { ?x dc:date ?date } . FILTER ( !bound(?date) ) }
Query 1.7: Graph pattern con test sul binding di una variabile La Query 1.7 rende i nomi delle persone per cui non è specificata una data di nascita. OPTIONAL aggiunge l’informazione della data di nascita e FILTEResclude le soluzioni per cui la data è definita.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?title
WHERE { ?x dc:title “That Seventies Show”@en . dc:title ?title .
FILTER ( langMatches(lang(?title), “FR”) ) } Query 1.8: Graph pattern con test sul tag di linguaggio
La Query 1.8 invece, eseguita su un grafo in cui sono memorizzati i titoli di programmi televisivi, rende il titolo francese della serie inglese “That Seventies Show”.
Queste non solo le uniche funzioni che possono essere usate con FILTER, altre possono essere definite nel service e usate esattamente come quelle viste fino ad ora.
1.2.4
Dataset
Un dataset RDF è un insieme di grafi RDF su cui è possibile eseguire la query. Il dataset contiene sempre un grafo di default senza nome, e altri grafi identificati da un nome (chiamati named graph ).
L’esecuzione della query avviene su un dataset e precisamente sul grafo di default di quel dataset. SPARQL permette di eseguire la query su un grafo differente o selezionare diverse informazioni da diversi grafi. Le possibilità sono:
1. all’atto della Request 2. all’interno della Query
È cioè possibile specificare grafi nella richiesta di esecuzione della query inviata al servizio competente oppure direttamente nella query mediante opportune clausole.
Se i grafi vengono indicati sia nella query che nella richiesta, il servizio prenderà in considerazione solo quelli specificati nella richiesta. Ci limite-remo comunque a prendere in considerazione solo le indicazioni dei grafi nella query.
Con la parola chiave FROM seguita da una IRI viene cambiato il grafo di default. Se vengono specificate più IRI il grafo di default sarà quello ottenuto dal merge dei grafi elencati.
Invece la IRI preceduta da FROM NAMED indica un named graph, che si aggiungerà alla lista dei grafi che potrebbero essere usati nella query.
La parola chiave GRAPH inserita all’interno della WHERE e seguita da una IRI (o da una variabile) e da un graph pattern, permette di far corrispondere il graph pattern al grafo indicato dalla IRI (o ai grafi indicati dal binding della variabile).
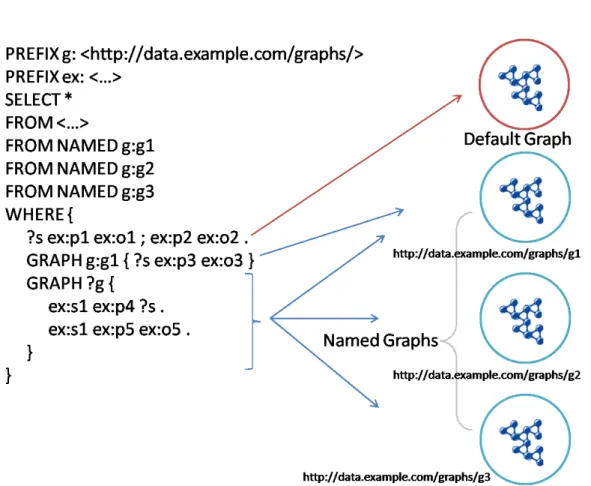
La Figura 1.7 mostra una query con tre named graph e un graph pattern complesso, e ne spiega l’esecuzione.
Un BGP esterno alle parole chiave GRAPH viene eseguito sul grafo di default. Il primo GRAPH esegue il suo BGP solo nel grafo g:g1 mentre il
Figura 1.7: Esecuzione di una query con i NAMED GRAPH RDF
secondo GRAPH esegue il suo BGP su tutti i valori che la variabile ?g può assumere (in questo caso tutti i named graph).
Un altro esempio è mostrato dalla Query 1.9 in cui il named graph viene scelto in base al valore che una variabile può assumere in un altro BGP. In questo caso il grafo attivo sarà selezionato in base al valore della variabile ?g ottenuto dal binding del primo triple pattern eseguito sul grafo di default.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?who ?g ?mbox
FROM <http://example.org/dft.ttl> FROM NAMED <http://example.org/alice> FROM NAMED <http://example.org/bob> WHERE { ?g dc:publisher ?who .
Query 1.9: Query con NAMED GRAPH
1.2.5
Modificatori di soluzione
I modificatori di soluzione, applicati alla tabella di binding modifi-cano il risultato della query crando un ordine, eliminando i duplicati o riducendo la cardinalità della soluzione.
Vediamoli uno ad uno nel dettaglio.
Ordinamento. Ordina le righe della tabella in ordine crescente o de-screscente secondo l’operatore “<”. Viene indicato con la parola chiave ORDER BYindicata dopo il WHERE. Di default l’ordine di ordinamento è cre-scente, se lo si vuole modificare basta inserire la parola chiave DESC seguita dal gruppo di variabili.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?doc ?autore
WHERE { ?doc dc:creator ?autore ; dc:date ?anno } ORDER BY ?autore DESC(?anno)
Query 1.10: Query con ordinamento
Proiezione. La proiezione sulla tabella dei binding avviene semplice-mente indicando dopo la SELECT la lista di variabili. Per proiettare l’intera tabella si indica il carattere “*”.
Duplicati. Rimuove i duplicati dalle colonne indicate. Si usa DISTINCT nella parte SELECT seguita dalla lista di variabili di cui si vogliono eliminare i duplicati. Per ogni valore (tupla di valori) ripetuto ne viene tenuto soltanto uno.
SPARQL mette a disposizione lo strumento REDUCED che in presenza di valori duplicati, ne tiene un numero casuale compreso tra 1 e il numero di valori senza nessun modificatore.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT REDUCED (?autore ?year)
Query 1.11: Query con eliminazione duplicati
Cardinalità. Sceglie una sottotabella della tabella di binding. Con LIMITindichiamo il limite superiore di soluzioni e con OFFSET la soluzione da cui partire.
Per esempio consideriamo la Query 1.12 che rende le informazioni delle e-mail contenute in una casella di posta.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?mittente ?oggetto ?data
WHERE { ?mail dc:creator ?mittente ;
dc:subject ?oggetto ; dc:date ?data } ORDER BY ?data
Query 1.12: Query con riduzione della cardinalità della soluzione (1) Se volessimo dividerle in pagine ognuna da 20 e-mail, per selezionare quelle della prima pagina aggiungeremo il limite delle soluzioni a 20 come mostra la Query 13.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?mittente ?oggetto ?data
WHERE { ?mail dc:creator ?mittente ;
dc:subject ?oggetto ; dc:date ?data } ORDER BY ?data
LIMIT 20
Query 1.13: Query con riduzione della cardinalità della soluzione (2) Se volessimo invece quelle della terza pagina le soluzioni sarebbero quelle dalla posizione 41 (compresa) alla posizione 60, come mostra la Query 1.14.
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?mittente ?oggetto ?data
WHERE { ?mail dc:creator ?mittente ;
dc:subject ?oggetto ; dc:date ?data } ORDER BY ?data
OFFSET 41
Query 1.14: Query con riduzione della cardinalità della soluzione (3)
1.2.6
Forme del risultato
Una delle caratteristiche interessanti di SPARQL è la possibilità di sce-gliere il tipo del risultato. Questo è il passo finale nel flusso di esecuzione della query, in cui si riceve la tabella di binding delle variabili e la si utilizza in modi diversi per ottenere risultati diversi.
Le opzioni sono: 1. SELECT
2. CONSTRUCT 3. DESCRIBE 4. ASK
La SELECT è quella che abbiamo visto in tutti gli esempi fatti. Restituisce una proiezione della tabella di binding.
La CONSTRUCT a partire dalla tabella di binding e da un template, co-struisce e rende un nuovo grafo. Il template non è altro che un insieme di triple.
Partendo dalla tabella di binding, i valori delle variabili vengono map-pati sulle triple del template creando così delle nuove triple che compor-ranno il grafo restituito.
Se dovessero comparire dei nodi blank sia nelle triple del template che nei valori della tabella, questi verrebbo sostituiti con dei nuovi nodi blank. Generalmente questo strumento viene utilizzato quando si vuole cam-biare lo schema dei dati. Per esempio la Query 1.15 seleziona dati foaf da un grafo e li trasforma in dati vCard.
La DESCRIBE restituisce le informazioni presenti nel grafo associate ad una risorsa sotto forma di un altro grafo RDF. Questa viene indicata subito dopo la parola chiave DESCRIBE tramite una IRI o il valore di una variabile. La scelta delle informazioni rese è fatta dal servizio.
È possibile richiedere delle informazioni di più di una risorsa come nella Query 1.16.
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX vCard: <http://www.w3.org/2001/vcard-rdf/3.0#> CONSTRUCT ?x vCard:FN ?name
?x vCard:URL ?url ?x vCard:TITLE ?title
FROM <http://www.w3.org/People/Berners-Lee/card> WHERE { OPTIONAL {?x foaf:name ?name .
FILTER isLiteral(?name) }
OPTIONAL {?x foaf:homepage ?url . FILTER isURI(?url) }
OPTIONAL {?x foaf:title ?title . FILTER isLiteral(?title) } }
Query 1.15: Query CONSTRUCT
PREFIX foaf: <http://xmlns.com/foaf/0.1/> DESCRIBE ?x ?y <http://example.org/alice/> WHERE { ?x foaf:knows ?y }
Query 1.16: Query DESCRIBE
Vengono descritte tutte le persone che conoscono altre persone, queste persone oltre che in particolare “alice”.
Il questo caso il graph pattern ha più soluzioni, per cui il grafo risultato è ottenuto dall’unione di tutti i grafi che descrivono una singola risorsa.
La ASK restituisce il booleano true nel caso in cui la tabella di binding sia non vuota, false altrimenti.
La Query 1.17 implementa la seguente domanda: esiste qualcuno che conosce qualcun’altro?
PREFIX foaf: <http://xmlns.com/foaf/0.1/> ASK
WHERE { ?x foaf:knows ?y } Query 1.17: Query ASK
1.2.7
SPARQL 1.1
La versione 1.0 di SPARQL è ormai standard dal 2008. Nel gennaio 2010 la W3C ha pubblicato un working draft in cui si introducono degli strumenti aggiuntivi al linguaggio, tipici di un linguaggio di interrogazione non presenti nello standard.
Il working draft contiene una serie di documenti reperibili nella home page del Working Group [18].
Espressioni nella proiezione. Nella clausola SELECT è possibile in-trodurre nuove variabili e inserire delle espressioni. Le nuove variabili rinominano una colonna esistente della tabella dei binding oppure sono legate al risultato di una espressione. Sono precedute dalla parola chiave AS.
PREFIX dc: <http://purl.org/dc/elements/1.1/> PREFIX ns: <http://example.org/ns/>
SELECT ?title (?p AS ?fullprice)
(?fullprice*(1-discount) AS customerprice) WHERE { ?x ns:price ?p ;
dc:title ?title ;
ns:discount ?discount }
Query 1.18: Query con espressioni nella SELECT
Funzioni di aggregazione. Le funzioni di aggregazione applicano delle espressioni a degli insiemi di variabili composti dalla parola chiave GROUP BY. Le funzioni proposte sono
• COUNT per contare gli elementi dell’insieme. • SUM per fare la somma.
• MIN e MAX per trovare rispettivamente il minimo e il massimo. • AVG calcola la media.
• SAMPLE sceglie un elemento dell’insieme.
Query annidate. Permette di esprimere una query all’interno di un graph pattern.
PREFIX ex: <http://people.example/> SELECT ?y ?minName
WHERE { ex:alice ex:knows ?y . {
SELECT ?y (MIN(?name) AS ?minName) WHERE { ?y ex:name ?name } GROUP BY ?y
} }
Query 1.19: Query annidate
Per esempio pensiamo di eseguire la Query 1.19 in un grafo RDF che elenca nomi di persone in cui ogni persona può avere più nomi. La sotto-query rende una tabella in cui ad ogni persona è associato il suo nome più breve. Quindi la query esterna renderà tutte le persone che alice conosce seguite dal loro nome più breve.
Esistenza del binding. Permette di verificare se un graph pattern ha una soluzione non vuota senza aggiungere nuovi binding. Per esempio la seguente query selezionerà le persone che non hanno un attributo nome.
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT ?persona
WHERE { ?persona rdf:type foaf:person .
NOT EXISTS {?persona foaf:name ?nome } }
Query 1.20: Query con test sull’esistenza del binding di un graph pattern
Se anche la variabile ?nome facesse parte della proiezione, allora il NOT EXISTS non avrebbe senso in quanto si potrebbe scrivere la query direttamente con un BGP composto dalle due triple.
Esiste anche la versione non negata usando solo EXISTS.
Path di proprietà. Un path di proprietà descrive un possibile percorso tra nodi del grafo RDF. L’esecuzione della query determina tutti i match dell’espressione di path e crea i binding per il soggetto e l’oggetto.
Per esempio la Query 1.21 visualizza il nome di ogni persona che Alice conosce.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX ex: <http://people.example/>
SELECT ?nome
WHERE { ?ex:Alice foaf:knows/foaf:name ?nome . } Query 1.21: Query con path nelle proprietà
È possibile definire path complessi usando opportune forme sintattiche alcune delle quali sono elencate nella Tabella 1.7.
Forma sintattica Corrispondenza
^item Path inverso, dall’oggetto al soggetto item1/ item2 Sequenza di due elementi del path item1| item2 Path alternativi
item* Zero o più occorrenze di un elemento item+ Una o più occorrenze di un elemento item? Zero o una occorrenza di un elemento
item{n,m} Un path tra n e m occorrenze di un elemento
item{n} Un path con esattamente n occorrenze di un elemento Tabella 1.7: Forme sintattiche per i path di proprietà